Материалы по тегу: hpc
|
10.07.2026 [18:50], Владимир Мироненко
Европейские ИИ-гигафабрики ÆTHER получат суверенные чипы Axelera и SiPearlЕвропейский консорциум ÆTHER (AETHER) сообщил о подаче заявки на участие в предстоящем тендере Европейской комиссии по созданию ИИ-гигафабрик (AI Gigafactory), объявленном в рамках стратегии ЕС в области цифрового и промышленного суверенитета, о чём пишет HPCwire. Сообщается, что консорциум объединил ведущих европейских игроков в энергетике, строительстве, облачных вычислениях, полупроводниках, высокопроизводительных вычислениях и ИИ, поставивших цель «продемонстрировать, что Европа обладает всеми необходимыми знаниями для проектирования, строительства, электроснабжения, эксплуатации и масштабирования инфраструктуры ИИ». ÆTHER объявил о начале активных переговоров по приобретению двух промышленных площадок в районе Страсбурга (Strasbourg, Франция) для строительства ЦОД. Ожидается, что сделка по приобретению первой площадки, FR-SXB1, будет завершена к концу октября, с последующим вводом в эксплуатацию в 2027 года. Приобретение второй площадки FR-SXB2 должно быть завершено к концу декабря, а к работе ЦОД приступит спустя несколько месяцев. Обе площадки имеют подключения к энергосети и необходимые разрешения. 
Источник изображения: SiPearl Два ЦОД первоначально обеспечат суммарную мощность в 42 МВт. Спустя 12 мес. будет добавлено ещё 40 МВт, с конечной целью увеличения мощности до 400 МВт. Сообщается, что к концу июля французскому оператору системы передачи электроэнергии RTE будут представлены предложения по обеспечению большей мощности на площадке FR-SXB1. Строительство ЦОД возглавит компания Nhood при поддержке Damthieu Bard и Equans. Аппаратное обеспечение будет предоставлено компанией 2CRSi (партнёр AMD и NVIDIA), занимающейся производством серверов, поставщиком ИИ-ускорителей Axelera AI и разработчиком CPU SiPearl. За энергоснабжение будут отвечать ÉS Group, Projex и Haffner Energy. «Объединив высокопроизводительные процессоры SiPearl с ускорителями Axelera в HPC-серверах 2CRSi, мы предоставим комплексное аппаратное решение, способное обрабатывать самые требовательные ИИ-задачи, с дополнительным преимуществом европейского суверенитета. Мы рады играть активную роль в консорциуме ÆTHER, что подтверждает важнейшую роль Европы в глобальной гонке за ИИ», — заявила SiPearl. Объявленный в феврале 2025 года проект ЕС AI Continent Action Plan по созданию ИИ-гигафабрик стоимостью €20 млрд ($22,8 млрд) предусматривает строительство от трёх до пяти крупных суперкомпьютерных кластеров по всему континенту, каждый из которых будет оснащен 100 тыс. ИИ-чипов для обучения самых современных и сложных моделей.
10.07.2026 [11:34], Сергей Карасёв
Национальный научный фонд США выделил $10 млн на суперкомпьютер Bridges-3 с AMD EPYC и NVIDIA B200Национальный научный фонд США (NSF), по сообщению Datacenter Dynamics, выделил $10 млн Питтсбургскому суперкомпьютерному центру (PSC) на создание вычислительного комплекса следующего поколения Bridges-3. Монтаж системы начнётся в начале следующего года. Новый суперкомпьютер станет преемником нынешней машины Bridges-2 (на изображении). Этот комплекс имеет гетерогенную архитектуру с узлами разных типов под различные задачи. В частности, задействованы 504 узла Regular Memory с 256/512 Гбайт оперативной памяти и двумя процессорами AMD EPYC 7742 каждый. Кроме того, присутствуют узлы Extreme Memory, несущие на борту по четыре чипа Intel Xeon Platinum 8260M Cascade Lake и 4 Тбайт ОЗУ. Наконец, применяются GPU-узлы в нескольких конфигурациях — в том числе с ускорителями NVIDIA H100 и NVIDIA L40S. 
