Материалы по тегу: dgx
|
20.03.2026 [11:44], Сергей Карасёв
Платформа NVIDIA DGX Rubin NVL8 использует процессоры Intel Xeon 6Корпорация Intel сообщила о том, что в составе платформы NVIDIA DGX Rubin NVL8 для агентного ИИ применяются CPU поколения Xeon 6. Эти чипы отвечают за критически важные функции, такие как управление памятью, оркестрация задач и распределение рабочей нагрузки. Система DGX Rubin NVL8 несёт на борту два процессора Xeon 6776P семейства Granite Rapids. Изделия содержат 64 вычислительных ядра с возможностью одновременной обработки до 128 потоков инструкций. Базовая тактовая частота составляет 2,3 ГГц, максимальная — 3,9 ГГц. В режиме Priority Core Turbo (PCT) с восемью ядрами частота достигает 4,6 ГГц. Показатель TDP равен 350 Вт. CPU специально оптимизированы Intel для ИИ-узлов. «Intel Xeon 6 обеспечивает превосходную производительность, эффективность и совместимость с обширной экосистемой программного обеспечения x86, на которую полагаются клиенты при выполнении инференса в масштабе», — говорит Джефф Маквей (Jeff McVeigh), корпоративный вице-президент и генеральный директор стратегических ЦОД-программ Intel. 
Источник изображения: NVIDIA В состав DGX Rubin NVL8 входят восемь ускорителей Rubin с суммарным объёмом памяти 2,3 Тбайт (пропускная способность — 160 Тбайт/с). Задействованы восемь однопортовых адаптеров NVIDIA ConnectX-9 VPI (до 800 Гбит/с NVIDIA Infiniband и Ethernet), а также два DPU NVIDIA BlueField-4. Общая пропускная способность шины NVIDIA NVLink достигает 28,8 Тбайт/с. Энергопотребление — приблизительно 24 кВт. Заявленное ИИ-быстродействие на задачах инференса NVFP4 составляет до 400 Пфлопс, при обучении моделей NVFP4 — 280 Пфлопс, при обучении FP8/FP6 — 140 Пфлопс. Среди поддерживаемого софта упомянуты NVIDIA DGX OS, Ubuntu, Red Hat Enterprise Linux, Rocky Linux.
06.01.2026 [14:28], Владимир Мироненко
NVIDIA объявила о запуске платформы Vera Rubin NVL72NVIDIA объявила о запуске платформы следующего поколения Rubin, которая приходит на смену Blackwell Ultra. Компания отметила, что платформа Rubin объединяет сразу пять инноваций, включая новейшие поколения интерконнекта NVIDIA NVLink, Transformer Engine, Confidential Computing и RAS Engine, а также процессор NVIDIA Vera. Примечательно, что NVIDIA снова решила вернуться к именованию на основе количества суперчипов (NVL72), а не ускорителей (NVL144), как обещала в прошлом году. Созданная с использованием экстремального совместного проектирования на аппаратном и программном уровнях, NVIDIA Vera Rubin обеспечивает десятикратное снижение стоимости токенов для инференса и четырёхкратное сокращение количества ускорителей для обучения моделей MoE по сравнению с платформой NVIDIA Blackwell. Коммутационные системы NVIDIA Spectrum-X Ethernet Photonics обеспечивают пятикратное повышение энергоэффективности и времени безотказной работы. 
