Материалы по тегу: рекорд
|
18.06.2026 [01:45], Владимир Мироненко
NVIDIA стала лидером во всех тестах MLPerf Training 6.0Консорциум MLCommons опубликовал результаты тестирования различных аппаратных решений в бенчмарке MLPerf Training 6.0. В нём появилось два новых теста — DeepSeek V3 и GPT-OSS 20B, что подчёркивает общеотраслевой переход к разреженным вычислениям, примером которого является архитектура MoE (Mixture-of-Experts). DeepSeek V3 — крупномасштабная MoE-модель c 671 млрд параметров, из которых 37 млрд активируются для генерации отдельного токена. Она предоставляет стандартизированную платформу для оценки эффективности обучения ведущей модели MoE с открытыми весами. GPT-OSS 20B — MoE-модель c 21 млрд параметров, из которых 3,6 млрд активируются для генерации одного токена. Она позволяет организациям оценивать сложную логику маршрутизации и шаблоны разреженных вычислений, характерные для архитектуры MoE, на аппаратных конфигурациях размером всего в один узел с восемью ускорителями. Версия MLPerf Training 6.0 установила новые рекорды по разнообразию представленных систем. Участники выложили результаты 95 уникальных систем, использующих тринадцать различных аппаратных ускорителей, 19 различных хост-процессоров и несколько различных программных фреймворков. 60 % систем были многоузловыми. При этом количество представленных облачных систем более чем вдвое больше, чем в раунде 5.1. 
Источник изображения: NVIDIA В раунде MLPerf Training v6.0 представлены заявки от 24 организаций: AMD, ASUSTeK, Azure, Cisco, CoreWeave, Dell, Fujitsu, GigaComputing, Google, HPE, Inventec, Krai, Lambda, MITAC, Nebius, Netweb Technologies India, NVIDIA, Oracle, Quanta Cloud Technologies, SCITIX, Supermicro, tinycorp, TTA и Vultr. «Мы особенно рады приветствовать участников, впервые представляющих свои результаты в MLPerf Training: Inventec, Netweb Technologies India, TTA и Vultr», — сообщил Дэвид Кантер (David Kanter), руководитель MLPerf в MLCommons. NVIDIA вновь стала лидером в новом раунде MLPerf Training, причём во всех тестах, в очередной раз став единственной платформой, которая предоставила результаты по всем тестам. Также NVIDIA была единственной платформой, представившей результаты по новым тестам, при этом система NVIDIA GB300 NVL72 «установила планку производительности благодаря оптимизированным программным стекам NVIDIA и конструкции, объединяющей 72 GPU Blackwell Ultra и 36 CPU Grace с использованием NVLink и NVLink Switch». В нескольких случаях партнёры NVIDIA масштабировали систему до 8192 ускорителей Blackwell, работающих согласованно в различных ЦОД. Эти результаты подтвердили реальную надёжность платформы Blackwell в масштабируемых кластерных средах, говорит NVIDIA. 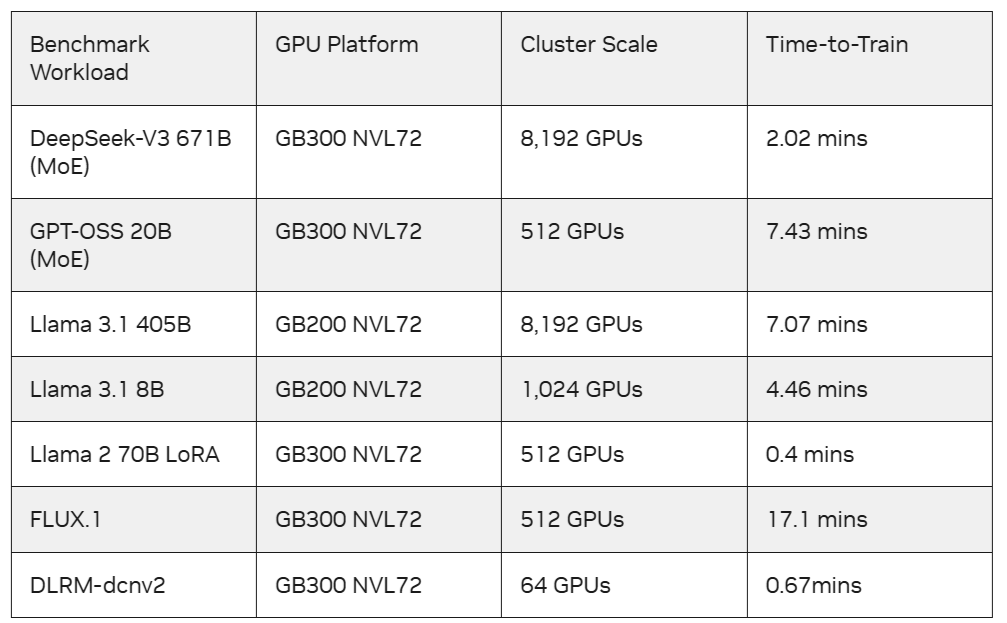
Источник изображения: NVIDIA Для достижения максимальной производительности таких моделей, как DeepSeek-V3, NVIDIA в этом раунде MLPerf Training применила несколько программных оптимизаций, включая использование итерационных графов CUDA для MoE без удаления токенов, применение CuTe DSL для продвинутых операций слияния ядер, алгоритм внимания MXFP8 для повышения производительности без ущерба для качества модели, оптимизацию маршрутизатора и оптимизацию схемы коммуникации 1F1B all-to-all overlap. Также NVIDIA оптимизировала компоновку и баланс параллельных этапов конвейера, минимизируя структурное простаивание. Для обработки DeepSeek-V3 671B компания NVIDIA использовала до 8192 GPU в системах GB200 NVL72, что стало самым масштабным результатом на основе Blackwell в MLPerf Training на сегодняшний день. NVIDIA также представила результаты на 5120 GPU с системами NVIDIA GB200 NVL72 в Llama 3.1 405B, одной из самых крупных LLM плотной архитектуры в этом бенчмарке. Результаты этого раунда также отражают тесное сотрудничество NVIDIA с компаниями-партнёрами в области системной архитектуры, сетей и ПО. Например, Microsoft Azure масштабировала обучение Llama 3.1 405B до 8192 GPU, используя системы GB200 NVL72, и достигла целевого эталонного значения за 7,07 мин., что является самым быстрым временем обучения для этого бенчмарка. А CoreWeave показала самое быстрое время обучения для DeepSeek-V3 671B, достигнув целевого качества за 2,02 мин. на 8192 GPU в составе GB300 NVL72, объединённых Spectrum-X Ethernet.
19.03.2026 [15:32], Руслан Авдеев
16 тыс. км без регенерации сигнала: Ciena и Meta✴ установили рекорд дальности и скорости передачи данных по подводному кабелю BifrotstКомпании Ciena и Meta✴ установили мировой рекорд дальности высокоскоростной передачи данных без регенерации сигнала по действующему подводному кабелю на одной несущей — 800 Гбит/с. Речь идёт о системе Bifrost длиной 16 608 км, объединяющей Сингапур, Индонезию, Филиппины, Гуам и США. Тесты проводились на паре волокон, принадлежащих Meta✴. Испытания увенчались успехом благодаря технологии GeoMesh Extreme компании Ciena, она включает когерентную оптическую систему WaveLogic 6 Extreme (WL6e) и компактную реконфигурируемую систему 6500 Reconfigurable Line System (RLS). Ciena заявляет, что установление мирового рекорда дальности передачи с подобными характеристиками связи подтверждает ценность WL6e в качестве технологии, способной обеспечить «800G повсюду». Опыты доказывают, что сверхвысокоскоростную передачу данных можно обеспечить на самых длинных и сложных подводных маршрутах. Компания подчёркивает, что общая пропускная способность оптоволоконных пар составила в ходе испытаний 18 Тбит/с с избыточным эксплуатационным резервом. Использовался компактный SLTE (submarine line terminal equipment) высотой всего 10U, который оказался вдвое энергоэффективнее в сравнении с решением Ciena предыдущего поколения. Партнёры подчеркнули, что результаты имеют исключительное значение с точки зрения эффективности использования пространства и электроэнергии. Это критически важно для посадочных станций. 
Источник изображения: Robert Boston/unsplash.com Для Meta✴ проект имеет особое значение, поскольку должен помочь в управлении совместимой с ИИ-оборудованием инфраструктурой на больших расстояниях с уменьшением углеродных выбросов благодаря сниженному энергопотреблению и компактному объёму. Не так давно Ciena сообщала о рекордной для компании выручке $1,43 млрд в I квартале финансового года, на 33 % больше год к году. Компания назвала результата «беспрецедентным». В июне 2025 года сообщалось, что Telxius и Ciena установили рекорд скорости передачи данных между США и Европой по трансатлантическому кабелю Marea.
22.10.2025 [14:13], Руслан Авдеев
Oracle и OpenAI помогли поставить новый рекорд на рынке ЦОД США: в III квартале было арендовано больше мощностей, чем за весь 2024 годТолько в III квартале 2025 года гиперскейлерами арендовано больше мощностей дата-центров в США, чем за весь 2024 год. В отчёте TD Cowen указывается, что рекордный объём аренды ЦОД достиг 7,4 ГВт, а портфель будущих сделок составляет порядка 10,2 ГВт, сообщает Datacenter Dynamics. Это самый большой рост спроса за всю историю отрасли. Совокупный объём аренды гиперскейлерами за текущий год составит приблизительно 11,3 ГВт, тогда как за весь 2024 год он составил 7 ГВт. При поквартальном учёте рост ещё заметнее — во II квартале 2025 года было арендовано всего 2 ГВт. Огромную долю рынка заняла Oracle. В III квартале она арендовала порядка 5,4 ГВт на нескольких площадках, мощности предназначены в основном для OpenAI. В TD Cowen отмечают, что Oracle и OpenAI являются основными драйверами спроса, но значительно активнее, чем раньше, ведут себя и Google, Meta✴, Microsoft, AWS, а также Anthropic. 
Источник изображения: Point3D Commercial Imaging Ltd./unsplash.com Google ведёт переговоры об аренде гигаваттных масштабов, Meta✴ ведёт переговоры об аренде гигаваттных мощностей помимо площадки в Луизиане, Anthropic активно работает над гигаваттными проектами отдельно от Amazon (AWS) и Google. Microsoft наращиваетнедостающие мощности за счёт внешних арендаторов и масштабирования облачного бизнеса. Наконец, Amazon (AWS) активно масштабирует Project Rainier. Второе место в рейтинге TD Cowen заняла Google, которая арендовала 600 МВт только в III квартале, на третьем — Anthropic с показателем 528 МВт за квартал. В начале июня TD Cowen сообщала, что аренда ЦОД возвращается к значительным масштабам после замедления в начале 2025 года. Amazon и Microsoft отложили или отменили проекты ЦОД, но утверждали, что это не является признаком общей системной проблемы. Тем временем Oracle активно анонсирует новые запланированные мощности, в том числе — очередную облачную сделку с OpenAI на сумму $300 млрд.
13.10.2025 [00:30], Владимир Мироненко
Вложи $5 млн — получи $75 млн: NVIDIA похвасталась новыми рекордами в комплексном бенчмарке InferenceMAX v1
b200
gb200
hardware
nvidia
open source
semianalysis
бенчмарк
ии
инференс
рекорд
финансы
энергоэффективность
NVIDIA сообщила о результатах, показанных суперускорителем GB200 NVL72, в новом независимом ИИ-бенчмарке InferenceMAX v1 от SemiAnalysis. InferenceMAX оценивает реальные затраты на ИИ-вычисления, определяя совокупную стоимость владения (TCO) в долларах на миллион токенов для различных сценариев, включая покупку и владение GPU в сравнении с их арендой. InferenceMAX опирается на инференс популярных моделей на ведущих платформах, измеряя его производительность для широкого спектра вариантов использования, а результаты может перепроверить любой желающий, говорят авторы бенчмарка. Суперускоритель GB200 NVL72 победил во всех категориях бенчмарка InferenceMAX v1. Чипы NVIDIA Blackwell показали наилучшую окупаемость инвестиций — вложение в размере $5 млн приносят $75 млн дохода от токенов DeepSeek R1, обеспечивая 15-кратную окупаемость (год назад NVIDIA обещала ROI на уровне 700 %). Также ускорители поколения Blackwell отличаются самой низкой совокупной стоимостью владения. например, оптимизация ПО NVIDIA B200 позволила добиться стоимости всего в два цента на миллион токенов на OpenAI gpt-oss-120b, обеспечив пятикратное снижение стоимости одного токена всего за два месяца. NVIDIA B200 первенствовал и по пропускной способности и интерактивности, обеспечив 60 тыс. токенов в секунду на ускоритель и 1 тыс. токенов в секунду на пользователя в gpt-oss с новейшим стеком NVIDIA TensorRT-LLM. NVIDIA сообщила, что постоянно повышает производительность путём оптимизации аппаратного и программного стека. Первоначальная производительность gpt-oss-120b на системе NVIDIA DGX Blackwell B200 с библиотекой NVIDIA TensorRT LLM уже была лидирующей на рынке, но команды NVIDIA и сообщество разработчиков значительно оптимизировали TensorRT LLM для ускорения исполнения открытых больших языковых моделей (LLM). 
