Материалы по тегу: nvidia
|
23.06.2026 [11:33], Сергей Карасёв
В Японии появился гибридный квантово-классический суперкомпьютер Roquo производительностью 19,8 ПфлопсВ Центре вычислительных наук японского Института физико-химических исследований (R-CCS) введён в строй гибридный квантово-классический суперкомпьютер Roquo, названный в честь горы Рокко к северу от города Кобе. В создании НРС-системы приняли участие DTS, NVIDIA, Giga Computing, DDN и ScaleWorX. Roquo состоит из 135 вычислительных узлов на базе NVIDIA GB200 NVL4. В общей сложности задействованы 540 чипов Blackwell и 270 чипов NVIDIA Grace. Применяется интерконнект NVIDIA Quantum-X800 InfiniBand с общей пропускной способностью до 3,2 Тбит/с (установлены коммутаторы Q3400, поддерживающие скорость передачи данных 800 Гбит/с на порт). Реализовано жидкостное охлаждение. Заявленная производительность на операциях FP64 составляет 19,8 Пфлопс, а теоретическое пиковое быстродействие на операциях FP8 превышает 5 Эфлопс. Суперкомпьютер использует интерфейс SQC, что позволяет формировать гибридные среды с поддержкой традиционных и квантовых вычислений. 
Источник изображения: RIKEN В рамках проекта по созданию Roquo корпорация DTS осуществляла общую разработку платформы в соответствии с требованиями R-CCS. В свою очередь, NVIDIA предоставила базовые вычислительные и сетевые компоненты, тогда как Giga Computing отвечала за проектирование и производство серверов. DDN предоставила высокоскоростное файловое хранилище. Наконец, специалисты ScaleWorX осуществили общую системную интеграцию. Суперкомпьютер Roquo, как ожидается, поможет ускорить разработку и оценку эффективности новых квантовых алгоритмов. Кроме того, система будет использоваться для решения сложных задач, с которыми не в состоянии справиться классические НРС-комплексы.
21.06.2026 [14:58], Владимир Мироненко
Франция развивает ИИ-инфраструктуру в сотрудничестве с NVIDIAПлатформа AI Factory France (AI2F) под руководством Национального управления высокопроизводительных вычислений (GENCI) Франции объявила о запуске в партнёрстве с NVIDIA программы по ускорению инноваций в области ИИ в стране. Программа обеспечит компаниям упрощённый доступ к передовой вычислительной инфраструктуре и специализированным ИИ-сервисам. Она объединяет глобальную экосистему NVIDIA с национальными и европейскими ресурсами ИИ Франции. Сотрудничество между AI Factory France (AI2F) и программами NVIDIA Inception, NVIDIA Connect, позволяет стартапам получить доступ к национальным суперкомпьютерным ресурсам, включая Jean Zay. Первые участники, включая Pleias, Nebula и Ryax Technologies, уже используют эту возможность для создания приложений. Представленные в рамках GTC Paris мероприятия уже реализуются с использованием технологий NVIDIA. Так, Mistral строит новый ЦОД мощностью 44 МВт на севере Франции. Первый дата-центр Mistral, анонсированный в 2025 году, уже получил 18 тыс. систем NVIDIA GB200 в рамках плана по созданию 200 МВт вычислительных мощностей по всей Европе к 2027 году. В сотрудничестве с французским государственным инвестиционным банком Bpifrance, инвестиционной компанией MGX и NVIDIA компания работает над расширением Campus AI, сети предприятий в сфере ИИ, планируя построить ЦОД на 1,4 ГВт, что сделает её одним из крупнейших ИИ-платформ в Европе. Облачный провайдер Scaleway получил NVIDIA B300. 
