Материалы по тегу: blackwell
|
20.06.2026 [15:45], Сергей Карасёв
В Словении запущена НРС-система FRIDA с ускорителями NVIDIA BlackwellЛюблянский университет в Словении (University of Ljubljana), по сообщению DataCenter Dynamics, запустил высокопроизводительную систему FRIDA, ориентированную на задачи ИИ и машинного обучения. Это не классический суперкомпьютер, а модульный контейнерный дата-центр, размещённый на крыше здания Факультета компьютерных и информационных наук (FRI) в Любляне. Известно, что в составе FRIDA задействованы 104 ускорителя на основе GPU. В частности, применяются изделия NVIDIA Blackwell B200 и B300. Суммарный объём GPU-памяти составляет 16,8 Тбайт. Комплекс оборудован гибридной воздушно-жидкостной системой охлаждения. Все вычислительные узлы связаны интерконнектом с высокой пропускной способностью. Отмечается, что производительность FRIDA при вычислениях с низкой точностью достигает 708 Пфлопс. Пиковое быстродействие при операциях с разреженными матрицами низкой точности заявлено на уровне 1,42 Эфлопс. FRIDA дополнит словенскую НРС-систему Vega, которая была введена в строй в 2021 году в рамках проекта Европейского совместного предприятия по развитию высокопроизводительных вычислений (EuroHPC JU). Эта машина, основанная на процессорах AMD и ускорителях NVIDIA, демонстрирует FP64-производительность на уровне 6,9 Пфлопс. 
Источник изображения: linkedin.com Vega задумывалась как универсальная платформа для сложных вычислений: она может применяться для решения задач в самых разных областях, включая биоинженерию и разработку новых лекарств, изучение климата и прогнозирование погоды, персонализированную медицину, создание новых материалов и пр. В свою очередь, система FRIDA ориентирована прежде всего на нагрузки, связанные с ИИ.
18.03.2026 [08:44], Сергей Карасёв
NVIDIA выпустила однослотовый ускоритель RTX Pro 4500 Blackwell Server Edition с 32 Гбайт памяти GDDR7Компания NVIDIA анонсировала ускоритель RTX Pro 4500 Blackwell Server Edition, подходящий для решения таких задач, как ИИ-инференс, анализ данных, обработка видеоматериалов и пр. Новинка ориентирована на дата-центры, облачные платформы и периферийные инфраструктуры. Решение выполнено на архитектуре Blackwell. Конфигурация включает 10 496 ядер CUDA, 82 ядра RT четвёртого поколения, а также 32 Гбайт GDDR7 с 256-бит шиной и пропускной способностью 800 Гбайт/с. Задействованы тензорные ядра пятого поколения, которые обеспечивают до трёх раз более высокую производительность по сравнению с более ранними изделиями и предлагают поддержку режима FP4. Карта получила однослотовое исполнение FHFL и пассивное охлаждение. Заявленное энергопотребление составляет 165 Вт. Для подключения служит интерфейс PCIe 5.0 x16. ИИ-быстродействие на операциях FP4 (Tensor Core) достигает 1,6 Пфлопс, FP8 (Tensor Core) — 811 Тфлопс, FP16/BF16 (Tensor Core) — 406 Тфлопс, TF32 (Tensor Core) — 203 Тфлопс. Как отмечает NVIDIA, по сравнению с системами, работающими только на основе CPU, ускоритель RTX Pro 4500 Blackwell Server Edition обеспечивает до 100 раз более высокую производительность при анализе видеоматериалов с помощью алгоритмов ИИ. Благодаря этому компании могут извлекать данные из видеопотока в режиме реального времени, ускоряя работу приложений компьютерного зрения — как в ЦОД, так и на периферии. 
Источник изображения: NVIDIA Предусмотрены три аппаратных движка NVIDIA NVENC девятого поколения. Они имеют поддержку кодирования 4:2:2 H.264 и HEVC, а также улучшают качество при работе с HEVC и AV1. Вместе с тем три движка NVIDIA NVDEC шестого поколения демонстрируют вдвое более высокую пропускную способность при декодировании материалов H.264, а также поддерживают 4:2:2 H.264 и HEVC.
20.01.2026 [10:02], Владимир Мироненко
FP64 у вас ненастоящий: AMD сомневается в эффективности эмуляции научных расчётов на тензорных ядрах NVIDIAВместо создания специализированных чипов для аппаратных FP64-вычислений NVIDIA использует эмуляцию для повышения производительности HPC на ИИ-ускорителях, пишет The Register. Компания отказалась от развития FP64-блоков в поколении Blackwell Ultra, а в новейших ускорителях Rubin пиковая заявленная производительность векторных FP64-вычислений составляет 33 Тфлопс, тогда как у H100, вышедшего четыре года назад, она была равна 34 Тфлопс, а у Blackwell — около 40 Тфлопс. Если включить программную эмуляцию в библиотеках CUDA от NVIDIA, ускоритель, как утверждается, может достичь производительности до 200 Тфлопс в матричных FP64-вычислениях. Впрочем, и Blackwell с эмуляций способен выдать в этом случае до 150 Тфлопс, тогда как у Hopper были «честные» 67 Тфлопс. «В ходе многочисленных исследований с партнёрами и собственных внутренних изысканий мы обнаружили, что точность, достигаемая с помощью эмуляции, как минимум не уступает точности, получаемой от аппаратных тензорных ядер», — сообщил ресурсу The Register Дэн Эрнст (Dan Ernst), старший директор по суперкомпьютерным продуктам NVIDIA. В свою очередь, в AMD считают, что это утверждение справедливо не для всех сценариев. «В некоторых бенчмарках она показывает довольно хорошие результаты, но в реальных физических научных симуляциях это не очевидно», — говорит Николас Малайя (Nicholas Malaya), научный сотрудник AMD. Он выразил мнение, что, хотя эмуляция FP64, безусловно, заслуживает дальнейших исследований и экспериментов, такое решение ещё не готово к широкому применению. AMD и сама изучает возможность программной эмуляции FP64 на Instinct MI355X, чтобы определить области её возможного применения. 
Источник изображения: Hilda Trinidad / Unsplash Хотя чипы всё чаще используют типы данных с более низкой точностью, FP64 остаётся золотым стандартом для научных вычислений, и на то есть веские причины — FP64 не имеет себе равных по динамическому диапазону. Современные же LLM обучаются с использованием FP8-вычислений, а компактные типы данных MXFP8/MXFP4 или NVFP4 позволяют получить достаточный для ИИ диапазон значений. Это хорошее решение для нечёткой математики больших языковых моделей, но это не замена FP64 для HPC. ИИ-нагрузки обладают высокой устойчивостью к ошибкам, а HPC-задачи требуют высокой точности. AMD указала на то, что эмуляция FP64 у NVIDIA не совсем соответствует стандарту IEEE. Алгоритмы NVIDIA не учитывают такие понятия, как положительные и отрицательные нули, ошибки NaN (Not a Number) и ошибки infinite number (бесконечное число). Из-за этого небольшие ошибки в промежуточных вычислениях, используемых для эмуляции более высокой точности, могут привести к искажениям, способным повлиять на точность конечного результата, пояснил Малайя. По его словам, целесообразность использования эмуляции FP64 зависит от конкретного приложения. Эмуляция FP64 лучше всего работает для хорошо обусловленных проблем, где малые изменения «на входе» приводят к малым же изменениям в конечном результате. Ярким примером такой задачи является бенчмарк Linpack (HPL). «Но если вы посмотрите на материаловедение, коды для расчёта процессов горения, системы ленточых матриц и т.п., то увидите, что это гораздо менее обусловленные системы, и внезапно всё начинает давать сбои», — сказал он. 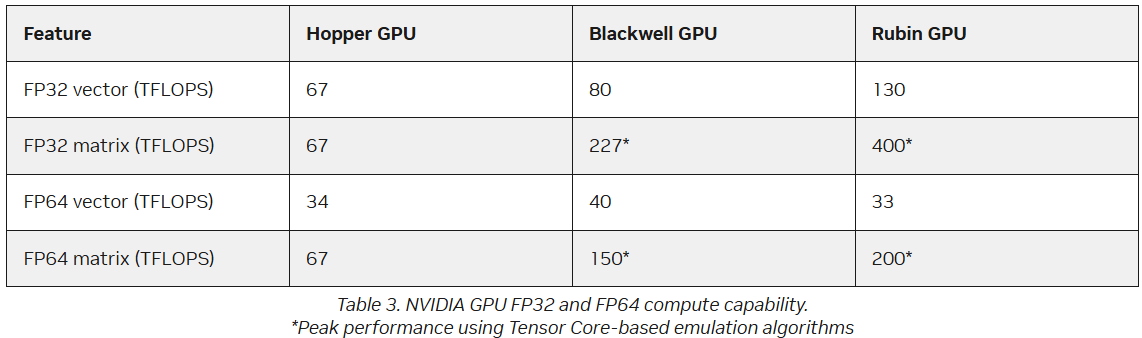
Источник изображения: NVIDIA Точность можно повысить, увеличив количество используемых операций, однако после определённого предела никаких преимуществ от эмуляции уже не будет. Вдобавок все эти операции требуют память. «У нас есть данные, которые показывают, что алгоритму Озаки требуется примерно вдвое больше памяти для эмуляции матриц FP64», — сказал Малайя. Поэтому компания готовит специализированные ускорители MI430X c повышенной FP64/FP32-производительностью, но, как опасаются учёные, она может оказаться не слишком в них заинтересована, поскольку ИИ-ускорители приносят больше денег. Эрнст утверждает, что для большинства специалистов в области HPC неполное соответствие стандарту IEEE не представляет большой проблемы. Всё во многом зависит от конкретного приложения. Тем не менее, NVIDIA разработала дополнительные алгоритмы для обнаружения и смягчения указанных выше ошибок и неэффективных операций эмуляции. Эрнст также признал, что использование памяти при эмуляции может быть несколько выше, но подчеркнул, что эти накладные расходы относятся к расчётам, а не к самому приложению — в большинстве случаев речь идёт о матрицах размером не более нескольких Гбайт. Впрочем, всё это не меняет того, что эмуляция полезна только для подмножества HPC-задач, которые полагаются на операции умножения плотных матриц (DGEMM). По словам Малайи, для 60–70 % рабочих нагрузок HPC эмуляция дает незначительные преимущества или ничего не меняет. «По нашим оценкам, подавляющее большинство реальных рабочих нагрузок HPC полагаются на векторное умножение (FMA), а не на DGEMM», — сказал он, отметив, что это действительно нишевый сегмент, хотя и не крошечная доля рынка. Для рабочих нагрузок, интенсивно использующих векторы, таких как вычислительная гидродинамика (CFD), ускорители Rubin по-прежнему будут полагаться на медленные векторные FP64-блоки.
19.12.2025 [18:35], Сергей Карасёв
NVIDIA выпустила ускоритель RTX Pro 5000 Blackwell с 72 Гбайт памяти для рабочих станцийКомпания NVIDIA сообщила о доступности ускорителя RTX Pro 5000 Blackwell с 72 Гбайт памяти GDDR7 (ECC) для мощных рабочих станций, ориентированных на ИИ-задачи, включая «тонкую» настройку больших языковых моделей (LLM). Новинка является собратом ранее выпущенной версии RTX Pro 5000 Blackwell с 48 Гбайт GDDR7, по сравнению с которой объём памяти увеличился в полтора раза. Оба ускорителя построены на чипе Blackwell с 14 080 ядрами CUDA. Задействованы тензорные ядра пятого поколения и RT-ядра четвёртого поколения. Говорится об использовании 512-бит шины памяти; пропускная способность — 1344 Гбайт/с. Новинка выполнена в виде двухслотовой карты расширения полной высоты с интерфейсом PCIe 5.0 x16. 
Источник изображения: NVIDIA Выпущенный ускоритель располагает четырьмя разъёмами DisplayPort 2.1b. Возможен одновременный вывод изображения на несколько мониторов в следующих конфигурациях: четыре с разрешением до 4096 × 2160 пикселей и частотой обновления 120 Гц, четыре с разрешением 5120 × 2880 точек и частотой 60 Гц или два с разрешением 7680 × 4320 пикселей и частотой 60 Гц. Заявлена поддержка DirectX 12, Shader Model 6.6, OpenGL 4.63, Vulkan 1.33, а также CUDA 12.8, OpenCL 3.0 и DirectCompute. Заявленная ИИ-производительность достигает 2142 TOPS. Карта оборудована 16-контактным разъёмом дополнительного питания. Энергопотребление находится на уровне 300 Вт. Применено активное охлаждение с вентилятором. Ускоритель RTX Pro 5000 Blackwell с 72 Гбайт памяти предлагается через партнёрские каналы, включая Ingram Micro, Leadtek, Unisplendour и xFusion.
31.10.2025 [13:49], Сергей Карасёв
NVIDIA представила платформу IGX Thor для «физического ИИ» на периферииКомпания NVIDIA анонсировала аппаратную платформу IGX Thor, предназначенную для «переноса» ИИ из цифрового мира в физический. Решение разработано специально для промышленных, робототехнических и медицинских сред. IGX Thor позволяет проектировать периферийные устройства с ИИ-функциями, поддерживающие получение информации от различных датчиков. В семейство IGX Thor входят комплекты для разработчиков IGX Thor Developer Kit и IGX Thor Developer Kit Mini, а также решения IGX T7000 (плата Micro-ATX) и IGX T5000 («система на модуле»). Комплекты IGX Thor Developer Kit, в свою очередь, представлены в версиях с ускорителем NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition и NVIDIA RTX Pro Blackwell 5000. Вариант IGX Thor Developer Kit Mini не предполагает наличие дискретного GPU. Старшая из новинок, IGX Thor Developer Kit с ускорителем NVIDIA RTX PRO 6000 Blackwell Max-Q Workstation Edition, содержит GPU на архитектуре Blackwell с 24 064 ядрами. Предусмотрено 96 Гбайт памяти GDDR7 с пропускной способностью до 1792 Гбайт/с. Заявленная ИИ-производительность достигает 5581 Тфлопс в режиме FP4-Sparse. Модификация IGX Thor Developer Kit на базе NVIDIA RTX Pro Blackwell 5000 несёт на борту GPU поколения Blackwell с 14 080 ядрами. Объём встроенной памяти составляет 48 Гбайт, её пропускная способность — 1344 Гбайт/с. Быстродействие ИИ достигает 4293 Тфлопс (FP4-Sparse). 
Источник изображения: NVIDIA Все три новинки, включая версию Mini (обладает ИИ-быстродействием 2070 Тфлопс), располагают интегрированным GPU на архитектуре Blackwell с 2560 ядрами и максимальной частотой 1,57 ГГц. Присутствует CPU с 14 ядрами Arm Neoverse-V3AE с частотой до 2,6 ГГц. Изделия оборудованы 128 Гбайт памяти LPDDR5X с пропускной способностью 273 Гбайт/с, а также накопителем M.2 NVMe (PCIe 5.0 x2) вместимостью 1 Тбайт. Старшие модели наделены двумя слотами PCIe 5.0 (x8 и x16), младшая — разъёмом M.2 Key E, в который установлен комбинированный адаптер Wi-Fi 6e / Bluetooth. Изделия поддерживают различные интерфейсы, включая (в зависимости от модели) USB 3.2 Gen2 Type-C, USB-3.2 Gen2 Type-A, DisplayPort 1.4a, HDMI 2.0b, 1/5GbE (RJ45), 25GbE (QSFP28), 100GbE (QSFP28) и пр. Для новинок гарантированы 10-летний жизненный цикл и долгосрочная поддержка программного стека NVIDIA AI. В продажу все изделия поступят в декабре нынешнего года.
10.10.2025 [14:50], Руслан Авдеев
Не для себя стараемся: Microsoft развернула для OpenAI первый в мире ИИ-кластер на базе суперускорителей NVIDIA GB300 NVL72Microsoft представила первый в мире ИИ-кластер, использующий более 4,6 тыс. NVIDIA Blackwell Ultra в составе суперускорителей NVIDIA GB300 NVL72, объединённых интерконнектом Quantum-X800 InfiniBand. Этот кластер — лишь первый из многих. Компания развернёт сотни тысяч ускорителей Blackwell Ultra в ИИ ЦОД по всему миру. Благодаря им Microsoft намерена стать первой, поддерживающей обучение для моделей с сотнями триллионов параметров. Как сообщают в Microsoft, запуск в Microsoft Azure суперкластера NVIDIA GB300 NVL72 стал важным шагом в развитии передовых ИИ-технологий. Разработанная совместно с NVIDIA система представляет собой первый в мире масштабируемый ИИ-кластер на основе GB300, обеспечивающий вычислительные мощности, необходимые OpenAI для обслуживания моделей с триллионами параметров. Речь идёт о новом стандарте ускоренных вычислений, говорят компании. Новые инстансы Azure ND GB300 v6 оптимизированы для рассуждающих моделей, агентных систем и мультимодального генеративного ИИ. Каждая стойка GB300 NVL72 обслуживает 18 виртуальных машин, а сам суперускоритель с производительностью до 1,44 Эфлопс (FP4 Tensor Core) включает:

Источник изображения: Microsoft Создание передовой инфраструктуры требует переосмысления всех уровней системы, включая вычисления, память, системы охлаждения и питания, ЦОД в целом как единой структуры. Новая архитектура стоек обеспечивает высокую пропускную способность инференса при меньших задержках на крупных моделях, это позволяет агентным и мультимодальным ИИ-системам быть более масштабируемыми и эффективными, чем когда-либо, говорит компания. Для масштабирования за пределы стойки используется NVIDIA Quantum-X800 InfiniBand, что гарантирует обучения сверхбольших моделей с применением десятков тысяч ИИ-ускорителей с минимальными накладными расходами на их синхронизацию, что дополнительно повышает производительность. 
