Материалы по тегу: gb300
|
24.06.2026 [01:23], Владимир Мироненко
Европа получит 35 суперкомпьютеров на чипах NVIDIANVIDIA объявила о разработке по всей Европе 35 суперкомпьютеров на базе её чипов, которые позволят более 3 млн исследователей ускорить проведение научных исследований и внедрение промышленных инноваций в сфере ИИ. Это крупнейшее за год расширение в Европе сети суперкомпьютеров, охватывающее национальные суперкомпьютерные центры, ИИ-фабрики и академические исследовательские институты. Эти системы будут поддерживать исследования в области климатологии, здравоохранения, декарбонизации чистой энергетики, квантовых вычислений и фундаментальной науки. Работу большей части европейских ИИ-фабрик обеспечивают платформы Blackwell и Hopper, при этом с прошлого года было развернуто или анонсировано 800 Эфлопс вычислительных мощностей для ИИ. Эти суперкомпьютеры, включая обновлённый EuroHPC MareNostrum5 AI Барселонского суперкомпьютерного центра (BSC-CNS), Blue Swan (BavariaAI), IT4LIA, HammerHAI Центра высокопроизводительных вычислений в Штутгарте (HLRS) и ИИ-фабрика Mimer Национальной академической суперкомпьютерной инфраструктуры Швеции (NAISS), основаны на передовой ИИ-инфраструктуре NVIDIA, говорит компания. Так, суперкомпьютер MareNostrum 5 будет дооснащён системами GB300 NVL72 и GB200 NVL4, объединённых интерконнектом NVIDIA Quantum-X800 InfiniBand. Система, обеспечивающая производительность до 20 Эфлопс при обучении ИИ и 33 Эфлопс при ИИ-инференсе, позволит ускорить работу генеративного ИИ, климатическое моделирование, исследования в области здравоохранения и биотехнологий, устойчивого сельского хозяйства, энергетических систем и госсервисов. 
Источник изображения: NVIDIA Система Blue Swan (BavariaAI) добавит 1 тыс. ускорителей (GB200 NVL4 и Quantum-2 InfiniBand) суперкомпьютерным центрам FAU Erlangen и LRZ. Платформа обеспечит производительность до 11 Эфлопс при обучении ИИ и 22 Эфлопс при ИИ-инференсе. Она будет поддерживать инициативу Баварии по созданию базовых моделей, продвигая открытые мультимодальные модели для науки, государственного управления, исследований в области здравоохранения, робототехники и т.д. HammerHAI (HLRS) представляет собой первую в Германии ИИ-фабрику с более чем 850 GPU на базе GB200 NVL4 с Quantum-X800 InfiniBand. Суперкомпьютер HammerHAI, обеспечивающий производительность до 8 Эфлопс при обучении ИИ и 15 Эфлопс при ИИ-инференсе, обеспечит исследователям и промышленным пользователям безопасную ИИ-инфраструктуру для инженерного моделирования, инференса и научных исследования. Суперкомпьютер Mimer EuroHPC AI Factory (NAISS), размещённый в Линчёпингском университете (LiU, Швеция), будет использовать 100 систем GB200 NVL4 и сеть ConnectX-8. Обеспечивая производительность до 4 Эфлопс при обучении ИИ и около 7 Эфлопс при ИИ-инференсе, Mimer AI Factory будет способствовать развитию шведской ИИ-экосистемы в таких областях, как биологические науки, материаловедение, автономные системы, доверенный ИИ и т.д. Наконец, ИИ-фабрика IT4LIA с более чем 8 тыс. GPU на базе GB200 NVL4 с Quantum-X800 InfiniBand и ПО NVIDIA AI Enterprise обеспечивает производительность в размере 82 Эфлопс при обучении ИИ и 164 Эфлопс при ИИ-инференсе.
