Бум больших языковых моделей (LLM) неизбежно порождает появление на рынке нового специализированного класса процессоров и ускорителей — и нередко такие решения оказываются эффективнее традиционного подхода с применением GPU. Компания SambaNova Systems, разработчик таких ускорителей и систем на их основе, представила новое, третье поколение ИИ-процессоров под названием SN40L.
Осенью 2022 года компания представила чип SN30 на базе уникальной тайловой архитектуры с программным управлением, уже тогда вполне осознавая тенденцию к увеличению объёмов данных в нейросетях: чип получил 640 Мбайт SRAM-кеша и комплектовался оперативной памятью объёмом 1 Тбайт.

Источник изображений здесь и далее: SambaNova (via EE Times)
Эта наработка легла и в основу новейшего SN40L. Благодаря переходу от 7-нм техпроцесса TSMC к более совершенному 5-нм разработчикам удалось нарастить количество ядер до 1040, но их архитектура осталась прежней. Впрочем, с учётом реконфигурируемости недостатком это не является.
Чип SN40L состоит из двух больших чиплетов, на которые приходится 520 Мбайт SRAM-кеша, 1,5 Тбайт DDR5 DRAM, а также 64 Гбайт высокоскоростной HBM3. Последняя была добавлена в SN40L в качестве буфера между сверхбыстрой SRAM и относительно медленной DDR. Это должно улучшить показатели чипа при работе в режиме LLM-инференса. Для эффективного использования HBM3 программный стек SambaNova был соответствующим образом доработан.
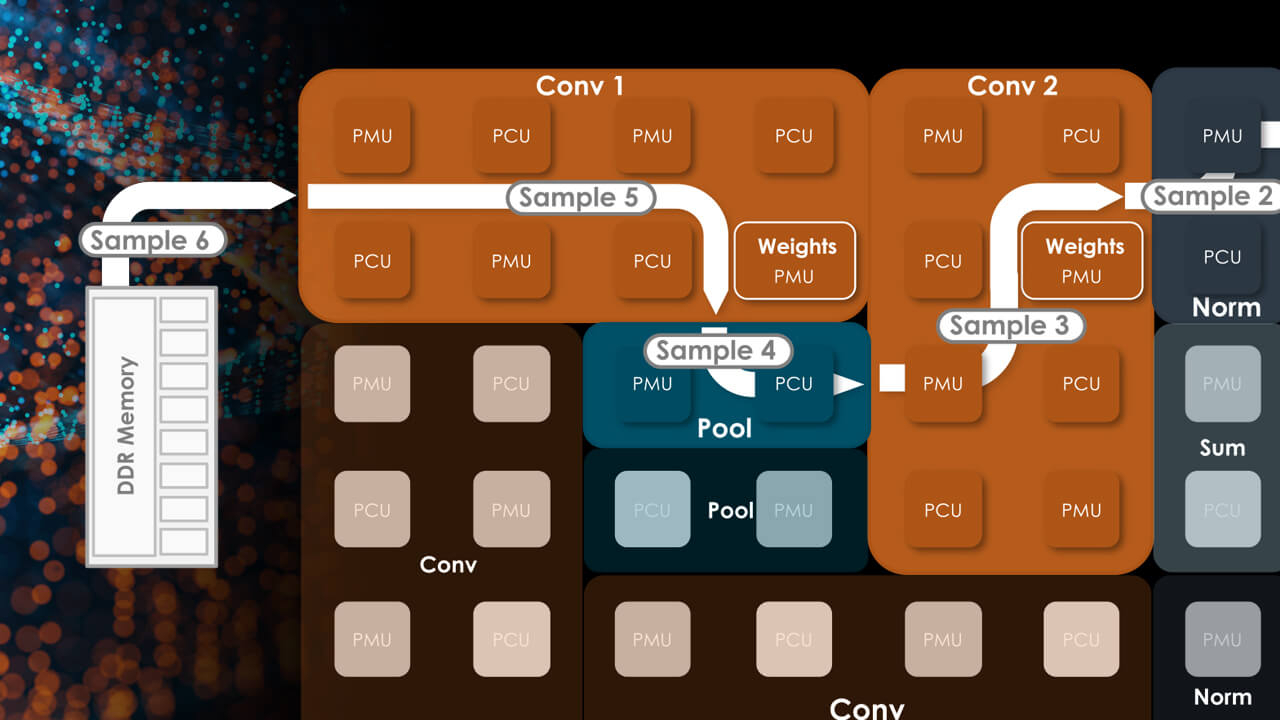
Тайловая архитектура SambaNova состоит из вычислительных тайлов PCU, SRAM-тайлов PMU, управляющей логики и меш-интерконнекта
По сведениям SambaNova, восьмипроцессорная система на базе SN40L сможет запускать и обслуживать ИИ-модель поистине титанических «габаритов» — с 5 трлн параметров и глубиной запроса более 256к. В описываемой модели речь идёт о наборе экспертных моделей с LLM Llama-2 в качестве своеобразного дирижёра этого оркестра. Архитектура с традиционными GPU потребовала бы для запуска этой же модели 24 сервера с 8 ускорителями каждый; впрочем, модель ускорителей не уточняется.
Как и прежде, сторонним клиентам чипы SN40L и отдельные вычислительные узлы на их основе поставляться не будут. Компания продолжит использовать модель Dataflow-as-a-Service (DaaS) — расширяемую платформу ИИ-сервисов по подписке, включающей в себя услуги по установке оборудования, вводу его в строй и управлению в рамках сервиса. Однако SN40L появится в рамках этой услуги позднее, а дебютирует он в составе облачной службы SambaNova Suite.
Источник:

