Американский стартап Cerebras Systems, специализирующийся на разработке ИИ-ускорителей, объявил о самом масштабном обновлении ИИ-платформы Cerebras Inference с момента её запуска. Производительность системы поднялась примерно в три раза.
Первый релиз Cerebras Inference состоялся в августе 2024 года. Основой облачной платформы являются ускорители собственной разработки WSE-3. На момент запуска быстродействие составляло до 1800 токенов в секунду на пользователя для ИИ-модели Llama3.1 8B и до 450 токенов в секунду для Llama3.1 70B (FP16). Разработчик заявлял, что Cerebras Inference — это «самая мощная в мире» ИИ-платформа для инференса.
Источник изображений: Cerebras Systems
Однако в сентябре нынешнего года у Cerebras Inference появился серьёзный конкурент. Компания SambaNova Systems запустила облачный сервис SambaNova Cloud, также назвав его «самой быстрой в мире платформой для ИИ-инференса». Система на основе чипов собственной разработки SN40L демонстрирует быстродействие до 461 токена в секунду при использовании Llama 3.1 70B. В ответ Cerebras Systems усовершенствовала своё решение путём «многочисленных улучшений программного обеспечения, оборудования и алгоритмов».
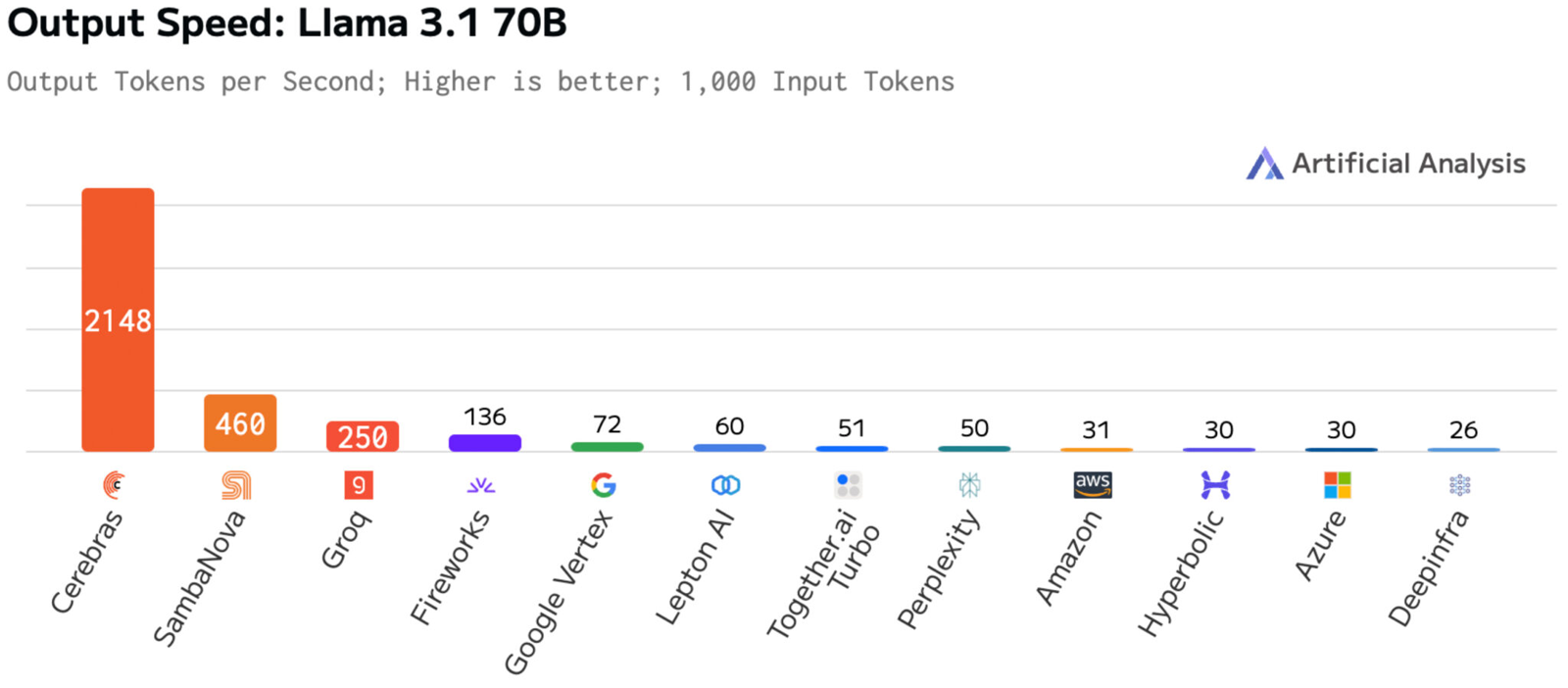
Утверждается, что обновлённая платформа Cerebras Inference при обслуживании Llama3.1 70B обеспечивает быстродействие 2148 токенов в секунду. Для сравнения: у AWS — лидера мирового облачного рынка — этот показатель равен 31 токену в секунду. А у Groq значение находится на уровне 250 токенов в секунду. Данные получены по результатам тестов Artificial Analysis.