Источник изображения: AI Factory France Bull и Foxconn намерены производить в Европе NVIDIA Vera Rubin NVL72. Системы будут производиться и первоначально тестироваться на заводах Foxconn в Чехии, после чего их будут собирать, интегрировать и полностью проверять на заводе Bull в Анжере (Angers). Консорциум из восьми ведущих французских компаний подал заявку на размещение европейской гигафабрики ИИ во Франции для укрепления европейской ИИ инфраструктуры и ускорения внедрения ИИ. В свою очередь Schneider Electric объединилась с NVIDIA для разработки проектов гигаваттных ИИ-фабрик для компаний, развивающих ИИ-инфраструктуры. Аналогичные инициативы внедряются по всей Европе, включая сотрудничество между NVIDIA и Барселонским суперкомпьютерным центром (BSC), в рамках которого создаётся сеть, соединяющая местную инфраструктуру со стартапами и учреждениями государственного сектора. Компания TotalEnergies построит Pangea 5, суперкомпьютер следующего поколения, разработанный совместно с Dell и NVIDIA, который будет использоваться для сейсмической съёмки, передового моделирования и исследований в области ИИ в энергетическом секторе.
20.06.2026 [15:45], Сергей Карасёв
В Словении запущена НРС-система FRIDA с ускорителями NVIDIA BlackwellЛюблянский университет в Словении (University of Ljubljana), по сообщению DataCenter Dynamics, запустил высокопроизводительную систему FRIDA, ориентированную на задачи ИИ и машинного обучения. Это не классический суперкомпьютер, а модульный контейнерный дата-центр, размещённый на крыше здания Факультета компьютерных и информационных наук (FRI) в Любляне. Известно, что в составе FRIDA задействованы 104 ускорителя на основе GPU. В частности, применяются изделия NVIDIA Blackwell B200 и B300. Суммарный объём GPU-памяти составляет 16,8 Тбайт. Комплекс оборудован гибридной воздушно-жидкостной системой охлаждения. Все вычислительные узлы связаны интерконнектом с высокой пропускной способностью. Отмечается, что производительность FRIDA при вычислениях с низкой точностью достигает 708 Пфлопс. Пиковое быстродействие при операциях с разреженными матрицами низкой точности заявлено на уровне 1,42 Эфлопс. FRIDA дополнит словенскую НРС-систему Vega, которая была введена в строй в 2021 году в рамках проекта Европейского совместного предприятия по развитию высокопроизводительных вычислений (EuroHPC JU). Эта машина, основанная на процессорах AMD и ускорителях NVIDIA, демонстрирует FP64-производительность на уровне 6,9 Пфлопс. 
Источник изображения: linkedin.com Vega задумывалась как универсальная платформа для сложных вычислений: она может применяться для решения задач в самых разных областях, включая биоинженерию и разработку новых лекарств, изучение климата и прогнозирование погоды, персонализированную медицину, создание новых материалов и пр. В свою очередь, система FRIDA ориентирована прежде всего на нагрузки, связанные с ИИ.
18.06.2026 [09:22], Руслан Авдеев
Глава NVIDIA лично поучаствовал в закладке нового производства оптических компонентов CoherentКомпания Coherent, выпускающая лазеры, оптические компоненты, полупроводники для ИИ-систем и 6″ пластины из фосфида индия (InP), начала строительство расширенного производственного корпуса в Шермане (Sherman, Техас). В церемонии открытия принял участие глава NVIDIA Дженсен Хуанг (Jensen Huang) и генеральный директор Coherent Джим Андерсон (Jim Anderson). Хуанг назвал Coherent жизненно важной компанией для будущего США. Новая фабрика позволит нарастить производство пластин из фосфида индия — ключевого компонента систем передачи данных между чипами, серверами и ЦОД, формирующего современный оптический «каркас» ИИ-инфраструктуры. Coherent заявила, что полученный в рамках CHIPS Act грант поможет профинансирвоать расширение производства. Ранее $17 млн было выделено в рамках техасской программы CHIPS и от локального фонда Sherman Economic Development Corporation. Импульс придаёт и обязательство NVIDIA организовать создание ИИ-инфраструктуры в США на сумму до $500 млрд. Полупроводники на основе фосфида индия или арсенида галлия лежат в основе высокоскоростных сетей, необходимых для современных ИИ-систем, таких как NVIDIA Vera Rubin Ultra NVL576. InP-лазеры используются в оптических модулях Coherent, устанавливаемых в сетевые коммутаторы NVIDIA. Те же модули применяются в коммутаторах NVIDIA Spectrum-X и Quantum-X с интегрированной оптикой (CPO), для которых Coherent поставляет внешние лазерные модули. 
