Материалы по тегу: 800gbe
|
03.07.2026 [08:51], Сергей Карасёв
Квартальные продажи Ethernet-коммутаторов взлетели на 40 %, а NVIDIA выбилась в лидеры в ЦОД-сегментеIDC подвела итоги исследования глобального рынка Ethernet-коммутаторов корпоративного класса в I квартале текущего года: продажи таких устройств в денежном выражении достигли $15,4 млрд, что на 39,8 % больше по сравнению с аналогичным периодом 2025-го. Отмечается, что в сегменте дата-центров выручка взлетела в годовом исчислении на 61,0 %, составив около $10 млрд. Столь значительный рост аналитики связывают с продолжающимся развитием инфраструктуры ИИ, а также расширением мощностей гиперскейлеров. В ЦОД-секторе 35,8 % продаж в деньгах обеспечили коммутаторы стандарта 800GbE, ещё 34,1 % — решения класса 200/400GbE. С географической точки зрения спрос на коммутаторы поднялся во всех ключевых регионах. Так, на американском рынке прибавка составила 49,7 % в годовом исчислении. В странах EMEA (Европа, Ближний Восток и Африка) зафиксирован рост на 32,2 %, а в Азиатско-Тихоокеанском регионе — на 25,9 %. 
Источник изображения: Lambda Подчёркивается, что в сегменте Ethernet-коммутаторов для дата-центров в лидеры вырвалась NVIDIA, у которой продажи в денежном выражении подскочили год к году на 192,7 % — до $2,1 млрд: это соответствует доли в 21,5 % в соответствующей области. Однако в целом по рынку лидирует Cisco с 29,3 % и выручкой в объёме $4,5 млрд (+24,0 % по отношению к I кварталу 2025 года). У Arista Networks продажи поднялись на 37,3 % — до $2,2 млрд, что соответствует 14,6 % отрасли. В пятёрку ведущих игроков также входят НРЕ с 6,4 % и $985 млн (+15,4 % г/г) и Huawei с 5,8 % и $895 млн (+27,2 %). В исследовании говорится, что продажи маршрутизаторов для предприятий и поставщиков услуг по итогам I четверти 2026 года составили $3,8 млрд, что соответствует росту на 11,3 % в годовом исчислении. На поставщиков услуг пришлось 77,2 % от указанной суммы, или $2,9 млрд (+12,9 % г/г). Еще $867 млн принесли маршрутизаторы корпоративного класса — +6,1 % по отношению к I кварталу прошлого года.
28.06.2026 [15:48], Сергей Карасёв
Китайские x86-процессоры Hygon C86-5G получили 128 ядер с поддержкой 512 потоковКитайская компания Hygon, по сообщениям сетевых источников, создала процессоры нового поколения с архитектурой x86. Речь идёт об изделиях C86-5G, которые, как ожидается, будут применяться в оборудовании для дата-центров. Кроме того, в разработке находятся другие продукты, включая ИИ-ускорители. Решения C86-5G придут на смену изделиям C86-4G, которые являются наследниками AMD Zen1. Чипы C86-4G насчитывают 16 вычислительных ядер с возможностью одновременной обработки до 32 потоков инструкций, а тактовая частота составляет 2,8 ГГц. Реализована поддержка оперативной памяти DDR5 и интерфейса PCIe 5.0. Известно, что процессоры C86-5G получат до 128 вычислительных ядер. Упомянута технология многопоточности SMT4, которая позволит каждому ядру обрабатывать четыре потока инструкций, что в сумме даст 512 потоков. Упомянута поддержка 104 линий PCIe 5.0, инструкций AVX512, а также режимов INT8 и BF16. Заявленная производительность — 10 Тфлопс на операциях FP64 (до 32 операций за такт). Ожидается, что в ЦОД-сегменте новые китайские процессоры станут альтернативой Intel Xeon 6. 
