Материалы по тегу: gpu
|
02.06.2026 [01:04], Владимир Мироненко
ИИ-ускоритель Intel Crescent Island получит до 480 Гбайт LPDDR5XIntel сообщила новые подробности о своём будущем ИИ-ускорителе для ЦОД с кодовым именем Crescent Island, который был анонсирован в прошлом году. Новый GPU основан на архитектуре Xe3P, представляющей усовершенствованную версию Xe3, которая используется в процессорах Core Ultra 300 семейства Panther Lake. Ожидается, что Xe3P также будет использоваться в GPU Intel серии Arc-C для клиентских устройств. Компания отметила, что чип разработан специально для рабочих нагрузок агентного ИИ. В то время как традиционные ИИ-ускорители от NVIDIA и AMD полагаются на дорогую память HBM, в новом чипе Intel используется LPDDR5X, и он предназначен для работы в серверах с воздушным охлаждением, а не с жидкостным. Crescent Island будет поддерживать до 480 Гбайт памяти LPDDR5X, хотя базовая эталонная конфигурация рассчитана на 160 Гбайт. Intel заявила, что Crescent Island оптимизирован по производительности на Вт — до TDP 350 Вт в версии с воздушным охлаждением и интерфейсом PCIe. 
Источник изображений: Intel Сообщается, что GPU будет поддерживать широкий спектр форматов данных от FP4 до FP64, а также полностью открытый программный стек oneAPI, что идеально подходит для поставщиков услуг «токены как услуга» и сценариев использования для инференса. Концептуально новинка напоминает Rubin CPX, от которого NVIDIA отказалась.  Intel уже оценивает свой открытый унифицированный программный стек для гетерогенных систем ИИ с помощью существующей линейки Arc Pro B-серии, поэтому будущие версии чипов получат доступ к этим оптимизациям на ранних этапах. Intel планирует начать тестирование GPU Crescent Island для клиентов во II половине 2026 года с общей доступностью в 2027 году.
11.05.2026 [15:13], Сергей Карасёв
Verda и Compal объединили усилия для создания ИИ-инфраструктуры следующего поколенияКомпании Compal Electronics и Verda (ранее известна как DataCrunch) объявили о стратегическом партнёрстве, направленном на формирование ИИ-инфраструктуры следующего поколения. Стороны сосредоточат усилия на реализации проектов в Европе и Азиатско-Тихоокеанском регионе. В рамках сотрудничества Compal будет поставлять серверные платформы высокой плотности на основе GPU-ускорителей. Говорится о применении жидкостного охлаждения. Серверы оптимизированы для ИИ-нагрузок нового типа, в том числе агентных приложений, которые используют машинное обучение для сбора и обработки огромных объёмов данных в реальном времени. Раннее сообщалось, что Verda готовится к развёртыванию систем на базе Arm AGI, а также GB300 и Vera Rubin. Отмечается, что готовящиеся к выпуску серверы обладают высокой тепловой эффективностью, что важно в плане устойчивого развития облачных решений Verda. Эта компания имеет дата-центры в Финляндии, полностью работающие на возобновляемой энергии. Кроме того, Verda управляет ЦОД в Исландии и намерена построить объект в Латвии. 
Источник изображения: Compal В целом, партнёрство направлено на усиление позиций Verda на рынке облачных услуг. Недавно компания сообщила о привлечении $117 млн для создания облачной инфраструктуры нового поколения для задач ИИ. Средства поступили от Lifeline Ventures, byFounders, Tesi, Varma и других инвесторов. В свою очередь, Compal усиливает собственную значимость в качестве инфраструктурного партнёра для неооблачных операторов. Compal обладает инженерными знаниями в области НРС, теплового проектирования и системной интеграции, что позволяет клиентам развёртывать энергоэффективные ИИ-инфраструктуры. Compal продолжает расширять свои производственные мощности на Тайване, во Вьетнаме и США, что помогает в удовлетворении потребностей заказчиков в различных регионах. При этом повышается надёжность работы цепочек поставок.
