Материалы по тегу: amd
|
30.07.2026 [12:54], Сергей Карасёв
MSI анонсировала серверы на базе AMD EPYC Venice с воздушным и жидкостным охлаждениемКомпания MSI представила широкий ассортимент серверов на аппаратной платформе AMD EPYC Venice. Дебютировали модели разных классов для задач ИИ и НРС, облачных инфраструктур, виртуализации и критических бизнес-приложений. В семейство вошли модели для 19″ и 21″ серверных стоек с воздушным и жидкостным охлаждением, в том числе многоузловые машины. Одной из новинок стала GPU-платформа CG681-S6093 типоразмера 6U с жидкостным охлаждением. Устройство допускает установку двух чипов Venice и восьми ИИ-ускорителей NVIDIA RTX Pro 6000 Blackwell Server Edition с 96 Гбайт памяти GDDR7, которые также входят в контур СЖО. Доступны 32 слота для модулей оперативной памяти DDR5. Задействованы сетевые адаптеры NVIDIA ConnectX-8 SuperNIC и SSD формата E1.S (NVMe). 
Источник изображения: MSI Анонсированы также системы, оптимизированные по показателям производительности и экономической эффективности. Кроме того, выйдут ORv3-решения для построения вычислительных инфраструктур высокой плотности. В целом, в новое семейство вошли следующие серверы:
29.07.2026 [16:35], Руслан Авдеев
AMD станет крупным клиентом Core Scientific — сначала 530 МВт, потом до 2,5 ГВтAMD арендует мощности ЦОД у компании Core Scientific — вплоть до 2,5 ГВт. Пока подписан договор приблизительно на 530 МВт на пяти площадках. Общая сумма базовой контрактной выручки по словам Core Scientific превышает $14 млрд., сообщает Datacenter Dynamics. В Техасе AMD намерена арендовать 185 МВт в Пекосе (Pecos) и 110 МВт в округе Хант (Hunt), в Далтоне (Dalton, Джорджия) — 120 МВт, в Маскоги (Muscogee, Оклахома) — 82 МВт, а в Оберне (Auburn, Алабама) — 32 МВт. Все 530 МВт Core Scientific намерена запустить к концу 2028 года, начиная с Пекоса и Оберна в I половине 2027 года. Также компания имеет потенциал расширения мощностей по 192 МВт в Ханте и Маскоги. В рамках соглашения Core Scientific и AMD намерены совместно разработать физическую инфраструктуру и развернуть чипы Instinct MI455X, EPYC Venice и стек ROCm. Также AMD получит гарантии покупки по рыночной цене обычных акций Core Scientific при соблюдении некоторых условий. Сообщается, что речь идёт о возможной покупке до 30 млн акций. 
Источник изображения: Core Scientific Дополнительно AMD намерена арендовать 50 МВт мощностей в Техасе у компании Riot. Как и Core Scientific, последняя является бывшим криптомайнинговым бизнесом, сменившим специализацию на ИИ и HPC. AMD арендует мощности на площадке в Рокдейле (Rockdale), которую сейчас переоборудуют с майнинга биткоинов на размещение ИИ-оборудования. Потенциально на этой площадке AMD может получить до 200 МВт. Тем временем во II квартале у Core Scientific общая выручка составила $164,2 млн, а чистый убыток — $1,155 млрд. Примечательно, что кварталом раньше убыток составлял $347,2 млн, а скорректированная EBITDA — $41,1 млн. Капитальные затраты выросли с $389,2 млн в I квартале 2026 года до $797,4 млн в текущем квартале. Для сравнения, во II квартале 2025 года они составляли $121,3 млн. В целом денежные средства компании и их эквиваленты составили $1,819 млрд. Всего «на балансе» Core Scientific есть 395 МВт, уже оплачиваемых клиентами, тогда в I квартале речь шла о 225 МВт. Всего законтрактовано около 1,1 ГВт, что эквивалентно более $24 млрд общей контрактной выручки. Кроме AMD, крупным клиентом Core Scientific является CoreWeave, она арендует мощности в Техасе, Джорджии, Оклахоме и Северной Каролине. Ранее CoreWeave, имеющая тесные связи с NVIDIA, планировала покупку Core Scientific, но в ноябре 2025 года акционеры последней не одобрили сделку.
29.07.2026 [14:41], Сергей Карасёв
Giga Computing представила серверы на базе AMD EPYC Venice 9006 с СЖОКомпания Giga Computing, подразделение Gigabyte, анонсировала серверы нового поколения на аппаратной платформе AMD EPYC Venice 9006. В частности, дебютировали модели R165-DG2-CS1 и B685-D80-LS1 с прямым жидкостным охлаждением (DLC). Поставки этих устройств начнутся в ноябре нынешнего года. Машина R165-DG2-CS1 выполнена в форм-факторе 1U. Допускается установка одного процессора EPYC 9006 в исполнении SP7 с показателем TDP до 600 Вт. Применена DLC-система с закрытым контуром и функцией обнаружения протечек. Доступны 16 слотов для модулей оперативной памяти DDR5 RDIMM-8000 и MRDIMM-12800, два коннектора для SSD формата M.2 2280/22110 с интерфейсом PCIe 4.0 x2, а также 12 фронтальных отсеков для SFF-накопителей NVMe/SATA/SAS-4. Есть слот PCIe 6.0 x16 для GPU-ускорителя и по одному слоту PCIe 6.0 x16 для дополнительных карт расширения форматов FHFL и FHHL. В оснащение входят контроллер ASPEED AST2700, двухпортовый сетевой адаптер 1GbE (Intel I350-AM2), выделенный сетевой порт управления. Питание обеспечивают два блока мощностью 3200 Вт с резервированием и сертификатом 80 PLUS Titanium. 
Источник изображений: Giga Computing Вторая новинка, B685-D80-LS1, имеет типоразмер 6U. Этот сервер получил 10-узловую конфигурацию, где каждый узел рассчитан на два чипа EPYC 9006 с TDP до 500 Вт и 32 модуля DDR5 RDIMM-8000 или MRDIMM-12800. В расчете на узел доступны два посадочных места для NVMe-накопителей E3.S (PCIe 6.0) и три слота PCIe 6.0 x16 для низкопрофильных карт расширения. Все эти компоненты входят в контур СЖО. Кроме того, узлы комплектуются контроллером ASPEED AST2700, сетевым портом управления и интерфейсом Mini-DP. В шасси установлены 12 блоков питания мощностью 3200 Вт с сертификатом 80 PLUS Titanium.  Новые серверы рассчитаны на эксплуатацию в температурном диапазоне от +10 до +30–35 °C. Опционально предлагается установка модуля TPM 2.0 для обеспечения безопасности.
28.07.2026 [10:14], Сергей Карасёв
ASUS выпустила одно- и двухсокетные серверы на платформе AMD EPYC VeniceКомпания ASUS анонсировала серверы нового поколения, построенные на аппаратной платформе AMD EPYC Venice 9006. Дебютировали флагманские двухсокетные системы серий RS700A/720A с высокой вычислительной плотностью, а также односокетные модели RS500A/520A, обеспечивающие эффективность и гибкость развёртывания. Устройство RS700A выполнено в форм-факторе 1U. Допускается установка двух чипов EPYC 9006 SP8 с показателем TDP до 400 Вт. Доступны 32 слота для модулей оперативной памяти DDR5 DIMM-8000 или MRDIMM-11200, по два разъёма PCIe 6.0 x16 (FHHL) и OCP 3.0. Подсистема хранения данных в зависимости от конфигурации имеет следующее исполнение: 4 × SFF/LFF (NVMe), 12 × SFF (NVMe) или 16 × E3.S (PCIe 6.0). Возможен монтаж двух однослотовых GPU-карт с TDP до 140 Вт. Питание обеспечивают два блока мощностью 2000 Вт с сертификатом 80 PLUS Titanium и резервированием. 
Источник изображения: ASUS Сервер RS500A типоразмера 1U рассчитан на один процессор EPYC 9006 (до 400 Вт) и 16 модулей ОЗУ. Подсистема хранения может иметь конфигурацию 12 × SFF (NVMe) + 4 × E1.S или 16 × E3.S. Поддерживаются два однослотовых GPU с величиной TDP до 72 Вт. Прочие характеристики аналогичны модели RS700A. Вариант RS720A формата 2U с поддержкой двух чипов Venice (до 400 Вт) располагает 32 разъёмами для модулей памяти DDR5. Он позволяет задействовать шесть слотов PCIe 6.0 x8 или три слота PCIe 6.0 x16 (FHFL), два разъёма PCIe 6.0 x16 (FHHL) и два слота OCP 3.0. Могут применяться до трёх двухслотовых GPU-ускорителей с TDP до 450 Вт. Доступны конфигурации с возможностью монтажа накопителей 12 × SFF/LFF (NVMe), 24 × SFF (NVMe) или 32 × E3.S (PCIe 6.0). Применены два блока питания мощностью 3200/2700 Вт с сертификатом 80 PLUS Titanium. Наконец, сервер RS520A стандарта 2U комплектуется одним процессором EPYC 9006. Есть 16 слотов для модулей ОЗУ, один разъём PCIe 6.0 x16 (FHFL), один или два разъёма OCP 3.0. Подсистема хранения выполнена по схеме 12 × SFF/LFF (NVMe) + 4 × E1.S или 24 × SFF (NVMe) или 16 × SFF (NVMe) + 8 × SFF (SAS). Могут применяться до трёх однослотовых GPU. Мощность двух блоков питания 80 PLUS Titanium — 2700 или 2000 Вт.
27.07.2026 [12:55], Сергей Карасёв
Supermicro представила серверы на платформе AMD EPYC VeniceКомпания Supermicro анонсировала серверы семейства H15, построенные на аппаратной платформе AMD EPYC Venice 9006. Эти машины, как утверждаются, обеспечивают 1,7-кратный прирост производительности по сравнению с устройствами предыдущего поколения. В серию H15 входит большое количество систем, оптимизированных для широкого спектра корпоративных и инфраструктурных приложений, включая ИИ-нагрузки. Это, в частности, флагманские двухпроцессорные устройства Hyper, одно- и двухсокетные решения CloudDC для облачных сред, 2U-серверы высокой плотности GrandTwin, модели FlexTwin формата 1OU, платформы хранения Petascale Storage типа All-Flash в корпусах 1U и 2U, модели SuperBlade и пр. Кроме того, дебютировали GPU-серверы AS-5126GS-TNRT и AS-5126GS-TNRT2, которые комплектуются соответственно восемью и десятью ускорителями AMD Instinct MI350P. Обе системы выполнены в форм-факторе 5U и оснащены воздушным охлаждением. Первая из этих машин располагает в общей сложности девятью слотами для карт PCIe 5.0 x16 FHFL, вторая — тринадцатью. Во фронтальной части корпуса расположены отсеки для SFF-накопителей. Питание обеспечивают шесть блоков мощностью 2700 Вт с сертификатом 80 PLUS Titanium. Реализованы два сетевых порта 10GbE (RJ45), выделенный сетевой порт управления 1GbE (RJ45) и разъём D-Sub. Заявлена совместимость с Oracle Linux 10.0, RHEL 9.6/10.0, RHEL AI 3.0, Windows Server 2022/2025. 
Источник изображения: Supermicro Supermicro также сообщила о сотрудничестве с AMD с целью поставок стоечной платформы Helios AI с 72 ускорителями Instinct MI455X. Она ориентирована на обучение ИИ-моделей в масштабе и на инференс с высокой пропускной способностью. Предусмотрено применение жидкостного охлаждения, сетевых устройств AMD Pensando и программного стека AMD ROCm.
27.07.2026 [12:30], Руслан Авдеев
AMD и Schneider Electric представили референсные дизайны для ИИ ЦОД на базе Helios AIAMD и Schneider Electric совместно разработали типовой проект для внедрения стоек HeliosAI в ИИ ЦОД, что позволит упростить и ускорить развёртывание и масштабирование ИИ-фабрик. Helios AI представляет собой унифицированную платформу, разработанную для обучения передовых ИИ-моделей и крупномасштабного инфреренса. Утверждается, что она обеспечивает лидерство в плотности вычислений, пропускной способности памяти и горизонтальном масштабировании. Helios AI представляет собой стойку двойной ширины, полностью интегрированную с CPU AMD EPYC Venic, ускорителями MI400 и сетю Pensando Vulcano. Новые референсные стандарты указывают, как именно Helios могут быть интегрированы с остальными системами ЦОД. Они включают информацию об электроснабжении объекта, охлаждении, IT-пространстве и ПО для управления жизненным циклом. Предполагается, что это позволит клиентам быстрее проходить путь от планирования до развёртывания. 
Источник изображения: AMD В Schneider Electric подчёркивают, что сотрудничество с AMD позволяет представить эталонный проект с инженерным обоснованием, способствующий связать передовые платформы для ИИ-вычислений, энергетические технологии и возможность практического внедрения новых решений в ЦОД. 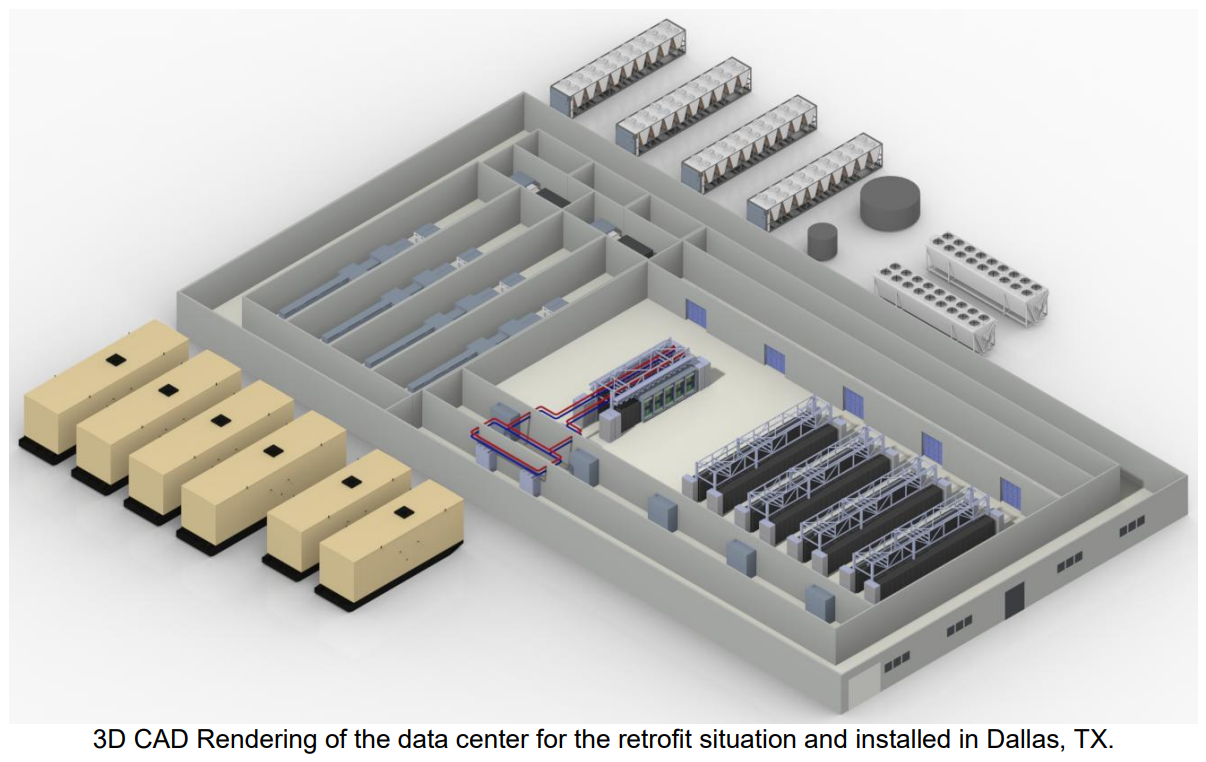
Источник изображения: Schneider Electric Дизайн рассчитан на типовые ИИ-кластеры мощностью 6,2–10,4 МВт на площадках Tier III и плотностью отдельных стоек до 246 кВт. Поддерживается передовое жидкостное охлаждение Motivair с CDU и гибридный подход с использованием решений на основе СЖО и воздушного охлаждения. В AMD подчёркивают важность того, чтобы, на фоне современных требований к ИИ-инфраструктуре, вычисления, сетевые системы, питание и охлаждения «с нуля» проектировались совместно.