Источник изображений: Hygon Производство C86-5G уже началось. Чипы станут основой ряда серверов, включая двухсокетную модель H620G59 формата 2U с воздушным охлаждением. Эта система оборудована 32 слотами для модулей DDR5-6400, тремя разъёмами PCIe 5.0 х16, двумя слотами ОСР 3.0, восемью фронтальными отсеками для накопителей стандарта SFF, а также двумя внутренними коннекторами для SSD типоразмера М.2. Кроме того, готовятся серверные стойки высокой плотности TC800G6 (PUE — 1,08) и TC8600H G5 (PUE — 1,04) с жидкостным охлаждением.  Вместе с тем Hygon намерена выпустить GPU с памятью HBM и высокоскоростным интерконнектом. Известно, что это устройство допускает работу в режимах FP64/PF16/BF16. Новинка, предположительно, сможет составить конкуренцию NVIDIA A100. Наконец, в разработке находятся коммутационные решения класса 400/800 Гбит/с. Это чип с поддержкой 104 линий PCIe 5.0, высокоскоростной интерконнект для вертикального масштабирования (сопоставим с NVLink), решение ScaleFabric 400G (для NIC), а также ScaleFabric 400/800G. Последняя из перечисленных новинок обеспечивает поддержку 80 портов на 400 Гбит/с с RDMA, а коммутационная способность достигает 64 Тбит/с. Это устройство рассматривается в качестве альтернативы InfiniBand NDR.
14.06.2026 [14:30], Руслан Авдеев
Colt и Ciena успешно испытали «постквантовый» трансатлантический 800-Гбит/с каналКомпании Colt Technology Services и Ciena успешно провели «самую быструю» квантово-защищённую передачу данных через Атлантику. Трафик между Нью-Йорком и Лондоном передавался со скоростью 800 Гбит/с через 6,9 тыс. км наземной и подводной кабельной инфраструктуры Colt с применением оптической платформы Ciena WaveLogic 6 Extreme (WL6e), сообщает Converge! Digest. Использование специальной защиты подчёркивает рост внимания отрасли к защите данных не только от актуальных сегодня угроз, но и от угроз будущего, в котором квантовые компьютеры теоретически будут довольно легко справляться с традиционными алгоритмами шифрования. При этом будет обеспечена по-прежнему высокая скорость передачи информации, что особенно важно для ИИ-нагрузок и операторов ЦОД. Тесты направлены на борьбу с современными атаками типа «собери сейчас — расшифруй потом» (harvest now, decrypt later). В этом случае злоумышленник сохраняет защищённые данные с целью их расшифровки уже тогда, когда появятся достаточно производительные для этого квантовые компьютеры. Платформа WL6e применяет постквантовую криптографию (PQC), соответствующую стандартам NIST — она интегрирована с 1,6 Тбит/с когерентной оптической технологией. Компании заявила, что испытания подтвердили возможность совмещать «постквантовую» защиту с передачей данных на высокой скорости на одном из самых загруженных каналов связи в мире. 
Источник изображения: Dynamic Wang/unsplash.com По данным Colt, испытание стало продолжением серии инициатив, направленных на внедрение новых технологий защиты в наземной и подводной инфраструктуре компании. Colt уже предлагает постквантовую криптографию (PQC), квантовое распределение ключей (QKD), инфраструктуру симметричных ключей (SKI) и гибридные архитектуры безопасности. Также партнёры отметили стабильность оптической сети и её готовность к новым требованиям к производительности, связанным с ИИ-трафиком — в этой сфере безопасная передача данных между ЦОД становится всё важнее. По словам Converge!, речь идёт о продолжении многолетнего взаимодействия Colt и Ciena, направленного на расширение возможностей трансокеанских ВОЛС. В 2024 года компании объявили о первой в отрасли передаче сигнала через Атлантический океан со скоростью 1,2 Тбит/с. В 2025 году они представили для нужд гиперскейлеров новую сеть терабитного уровня. Теперь акцент смещается с обычного наращивания пропускной способности на дополнительное обеспечение безопасности в преддверии начала массовых квантовых вычислений.
