Материалы по тегу: 800gbe
|
15.09.2025 [14:48], Сергей Карасёв
Продажи Ethernet-коммутаторов и маршрутизаторов корпоративного класса растут на фоне бума ИИКомпания International Data Corporation (IDC) обнародовала результаты исследования мирового рынка сетевого оборудования корпоративного класса во II квартале текущего года. Отрасль демонстрирует рост на фоне бума ИИ: гиперскейлеры и поставщики облачных услуг активно расширяют инфраструктуру для удовлетворения растущих потребностей в вычислительных мощностях. По оценкам, продажи Ethernet-коммутаторов в период с апреля по июнь включительно составили $14,5 млрд: это на 42,1 % больше по сравнению со II четвертью 2024 года. В сегменте решений для дата-центров выручка подскочила на 71,6 % в годовом исчислении. В данном секторе быстро укрепляет позиции компания NVIDIA, у которой продажи взлетели на 647 % — до $2,3 млрд, что обеспечило ей наибольшую рыночную долю — 25,9 %. IDC отмечает стремительный рост спроса на коммутаторы стандарта 800GbE, продажи которых поднялись на 222,1 % по сравнению с I четвертью 2025 года, а их доля в общем объёме ЦОД-рынка составила 12,8 %. Поставки коммутаторов стандартов 200/400GbE для дата-центров в годовом исчислении выросли на 175,5 %, тогда как их доля находится на уровне 49,5 %. 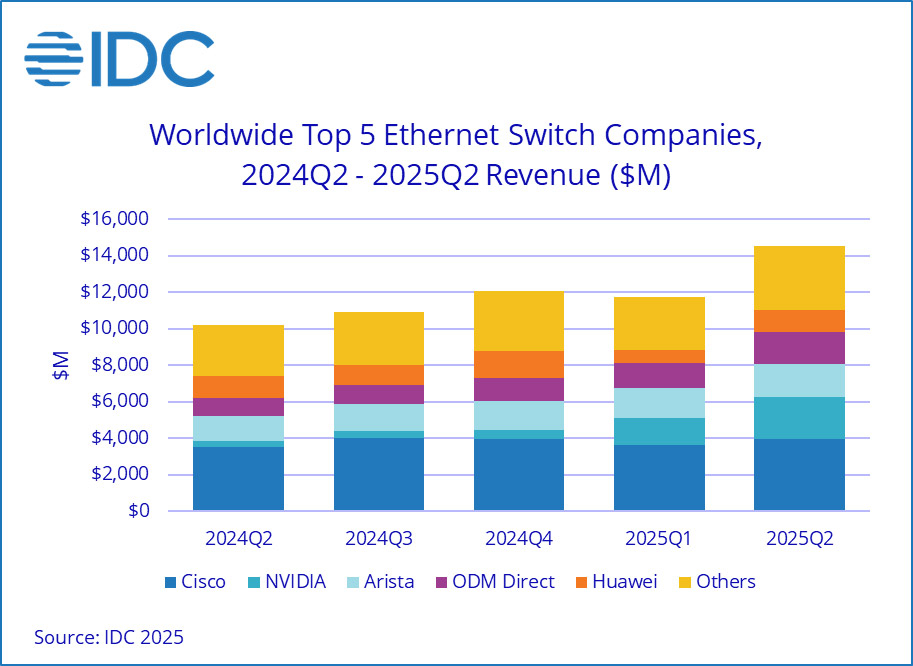
Источник изображения: IDC В сегменте коммутаторов, не связанных с ЦОД, продажи за год поднялись на 12,5 %. Поставки изделий 1GbE, на которые приходится более половины выручки, выросли на 11,3 % в денежном выражении. Спрос на устройства 25/50GbE поднялся на 27,5 % год к году. С географической точки зрения в Северной и Южной Америке рынок Ethernet-коммутаторов корпоративного класса показал рост на 56,8 % в годовом исчислении. В Европе, на Ближнем Востоке и в Африке (EMEA) продажи увеличились на 33,8 %, а в Азиатско-Тихоокеанском регионе — на 24,0 %. В список ведущих мировых поставщиков коммутаторов Ethernet входят Cisco, Arista Networks, NVIDIA, Huawei и HPE Aruba Networking с долями соответственно 27,3 %, 12,6 %, 15,7 %, 8,3 % и 4,7 %. В секторе маршрутизаторов общая выручка во II квартале 2025 года достигла $3,6 млрд, что на 12,5 % больше по сравнению с аналогичным периодом предыдущего года. На поставщиков услуг пришлось 73,2 % от общего объёма данного сегмента с ростом на 13,8 % в годовом исчислении. Корпоративный сектор обеспечил 26,8 % продаж, показав прибавку в 9,1 %. В региональном разрезе объём рынка маршрутизаторов в Северной и Южной Америке вырос на 24,5 % в годовом исчислении, в Азиатско-Тихоокеанском регионе — на 11,4 %. Вместе с тем в регионе EMEA отмечено падение на 1,0 %.
03.09.2025 [11:51], Сергей Карасёв
FS представила оптические коммутаторы DCS-W и 800G LPO-трансивер для задач ИИ и НРСКомпания FS анонсировала полностью оптические коммутаторы (OCS) семейства DCS-W, разработанные специально для удовлетворения растущих потребностей кластеров ИИ, платформ НРС и систем машинного обучения. Утверждается, что изделия сочетают в себе неблокируемую архитектуру оптического матричного коммутатора с интуитивно понятным веб-интерфейсом управления. В отличие от традиционных оптико-электро-оптических (OEO) устройств, в полностью оптических коммутаторах DCS-W устраняется преобразование сигнала. Благодаря этому достигается передача данных на высокой скорости со сверхнизкой задержкой и небольшим энергопотреблением. 
Источник изображения: FS Устройства семейства DCS-W представлены в виде матриц 8 × 8, 16 × 16 и 32 × 32. Скорость передачи данных варьируется от 1 Гбит/с до 800 Гбит/с с повышением до 1,6 Тбит/с в будущем. Заявлена совместимость с различными протоколами, включая Ethernet, OTN, SDH и Fibre Channel. Специальная функция контроля мощности OPD (Optical Power Detection) непрерывно отслеживает уровень сигнала портов, выявляя затухание или повреждение волокна, что значительно сокращает время обнаружения и устранения неисправностей. Интерфейс управления на основе браузера отображает состояние портов и информацию о неполадках. 
Источник изображения: FS Кроме того, компания FS представила модуль-трансивер 800G Linear Pluggable Optics (LPO) для ИИ-систем. Это решение, как утверждается, обеспечивает оптимальный баланс между производительностью и энергоэффективностью в дата-центрах. Устройство соответствует стандартам CMIS 5.0, LPO MSA 1.0 и OSFP MSA. Встроенная функция цифрового диагностического мониторинга (DDM) предоставляет доступ к рабочим параметрам в режиме реального времени. Модуль может работать с кабелями длиной 500 м. Заявленное энергопотребление составляет менее 8,5 Вт. Цена — около €1660.
05.08.2025 [10:39], Сергей Карасёв
HyperPort на 3,2 Тбит/с: Broadcom выпустила чип-коммутатор Jericho4 для распределённой ИИ-инфраструктурыКомпания Broadcom объявила о начале поставок коммутационного чипа Jericho4, специально разработанного для распределённой инфраструктуры ИИ. Изделие, как утверждается, позволяет объединять более миллиона ускорителей (GPU, TPU) в географически разнесённых дата-центрах, преодолевая традиционные ограничения масштабирования. Отмечается, что по мере роста размера и сложности моделей ИИ требования к инфраструктуре ЦОД повышаются: создаётся необходимость в объединении ресурсов нескольких площадок, каждая из которых обеспечивает мощность в десятки или сотни мегаватт. Для этого требуется оборудование нового поколения, оптимизированное для сверхширокополосной и безопасной передачи данных на значительные расстояния. Новинка позволяет решить проблему. Jericho4 обладает коммутационной способностью 51,2 Тбит/с. Благодаря глубокой буферизации и интеллектуальному управлению перегрузкой изделие обеспечивает поддержку RoCE без потерь на расстоянии более 100 км, что позволяет формировать распределённую инфраструктуру ИИ, говорит Broadcom. 
Источник изображений: Broadcom Могут быть задействованы интерфейсы 50GbE, 100GbE, 200GbE, 400GbE, 800GbE и 1.6TbE. Реализована технология HyperPort, которая объединяет четыре порта 800GbE в один канал с пропускной способность 3,2 Тбит/с, что упрощает проектирование и управление сетью. Единая инфраструктура на базе Jericho4 может масштабироваться до 36 тыс. портов HyperPort, каждый из которых работает со скоростью 3,2 Тбит/с. Jericho4 поддерживает шифрование MACsec на каждом порту на полной скорости для защиты передаваемой между ЦОД информации без ущерба для производительности — даже при самых высоких нагрузках. Новинка полностью соответствует спецификациям, разработанным консорциумом Ultra Ethernet (UEC): благодаря этому достигается бесшовная интеграция с широкой экосистемой сетевых карт, коммутаторов и программных стеков. 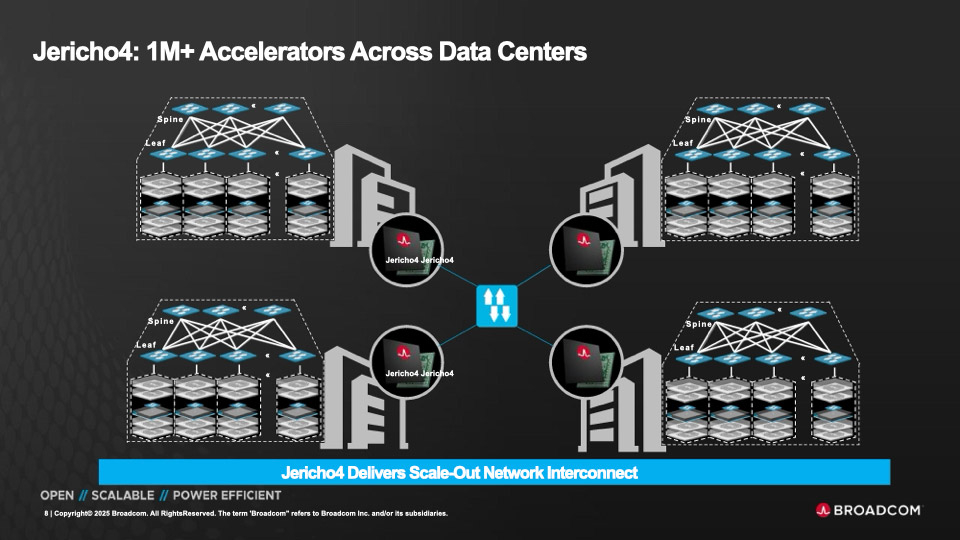 Чип Jericho4 производится по 3-нм технологии. Он оснащён модулями Broadcom PAM4 SerDes 200G. Это устраняет необходимость в дополнительных компонентах, таких как ретаймеры, что способствует снижению энергопотребления и повышению надёжности системы в целом. В частности, энергозатраты уменьшены на 40 % в расчёте на бит по сравнению с решениями предыдущего поколения. Это помогает организациям снижать эксплуатационные расходы и достигать целей устойчивого развития, говорит Broadcom.