02.05.2026 [13:22], Сергей Карасёв
AMD EPYC и NVIDIA RTX Pro Blackwell: QNAP представила хранилище QAI-h1290FX для ИИ-задачКомпания QNAP Systems анонсировала сервер хранения QAI-h1290FX, предназначенный для решения ИИ-задач на периферии. Устройство подходит для работы с большими языковыми моделями (LLM), генеративными приложениями, поисковыми сервисами на базе RAG и пр. 
Источник изображений: QNAP Systems Новинка построена на платформе AMD с процессором EPYC Rome 7302P (16C/32T; до 3,3 ГГц). Объём оперативной памяти DDR4 ECC в базовой конфигурации составляет 128 Гбайт, в максимальной — 1 Тбайт. Во фронтальной части расположены 12 отсеков для SFF-накопителей U.2 с интерфейсом PCIe 4.0 x4 (NVMe) или SATA-3 с возможностью горячей замены.  Система оснащена тремя слотами PCIe 4.0 x16 и одним слотом PCIe 4.0 x8. Возможна установка GPU-ускорителя NVIDIA RTX Pro 6000 Blackwell Max-Q Workstation Edition с 96 Гбайт памяти GDDR7 или NVIDIA RTX Pro 4500 Blackwell с 32 Гбайт памяти GDDR7. В первом случае обеспечивается возможность использования LLM с более чем 70 млрд параметров, во втором — 30 млрд параметров. Применена ОС QuTS hero h5.2.9. Упомянуты такие предустановленные ИИ-инструменты, как AnythingLLM, OpenWebUI, Ollama, Stable Diffusion, ComfyUI, n8n и vLLM. 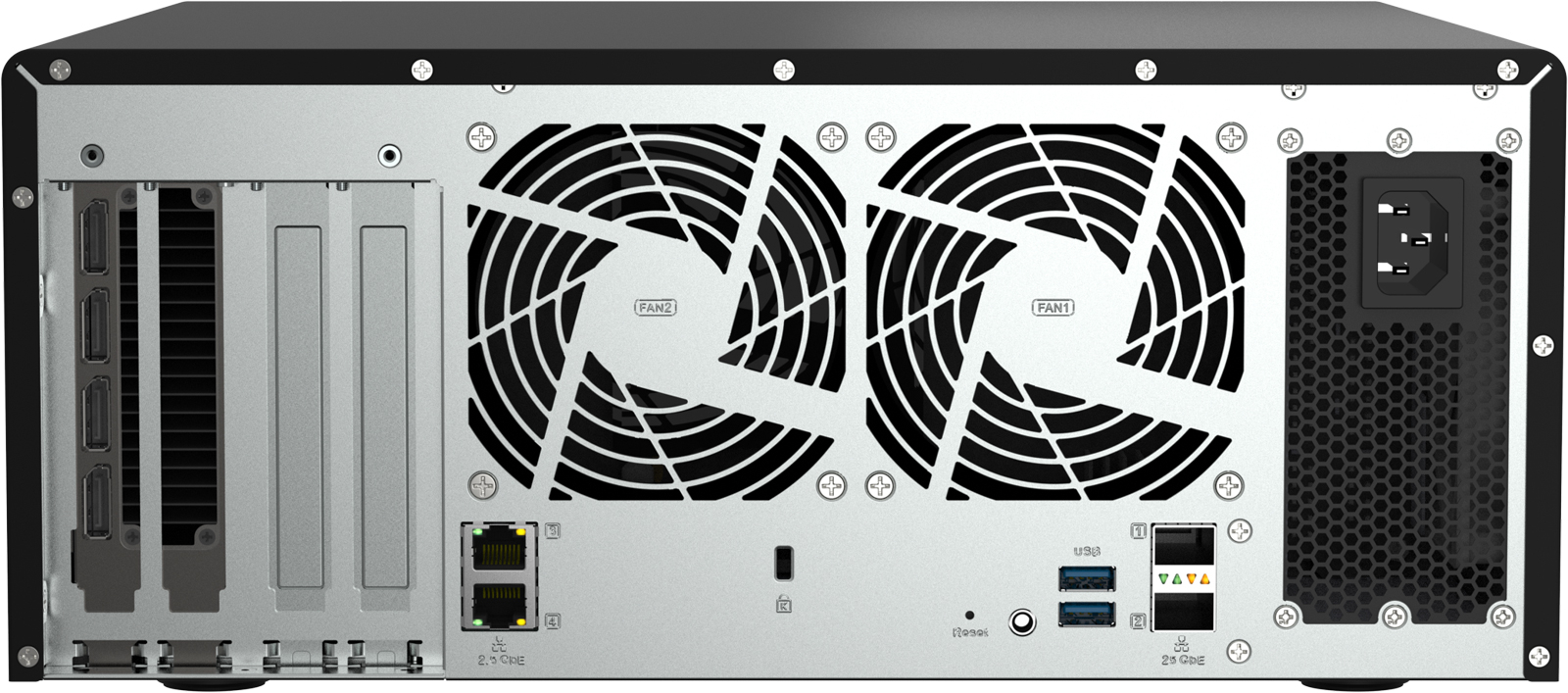 Устройство располагает двумя портами 2.5GbE и двумя 25GbE-портами SFP28 (SmartNIC), а также тремя разъёмами USB 3.0 Type-A (один находится спереди, два — сзади). Дополнительно может быть установлен сетевой адаптер 100GbE. Габариты сервера составляют 150 × 368 × 362 мм, масса — 10,4 кг. Диапазон рабочих температур — от 0 до +40 °C. Задействованы два вентилятора охлаждения диаметром 92 мм и блок питания мощностью 750 Вт. Производитель предоставляет на новинку пятилетнюю гарантию.
01.05.2026 [14:07], Сергей Карасёв