Источник изображений: NVIDIA Компания отметила, что выпуск TensorRT LLM v1.0 стал значительным прорывом в повышении скорости инференса LLM благодаря распараллеливанию и оптимизации IO-операций. А у недавно вышедшей модели gpt-oss-120b-Eagle3-v2 используется спекулятивное декодирование — интеллектуальный метод, позволяющий предсказывать несколько токенов одновременно. Это уменьшает задержку и обеспечивает получение ещё более быстрых результатов — пропускная способность выросла втрое, до 100 токенов в секунду на пользователя (TPS/пользователь), а общая производительность на ускоритель выросла с 6 до 30 тыс. токенов. 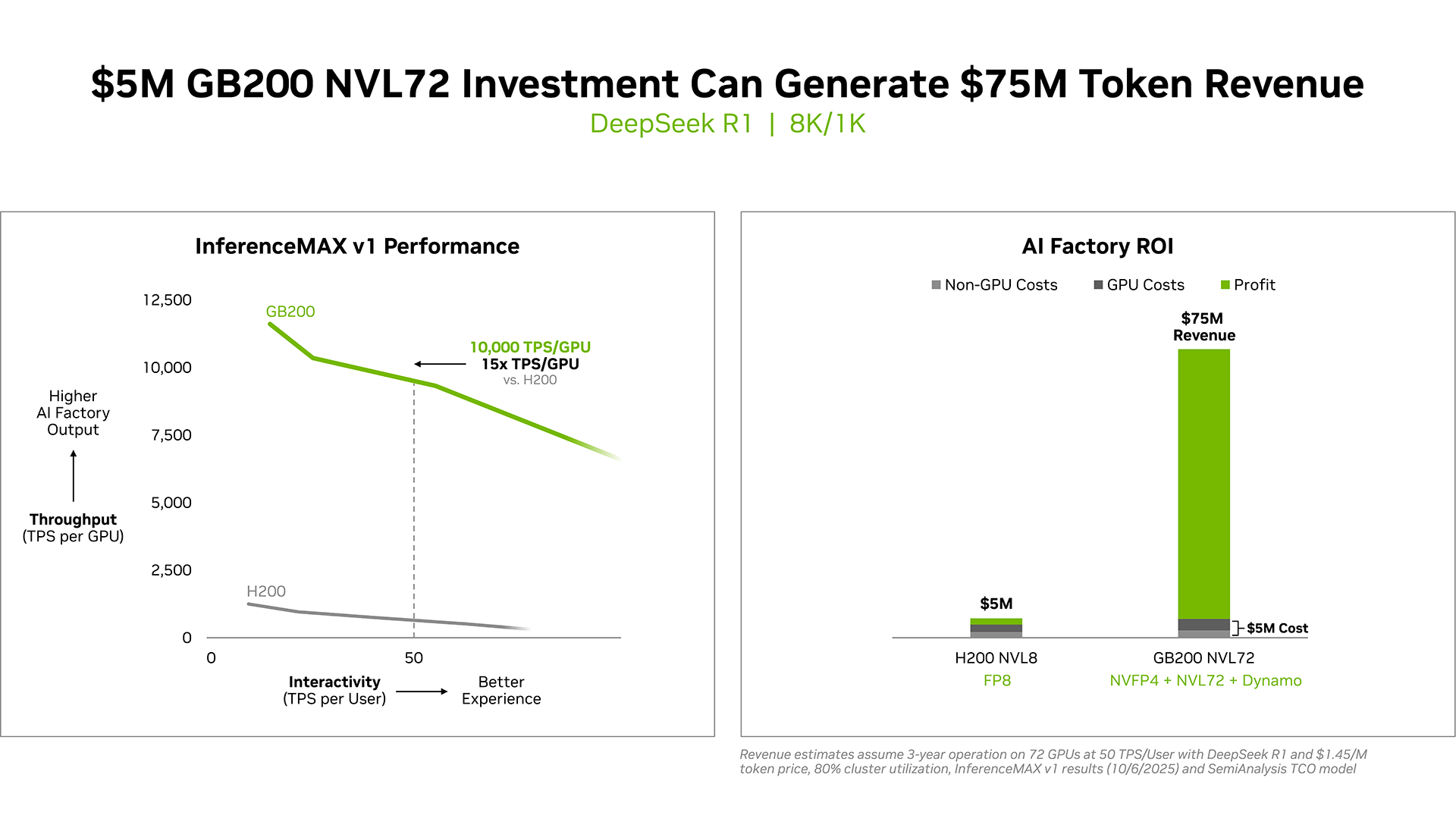 Для моделей с «плотной» архитектурой (Dense AI), таких как Llama 3.3 70b, которые требуют значительных вычислительных ресурсов из-за большого количества параметров и одновременного использования всех параметров в процессе инференса, NVIDIA Blackwell B200 достиг нового рубежа производительности в бенчмарке InferenceMAX v1, отметила NVIDIA. Суперускоритель показал более 10 тыс. токенов/с (TPS) на GPU при 50 TPS на пользователя, т.е. вчетверо более высокую пропускную способность на GPU по сравнению с NVIDIA H200. 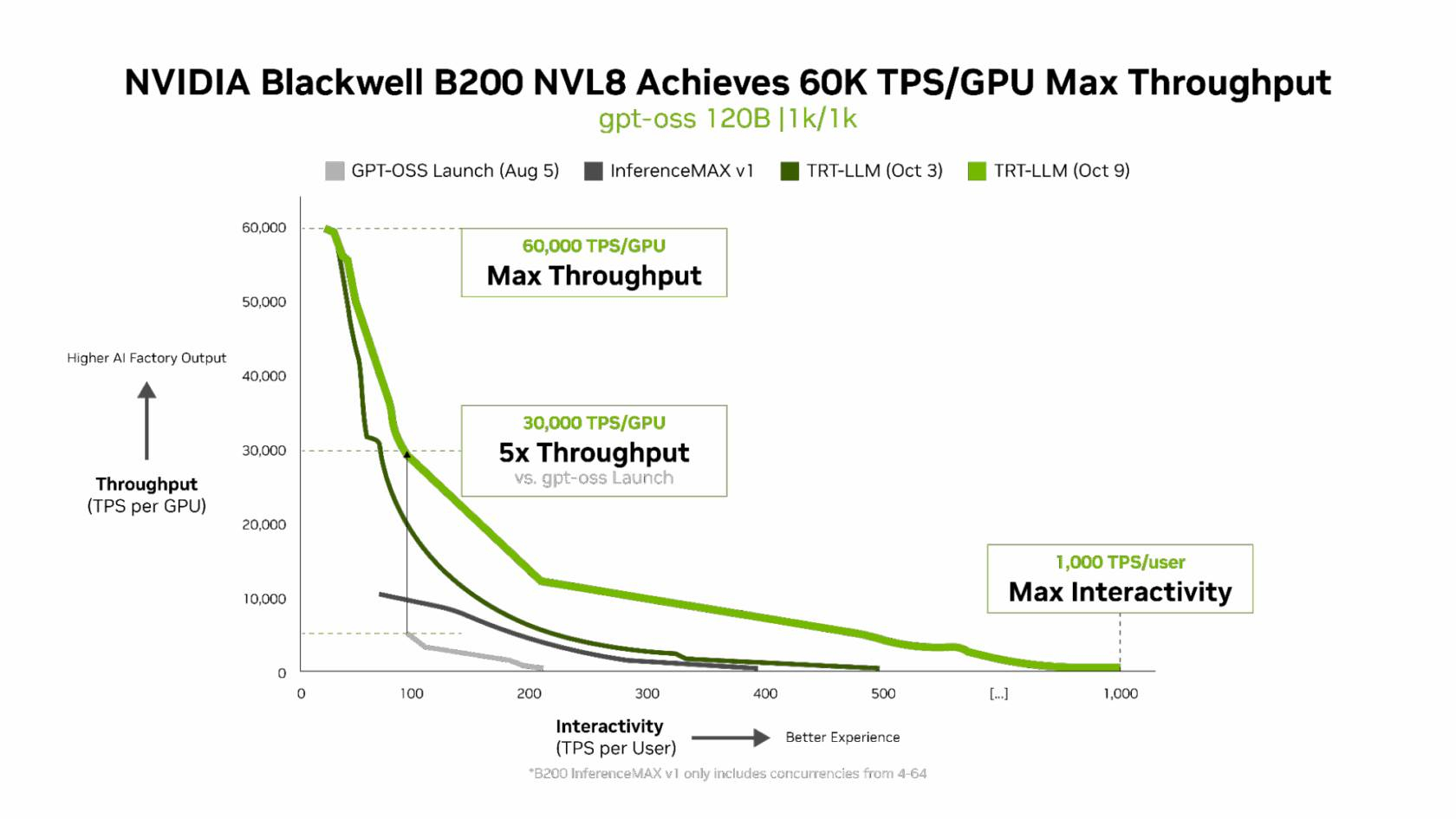 NVIDIA подчеркнула, что такие показатели, как количество токенов на Вт, стоимость на миллион токенов и TPS/пользователь не уступают по важности пропускной способности. Фактически, для ИИ-фабрик с ограниченной мощностью ускорители с архитектурой Blackwell обеспечивают до 10 раз лучшую производительность на МВт по сравнению с предыдущим поколением и позволяют получать более высокий доход от токенов. 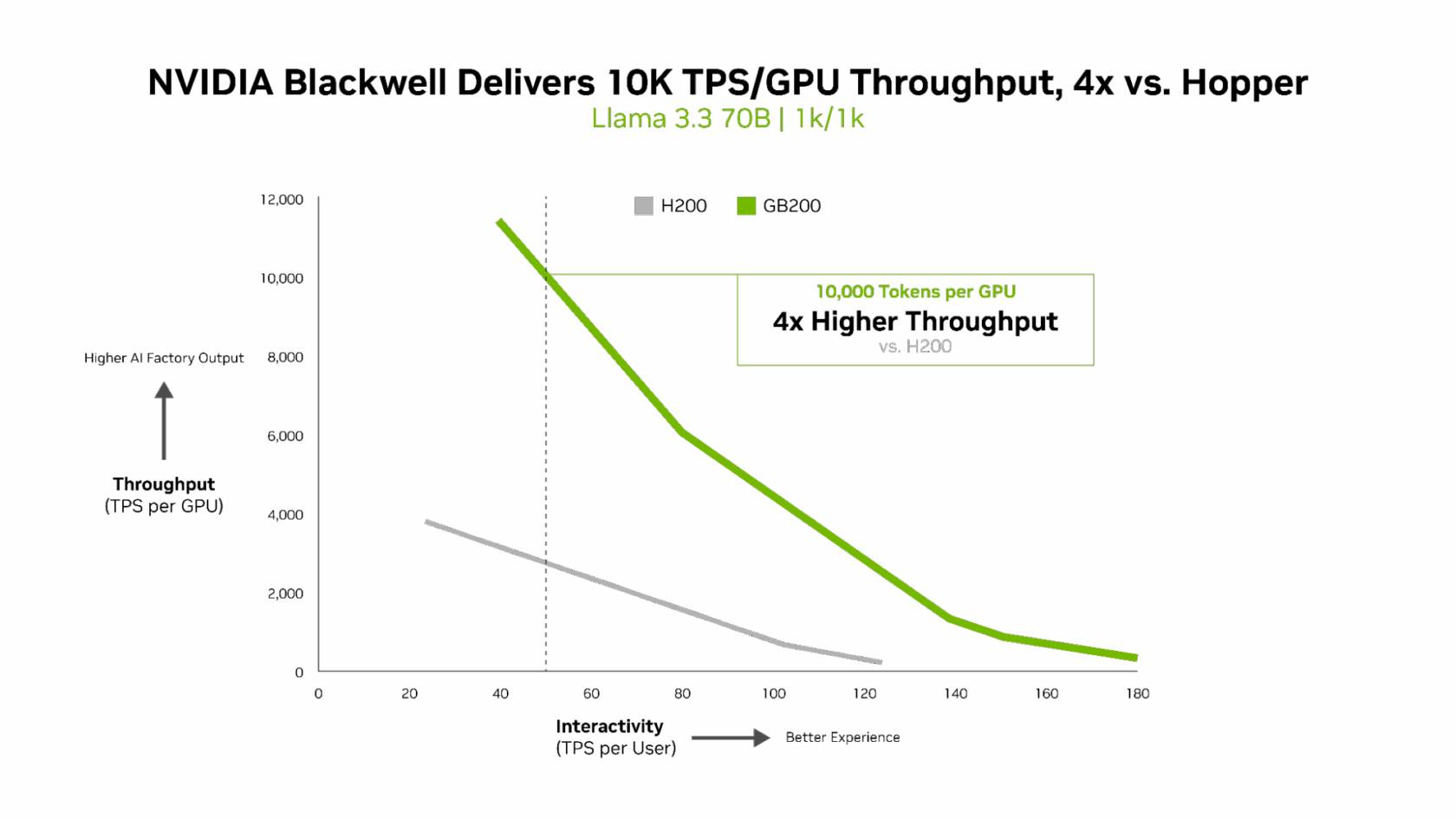 Компания отметила, что стоимость обработки одного токена (Cost per Token) имеет решающее значение для оценки эффективности ИИ-модели и напрямую влияет на эксплуатационные расходы. NVIDIA утверждает, что в целом архитектура NVIDIA Blackwell позволила снизить стоимость обработки миллиона токенов в 15 раз по сравнению с предыдущим поколением. 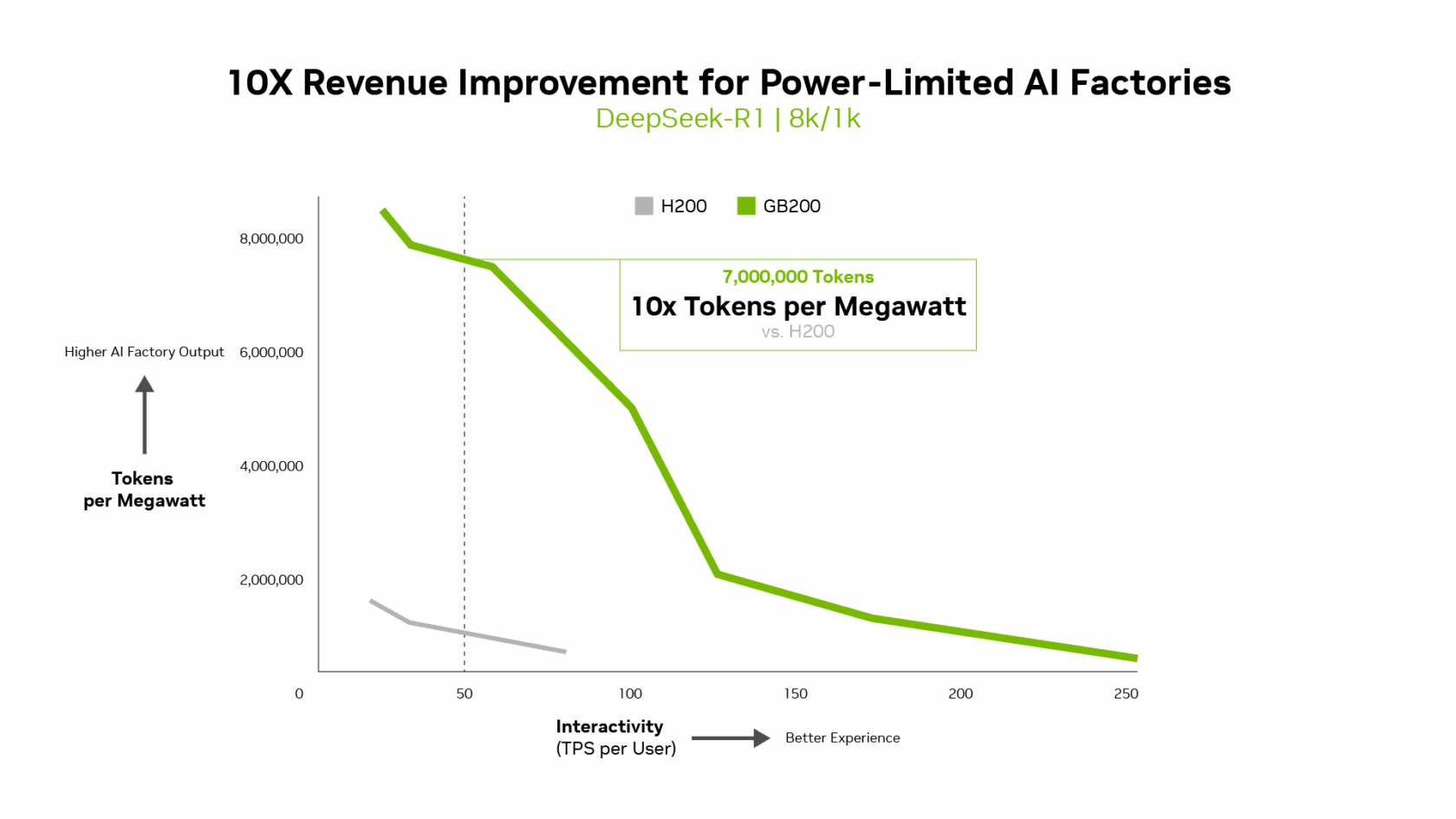 В InferenceMAX используется метод оценки эффективности Pareto front, определяющий наилучшее (компромиссное) сочетание различных факторов для оценки производительности ускорителя. Это показывает, насколько Blackwell лучше конкурентов справляется с балансом