Материалы по тегу: habana
|
20.10.2025 [16:00], Сергей Карасёв
Экономичный гибрид: Intel объединила ускорители Gaudi 3 и NVIDIA B200 в одной ИИ-платформеКорпорация Intel показала гибридную стоечную систему Устройство объединяет посредством Ethernet массивы ускорителей Gaudi3 и NVIDIA B200. Платформа Gaudi3 Rack Scale 64 содержит до 16 вычислительных узлов. Каждый из них оснащён двумя неназванными процессорами Intel Xeon, четырьмя OAM-ускорителями Intel Gaudi 3 (64 в одном домене), четырьмя 400GbE-адаптерами NVIDIA ConnectX-7 и одним DPU NVIDIA BlueField-3, отмечает SemiAnalysis. Суммарно доступно 8,2 Тбайт HBM2e, а агрегированная пропускная способность составляет 76,8 Тбайт/с. Мощность суперускорителя составляет 120 кВт. Кроме того, задействованы 12 коммутаторов на чипах Broadcom Tomahawk 5 (51,2 Тбит/с). Для масштабирования и связи с другими узлами, в том числе NVIDIA, используется именно Ethernet. В составе гибридной системы ускорители Intel Gaudi 3 используются на decode-стадии, т.е. для генерации токенов, где важен объём и пропускная способность памяти, тогда как чипы NVIDIA B200 отвечают за prefill-задачи инференса, т.е. за обработку контекста и заполнение KVCache, где важна скорость вычислений. NVIDIA сама стремится к этому же подходу и уже анонсировала соускорители Rubin CPX, которые как раз будут заниматься работой с контекстом в сверхбольших моделях и созданием KV-кеша. 
Источник изображений: Intel Intel утверждает, что гибридная конфигурация из Gaudi3 и B200 позволяет достичь 1,7-кратного прироста производительности в расчёте на доллар совокупной стоимости владения (TCO) по сравнению с платформами, использующими только B200. Однако, как отмечается, эти заявления пока не подтверждены независимыми тестами. К тому же, программная платформа Gaudi3 отстаёт от платформы NVIDIA и является закрытой. Кроме того, нынешняя архитектура Gaudi приближается к концу своего существования, что ставит под сомнение жизнеспособность предложенной платформы в долгосрочной перспективе.  Для Intel это, возможно, один из немногих шансов продать остатки Gaudi3. Между тем Intel недавно анонсировала GPU-ускоритель Crescent Island, разработанный специально для ИИ-инференса. Решение, в основу которого положена архитектура Xe3P, получит 160 Гбайт памяти LPDDR5X. Массовые поставки будет организованы не ранее 2027 года. Ранее компания отказалась от планов по выпуску Falcon Shores, сосредоточившись на Jaguar Shores. Сейчас же компания начала сворачивать поддержку ускорителей Ponte Vecchio (Intel Max) и Arctic Sound (Flex).
18.09.2025 [10:52], Сергей Карасёв
Dell представила ИИ-сервер PowerEdge XE7740 с ускорителями Intel Gaudi 3Компания Dell полностью раскрыла характеристики стоечного сервера PowerEdge XE7740, о подготовке которого впервые стало известно в ноябре 2024 года. Новинка ориентирована на решение ресурсоёмких задач в области ИИ, включая тонкую настройку больших языковых моделей (LLM), инференс, распознавание изображений и речи, выявление мошенничества в сфере финансовых услуг и пр. Сервер, выполненный в форм-факторе 4U, рассчитан на установку двух процессоров Intel Xeon 6 поколения Granite Rapids-SP, которые могут насчитывать до 86 вычислительных ядер. Доступны 32 слота для модулей DDR5-6400 суммарным объёмом до 4 Тбайт. Во фронтальной части расположены восемь отсеков для NVMe SSD стандарта E3.S вместимостью до 122,88 Тбайт. Кроме того, доступны два внутренних коннектора M.2 для загрузочных NVMe-накопителей. 
Источник изображений: Dell Машина может нести на борту до восьми ИИ-ускорителей Intel Gaudi 3. В зависимости от конфигурации возможна установка восьми карт FHFL двойной ширины (до 600 Вт) с интерфейсом PCIe 5.0 x16 или 16 карт FHFL одинарной ширины (75 Вт). Кроме того, есть слот OCP NIC 3.0.  Сервер оборудован системой воздушного охлаждения. За питание отвечают блоки мощностью 3200 Вт с сертификатом 80 PLUS Titanium. На лицевую панель выведены по одному порту USB 2.0 Type-A (iDRAC/BMC Direct), USB 2.0 Type-A (опционально) и Mini-DisplayPort. Сзади расположены два порта USB 3.1 Type-A, коннектор D-Sub и выделенный Ethernet-порт (iDRAC). Габариты составляют 899,56 × 482,0 × 174,3 мм, масса — 71,35 кг. Заявлена совместимость с Ubuntu Server LTS, Red Hat Enterprise Linux, SUSE Linux Enterprise Server и VMWare ESXi.
19.11.2024 [23:28], Алексей Степин
HPE обновила HPC-портфолио: узлы Cray EX, СХД E2000, ИИ-серверы ProLiant XD и 400G-интерконнект Slingshot
400gbe
amd
epyc
gb200
h200
habana
hardware
hpc
hpe
intel
mi300
nvidia
sc24
turin
ии
интерконнект
суперкомпьютер
схд
Компания HPE анонсировала обновление модельного ряда HPC-систем HPE Cray Supercomputing EX, а также представила новые модели серверов из серии Proliant. По словам компании, новые HPC-решения предназначены в первую очередь для научно-исследовательских институтов, работающих над решением ресурсоёмких задач. 