Источник изображения: Microsoft Передовые системы охлаждения Azure используют автономные теплообменники, чтобы свести к минимуму расход воды и поддерживать температурную стабильность для высокоплотных кластеров. Также продолжается разработка и внедрение новых моделей распределения питания, обеспечивающих высокую энергетическую плотность и динамический баланс нагрузок. Дополнительную помощь в оптимизации работы оказывает и модернизированное программное обеспечение. Ранее Microsoft обладала эксклюзивными правами на предоставление облачных сервисов компании OpenAI, но в январе 2025 года появилась новость, что ИИ-стартапу разрешили пользоваться и облаками других провайдеров, если у Microsoft не хватит собственных мощностей. Разногласия между компаниями продолжают нарастать. Формально первенство по создание кластера на базе GB300 NVL72 принадлежит CoreWeave, имеющей тесные отношения с NVIDIA и обслуживающей OpenAI — как напрямую, так и при посредничестве Microsoft.
03.09.2025 [09:47], Владимир Мироненко
Гибридный суперчип NVIDIA GB10 оказался технически самым совершенным в семействе BlackwellNVIDIA поделилась подробностями о суперчипе GB10 (Grace Blackwell), который ляжет в основу рабочих станций DGX Spark (ранее DIGITS) для ИИ-задач, пишет ресурс ServeTheHome. 
Источник изображений: NVIDIA via Wccftech Ранее сообщалось, что GB10 был создан NVIDIA в сотрудничестве MediaTek. GB10 объединяет чиплет CPU от MediaTek (S-Dielet) с ускорителем Blackwell (G-Dielet) с помощью 2.5D-упаковки. Оба кристалла изготавливаются по 3-нм техпроцессу TSMC. Как отметил ServeTheHome, GB10 технически является самым передовым продуктом на архитектуре Blackwell на сегодняшний день.  CPU включает 20 ядер на базе архитектуры Armv9.2, которые разбиты на два кластера по десять ядер (Cortex-X925 и Cortex-A725). На каждый кластер приходится 16 Мбайт кеш-памяти L3. Унифицированная оперативная память LPDDR5X-9400 ёмкостью 128 Гбайт подключена напрямую к CPU через 256-бит интерфейс с пропускной способностью 301 Гбайт/с. Объёма памяти достаточно для работы с моделями с 200 млрд параметров.  