Материалы по тегу: tpu
|
09.06.2026 [00:29], Владимир Мироненко
Google заказала у Intel упаковку 3 млн TPU — у TSMC спрос превысил возможности производстваХолдинг Alphabet, материнская структура Google, заключил сделку с Intel, в рамках которой та изготовит для него в 2028 году более 3 млн кастомных TPU. Сообщивший об этом ресурс The Information добавил, что Google в течение нескольких месяцев тестировала технологии Intel, прежде чем принять решение о сделке. The Information отметил, что Intel получает заказы от таких компаний, как Google, в то время как тайваньский производитель микросхем TSMC испытывает трудности с удовлетворением спроса на выпускаемую им продукцию из-за нехватки производственных мощностей. Как пишет Bloomberg, акции Intel недавно достигли рекордного уровня после того, как её прогноз продаж превзошёл ожидания Уолл-стрит, показав, что компания наконец-то извлекает выгоду из бума инвестиций в ИИ. Оптимистичный прогноз свидетельствует о том, что генеральный директор Лип-Бу Тан (Lip-Bu Tan) добился успеха в стремлении вывести компанию из стагнации. После крупных инвестиций в Intel в прошлом году, которые помогли укрепить баланс компании, он теперь выполняет обещание улучшить её операционную деятельность. 
Источник изображения: Intel По данным The Information, NVIDIA также тестирует возможность использования технологии Intel для создания будущего процессора, объединяющего четыре графических чипа в одном блоке. Однако NVIDIA никак не прокомментировала эту публикацию. Ранее стало известно о планах Илона Маска (Elon Musk) использовать техпроцесс Intel следующего поколения 14A для производства чипов на будущем заводе Terafab в Остине (Austin). Вместе с тем остаётся неясным, насколько Google и другие компании будут полагаться на бизнес Intel по производству полупроводников, по сравнению с услугой упаковки, пишет Bloomberg. Последняя услуга включает в себя помещение чипов в корпус и подготовку их к подключению к другим схемам. Intel сообщила инвесторам, что накопила многомиллиардный портфель заказов на работы по упаковке микросхем. Этот этап в производстве полупроводников традиционно имеет меньшее значение и обходится дешевле, чем процесс создания электронных компонентов из кремниевых пластин. Но его важность возросла, поскольку объединение микросхем в одном корпусе всё чаще рассматривается как способ достижения лучшей производительности, особенно в случае компонентов для ЦОД. Как отметил Bloomberg, заказ на 3 млн чипов не изменит финансовое состояние убыточного производственного бизнеса Intel в одночасье. Это эквивалентно объёму производства крупного завода за месяц или даже меньше. Тем не менее обращения крупных компаний, свидетельствующие о готовности доверять Intel реализацию важных задач, помогут укрепить позиции её технологий и повысить шансы на привлечение других клиентов.
19.05.2026 [21:50], Руслан Авдеев
«Обезгугленные» TPU: Blackstone и Google развернут 500-МВт облако с фирменными ИИ-ускорителями Google без участия Google CloudBlackstone и Google создали совместное предприятие для строительства в США новой облачной платформы, клиенты которой получат доступ к фирменным ИИ-ускорителям Google TPU, но без участия Google Cloud, сообщает Datacenter Dynamics. Blackstone инвестирует $5 млрд собственного капитала. Компании намерены ввести в эксплуатацию 500 МВт вычислительных мощностей к 2027 году. В будущем планируется расширение платформы. Google выступит поставщиком TPU и другого оборудования, а также программного обеспечения и сопутствующих сервисов. Генеральным директором компании назначен топ-менеджер Google Бенджамин Трейнор Сносс (Benjamin Treynor Sloss), более двадцати лет проработавший в компании. По словам Blackstone, партнёрство с Google позволит объединить высококлассные TPU и компетенции последней в сфере ИИ с «исключительными преимуществами» Blackstone в сфере энергетики и цифровой инфраструктуры. В ходе последнего финансового отчёта Google рассказала о планах предлагать свои TPU клиентам за пределами Google Cloud Platform. Предполагалось, что TPU начнут поставлять избранной группе клиентов, которые смогут использовать их в собственных ЦОД для расширения потенциала рынка. По такой схеме будет действовать Anthropic, которая купит TPU напрямую у Broadcom, но с тем нюансом, что размещаться они будут в ЦОД Fluidstack, за которой сейчас тоже стоит Google. Meta✴ тоже получит TPU, но у неё, в отличие от Anthropic, хотя бы есть обширный опыт строительства и эксплуатации дата-центров. 
Источник изображения: Google Ранее Blackstone объявила о намерении вывести на IPO созданный недавно REIT-фонд, специализирующийся на инвестициях в недвижимость — преимущественно в дата-центры. Подразделение будет покупать стабильные, недавно построенные ЦОД, в основном на рынках первого эшелона в Северной Америке. Компания неоднократно инвестировала значительные средства в сегмент ЦОД. Ей принадлежит QTS и AirTrunk, а также доли в Vnet, Lumina CloudInfra, Copeland, Park Place Technologies и Winthrop Technologies. Кроме того, Blackstone не так давно приобрела миноритарный, но крупный пакет акций американской Rowan, также специализирующейся на дата-центрах. В апреле Blackstone объявила о создании специального ИИ-подразделения Blackstone N1 (BXN1). Представители последней заявили, что для создания масштабных ИИ-платформ недостаточно просто денег. Необходимо правильно выбранные партнёры, правильная структура взаимодействия и убеждённость в необходимости поддержки тех или иных уникальных возможностей. TPU Google, развивающиеся более десяти лет, стали важной частью ИИ-экономики и именно для инвестиций в подобные решения создавалась BXN1.
03.05.2026 [23:30], Владимир Мироненко
Поборы Broadcom вынудили Google обратиться к MediaTek для создания ИИ-ускорителей TPUСогласно свежему отчёту Foundry Quarterly and Monthly Intelligence от Counterpoint Research, благодаря сотрудничеству с Google доля компании MediaTek на рынке ИИ-серверов на базе кастомных ускорителей (ASIC) может вырасти к 2028 году до 26 %. В результате MediaTek может выйти на второе место, уступив лишь Broadcom. Google представила в апреле два TPU восьмого поколения: TPU 8t (Sunfish) для обучения ИИ и TPU 8i (Zebrafish) для ИИ-инференса. Как сообщается в отчёте Counterpoint Research, TPU v8t занимает ключевое место в стратегии Google в области ИИ. «Мы рассматриваем это поколение как переломный момент с точки зрения цепочки поставок, поскольку оно знаменует собой первый важный шаг в диверсификации Google от простой модели ASIC Broadcom “под ключ”», — отметили в Counterpoint Research. Что касается основной причины соглашения Google с MediaTek, в рамках которого Google разрабатывает вычислительный кристалл, а MediaTek предоставляет кристалл I/O, то Counterpoint Research объясняет это экономикой закупок HBM. В рамках модели поставок «под ключ» Broadcom сама занимается поиском поставщиков HBM, прибавляя к стоимости памяти ещё 15–20 %. С учётом того, что на HBM приходится всё более значительная доля в себестоимости ASIC, такая наценка становится всё более обременительной для Google, которая к тому же наращивает темпы развёртывания TPU в ЦОД. Взяв на себя разработку чипов и закупку HBM, начиная с TPU 8t, Google устраняет поборы посредников и снижает себестоимость своих чипов. 
Источник изображения: Google Объём производства MediaTek значительно возрастёт после того, как начнётся выпуск TPU 8t в конце 2026 года и его преемника TPU v8e (Humufish) в период до 2028 года. Исходя из последнего прогноза глобальных поставок ASIC для ИИ-вычислений, аналитики ожидают, что совокупные поставки TPU v8t и v8e приблизятся к 5 млн единиц в 2028 году, что более чем в 10 раз больше по сравнению с отгрузкой примерно 400 тыс. чипов в 2026 году. Это станет возможным благодаря ускоренному внедрению TPU Google как для внутренних рабочих нагрузок, так и для облачных клиентов. Комментируя прогноз, Counterpoint Research уточняет, что он не учитывает реализацию проекта Meta✴ MTIA. Кроме того, достижение прогнозируемого объёма зависит от наличия достаточных мощностей по упаковке TSMC CoWoS и Intel EMIB-T. Основной риск для реализации прогноза связан с TPU v8e, для которого MediaTek предлагает упаковку Intel EMIB-T: «В настоящее время компания находится на стадии проектирования и квалификации, а массовое производство запланировано не ранее конца 2027 года, и этот переход сопряжён с весьма специфическими рисками для исполнения». К числу ключевых факторов отнесены необходимое для этого увеличение производительности Intel Foundry Services (IFS) и готовность поставщиков подложек, что в конечном итоге может повлиять на объём поставок MediaTek.
01.05.2026 [22:57], Владимир Мироненко
Google планирует начать продажу собственных ИИ-ускорителей TPUХолдинг Alphabet, включающий компанию Google, сообщил финансовые результаты I квартала 2026 года, завершившегося 31 марта. Выручка и прибыль Alphabet превзошли прогнозы Уолл-стрит, в основном, благодаря ускорению роста продаж облачного подразделения Google Cloud. Все три ведущих поставщика облачной инфраструктуры — Amazon, Google и Microsoft — превзошли прогнозы аналитиков за прошедший квартал, но Google оказалась первой, продемонстрировав самый быстрый темп роста за всю историю. Выручка Alphabet выросла год к году на 22 % до $109,9 млрд против $107,2 млрд, ожидаемых аналитиками, опрошенными LSEG (по данным CNBC). Скорректированная разводнённая прибыль на акцию составила $5,11 при прогнозе $2,63. Чистая прибыль Alphabet (GAAP) составила $62,58 млрд, что на 81 % больше по сравнению с предыдущим годом. Годом ранее чистая прибыль составляла $34,54 млрд, или $2,81 на акцию. Google Cloud превзошла ожидания Уолл-стрит, зафиксировав рост выручки на 63 % по сравнению с прошлым годом до $20,03 млрд, превысив консенсус-прогноз StreetAccount в $18,05 млрд. Это самый высокий темп роста за любой период с 2020 года, когда Google начала публиковать результаты работы облачных сервисов. Компания заявила, что рост был обусловлен увеличением доли Google Cloud Platform (GCP) в корпоративных решениях и ИИ-инфраструктуре. 
Источник изображений: Alphabet Сообщается, что портфель заказов Google Cloud составляет $462 млрд, что почти вдвое больше, чем в предыдущем квартале. Теперь он включает обязательства по поставке TPU. Генеральный директор Сундар Пичаи (Sundar Pichai) сообщил, что компания намерена продавать TPU, а не просто предоставлять к ним доступ посредством Google Cloud. «По мере роста спроса на TPU со стороны ИИ-лабораторий, компаний, работающих на рынках капитала, и приложений для высокопроизводительных вычислений, мы начнем поставлять TPU избранной группе клиентов в их собственные ЦОД в аппаратной конфигурации, чтобы расширить наши потенциальные рыночные возможности», — заявил Пичаи, о чём пишет DataCenter Dynamics. Финансовый директор Alphabet Анат Ашкенази (Anat Ashkenazi) не стала уточнять, насколько много сейчас в портфеле заказов сделок по поставке TPU, лишь отметив, что «большая часть портфеля заказов по-прежнему состоит из соглашений с GCP». «Если говорить об общем объёме невыполненных заказов, то чуть более половины из них превратятся в выручку в течение следующих 24 мес. Что касается продаж аппаратного обеспечения TPU, то мы ожидаем, что небольшой процент из них принесёт выручку в конце этого года, а большая часть — в 2027 году», — добавила она. Впрочем, пока речь идёт в основном о сделке с Anthropic, которая фактически закупит TPU у Broadcom и разместит их в ЦОД Fluidstack, поддерживаемых самой Google. 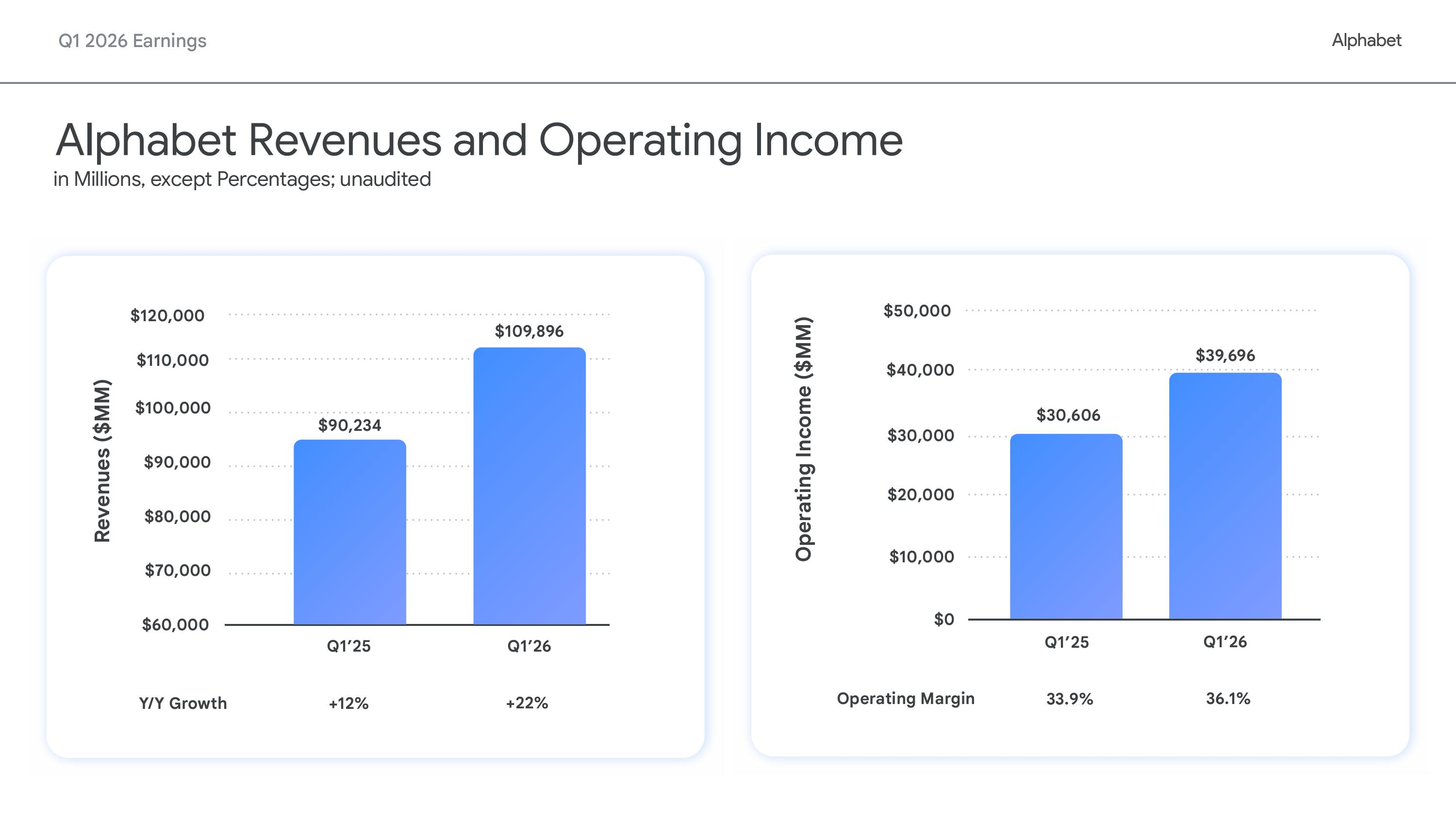 Сундар Пичаи также сообщил, что «корпоративные решения в области ИИ впервые стали нашим основным драйвером роста в облачной сфере». Он имел в виду предложения в области ИИ, такие как Gemini Enterprise, где число платных ежемесячно активных пользователей выросло на 40 % по сравнению с предыдущим кварталом. Компания сообщила, что собственные ИИ-модели обрабатывают более 16 млрд токенов в минуту через API, что на 60 % больше, чем в предыдущем квартале, подчёркивая масштаб вычислительных потребностей ИИ-стека Google. По словам Пичаи, выручка от продуктов, созданных с использованием генеративных ИИ-моделей Google, выросла на 800 %. Alphabet заявила, что обновляет свой прогноз капитальных затрат на 2026 год до $180–$190 млрд по сравнению с предыдущей оценкой в $175–$185 млрд. Финансовый директор предупредила инвесторов, что компания ожидает «значительного увеличения» капитальных затрат в 2027 финансовом году по сравнению с текущим годом. В предыдущем квартале капитальные затраты компании составили $35,7 млрд. Как и другие компании в сфере облачных вычислений, Alphabet вкладывает значительные средства в свою ИИ-инфраструктуру, стремясь извлечь выгоду из растущего спроса на ИИ. «В краткосрочной перспективе мы ограничены в вычислительных мощностях, — сказал Пичай. — Наша выручка от облачных вычислений была бы выше, если бы мы смогли удовлетворить спрос». 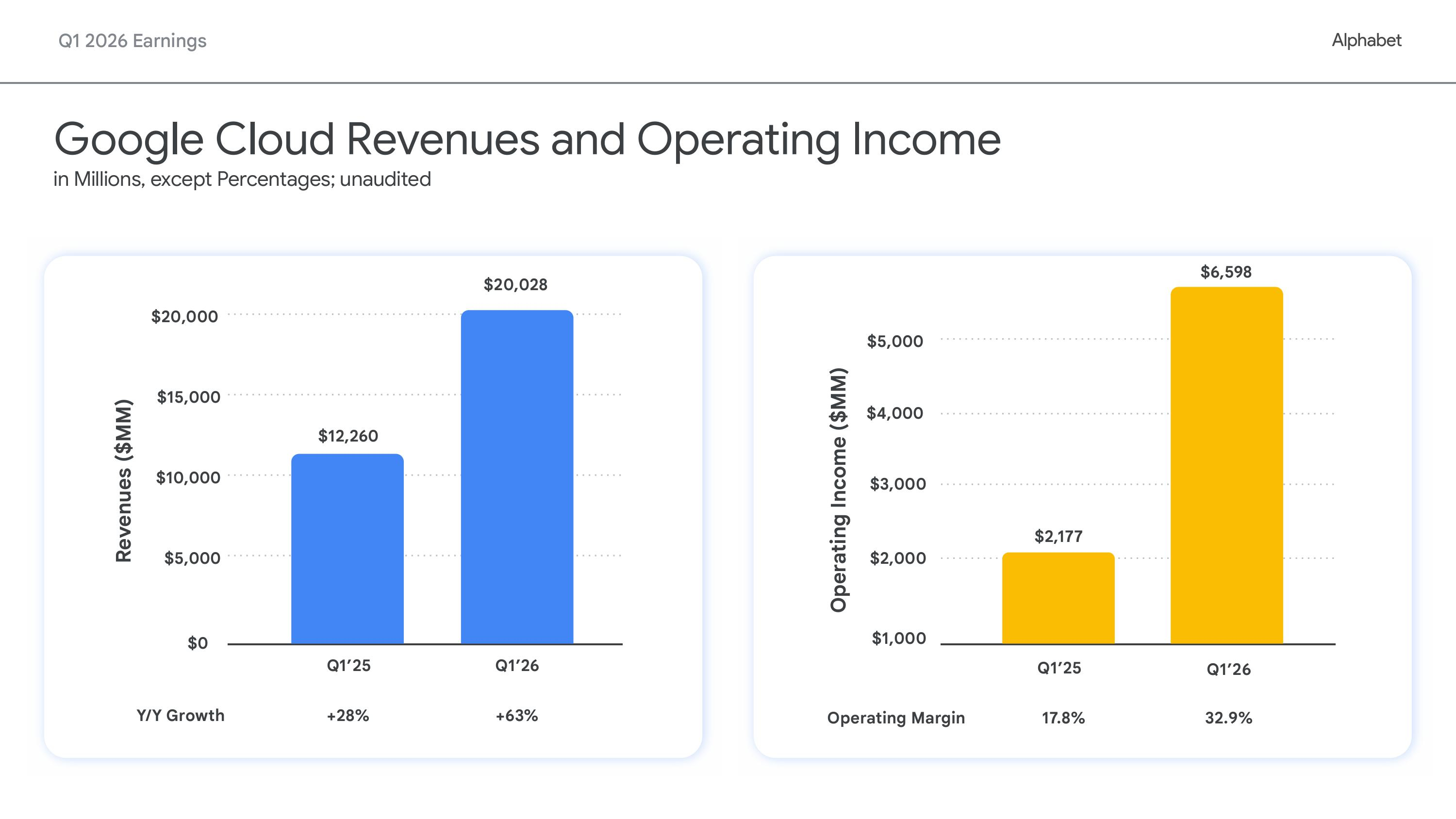 На фоне обеспокоенности инвестором стремительным ростом капитальных расходов поставщиков инфраструктуры Alphabet показала, что её прогноз капзатрат находится в пределах её возможностей благодаря устойчивости и качеству кривой роста выручки, сообщил ресурсу SiliconANGLE аналитик Investing.com Томас Монтейро (Thomas Monteiro). Он отметил, что компании удалось оптимизировать капзатраты, сместив акцент с инфляции затрат и маржи на то, кто обладает достаточными ресурсами для конкуренции на рынке ИИ-инфраструктуры в плане выручки. «Ответ таков: на данный момент практически никто не может конкурировать с Alphabet, — говорит Монтейро. — В то время как другие продолжают тратить деньги и наращивать долговую нагрузку, Alphabet продолжает лидировать, демонстрируя высокую рентабельность и имея возможности для дальнейшего ускорения роста при необходимости». «На рынке, где всем требуется больше вычислительных мощностей, Alphabet доказывает, что может позволить себе участвовать в гонке, одновременно расширяя все направления бизнеса», — добавил он. 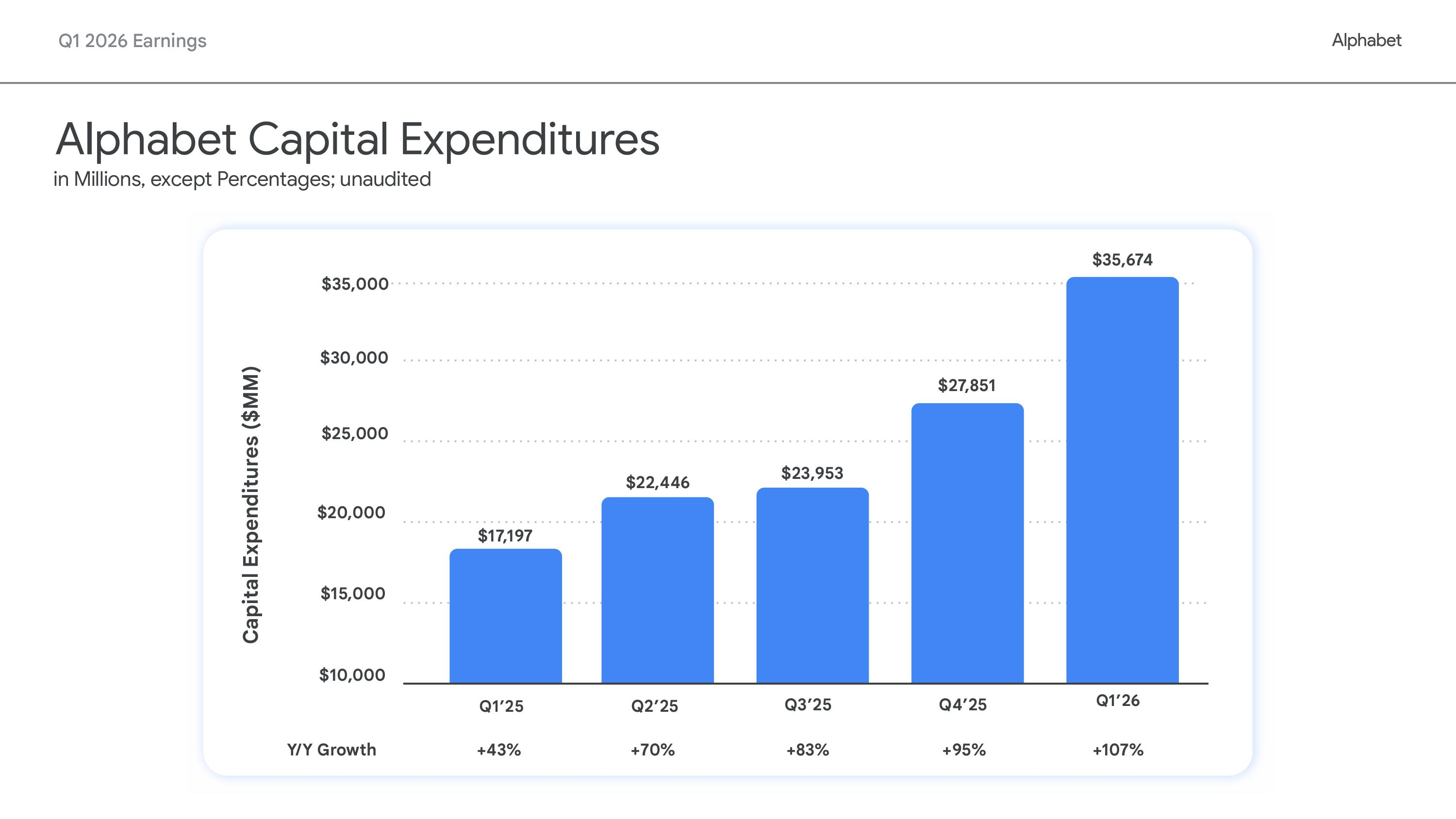 Другие направления бизнеса Alphabet также показали хорошие результаты. Выручка от Google Services — включая поиск, YouTube и подписки — составила $89,64 млрд, что на 16 % больше год к году. Выручка от поиска и прочих услуг выросла на 19 % до $60,4 млрд. Выручка от рекламы на YouTube составила $9,88 млрд, увеличившись на 11 %.
23.04.2026 [01:20], Владимир Мироненко
Для обучения и инференса — Google анонсировала ИИ-ускорители TPU 8t и TPU 8iGoogle представила два TPU восьмого поколения: TPU 8t (Sunfish) для обучения ИИ и TPU 8i (Zebrafish) для ИИ-инференса. Компания и раньше экспериментировала с различными вариантами TPU, в частности, со своими чипами пятого поколения V5p и V5e, но последние поколения, такие как Trillium и Ironwood, в основном следовали единому подходу. По словам Амина Вахдата (Amin Vahdat), старшего вице-президента и главного технолога Google по ИИ и инфраструктуре, TPU 8t и TPU 8i — результат десятилетней разработки (первые TPU были анонсированы в мае 2016 г.), специально созданные для обеспечения работы суперкомпьютеров следующего поколения с высокой эффективностью и масштабируемостью. Вахдат описывает TPU 8t как «мощную платформу для обучения», созданную для «сокращения цикла разработки моделей с месяцев до недель». Она предлагает в 2,8 раза лучшее соотношение цены и производительности, чем предыдущее поколение. 
Источник изображений: Google В TPU 8t используются векторные, матричные и SparseCore-ядра, дополненные 128 Мбайт SRAM и 216 Гбайт HBM3e (6,5 Тбайт/с). FP4-производительность составляет до 12,6 Пфлопс (также поддерживаются BF16/FP8/INT8). Для вертикального масштабирования используется межчиповый интерконнект (ICI) со скоростью 19,2 Тбит/с (в каждую сторону), для горизонтального — 400 Гбит/с. Кластер с TPU 8t может масштабироваться до 9,6 тыс. чипов, предлагая 2 Пбайт памяти HBM, 121 Эфлопс и вдвое большую межчиповую пропускную способность по сравнению с Ironwood, позволяя самым сложным моделям использовать единый, огромный пул памяти. 