Материалы по тегу: cpu
|
24.07.2026 [00:34], Владимир Мироненко
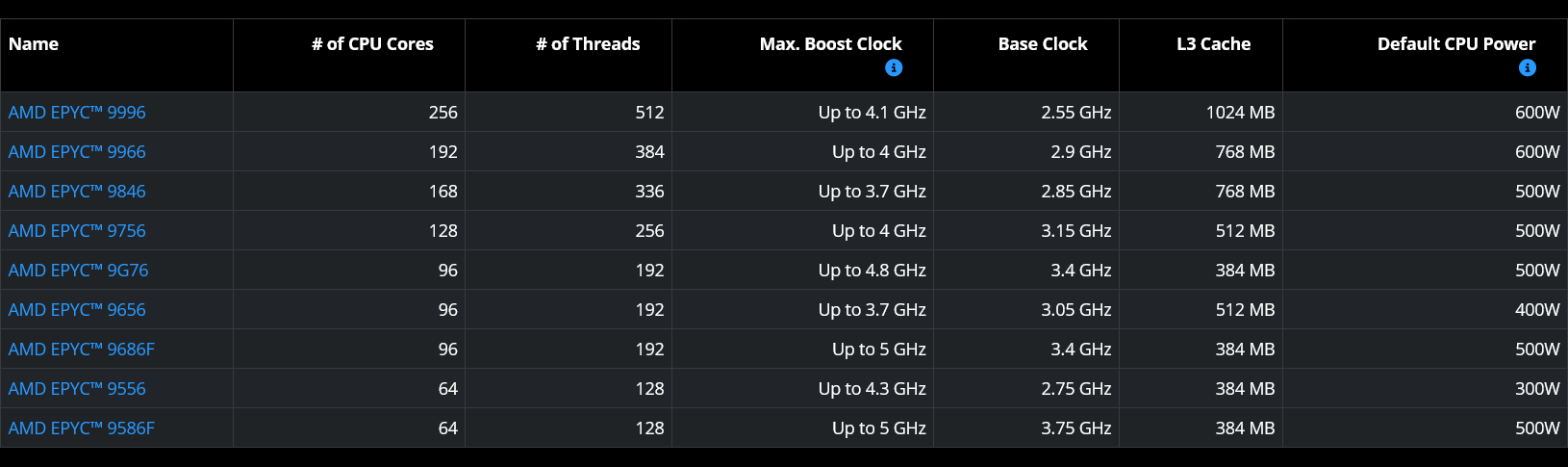
AMD представила процессоры EPYC Venice 9006: до 256 ядер и 1 Гбайт L3-кешаAMD представила семейство новых 2-нм процессоров EPYC Venice 9006, которое включает модели EPYC 9006 SP7, EPYC 9006 SP8, EPYC 9006X SP7, сообщил ресурс Computerbase.de. Также объявлено, что в разработке находится AMD EPYC 9006 LP Verano. EPYC 9006 SP7 и SP8 будут доступны в IV квартале 2026 года. Остальные модели появятся на рынке в 2027 году. 
Источник изображений: AMD Процессор AMD EPYC 9006 SP7 создан для высокопроизводительного выполнения агентских песочниц и имеет конфигурацию 256C/512T (Zen 6c, до 4,1 ГГц, 8 × 32 ядер, два IOD) или 96C/192T (Zen 6, до 5.0 ГГц, 8 × 12 ядер, два IOD). SP7-вариант поддерживает до 16 каналов памяти DDR5-8000 и MRDIMM-12800 второго поколения c заявленной максимальной пропускную способностью 1,6 Тбайт/с. Старший вариант EPYC 9996 включает 1 Гбайт L3-кеша. 


В высокочастотных HF-конфигурациях (до 5.0 ГГц) EPYC 9006 SP7 также служит хост-узлом для ИИ, предлагая 128 линий PCIe 6.0 (160 в двухсокетной конфигурации) и поддержку CXL 3.1, а также обеспечивая значительное улучшение производительности, что позволяет максимально эффективно использовать агенты в расчёте на Вт, доллар и стойку. Сокет SP7 рассчитан на потребление до 600 Вт. 


AMD EPYC 9006 SP8 создан для эффективной работы и обеспечения оптимальной производительности в критически важных корпоративных задачах и при выполнении агентских песочниц, где эффективность является приоритетом. Эти процессоры включают от 8 до 128 ядер Zen 6c и имеет более низкое энергопотребление (до 400 Вт), что расширяет области применения новинок — от периферийных станций и стоек с ограниченным энергопотреблением до небольших кластеров и серверов общего назначения, разработанных для обеспечения лидирующей производительности на доллар. Эти чипы предлагают только восемь каналов памяти (2DPC) и всё те же 128 линий PCIe 6.0. 
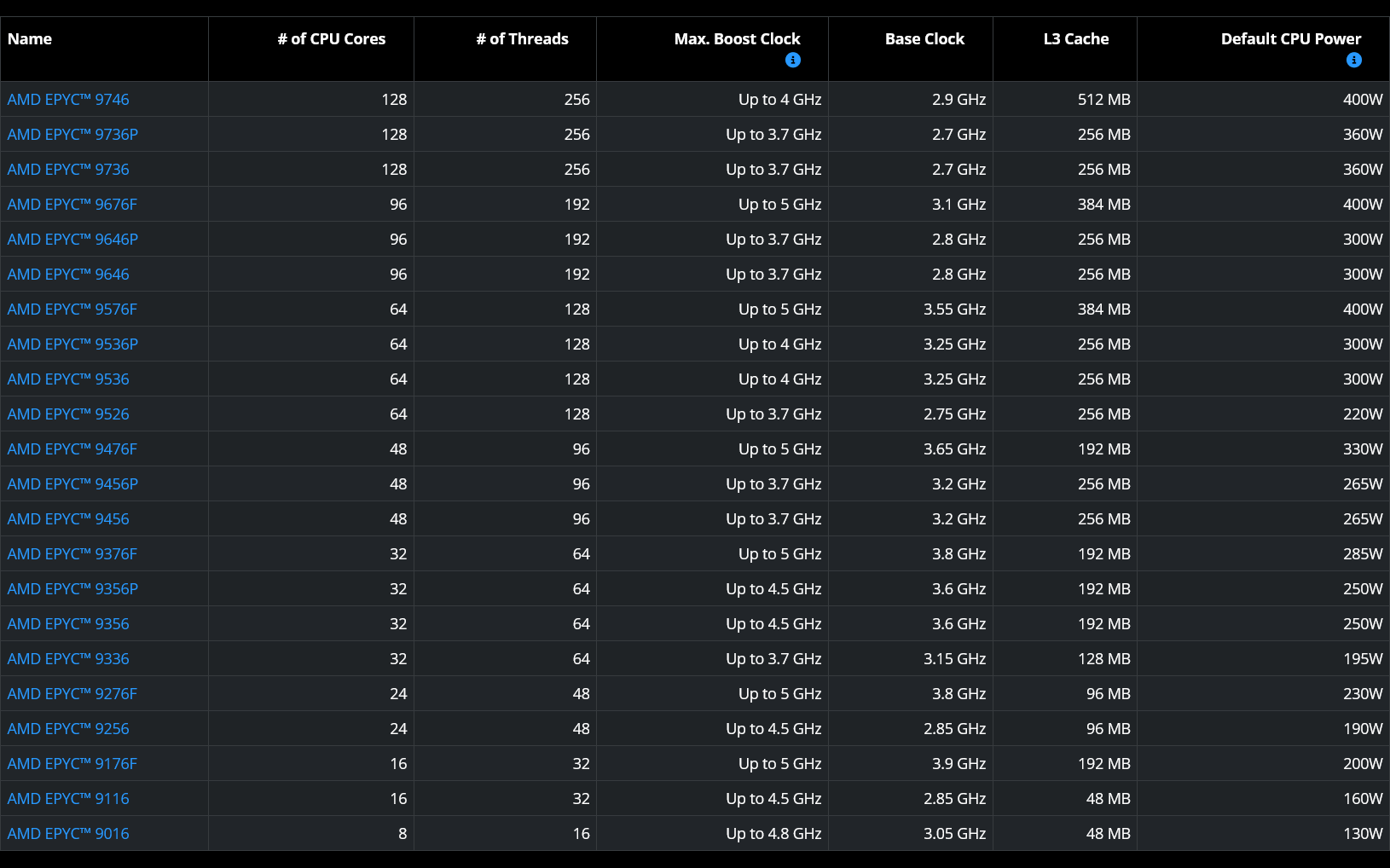
Процессор EPYC 9006X создан для высокопроизводительных технически вычислений и ресурсоёмких задач, требующих высокой пропускной способности кеша и памяти, например, моделирование, крупномасштабная аналитика, поиск информации и другие задачи. Он включает до 1152 Мбайт L3-кеша (3D V-Cache), поддерживает 16 каналов MRDIMM-12800 или DDR5 и имеет до 96 ядер с частотой до 5,15 ГГц. 

Ранее известный под кодовым названием Verano, процессор AMD EPYC 9006 LP разработан как CPU для узлов ИИ в стоечных системах следующего поколения. Процессор содержит до 72 ядер с частотой до 5 ГГц, поддерживает до 24 каналов памяти LPDDR5X (SOCAMM2), помогая обеспечивать работу ускорителей в плотных, насыщенных ускорителями стойках и позволяя масштабировать использование системы по мере роста развёртывания от отдельных узлов до ИИ-фабрик. В 2028 году AMD представит EPYC семейства Florence. 
21.07.2026 [16:27], Владимир Мироненко
Некоторые Intel Xeon 6700P получат поддержку DDR5-8000 RDIMM, а 6900P — MRDIMM-8800 второго поколенияIntel объявила, что ряд процессоров Xeon 6700P получит поддержку «более новой и более быстрой памяти». Начиная с августа этого года, Intel добавит им поддержку модулей DDR5-8000 RDIMM вместо DDR5-6400. Кроме того, в I квартале 2027 года компания добавит поддержку модулей MRDIMM второго поколения для процессоров Xeon 6900P, пусть и без поддержки более высоких частот. По словам Intel, пропускная способность памяти является узким местом для современных ИИ-задач, и поэтому компания предложит поддержку более быстрой памяти на некоторых существующих моделях процессоров Xeon 6, чтобы клиенты могли беспррблемно собирать и модернизировать свои серверы. Так, некоторые модели процессоров Intel Xeon 6700P (Granite Rapids-SP) будут поддерживать конфигурацию DDR5-8000, но только в режиме 1DPC. Тем не менее, переход от модулей 6400 МТ/с к 8000 МТ/с обеспечивает увеличение пропускной способности на 25 % и снижение задержки памяти на 6 %. 
Источник изображения: Intel По словам компании, внедрение в процессоры Intel Xeon 6+ и Intel Xeon 6 поддержки DDR5-8000 станет первым подобным решением среди основных серверных платформ. Оно будет сделано посредством обновления BIOS в рамках UPLR в августе-сентябре 2026 года. В I квартале 2027 года Intel планирует внедрить поддержку MRDIMM второго поколения для процессоров Intel Xeon 6900P (Granite Rapids-AP). Правда, поддержка будет ограничена только модулями 8800 МТ/с, а не более быстрыми 12800 МТ/с.
17.07.2026 [17:12], Владимир Мироненко
Евросоюз объявил об успешном завершении второго этапа EPI для укрепления технологического суверенитетаВ Люксембурге состоялся заключительный обзор Европейской инициативы по процессорам (EPI), финансируемой EuroHPC. По итогам было объявлено об успешном завершении второго этапа проекта — EPI SGA2, целью которого было содействие укреплению технологического суверенитета Европы. В рамках обзора была проведена демонстрация уникальных технологий и микросхем, разработанных на обоих этапах проекта EPI. В частности, был продемонстрирован первый Arm-процессор SiPearl Rhea1, работающий с полным ПО для HPC. Чип запустили на тестовой плате со стандартным дистрибутивом Linux, работающим с высокоскоростной памятью HBM и соответствующими аппаратными счетчиками мониторинга производительности. Он успешно прошёл тесты HPL и STREAM, демонстрируя готовность всей аппаратной и программной экосистемы Rhea1 к высокопроизводительным вычислениям для систем экзафлопсного уровня. Также было проведено пять демонстраций, наглядно подтверждающих, что технология RISC-V, используемая EPI, перешла от отдельных блоков к полному программному стеку, реальному оборудованию и реальным приложениям и инструментам, которыми может воспользоваться обычный пользователь. Так, был развёрнут полный кластер на ускорителе VEC. Был показан новейший RTL-код (ядро RISC-V с внеочередным выполнением инструкций от Semidynamics, улучшенный векторный блок от Барселонского суперкомпьютерного центра) для запуска на FPGA в инфраструктуре MEEP. Было запущено реальное научное приложение Mini-Fall3D для оценки диффузии пыли в атмосфере, распараллеленное с помощью OpenMP и MPI, скомпилированное с использованием инструментария EPI LLVM и профилированное с помощью стандартных инструментов (PAPI, Extrae/Paraver). Запуски показали масштабируемость, продемонстрировав выполнения скалярных и векторных задач на разных узлах. Источник изображения: european-processor-initiative.eu Также был продемонстрирован готовый ИИ-чип EPAC 1.5 на базе RISC-V, подключённый к Arm-хосту через PCIe. Компилятор проекта генерирует один двоичный файл, содержащий код как Arm, так и RISC-V. Код RISC-V передаётся по PCIe через DMA, динамически загружается, выполняется, а результаты копируются обратно. Это демонстрирует оригинальную идею EPI по созданию гетерогенных систем с разными ISA и операционными средами, эффективно работающих вместе на реальном оборудовании. Kalray показала успешную доработку и оптимизацию ПО для своих KVX-процессоров на базе VLIW, которые также могут работать в режиме RISC-V. Menta продемонстрировала результаты оптимизации своей EDA Origami для больших eFPGA, которые позволили кратно ускорить разработку чипов и схем. Наконц, было продемонстрировано успешное использование технологии сжатия памяти в реальном времени ZeroPoint (DenseMem) на EPAC 1.5. Подводя итоги длившегося три года этапа SGA1 и четырёхлетнего SGA2, руководители проекта отметили, что путь к европейскому суверенитету в цифровых технологиях лежит в дальнейшем развитии этих результатов. Для этого научные партнёры проекта опубликуют результаты обширных исследований проекта, а промышленные партнёры продолжат дальнейшее развитие IP-блоков, полученных в его рамках.