Источник изображения: PSC Технические характеристики Bridges-3 пока полностью не раскрываются. Но известно, что созданием вычислительного комплекса займётся HPE. Система получит серверы на основе неназванных процессоров AMD с «большим количеством ядер». Будут применяться ИИ-ускорители NVIDIA B200. Упомянуты интерконнект InfiniBand и хранилище типа All-Flash на базе Lustre. Бруно Абреу (Bruno Abreu), заместитель научного директора PSC и главный специалист проекта Bridges-3 отмечает, что проектируемая система сохранит все ключевые возможности своего предшественника, получив при этом современные CPU и GPU, обеспечивающие существенное повышение производительности для задач моделирования, симуляции, анализа данных и ИИ. Суперкомпьютер расположится в новом дата-центре PSC. Ввод Bridges-3 в эксплуатацию намечен на лето 2027 года.
28.06.2026 [22:32], Владимир Мироненко
Платформа HPE Supercomputing Programming Software упростит работу с мультивендорными системами ИИ и HPC
amd
hpc
hpe
intel
nvidia
open source
software
ии
контейнеризация
конфиденциальность
разработка
утилизация
Компания HPE представила новую унифицированную программную платформу HPE Supercomputing Programming Software, предназначенную для того, чтобы помочь клиентам справляться с растущей сложностью работы с HPC-средами мультивендорных систем, обеспечивая согласованность между системами HPE. HPE отметила, что разработка приложений для работы на HPC-платформах, таких как кластеры HPE Cray GX5000, требует от разработчиков использования языков программирования и фреймворков, специфичных для конкретной архитектуры чипа. Клиенты используют пакеты, предлагаемые AMD, Intel или NVIDIA, и т.д., и задача клиента — убедиться, что они совместимы с её платформой Cray. HPE будет сотрудничать с производителями чипов для объединения их инструментов разработки в рамках новой платформы, заявил Джим Лухан (Jim Lujan), вице-президент по системной инженерии HPE в интервью HPCwire. По его словам, с помощью HPE Supercomputing Programming Software компания предоставит, по сути, контейнеры с поддержкой их экосистем. HPE берёт на себя обеспечение первой линии поддержки, когда у клиентов возникают проблемы — вместо того, чтобы просто переправлять сообщения производителям чипов, сказал Лухан. Он также отметил, что HPE всё больше переходит на open source, дополняя проприетарные компоненты софтом из открытой экосистемы, что расширяет возможности клиентов. Нынешнее обновление поддерживает Kubernetes, а также открытые инструменты разработки AMD и NVIDIA. 
Источник изображения: HPE HPE Supercomputing Programming Software предлагает простой подход к многовендорным средам и процессу интеграции, помогая ускорить циклы развёртывания и минимизировать риск нестабильности системы. Платформа поддерживает серверы HPE ProLiant, включая модели HPE ProLiant DL и XD, оптимизированные для различных задач обучения, настройки и ИИ-инференса, что обеспечивает согласованный и упрощённый опыт работы на разных платформах для крупных предприятий. Новый программный стек также обеспечивает больше возможностей для разработки клиентами приложений ИИ и HPC с многопользовательским режимом, важность которого возросла в основном из-за требований суверенитета, предъявляемых компаниями, организациями и государственными учреждениями, находящимися за пределами США. HPE добавила многопользовательский режим в инструмент Smart Update Manager (SUM), чтобы клиенты могли изолировать свои данные, а также его поддержку в уже поставленных потребителям коммутаторах Slingshot 400 и СХД Cray E2000. «В последнее время наблюдается большой спрос на многопользовательский режим и его поддержку, — сообщил Лухан. — Мы всегда поддерживали множество пользователей, но теперь есть желание добиться большей изоляции данных и их разделения для некоторых наших клиентов». HPE также расширила свою программу вывода из эксплуатации систем, включив в нее серверы с воздушным охлаждением для ИИ и HPC. Согласно данным компании, в в 2025 году 85 % серверов, прошедших через центры обновления, были переработаны и возвращены в активное использование, а 1,7 Эбайт данных были надёжно удалены.
