Материалы по тегу: blackwell
|
26.05.2025 [14:38], Руслан Авдеев
NVIDIA выпустит для Китая дешёвый ускоритель семейства BlackwellNVIDIA намерена выпустить новый ИИ-ускоритель для Китая, который будет значительно дешевле недавно запрещённой к продаже в КНР модели H20. По данным источников Reuters, начало массового производства запланировано на июнь. Новинка войдёт в серию Blackwell и будет стоить $6,5–$8 тыс., т.е. намного меньше, чем H20, которые продавались по $10–$12 тыс. Вероятное название новинки — B40. Ускоритель предположительно получит чип от NVIDIA RTX Pro 6000D, будет использовать память GDDR7 вместо HBM и лишится поддержки NVLink. Кроме того, модель не будет использовать передовую технологию упаковки TSMC CoWoS (Chip-on-Wafer-on-Substrate). Представитель NVIDIA заявил, что компания всё ещё оценивает урезанные варианты ускорители — до того, как компания утвердит новый дизайн продукта и получит одобрение американских регуляторов, она фактически изолирована от китайского рынка объёмом $50 млрд. В TSMC слухи не комментируют. Китай долго оставался огромным рынком для NVIDIA, на который пришлось 13 % всех продаж за прошлый финансовый год. Уже в третий раз NVIDIA вынуждена ухудшать свои ИИ-ускорители из-за американских санкций, пытающихся замедлить технологическое развитие КНР (ранее пришлось выпустить A800, H800, H20 и др.). Запрет на продажи H20 фактически заставил NVIDIA списать $5,5 млрд и упустить $15 млрд потенциальных продаж. При этом дальнейшее ухудшение характеристик H20 невозможно. 
Источник изображения: NVIDIA Новый ускоритель хотя и намного слабее H20, должен помочь сохранить конкурентоспособность NVIDIA на китайском рынке, несмотря на значительные потери выручки из-за торговых ограничений со стороны США. Основным конкурентом компании является Huawei, выпускающая чипы Ascend. По словам экспертов Oak Capital Partners, производительность китайских ускорителей достигнет показателей ослабленных моделей NVIDIA в течение года-двух, но NVIDIA сохранит преимущество благодаря программной экосистеме CUDA, сопоставимых альтернатив которой у Huawei пока нет. До 2022 года, т.е до ввода серьёзных экспортных ограничений со стороны США, доля NVIDIA на китайском рынке ускорителей составляла 95 %, а сейчас она упала до 50 % — об этом сообщил глава компании Дженсен Хуанг (Jensen Huang). Он также предупредил об неэффективности санкций и заявил, что продолжение ограничений приведёт к тому, что чипов Huawei будут покупать всё больше, а вместо того, чтобы замедлить развитие ИИ-индустрии Китая, американские власти способствуют её прогрессу. Новейшие экспортные ограничения в очередной раз коснулись пропускной способности памяти и интерконнекта, этот показатель чрезвычайно важен для ИИ-чипов. По оценкам инвестиционного банка Jefferies новые правила ограничивают пропускную способность на уровне 1,7–1,8 Тбайт/с. H20 обеспечивает 4 Тбайт/с. GF Securities прогнозирует, что GDDR7 позволит получить допустимые 1,7 Тбайт/с. По словам двух источников Reuters, NVIDIA создаёт ещё один чип на архитектуре Blackwell для Китая, производство которого должно начаться в сентябре, но его характеристики пока неизвестны.
14.04.2025 [19:28], Алексей Степин
NVIDIA будет производить часть ИИ-ускорителей и платформ в СШАNVIDIA заявила, что не собирается ограничиваться исключительно тайваньскими производственными мощностями. Выпуск чипов Blackwell уже стартовал на площадке TSMC в Фениксе, штат Аризона. Здесь же в сотрудничестве с Amkor и SPIL будут налажены упаковка и тестирование новых GPU. Техасу отводится роль производителя суперкомпьютеров и платформ: NVIDIA строит соответствующие заводы совместно с Foxconn в Хьюстоне и с Wistron в Далласе. Всего компания застолбила почти 93 тыс. м2 производственных площадей в Аризоне и Техасе. Ожидается, что вышеупомянутые заводы выйдут на проектную мощность уже в течение ближайших 12–15 месяцев, а в течение четырёх следующих лет компания планирует произвести в США ИИ-платформ на $500 млрд. Как отмечает глава NVIDIA, Дженсен Хуанг (Jensen Huang), размещение производственных мощностей в США позволит компании лучше справляться с растущим спросом на ИИ-решения и суперкомпьютеры, укрепит её цепочки поставок и в целом поспособствует большей гибкости в решениях. Описываемое заявление NVIDIA сделала практически сразу после того, как ей удалось избежать экспортных ограничений на чип H20, наиболее производительный ИИ-ускоритель, разрешённый к экспорту в Китай. Согласно изданию NPR, этому помогло обещание крупных капиталовложений в ИИ-инфраструктуру США со стороны руководства компании. Многие другие разработчики и производители в сфере ИИ также вынуждены соглашаться с политикой текущей администрации США, дабы избежать огромных пошлин. 
Источник изображения: NVIDIA Хотя NVIDIA и заявляет, что инициатива с размещением производства чипов в США создаст сотни тысяч рабочих мест и увеличит активность экономики на триллионы долларов, всё не так просто, как может показаться. Реализации данных планов не способствуют ограничения, наложенные на торговлю с КНР и могущие помешать поставкам исходных материалов для производства микрочипов. Также упоминается нехватка квалифицированной рабочей силы. Меж тем, усилия администрации текущего президента США по отмене «закона о чипах» (CHIPS and Science Act), принятого в 2022 году и включающего в себя серьёзные субсидии иностранным высокотехнологичным компаниям, могут отпугнуть потенциальных инвесторов в лице полупроводниковых гигантов.
19.03.2025 [08:28], Сергей Карасёв
NVIDIA представила ускоритель RTX Pro 6000 Blackwell Server Edition с 96 Гбайт памяти GDDR7Компания NVIDIA анонсировала ускоритель RTX Pro 6000 Blackwell Server Edition для требовательных приложений ИИ и рендеринга высококачественной графики. Ожидается, что новинка будет востребована среди заказчиков из различных отраслей, включая архитектуру, автомобилестроение, облачные платформы, финансовые услуги, здравоохранение, производство, игры и развлечения, розничную торговлю и пр. Как отражено в названии, в основу решения положена архитектура Blackwell. Задействован чип GB202: конфигурация включает 24 064 ядра CUDA, 752 тензорных ядра пятого поколения и 188 ядер RT четвёртого поколения. Устройство несёт на борту 96 Гбайт памяти GDDR7 (ECC) с пропускной способностью до 1,6 Тбайт/с. Ускоритель RTX Pro 6000 Blackwell Server Edition использует интерфейс PCIe 5.0 x16. Энергопотребление может настраиваться в диапазоне от 400 до 600 Вт. Реализована поддержка DisplayPort 2.1 с возможностью вывода изображения в форматах 8K / 240 Гц и 16K / 60 Гц. Аппаратный движок NVIDIA NVENC девятого поколения значительно повышает скорость кодирования видео (упомянута поддержка 4:2:2 H.264 и HEVC). Всего доступно по четыре движка NVENC/NVDEC. 
Источник изображения: NVIDIA По заявлениям NVIDIA, по сравнению с ускорителем предыдущего поколения L40S Ada Lovelace модель RTX PRO 6000 Blackwell Server Edition обеспечивает многократное увеличение производительности в широком спектре рабочих нагрузок. В частности, скорость инференса больших языковых моделей (LLM) повышается в пять раз для приложений агентного ИИ. Геномное секвенирование ускоряется практически в семь раз, а быстродействие в задачах генерации видео на основе текстового описания увеличивается в 3,3 раза. Достигается также двукратный прирост скорости рендеринга и примерно такое же повышение скорости инференса рекомендательных систем. Ускоритель RTX PRO 6000 Blackwell Server Edition может использоваться в качестве четырёх полностью изолированных экземпляров (MIG) с 24 Гбайт памяти GDDR7 каждый. Это обеспечивает возможность одновременного запуска различных рабочих нагрузок — например, ИИ-задач и обработки графики. Упомянута поддержка TEE.
27.02.2025 [16:27], Владимир Мироненко
NVIDIA увеличила выручку, но снизила валовую прибыль — продукты стали сложнее и дороже, а спрос на Blackwell потрясающийNVIDIA объявила финансовые результаты за IV квартал и 2025 финансовый год, завершившийся 26 января 2025 года. Выручка компании в IV квартале составила $39,3 млрд, что на 12 % выше результата предыдущего квартала и на 78 % больше год к году при консенсус-прогнозе аналитиков, опрошенных LSEG, в размере $38,05 млрд. Вместе с тем компания сообщила о снижении валовой прибыли в отчётном квартале на 3 п.п. в годовом исчислении 73 %, объяснив это выходом новых продуктов для ЦОД, которые стали сложнее и дороже. Чистая прибыль (GAAP) выросла год к году на 80 % до $22,09 млрд. Чистая прибыль на разводнённую акцию (GAAP) составила $0,89, что на 14 % больше, чем в предыдущем квартале и на 82 % больше год к году. Скорректированная чистая прибыль на разводнённую акцию (Non-GAAP) составила $0,89, что на 10 % больше, чем в предыдущем квартале и на 71% больше, чем годом ранее, а также больше консенсус-прогноза аналитиков Уолл-стрит согласно опросу LSEG в размере $0,84. 
