Материалы по тегу: инференс
|
26.06.2026 [12:23], Владимир Мироненко
Cornelis и NextSilicon создадут эталонные архитектуры для ИИ и HPCCornelis и NextSilicon объявили о сотрудничестве с целью разработки эталонных архитектур для ИИ и HPC. В рамках проекта компании приступили к оценке возможности использования 400G-интерконнекта Cornelis CN5000 в паре с вычислительной платформой NextSilicon Maverick-2. На первом этапе проверяется совместная работа интерконнекта и вычислительных ресурсов в различных конфигурациях, причём партнёры начали с проверенных комбинаций. Компании планируют расширить тестирование на интерконнект CN6000 со скоростью 800 Гбит/с, запуск которого запланирован на II половину 2026 года. Обе компании нацелены на решение проблемы в своей сфере. Стандартный Ethernet не рассчитан на обработку небольших, чувствительных к задержке сообщений, которые генерируются в больших масштабах при выполнении задач ИИ-инференса и симуляции HPC. Возникает перегрузка, и дорогостоящие вычислительные ресурсы простаивают в ожидании данных. CN5000 разработан для устранения этого простоя. 
Источник изображений: Cornelis Networks Вычислительные ресурсы простаивают при обработке нерегулярных, зависящих от данных рабочих нагрузок, которые доминируют в ИИ и HPC. Израильская компания NextSilicon построила ускоритель Maverick-2 на основе своей интеллектуальной вычислительной архитектуры (ICA) — программно-определяемой архитектуры с управлением потоками данных (dataflow), в которой вычисления запускаются не последовательными инструкциями, а по факту поступления данных. Платформа переконфигурируется для каждой рабочей нагрузки во время выполнения без изменения существующего кода. Сочетание подходов Cornelis и NextSilicon позволяет решить обе проблемы, обеспечивая передачу данных и поддерживая постоянную работу вычислительных ресурсов. Совместные эталонные архитектуры предоставят OEM-партнерам план создания систем, которые они смогут построить и вывести на рынок.  «Операторы постоянно говорят нам, что их самые дорогие системы простаивают, ожидая подключения к сети, — говорит Лиза Спелман (Lisa Spelman), генеральный директор Cornelis. — Мы создали CN5000, чтобы положить конец этому ожиданию. NextSilicon бросает вызов аналогичной проблеме в вычислительной сфере, поэтому это сотрудничество является естественным шагом. Вместе мы можем показать партнерам и клиентам, что дают бесперебойная сеть и вычислительная архитектура, ориентированная на рабочие нагрузки, в рамках единого решения». Наряду с HPC, сотрудничество также будет направлено на переход в ИИ-инференсе к моделям смешанных экспертов (MoE) и агентному ИИ. Инференс в продуктовых средах для этих рабочих нагрузок больше не выполняется как одна модель на одном ускорителе. Он разделяется на этапы, и данные перемещаются между этапами по сети. Дезагрегированный инференс делает сетевую инфраструктуру частью вычислительного пути. Он применим для сети, которая обрабатывает небольшие, импульсные, чувствительные к задержкам сообщения без перегрузки, и вычислительных ресурсов, которые адаптируются к каждому этапу конвейера.
25.06.2026 [16:11], Владимир Мироненко
Qualcomm анонсировала HBC — альтернативу HBM на базе LPDDRQualcomm анонсировала High Bandwidth Compute (HBC), гибридное решение для вычислений и памяти, разработанное в качестве альтернативы памяти HBM и обеспечения большей производительности, эффективности и пропускной способности. В нём используется трёхмерная архитектура Near-Memory Computing (NMC), обеспечивающая предельно близкое расположение быстрой памяти к вычислительным ядра. В HBC используется память LPDDR, размещённая вертикально в несколько слоёв, соединённых сквозными кремниевыми контактами (TSV). Такой подход обеспечивает лучшую энергоэффективность, чем традиционная HBM, в которой в вертикальных слоях размещается память DDR, поскольку микросхемы LPDDR потребляют меньше энергии, обеспечивая при этом аналогичную пропускную способность и ёмкость. При этом в основании HBC лежит вычислительный кристалл, который берёт на себя часть обработки данных основного процессора, тем самым разгружая его. Как отметил ресурс Techpowerup, эта технология аналогична используемой в памяти HBM4, где базовый кристалл представляет собой логический кристалл для лучшей интеграции вычислительных решений, таких как трассировка пакетов и подготовка данных для ввода и вывода из HBM. 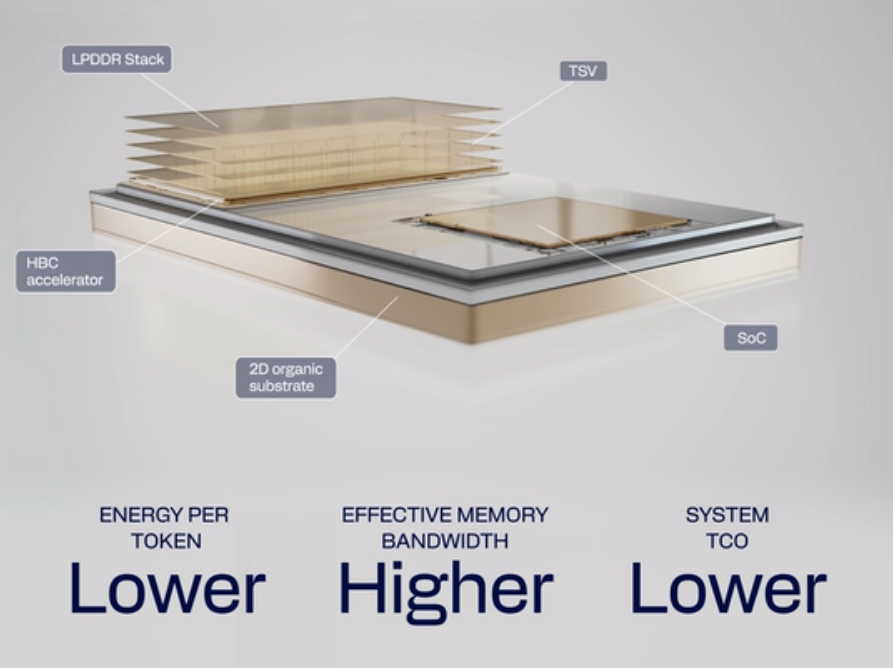