15.07.2026 [01:40], Владимир Мироненко
Arm-процессоры Graviton5 оказались быстрее Intel Xeon 6, но отстали от AMD EPYC Turin в тестах инстансов AWSПосле запуска серии AWS M9g, первых инстансов на базе процессоров Graviton5, ресурс Phoronix провёл сравнительные тесты производительности процессоров Graviton4 и Graviton5. Тесты показали значительное повышение производительности новых процессоров AWS Graviton благодаря переходу от ядер Arm Neoverse-V2 к Neoverse-V3 и от памяти DDR5-5600 к DDR5-8800, а также другим улучшениям. Кроме того, для сравнения были добавлены тесты инстансов m8a.4xlarge и m8i.4xlarge на базе актуальных AMD EPYC и Intel Xeon в семействе EC2 M. Инстансы M8a используют кастомные AMD EPYC 9R45 поколения Turin с максимальной частотой 4,5 ГГц и памятью DDR5-6400. Каждый vCPU в M8a поддерживается физическим ядром CPU (без SMT). Стоимость использования m8a.4xlarge по запросу на момент тестирования составила $0,97376/час, что значительно выше, чем $0,78272/час для m8g.4xlarge на базе Graviton5. Инстансы M8i используют кастомные же Intel Xeon 6975P-C поколения Granite Rapids-AP с турбочастотой 3,9 ГГц для всех ядер и памятью DDR5-7200 (хотя сами CPU поддерживают MRDIMM-8800). В отличие от инстансов M8g/M9g и M8a, в M8i используется SMT, так что 16 vCPU являются восемью физическими ядрами с HT. Почасовая стоимость по запросу для m8i.4xlarge составила $0,84672 — дешевле m8a.4xlarge, но всё ещё дороже m9g.4xlarge, да ещё и физических ядер вдвое меньше. В общей сложности порталом Phoronix было проведено более 120 тестов производительности для четырех типов инстансов Amazon EC2. При вычислении геометрического среднего всех показателей производительности инстанс с Graviton5 превзошел экземпляр с Intel Xeon 6, в то время как инстанс с Graviton4 ему немного уступил. Инстанс m9g.4xlarge с Graviton5 оказался примерно на 19 % быстрее, чем экземпляр m8i.4xlarge, хотя важно отметить, что в случае с инстансом на Intel Xeon речь идёт об SMT (HT). Помимо того, что Graviton5 на 19 % быстрее, чем Xeon 6, в этом сравнении почасовая стоимость по запросу была примерно на 8 % ниже, чем у экземпляра на базе Granite Rapids-AP. 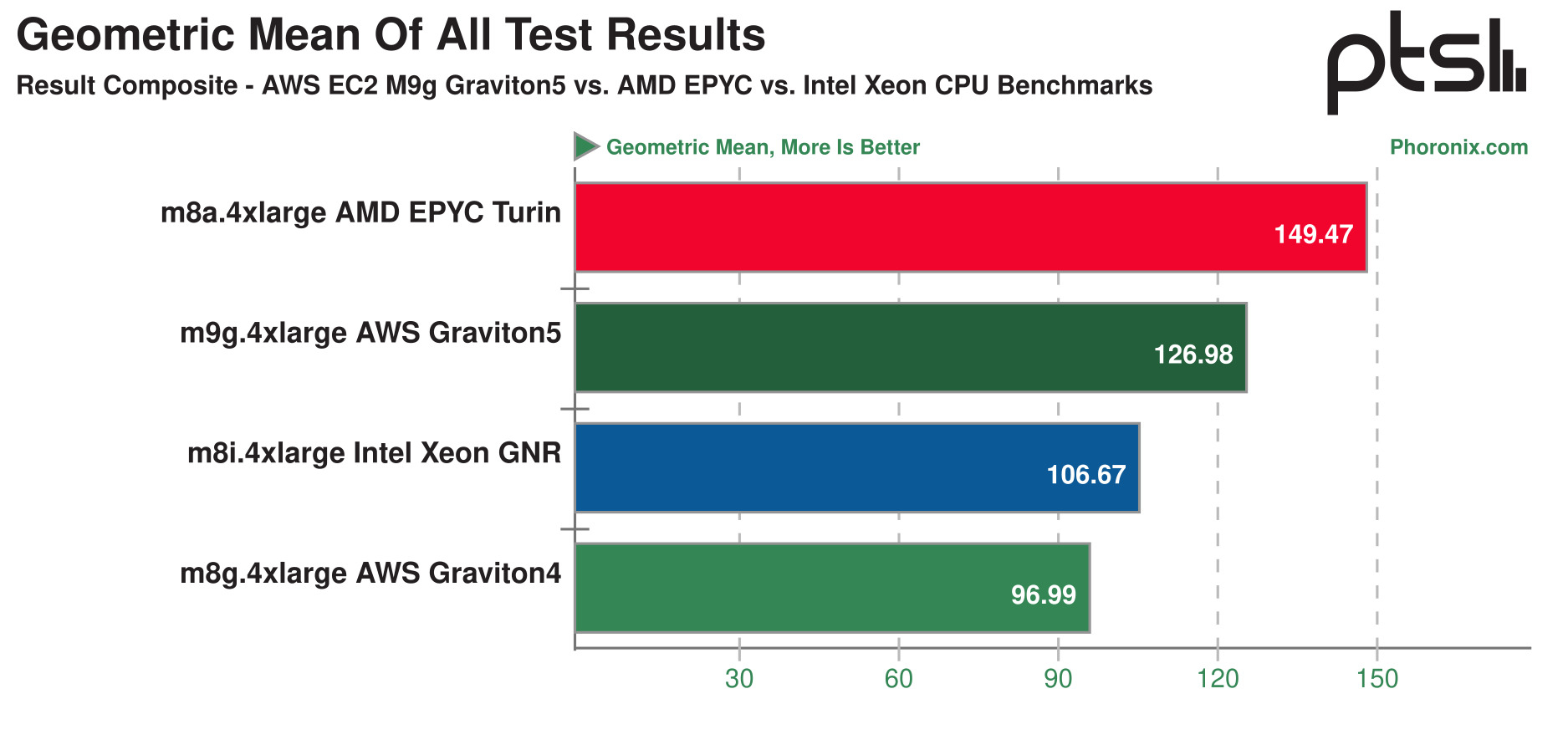
Источник изображения: phoronix.com Инстанс m8a.4xlarge на AMD EPYC Turin показал на 17 % выше производительность, чем инстанс на Graviton5 того же размера. Хотя при текущей ценовой политике по запросу инстанс m8a.4xlarge примерно на 24 % дороже в час, чем m9g.4xlarge с Graviton5, у Graviton5 всё ещё есть ценовое преимущество, поскольку это собственная разработка AWS. Однако, для некоторых рабочих нагрузок инстанс m8a.4xlarge обеспечил как лучшую производительность, так и соотношение производительности и цены, отметил Phoronix.
28.06.2026 [15:48], Сергей Карасёв
Китайские x86-процессоры Hygon C86-5G получили 128 ядер с поддержкой 512 потоковКитайская компания Hygon, по сообщениям сетевых источников, создала процессоры нового поколения с архитектурой x86. Речь идёт об изделиях C86-5G, которые, как ожидается, будут применяться в оборудовании для дата-центров. Кроме того, в разработке находятся другие продукты, включая ИИ-ускорители. Решения C86-5G придут на смену изделиям C86-4G, которые являются наследниками AMD Zen1. Чипы C86-4G насчитывают 16 вычислительных ядер с возможностью одновременной обработки до 32 потоков инструкций, а тактовая частота составляет 2,8 ГГц. Реализована поддержка оперативной памяти DDR5 и интерфейса PCIe 5.0. Известно, что процессоры C86-5G получат до 128 вычислительных ядер. Упомянута технология многопоточности SMT4, которая позволит каждому ядру обрабатывать четыре потока инструкций, что в сумме даст 512 потоков. Упомянута поддержка 104 линий PCIe 5.0, инструкций AVX512, а также режимов INT8 и BF16. Заявленная производительность — 10 Тфлопс на операциях FP64 (до 32 операций за такт). Ожидается, что в ЦОД-сегменте новые китайские процессоры станут альтернативой Intel Xeon 6. 
Источник изображений: Hygon Производство C86-5G уже началось. Чипы станут основой ряда серверов, включая двухсокетную модель H620G59 формата 2U с воздушным охлаждением. Эта система оборудована 32 слотами для модулей DDR5-6400, тремя разъёмами PCIe 5.0 х16, двумя слотами ОСР 3.0, восемью фронтальными отсеками для накопителей стандарта SFF, а также двумя внутренними коннекторами для SSD типоразмера М.2. Кроме того, готовятся серверные стойки высокой плотности TC800G6 (PUE — 1,08) и TC8600H G5 (PUE — 1,04) с жидкостным охлаждением.  Вместе с тем Hygon намерена выпустить GPU с памятью HBM и высокоскоростным интерконнектом. Известно, что это устройство допускает работу в режимах FP64/PF16/BF16. Новинка, предположительно, сможет составить конкуренцию NVIDIA A100. Наконец, в разработке находятся коммутационные решения класса 400/800 Гбит/с. Это чип с поддержкой 104 линий PCIe 5.0, высокоскоростной интерконнект для вертикального масштабирования (сопоставим с NVLink), решение ScaleFabric 400G (для NIC), а также ScaleFabric 400/800G. Последняя из перечисленных новинок обеспечивает поддержку 80 портов на 400 Гбит/с с RDMA, а коммутационная способность достигает 64 Тбит/с. Это устройство рассматривается в качестве альтернативы InfiniBand NDR.
