Материалы по тегу: 800gbe
|
15.12.2025 [12:11], Сергей Карасёв
Квартальные продажи Ethernet-коммутаторов подскочили на треть благодаря спросу со стороны ЦОДКомпания International Data Corporation (IDC) подсчитала, что в III квартале уходящего года объём мирового рынка Ethernet-коммутаторов корпоративного класса достиг $14,7 млрд: это на 35,2 % больше по сравнению с аналогичным периодом 2024-го. Вместе с тем продажи маршрутизаторов для предприятий и поставщиков услуг увеличились на 15,8 % в годовом исчислении — до $3,6 млрд. Значительная положительная динамика обусловлена прежде всего развитием сегмента дата-центров. Гиперскейлеры и крупные облачные провайдеры активно закупают сетевое оборудование на фоне стремительного внедрения ИИ, которое сопровождается расширением инфраструктуры ЦОД. Поставки Ethernet-коммутаторов для дата-центров в денежном выражении выросли на 62,0 % по отношению к III четверти 2024 года. Выручка от устройств стандарта 800GbE подскочила на 91,6 % в квартальном исчислении, а их доля в общем объёме ЦОД-рынка составила 18,3 %. Продажи решений 200/400GbE взлетели на 97,8 % в годовом исчислении: на них приходится 43,9 % от общей выручки в сегменте дата-центров. В категории Ethernet-коммутаторов, не связанных с ЦОД, продажи за год поднялись на 8,2 %. Выручка от поставок решений 1GbE выросла на 1,2 %, 10GbE — на 14,3 %, 25/50GbE — на 20,9 % по сравнению с III кварталом 2024-го. 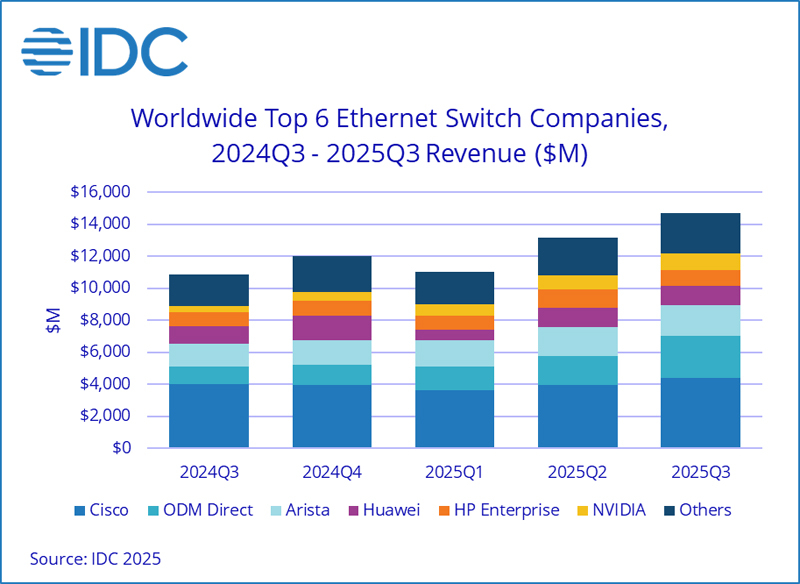
Источник изображения: IDC С географической точки зрения в Северной и Южной Америке рынок коммутаторов Ethernet в целом расширился на 41,6 %, чему способствовал активный рост в дата-центрах США. В регионе EMEA (Европа, Ближний Восток и Африка) продажи поднялись на 24,7 % в годовом исчислении, в Азиатско-Тихоокеанском регионе — на 32,7 %. В рейтинг крупнейших поставщиков коммутаторов Ethernet в глобальном масштабе входят Cisco, Arista Networks, HPE, NVIDIA и Huawei с долями соответственно 29,8 %, 12,8 %, 12,5 %, 11,6 % и 8,2 %. Отмечается, что выручка NVIDIA на рынке Ethernet-коммутаторов за год взлетела на 167,7 %. В секторе маршрутизаторов на поставщиков услуг пришлось 74,0 % от общего объёма выручки с ростом на 20,2 % в годовом исчислении. Корпоративное направление принесло 26,0 % продаж, показав прибавку на уровне 4,7 %. В региональном плане поставки маршрутизаторов в Северной и Южной Америке поднялись на 31,5 % в годовом исчислении, в Азиатско-Тихоокеанском регионе — на 7,7 %, а в регионе EMEA — на 3,5 %.