11.06.2026 [09:18], Сергей Карасёв
СЖО и 1,6 Тбит/с на порт: Arista представила коммутаторы 7060XE7 для ИИ ЦОДКомпания Arista Networks анонсировала коммутаторы семейства 7060XE7, ориентированные на масштабные ИИ-инфраструктуры следующего поколения с высокой интенсивностью обмена данными. Устройства обеспечивают коммутационную способность до 102,4 Тбит/с. В основу изделий положен чип Broadcom Tomahawk 6. Объём оперативной памяти составляет 32 Гбайт, вместимость встроенного SSD — 480 Гбайт. Для управления предусмотрены два разъёма RJ45, консольный порт и коннектор USB. Реализована технология LPO (Linear Pluggable Optics), которая позволяет формировать прямые соединения между оптоволоконными модулями, устраняя необходимость в традиционных компонентах вроде цифровых сигнальных процессоров (DSP). Благодаря этому повышается энергетическая эффективность. В серию вошли модели 7060XE7-64PS / 7060XE7-64PRS с 64 портами OSFP с пропускной способностью 1,6 Тбит/с, которые могут использоваться в режимах 200GbE/400GbE/800GbE. Кроме того, дебютировала версия 7060XE7-128PE со 128 портами OSFP со скоростью 800 Гбит/с (поддерживаются также режимы 100GbE/200GbE/400GbE). Все эти коммутаторы выполнены в форм-факторе 4U и оснащены воздушным охлаждением. 
Источник изображения: Arista Networks Ещё одним представителем семейства стала модель 7060XE7-64PRS-RV3-L типоразмера 2OU, наделённая системой жидкостного охлаждения. Этот коммутатор оборудован 64 портами OSFP на 1,6 Тбит/с (с поддержкой режимов 200GbE/400GbE/800GbE). Питание осуществляется от централизованного шинопровода. В качестве программной платформы на устройствах используется Arista EOS (Extensible Operating System). Говорится о поддержке функций балансировки нагрузки DLB (Dynamic Load Balancing) и CLB (Cluster Load Balancing). Поставки коммутаторов планируется начать в IV квартале текущего года.
04.06.2026 [10:29], Сергей Карасёв
NVIDIA разработала CPO-коммутатор Quantum-X InfiniBand Photonics Q3450-LD со 144 портами 800GСтартап Lambda, развивающий неооблачную ИИ-платформу, поделился подробностями о коммутаторе Quantum-X InfiniBand Photonics Q3450-LD, разработанном компанией NVIDIA для крупных дата-центров, ориентированных на ресурсоёмкие нагрузки ИИ. Устройство, анонсированное в прошлом году, выполнено в форм-факторе 4U по технологии CPO (Co-Packaged Optics). Реализованы 144 порта 800G InfiniBand (коннекторы MPO — Multi-fiber Push-On). Заявленная неблокируемая коммутационная способность составляет 115,2 Тбит/с. Коммутаторы CPO не требуют традиционных подключаемых трансиверов. Применяются 18 съёмных внешних модулей источников света, каждый из которых обслуживает восемь портов MPO. 
Источник изображений: Lambda Рич Андервуд (Rich Underwood), системный архитектор высокопроизводительных вычислений в компании Lambda, отмечает, что для традиционного 72-портового коммутатора необходимы 72 трансивера, каждый из которых потребляет примерно 25 Вт. Исключение этих компонентов из системы обеспечивает существенную экономию энергии. Коммутатор NVIDIA Photonics CPO потребляет 3,95 кВт против 7,0 кВт у стандартного устройства сопоставимого класса. Таким образом, достигается экономия 3,05 кВт на каждый коммутатор: эта мощность может быть перераспределена на другие задачи, в частности, на питание ИИ-ускорителей.  Кроме того, использование CPO позволяет повысить надёжность. Для дата-центра со 128 тыс. GPU требуется приблизительно 655 тыс. дискретных модулей трансиверов. Каждый из них является потенциальной точкой отказа. Технология CPO полностью исключает этот класс компонентов, а следовательно, повышает стабильность работы и минимизирует количество сбоев. Устройство Quantum-X InfiniBand Photonics Q3450-LD оснащено двухконтурным жидкостным охлаждением. Для питания служит шина постоянного тока 48 В.
