Материалы по тегу: hpe
|
28.06.2026 [22:32], Владимир Мироненко
Платформа HPE Supercomputing Programming Software упростит работу с мультивендорными системами ИИ и HPC
amd
hpc
hpe
intel
nvidia
open source
software
ии
контейнеризация
конфиденциальность
разработка
утилизация
Компания HPE представила новую унифицированную программную платформу HPE Supercomputing Programming Software, предназначенную для того, чтобы помочь клиентам справляться с растущей сложностью работы с HPC-средами мультивендорных систем, обеспечивая согласованность между системами HPE. HPE отметила, что разработка приложений для работы на HPC-платформах, таких как кластеры HPE Cray GX5000, требует от разработчиков использования языков программирования и фреймворков, специфичных для конкретной архитектуры чипа. Клиенты используют пакеты, предлагаемые AMD, Intel или NVIDIA, и т.д., и задача клиента — убедиться, что они совместимы с её платформой Cray. HPE будет сотрудничать с производителями чипов для объединения их инструментов разработки в рамках новой платформы, заявил Джим Лухан (Jim Lujan), вице-президент по системной инженерии HPE в интервью HPCwire. По его словам, с помощью HPE Supercomputing Programming Software компания предоставит, по сути, контейнеры с поддержкой их экосистем. HPE берёт на себя обеспечение первой линии поддержки, когда у клиентов возникают проблемы — вместо того, чтобы просто переправлять сообщения производителям чипов, сказал Лухан. Он также отметил, что HPE всё больше переходит на open source, дополняя проприетарные компоненты софтом из открытой экосистемы, что расширяет возможности клиентов. Нынешнее обновление поддерживает Kubernetes, а также открытые инструменты разработки AMD и NVIDIA. 
Источник изображения: HPE HPE Supercomputing Programming Software предлагает простой подход к многовендорным средам и процессу интеграции, помогая ускорить циклы развёртывания и минимизировать риск нестабильности системы. Платформа поддерживает серверы HPE ProLiant, включая модели HPE ProLiant DL и XD, оптимизированные для различных задач обучения, настройки и ИИ-инференса, что обеспечивает согласованный и упрощённый опыт работы на разных платформах для крупных предприятий. Новый программный стек также обеспечивает больше возможностей для разработки клиентами приложений ИИ и HPC с многопользовательским режимом, важность которого возросла в основном из-за требований суверенитета, предъявляемых компаниями, организациями и государственными учреждениями, находящимися за пределами США. HPE добавила многопользовательский режим в инструмент Smart Update Manager (SUM), чтобы клиенты могли изолировать свои данные, а также его поддержку в уже поставленных потребителям коммутаторах Slingshot 400 и СХД Cray E2000. «В последнее время наблюдается большой спрос на многопользовательский режим и его поддержку, — сообщил Лухан. — Мы всегда поддерживали множество пользователей, но теперь есть желание добиться большей изоляции данных и их разделения для некоторых наших клиентов». HPE также расширила свою программу вывода из эксплуатации систем, включив в нее серверы с воздушным охлаждением для ИИ и HPC. Согласно данным компании, в в 2025 году 85 % серверов, прошедших через центры обновления, были переработаны и возвращены в активное использование, а 1,7 Эбайт данных были надёжно удалены.
15.06.2026 [12:58], Сергей Карасёв
В Сингапуре запущен суперкомпьютер ASPIRE 2B на базе NVIDIA H200 и AMD EPYC Turin с быстродействие 115 ПфлопсНациональный суперкомпьютерный центр Сингапура (NSCC) объявил о запуске вычислительного комплекса ASPIRE 2B с производительностью 115 Пфлопс. Систему планируется использовать для решения сложных задач в области климатологии и метеорологии, здравоохранения, разработки материалов, передового производства, ИИ и пр. В основу ASPIRE 2B положены 96-ядерные процессоры AMD EPYC 9655 поколения Turin: суммарное количество вычислительных ядер в составе суперкомпьютера достигает 184 320 (задействованы 1920 чипов). Быстродействие CPU-секции находится на уровне 12 Пфлопс. GPU-раздел машины объединяет 1536 ускорителей NVIDIA H200 со 141 Гбайт памяти HBM3e. Их суммарная пиковая производительность указана на отметке 103 Пфлопс. Объём системной памяти составляет 1072 Тбайт, вместимость подсистемы хранения данных — 63,5 Пбайт. Применяется интерконнект Slingshot с пропускной способностью 400 Гбит/с. Суперкомпьютер ASPIRE 2B планируется интегрировать с квантовой системой Helios компании Quantinuum, установка которой в Сингапуре запланирована на конец нынешнего года. Это позволит осуществлять гибридные квантово-классические вычисления в рамках комплексных проектов, связанных с молекулярным моделированием и созданием перспективных материалов. 
Источник изображения: NSCC Отмечается также, что NSCC меняет модель доступа пользователей к вычислительным ресурсам страны. Приоритет будет отдаваться национальным программам исследований и инноваций. Это должно способствовать ускорению развития передовых технологий и расширению сферы предпринимательства.