26.06.2026 [12:44], Сергей Карасёв
Два кристалла, 304 ядра и 32 Гбайт HBM: подробности об Arm-чипах LX2 в китайском суперкомпьютере LineShineКитайский национальный суперкомпьютерный центр в Шэньчжэне (NSCCSZ) обнародовал дополнительную информацию о вычислительном комплексе LineShine, который возглавил свежий рейтинг самых мощных НРС-систем мира TOP500. FP64-производительность LineShine в тесте Linpack достигает 2,198 Эфлопс. В основу LineShine положены китайские 304-ядерные процессоры LX2 с архитектурой Arm. Конструкция этих изделий включает два вычислительных кристалла, каждый из которых содержит 152 ядра Armv9 с поддержкой Scalable Vector Extension (SVE) и Scalable Matrix Extension (SME). Тактовая частота составляет 1,55 ГГц. Каждый из кристаллов, в свою очередь, разделён на четыре NUMA-домена по 38 ядер. В состав каждого домена входят 4 Гбайт памяти HBM и 32 Гбайт памяти DDR5. Таким образом, в общей сложности используются 32 Гбайт HBM и 256 Гбайт DDR5. Энергопотребление LX2 находится на уровне 690 Вт. 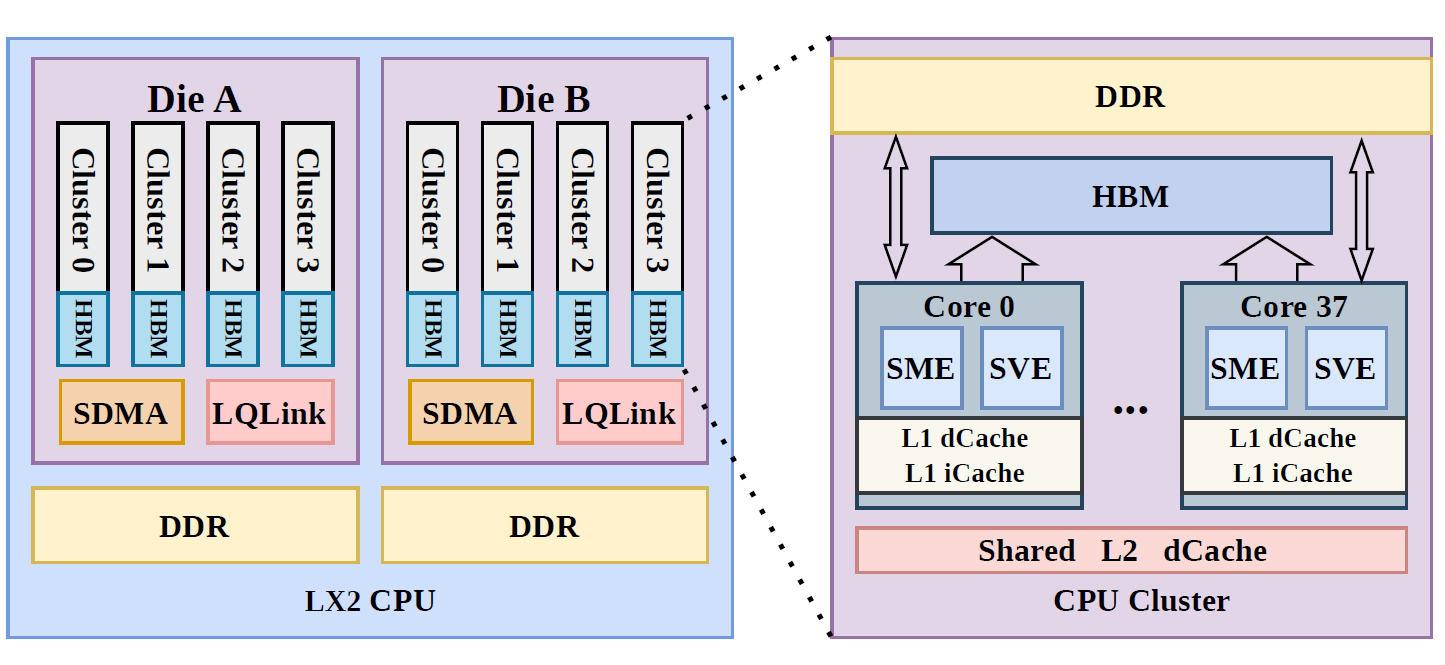
Источник изображения: NSCCSZ В составе LineShine два процессора LX2 формируют один вычислительный узел. Восемь таких узлов входят в один blade-сервер, а 16 серверов — в одно шасси. В одной стойке задействованы два шасси, что в сумме обеспечивает 512 процессоров. В целом, суперкомпьютер насчитывает около 90 стоек и примерно 14 млн вычислительных ядер. Энергопотребление LineShine достигает 42,2 МВт. Реализовано полностью жидкостное охлаждение на основе двусторонних водоблоков. Платформа использует проприетарный интерконнект LingQi, который обеспечивает пропускную способность между узлами до 1,6 Тбит/с. Технология LingQi поддерживает 2 млн портов и может масштабироваться до более чем 100 тыс. узлов. Вместимость подсистемы хранения данных LineShine составляет 200 Пбайт. Каждая стойка получает питание от шины постоянного тока LVDC на 380 В, обеспечивая вычислительную мощность до 580 кВт.
26.06.2026 [12:23], Владимир Мироненко
Cornelis и NextSilicon создадут эталонные архитектуры для ИИ и HPCCornelis и NextSilicon объявили о сотрудничестве с целью разработки эталонных архитектур для ИИ и HPC. В рамках проекта компании приступили к оценке возможности использования 400G-интерконнекта Cornelis CN5000 в паре с вычислительной платформой NextSilicon Maverick-2. На первом этапе проверяется совместная работа интерконнекта и вычислительных ресурсов в различных конфигурациях, причём партнёры начали с проверенных комбинаций. Компании планируют расширить тестирование на интерконнект CN6000 со скоростью 800 Гбит/с, запуск которого запланирован на II половину 2026 года. Обе компании нацелены на решение проблемы в своей сфере. Стандартный Ethernet не рассчитан на обработку небольших, чувствительных к задержке сообщений, которые генерируются в больших масштабах при выполнении задач ИИ-инференса и симуляции HPC. Возникает перегрузка, и дорогостоящие вычислительные ресурсы простаивают в ожидании данных. CN5000 разработан для устранения этого простоя. 
Источник изображений: Cornelis Networks Вычислительные ресурсы простаивают при обработке нерегулярных, зависящих от данных рабочих нагрузок, которые доминируют в ИИ и HPC. Израильская компания NextSilicon построила ускоритель Maverick-2 на основе своей интеллектуальной вычислительной архитектуры (ICA) — программно-определяемой архитектуры с управлением потоками данных (dataflow), в которой вычисления запускаются не последовательными инструкциями, а по факту поступления данных. Платформа переконфигурируется для каждой рабочей нагрузки во время выполнения без изменения существующего кода. Сочетание подходов Cornelis и NextSilicon позволяет решить обе проблемы, обеспечивая передачу данных и поддерживая постоянную работу вычислительных ресурсов. Совместные эталонные архитектуры предоставят OEM-партнерам план создания систем, которые они смогут построить и вывести на рынок.  «Операторы постоянно говорят нам, что их самые дорогие системы простаивают, ожидая подключения к сети, — говорит Лиза Спелман (Lisa Spelman), генеральный директор Cornelis. — Мы создали CN5000, чтобы положить конец этому ожиданию. NextSilicon бросает вызов аналогичной проблеме в вычислительной сфере, поэтому это сотрудничество является естественным шагом. Вместе мы можем показать партнерам и клиентам, что дают бесперебойная сеть и вычислительная архитектура, ориентированная на рабочие нагрузки, в рамках единого решения». Наряду с HPC, сотрудничество также будет направлено на переход в ИИ-инференсе к моделям смешанных экспертов (MoE) и агентному ИИ. Инференс в продуктовых средах для этих рабочих нагрузок больше не выполняется как одна модель на одном ускорителе. Он разделяется на этапы, и данные перемещаются между этапами по сети. Дезагрегированный инференс делает сетевую инфраструктуру частью вычислительного пути. Он применим для сети, которая обрабатывает небольшие, импульсные, чувствительные к задержкам сообщения без перегрузки, и вычислительных ресурсов, которые адаптируются к каждому этапу конвейера.