Источник изображений: NVIDIA Платформа Rubin построена на шести чипах — Arm-процессоре Vera, ускорителе Rubin, коммутаторе NVLink 6, адаптере ConnectX-9 SuperNIC, DPU BlueField-4 и Ethernet-коммутаторе NVIDIA Spectrum-6. Ускорители Rubin поначалу будут доступны в двух форматах. В первом случае — в составе стоечной платформы DGX Vera Rubin NVL72, которая объединяет 72 ускорителя Rubin и 36 процессоров Vera, NVLink 6, ConnectX-9 SuperNIC и BlueField-4. Также ускорители Rubin будут доступны в составе платформы DGX/HGX Rubin NVL8 на базе x86-процессоров. Обе платформы будут поддерживаться кластерами NVIDIA DGX SuperPod, сообщил ресурс CRN.  Как отметила NVIDIA, разработанный для агентного мышления, процессор NVIDIA Vera является самым энергоэффективным процессором для крупномасштабных ИИ-фабрик. Он оснащён 88 кастомными Armv9.2-ядрами Olympus с 176 потоками с новой технологией пространственной многопоточности NVIDIA, 1,5 Тбайт системной памяти SOCAMM LPDDR5x (1,2 Тбайт/с), возможностями конфиденциальных вычислений и быстрым интерконнектом NVLink-C2C (1,8 Тбайт/с в дуплексе). 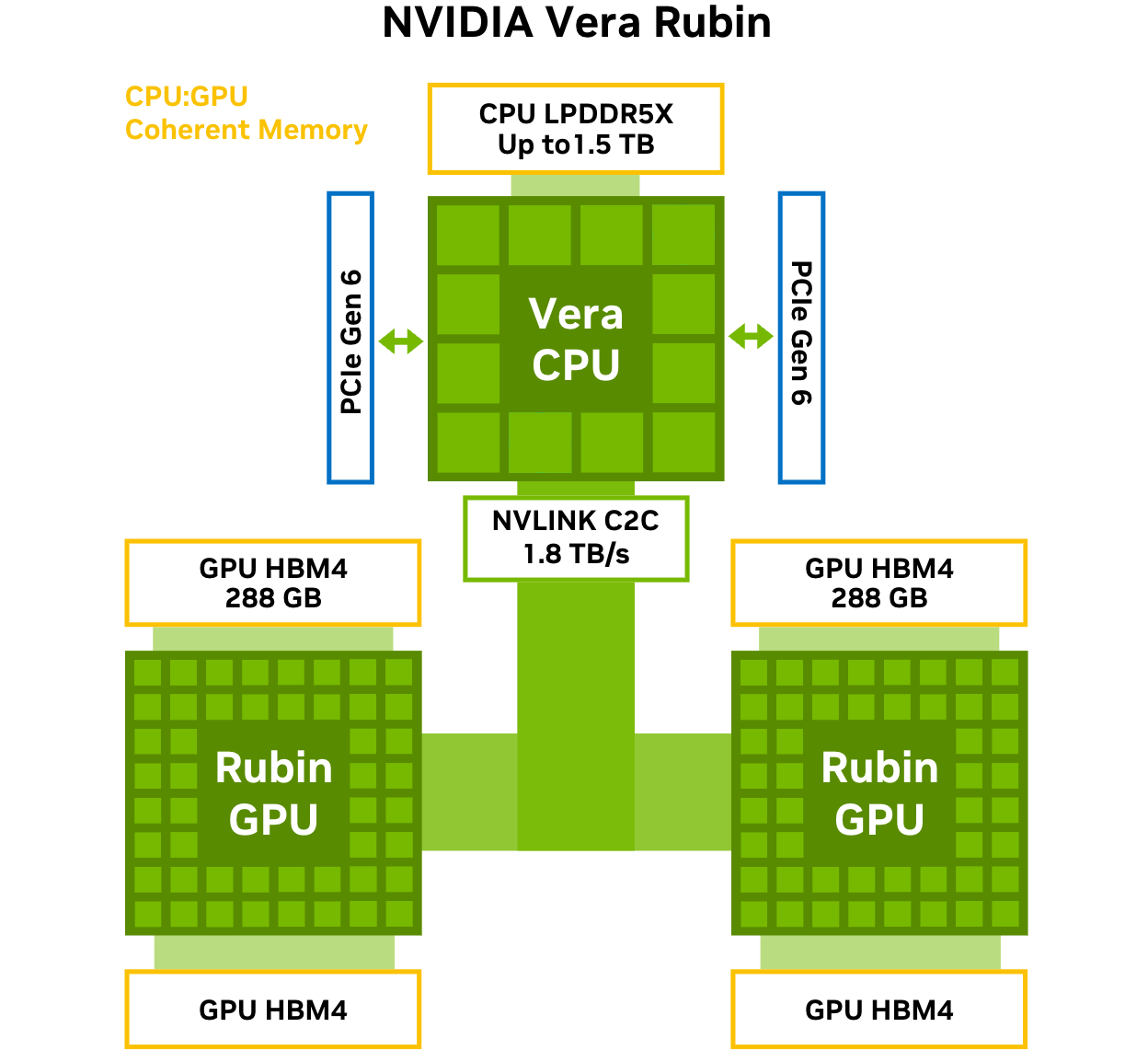 NVIDIA Rubin с аппаратным адаптивным сжатием данных обеспечивает до 50 Пфлопс (NVFP4) для инференса, что в пять раз быстрее, чем Blackwell. Он также обеспечивает до 35 Пфлопс (NVFP4) в режиме, что в 3,5 раза быстрее, чем его предшественник. Пропускная способность 288 Гбайт HBM4 составляет 22 Тбайт/с, что в 2,8 раза быстрее предшественника, а пропускная способность NVLink на один ускоритель вдвое выше — 3,6 Тбайт/с (в дуплексе).  NVIDIA также сообщила, что Vera Rubin NVL72 обладает 54 Тбайт памяти LPDDR5x, что в 2,5 раза больше, чем у Blackwell, и 20,7 Тбайт памяти HBM4, что на 50 % больше, чем у предшественника. Агрегированная пропускная способность HBM4 достигает 1,6 Пбайт/с, что в 2,8 раза больше, а скорость интерконнекта составляет 260 Тбайт/с, что вдвое больше, чем у платформы Blackwell NVL72, и «больше, чем пропускная способность всего интернета». Ожидаемый уровень энергопотребления составит от 190 до 230 кВт на стойку.  Компания отметила, что Vera Rubin NVL72 — первая стоечная платформа, обеспечивающая конфиденциальные вычисления, которая поддерживает безопасность данных на уровне доменов CPU, GPU и NVLink. Коммутатор NVLink 6 с жидкостным охлаждением оснащён 400G-блоками SerDes, обеспечивает пропускную способность 3,6 Тбайт/с на каждый GPU для связи между всеми GPU, общую пропускную способность 28,8 Тбайт/с и 14,4 Тфлопс внутрисетевых вычислений в формате FP8.  