09.12.2025 [22:15], Владимир Мироненко
Дефицит добрался и до лазеров: NVIDIA зарезервировала чуть ли не всю продукцию ключевых поставщиковВ настоящее время высокоскоростные оптические соединения играют ключевую роль в обеспечении производительности и масштабируемости ИИ ЦОД, особенно по мере того, как они превращаются в крупные кластеры, сообщается в исследовании TrendForce. Согласно её прогнозу, в 2025 году мировые поставки оптических трансиверов с поддержкой скорости 800 Гбит/с и выше составят 24 млн шт. с последующим ростом в 2,6 раза почти до 63 млн шт. в 2026 году. Аналитики отметили, что резкий рост спроса на оптические трансиверы привёл к значительному дефициту в сфере производства источников лазерного излучения на глобальном рынке. NVIDIA в рамках стратегии развития зарезервировала крупные объёмы продукции у ключевых поставщиков EML-лазеров, что привело к увеличению сроков поставки — не ранее 2027 года. В связи с этим производители оптических модулей и провайдеры облачных услуг (CSP) вынуждены заниматься поиском вторичных поставщиков и альтернативных решений, что ведёт к изменениям в отрасли, отметили в TrendForce. Помимо лазеров VCSEL, используемых в линиях связи малой и средней дальности, оптические модули для линий средней и большой дальности в основном включают два типа лазеров: EML, отличающиеся большой дальностью действия и целостностью сигнала, и лазеры непрерывного излучения (CW). В EML-лазерах все ключевые функции объединены на одном кристалле, что делает их чрезвычайно сложными и трудоёмкими в изготовлении. Их производством занимается всего лишь несколько поставщиков, таких как Lumentum, Coherent (Finisar), Mitsubishi, Sumitomo и Broadcom. Впрочем, о дефиците Mitsubishi предупреждала более года назад. А Broadcom, вероятно, будет отдавать приоритет собственным продуктам. 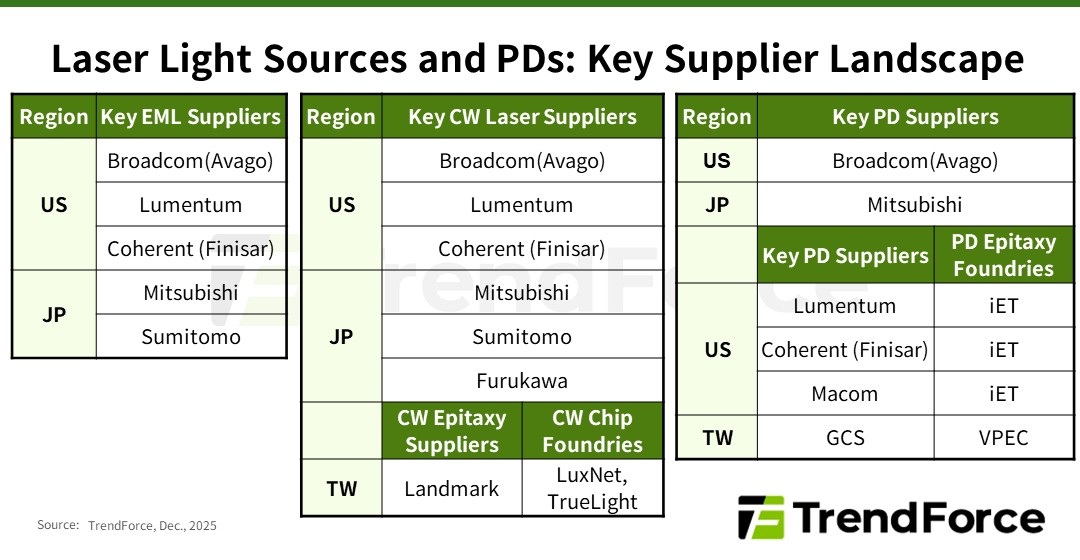
Источник изображения: TrendForce EML-лазеры играют важную роль в масштабировании вычислительных кластеров с увеличением расстояния между ЦОД. Планы NVIDIA по развитию кремниевой фотоники и интегрированной оптики (CPO) реализуются медленнее, чем предполагалось, что приводит к постоянной зависимости от подключаемых модулей для расширения кластеров. Чтобы обеспечить стабильную работу в этом направлении, NVIDIA заранее зарезервировала значительную часть мощностей по производству EML-лазеров, что отразилось на доступности компонента для остальных компаний. CW-лазеры, используемые в паре с кремниевыми фотонными чипами, отличаются более простой конструкцией, обусловленной отсутствием встроенной возможности модуляции, что упрощает производство и расширяет круг поставщиков. В результате CW-лазеры в сочетании с кремниевой фотоникой стали основным альтернативным решением для провайдеров облачных услуг в связи с дефицитом EML-лазеров. Впрочем, здесь тоже наблюдаются проблемы. Производство CW-лазеров сталкивается с растущими ограничениями, обусловленными рядом факторов: длительные сроки поставки оборудования ограничивают расширение производства, а строгие стандарты надёжности требуют трудоемких тестов. В результате многие поставщики передают эти этапы на аутсорсинг, что создает дополнительные узкие места в производственной цепочке. Ввиду того, что экосистема производства CW-лазеров приближается к дефициту мощностей, поставщики вынуждены форсировать усилия по расширению производства. 
Источник изображения: NVIDIA Помимо лазерных передатчиков, для изготовления оптических модулей требуются высокоскоростные фотодиоды (PD) для приёма сигналов. Ведущие поставщики, такие как Coherent, MACOM, Broadcom и Lumentum, выпускают фотодиоды PD 200G с поддержкой скорости передачи данных 200 Гбит/с на канал. Фотодиоды производятся на эпитаксиальных пластинах из фосфида индия (InP), аналогично EML- и CW-лазерам. Поскольку производители лазеров стремятся расширить мощности для эпитаксии, многие из них передают заказы на InP-эпитаксию (процесс выращивания эпитаксиальных листов из фосфида индия на подложке) специализированным заводам, таким как IntelliEPI и VPEC, сообщили в TrendForce. TrendForce прогнозирует, что спрос, обусловленный ИИ, приведёт не только к сокращению предложения модулей памяти, но и отразится на экосистеме производства лазеров в целом. Стремление NVIDIA обеспечить необходимые объёмы поставок EML-лазеров привело к ускорению перехода к CW-решениям и кремниевой фотоники среди других производителей. В то же время общеотраслевая гонка за производственными мощностями меняет роли в цепочке поставок и стимулирует рост производства у поставщиков технологий эпитаксии и обработки полупроводниковых соединений, говорят аналитики.
24.11.2025 [08:45], Сергей Карасёв
Cornelis анонсировала 800G-адаптер CN6000 SuperNIC с поддержкой Omni-Path, RoCEv2 и Ultra Ethernet для ИИ и НРСКомпания Cornelis Networks анонсировала сетевой адаптер CN6000 SuperNIC со скоростью передачи данных до 800 Гбит/с, разработанный для систем ИИ и НРС. О намерении использовать решение объявили многие отраслевые игроки, включая Lenovo, Synopsys и Atipa Technologies. В устройстве реализована архитектура Omni-Path. Говорится о полной совместимости со стандартами Ultra Ethernet и RoCEv2. Таким образом, адаптер может применяться в высоконагруженных средах, где требуются максимальная пропускная способность при низких задержках. Адаптер CN6000 SuperNIC обеспечивает быстродействие до 1,6 млрд сообщений в секунду. Утверждается, что новинка поможет организациям ускорить обучение крупных ИИ-моделей при одновременном снижении расходов на электроэнергию и эксплуатацию дата-центров. 