24.06.2026 [01:23], Владимир Мироненко
Европа получит 35 суперкомпьютеров на чипах NVIDIANVIDIA объявила о разработке по всей Европе 35 суперкомпьютеров на базе её чипов, которые позволят более 3 млн исследователей ускорить проведение научных исследований и внедрение промышленных инноваций в сфере ИИ. Это крупнейшее за год расширение в Европе сети суперкомпьютеров, охватывающее национальные суперкомпьютерные центры, ИИ-фабрики и академические исследовательские институты. Эти системы будут поддерживать исследования в области климатологии, здравоохранения, декарбонизации чистой энергетики, квантовых вычислений и фундаментальной науки. Работу большей части европейских ИИ-фабрик обеспечивают платформы Blackwell и Hopper, при этом с прошлого года было развернуто или анонсировано 800 Эфлопс вычислительных мощностей для ИИ. Эти суперкомпьютеры, включая обновлённый EuroHPC MareNostrum5 AI Барселонского суперкомпьютерного центра (BSC-CNS), Blue Swan (BavariaAI), IT4LIA, HammerHAI Центра высокопроизводительных вычислений в Штутгарте (HLRS) и ИИ-фабрика Mimer Национальной академической суперкомпьютерной инфраструктуры Швеции (NAISS), основаны на передовой ИИ-инфраструктуре NVIDIA, говорит компания. Так, суперкомпьютер MareNostrum 5 будет дооснащён системами GB300 NVL72 и GB200 NVL4, объединённых интерконнектом NVIDIA Quantum-X800 InfiniBand. Система, обеспечивающая производительность до 20 Эфлопс при обучении ИИ и 33 Эфлопс при ИИ-инференсе, позволит ускорить работу генеративного ИИ, климатическое моделирование, исследования в области здравоохранения и биотехнологий, устойчивого сельского хозяйства, энергетических систем и госсервисов. 
Источник изображения: NVIDIA Система Blue Swan (BavariaAI) добавит 1 тыс. ускорителей (GB200 NVL4 и Quantum-2 InfiniBand) суперкомпьютерным центрам FAU Erlangen и LRZ. Платформа обеспечит производительность до 11 Эфлопс при обучении ИИ и 22 Эфлопс при ИИ-инференсе. Она будет поддерживать инициативу Баварии по созданию базовых моделей, продвигая открытые мультимодальные модели для науки, государственного управления, исследований в области здравоохранения, робототехники и т.д. HammerHAI (HLRS) представляет собой первую в Германии ИИ-фабрику с более чем 850 GPU на базе GB200 NVL4 с Quantum-X800 InfiniBand. Суперкомпьютер HammerHAI, обеспечивающий производительность до 8 Эфлопс при обучении ИИ и 15 Эфлопс при ИИ-инференсе, обеспечит исследователям и промышленным пользователям безопасную ИИ-инфраструктуру для инженерного моделирования, инференса и научных исследования. Суперкомпьютер Mimer EuroHPC AI Factory (NAISS), размещённый в Линчёпингском университете (LiU, Швеция), будет использовать 100 систем GB200 NVL4 и сеть ConnectX-8. Обеспечивая производительность до 4 Эфлопс при обучении ИИ и около 7 Эфлопс при ИИ-инференсе, Mimer AI Factory будет способствовать развитию шведской ИИ-экосистемы в таких областях, как биологические науки, материаловедение, автономные системы, доверенный ИИ и т.д. Наконец, ИИ-фабрика IT4LIA с более чем 8 тыс. GPU на базе GB200 NVL4 с Quantum-X800 InfiniBand и ПО NVIDIA AI Enterprise обеспечивает производительность в размере 82 Эфлопс при обучении ИИ и 164 Эфлопс при ИИ-инференсе.
23.06.2026 [12:00], Игорь Осколков
Китайский суперкомпьютер LineShine стал самым производительным в мире и возглавил TOP500Июньский рейтинг самых производительных суперкомпьютеров мира TOP500 принёс неожиданный сюрприз — впервые за несколько лет в список попала новая, крупная машина LineShine из Китая. И не только попала, но и сразу заняла в нём первое место. Более того, она же первой публично преодолела порог FP64-производительности 2 Эфлопс, опираясь только на CPU. Импортонезависимая система LineShine достигла 2,198 Эфлопс в бенчмарке HPL, что составляет порядка 80 % от пиковой теоретической производительности (2,736 Эфлопс), что для столь крупной машины хороший результат. Не менее примечательно, что и в HPCG эта система тоже занимает первое место с результатом 22 Пфлопс, обгоняя El Capitan (17,41 Пфлопс) и Fugaku (16,00). В Green500, правда, она занимает аж 50 место, поскольку потребляет 42,2 МВт, что даёт около 52,07 Гфлопс/Вт. Но, во-первых, данный суперкомпьютер лишён ускорителей, а во-вторых — улучшать энергоэффективность сложнее, чем производительность. LineShine находится в Национальном суперкомпьютерном центре Шэньчжэня (NSCCSZ) и базируется на кастомным китайских 304-ядерных Arm-процессорах LX2 (1,55 ГГц) и платформе LingKun.Всего 13,79 млн ядер, объединённых проприетарным интерконнектом LingQi работающих под управлением ОС Kylin. В ИИ-бенчмарке HPL-MxP система заняла четвёртое место с показателем 7,92 Эфлопс, т.е. разница между FP64-вычислениями в традиционном Linpack и вычислениями со смешанной точностью составляет довольно скромные 3,6x, что опять-таки указывает на архитектуру без выделенных ИИ-ускорителей. 