Хотя NVIDIA заявила, что Rubin находится в «полномасштабном производстве», аналогичные продукты от партнёров появятся только во II половине этого года. Среди ведущих мировых ИИ-лабораторий, поставщиков облачных услуг, производителей компьютеров и стартапов, которые, как ожидается, внедрят Rubin, компания назвала Amazon Web Services (AWS), Anthropic, Black Forest Labs, Cisco, Cohere, CoreWeave, Cursor, Dell Technologies, Google, Harvey, HPE, Lambda, Lenovo, Meta✴, Microsoft, Mistral AI, Nebius, Nscale, OpenAI, OpenEvidence, Oracle Cloud Infrastructure (OCI), Perplexity, Runway, Supermicro, Thinking Machines Lab и xAI.  ИИ-лаборатории, включая Anthropic, Black Forest, Cohere, Cursor, Harvey, Meta✴, Mistral AI, OpenAI, OpenEvidence, Perplexity, Runway, Thinking Machines Lab и xAI, рассматривают платформу NVIDIA Rubin для обучения более крупных и мощных моделей, а также для обслуживания мультимодальных систем с длинным контекстом с меньшей задержкой и стоимостью по сравнению предыдущими поколениями ускорителей. Партнёры по инфраструктурному ПО и хранению данных AIC, Canonical, Cloudian, DDN, Dell, HPE, Hitachi Vantara, IBM, NetApp, Nutanix, Pure Storage, Supermicro, SUSE, VAST Data и WEKA работают с NVIDIA над разработкой платформ следующего поколения для инфраструктуры Rubin.  В связи с тем, что рабочие нагрузки агентного ИИ генерируют огромные объёмы контекстных данных, NVIDIA также представляла новую платформу хранения контекста инференса NVIDIA Inference Context Memory Storage Platform — новый класс инфраструктуры хранения, разработанной для масштабирования контекста инференса.  Сообщается, что платформа, работающая на базе BlueField-4, обеспечивает эффективное совместное использование и повторное применение данных KV-кеша в рамках всей ИИ-инфраструктуры, повышая скорость отклика и пропускную способность, а также обеспечивая предсказуемое и энергоэффективное масштабирование агентного ИИ. Дион Харрис (Dion Harris), старший директор NVIDIA по высокопроизводительным вычислениям и решениям для ИИ-инфраструктуры, сообщил, что по сравнению с традиционными сетевыми хранилищами для данных контекста инференса, новая платформа обеспечивает до пяти раз больше токенов в секунду, в пять раз лучшую производительность на доллар и в пять раз лучшую энергоэффективность.
