Материалы по тегу: h100
|
24.01.2026 [14:15], Сергей Карасёв
Nokia и Hypertec построили в Канаде 15-Пфлопс суперкомпьютер Nibi с погружным охлаждением
amd
emerald rapids
granite rapids
h100
hardware
hpc
intel
mi300
nokia
nvidia
ии
канада
отопление
погружное охлаждение
суперкомпьютер
Компании Nokia и Hypertec объявили о запуске суперкомпьютера Nibi, смонтированного в Университете Ватерлоо (University of Waterloo) в Канаде. Эта НРС-платформа будет использоваться для решения широкого спектра задач, в том числе в области ИИ. Проект Nibi финансируется канадским Министерством инноваций, науки и экономического развития через Канадский альянс цифровых исследований, а также Министерством колледжей, университетов, научных исследований и безопасности через некоммерческую организацию Compute Ontario. 
Источник изображения: Nokia Система насчитывает в общей сложности более 750 вычислительных узлов. Это, в частности, 700 узлов CPU, каждый из которых несёт на борту два процессора Intel Xeon 6972P поколения Granite Rapids-AP (96C/192T, до 3,9 ГГц) и 748 Гбайт оперативной памяти. Кроме того, задействованы 10 узлов с двумя чипами Xeon 6972P и 6 Тбайт памяти каждый. 
Источник изображений: Университет Ватерлоо В состав суперкомпьютера также входят 36 узлов GPU, которые содержат по два процессора Intel Xeon Platinum 8570 серии Emerald Rapids (56C/112T, до 4 ГГц), 2 Тбайт оперативной памяти и восемь ускорителей NVIDIA H100 SXM (80 GB), связанных посредством NVLink. Наконец, Nibi оперирует шестью узлами с четырьмя ускорителями AMD Instinct MI300A.  Подсистема хранения VAST Data выполнена на основе SSD суммарной вместимостью 25 Пбайт. Пропускная способность каналов передачи данных между CPU- и GPU-узлами составляет 200 Гбит/с. Подключение к хранилищу обеспечивается благодаря 24 линиям на 100 Гбит/с. Заявленная пиковая производительность Nibi достигает 15 Пфлопс. Новая НРС-платформа оборудована высокоэффективной системой погружного жидкостного охлаждения. Сгенерированное тепло используется для обогрева центра квантовых и нанотехнологий имени Майка и Офелии Лазаридис (Mike and Ophelia Lazaridis Quantum-Nano Centre).
16.10.2025 [15:53], Руслан Авдеев
NVIDIA поможет Starcloud отправить в космос первый ИИ-спутник с H100Появление массовых космических дата-центров уже не за горами. В скором времени вывести на орбиту ИИ-спутник намерен стартап Starcloud (ранее Lumen Orbit), участвующий в грантовой программе NVIDIA Inception. В Starcloud заявляют, что в космосе доступна практически неограниченная возобновляемая энергия, которая даже с учётом расходов на запуск на порядок дешевле, чем на Земле. При этом постоянное нахождение Солнца в «пределах прямой видимости» позволяет отказаться от мощных резервных источников питания. Затраты ожидаются в основном до вывода в космос, а после предполагается десятикратная «экономия» углеродных выбросов в течение всего жизненного цикла в сравнении с ЦОД на Земле. Охлаждение в космосе тоже практически «бесплатное» и «безлимитное». Запуск спутника запланирован на ноябрь 2025 года. Речь идёт о дебютном использовании ИИ-ускорителей NVIDIA H100 в космосе. 60-килограммовый спутник Starcloud-1 размером с небольшой холодильник должен обеспечить в 100 раз более эффективные вычисления, чем любой предыдущий космический проект аналогичного назначения. 
Источник изображения: Starcloud На начальном этапе космические дата-центры будут применяться для анализа данных наблюдений за земной поверхностью. Обработка данных в режиме реального времени в космосе обеспечивает огромные преимущества в критических ситуациях — при распознавании лесных пожаров, получении сигналов о бедствии и др. Инференс в космосе, т.е. там же, где будут собираться данные, позволяет выдавать результаты практически немедленно, снижая задержки с часов до минут. Методы наблюдения за Землёй включают съёмки камерами в нескольких диапазонах и радарами с синтезированной апертурой (SAR) для создания трёхмерных карт с высоким разрешением. SAR, в частности, генерируют около 10 Гбайт данных в секунду, поэтому обрабатывать информацию на месте намного выгоднее, чем отправлять её на Землю. 