26.06.2026 [12:44], Сергей Карасёв
Два кристалла, 304 ядра и 32 Гбайт HBM: подробности об Arm-чипах LX2 в китайском суперкомпьютере LineShineКитайский национальный суперкомпьютерный центр в Шэньчжэне (NSCCSZ) обнародовал дополнительную информацию о вычислительном комплексе LineShine, который возглавил свежий рейтинг самых мощных НРС-систем мира TOP500. FP64-производительность LineShine в тесте Linpack достигает 2,198 Эфлопс. В основу LineShine положены китайские 304-ядерные процессоры LX2 с архитектурой Arm. Конструкция этих изделий включает два вычислительных кристалла, каждый из которых содержит 152 ядра Armv9 с поддержкой Scalable Vector Extension (SVE) и Scalable Matrix Extension (SME). Тактовая частота составляет 1,55 ГГц. Каждый из кристаллов, в свою очередь, разделён на четыре NUMA-домена по 38 ядер. В состав каждого домена входят 4 Гбайт памяти HBM и 32 Гбайт памяти DDR5. Таким образом, в общей сложности используются 32 Гбайт HBM и 256 Гбайт DDR5. Энергопотребление LX2 находится на уровне 690 Вт. 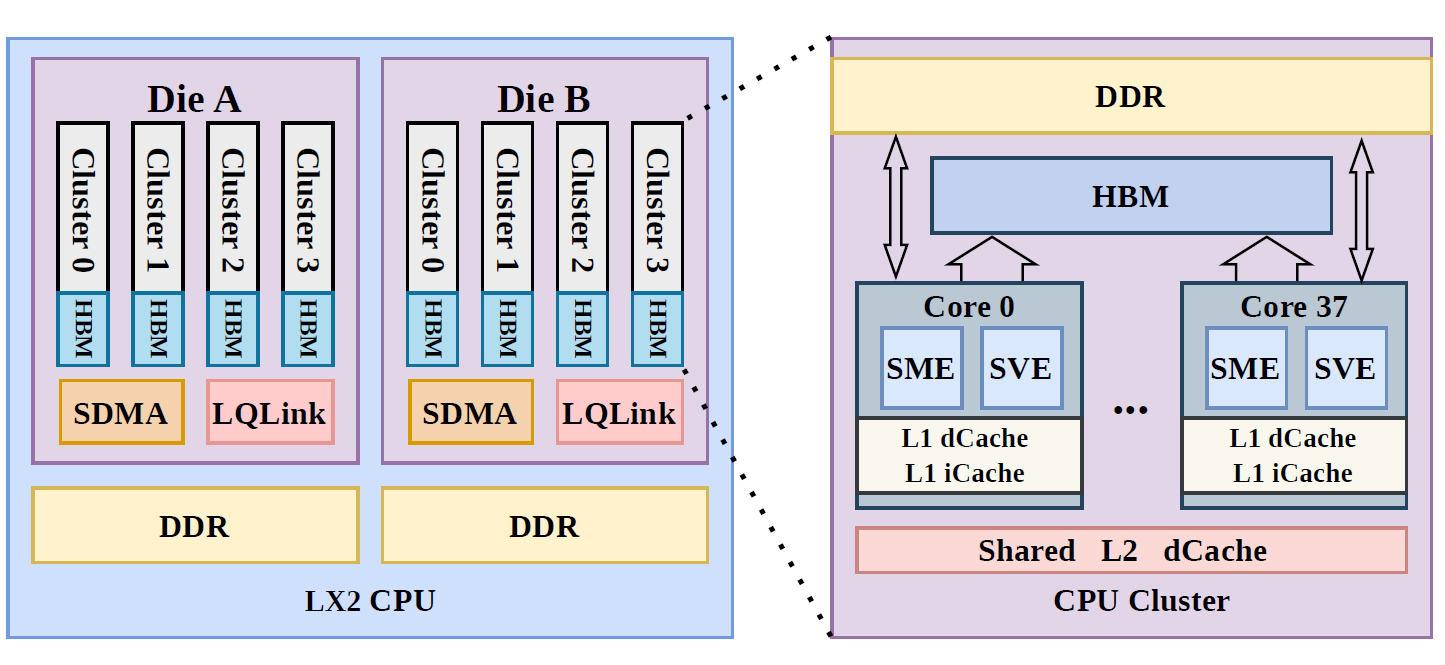
Источник изображения: NSCCSZ В составе LineShine два процессора LX2 формируют один вычислительный узел. Восемь таких узлов входят в один blade-сервер, а 16 серверов — в одно шасси. В одной стойке задействованы два шасси, что в сумме обеспечивает 512 процессоров. В целом, суперкомпьютер насчитывает около 90 стоек и примерно 14 млн вычислительных ядер. Энергопотребление LineShine достигает 42,2 МВт. Реализовано полностью жидкостное охлаждение на основе двусторонних водоблоков. Платформа использует проприетарный интерконнект LingQi, который обеспечивает пропускную способность между узлами до 1,6 Тбит/с. Технология LingQi поддерживает 2 млн портов и может масштабироваться до более чем 100 тыс. узлов. Вместимость подсистемы хранения данных LineShine составляет 200 Пбайт. Каждая стойка получает питание от шины постоянного тока LVDC на 380 В, обеспечивая вычислительную мощность до 580 кВт.
25.06.2026 [12:45], Владимир Мироненко
Qualcomm представила 250-ядерный серверный Arm-процессор Dragonfly C1000Qualcomm представила Qualcomm Dragonfly C1000 — специально разработанный для использования в ЦОД процессор, который по утверждению компании обеспечивает «лидирующие показатели производительности и эффективности использования для рабочих нагрузок агентов, общего назначения и узлов ИИ с лучшей в своем классе энергоэффективностью и совокупной стоимостью владения». В 2017 году компания уже пыталась выйти на серверный рынок, выпустив 10-нм 48-ядерные CPU Centriq 2400, но затем отменила проект в 2019 году. Qualcomm Dragonfly C1000 имеет чиплетную конструкцию с более чем 250 кастомизированными ядрами Qualcomm Oryon с частотой более 5 ГГц. По словам компании, чиплетная конструкция обеспечивает высокую производительность на ядро для агентных рабочих нагрузок, развёрнутых в масштабе. Также заявлено, что чип обеспечит лидирующую производительность в однопоточных вычислениях и в два раза лучшую производительность на Вт по сравнению с существующими эталонными показателями для конкурентных предложений серверных процессоров. 
Источник изображений: Qualcomm Qualcomm утверждает, что архитектура и конструкция Dragonfly C1000 обеспечивают оптимальную пропускную способность, масштабируемость, быстродействие и использование инфраструктуры для критически важных ЦОД, а также снижают капитальные и операционные затраты, обеспечивая лучшую в своём классе производительность на единицу совокупной стоимости владения в масштабе. Также многочиплетная архитектура обеспечивает модульную интеграцию с передовыми технологиями упаковки для масштабирования производительности и I/O, охватывая как процессоры общего назначения, так и ИИ-процессоры в ЦОД.  Процессор получит контроллер PCIe 7.0 (более 2 Тбайт/с) с CXL, поддержку ускорителей следующего поколения, таких как собственные продукты серии AI от Qualcomm, а также высокоскоростных сетей, хранилищ и дезагрегацию памяти с опциональным подключением модуля HBC (High Bandwidth Compute). Благодаря поддержке как воздушного, так и жидкостного охлаждения систему можно развёртывать в различных средах ЦОД с использованием стоек и серверов, совместимых с OCP ORv3. Что касается безопасности, Dragonfly C1000 получил расширенные функции надёжности, доступности и обслуживания (RAS), включая коррекцию ошибок памяти ECC, изоляцию неисправностей и отладку после ошибок, что обеспечивает отказоустойчивую работу в масштабе. Qualcomm сообщила, что коммерческая доступность Dragonfly C1000 ожидается в 2028 году.
17.06.2026 [15:09], Руслан Авдеев
IDC: на x86 теперь приходится лишь чуть более половины рынка серверов, в основном из-за ИИНовейшая статистика свидетельствует, что почти половины выручки на мировом рынке серверов приходится на архитектуры, отличные от «классической» x86, сообщает The Register со ссылкой на исследование IDC. Ситуацию определяют спрос на ИИ-системы и дефицит памяти DRAM и NAND. В отчёте IDC Worldwide Quarterly Server Tracker за I квартал 2026 года говорится, что на x86-серверы с процессорами AMD и Intel приходится чуть более 50 % выручки, а на прочие архитектуры — 47,9 %. При этом последние показали рост на 107 % г/г ($58,7 млрд), тогда как x86-платформы упали, но лишь на 2,9 % г/г ($63,9 млрд). Рынок в целом вырос до $122,6 млрд, на 30,4 % г/г. Аналитики связывают такое изменение сил с ростом продаж систем NVIDIA, которые включают Arm-процессоры. Спрос на них чрезвычайно высок, а стоят они значительно выше чипов для обычных серверов ЦОД. И, если гиперскейлеры и крупные облачные провайдеры и не думают замедлять инвестиции, то рынок классических серверов, не связанных с ИИ-ускорителями, чувствует себя не особенно бодро, во многом из-за приоритетных инвестиций и поставок в ИИ. Так, производители памяти предпочитают выпускать более маржинальные продукты для ИИ-платформ, поэтому прочим сегмента рынка памяти не хватает. По данным IDC, дефицит DRAM и NAND определяет дефицит поставок обычных серверов в краткосрочной перспективе, хотя спрос на них тоже довольно высок. Но высокие цены вынуждают откладывать закупки. 
Источник изображения: Towfiqu barbhuiya/unsplash.com Серверы с GPU-ускорителями принесли $68,9 млрд, рост составил около 25 % г/г. На прочие «ускоренные» серверы с FPGA/ASIC пришлось $17,7 млрд, рост составил 122 % г/г. В IDC считают, что внедрение ИИ-инфраструктуры более не ограничено спросом гиперскейлеров. Например, суверенные ИИ-мощности пытаются создавать по всему миру на государственном уровне. IDC рассчитывает, что ситуация начнёт нормализоваться с 2027 года, когда производители чипов введут в строй новые фабрики и расширят имеющиеся производственные мощности. За последние два десятилетия на серверы, построенные не на x86-архитектуре, приходилось менее 10 % выручки, большинство из которой доставалась IBM (POWER и z-менфреймы), которая фактически была единственным крупным поставщиком проприетарных серверных решений после того, как Oracle разочаровалась в платформе Sun SPARC, а HPE решила, что поддерживать бизнес на основе «экзотических» архитектур вроде Itanium нецелесообразно. Архитектура RISC-V весьма популярна в Китае, поскольку на неё не распространяются многие ограничения политических оппонентов, однако массовыми крупные серверные CPU на её базе так и не стали, хотя цифры по отгруженным ядрам впечатляют. Так что надежды Arm занять более половины рынка чипов для ЦОД оправдались. Так, у Microsoft есть собственные Arm-процессоры Cobalt 200, у AWS — Graviton 5, у Alibaba Cloud — Yitian 710, а у Google — Axion. Среди крупных независимых остались Ampere Computing (используется Oracle), которая теперь принадлежит SoftBank, и Huawei со своими Kunpeng. Собственные Arm-процессоры также готовят сама Arm, Qualcomm, Fujitsu и NVIDIA. Причём последняя позиционирует их именно как конкурентов x86.
16.06.2026 [09:46], Сергей Карасёв
NextSilicon готовит 128-ядерные серверные RISC-V-процессоры для ИИ и НРСКомпания NextSilicon сообщила о том, что её вычислительные ядра Arbel с архитектурой RISC-V лягут в основу процессоров корпоративного класса, ориентированных на задачи ИИ и НРС. Организовать серийное производство таких изделий планируется в I квартале 2028 года. NextSilicon проектировала Arbel с чистого листа, а первоначальной целью было создание хост-процессора для ИИ-ускорителей Maverick-3. Конструкция Arbel предусматривает наличие массивного конвейера инструкций шириной 10 команд и буфера переупорядочивания на 480 записей. Возможно выполнение 16 скалярных инструкций за цикл. Задействованы четыре интегрированных 128-бит векторных блока для обеспечения высокой производительности при параллельной обработке данных, включая нагрузки, связанные с ИИ-инференсом. 
Источник изображения: NextSilicon Сообщается, что создаваемые процессоры будут доступны в модификациях с 64 и 128 ядрами Arbel. Тактовая частота заявлена на отметке 3,4 ГГц. Тестовые изделия Arbel предполагали применение 5-нм технологии TSMC. Серийные решения будут изготавливаться по более совершенной методике для удовлетворения растущих требований к энергоэффективности и повышению плотности размещения компонентов в дата-центрах. Упомянут алгоритм прогнозирования ветвлений TAG. Говорится о полноценной поддержке профиля RVA23, который стандартизирует ISA. В RVA23 предусмотрены такие функции, как векторные операции, инструкции с плавающей запятой и атомарные инструкции, а также поддержка гипервизоров. Заявлена совместимость со стандартными дистрибутивами Linux. Ожидается, что рынок чипов с архитектурой RISC-V для дата-центров и НРС-платформ будет демонстрировать среднегодовой темп роста на уровне 33,1 % в период с 2025 по 2034 год. В результате его объём превысит $200 млрд.
01.06.2026 [21:33], Владимир Мироненко
Intel выпустит 192-ядерные процессоры Xeon Diamond Rapids на техпроцессе 18A-P в 2027 годуВместе с объявлением о выходе серии чипов Xeon 6+ (Clearwater Forest) компания Intel предоставила некоторые подробности о Xeon Diamond Rapids, выход которых намечен на 2027 год. Новый процессор будет выпускаться по техпроцессу 18A-P, усовершенствованной версии 2-нм техпроцесса. Компания сообщила, что Xeon Diamond Rapids получит на 50 % больше ядер, чем Granite Rapids-AP (6900P), т.е. 192 P-ядра. Это значительный прирост, но всё же меньше, чем у AMD, которая, как ожидается, уже в этом году предложит до 256 ядер Zen 6C в EPYC Venice. При этом Diamond Rapids не будет поддерживать Hyper-Threading (SMT). Эта технология вновь появится в Xeon Coral Rapids в 2028 году. Как сообщает The Register, на рендерах, представленных в пресс-релизе Intel, видно, что два I/O-чиплета обслуживают четыре вертикально расположенных вычислительных блока, собранных с использованием упаковки Foveros. Аналогичная компоновка используется в Clearwater Forest. Перенос L3-кеша на базовый тайл освобождает значительную площадь вычислительного чиплета. Здесь таковых четыре, по 48 ядер в каждом. The Register отметил, что в этом отношении Diamond Rapids похож на Fujitsu Monaka, который использует почти идентичную компоновку и 3.5D-упаковку Broadcom, хотя и с одним чиплетом I/O. А вот контроллеры памяти могут оказаться и на базовых тайлах, и в составе I/O-чиплетов. 
Источник изображений: Intel В отличие от Granite Rapids-SP, не стоит ожидать широкого распространения Diamond Rapids в корпоративных системах виртуализации или СХД. Как сообщила Intel, Diamond Rapids «оптимизирован для высоконагруженных IaaS-систем с высокой производительностью на поток», что ставит его в один ряд с процессорами 6900P, больше ориентированными на HPC-нагрузки. Intel уже говорила, что новинки получат 16-канальный контроллер памяти с поддержкой MRDIMM, что важно для таких задач. Чипы также будут поддерживать PCIe 6.0, предлагая высокую скорость и масштабируемость для сценариев с интенсивным использованием I/O.  Далее Intel представит Coral Rapids, вернув P-ядрам поддержку SMT. Ожидается, что линейка будет запущена в середине 2028 года с 8-канальными платформами, но, судя по недавним заявлениям генерального директора Лип-Бу Тана (Lip-Bu Tan), её выпуск, вероятно, будет ускорен из-за возросшего спроса на процессоры для рабочих нагрузок агентного ИИ. |
|