На кристалле CPU также находятся контроллеры HSIO для PCIe, USB и Ethernet. Для адаптера ConnectX-7 с поддержкой RDMA и GPUDirect выделено всего восемь линий PCIe 5.0, что не позволит работать обоим имеющимся портам в режиме 200GbE. Именно этот адаптер позволяет объединить две системы DGX Spark в пару для работы с ещё более крупными моделями.  G-Die имеет ту же архитектуру, что и B100. Ускоритель оснащён тензорными ядрами пятого поколения и RT-ядрами четвёртого поколения и обеспечивает производительность 31 Тфлопс в FP32-вычислениях. ИИ-производительность в формате NVFP4 составляет 1000 TOPS. Ускоритель подключён к CPU через шину NVLink C2C с пропускной способностью 600 Гбайт/с. G-Die оснащён 24 Мбайт кеш-памяти L2, которая также доступна ядрам CPU в качестве кеша L4, что обеспечивает когерентность памяти между CPU и GPU на аппаратном уровне. 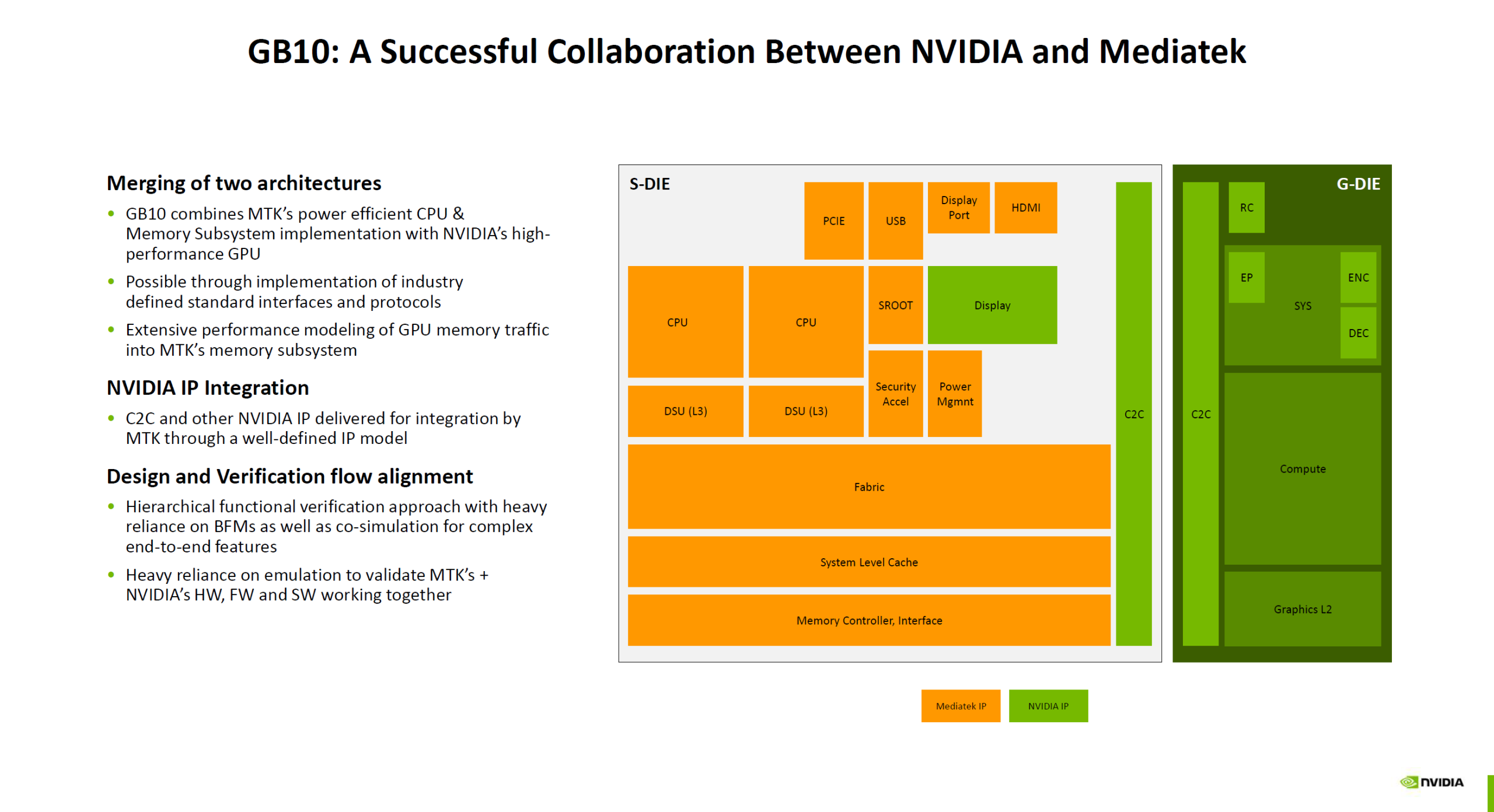 Поддерживается технология SR-IOV, интегрированы движки NVDEC и NVENC. Возможно подключение до четырёх дисплеев: три DisplayPort Alt-mode (4K@120 Гц) и один HDMI 2.1a (8K@120 Гц). Что касается безопасности, есть выделенные процессоры SROOT и OSROOT, а также поддержка fTPM и дискретного TPM (по данным Wccftech). TDP GB10 составляет 140 Вт.
21.08.2025 [10:03], Сергей Карасёв
NVIDIA представила ИИ-платформу Jetson AGX Thor Developer Kit с GPU BlackwellКомпания NVIDIA анонсировала вычислительные модули Jetson T5000 и T4000, а также комплект для разработчиков Jetson AGX Thor Developer Kit. Изделия предназначены для создания роботов, периферийных ИИ-систем, обработки данных от камер и сенсоров и других задач. Решение Jetson T5000 объединяет CPU с 14 вычислительными 64-бит ядрами Arm Neoverse-V3AE с максимальной тактовой частотой 2,6 ГГц, а также 2560-ядерный GPU на архитектуре Blackwell с частотой до 1,57 ГГц (задействованы 96 тензорных ядер пятого поколения). Объём памяти LPDDR5X с пропускной способностью 273 Гбайт/с составляет 128 Гбайт. Заявленная производительность достигает 2070 Тфлопс (FP4—Sparse). Реализована поддержка четырёх интерфейсов 25GbE. 