16.06.2026 [12:10], Руслан Авдеев
Австралийская SharonAI Holdings купит 40 тыс. ускорителей GB300 и поделится с NVIDIA выручкой от ИИ-облакаSharonAI Holdings заключила с NVIDIA стратегическое соглашение сроком на шесть лет для поддержки развёртывания ИИ-фабрики мощностью 72 МВт в Австралии. Договор позволяет SharonAI масштабировать свою облачную ИИ-платформу, использовав до 40 тыс. ускорителей NVIDIA GB300. Мощности рассчитаны на спрос со стороны корпоративных клиентов, ИИ-стартапов, университетов, госсектора и исследовательских структур, требующих суверенных вычислительных мощностей, сообщает Converge! Digest. В основе сотрудничества — использование платформы для ИИ-фабрик NVIDIA DSX (на том же пакете технологий намерена строить ЦОД компания Helix Digital Infrastructure). Предусмотрено распределение средств, позволяющее ускорить развёртывание крупномасштабной ИИ-инфраструктуры. Sharon будет предоставлять облачные сервисы на основе продуктов NVIDIA, а последняя получит не только средства от продажи самих ускорителей и оборудования, но и долю «облачной» выручки. Это позволяет снизить капитальные затраты, одновременно расширяя доступ к передовым вычислительным ресурсам. 
Источник изображения: Jamie Davies/unsplash.com По итогам соглашения общая мощность объектов Sharon AI вырастет до 132 МВт, 102 МВт уже законтрактованы будущими клиентами. Компания рассчитывает развернуть более 55 тыс. ускорителей NVIDIA к середине 2027 года. Она обладает статусом NVIDIA Cloud Partner и утверждает, что новое соглашение укрепит её позиции в формирующейся ИИ-экосистеме Австралии и поможет развитию ИИ-фабрик для коммерческих и государственных структур страны. По словам Converge!, соглашение отражает растущий тренд, предусматривающий более тесную работу NVIDIA с облачными провайдерами и «неооблачными» компаниями для ускоренного развёртывания ИИ-инфраструктуры. Вместо того, чтобы просто полагаться на гиперскейлеров, NVIDIA всё чаще поддерживает проекты региональных ИИ-фабрик, создающихся для обеспечения суверенными мощностями правительств, коммерческих компаний, университетов и стартапов. Примечателен масштаб планируемого проекта. Полностью укомплектованная экосистема на 40 тыс. GB300 может считаться одной из крупнейших в Азиатско-Тихоокеанском регионе. Более того, речь идёт об эволюции бизнес-моделей в сфере ИИ — поставщики оборудования стремятся участвовать в бизнесе, постоянно получая долю выручки от облачных сервисов, не ограничиваясь только продажей оборудования. Кроме того, компания для поддержки кластера также заключила с VAST Data соглашение о развёртывании 600 Пбайт под управлением AI OS.
22.04.2026 [10:45], Сергей Карасёв
Foxconn наладит массовое производство CPO-коммутаторов в III квартале 2026 годаТайваньский контрактный производитель электроники Foxconn начал пробные поставки коммутаторов с интегрированной оптикой CPO (Co-Packaged Optics). Об этом, как сообщает DigiTimes, рассказал Брэнд Ченг (Brand Cheng), председатель совета директоров Foxconn Industrial Internet (FII) — подразделения, которое специализируется на сетевых продуктах для облачных платформ. По его словам, отгрузки образцов CPO-коммутаторов FII организовала в I квартале 2026-го, тогда как их массовое производство запланировано на III четверть текущего года. Ожидается, что спрос на такое оборудование будет стремительно расти. По данным отраслевых исследований, продажи CPO-коммутаторов увеличатся с примерно 23 тыс. единиц в 2026 году до более чем 200 тыс. штук в 2030-м. Таким образом, прогнозируемый показатель CAGR (среднегодовой темп роста в сложных процентах) составляет 144 %. Как отмечает Ченг, FII рассчитывает на годовой объём продаж CPO-коммутаторов более 10 тыс. штук. По оценкам компании, выпуск таких устройств обеспечит существенно более высокую валовую прибыль по сравнению с нынешними продуктами 400–800G. Подчёркивается, что экосистема технологий CPO развивается в комплексе с архитектурами NVIDIA QuantumX и SpectrumX, а также Broadcom Tomahawk. Речь идёт о проектировании специализированных чипсетов и оптических компонентов, внедрении передовых технологий упаковки, системной интеграции и пр. По сложности такие решения значительно превосходят традиционные сетевые устройства. 
Источник изображения: Foxconn Ченг также сообщил о масштабировании производства ИИ-ускорителей NVIDIA GB200 и GB300. Кроме того, наблюдается рост заказов на выпуск ASIC-изделий со стороны крупнейших облачных провайдеров: ожидается, что отгрузки таких продуктов значительно увеличатся во II половине года. Ченг подчеркнул, что более 60 % основных элементов серверных ИИ-стоек теперь производится собственными силами. Компания сформировала необходимые запасы компонентов, в том числе чипов памяти, для выполнения заказов в сфере ИИ, включая выпуск GB200 и GB300. В 2025 году выручка FII составила ¥902,89 млрд ($132,36 млрд), что на 48,2 % больше, чем годом ранее. При этом чистая прибыль поднялась на 51,99 %, достигнув ¥35,286 млрд ($5,17 млрд). Выручка в облачном сегменте составила ¥602,679 млрд ($88,35 млрд), увеличившись на 88,7 % в годовом исчислении: на неё пришлось почти 70 % от общего объёма поступлений.
29.03.2026 [19:24], Сергей Карасёв
MSI XpertStation WS300 — рабочая станция для ИИ на базе NVIDIA GB300Компания MSI официально представила мощную рабочую станцию XpertStation WS300, ориентированную на задачи ИИ. Новинка построена на платформе NVIDIA DGX Station, сердцем которой является суперчип GB300. Утверждается, что устройство предлагает производительность уровня ЦОД в формате десктопа. Габариты системы составляют 247,8 × 527,9 × 567,7 мм. Задействованы процессор NVIDIA Grace с 72 ядрами Arm Neoverse V2 (Demeter) и ускоритель Blackwell Ultra. При этом CPU использует 496 Гбайт LPDDR5X с пропускной способностью до 396 Гбайт/с, а GPU — 252 Гбайт HBM3e (ПСП 7,1 Тбайт/с). Применён модуль жидкостного охлаждения (CPU+GPU). Доступны по два разъёма M.2 2280/22110 для SSD с интерфейсом PCIe 5.0 x4 и PCIe 6.0 x4, а также коннектор M.2 2230 для комбинированного адаптера Wi-Fi/Bluetooth. Есть один слот PCIe 5.0 x16 для карты расширения FHFL двойной ширины и два слота PCIe 5.0 x16 для карт FHFL одинарной ширины. В качестве опции предлагается установка ускорителей RTX PRO 6000 Blackwell Workstation Edition, RTX PRO 6000 Blackwell Max-Q Workstation Edition, RTX PRO 4000 Blackwell SFF Edition и RTX PRO 2000 Blackwell. 
Источник изображения: MSI В оснащение входят контроллер ASPEED AST2600 с выделенным портом управления 1GbE, сетевой адаптер NVIDIA ConnectX-8 SuperNIC с двумя портами QSFP112, а также 10GbE-контроллер Marvell AQC113. Есть четыре порта USB 3.1 Type-A, интерфейсы Mini-DP и Micro-USB (COM). Питание обеспечивает блок мощностью 1600 Вт с сертификатом 80 PLUS Titanium. За безопасность отвечает модуль TPM 2.0. Диапазон рабочих температур — от +10 до +35 °C.
