Материалы по тегу: mi300
|
24.01.2026 [14:15], Сергей Карасёв
Nokia и Hypertec построили в Канаде 15-Пфлопс суперкомпьютер Nibi с погружным охлаждением
amd
emerald rapids
granite rapids
h100
hardware
hpc
intel
mi300
nokia
nvidia
ии
канада
отопление
погружное охлаждение
суперкомпьютер
Компании Nokia и Hypertec объявили о запуске суперкомпьютера Nibi, смонтированного в Университете Ватерлоо (University of Waterloo) в Канаде. Эта НРС-платформа будет использоваться для решения широкого спектра задач, в том числе в области ИИ. Проект Nibi финансируется канадским Министерством инноваций, науки и экономического развития через Канадский альянс цифровых исследований, а также Министерством колледжей, университетов, научных исследований и безопасности через некоммерческую организацию Compute Ontario. 
Источник изображения: Nokia Система насчитывает в общей сложности более 750 вычислительных узлов. Это, в частности, 700 узлов CPU, каждый из которых несёт на борту два процессора Intel Xeon 6972P поколения Granite Rapids-AP (96C/192T, до 3,9 ГГц) и 748 Гбайт оперативной памяти. Кроме того, задействованы 10 узлов с двумя чипами Xeon 6972P и 6 Тбайт памяти каждый. 
Источник изображений: Университет Ватерлоо В состав суперкомпьютера также входят 36 узлов GPU, которые содержат по два процессора Intel Xeon Platinum 8570 серии Emerald Rapids (56C/112T, до 4 ГГц), 2 Тбайт оперативной памяти и восемь ускорителей NVIDIA H100 SXM (80 GB), связанных посредством NVLink. Наконец, Nibi оперирует шестью узлами с четырьмя ускорителями AMD Instinct MI300A.  Подсистема хранения VAST Data выполнена на основе SSD суммарной вместимостью 25 Пбайт. Пропускная способность каналов передачи данных между CPU- и GPU-узлами составляет 200 Гбит/с. Подключение к хранилищу обеспечивается благодаря 24 линиям на 100 Гбит/с. Заявленная пиковая производительность Nibi достигает 15 Пфлопс. Новая НРС-платформа оборудована высокоэффективной системой погружного жидкостного охлаждения. Сгенерированное тепло используется для обогрева центра квантовых и нанотехнологий имени Майка и Офелии Лазаридис (Mike and Ophelia Lazaridis Quantum-Nano Centre).
28.12.2025 [14:14], Руслан Авдеев
AMD готовится стать крупным поставщиком ИИ-ускорителей для китайской AlibabaПока NVIDIA готовится начать масштабные поставки в Китай ускорителей H200, на рынок Поднебесной спешит выйти и AMD, которая готова поставить Alibaba 40–50 тыс. ослабленных ускорителей Instinct MI308, сообщает Times of AI. Это одна из крупнейших сделок по покупке американских ускорителей бизнесом из КНР после введения жёстких антикитайских ограничений. Впрочем, по данным СМИ, в США, вероятно, рассчитывают на ограниченные партии, а выдачу разрешений будут жёстко контролировать. Хотя китайский бизнес активно интересуется возможными поставками американских чипов, он может столкнуться с ограничениями не только со стороны США, но и китайских властей, желающих наращивать продажи собственных ускорителей вроде Huawei Ascend. При этом китайские ускорители пока значительно уступают американским как по производительности, так и по соотношению цены и вычислительных мощностей. По данным TechNode, для экспорта AMD придётся платить американским властям пошлину в 15 % от стоимости чипов, т.е. пошлина, в отличие от NVIDIDA H200, не выросла. Ускорители стоят приблизительно $12 тыс., на 15 % меньше, чем NVIDIA H20. Успех сделки будет означать значительный прогресс для AMD на китайском рынке, а у китайских покупателей будет больше выбора. Ещё в июле AMD заявляла о вероятном возобновлении поставок MI308 в Китай, но конкретные результаты, похоже, будут достигнуты только теперь, после длительных перебоев. 
Источник изображения: AMD Ранее американские власти, наконец, дали разрешение на продажи в Поднебесную ускорителей NVIDIA H200 с 25 % пошлиной, и уже в середине февраля планируются масштабные поставки. Модель H200 значительно уступает по производительности передовым чипам поколений Blackwell и, тем более, Rubin, но в разы эффективнее модели H20, которую можно было продавать в Китай раньше.
05.11.2025 [14:37], Владимир Мироненко
AMD объявила о рекордной квартальной выручке и предсказала дальнейший значительный ростAMD сообщила о рекордной выручке в III квартале 2025 года, составившей $9,25 млрд, что на 36 % больше результата аналогичного периода 2024 года и превышает консенсус-прогноз аналитиков, опрошенных LSEG, в размере $8,74 млрд (по данным CNBC). Скорректированная прибыль (Non-GAAP) на разводнённую акцию также превысила прогноз LSEG — $1,20 против ожидавшихся $1,16. Чистая прибыль (GAAP) AMD увеличилась в годовом исчислении на 61 % — до $1,24 млрд, или $0,75 на разводнённую акцию, с $771 млн, или $0,47 на акцию годом ранее. В IV квартале AMD ожидает выручку около $9,6 млрд ± 300 млн, что соответствует росту на 25 % в середине диапазона. Это превышает консенсус-прогноз LSEG в $9,15 млрд. AMD также прогнозирует скорректированную валовую рентабельность в размере 54,5 % за квартал, что совпадает с консенсус-прогнозом StreetAccount. AMD заявила, что прогноз не включает выручку от поставок чипов Instinct MI308 в Китай. То же самое компания отмечала в предыдущем квартале, однако теперь сообщила о возможности получения дохода от этих поставок. «Мы получили несколько лицензий на MI308, — заявила аналитикам генеральный директор AMD Лиза Су (Lisa Su) в ходе конференции по итогам квартала. — Мы продолжаем работать с нашими клиентами над оценкой спроса и общих возможностей». 
Источник изображений: AMD Подразделение ЦОД AMD, которое поставляет CPU и ИИ-ускорители, получило выручку в $4,34 млрд, увеличившуюся на 22 % в годовом исчислении — в основном благодаря высокому спросу на EPYC Turin и Instinct MI350. Это выше прогноза аналитиков StreetAccount в размере $4,13 млрд. Операционная прибыль подразделения ЦОД составила $1,07 млрд, немного превысив прошлогодний показатель $1,04 млрд. Компания ожидает очередного двузначного роста в сегменте в IV квартале благодаря высокому спросу на серверы и продолжающемуся росту продаж ускорителей серии MI350, пишет TrendForce. 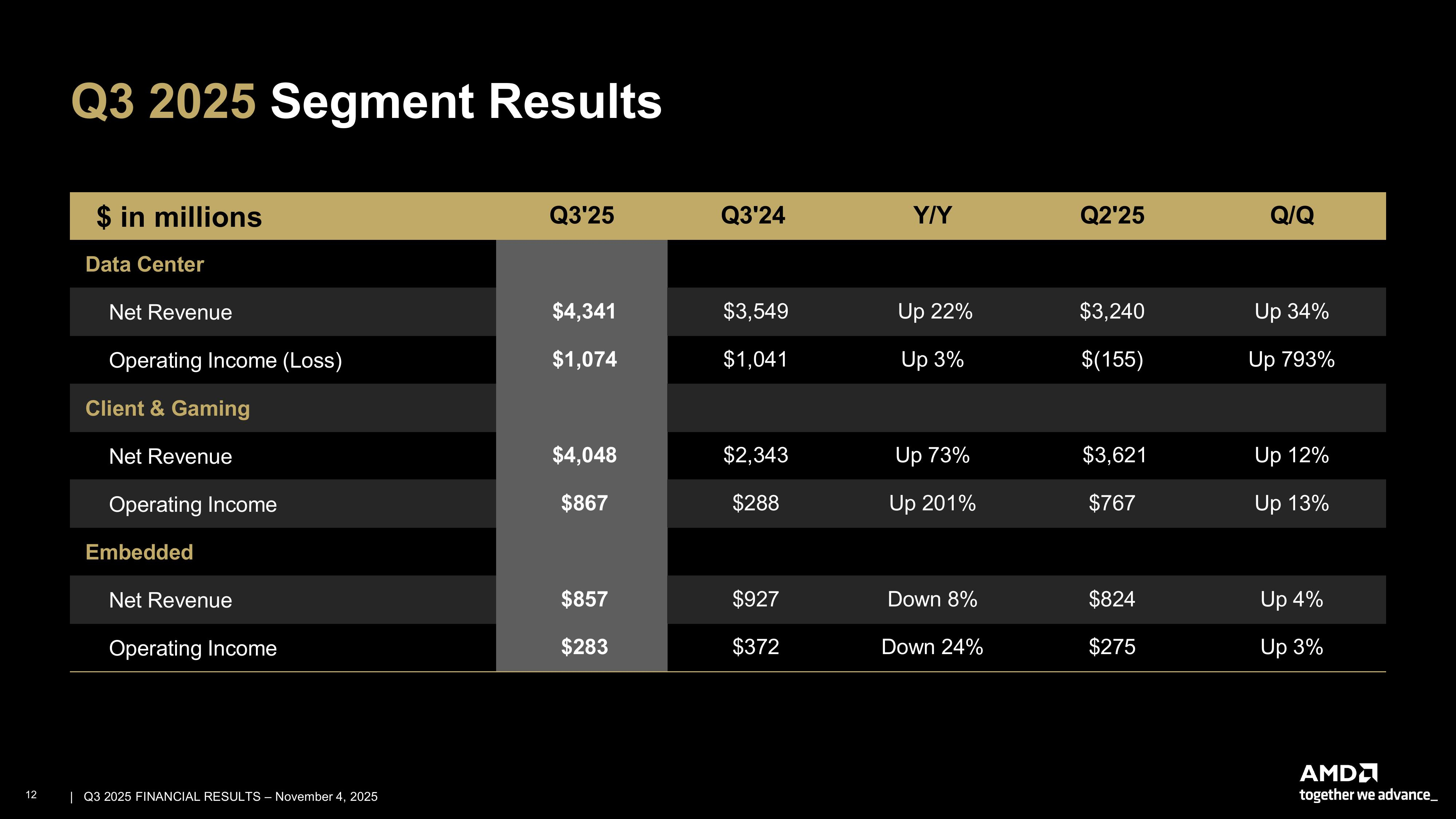 Выручка в сегменте встраиваемых систем составила $857 млн, снизившись на 8 % по сравнению с аналогичным периодом прошлого года, а операционная прибыль упала до $283 млн с $372 млн годом ранее. Выручка в клиентском и игровом сегментах составила $4,05 млрд (т.е. меньше, чем в сегмнете ЦОД), увеличившись на 73 % в годовом исчислении. В частности, в клиентском сегменте выручка достигла $2,75 млрд, что на 46 % больше консенсус-прогноза StreetAccount в $2,61 млрд. Выручка от игрового направления составила $1,30 млрд, увеличившись год к году в 2,8 раза при консенсус-прогнозе StreetAccount в $1,05 млрд. 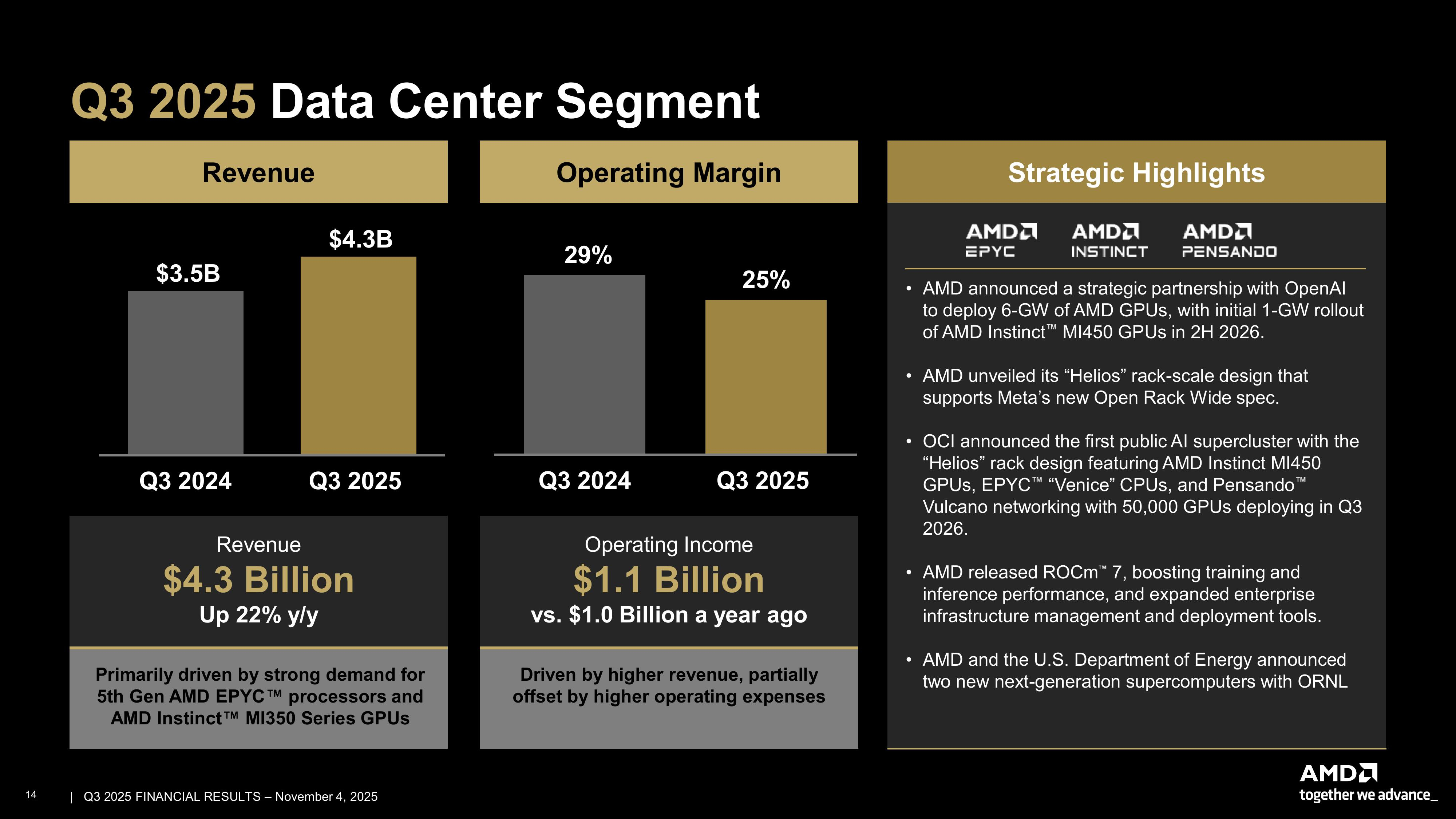 Говоря о перспективах бизнеса на фоне растущих опасений по поводу грядущего ИИ-пузыря, Лиза Су, как сообщает TrendForce, заявила, что сделка AMD с OpenAI, которая начнётся с поставок ускорителей MI450 на 1 ГВт во II половине 2026 года и в конечном итоге приведёт к развёртывания инфраструктуры на 6 ГВт, может дать мощный импульс бизнесу компании в области ИИ для ЦОД, потенциально принеся более $100 млрд дохода в ближайшие годы. 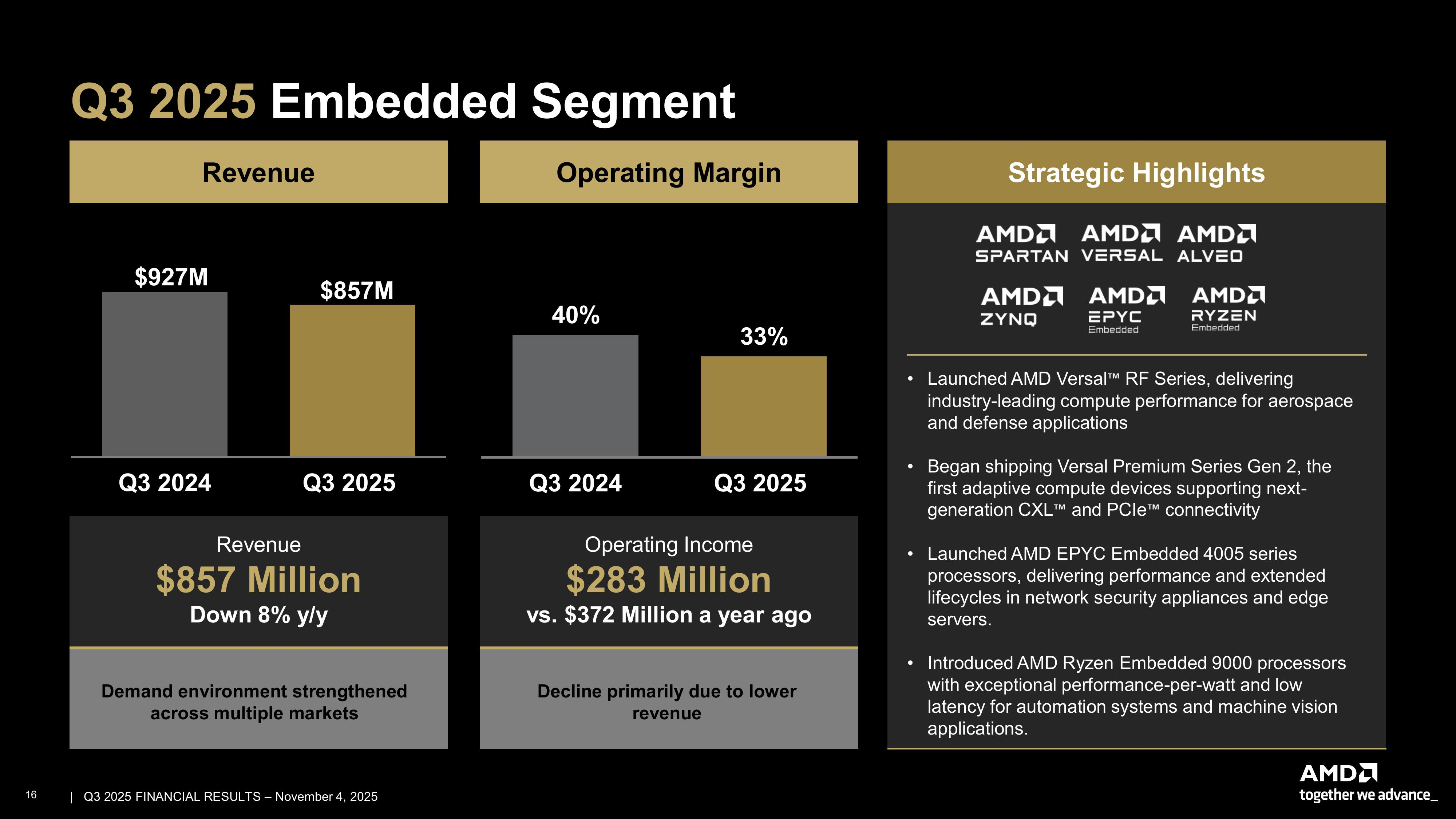 Су также отметила, что компания пока не предоставляет полный прогноз на следующий год, но «исходя из текущих тенденций, мы ожидаем очень высокого спроса в 2026 году». Она добавила, что ожидается дальнейшее наращивание продаж ускорителей MI355 в первой половине 2026 года, тогда как серия MI450 поступит в продажу во второй половине, что обеспечит более резкий рост направления в сегменте ИИ-продуктов для ЦОД. Су признала, что рентабельность производства ускорителей для ЦОД обычно растёт по мере выхода новых продуктов на рынок после первоначального переходного периода. Хотя прогноз на 2026 год пока не определён, она подчеркнула, что основное внимание уделяется увеличению выручки и валовой рентабельности, а также постепенному повышению процентной маржи. Следует отметить, что инвесторы ожидали более высокого роста валовой рентабельности, чем на уровне прогнозов Уолл-стрит. Поэтому акции компании упали примерно на 3 % в ходе торгов, сообщило агентство Reuters, добавив, что в этом году акции AMD выросли более чем вдвое, при этом их рост опережает динамику ценных бумаг лидера рынка — NVIDIA.
25.09.2025 [11:37], Сергей Карасёв
Edgecore Networks представила ИИ-сервер AGS8600 на базе AMD EPYC Turin и Instinct MI325XКомпания Edgecore Networks анонсировала сервер AGS8600 формата 8U, построенный на аппаратной платформе AMD. Устройство, уже доступное для заказа, предназначено для решения ресурсоёмких задач в сферах ИИ, машинного обучения, НРС, научных исследований и пр. Система несёт на борту два 64-ядерных процессора EPYC 9575F поколения Turin с показателем TDP в 400 Вт. Доступны 24 слота для модулей оперативной памяти DDR5. Во фронтальной части расположены восемь отсеков для SFF-накопителей U.2 (NVMe): базовая конфигурация включает шесть SSD вместимостью 7,68 Тбайт каждый и два SSD на 1,92 Тбайт. Сервер укомплектован восемью GPU-ускорителями Instinct MI325X с 256 Гбайт памяти HBM3e и производительностью до 2,6 Пфлопс в режиме FP8. Задействованы семь линий Infinity Fabric в расчёте на GPU. В оснащение включены восемь однопортовых сетевых адаптеров BCM957608-P1400GDF00 400G QSFP112-DD PCIe Ethernet NIC. Кроме того, присутствуют два двухпортовых адаптера BCM957608-P2200GQF00 200GbE QSFP112 PCIe Ethernet NIC, выделенный сетевой порт управления 1GbE, контроллер ASPEED AST2600, два порта USB 3.0 и интерфейс D-Sub. 
Источник изображения: Edgecore Networks За возможности расширения отвечают восемь слотов PCIe 5.0 x16 для карт половинной высоты и четыре разъёма PCIe 5.0 x16 для карт полной высоты. Питание обеспечивают шесть блоков мощностью 3300 Вт с сертификатом 80 Plus Titanium. Применена система воздушного охлаждения с 15 вентиляторами, допускающими горячую замену. Габариты составляют 448 × 850 × 351 мм. Диапазон рабочих температур — от +10 до +35 °C. На сервере используется ОС с ядром Linux. Среди поддерживаемого ПО упомянуты ROCm 6.2.4, RCCL 2.20.5, PyTorch 2.3/2.2/2.1/2.0/1.13, TensorFlow 2.16.1/2.15.1/2.14.1, JAX 0.4.26 и ONNX Runtime 1.17.3.
11.08.2025 [10:55], Руслан Авдеев
NVIDIA и AMD будут выплачивать правительству США 15 % выручки от продажи ИИ-ускорителей в КитаеNVIDIA и AMD пришли к соглашению с американскими властями, в результате которого компании будут обязаны отдавать правительству США 15 % выручки от продажи ИИ-ускорителей в КНР. За это они будут получать лицензии на продажу полупроводников в Поднебесную, сообщает The Financial Times. Как свидетельствуют «осведомлённые источники», экспортные лицензии для китайского рынка получены на днях именно на таких условиях. По словам источника из числа чиновников, NVIDIA согласилась платить за поставки H20 в Китай, AMD придётся раскошелиться за продажи MI308. Как сообщает издание, Министерство торговли США начало выдавать экспортные лицензии на H20 в минувшую пятницу, через два дня после встречи главы NVIDIA Дженсена Хуанга (Jensen Huang) с президентом США Дональдом Трампом (Donald Trump). Ранее Хуанг жёстко раскритиковал ограничения на поставки ИИ-ускорителей в Китай, заявив, что это станет для КНР лишь дополнительным стимулом для развития собственных технологий. По данным источников, лицензии начали выдавать и AMD. Стоит отметить, что такое соглашение считается «беспрецедентным». По словам экспертов, ни одна компания в истории США не соглашалась платить часть выручки за получение экспортных лицензий. Впрочем, вполне вероятно, что администрация США собирает все доступные средства для реиндустриализации самих Соединённых Штатов. Сами вендоры ситуацию не комментируют и лишь заявили, что следуют установленным правительством правилам для обеспечения своего присутствия на мировых рынках. 
Источник изображения: Priscilla Du Preez/unsplash.com По словам аналитиков Bernstein, до введения экспортных ограничений прогнозировалось, что NVIDIA могла бы продать в 2025 году Китаю порядка 1,5 млн ускорителей H20, что принесло бы около $23 млрд выручки. В апреле администрация США объявила о запрете поставок H20 в Китай, но этим летом изменила своё решение после встречи с Хуангом. Однако Бюро промышленности и безопасности (BIS) так и не начало выдавать экспортные лицензии до прошлой пятницы. Некоторые американские эксперты по безопасности подчёркивают ошибочность решения, утверждая, что H20 поможет военным КНР и подорвёт лидерство США в сфере ИИ. Некоторые горько шутят, что дальше, вероятно, стоит ожидать продаж Китаю F-35 при условии уплаты 15 % комиссии правительству. Не так давно 20 экспертов по безопасности направили в администрацию письмо, в котором призывали на выдавать лицензии на продажи H20 в Китай. По их словам, это всё ещё достаточно мощный ускоритель, который в конечном счёте будет использоваться китайскими военными. В самой NVIDIA такие предположения опровергают. В субботу, 9 августа, было заявлено, что H20 уже несколько месяцев не поставляются в Китай, но в компании надеются, что экспортные правила позволят Америке конкурировать в Китае и во всём мире. Американский стек ИИ-технологий может стать мировым стандартом при глобальном распространении своих технологий. Сейчас между США и Китаем ведутся торговые переговоры, которые, как надеются в администрации США, будут содействовать организации саммита между президентом Трампом и председателем КНР Си Цзиньпином. Министерству торговли уже приказали заморозить новые меры экспортного контроля в отношении КНР, чтобы не испортить отношения с Пекином. Опасения экспертов возникли на фоне усилий КНР, предпринимаемых чтобы смягчить контроль над поставками HBM-чипов, которые являются важнейшим компонентом современных ИИ-ускорителей. Ещё до ослабления запретов выяснилось, что в КНР «просочились» передовые ускорители NVIDIA на $1 млрд, а в конце июля появилась новость, что NVIDIA заказала у TSMC производство 300 тыс. ИИ-ускорителей H20 в ответ на высокий спрос в Китае — в дополнение к уже имеющимся запасам.
19.05.2025 [11:29], Сергей Карасёв
ИИ-облако TensorWave с ускорителями AMD получило ещё $100 млн, в том числе от самой AMDКомпания TensorWave, создающая облачную ИИ-платформу на ускорителях AMD, объявила о проведении раунда финансирования Series A, в ходе которого получено $100 млн. Инвестиционную программу возглавили Magnetar и AMD Ventures при участии Maverick Silicon, Nexus Venture Partners и Prosperity7. В апреле 2024 года TensorWave начала развёртывание облачной ИИ-системы с ускорителями Instinct MI300X. Кроме того, внедряются решения Instinct MI325X. Платформа TensorWave предполагает применение прямого жидкостного охлаждения (DLC) и высокопроизводительного хранилища. Утверждается, что при решении определённых задач, таких как запуск крупных ИИ-моделей в FP16-формате, ускорители AMD обеспечивают преимущества перед изделиями NVIDIA благодаря большему объёму памяти. В результате, ускоряется внедрение сервисов и снижается стоимость услуг для заказчиков. В конце прошлого года стартап TensorWave привлёк $43 млн на закупку ускорителей AMD. В раунде финансирования приняли участие Maverick Capital, Translink Capital, Javelin Venture Partners, Granite Partners и AMD Ventures. Новое финансирование в размере $100 млн по срокам совпало с развёртыванием 8192 ускорителей Instinct MI325X для ИИ-кластера в дата-центре в Тусоне (Аризона, США). 
Источник изображения: TensorWave Полученные средства, как ожидается, будут способствовать развитию бизнеса TensorWave, расширению штата и ускорению создания облачной платформы на базе Instinct MI325X. Рынок инфраструктуры ИИ переживает беспрецедентный рост: по оценкам, к 2027 году затраты в данном секторе превысят $400 млрд. Аналитическая фирма Fortune Business Insights подсчитала, что объём мирового рынка ИИ в целом в 2024 году достиг $233 млрд. Прогнозируется, что показатель увеличится примерно до $1,7 трлн долларов к 2032 году. «Финансирование в размере $100 млн поддерживает миссию TensorWave по демократизации доступа к передовым вычислительным ресурсам. Кластер из 8192 ускорителей Instinct MI325X — это только начало», — сказал Даррик Хортон (Darrick Horton), генеральный директор TensorWave.
20.02.2025 [13:12], Сергей Карасёв
Облако Vultr первым получило ускорители AMD Instinct MI325XVultr, крупнейший в мире частный облачный провайдер, объявил о том, что в его инфраструктуре появились ускорители AMD Instinct MI325X, предназначенные для ресурсоёмких ИИ-нагрузок. Говорится об использовании открытого программного стека ROCm и о поддержке ключевых фреймворков. Vultr стал первым поставщиком облачных услуг, взявшим на вооружение изделия AMD Instinct MI325X. Ускорители развёрнуты в дата-центре компании в Чикаго (Иллинойс, США). Внедрение этих решений является частью усилий по расширению сотрудничества с AMD: в сентябре прошлого года в облаке Vultr появились ускорители Instinct MI300X. Изделия Instinct MI325X несут на борту 256 Гбайт памяти HBM3E с пропускной способностью до 6 Тбайт/с. Пиковая производительность достигает 1,3 Пфлопс в режиме FP16 и 2,6 Пфлопс в режиме FP8. Решения подходят в том числе для задач инференса. 
Источник изображения: AMD Отмечается, что Vultr использует ускорители Instinct MI325X в составе серверов Supermicro AS-8126GS-TNMR типоразмера 8U. Эти машины комплектуются двумя процессорами AMD EPYC 9005/9004 с показателем TDP до 500 Вт. Доступны 24 слота для модулей DDR5-6000 суммарным объёмом до 9 Тбайт. Во фронтальной части расположены десять отсеков для SFF-накопителей в конфигурации 8 × NVMe и 2 × SATA. Кроме того, есть два коннектора М.2 (NVMe). Предусмотрены восемь слотов PCIe 5.0 x16 LP и два слота PCIe 5.0 x16 FHHL. За питание отвечают шесть блоков мощностью 5250 Вт с сертификатом Titanium. Применяется воздушное охлаждение. «Ускорители AMD Instinct MI325X устанавливают новые стандарты в области ИИ, обеспечивая невероятную производительность и эффективность для задач инференса», — говорит глава Vultr. Цены на новые инстансы пока не названы.
19.01.2025 [22:43], Сергей Карасёв
Германия запустила «переходный» 48-Пфлопс суперкомпьютер Hunter на базе AMD Instinct MI300AЦентр высокопроизводительных вычислений HLRS при Штутгартском университете в Германии объявил о вводе в эксплуатацию НРС-системы Hunter. Этот суперкомпьютер планируется использовать для решения широко спектра задач в области инженерии, моделирования погоды и климата, биомедицинских исследований, материаловедения и пр. Кроме того, комплекс будет применяться для крупномасштабного моделирования, ИИ-приложений и анализа данных. О создании Hunter сообщалось в конце 2023 года: соглашение на строительство системы стоимостью примерно €15 млн было заключено с HPE. Проект финансируется Федеральным министерством образования и исследований Германии и Министерством науки, исследований и искусств Баден-Вюртемберга. Hunter базируется на той же архитектуре, что El Capitan — самый мощный в мире суперкомпьютер. Задействована платформа Cray EX4000, а каждый из узлов оснащён четырьмя адаптерами HPE Slingshot. Суперкомпьютер использует комбинацию из APU Instinct MI300A и процессоров EPYC Genoa. Как отмечает The Register, в общей сложности система объединяет 188 узлов с жидкостным охлаждением и насчитывает суммарно 752 APU и 512 чипов Epyc с 32 ядрами. Применена СХД HPE Cray Supercomputing Storage Systems E2000, специально разработанная для суперкомпьютеров HPE Cray. 