Источник изображений: NVIDIA В свою очередь, модель Jetson T4000 содержит CPU с 12 ядрами Arm Neoverse-V3AE (до 2,6 ГГц) и 1536-ядерный GPU на архитектуре Blackwell (до 1,57 ГГц; 64 тензорных ядра пятого поколения). Объём памяти LPDDR5X равен 64 Гбайт (273 Гбайт/с). У этого решения быстродействие составляет до 1200 Тфлопс (FP4—Sparse). Упомянуты три интерфейса 25GbE. Обе новинки обеспечивают возможность кодирования видео в многопоточных режимах: 6 × 4Kp60 (H.265), 12 × 4Kp30 (H.265), 24 × 1080p60 (H.265), 50 × 1080p30 (H.265), 48 × 1080p30 (H.264) или 6 × 4Kp60 (H.264). Декодирование возможно в следующих форматах: 4 × 8Kp30 (H.265), 10 × 4Kp60 (H.265), 22 × 4Kp30 (H.265), 46 × 1080p60 (H.265), 92 × 1080p30 (H.265), 82 × 1080p30 (H.264) и 4 × 4Kp60 (H.264). Допускается подключение до 20 камер посредством HSB, до 6 камер через 16 линий MIPI CSI-2 или до 32 камер через виртуальные каналы.  Среди прочего упомянута поддержка восьми линий PCIe 5.0, интерфейсов USB 3.2 (×3) и USB 2.0 (×4), HDMI 2.1 и DisplayPort 1.4a, I2S/2x (×5), DMIS (×2), UART (×4), SPI (×3), I2C (×13), PWM (×6). Габариты модулей составляют 100 × 87 мм. Решение Jetson AGX Thor Developer Kit построено на основе Jetson T5000. Система несёт на борту накопитель M.2 NVMe SSD вместимостью 1 Тбайт и комбинированный адаптер Wi-Fi 6E / Bluetooth (M.2 Key-E). Реализованы порты HDMI 2.0b и DisplayPort 1.4a, 5GbE RJ45 и QSFP28 (4 × 25 GbE), по два разъёма USB 3.2 Type-A и USB 3.1 Type-C. Размеры устройства составляют 243,19 × 112,4 × 56,88 мм. Комплект доступен для заказа по ориентировочной цене $3500.
19.08.2025 [23:10], Руслан Авдеев
NVIDIA готовит для Китая урезанный ИИ-ускоритель на архитектуре BlackwellNVIDIA работает над новым ИИ-ускорителем, предназначенным специально для китайского рынка. Модель на основе новейшей архитектуры Blackwell будет мощнее модели H20, допущенной для продаж в КНР, сообщает Reuters со ссылкой на осведомлённые источники. Как сообщают источники, новый чип, предварительно названный B30A, будет представлять собой однокристальную систему, которая, вероятно, обеспечит половину чистой вычислительной мощности флагманской модели NVIDIA B300 на двух кристаллах. Новый чип получит высокоскоростную память и поддержку технологии NVIDIA NVLink. Впрочем, эти функции имеются и в H20, основанном на устаревшей архитектуре Hopper. Источники сообщают, что окончательные характеристики чипа не определены, но NVIDIA рассчитывает предоставить китайским клиентам образцы для тестирования уже в следующем месяце. Компания подчёркивает, что рассматривает выпуск различных продуктов в той мере, в какой это позволяет американское правительство. Всё, что предлагается, одобрено компетентными органами и предназначено исключительно для коммерческого использования. В прошлом году на долю Китая пришлось 13 % выручки NVIDIA, поэтому глава компании Дженсен Хуанг (Jensen Huang) жёстко раскритиковал американские запреты. Ускоритель H20 был разработан специально для КНР ещё в 2023 году, но в апреле 2025 года он попал под санкции. AMD также разработала для Китая ослабленные ускорители MI308, которые тоже попали под санкции. Теперь уже сам Китай говорит, что H20 может представлять опасность для национальной безопасности и призывает отказаться от использования этих чипов. 