Источник изображения: Cornelis Networks Cornelis заявляет, что традиционные архитектуры RoCEv2 испытывают трудности при масштабировании в рамках масштабных GPU-кластеров из-за требований к ресурсам памяти при управлении парами связанных очередей (Queue Pair, QP) для отправки и приёма данных. CN6000 SuperNIC позволяет решить проблему благодаря принципиально иной конструкции: задействованы «облегчённые» алгоритмы QP и аппаратно-ускоренные таблицы RoCEv2 In-Flight (RiF), что даёт возможность отслеживать миллионы одновременных операций с минимальными требованиями к ресурсам. Это гарантирует предсказуемую задержку при максимальной пропускной способности в системах любого масштаба. Пробные поставки CN6000 SuperNIC планируется начать к середине 2026 года, после чего будет организовано массовое производство.
17.11.2025 [12:14], Сергей Карасёв
Nokia представила коммутаторы с пропускной способностью до 102,4 Тбит/сКомпания Nokia анонсировала высокопроизводительные коммутаторы семейства 7220 IXR-H6 для дата-центров, ориентированных на ресурсоёмкие нагрузки ИИ. Новинки соответствуют спецификациям Ultra Ethernet Consortium (UEC), поддерживая расширенные функции для оптимизации и управления потоками данных, предотвращения перегрузок и повышения эффективности в крупномасштабных средах. Коммутаторы обеспечивают пропускную способность до 102,4 Тбит/с благодаря интерфейсам 800GbE и 1.6TbE, что вдвое больше по сравнению с решениями предыдущего поколения. В серию 7220 IXR-H6 вошли две модели с 64 портами (1.6TbE), оборудованные воздушным и жидкостным охлаждением. В первом случае допускается горячая замена блоков вентиляторов. Кроме того, дебютировала модификация со 128 портами (800GbE). О типе применённого чипсета пока ничего не сообщается. 
Источник изображения: Nokia Устройства комплектуются блоками питания с резервированием и возможностью горячей замены. Предусмотрены сетевой порт управления RJ45, разъём USB 3.0 и консольный порт. Коммутаторы могут поставляться с сетевой операционной системой SR Linux NOS или SONiC (Software for Open Networking in the Cloud). По заявлениям Nokia, решения семейства 7220 IXR-H6 могут применяться в составе платформ облачных провайдеров и гиперскейлеров, а также в ИИ-кластерах, насчитывающих более 1 млн ускорителей разных типов (XPU). Говорится о совместимости с серверными стойками различных конфигураций. В продажу коммутаторы поступят в I квартале следующего года.
05.11.2025 [14:30], Сергей Карасёв
Arista представила 800G-коммутаторы серии R4 для ИИ и облачных платформКомпания Arista анонсировала высокопроизводительные коммутаторы семейства R4 для крупномасштабных кластеров ИИ, дата-центров и облачных платформ. В серию вошли модели 7800R4, 7280R4 и 7020R4 для различных вариантов развёртывания. В основу новинок положен чип Broadcom Jericho3 Qumran3D. Для устройств заявлена поддержка современных архитектур, таких как EVPN, VXLAN, MPLS, SR/SRv6 и Segment Routing-TE. В некоторых моделях реализована технология HyperPort, которая объединяет четыре порта 800GbE в один канал с пропускной способность 3,2 Тбит/с. Модульная система Arista 7800R4 обеспечивает ёмкость до 460 Тбит/с, или до 920 Тбит/с в полнодуплексном режиме. Возможны конфигурации с 576 портами 800GbE, 1152 портами 400GbE или 4608 портами 100GbE. Пропускная способность достигает 173 млрд пакетов в секунду. Задержка — менее 4 мкс. Предусмотрены варианты исполнения 10U, 16U, 23U и 32U. Энергопотребление варьируется от 6,8 до 28 кВт. Упомянута поддержка HyperPort. 
Источник изображения: Arista Коммутатор 7280R4, в свою очередь, предлагается в конфигурациях с 32 портами 800GbE (OSFP/QSFP-DD) или с 64 портами 100GbE + 10 портов 800GbE. Ёмкость достигает 25,6 Тбит/с (51,2 Тбит/с в полнодуплексном режиме), пропускная способность — 9,6 млрд пакетов в секунду. Устройство укомплектовано 8-ядерным процессором с архитектурой x86, 64 Гбайт DRAM и SSD вместимостью 480 Гбайт. Версия Arista 7020R4 может оснащаться 48 портами 1/10/25GbE SFP или RJ45 (плюс 4 или 8 восходящих каналов 100GbE). Ёмкость составляет до 2 Тбит/с, пропускная способность — до 1 млрд пакетов в секунду. Коммутатор несёт на борту 4-ядерный чип x86, 32 Гбайт DRAM и SSD на 120 Гбайт. Заявленная задержка находится на уровне 3,8 мкс.
01.11.2025 [14:52], Сергей Карасёв
Cisco представила свои первые коммутаторы на чипах NVIDIA — N9100 с пропускной способностью 51,2 Тбит/сКомпания Cisco анонсировала высокопроизводительный коммутатор серии N9100, предназначенный для использования в ИИ ЦОД. Устройство, выполненное на платформе NVIDIA Spectrum-X Ethernet, создано в рамках инициативы NVIDIA Cloud Partner (NCP). Речь идёт о предоставлении эталонной архитектуры, ориентированной в том числе на провайдеров суверенного облака. Представленный коммутатор (модель Cisco N9164E-NS4-O) оснащён ASIC NVIDIA Spectrum-4. Устройство наделено 64 портами 800G OSFP, что в сумме обеспечивает пропускную способность до 51,2 Тбит/с. Возможно использование Cisco NX-OS (Nexus Operating System) и SONiC. 
Источник изображения: Cisco Новинка несёт на борту процессор Intel Xeon D-1734NT (Ice Lake-D; 8C/16T, до 3,1 ГГц). Объём системной памяти составляет 64 Гбайт. Предусмотрен встроенный SSD вместимостью 240 Гбайт. Питание обеспечивают два блока мощностью 3000 Вт. За охлаждение отвечают четыре вентилятора с возможностью горячей замены. Диапазон рабочих температур — от 0 до +40 °C. Устройство, выполненное в форм-факторе 2RU, имеет размеры 439,2 × 705 × 87,9 мм. В целом, коммутаторы N9100 объединяют программный и сетевой стек Cisco с высокопроизводительным чипом NVIDIA, обеспечивая гибкость и масштабируемость при формировании крупных инфраструктур ИИ. При этом система управления и автоматизации Cisco Nexus Dashboard упрощает эксплуатацию дата-центра благодаря всестороннему мониторингу и гибким инструментам устранения неполадок.
28.10.2025 [20:35], Сергей Карасёв
NVIDIA анонсировала DPU BlueField-4: 800G-порты, ConnectX-9, CPU Grace и PCIe 6.0NVIDIA анонсировала DPU BlueField 4, рассчитанный на использование в составе масштабных инфраструктур ИИ. Устройство оснащено 800G-портами. Новинка в этом отношении вдвое быстрее BlueField-3, дебютировавших ещё в 2021 году. NVIDIA отмечает, что ИИ-фабрики продолжают развиваться с беспрецедентной скоростью. При этом требуется обработка колоссальных массивов структурированных и неструктурированных данных. Для удовлетворения этих потребностей необходимо формирование инфраструктуры нового класса, на которую как раз и ориентирован DPU BlueField-4. Новинка использует программно-определяемую архитектуру для ускорения сетевых операций, функций безопасности и задач хранения данных. По заявлениям NVIDIA, BlueField-4 позволяет трансформировать дата-центры в безопасную интеллектуальную ИИ-инфраструктуру с высокой производительностью. BlueField-4 объединяет 64-ядерный Arm-процессор NVIDIA Grace (114 Мбайт L3-кеш), 128 Гбайт LPDDR5, 512 Гбайт SSD, сетевой адаптер NVIDIA ConnectX-9 SuperNic (1,6 Тбит/с), а также коммутатор PCIe 6.0 с 48 линиями. Новинка будет доступна в виде карты расширения (PCIe 6.0 x16) и в виде модуля для узлов VR NVL144. Утверждается, что по сравнению с BlueField-3 вычислительная производительность выросла в шесть раз. При этом возможно формирование ИИ-фабрик вчетверо большего масштаба. Кроме того, BlueField-4 поддерживает многопользовательскую сеть, быстрый доступ к данным и микросервисы NVIDIA DOCA. Задействована архитектура NVIDIA BlueField Advanced Secure Trusted Resource Architecture. 
Источник изображения: NVIDIA Предполагается, что BlueField-4 возьмут на вооружение такие производители серверов и платформ хранения данных, как Cisco, DDN, Dell Technologies, HPE, IBM, Lenovo, Supermicro, VAST Data и WEKA. О поддержке новинки заявили Armis, Check Point, Cisco, F5, Forescout, Palo Alto Networks и Trend Micro, а также системные интеграторы Accenture, Deloitte и World Wide Technology. Интегрировать BlueField-4 в свои платформы намерены Canonical, Mirantis, Nutanix, Rafay, Red Hat, Spectro Cloud и SUSE. На рынок BlueField-4 поступит в 2026 году как часть экосистемы Vera Rubin.
15.10.2025 [14:00], Сергей Карасёв
Broadcom представила первые в мире 800GbE-адаптеры Thor Ultra с поддержкой Ultra Ethernet для масштабных ИИ-кластеровКомпания Broadcom анонсировала изделия Thor Ultra: это, как утверждается, первые в отрасли сетевые Ethernet-адаптеры (NIC) стандарта 800G, которые могут использоваться в составе масштабных ИИ-кластеров, объединяющих сотни тысяч ускорителей XPU для обработки моделей с триллионами параметров. Изделия выполнены в соответствии с открытой спецификацией Ultra Ethernet Consortium (UEC). Реализованы передовые возможности RDMA, включая многоканальное распределение на уровне пакетов для эффективной балансировки нагрузки, избирательную ретрансляцию для высокопроизводительной передачи данных, доставку пакетов вне очереди напрямую в память XPU, а также программируемые алгоритмы управления перегрузкой на уровне отправителя и получателя. 
Источник изображений: Broadcom Адаптеры Thor Ultra доступны в виде карт PCIe и OCP 3.0. Используется хост-интерфейс PCIe 6.0 x16. Реализован один порт с возможностью использования в режимах 800/400/200/100G/50/25GbE. Допускается шифрование и дешифрование данных на линейной скорости, что освобождает CPU/XPU от ресурсоёмких вычислительных задач. Благодаря применению 200G/100G PAM4 SerDes обеспечивается большая дальность пассивного медного соединения.  В качестве ключевых сфер использования названы серверы для задач ИИ и машинного обучения, публичные и частные облачные платформы, высокопроизводительные серверы хранения, а также системы HPC. Адаптеры Thor Ultra совместимыми с такими коммутационными решениями, как Broadcom Tomahawk 6. Упомянуты развитые функции телеметрии и обеспечения безопасности.
14.10.2025 [20:58], Владимир Мироненко
Oracle анонсировала крупнейший в мире зеттафлопсный ИИ-кластер OCI Zettascale10: до 800 тыс. ускорителей NVIDIA в нескольких ЦОД
800gbe
ethernet
hardware
hpc
nvidia
oracle
oracle cloud infrastructure
stargate
ии
интерконнект
кластер
сша
цод
Oracle анонсировала облачный ИИ-кластер OCI Zettascale10 на базе сотен тысяч ускорителей NVIDIA, размещённых в нескольких ЦОД, который имеет пиковую ИИ-производительность 16 Зфлопс (точность вычислений не указана). OCI Zettascale10 — это инфраструктура, на которой базируется флагманский ИИ-суперкластер, созданный совместно с OpenAI в техасском Абилине (Abilene) в рамках проекта Stargate и основанный на сетевой архитектуре Oracle Acceleron RoCE нового поколения. OCI Zettascale10 использует NVIDIA Spectrum-X Ethernet — первую, по словам NVIDIA, Ethernet-платформу, которая обеспечивает высокую масштабируемость, чрезвычайно низкую задержку между ускорителями в кластере, лидирующее в отрасли соотношение цены и производительности, улучшенное использование кластера и надежность, необходимую для крупномасштабных ИИ-задач. Как отметила Oracle, OCI Zettascale10 является «мощным развитием» первого облачного ИИ-кластера Zettascale, который был представлен в сентябре 2024 года. Кластеры OCI Zettascale10 будут располагаться в больших кампусах ЦОД мощностью в гигаватты с высокоплотным размещением в радиусе двух километров, чтобы обеспечить наилучшую задержку между ускорителями для крупномасштабных задач ИИ-обучения. Именно такой подход выбран для кампуса Stargate в Техасе. Oracle отметила, что помимо возможности создавать, обучать и развёртывать крупнейшие ИИ-модели, потребляя меньше энергии на единицу производительности и обеспечивая высокую надёжность, клиенты получат свободу работы в распределённом облаке Oracle со строгим контролем над данными и суверенитетом ИИ. 