13.04.2026 [13:05], Сергей Карасёв
Aria Networks представила «думающую» сетевую платформу Deep Networking для высокоэффективных ИИ-инфраструктурКомпания Aria Networks анонсировала сетевую платформу Deep Networking, призванную повысить эффективность работы ИИ-систем. Предложенное решение объединяет специализированное коммутационное оборудование, сетевую ОС SONiC, высокоточную телеметрию на коммутаторах, трансиверах и сетевых картах, а также ИИ-алгоритмы на разных уровнях вычислительной инфраструктуры. Стартап Aria Networks основан в январе 2025 года Мансуром Карамом (Mansour Karam), учредителем фирмы Apstra, которую в 2019-м приобрёл американский производитель сетевого оборудования Juniper Networks. Aria Networks занимается разработкой высокопроизводительных решений, сочетающих возможности стандартного Ethernet со специализированным ПО для управления большим количеством модульных коммутаторов как единой системой. На сегодняшний день стартап привлёк в общей сложности $125 млн инвестиций от Sutter Hill Ventures, Atreides Management, Valor Equity Partners и Eclipse Ventures. Идея Deep Networking заключается в том, чтобы рассматривать сеть в качестве активного участника кластера ИИ, а не в роли пассивного слоя. Это достигается путём сбора детальной телеметрии с коммутационных ASIC, внедрения интеллектуальных агентов на каждом уровне и постоянного распространения обновлений ПО через облако. 
Источник изображений: Aria Networks В качестве ключевых показателей быстродействия Aria Networks рассматривает MFU (уровень утилизации оборудования при обучении) и Token Efficiency (эффективность токенов). Первый параметр отражает, какой процент от теоретической максимальной производительности ИИ-ускорителя (пиковых FLOPS) реально тратится на полезные вычисления для обучения или инференса. В свою очередь, эффективность токенов показывает, уровень MFU или время на обработку одного токена. Основное техническое преимущество Deep Networking заключается в получении детализированной телеметрии. Традиционные инструменты мониторинга сети собирают данные постфактум — с относительно невысокой точностью. Решение Aria Networks обрабатывает телеметрию в реальном времени непосредственно с ASIC. Благодаря этому обеспечивается адаптивная настройка параметров DLB (динамическая балансировка нагрузки) и DCQCN (механизм управления перегрузками). 