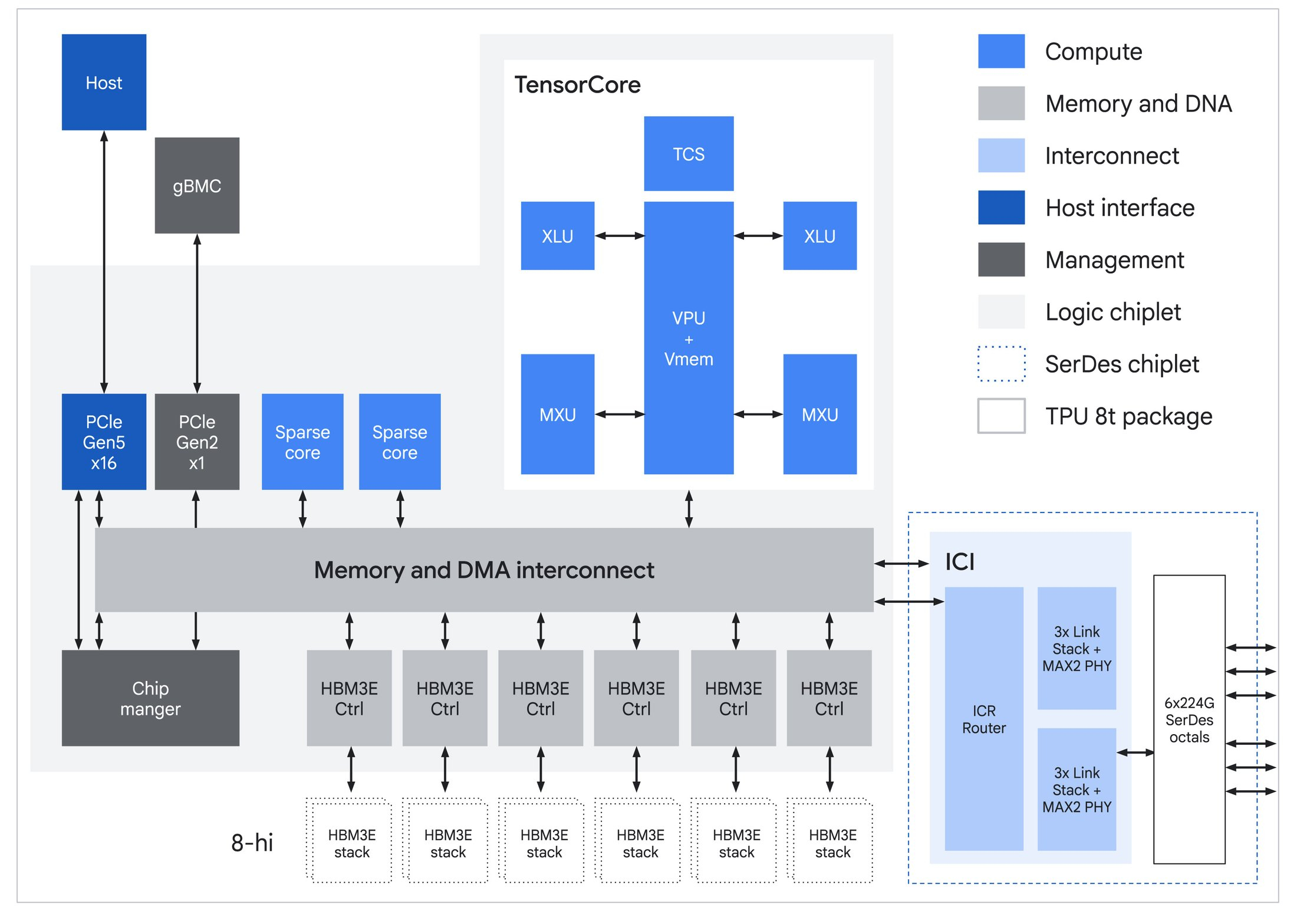 8t-кластеры объдиняет сеть Virgo Network, которая использует плоскую двухуровневую неблокирующую топологию, обеспечивает четырёхкратное увеличение пропускной способности в ЦОД и построена на коммутаторах с высокой степенью защиты, что сокращает количество сетевых уровней. В рамках одного ЦОД Virgo Network позволяет объединить до 134 тыс. чипов, что даёт до 47 Пбит/с неблокирующих соединений и более 1,6 Ифлопс с почти линейным масштабированием. А в рамках нескольких ЦОД в единый кластер можно объединить более 1 млн TPU. 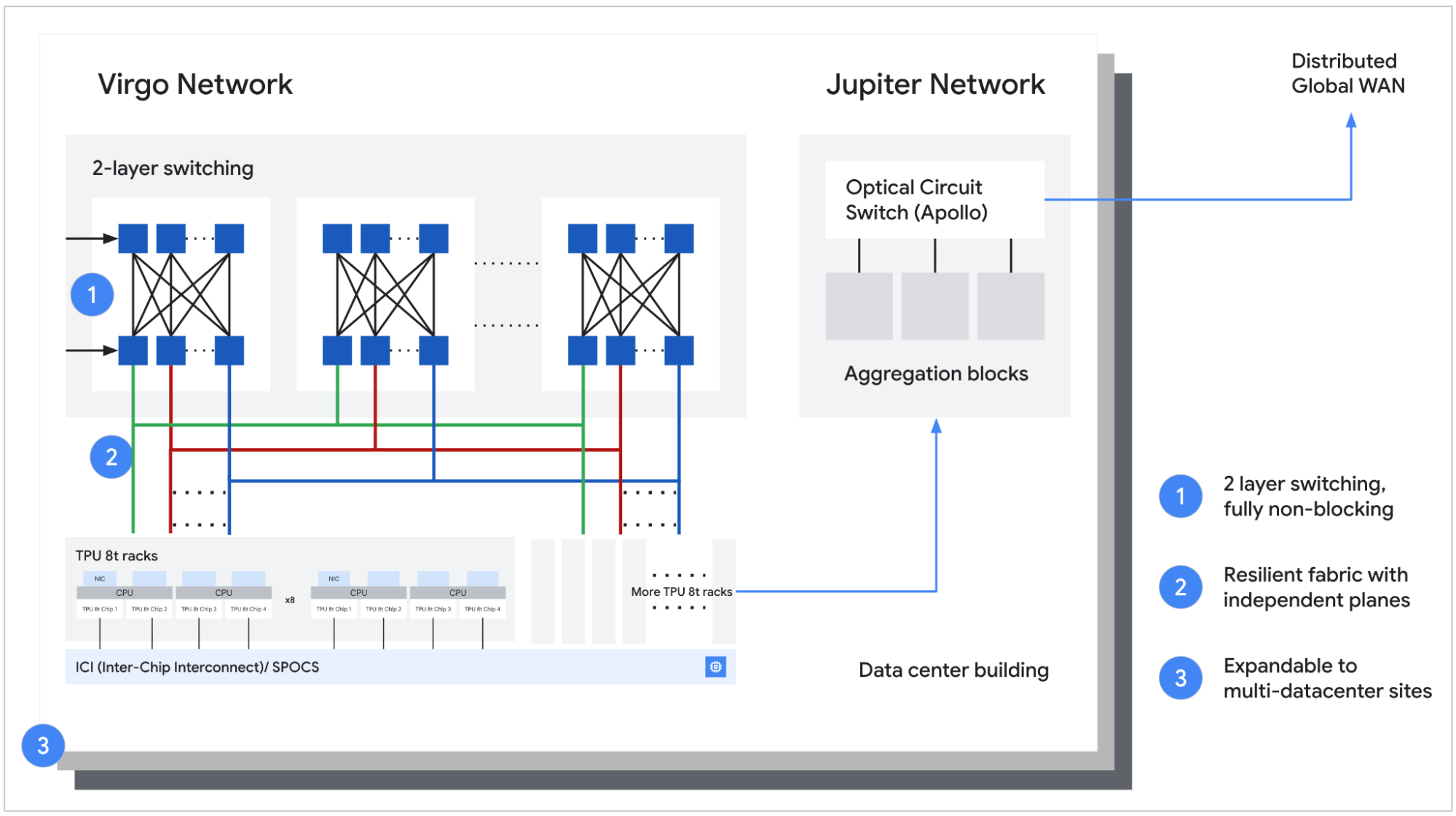 В TPU 8t используются технологии TPUDirect RDMA и TPUDirect Storage. TPU Direct RDMA обеспечивает прямую передачу данных между HBM и NIC, минуя CPU и DRAM хоста, а TPUDirect Storage напрямую связывает память TPU и СХД, таким как 10T Lustre, которая обеспечивает до 10 Тбайт/с, что даёт на порядок более быстрый доступ к хранилищу в сравнении с Ironwood и позволяет доставлять петабайты данных к ускорителям. 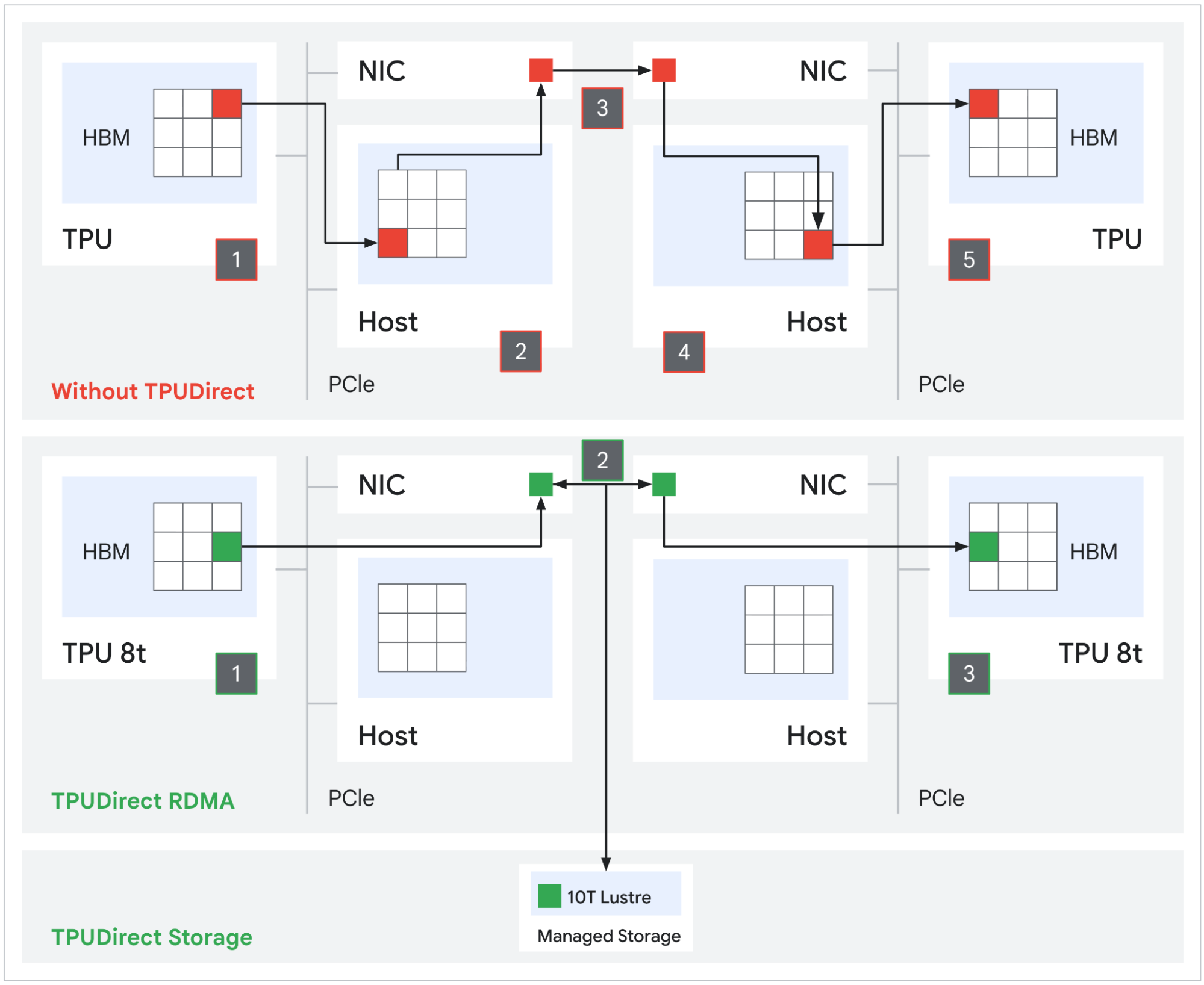 Кроме того, TPU 8t получили расширенные возможности RAS. К ним относятся телеметрия в реальном времени для десятков тысяч чипов, автоматическое обнаружение неисправных каналов ICI и перенаправление трафика без прерывания задания, а также оптическая коммутация каналов (OCS), которая перенастраивает оборудование в случае сбоев без участия человека. Всё это позволяет довести уровень утилизации чипа до 97 %.  