Источник изображения: Starcloud В Starcloud подчёркивают необходимость быть конкурентоспособными на фоне наземных ЦОД, поэтому компания выбрала ИИ-ускорители NVIDIA. Вместе с тем Starcloud — недавний «выпускник» программы Google for Startups Cloud AI Accelerator, поэтому для тестов будет использоваться LLM Gemma. Что касается будущих запусков, в перспективе Starcloud рассчитывает перейти на платформу NVIDIA Blackwell. Ещё осенью 2024 года сообщалось, что Lumen Orbit проектирует на орбите гигантские гигаваттные дата центры. Идея популярна — основатель Amazon Джефф Безос (Jeff Bezos) в начале октября заявлял, что в космосе скоро появится множество ЦОД гигаваттного масштаба.
28.08.2025 [13:03], Руслан Авдеев
Китайский бизнес переходит на подержанные ускорители NVIDIA A100 и H100 из-за проблем с поставками H20Китайская ИИ-индустрия постепенно переходит на восстановленные или подержанные ИИ-ускорители NVIDIA A100 и H100 после того, как очередные экспортные ограничения на NVIDIA H20 заставили компании искать альтернативы этому продукту. Искусственно ослабленный ускоритель H20 должен был сохранить присутствие NVIDIA на китайском рынке, но чип фактически «оказался на обочине» даже после того, как на его продажи вновь дали зелёный свет после временного запрета — китайские регуляторы поставили под сомнение его безопасность, сообщает Tom’s Hardware со ссылкой на Digitimes. Всё это привело к стремительному росту спроса на старые модели A100 и H100, китайские компании проводят некую «реконфигурацию» таких ускорителей для использования в недорогих, но высокопроизводительных системах инференса. Последний требует значительно меньше ресурсов, чем обучение ИИ-моделей, рабочие нагрузки могут эффективно выполняться на относительно слабом оборудовании. Именно поэтому даже A100 с 80 Гбайт HBM2e (2 Тбайт/с), представленный ещё в 2020 году, в некоторых случаях остаётся вполне востребованным. Хотя архитектура Ampere уступает Hopper по пиковой производительности, она всё ещё эффективна для инференса благодаря относительно большому объёму памяти и развитой экосистеме ПО CUDA. Для чат-ботов и рекомендательных систем экономически эффективно использовать системы без самых современных чипов. Представленные в 2022 году H100 значительно производительнее A100 в задачах, связанных с обучением. В то же время H20 изначально был оптимизирован для менее ресурсоёмкого инференса, но его возможности урезали так сильно, что производительность в сравнении с H100 у этой модели ниже в 3–7 раз, а в задачах, связанных с вычислениями FP64, он медленнее более чем в 30 раз. Другими словами, даже A100 всё ещё могут быть привлекательнее для китайских покупателей, чем новые H20. 
Источник изображения: NVIDIA Поскольку пока никому не удалось создать что-то сопоставимое с программной экосистемой NVIDIA CUDA, старые GPU вполне востребованы. Тем более что оборудование для инференса менее требовательно во всех отношениях, а китайские ЦОД, по-видимому, не испытывают проблем с энергий и готовы платит за восстановленную устаревшую электронику, даже с пониженной надёжностью. В результате NVIDIA оказалась в странном положении. Компания в своё время списала $5,5 млрд из-за нераспроданных запасов H20 — когда в США решили полностью запретить их поставки в Китай. После снятия запрета компания резко нарастила выпуск H20, но теперь столкнулась уже с нежеланием властей КНР видеть эти чипы в стране. Тем не менее, её ускорители по-прежнему являются одним из главных катализаторов бума ИИ в Китае. Другими словами, чипы компании по-прежнему доминируют на рынке Поднебесной, но активность на теневых рынках может снизить выгоду от бизнеса с Китаем. Впрочем, уже появилась информация о разработке нового ускорителя на основе современной архитектуры Blackwell — хотя и тоже ослабленного.