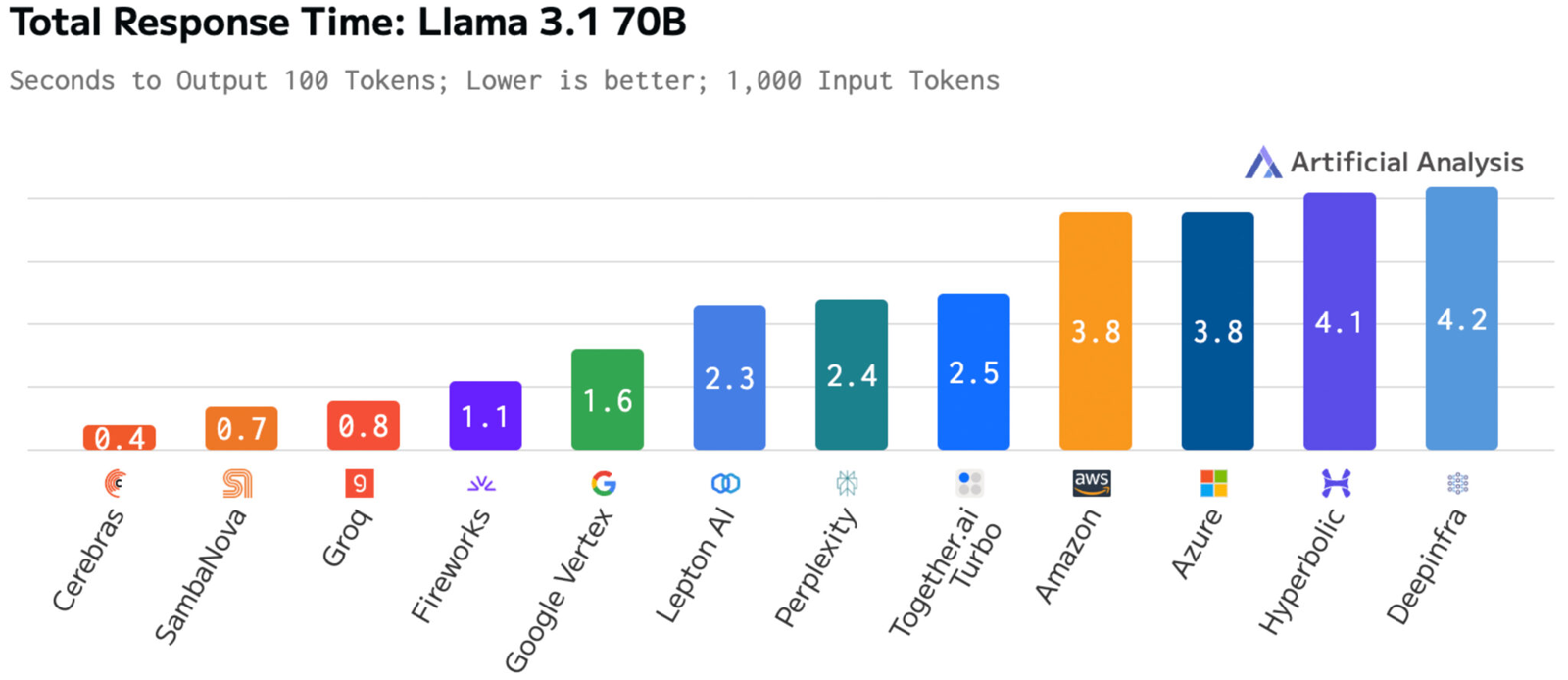
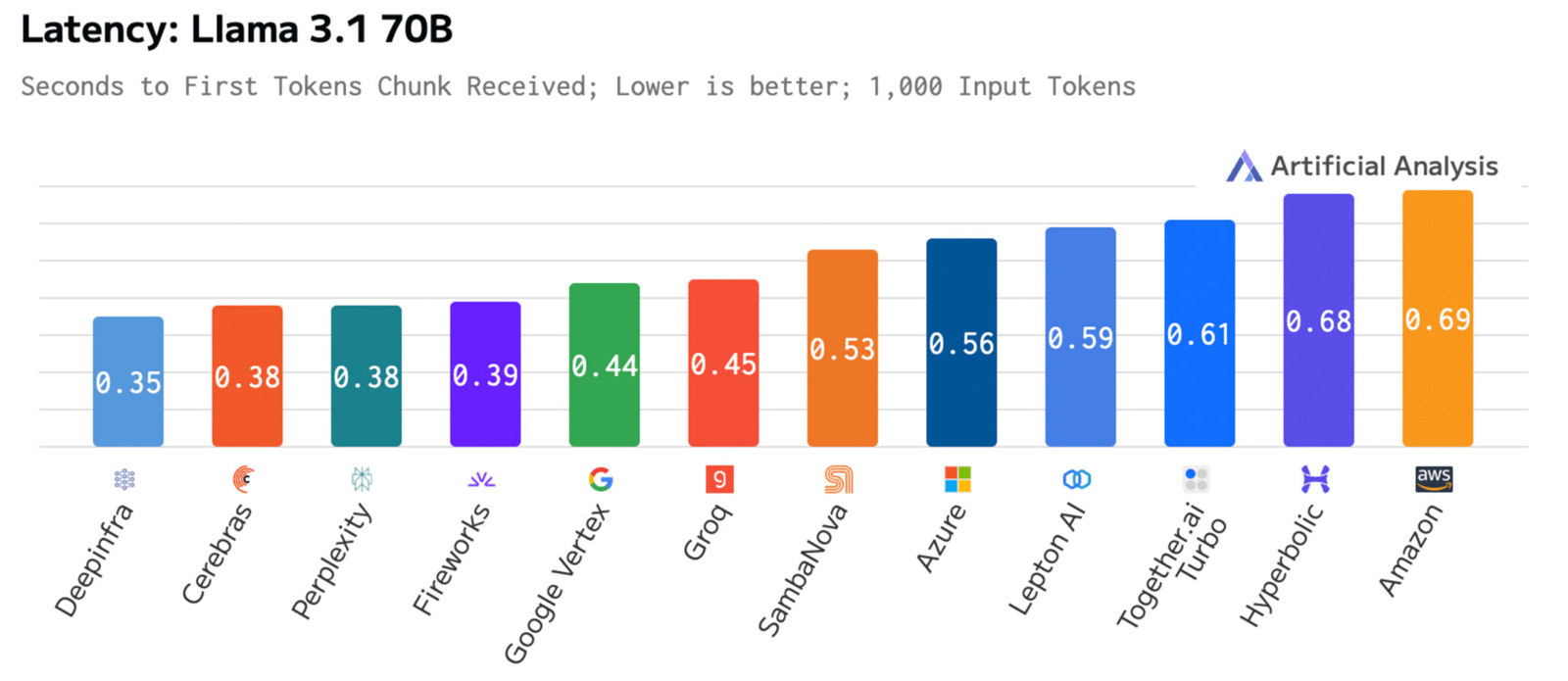
Время до получения первого токена имеет решающее значение для приложений реального времени. Cerebras находится на втором месте с показателем 0,38 с, уступая только Deep Infra (0,35 с). Вместе с тем Cerebras лидирует по общему времени отклика для 100 токенов на выходе с показателем 0,4 с против 0,7 с у SambaNova, которая находится на втором месте. В целом, как отмечается, платформа Cerebras Inference при работе с Llama3.1 70B опережает сервисы конкурентов на основе GPU, обрабатывающие модель Llama3.1 3B, которая в 23 раза меньше.