В свою очередь, TPU 8i создан для обработки «сложной, совместной, итеративной работы множества специализированных агентов», которые появляются с развитием агентного ИИ. TPU 8i использует 288 Гбайт памяти HBM (8,6 Тбайт/с) в паре с 384 Мбайт SRAM — втрое больше, чем в предыдущем поколении. По словам Google, такой объём SRAM помогает TPU 8i удерживать большую часть KV-кеша на кристалле, что значительно сокращает время простоя ядер во время декодирования длинных контекстов. Компания отказалась от SparseCores в пользу нового встроенного механизма ускорения коллективных операций (CAE), снижая задержки на уровне кристалла и разгружая коллективные коммуникации, которые в противном случае привели бы к простою тензорных ядер чипа, отметил The Register. 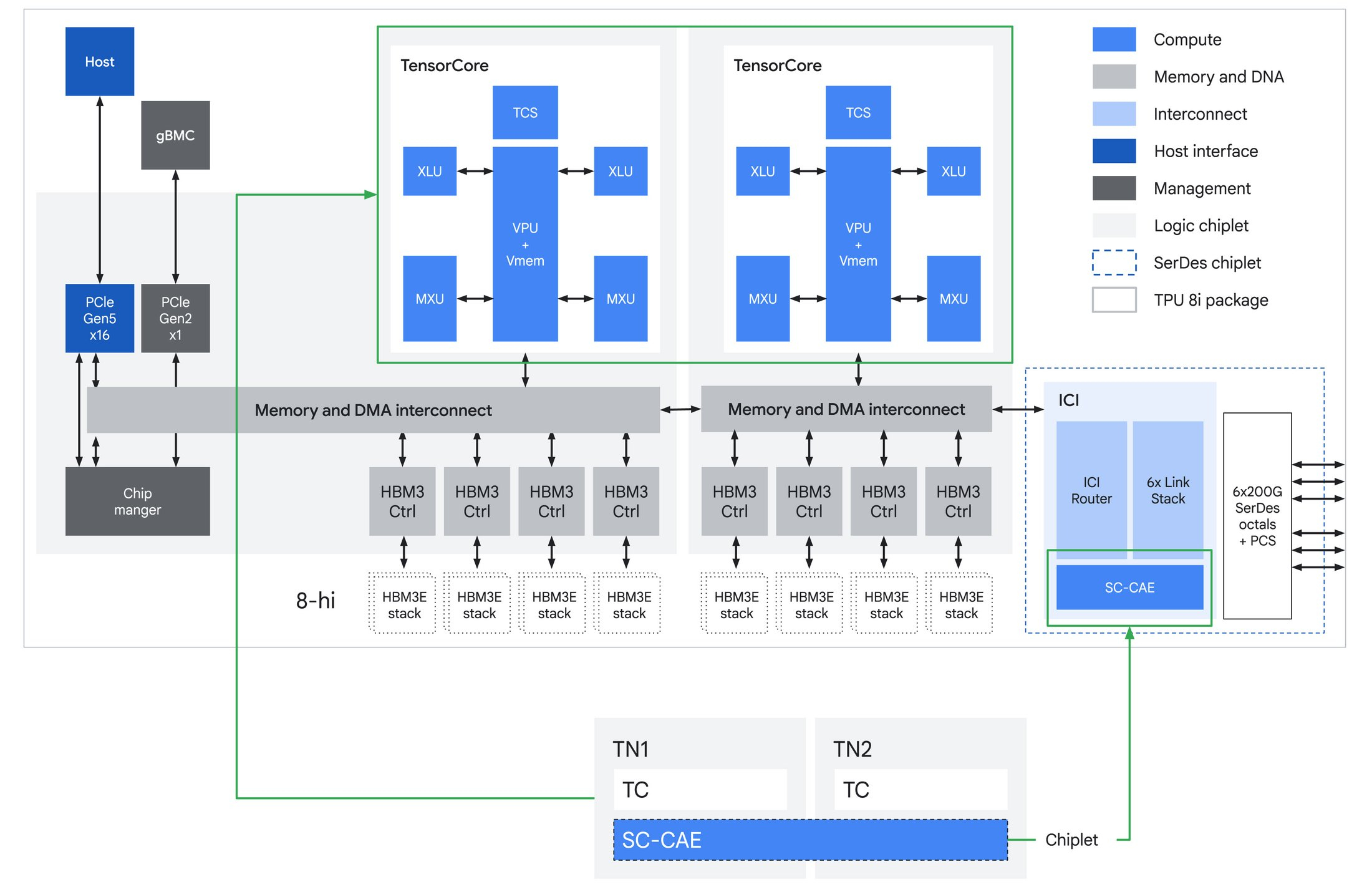 TPU 8i масштабируется до 1152 чипов в одном кластере (впрочем, в каждый момент активно не более 1024): 11,6 Эфлопс и 331,8 Тбайт HBM. ICI у 8i такой же, что у 8t, однако для объединения чипов используется топология Boardfly вместо 3D-тора, поскольку для MoE-инференса важно меньшее количество сетевых переходов между чипами. Эти инновации обеспечивают на 80 % лучшую производительность на доллар по сравнению с предыдущим поколением, позволяя предприятиям обслуживать почти вдвое больше клиентов при тех же затратах, сообщила компания. 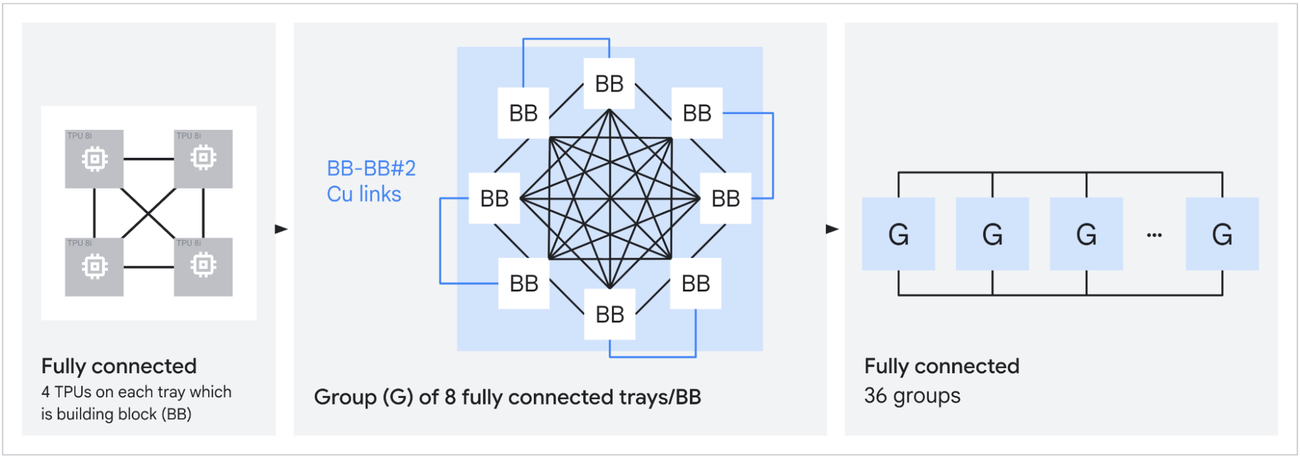 Как TPU 8t, так и 8i работают на базе собственного Arm-процессора Axion и поддерживают СЖО. Компания также заявила, что оптимизировала эффективность всей системы для обеспечения интегрированного управления питанием, которое может регулировать потребление энергии в зависимости от спроса в реальном времени, что приводит к повышению производительности на ватт до двух раз по сравнению с Ironwood. 