Источник изображения: Markus Winkler / Unsplash Ещё один новичок в первой десятке TOP500 — итальянский суперкомпьютер Eni HPC7 с устоявшейся производительностью 571,5 Пфлопс (в пике 861,13 Пфлопс), который занял шестое место. Он построен на ровно той же платформе, что и бывший лидер списка El Capitan: узлы HPE Cray EX255a с APU AMD Instinct MI300A. При этом у Eni теперь сразу две машины в Топ-10, поскольку система HPC6 (477,9/606,97 Пфлопс) находится на восьмом месте. Они бы, к слову, могли бы оказаться непосредственными соседями, если бы Microsoft решила обновить тесты своего облачного суперкомпьютера Eagle. Ресурсы у неё точно есть, а вот желание трать драгоценное машинное время ИИ-ускорителей на бенчмарки вряд ли есть. Система Fugaku также остаётся в первой десятке, уже шестой год подряд. Впрочем, если бы не нежелание Китая делиться информацией о своих системах, дефицита в которых явно нет, апдейты к TOP500 были бы гораздо чаще и интереснее. Авторы рейтинга отдельно отмечают разнообразие аппаратных платформ, подчёркивая, что добраться до экзафлопса можно разными путями. Речь и про процессоры, и про ускорители, и про интерконнекты. Всего в новом списке TOP500 появилось 44 новых машины, а минимальный порог вхождения повысился до округлённо 2,66 Пфлопс. Для вхождения же в первую десятку нужно как минимум 434,9 Пфлопс. Среди поставщиков в Топ-10 с точки зрения производительности лидирует HPE (El Capitan, Frontier, Aurora, HPC7, HPC6 и Alps). По процессорам в лидерах снова AMD (El Capitan, Frontier, HPC7 и HPC6). NVIDIA представлена в трёх системах (JUPITER Booster, Eagle, and Alps), а Intel — в двух (Aurora и Eagle). Atos/Eviden/Bull и Fujitsu поставили по одной системе, JUPITER Booster и Fugaku соответственно. Ну а LineShine гордо стоит в стороне от всех основных вендоров. Новых заявок от российских компаний по-прежнему нет. А из новичков среди стран можно упомянуть Индонезию с системой на объекте ASEAN-Korea HPC (436 место) и Узбекистан с государственным суперкомпьютером (321 место).
23.06.2026 [11:33], Сергей Карасёв
В Японии появился гибридный квантово-классический суперкомпьютер Roquo производительностью 19,8 ПфлопсВ Центре вычислительных наук японского Института физико-химических исследований (R-CCS) введён в строй гибридный квантово-классический суперкомпьютер Roquo, названный в честь горы Рокко к северу от города Кобе. В создании НРС-системы приняли участие DTS, NVIDIA, Giga Computing, DDN и ScaleWorX. Roquo состоит из 135 вычислительных узлов на базе NVIDIA GB200 NVL4. В общей сложности задействованы 540 чипов Blackwell и 270 чипов NVIDIA Grace. Применяется интерконнект NVIDIA Quantum-X800 InfiniBand с общей пропускной способностью до 3,2 Тбит/с (установлены коммутаторы Q3400, поддерживающие скорость передачи данных 800 Гбит/с на порт). Реализовано жидкостное охлаждение. Заявленная производительность на операциях FP64 составляет 19,8 Пфлопс, а теоретическое пиковое быстродействие на операциях FP8 превышает 5 Эфлопс. Суперкомпьютер использует интерфейс SQC, что позволяет формировать гибридные среды с поддержкой традиционных и квантовых вычислений. 