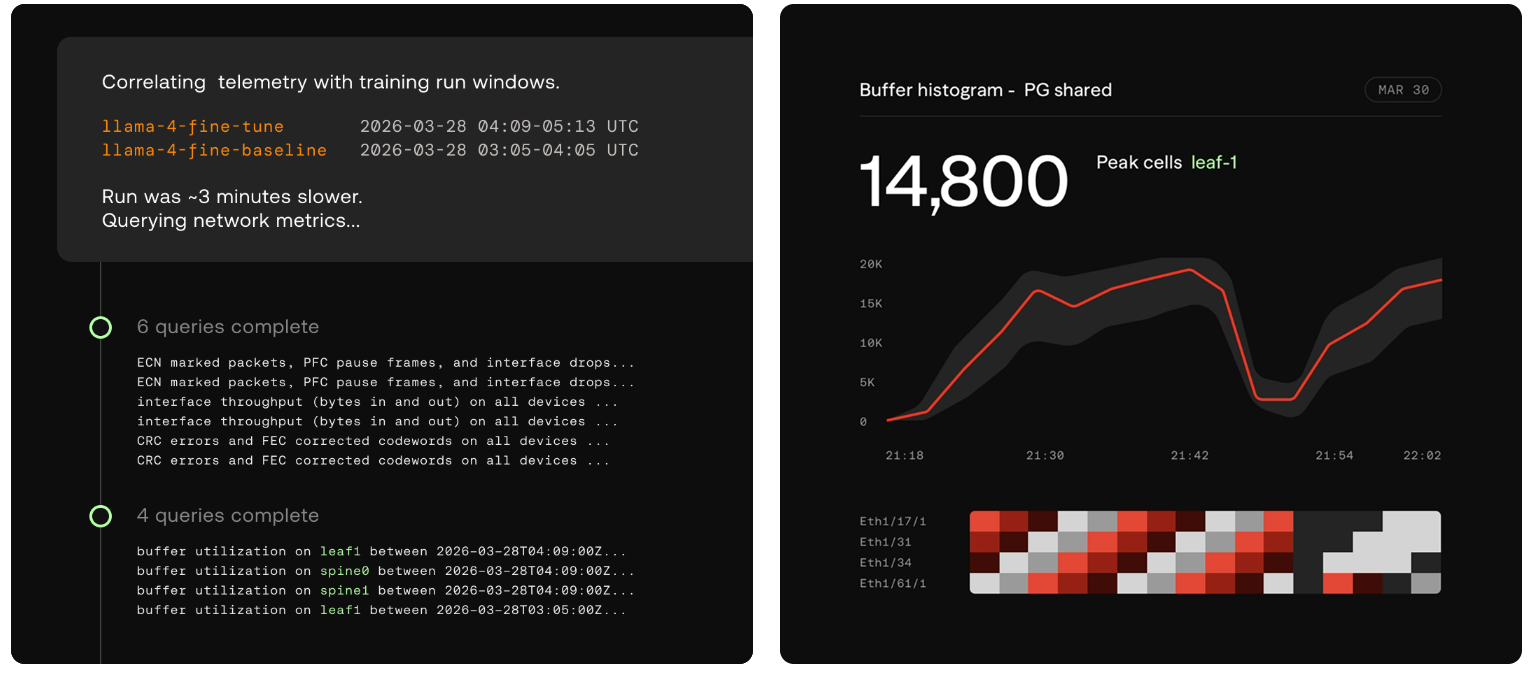 Сама платформа Deep Networking имеет многоуровневую архитектуру. На самых нижних уровнях ИИ-агенты в течение микросекунд реагируют на такие события, как сбои в работе трансиверов, перенаправляя трафик между коммутаторами. На более высоких уровнях принимаются стратегические решения о перераспределении потоков в кластере. Кроме того, внешние системы, например, планировщики заданий и маршрутизаторы, могут напрямую запрашивать сведения о состояние сети и интегрировать их в процесс принятия собственных решений. С аппаратной точки зрения инфраструктура Deep Networking базируется на коммутаторах Aria Switch 800G, Aria Switch 1.6T High Radix и Aria Switch 1.6T, оснащённых чипами Broadcom. Платформа непрерывно настраивает каждый аспект сетевой инфраструктуры для конкретного обслуживаемого ИИ-кластера без ручного вмешательства, что сводит к минимуму задержки и устраняет ошибки, обусловленные человеческим фактором. Администраторам достаточно указать свои потребности, после чего платформа соответствующим образом оптимизирует сеть. При этом система постоянно оценивает состояние сети и в режиме реального времени принимает меры для обеспечения наилучшей производительности и бесперебойной работы.  Aria Networks утверждает, что один неисправный сетевой адаптер в кластере из 10 тыс. XPU может снизить показатель MFU на 1,7 %. А сбой трансивера способен спровоцировать некорректную переадресацию трафика, что приведёт к существенным финансовым потерям. Архитектура Deep Networking позволяет эффективно решать подобные проблемы, одновременно улучшая производительность. Так, повышение MFU на 3 % в кластере из 10 тыс. XPU, по оценкам стартапа, приводит к увеличению годовой выручки на $49,8 млн.
23.03.2026 [09:31], Сергей Карасёв
HPE представила узлы на базе NVIDIA Vera для платформы Cray Supercomputing GX5000Компания HPE анонсировала новые решения семейства NVIDIA AI Computing by HPE, ориентированные на крупномасштабные ИИ-платформы и суперкомпьютерные системы. О намерении использовать такие инфраструктурные продукты в числе прочих сообщили Аргоннская национальная лаборатория (ANL) Министерства энергетики США (DOE), Hudson River Trading (HRT), Корейский институт научно-технической информации (KISTI) и Центр высокопроизводительных вычислений HLRS при Штутгартском университете в Германии. В частности, представлены новые узлы для суперкомпьютерной платформы HPE Cray Supercomputing GX5000 — blade-серверы HPE Cray Supercomputing GX240. Эти устройства могут нести на борту до 16 процессоров NVIDIA Vera (88C/176T). В одной стойке могут быть размещены до 40 узлов, что в сумме даёт 640 чипов Vera и 56 320 ядер Olympus. Реализовано жидкостное охлаждение. Система предназначена для решения наиболее ресурсоёмких вычислительных задач в области ИИ. Новые серверы появятся на рынке в следующем году. Для платформы HPE Cray Supercomputing GX5000 также будут доступны коммутаторы NVIDIA Quantum-X800 InfiniBand, предоставляющие 144 порта с пропускной способностью до 800 Гбит/с. В этих устройствах реализованы развитые функции снижения энергопотребления. Кроме того, HPE готовит OCP-серверы высокой плотности Compute XD700 для обучения LLM и инференса. В основу данной системы положена платформа NVIDIA HGX Rubin NVL8, а одна стойка может насчитывать до 128 ускорителей Rubin. Данное решение появится в начале 2027-го. 
Источник изображений: HPE Помимо этого, анонсирована стоечная система нового поколения NVIDIA Vera Rubin NVL72 by HPE — это флагманская ИИ-платформа, разработанная для моделей с более чем 1 трлн параметров. Конфигурация включает 36 процессоров Vera, 72 чипа Rubin, интерконнект NVIDIA NVLink шестого поколения, сетевые адаптеры NVIDIA ConnectX-9 SuperNIC и DPU NVIDIA BlueField-4. Система поступит в продажу в декабре 2026 года. 
19.03.2026 [15:32], Руслан Авдеев
16 тыс. км без регенерации сигнала: Ciena и Meta✴ установили рекорд дальности и скорости передачи данных по подводному кабелю BifrotstКомпании Ciena и Meta✴ установили мировой рекорд дальности высокоскоростной передачи данных без регенерации сигнала по действующему подводному кабелю на одной несущей — 800 Гбит/с. Речь идёт о системе Bifrost длиной 16 608 км, объединяющей Сингапур, Индонезию, Филиппины, Гуам и США. Тесты проводились на паре волокон, принадлежащих Meta✴. Испытания увенчались успехом благодаря технологии GeoMesh Extreme компании Ciena, она включает когерентную оптическую систему WaveLogic 6 Extreme (WL6e) и компактную реконфигурируемую систему 6500 Reconfigurable Line System (RLS). Ciena заявляет, что установление мирового рекорда дальности передачи с подобными характеристиками связи подтверждает ценность WL6e в качестве технологии, способной обеспечить «800G повсюду». Опыты доказывают, что сверхвысокоскоростную передачу данных можно обеспечить на самых длинных и сложных подводных маршрутах. Компания подчёркивает, что общая пропускная способность оптоволоконных пар составила в ходе испытаний 18 Тбит/с с избыточным эксплуатационным резервом. Использовался компактный SLTE (submarine line terminal equipment) высотой всего 10U, который оказался вдвое энергоэффективнее в сравнении с решением Ciena предыдущего поколения. Партнёры подчеркнули, что результаты имеют исключительное значение с точки зрения эффективности использования пространства и электроэнергии. Это критически важно для посадочных станций. 