03.08.2025 [12:14], Сергей Карасёв
Enfabrica представила технологию EMFASYS для расширения памяти ИИ-системКомпания Enfabrica анонсировала технологию EMFASYS, которая объединяет Ethernet RDMA и CXL для создания пулов памяти, предназначенных для работы с серверными ИИ-стойками на базе GPU. Решение позволяет снизить нагрузку на HBM-память ИИ-ускорителей и тем самым повысить эффективность работы всей системы в целом. Enfabrica основана в 2019 году. Стартап предлагает CXL-платформу ACF на базе ASIC собственной разработки, которая позволяет напрямую подключать друг к другу любую комбинацию GPU, CPU, DDR5 CXL и SSD, а также предоставляет 800GbE-интерконнект. Компания создала чип ACF SuperNIC (ACF-S) для построения высокоскоростного интерконнекта в составе кластеров ИИ на основе GPU. В рамках платформы EMFASYS специализированный пул памяти подключается к GPU-серверам через чип-коммутатор ACF-S с пропускной способностью 3,2 Тбит/с, который объединяет PCIe/CXL и Ethernet. Поддерживаются интерфейсы 100/400/800GbE, 32 сетевых порта и 160 линий PCIe. Могут быть задействованы до 144 линий CXL 2.0, что позволяет использовать до 18 Тбайт памяти DDR5 (в перспективе — до 28 Тбайт). Вместо копирования и перемещения данных между несколькими чипами на плате Enfabrica использует один SuperNIC, который позволяет представлять память в качестве целевого RDMA-устройства для приложений ИИ. 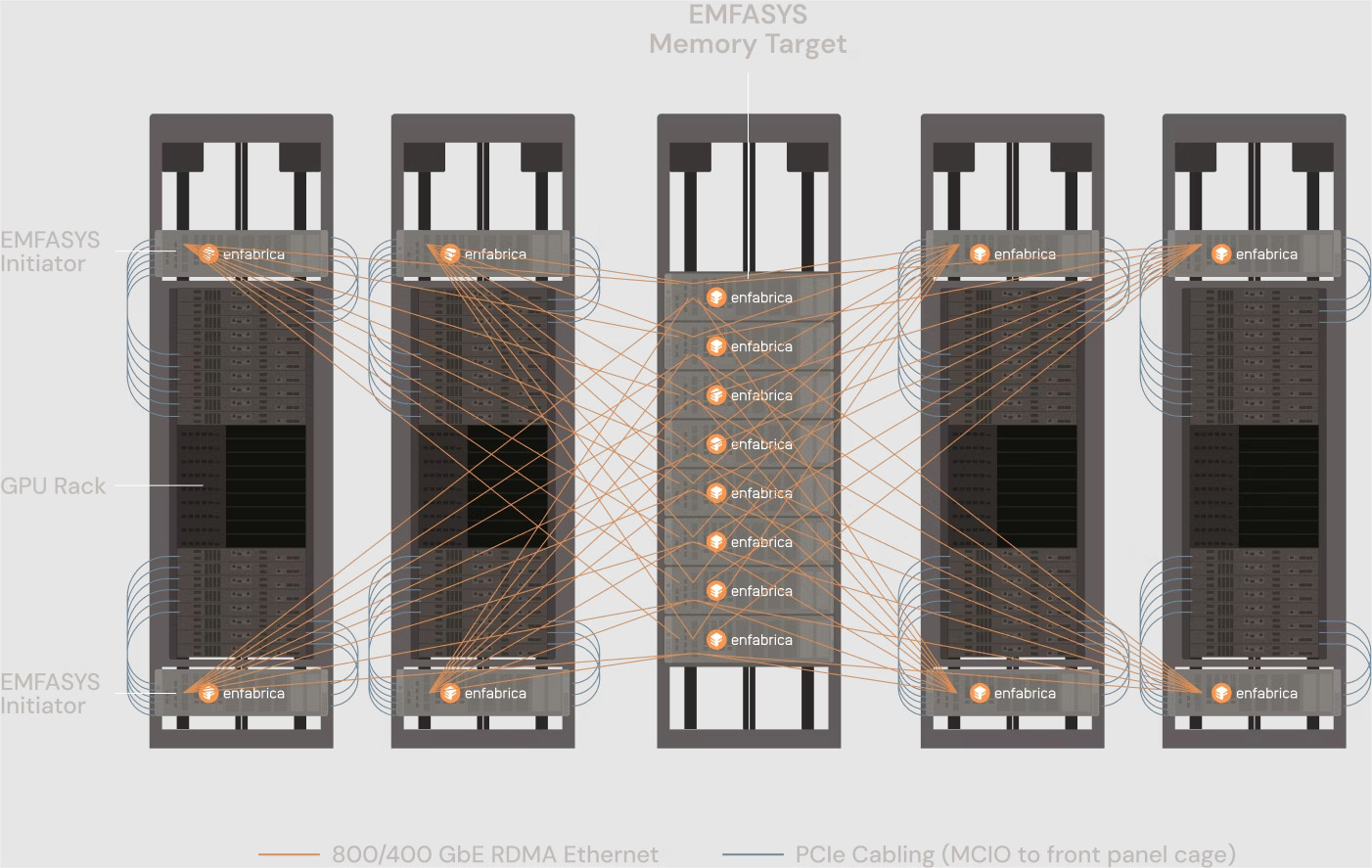
Источник изображений: Enfabrica Высокая пропускная способность памяти достигается за счёт распределения операций более чем по 18 каналам на систему. Время доступа при чтении измеряется в микросекундах. Программный стек на базе InfiniBand Verbs обеспечивает массовую параллельную передачу данных с агрегированной полосой пропускания между GPU-серверами и памятью DRAM через группы сетевых портов 400/800GbE. 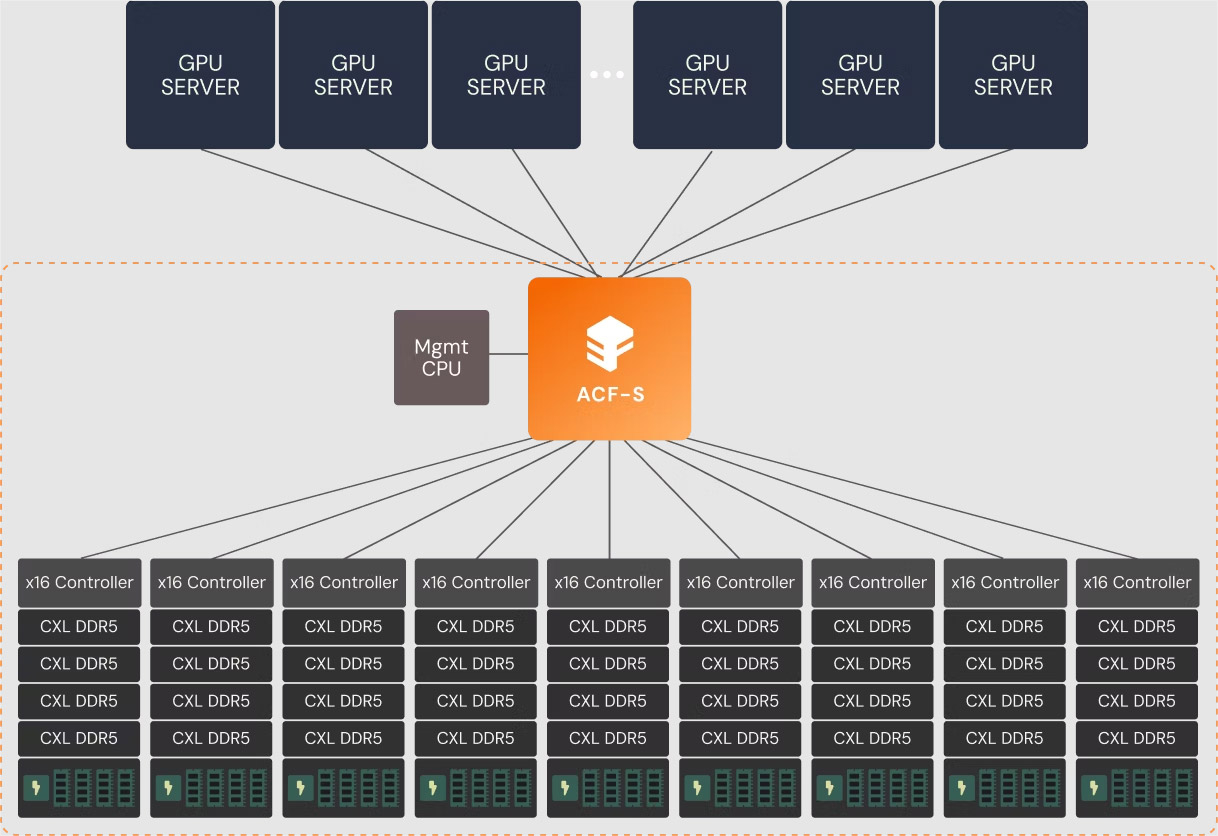 Enfabrica отмечает, что рабочие нагрузки генеративного, агентного и рассуждающего ИИ растут экспоненциально. Во многих случаях таким приложениям требуется в 10–100 раз больше вычислительной мощности на запрос, чем большим языковым моделям (LLM) предыдущего поколения. Если память HBM постоянно загружена, дорогостоящие ускорители простаивают. Технология EMFASYS позволяет решить проблему посредством расширения памяти: в этом случае ресурсы GPU используются более полно, а заявленная экономия достигает 50 % в расчёте на токен на одного пользователя.
16.07.2025 [11:44], Сергей Карасёв
Broadcom представила 51,2-Тбит/с чип-коммутатор Tomahawk Ultra — альтернативу NVIDIA InfiniBand и NVLinkКомпания Broadcom анонсировала чип-коммутатор Tomahawk Ultra, специально разработанный для кластеров НРС и платформ ИИ. Новинка, как ожидается, составит конкуренцию InfiniBand в традиционных суперкомпьютерах, NVLink в стоечных решениях вроде NVIDIA GB200 NVL72, а также Ultra Accelerator Link (UALink) в масштабируемых системах ИИ в дата-центрах. Решение Tomahawk Ultra разработано в рамках инициативы Broadcom Scaling Up Ethernet (SUE). Утверждается, что эта технология будет поддерживать масштабируемые системы с не менее чем 1024 ускорителями ИИ. Для сравнения, NVIDIA заявляет, что её коммутационная система NVLink 5/6 позволяет объединить до 576 ускорителей в одном домене. Broadcom подчёркивает, что чип Tomahawk Ultra разработан с нуля специально для удовлетворения потребностей высоконагруженных НРС-сред и ИИ-кластеров. Новинка обеспечивает коммутационную способность 51,2 Тбит/с при размере пакетов 64 байта. Задержка составляет 250 нс, что значительно меньше, чем у коммутаторов с более высокой пропускной способностью. А общая задержка при общении XPU между собой составляет не более 400 нс. Поддерживается обработка до 77 млрд пакетов в секунду. 
Источник изображений: Broadcom Основная часть трафика, передаваемого через коммутаторы Ethernet, состоит из пакетов большего размера. Поэтому при проектировании сетевого оборудования внимание уделяется прежде всего увеличению размера пакетов для оптимизации пропускной способности. Вместе с тем обмен пакетами небольшого размера широко распространен в платформах НРС/ИИ: представленная новинка Broadcom нацелена именно на такие среды.
Чип-коммутатор Tomahawk Ultra (семейство BCM78920) поддерживают 64 порта 800GbE, 128 портов 400GbE или 256 портов 200GbE. Изделие использует блоки Peregrine 106.25G PAM4 SerDes. Решение совместимо по выводам с Broadcom Tomahawk 5 (TH5). Поддерживаются функции, предназначенные для масштабируемых нагрузок ИИ и HPC, включая Link Layer Retry (LLR), Credit-based Flow Control (CBFC) и AI Fabric Headers (AFH). Кроме того, непосредственно в ASIC реализована поддержка коллективных операций вроде AllReduce and AllGather. Используются измененные заголовки Ethernet, размер которых уменьшен с 46 до 10 байт: это позволяет оптимизировать общее соотношение размера заголовка к полезной нагрузке. Упомянута совместимость с современными топологиями сетей HPC, такими как Mesh, Torus и Dragonfly. Кроме того, заявлена совместимость с Ultra Ethernet (UEC). Поставки Tomahawk Ultra уже начались.
12.07.2025 [15:13], Сергей Карасёв
От 100GbE до 800GbE, недорого: стартап TORmem обещает трансформировать рынок ЦОД-коммутаторовСтартап TORmem, специализирующийся на решениях для дезагрегации памяти в дата-центрах, обнародовал планы по выпуску коммутаторов для сетей с высокой пропускной способностью. В семейство войдут модели с поддержкой стандартов от 100GbE до 800GbE. По утверждениям TORmem, она потратила четыре года на разработку «революционной технологии дезагрегации», которая позволяет реализовывать концепцию вычислений в оперативной памяти (IMC) в масштабах ЦОД. Полученный опыт стартап намерен использовать для решения другой проблемы современных дата-центров — высокой стоимости корпоративной сетевой инфраструктуры. TORmem обещает трансформировать сегмент коммутаторов корпоративного класса, выпустив высокопроизводительные устройства по цене в два раза меньше по сравнению с аналогичными решениями, уже представленными на рынке. В частности, TORmem предлагает для заказа модель стандарта 100GbE (S6500-32X) с 32 портами на основе ASIC Marvell: устройство стоит $7 тыс. против $14 тыс. или более у «стандартных продуктов», говорит компания. 
Источник изображений: TORmem В конце текущего года стартап намерен подготовиться к началу производства коммутаторов 200GbE/400GbE, которые, как ожидается, также окажутся на 50 % дешевле конкурирующих изделий: их цена составит от $12 тыс. до $20 тыс. против $25–$40 тыс., которые, как утверждается, будут просить конкуренты. Кроме того, в разработке находятся модели класса 800GbE.  На сайте Unipoe.net удалось обнаружить описание коммутатора RZ-S6500-32X. Он располагает 32 портами 40/100GbE QSFP28, а коммутируемая ёмкость достигает 6,4 Тбит/с. Устройство выполнено в форм-факторе 1U с габаритами 440 × 470 × 43 мм. Предусмотрены сетевой порт управления, консольный порт и разъём USB 2.0. В оснащение входят два блока питания и пять модульных вентиляторов с возможностью горячей замены. Максимальное энергопотребление составляет менее 650 Вт. Диапазон рабочих температур — от 0 до +40 °C. Упомянута поддержка протоколов RIP, IS-IS, RIPng, OSPFv3, BGP4+ и пр. Отраслевые аналитики прогнозируют, что объём глобального рынка высокоскоростных коммутаторов увеличится с примерно $8 млрд в 2025 году до более чем $15 млрд в 2027-м. Основным драйвером отрасли называется внедрение решений стандарта 200GbE и выше.
09.04.2025 [00:49], Алексей Степин
Все против NVIDIA: представлена открытая альтернатива NVLink — интерконнект UALink 200G 1.0Консорциум UALink, в состав которой входят AMD, AWS, Astera Labs, Cisco, Google, HPE, Intel, Meta✴ и Microsoft, опубликовала первые спецификации на разрабатываемую в рамках альянса более доступную альтернативу проприетарным решениям NVIDIA. Интерконнект UALink призван заменить в первую очередь NVLink и во многом опирается на AMD Infinity Fabric, хотя пока что по скоростям составляет конкуренцию скорее Ethernet и InfiniBand. Консорциум Ultra Accelerator Link был сформирован в конце прошлого года с целью создания высокоскоростного интерконнекта с низкими задержками, базирующегося на открытых технологиях. Речь здесь не только о приверженности открытым стандартам, но и о солидном потенциальном куске рынка — только за прошедший финансовый год сетевое подразделение NVIDIA выручило $13 млрд. 