Источник изображений: NVIDIA Выручка компании в 2025 финансовом году выросла на 114 % до $130,5 млрд. Чистая прибыль (GAAP) увеличилась на 145 % с $29,76 млрд или $1,19 на разводнённую акцию в предыдущем финансовом году до $72,88 млрд или $2,94 на акцию в отчётном. Скорректированная чистая прибыль (Non-GAAP) выросла за год на 130 % до $2,99 на разводнённую акцию. В сегменте решений для ЦОД выручка за IV квартал составила $35,6 млрд, увеличившись на 93 % в годовом исчислении и опередив прогноз Уолл-стрит в $33,65 млрд. За год выручка этого сегмента увеличилась на 142 % до $115,2 млрд. Как отметил ресурс SiliconANGLE, на данный сегмент пришлось 91 % от общего дохода компании за IV квартал, по сравнению с 83 % год назад и всего 60 % в аналогичном квартале 2023 финансового года. Доход компании от продуктов для ЦОД вырос за последние два года почти в десять раз. Вместе с тем выручка от продаж сетевого оборудование упала за квартал на 9 % до $3 млрд, но компания наверняка увеличит продажи, т.к. решениями Spectrum-X буду оснащатсья первые ЦОД ИИ-мегапроекта Stargate. 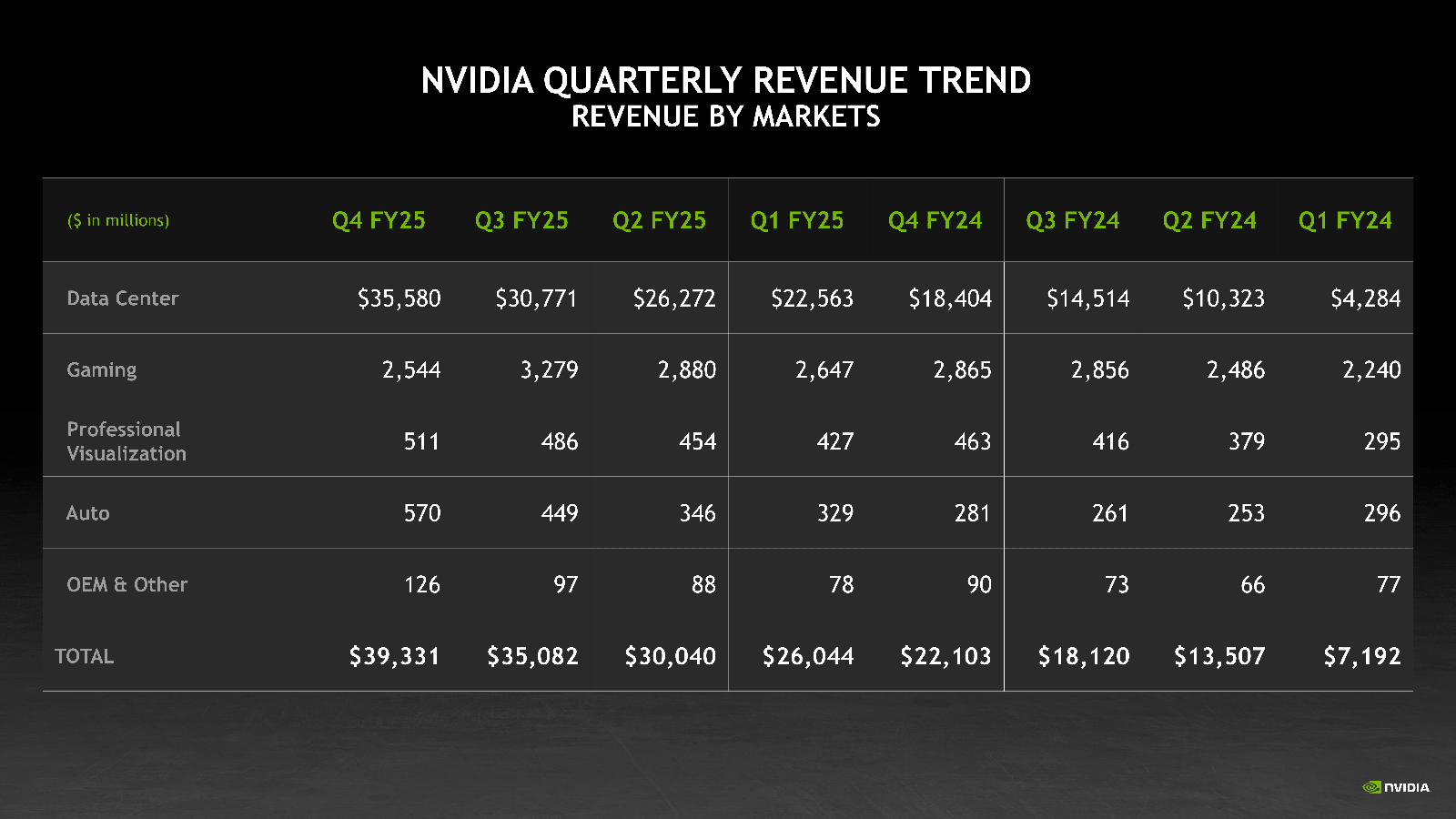 NVIDIA сообщила, что доход от продаж чипов с архитектурой Blackwell составил за квартал $11 млрд, что является «самым быстрым ростом продукта» в её истории. «Спрос на Blackwell потрясающий», — цитирует Bloomberg заявление гендиректора NVIDIA Дженсена Хуанга (Jensen Huang). Финансовый директор NVIDIA Колетт Кресс (Colette Kress) сообщила, что чипы Blackwell были лидерами по продажам для дата-центров и принесли порядка 50 % всего дохода сегмента ЦОД. В ходе телефонной конференции Хуанг сообщил, что предыдущие поколения чипов компании в основном использовались для обучения моделей ИИ, а новые чипы Blackwell в основном применяются для инференса. Некоторые инвесторы высказывали опасения, что спрос на самые мощные чипы NVIDIA может упасть из-за прогресса китайской DeepSeek, чья недорогая модель со способностью к рассуждениям DeepSeek R1 произвела фурор в отрасли, хотя на её разработку якобы ушло всего несколько миллионов долларов.  В ответ на это Кресс сообщила, что новые модели, разработанные для более тщательного «обдумывания» своих ответов, вероятно, потребуют гораздо больше вычислительной мощности по сравнению с более ранними моделями генеративного ИИ. «Для продолжительно думающего, рассуждающего ИИ может потребоваться в 100 раз больше вычислений на задачу по сравнению с однократными инференсами», — сказала она. Хуанг поддержал её, заявив, что «подавляющее большинство вычислений сегодня на самом деле относится к инференсу». Он выразил мнение, что в ближайшие годы ИИ-модели нового поколения могут потребовать «в миллионы раз» больше вычислительных мощностей, чем доступно сейчас. Опасения инвесторов также вызывает то, что AWS, Google и Microsoft, разрабатывающие собственные, кастомизированные ускорители, могут создать сильную конкуренцию NVIDIA. В ответ Хуанг заявил, что этим конкурентам ещё предстоит пройти долгий путь, и то, что чип разработан вовсе не означает, что он будет выпускаться.  Что касается результатов остальных подразделений компании, то игровой бизнес компании, включающий графические процессоры для 3D-игр, принёс ей $2,5 млрд, что меньше год к году на 11 %, а также меньше прогноза StreetAccount в размере $3,04 млрд. В сегменте профессиональной визуализации продажи за квартал составили $511 млн, что на 10 % больше год к году. За весь год выручка подразделения увеличилась на 21 % до $1,9 млрд. В автомобильном секторе выручка компании за отчётный квартал увеличилась в годовом исчислении на 103 % до $570 млн. За год выручка составила $1,7 млрд (рост — 55 %). Прогноз NVIDIA на I квартал 2026 финансового года по выручке равен $43 млрд ± 2 %, против $41,78 млрд, ожидаемых по оценкам LSEG. Это означает рост примерно на 65 % год к году, что является замедлением темпов роста компании по сравнению с ростом на 262 % за тот же период годом ранее. Компания также предупредила, что валовая прибыль будет меньше, чем ожидалось, поскольку она спешит выпустить новый дизайн чипа с архитектурой Blackwell. И также есть риск, что введение пошлин на импорт Соединёнными Штатами повлияет на результаты её работы. Акции NVIDIA выросли чуть более чем на 1 % в ходе расширенных торгов, что добавилось к росту более чем на 3 % в ходе обычной торговой сессии, отметил Bloomberg.
08.01.2025 [22:50], Владимир Мироненко
NVIDIA и партнёры запустили полномасштабное производство серверов на базе BlackwellNVIDIA и её партнёры запустили полномасштабное производство систем с ускорителями Blackwell, заявил глава компании Дженсен Хуанг (Jensen Huang): «Каждый поставщик облачных услуг теперь имеет работающие системы». Первой компанией, которая начала поставки серверов на базе Blackwell, стала Dell. Отдельные провайдеры облачных услуг ещё в середине ноября прошлого года стали обладателями её платформ, передаёт Tom's Hardware. На данный момент, по словам NVIDIA, круг поставщиков заметно расширился. Их предложения включают системы на базе Blackwell в более чем 200 различных конфигурациях. «Есть системы от примерно 15 производителей с 200 различными наименованиями в 200 различных конфигурациях, — сказал Хуанг. — Есть с жидкостным охлаждением, воздушным охлаждением, с чипами x86, с NVIDIA Grace, NVL36×2, NVL72. Целый ряд различных типов систем, которые подойдут практически к любому ЦОД в мире». 
Источник изображения: NVIDIA Он отметил, что такие системы производятся на 45 заводах, что говорит о том, насколько активно отрасль переходит на выпуск систем с ИИ. Blackwell от Nvidia значительно увеличивают производительность вычислений для приложений ИИ и HPC по сравнению с чипами поколения Hopper, но при этом потребляют значительно больше энергии, что предъявляет повышенные требования к мощности ЦОД и его системам охлаждения. Если стойка на базе Hopper потребляет 40 кВт, то суперускоритель GB200 NVL72 потребляет порядка 120 кВт или даже больше.
07.01.2025 [16:10], Владимир Мироненко
NVIDIA представила «персональный ИИ-суперкомпьютер» Project DIGITS на базе гибридного ускорителя GB10Компания NVIDIA представила «персональный ИИ-суперкомпьютер» Project DIGITS — это самая компактная аппаратная платформа на базе суперчипов Grace Blackwell. Разработанная для исследователей ИИ, специалистов по данным и студентов система поставляется с полным набором ПО для создания, тюнинга и инференса ИИ-моделей. Это позволяет локально создавать и дорабатывать модели, а затем разворачивать их в облаке или ЦОД. Project DIGITS будет доступен в мае по цене от $3000. Project DIGITS оснащён чипом GB10 с FP4-производительностью до 1 Пфлопс, разработанным в партнёрстве с MediaTek. GB10 включает ускоритель Blackwell, подключённый посредством NVLink-C2C к 20-ядерному Arm-процессору Grace, 128 Гбайт унифицированной когерентной памяти LPDDR5x и 4-Тбайт NVMe SSD. В оснащение также входит адаптеры Wi-Fi, Bluetooth и Ethernet (RJ45). На задней стенке есть видеовыход HDMI и четыре разъёма USB-C. По словам компании, Project DIGITS позволит запускать модели размером до 200 млрд параметров, а при объединении двух таких систем посредством NIC ConnectX (два порта SFP28) возможен запуск моделей с 405 млрд параметров. 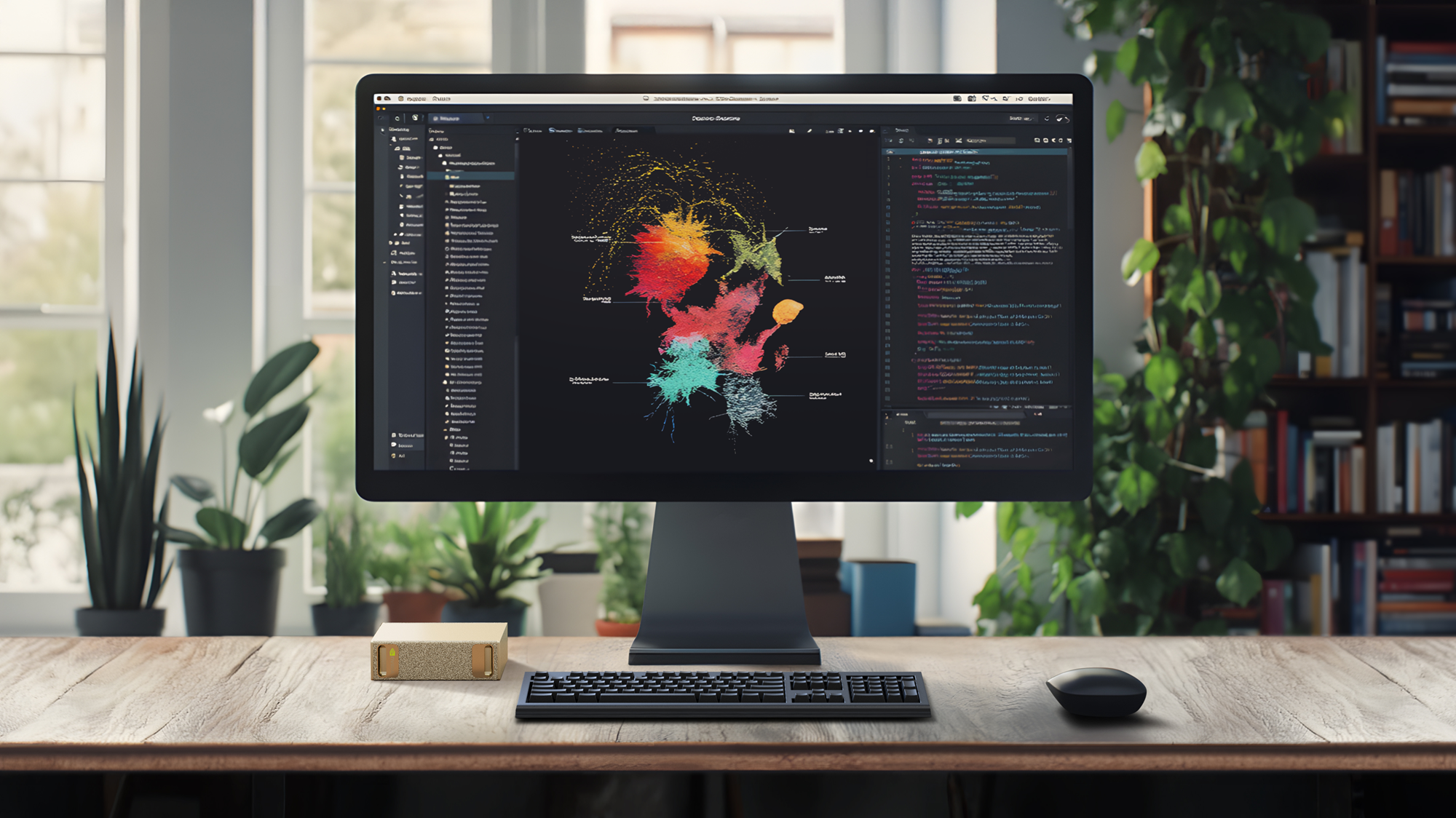
Источник изображений: NVIDIA Работает новинка под управлением NVIDIA DGX OS — специализированной сборки Ubuntu Linux, оптимизированной для работы с ИИ-нагрузками. Пользователи Project DIGITS получат доступ к обширной библиотеке ПО NVIDIA AI, включая комплекты для разработки ПО, инструменты оркестрации, фреймворки и модели, доступные в каталоге NVIDIA NGC и на портале NVIDIA Developer. Разработчики смогут настраивать модели с помощью фреймворка NVIDIA NeMo, использовать в работе с данными библиотеки NVIDIA RAPIDS и задействовать популярные программные платформы, включая PyTorch, Python и Jupyter notebooks. 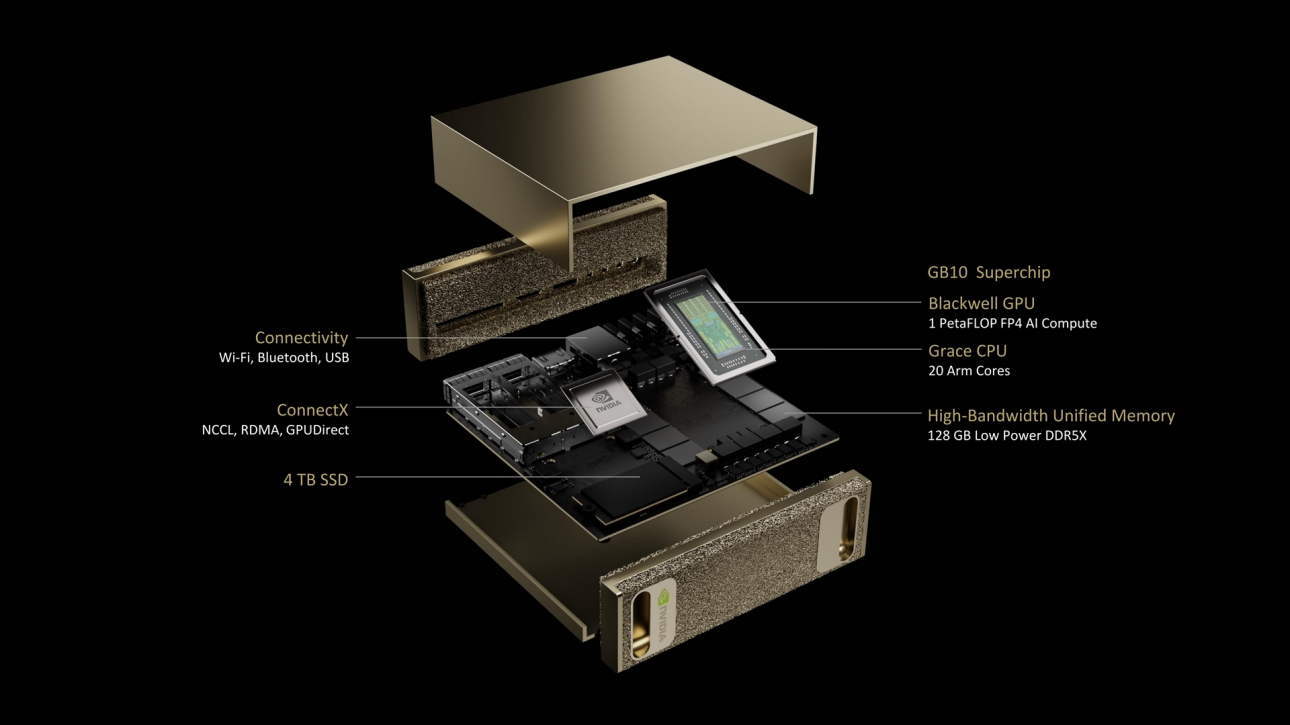 Для создания агентских приложений AI можно будет использовать NVIDIA Blueprints и микросервисы NVIDIA NIM, доступные для исследований, разработки и тестирования в рамках программы NVIDIA Developer Program. Благодаря единой архитектуре Grace Blackwell предприятия и индивидуальные исследователи смогут прототипировать, настраивать и тестировать ИИ-модели на локальных системах Project DIGITS с последующим развёртыванием в NVIDIA DGX Cloud, облачных инстансах или собственной инфраструктуре ЦОД.