26.07.2025 [01:05], Руслан Авдеев
Несмотря на запреты США в Китай «просочились» передовые ускорители NVIDIA на $1 млрдЗа три месяца действия новых правил США по ужесточению контроля за экспортом ИИ-чипов в КНР всё равно попали ускорители NVIDIA на сумму не менее $1 млрд. Возможности Вашингтона по борьбе с контрабандой оказались весьма ограниченными, сообщает The Financial Times. Проведённый анализ самых разных коммерческих документов и беседы с информаторами позволили выяснить, что наиболее востребованы ускорители NVIDIA B200. Причём они широко доступны на чёрном рынке, хотя их продажа клиентам из КНР запрещена. По данным The Financial Times, в мае некоторые китайские дистрибуторы начали продавать B200 для местных ИИ ЦОД — вскоре после того, как Трамп ограничил поставки в Китая ослабленных ускорителей H20. Юристы утверждают, что в Китае активно поддерживается «параллельный импорт» — ввоз новинок в страну вполне легален, если оплатить таможенные пошлины. При этом поставщики нарушают законы США. По словам экспертов, после появления слухов об ограничении поставок ускорителей в Юго-Восточную Азию, покупатели поспешили с заказами, стремясь создать запасы до того, как правила вступят в силу. Не так давно глава NVIDIA Дженсен Хуанг (Jensen Huang) жёстко раскритиковал запрет на поставки ускорителей NVIDIA в Китай, а на днях объявил, что администрация Трампа снова разрешила их поставку в страну. Правда, три месяца запретов не помешали китайским дистрибьюторам довольно свободно продавать B200, H100 и H200, а также другие ускорители, ввоз которых в КНР запрещён. В NVIDIA подчёркивают, что доказательства причастности производителей к контрабанде отсутствуют, а использование чипов с чёрного рынка вообще неэффективно, поскольку для них нужна официальная поддержка. Решения на базе B200 пользуются повышенным спросом из-за их относительной простоты и высокой производительности. 
Источник изображения: Christian Lue/unsplash.com Тем не менее попавшие, в руки журналистов документы свидетельствуют о том, что компания из провинции Аньхой, название которой переводится как Gate of the Era («Врата эпохи»), была основана в феврале 2025 года шанхайской бизнес-группой. Чипы продавались в составе готовых платформ с восемью B200, необходимым ПО и вспомогательным оборудованием. Текущая рыночная цена — $489 тыс. за единицу — примерно на 50 % больше, чем в США. С середины мая компания получила как минимум две партии стоек по несколько сотен штук, продано оборудования на сумму около $400 млн. Крупнейшим акционером бизнеса является китайская ИИ-компания China Century (Huajiyuan). Судя по сайту последней, у неё есть даже офис в Кремниевой долине и узел цепочки поставок в Сингапуре, а также более 100 деловых партнёров, включая AliCloud, ByteDance Huoshan Cloud и Baidu Cloud, хотя представители некоторых бизнесов опровергают факт сотрудничества. В самой China Century сообщают, что занимаются умными городами и никаких чипов NVIDIA не закупали. Как показало расследование The Financial Times, многие решения, проданные Gate of the Era и другими китайскими дистрибьюторами за последние месяцы, были произведены Supermicro, Dell и Asus. Правда, предполагать причастность производителей к контрабанде оснований нет. По словам одного из китайских ЦОД, экспортный контроль США не эффективен и лишь даёт огромные прибыли посредникам, готовым рисковать. Некоторые китайские поставщики открыто предлагают стойки B200 в социальных сетях и даже предлагают протестировать их. А некоторые компании уже рекламируют грядущие поставки B300, которые должны появиться к концу года. 
Источник изображения: Gene Brutty/unsplash.com Конечно, экспортный контроль США не мог не повлиять на структуру рынка ускорителей. Доходит до того, что многие китайские компании пользуются услугами облачных посредников из третьих стран, которым разрешено покупать ускорители. Впрочем, эксперты ожидают, что возобновление продаж H20 в КНР приведёт к их массовой закупке, хотя они и значительно слабее B200. По данным дистрибуторов, продажи B200 и других чипов упали после объявления об ослаблении запрета на H20. Впрочем, утверждается, что спрос на передовые продукты всегда будет. По словам отраслевых экспертов, китайский бизнес активно скупал «запрещённые» чипы в странах Юго-Восточной Азии. Министерство торговли США уже обсуждает возможность ограничить экспорт в страны вроде Таиланда. Малайзия ужесточила экспортный контроль, ограничив возможность перепродажи передовых ИИ-чипов другим страна, в первую очередь — в Китай. Впрочем, даже если эти лазейки закроют, китайские отраслевые эксперты уверены, что появятся новые маршруты поставок. Более того, они якобы уже начались через европейские страны, не попадающие под экспортные ограничения. По словам одного из дистрибуторов, история уже не раз доказывала, что, с учётом огромной прибыли, посредники всегда найдут способ обойти ограничения.