Источник изображения: RIKEN В рамках проекта по созданию Roquo корпорация DTS осуществляла общую разработку платформы в соответствии с требованиями R-CCS. В свою очередь, NVIDIA предоставила базовые вычислительные и сетевые компоненты, тогда как Giga Computing отвечала за проектирование и производство серверов. DDN предоставила высокоскоростное файловое хранилище. Наконец, специалисты ScaleWorX осуществили общую системную интеграцию. Суперкомпьютер Roquo, как ожидается, поможет ускорить разработку и оценку эффективности новых квантовых алгоритмов. Кроме того, система будет использоваться для решения сложных задач, с которыми не в состоянии справиться классические НРС-комплексы.
22.06.2026 [12:53], Сергей Карасёв
Intersect360: годовой объём мирового рынка ИИ-инфраструктур превысил $300 млрдПо оценкам аналитической компании Intersect360 Research, затраты на глобальном рынке инфраструктур для дата-центров, ориентированных на ИИ-нагрузки, в 2025 году увеличились на 60,1 %, превысив $300 млрд. Ключевым драйвером отрасли выступают гиперскейлеры, продолжающие активно наращивать вычислительные мощности. Отмечается, что в абсолютном выражении доминирует именно сегмент гиперскейлеров, на который пришлось более $200 млрд расходов. В то же время затраты в области корпоративных ИИ-инфраструктур (включая HPC-направление) в 2025-м оказались на уровне $71,6 млрд. В дальнейшем, по мнению аналитиков, среднегодовой темп роста в сложных процентах (CAGR) на мировом рынке ИИ-инфраструктур будет исчисляться двузначными числами процентов. В результате, к 2030-му суммарные расходы преодолеют отметку в $500 млрд. В сегменте корпоративных ИИ-инфраструктур показатель прогнозируется в объёме более $130 млрд. Вместе с тем специалисты Intersect360 Research указывают на трансформацию рассматриваемой отрасли. В частности, наблюдается сдвиг в сторону облачных платформ для задач ИИ и суверенных дата-центров, оптимизированных для соответствующих нагрузок. 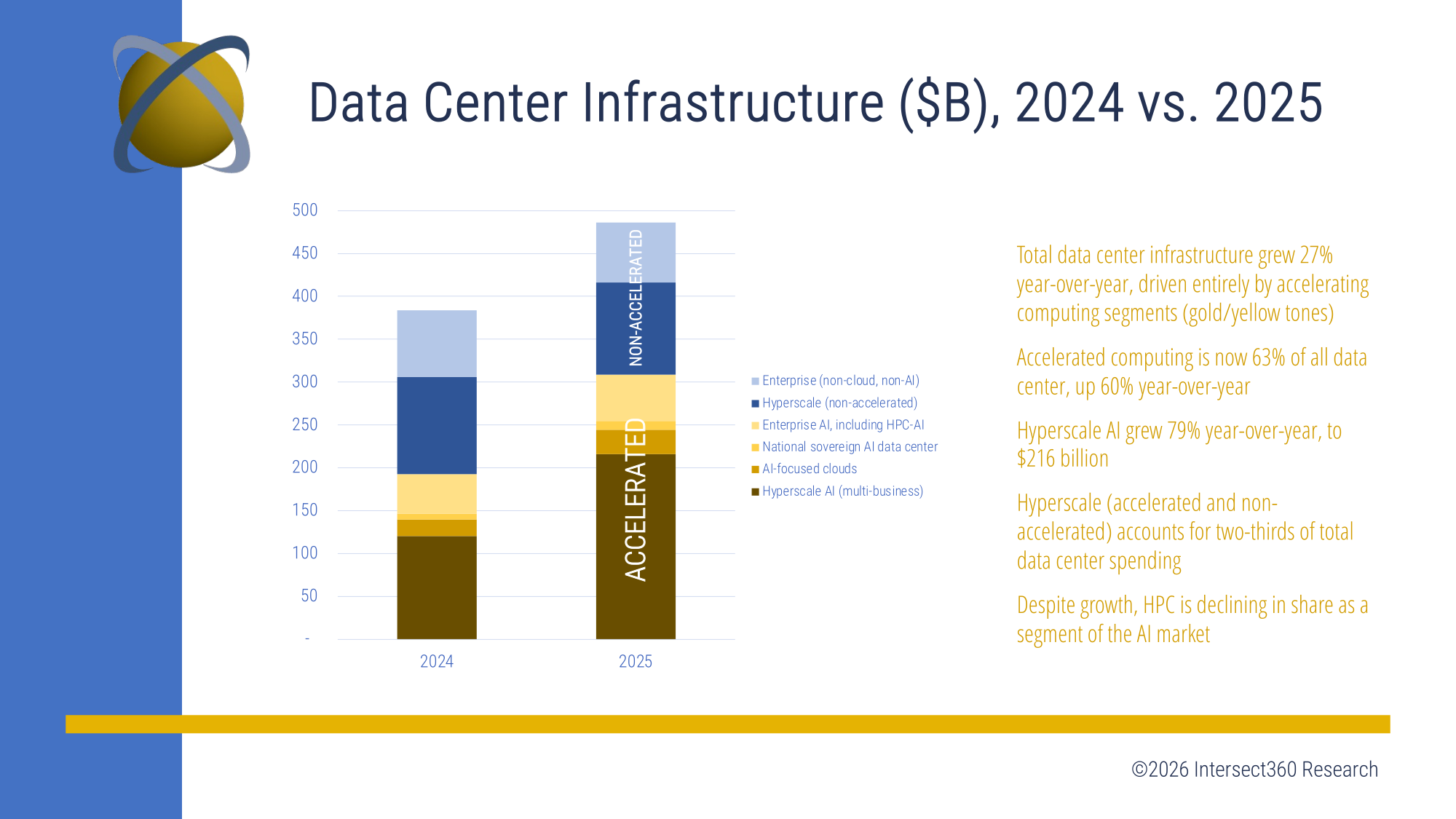
Источник изображения: Intersect360 Причём направление суверенных ЦОД демонстрирует самые высокие темпы роста, что связано со сформировавшейся геополитической обстановкой и санкционными ограничениями. Такие площадки функционируют полностью в пределах географических границ конкретной страны, что устраняет риски, обусловленные применением иностранных платформ.