29.12.2024 [17:40], Владимир Мироненко
Конструктор вместо монолита: NVIDIA дала больше свободы в кастомизации GB300 NVL72Для новых суперускорителей (G)B300 компания NVIDIA существенно поменяла цепочку поставок, сделав её более дружелюбной к гиперскейлерам, то есть основным заказчиком новинок, передаёт SemiAnalysis. В случае GB200 компания поставляла готовые, полностью интегрированные платы Bianca, включающие ускорители Blackwell, CPU Grace, 512 Гбайт напаянной LPDDR5X, VRM и т.д. GB300 будут поставляться в виде модулей (дизайн Cordelia): SXM Puck B300, CPU Grace в корпусе BGA, HMC от Axiado (вместо Aspeed). А в качестве системной RAM будут применяться модули LPCAMM, преимущественно от Micron. Переход на SXM Puck даст возможность создавать новые системы большему количеству OEM- и ODM-поставщиков, а также самим гиперскейлерам. Если раньше только Wistron и Foxconn могли производить платы Bianca, то теперь к процессу сборки ускорителей могут подключиться другие. Wistron больше всех потеряет от этого решения, поскольку лишится доли рынка производителей Bianca. Для Foxconn же, которая благодаря NVIDIA вот-вот станет крупнейшим в мире поставщиком серверов, потеря компенсируется эксклюзивным производством SXM Puck. 
Источник изображений: NVIDIA Еще одно важное изменение касается VRM. Хотя на SXM Puck есть некоторые компоненты VRM, большая часть остальных комплектующих будет закупаться гиперскейлерами и вендорами напрямую у поставщиков VRM. Стоечные NVSwitch-коммутаторы и медный backplane по-прежнему будут поставляться самой NVIDIA. Для GB300 компания предлагает 800G-платформу InfiniBand/Ethernet Quantum-X800/Spectrum-X800 с адаптерами ConnectX-8, которые не попали GB200 из-за нестыковок в сроках запуска продуктов. Кроме того, у ConnectX-8 сразу 48 линий PCIe 6.0, что позволяет создавать уникальные архитектуры, такие как MGX B300A с воздушным охлаждением.  Сообщается, что все ключевые гиперскейлеры уже приняли решение перейти на GB300. Частично это связано с более высокой производительностью и экономичностью GB300, но также вызвано и тем, что теперь они сами могут кастомизировать платформу, систему охлаждения и т.д. Например, Amazon сможет, наконец, использовать собственную материнскую плату с водяным охлаждением и вернуться к архитектуре NVL72, улучшив TCO. Ранее компания единственная из крупных игроков выбрала менее эффективный вариант NVL36 из-за использования собственных 200G-адаптеров и PCIe-коммутаторов с воздушным охлаждением. Впрочем, есть и недостаток — гиперскейлерам придётся потратить больше времени и ресурсов на проектирование и тестирование продукта. Это, пожалуй, самая сложная платформа, которую когда-либо приходилось проектировать гиперскейлерам (за исключением платформ Google TPU), отметил ресурс SemiAnalysis.