10.07.2025 [17:30], Сергей Карасёв
Bloomberg: Китай строит в пустыне гигантский комплекс ИИ ЦОД для 115 тыс. ускорителей NVIDIA, поставки которых запрещены СШАНа окраине пустыни Гоби в Синьцзяне (автономный район на северо-западе Китая), по сообщению Bloomberg News, ведутся активные работы по строительству кампуса ЦОД для ИИ-задач. Согласно имеющейся информации, в этих дата-центрах будут применяться серверы с ускорителями NVIDIA, поставки которых запрещены в КНР в соответствии с американскими санкциями. Специалисты Bloomberg News проанализировали сведения, содержащиеся в инвестиционных одобрениях, тендерных документах и заявках китайских компаний. Утверждается, что масштабные планы Китая в отношении развития ИИ прямо предусматривают использование «запрещённых» продуктов NVIDIA, а не только местных решений вроде Huawei Ascend. В частности, в IV квартале 2024 года власти Синьцзяна (Xinjiang) и соседней провинции Цинхай (Qinghai) одобрили создание в общей сложности 39 дата-центров, в которых будет задействовано более 115 тыс. ИИ-ускорителей NVIDIA. Причём во всех случаях речь идёт об H100 и H200. Операторы ЦОД в Синьцзяне намерены разместить львиную долю этих ускорителей в одном крупном комплексе, который будет использоваться для обучения передовых ИИ-моделей и других ресурсоёмких нагрузок. Строительные работы организованы в уезде Иу (Yìwū). Сотрудникам Bloomberg News не удалось установить, каким способом китайские компании намерены приобретать изделия NVIDIA, закупки которых запрещены без получения специальных лицензий от правительства США. Местные операторы дата-центров, государственные чиновники и представители центрального правительства в Пекине отказались давать какие-либо комментарии по данному вопросу. Между тем, как отмечается в публикации, стоимость 115 тыс. указанных ИИ-ускорителей может составить миллиарды долларов, исходя из цен на чёрном рынке Китая. 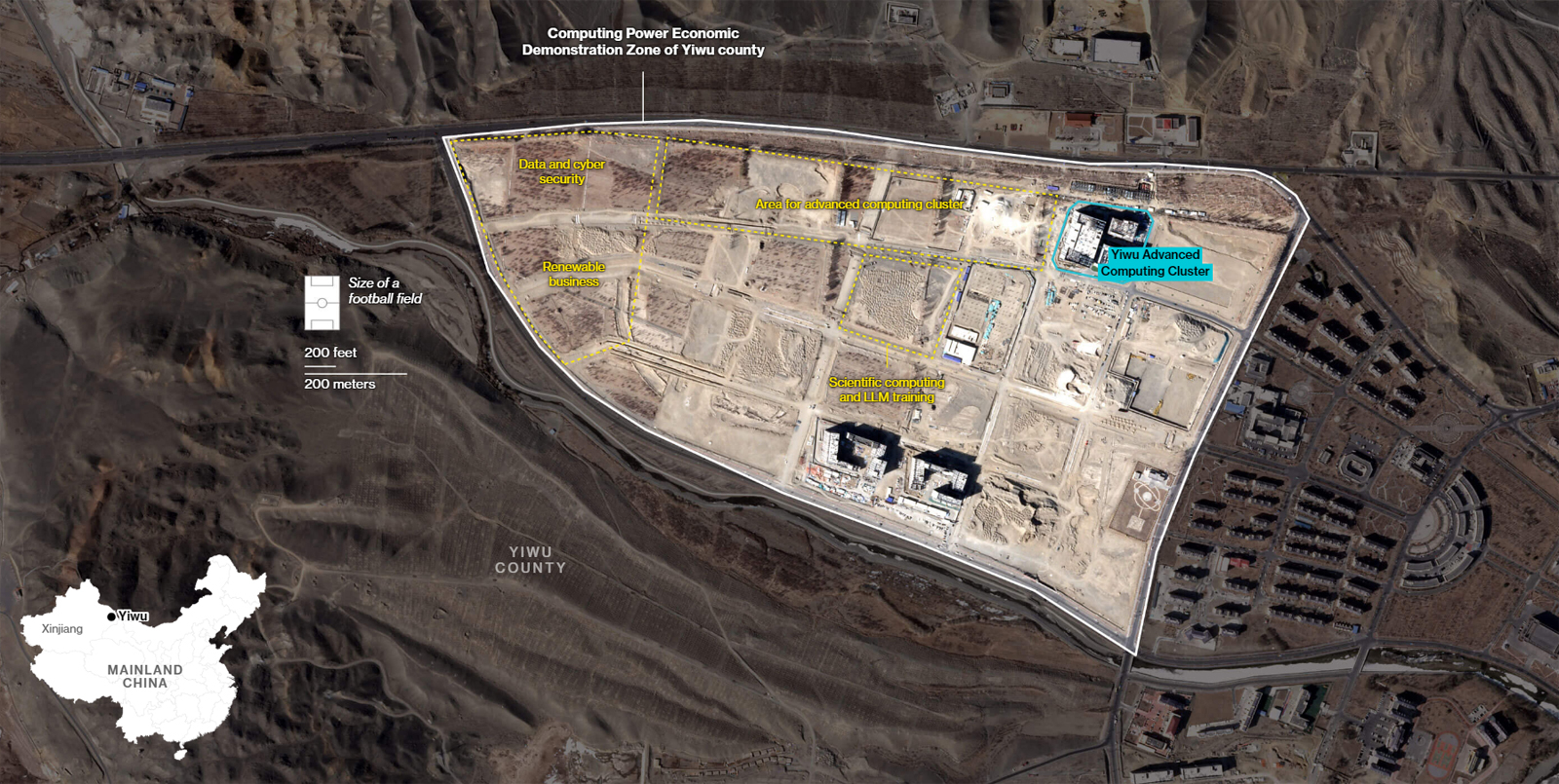