Источник здесь и далее: UALink Появление более доступной и открытой альтернативы теоретически должно пошатнуть позиции последней в этом секторе, а также позволить разработчикам HPC-систем и ИИ-кластеров избежать жёсткой привязки к одному вендору. В том числе речь идёт о возможности организации сети UALink, включающей в себя GPU и ускорители разных поставщиков. Упор в первой версии стандарта сделан на общий доступ к памяти ускорителей с высокой скоростью, низкими задержками и простыми атомарными операциями 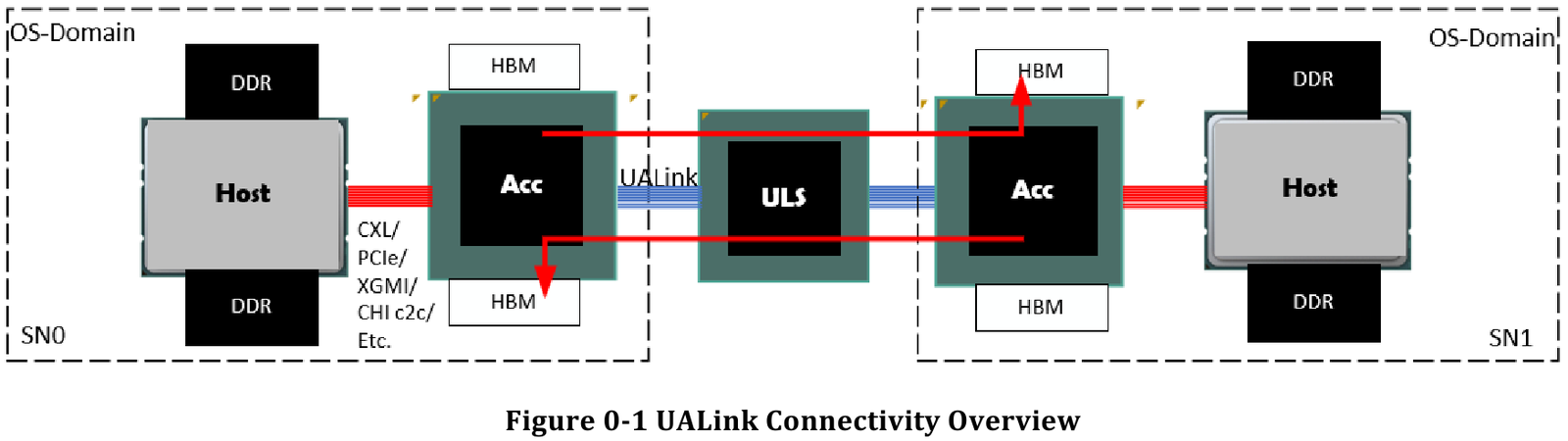 Впервые опубликованные спецификации описывают стандарт UALink 200G 1.0. В основе лежит коммутируемая сеть с пропускной способностью 200 Гбит/с на каждую линию, во многом наследующая AMD Infinity Fabric, но дополненная разработками других участников альянса. Максимальное количество линий на один ускоритель может достигать четырёх, что позволяет поднять пропускную способность до 800 Гбит/с. Поддерживается бифуркация. 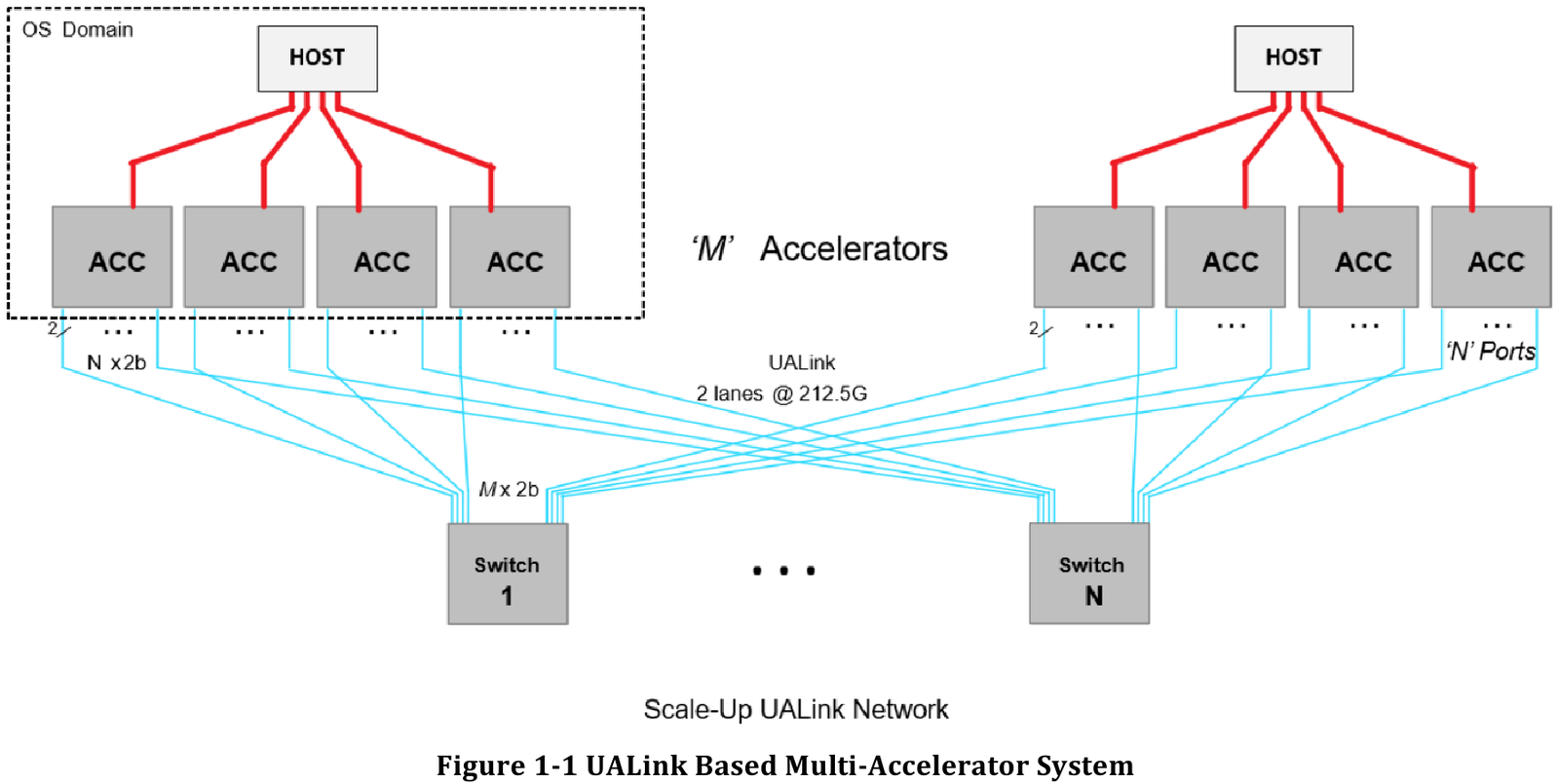 Размер кластера в данной версии стандарта UALink ограничен 1024 узлами, не считая коммутаторов. При этом гарантируются линейные скорости на уровне соответствующих версий Ethernet, но c энергопотреблением от трети до половины от аналогичного показателя последних, при времени отклика на уровне коммутируемых вариантов PCI Express. Задержка от порта к порту должна составить менее 100 нс, на уровне коммутаторов UASwitch — 100–150 нс. Для сравнения: NVLink 5/6 позволяет объединить до 576 ускорителей в одном домене со скоростью до 0,9–1,8 Тбайт/с на ускоритель.  Также предусмотрена совместная работа с Ethernet в составе GPU-кластера, где хост-процессоры общаются между собой посредством традиционной сети (в том числе Ultra Ethernet), а ускорители могут использовать либо прямое, либо коммутируемое подключение UALink. 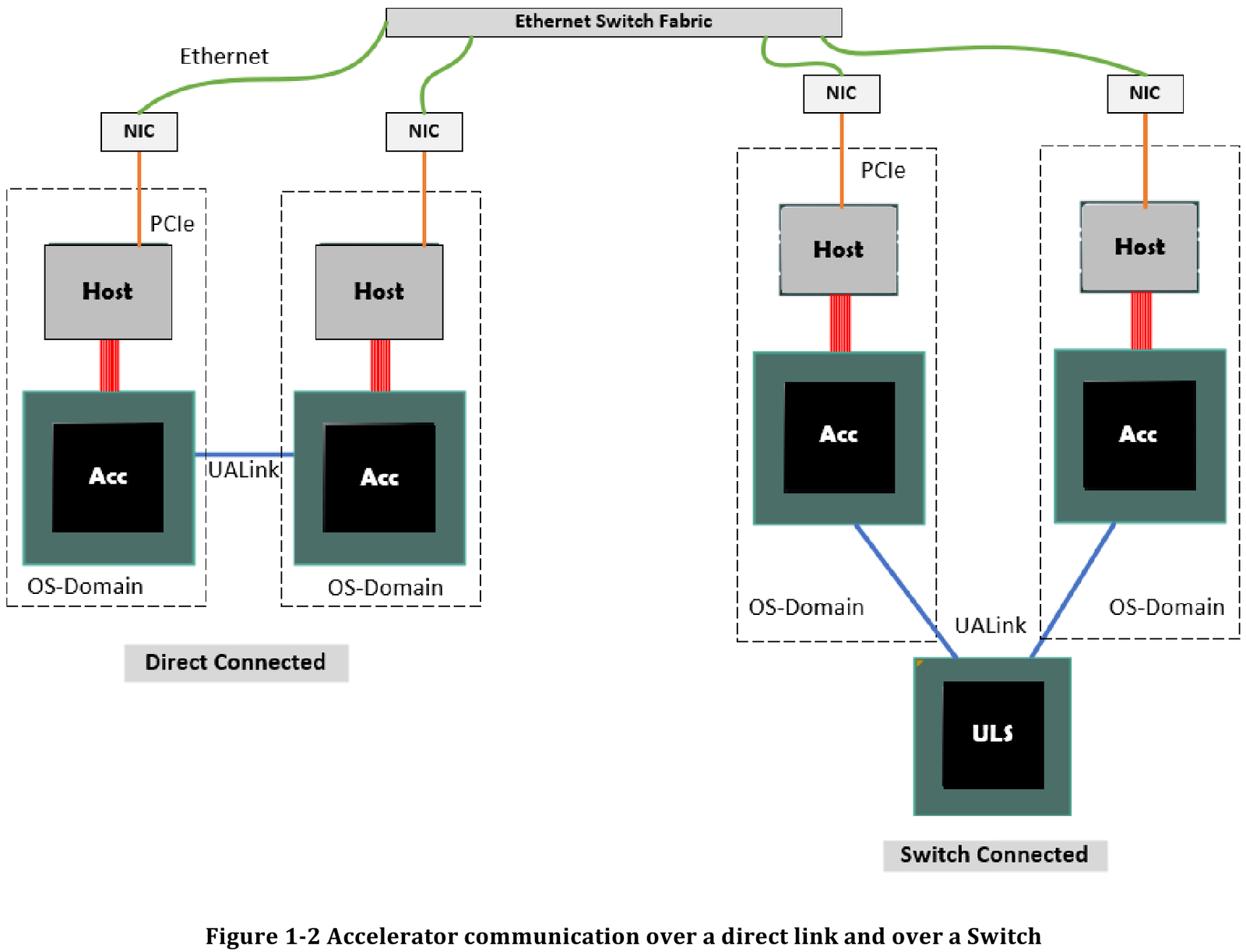 Передача данных осуществляется словами длиной 680 байт: 640-байт флит-пакеты + 40 байт накладных расходов на упреждающую коррекцию ошибок (FEC) и кодирование 256B/257B. Реализованы механизмы доступа к удалённой памяти, но когерентность на аппаратном уровне не поддерживается, также имеются различия на подуровне PCS (Physical coding sublayer). На физическом уровне используется стандарт IEEE 802.3dj: 200GBASE-KR1/CR1, 400GBASE-KR2/CR2 и 800GBASE-KR4/CR4. Имеющиеся ретаймеры для Ethernet также совместимы с UALink. 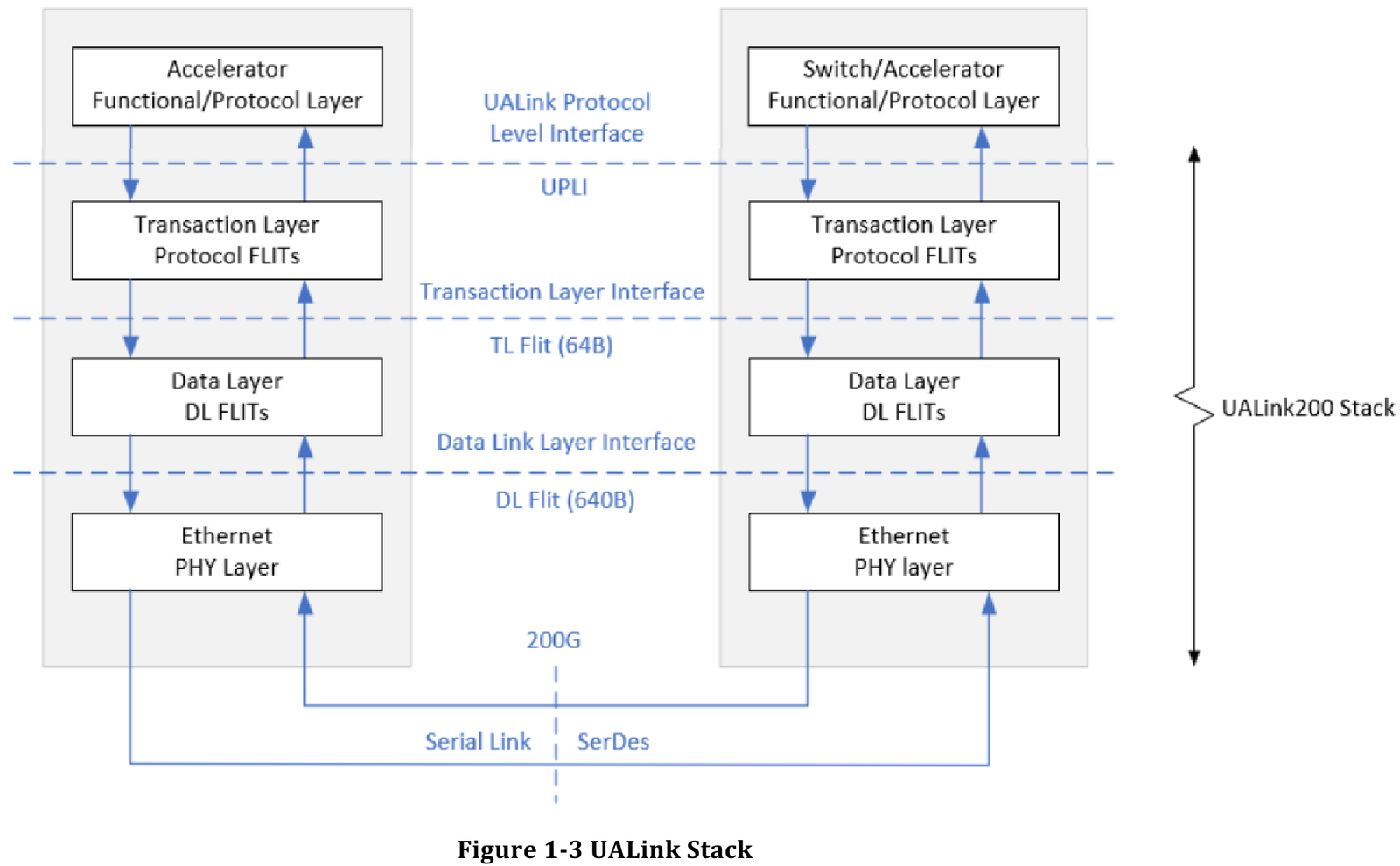 Спецификации UALink 200G 1.0 доступны на сайте проекта. Глава консорциума UALink, Кёртис Боумен (Kurtis Bowman) настроен оптимистично и говорит примерно о 18 месяцах до появления первых аппаратных решений, что на полгода быстрее типичных сценариев воплощения спецификаций «в железо». Тем временем, альянс уже начал работу над второй версией UALink, использующей стек технологий 400G.
29.03.2025 [10:11], Алексей Степин
Bolt Graphics анонсировала универсальную видеокарту со слотами SO-DIMM, которая может потягаться с RTX 5080Все современные графические ускорители предлагаются с жёстко заданным при производстве объёмом видеопамяти, а в наиболее производительных моделях память типа HBM вообще интегрирована на одной с основным кристаллом подложке. Однако требования к объёму памяти в последнее время растут быстрее, а за дополнительный объём вендор просят всё больше. Кардинально иной подход предлагает компания Bolt Graphics, недавно анонсировавшая серию ускорителей Zeus. Несмотря на «ИИ-пандемию», Bolt Graphics в своём анонсе не делает упор на искусственный интеллект, а называет Zeus первым GPU, специально созданным для целей HPC, рендеринга, трассировки лучей и даже компьютерных игр. Что интересно, в основе Zeus лежит не некая закрытая архитектура: скалярная часть нового GPU построена на базе спецификации RISC-V RVA23, векторная представлена FP64 ALU на базе несколько модифицированной RVV 1.0. Прочие функции реализованы путём кастомных расширений и отдельных блоков-ускорителей. Все они пользуются общим кешем объёмом 128 Мбайт. Дополняет картину блок телеметрии и внутренний интерконнект для общения с другими вычислительным блоками. 