28.12.2024 [01:55], Владимир Мироненко
Дороже, но втрое эффективнее: NVIDIA готовит ускорители GB300 с 288 Гбайт HBM3E и TDP 1,4 кВтNVIDIA выпустила новые ускорители GB300 и B300 всего через шесть месяцев после выхода GB200 и B200. И это не минорное обновление, как может показаться на первый взгляд — появление (G)B300 приведёт к серьёзной трансформации отрасли, особенно с учётом значительных улучшений в инференсе «размышляющих» моделей и обучении, пишет SemiAnalysis. При этом с переходом на B300 вся цепочка поставок меняется, и от этого кто-то выиграет, а кто-то проиграет. Конструкция вычислительного кристалла B300 (ранее известного как Blackwell Ultra), изготавливаемого с использованием кастомного техпроцесса TSMC 4NP. Благодаря этому он обеспечивает на 50 % больше Флопс (FP4) по сравнению с B200 на уровне продукта в целом. Часть прироста производительности будет получена за счёт увеличения TDP, достигающим 1,4 кВт и 1,2 кВт для GB300 и B300 HGX соответственно (по сравнению с 1,2 кВт и 1 кВт для GB200 и B200). Остальное повышение производительности связано с архитектурными улучшениями и оптимизациями на уровне системы, такими как динамическое распределение мощности между CPU и GPU. Кроме того, в B300 применяется память HBM3E 12-Hi, а не 8-Hi, ёмкость которой выросла до 288 Гбайт. Однако скорость на контакт осталась прежней, так что суммарная пропускная способность памяти (ПСП) по-прежнему составляет 8 Тбайт/с. В качестве системной памяти будут применяться модули LPCAMM. Разница в производительности и экономичности из-за увеличения объёма HBM намного больше, чем кажется. Усовершенствования памяти имеют решающее значение для обучения и инференса больших языковых моделей (LLM) в стиле OpenAI O3, поскольку более длинные последовательности токенов негативно влияют на скорость обработки и задержку. 
Источник изображения: NVIDIA На примере обновления H100 до H200 хорошо видно, как память влияет на производительность ускорителя. Более высокая ПСП (H200 — 4,8 Тбайт/с, H100 — 3,35 Тбайт/с) в целом улучшила интерактивность в инференсе на 43 %. А большая ёмкость памяти снизила объём перемещаемых данных и увеличила допустимый размер KVCache, что увеличило количество генерируемых токенов в секунду втрое. Это положительно сказывается на пользовательском опыте, что особенно важно для всё более сложных и «умных» моделей, которые могут приносить больше дохода с каждого ускорителя. Валовая прибыль от использования передовых моделей превышает 70 %, тогда как для отстающих моделей в конкурентной open source среде она составляет менее 20 %. 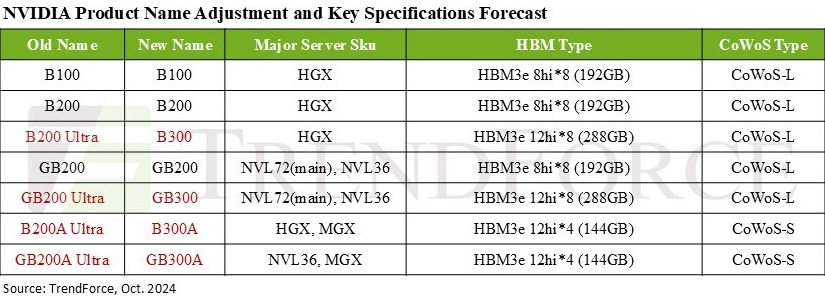
Источник изображения: TrendForce Однако одного наращивания скорости и памяти, как это делает AMD в Instinct MI300X (192 Гбайт), MI325X и MI355X (256 Гбайт и 288 Гбайт соответственно), мало. И дело не в том, что забагованное ПО компании не позволяет раскрыть потенциал ускорителей, а в особенности общения ускорителей между собой. Только NVIDIA может предложить коммутируемое соединение «все ко всем» посредством NVLink. В GB200 NVL72 все 72 ускорителя могут совместно работать над одной и той же задачей, что повышает интерактивность, снижая задержку для каждой цепочки размышлений и в то же время увеличивая их максимальную длину. На практике NVL72 — единственный способ увеличить длину инференса до более чем 100 тыс. токенов и при этом экономически эффективный, говорит SemiAnalysis. По оценкам, GB300 NVL72 обойдётся заказчиками минимум в $7,5 млн, тогда как GB200 NVL72 стоил порядка $3 млн.
18.11.2024 [21:30], Сергей Карасёв
Счетверённые H200 NVL и 5,5-кВт GB200 NVL4: NVIDIA представила новые ИИ-ускорителиКомпания NVIDIA анонсировала ускоритель H200 NVL, выполненный в виде двухслотовой карты расширения PCIe. Изделие, как утверждается, ориентировано на гибко конфигурируемые корпоративные системы с воздушным охлаждением для задач ИИ и НРС. Как и SXM-вариант NVIDIA H200, представленный ускоритель получил 141 Гбайт памяти HBM3e с пропускной способностью 4,8 Тбайт/с. При этом максимальный показатель TDP снижен с 700 до 600 Вт. Четыре карты могут быть объединены интерконнкетом NVIDIA NVLink с пропускной способностью до 900 Гбайт/с в расчёте на GPU. При этом к хост-системе ускорители подключаются посредством PCIe 5.0 x16. В один сервер можно установить две такие связки, что в сумме даст восемь ускорителей H200 NVL и 1126 Гбайт памяти HBM3e, что весьма существенно для рабочих нагрузок инференса. Заявленная производительность FP8 у карты H200 NVL достигает 3,34 Пфлопс против примерно 4 Пфлопс у SXM-версии. Быстродействие FP32 и FP64 равно соответственно 60 и 30 Тфлопс. Производительность INT8 — до 3,34 Пфлопс. Вместе с картами в комплект входит лицензия на программную платформа NVIDIA AI Enterprise. 
