Материалы по тегу: ии
|
23.06.2026 [16:29], Руслан Авдеев
SpaceX предоставит стартапу Reflection AI ИИ-мощности на $6,3 млрдКомпания SpaceX подписала крупное соглашение о предоставлении вычислительных мощностей стартапу Reflection AI, работающему над созданием открытых ИИ-моделей и ИИ-агентов. Пока это последняя из не принадлежащих империи Маска компаний, запросивших у него доступ к инфраструктуре Colossus, сообщает CNBC. В рамках соглашения Reflection немедленно получит доступ к системам NVIDIA GB300. Стартап согласился платить SpaceX по $150 млн ежемесячно, начиная с 1 июля 2026 года до 2029 года. Общий объём платежей составит около $6,3 млрд, если соглашение будет действовать до конца названного срока. Через три месяца после старта проекта любая из сторон сможет расторгнуть контракт, уведомив об этом партнёра за 90 дней. Аналогичные соглашения о предоставлении вычислительных мощностей подписаны с Anthropic и Google, а вот Cursor была выкуплена xAI. Reflection стратегически отличается от них — это ИИ-хаб с фокусом на open source моделях: в момент, когда государства и корпорации стремятся избавиться от зависимости от закрытых ИИ-систем. Время как нельзя подходящее — после закрытия доступа к Anthropic к Fable и Mythos интерес к открытым решениям снова вырос. Reflection как раз и делает ставку на отказ от зависимости от закрытых моделей для критически важных задач. 
Источник изображения: chris robert/unsplash.com Последняя оценка стартапа составила $25 млрд. Он пытается создавать открытые модели, способные конкурировать с передовыми ИИ-системами OpenAI, Anthropic и Google. Впрочем, пока стартап не выпустил ни одной крупной передовой модели, хотя активно взаимодействует с заказчиками из числа госструктур и, в числе прочих, ответственных за национальную безопасность. Так, компания связана с программой Genesis Mission Министерства энергетики США (DoE) и участвует в ИИ-инициативах Пентагона.
23.06.2026 [16:09], Руслан Авдеев
Большой апгрейд: Microsoft построит 2-ГВт ИИ ЦОД в техасском ПекосеMicrosoft объявила об одном из крупнейших разовых увеличений мощностей ЦОД в истории компании. В Пекосе (Pecos, Техас) она строит кампус на 2 ГВт. В следующие 5–7 лет многомиллиардная инвестиция поможет осуществить инновации нового поколения с прицелом на долгосрочную перспективу, говорит компания, у которой уже есть успешный опыт развития ЦОД в регионе Сан-Антонио в течение более чем десяти лет. Новый объект дополнит крупные ЦОД проекта Fairwater в Атланте и Висконсине. Спрос клиентов на ИИ и облака продолжит расти, и для его удовлетворения потребуется не просто больше мощностей ЦОД, а предсказуемых, устойчивых мощностей, способных быстро масштабироваться, говорит Microsoft. Именно поэтому кампус в Пекосе получит собственные генерирующие мощности непосредственно на площадке, что позволит вводить объекты в эксплуатацию в темпе, необходимом клиентам, с сохранением устойчивой работы. Энергетическая инфраструктура оплачивается самой Microsoft. При этом компания руководствуется принципом Community First, в соответствии с которым уделяется внимание интересам местного населения. Помимо создания новых рабочих мест, компания будет инвестировать в подготовку кадров, в первую очередь для своих же ЦОД, и поддержку малого бизнеса. Впрочем, инвестиции касаются не только непосредственно ЦОД, но и поддержки НКО и прочих структур. Кроме того, компания систематически повышает энергоэффективность своей инфраструктуры. В Техасе она законтрактовала уже 4,7 ГВт энергии из возобновляемых источников и продолжает наращивать возможности в этой сфере по мере изменения спроса. 
Источник изображения: Microsoft На начальном этапе кампус ЦОД будет работать от расположенной рядом газовой электростанции «за счётчиком», оснащённой системой Selective Catalytic Reduction для снижения выбросов оксидов азота. В дальнейшем планируется подключить кампус к электросети и сделать генерирующие мощности частью региональной электросистемы. Также Microsoft планирует использовать в своих ЦОД замкнутые системы охлаждения, существенно сокращающие потребность в чистой воде. Планируется минимизировать зависимость от источников пресной воды в целом, используя, где можно, непитьевую воду. По данным Converge! Digest, Microsoft и Chevron подписали соглашение сроком на 20 лет о покупке «чистой» энергии в рамках инициативы Project Kilby в Западном Техасе. Строительство генерирующих мощностей будет осуществляться дочерней структурой Chevron — Energy Forge One совместно с Engine No. 1. Поэтапно будут введены 2,67 ГВт генерируюших мощностей, преимущественно на базе газовых турбин GE Vernova, а также Caterpillar (Solar Turbines). Окончательное решение об инвестициях будет принято до конца 2026 года, подача энергии должна начаться в 2028 году.
23.06.2026 [11:41], Руслан Авдеев
Micron и Anthropic анонсировали стратегическое партнёрство для масштабирования ИИ-инфраструктуры нового поколенияMicron Technology анонсировала стратегическое соглашение с Anthropic, касающееся проектирования архитектуры памяти и СХД для ИИ, вопросов поставок и спроса, внедрения ИИ Claude внутри корпоративной структуры Micron и стратегических инвестиций в Anthropic в раунде финансирования серии H. Соглашение напрямую связывает спрос передовых ИИ-моделей с вопросами разработки инфраструктуры, поставок и внедрения ИИ-решений. По словам Micron, революция в области ИИ навсегда повысила роль памяти и решений для хранения данных, как в сфере ЦОД, так и, в частности, периферийных вычислений. Поэтому компании займутся разработкой инфраструктуры нового поколения. Как считают в Anthropic, стратегия компании зависит от того, насколько качественно выстроены уровни технологического стека, а память и вычислительные системы влияют на то, насколько эффективно можно обучать Claude и эксплуатировать его. По мере роста спроса на Claude будут масштабироваться и мощности. Ключевым для сотрудничества является целенаправленная работа над технологиями памяти и хранения данных, позволяющая эффективнее масштабировать ИИ-системы. Портфолио Micron включает HBM, DRAM и SSD, что обеспечивает высокую производительность, энергоэффективность и оптимизацию совокупной стоимости владения при обучении и инференсе. 
Источник изображения: Micron Micron и Anthropic намерены проанализировать работу подсистем памяти и хранения при разных нагрузках, а также то, как они будут взаимодействовать в пределах всего стека. Ожидается, что это повысит производительность памяти и хранилищ данных, повысит энергоэффективность и обеспечит ИИ-инфраструктуре Anthropic более выгодную «экономику токенов». Помимо технического сотрудничества, компании договорились о поставках памяти и систем хранения данных из портфолио Micron. Это позволит последней поддержать активный рост Anthropic и будущее масштабирование её ИИ-инфраструктуры. Micron уже внедрила модели Claude для ускорения выполнения задач разработки и выполнения более передовых агентных сценариев для инженерных и корпоративных задач, а также производства. Утверждается, что эти модели уже отвечают за инновации и заметный рост производительности Micron. По мере усложнения и роста автономности систем компания рассчитывает найти новые способы проектирования своих решений, создания и управления масштабными процессами. Помимо технологического сотрудничества и соглашения о поставках, Micron осуществила стратегические инвестиции в раунде серии H ($65 млрд). Это отражает общий фокус компании на развитии инфраструктуры, нужной для поддержки следующего поколения систем искусственного интеллекта.
22.06.2026 [19:14], Владимир Мироненко
Законопроект о регулировании ИИ в России кардинально сократили и упростили22 июня в комиссии правительства по законопроектной деятельности пройдёт рассмотрение законопроект «О поддержке развития технологий ИИ в РФ», который, по словам источника «Коммерсанта», должны внести в Госдуму до конца недели. Сообщается, что документ претерпел значительные изменения по сравнению с первоначальным вариантом. Его сократили до 13 страниц и 13 статей, при этом действие законопроекта распространяется только на большие фундаментальные модели (LLM) с более 1 млрд параметров. Модели с меньшим количеством параметров, в том числе open source, были исключены из первоначального варианта законопроекта также, как и формулировка «доверенные» модели, после чего в нём теперь указаны только «суверенные» и «национальные». Отмечается, что от добавления в документ «доверенных» моделей для КИИ отказались, так как требования к софту, куда относится и ИИ, уже прописаны ФСТЭК и ФСБ. На объектах КИИ можно будет использовать только с «суверенные» и «национальные» модели, разработка которых может рассчитывать на господдержку. 
Источник изображения: Steve A Johnson/unsplash.com В документе указано, что «суверенная» модель ИИ может быть разработана на всех этапах только российским юрлицом и использоваться только на инфраструктуре в РФ. «Национальная» модель должна быть существенно разработана российским юрлицом, хотя её компоненты могут быть open source. Основные положения законопроекта вступают в силу с 1 сентября 2026 года, положения о полномочиях правительства (применение моделей, их определение, обязанности разработчиков и т. д.) — с 1 марта 2027 года. Если же до 1 марта 2027 года уже внедрены ИИ-модели, не подпадающие под критерии документа, переходный период для них продлён до 1 сентября 2032 года в случае, если данные обрабатываются в РФ. «Коммерсантъ» отметил, что в итоговой версии отказались от требования обеспечить маркировку синтезированного ИИ контента и усилить ответственность владельцев ИИ-сервисов за правонарушения при использовании технологии. Также из первоначальной версии были исключены вопросы, касающиеся регулирования ИИ ЦОД и практически полностью — вопросы, касающиеся авторского права.
22.06.2026 [13:00], Руслан Авдеев
Саудовская DataVolt строит в Узбекистане 12-МВт дата-центр стоимостью $150 млнБазирующаяся в Саудовской Аравии компания DataVolt занимается строительством в Ташкенте (Узбекистан) дата-центра мощностью 12 МВт, сообщает Datacenter Dynamics. На днях компания объявила, что привлекла для реализации проекта строительства ЦОД TAS-1 $150 млн. В числе инвесторов — немецкая German Investment and Development Company, Европейский банк реконструкции и развития, Фонд международного развития ОПЕК и подразделение Французского агентства развития (AFD) — компания Proparco. В мае 2024 года Министерство цифровых технологий Узбекистана объявило, что проект будет финансироваться исключительно за счёт прямых зарубежных инвестиций. Объект TAS-1 в технопарке IT Park Uzbekistan был заложен в мае 2024 года, тогда DataVolt заявила, что дата-центр заработает в конце 2026 года. По данным Министерства цифровых технологий, речь идёт о первой фазе более крупного проекта ЦОД. Ещё два дата-центра по 250 МВт должны быть построены на участках по 25 га в «Новом Ташкенте» и Бухаре соответственно. Представители узбекских властей сообщали, что к 2030 году «зарубежный партнёр» инвестирует $5 млрд в строительство объектов. 
Источник изображения: Министерство цифровых технологий Узбекистана Подразделение телеком-компании Veon — Beeline Uzbekistan, возможно, будет «ключевым арендатором» нового ЦОД, согласно одному из двух меморандумов о взаимопонимании, подписанных DataVolt. Второй меморандум утверждает программу оценки возможного совместного строительства и эксплуатации ЦОД в Бухаре. Стоит отметить, что меморандумы не обязательны к исполнению. Основанная в 2023 году компания DataVolt полностью принадлежит саудовской инвестиционной и холдинговой компании Vision Invest, занимающейся проектами в сфере критической инфраструктуры. Значительная часть руководства DataVolt, включая генерального директора, пришла из саудовской ACWA Power, занимающейся строительством энергогенерирующих мощностей и заводов по опреснению воды. Последняя тоже принадлежит Vision Invest. Штаб-квартира Veon находится в Дубае. Компания ушла с российского рынка в октябре 2023 года, и теперь занимается бизнесом в Бангладеш, Казахстане, Пакистане, Узбекистане и в других странах. В декабре 2025 года её подразделение Beeline Kazakhstan начало строительство в Казахстане 2-МВт дата-центра в Алматы, который должен заработать к концу 2026 года.
22.06.2026 [12:53], Сергей Карасёв
Intersect360: годовой объём мирового рынка ИИ-инфраструктур превысил $300 млрдПо оценкам аналитической компании Intersect360 Research, затраты на глобальном рынке инфраструктур для дата-центров, ориентированных на ИИ-нагрузки, в 2025 году увеличились на 60,1 %, превысив $300 млрд. Ключевым драйвером отрасли выступают гиперскейлеры, продолжающие активно наращивать вычислительные мощности. Отмечается, что в абсолютном выражении доминирует именно сегмент гиперскейлеров, на который пришлось более $200 млрд расходов. В то же время затраты в области корпоративных ИИ-инфраструктур (включая HPC-направление) в 2025-м оказались на уровне $71,6 млрд. В дальнейшем, по мнению аналитиков, среднегодовой темп роста в сложных процентах (CAGR) на мировом рынке ИИ-инфраструктур будет исчисляться двузначными числами процентов. В результате, к 2030-му суммарные расходы преодолеют отметку в $500 млрд. В сегменте корпоративных ИИ-инфраструктур показатель прогнозируется в объёме более $130 млрд. Вместе с тем специалисты Intersect360 Research указывают на трансформацию рассматриваемой отрасли. В частности, наблюдается сдвиг в сторону облачных платформ для задач ИИ и суверенных дата-центров, оптимизированных для соответствующих нагрузок. 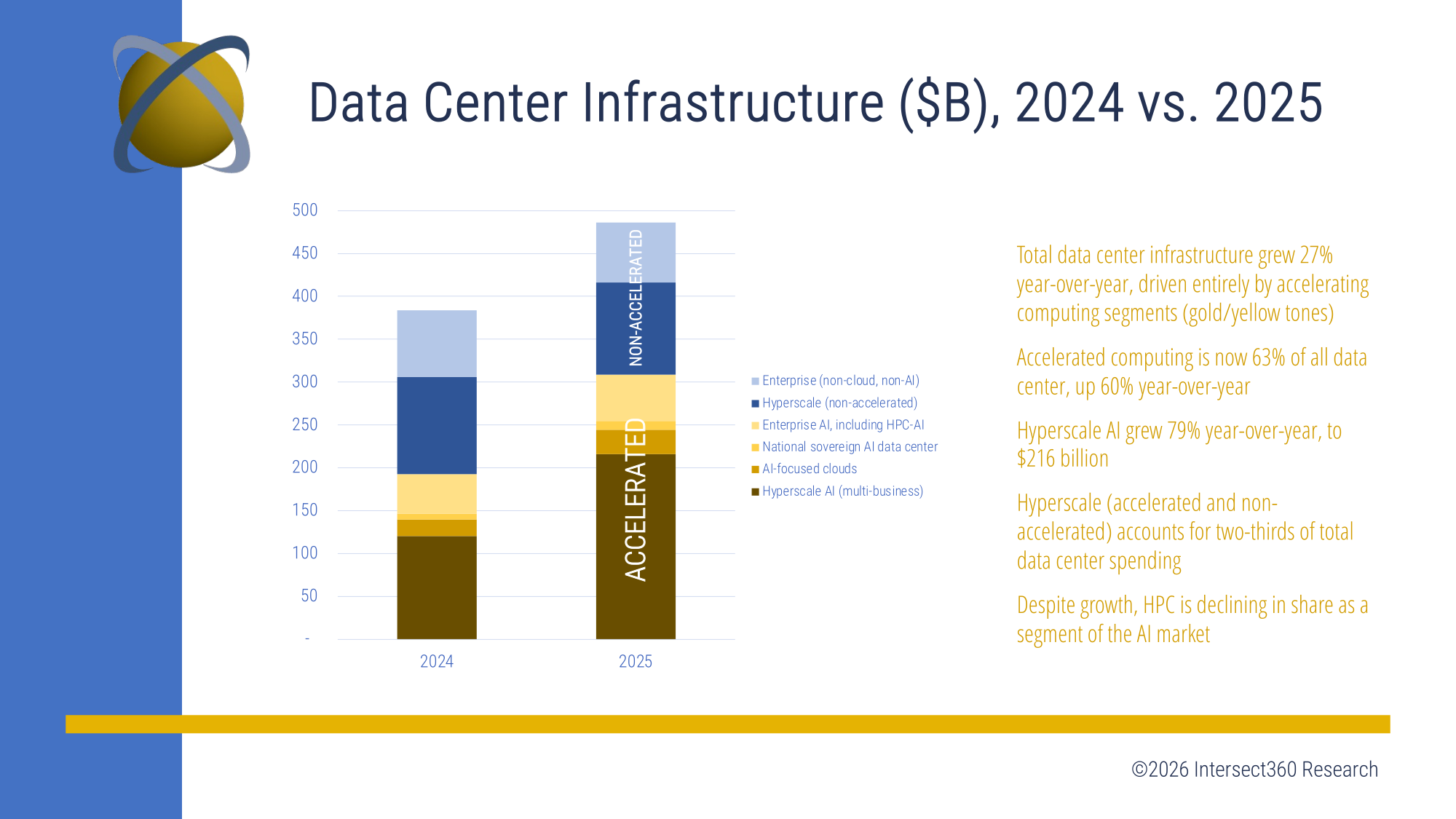
Источник изображения: Intersect360 Причём направление суверенных ЦОД демонстрирует самые высокие темпы роста, что связано со сформировавшейся геополитической обстановкой и санкционными ограничениями. Такие площадки функционируют полностью в пределах географических границ конкретной страны, что устраняет риски, обусловленные применением иностранных платформ.