Zeus 1c26-032 (Источник изображений: Bolt Graphics) Используется чиплетный подход. Базовый «строительный блок» Zeus 1c26-032 включает GPU-чиплет, который соединён с 32 Гбайт набортной памяти LPDDR5x (273 Гбайт/с) и контроллером внешней памяти DDR5 (90 Гбайт/с), т.е. при желании можно установить ещё 128 Гбайт RAM (два модуля SO-DIMM). В GPU-чиплет встроены контроллеры DisplayPort 2.1a и HDMI 2.1b, а с внешним миром он общается посредством IO-чиплета, с которым он соединён 256-Гбайт/с каналом. IO-чиплет предлагает необычный набор портов. Помимо сразу двух интерфейсов PCIe 5.0 x16 (64 Гбайт/с каждый) имеется выделенный порт RJ-45 для BMC и 400GbE-порт QSFP-DD. Наконец, есть аппаратный блок видеокодирования, способный справиться с двумя потоками 8K@60 AV1/H.264/H.265.  Заявленный уровень производительности в векторных FP64/FP32/FP16-вычислениях составляет 5/10/20 Тфлопс, а в матричных INT16/INT8 — 307,2/614,4 Топс. Аппаратный блок ускорения лучей (path tracing) выдаёт до 77 гигалучей. Для сравнения: NVIDIA RTX 5090 способна выдавать 32 гигалуча, а FP64-производительность составляет 1,6 Тфлопс. В то же время в расчётах пониженной точности актуальные решения NVIDIA всё равно быстрее Zeus 1c26-032. Однако у новинки есть важное преимущество — её уровень TDP составляет всего 120 Вт. Второй интерфейс PCIe 5.0 x16 можно использовать для прямого объединения двух карт. 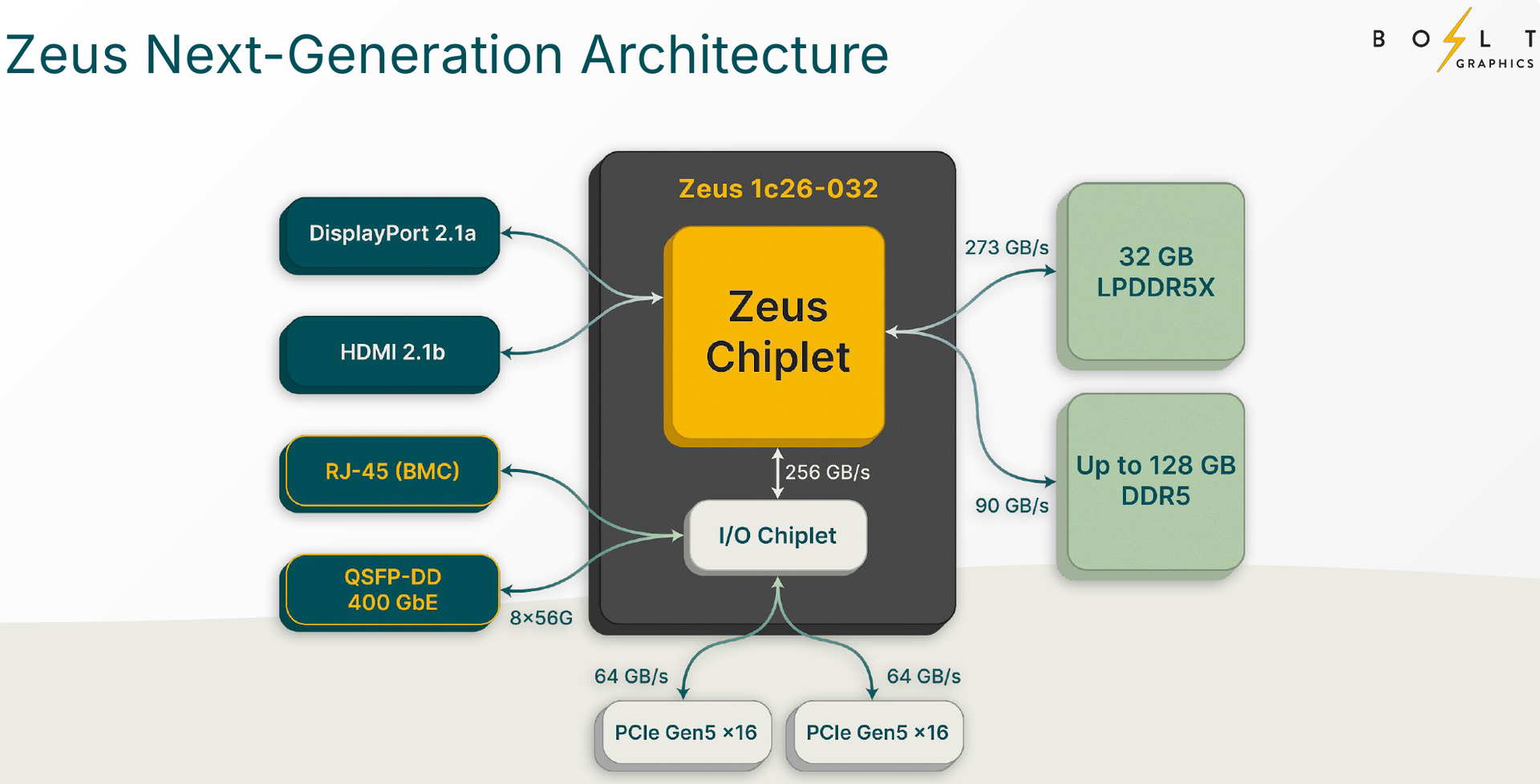 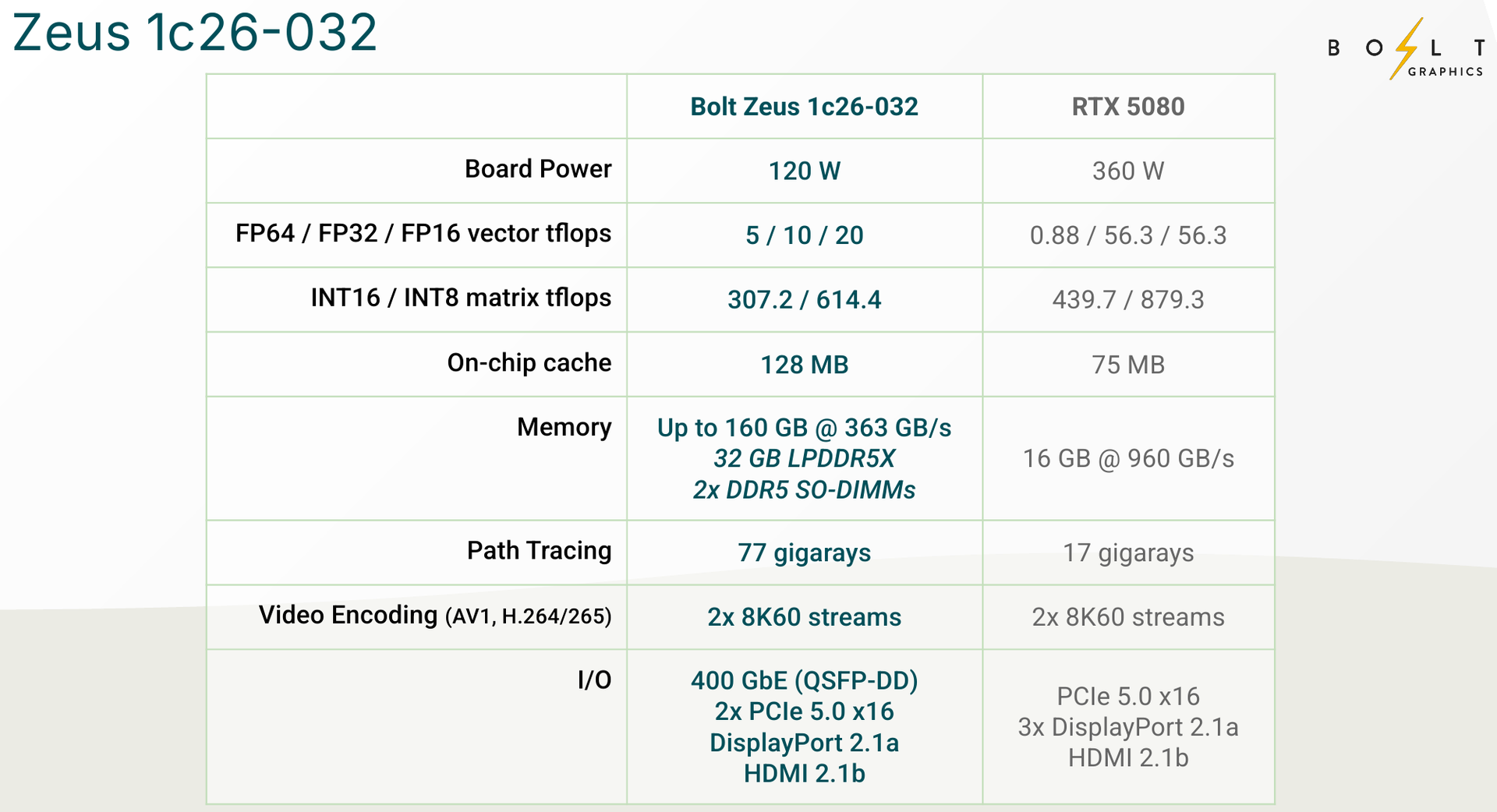 Вариант ускорителя с двумя чиплетами носит название Zeus 2c26-064/128, а с четырьмя — 4c26-256. Последние числа обозначают объём распаянной памяти LPDDR5X. Что касается расширяемой памяти, то количество доступных разъёмов SO-DIMM также зависит от модели и составляет до восьми, так что во флагманской конфигурации базовые 256 Гбайт LPDDR5x можно дополнить аж 2 Тбайт DDR5. Производительность с увеличением количеств GPU-чиплетов растёт практически пропорционально, но есть некоторые другие нюансы. Так, в Zeus 2c26-064 и Zeus 2c26-128 (оба варианта имеют TDP 250 Вт) есть только один IO-чиплет, а GPU-чиплеты объединены шиной со скоростью 768-Гбайт. 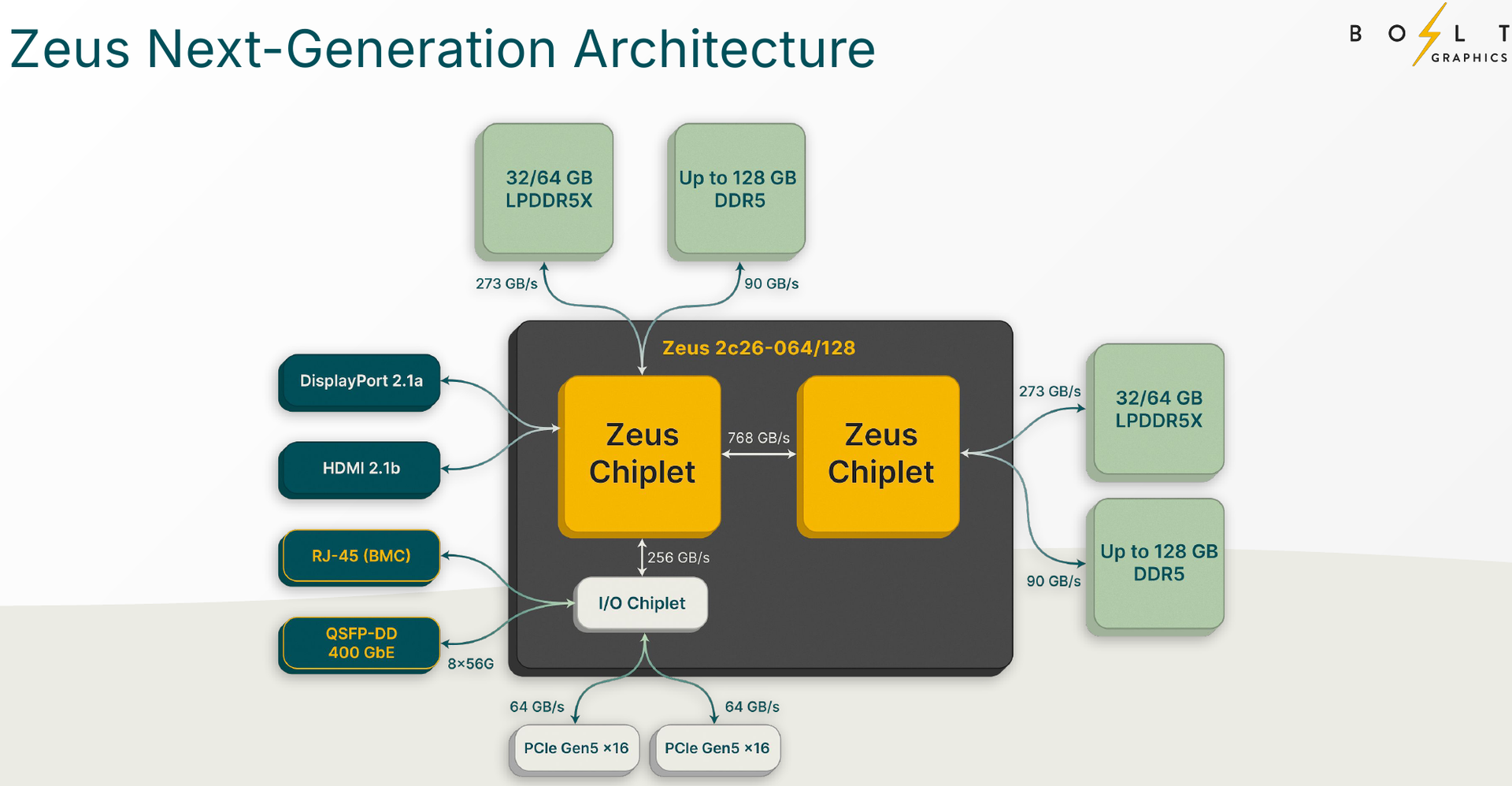  Zeus 4c26-256 имеет сразу четыре I/O чиплета в составе, которые дают восемь контроллеров PCIe 5.0 x4 (один чиплет, совокупно 32 линии) и шесть 800GbE-портов OSFP (три чиплета). Между собой GPU-чиплеты объединены шиной со скоростью 512-Гбайт/с. Каждый из них соединён с собственным IO-чиплетом на скорости 256 Гбайт/с. Теплопакет флагмана составляет 500 Ватт, ускоритель, если верить Bolt Graphnics, развивает 20 Тфлопс в режиме FP64, почти 2500 Топс на вычислениях FP8 и способен обрабатывать до 307 гигалучей. 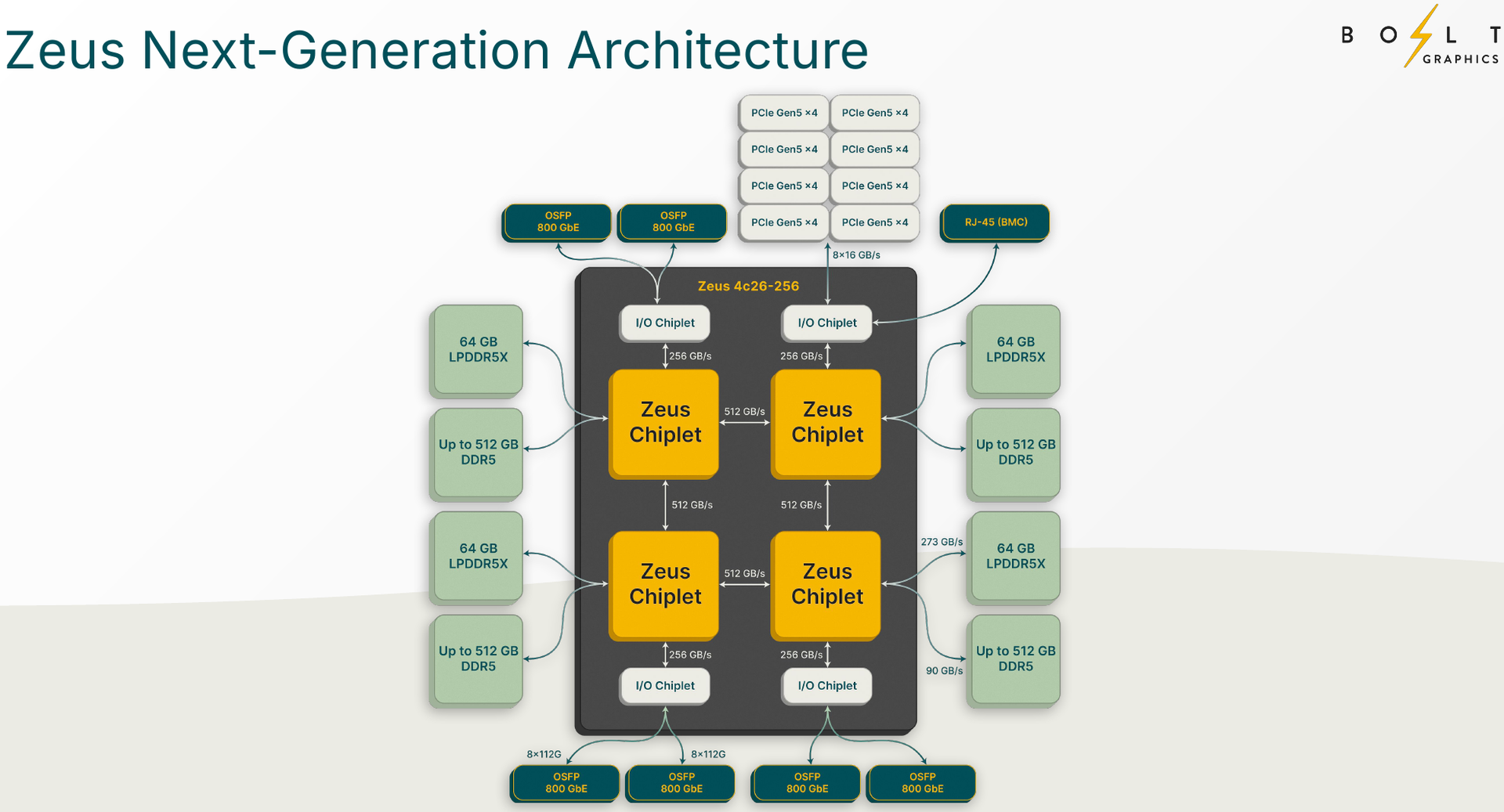 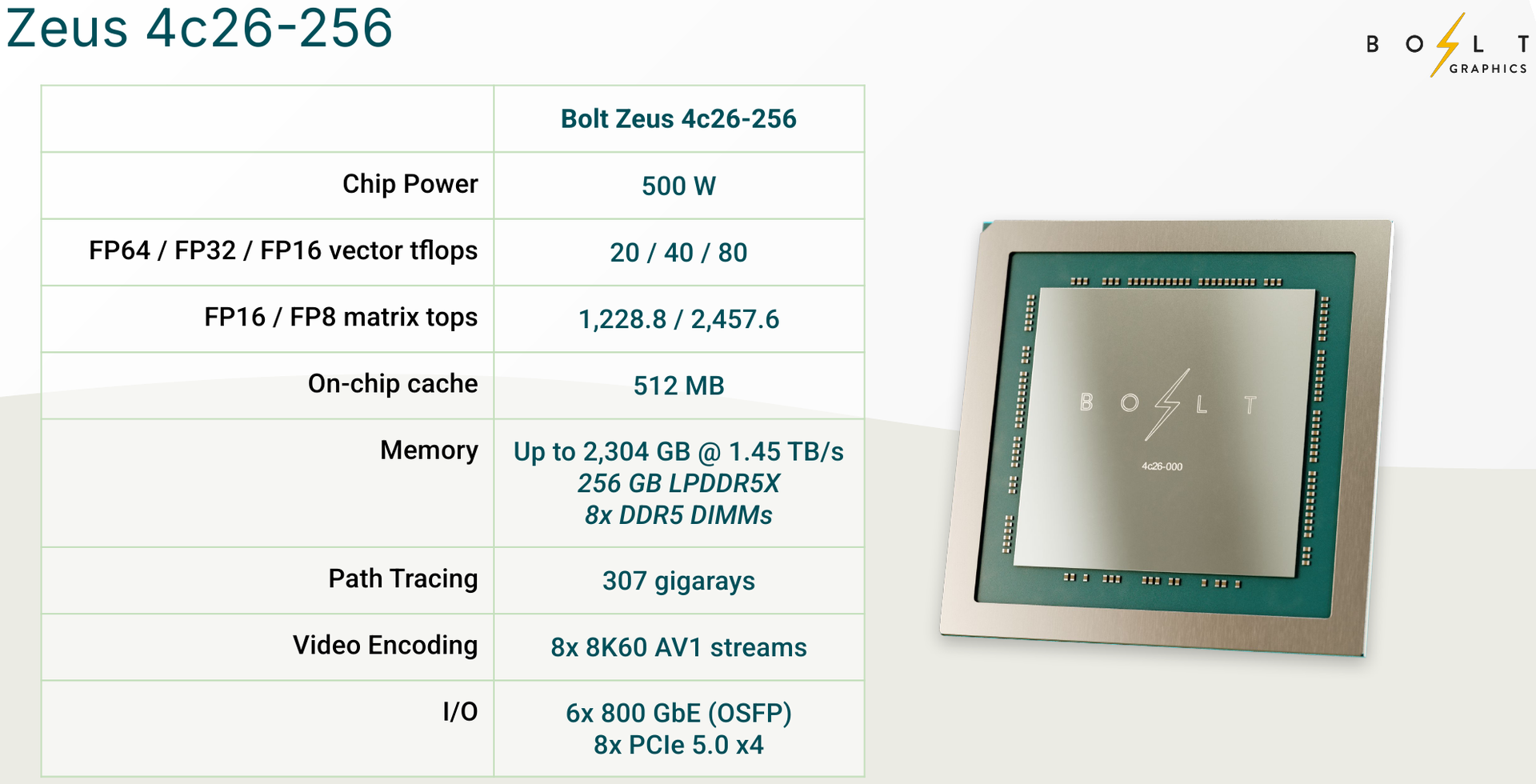 Разработчики явно заложили в своё детище широкие возможности кластеризации, о чём свидетельствует наличие мощной сетевой подсистемы. Поддерживаются как скромные конфигурации из двух GPU, соединённых непосредственно по Ethernet 400GbE, так и масштабные системы уровня стойки, содержащей 80 плат Zeus 4c26-256, соединённых