Материалы по тегу: sc24
|
05.12.2024 [16:14], Сергей Карасёв
Запущен британский Arm-суперкомпьютер Isambard 3 с суперчипами NVIDIA GraceВ Великобритании введён в эксплуатацию суперкомпьютер Isambard 3, предназначенный для ресурсоёмких приложений ИИ и задач НРС. Реализация проекта обошлась приблизительно в £10 млн, или примерно $12,7 млн. Машина пришла на смену комплексу Isambard 2, который отправился на покой в сентябре нынешнего года. Система Isambard 3 создана в рамках сотрудничества между исследовательским консорциумом GW4 Alliance, в который входят университеты Бата, Бристоля, Кардиффа и Эксетера, а также компаниями HPE, NVIDIA и Arm. Суперкомпьютер назван в честь британского инженера Изамбарда Кингдома Брюнеля, внесшего значимый вклад в Промышленную революцию. Полностью технические характеристики Isambard 3 не раскрываются. Известно, что в основу машины положены 384 суперпроцессорами NVIDIA Grace со 144 ядрами (2 × 72) Arm Neoverse V2 (Demeter), общее количество которых превышает 55 тыс. Задействована высокопроизводительная СХД HPE, которая обеспечивает расширенные IO-возможности с интеллектуальным распределением данных по нескольким уровням. Благодаря этому достигается эффективная обработка задач с интенсивным использованием информации, таких как обучение моделей ИИ. Известно также, что в составе комплекса применяется фирменный интерконнект HPE Slingshot, а в качестве внутреннего интерконнекта служит технология NVLink-C2C, которая в семь раз быстрее PCIe 5.0. Каждый узел суперкомпьютера содержит один суперчип Grace и сетевой адаптер Cassini с пропускной способностью до 200 Гбит/с. Объём системной памяти составляет 2 × 120 Гбайт (240 Гбайт). 
Источник изображения: GW4 Отмечается, что Isambard 3 демонстрирует в шесть раз более высокую производительность и в шесть раз лучшую энергоэффективность по сравнению с Isambard 2. Пиковое быстродействие FP64 у Isambard 3 достигает 2,7 Пфлопс при энергопотреблении менее 270 кВт. Применять новый суперкомпьютер планируется для таких задач, как проектирование оптимальной конфигурации ветряных электростанций на суше и воде, моделирование термоядерных реакторов, исследования в сфере здравоохранения и пр. Суперкомпьютер расположен в автономном дата-центре с системой самоохлаждения HPE Performance Optimized Data Center (POD) в Национальном центре композитов в Научном парке Бристоля и Бата. Там же ведётся монтаж ИИ-комплекса Isambard-AI стоимостью £225 млн ($286 млн), который должен стать самым быстрым и мощным суперкомпьютером в Великобритании. Проект Isambard-AI реализуется в несколько этапов. Первая фаза предполагает монтаж 42 узлов, каждый из которых несёт на борту четыре суперчипа NVIDIA GH200 Grace Hopper и 4 × 120 Гбайт памяти для CPU (доступно 460 Гбайт — по 115 Гбайт на CPU), а также 4 × 96 Гбайт памяти для GPU (H100). В ходе второй фазы будут добавлены 1320 узлов, насчитывающих в сумме 5280 суперчипов NVIDIA GH200 Grace Hopper. Кроме того, в состав Isambard 3 входит экспериментальный x86-модуль MACS (Multi-Architecture Comparison System), включающий сразу восемь разновидностей узлов на базе процессоров AMD EPYC и Intel Xeon нескольких поколений, часть из них также имеет ускорители AMD Instinct MI100 и NVIDIA H100/A100. Все они объединены 200G-интерконнектом HPE Slingshot.