27.07.2026 [11:40], Сергей Карасёв
81 920 ядер на стойку: HPE представила узлы Cray Supercomputing GX5000 на базе AMD EPYC Venice 9006Компания HPE обновила суперкомпьютерную платформу HPE Cray Supercomputing GX5000 нового поколения. Система высокой плотности ориентирована на НРС-задачи и ресурсоёмкие нагрузки, связанные с ИИ. В основу положены серверы с процессорами AMD EPYC Venice 9006. В конфигурации с чипами EPYC 9996 (256 вычислительных ядер) суммарное количество ядер на серверную стойку достигает 81 920. По заявлениям производителя, это на 40 % больше по сравнению с ближайшей конкурирующей системой высокой плотности. Для новой платформы будут доступны серверы HPE Cray Supercomputing GX350a Accelerated Blade и HPE Cray Supercomputing GX250 Compute Blade. Первые ориентированы на смешанные вычисления: они объединяют один процессор AMD EPYC Venice и четыре ускорителя AMD Instinct MI430X. В одной стойке могут быть размещены до 28 таких узлов, что в сумме даст 112 ускорителей. В свою очередь, сервер GX250 рассчитан на FP64-операции: он несёт на борту восемь процессоров EPYC Venice 9006 (без ускорителей). В одной стойке могут размещаться до 40 узлов, содержащих в сумме 320 CPU. Предусмотрена возможность использования прямого жидкостного охлаждения. По сравнению с системами предыдущего поколения новая платформа HPE Cray Supercomputing GX5000 обеспечивает возможность сокращения пространства в дата-центре на 25 % при сопоставимой вычислительной мощности. 
Источник изображения: HPE Отмечается, что в число первых пользователей платформы входят Окриджская национальная лаборатория (ORNL) Министерства энергетики США (DOE) и Центр высокопроизводительных вычислений Штутгартского университета (HLRS).
25.07.2026 [21:30], Сергей Карасёв
ИИ-платформа Liqid UltraStack объединяет 30 ускорителей AMD Instinct MI350PКомпания Liqid объявила о стратегическом сотрудничестве с AMD, направленном на создание решений следующего поколения для ИИ-инфраструктур. В рамках партнёрства представлена аппаратная платформа Liqid UltraStack 30, оптимизированная для задач инференса. В состав системы входят сервер с двумя процессорами AMD EPYC 9005 Turin и коммутатор Liqid PCIe Fabric Switch. Ключевыми компонентами являются три GPU-блока, каждый из которых содержит десять ускорителей AMD Instinct MI350P (144 Гбайт памяти HBM3E с 4096-бит шиной). Таким образом, в общей сложности задействованы 30 названных карт и 4,3 Тбайт памяти HBM3E. Заявленная производительность достигает 69 Пфлопс в режиме FP8. Говорится о возможности работы с общими пулами памяти по высокоскоростному стандарту CXL. Суммарное энергопотребление платформы находится на уровне 22 кВт. По заявлениям Liqid, система обеспечивает 3,7-кратный прирост показателя токенов в секунду по сравнению с традиционными решениями. Количество токенов в пересчете на $1 увеличивается в 2,1 раза, а токенов на 1 Вт затрачиваемой энергии — в 1,8 раза. Затраты на развёртывание могут быть уменьшены на 65 %. 
Источник изображения: Liqid Программное обеспечение Liqid Matrix объединяет GPU-ускорители и в реальном времени распределяет их ресурсы между рабочими нагрузками через высокоскоростную PCIe-шину. При этом все карты остаются в пределах одного узла. В целом, платформа Liqid UltraStack 30, как утверждается, устраняет накладные расходы, связанные с использованием нескольких узлов, обеспечивает предсказуемое линейное масштабирование и доводит загрузку GPU почти до 100 %. Упомянута поддержка Kubernetes для работы с несколькими моделями.
25.07.2026 [21:20], Сергей Карасёв
В семейство AMD Ryzen AI Embedded X100 вошли процессоры с 8–16 ядрамиВ январе нынешнего года компания AMD формально анонсировала процессоры Ryzen AI Embedded X100 для встраиваемых и автономных систем с ИИ-функциями. Теперь раскрыты технические характеристики этих изделий. Кроме того, представлены вычислительный модуль Kria AI SoM на базе чипа X100 и платформа для разработчиков Kria AI Robotics Developer Platform. В семейство Ryzen AI Embedded X100 вошли шесть моделей — X168i, X168, X188i, X188, X199i и X199. У изделий с суффиксом «i» в обозначении диапазон рабочих температур простирается от -40 до +105 °C, у других — от 0 до +105 °C. Процессоры X168i и X168 получили восемь ядер с частотой до 5 ГГц и GPU с 32 вычислительными блоками (CU). Решения X188i и X188 имеют аналогичные характеристики, но содержат 12 ядер CPU. Чипы X199i и X199 объединяют 16 ядер с частотой 5,1 ГГц и GPU с 40 вычислительными блоками. 
Источник изображений: CNX Software Все процессоры поддерживают оперативную память LPDDR5x-8533 (до 8 каналов) и 16 линий PCIe 4.0. Реализованы интерфейсы HDMI 2.1, DP 2.0, eDP v1.4, DVI, USB4 (×2), USB 3.2 (×2), USB 2.0 (×3), I2C, SMBus, SPI, UART. Изделия выполнены в корпусе с размерами 45 × 37,5 мм.  Утверждается, что по сравнению с аналогичными процессорами Intel Core Ultra Series 3 чипы Ryzen AI Embedded X100 обеспечивают прирост производительности в 2,1 раза в многопоточном режиме (CoreMark). Графический блок при этом демонстрирует 1,7-кратную прибавку (OpenGL, GFXBench 5.0.0). По сравнению с платформой NVIDIA Jetson Thor T5000 процессоры Ryzen AI Embedded X100 Series демонстрируют 3-кратный рост пиковой производительности в формате FP32. Вычислительный блок AMD Kria AI SoM, по информации ресурса CNX Software, несёт на борту 64 или 128 Гбайт памяти LPDDR5x. Возможно подключение до восьми камер через коннекторы FAKRA. Упомянуты интерфейсы CAN-FD, RS485, 10GbE QSFP.  В свою очередь, платформа для разработчиков Kria AI Robotics Developer Platform оснащена модулем Kria AI SoM и FPGA Spartan UltraScale+. Предусмотрены коннектор Oculink PCIe, разъём M.2 2280 Key-M для NVMe SSD и слот M.2 2230 Key-E для комбинированного адаптера Wi-Fi/Bluetooth. В оснащение входят два интерфейса Mini DisplayPort, по одному коннектору FAKRA x4 (GMSL2/3) и FAKRA x4 (GMSL1/2), 3,5-мм аудиогнездо, по два сетевых порта 5GbE RJ45 и 1GbE RJ45 (EtherCAT/TSN), порт 10GbE QFSP, интерфейсы USB4 Type-C (×2), USB 3.2 Type-C (×3) и USB 2.0 Type-A (×2), два последовательных порта CAN-FD/RS485.
24.07.2026 [17:43], Сергей Карасёв
От Флоренции до Равенны: AMD готовит процессоры EPYC Florence и Ravenna, а также ускорители MI500 и MI600AMD в ходе конференции Advancing AI 2026 представила серверные процессоры EPYC Venice 9006 на архитектуре Zen 6/6c, ускорители Instinct MI455X и стойки Helios AI на их основе, а также поделилась планами по выпуску чипов EPYC и ускорителей Instinct на ближайшие годы. Кроме того, компания раскрыла предварительные детали о новых платформах Helios, ориентированных на задачи ИИ. 