Источник изображения: NVIDIA NVIDIA и Coherent сотрудничают почти 20 лет. В марте они заключили многолетнее стратегическое соглашение, в рамках которого NVIDIA инвестирует $2 млрд в Coherent для поддержки разработок и исследований, а также организации производства на территории США. Кроме того, NVIDIA обязалась закупать у Cohere передовые лазерные и оптические сетевые продукты. Ранее она также заключила крупное соглашение с поставщиком оптоволокна Corning, который тоже расширит производство на территории США. Завод в Шермане занимается выпуском не одного конкретного продукта, а производством всевозможных лазеров, трансиверов, подключаемых оптических модулей и др., обеспечивающих передачу данных в экосистеме NVIDIA. Переход на современные 6″ пластины из фосфида индия позволит приблизительно вчетверо увеличить выход продукции. Большинство других поставщиков до сих пор использует только 3″–4″ пластины.
18.06.2026 [01:45], Владимир Мироненко
NVIDIA стала лидером во всех тестах MLPerf Training 6.0Консорциум MLCommons опубликовал результаты тестирования различных аппаратных решений в бенчмарке MLPerf Training 6.0. В нём появилось два новых теста — DeepSeek V3 и GPT-OSS 20B, что подчёркивает общеотраслевой переход к разреженным вычислениям, примером которого является архитектура MoE (Mixture-of-Experts). DeepSeek V3 — крупномасштабная MoE-модель c 671 млрд параметров, из которых 37 млрд активируются для генерации отдельного токена. Она предоставляет стандартизированную платформу для оценки эффективности обучения ведущей модели MoE с открытыми весами. GPT-OSS 20B — MoE-модель c 21 млрд параметров, из которых 3,6 млрд активируются для генерации одного токена. Она позволяет организациям оценивать сложную логику маршрутизации и шаблоны разреженных вычислений, характерные для архитектуры MoE, на аппаратных конфигурациях размером всего в один узел с восемью ускорителями. Версия MLPerf Training 6.0 установила новые рекорды по разнообразию представленных систем. Участники выложили результаты 95 уникальных систем, использующих тринадцать различных аппаратных ускорителей, 19 различных хост-процессоров и несколько различных программных фреймворков. 60 % систем были многоузловыми. При этом количество представленных облачных систем более чем вдвое больше, чем в раунде 5.1. 
Источник изображения: NVIDIA В раунде MLPerf Training v6.0 представлены заявки от 24 организаций: AMD, ASUSTeK, Azure, Cisco, CoreWeave, Dell, Fujitsu, GigaComputing, Google, HPE, Inventec, Krai, Lambda, MITAC, Nebius, Netweb Technologies India, NVIDIA, Oracle, Quanta Cloud Technologies, SCITIX, Supermicro, tinycorp, TTA и Vultr. «Мы особенно рады приветствовать участников, впервые представляющих свои результаты в MLPerf Training: Inventec, Netweb Technologies India, TTA и Vultr», — сообщил Дэвид Кантер (David Kanter), руководитель MLPerf в MLCommons. NVIDIA вновь стала лидером в новом раунде MLPerf Training, причём во всех тестах, в очередной раз став единственной платформой, которая предоставила результаты по всем тестам. Также NVIDIA была единственной платформой, представившей результаты по новым тестам, при этом система NVIDIA GB300 NVL72 «установила планку производительности благодаря оптимизированным программным стекам NVIDIA и конструкции, объединяющей 72 GPU Blackwell Ultra и 36 CPU Grace с использованием NVLink и NVLink Switch». В нескольких случаях партнёры NVIDIA масштабировали систему до 8192 ускорителей Blackwell, работающих согласованно в различных ЦОД. Эти результаты подтвердили реальную надёжность платформы Blackwell в масштабируемых кластерных средах, говорит NVIDIA. 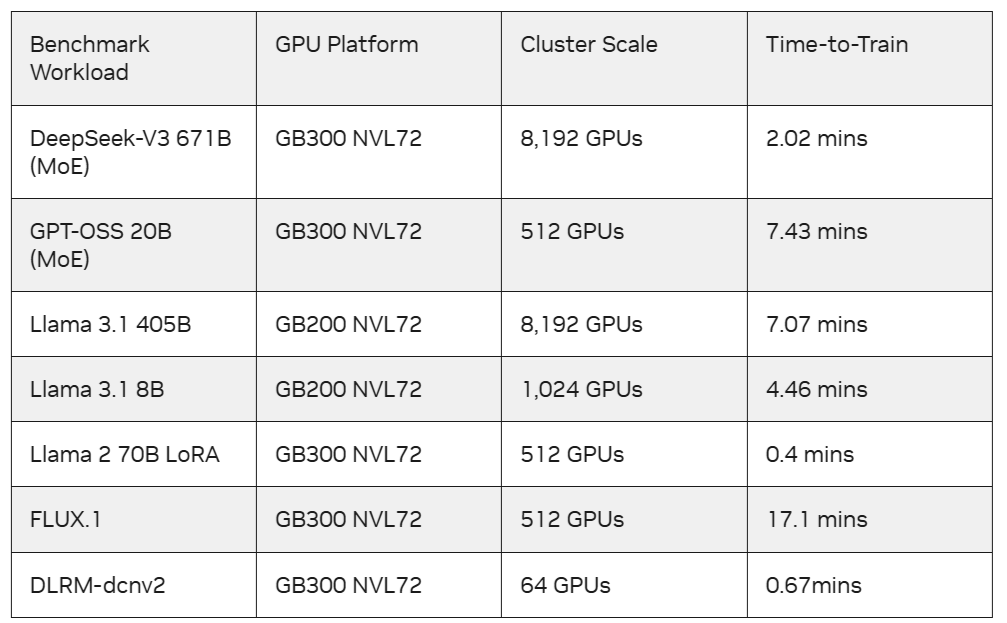