HPE представила серверы ProLiant Compute EL220/EL240 Gen12 для ИИ-задач на периферии
amd
epyc
gpu
granite rapids
hardware
hpe
intel
sierra forest
sorano
xeon
периферийные вычисления
сервер
HPE анонсировала серверы ProLiant Compute EL220 и EL240 Gen12 для приложений ИИ и критически важных рабочих нагрузок на периферии. Устройства выполнены на основе шасси ProLiant Compute EL2000, которое спроектировано специально для эксплуатации в суровых условиях. Системы на базе EL2000 могут использоваться при температурах от -40 до +55 °C и влажности до 95 %. Говорится об устойчивости к воздействию сильных вибраций, которые могут наблюдаться, например, на борту самолётов или наземной техники. 
Источник изображений: HPE Шасси допускает установку двух серверов ProLiant Compute EL220 Gen12 типоразмера 1U или одного сервера ProLiant Compute EL240 Gen12 в форм-факторе 2U. Эти устройства выполнены на процессорах Intel Xeon 6700 (Sierra Forest-SP/Granite Rapids-SP), которые могут насчитывать до 144 вычислительных ядер. Объём оперативной памяти DDR5 достигает 2 Тбайт. Возможен монтаж двух SSD формата М.2 (NVMe) и четырёх накопителей EDSFF. Модификация ProLiant Compute EL240 Gen12 также может быть укомплектована двумя GPU-ускорителями одинарной ширины или одной картой двойной ширины. Упомянуты средства управления iLO 7. В продажу новинки поступят позднее в текущем году.  Кроме того, HPE представила обновлённую версию компактного edge-сервера ProLiant DL145 Gen11 на аппаратной платформе AMD. Это устройство переведено на процессоры EPYC 8005 Sorano, насчитывающие до 84 ядер. Поддерживается до 768 Гбайт DDR5. Система может быть оборудована двумя SFF-накопителями или шестью EDSFF-изделиями. Могут быть задействованы до трёх GPU одинарной ширины или один ускоритель двойной ширины. Сервер уже доступен для заказа.
27.04.2026 [13:35], Сергей Карасёв
«Гравитон» представил российские серверы на базе Intel Xeon для облаков, виртуализации и ИИ
emerald rapids
gpu
granite rapids
hardware
intel
sapphire rapids
sierra forest
xeon
гравитон
сделано в россии
сервер
Российский разработчик и производитель вычислительной техники «Гравитон» представил шесть серверов на аппаратной платформе Intel, предназначенных для реализации масштабных IT-проектов в сегментах, где наличие техники в реестре Минпромторга РФ не является обязательным требованием. В зависимости от модификации устройства подходят для решения различных задач — от облачных сервисов и виртуализации до нагрузок ИИ и НРС. В частности, дебютировали модели СН2124И5 и СН2127И5 в форм-факторе 4U и 7U соответственно. Они рассчитаны на два процессора Xeon Sapphire Rapids или Xeon Emerald Rapids с TDP до 350 Вт. Поддерживается до 8 Тбайт оперативной памяти DDR5 в виде 32 модулей. У сервера СН2124И5 слоты расширения выполнены по схеме 10 × PCIe 5.0 х16 FHFL + 1 × OCP NIC. Есть 12 фронтальных отсеков для LFF-накопителей NVMe/SATA/SAS и два коннектора M.2 2280/22110 (PCIe 5.0). Возможна установка восьми GPU с энергопотреблением до 350 Вт. В свою очередь, система СН2127И5 имеет аналогичные характеристики, но позволяет использовать до восьми GPU с TDP до 600 Вт. Кроме того, анонсированы серверы СН2122И6 (2U), СН2242И6 (2U), СН2124И6 (4U) и СН2127И6 (7U) с поддержкой двух чипов Xeon 6 (Sierra Forest-SP/Granite Rapids-SP) с показателем TDP до 350 Вт. У первой из этих систем слоты расширения выполнены по схеме 6 × PCIe 5.0 х16 FHFL + 2 × OCP NIC (или 6 × PCIe 5.0 х16 FHFL + 2 × PCIe 5.0 х8 HHHL + 2 × OCP NIC), у трёх других — 10 × PCIe 5.0 х16 FHFL + 1 × OCP NIC. Во всех случаях возможно использование до 8 Тбайт памяти DDR5 (32 модуля). 
Источник изображений: «Гравитон» Модель СН2122И6 поддерживает следующие накопители: 12 × LFF NVMe/SATA/SAS во фронтальной части, 2 × SFF SATA/SAS или 4 × SFF NVMe/SATA/SAS, а также 2 × M.2 2280/22110 (PCIe 5.0). Модификации СН2242И6, СН2124И6 и СН2127И6 рассчитаны на накопители в конфигурации 12 × LFF NVMe/SATA/SAS и 2 × M.2 2280/22110 (PCIe 5.0). Две старшие версии поддерживают восемь GPU с TDP до 350 и 600 Вт.  Все серверы располагают контроллером Aspeed AST2600 с выделенным сетевым портом управления 1GbE и воздушной системой охлаждения. Устанавливаются блоки питания мощностью до 3000 Вт с сертификатом 80 Plus Platinum. Заявлена совместимость с Windows и Linux. Гарантия производителя составляет три года.