В целом, указывают аналитики, до 2030 года основную часть прироста рынка обеспечат ускорители на базе GPU, высокопроизводительные серверы и облачные сервисы, оптимизированные для ИИ. При этом затраты в сегменте традиционной корпоративной инфраструктуры останутся на прежнем уровне или даже сократятся в реальном выражении.
22.06.2026 [09:36], Руслан Авдеев
Hyperscale Data откроет «школу» для роботов-гуманоидов в собственном ЦОДАмериканская Hyperscale Data (ранее Ault Alliance), работающая в сфере робототехники и инфраструктурных ИИ-решений, намерена внедрить роботов-гуманоидов в собственном ЦОД в Мичигане. Недавно компания объявила, что полностью принадлежащая ей Omnipresent Robotics в III квартале 2026 года начнёт выпуск первых 30 гуманоидных роботов OPR-R2, сообщает Datacenter Dynamics. Предполагается, что роботы будут учиться и работать на территории лаборатории Robotics Research, Testing, and Innovation Center площадью 9 290 м2. Они предназначены для поддержки разработки систем физического ИИ, автономных рабочих процессов и передовых систем робототехники. В рамках проекта Hyperscale и её дочерняя структура заключили партнёрское соглашение с китайской Agibot PTE, занимающейся робототехникой. Всего компания рассчитывает внедрить 143 таких робота, купленных у Agibot за $13,4 млн. При этом Omnipresent дано право организовать перепродажу роботов под собственным брендом. Первые 30 машин отправят на площадку Model Training Laboratory компании Omnipresent Robotics, где они станут работать буквально рука об руку с людьми, обучаясь в реальных условиях. В Hyperscale сообщили, что роботы помогут в сборе информации, обучении моделей, оценке симуляций, эксплуатации объекта и разработке систем физического ИИ следующего поколения. Компания рассчитывает, что внедрение роботов-гуманоидов в ЦОД создаст уникальную среду для разработки и оценки ИИ-систем новейшего поколения, способных действовать в условиях реального мира. 
Источник изображения: Agibot Hyperscale владеет дата-центром в Мичигане, расположенном на площадке около 14 га. 30-МВт ЦОД площадью 57 320 м2 был куплен в мае 2022 года. Построенное в 1972 году здание изначально использовалось как промышленный объект, но теперь в нём находятся мощности для майнинга биткоинов, HPC-проектов, колокации и упомянутой выше робототехнической лаборатории. В перспективе компания намерена увеличить мощность до 340 МВт, в том числе предусмотрено создание газовых энергогенерирующих мощностей «за счётчиком» на 40 МВт. По словам Hyperscale, компания сделала ставку на ИИ — если современные ИИ-модели отлично справляются с рассуждениями и генерацией контента, то в будущем ИИ должен уметь разбираться в физическом мире и взаимодействовать с ним. Кампус в Мичигане создаётся для формирования масштабной среды, в которой гуманоидные роботы и передовой ИИ смогут постоянно учиться, тренироваться и совершенствоваться. Ранее Hyperscale под своим прежним именем инвестировала в разведку нефти, оборонно-аэрокосмический сектор, производство, автомобильную промышленность и другие отрасли, включая медицину и биофармацевтику, гостиничный бизнес и выпуск текстиля. В 2025 году она анонсировала полный разворот бизнеса в направлении ИИ и ЦОД, сменила название и объявила о решении избавиться от всех активов, не связанных с дата-центрами. Теперь контрольный пакет Hyperscale Data принадлежит Ault & Company. Основанная в 2023 году шанхайская Agibot разрабатывает роботов-гуманоидов, робособак, колёсные автономные машины. Компания заявила, что выпустила более 1 тыс. универсальных роботов-гуманоидов для выполнения широкого круга «физических» задач в реальном мире. В конце апеля сообщалось, что японский техногигант SoftBank намерен использовать роботов для ускоренного строительства дата-центров, в первую очередь в США.