Источник изображения: NVIDIA Для достижения максимальной производительности таких моделей, как DeepSeek-V3, NVIDIA в этом раунде MLPerf Training применила несколько программных оптимизаций, включая использование итерационных графов CUDA для MoE без удаления токенов, применение CuTe DSL для продвинутых операций слияния ядер, алгоритм внимания MXFP8 для повышения производительности без ущерба для качества модели, оптимизацию маршрутизатора и оптимизацию схемы коммуникации 1F1B all-to-all overlap. Также NVIDIA оптимизировала компоновку и баланс параллельных этапов конвейера, минимизируя структурное простаивание. Для обработки DeepSeek-V3 671B компания NVIDIA использовала до 8192 GPU в системах GB200 NVL72, что стало самым масштабным результатом на основе Blackwell в MLPerf Training на сегодняшний день. NVIDIA также представила результаты на 5120 GPU с системами NVIDIA GB200 NVL72 в Llama 3.1 405B, одной из самых крупных LLM плотной архитектуры в этом бенчмарке. Результаты этого раунда также отражают тесное сотрудничество NVIDIA с компаниями-партнёрами в области системной архитектуры, сетей и ПО. Например, Microsoft Azure масштабировала обучение Llama 3.1 405B до 8192 GPU, используя системы GB200 NVL72, и достигла целевого эталонного значения за 7,07 мин., что является самым быстрым временем обучения для этого бенчмарка. А CoreWeave показала самое быстрое время обучения для DeepSeek-V3 671B, достигнув целевого качества за 2,02 мин. на 8192 GPU в составе GB300 NVL72, объединённых Spectrum-X Ethernet.
17.06.2026 [15:09], Руслан Авдеев
IDC: на x86 теперь приходится лишь чуть более половины рынка серверов, в основном из-за ИИНовейшая статистика свидетельствует, что почти половины выручки на мировом рынке серверов приходится на архитектуры, отличные от «классической» x86, сообщает The Register со ссылкой на исследование IDC. Ситуацию определяют спрос на ИИ-системы и дефицит памяти DRAM и NAND. В отчёте IDC Worldwide Quarterly Server Tracker за I квартал 2026 года говорится, что на x86-серверы с процессорами AMD и Intel приходится чуть более 50 % выручки, а на прочие архитектуры — 47,9 %. При этом последние показали рост на 107 % г/г ($58,7 млрд), тогда как x86-платформы упали, но лишь на 2,9 % г/г ($63,9 млрд). Рынок в целом вырос до $122,6 млрд, на 30,4 % г/г. Аналитики связывают такое изменение сил с ростом продаж систем NVIDIA, которые включают Arm-процессоры. Спрос на них чрезвычайно высок, а стоят они значительно выше чипов для обычных серверов ЦОД. И, если гиперскейлеры и крупные облачные провайдеры и не думают замедлять инвестиции, то рынок классических серверов, не связанных с ИИ-ускорителями, чувствует себя не особенно бодро, во многом из-за приоритетных инвестиций и поставок в ИИ. Так, производители памяти предпочитают выпускать более маржинальные продукты для ИИ-платформ, поэтому прочим сегмента рынка памяти не хватает. По данным IDC, дефицит DRAM и NAND определяет дефицит поставок обычных серверов в краткосрочной перспективе, хотя спрос на них тоже довольно высок. Но высокие цены вынуждают откладывать закупки. 