23.04.2026 [11:38], Сергей Карасёв
Selectel представил российский «AI-Сервер» с поддержкой до 16 GPUРоссийский провайдер облачной инфраструктуры Selectel анонсировал «AI-Сервер» — высокопроизводительную систему формата 8U, ориентированную на ресурсоёмкие нагрузки, такие как обучение ИИ-моделей, инференс, рендеринг, финансовое моделирование, виртуальные рабочие столы и аналитика в реальном времени. В состав платформы входят плата Selectel SSE-MB-201 и специализированное шасси SSECH-812. Задействованы два процессора Intel Xeon 6 6500/6700 поколения Granite Rapids-SP. Поддерживается до 8 Тбайт оперативной памяти DDR5-6400 в виде 32 модулей. Могут быть установлены 12 накопителей с интерфейсом NVMe/SAS/SATA, а также два SSD типоразмера M.2 с интерфейсом PCIe 5.0. Упомянуты контроллер BMC AST2600, модуль TPM 2.0, 176 линий PCIe (PCIe 5.0 / CXL и OCP 3.0) и два сетевых порта 1GbE. Сервер допускает монтаж до 16 ускорителей на базе GPU формата FHFL двойной ширины или до восьми ускорителей FHFL тройной ширины. В частности, могут применяться карты NVIDIA H100, H200, RTX Pro 6000 Blackwell Server Edition и др. Питание обеспечивают семь блоков мощностью 2000 Вт с сертификатом 80 Plus Platinum. 
Источник изображений: Selectel Selectel разрабатывает BIOS и BMC собственными силами: это, как утверждается, даёт полный контроль над процессом и возможность оперативно вносить изменения и дорабатывать функциональность в соответствии с запросами заказчиков. Подчёркивается, что усиленные подсистемы питания и охлаждения рассчитаны на высокую плотность ускорителей и длительную работу под нагрузкой. Конструкция упрощает обслуживание и эксплуатацию сервера в ЦОД.  «Запуск нового AI-сервера является частью стратегии Selectel по формированию собственного портфеля серверных решений, включая специализированные инфраструктурные продукты для задач в сфере ИИ. Новая аппаратная платформа обеспечит стабильную, быструю и предсказуемую работу AI-моделей в реальных условиях с полным контролем над данными и производительностью», — говорит компания.
08.04.2026 [17:04], Владимир Мироненко
ВТБ заменит ИИ-ускорители NVIDIA на китайские решенияБанк ВТБ будет использовать GPU китайских производителей вместо ИИ-ускорителей NVIDIA для работы внутрибанковских сервисов на основе ИИ, сообщил «Ведомостям» зампред правления ВТБ Вадим Кулик. По его словам, GPU будут использоваться для работы с компьютерным зрением, обработки, анализа текста и распознаванием речи, а также для моделей генеративного ИИ банка. Топ-менеджер отметил, что в ходе тестирования китайские чипы показали стабильную производительную работу с существующими IT-системами банка. «Внедрение китайских GPU проходит без существенных доработок и с высокой производительностью. Это ускорит развитие ИИ-технологий, включая цифровых помощников и ИИ-агентов», — сообщил он. Замена ускорителей NVIDIA на китайские GPU проводится в рамках совместной работы в центре компетенций ВТБ по ИИ в Китае. Центр представляет собой площадку для прикладных совместных исследований российских и китайских специалистов и быстрого тестирования устройств с ИИ без необходимости их поставки в Россию. Здесь и проходило тестирование GPU из КНР в марте. Зампред отметил, что Китай богат на технологии, но существуют сложности с их поиском, апробацией и доставкой в Россию в промышленных масштабах. «Центр создан для того, чтобы помочь компаниям из России и Китая совместно внедрять новейшие технологии. Сейчас мы сконцентрированы на поиске партнёров, заинтересованных в применении ИИ-технологий», — рассказал он. 
Источник изображения: John Lucas / Unsplash Согласно исследованию IT-холдинга Т1, совокупный рынок российских GPU в 2025 году вырос на 21 % до около 63 млрд руб. Доля NVIDIA на мировом рынке оценивается в исследовании в 80 %. По его оценкам, с учётом дополнительных затрат на серверные платформы, сетевое оборудование, ПО и обслуживание, капитальные вложения на замещение чипов NVIDIA могут составить порядка 2–5 млрд руб. Ранее «Ведомости» сообщали, что китайские серверы тестируют «Сбер» и Т-банк, а Альфа-банк тоже рассматривает возможность их использования. Среди поставщиков ИИ-ускорителей в Китае есть Huawei, Alibaba, MetaX, Moore Threads, Cambricon, Iluvatar, Biren, Sophgo и др. Собеседник «Ведомостей» в одном из топ-20 банков России считает, что реальных альтернатив чипам NVIDIA для банковской сферы всё же нет, ни сейчас, ни в обозримом будущем. Даже самые сильные китайские GPU пока уступают решениям американской компании не только по «железу», но и по зрелости программной среды, под которую уже разработано множество банковских решений. Переход на альтернативные GPU потребует серьезных вложений в адаптацию и переработку программных продуктов, а проведенные испытания показывают, что такие решения пока заметно проигрывают по скорости обработки запросов и обучению классических ML-моделей, отметил собеседник издания.
18.03.2026 [08:44], Сергей Карасёв
NVIDIA выпустила однослотовый ускоритель RTX Pro 4500 Blackwell Server Edition с 32 Гбайт памяти GDDR7Компания NVIDIA анонсировала ускоритель RTX Pro 4500 Blackwell Server Edition, подходящий для решения таких задач, как ИИ-инференс, анализ данных, обработка видеоматериалов и пр. Новинка ориентирована на дата-центры, облачные платформы и периферийные инфраструктуры. Решение выполнено на архитектуре Blackwell. Конфигурация включает 10 496 ядер CUDA, 82 ядра RT четвёртого поколения, а также 32 Гбайт GDDR7 с 256-бит шиной и пропускной способностью 800 Гбайт/с. Задействованы тензорные ядра пятого поколения, которые обеспечивают до трёх раз более высокую производительность по сравнению с более ранними изделиями и предлагают поддержку режима FP4. Карта получила однослотовое исполнение FHFL и пассивное охлаждение. Заявленное энергопотребление составляет 165 Вт. Для подключения служит интерфейс PCIe 5.0 x16. ИИ-быстродействие на операциях FP4 (Tensor Core) достигает 1,6 Пфлопс, FP8 (Tensor Core) — 811 Тфлопс, FP16/BF16 (Tensor Core) — 406 Тфлопс, TF32 (Tensor Core) — 203 Тфлопс. Как отмечает NVIDIA, по сравнению с системами, работающими только на основе CPU, ускоритель RTX Pro 4500 Blackwell Server Edition обеспечивает до 100 раз более высокую производительность при анализе видеоматериалов с помощью алгоритмов ИИ. Благодаря этому компании могут извлекать данные из видеопотока в режиме реального времени, ускоряя работу приложений компьютерного зрения — как в ЦОД, так и на периферии. 
Источник изображения: NVIDIA Предусмотрены три аппаратных движка NVIDIA NVENC девятого поколения. Они имеют поддержку кодирования 4:2:2 H.264 и HEVC, а также улучшают качество при работе с HEVC и AV1. Вместе с тем три движка NVIDIA NVDEC шестого поколения демонстрируют вдвое более высокую пропускную способность при декодировании материалов H.264, а также поддерживают 4:2:2 H.264 и HEVC.
09.03.2026 [16:39], Владимир Мироненко
Ubitium стала на шаг ближе к выпуску универсального RISC-V процессора, заменяющего CPU, GPU, DSP и FPGAНемецкий стартап Ubitium объявил о завершении стадии tape-out (финальный этап проектирования) универсального RISC-V-процессора, изготовленного по 8-нм техпроцессу Samsung Foundry и предназначенного для рынка встроенных вычислительных систем автомобилей, промышленного оборудования и бытовой электроники, включая радарные и многосенсорные сигнальные цепи, аудио и голосовую связь в реальном времени, компьютерное зрение, периферийный ИИ, промышленный человеко-машинный интерфейс (HMI) и т.д. В основе процессора Ubitium лежит «универсальный процессорный массив» (Universal Processing Array) — программно-определяемая система с 256 элементами, объединяющая функции CPU, GPU, DSP и FPGA и способная мгновенно менять режимы выполнения во время работы. Такая унификация позволяет чипу переключаться между режимом работы в качестве CPU общего назначения для обслуживания ОС и режимом работы в качестве ИИ-ускорителя, избегая задержек при передаче данных между отдельными чипами. 
Источник изображения: Ubitium Завершение tape-out на 8-нм техпроцессе Samsung подтверждает работоспособность основного процессорного массива и интерфейса LPDDR5. Для Ubitium доказательство того, что один процессор может обрабатывать общие вычислительные задачи, задачи обработки в реальном времени и задачи ИИ на одном кристалле, является важным шагом на пути к коммерческой жизнеспособности, отметил EE Times. «Это решение претворяет давно существующую концепцию в жизнь», — заявил Мартин Форбах (Martin Vorbach), технический директор Ubitium. «Встроенные системы переросли архитектуры, на которые сегодня опирается отрасль. Консолидация больше не является необязательной. Она неизбежна», — добавил он. Технология, лежащая в основе этого проекта, совершенствовалась более 15 лет. Для её воплощения в жизнь Форбахом совместно с рядом специалистов была создана в 2024 году компания Ubitium. Ускорить разработку позволило привлечение $3,7 млн в рамках посевного раунда в конце прошлого года, который совместно возглавили Runa Capital, Inflection и KBC Focus Fund. Инвестиции позволили Ubitium проверить архитектуру и подготовить наборы для разработки (IDK) для первых клиентов. 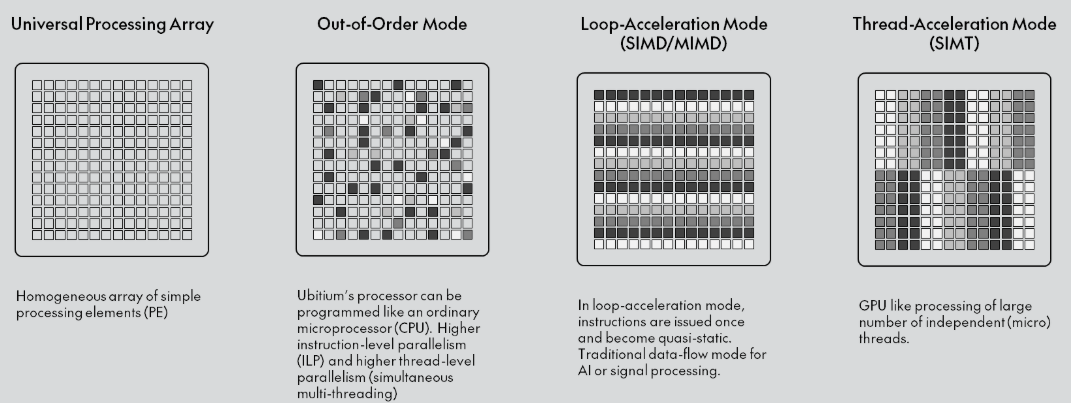
Источник изображения: Ubitium «Индустрия процессоров объёмом $500 млрд построена на жёстких границах между вычислительными задачами», — сказал Хён Шин Чо (Hyun Shin Cho), генеральный директор Ubitium и соучредитель. — Мы стираем эти границы. Наш универсальный процессор делает всё — CPU, GPU, DSP, FPGA — на одном чипе, в одной архитектуре. Это не просто постепенное улучшение. Это смена парадигмы. Это архитектура процессора, которую требует эпоха ИИ». Как отметил EE Times, завершение tape-out продукта — это не просто большая победа для Ubitium. Это также поворотный момент для экосистемы RISC-V. Открытая архитектура RISC-V используется большей частью для создания обычных ядер, которые полагаются на внешние ускорители для сложных рабочих нагрузок. Ubitium расширяет границы использования архитектуры, сохраняя полную совместимость с RISC-V. Процессор поддерживает стандартные наборы инструментов RISC-V для разработки ПО и может работать под управлением Linux и RTOS. Кроме того, унифицированный программный стек устраняет необходимость в компиляторах для конкретного поставщика или проприетарных языках, что позволяет быстро внедрять инновации и сократить время разработки. Компания сотрудничает с Samsung Foundry и ADTechnology для завершения проектирования и с Siemens Digital Industries Software — для проверки микросхемы (pre-silicon validation). Вторая стадия tape-out запланирована на конец этого года, а серийное производство начнётся в 2027 году, сообщила компания.