22.06.2026 [09:05], Сергей Карасёв
Одноплатный компьютер Orange Pi 6 получил 12-ядерный процессор и два порта 2.5GbEВ октябре 2025 года дебютировал одноплатный компьютер Orange Pi 6 Plus, предназначенный для построения различных устройств с ИИ-функциями. Теперь у этого изделия появился младший собрат в виде модели Orange Pi 6, которая подходит для создания промышленных контроллеров, интеллектуальных роботов, мини-серверов и пр. Как и Plus-версия, новинка выполнена на процессоре CIX P1 (CD8180) с 12 вычислительными ядрами — это квартеты Arm Cortex-A720 с тактовой частотой до 2,8 ГГц, Arm Cortex-A720 с частотой 2,4 ГГц и Arm Cortex-A520 с частотой 1,8 ГГц. В состав чипа входят графический ускоритель Arm Immortalis-G720 MC10 и нейропроцессорный модуль с ИИ-быстродействием 28,8 TOPS. Суммарная производительность (CPU+NPU+GPU) на операциях ИИ достигает 45 TOPS. 
Источник изображения: Orange Pi Одноплатный компьютер имеет размеры 90 × 90 мм. Объём оперативной памяти LPDDR5 может составлять 8, 16 или 24 Гбайт (до 64 Гбайт у Orange Pi 6 Plus). Доступны два коннектора M.2 2280 M-Key для SSD с интерфейсом PCIe 4.0 x4 (NVMe), слот для карты microSD и разъём M.2 E-Key для опционального адаптера Wi-Fi. Реализованы два сетевых порта 2.5GbE (против 5GbE у старшей модификации). Новинка получила по два порта USB 3.0 Type-C, USB 3.0 Type-A и USB 2.0 Type-A, по одному интерфейсу DisplayPort 1.4, HDMI 2.0 и eDP, аудиогнездо на 3,5 мм, два коннектора RJ45 для сетевых кабелей, два интерфейса MIPI-CSI (4 линии) и 40-контактную колодку GPIO (UART, I2C, SPI, PWM). Может быть подключён вентилятор охлаждения с ШИМ-управлением. Заявлена совместимость с ОС OpenHarmony, Debian, Ubuntu, Android, Windows, ROS2.
21.06.2026 [15:08], Руслан Авдеев
Crusoe обеспечит Meta✴ 1,6 ГВт новых мощностей ЦОДКомпания Meta✴ заключила с Crusoe соглашение не поставку 1,6 ГВт вычислительных мощностей ЦОД, сообщает Datacenter Dynamics. Подписаны контракты на покупку мощностей на объектах Crusoe в Чайлдрессе (Childress, Техас) и Уоррентоне (Warrenton, Миссури). Стоимость сделки не называется. Ранее в июне Crusoe объявила, что законтрактованные инфраструктурные мощности компании достигли 4,9 ГВт, в том числе речь идёт как о проектах ЦОД для внешних клиентов, так и о собственной облачной ИИ-платформе Crusoe Cloud. В целом портфолио проектов компании превышает 40 ГВт, хотя и не все запланированные кампусы строятся так, как планировалось, например, в Вайоминге. Кампус в Уоррентоне планируется возвести на участке площадью около 137 га, речь идёт о двух зданиях ЦОД площадью по 74 786 м2 и административном здании площадью 3 716 м2. Crusoe известна в первую очередь кампусом ЦОД в Абилине (Abilene, Техас), созданном на принадлежащей Lancium земле для Oracle и сданном в аренду OpenAI. Недавно там же стартовало строительство ещё одного кампуса мощностью 900 МВт для Microsoft. По слухам, эти мощности хотела получить и Meta✴, но в итоге они достались сопернику. 