стоимости, энергоэффективности, пропускной способности и скорости отклика. Системы, оптимизированные только для одной метрики, могут демонстрировать пиковую производительность «в вакууме», но такая «экономика» не масштабируется в производственных средах. 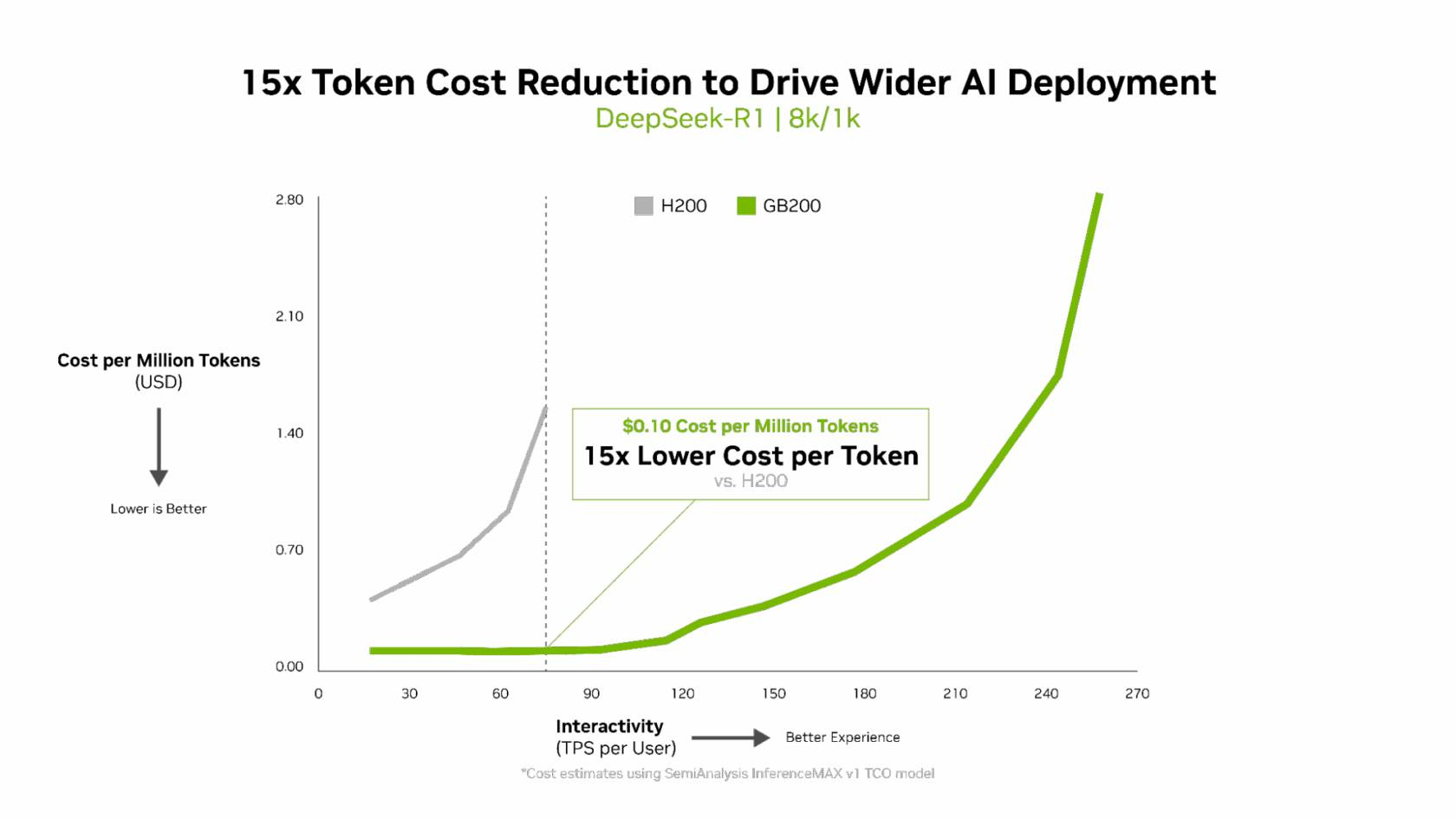 Компания отметила, что ИИ переходит от экспериментальных пилотных проектов к ИИ-фабрикам — инфраструктуре, которая производит интеллектуальные решения, преобразуя данные в токены и решения в режиме реального времени. Фреймворк NVIDIA Think SMART помогает предприятиям ориентироваться в этом переходе, демонстрируя, как полнофункциональная платформа инференса обеспечивает измеримую окупаемость инвестиций. Обещая 15-кратную окупаемость инвестиций и непрерывный рост производительности за счёт ПО, NVIDIA не просто лидирует в текущей гонке ИИ-технологий, но и задаёт правила для следующего этапа, где экономика будет определять победителей рынка, пишет The Tech Buzz. Для предприятий, делающих ставку на конкурирующие платформы в своих стратегиях по развёртыванию ИИ, результаты таких бенчмарков должны побудить к пересмотру выбора ИИ-инфраструктуры.