Источник изображения: OpenAI Изначально кластеры OCI Zettascale10 будут рассчитаны на развёртывание до 800 тыс. ускорителей NVIDIA, обеспечивая предсказуемую производительность и высокую экономическую эффективность, а также высокую пропускную способность между ними благодаря RoCEv2-интерконнекту Oracle Acceleron со сверхнизкой задержкой. Acceleron предлагает 400G/800G-подключение со сверхнизкой задержкой, двухуровневую топологию, множественное подключение одного NIC к нескольким коммутатором с физической и логической изоляцией сетевых потоков, поддержку LPO/LRO и гибкость конфигурации. DPU Pensando от AMD в Acceleron место тоже нашлось. 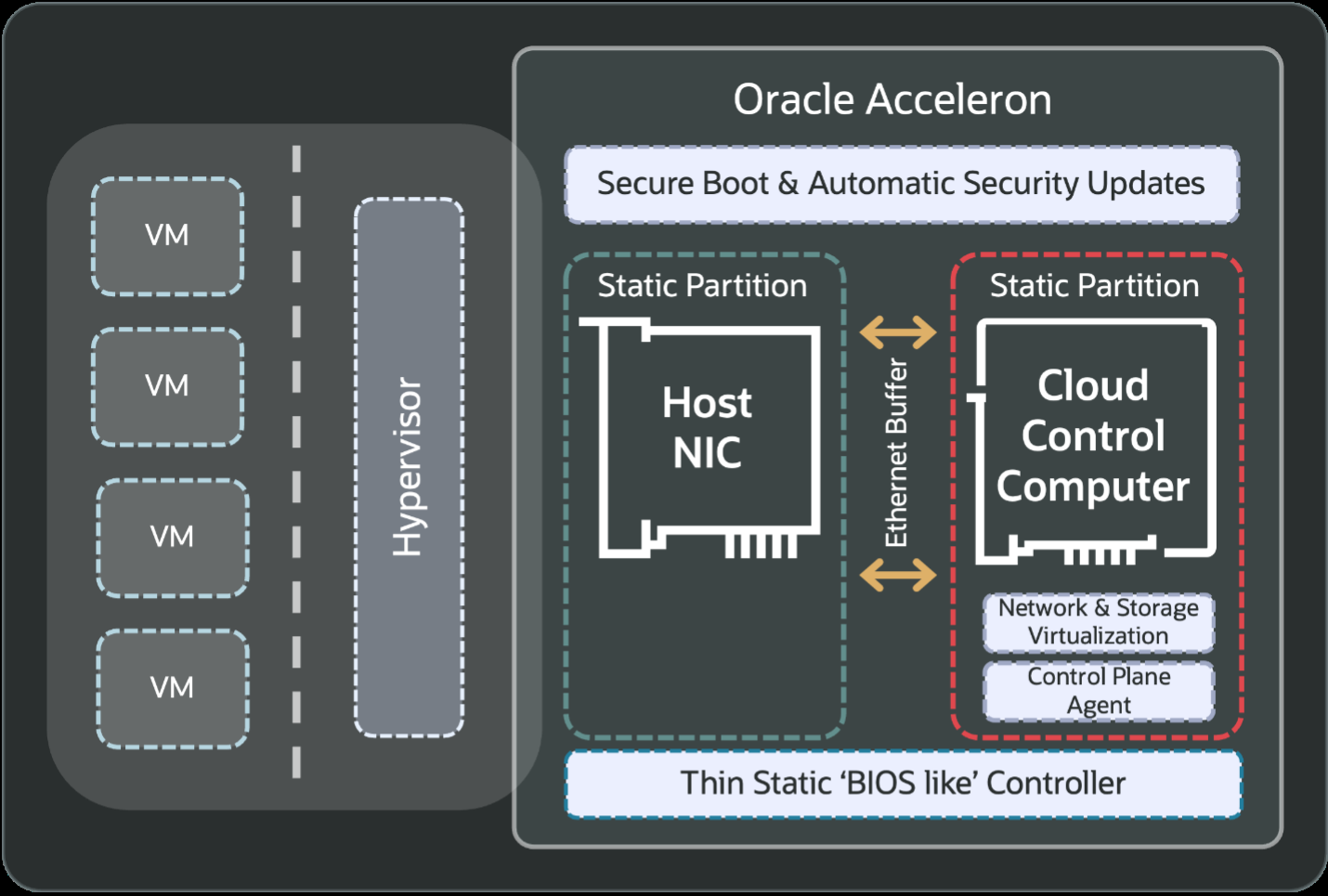
Источник изображения: Oracle OCI уже принимает заказы на OCI Zettascale10, который поступит в продажу во II половине следующего календарного года. В августе NVIDIA анонсировала решение Spectrum-XGS Ethernet для объединения нескольких ЦОД в одну ИИ-суперфабрику, которым, по-видимому, воспользуется не только Oracle, но и Meta✴.
09.10.2025 [11:12], Сергей Карасёв
Представлен маршрутизатор Cisco 8223 с пропускной способностью 51,2 Тбит/с для распределённых ИИ-кластеровКомпания Cisco анонсировала высокопроизводительную систему маршрутизации Cisco 8223, предназначенную для формирования масштабных ИИ-кластеров на базе географических распределённых дата-центров. Утверждается, что такие платформы способны обрабатывать более 20 млрд пакетов в секунду и обеспечивать общую пропускную способность до 3 Эбит/с. При подобных развёртываниях расстояние между ЦОД-площадками может достигать 