02.12.2024 [11:39], Сергей Карасёв
Один из модулей будущего европейского экзафлопсного суперкомпьютера JUPITER вошёл в двадцатку самых мощных систем мираЮлихский исследовательский центр (FZJ) в Германии объявил о достижении важного рубежа в рамках проекта JUPITER (Joint Undertaking Pioneer for Innovative and Transformative Exascale Research) по созданию европейского экзафлопсного суперкомпьютера. Введён в эксплуатацию JETI — второй модуль этого НРС-комплекса. Напомним, контракт на создание JUPITER заключён между Европейским совместным предприятием по развитию высокопроизводительных вычислений (EuroHPC JU) и консорциумом, в который входят Eviden (подразделение Atos) и ParTec. Суперкомпьютер JUPITER создаётся на базе модульного дата-центра, за строительство которого отвечает Eviden. Система JUPITER получит, в частности, энергоэффективные высокопроизводительные Arm-процессоры SiPearl Rhea1 с HBM. Кроме того, в состав машины входят узлы с NVIDIA Quad GH200, а общее количество суперчипов GH200 Grace Hopper составит почти 24 тыс. Узлы объединены интерконнектом NVIDIA Mellanox InfiniBand. Запущенный модуль JETI (JUPITER Exascale Transition Instrument) обладает FP64-производительностью 83,14 Пфлопс, тогда как пиковый теоретический показатель достигает 95 Пфлопс. С такими результатами эта машина попала на 18-ю строку нынешнего рейтинга мощнейших суперкомпьютеров мира TOP500. В составе JETI задействованы в общей сложности 391 680 ядер. Энергопотребление модуля равно 1,31 МВт. Отмечается, что JETI обеспечивает примерно одну двенадцатую от общей расчётной производительности машины JUPITER. Попутно JETI занял шестое место в рейтинге энергоэффективных систем Green500. 
Источник изображения: Eviden Ожидается, что после завершения строительства суммарное быстродействие JUPITER на операциях обучения ИИ составит до 93 Эфлопс, а FP64-производительность превысит 1 Эфлопс. Затраты на создание комплекса оцениваются в €273 млн, включая доставку, установку и обслуживание НРС-системы.
27.11.2024 [11:48], Сергей Карасёв
El Dorado, младший брат самого мощного в мире суперкомпьютера El Capitan, вошёл в двадцатку TOP500Сандийские национальные лаборатории (SNL) Министерства энергетики США (DOE) объявили о том, что новый НРС-комплекс El Dorado занял 20-е место в свежем рейтинге самых мощных суперкомпьютеров мира TOP500, обнародованном на конференции SC24. На вершине ноябрьского списка TOP500 находится машина El Capitan, построенная специалистами HPE Cray. Эта система демонстрирует FP64-быстродействие на уровне 1,742 Эфлопс в тесте Linpack (HPL), а пиковый теоретический показатель достигает 2,746 Эфлопс. Основой El Capitan служит платформа HPE Cray Shasta на базе AMD Instinct MI300A. Отмечается, что комплекс El Dorado, по сути, приходится младшим братом El Capitan. Машина El Dorado меньше по масштабу, но архитектурно идентична лидеру рейтинга TOP500. Система построена компанией HPE на платформе Cray EX4000: в общей сложности задействованы 384 узла на основе Instinct MI300A. Суммарное количество ядер составляет 383 040. Используется интерконнект HPE Slingshot-11. Вычислительные узлы используют прямое жидкостное охлаждение. 
Источник изображения: SNL Производительность El Dorado достигает 68,02 Пфлопс, а теоретическое пиковое быстродействие находится на отметке 95,29 Пфлопс. Суперкомпьютер фактически представляет собой мощную тестовую площадку для создания, тестирования и подготовки программного кода перед запуском на машине экзафлопсного класса El Capitan. Кроме того, El Dorado позволит осуществлять определённые научно-исследовательские и опытно-конструкторские работы.
25.11.2024 [11:40], Владимир Мироненко
Hyperion Research: рынок HPC куда больше, чем считается, и растёт он куда быстрееАналитики The Next Platform считают, что обучение и инференс ИИ в ЦОД также относятся к высокопроизводительным вычислениям (HPC), хотя в некоторых случаях могут значительно отличаться от их традиционного определения. HPC используют небольшой набор данных, расширяя его до огромных симуляций, таких как прогнозы погоды или климата, в то время как ИИ анализирует массу данных о мире и преобразует их в модель, в которую можно добавлять новые данные для ответа на вопросы, сообщается на ресурсе The Next Platform. HPC и ИИ имеют разные потребности в вычислительных ресурсах, памяти и пропускной способности на разных этапах обработки приложений. Но в конечном итоге как при HPC, так и при обучении ИИ компании стремятся объединить множество узлов в единую систему для выполнения больших объёмов работы, которые невозможно выполнить иначе. 