Источник изображения: Robert Boston/unsplash.com Для Meta✴ проект имеет особое значение, поскольку должен помочь в управлении совместимой с ИИ-оборудованием инфраструктурой на больших расстояниях с уменьшением углеродных выбросов благодаря сниженному энергопотреблению и компактному объёму. Не так давно Ciena сообщала о рекордной для компании выручке $1,43 млрд в I квартале финансового года, на 33 % больше год к году. Компания назвала результата «беспрецедентным». В июне 2025 года сообщалось, что Telxius и Ciena установили рекорд скорости передачи данных между США и Европой по трансатлантическому кабелю Marea.
06.02.2026 [11:30], Сергей Карасёв
102,4 Тбит/с и СЖО: Aria Networks представила коммутаторы на платформе Broadcom Tomahawk 6 для ИИ-инфраструктурСтартап Aria Networks, базирующийся в Санта-Кларе (Калифорния, США), вышел из скрытого режима, анонсировав высокопроизводительные коммутаторы для крупномасштабных кластеров ИИ. В основу устройств положена аппаратная платформа Broadcom Tomahawk 6 (TH6). В новое семейство вошли три модели: Aria Tomahawk 6 (High Radix), Aria Tomahawk 6 (Liquid) и Aria Tomahawk 6 (Air). Все они обеспечивают суммарную коммутационную способность до 102,4 Тбит/с. Разработчик заявляет, что устройства могут применяться в составе ИИ-платформ с любыми типами ускорителей, будь то GPU NVIDIA и AMD, тензорные чипы или специализированные решения вроде Cerebras. 
Источник изображения: Aria Networks Модель Aria Tomahawk 6 (Air) выполнена в форм-факторе 4U и оборудована воздушным охлаждением. Задействованы 512 блоков SerDes 200G. Коммутатор располагает 64 портами с пропускной способностью 1,6 Тбит/с каждый. Модификация Aria Tomahawk 6 (Liquid) имеет аналогичные технические характеристики, но заключена в 2U-корпус с жидкостным охлаждением. Наконец, вариант Aria Tomahawk 6 (High Radix) типоразмера 4U использует 1024 блока SerDes 100G. Устройство оборудовано 128 портами 800GbE; применяется воздушное охлаждение. На базе этого коммутатора могут формироваться кластеры с простой двухуровневой топологией, насчитывающие до 32 тыс. ИИ-ускорителей. Компания Aria Networks основана Мансуром Карамом (Mansour Karam), учредителем фирмы Apstra, которую в 2019 году приобрёл американский производитель сетевого оборудования Juniper Networks. Стартап Aria Networks фокусируется на разработке высокопроизводительных решений, сочетающих возможности стандартного Ethernet со специализированным программным уровнем, позволяющим управлять большим количеством модульных коммутаторов как единой системой. Утверждается, что этот унифицированный программный слой оптимизирует производительность и гарантирует надёжность инфраструктуры. Для эффективного управления коммутаторами применяются ИИ-алгоритмы.