04.06.2026 [12:56], Владимир Мироненко
Акции HPE взлетели более чем на 25 % после отчёта об ажиотажном спросе на серверы и сетиАкции HPE выросли в цене более чем на 25 % после публикации финансовых результатов за II квартал 2026 финансового года, закончившийся 30 апреля 2026 года, поскольку благодаря росту продаж ИИ-серверов компания превысила ожидания Уолл-стрит по прибыли и выручке, сообщил ресурс SiliconANGLE. Скорректированная прибыль HPE на разводнённую акцию (Non-GAAP) составила 79¢, значительно превысив консенсус-прогноз аналитиков в 53¢ на акцию. Выручка за этот период составила $10,68 млрд, что на 40 % больше год к году и значительно превышает прогноз аналитиков в $9,79 млрд. Этот квартал стал самым успешным по показателю прибыли на акцию с февраля 2018 года. Чистая прибыль (GAAP) компании составила $595 млн или $0,44 на разводнённую акцию, тогда как год назад у неё были убытки в размере $1,079 млрд или $0,82 на разводнённую акцию. 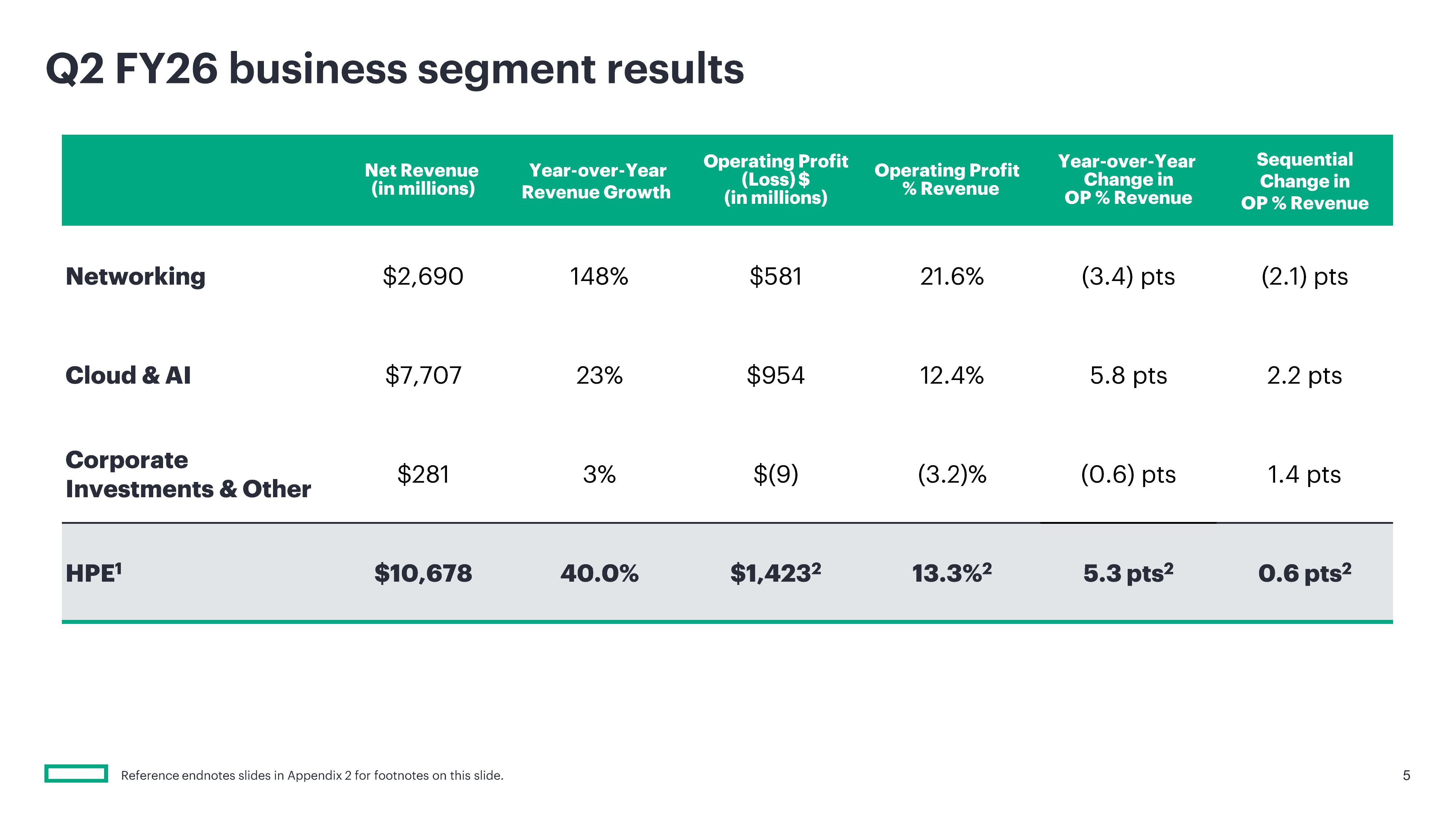
Источник изображений: HPE Главной причиной успешности квартала стал ИИ. Выручка сегмента HPE «Облачные технологии и ИИ» составила $7,7 млрд, что на 22,9 % больше год к году и выше прогноза аналитиков в размере $6,87 млрд. При этом выручка от продажи серверов составила $5,45 млрд (рост год к году на 32,7 %), превысив прогнозируемые аналитиками $4,66 млрд. Более того, несмотря на то что рентабельность продаж ИИ-серверов, как известно, невелика, HPE удалось выйти на чистую прибыль, тогда как годом ранее у неё были убытки. Антонио Нери (Antonio Neri), президент и генеральный директор HPE назвал рост выручки этого сегмента «исключительным» и заявил аналитикам на телефонной конференции, что агентный ИИ стал «ключевым фактором ускорения спроса», пишет CNBC. Нери заявил, что объёмы заказов на традиционные серверы выросли на трёхзначное число процентов по сравнению с прошлым годом, достигнув самой большой величины в истории компании. Он пояснил, что у клиентов в отраслях, ориентированных на безопасность, значительно выросла потребность в локальных серверах и ИИ-инфраструктуре, в отличие от облачных ИИ-ресурсов. Это вполне устраивает HPE, поскольку она в первую очередь ориентируется на предприятия и государственные учреждения, а не на гиперскейлеров, которые предпочитают закупать небрендированные серверы и оборудование оптом. 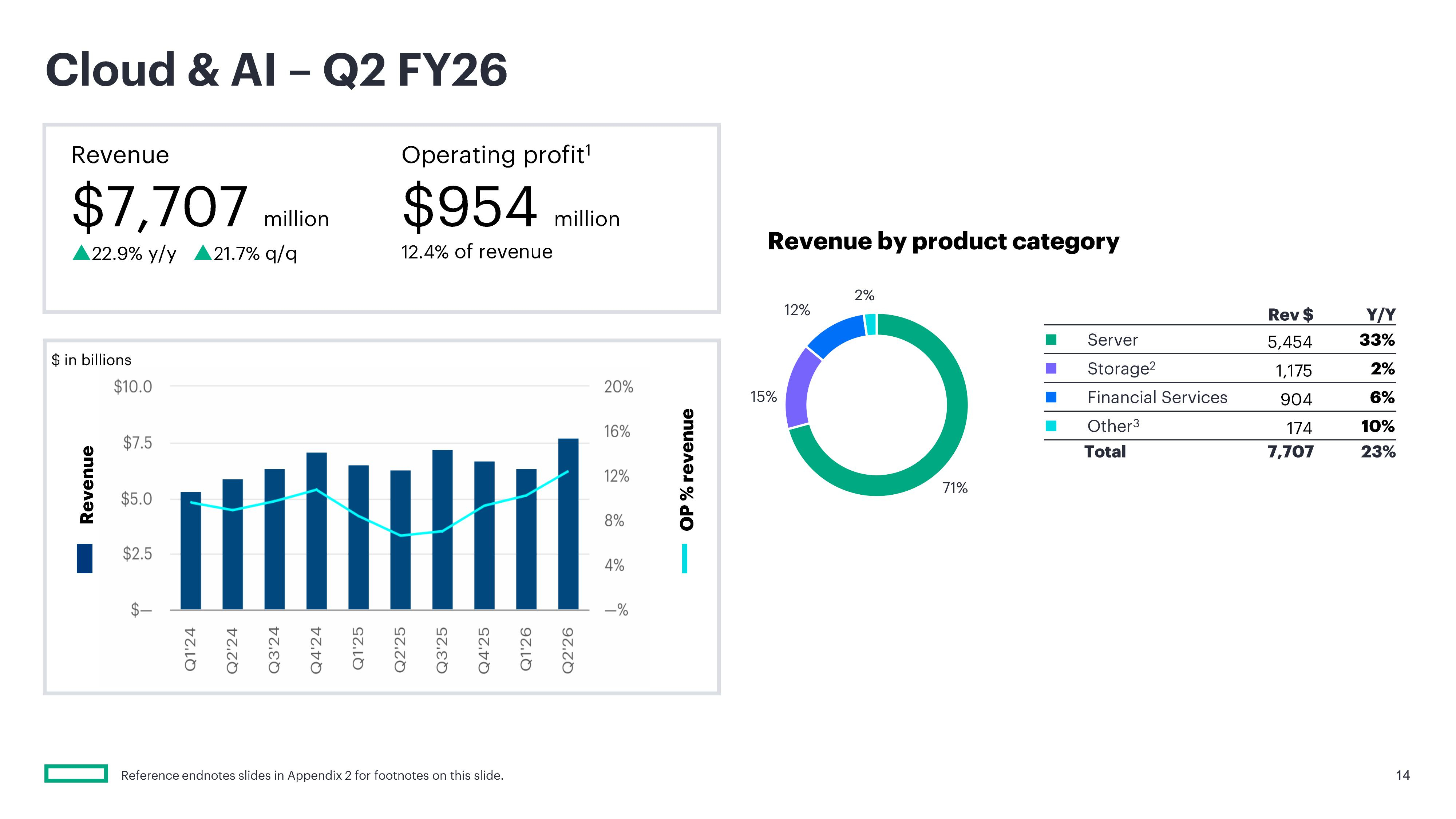 Аналитик Патрик Мурхед (Patrick Moorhead) из Moor Insights & Strategy заявил, что HPE сосредоточена на более высокодоходных возможностях, которые предоставляют эти клиенты, в отличие от своего главного конкурента Dell, который нацелен на неооблака, такие как CoreWeave. «Её рост обусловлен повышением прибыльности ИИ и тем фактом, что она достигает своих целей на полтора года раньше», — сказал он. Как отметило агентство Reuters, успешный квартал позволил компании приблизиться к достижению долгосрочных финансовых целей на два года раньше запланированного срока. Финансовый директор Мари Майерс (Marie Myers) также подчеркнула резкий рост числа клиентов, запрашивающих серверные мощности для ИИ-приложений, отметив, что эти рабочие нагрузки предъявляют гораздо более высокие вычислительные требования к инфраструктуре, чем традиционные задачи. 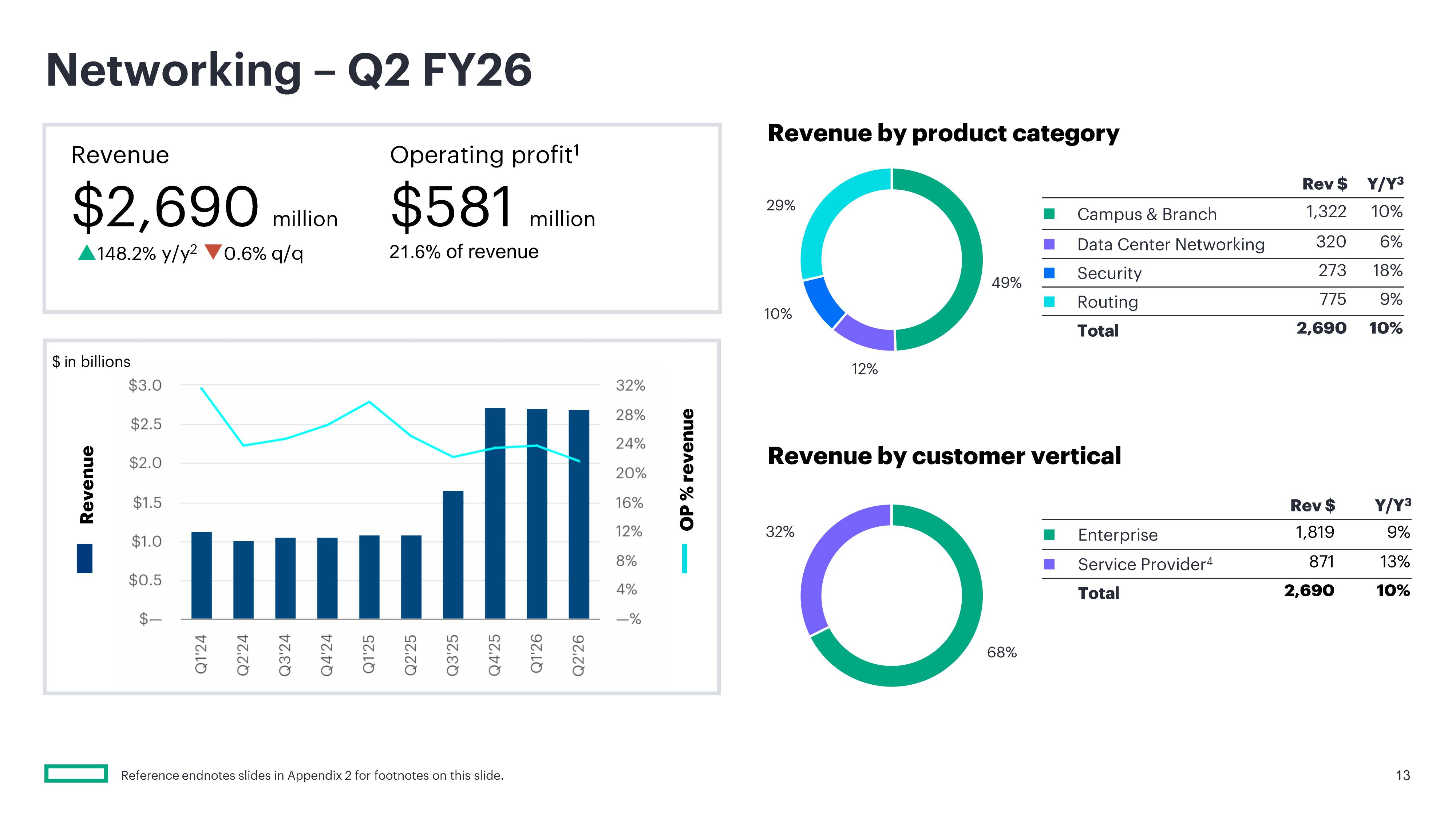 Выручка сегмента «Сетевое оборудование», который включает бизнес Juniper Networks, составила $2,7 млрд, что на 148,2 % больше, чем за аналогичный период прошлого года. В том числе выручка от кампусных и филиальных сетей (Campus & Branch) выросла на 50,2 % до $1,3 млрд. Продажи сетевого оборудования для ЦОД принесли $320 млн (рост на 288,3 %), продукты безопасности — $273 млн выручки, что на 151,2 % больше год к году, а направление маршрутизации — $775 млн по сравнению с $1 млн годом ранее. Продажи СХД выросли на 2,4 % до $1,2 млрд, выручка от финансовых услуг выросла на 5,6 % до $0,9 млрд. Выручка от корпоративных инвестиций и прочих услуг выросла на 3,3 % до $281 млн. 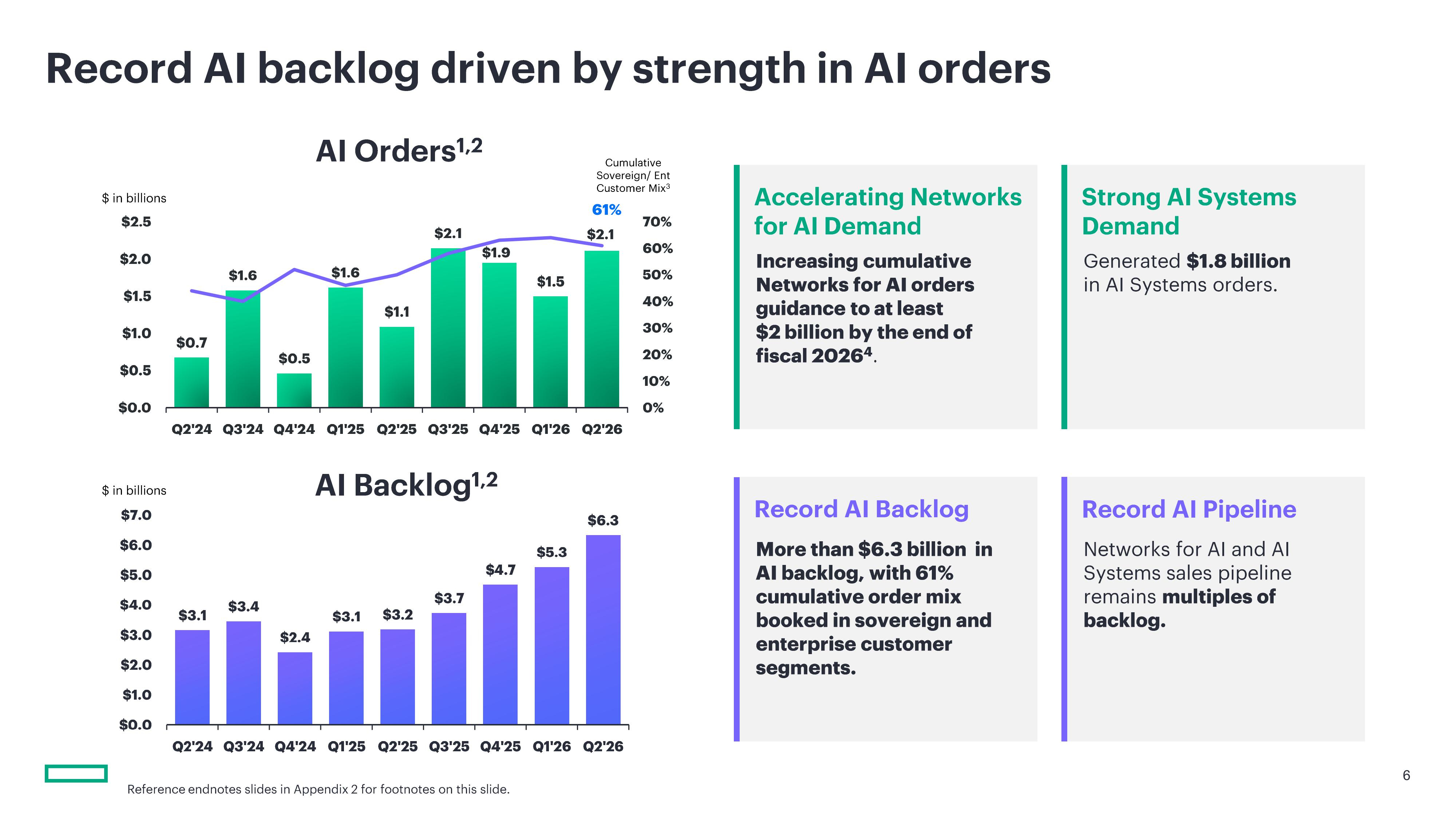 На III финансовый квартал HPE прогнозирует выручку в размере от $11,5 до $12,1 млрд и скорректированную прибыль на акцию в размере от $0,88 до $0,93. Аналитики Уолл-стрит прогнозируют прибыль всего в $0,66 на акцию при выручке в $10,9 млрд. Компания также повысила свой прогноз роста выручки на 2026 финансовый год до 29–33 %, в том числе в сегменте сетевого оборудования до 72–75 %. По скорректированной прибыли на акцию прогноз на год увеличен на $1 до диапазона от $3,35 до $3,45, по сравнению с предыдущей оценкой в $2,30–$2,50 на акцию. В то же время аналитики Уолл-стрит ожидают прибыль за весь финансовый год всего в $2,43 на акцию.
02.06.2026 [11:12], Сергей Карасёв
HPE представила сервер ProLiant Compute DL394 Gen12 на платформе NVIDIA VeraКомпания HPE анонсировала сервер ProLiant Compute DL394 Gen12 для ресурсоёмких нагрузок в области ИИ и обработки данных. Система выполнена на аппаратной платформе NVIDIA Vera. Изделия Vera насчитывают 88 ядер Olympus, совместимых с набором инструкций Arm v9.2. Возможна одновременная обработка до 176 потоков инструкций. Поддерживается до 1,5 Тбайт LPDDR5X с пропускной способностью до 1,2 Тбайт/с. Характеристики ProLiant Compute DL394 Gen12 пока полностью не раскрываются. Известно, что новинка выполнена в форм-факторе 2U. HPE отмечает, что изделия Vera благодаря монолитной конструкции позволяют решить проблему неоднородного доступа к памяти, которая может наблюдаться при использовании традиционных чиплетных архитектур с большим количеством ядер. Эта особенность приводит к переменным задержкам и непредсказуемой производительности. В случае Vera каждому вычислительному ядру предоставляется полоса пропускания до 14 Гбайт/с, что даёт возможность обрабатывать данные на стабильно высокой скорости. 
Источник изображения: HPE В сервере реализованы средства управления HPE Integrated Lights-Out (HPE iLO 7). Говорится о защите от будущих кибератак, основанных на квантовых вычислениях, в соответствии с требованиями Национального института стандартов и технологий США (NIST). Средства HPE Compute Ops Management (COM) обеспечивают унифицированное управление серверной инфраструктурой из единой консоли. ProLiant Compute DL394 Gen12 может применяться для агентного ИИ, обработки больших объёмов транзакций и других задач. В продажу сервер поступит осенью текущего года.
12.05.2026 [14:47], Сергей Карасёв
До 64 Тбайт RAM: HPE представила модульный суперсервер Compute Scale-up Server 3250Компания HPE анонсировала сервер Compute Scale-up Server 3250 на аппаратной платформе Intel для нагрузок, которым требуется большой объём оперативной памяти. Это могут быть резидентные базы данных, аналитические приложения, транзакционные платформы и пр. Новинка выполнена на модульной архитектуре, обеспечивающей гибкое масштабирование. Шасси стандарта 5U рассчитано на четыре процессора Intel Xeon 6700P (до 86 ядер). Доступны 64 слота для модулей оперативной памяти DDR5 ёмкостью до 256 Гбайт каждый: таким образом, суммарный объём ОЗУ может достигать 16 Тбайт. В одну систему могут быть объединены до четырёх серверов, что даст 16 CPU и 64 Тбайт RAM. Платформа управляется внешним контроллером узлов, который отвечает за интерконнект. Доступны различные конфигурации слотов PCIe 5.0 для карт расширения: 4 × FH + 2 × LP, 8 × FH + 4 × LP или 16 × LP. В оснащение входят сетевые контроллеры 1GbE и 10GbE/25GbE (SFP28), оптический привод DVD-RW (опционально) и вентиляторы охлаждения с возможностью горячей замены. Подсистема хранения данных базируется на накопителях E3.S (NVMe), количество которых может достигать 24. Есть три порта USB 3.0 Type-A (один располагается во фронтальной части, два — сзади). 
Источник изображений: HPE Габариты сервера составляют 905 × 445 × 219,2 мм, масса — от 40,82 до 56,7 кг в зависимости от комплектации. Диапазон рабочих температур простирается от +5 до +35 °C. Задействованы блоки питания мощностью 2400 Вт с сертификатом 80 Plus Titanium. Реализованы средства управления HPE Integrated Lights-Out (HPE iLO).  Отмечается, что Compute Scale-up Server 3250 — это первый масштабируемый сервер HPE на платформе Xeon 6, имеющий модульную архитектуру, оптимизированную для ресурсоёмких вычислительных задач и агентного ИИ. Кроме того, по словам компании, это первая в своём класса система, прошедшая валидацию в бенчмарках SAP BW для платформ с 48+ Тбайт RAM. Приём заказов на новинку уже начался. Производитель предоставляет на систему трёхлетнюю гарантию.
01.05.2026 [14:07], Сергей Карасёв
HPE представила серверы ProLiant Compute EL220/EL240 Gen12 для ИИ-задач на периферии
amd
epyc
gpu
granite rapids
hardware
hpe
intel
sierra forest
sorano
xeon
периферийные вычисления
сервер
HPE анонсировала серверы ProLiant Compute EL220 и EL240 Gen12 для приложений ИИ и критически важных рабочих нагрузок на периферии. Устройства выполнены на основе шасси ProLiant Compute EL2000, которое спроектировано специально для эксплуатации в суровых условиях. Системы на базе EL2000 могут использоваться при температурах от -40 до +55 °C и влажности до 95 %. Говорится об устойчивости к воздействию сильных вибраций, которые могут наблюдаться, например, на борту самолётов или наземной техники. 
Источник изображений: HPE Шасси допускает установку двух серверов ProLiant Compute EL220 Gen12 типоразмера 1U или одного сервера ProLiant Compute EL240 Gen12 в форм-факторе 2U. Эти устройства выполнены на процессорах Intel Xeon 6700 (Sierra Forest-SP/Granite Rapids-SP), которые могут насчитывать до 144 вычислительных ядер. Объём оперативной памяти DDR5 достигает 2 Тбайт. Возможен монтаж двух SSD формата М.2 (NVMe) и четырёх накопителей EDSFF. Модификация ProLiant Compute EL240 Gen12 также может быть укомплектована двумя GPU-ускорителями одинарной ширины или одной картой двойной ширины. Упомянуты средства управления iLO 7. В продажу новинки поступят позднее в текущем году.  Кроме того, HPE представила обновлённую версию компактного edge-сервера ProLiant DL145 Gen11 на аппаратной платформе AMD. Это устройство переведено на процессоры EPYC 8005 Sorano, насчитывающие до 84 ядер. Поддерживается до 768 Гбайт DDR5. Система может быть оборудована двумя SFF-накопителями или шестью EDSFF-изделиями. Могут быть задействованы до трёх GPU одинарной ширины или один ускоритель двойной ширины. Сервер уже доступен для заказа.
23.03.2026 [09:31], Сергей Карасёв
HPE представила узлы на базе NVIDIA Vera для платформы Cray Supercomputing GX5000Компания HPE анонсировала новые решения семейства NVIDIA AI Computing by HPE, ориентированные на крупномасштабные ИИ-платформы и суперкомпьютерные системы. О намерении использовать такие инфраструктурные продукты в числе прочих сообщили Аргоннская национальная лаборатория (ANL) Министерства энергетики США (DOE), Hudson River Trading (HRT), Корейский институт научно-технической информации (KISTI) и Центр высокопроизводительных вычислений HLRS при Штутгартском университете в Германии. В частности, представлены новые узлы для суперкомпьютерной платформы HPE Cray Supercomputing GX5000 — blade-серверы HPE Cray Supercomputing GX240. Эти устройства могут нести на борту до 16 процессоров NVIDIA Vera (88C/176T). В одной стойке могут быть размещены до 40 узлов, что в сумме даёт 640 чипов Vera и 56 320 ядер Olympus. Реализовано жидкостное охлаждение. Система предназначена для решения наиболее ресурсоёмких вычислительных задач в области ИИ. Новые серверы появятся на рынке в следующем году. Для платформы HPE Cray Supercomputing GX5000 также будут доступны коммутаторы NVIDIA Quantum-X800 InfiniBand, предоставляющие 144 порта с пропускной способностью до 800 Гбит/с. В этих устройствах реализованы развитые функции снижения энергопотребления. Кроме того, HPE готовит OCP-серверы высокой плотности Compute XD700 для обучения LLM и инференса. В основу данной системы положена платформа NVIDIA HGX Rubin NVL8, а одна стойка может насчитывать до 128 ускорителей Rubin. Данное решение появится в начале 2027-го. 
Источник изображений: HPE Помимо этого, анонсирована стоечная система нового поколения NVIDIA Vera Rubin NVL72 by HPE — это флагманская ИИ-платформа, разработанная для моделей с более чем 1 трлн параметров. Конфигурация включает 36 процессоров Vera, 72 чипа Rubin, интерконнект NVIDIA NVLink шестого поколения, сетевые адаптеры NVIDIA ConnectX-9 SuperNIC и DPU NVIDIA BlueField-4. Система поступит в продажу в декабре 2026 года. 
11.03.2026 [11:20], Владимир Мироненко
Спрос на сетевые решения для ИИ обеспечил HPE один из самых прибыльных кварталовКомпания HPE объявила финансовые результаты за I квартал 2026 финансового года, закончившийся 31 января 2026 года. Показатели в основном превзошли ожидания аналитиков благодаря растущему спросу на сетевые решения для ИИ, отметил ресурс Datacenterknowledge.com. Выручка компании выросла год к году на 18 % — до $9,30 млрд, что немного ниже консенсус-прогноза аналитиков, опрошенных LSEG, в размере $9,33 млрд (по данным Reuters). Скорректированная прибыль (non-GAAP) на разводнённую акцию в размере $0,65 превысила прогноз Уолл-стрит в $0,59. Чистая прибыль (GAAP) составила $423 млн и $0,31 на разводнённую акцию, что ниже показателей годом ранее — $598 млн и $0,44, но выше собственного прогноза компании. 
Источник изображений: HPE Антонио Нери (Antonio Neri), президент и генеральный директор HPE, заявил, что это был один из самых прибыльных кварталов за всю историю компании. «Высокий спрос, разумное управление затратами и более быстрая, чем планировалось, синергия Juniper и Catalyst способствовали нашим результатам», — сообщила финансовый директор Мари Майерс (Marie Myers). Выручка нового сегмента HPE «Облачные технологии и ИИ», объединяющего бизнес HPE в области серверов, хранения данных и финансовых услуг, составила $6,3 млрд, что на 2,7 % меньше, чем за аналогичный период прошлого года, при этом маржа операционной прибыли составила 10,2 % против 8,4 % годом ранее. В том числе выручка от продаж серверов составила $4,2 млрд (снижение год к году на 2,7 %), продажи СХД — $1,1 млрд (рост на 0,6 %), выручка от финансовых услуг — $0,9 млрд (рост на 0,3 %).  Выручка сегмента «Сетевое оборудование», который включает бывший сегмент «Интеллектуальная периферия» и Juniper Networks, составила $2,7 млрд, что на 151,5 % больше, чем за аналогичный период прошлого года. В том числе выручка от кампусных и филиальных сетей (Campus & Branch) достигла $1,2 млрд (рост на 42 % год к году). Продажи сетевого оборудования для ЦОД принесли $444 млн (рост на 382,6 %) благодаря увеличению спроса на высокопроизводительные сети, используемые в ИИ-кластерах. Продукты безопасности принесли $255 млн выручки, что на 114 % больше год к году, а направление маршрутизации — $780 млн по сравнению с $1 млн в аналогичном периоде прошлого года, что отражает добавление портфеля маршрутизации Juniper. Операционная маржа сегмента составила 23,7 %, что ниже, чем в прошлом году (29,7 %), в основном из-за затрат на интеграцию и изменений в ассортименте продукции. Выручка от корпоративных инвестиций и прочих услуг составила $261 млн, что на 2,2 % меньше, чем за аналогичный период прошлого года, при этом маржа операционной прибыли составила −4,6 % по сравнению с −3,0 % годом ранее. В этот сегмент входят консультационные и профессиональные услуги, а также результаты деятельности лаборатории Hewlett Packard. В него также в 2026 финансовом году были включены телекоммуникационный бизнес и Instant On.  HPE сообщила, что её портфель заказов на ИИ-решения превысил $5 млрд, при этом на корпоративных и государственных клиентов приходится 64 % от общего объёма заказов. В текущем финансовом квартале компания ожидает, что квартальная выручка составит от $9,6 до $10,0 млрд, что выше средней оценки аналитиков, опрошенных LSEG, в $9,58 млрд. HPE повысила свой прогноз по скорректированной прибыли на акцию (non-GAAP) на 2026 финансовый год до $2,30–$2,50 по сравнению с предыдущим прогнозом в $2,25–$2,45. Также компания повысила прогноз по годовому росту выручки в сегменте сетевого оборудования до 68–73 %. Акции компании выросли примерно на 1,3 % на дополнительных торгах после публикации финансовых результатов. Вместе с тем с начала года акции HPE упали примерно на 9 %, в то время как у конкурента, компании Dell, был зафиксирован рост на 16,4 %.
09.02.2026 [13:17], Сергей Карасёв
«Ядерный» суперкомпьютер Teton производительностью 20,8 Пфлопс полагается только на AMD EPYC TurinНациональная лаборатория Айдахо (INL) в составе Министерства энергетики США (DOE) сообщила о запуске суперкомпьютера Teton. Система присоединилась к четырём другим НРС-комплексам лаборатории — Bitterroot, Hoodoo, Wind River и Sawtooth, увеличив доступные вычислительные ресурсы вчетверо. В основу Teton положена платформа HPE Cray EX 4000. Объединены 1024 вычислительных узла, каждый из которых содержит 384 ядра CPU и 768 Гбайт памяти. Задействованы процессоры AMD EPYC 9005 поколения Turin. Таким образом, в общей сложности используются около 393 тыс. CPU-ядер и 768 Тбайт памяти. Как отмечает INL, на сегодняшний день Teton — это один из самых мощных суперкомпьютеров в мире, архитектура которого базируется исключительно на CPU (без применения GPU и других специализированных компонентов). Такая конфигурация обусловлена спецификой использования системы: комплекс предназначен для сложных физических моделирований в рамках проектов по разработке передовых реакторов на быстрых нейтронах, малых модульных реакторов и микрореакторов. Утверждается, что традиционные CPU лучше подходят для подобных расчётов, нежели GPU. 
Источник изображений: INL «Teton позволит исследователям моделировать ядерные технологии следующего поколения с беспрецедентной точностью, что значительно сократит время работ от создания концепции до внедрения критически важных проектов в области ядерной энергетики», — отмечает Бренден Хайдрих (Brenden Heidrich), руководитель научной программы Nuclear Science User Facilities (NSUF), реализуемой DOE.  В рамках NSUF исследователям в области ядерной энергетики предоставляется доступ к широкому спектру ресурсов INL и других учреждений. Новый суперкомпьютер поможет учёным моделировать сложную физику реакторов, поведение перспективных материалов и процессы топливного цикла.
20.01.2026 [23:54], Владимир Мироненко
Intel переманила «крёстного отца» экзафлопсного суперкомпьютера FrontierIntel провела кадровые перестановки в руководящем составе, наняв двух специалистов «со стороны» в рамках запланированного развития на рынке ИИ-инфраструктуры, сообщил ресурс CRN со ссылкой на служебную записку компании. Согласно документу, Николя Дюбе (Nicolas Dubé) ранее занимавший пост старшего вице-президента в Arm, был назначен на должность главы подразделения систем для ЦОД, а Эрик Демерс (Eric Demers), бывший топ-менджер Qualcomm, на должность главы подразделения разработки GPU. О назначениях объявил вице-президент и генеральный директор группы ЦОД Intel Кеворк Кечичян (Kevork Kechichian), которому будут непосредственно подчиняться оба руководителя. После реорганизации ему также будет подчиняться Жан-Дидье Аллегруччи (Jean-Didier Allegrucci), вице-президент по разработке SoC для ИИ. Генеральный директор Intel Лип-Бу Тан (Lip-Bu Tan) назвал способность конкурировать с чипами NVIDIA и других участников рынка одним из своих главных приоритетов в рамках плана возвращения компании на рынок после того, как она столкнулась с трудностями в привлечении клиентов к своим предыдущим ускорителям. «Объединение усилий в области Xeon, сетевых технологий и телекоммуникаций, а теперь и ИИ, укрепляет позиции x86, что является одним из ключевых преимуществ по мере того, как ИИ смещается в сторону инференса и агентных систем», — написал Кечичян в служебной записке. 
Источник изображения: Alex Kotliarskyi/unsplash.com Эта реорганизация представляет собой отмену решения Тана, который в апреле прошлого года вывел группу разработчиков ИИ-ускорителей из подразделения, ранее называвшегося группой ЦОД и ИИ. Этот шаг снова меняет организационную структуру Intel: Кечичян принимает на себя обязанности по разработке ИИ-ускорителей от Тана. Генеральный директор возглавил её в ноябре прошлого года после того, как предыдущий руководитель команды, Сачин Катти (Sachin Katti), внезапно покинул компанию в связи с переходом в OpenAI. По поводу решения Тана вернуть команду разработчиков ИИ-ускорителей в группу ЦОД, Кечичян пояснил: «ИИ и современный ЦОД фундаментально связаны». В качестве руководителя подразделения Intel по системам и решениям для ЦОД Дюбе будет «определять техническую архитектуру и стратегию [группы ЦОД] в направлении создания комплексных систем и решений, от микросхем до приложений, обеспечивая интегрированные решения в области вычислительных ресурсов, хранения данных и сетей», — сообщил Кечичян в служебной записке. Дюбе также возьмёт на себя руководство командой Intel по интегрированным решениям в области кремниевой фотоники, которая ранее подчинялась исполнительному директору компании Джеффу Маквейгу (Jeff McVeigh). При этом Дюбе будет использовать свой опыт системной инженерии в Arm, а также опыт 13 лет работы в HPE, где «он руководил проектированием, реализацией и внедрением» программы компании по созданию первого в США экзафлопсного суперкомпьютера Frontier. По поводу обязанностей Демерса, Кечичян заявил, что топ-менджер, ранее возглавлявший разработку GPU в Qualcomm, будет руководить разработкой IP-блоков для GPU и курировать решения Intel для ЦОД на базе GPU. Круг его обязанностей будет включать в себя «координацию работы по архитектуре, компиляторам и драйверам для успешной разработки интегрированного аппаратного и ПО», добавил он. Демерс «будет тесно сотрудничать» с Лизой Пирс (Lisa Pearce), корпоративным вице-президентом и генеральным директором группы разработки ПО компании, а также с командой разработчиков ПО для GPU, чтобы «оптимизировать работу команд и рабочий процесс для достижения максимального эффекта», указал Кечичян в служебной записке. |
|