Источник изображения: Towfiqu barbhuiya/unsplash.com Серверы с GPU-ускорителями принесли $68,9 млрд, рост составил около 25 % г/г. На прочие «ускоренные» серверы с FPGA/ASIC пришлось $17,7 млрд, рост составил 122 % г/г. В IDC считают, что внедрение ИИ-инфраструктуры более не ограничено спросом гиперскейлеров. Например, суверенные ИИ-мощности пытаются создавать по всему миру на государственном уровне. IDC рассчитывает, что ситуация начнёт нормализоваться с 2027 года, когда производители чипов введут в строй новые фабрики и расширят имеющиеся производственные мощности. За последние два десятилетия на серверы, построенные не на x86-архитектуре, приходилось менее 10 % выручки, большинство из которой доставалась IBM (POWER и z-менфреймы), которая фактически была единственным крупным поставщиком проприетарных серверных решений после того, как Oracle разочаровалась в платформе Sun SPARC, а HPE решила, что поддерживать бизнес на основе «экзотических» архитектур вроде Itanium нецелесообразно. Архитектура RISC-V весьма популярна в Китае, поскольку на неё не распространяются многие ограничения политических оппонентов, однако массовыми крупные серверные CPU на её базе так и не стали, хотя цифры по отгруженным ядрам впечатляют. Так что надежды Arm занять более половины рынка чипов для ЦОД оправдались. Так, у Microsoft есть собственные Arm-процессоры Cobalt 200, у AWS — Graviton 5, у Alibaba Cloud — Yitian 710, а у Google — Axion. Среди крупных независимых остались Ampere Computing (используется Oracle), которая теперь принадлежит SoftBank, и Huawei со своими Kunpeng. Собственные Arm-процессоры также готовят сама Arm, Qualcomm, Fujitsu и NVIDIA. Причём последняя позиционирует их именно как конкурентов x86.
16.06.2026 [12:10], Руслан Авдеев
Австралийская SharonAI Holdings купит 40 тыс. ускорителей GB300 и поделится с NVIDIA выручкой от ИИ-облакаSharonAI Holdings заключила с NVIDIA стратегическое соглашение сроком на шесть лет для поддержки развёртывания ИИ-фабрики мощностью 72 МВт в Австралии. Договор позволяет SharonAI масштабировать свою облачную ИИ-платформу, использовав до 40 тыс. ускорителей NVIDIA GB300. Мощности рассчитаны на спрос со стороны корпоративных клиентов, ИИ-стартапов, университетов, госсектора и исследовательских структур, требующих суверенных вычислительных мощностей, сообщает Converge! Digest. В основе сотрудничества — использование платформы для ИИ-фабрик NVIDIA DSX (на том же пакете технологий намерена строить ЦОД компания Helix Digital Infrastructure). Предусмотрено распределение средств, позволяющее ускорить развёртывание крупномасштабной ИИ-инфраструктуры. Sharon будет предоставлять облачные сервисы на основе продуктов NVIDIA, а последняя получит не только средства от продажи самих ускорителей и оборудования, но и долю «облачной» выручки. Это позволяет снизить капитальные затраты, одновременно расширяя доступ к передовым вычислительным ресурсам. 
Источник изображения: Jamie Davies/unsplash.com По итогам соглашения общая мощность объектов Sharon AI вырастет до 132 МВт, 102 МВт уже законтрактованы будущими клиентами. Компания рассчитывает развернуть более 55 тыс. ускорителей NVIDIA к середине 2027 года. Она обладает статусом NVIDIA Cloud Partner и утверждает, что новое соглашение укрепит её позиции в формирующейся ИИ-экосистеме Австралии и поможет развитию ИИ-фабрик для коммерческих и государственных структур страны. По словам Converge!, соглашение отражает растущий тренд, предусматривающий более тесную работу NVIDIA с облачными провайдерами и «неооблачными» компаниями для ускоренного развёртывания ИИ-инфраструктуры. Вместо того, чтобы просто полагаться на гиперскейлеров, NVIDIA всё чаще поддерживает проекты региональных ИИ-фабрик, создающихся для обеспечения суверенными мощностями правительств, коммерческих компаний, университетов и стартапов. Примечателен масштаб планируемого проекта. Полностью укомплектованная экосистема на 40 тыс. GB300 может считаться одной из крупнейших в Азиатско-Тихоокеанском регионе. Более того, речь идёт об эволюции бизнес-моделей в сфере ИИ — поставщики оборудования стремятся участвовать в бизнесе, постоянно получая долю выручки от облачных сервисов, не ограничиваясь только продажей оборудования.
15.06.2026 [12:58], Сергей Карасёв
В Сингапуре запущен суперкомпьютер ASPIRE 2B на базе NVIDIA H200 и AMD EPYC Turin с быстродействие 115 ПфлопсНациональный суперкомпьютерный центр Сингапура (NSCC) объявил о запуске вычислительного комплекса ASPIRE 2B с производительностью 115 Пфлопс. Систему планируется использовать для решения сложных задач в области климатологии и метеорологии, здравоохранения, разработки материалов, передового производства, ИИ и пр. В основу ASPIRE 2B положены 96-ядерные процессоры AMD EPYC 9655 поколения Turin: суммарное количество вычислительных ядер в составе суперкомпьютера достигает 184 320 (задействованы 1920 чипов). Быстродействие CPU-секции находится на уровне 12 Пфлопс. GPU-раздел машины объединяет 1536 ускорителей NVIDIA H200 со 141 Гбайт памяти HBM3e. Их суммарная пиковая производительность указана на отметке 103 Пфлопс. Объём системной памяти составляет 1072 Тбайт, вместимость подсистемы хранения данных — 63,5 Пбайт. Применяется интерконнект Slingshot с пропускной способностью 400 Гбит/с. Суперкомпьютер ASPIRE 2B планируется интегрировать с квантовой системой Helios компании Quantinuum, установка которой в Сингапуре запланирована на конец нынешнего года. Это позволит осуществлять гибридные квантово-классические вычисления в рамках комплексных проектов, связанных с молекулярным моделированием и созданием перспективных материалов. 
Источник изображения: NSCC Отмечается также, что NSCC меняет модель доступа пользователей к вычислительным ресурсам страны. Приоритет будет отдаваться национальным программам исследований и инноваций. Это должно способствовать ускорению развития передовых технологий и расширению сферы предпринимательства.
15.06.2026 [12:54], Руслан Авдеев
Helix Digital Infrastructure привлекла более $10 млрд на строительство ИИ-инфраструктуры «под ключ»KKR, Кувейтское инвестиционное управление (Kuwait Investment Authority, KIA), NVIDIA и крупная энергетическая компания Vistra создали совместное предприятие Helix Digital Infrastructure для строительства ИИ ЦОД для облачных гиперскейлеров, сообщает Silicon Angle. Предприятие уже привлекло более $10 млрд на свои проекты и рассчитывает привлечь и других инвесторов в будущем. Возглавляет новую структуру бывший гендиректор AWS Адам Селипски (Adam Selipsky), перешедший в KKR, а руководитель направления цифровой инфраструктуры KKR Вальдемар Шлезак (Waldemar Szlezak) стал её директором по инвестициям. Компания рассчитывает строить ЦОД на основе пакета технологий NVIDIA DSX, предназначенного для создания крупных ИИ-кластеров. Специальный инструмент для симуляций позволяет тестировать проекты ЦОД до их развёртывания, а ПО DSX OS позволяет автоматизировать повседневные задачи по обслуживанию ИИ-инфраструктуры. Helix назвала NVIDIA стратегическим партнёром, которая поможет с развёртыванием ИИ-инфраструктуры. Vistra, совокупные генерирующие мощности которой составляют 44 ГВт, станет ключевым поставщиком электроэнергии. 
Источник изображения: CHUTTERSNAP/unsplash.com Helix позиционирует себя как универсального поставщика ИИ-инфраструктуры «под ключ». Планируются не только инвестиции в ЦОД, но и в ВОЛС, энергетическую инфраструктуру, включая электростанции и ЛЭП, и связанные активы. У Blackrock есть аналогичная инициатива AIP (AI Infrastructure Partnership), в которой тоже участвуют KIA и NVIDIA, а Blackstone договорилась с Broadcom о развёртывании крупных ИИ-мощностей. Решение создать новую структуру, возможно, частично обусловлено чередой многомиллиардных сделок, подписанных строителями ИИ ЦОД за последний год. Так, в апреле CoreWeave заключила контракт на $21 млрд на поставку облачных мощностей Meta✴ Platforms до 2032 года. За несколько недель до этого Nebius Group заключила с Meta✴ аналогичный договор на $27 млрд. Тем временем Microsoft обязалась приобрести вычислительные мощности ИИ-ускорителей у Nscale. При этом CoreWeave не только строит инфраструктуру для гиперскейлеров, но и управляет собственным публичным облаком. Helix может избрать аналогичный подход. Возможно, что компания направит часть капитала на создание собственных технологий ЦОД, и это позволит получить перед конкурентами технологическое преимущество.
15.06.2026 [09:32], Сергей Карасёв
96 NVMe SSD с СЖО и четыре RTX Pro 6000: Wiwynn показала сверхбыстрое хранилище на базе NVIDIA SCADAКомпания Wiwynn (дочерняя структура Wistron), по сообщению ресурса Tom's Hardware, продемонстрировала один из первых в отрасли серверов хранения NVIDIA SCADA (SCaled Accelerated Data Access). Устройство ориентировано на высокопроизводительную обработку больших объёмов данных в рамках задач обучения ИИ-моделей и инференса. 
Источник изображений: Wiwynn Новинка выполнена в MGX-шасси высотой 6U и рассчитана на монтаж в 19″ серверную стойку. Задействован процессор NVIDIA Vera, который содержит 88 ядер Olympus, или Intel Xeon (в составе HPM-). Доступны восемь слотов для модулей DDR5. Система несёт на борту четыре ускорителя NVIDIA RTX Pro 6000 Blackwell Server Edition, четыре коммутатора PCIe 6.x и четыре 800G-карты ConnectX-9 SuperNIC/DPU BlueField-4 (опционально GPU можно поменять на DPU). Реализовано полностью жидкостное охлаждение.  Сервер рассчитан на 96 накопителей EDSFF E3.S SSD с вертикальной загрузкой. При использовании изделий Micron 9650 Pro вместимостью 30,72 Тбайт с интерфейсом PCIe 6.0 суммарная ёмкость достигает 2,949 Пбайт. При этом обеспечивается показатель IOPS на операциях случайного чтения до 528 млн. Максимальное энергопотребление новинки — 9 кВт (питание DC 50 В). Кабели питания и гибкие шланги СЖО расположенные в нишах по бокам, что позволяет выдвигать лоток с накопителями и производить «горячую» замену SSD. 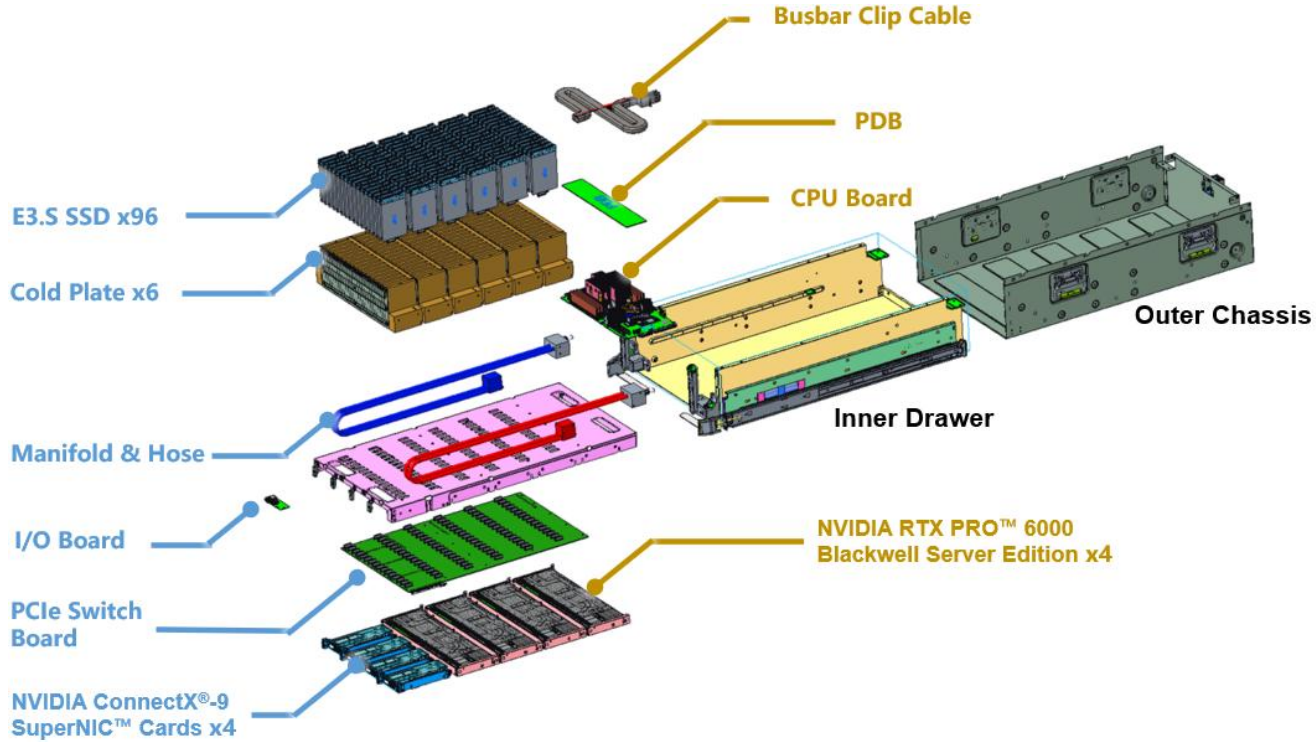 Отмечается, что традиционные серверы на основе CPU плохо справляются с такими задачами, как векторный поиск, генерация с дополненной выборкой (RAG), анализ графов и извлечение данных из KV-кеша. При таких нагрузках процессору необходимо выдавать команды, обрабатывать запросы и контролировать передачу данных, из-за чего создаются узкие места. 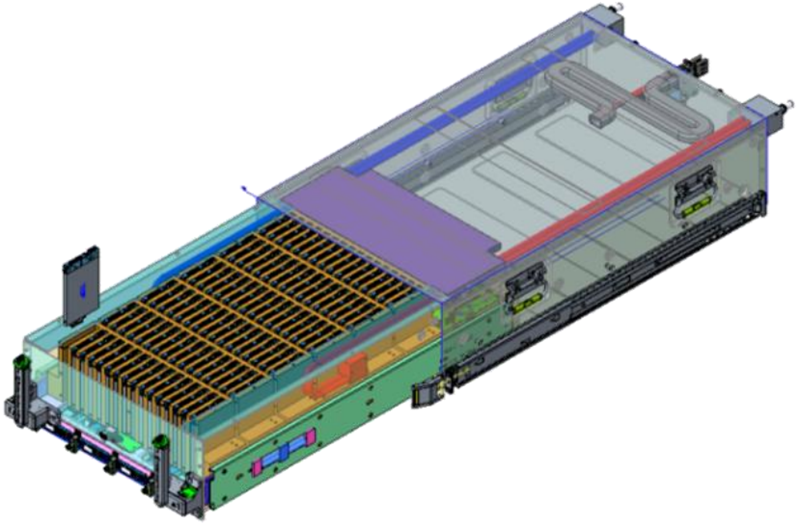 Платформа SCADA позволяет решить проблему благодаря тому, что операции ввода-вывода и обработка данных возлагаются на GPU — без участия CPU. По сути, ускорители RTX Pro 6000 Blackwell Server Edition в составе машины выполняют функции процессоров хранения, которые инициируют и обрабатывают транзакции и миллионы запросов со стороны ИИ-приложений, а также передают данные на вычислительные узлы посредством карт ConnectX-9. |
|