04.07.2025 [12:52], Руслан Авдеев
Петабит на пару: японская NICT поставила очередной рекорд скорости передачи данных по оптоволокнуЯпония регулярно бьёт рекорды по скорости передачи данных по оптоволокну на большие дистанции. NEC и японский Национальный институт коммуникационных технологий (National Institute of Communication Technology, NICT) чуть ли не каждый полгода объявляют о новом достижении. На этот раз NICT преодолела барьер в 1 Пбит/с на пару волокон на расстоянии почти 2 тыс. км, сообщает блог Subsea Cables & Internet Infrastructure. NICT использовала 19-ядерное оптоволокно Sumitomo Electric со стандартными размерами, сравнимыми с волокнами G.652d или G.657a, что важно для совместимости с существующими и будущими сетями. NICT добилась прогресса в решении проблемы перекрёстных помех в многоядерных волокнах. Общее расстояние в эксперименте составило 1808 км, а усилители были расположены каждые 82 км. Частота ошибок (BER) не раскрывается. Каждое из 19 ядер использовало диапазоны C+L. Таким образом, одно волокно способно выполнять работу за 38. Каждый усилитель фактически состоял из двух — для диапазона C и диапазона L. Пока только Subcom реализовала подобное решение в кабеле PLCN. Применение схемы модуляции 16QAM и MIMO позволило суммарно получить 180 рабочих каналов в C- и L-диапазонах. Использование пары таких волокон позволило получить скорость 1,02 Пбит/с. Удельный показатель — 1,86 Эбит/с на 1 км 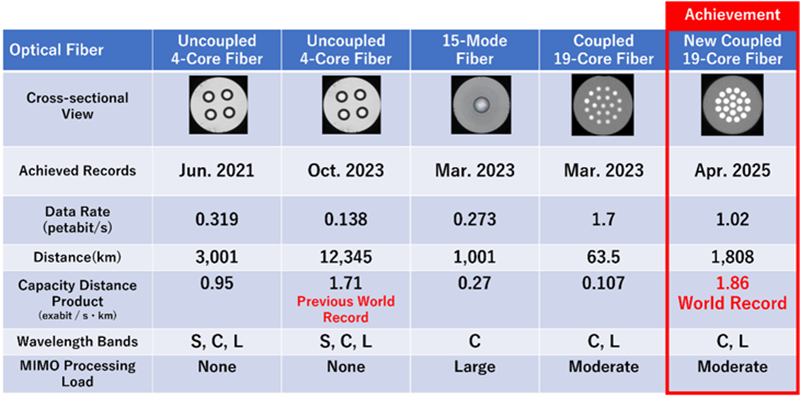
Источник изображения: NICT Пока проблемой является необходимость разработки доступных, компактных и экономичных усилителей. Сложность в том, что высокая начальная стоимость усилителей снизится только с масштабированием производства, а энергопотребление всегда ограничено параметрами самого кабеля. Некоторые эксперты предполагают, что до начала коммерческой эксплуатации подобных систем остаётся не менее 5–10 лет.
26.06.2025 [16:36], Руслан Авдеев
Telxius и Ciena установили рекорд скорости передачи данных между США и Европой по трансатлантическому кабелю MareaКомпании Telxius и Ciena объявили о достижении рекорда скорости передачи данных по подводному оптоволоконному кабелю Marea. Он соединяет Вирджиния-Бич (Virginia Beach, США) и Бильбао (Bilbao, Испания). В рамках испытаний удалось добиться 1,3 Тбит/с на одной длине волны — это рекордное достижение для трансантлантических ВОЛС, сообщает Converge Digest. Испытания с использованием когерентной оптики Ciena WaveLogic 6 Extreme (WL6e) позволили установить новый рекорд спектральной эффективности на уровне 7,0 бит/с/Гц. Технология WL6e с использованием 3-нм решений позволяет на 50 % снизить энергопотребление и занимаемое пространство на каждый передаваемый бит. Испытания — отражение растущих потребностей бизнеса в высокопроизводительной кабельной инфраструктуре для обеспечения передачи трафика, связанного с ИИ, потоковым видео, облачными сервисами и интерконнектами между ЦОД (DCI). 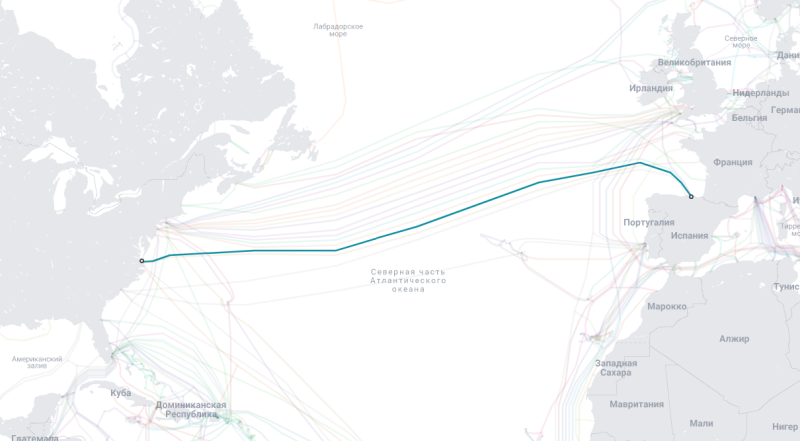
Источник изображения: Submarine Cable Map Компания Telxius управляет обширной волоконно-оптической экосистемой, включающей девять подводных кабелей нового поколения, более 100 тыс. км наземной инфраструктуры, 26 станций и ЦОД, а также 100 точек присутствия по всему миру. Обновление гарантирует, что кабель Marea продолжит обеспечивать надежную и высокоскоростную связь для цифровых приложений и платформ новых поколений. В дальнейшем планируется более широкое внедрение новых технологий. В частности, в компании заявили, что намерены широко внедрять WL6e на ключевых участках своей глобальной подводной сети с 2025 года.