Источник изображений: Qualcomm Qualcomm сообщила, что HBC обеспечивает шестикратное увеличение пропускной способности на Вт по сравнению с HBM, согласно опубликованным характеристикам конкурирующих продуктов, нормализованным на уровне платы, а также 200-кратное увеличение ёмкости на Вт по сравнению с SRAM, согласно опубликованным характеристикам конкурирующих продуктов, нормализованным на уровне стойки.  HBC первого поколения (HBC Gen 1) достигла пропускной способности 133 Тбайт/с на ускорителе AI250, что в 18 раз больше, чем у AI200 на базе LPDDR5X. Коммерческое тестирование HBC1 с AI250 ожидается в середине 2027 года. Компания планирует выпуск решения HBC Gen 2 в 2028 году. Это решение выйдет с ИИ-ускорителем Qualcomm Dragonfly AI300 и обеспечит 54-кратное увеличение эффективной пропускной способности по сравнению с AI200 и семикратное увеличения пропускной способности на Вт по сравнению с HBM.  Dragonfly AI300 интегрирует HBC2, обеспечив высокую пропускную способность и низкую задержку для инференса больших языковых и мультимодальных моделей (LLM, LMM) и агентного ИИ. По данным Qualcomm, ожидается в 4–8 раз более высокая производительность по сравнению с существующими архитектурами на базе GPU по пропускной способности памяти на Вт на карту. Масштабирование решения будет осуществляться с помощью интерконнектов UALink и ESUN с использованием медных и оптических кабелей. Коммерческое производство образцов Dragonfly AI300 начнётся в 2028 году.
25.06.2026 [12:45], Руслан Авдеев
Qualcomm прогнозирует продажи чипов для ЦОД на $15 млрд к 2029 году, Meta✴ и Microsoft — в числе ключевых покупателейКомпания Qualcomm заявила о намерении продать полупроводники в рамках связанного с ЦОД бизнеса на сумму $15 млрд к 2029 году. Она отходит от выпуска преимущественно чипсетов для смартфонов и прочей потребительской электроники — новость вызвала рост акций компании после закрытия торгов в среду на 12 %, сообщает Reuters. По словам представителя компании, связанный с ЦОД бизнес принесёт в 2027 финансовом году $5 млрд, из них $1 млрд поступит от покупателей новых кастомных чипов. Также компания объявила, что рассчитывает получить к 2029 году $40 млрд выручки за пределами связанного со смартфонами бизнеса (ранее говорилось о $22 млрд), к тому времени выручка от решений для смартфонов будет не превышать трети от общей. Ранее аналитики Bank of America заявляли, что ежегодная выручка Qualcomm от связанного с ЦОД бизнеса к 2027–2028 гг. будет значительно скромнее, приблизительно $2–$5 млрд ежегодно. 
Источник изображений: Qualcomm После озвученного прогноза на 5 % выросли в цене и акции Arm Holdings, на основе технологий которой Qualcomm разрабатывает многие из своих чипов. Также объявлено, что новые чипы компании будут покупать Meta✴ и Microsoft. Qualcomm рассчитывает выпускать и кастомные чипы для двух других неназванных гиперскейлеров. Рост интереса Qualcomm к ИИ-чипам отражает рост давления на рынке смартфонов, который страдает от дефицита чипов памяти, вызванного стремительным ростом спроса на ИИ-инфраструктуру. Кроме того, крупные производители смартфонов вроде Apple и Samsung разрабатывают чипы самостоятельно. В среду Qualcomm объявила, что Microsoft будет использовать новую категорию решений компании, использующих дешёвые чипы памяти, применяемые в смартфонах и ноутбуках, вместо дорогой HBM-памяти, применяемой NVIDIA или SRAM-модулей, используемых Cerebras Systems. Qualcomm назвала категорию High Bandwidth Compute (HBC). Утверждается, что индустрия получит невероятно ценное предложение в плане соотношения цены и производительности.  По данным Qualcomm, компания Meta✴ будет использовать её новый CPU, получивший название Dragonfly C1000, специально разработанный для ИИ ЦОД — на этом рынке уже есть решения NVIDIA и самой Arm. О двух других гиперскейлерах сообщается, что для них будут выпускаться кастомные чипы, а выручка начнёт поступать ещё до конца текущего календарного года. По данным Qualcomm, запрос на такие решения исходил от самих гиперскейлеров. Qualcomm, неоднократно пытавшаяся развивать свой бизнес, связанный с ЦОД, снова делает попытку выйти на рынок ИИ и серверов, полный сильных игроков вроде NVIDIA и прочих разработчиков, включая Amazon (Graviton), Google (Axion), Microsoft (Cobalt). Весной заявлялось, что компания планирует начать поставки чипов для ЦОД «ведущему гиперскейлеру» «в декабрьском квартале» и ожидает сотрудничество на несколько поколений чипов. Также по её данным ведётся работа над тремя вариантами чипов: CPU, ускорителями ИИ-инференса и кастомными ASIC-модулями — в последнем сегменте активно действуют Broadcom и Marvell. Ключевым «полем битвы» называется ниша чипов для ИИ-инференса.
24.06.2026 [18:24], Владимир Мироненко
OpenAI и Broadcom представили кастомный ускоритель Jalapeño для ИИ-инференсаOpenAI и Broadcom представили кастомный чип Jalapeño, разработанный в тесном сотрудничестве «в соответствии с видением OpenAI будущего инференса LLM». Согласно первым тестам, ускоритель первого поколения обеспечивает производительность на ватт значительно выше, чем у современных аналогов. Как сообщает OpenAI, Jalapeño был разработан с нуля для текущих и будущих LLM. Благодаря использованию ИИ-моделей OpenAI от начала проектирования до выхода на производство чипа потребовалось всего лишь девять месяцев. OpenAI отметила, что разрабатывала Jalapeño, «руководствуясь своим планом развития моделей, ядер, систем обслуживания и потребностей продукта, совместно с партнёрами Broadcom и Celestica». Чип спроектирован не как отдельный ускоритель, а как часть масштабируемого програмнно-аппаратного комплекса. Инженерные образцы Jalapeño работают в лаборатории с задачами машинного обучения на целевой частоте и энергопотреблении, включая GPT‑5.3‑Codex‑Spark. Компания пообещала предоставить подробный технический отчёт о производительности ускорителя в ближайшие месяцы. Как сообщает Bloomberg, по словам генерального директора Broadcom Хока Тана (Hock Tan), на данный момент ускоритель демонстрирует экономию средств примерно на 50 % по сравнению с типовыми ИИ-ускорителями. 
Источник изображения: OpenAI Сообщается, что архитектура чипа снижает перемещение данных и обеспечивает баланс вычислительных и сетевых ресурсов, а также памяти для достижения фактического использования, гораздо более близкого к теоретической пиковой производительности. Реализация аппаратных и сетевых технологий Broadcom, включая Tomahawk, помогают вывести платформу на крупномасштабный производственный уровень. OpenAI отметила, что стремится создать полный стек для продукта. Она не только разрабатывает передовые модели и решения на их основе. Компания проектирует инфраструктуру под ними: архитектуру чипов, ядра, системы памяти, сети, управление, системы развёртывания и пользовательский опыт. Благодаря этому каждый слой стека может быть оптимизирован для достижения главной цели компании: сделать свои модели быстрее, надёжнее и доступнее для пользователей. Стремясь оптимизировать затраты на ИИ-инфраструктуру, Amazon (Trainium), Google (TPU), Meta✴ (MTIA) и Microsoft (Maia) тоже работают над собственными кастомными ИИ-ускорителями. Во многом это связано и с желанием снизить зависимость от чипов NVIDIA.
23.06.2026 [12:00], Руслан Авдеев
Groq привлекла $650 млн на развитие своей облачной инференс-платформыСтартап Groq, занимающийся разработкой чипов для инференса и купленный NVIDIA за $20 млрд, объявил о привлечении $650 млн на развитие собственного облака, сообщает Silicon Angle. Возглавили раунд инвестиционная группа Disruptive и хеджевый фонд Infinitum. В декабре 2025 года NVIDIA согласилась заключить исключительное лицензионное соглашение на технологии и наняла нескольких сотрудников Groq, в том числе её основателя и генерального директора. При этом формально «зелёным» облако GroqCloud в рамках сделки не досталось. Компания раскрыла, что её облачная платформа обрабатывает триллионы токенов в неделю для 5 млн разработчиков. 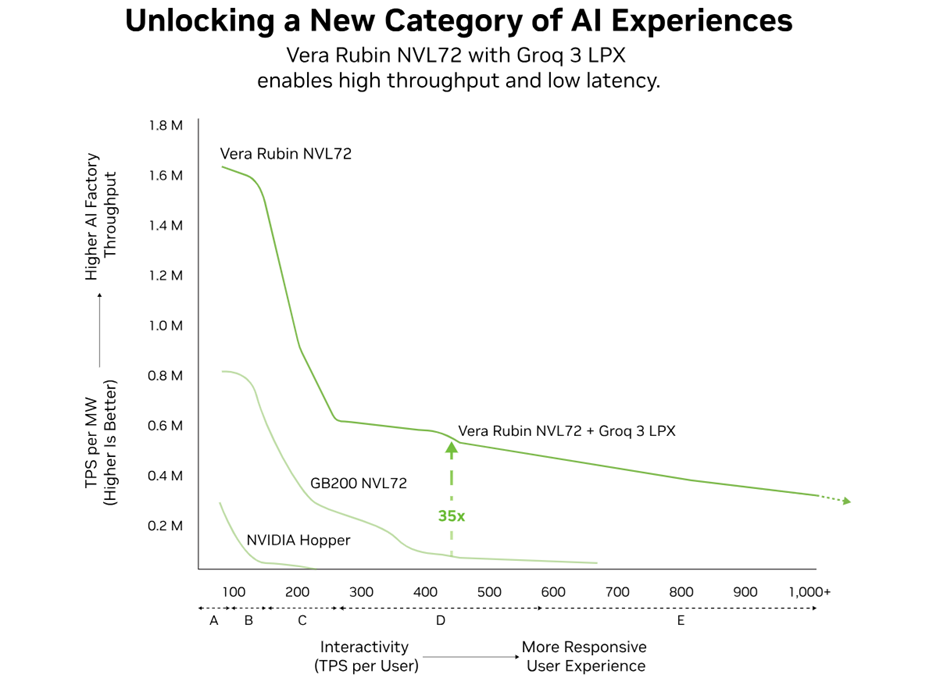
Источник изображения: NVIDIA Облачная инфраструктура Groq работает на базе 13 ЦОД на нескольких континентах. Компания рассчитывает потратить привлечённые средства для расширения мощностей до 200 МВт к 2027 году. В Groq утверждают, что часть новых вычислительных мощностей получит системы NVIDIA LPX на основе LPU 3. Прочие облачные операторы в теории тоже способны создать сервис для инференса на основе решений NVIDIA/Groq.
19.06.2026 [19:34], Владимир Мироненко
«Логарифмический» ИИ-ускоритель Tensordyne Napier обещает выскоую производительность при минимальном энергопотребленииИИ-стартап Tensordyne (ранее Recogni) анонсировал платформу Tensordyne Napier (TDN) для ИИ-инференса, разработанную в партнёрстве с Broadcom и HPE Juniper Networks, которая «сочетает в себе инновационные логарифмические математические вычисления в области ИИ, тесно интегрированную архитектуру памяти и высокопроизводительный масштабируемый интерконнект, обеспечивая существенно более высокую пропускную способность, меньшее энергопотребление и улучшенную экономику инфраструктуры для крупномасштабных задач ИИ-инференса». По словам Tensordyne, новый «логарифмический» чип позволит решить, как проблему скорости, так и стоимости ИИ-инференса. В нём компания заменила крупномасштабные операции умножения упрощёнными вычислениями на основе сложения, значительно повысив эффективность на Вт. Сумматоры меньше размером и как правило потребляют меньше энергии, чем умножители, поэтому их использование обеспечит больше полезной площади для SRAM и лучшую сбалансированность системы. 
Источник изображений: Tensordyne Чип включает 138 млрд транзисторов и поддерживает обработку данных в режимах NVFP4, FP8 и FP16. Tensordyne сообщила о 2,1 Пфлопс в формате плотных вычислений FP8 на кристалл. Частота ядра ускорителя составляет 1,33 ГГц, поддерживающих ядер RISC-V — 1,5 ГГц. Чип получил четыре блока HBM4 (по данным ServeTheHome — HBM3E), каждый по 36 Гбайт (144 Гбайт в сумме) с пропускной способностью 4,7 Тбайт/с. Также на чипе размещено 256 Мбайт SRAM с суммарной пропускной способностью 40 Тбайт/с. Интеграция значительного объёма быстрой SRAM с HBM позволила минимизировать циклы простоя вычислений и обеспечить эффективную поддержку выполнения самых больших моделей в отрасли.  Как рассказал ресурсу The Next Platform Р.К. Ананд (RK Anand), сооснователь и директор по продуктам Tensordyne, ускоритель имеет 48 ядер, которые связаны с блоками обработки векторов. В векторном блоке тоже есть ALU, но он также может использовать таблицу поиска (LUT) и работать полностью параллельно. В целом доступны чередование операций и управляемый конвейер. По словам Ананд, Napier потребляет всего 300 Вт по сравнению с 1200-Вт NVIDIA B300, поскольку новый чип довольно компактен. Ананд не уточнил, состоит ли чип Napier из чиплетов или представляет собой монолитный кристалл. 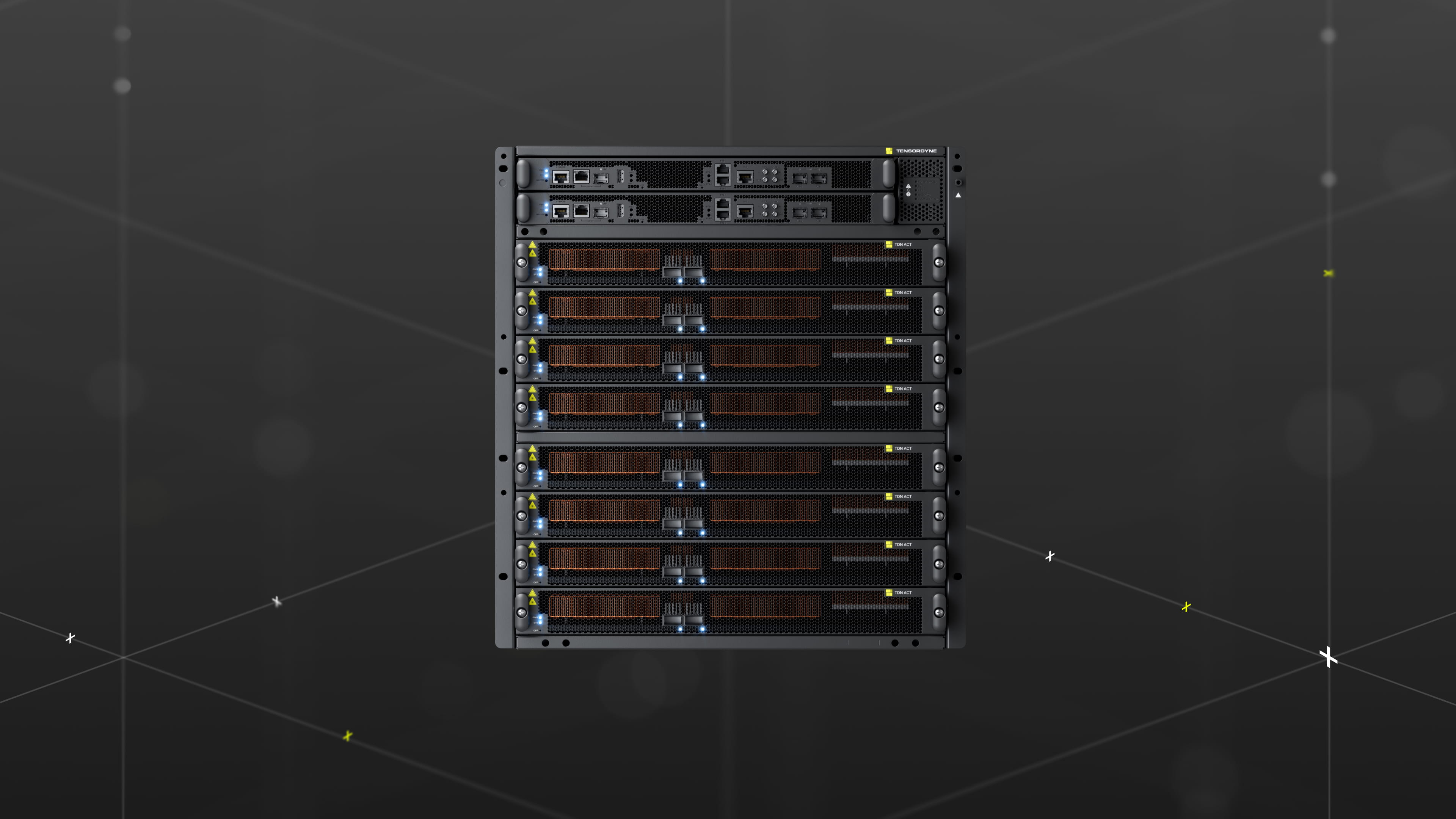 Девять чипов TDN могут размещаться в 1U-узле, в котором установлен 40-ядерный процессор Xeon для управления хостом и выполнения некоторых задач декодирования, а также 8-Тбайт NVMe SSD. Узел имеет два 200GbE-порта QSFP, а на задней панели расположены шесть портов для фирменного интерконнекта TDNLink, используемого для соединения 72 чипов TDN. Узел обеспечивает 19 Пфлопс в режиме FP8, 1,3 Тбайт HBM и 2,25 Гбайт SRAM с агрегированной пропускной способностью 42 Тбайт/с и 360 Тбайт/с соответственно. Узлы Napier, подобно NVIDIA NVLink, соединены через объединительную плату посредством проприетарного интерконнекта TDNLink. Суперускоритель TDN72 объединяет 72 чипа TDN (восемь узлов), причём TDNLink способен обеспечить задержку менее микросекунды между чипами при пропускной способности 1 Тбайт/с.  TDN72 ориентирован на модели с количеством параметров от 10 до 20 трлн, для работы с которыми важны объём памяти и MoE-маршрутизация. «В каждом TDN72 у нас 320 ядер Xeon и 4608 ядер RISC-V», — отметил сооснователь и вице-президент Tensordyne Жиль Бакхус (Gilles Backhus). «Мы применяем двухуровневый подход к решению проблемы с CPU. Вся работа, выполняемая непосредственно вблизи вычислительных процессов ИИ в рамках цикла обработки токенов и авторегрессионного цикла LLM, в основном проводится на ядрах RISC-V. Здесь же осуществляется маршрутизация MoE, проверка по словарю для отбрасывания определённых токенов и т.д. Прочая обработка данных для инференса происходит на процессорах Intel Xeon».  Четыре TDN72 помещаются в стандартную 52U-стойку Tensordyne Napier, что даёт 608 Пфлопс (FP8), 42 Тбайт HBM, 74 Гбайт SRAM, 256 Тбайт NVMe SSD, 275-Тбайт/с соединение TDNLink и 64 порта 200GbE. При этом такая стойка потребляет всего 120 кВт и может обходиться воздушным охлаждением. Как сообщила компания, стойка Tensordyne Napier обеспечивает по сравнению с полноразмерной стойкой NVIDIA NVL72:
Система поддерживает дезагрегированное обслуживание и выполнение моделей с многотриллионными параметрами со скоростью более 1000 токенов в секунду на пользователя. Для достижения той же пропускной способности потребовалось бы как минимум девять стоек NVIDIA Rubin + Groq LPX, отметила Tensordyne.
Самой сложной составляющей запуска платформы может стать ПО. Tensordyne сообщила о выпуске на платформе Hugging Face центра моделей со своим SDK, прямой компиляцией моделей для PyTorch/Triton и кастомным eDSL для Python. Следует отметить, что одним из важных преимуществ ускорителей NVIDIA является экосистема CUDA — огромная база фреймворков, ядер, инструментов профилирования, шаблонов развёртывания и моделей поведения разработчиков. Любой новый ИИ-ускоритель должен сопровождаться достаточно простым ПО, чтобы клиенты захотели его внедрять в своих системах.
15.06.2026 [16:47], Владимир Мироненко
ByteDance ведёт переговоры о покупке китайских ИИ-ускорителей Iluvatar CoreX и BaiduByteDance, материнская компания TikTok, ведёт переговоры с шанхайской компанией Iluvatar CoreX о покупке ИИ-чипов, сообщило агентство Reuters со ссылкой на источники. В случае достижения договорённости, Iluvatar CoreX станет третьим крупным отечественным поставщиком GPU для ByteDance после Huawei и Cambricon, отметили источники агентства. По их данным, в этом году Iluvatar CoreX поставит ByteDance не менее 50 тыс. чипов, и большая часть из них будет использоваться для задач инференса, поскольку ByteDance стремится расширить клиентскую базу своего ИИ-чат-бота Doubao. Впрочем, переговоры ещё не завершены и окончательные условия сделки могут измениться. Кроме того, по данным источников Reuters, ByteDance, также рассматривает возможность использования ускорителей Baidu Kunlunxin. Раннее стало известно о разработке ByteDance собственных ИИ-чипов и закупке миллионов ИИ ASIC Qualcomm. По словам одного из источников, чипы Kunlunxin уже используются Tencent Cloud. Публикация агенства о возможных сделках в Китае свидетельствует о том, что выпуск китайскими производителями ИИ-чипов набирает обороты. Этому способствует поддержка властями использования разработанных на местном уровне чипов для повышения самодостаточности на фоне экспортного контроля США над передовыми чипами. Китайские производители GPU и чипов для ИИ в прошлом году заняли почти 41 % китайского рынка ИИ-серверов, на котором некогда доминировала NVIDIA. Рыночная доля американской компании в Китае, одном из важнейших для неё рынков, упала до нуля, утверждает глава NVIDIA Дженсен Хуанг (Jensen Huang). 
Источник изображения: Iluvatar CoreX До сих пор Iluvatar CoreX в основном поставляла чипы для государственных закупок, сообщил один из источников. Поэтому сделка с ByteDance, одной из крупнейших китайских технологических компаний и крупным инвестором в ИИ-инфраструктуру, крайне важна для неё. Iluvatar CoreX вышла на Гонконгскую биржу в январе этого года. Её выручка в 2025 году составила ¥1 млрд ($148 млн), причём около 90 % продаж пришлось на GPU. Согласно информации на сайте компании, чипы серии Tiangai предназначены для ИИ-обучения, а чипы серии Zhikai — для задач инференса. По прогнозам Huatai Securities, выручка Iluvatar CoreX в этом году достигнет ¥3,04 млрд ($449,8 млн), а общий объём поставок превысит 100 тыс. чипов (рост год к году — на 139 %). По оценкам аналитиков, средняя цена чипов Zhikai составляет ¥12 тыс. ($1775)/шт.
09.06.2026 [13:58], Руслан Авдеев
AMD поддержит суверенный ИИ в Великобритании, инвестировав в ИИ-отрасль страны £2 млрд
amd
dell
epyc
hardware
hpc
instinct
великобритания
ии
инвестиции
инференс
суперкомпьютер
финансы
фотоника
В следующие пять лет AMD рассчитывает инвестировать в усиление ИИ-экосистемы Великобритании до £2 млрд ($2,7 млрд), создав новую инфраструктуру, программы совместных исследований и подготовки кадров. По словам представителя техногиганта, новая стратегия согласуется с правительственным проектом AI Opportunities Action Plan и стратегией AI Hardware Strategy, с основным акцентом на суверенные ИИ-возможности, научные вычисления и передовые исследования, сообщает Converge! Digest. Ключевой компонент инициативы — расширение вычислительной ИИ-инфраструктуры. AMD и Dell Technologies поддерживают две новые суперкомпьютерные системы в Кембриджском университете. Суперкомпьютер Zenith AI, финансирование которого осуществляется Министерством науки, инноваций и технологий (DSIT) и структурой UK Research and Innovation (UKRI), строится как платформа для использования ИИ в науке. Система Sunrise создаётся совместно с Управлением по атомной энергии Великобритании для поддержки исследований в сфере термоядерных технологий. Оба суперкомпьютера будут использовать ускорители AMD Instinct, процессоры EPYC и ПО AMD для решения задач в сфере здравоохранения, климатологии, материаловедения, разработки научных ИИ-моделей и др. Также AMD анонсировала исследовательские партнёрства с Имперским колледжем Лондона и компанией Oriole Networks. В первом случае взаимодействие сосредоточено на вычислительных дисциплинах, здравоохранении, моделировании климата, ИИ-оптимизации, обработке значительных объёмов данных и др. В то же время AMD и Oriole Networks принимают участие в проекте Scaling Inference Lab британского агентства ARIA (Advanced Research and Invention Agency). Проект стоимостью £50 млн направлен на устранение ряда проблем современной ИИ-инфраструктуры. Он объединяет фотонную сетевую архитектуру PRISM компании Oriole, ускорители AMD Instinct, а также процессоры EPYC для оценки новых подходов к масштабированию задач ИИ-инференса с меньшей задержкой и повышенной энергоэффективностью. 
Источник изображения: Robert Bye/unsplash.com По словам Converge!, лондонский стартап Oriole Networks намерен преодолеть традиционные ограничения классических ИИ-кластеров. Если в стандартных сетях на основе InfiniBand или Ethernet многократные преобразования оптического сигнала в электрический и обратно создают дополнительные задержки, то архитектура PRISM (Photonic Routing Infrastructure for Scalable Models) заменяет активные электронные коммутаторы «пассивным» оптическим ядром маршрутизации. Прямые оптические соединения узлов позволяют сократить время простоя GPU, связанное с ожиданием обмена данными, что мешает масштабным ИИ-нагрузкам. PRISM обеспечивает обработку динамического ИИ-трафика без использования электрических буферов пакетов данных. Многомерная коммутация каналов позволяет перенастраивать соединения в режиме реального времени и оптимизировать сеть под интенсивный обмен данными, характерный для больших языковых моделей. Кроме того, Oriole утверждает, что её технология позволяет объединять до миллиона оконечных устройств. В конечном счёте сокращение энергопотребления сетевого ядра может составить до 81 %. Ключевым элементом архитектуры PRISM является независимость от конкретного типа используемых процессоров и ускорителей. Вместо использования проприетарных интерконнектов, «привязывающих» операторов к определённой аппаратной платформе, Oriole разделяет транспортный и вычислительный уровни инфраструктуры. Компания заявляет, что её технологии интегрируются в существующие стеки ПО через стандартные драйверы PCIe и специализированные библиотеки ускорения вроде NCCL для NVIDIA или RCCL для AMD. Благодаря этому можно поддерживать разные аппаратные платформы без трансформации базовых ИИ-фреймворков. Будущее внедрение технологии в рамках ARIA Scaling Inference Lab станет значимой проверкой её жизнеспособности для отрасли и продемонстрирует, способны ли полностью фотонные сети гарантировать предсказуемую производительность и обеспечивать открытость проприетарных вычислительных систем в промышленных масштабах.
08.06.2026 [15:33], Руслан Авдеев
Стартап Windrose Electric, разрабатывающий электрические грузовики, представил концепцию ИИ ЦОД на колёсах
hardware
автомобиль
аккумулятор
ии
инференс
контейнер
микро-цод
модульный
цод
электропитание
энергетика
Бельгийский стартап, занимающийся разработкой и выпуском электромобилей, представил концепцию контейнерных мобильных ЦОД. Ранее в этом году компания уже озвучила планы по созданию контейнерных ИИ- и энергетических решений на колёсах, которые можно будет легко доставлять туда, где они необходимы, с использованием её электрогрузовика с полуприцепом — R700, сообщает Datacenter Dynamics. Windrose Electric заявила о премьере новой продуктовой линейки «ИИ в коробке» для хранения электроэнергии, а также «модульного» решения для ИИ-инференса в отдельном контейнере. Сообщалось, что контейнер с вычислительным оборудованием может обеспечить инференс-нагрузки мощностью 500 кВт, а аккумуляторный контейнер способен хранить до 4 МВт·ч. Контейнерные дата-центры и соответствующая инфраструктура уже широко представлены в отрасли ИИ-решений, но обычно они перевозятся на крупных бортовых грузовиках с последующей разгрузкой, тогда как решения Windrose не предусматривают разгрузки и остаются в кузове или на колёсной платформе. Насколько практично подобное решение, пока не вполне понятно. Вычислительный модуль мощностью 500 кВт с питанием только от аккумуляторов ёмкостью 4 МВт·ч израсходует весь запас энергии в течение одного дня, после чего ему потребуется либо новое энергохранилище, либо подключение к внешнему источнику питания. 
Источник изображения: Windrose Electric В этом месяце было объявлено, что Windrose работает с китайской энергетической компанией LiFe-Younger над мобильным контейнером для обеспечения ЦОД электроэнергией. В частности, сообщалось о планах разработать контейнерный аккумуляторный модуль с грузовиком-тягачом, обеспечивающим 2 МВт мощности в 20′ контейнере, который способен помочь справиться с нехваткой энергии в электросетях. В качестве энергетического модуля будет использоваться разработка iMContainer компании LiFe-Younger. Основанная в Китае в 2022 году, компания Windrose переместила штаб-квартиру в Бельгию и выпускает мощные электрические грузовики с большим запасом хода для коммерческой логистики. В настоящее время они способны проехать более 670 км без подзарядки с грузом массой 49 т. Основанная в 2016 году компания LiFe-Younger предлагает мобильные и стационарные решения для зарядки электромобилей и системы хранения энергии.
08.06.2026 [09:00], Владимир Мироненко
FirstVDS запустил vGPU-серверы на базе NVIDIA L40S и сравнил их с физическими GPU в реальных тестахПровайдер FirstVDS запустил тарифы с виртуальными GPU (vGPU) на базе NVIDIA L40S. Теперь в линейке два варианта: можно арендовать физическую видеокарту целиком (доступно с ноября 2025 года) или получить гарантированную долю виртуальной видеокарты. Компания также сравнила обе технологии в тестах и опубликовала результаты: скорость инференса LLM, генерацию видео и потребление видеопамяти. Доступны четыре тарифа vGPU — от 4 до 16 Гбайт видеопамяти. Технология vGPU делит физическую видеокарту на несколько профилей с фиксированной долей ресурсов. Серверы работают на виртуализации KVM с процессорами AMD EPYC. Стоимость — от 299 рублей в сутки. Для сравнения: тарифы с физическим GPU (Passthrough) стартуют от 1150 руб./сутки. В них доступны RTX 4090 и 5090, L4 и L40S — вся видеокарта полностью закрепляется за одной виртуальной машиной. За последние полгода спрос на GPU-серверы вырос кратно — в первую очередь из-за задач, связанных с LLM, генерацией изображений и видео. Но не каждому проекту нужна 100 % мощность физической карты. Разработчики, Data Science-команды и небольшие студии часто ищут более доступный вход с предсказуемой долей ресурсов. vGPU как раз закрывает этот запрос. Никита Попов, директор по продукту FirstVDS: «В ноябре мы закрыли потребность в сырой мощности, запустив GPU Passthrough. Но рынку нужен не только потолок производительности, но и адекватная юнит-экономика. vGPU закрывает именно этот сегмент — снижает порог входа до 300 руб. в сутки. Мы прогнали бенчмарки. Сравнивать виртуалку с выделенной картой в лоб бессмысленно — физика берет свое, чудес не бывает. Наша цель была другой: четко очертить границы применимости. Показать механику, при которой vGPU вытягивает нагрузку, и где проходит черта, за которой пора брать полноценное железо». Что показало тестированиеКомпания протестировала две конфигурации: GPU Passthrough (L40S, 48 Гбайт, 16 ядер CPU) и vGPU 16 Гбайт (8 ядер CPU). В сценариях использовались инференс LLM через llama.cpp (модели Qwen 2.5 и 3.6) и генерация видео через ComfyUI с шаблоном Wan2.2 TI2V 5B Hybrid. Результаты в целом предсказуемы: физическая карта ожидаемо обгоняет виртуальные GPU по производительности. Но обнаружилось два важных нюанса. Во-первых, при тестировании моделей среднего размера (qwen2.5-14b в двух вариантах квантизации — q3_k_m и q4_0) на vGPU-16 и Passthrough оказалось, что при полной загрузке модели в видеопамять скорость генерации токенов практически не отличается. Разница возникает только в смешанном режиме CPU+GPU (до 30–40 слоёв), где vGPU-16 сдерживает вдвое меньшее количество ядер процессора. 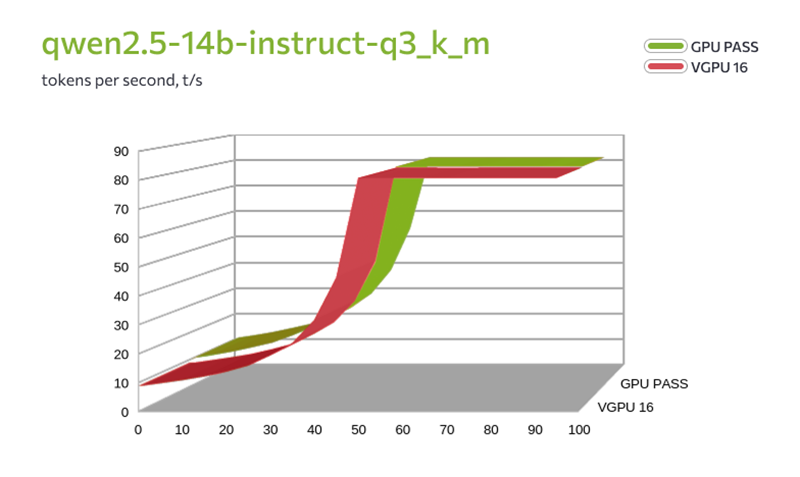
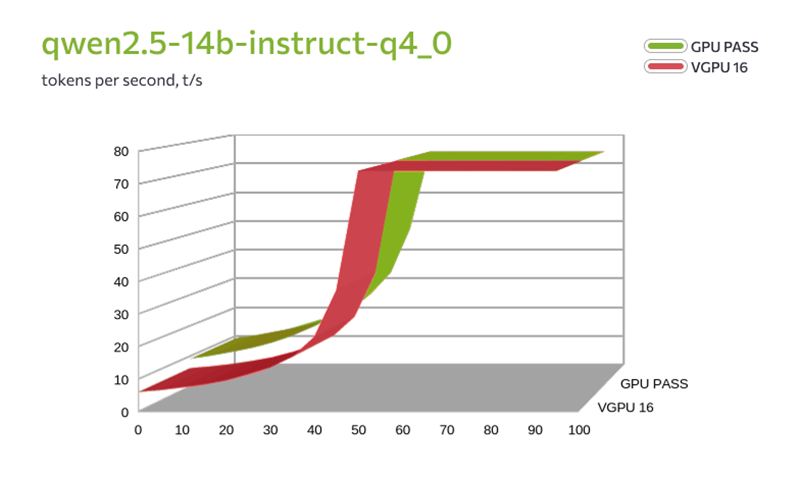
Сравнение скорости генерации токенов (qwen2.5-14b) в зависимости от количества слоёв, загруженных в GPU. Passthrough vs vGPU 16 Гбайт Во-вторых, более крупные модели (Qwen3.6-35B) в vGPU-16 полностью не загружаются — памяти не хватает, они работают только в смешанном режиме CPU+GPU со снижением скорости. Генерация видео (ComfyUI) на vGPU-16 тоже работает, но с оговорками: пришлось отключать часть функций и добавлять swap — иначе приложение аварийно завершалось. Время генерации на vGPU-16 ожидаемо выше, чем на Passthrough (для 5-секундного ролика — 293 с против 144). Таким образом, несмотря на общее преимущество физической карты, виртуальный GPU способен решать определённые задачи — например, инференс средних языковых моделей при полной загрузке в видеопамять. Это делает vGPU осмысленным выбором, когда важнее доступная цена. Для более тяжёлых сценариев (крупные модели, комфортная генерация видео без доработок) производительности vGPU может не хватить. Подробные результаты тестирования — в отдельной статье. О компанииFirstVDS — российский провайдер виртуальных серверов. В портфеле — готовые и гибкие конфигурации VPS/VDS: от высокопроизводительных CPU-серверов (линейка «CPU.Турбо 2.0» до 5,7 ГГц) до GPU-решений (Passthrough и vGPU). Также доступны S3-хранилище, домены, SSL и техподдержка 24/7. Дата-центры в Москве, Нидерландах и Казахстане. Более 20 лет на рынке. |
|