Источник изображений: AMD В частности, сообщается, что в 2028 году появятся изделия EPYC с кодовым именем Florence, построенные на ядрах Zen 7 и Zen 7c. Для этих CPU предусмотрено применение технологии производства «следующего поколения». Говорится о поддержке передовой памяти типа MRDIMM и LPDDR. Известно, что Florence станут первыми чипами серии EPYC, которые получат поддержку инструкций ACE (AI Compute Extensions), предназначенных для умножения матриц и работы с алгоритмами ИИ. Эти инструкции разрабатываются совместно специалистами AMD и Intel в рамках Консультативной группы экосистемы x86 (x86 Ecosystem Advisory Group).   Процессоры Florence будут предлагаться в вариантах исполнения SP7 и SP8. Изделия первого типа проектируются с прицелом на обеспечение максимальной производительности — они получат наибольшее количество вычислительных ядер. В свою очередь, решения под сокет SP8 будут ориентированы на корпоративные системы с оптимальным соотношением быстродействия и стоимости. Помимо этого, упомянуты чипы Ferrara на базе Zen 7 для хост-узлов ИИ и Fidenza для систем, оптимизированных по показателю производительности в расчёте на Вт. На 2030 год компания AMD наметила выпуск процессоров EPYC с кодовым именем Ravenna. В их основу ляжет архитектура Zen 8, но дополнительные подробности пока не раскрываются.  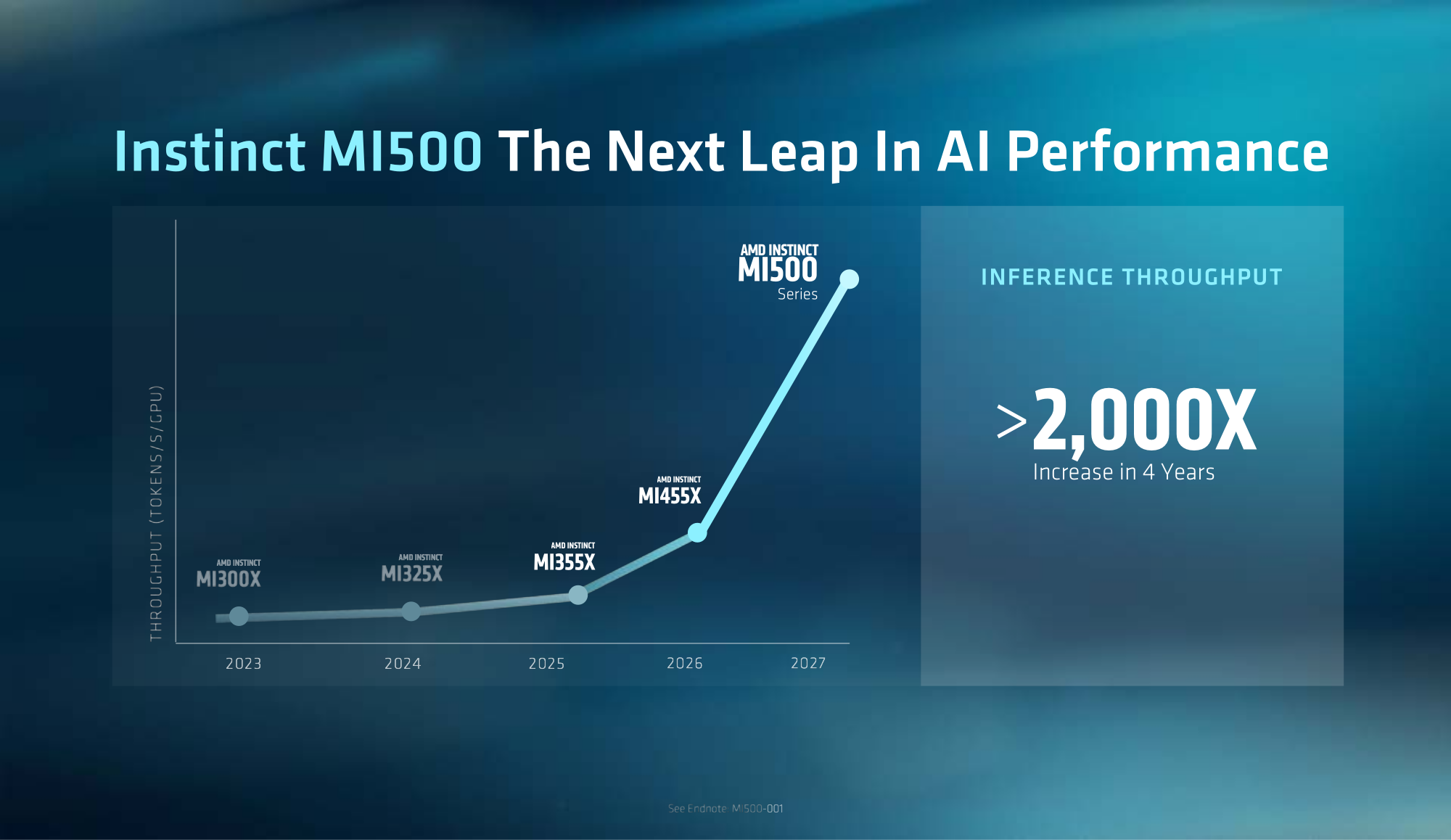 В сегменте ИИ-ускорителей в 2027 году ожидается появление изделий Instinct MI500 на архитектуре CDNA 6 с памятью HBM4e. Они станут частью платформы Helios 500 вместе с чипами EPYC Verano, а также сетевыми процессорами Pensando Como и Monza. В 2028-м должны выйти карты Instinct MI600 на базе CDNA Next. Эти решения войдут в состав платформы AMD Helios 600, наряду с чипами EPYC Ferrara, а также сетевыми компонентами Pensando Palma и Levanzo. |
|