Источник изображения: NVIDIA Кроме того, NVIDIA анонсировала ускорители GB200 NVL4 с жидкостным охлаждением. Они включает два суперчипа Grace-Backwell, что даёт два 72-ядерных процессора Grace и четыре ускорителя B100. Объём памяти LPDDR5X ECC составляет 960 Гбайт, памяти HBM3e — 768 Гбайт. Задействован интерконнект NVlink-C2C с пропускной способностью до 900 Гбайт/с, при этом всем шесть чипов CPU-GPU находятся в одном домене. 
Источник изображения: NVIDIA Система GB200 NVL4 наделена двумя коннекторами M.2 22110/2280 для SSD с интерфейсом PCIe 5.0, восемью слотами для NVMe-накопителей E1.S (PCIe 5.0), шестью интерфейсами для карт FHFL PCIe 5.0 x16, портом USB, сетевым разъёмом RJ45 (IPMI) и интерфейсом Mini-DisplayPort. Устройство выполнено в форм-факторе 2U с размерами 440 × 88 × 900 мм, а его масса составляет 45 кг. TDP настраиваемый — от 2,75 кВт до 5,5 кВт.
23.10.2024 [16:57], Владимир Мироненко
NVIDIA переименовала будущие ИИ-ускорители Blackwell Ultra в B300Согласно данным аналитической компании TrendForce, NVIDIA решила переименовать продукты семейства Blackwell Ultra в серию B300. В связи с этим ускоритель B200 Ultra стал B300, а GB200 Ultra теперь называется GB300. Кроме того, B200A Ultra и GB200A Ultra получили имена B300A и GB300A соответственно. Серия ускорителей B300, как ожидается, выйдет в I–II квартале 2025 года, а поставки (G)B200 начнутся не позднее I квартал 2025 года. TrendForce отметила, что NVIDIA совершенствует сегментацию чипов Blackwell, чтобы лучше соответствовать требованиям по стоимости и производительности со стороны облачных провайдеров (CSP) и OEM-производителей серверов и смягчить требования к цепочкам поставок. Так, модель B300A нацелена на OEM-клиентов, её массовое производство планируется начать во II квартале 2025 года после пика поставок H200. Изначально NVIDIA хотела предложить данному сегменту упрощённый вариант B200A, но, судя по всему, спрос на него оказался более слабом, чем ожидалось. Вместе с тем переход с GB200A на GB300A для стоечных решений может привести к увеличению первоначальных затрат для корпоративных клиентов, что также может отразиться на спросе. 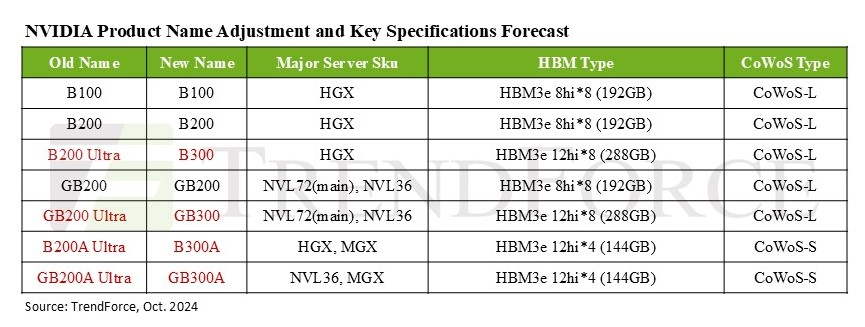
Источник изображения: TrendForce Сейчас компания вкладывает значительные средства в улучшение стоечных решений NVL, помогая поставщикам серверных систем с оптимизацией производительности и жидкостным охлаждением для систем NVL72, а AWS и Meta✴ настоятельно призывают перейти с NVL36 на NVL72. TrendForce также ожидает, что предложение топовых ускорителей NVIDIA будет расширяться, а их общая доля в поставках, как ожидается, достигнет около 50 % в 2024 году, то есть вырастет на 20 п.п. год к году. Ожидается, что выпуск ускорителей Blackwell увеличит этот показатель до 65 % в 2025 году. Аналитики также отметили роль NVIDIA в стимулировании спроса на технологию упаковки CoWoS. Благодаря Blackwell спрос на данный тип упаковки вырастет более чем на 10 п.п. в годовом исчислении. NVIDIA, скорее всего, сосредоточится на поставках чипов B300 и GB300 крупным североамериканским гиперскейлерам — оба варианта используют технологию CoWoS-L. Компания активно наращивает закупки HBM — согласно прогнозам, в 2025 году на NVIDIA придётся более 70 % мирового рынка HBM (рост на 10 п.п. год к году). TrendForce также отмечает, что все чипы серии B300 будут оснащены памятью HBM3e 12Hi, производство которой начнётся не позднее I квартал 2025 года. Но поскольку это будут первые массовые продукты с таким типом памяти, поставщикам, как ожидается, потребуется не менее двух кварталов для отработки процессов и стабилизации объёмов производства. |
|