05.11.2025 [10:16], Владимир Мироненко
NVIDIA и Deutsche Telekom строят в Германии ИИ-фабрику стоимостью €1 млрд
b200
deutsche telekom
dgx
hardware
nvidia
omniverse
германия
ии
конфиденциальность
промышленность
цод
NVIDIA и Deutsche Telekom представили первое в мире промышленное ИИ-облако (Industrial AI Cloud) — суверенную корпоративную платформу, запуск которой запланирован на начало 2026 года в рамках совместного проекта стоимостью €1 млрд. Платформа использует передовое оборудование NVIDIA, включая системы DGX B200 и серверы RTX PRO, а также ПО, в том числе NVIDIA AI Enterprise, CUDA-X и Omniverse, полностью интегрированное в облачную и сетевую экосистему Deutsche Telekom. Deutsche Telekom сообщила, что NVIDIA поставит более тысячи систем NVIDIA DGX B200 и серверов NVIDIA RTX PRO с 10 тыс. ускорителей NVIDIA Blackwell. Оборудование уже устанавливается в модернизированном дата-центре в Мюнхене. Объект начнёт работу в I квартале 2026 года, ИИ-производительность его систем составит 500 Пфлопс (точность вычислений не указана). Сообщается, что благодаря запуску этой ИИ-фабрики вычислительная мощность ИИ-решений в Германии увеличится сразу на 50 %. Управление объектом площадью в несколько тысяч квадратных метров будет осуществлять Deutsche Telecom, а компания SAP, занимающаяся разработкой корпоративного программного обеспечения, предоставит свою платформу SAP Business Technology Platform и соответствующие приложения. Европейская компания Polarise, занимающаяся разработкой ЦОД, также будет участвовать в проекте, пишет DataCenter Dynamics. «Благодаря этим вычислительным мощностям Германия станет ведущей в Европе суверенной точкой ИИ-доступа, созданной в рамках исключительно частной инициативы», — отметила Deutsche Telekom. 
Источник изображения: NVIDIA Сообщается, что Industrial AI Cloud — один из первых флагманских проектов инициативы Made for Germany («Сделано для Германии»), в которой участвуют более 100 компаний. Цель инициативы — укрепить позиции Германии как бизнес-площадки и ускорить цифровизацию экономики и управления страны. Компании смогут резервировать вычислительные мощности для разработки промышленных приложений ИИ. Облако также будет обслуживать государственные службы и оборонный сектор, пишет Reuters. Deutsche Telekom сообщила, что среди первых партнёров проекта — Agile Robots, чьи роботы, по слухам, будут использоваться для установки серверных стоек на объекте. Благодаря использованию NVIDIA Omniverse она расширит свои возможности по обучению, тестированию и валидации базовых моделей робототехники для целых парков роботов. Также в числе первых партнёров компания Perplexity, которая будет использовать новый ИИ ЦОД для предоставления услуг ИИ-инференса немецким пользователям и компаниям. Siemens сообщила, что будет использовать облачную платформу для ускорения внедрения промышленного ИИ, в том числе для собственных сервисов и для предложения решений на базе ИИ клиентам и партнёрам. По данным Siemens, такие автопроизводители, как Mercedes-Benz и BMW, будут использовать Industrial AI Cloud для проведения сложных симуляций с использованием цифровых двойников на базе ИИ, что значительно ускорит разработку автомобилей.
21.09.2025 [13:23], Сергей Карасёв
В Германии запущена квантово-классическая система с суперчипами NVIDIA GH200Компании Quantum Machines и Arque Systems развернули в Юлихском суперкомпьютерном центре в Германии (Jülich Supercomputing Centre, JSC) гибридную квантово-классическую вычислительную систему на платформе NVIDIA DGX Quantum. Это первый подобный проект, реализованный на базе крупной НРС-площадки в Европе. Новая система сочетает суперчипы NVIDIA GH200, 5-кубитный квантовый процессор Arque Systems и гибридный квантово-классический контроллер Quantum Machines OPX1000. Использованная архитектура, как утверждается, обеспечивает возможность квантовой коррекции ошибок (QEC), что является критически важным требованием при организации практических квантовых вычислений. Контроллер OPX1000, как отмечается, обеспечивает бесшовное взаимодействие между классическими и квантовыми вычислительными ресурсами. Достигается двусторонняя передача данных с задержкой менее 4 мкс, что в 1000 раз лучше, чем в предыдущих подобных реализациях. 
Источник изображения: Arque Systems Ключевыми задачами проекта названы ускорение процедур калибровки кубитов и тестирование производительности квантовой коррекции ошибок. Кроме того, на базе комплекса планируется осуществлять разработку гибридных квантово-классических вычислительных алгоритмов. Одним из главных преимуществ платформы названа возможность запуска нейронных сетей и моделей машинного обучения на высокопроизводительных GPU с сохранением взаимодействия с квантовой подсистемой с низкой задержкой. Такой уровень интеграции, как подчёркивается, недоступен ни в одной другой современной системе квантовых вычислений. «Объединяя квантовые и классические вычислительные ресурсы на базе ведущего европейского суперкомпьютерного центра, мы открываем новые возможности для исследователей в плане изучения гибридных квантово-классических алгоритмов», — говорит доктор Кристель Михильсен (Kristel Michielsen), директор JSC. Нужно отметить, что JSC является оператором первого в Европе экзафлопсного суперкомпьютера — машины JUPITER, которая была официально запущена в эксплуатацию в сентябре 2025 года. Система использует примерно 6000 вычислительных узлов с гибридными ускорителями NVIDIA Quad GH200 и интерконнектом InfiniBand NDR200 (4×200G на узел, DragonFly+): в общей сложности задействованы почти 24 тыс. NVIDIA GH200.
25.07.2025 [17:41], Сергей Карасёв
SoftBank развернула крупнейшую в мире ИИ-платформу на базе NVIDIA DGX B200Японский холдинг SoftBank объявил о расширении вычислительной ИИ-инфраструктуры на платформе NVIDIA DGX SuperPOD: развёрнуты системы DGX B200, насчитывающие в общей сложности 4 тыс. ускорителей поколения Blackwell. О планах SoftBank по созданию первого в мире ИИ-суперкомпьютер на базе NVIDIA DGX B200 стало известно в конце прошлого года. Вычислительная система использует интерконнект Quantum-2 InfiniBand и поддерживается программной платформой NVIDIA AI Enterprise. Холдинг SoftBank изначально внедрил DGX SuperPOD с более чем 2 тыс. ускорителями поколения NVIDIA Ampere в сентябре 2023 года: на тот момент производительность достигала 0,7 Эфлопс на операциях ИИ (точность вычислений не раскрывается). В октябре 2024 года завершился первый этап модернизации, в ходе которого были добавлены 4000 ускорителей семейства NVIDIA Hopper. В результате, суммарное быстродействие поднялось до 4,7 Эфлопс. После установки DGX B200 показатель вырос до 13,7 Эфлопс. 
Отмечается, что на сегодняшний день новая вычислительная инфраструктура SoftBank является крупнейшей в мире ИИ-платформой на основе DGX B200. При этом в общей сложности задействованы свыше 10 тыс. ускорителей. Изначально систему будет использовать SB Intuitions Corp. — дочерняя структура SoftBank, которая специализируется на разработке собственных больших языковых моделей (LLM), адаптированных для Японии. SB Intuitions уже создала LLM с примерно 460 млрд параметров, а в текущем 2025 финансовом году, который заканчивается 31 марта 2026-го, компания планирует представить коммерческую ИИ-модель Sarashina mini с 70 млрд параметров. Нужно отметить, что ранее SoftBank и OpenAI объявили о формировании совместного предприятия SB OpenAI для развития корпоративных ИИ-сервисов в Японии. Кроме того, SoftBank участвует в мегапроект Stargate — это совместное предприятие с OpenAI и Oracle по развитию ИИ-инфраструктуры в США. Предполагается, что суммарные затраты на реализацию Stargate достигнут $500 млрд. Впрочем, пока проект продвигается с большим трудом.