18.02.2026 [09:19], Сергей Карасёв
Meta✴ развернёт ИИ-инфраструктуру на «миллионах ускорителей NVIDIA Blackwell и Rubin», а также Arm-чипах GraceКомпании NVIDIA и Meta✴ объявили о многолетнем стратегическом партнёрстве, охватывающем локальную, облачную и ИИ-инфраструктуры. В частности, Meta✴ будет использовать в своих дата-центрах решения NVIDIA как для обучения больших языковых моделей (LLM), так и для инференса. Сообщается, что Meta✴ возьмёт на вооружение чипы NVIDIA Grace, которые будут использоваться в серверах, основанных исключительно на CPU-архитектуре (без ускорителей на основе GPU). Изделия Grace, напомним, объединяют 72 вычислительных ядра Armv9 Neoverse V2 (Demeter) с тактовой частотой до 3,35 ГГц и до 480 Гбайт памяти LPDDR5x. Доступна также сборка Grace Superchip, которая состоит из двух кристаллов Grace и чипов памяти LPDDR5x общим объёмом до 960 Гбайт. Meta✴ намерена применять изделия Grace для решения общих задач, а также поддержания работы ИИ-агентов, которым не требуются ИИ-ускорители. Вице-президент NVIDIA Иэн Бак (Ian Buck) отмечает, что решения Grace способны обеспечить вдвое большую производительность на 1 Вт при выполнении операций общего назначения по сравнению с альтернативными платформами. В дальнейшем Meta✴ планирует использовать Arm-процессоры NVIDIA следующего поколения — решения Vera. Крупномасштабные развёртывания систем на базе Vera намечены на 2027 год, что поможет Meta✴ в развитии энергоэффективных вычислений и формировании широкой экосистемы Arm. 
Источник изображения: Meta✴ Кроме того, в рамках партнёрства Meta✴ будет использовать «миллионы ускорителей NVIDIA Blackwell и Rubin». Так, на основе изделий NVIDIA GB300 компании создадут единую среду, охватывающую локальные дата-центры и облачные ресурсы, что позволит упростить операции при одновременном улучшении производительности и масштабируемости. Среди прочего Meta✴ будет применять сетевую платформу NVIDIA Spectrum-X Ethernet и технологию NVIDIA Confidential Computing для защиты данных. «Мы рады расширить партнёрство с NVIDIA с целью создания передовых кластеров на основе платформы Vera Rubin — это позволит предоставить персональный суперинтеллект каждому человеку в мире», — говорит Марк Цукерберг (Mark Zuckerberg), основатель и генеральный директор Meta✴. Нужно отметить, что среди гиперскейлеров только Meta✴ и Oracle используют в своих инфраструктурах сторонние чипы с архитектурой Arm. В то же время AWS, Google и Microsoft развивают собственные Arm-проекты — изделия Graviton, Axion и Cobalt соответственно.
11.02.2026 [13:38], Руслан Авдеев
Армения получит ещё 41 тыс. NVIDIA GB300 для ИИ ЦОД Firebird за $4 млрдАмериканская компания Firebird, специализирующаяся на облачных и инфраструктурных решениях для ИИ, объявила о реализации второго этапа суперкомпьютерного мегапроекта в Армении. Она получила экспортные лицензии США и разрешения регуляторов на поставку в страну ещё 41 тыс. ускорителей NVIDIA GB300, сообщает HPC Wire. Расширение вычислительного кластера в Армении знаменует собой важную веху. Предполагается, что страна войдёт в пятёрку мест размещения крупнейших кластеров ИИ-ускорителей. Проект стоимостью $4 млрд — одно из крупнейших капиталовложений в технологическую сферу в истории страны. Подробности в ходе визита в Ереван раскрыл вице-президент США Джей Ди Вэнс (JD Vance) при участии вице-президента NVIDIA. По словам Вэнса, США «с гордостью» одобрили замечательное техническое соглашение с NVIDIA. Речь идёт об открытии новых рынков и новых рабочих мест как для американских работников, так и для армянских. 
Источник изображения: Firebird 8 августа прошлого года Армения и США подписали меморандум в сфере ИИ и полупроводников. Выданная США экспортная лицензия свидетельствует о том, что проект полностью соответствует американским требованиям. Второй этап — продолжение реализации плана Firebird, выделившей $500 млн на создание в Армении первого ИИ-кластера. Реализация двух этапов обеспечит качественный скачок в технологической инфраструктуре страны. Он позволит проводить исследования в биологии, робототехнике, космической сфере и в сфере ИИ нового поколения. По словам представителей Firebird, новый кластер превращает Армению в глобальный центр суперкомпьютерных вычислений.
26.11.2025 [13:48], Сергей Карасёв
MSI представила рабочую станцию CT60-S8060 на базе NVIDIA GB300Компания MSI анонсировала мощную рабочую станцию CT60-S8060, ориентированную на ресурсоёмкие задачи в сфере ИИ, такие как обучение больших языковых моделей и инференс, а также на анализ крупных массивов данных и пр. Новинка построена на аппаратной платформе NVIDIA. В основу системы положен «персональный ИИ-суперкомпьютер» DGX Station. Используется суперчип GB300: объединены ускоритель B300 с 288 Гбайт памяти HBM3E (до 8 Тбайт/с) и процессор Grace с 72 Arm-ядрами. Присутствуют 496 Гбайт памяти LPDDR5X с пропускной способностью до 396 Гбайт/с. Блоки CPU и GPU связаны интерконнектом NVLink-C2C, который обеспечивает скорость передачи данных до 900 Гбайт/с. Рабочая станция заключена в корпус с габаритами 245 × 528,4 × 595 мм. Доступны два слота PCIe 5.0 x16 (на уровне сигналов x8 каждый) для карт расширения одинарной ширины и слот PCIe 5.0 x16 для карты двойной ширины. Кроме того, есть по два разъёма М.2 2280 с интерфейсом PCIe 5.0 x2 (NVMe) и M.2 2280 с интерфейсом PCIe 6.0 x4 (NVMe) для SSD, а также коннектор М.2 2232 (PCIe x1) для комбинированного адаптера Wi-Fi/Bluetooth. 
Источник изображения: MSI Система располагает контроллером Aspeed AST2600 BMC, сетевым адаптером NVIDIA ConnectX-8 с двумя портами 400GbE QSFP и контроллером Marvel AQC113, на основе которого реализован порт 10GbE RJ45. В тыльной части сосредоточены аудиогнёзда, порты USB Type-A и USB Type-C. Питание обеспечивает блок формата ATX мощностью 1600 Вт с сертификатом 80 PLUS Titanium.
21.11.2025 [14:14], Руслан Авдеев
AWS и Humain построят в Эр-Рияде кампус AI Zone, где развернут до 150 тыс. ИИ-ускорителей NVIDIA GB300 и Amazon TrainiumAWS и инвестиционная компания Humain из Саудовской Аравии объявили о планах развёртывания в кампусе AI Zone в Эр-Рияде до 150 тыс. ИИ-ускорителей. В рамках расширенного партнёрства компании намерены предоставлять вычислительные мощности и ИИ-сервисы из Саудовской Аравии клиентам со всего мира. Первый в своём роде в Саудовской Аравии кампус AI Zone будет применяться для обучения ИИ и инференса, с доступом к новейшей ИИ-инфраструктуре на основе ускорителей NVIDIA GB300 и Amazon Trainium. Клиенты смогут быстро переходить от стадии концепции к непосредственно работам, а «железо» и ПО NVIDIA будут бесшовно интегрированы с инфраструктурой и сервисами AWS. Поддержка Amazon Bedrock, AgentCore и SageMaker обеспечит клиентам немедленный доступ к базовым моделям в рамках единой платформы без необходимости управления базовой инфраструктурой. Для расширения возможностей AI Zone компания Humain присоединится к программе AWS Solution Provider Program. Это поможет реализации совместного плана, анонсированного в мае 2025 года и предусматривающего инвестиции более $5 млрд в ИИ-инфраструктуру, сервисы AWS, обучение и развитие ИИ-специалистов в Саудовской Аравии. Представитель AWS в регионе EMEA заявил, что объединяя локальный опыт и инвестиции Humain с решениями AWS в сфере ИИ, а также аппаратные решения NVIDIA, инновационную платформу Amazon Bedrock и решения для бизнес-пользователей, включая Amazon Quick Suite, партнёры создают инновационный центр мирового уровня, способный обслуживать клиентов по всему миру. AWS и Humain также ускорят внедрение ИИ в государственном и частном секторах, в том числе развитие LLM с поддержкой арабского языка, включая ALLAM, и создание единого маркетплейса ИИ-агентов для правительственных сервисов. 