Источник изображений: HPE Обновление касается всех компонентов HPE Cray Supercomputing EX. Открывают список новые процессорные модули HPE Cray Supercomputing EX4252 Gen 2 Compute Blade. В их основе лежит пятое поколение серверных процессоров AMD EPYС Turin, которое на сегодняшний день является самым высокоплотным x86-решениями. Новые модули позволят разместить до 98304 ядер в одном шкафу. Отчасти это также заслуга фирменной системы прямого жидкостного охлаждения. Она охватывает все части суперкомпьютера, включая СХД и сетевые коммутаторы. Начало поставок узлов намечено на весну 2025 года. 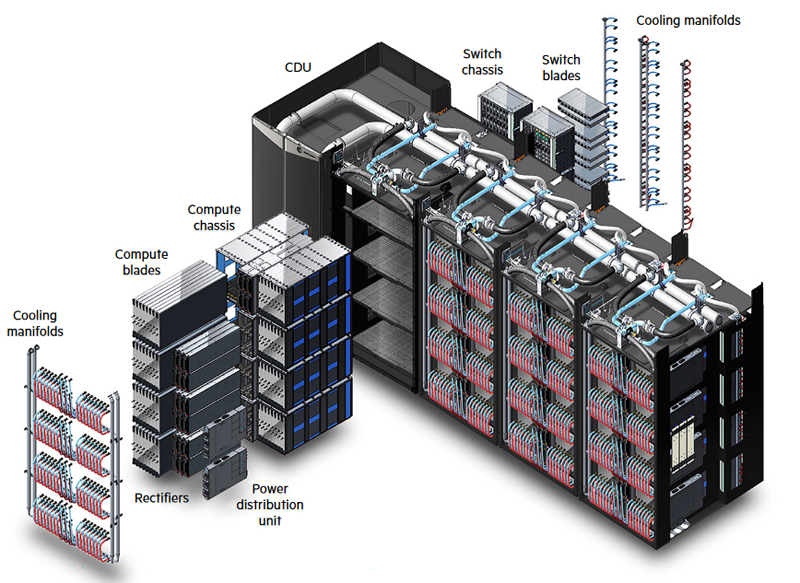 Процессорные «лезвия» дополнены новыми GPU-модулями HPE Cray Supercomputing EX154n Accelerator Blade, позволяющими разместить в одном шкафу до 224 ускорителей NVIDIA Blackwell. Речь идёт о новейших сборках NVIDIA GB200 NVL4 Superchip. Этот компонент появится на рынке позднее — HPE говорит о конце 2025 года. Обновление коснулось и управляющего ПО HPE Cray Supercomputing User Services Software, получившего новые возможности для пользовательской оптимизации вычислений, в том числе путём управления энергопотреблением. Апдейт получит и фирменный интерконнект HPE Slingshot, который «дорастёт» до 400 Гбит/с, т.е. станет вдвое быстрее нынешнего поколения Slingshot. Пропускная способность коммутаторов составит 51,2 Тбит/c. В новом поколении будут реализованы функции автоматического устранения сетевых заторов и адаптивноой маршрутизации с минимальной латентностью. Дебютирует HPE Slingshot interconnect 400 осенью 2024 года.  Ещё одна новинка — СХД HPE Cray Supercomputing Storage Systems E2000, специально разработанная для применения в суперкомпьютерах HPE Cray. В сравнении с предыдущим поколением, новая система должна обеспечить более чем двукратный прирост производительности: с 85 и 65 Гбайт/с до 190 и 140 Гбайт/с при чтении и записи соответственно. В основе новой СХД будет использована ФС Lustre. Появится Supercomputing Storage Systems E2000 уже в начале 2025 года.  Что касается новинок из серии Proliant, то они, в отличие от вышеупомянутых решений HPE Cray, нацелены на рынок обычных ИИ-систем. 5U-сервер HPE ProLiant Compute XD680 с воздушным охлаждением представляет собой решение с оптимальным соотношением производительности к цене, рассчитанное как на обучение ИИ-моделей и их тюнинг, так и на инференс. Он оснащён восемью ускорителями Intel Gaudi3 и двумя процессорами Intel Xeon Emerald Rapids. Новинка поступит на рынок в декабре текущего года.  Более производительный HPE ProLiant Compute XD685 всё так же выполнен в корпусе высотой 5U, но рассчитан на жидкостное охлаждение. Он будет оснащаться восемью ускорителями NVIDIA H200 в формате SXM, либо более новыми решениями Blackwell, но последняя конфигурация будет доступна не ранее 2025 года, когда ускорители поступят на рынок. Уже доступен ранее анонсированный вариант с восемью ускорителями AMD Instinict MI325X и процессорами AMD EPYC Turin.
02.11.2024 [14:06], Руслан Авдеев
Intel катастрофически отстала от NVIDIA и AMD по объёмам продаж ИИ-ускорителей, не продав Gaudi даже на $500 млнNVIDIA стала самым быстрорастущим производителем ИИ-ускорителей, своим успехом стимулируя работу AMD, тоже желающей воспользоваться высоким спросом на ИИ-решения. А вот у Intel, по данным The Verge, рассчитывавшей заработать $1–2 млрд в 2024 году на ИИ-ускорителях Gaudi, похоже, не выйдет получить и $500 млн. Об этом прямо заявил в ходе последнего отчёта года глава компании Пат Гэлсингер (Pat Galsinger). Хотя компания представила новейшие ускорители Gaudi3 в прошлом квартале, распространение Gaudi в целом было более медленным, чем ожидалось — на это повлиял переход с Gaudi2 на Gaudi 3 и специфика ПО. В 2025 году, как ожидается, поставки Gaudi3 тоже будут не столь велики, как планировалось ранее. Несмотря на то, что заявленных целей добиться не получится, компания «остаётся воодушевлена» рынком ИИ. Хотя Гелсингер не скрыл разочарования, по его словам, имеется очевидная необходимость в более выгодных с точки зрения TCO ИИ-решениях на основе открытых стандартов, так что Intel будет работать над дальнейшим улучшением Gaudi. 
Источник изображения: Intel Гелсингер также выразил недовольство огромными расходами индустрии на чипы, нацеленные на обучение моделей в облаках, сравнив такую «тренировку ИИ» с «созданием погодной модели без её использования». В его видении ИИ необходимо интегрировать вообще во все чипы, что может оказаться важным в долгосрочной перспективе. В прошлом квартале Intel анонсировала план снижения расходов на $10 млрд и увольнении более 15 тыс. человек. Также известно о структурных изменениях самого бизнеса, включая передачу подразделения, занятого edge-системами в Client Computing Group, которая вообще-то работает над решениями для настольных ПК и ноутбуков. Кроме того, предполагается интеграция команд разработчиков ПО в основные подразделения компании. По словам Гелсингера, Intel будет фокусировать внимание на меньшем числе проектов, главной задачей станет максимизация ценности x86-франшизы на рынках клиентских устройств, периферийных вычислений и центров обработки данных.
08.10.2024 [12:36], Сергей Карасёв
Inflection AI и Intel представили ИИ-систему на базе Gaudi3Стартап Inflection AI и корпорация Intel объявили о сотрудничестве с целью ускорения внедрения ИИ в корпоративном секторе. В рамках партнёрства состоялся анонс Inflection for Enterprise — первой в отрасли ИИ-системы корпоративного класса на базе ускорителей Intel Gaudi3 и облака Intel Tiber AI Cloud (AI Cloud). Inflection AI основана в 2022 году Мустафой Сулейманом (Mustafa Suleyman), одним из основателей Google DeepMind, а также Ридом Хоффманом (Reid Hoffman), одним из учредителей LinkedIn. Стартап специализируется на технологиях генеративного ИИ. В середине 2023 года Inflection AI получила на развитие $1,3 млрд: в число инвесторов вошли Microsoft и NVIDIA. Inflection for Enterprise объединяет Gaudi3 с большой языковой моделью (LLM) Inflection 3.0. Утверждается, что это ПО при использовании на аппаратной платформе Intel демонстрирует вдвое более высокую экономическую эффективность по сравнению с некоторыми конкурирующими изделиями. Заказчики получат LLM, настроенную в соответствии с их пожеланиями. Для удовлетворения потребностей каждого конкретного клиента применяется обучение с подкреплением на основе отзывов людей (RLHF). При этом используются данные, предоставленные самим заказчиком. 
Источник изображения: Intel Отмечается, что облако AI Cloud упрощает создание, тестирование и развёртывание ИИ-приложений в единой среде, ускоряя время выхода продуктов на рынок. Тонко настроенные ИИ-модели доступны исключительно клиенту и не передаются в третьи руки. На первом этапе системы Inflection for Enterprise будут предлагаться через облако AI Cloud. В I квартале 2025 года планируется организовать поставки программно-аппаратных комплексов.
07.10.2024 [15:16], Руслан Авдеев
Intel может почти на треть сократить поставки ИИ-ускорителей Gaudi 3 в 2025 годуКомпания Intel борется за выживание на рынке ИИ-решений и в конце сентября официально представила свой новейший ускоритель — 5-нм Gaudi 3. Однако по данным аналитического агентства TrendForce, IT-гигант сократил планы поставок соответствующих чипов более чем на 30 % в 2025 году. Это может повлиять на бизнес-партнёров компании из цепочки поставок на Тайване. Агентство ссылается на отчёт Economic Daily News. В нём указывается, что новые меры могут быть связаны с изменением внутренней политики Intel и спроса, что побудило компанию сократить заказы на Тайване. После снижения объёмов выпуска место IT-гиганта на фабриках TSMC займут другие клиенты. То же касается и ASE, а также её дочерней SPIL, оказывающих Intel услуги по упаковке и тестированию микросхем. Для Alchip, проектирующей специализированные ASIC для Intel Gaudi 2 и Gaudi 3, ситуация может оказаться более сложной. Unimicron, которая считается главным поставщиком подложек для чипов Intel, тоже довольно сильно зависит от объёмов заказов последней. Но в Unimicron сохраняют оптимизм, поскольку рассчитывают, что во II половине 2024 года спрос на ИИ-ускорители и оптические модули вырастет. 
Источник изображения: Intel Отраслевые источники сообщают, что изначально в 2025 году планировалось отгрузить 300–350 тыс. ускорителей Gaudi 3, но теперь речь идёт лишь о 200–250 тыс. По имеющимся данным, после покупки израильского производителя Habana Labs в 2019 году, Intel, вероятно, весьма прохладно относится к идее совместной разработки ИИ-ускорителей нового поколения со сторонними компаниями. Более того, она ускоренно сворачивает выпуск Gaudi 2. Новость об изменениях структуры производства компании отнюдь не первая в 2024 году. В мае сообщалось, что Intel отказалась от ускорителей Ponte Vecchio в пользу Gaudi и Falcon Shores. Позже появились предположения о том, что создание Falcon Shores будет свёрнуто в рамках плана по выводу компании из кризиса, но Intel поспешила развеять сомнения, сообщив, что эту серию ускорителей всё же выпустят. Вероятно и то, что в них интегрируют элементы Gaudi.
29.09.2024 [00:30], Алексей Степин
Рождение экосистемы: Intel объявила о доступности ИИ-ускорителей Gaudi3 и решений на их основеПро ускорители Gaudi3 компания Intel достаточно подробно рассказала ещё весной этого года — 5-нм новинка стала дальнейшим развитием идей, заложенных в предыдущих поколениях Gaudi. Объявить о доступности новых ИИ-ускорителей Intel решила одновременно с анонсом новых серверных процессоров Xeon 6900P (Granite Rapids), которые в видении компании являют собой «идеальную пару». Впрочем, в компании признают лидерство NVIDIA, так что обещают оптимизировать процессоры для работы с ускорителями последней. А вот ускорителей Falcon Shores, вполне вероятно, с новой политикой Intel потенциальные заказчики не дождутся. 
Источник изображений здесь и далее: Intel На данный момент главной новостью является то, что в распоряжении Intel не просто есть некий ИИ-ускоритель с более или менее конкурентоспособной архитектурой и производительностью, а законченное и доступное заказчикам решение, уже успевшее привлечь внимание крупных производителей и поставщиков серверного оборудования. 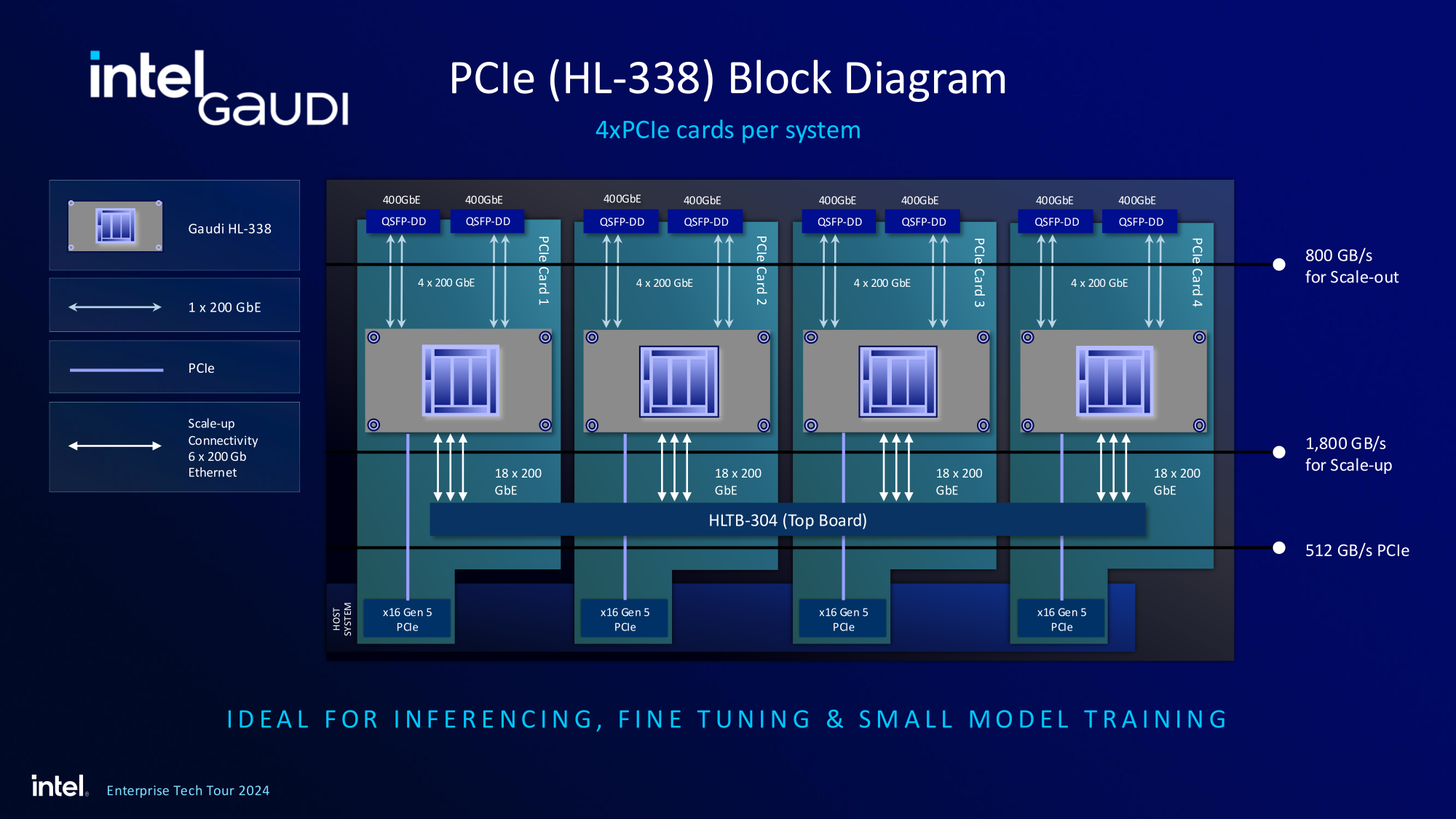 Впрочем, на презентации были продемонстрированы любопытные слайды, в частности, касающиеся архитектуры и принципов работы блоков матричной математики (MME), тензорных ядер (TPC), а также устройство подсистемы памяти. 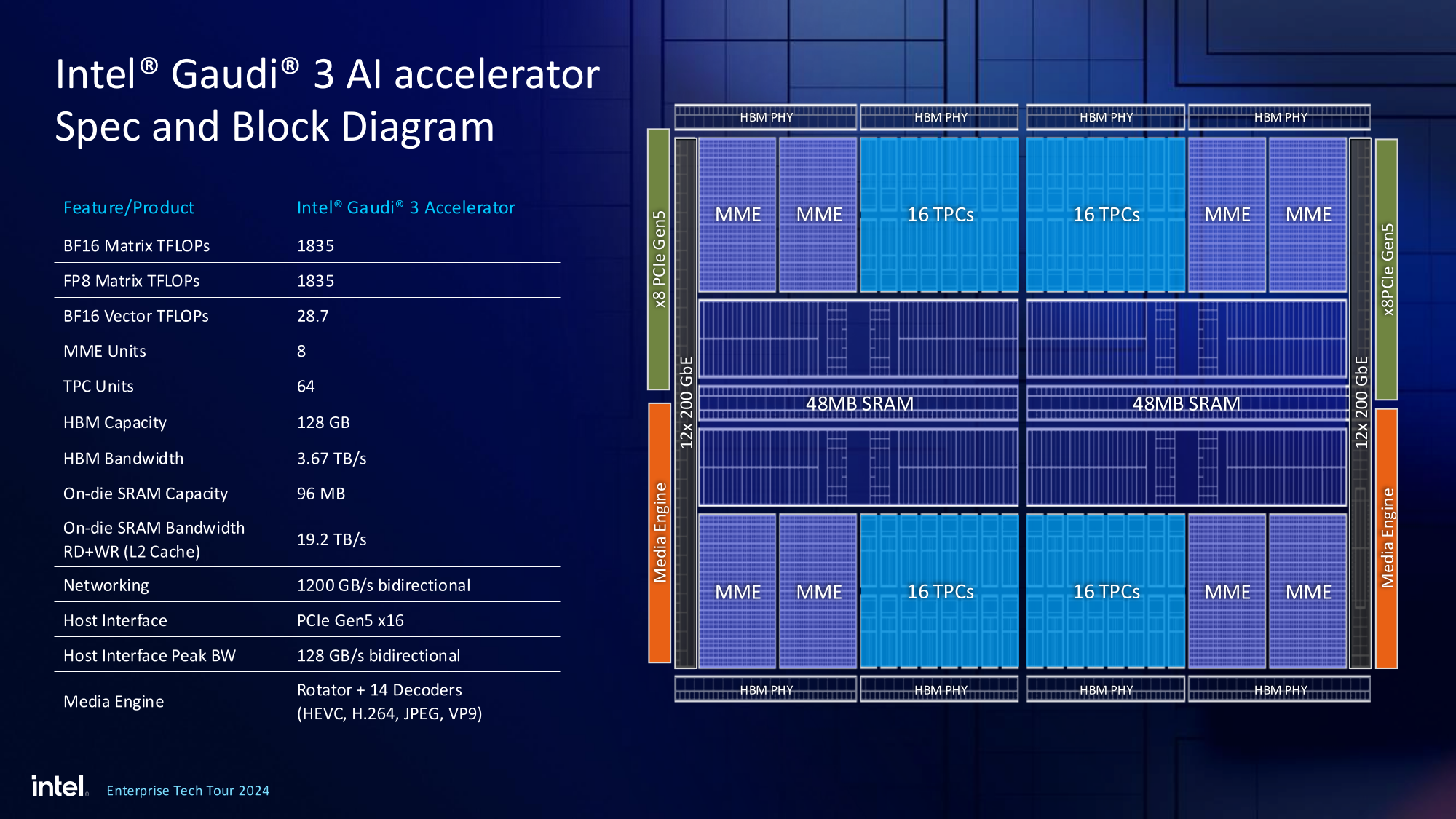 В последнем случае любопытен максимальный отход от иерархических принципов построения в пользу единого унифицированного пространства памяти, включающего в себя кеши L2 и L3, а также набортные HBM2e-стеки ускорителя. Общение с сетевым интерконнектом при этом организовано из пространства L3, что должно минимизировать задержки.  При этом сетевые порты доступны операционной системе как NIC через драйвер Gaudi3, с управлением посредством RDMA verbs. Благодаря большому количеству таких виртуальных NIC, организация интерконнекта внутри сервера-узла не требует никаких коммутаторов, а совокупная внутренняя производительность при этом достигает 67,2 Тбит/с.  Хотя основой экосистемы Gaudi3 станут в первую очередь ускорители HL-325L и UBB-платы HLB-325, есть у Intel и PCIe-вариант в виде FHFL-платы HL-338: 1,835 Пфлопс в режиме FP8 при теплопакете 600 Вт. Оно имеет только 22 200GbE-контроллера, а в остальном повторяет конфигурацию HL-325L с восемью блоками матричной математики (MME).  Эти ускорители получат пару портов QSFP-DD, каждый из которых будет поддерживать скорость 400 Гбит/с, а между собой платы в пределах одного сервера смогут общаться при помощи специального бэкплейна. 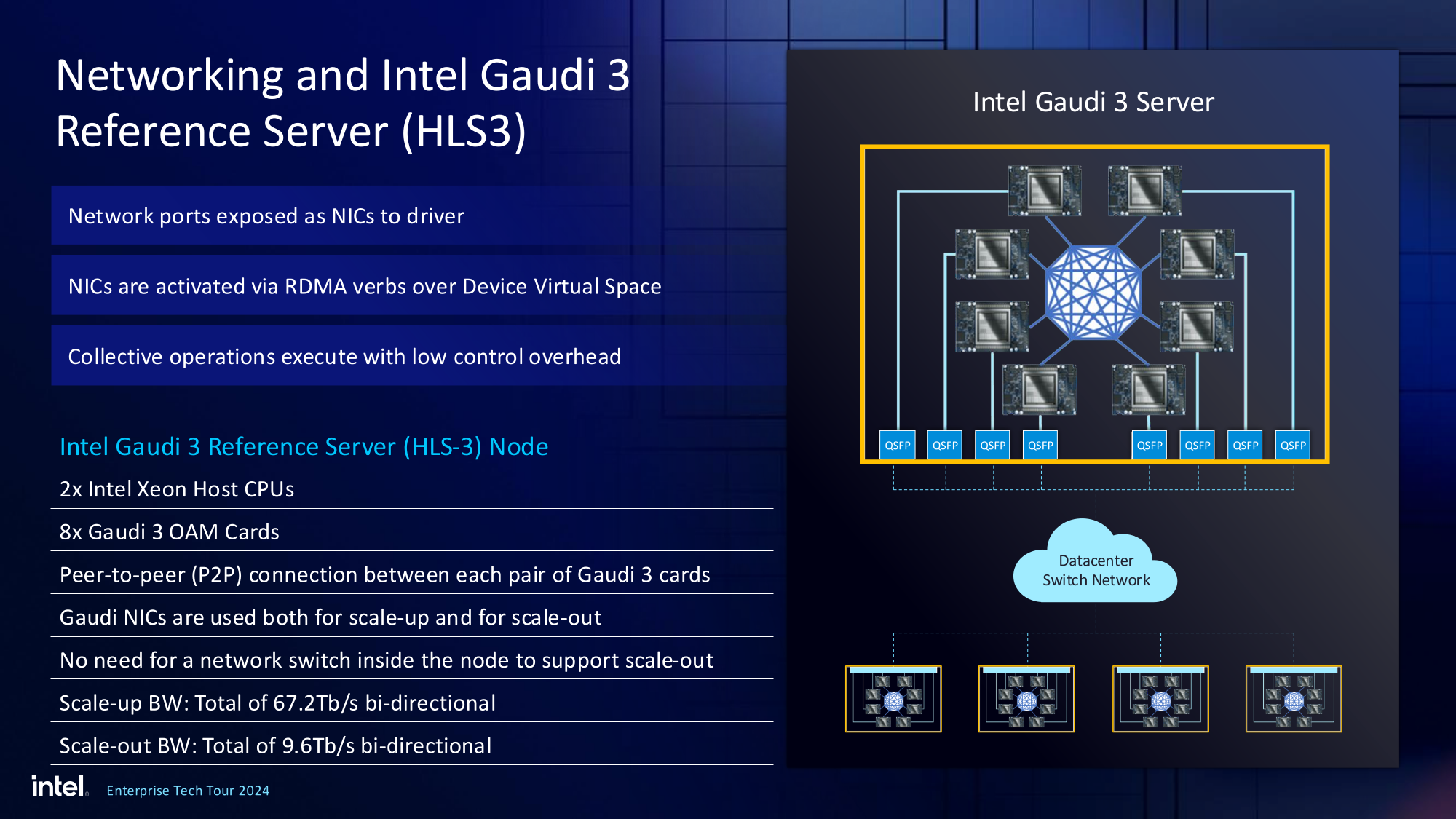 Важно то, что Gaudi3 успешно прошёл путь от анонса до становления сердцем полноценной аппаратно-программной экосистемы, в том числе благодаря ставке на программное обеспечение с открытым кодом. В настоящее время Intel в содействии с партнёрами могут предложить широчайший по масштабу спектр решений на базе Gaudi3 — от рабочих станций и периферийных серверов до вычислительных узлов, собирающихся в стойки, кластеры и даже суперкластеры. 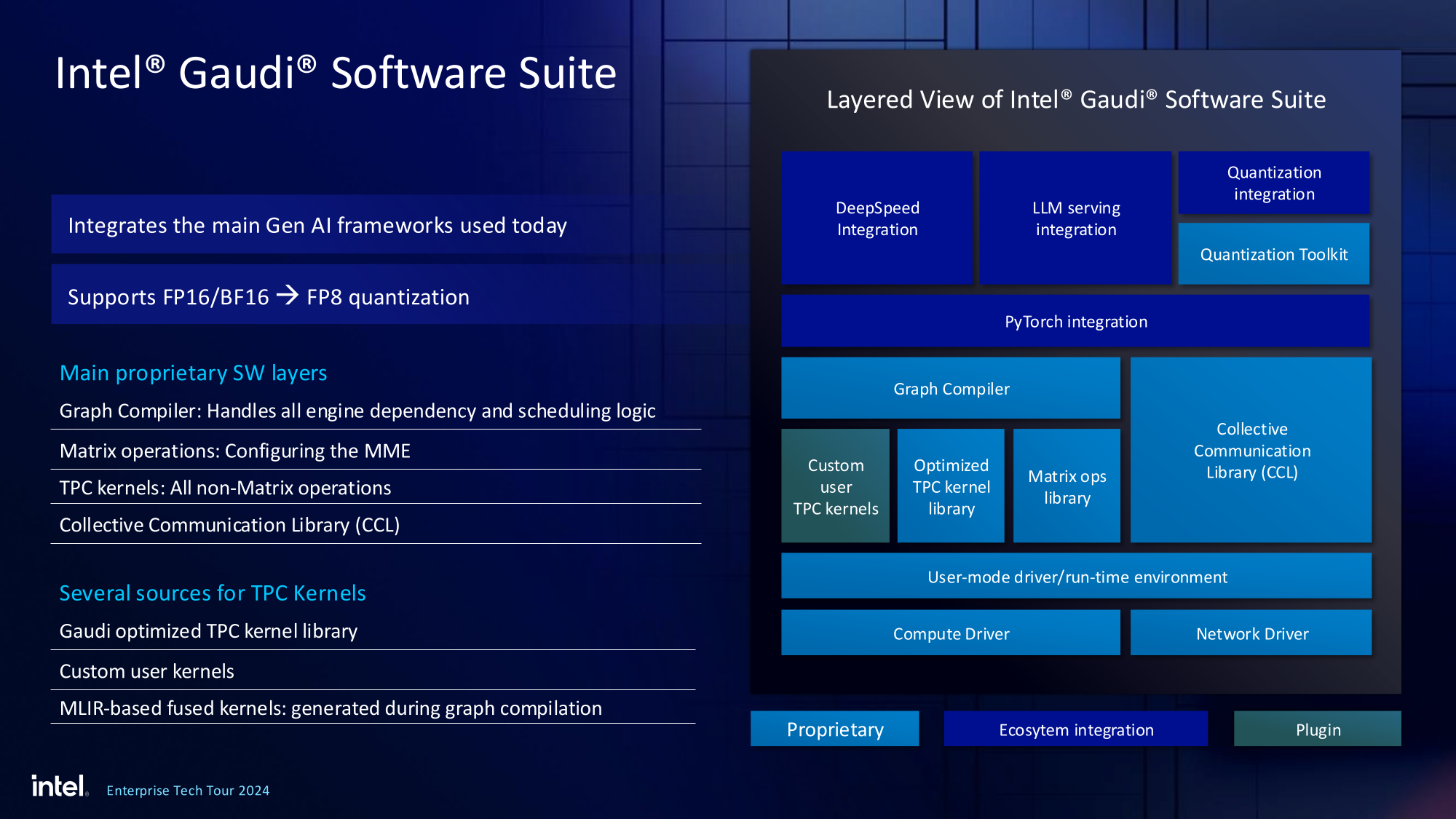 В числе крупнейших партнёров Intel по новой экосистеме есть Dell и Supermicro, представившие серверные системы c Gaudi3. Начало массовых поставок этих систем запланировано на октябрь 2024 года. Вряд ли такие серверы будут развёртываться по одному, поэтому Intel рассказала о возможностях масштабирования Gaudi3-платформ.  Один узел с восемью OAM-модулями HL-325L, развивающий 14,7 Пфлопс в режиме FP8 и располагающий 1 Тбайт HBM станет основой для 32- и 64-узловых кластеров с 256 и 512 Gaudi3 на борту, благо нехватка пропускной способности сетевой части Gaudi3 не грозит — она составляет 9,6 Тбайт/с для одного узла. Из таких кластеров может быть составлен суперкластер с 4096 ускорителями или даже мегакластер, где их число достигнет 8192. Производительность в этом случае составит 15 Эфлопс при объёме памяти 1 Пбайт и совокупной производительности сети 9,8 Пбайт/с. 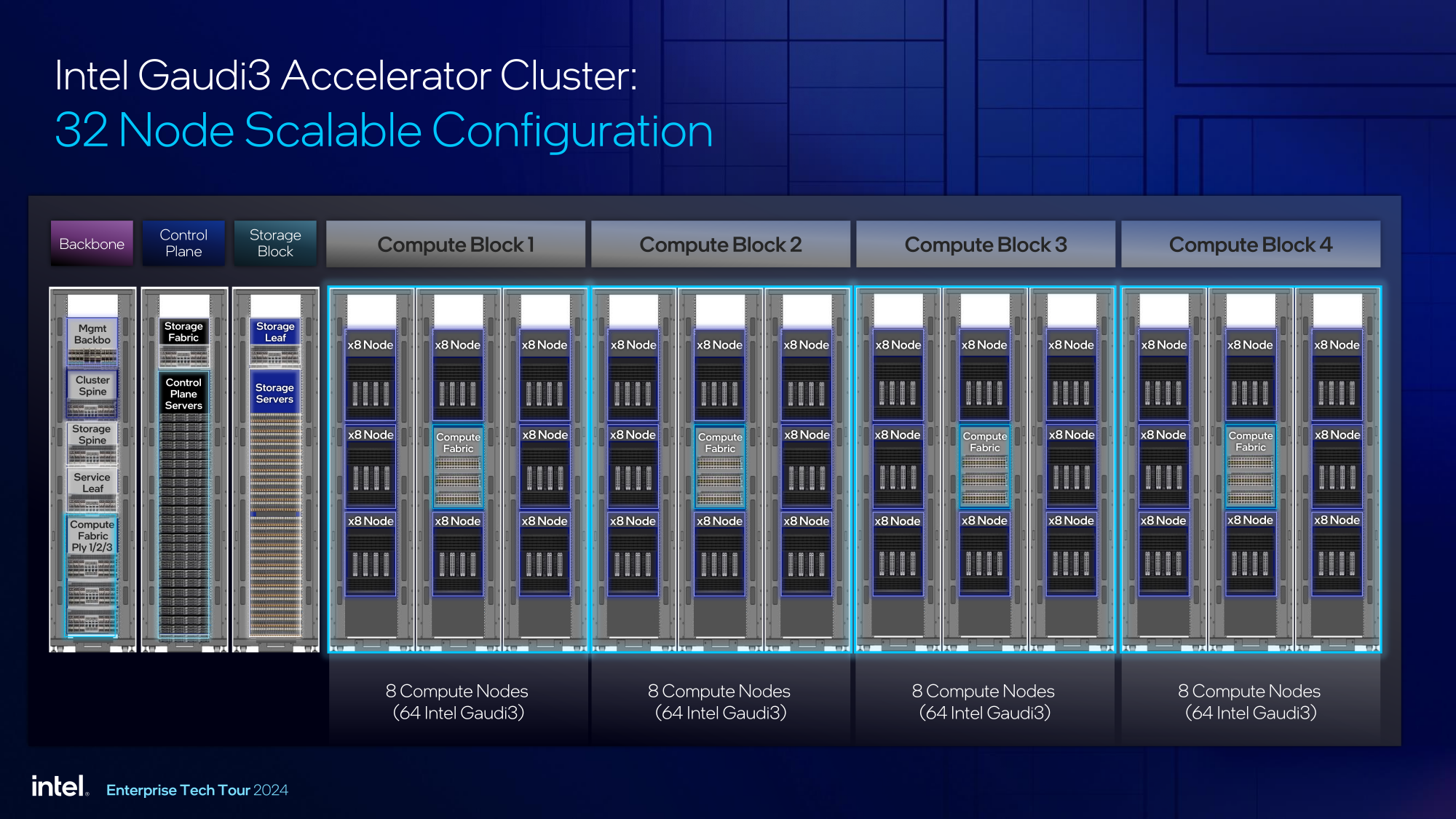 Типовой 32-узловой кластер на базе Gaudi3 Intel — это решение средней плотности с 15 стойками, содержащими не только вычислительные узлы, но и управляющие серверы, сетевые коммутаторы и подсистему хранения данных. Благодаря тому, что Intel в качестве интерконнекта для Gaudi3 избрала открытый и широко распространённый стандарт Ethernet (200GbE RoCE, 24 контроллера на ускоритель), не должно возникнуть проблем с совместимостью и привязкой к аппаратному обеспечению единственного вендора, как это имеет место быть c NVIDIA InfiniBand и NVLink.  Вкупе с программным обеспечением, основой которого является открытый OneAPI, и развитой системой техподдержки, системы на базе Gaudi3 станут надёжной основой для развёртывания ИИ-систем класса RAG, позволяющих заказчику в кратчайшие сроки запускать сети LLM с собственными датасетами без переобучения модели с нуля, говорит компания.  Именно в сферах, так или иначе связанных с большими языковыми моделями, Gaudi3 и системы на его основе должны помочь Intel укрепить свои позиции. Компания приводит данные, что Gaudi3 производительнее H100 примерно в 1,19 раза без учёта энергоэффективности, но в пересчёте «ватт на доллар» эти ускорители превосходят NVIDIA H100 уже в два раза.  Правда, H100 арсенал NVIDIA уже не ограничивается, но с массовой доступности новых решений Intel они могут оказаться привлекательнее. К тому же платформа совместима со всеми основными фреймворками, библиотеками и средствами управления. Впрочем, на примере AMD прекрасно видно, насколько индустрия привязана к решениям NVIDIA, причём в первую очередь программным.
30.08.2024 [13:11], Руслан Авдеев
ИИ-ускорители Intel Gaudi 3 дебютируют в облаке IBM CloudКомпании Intel и IBM намерены активно сотрудничать в сфере облачных ИИ-решений. По данным HPC Wire, доступ к ускорителям Intel Gaudi 3 будет предоставляться в облаке IBM Cloud с начала 2025 года. Сотрудничество обеспечит и поддержку Gaudi 3 ИИ-платформой IBM Watsonx. IBM Cloud станет первым поставщиком облачных услуг, принявшим на вооружение Gaudi 3 как для гибридных, так и для локальных сред. Взаимодействие компаний позволит внедрять и масштабировать современные ИИ-решения, а комбинированное использование Gaudi 3 с процессорами Xeon Emerald Rapids откроет перед пользователями дополнительные возможности в облаках IBM. Gaudi 3 будут применяться и в задачах инференса на платформе Watsonx — клиенты смогут оптимизировать исполнение таких нагрузок с учётом соотношения цены и производительности. Для помощи клиентам в различных отраслях, в том числе тех, деятельность которых жёстко регулируется, компании предложат возможности IBM Cloud для гибкого масштабирования нагрузок, а интеграция Gaudi 3 в среду IBM Cloud Virtual Servers for VPC позволит компаниям, использующим аппаратную базу x86, быстрее и безопаснее использовать свои решения, чем до интеграции. 
Источник изображения: Intel Ранее сообщалось, что модель Gaudi 3 готова бросить вызов ускорителям NVIDIA. В своё время Intel выступила с заявлением о 50 % превосходстве новинки в инференс-сценариях над NVIDIA H100, а также о 40 % преимуществе в энергоэффективности при значительно меньшей стоимости. Позже Intel публично раскрыла стоимость новых ускорителей, нарушив негласные правила рынка.
10.05.2022 [22:46], Игорь Осколков
Intel анонсировала ИИ-ускорители Habana Gaudi2 и GrecoНа мероприятии Intel Vision было анонсировано второе поколение ИИ-ускорителей Habana: Gaudi2 для задач глубокого обучения и Greco для инференс-систем. Оба чипа теперь производятся с использованием 7-нм, а не 16-нм техпроцесса, но это далеко не единственное улучшение. Gaudi2 выпускается в форм-факторе OAM и имеет TDP 600 Вт. Это почти вдвое больше 350 Вт, которые были у Gaudi, но второе поколение чипов значительно отличается от первого. Так, объём набортной памяти увеличился втрое, т.е. до 96 Гбайт, и теперь это HBM2e, так что в итоге и пропускная способность выросла с 1 до 2,45 Тбайт/с. Объём SRAM вырос вдвое, до 48 Мбайт. Дополняют память DMA-движки, способные преобразовывать данные в нужную форму на лету. 
Изображения: Intel/Habana В Gaudi2 имеется два основных типа вычислительных блоков: Matrix Multiplication Engine (MME) и Tensor Processor Core (TPC). MME, как видно из названия, предназначен для ускорения перемножения матриц. TPC же являются программируемыми VLIW-блоками для работы с SIMD-операциями. TPC поддерживают все популярные форматы данных: FP32, BF16, FP16, FP8, а также INT32, INT16 и INT8. Есть и аппаратные декодеры HEVC, H.264, VP9 и JPEG.  Особенностью Gaudi2 является возможность параллельной работы MME и TPC. Это, по словам создателей, значительно ускоряет процесс обучения моделей. Фирменное ПО SynapseAI поддерживает интеграцию с TensorFlow и PyTorch, а также предлагает инструменты для переноса и оптимизации готовых моделей и разработки новых, SDK для TPC, утилиты для мониторинга и оркестрации и т.д. Впрочем, до богатства программной экосистемы как у той же NVIDIA пока далеко. 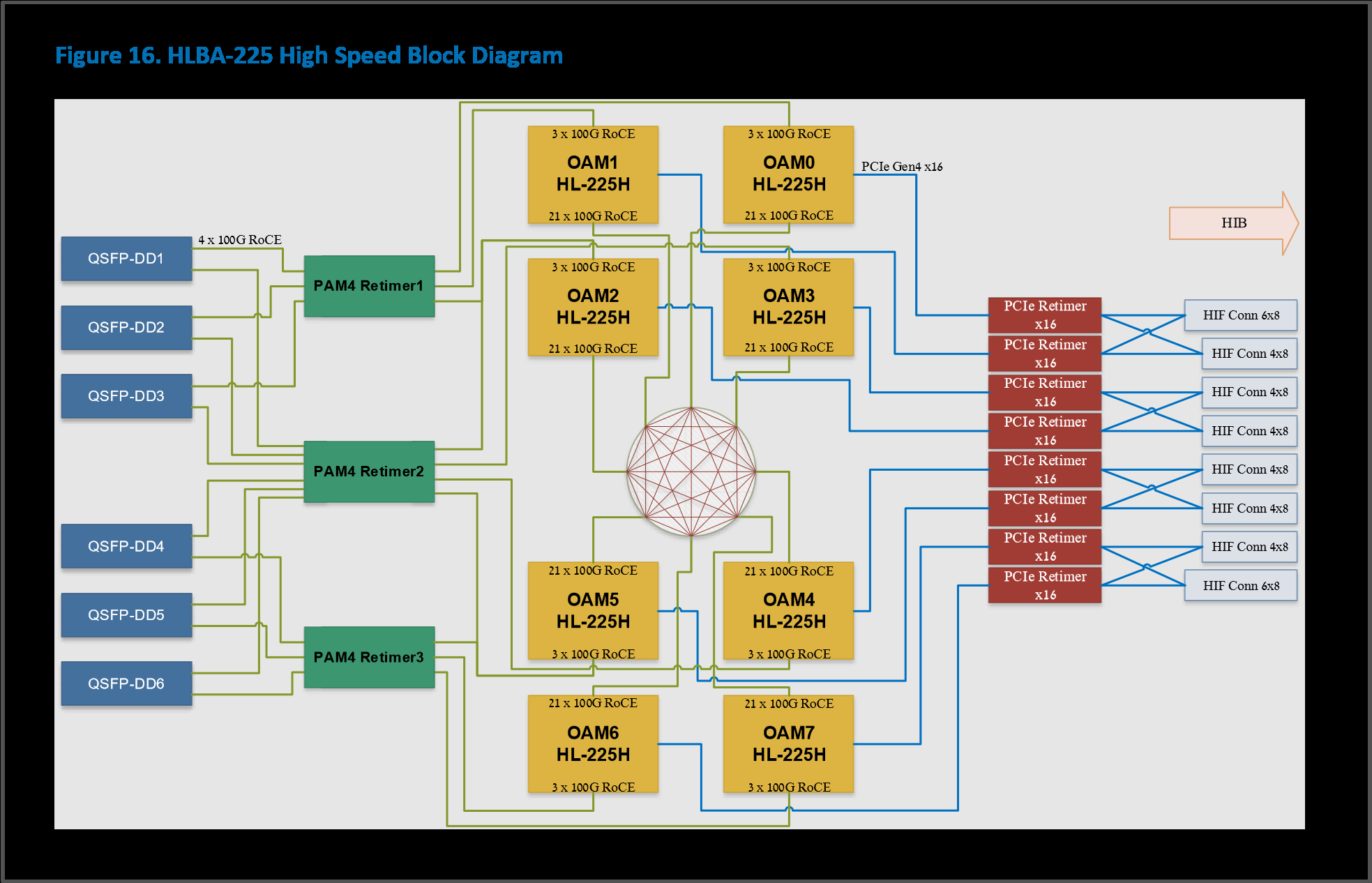 Интерфейсная часть новинок включает PCIe 4.0 x16 и сразу 24 (ранее было только 10) 100GbE-каналов с RDMA ROcE v2, которые используются для связи ускорителей между собой как в пределах одного узла (по 3 канала каждый-с-каждым), так и между узлами. Intel предлагает плату HLBA-225 (OCP UBB) с восемью Gaudi2 на борту и готовую ИИ-платформу, всё так же на базе серверов Supermicro X12, но уже с новыми платами, и СХД DDN AI400X2. 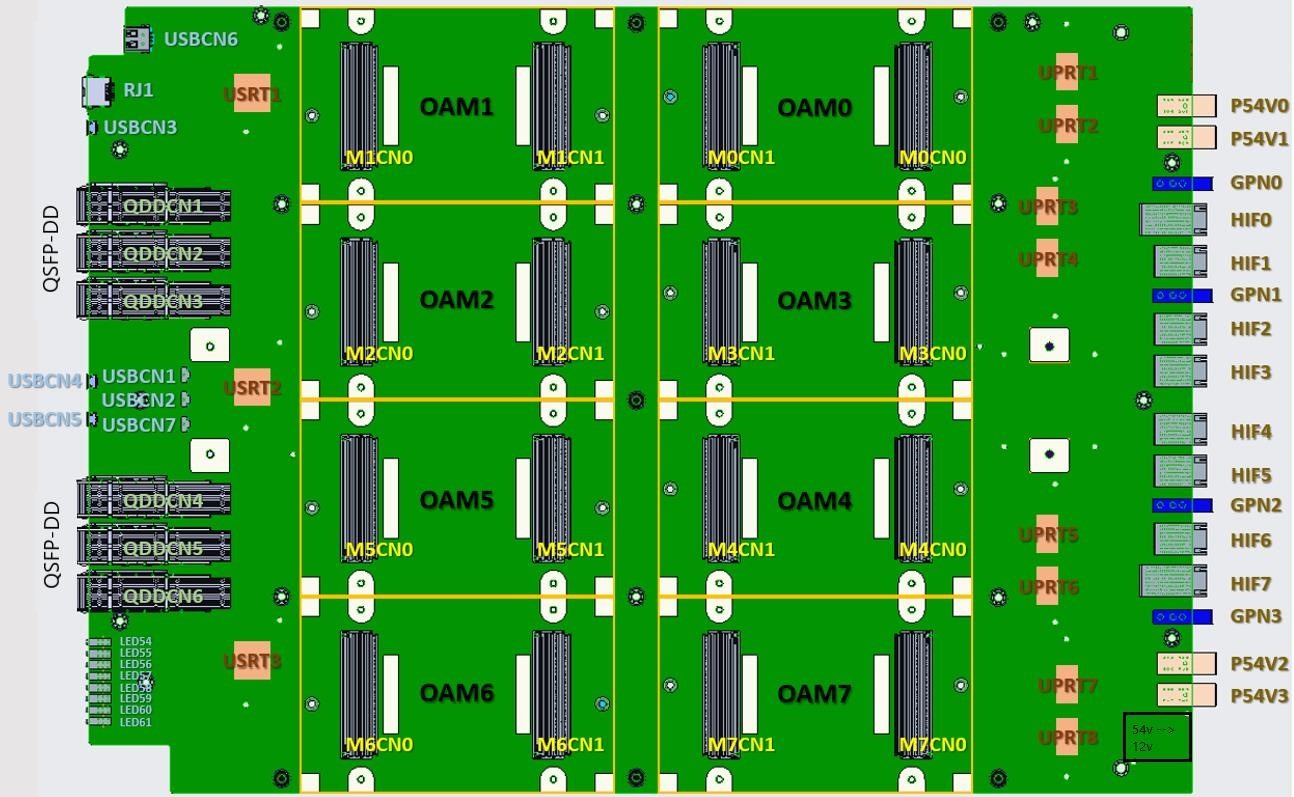 Наконец, самое интересное — сравнение производительности. В ряде популярных нагрузок новинка оказывается быстрее NVIDIA A100 (80 Гбайт) в 1,7–2,8 раз. На первый взгляд результат впечатляющий. Однако A100 далеко не новы. Более того, в III квартале этого года ожидается выход ускорителей H100, которые, по словам NVIDIA, будут в среднем от трёх до шести раз быстрее A100, а благодаря новым функциям прирост в скорости обучения может быть и девятикратным. Ну и в целом H100 являются более универсальными решениями. 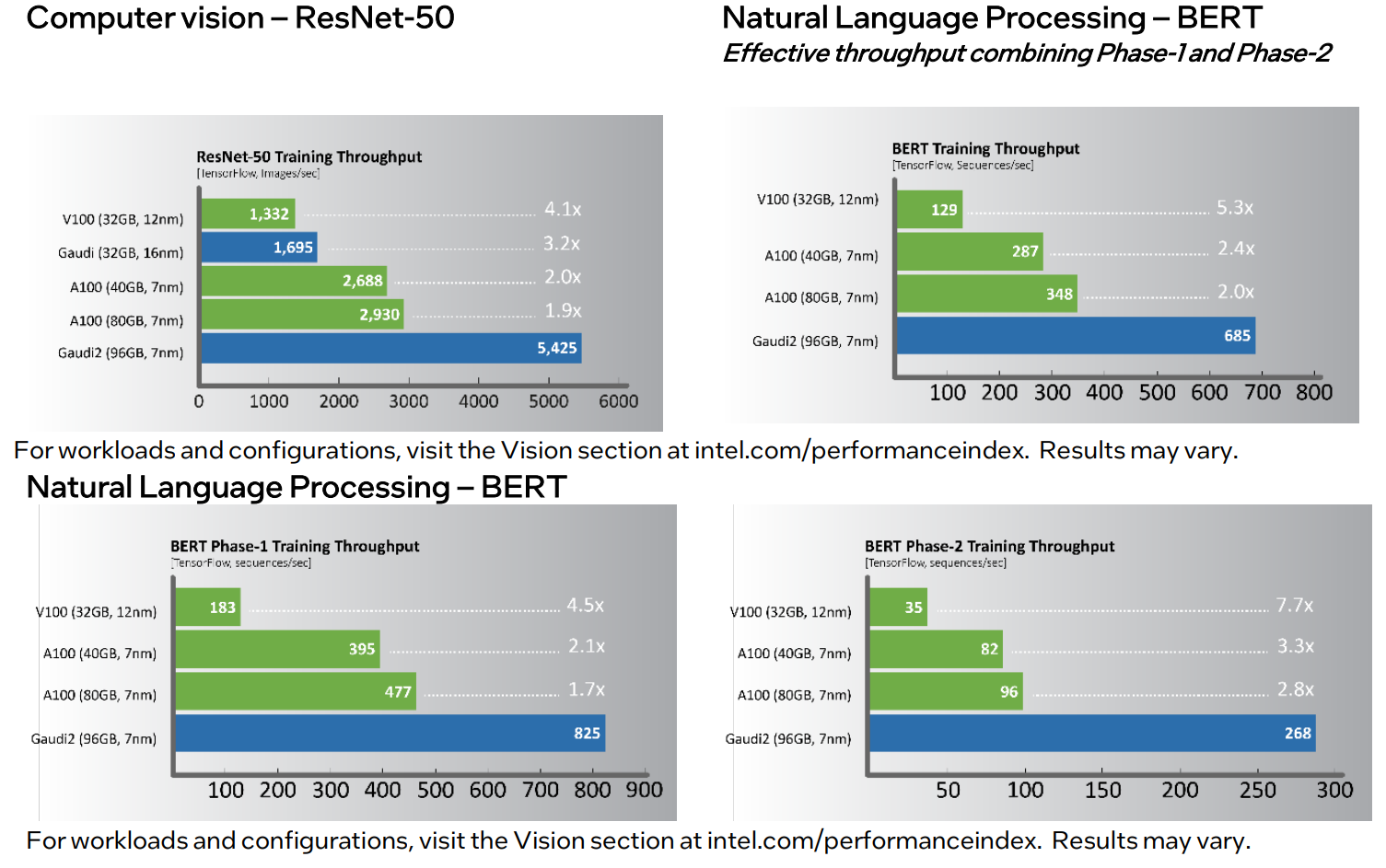 Gaudi2 уже доступны клиентам Habana, а несколько тысяч ускорителей используются самой Intel для дальнейшей оптимизации ПО и разработки чипов Gaudi3. Greco будут доступны во втором полугодии, а их массовое производство намечено на I квартал 2023 года, так что информации о них пока немного. Например, сообщается, что ускорители стали намного менее прожорливыми по сравнению с Goya и снизили TDP с 200 до 75 Вт. Это позволило упаковать их в стандартную HHHL-карту расширения с интерфейсом PCIe 4.0 x8.  Объём набортной памяти всё так же равен 16 Гбайт, но переход от DDR4 к LPDDR5 позволил впятеро повысить пропускную способность — с 40 до 204 Гбайт/с. Зато у самого чипа теперь 128 Мбайт SRAM, а не 40 как у Goya. Он поддерживает форматы BF16, FP16, (U)INT8 и (U)INT4. На борту имеются кодеки HEVC, H.264, JPEG и P-JPEG. Для работы с Greco предлагается тот же стек SynapseAI. Сравнения производительности новинки с другими инференс-решениями компания не предоставила.  Впрочем, оба решения Habana выглядят несколько запоздалыми. В отставании на ИИ-фронте, вероятно, отчасти «виновата» неудачная ставка на решения Nervana — на смену так и не вышедшим ускорителям NNP-T для обучения пришли как раз решения Habana, да и новых инференс-чипов NNP-I ждать не стоит. Тем не менее, судьба Habana даже внутри Intel не выглядит безоблачной, поскольку её решениям придётся конкурировать с серверными ускорителями Xe, а в случае инференс-систем даже с Xeon. |
|