как с коммутатором, так и напрямую друг с другом. Такой кластер потребляет 44 кВт, но зато способен обеспечивать запуск крупных физических симуляций или обучение ИИ моделей за счёт огромного массива общей памяти, составляющего 160 Тбайт. Вычислительная производительность такого кластера достигает 1,6 Пфлопс в режиме FP64 и 196 Попс в режиме FP8. 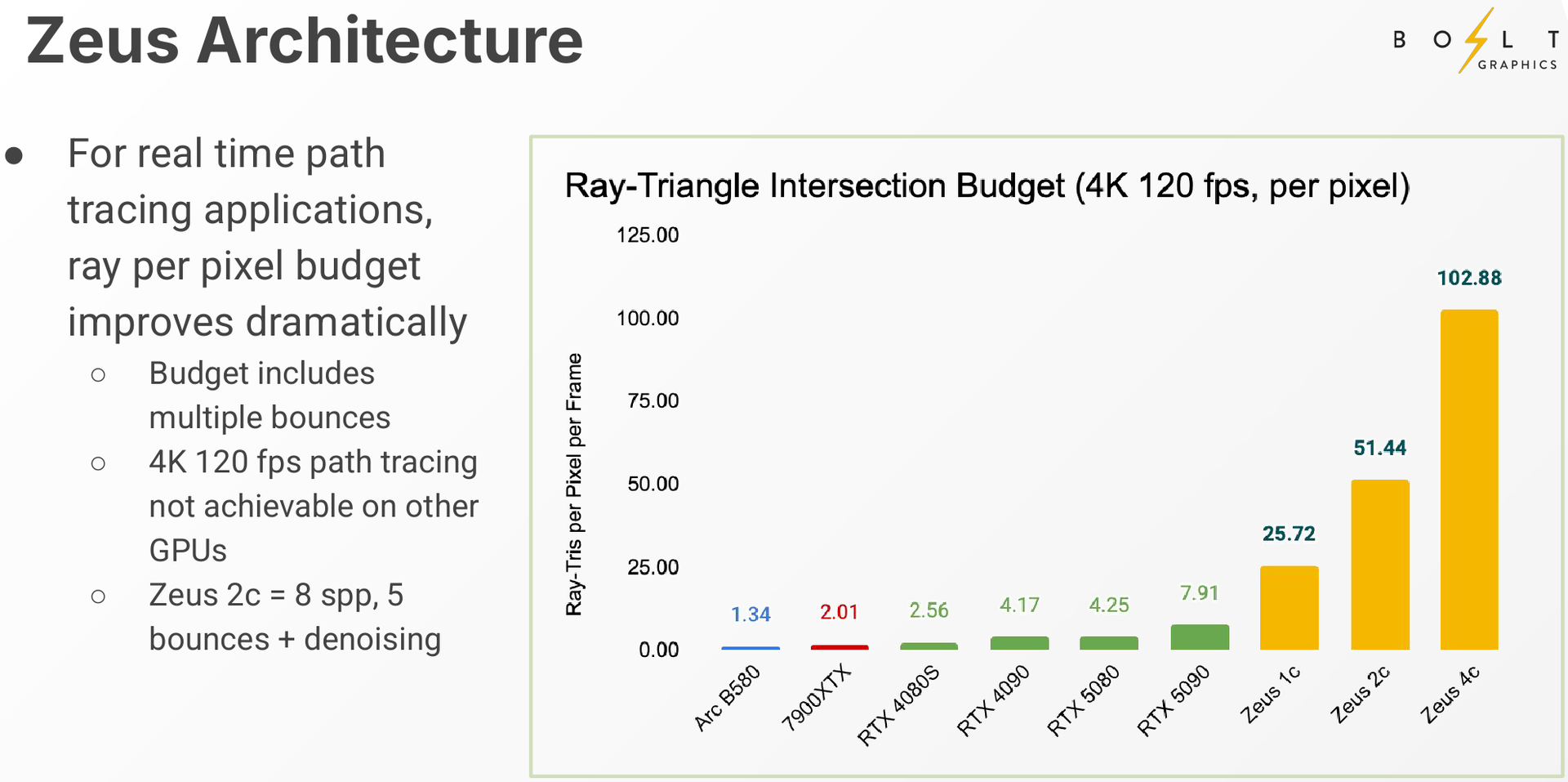  Одной из особенностей новинок является трассировщик лучей Glowstick, способный работать в режиме реального времени практически во всех современных пакетах 3D-моделирования или видеоредактирования, таких как Maya, 3ds Max, Blender, SketchUp, Houdini и Nuke. Он будет дополнен фирменной библиотекой Bolt MaterialX, содержащей более 5000 текстур высокого качества. А благодаря поддержке стандарта OpenUSD он сможет легко интегрироваться в любую цепочку рендеринга и пост-обработки. Также запланирован электромагнитный симулятор Bolt Apollo. Обещаны фирменные драйверы Vulkan/DirectX и SDK с использованием LLVM. 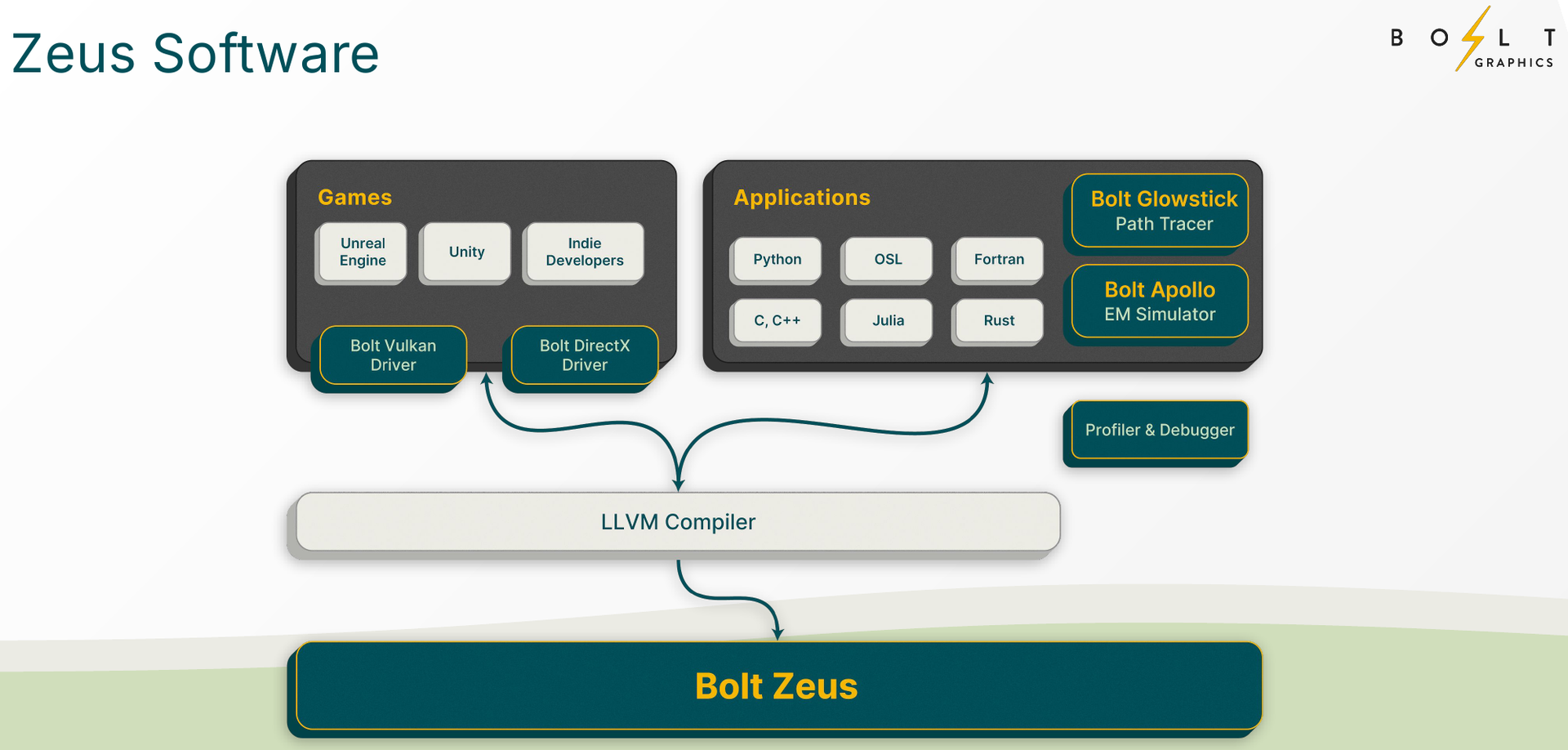 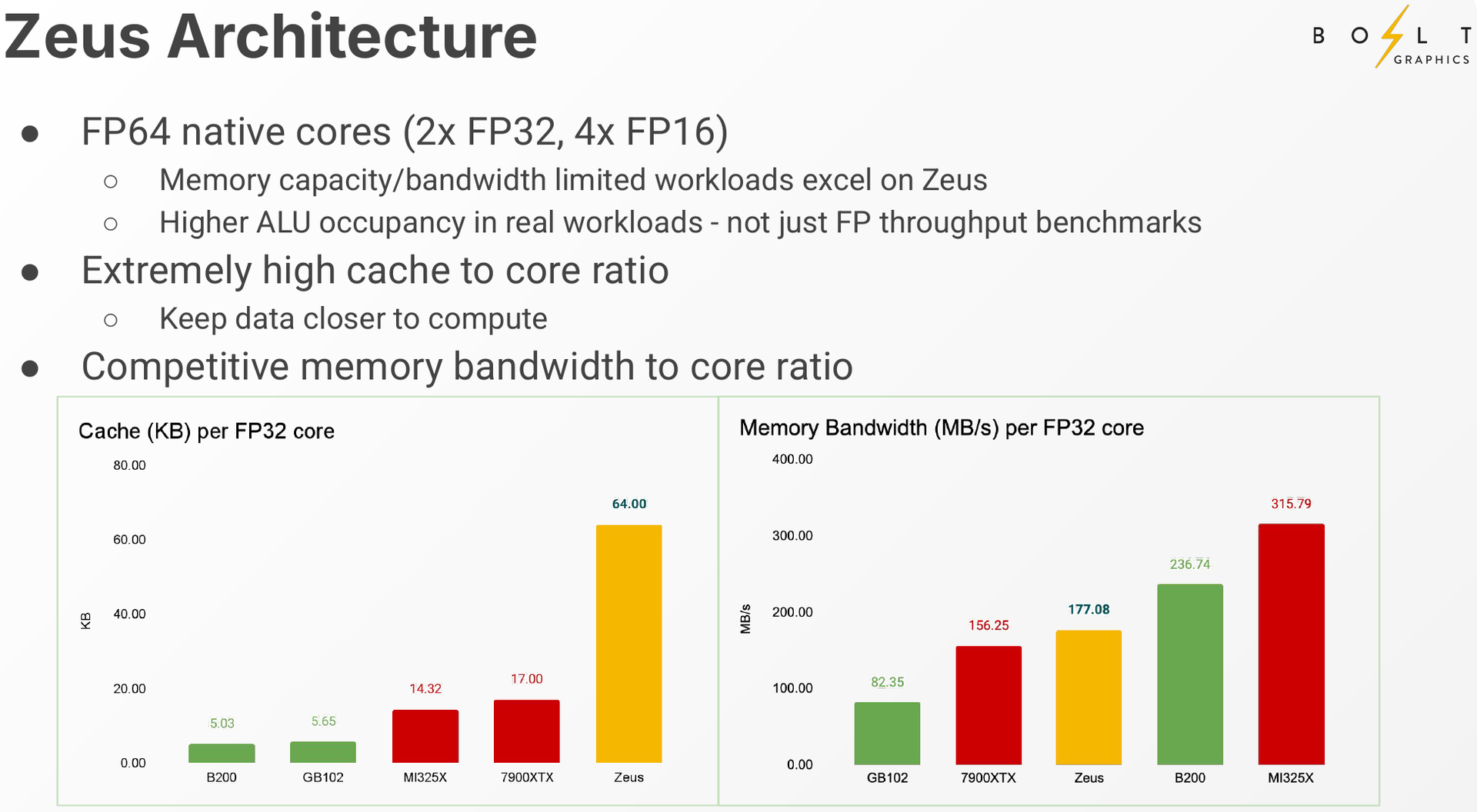 Ранний доступ к комплектам разработчика Bolt Graphics наметила на IV квартал текущего года. В III квартале 2026 года должны появиться 2U-серверы на базе Zeus, а массовые поставки серверов и PCIe-карт начнутся не ранее IV квартала того же года. Пока сложно сказать, насколько хорошо новая архитектура себя проявит, но если верить предварительным тестам Zeus, выигрыш в сравнении с существующими ускорителями существенен, особенно в энергопотреблении.
18.03.2025 [23:12], Алексей Степин
Интегрированная фотоника и СЖО: NVIDIA анонсировала 800G-коммутаторы Spectrum-X и Quantum-XГонка в области ИИ накладывает отпечаток на облик ЦОД: сетевая инфраструктура становится всё сложнее и сложнее в погоне за высокой пропускной способностью и минимальными задержками. За это приходится платить повышенным расходом энергии на обеспечение работы оптических трансиверов. Поэтому NVIDIA представила новое поколение коммутаторов с интегрированной кремниевой фотоникой, которое должно решать эту проблему, а заодно обеспечить повышенную надёжность и скорость развёртывания сетевой инфраструктуры. По оценкам NVIDIA, традиционный облачный дата-центр на каждые 100 тысяч серверов расходует 2,3 МВт энергии на обеспечение работы оптических трансиверов, но в ИИ-кластерах, где каждому ускорителю нужно своё быстрое сетевое подключение, эта величина может достигать уже 40 МВт, т.е. до 10 % от общего уровня энергопотребления всего комплекса. Гораздо разумнее было тратить эту энергию на вычислительную, а не сетевую инфраструктуру. 
Источник здесь и далее: NVIDIA Новые коммутаторы Spectrum-X и Quantum-X должны решить эту проблему кардинально. В них применены новые ASIC, объединяющие на одной подложке чип-коммутатор и фотонные модули. Такой подход позволяет отказаться сразу от нескольких звеньев традиционной цепочки, входящих в классический оптический трансивер. Современный высокоскоростной трансивер включает восемь лазеров, которые потребляют порядка 10 Вт, и DSP-блок, который требует 20 Вт. 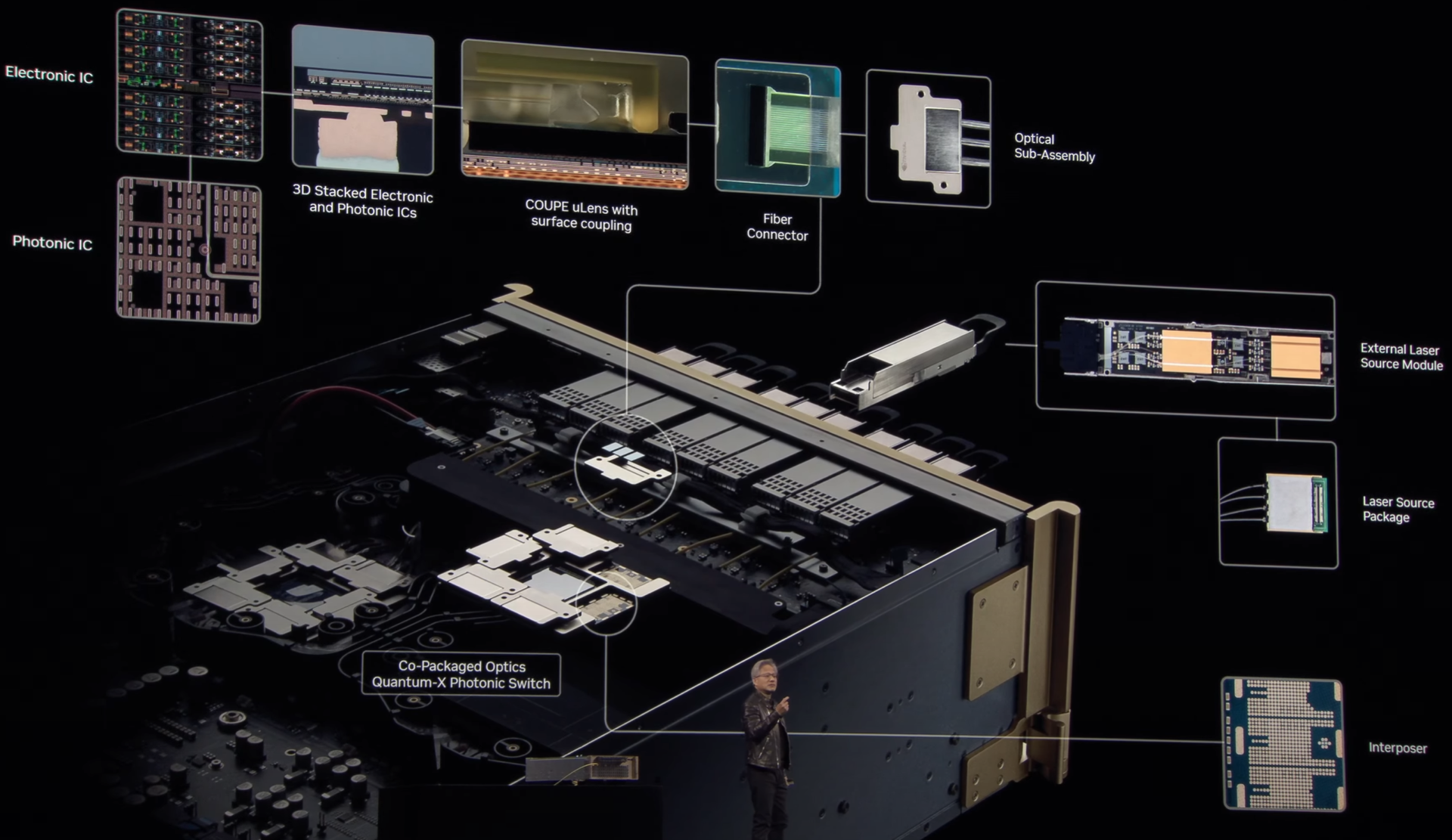 Интегрированная фотоника (CPO) позволяет обойтись всего двумя внешними лазерами для обеспечения работы одного порта 1,6 Тбит/с. Лазеры соединяется в этой схеме непосредственно с фотонным модулем на борту новых ASIC. Собственно оптический движок в составе ASIC потребляет всего 7 Вт, ещё 2 Вт требует лазер. Разница в энергопотреблении минимум трёхкратная.  Кроме того, упрощение схемы соединений способствует повышению надёжности: NVIDIA говорит о 63-кратном улучшении целостности сигнала, которому не приходится добираться через несколько электрических соединений от ASIC до трансивера и внутри последнего, и о десятикратном повышении общей надёжности сети. Если в традиционной схеме потери сигнала на его электрическом пути могут составлять 22 дБ, то для схемы с фотонным модулем этот показатель составляет всего 4 дБ.  Новая схема упаковки ASIC достаточно сложна: в ней реализованы разъёмные оптические соединители, позволяющие реализовывать сценарии с различной конфигурацией портов коммутаторов, со скоростями от 200 до 800 Гбит/с. Флагманский коммутатор Spectrum SN6800 включает 512 портов 800GbE с совокупной скоростью коммутации 409,6 Тбит/с. Модель SN6810 компактнее, она предлагает 128 портов 800GbE и коммутацию до 102,4 Тбит/с.  Серия Quantum-X пока представлена моделью Quantum 3450-LD: 144 порта 800G InfiniBand с совокупной производительностью 115 Тбит/с. Сочетание высокой плотности с такими скоростями потребовала разработки и интеграции кастомной системы жидкостного охлаждения. Новые коммутаторы Quantum-X станут доступны во II половине этого года, а Spectrum-X — во II половине 2026 года.  В оптических движках собственной разработки NVIDIA использованы микрокольцевые модуляторы (MRM), реализация которых стала доступной благодаря сотрудничеству NVIDIA с TSMC в области упаковки «многоэтажных» чипов COUPE. Помимо TSMC в создании новых коммутаторов приняли участие компании Browave, Coherent, Corning Incorporated, Fabrinet, Foxconn, Lumentum, SENKO, SPIL, Sumitomo Electric Industries и TFC Communication.  Особенно серьёзно преимущества новой схемы проявляют себя в больших масштабах, на уровне сотен тысяч ускорителей. Время развёртывания снижается в 1,3 раза, а общая надёжность сети становится на порядок выше. Правда, пока что речь идёт только о коммутаторах — оптические кабели будут напрямую подключаться к их портам. Однако другой конец кабеля всё равно будет уходить в трансивер, обслуживающий отдельный ускоритель или узел. Также пока нет никаких планов по переводу NVLink на «оптику», поскольку внутри узла и NVL-стойки работать с «медью» по-прежнему проще и выгоднее.
22.02.2025 [22:38], Сергей Карасёв
STMicroelectronics представила фотонный чип для 1,6-Тбит/с сетейКомпания STMicroelectronics объявила о разработке фотонного чипа PIC100, предназначенного для организации высокоскоростного оптического интерконнекта в дата-центрах, ориентированных на задачи ИИ. Изделие создано в сотрудничестве с Amazon Web Services (AWS). Чипы PIC100 планируется изготавливать с использованием технологического процесса BiCMOS на основе 300-мм кремниевых пластин. Метод BiCMOS предполагает объединение биполярных и КМОП-транзисторов на одном кристалле. Такой подход позволяет совместить преимущества компонентов обоих типов: технология обеспечивает улучшенную производительность по сравнению с КМОП-решениями при меньшей рассеиваемой мощности по сравнению с продуктами на основе только биполярных транзисторов. По заявлениям STMicroelectronics, на начальном этапе чипы PIC100 смогут поддерживать пропускную способность до 200 Гбит/с на линию. Это даёт возможность формировать соединения, обеспечивающие скорость передачи данных до 800 Гбит/с и 1,6 Тбит/с. Более того, STMicroelectronics работает над решениями с пропускной способностью до 400 Гбит/с на линию, что в конечном итоге, как ожидается, позволит создавать оптические интерконнекты со скоростью до 3,2 Тбит/с. 
Источник изображения: STMicroelectronics Одной из проблем на пути практического применения подобных изделий являет рост выделяемого тепла, что может приводить к снижению производительности или увеличению частоты сбоев оборудования. Для минимизации таких негативных эффектов специалисты STMicroelectronics разработали специальные волноводы и оптоволоконные адаптеры. Производить чипы PIC100 планируется на предприятии STMicroelectronics в Кроле (Crolles) во Франции. Выпуск будет организован к концу текущего года. |
|