19.02.2026 [12:26], Сергей Карасёв
«НВБС» представила российские серверы «Необайт» на платформах Intel и AMDКомпания «НВБС», российский системный интегратор и производитель технологических решений, анонсировала собственные серверы семейства «Необайт». Дебютировали модели NeoByte NBR220 и NeoByte NBR680 на аппаратной платформе Intel, а также NeoByte NBR685 с процессорами AMD. По словам компании, новинки «сопоставимы с решениями ведущих компаний на рынке, но при этом в среднем стоят на 10–15 % дешевле за счёт широкого пула поставщиков и оптимизированной логистики». Система NeoByte NBR220 типоразмера 2U может нести на борту два чипа Intel Xeon Sapphire Rapids или Emerald Rapids с показателем TDP до 350 Вт. Доступны 32 слота для модулей оперативной памяти DDR5-4800. В зависимости от конфигурации во фронтальной части возможна установка 12 накопителей LFF/SFF или 24 устройств SFF с интерфейсом SATA/SAS/NVMe. В тыльной зоне корпуса расположены посадочные места ещё для четырёх накопителей LFF/SFF (SATA/SAS/NVMe), тогда как внутри есть два коннектора для SSD формата M.2 (SATA/NVMe). Реализована поддержка до 10 стандартных слотов PCIe и одного слота OCP 3.0. В оснащение входят контроллер AST2600, два сетевых порта 1GbE, выделенный сетевой порт управления 1GbE, четыре порта USB 3.0 (по два спереди и сзади), два интерфейса D-Sub (по одному спереди и сзади) и последовательный порт. Питание обеспечивают два блока с резервированием мощностью 800/1300/1600/2000 Вт. Сервер оптимизирован для ИИ-задач, виртуализации, баз данных и файловых хранилищ. Платформа практически идентична представленным ранее серверам «Аквариус» AQserv T50 D224RS и T50 D212RS. 
Источник изображений: «НВБС» Модель NeoByte NBR680 стандарта 6U имеет аналогичные характеристики подсистем CPU, ОЗУ, хранения данных и интерфейсов ввода/вывода. При этом возможна установка до восьми GPU-ускорителей двойной ширины. Есть пять стандартных слотов PCIe и один слот OCP; передняя панель поддерживает до трёх стандартных слотов PCIe и один слот OCP. Мощность каждого из двух блоков питания — 2700 или 3200 Вт. Машина предназначена для научных исследований и крупных ИИ-проектов.  В свою очередь, GPU-сервер NeoByte NBR685 формата 6U рассчитан на два процессора AMD EPYC 9005 Turin или EPYC 9004 Genoa с показателем TDP до 500 Вт. Предусмотрены 24 слота для модулей оперативной памяти DDR5-4800. Прочие характеристики идентичны версии NeoByte NBR680, включая поддержку восьми GPU-ускорителей двойной ширины. Система подходит для анализа больших данных в реальном времени, криптографии и блокчейна.  Все новинки могут быть опционально укомплектованы контроллером SAS RAID/HBA. Заявлена совместимость с Windows Server 2022 SLES 12.5 и выше, RHEL7.8 и выше, Ubuntu18.04 и выше, CentOS7.6 и выше, Vmware ESXi 7.0 GA и выше. Гарантия производителя достигает пяти лет. Также «НВБС» говорит, что «не зависит от санкций, что снижает риски ограничения поставок». |
|