15.12.2025 [12:11], Сергей Карасёв
Квартальные продажи Ethernet-коммутаторов подскочили на треть благодаря спросу со стороны ЦОДКомпания International Data Corporation (IDC) подсчитала, что в III квартале уходящего года объём мирового рынка Ethernet-коммутаторов корпоративного класса достиг $14,7 млрд: это на 35,2 % больше по сравнению с аналогичным периодом 2024-го. Вместе с тем продажи маршрутизаторов для предприятий и поставщиков услуг увеличились на 15,8 % в годовом исчислении — до $3,6 млрд. Значительная положительная динамика обусловлена прежде всего развитием сегмента дата-центров. Гиперскейлеры и крупные облачные провайдеры активно закупают сетевое оборудование на фоне стремительного внедрения ИИ, которое сопровождается расширением инфраструктуры ЦОД. Поставки Ethernet-коммутаторов для дата-центров в денежном выражении выросли на 62,0 % по отношению к III четверти 2024 года. Выручка от устройств стандарта 800GbE подскочила на 91,6 % в квартальном исчислении, а их доля в общем объёме ЦОД-рынка составила 18,3 %. Продажи решений 200/400GbE взлетели на 97,8 % в годовом исчислении: на них приходится 43,9 % от общей выручки в сегменте дата-центров. В категории Ethernet-коммутаторов, не связанных с ЦОД, продажи за год поднялись на 8,2 %. Выручка от поставок решений 1GbE выросла на 1,2 %, 10GbE — на 14,3 %, 25/50GbE — на 20,9 % по сравнению с III кварталом 2024-го. 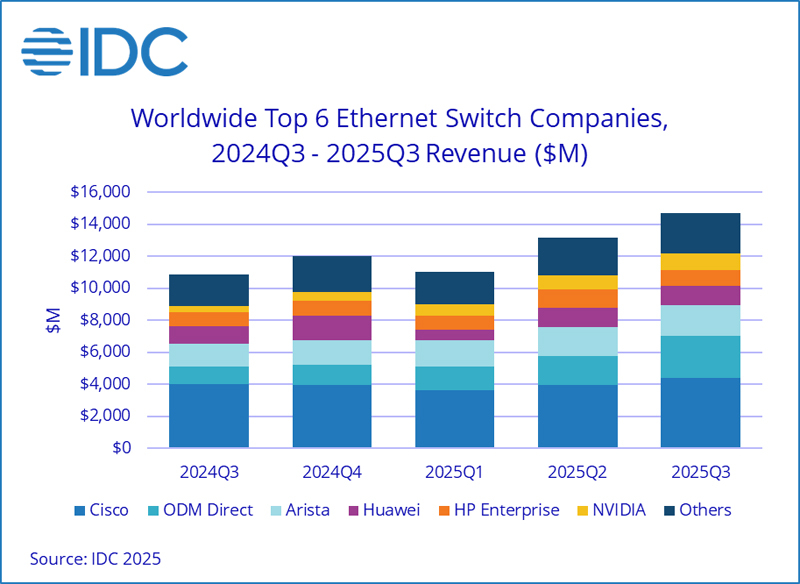
Источник изображения: IDC С географической точки зрения в Северной и Южной Америке рынок коммутаторов Ethernet в целом расширился на 41,6 %, чему способствовал активный рост в дата-центрах США. В регионе EMEA (Европа, Ближний Восток и Африка) продажи поднялись на 24,7 % в годовом исчислении, в Азиатско-Тихоокеанском регионе — на 32,7 %. В рейтинг крупнейших поставщиков коммутаторов Ethernet в глобальном масштабе входят Cisco, Arista Networks, HPE, NVIDIA и Huawei с долями соответственно 29,8 %, 12,8 %, 12,5 %, 11,6 % и 8,2 %. Отмечается, что выручка NVIDIA на рынке Ethernet-коммутаторов за год взлетела на 167,7 %. В секторе маршрутизаторов на поставщиков услуг пришлось 74,0 % от общего объёма выручки с ростом на 20,2 % в годовом исчислении. Корпоративное направление принесло 26,0 % продаж, показав прибавку на уровне 4,7 %. В региональном плане поставки маршрутизаторов в Северной и Южной Америке поднялись на 31,5 % в годовом исчислении, в Азиатско-Тихоокеанском регионе — на 7,7 %, а в регионе EMEA — на 3,5 %. |
|