Источник изображения: HLRS HLRS оценивает пиковую теоретическую FP64-производительность Hunter в 48,1 Пфлопс на операциях двойной точности, что практически вдвое выше, чем у предшественника Hawk. В режимах BF16 и FP8 быстродействие, как ожидается, будет варьироваться от 736 Пфлопс до 1,47 Эфлопс. При этом Hunter потребляет на 80% меньше энергии, нежели Hawk. 
Источник изображения: Штутгартский университет Отмечается, что Hunter задуман как переходная система, которая подготовит почву для суперкомпьютера HLRS следующего поколения под названием Herder. Ввести этот комплекс в эксплуатацию планируется в 2027 году. Предполагается, что он обеспечит производительность «в несколько сотен петафлопс».
15.12.2024 [13:00], Сергей Карасёв
Vultr запустил облачный ИИ-кластер на базе AMD Instinct MI300XКрупнейший в мире частный облачный провайдер Vultr объявил о заключении соглашения о четырёхстороннем стратегическом сотрудничестве с целью развёртывания нового суперкомпьютерного кластера. В проекте принимают участие AMD, Broadcom и Juniper Networks. Применяются ускорители AMD Instinct MI300X и открытый программный стек ROCm. Данные о количестве ускорителей и общей производительности платформы пока не раскрываются. Кластер размещён в дата-центре Vultr Centersquare в Лайле (юго-западный пригород Чикаго; Иллинойс; США). Новая НРС-система построена с использованием Ethernet-коммутаторов Broadcom и оптимизированных для ИИ-задач сетевых Ethernet-решений Juniper Networks. Благодаря этим компонентам, как утверждается, возможно построение безопасной высокопроизводительной инфраструктуры. Кластер ориентирован прежде всего на обучение ИИ-моделей и ресурсоёмкие нагрузки инференса. «Сотрудничество с AMD, Broadcom и Juniper Networks позволяет предприятиям и специалистам в области ИИ использовать весь потенциал ускоренных вычислений при одновременном обеспечении гибкости, масштабируемости и безопасности», — говорит Джей Джей Кардвелл (J.J. Kardwell), генеральный директор Vultr. 
Источник изображения: AMD О доступности Instinct MI300X в своей облачной инфраструктуре компания Vultr сообщила в сентябре нынешнего года. Ускорители AMD интегрируются с Vultr Kubernetes Engine for Cloud GPU для формирования кластеров Kubernetes, использующих ускорители. Предложение ориентировано на задачи ИИ и НРС. Vultr ставит своей целью сделать высокопроизводительные облачные вычисления простыми в использовании и доступными для предприятий и разработчиков по всему миру. На сегодняшний день экосистема Vultr включает 32 облачные зоны, в том числе площадки в Северной Америке, Южной Америке, Европе, Азии, Австралии и Африке.
20.11.2024 [13:04], Руслан Авдеев
IBM и AMD расширяют сотрудничество: Instinct MI300X появится в облаке IBM CloudКомпания IBM объявила о расширении сотрудничества с AMD для предоставления ускорителей Instinct MI300X в формате «ускорители как услуга» (Accelerators-as-a-Service). По словам IBM, новое решение расширяет возможности и энергоэффективность генеративных ИИ-моделей и HPC-приложений. AMD Instinct MI300X станут доступны в IBM watsonx, а также будут поддерживаться в Red Hat Enterprise Linux AI. Они дополнят портфолио IBM Cloud, уже включающее Intel Gaudi 3 и NVIDIA H100. Ускоритель AMD Instinct MI300X оснащён 192 Гбайт памяти HBM3. И относительно малое количество ускорителей способно обеспечить работу больших ИИ-моделей, что позволяет снизить затраты с сохранением производительности и масштабируемости. Ускорители будут доступны в составе виртуальных серверов и частных виртуальных облаков, а также в контейнеризированных средах IBM Cloud Kubernetes Service и IBM Red Hat OpenShift. 
Источник изображения: AMD Кроме того, для MI300X будут доступны LLM Granite и инструмент InstructLab. Речь идёт в том числе об интеграции программных решений IBM с ПО AMD ROCm. По словам компании, предложенные решения обеспечит клиентов гибкой, безопасной, высокопроизводительной и масштабируемой средой для рабочих нагрузок ИИ. AMD Instinct MI300X станут доступны пользователям IBM Cloud в I половине 2025 года. |
|