Фото: Sundar Pichai TPU 8 станут общедоступными на Google Cloud Platform позже в этом году в виде отдельных инстансов или как часть полнофункциональной платформы AI Hypercomputer, которая объединяет все сетевые ресурсы, хранилище, вычислительные мощности и ПО, необходимые для развёртывания или обучения LLM в масштабе. Также ожидается, что вскоре Google представит TPU v8e (Humufish). 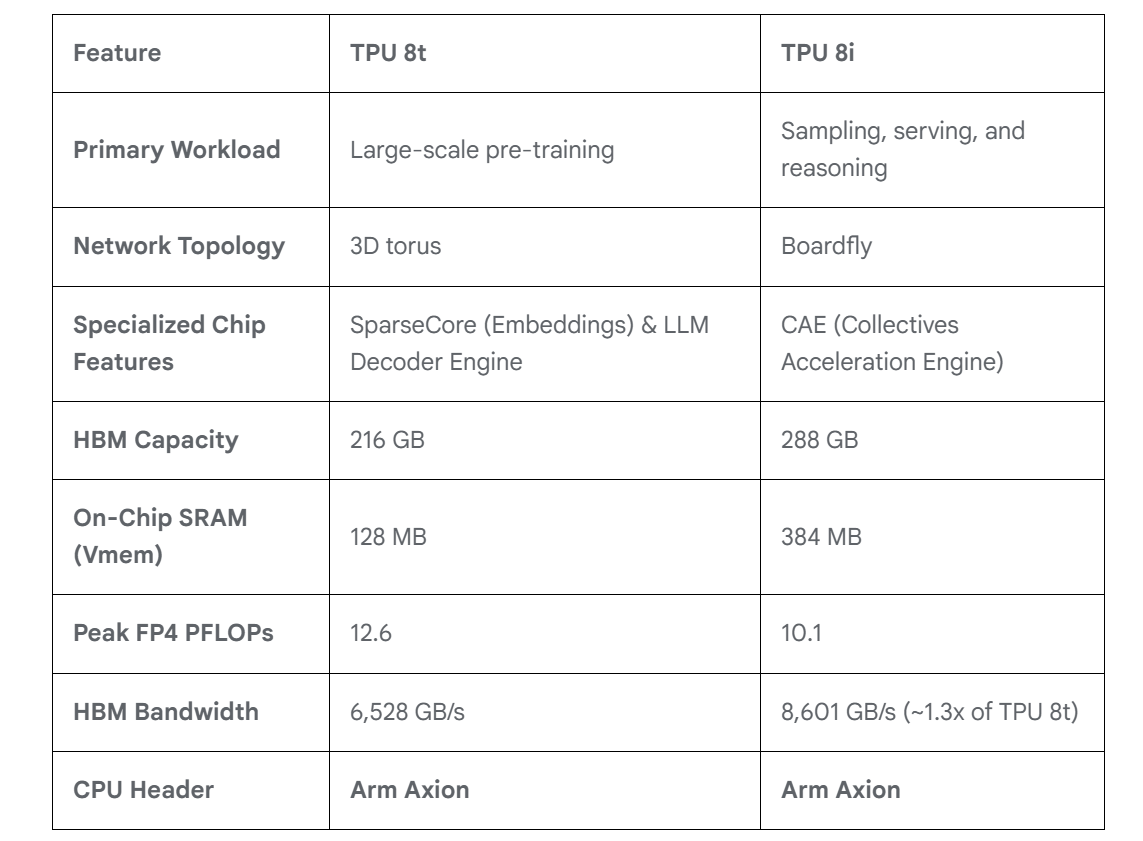
19.04.2026 [21:20], Владимир Мироненко
Google договаривается с Marvell о разработке двух кастомных чипов для ИИ-инференсаКомпания Google (Alphabet) ведёт переговоры с Marvell Technology о совместной разработке двух кастомных чипов, предназначенных для более эффективного ИИ-инференса, сообщил ресурс The Information со ссылкой на информированные источники. Как отметил The Information, эти переговоры свидетельствуют о стремлении Google, исторически зависящей от Broadcom в отношении базовой инфраструктуры TPU, к диверсификации поставщиков. Этот потенциальный альянс в области разработки чипов является прямым ответом на меняющуюся экономику ИИ, когда огромные вычислительные затраты на обучение масштабных моделей быстро уступают место постоянным ежедневным расходам на инференс. Один из чипов относится к подсистеме памяти TPU, второй — собственно TPU следующего поколения, созданный специально для запуска ИИ-моделей. Эти чипы предназначены для совместной работы, при этом каждый из них выполняет свою часть задачи. Как подчёркивается в публикации, «текущие обсуждения направлены на разработку полупроводников исключительно для нужд Google». 
Источник изображения: Marvell Technology Помимо технической оптимизации ИИ-инференса, привлечение Marvell — это классическая тактика диверсификации поставщиков, пишет Startup Fortune. Broadcom долгое время занимала исключительно доминирующее положение на рынке заказных чипов, тесно сотрудничая с Google в разработке TPU. Но сильная зависимость от одного партнёра по проектированию неизбежно создаёт ценовые разногласия и узкие места. Добавление ещё одного партнёра даёт Google более сильные рычаги влияния во время переговоров по контрактам, а также защищает её ЦОД от геополитических и логистических сбоев. Следует отметить, что авторитет Marvell заметно вырос за последнее время. Компания недавно заключила многомиллиардное партнёрство с NVIDIA, ориентированное на оптические сети и кастомные чипы. Её акции выросли более чем на 50 % с начала года, в основном благодаря доверию инвесторов к её опыту в области инфраструктуры данных и проектирования заказных чипов. Вместе с тем Broadcom остается ключевым партнёром в реализации планов Google. В этом месяце компании подписали соглашение о продолжении работы над новыми чипами до 2031 года, сообщается в документе, направленном Broadcom регулятору. Если переговоры пройдут успешно, Marvell укрепит свой статус ведущей альтернативы Broadcom в сегменте разработки кастомных ИИ-микросхем. Также следует ждать, что капитальные затраты гиперскейлеров будут всё больше смещаться в сторону оптимизации инференса, а не просто увеличения вычислительной мощности. Аналитики отрасли в настоящее время прогнозируют, что поставки серверных ASIC для ИИ-вычислений утроятся к 2027 году, и эта тенденция почти полностью обусловлена потребностями в развёртывании больших языковых моделей.
07.04.2026 [15:54], Сергей Карасёв
Anthropic развернёт 3,5 ГВт ИИ-мощностей на базе Google TPUАмериканская компания Anthropic, занимающаяся разработками в сфере ИИ, сообщила о расширении использования облачной инфраструктуры Google Cloud, а также ускорителей Google TPU. Это поможет в масштабировании больших языковых моделей (LLM), а также в развитии агентного ИИ и корпоративных приложений. О том, что Anthropic намерена закупить огромную партию чипов Google TPU, стало известно в конце прошлого года. Тогда говорилось, что будут приобретены около 1 млн ускорителей TPU v7 (Ironwood) общей мощностью примерно 1 ГВт. Позднее сообщалось, что часть изделий будет куплена напрямую у Broadcom, которая занимается выпуском TPU для Google. Как теперь отмечается, в общей сложности Anthropic получит доступ к «нескольким гигаваттами мощности на базе TPU»: ввод этих вычислительных ресурсов в эксплуатацию ожидается в начале 2027 года. Доступ к части ускорителей будет осуществляться посредством Google Cloud Platform (GCP). Ресурс The Register уточняет, что в общей сложности Anthropic получит 3,5 ГВт мощностей для ИИ-вычислений с использованием Google TPU. 
Источник изображения: Google Вместе с тем Anthropic прогнозирует значительное увеличение выручки: ожидается, что в 2026 году она превысит $30 млрд. Недавно компания провела раунд финансирования на $30 млрд, в результате чего её капитализация достигла $380 млрд. Anthropic подчёркивает, что всего за два месяца количество её клиентов, которые платят не менее $1 млн ежегодно, поднялось в два раза, превысив 1 тыс. Сообщается также, что Anthropic продолжает расширять использование облачных сервисов Google Cloud, включая BigQuery, Cloud Run и AlloyDB. Тысячи клиентов получают доступ к ИИ-моделям Anthropic Claude именно через платформу Google Cloud: в числе таких пользователей названы Coinbase, Cursor, Palo Alto Networks, Replit и Shopify.
27.02.2026 [20:06], Руслан Авдеев
Meta✴ получит миллионы ИИ-ускорителей Google TPUMeta✴ заключила многомиллиардную сделку по аренде ИИ-ускорителей TPU у Google для обучения и инференса LLM, сообщили анонимные источники The Information. Пока в индустрии ИИ-чипов доминируют решения NVIDIA, но TPU во многих случаях представляют собой более дешёвую и привлекательную альтернативу. В последние годы они стали одним из ключевых драйверов роста облачной платформы Google. Новая сделка важна для Meta✴, поскольку компания намерена диверсифицировать вычислительные мощности, снизив зависимость от NVIDIA. Meta✴ — один из крупнейших клиентов компании. Ранее она уже объявила о покупке миллионов новейших ускорителей Vera Rubin и закупках процессоров Grace. Кроме того, Meta✴ заключила сделку с AMD на поставку 6 ГВт GPU Instinct и CPU EPYC нового поколения. Каждый из ускорителей имеет собственные преимущества и недостатки, поэтому Meta✴ может экспериментировать, подбирая оптимальные типы чипов под отдельные задачи. Кроме того, вендоры обеспечат ей оптимальные цены и условия, если будут конкурировать друг с другом. 
Источник изображения: Mina Rad/unsplash.com Тем временем Google намерена лишить NVIDIA монополии на рынке ИИ-ускорителей. Компания готова предложить потенциальным клиентам привлекательные альтернативы чипам конкурента. Ранее TPU были доступны только в Google Cloud, но теперь компания намерена продавать их напрямую клиентам для сторонних ЦОД. Одной из первых компаний, которая активно займётся пряой закупкой и размещением TPU, стала Anthropic. Сделка на сумму в «десятки миллиардов» долларов охватывает 1 млн TPU и 1 ГВт мощностей. В Google рассчитывают ближайшие годы получить до 10 % выручки NVIDIA от ЦОД. В отчёте The Information сообщается, что Meta✴ ведёт переговоры с Google о покупке миллионов TPU для своих собственных ЦОД, причём речь идёт об отдельной сделке, напрямую не связанной с нынешним «облачным» соглашением. Наконец, у Meta✴ есть и ускорители MTIA собственной разработки. По имеющимся данным, все чипы MTIA нового поколения оптимизированы для обучения ИИ-моделей, в этой сфере ускорители первого поколения сталкивались с определёнными трудностями. Впрочем, считается, что при разработке новинок компания тоже столкнулась с «техническими проблемами», из-за которых задержался их выпуск.
05.01.2026 [18:25], Владимир Мироненко
Anthropic купит сотни тысяч ИИ-ускорителей Google TPU напрямую у BroadcomAnthropic приобретёт около 1 млн Google TPU v7 (Ironwood) с тем, чтобы запустить их на контролируемых ею объектах, сообщил в соцсети Х ресурс SemiAnalysis. Ранее сообщалось, что примерно 400 тыс. компания купит напрямую у Broadcom в стойках за примерно $10 млрд, а остальные 600 тыс. единиц TPU v7 будут доступны посредством Google Cloud Platform (GCP) в рамках сделки на сумму около $42 млрд, что составляет большую часть увеличения портфеля заказов GCP на $49 млрд или на 46 %, о котором сообщалось в отчёте за III квартал 2025 года. В случае с закупаемыми напрямую ускорителями TeraWulf и Cipher Mining будут ответственны за инфраструктуру ЦОД, а европейское неооблако Fluidstack будет заниматься настройкой оборудования на месте, прокладкой кабелей, первичным тестированием, испытаниями при приёмке и удалённым обслуживанием, освободив Anthropic от бремени управления физическими серверами. По слухам, эти системы получат упрощённую топологию интерконнекта. Сделки Fluidstack с обоими операторами ЦОД, ранее ориентированными на криптомайнинг, финансово застрахованы Google, которая к тому же является совладельцем TeraWulf и может получить долю в Cipher Mining. Любопытно, что оба оператора частично связаны и с AWS. Хотя Google закупает TPU через Broadcom, которая тоже хочет свою маржу, это всё равно лучше, чем та маржа, что требует NVIDIA не только за продаваемые ускорители, но и за всю систему целиком, включая процессоры, коммутаторы, сетевые карты, системную память, кабели, разъёмы и т.п. По оценкам, SemiAnalysis, совокупная стоимость владения (TCO) на один чип Ironwood для полной конфигурации с топологией 3D-тор примерно на 44 % ниже, чем у серверов GB200, что с лихвой компенсирует примерно 10-% отставание TPU от GB200 по пиковым производительности и пропускной способности памяти. 
Источник изображения: Google При этом реальная, а не теоретическая производительность (Model FLOP Utilization, MFU) у TPU, по мнению SemiAnalysis, может быть выше, чем у конкурентов. Основная причина заключается в том, что заявляемые NVIDIA и AMD показатели производительности (Флопс) значительно завышены. Даже в синтетических тестах, значительно отличающиеся от реальных рабочих нагрузок, Hopper достиг лишь около 80 % пиковой производительности, Blackwell — около 70 %, а серия MI300 от AMD — 50–60 %. Как полагают в SemiAnalysis, даже сдача ускорителей на сторону выгодна Google за счёт того, что TCO в пересчёте на час аренды может быть примерно на 30 % ниже, чем у GB200, и примерно на 41 % ниже, чем у GB300. Несмотря на высокий спрос, Google не может поставлять TPU в желаемом темпе, отметил SemiAnalysis, полагая, что основная проблема заключается в бюрократии Google — от первоначальных обсуждений до подписания генерального соглашения об оказании услуг (Master Services Agreement) проходит до трёх лет. Неооблака, включая Fluidstack, отличаются гибкостью и оперативностью, что облегчает им взаимодействие с новыми поставщиками услуг дата-центров, например, с реорганизованными криптомайнерами. Однако у неооблаков, среди инвесторов которых числится NVIDIA, таких как CoreWeave, Nebius, Crusoe, Together, Lambda, Firmus и Nscale, есть существенный стимул не внедрять конкурирующие технологии в своих дата-центрах: TPU, ускорители AMD и даже коммутаторы Arista — всё это под запретом. Это оставляет огромную нишу на рынке хостинга TPU, которая в настоящее время заполняется комбинацией майнеров криптовалют и Fluidstack, сообщил SemiAnalysis. По мнению SemiAnalysis, в ближайшие месяцы всё большему числу компаний-неооблаков предстоит принимать непростое решение между развитием возможностей хостинга TPU и получением квот на новейшие и лучшие системы NVIDIA Rubin.
03.12.2025 [09:33], Владимир Мироненко
Foxconn поможет Google c TPU-серверами, а Google поможет Foxconn с «умными» роботамиFoxconn получила крупный заказ Google на поставку TPU-узлов, сообщил ресурс Taiwan Economic Daily со ссылкой на информированные источники. С учётом того, что Meta✴ планирует использовать ИИ-ускорители TPU в своих ИИ ЦОД в 2027 году, у Foxconn появилась возможность укрепить партнёрство с обоими гиперскейлерами. Да и самой Google уже сейчас катастрофически не хватает TPU для собственного облака. Foxconn уже является ключевым поставщиком платформ NVIDIA, хотя последняя всё больше ужесточает контроль над производством. По данным источников, ИИ-серверы для Google в основном поставляются в виде стоек с TPU. В этом году Google анонсировала тензорный ускоритель седьмого поколения TPU v7 Ironwood, первый чип компании, специально созданный для инференса, хотя область его применения также включает обучение крупномасштабных моделей и сложное обучение с подкреплением (RL). На его базе можно создавать кластеры (Pod) с объединением в единый вычислительный комплекс до 9216 чипов. По собственным данным Foxconn, он уже способна выпускать более 1000 ИИ-стоек в неделю. К концу 2026 года компания планирует увеличить этот показатель до более 2000 ед./нед. Также планы Foxconn включают расширение присутствия в США, где компания намерена не только осуществлять сборку серверов, но и наладить производство ключевых компонентов, таких как кабели, сетевое оборудование, системы теплоотвода и электропитания. 
Источник изображения: Google Помимо выпуска ASIC-серверов, сотрудничество Foxconn и Google включает создание роботов, управляемых ИИ. Foxconn заключила партнерство с Intrinsic, робототехнической компанией, входящей в состав Alphabet, материнской компании Google, с целью создания совместного предприятия в США для строительства завода по выпуску роботов с поддержкой ИИ. Партнёры планируют интегрировать ИИ-платформу Intrinsic и интеллектуальную производственную платформу Foxconn для создания адаптивных интеллектуальных робототехнических решений, что ещё больше повысит эффективность производственных объектов Foxconn и всей её экосистемы. В прошлом месяце Google выпустила большую языковую модель Gemini 3, которая, как утверждается, превзошла OpenAI GPT-5 по нескольким ключевым показателям и ИИ-модели других конкурентов, что также способствовало росту популярности TPU. Согласно данным инсайдеров, Google призвала цепочку поставок ускориться в связи с предстоящим поступлением новых крупных заказов на TPU. |
|