21.05.2025 [22:58], Владимир Мироненко
Curator отразила атаку крупнейшего в истории DDoS-ботнета из 4,6 млн устройствКомпания Curator сообщила об успешной нейтрализации атаки самого крупного за всю историю наблюдений DDoS-ботнета, состоявшего из 4,6 млн устройств. Для сравнения, самый большой DDoS-ботнет, выявленный в прошлом году, состоял из 227 тыс. устройств, а крупнейший ботнет, зафиксированный в 2023 году — из 136 тыс. устройств. По данным Curator, 16 мая 2025 года атаке подверглась организация из сегмента «Государственные ресурсы», микросегмент — «Общественные организации». Атака проводилась в несколько этапов. На первом этапе в ней было задействовано порядка 2 млн устройств. На втором этапе ботнет пополнился ещё 1,5 млн устройств, а на третьем этапе количество устройств достигло 4,6 млн. Как полагают аналитики Curator, преступники в итоге задействовали все имеющиеся ресурсы. 
Источник изображения: Kevin Horvat/unsplash.com Большая часть устройств, входивших в ботнет, была из Южной и Северной Америки. Около 1,37 млн заблокированных во время атаки IP-адресов (30 % всего ботнета), были зарегистрированы в Бразилии, порядка 555 тыс. были из США, 362 тыс. — из Вьетнама, 135 тыс. — из Индии и 127 тыс. — из Аргентины. 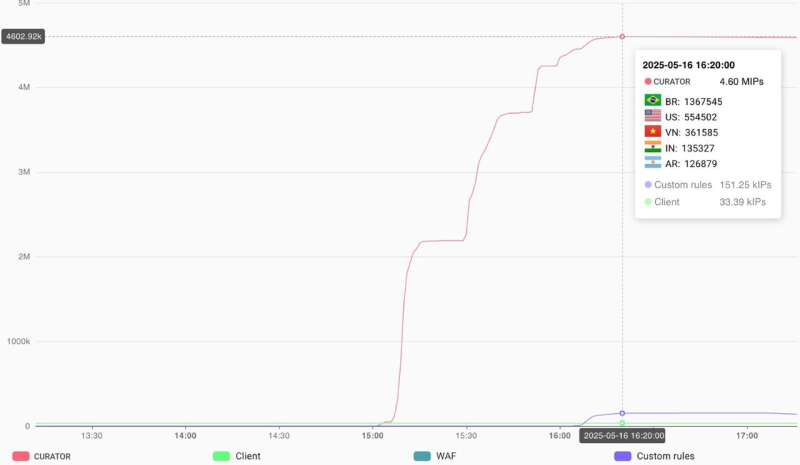
Источник изображения: Curator В Curator сообщили, что с этим ботнетом они сталкивались ранее в этом году, но тогда он включал всего 1,33 млн IP-адресов. Ботнет таких размеров может генерировать десятки миллионов запросов в секунду, что несёт угрозу выхода из строя атакуемых серверов в случае неудовлетворительной организации защиты. По словам Curator, такую атаку может выдержать не каждый провайдер DDoS-защиты, «что потенциально может поставить под угрозу доступность ресурсов всех клиентов одновременно».
15.01.2025 [15:35], Руслан Авдеев
Рынок ЦОД поставил рекорд по сделкам в 2024 году — $73 млрдКак свидетельствуют новые данные консалтинговой компании Synergy Research Group, после относительного затишья в 2024 году стоимость закрытых сделок, связанных со слияниями и поглощениями (M&A) ЦОД, стала рекордной, достигнув $73 млрд, сообщает пресс-служба компании. До этого рекордным был 2022 год. Совокупная стоимость официально закрытых сделок превысила $52 млрд, в 2023 году был двухкратный спад до $26 млрд. Впрочем, даже в 2022 году такого уровня не удалось бы добиться без двух крупнейших сделок в данной сфере, объёмом от $11 млрд каждая. Другими словами, «обычные» сделки объёмом до $2 млрд обеспечили довольно скромную статистику и в 2022 году. В этой отношении пиковым был 2021 год. Примечательно, что помимо уже закрытых сделок в 2024 году также имеются оформленные, но ещё не закрытые соглашения на сумму $29 млрд. Также возможны сделки ещё на $15 млрд — компании ищут финансирование или рассматривают доступные варианты. 2025 год тоже имеет все шансы стать рекордным для индустрии ЦОД. 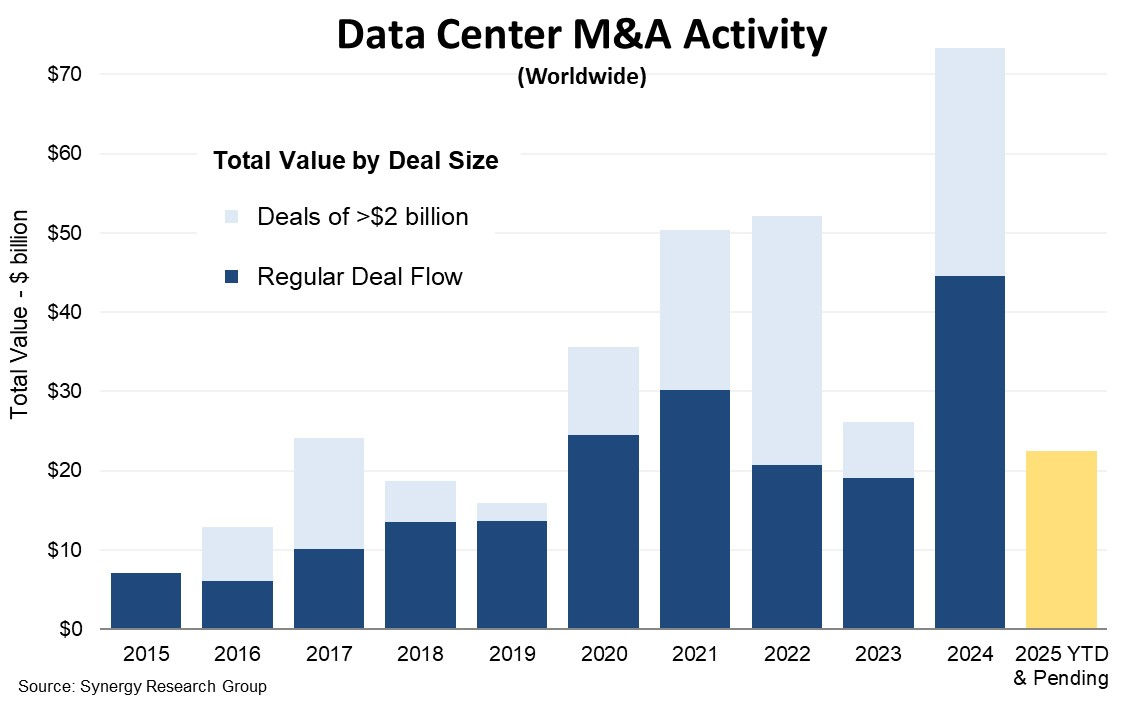
Истчоник: Synergy Research Всего с 2015 года Synergy Research зарегистрировала 1498 сделок слияния и поглощения на рынке ЦОД, общая стоимость составила $300 млрд. В основном речь идёт о покупке компаний целиком, но также были учтены миноритарные инвестиции в акционерный капитал и другие финансовые вложения вплоть до покупки отдельных дата-центров, земли для них и др. В 2021–2022 гг. были закрыты четыре сделки стоимостью от $10 млрд: покупка CyrusOne, Switch, CoreSite и QTS, входящих в Топ-15 колокейшн-провайдеров. В 2024 году в Vantage Data Centers инвестировали в ходе двух сделок $9,2 млрд. Кроме того, компания дважды получила вливания в акционерный капитал в регионе EMEA на общую сумму $3,1 млрд. Также крупные вливания в 2024 году получили EdgeConneX и DataBank. При этом в последние годы на рынок буквально заполонили частные капиталовложения. Если в 2020 году на такие инвестиции пришлось лишь 54 % стоимости закрытых сделок, то в 2021 году их доля увеличилась до 65 %. С тех пор доля выросла до 80–90 % и держится на этом уровне. В Synergy Research подчёркивают, что стремительный рост спроса на мощности ЦОД обусловлен развитием облачных сервисов, социальных сетей и всевозможных цифровых сервисов потребительского и корпоративного уровня. ИИ только усиливает и без того высокий спрос. Уточняется, что сами операторы ЦОД не могли или не хотели инвестировать собственные средства, тогда как частные инвесторы оказались готовыми вложиться в рост рынка. UPD 29.01.2024: Synergy обновила доклад, посвящённый сделкам на рынке ЦОД в 2024 году. Если ранее сообщалось, что их общая сумма составляла $57 млрд, то уточнённые показатели свидетельствуют, что она оказалась выше на целых $16 млрд и составила $73 млрд. В докладе указывается, что добавилась сделка, которая должна была быть закрыта лишь в начале 2025 года, но закрылась в конце декабря. Речь идёт о покупке Blackstone компании AirTrunk, состоявшейся ещё в сентябре, но завершившейся лишь перед самым Новым годом.