Источник изображений: Hyperion Research Для получения «реальных» данных о рынке HPC необходимо добавить к расходам на традиционные платформы ModSim (моделирование и симуляция) средства, потраченные на применение технологий генеративного ИИ, традиционное обучение и инференс ИИ в ЦОД. Исходя из этого, Hyperion Research значительно пересмотрела оценку рынка, учтя продажи серверов ИИ, которые ранее не включались в расчёты, в том числе решения компаний NVIDIA, Supermicro и других.  В обновлённом прогнозе рынка HPC, представленном Hyperion Research в минувший вторник, расходы на серверы значительно выросли благодаря добавлению «нетрадиционных поставщиков». В 2021 году было продано серверов в объединённом секторе HPC/ИИ на $1,34 млрд, в 2022 году расходы на их покупку составили $3,44 млрд, а в 2023 году, благодаря буму на генеративный ИИ, они подскочили до $5,78 млрд. Hyperion Research ожидает, что эти производители заработают на серверах $7,46 млрд в 2024 году, и их доходы почти удвоятся к 2028 году, достигнув $14,97 млрд.  Историческая часть рынка серверов HPC/ИИ (согласно прежней методике), показанная синим цветом на диаграмме, как ожидается, составит $17,93 млрд в этом году и вырастет до $26,81 млрд к 2028 году. Объединённый рынок HPC/ИИ с учётом нового подхода составит в этом году $25,39 млрд и будет расти ежегодно на 15 %, достигнув $41,78 млрд к 2028 году.  Как отметили в Hyperion Research, теперь не все расходы на вычисления HPC и ИИ осуществляются локально (on-premise). Большая часть ИТ-бюджета на рабочие нагрузки HPC и ИИ переносится в облако.  Hyperion подсчитала, что приложения HPC и ИИ, работающие в облаке, в совокупности «потребили» $7,18 млрд виртуальных серверных мощностей в 2023 году и что эти цифры вырастут на 21,2 % до $8,71 млрд в 2024 году. К 2028 году расходы на вычислительные мощности HPC и ИИ в облаке составят $15,11 млрд, а совокупные годовые темпы роста с 2023 по 2028 год составят 16,1 %.  Помимо затрат на вычисления, бюджет HPC и ИИ включает расходы на хранение, ПО и сервисы. Hyperion ожидает, что в 2024 году общие расходы на HPC и ИИ вырастут на 22,4 %, с $42,4 млрд до $51,9 млрд. При совокупном годовом темпе роста в 15 % в период с 2023 по 2028 год все затраты на HPC и ИИ составят к 2028 году $85,5 млрд, что в два раза превышает показатель нынешнего года.  Согласно данным Hyperion, в 2021 году в Китае было установлено две экзафлопсные системы стоимостью $350 млн каждая. Также по одной системе с такой же стоимостью было установлено в 2023 году и нынешнем году. Hyperion ожидает, что в 2025 году Китай установит ещё одну или две экзафлопсные системы с оценочной стоимостью $300 млн за штуку и ещё две с такой же стоимостью в 2026 году. Общая стоимость девяти экзафлопсных систем составит около $2,95 млрд — примерно столько стартап xAI, курируемый Илоном Маском (Elon Musk), израсходовал на создание кластера Colossus из 100 000 ускорителей NVIDIA H100. В Японии до сих пор нет суперкомпьютера эксафлопсного класса (речь об FP64-производительности), и она получит свой первый такой суперкомпьютер стоимостью $200 млн в 2026 году. В 2027 и 2028 годах, как ожидает Hyperion, Япония построит две или три такие суперкомпьютерные системы стоимостью около $150 млн за единицу, потратив в общей сложности $300–450 млн. В Европе есть несколько преэкзафлопсных систем, и в 2025 году она получит две экзафлопсные системы по оценочной стоимости $350 млн каждая, а в 2026 году здесь появится ещё две или три системы стоимостью около $325 млн. Также следует ожидать строительство двух или трёх машин в 2027 году стоимостью $300 млн каждая и двух или трёх в 2028 году стоимостью $275 млн каждая. То есть в предстоящие несколько лет в Европе будет построено одиннадцать экзафлопсных суперкомпьютеров общей стоимостью $3,4 млрд. 