В целом, указывают аналитики, до 2030 года основную часть прироста рынка обеспечат ускорители на базе GPU, высокопроизводительные серверы и облачные сервисы, оптимизированные для ИИ. При этом затраты в сегменте традиционной корпоративной инфраструктуры останутся на прежнем уровне или даже сократятся в реальном выражении.
20.06.2026 [15:45], Сергей Карасёв
В Словении запущена НРС-система FRIDA с ускорителями NVIDIA BlackwellЛюблянский университет в Словении (University of Ljubljana), по сообщению DataCenter Dynamics, запустил высокопроизводительную систему FRIDA, ориентированную на задачи ИИ и машинного обучения. Это не классический суперкомпьютер, а модульный контейнерный дата-центр, размещённый на крыше здания Факультета компьютерных и информационных наук (FRI) в Любляне. Известно, что в составе FRIDA задействованы 104 ускорителя на основе GPU. В частности, применяются изделия NVIDIA Blackwell B200 и B300. Суммарный объём GPU-памяти составляет 16,8 Тбайт. Комплекс оборудован гибридной воздушно-жидкостной системой охлаждения. Все вычислительные узлы связаны интерконнектом с высокой пропускной способностью. Отмечается, что производительность FRIDA при вычислениях с низкой точностью достигает 708 Пфлопс. Пиковое быстродействие при операциях с разреженными матрицами низкой точности заявлено на уровне 1,42 Эфлопс. FRIDA дополнит словенскую НРС-систему Vega, которая была введена в строй в 2021 году в рамках проекта Европейского совместного предприятия по развитию высокопроизводительных вычислений (EuroHPC JU). Эта машина, основанная на процессорах AMD и ускорителях NVIDIA, демонстрирует FP64-производительность на уровне 6,9 Пфлопс. 
Источник изображения: linkedin.com Vega задумывалась как универсальная платформа для сложных вычислений: она может применяться для решения задач в самых разных областях, включая биоинженерию и разработку новых лекарств, изучение климата и прогнозирование погоды, персонализированную медицину, создание новых материалов и пр. В свою очередь, система FRIDA ориентирована прежде всего на нагрузки, связанные с ИИ. |
|