Источник изображения: Bloomberg И всё же строительство комплекса ЦОД продолжается. Синьцзян, и особенно регион Хами (Hāmì), включающий уезд Иу, богаты ветровой и солнечной энергией, а также углём. Это позволит решить вопросы, связанные с энергообеспечением дата-центров. Дополнительными достоинствами выбранного региона являются доступность больших территорий, низкая стоимость земли и прохладный климат в высотных районах. Согласно тендерной документации, полученной Bloomberg, по состоянию на июнь 2025 года по семи проектам ЦОД в Синьцзяне либо начаты строительные работы, либо выиграны тендеры на услуги ИИ-вычислений. В частности, один из крупнейших проектов связан с энергокомпанией Nyocor из Тяньцзиня (Tianjin), которая специализируется на солнечной и ветровой энергетике. Инициатива предусматривает создание дата-центра на базе 625 серверов с ускорителями H100. Nyocor продаёт вычислительные мощности корпорации Infinigence AI — одной из крупнейших организаций в сфере ИИ-инфраструктуры в Китае. В документах по 27 другим проектам ЦОД, одобренным в Синьцзяне и Цинхае в прошлом году, упоминаются в общей сложности более 9 тыс. серверов и около 72 тыс. ускорителей H100/H200. Два высокопоставленных чиновника американской администрации заявили, что по их оценкам, в Китае имеется примерно 25 тыс. запрещенных ИИ-ускорителей NVIDIA: такое количество, как утверждается, не вызывает серьёзного беспокойства. Более того, даже в случае приобретения ещё 115 тыс. карт NVIDIA масштабы соответствующих ИИ-платформ в КНР окажутся несопоставимы с мощью развитой инфраструктурой ИИ в США. Нужно отметить, что за последние годы власти Китая потратили $6,1 млрд на строительство крупных кампусов ЦОД, тогда как ещё $28 млрд вложили частные инвесторы. Площадки дата-центров появились в регионе Внутренняя Монголия, провинциях Нинся, Ганьсу, Гуйчжоу, регионе Пекин-Тяньцзинь-Хэбэй, а также в дельте Янцзы и на других территориях. Однако многие подобные объекты оказались невостребованными из-за переоценённого спроса и архитектурных недоработок.