Источник изображения: LLNL В США установили одну экзафлопсную систему в 2022 году (Frontier в Ок-Риджской национальной лаборатории, ORNL) и две — в 2024 году (Aurora в Аргоннской национальной лаборатории и El Capitan в Ливерморской национальной лаборатории им. Э. Лоуренса). По оценкам The Next Platform, за последние годы Соединённые Штаты потратили $1,4 млрд на установку трёх экзафлопсных машин. Согласно прогнозу Hyperion Research, в Соединённых Штатах в 2025 году установят две экзафлопсные системы стоимостью около $600 млн каждая, в 2026 году — одну или две стоимостью $325 млн каждая и одну или две стоимостью $275 млн каждая в 2027 и 2028 годах. В общей сложности будет потрачено $4,35 млрд на одиннадцать экзафлопсных систем.
24.11.2024 [09:54], Сергей Карасёв
AIC и ScaleFlux представили JBOF-массив на основе NVIDIA BlueField-3Компании AIC и ScaleFlux анонсировали систему F2026 Inference AI для ресурсоёмких приложений ИИ с интенсивным использованием данных. Решение выполнено в форм-факторе 2U. В оснащение входят два DPU NVIDIA BlueField-3, которые могут работать на скорости до 400 Гбит/с. Эти изделия способны ускорять различные сетевые функции, а также операции, связанные с передачей и обработкой больших массивов информации. Во фронтальной части F2026 Inference AI расположены 26 отсеков для высокопроизводительных вычислительных SSD семейства ScaleFlux CSD5000 (U.2). Накопители с интерфейсом PCIe 5.0 (NVMe 2.0b) имеют вместимость 3,84, 7,68, 15,36, 30,72, 61,44 и 122,88 Тбайт, а с учётом компрессии эффективная ёмкость может достигать приблизительно 256 Тбайт. Реализована поддержка TCG Opal 2.02 и шифрования AES-256, NVMe Thin Provisioned Namespaces Virtualization (48PF/32VF), ZNS, FDP. Платформа F2026 Inference AI представляет собой JBOF-массив, способный на сегодняшний день хранить 1,6 Пбайт информации (эффективный объём). В следующем году показатель будет доведён до 6,6 Пбайт. Утверждается, что сочетание BlueField-3 и энергоэффективной технологии хранения ScaleFlux помогает минимизировать энергопотребление, а также повысить долговечность и надёжность. Результаты проведённого тестирования F2026 Inference AI демонстрируют пропускную способность при чтении до 59,49 Гбайт/с, при записи — более 74,52 Гбайт/с. Благодаря объединению средств хранения, сетевых функций и инструментов безопасности в одну систему достигается снижение эксплуатационных расходов, что позволяет оптимизировать совокупную стоимость владения (TCO). 
Источник изображения: AIC Новинка является лишь одной из вариаций решений на базе F2026. Платформа, в частности, поддерживает работу других DPU, включая Kalray 200 и Chelsio T7. Также упоминается вариант шасси на 32 накопителя EDSFF E3.S/E3.L.
21.11.2024 [12:23], Руслан Авдеев
Суперкомпьютеры Eviden заняли первые места в рейтинге энергоэффективных систем Green500Входящая в группу Atos компания Eviden объявила, что 55 её суперкомпьютеров вошли в список TOP500 наиболее производительных вычислительных машин, а два из них лидируют в рейтинге наиболее энергоэффективных суперкомпьютеров мира Green500. За последние 10 лет экспоненциально выросла вычислительная мощность, что в том числе обусловлено достижениями в области систем искусственного интеллекта. При этом растёт и энергопотребление — его снижение стало одной из главных задач при разработке и строительстве суперкомпьютеров. В первую десятку рейтинга Green500 вошли три машины Eviden, в каждой из которых применяется проприетарная технология прямого жидкостного охлаждения, предусматривающая охлаждение суперкомпьютера тёплой водой с температурой до +40 °C, это помогает добиться отвода более 97 % тепла. 
Источник изображения: Eviden Первое место в рейтинге занимает модуль JEDI суперкомпьютера JUPITER — первой системы экзафлопсного класса в Европе, созданный EuroHPC. На втором месте — ROMEO 2025, построенный для Университета Реймса Шампань-Арденн (URCA). Шестое место в Green500 занимает ещё один модуль суперкомпьютера JUPITER — JETI. Другими словами, Eviden стремится предлагать клиентам не только высокопроизводительные, но и экоустойчивые, экономичные машины. В TOP500 наиболее производительных суперкомпьютеров из построенных компанией вошли французская система Jean Zay (№ 27), новейший немецкий модуль JETI для JUPITER (№ 18) и система Gefion для Датского центра инноваций в области искусственного интеллекта (DCAI) под номером 21. По словам представителя Eviden, системы компании лидируют в рейтинге Green500 и «укрепляют лидерство Европы» на рынке HPC. Eviden, на которую работает 41 тыс. человек, предлагает решения в области ИИ, облачных платформ и предоставляет услуги более чем в 47 странах. Годовая выручка этого подразделения Atos Group составляет около €5 млрд. Сама же Atos находится не в лучшем состоянии.
21.11.2024 [10:09], Сергей Карасёв
Lenovo представила сервер ThinkSystem SC750 V4 Neptune на базе Intel Xeon Granite Rapids с СЖОКомпания Lenovo анонсировала сервер ThinkSystem SC750 V4 Neptune, предназначенный для технических вычислений и обработки данных в различных областях, таких как аналитика, научные исследования, энергетика, проектирование и финансовое моделирование. Система ThinkSystem SC750 V4 Neptune объединяет два узла, которые заключены в 19″ корпус с возможностью вертикального монтажа. Каждый узел может нести на борту два процессора Intel Xeon 6900 поколения Granite Rapids (до 128 ядер) с показателем TDP до 500 Вт. В расчёте на узел доступны 24 слота для модулей оперативной памяти TruDDR5 RDIMM-6400 или MRDIMM-8800 (в сумме до 3 Тбайт). Каждый узел может комплектоваться шестью накопителями EDSFF E3.S NVMe SSD общей вместимостью до 92,16 Тбайт. Есть два сетевых порта 25GbE SFP28 на основе контроллера Broadcom 57414, один порт 1GbE RJ45 на базе Intel I210, два слота PCIe 5.0 x16. Габариты составляют 546 × 53 × 760 мм, масса — 37,2 кг. Говорится о совместимости с Red Hat Enterprise Linux, SUSE Linux Enterprise Server, Ubuntu и пр. 
Источник изображения: Lenovo Применено прямое жидкостное охлаждение Lenovo Neptune. Утверждается, что по сравнению с аналогичной системой с воздушным охлаждением сервер ThinkSystem SC750 V4 Neptune обеспечивает увеличение общей производительности до 10 % благодаря постоянной работе процессоров в турбо-режиме. При этом энергопотребление ЦОД от серверов может быть уменьшено на 40 %, тогда как шум от вентиляторов устраняется полностью.  Восемь лотков ThinkSystem SC750 V4 Neptune могут быть установлены в шасси ThinkSystem N1380 формата 13U: в сумме это даёт 16 узлов. Шасси может быть оборудовано четырьмя узлами Power Conversion Stations (PCS) с сертификатом 80 PLUS Titanium.
21.11.2024 [09:44], Сергей Карасёв
Maxwell Labs представила технологию фотонного охлаждения для ЦОДMaxwell Labs анонсировала программу раннего доступа к первому в мире решению для твердотельного фотонного охлаждения оборудования в дата-центрах. Система под названием MXL-Gen1 призвана удовлетворить растущие потребности в ресурсоёмких нагрузках, связанных с ИИ и HPC. Технология фотонного охлаждения Maxwell Labs преобразует тепло, генерируемое серверными компонентами, в свет. Ожидается, что данное решение произведёт революцию в сфере охлаждения ЦОД на фоне повышения мощности чипов и увеличения плотности размещения оборудования в стойках. В детали относительно архитектуры MXL-Gen1 компания не вдаётся. Отмечается, что в системе применяются лазеры, тогда как побочным продуктом работы изделия является свет, который можно использовать для генерации электричества с целью возвращения в дата-центр. У системы отсутствуют подвижные части, а для работы не требуются жидкости. Это повышает надёжность, исключает риск утечек, снижает затраты на техническое обслуживание и упрощает эксплуатацию в целом. 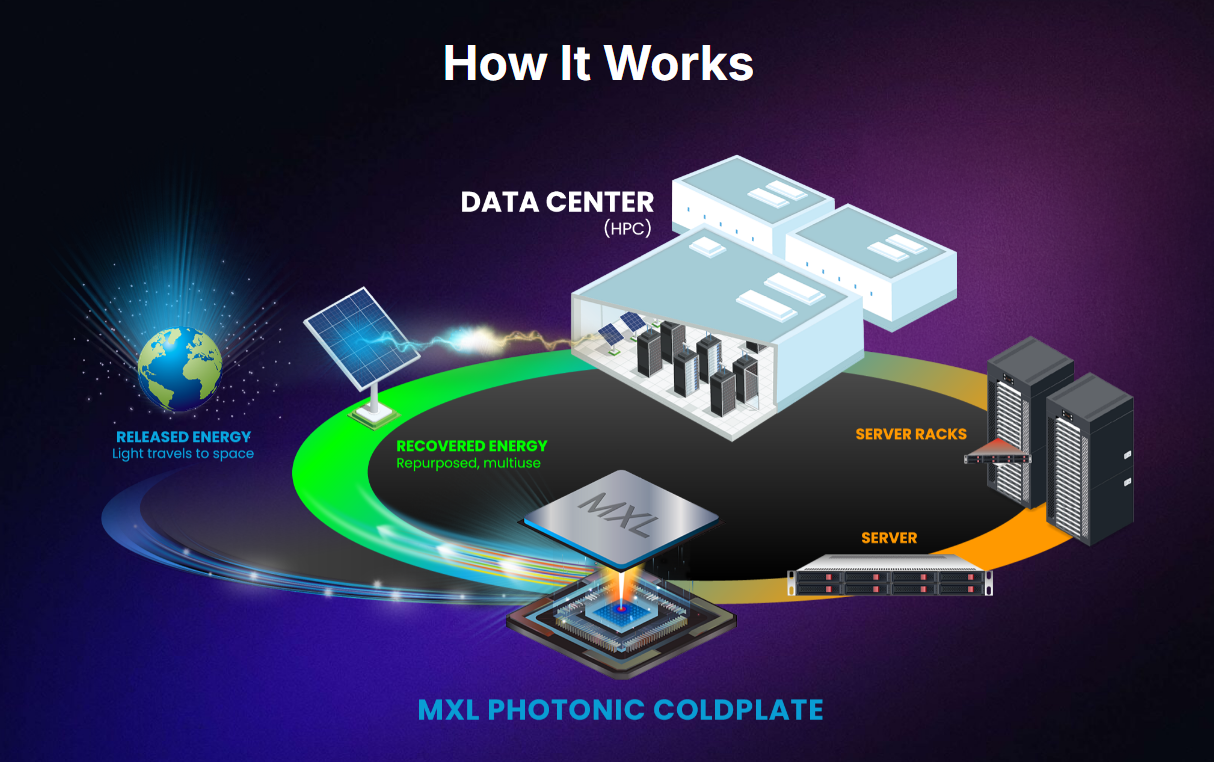
Источник изображения: Maxwell Labs Подчёркивается, что MXL-Gen1 легко интегрируется в существующую инфраструктуру дата-центров. При этом обеспечивается масштабируемость в соответствии с будущими требованиями к характеристикам микросхем и энергопотреблению без необходимости внесения значительных изменений в конструкцию. Технология подходит для отвода тепла от CPU и GPU. Утверждается, что по сравнению с существующими решениями MXL-Gen1 обеспечивает трёхкратный рост производительности и десятикратное повышение плотности вычислений. Пилотная фаза предварительного лицензирования стартует в декабре 2024 года.
20.11.2024 [12:11], Сергей Карасёв
Dell представила ИИ-серверы PowerEdge XE9685L и XE7740Компания Dell анонсировала серверы PowerEdge XE9685L и PowerEdge XE7740, предназначенные для НРС и ресурсоёмких рабочих нагрузок ИИ. Устройства могут монтироваться в 19″ стойку высокой плотности Dell Integrated Rack 5000 (IR5000), что позволяет экономить место в дата-центрах. 
Источник изображений: Dell Модель PowerEdge XE9685L в форм-факторе 4U рассчитана на установку двух процессоров AMD EPYC Turin. Применяется жидкостное охлаждение. Доступны 12 слотов для карт расширения PCIe 5.0. Говорится о возможности использования ускорителей NVIDIA HGX H200 или B200. По заявлениям Dell, система PowerEdge XE9685L предлагает самую высокую в отрасли плотность GPU с поддержкой до 96 ускорителей NVIDIA в расчёте на стойку. Новинка подходит для организаций, решающих масштабные вычислительные задачи, такие как создание крупных моделей ИИ, запуск сложных симуляций или выполнение геномного секвенирования. Конструкция сервера обеспечивает оптимальные тепловые характеристики при высоких рабочих нагрузках, а наличие СЖО повышает энергоэффективность.  Вторая модель, PowerEdge XE7740, также имеет типоразмер 4U, но использует воздушное охлаждение. Допускается установка двух процессоров Intel Xeon 6 на базе производительных ядер P-core (Granite Rapids). Заказчики смогут выбирать конфигурации с восемью ИИ-ускорителями двойной ширины, включая Intel Gaudi 3 и NVIDIA H200 NVL, а также с 16 ускорителями одинарной ширины, такими как NVIDIA L4.  Сервер подходит для различных вариантов использования, например, для тонкой настройки генеративных моделей ИИ, инференса, аналитики данных и пр. Конструкция машины позволяет эффективно сбалансировать стоимость, производительность и масштабируемость. Dell также готовит к выпуску новый сервер PowerEdge XE на базе NVIDIA GB200 NVL4. Говорится о поддержке до 144 GPU на стойку формата 50OU (Dell IR7000).
20.11.2024 [10:56], Сергей Карасёв
Microsoft представила инстансы Azure HBv5 на основе уникальных чипов AMD EPYC 9V64H с памятью HBM3Компания Microsoft на ежегодной конференции Ignite для разработчиков, IT-специалистов и партнёров анонсировала облачные инстансы Azure HBv5 для HPC-задач, которые предъявляют наиболее высокие требования к пропускной способности памяти. Новые виртуальные машины оптимизированы для таких приложений, как вычислительная гидродинамика, автомобильное и аэрокосмическое моделирование, прогнозирование погоды, исследования в области энергетики, автоматизированное проектирование и пр. Особенность Azure HBv5 заключается в использовании уникальных процессоров AMD EPYC 9V64H (поколения Genoa). Эти чипы насчитывают 88 вычислительных ядер Zen4, тактовая частота которых достигает 4 ГГц. Ближайшим родственником является изделие EPYC 9634, которое содержит 84 ядра (168 потоков) и функционирует на частоте до 3,7 ГГц. По данным ресурса ComputerBase.de, чип EPYC 9V64H также фигурирует под именем Instinct MI300C: по сути, это процессор EPYC, дополненный памятью HBM3. При этом клиентам предоставляется возможность кастомизации характеристик. Отметим, что ранее x86-процессоры с набортной памятью HBM2e были доступны в серии Intel Max (Xeon поколения Sapphire Rapids). Каждый инстанс Azure HBv5 объединяет четыре процессора EPYC 9V64H, что в сумме даёт 352 ядра. Система предоставляет доступ к 450 Гбайт памяти HBM3, пропускная способность которой достигает 6,9 Тбайт/с. Задействован интерконнект NVIDIA Quantum-2 InfiniBand со скоростью передачи данных до 200 Гбит/с в расчёте на CPU. 
Источник изображений: Microsoft Применены сетевые адаптеры Azure Boost NIC второго поколения, благодаря которым пропускная способность сети Azure Accelerated Networking находится на уровне 160 Гбит/с. Для локального хранилища на основе NVMe SSD заявлена скорость чтения информации до 50 Гбайт/с и скорость записи до 30 Гбайт/с. 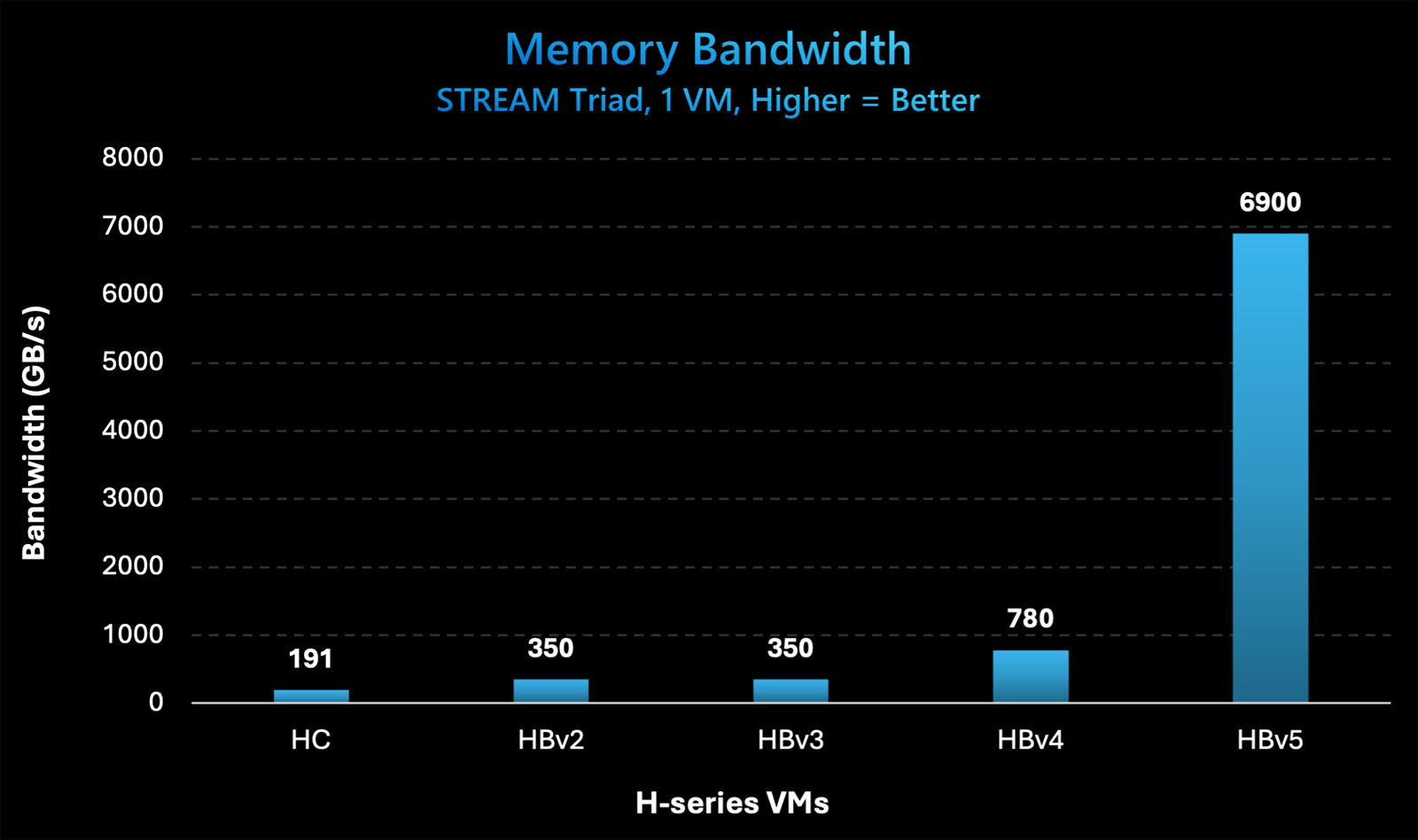 Отмечается, что по показателю пропускной способности памяти виртуальные машины Azure HBv5 примерно в 8 раз превосходят новейшие альтернативы bare-metal и cloud, в 20 раз опережают инстансы Azure HBv3 и Azure HBv2 (на базе EPYC Milan-X и EPYC Rome) и в 35 раз обходят HPC-серверы возрастом 4–5 лет, жизненный цикл которых приближается к завершению. Машины Azure HBv5 станут доступны в I половине 2025 года. |
|