Источник изображения: Boudewijn Huysmans/unsplash.com На прошлой неделе США допустили возможность продажи в Китай урезанных чипов нового поколения. Информация появилась после сделки, в результате которой NVIDIA и AMD будут отдавать правительству США 15 % выручки от продаж ИИ-ускорителей в Китае. По данным CNBC, Трамп заявлял, что сначала он рассчитывал на 20 %, но позже согласился и на меньшее. Тем не менее, американские парламентарии обеспокоены продажей даже ослабленных чипов в Китай. Предполагается, что это помешает США добиться мирового лидерства в сфере ИИ. NVIDIA и другие компании уверены, что интерес Китая к американской продукции необходимо сохранить, иначе бизнесы из Поднебесной перейдут на продукцию местных конкурентов. Ранее сообщалось, что NVIDIA готовит для Китая чипы на архитектуре Blackwell, предназначенные для инференса. В мае Reuters сообщало, что ускоритель на базе RTX6000D (возможно, B30/B40) будет дешевле H20. Он разработан с учётом ограничений, введённых американскими властями, и использует обычную память GDDR с пропускной способностью 1398 Гбайт/сек, т.е. чуть ниже установленного регуляторами «экспортного» порога в 1,4 Тбайт/с — якобы именно из-за этого H20 и попал под запрет. Один из источников сообщает, что поставки небольших партий в Китай NVIDIA намеревается начать уже в сентябре 2025 года.
12.08.2025 [14:51], Владимир Мироненко
NVIDIA анонсировала компактные ускорители RTX PRO 4000 Blackwell SFF Edition и RTX PRO 2000 BlackwellNVIDIA объявила о предстоящем выходе GPU NVIDIA RTX PRO 4000 Blackwell SFF Edition и NVIDIA RTX PRO 2000 Blackwell, «воплощающих мощь архитектуры NVIDIA Blackwell в компактном и энергоэффективном форм-факторе», которые «обеспечат ИИ-ускорение для профессиональных рабочих процессов в различных отраслях». Новинки отличаются вдвое меньшими размерами по сравнению с традиционными GPU, и при этом оснащены RT-ядрами четвёртого поколения и тензорными ядрами пятого поколения с пониженным энергопотреблением. Как сообщает NVIDIA, новые ускорители разработаны для обеспечения производительности нового поколения для различных профессиональных рабочих процессов, обеспечивая «невероятное» ускорение процессов проектирования, дизайна, создания контента, ИИ и 3D-визуализации. По сравнению с ускорителем предыдущего поколения RTX A4000 SFF, модель RTX PRO 4000 SFF обеспечивает до 2,5 раза более высокую производительность в обработке ИИ-нагрузок и в 1,5 раза более высокую пропускную способность памяти, обеспечивая большую эффективность при том же максимальном энергопотреблении 70 Вт. 
Источник изображений: NVIDIA Ускоритель включает 8960 ядер NVIDIA CUDA, 24 Гбайт памяти GDDR7 ECC со 192-бит шиной и пропускной способностью 432 Гбайт/с. Используется интерфейс PCIe 5.0 x8. ИИ-производительность составляет 770 TOPS, RT-ядер — 73 TOPS, в формате FP32 — 24 TOPS. Доступно 2 движка NVENC девятого поколения и 2 движка NVDEC шестого поколения. Есть 4 разъёма DisplayPort 2.1b. Оптимизированная для массового проектирования и рабочих ИИ-процессов, RTX PRO 2000 обеспечивает до 1,6 раза более быстрое 3D-моделирование, в 1,4 раза более высокую производительность систем автоматизированного проектирования (САПР) и в 1,6 раза более высокую скорость рендеринга по сравнению с предыдущим поколением. Компания отметила, что инженеры САПР, продуктовые инженеры и специалисты творческих профессий по достоинству оценят 1,4-кратный прирост производительности RTX PRO 2000 при генерации изображений и 2,3-кратный прирост производительности при генерации текста, что обеспечивает более быструю итерацию, быстрое прототипирование и бесперебойную совместную работу.  RTX PRO 2000 оснащена 4352 ядрами NVIDIA CUDA, 16 Гбайт памяти GDDR7 ECC со 128-бит шиной и пропускной способностью 288 Гбайт/с. Используется интерфейс PCIe 5.0 x8. ИИ-производительность составляет 545 TOPS, RT-ядер — 54 TOPS, в формате FP32 — 17 TOPS. Доступно по одному движку NVENC девятого поколения и NVDEC шестого поколения. Есть 4 разъёма DisplayPort 2.1b. NVIDIA сообщила, что ускорители NVIDIA RTX PRO 2000 Blackwell и NVIDIA RTX PRO 4000 Blackwell SFF Edition поступят в продажу позже в этом году, не указав конкретные сроки. |
|