08.07.2025 [17:09], Владимир Мироненко
Российский суперкомпьютер «Говорун» получил два узла «РСК Экзастрим ИИ» с NVIDIA H100 и фирменной СЖО
emerald rapids
h100
h200
hpc
intel
nvidia
sapphire rapids
xeon
россия
рск
сделано в россии
сервер
суперкомпьютер
ГК РСК продемонстрировала 2U-узел (912 × 508 × 88 мм) собственной разработки «РСК Экзастрим ИИ» на базе восьми ускорителей NVIDIA H100 с прямым жидкостным охлаждением. Два таких узла были установлены в суперкомпьютере «Говорун» в Дубне. «РСК Экзастрим ИИ» включает:
«РСК Экзастрим ИИ» имеет локальную подсистему хранения «тёплых данных», сетевую подсистему с доступом на основе технологии GPUDirect. Также есть возможность расширения ресурсов путём подключения дополнительных пар ускорителей или системы внешнего хранения данных на базе пула JBOF, подключаемой напрямую. Производительность «РСК Экзастрим ИИ» составляет до 208 Тфлопс (FP64). При установке 21 сервера в шкаф «РСК Экзастрим» пиковая производительность достигает 4,26 Пфлопс (FP64). Сервер отличается высокой энергоэффективностью, сверхвысокой плотностью монтажа и надёжной работой. Он может использоваться для решения ресурсоёмких задач в области машинного обучения и ИИ, создания мощных вычислительных ресурсов облачных провайдеров и в частных облаках и т.д. 
Источник изображений: РСК Два узла «РСК Экзастрим ИИ» были установлены в суперкомпьютере «Говорун» в Лаборатории информационных технологий им М.Г. Мещерякова Объединенного института ядерных исследований (ЛИТ ОИЯИ) в Дубне в рамках нового этапа модернизации, проведенной силами специалистов ГК РСК и лаборатории.  Как сообщается, новые серверы «РСК Экзастрим ИИ» уникальны и были сконструированы и изготовлены для СК «Говорун» с учётом его архитектурных особенностей. При этом пиковая FP64-производительность GPU-компоненты суперкомпьютера «Говорун» выросла на 36 % и достигла 1,4 Пфлопс, пиковая суммарная FP64-производительность суперкомпьютера теперь составляет 2,2 Пфлопс. Характеристики серверов «РСК Экзастрим ИИ», установленных в ОИЯИ:
 В конце 2024 года было проведено расширение СХД суперкомпьютера «Говорун», после чего её ёмкость увеличилась до 10 Пбайт. В СХД вычислительного комплекса ОИЯИ были добавлены два узла хранения данных RSC Tornado AFS ёмкостью 1 Пбайт каждый. Обновленная модификация СХД RSC Tornado AFS включает серверную плату на базе процессоров Intel Xeon Sapphire Rapids, а также коммутатор с интерфейсом PCIe 4.0, что позволило установить по два адаптера интерконнекта с пропускной способностью 200 Гбит/с каждый.  СХД RSC Tornado AFS поддерживает технологию GPUDirect Storage (GDS), которая обеспечивает прямую передачу данных между локальным или удалённым хранилищем и памятью ускорителя. Две СХД, установленные ранее специалистами РСК в суперкомпьютере «Говорун» входят в мировой рейтинг IO500 самых высокопроизводительных системам хранения данных. В суперкомпьютере «Говорун» используются интегрированный программный комплекс «РСК БазИС 4» и модуль «РСК БазИС СХД» (включены в Реестр российского ПО). Микроагентная архитектура «РСК БазИС 4» обеспечивает функционирование объектов системы, позволяя также взаимодействовать с ними. «РСК БазИС» в сочетании с аппаратными платформами РСК позволяет создавать гиперконвергентные решения для HPC и эффективной обработки больших объёмов данных.
29.06.2025 [21:11], Сергей Карасёв
Таёжное облако: ИИ-кластер Northern Data Njoerd вошёл в рейтинг TOP500
h100
hardware
hpc
hpe
intel
northern data
nvidia
sapphire rapids
xeon
великобритания
ии
облако
суперкомпьютер
Немецкая компания Northern Data Group, поставщик решений в области ИИ и НРС, объявила о том, что её система Njoerd вошла в июньский рейтинг мощнейших суперкомпьютеров мира TOP500. Этот вычислительный комплекс, расположенный в Великобритании, построен на платформе HPE Cray XD670. Машина Njoerd попала на 26-е место списка TOP500. Она объединяет 244 узла, каждый из которых содержит восемь ускорителей NVIDIA H100. В общей сложности задействованы примерно 28,5 млн ядер CUDA. Кроме того, в составе системы используются процессоры Intel Xeon Platinum 8462Y+ (32C/64C, 2,8–4,1 ГГц, 300 Вт). Применён интерконнект Infiniband NDR400. FP64-производительность Njoerd достигает 78,2 Пфлопс, а теоретическое пиковое быстродействие составляет 106,28 Пфлопс. При рабочих нагрузках ИИ суперкомпьютер демонстрирует производительность 3,86 Эфлопс в режиме FP8 и 1,93 Эфлопс в режиме FP16. Заявленный показатель MFU (Model FLOPs Utilization) при предварительном обучении современных больших языковых моделей (LLM) находится на уровне 50–60 %. Таким образом, как утверждается, система Njoerd на сегодняшний день представляет собой наиболее эффективный кластер H100 подобного размера, оптимизированный для ресурсоёмких рабочих нагрузок ИИ и HPC. Суперкомпьютер входит в состав Taiga Cloud — одной из крупнейших в Европе облачных платформ, ориентированных на задачи генеративного ИИ. Эта вычислительная инфраструктура использует на 100 % безуглеродную энергию. Показатель PUE варьируется от 1,15 до 1,06. Доступ к ресурсам предоставляется посредством API или через портал самообслуживания. Одним из преимуществ Taiga Cloud компания Northern Data Group называет суверенитет данных. 
Источник изображения: Northern Data Group
22.06.2025 [23:30], Руслан Авдеев
Meta✴ ведёт переговоры о покупке венчурного фонда NFDG, у которого есть собственный ИИ-кластер AndromedaMeta✴ Platforms решила обновить свои компетенции в сфере ИИ, наняв ведущих отраслевых игроков — Ната Фридмана (Nat Friedman) и Дэниэла Гросса (Daniel Gross). Также компания намерена выкупить их венчурный фонд NFDG, сообщает The Information. Марк Цукерберг (Mark Zuckerberg) сначала пытался купить ИИ-стартап Safe Superintelligence (SSI) бывшего «главным учёным» OpenAI Ильи Суцкевера (Ilya Sutskever). После отказа Цукерберг попросту собрался нанять генерального директора SSI — Гросса. Ранее тот руководил ИИ-разработками в Apple и был партнёром Y Combinator. Фридман был главой GitHub и советником Midjourney. Гросс и Фридман были соучредителями инвестиционного фонда NFDG. NFDG имеет доли в в известных ИИ-компаниях, включая SSI, Perplexity и Character.ai. Ранее компания инвестировала в Weights & Biases, которую приобрела CoreWeave. NFDG занимается не только финансированием компаний, но и предлагает программу грантов, в рамках которой стартапам предоставляется финансирование на $250 тыс., а также $250 тыс. в виде облачных кредитов Microsoft Azure. В период дефицита ИИ-ускорителей NFDG построил собственный суперкомпьютер. Кластер Andromeda изначально включал 2512 ускорителей NVIDIA H100. С тех пор он вырос до 3 200 H100 в 400 узлах и ещё 432 H100 в 54 узлах, связанных 400G-интерконнектом InfiniBand, а также 768 A100 с 200G InfiniBand. Теперь Andromeda могут арендовать и компании, которые не относятся к NFDG, за $2,4–$3 за ускоритель в час. Сейчас можно арендовать до 2 тыс. H100 и получить доступ к ним в течение нескольких часов. 
Источник изображения: Amina Atar/unspalsh.com Помимо возможного найма Гросса и Фридмана, Meta✴ ведёт переговоры, конечной целью которых является выкуп значительной части активов NFDG и вывод из него партнёров за сумму более $1 млрд. При этом сделка не даст Meta✴ контроля над фондом или информации о бизнесе. Кому достанется Andromeda, не уточняется. Если сделка будет завершена, она войдёт в число более масштабных реформ в Meta✴, связанных с ИИ. Цукерберг планирует сформировать новую лабораторию по разработке «суперинтеллекта» и пересмотреть стратегию выкупа продуктов. В этом месяце Meta✴ уже подтвердила, что намерена потратить порядка $14 млрд на долю в Scale AI, специализирующейся на разметке данных для обучения ИИ.
11.06.2025 [09:11], Владимир Мироненко
AWS резко снизила стоимость EC2-инстансов с ускорителями NVIDIA, но только для старых моделейAWS объявила об очередном снижении тарифов на GPU-инстансы, которое, по словам компании, стало регулярной практикой благодаря активной работе над снижением расходов. Впрочем, в период острого дефицита вычислительных мощностей в последние год-два, когда использование ускорителей даже для внутренних нужд было резко ограничено, компания наверняка заработала достаточно, чтобы неоднократно окупить закупку и обслуживание соответствующего «железа». На прошлой неделе была снижена до 45 % стоимость использования инстансов EC2 на базе ускорителей NVIDIA, включая семейства P4 (P4d и P4de на базе A100) и P5 (P5 и P5en на базе H100 и H200 соответственно). Снижение стоимости тарифов On-Demand и Savings Plan распространяется на все регионы, где доступны эти инстансы. На On-Demand — с 1 июня, на Savings Plan — после 4 июня. Savings Plans предлагает гибкую модель ценообразования с низкими ценами на использование вычислений в обмен на обязательство по постоянному объёму использования (измеряется в $/час) в течение 1 года или 3 лет. AWS предлагает два типа Savings Plans:
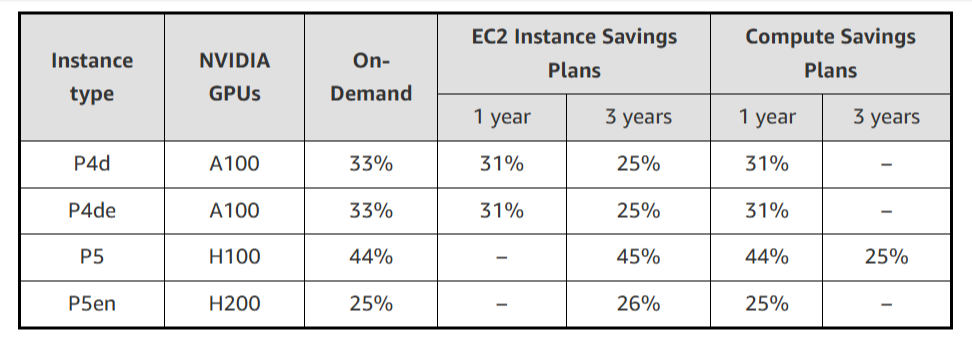
Источник изображения: AWS Чтобы обеспечить повышенную доступность по сниженным ценам, AWS предоставляет масштабируемую ёмкость в рамках тарифа On-Demand для:
Также теперь AWS предлагает инстансы Amazon EC2 P6-B200 в рамках тарифа Savings Plan для поддержки крупномасштабных развёртываний, которые стали доступны 15 мая 2025 года при запуске только через EC2 Capacity Blocks для машинного обучения. Инстансы EC2 P6-B200 на базе ускорителей NVIDIA Blackwell обеспечивают обработку широкого спектра рабочих нагрузок, но особенно хорошо подходят для крупномасштабного распределённого обучения и ИИ-инференса, отметила AWS.
20.05.2025 [12:10], Сергей Карасёв
NVIDIA открыла центр с самым мощным в мире исследовательским квантовым суперкомпьютеромКомпания NVIDIA объявила об открытии Глобального центра исследований и разработок для бизнеса в области искусственного интеллекта на базе квантовых технологий (Global Research and Development Center for Business by Quantum-AI Technology, G-QuAT). На этой площадке размещена система ABCI-Q — крупнейший в мире исследовательский суперкомпьютер, предназначенный для квантовых исследований. Система интегрирована с тремя квантовыми компьютерами. О проекте ABCI-Q сообщалось в марте 2024 года. Названный суперкомпьютер разработан Национальным институтом передовых промышленных наук и технологий Японии (AIST). В основу положены 2020 ускорителей NVIDIA H100. Задействованы интерконнект NVIDIA Quantum-2 InfiniBand, а также платформа с открытым исходным кодом NVIDIA CUDA-Q для организации гибридных квантово-классических вычислений. Ожидается, что сотрудничество NVIDIA и AIST будет способствовать ускорению разработок в таких областях, как квантовая коррекция ошибок и ИИ-приложения с поддержкой квантовых вычислений. В конечном итоге, проект призван помочь в решении некоторых из самых сложных глобальных задач, охватывающих различные отрасли, включая здравоохранение, энергетику и финансы. 
Источник изображения: NVIDIA Суперкомпьютер ABCI-Q интегрирован с процессором на сверхпроводящих кубитах Fujitsu, квантовым чипом на нейтральных атомах QuEra и фотонным процессором OptQC. Благодаря этому становится возможным выполнение рабочих нагрузок в нескольких модальностях кубитов. Исследователи смогут экспериментировать с вычислениями, основанными на GPU-ускорителях и квантовых процессорах разного типа. При этом будет обеспечиваться бесшовная интеграция квантового оборудования и классического суперкомпьютера. |
|