1000 км. В основу Cisco 8223 положена ASIC собственной разработки Silicon One P200. Это, как утверждается, первый в отрасли полнодуплексный процессор маршрутизации с пропускной способностью 51,2 Тбит/с. Поддерживается гибкая конфигурация портов в режимах 10/25/40/50/100/200/400/800GbE. Заявлена совместимость со стандартами 802.1d, 802.1p, 802.1q, 802.1ad. 
Источник изображения: Cisco Новая система маршрутизации представлена в вариантах 8223-64EF (OSFP) и 8223-64E (QSFP). Устройства выполнены в форм-факторе 3U и оснащены 64 портами 800G. Суммарная пропускная способность достигает 51,2 Тбит/с. Маршрутизаторы несут на борту процессор AMD с восемью вычислительными ядрами, который функционирует в тандеме с 64 Гбайт оперативной памяти. Установлен SSD вместимостью 128 Гбайт. На фронтальную панель выведены консольный порт RS-232, сетевые порты управления 10G SFP+ и 1GbE RJ45, порт QSFP28 PIE и разъём USB Type-C. Установлены четыре блока питания мощностью 3000 Вт. В системе охлаждения задействованы семь вентиляторов. Габариты составляют 132,1 × 439,6 × 640,8 мм, масса — 31,75 кг. Cisco говорит о развитых средствах обеспечения безопасности. В частности, предусмотрены средства непрерывного мониторинга и шифрования данных на полной скорости с использованием устойчивых постквантовых алгоритмов. При объединении в одной инфраструктуре тысяч маршрутизаторов Cisco 8223 может поддерживаться совместная работа миллионов высокопроизводительных ИИ-ускорителей. Это позволяет решать наиболее сложные задачи в области обучения больших языковых моделей и инференса. |
|