Истчоник изображения: backer Sha/unsplash.com Для подготовки квалифицированных кадров AWS обучит 100 тыс. граждан Саудовской Аравии работе с облачными технологиями и специфике генеративного ИИ в рамках программы Amazon Academy, отдельно планируется поддержать программу повышения квалификации для 10 тыс. женщин. Усилия направлены на подготовку кадров для «ИИ-центричной» экономики, которая, по прогнозам, к 2030 году внесёт в ВВП страны вклад в объёме $130 млрд. Подобные проекты стали возможны во многом благодаря визиту в США наследного принца Саудовской Аравии Мохаммеда бин Салмана (Mohammed bin Salman). Визит способствовал ряду соглашений американских компаний с саудовским бизнесом и Humain в частности — с участием AMD, xAI, NVIDIA и др., а также открыл дорогу для поставок в королевство передовых ИИ-чипов.
14.11.2025 [01:55], Владимир Мироненко
NVIDIA вновь впереди всех в новом раунде MLPerf Training v5.1Консорциум MLCommons опубликовал результаты тестирования различных аппаратных решений в бенчмарке MLPerf Training v5.1. На этот раз был установлен новый рекорд по разнообразию представленных систем. Участники этого раунда тестирования представили 65 уникальных систем, оснащённых 12 различными аппаратными ускорителями и различными программными платформами. Почти половина заявок была для многоузловых систем, что на 86 % больше, чем в раунде MLPerf Training 4.1 год назад, причём они так же отличались разнообразием сетевых архитектур. Раунд MLPerf Training v5.1 включает в себя результаты 20 компаний, подавших заявки: AMD, ASUS, Cisco, Dell, Giga Computing, HPE, Krai, Lambda, Lenovo, MangoBoost, MiTAC, Nebius, NVIDIA, Oracle, Quanta Cloud Technology (QCT), Supermicro, Supermicro + MangoBoost, Университет Флориды, Verda (DataCrunch), Wiwynn. 
Источник изображений: NVIDIA Также сообщается, что структура заявок свидетельствует о растущем внимании к тестам, ориентированным на задачи генеративного ИИ: количество заявок на тест Llama 2 70B LoRa увеличилось на 24 %, а на новый тест Llama 3.1 8B — на 15 % по сравнению с тестом, который он заменил (BERT). NVIDIA объявила, что её чипы на архитектуре NVIDIA Blackwell заняли первые позиции во всех семи тестах MLPerf Training v5.1, обеспечив максимально быстрое обучение в работе с большими языковыми моделями (LLM), генерацией изображений, рекомендательными системами, компьютерным зрением и графическими нейронными сетями. 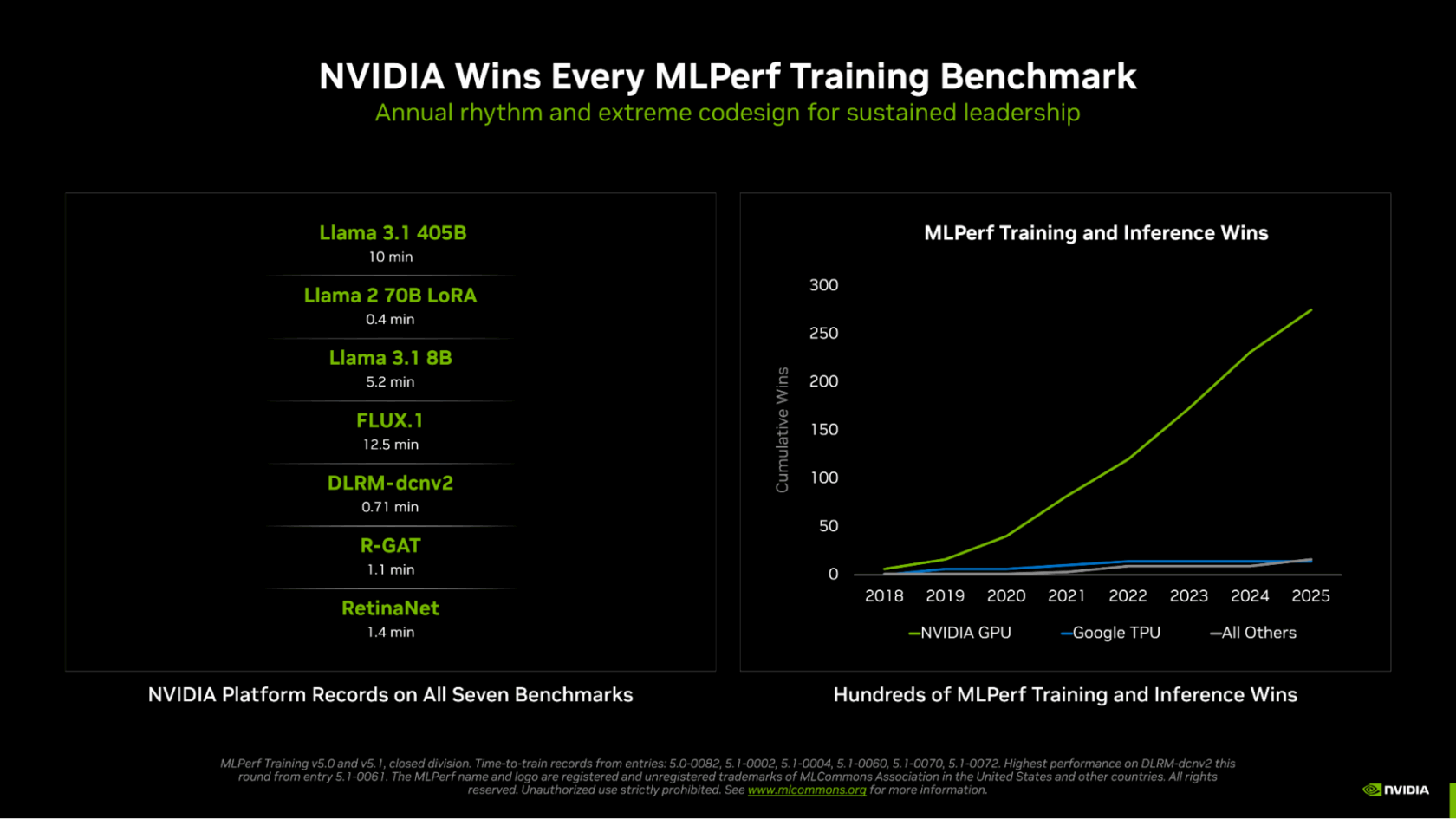 NVIDIA подчеркнула, что была единственной платформой, которая предоставила результаты по всем тестам — это, по словам компании, «подчёркивает широкие возможности программирования ускорителей NVIDIA, а также зрелость и универсальность программного стека CUDA». Компания сообщила, что в этом раунде MLPerf Training дебютировала стоечная система GB300 NVL72, работающая на базе ускорителя NVIDIA Blackwell Ultra, показав рекордные результаты и доказав, что является наилучшим выбором для интенсивных рабочих ИИ-нагрузок. При предварительном обучении Llama 3.1 40B ускорители GB300 обеспечивают более чем вчетверо большую производительность по сравнению с H100 и почти вдвое — по сравнению с GB200. Аналогичным образом, при точной настройке Llama 2 70B восемь ускорителей GB300 обеспечили в пять раз большую производительность по сравнению с H100.  NVIDIA отметила, что этого удалось достичь благодаря архитектурным усовершенствованиям Blackwell Ultra, включая новые тензорные ядра, которые обеспечивают ИИ-производительность в формате NVFP4 в размере 15 Пфлопс, вдвое большую производительность в работе механизма внимания (attention-layer compute) и 279 Гбайт HBM3e, а также новые методы обучения, которые позволили повысить вычислительную производительность архитектуры NVFP4. В MLPerf также дебютировала 800G-платформа Quantum-X800 InfiniBand, объединяющая несколько систем GB300 NVL72, которая удвоила пропускную способность сети по сравнению с предыдущим поколением. Но по словам компании, «ключом к выдающимся результатам в этом раунде было выполнение вычислений с использованием NVFP4 — впервые в истории MLPerf Training». NVIDIA обеспечила поддержку FP4 для обучения LLM на каждом уровне, что позволило удвоить скорость вычислений по сравнению с FP8. Ускоритель NVIDIA Blackwell может выполнять вычисления в формате FP4 (в т.ч. NVFP4 и др.) с удвоенной скоростью по сравнению с FP8, а Blackwell Ultra — с утроенной.  На сегодняшний день NVIDIA является единственной платформой, которая представила результаты MLPerf Training с вычислениями, выполненными с использованием FP4 при соблюдении строгих требований к точности в тесте. Эти результаты были получены с использованием 5120 ускорителей Blackwell GB200, которым потребовалось всего 10 мин. на бенчмарк Llama 3.1 405B, что является новым рекордом. Это в 2,7 раза быстрее, чем лучший результат с использованием архитектуры Blackwell, показанный в предыдущем раунде бенчмарка. NVIDIA также установила рекорды производительности в двух новых тестах: Llama 3.1 8B и FLUX.1. Llama 3.1 8B — компактная, но обладающая высокой производительностью LLM — заменила модель BERT-large, добавив в линейку базовых моделей современную LLM малого размера. NVIDIA представила результаты с использованием до 512 ускорителей Blackwell Ultra, потратив 5,2 мин. на прохождение теста. FLUX.1 — современная модель генерации изображений — заменила Stable Diffusion v2, и только платформа NVIDIA представила результаты этого теста. NVIDIA представила результаты с использованием 1152 ускорителей Blackwell, установив рекорд — 12,5 мин. обучения.
12.11.2025 [15:17], Руслан Авдеев
Microsoft инвестирует $10 млрд в ИИ ЦОД в ПортугалииMicrosoft потратит $10 млрд на ИИ ЦОД на побережье Португалии. Это станет одной из крупнейших инвестиций компании в Европе в 2025 году, сообщает Bloomberg. Речь о проекте кампуса в Синише (Sines) в 150 км от Лиссабона. Строительством парка занимается Microsoft совместно с португальской Start Campus и британским стартапом Nscale. Информацию о проекте и сумме подтвердил президент Microsoft Брэд Смит (Brad Smith). Как отмечает Datacenter Dynamics, в начале года в кампусе введён в эксплуатацию первый из шести планируемых объектов — ЦОД SIN01. $10 млрд покроют расходы на развитие второй фазы проекта. Второй ЦОД SIN02 обеспечит 180 МВт и уже строится. Общая мощность кампуса должна составить 1,2 ГВт. Пока неизвестно, в скольких проектах ЦОД на площадке Microsoft и Nscale будут участвовать совместно. Партнёрство Microsoft, Nscale и Start Campus было анонсировано в октябре 2025 года. Nscale развернёт для Microsoft в Синише 12,6 тыс. ускорителей NVIDIA GB300. Столкнувшись с нехваткой мощностей, компания подписала соглашения с несколькими неооблаками на $60 млрд, в том числе с CoreWeave, Nebius, IREN и Lambda. Только за последний квартал на аренду потрачено $11,1 млрд. Мощности Nscale компания намерена арендовать в Великобритании, США и Норвегии. Всего Microsoft намерена арендовать у Nscale 116 тыс. ускорителей GB300. Хотя большинство ЦОД расположены в районе Лиссабона (присутствуют объекты AtlasEdge, Claranet, Edged, Tata Communications и Equinix), прибрежный город Синиш с населением порядка 15 тыс. человек становится ключевым инвестиционным хабом Португалии. Отсюда проложены и подводные кабели, ещё больше появится в будущем — Medusa, New CAM Ring, Nuvem и Olisipo. 
Источник изображения: Maksym Kaharlytskyi/unsplash.com В мае китайская CALB Group начала строить в городе фабрику по производству аккумуляторов за €2 млрд ($2,3 млрд). Также Синиш, возможно, станет домом для «ИИ-гигафабрики», поддерживаемой Евросоюзом. |
|