Источник изображения: James Sullivan/unsplash.com Хотя Crusoe не выделяет проект в Чайлдрессе на своём сайте, ранее компания уже заявляла, что имеет контракты на строительство ещё двух крупных кампусов в Техасе и одного — в Миссури. Подчёркивалось, что проекты на разных стадиях готовности. Lancium, работавшая с Crusoe в Абилине, участвует и в проекте в Чайлдрессе. Указывается, что площадка имеет возможность получения от местной энергосети 1 ГВт и получила разрешение техасского регулятора ERCOT. По словам главы Meta✴ Марка Цукерберга (Mark Zuckerberg), компания не исключает запуск собственного облачного сервиса при определённых условиях. Компания активно наращивает вычислительные мощности, и в начале года создала специальное подразделение Meta✴ Compute для расширения ёмкости ЦОД. Цукерберг заявил, что планируется построить десятки гигаватт в текущем десятилетии и «сотни или больше» — в долгосрочной перспективе. Попутно компания заключает соглашения об аренде мощностей у облачных и неооблачных компаний. Так, с Nebius она подписала соглашение на $27 млрд, сделка на $21 млрд заключена и с CoreWeave. Кроме того, с AWS подписан договор об использовании чипов Graviton5.
21.06.2026 [14:58], Владимир Мироненко
Франция развивает ИИ-инфраструктуру в сотрудничестве с NVIDIAПлатформа AI Factory France (AI2F) под руководством Национального управления высокопроизводительных вычислений (GENCI) Франции объявила о запуске в партнёрстве с NVIDIA программы по ускорению инноваций в области ИИ в стране. Программа обеспечит компаниям упрощённый доступ к передовой вычислительной инфраструктуре и специализированным ИИ-сервисам. Она объединяет глобальную экосистему NVIDIA с национальными и европейскими ресурсами ИИ Франции. Сотрудничество между AI Factory France (AI2F) и программами NVIDIA Inception, NVIDIA Connect, позволяет стартапам получить доступ к национальным суперкомпьютерным ресурсам, включая Jean Zay. Первые участники, включая Pleias, Nebula и Ryax Technologies, уже используют эту возможность для создания приложений. Представленные в рамках GTC Paris мероприятия уже реализуются с использованием технологий NVIDIA. Так, Mistral строит новый ЦОД мощностью 44 МВт на севере Франции. Первый дата-центр Mistral, анонсированный в 2025 году, уже получил 18 тыс. систем NVIDIA GB200 в рамках плана по созданию 200 МВт вычислительных мощностей по всей Европе к 2027 году. В сотрудничестве с французским государственным инвестиционным банком Bpifrance, инвестиционной компанией MGX и NVIDIA компания работает над расширением Campus AI, сети предприятий в сфере ИИ, планируя построить ЦОД на 1,4 ГВт, что сделает её одним из крупнейших ИИ-платформ в Европе. Облачный провайдер Scaleway получил NVIDIA B300. 
Источник изображения: AI Factory France Bull и Foxconn намерены производить в Европе NVIDIA Vera Rubin NVL72. Системы будут производиться и первоначально тестироваться на заводах Foxconn в Чехии, после чего их будут собирать, интегрировать и полностью проверять на заводе Bull в Анжере (Angers). Консорциум из восьми ведущих французских компаний подал заявку на размещение европейской гигафабрики ИИ во Франции для укрепления европейской ИИ инфраструктуры и ускорения внедрения ИИ. В свою очередь Schneider Electric объединилась с NVIDIA для разработки проектов гигаваттных ИИ-фабрик для компаний, развивающих ИИ-инфраструктуры. Аналогичные инициативы внедряются по всей Европе, включая сотрудничество между NVIDIA и Барселонским суперкомпьютерным центром (BSC), в рамках которого создаётся сеть, соединяющая местную инфраструктуру со стартапами и учреждениями государственного сектора. Компания TotalEnergies построит Pangea 5, суперкомпьютер следующего поколения, разработанный совместно с Dell и NVIDIA, который будет использоваться для сейсмической съёмки, передового моделирования и исследований в области ИИ в энергетическом секторе. |
|