12.12.2024 [23:59], Руслан Авдеев
Царь-ускоритель Cerebras WSE-3 в одиночку обучил ИИ-модель с 1 трлн параметровCerebras Systems совместно с Сандийскими национальными лабораториями (SNL) Министерства энергетики США (DOE) провели успешный эксперимент по обучению ИИ-модели с 1 трлн параметров с использованием единственной системы CS-3 с царь-ускорителем WSE-3 и 55 Тбайт внешней памяти MemoryX. Обучение моделей такого масштаба обычно требует тысяч ускорителей на базе GPU, потребляющих мегаватты энергии, участия десятков экспертов и недель на наладку аппаратного и программного обеспечения, говорит Cerebras. Однако учёным SNL удалось добиться обучения модели на единственной системе без внесения изменений как в модель, так и в инфраструктурное ПО. Более того, они смогли добиться и практически линейного масштабирования — 16 систем CS-3 показали 15,3-кратный прирост скорости обучения. 
Источник изображения: Cerebras Модель такого масштаба требует терабайты памяти, что в тысячи раз больше, чем доступно отдельному GPU. Другими словами, классические кластеры из тысяч ускорителей необходимо корректно подключить друг к другу ещё до начала обучения. Системы Cerebras для хранения весов используют внешнюю память MemoryX на базе 1U-узлов с самой обычной DDR5, благодаря чему модель на триллион параметров обучать так же легко, как и малую модель на единственном ускорителе, говорит компания. Ранее SNL и Cerebras развернули кластер Kingfisher на базе систем CS-3, который будет использоваться в качестве испытательной платформы при разработке ИИ-технологий для обеспечения национальной безопасности.
29.11.2024 [10:15], Сергей Карасёв
Система Cerebras с ускорителями WSE установила рекорд в молекулярной динамике, превзойдя суперкомпьютер FrontierАмериканский стартап Cerebras Systems, специализирующийся на создании чипов для систем машинного обучения и других ресурсоёмких задач, объявил об установлении нового мирового рекорда производительности в области молекулярной динамики. В эксперименте приняли участие Сандийские национальные лаборатории (SNL), Ливерморская национальная лаборатория имени Лоуренса (LLNL) и Лос-Аламосская национальная лаборатория (LANL) в составе Министерства энергетики США (DOE). Вычисления выполнялись на системе, оснащённой фирменными ускорителями Cerebras Wafer Scale Engine (WSE). Говорится, что впервые в истории молекулярной динамики исследователи достигли результата более 1 млн шагов моделирования в секунду (timesteps per second, TPS). В частности, показано значение на уровне 1,1 млн TPS на платформе Cerebras CS-2, оборудованной чипами WSE-2, которые насчитывают 850 тыс. тензорных ядер и несут на борту 40 Гбайт памяти SRAM. Для сравнения: в случае суперкомпьютера экзафлопсного класса Frontier, который в нынешнем рейтинге TOP500 занимает второе место, результат составляет 1470 TPS. Таким образом, система Cerebras обеспечивает 748-кратный выигрыш в быстродействии на задачах молекулярной динамики. При этом энергопотребление комплекса Cerebras составляет 27 кВт против 21 МВт у Frontier. 
Источник изображения: Cerebras Кроме того, комплекс Cerebras превзошел Anton 3 — самый мощный в мире специализированный суперкомпьютер для молекулярной динамики. Anton 3 использует 512 кастомных ASIC, а его энергопотребление находится на уровне 400 кВт. Показатель быстродействия Anton 3 достигает 980 тыс. TPS. То есть, система Cerebras показывает выигрыш примерно в 20 %. Предполагается, что ускорители Cerebras предоставят качественно новые возможности для исследований в различных областях, включая разработку материалов следующего поколения, перспективных лекарственных препаратов и решений в сфере возобновляемой энергетики. Нужно отметить, что ранее Сандийские национальные лаборатории запустили ИИ-систему Kingfisher на чипах Cerebras WSE-3. А сама компания Cerebras развернула «самую мощную в мире» ИИ-платформу для инференса. |
|