13.04.2025 [23:54], Владимир Мироненко
ИИ-агенты под присмотром: Google Distributed Cloud заработает на on-premise платформах NVIDIA Blackwell DGX/HGX
b200
dgx
google cloud platform
hardware
hgx
nvidia
гибридное облако
ии
ии-агент
инференс
конфиденциальность
облако
частное облако
NVIDIA объявила о стратегическом партнёрстве с Google Cloud с целью внедрения агентного ИИ на предприятиях, которые хотели бы локально использовать семейство моделей Google Gemini с помощью платформ NVIDIA Blackwell HGX/DGX, а также функции NVIDIA Confidential Computing для повышения безопасности данных. Интеграция платформы NVIDIA Blackwell с портфелем программно-аппаратных решений Google Distributed Cloud позволяет локальным ЦОД соответствовать нормативным требованиям и законам о суверенитете данных, блокируя доступ к конфиденциальной информации, включая истории болезни пациентов, финансовые транзакции и секретную правительственную информацию. NVIDIA Confidential Computing защищает конфиденциальный код в моделях Gemini от несанкционированного доступа и утечек данных — запросы пользователя к API Gemini, а также данные, которые они использовали для тонкой настройки, остаются в безопасности и защищены от несанкционированного доступа или изменений. Сачин Гупта (Sachin Gupta), вице-президент и генеральный менеджер по инфраструктуре и решениям в Google Cloud, отметил, что партнёрство позволяет предприятиям в полной мере использовать весь потенциал агентного ИИ, внедряя модели Gemini в локальные системы, и объединяя производительность NVIDIA Blackwell и возможности конфиденциальных вычислений. Хотя многие уже могут использовать модели с мультимодальным рассуждением — интегрируя текст, изображения, код и другие типы данных для решения сложных проблем и создания облачных приложений агентного ИИ, предприятия с повышенными требованиями к безопасности или суверенитету данных столкнулись с трудностями при внедрении этих технологий. Данное партнёрство позволит решить эти проблемы, благодаря чему Google Cloud становится одним из первых поставщиков, предлагающих возможности конфиденциальных вычислений для защиты рабочих нагрузок ИИ-агентов в любой среде, как облачной, так и гибридной. 
Источник изображения: NVIDIA Масштабирование агентного ИИ требует надёжного мониторинга и безопасности для обеспечения стабильной производительности и соответствия требованиям. Google Cloud представила новый шлюз GKE Inference Gateway, созданный для оптимизации развёртывания рабочих нагрузок ИИ-агентов с расширенной маршрутизацией и масштабируемостью. Интеграция с NVIDIA Triton Inference Server и NVIDIA NeMo Guardrails обеспечивает интеллектуальную балансировку нагрузки, которая повышает производительность и снижает затраты на обслуживание, также обеспечивая централизованную безопасность и управление моделями. В дальнейшем Google Cloud планирует улучшить отслеживания рабочих нагрузок агентского ИИ, интегрировав NVIDIA Dynamo, библиотеку с открытым исходным кодом, предназначенную для обслуживания и масштабирования рассуждающих моделей. Этот перспективный подход гарантирует, что предприятия смогут уверенно масштабировать свои приложения агентского ИИ, сохраняя при этом безопасность и соответствие требованиям.
05.04.2025 [10:36], Сергей Карасёв
Европейский суперкомпьютер Discoverer получил обновление в виде NVIDIA DGX H200Европейское совместное предприятие по развитию высокопроизводительных вычислений (EuroHPC JU) объявило о модернизации суперкомпьютера Discoverer, установленного в Софийском технологическом парке в Болгарии. Обновленная НРС-система получила название Discoverer+. Комплекс Discoverer, построенный на платформе BullSequana XH2000, был введён в эксплуатацию в 2021 году. Изначальная конфигурация включала 1128 вычислительных узлов, каждый из которых содержит два 64-ядерных процессора AMD EPYC 7H12 поколения Rome. Производительность (FP64) достигала 4,52 Пфлопс с пиковым значением в 5,94 Пфлопс. С такими показателями система находится на 221-й позиции в ноябрьском рейтинге мощнейших суперкомпьютеров мира TOP500. В рамках модернизации добавлен GPU-раздел на основе четырёх модулей NVIDIA DGX H200. Каждый из них содержит восемь ускорителей H200 и два процессора Intel Xeon Platinum 8480C поколения Sapphire Rapids с 56 ядрами (до 3,8 ГГц). Модули обладают быстродействием до 32 Пфлопс каждый в режиме FP8. Кроме того, обновлённый комплекс получил Lustre-хранилище вместимостью 5,1 Пбайт, систему хранения Weka ёмкостью 273 Тбайт и дополнительную ИБП-систему. 
Источник изображения: EuroHPC JU Как отмечается, Discoverer стал первым суперкомпьютером EuroHPC, прошедшим серьёзную модернизацию с момента своего первоначального запуска. После наращивания мощностей комплекс планируется использовать для крупномасштабных проектов в области ИИ, таких как обучение нейронных сетей, создание цифровых двойников сложных объектов и пр. В декабре 2024 года консорциум EuroHPC выбрал площадки для первых европейских ИИ-фабрик (AI Factory): они расположатся в Финляндии, Германии, Греции, Италии, Люксембурге, Испании и Швеции. Кроме того, такие объекты планируется создать в Австрии, Болгарии, Франции, Германии, Польше и Словении. Эти площадки станут частью высококонкурентной и инновационной экосистемы ИИ в Европе.
24.03.2025 [20:02], Владимир Мироненко
ИИ в один клик: NVIDIA и Equinix предложат готовые к использованию кластеры DGX GB300 и DGX B300 в 45 регионах по всему мируЧтобы удовлетворить растущий спрос на ИИ-инфраструктуру, NVIDIA представила NVIDIA Instant AI Factory — управляемый сервис на базе платформ NVIDIA DGX SuperPOD с ускорителями Blackwell Ultra и ПО NVIDIA Mission Control. NVIDIA сообщила, что её партнёр Equinix станет первой компанией, которая предложит новые системы DGX GB300 и DGX B300 в своих предварительно сконфигурированных ЦОД с жидкостным или воздушным охлаждением, готовых к обработке ИИ-нагрузок и расположенных на 45 рынках по всему миру. Как пишет SiliconANGLE, Тони Пейкдей (Tony Paikeday), старший директор NVIDIA по маркетингу продуктов и систем ИИ, заявил, что партнёрство с Equinix позволит компании выйти на более чем 45 рынков по всему миру «с предварительно настроенными объектами, которые готовы в зависимости от спроса клиентов масштабировать, эксплуатировать и управлять ИИ-инфраструктурой». NVIDIA отметила, что сервис предоставит предприятиям полностью готовые ИИ-фабрики, оптимизированные для обучения современных моделей и рабочих нагрузок моделей рассуждений в реальном времени, что избавит от многомесячного планирования инфраструктуры перед развёртыванием. 
Источник изображения: NVIDIA Поскольку Equinix предоставляет средства и инфраструктуру для разработки ИИ, Пейкдей возлагает большие надежды на платформу SuperPOD и считает, что она окажет позитивное влияние на развёртывание ИИ компаниями. «Equinix — ключевой компонент этой платформы, потому что вам нужно жидкостное охлаждение, вам нужны ЦОД следующего поколения, вам нужны сверхскоростные соединения с внешним миром, чтобы передавать эти данные», — заявил он.
06.12.2024 [16:42], Сергей Карасёв
iGenius анонсировала Colosseum — один из мощнейших в мире ИИ-суперкомпьютеров на базе NVIDIA DGX GB200 SuperPodКомпания iGenius, специализирующаяся на ИИ-моделях для отраслей со строгим регулированием, анонсировала вычислительную платформу Colosseum. Это, как утверждается, один из самых мощных в мире ИИ-суперкомпьютеров на платформе NVIDIA DGX SuperPOD с тысячами ускорителей GB200 (Blackwell). Известно, что комплекс Colosseum располагается в Европе. Полностью характеристики суперкомпьютера не раскрываются. Отмечается, что он обеспечивает производительность до 115 Эфлопс на операциях ИИ (FP4 с разреженностью). Говорится о применении передовой системы жидкостного охлаждения. Для питания используется энергия из возобновляемых источников в Италии. По информации Reuters, в состав Colosseum войдут около 80 суперускорителей GB200 NVL72. Таким образом, общее количество ускорителей Blackwell достигает 5760. Общее энергопотребление системы должно составить почти 10 МВт. Стоимость проекта не называется. Но глава iGenius Ульян Шарка (Uljan Sharka) отмечает, что компания в течение 2024 года привлекла на развитие примерно €650 млн и намерена получить дополнительное финансирование для проекта Colosseum. При этом подчёркивается, что iGenius — один из немногих стартапов в области ИИ в Европе, капитализация которого превышает $1 млрд. 
Источник изображения: iGenius iGenius планирует применять Colosseum для ресурсоёмких приложений ИИ, включая обучение больших языковых моделей (LLM) с триллионом параметров, а также работу с открытыми моделями генеративного ИИ. Подчёркивается, что создание Colosseum станет основой для следующего этапа сотрудничества между iGenius и NVIDIA в области ИИ для поддержки задач, требующих максимальной безопасности данных, надёжности и точности: это может быть финансовый консалтинг, обслуживание пациентов в системе здравоохранения, государственное планирование и пр. Модели iGenius AI, созданные с использованием платформы NVIDIA AI Enterprise, NVIDIA Nemotron и фреймворка NVIDIA NeMo, будут предлагаться в виде микросервисов NVIDIA NIM. По заявлениям iGenius, Colosseum поможет удовлетворить растущие потребности в ИИ-вычислениях. Colosseum также будет служить неким хабом, объединяющим предприятия, академические учреждения и государственные структуры. Нужно отметить, что около месяца назад компания DeepL, специализирующаяся на разработке средств автоматического перевода на основе ИИ, объявила о намерении развернуть платформу на базе NVIDIA DGX GB200 SuperPod в Швеции. DeepL будет применять этот комплекс для исследовательских задач, в частности, для разработки передовых ИИ-моделей.
14.11.2024 [08:17], Владимир Мироненко
SoftBank построит в Японии первый в мире ИИ-суперкомпьютер на базе NVIDIA DGX B200NVIDIA объявила о серии совместных проектов с SoftBank, направленных на ускорение суверенных инициатив Японии в области ИИ, которые также обеспечат возможность получения дохода от ИИ для поставщиков телекоммуникационных услуг по всему миру. В выступлении на саммите NVIDIA AI Summit Japan генеральный директор NVIDIA Дженсен Хуанг (Jensen Huang) объявил, что SoftBank создаёт самый мощный в Японии ИИ-суперкомпьютер с использованием платформы NVIDIA DGX SuperPOD B200 и интерконнекта Quantum-2 InfiniBand. Эта система станет первой в мире, которая получит системы DGX B200. Она будет использоваться компанией для разработки генеративного ИИ и развития других бизнес-решений, а также для предоставления вычислительных услуг университетам, научно-исследовательским институтам и предприятиям в стране. Суперкомпьютер идеально подойдёт для разработки больших языковых моделей (LLM), говорится в пресс-релизе. Пока что на звание самого мощного ИИ-суперкомьютера Японии претендует система ABCI 3.0 на базе NVIDIA H200. Впрочем, Softbank не сидит сложа руки и планирует построить ещё один суперкомпьютер, на этот раз на базе суперускорителей GB200 NVL72. Они же будут использоваться в проекте Sharp, KDDI и Supermicro по созданию «крупнейшего в Азии» ИИ ЦОД. 
Источник изображения: NVIDIA Также в ходе саммита было объявлено, что SoftBank, используя платформу ускоренных вычислений NVIDIA AI Aerial, успешно запустил первую в мире телекоммуникационную сеть, объединяющую возможности ИИ и 5G. В ходе испытаний, проведенных в префектуре Канагава, SoftBank продемонстрировала, что решение AI-RAN достигло производительности 5G операторского класса, используя ресурсы ускорителя для одновременной обработки сетевого трафика и инференса. Отмечается, что мобильные сети традиционно рассчитаны на обработку пиковых нагрузок и в среднем задействуют только треть аппаратных ресурсов, что позволяет монетизировать оставшиеся две трети путём предоставления ИИ-сервисов. NVIDIA и SoftBank также сообщили, что с помощью ПО NVIDIA AI Enterprise японская компания будет создавать локализованные безопасные ИИ-сервисы. |
|