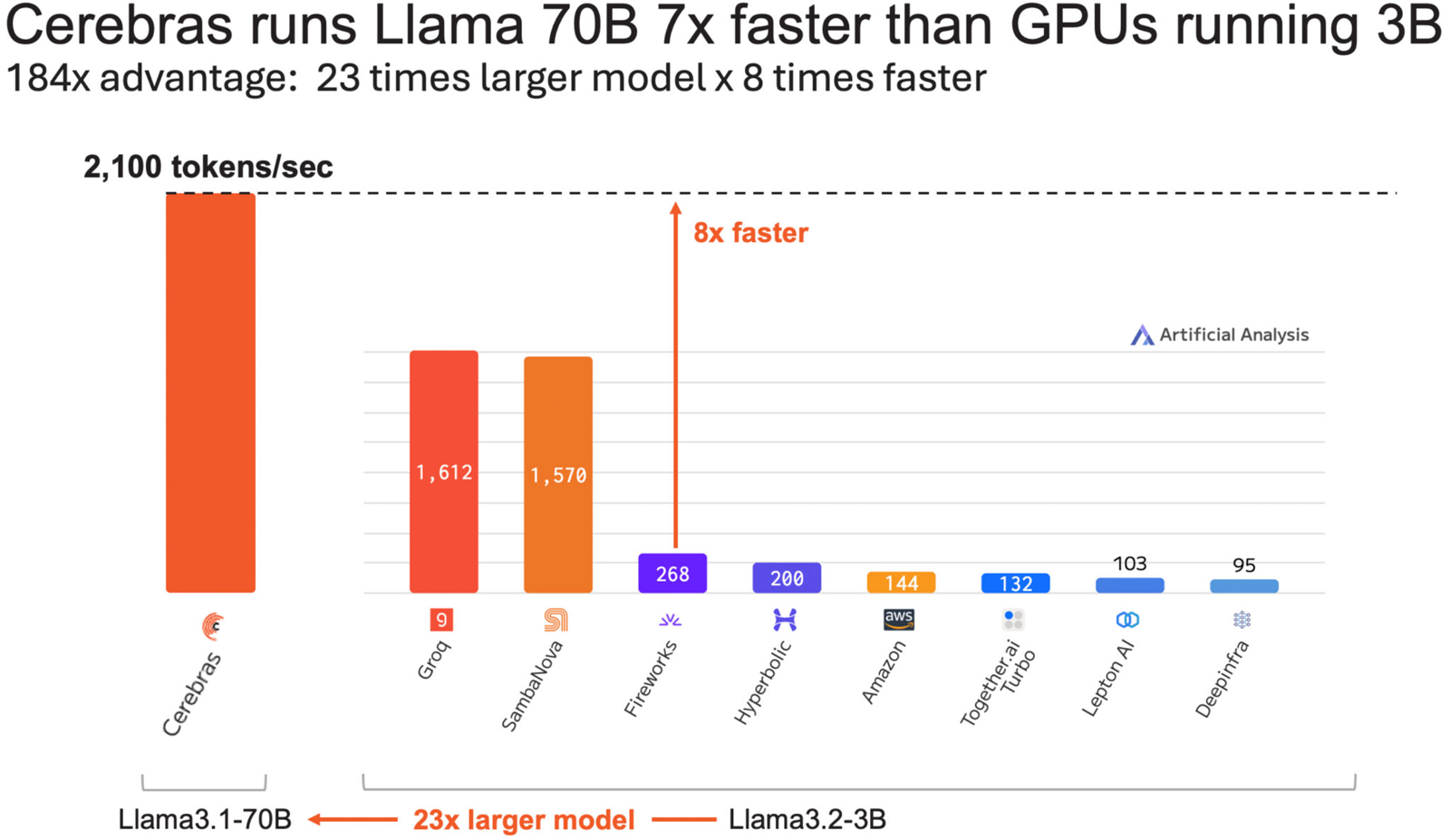
Источник:

