Материалы по тегу: top500
|
23.06.2026 [12:00], Игорь Осколков
Китайский суперкомпьютер LineShine стал самым производительным в мире и возглавил TOP500Июньский рейтинг самых производительных суперкомпьютеров мира TOP500 принёс неожиданный сюрприз — впервые за несколько лет в список попала новая, крупная машина LineShine из Китая. И не только попала, но и сразу заняла в нём первое место. Более того, она же первой публично преодолела порог FP64-производительности 2 Эфлопс, опираясь только на CPU. Импортонезависимая система LineShine достигла 2,198 Эфлопс в бенчмарке HPL, что составляет порядка 80 % от пиковой теоретической производительности (2,736 Эфлопс), что для столь крупной машины хороший результат. Не менее примечательно, что и в HPCG эта система тоже занимает первое место с результатом 22 Пфлопс, обгоняя El Capitan (17,41 Пфлопс) и Fugaku (16,00). В Green500, правда, она занимает аж 50 место, поскольку потребляет 42,2 МВт, что даёт около 52,07 Гфлопс/Вт. Но, во-первых, данный суперкомпьютер лишён ускорителей, а во-вторых — улучшать энергоэффективность сложнее, чем производительность. LineShine находится в Национальном суперкомпьютерном центре Шэньчжэня (NSCCSZ) и базируется на кастомным китайских 304-ядерных Arm-процессорах LX2 (1,55 ГГц) и платформе LingKun.Всего 13,79 млн ядер, объединённых проприетарным интерконнектом LingQi работающих под управлением ОС Kylin. В ИИ-бенчмарке HPL-MxP система заняла четвёртое место с показателем 7,92 Эфлопс, т.е. разница между FP64-вычислениями в традиционном Linpack и вычислениями со смешанной точностью составляет довольно скромные 3,6x, что опять-таки указывает на архитектуру без выделенных ИИ-ускорителей. 
Источник изображения: Markus Winkler / Unsplash Ещё один новичок в первой десятке TOP500 — итальянский суперкомпьютер Eni HPC7 с устоявшейся производительностью 571,5 Пфлопс (в пике 861,13 Пфлопс), который занял шестое место. Он построен на ровно той же платформе, что и бывший лидер списка El Capitan: узлы HPE Cray EX255a с APU AMD Instinct MI300A. При этом у Eni теперь сразу две машины в Топ-10, поскольку система HPC6 (477,9/606,97 Пфлопс) находится на восьмом месте. Они бы, к слову, могли бы оказаться непосредственными соседями, если бы Microsoft решила обновить тесты своего облачного суперкомпьютера Eagle. Ресурсы у неё точно есть, а вот желание трать драгоценное машинное время ИИ-ускорителей на бенчмарки вряд ли есть. Система Fugaku также остаётся в первой десятке, уже шестой год подряд. Впрочем, если бы не нежелание Китая делиться информацией о своих системах, дефицита в которых явно нет, апдейты к TOP500 были бы гораздо чаще и интереснее. Авторы рейтинга отдельно отмечают разнообразие аппаратных платформ, подчёркивая, что добраться до экзафлопса можно разными путями. Речь и про процессоры, и про ускорители, и про интерконнекты. Всего в новом списке TOP500 появилось 44 новых машины, а минимальный порог вхождения повысился до округлённо 2,66 Пфлопс. Для вхождения же в первую десятку нужно как минимум 434,9 Пфлопс. Среди поставщиков в Топ-10 с точки зрения производительности лидирует HPE (El Capitan, Frontier, Aurora, HPC7, HPC6 и Alps). По процессорам в лидерах снова AMD (El Capitan, Frontier, HPC7 и HPC6). NVIDIA представлена в трёх системах (JUPITER Booster, Eagle, and Alps), а Intel — в двух (Aurora и Eagle). Atos/Eviden/Bull и Fujitsu поставили по одной системе, JUPITER Booster и Fugaku соответственно. Ну а LineShine гордо стоит в стороне от всех основных вендоров. Новых заявок от российских компаний по-прежнему нет. А из новичков среди стран можно упомянуть Индонезию с системой на объекте ASEAN-Korea HPC (436 место) и Узбекистан с государственным суперкомпьютером (321 место).
18.11.2025 [01:10], Игорь Осколков
Европа присоединилась к экзафлопсному клубу с суперкомпьютером JUPITERЕвропейский суперкомпьютер JUPITER (Joint Undertaking Pioneer for Innovative and Transformative Exascale Research) в Юлихском исследовательском центре (FZJ) в Германии официально преодолел важную отметку — FP64-производительность его GPU-модуля Booster достигла ровно 1 Эфлопс при пиковой теоретической 1,227 Эфлопс. Таким образом в нынешнем рейтинге TOP500 он занял четвёртое место, совсем чуть-чуть не дотянув до суперкомпьютера Aurora с его 1,012 Эфлопс. Впервые машина попала в июньский рейтинг TOP500 с показателем 793 Пфлопс, но тогда она не была полностью готова. Официальный запуск состоялся лишь в сентябре. Впрочем, за прошедшие с момента выхода прошлого рейтинга его лидер El Capitan тоже нарастил мощность, с 1,742 Эфлопс до 1,809 Эфлопс. Frontier же остался на втором месте с показателем 1,353 Эфлопс, хотя изначально он «дотягивался» только до 1,102 Эфлопс. Таким образом, JUPITER формально стал первой публичной экзафлопсной системой за пределами США, если не брать в расчёт китайские системы, о которых КНР предпочитает не распространяться. Мощные суперкомпьютеры, не участвующие в TOP500, бывали и раньше, но вот есть ли среди них машина такого класса, остаётся только гадать. 
Источник изображения: Forschungszentrum Jülich / Sascha Kreklau Так что если через полгода не будет развёрнут ещё какой-нибудь крупный суперкомпьютер, что вполне реально с нынешними возможностями (нео-)облаков, то JUPITER наверняка поднимется в рейтинге на строчку выше. Сейчас Booster включает порядка 6 тыс. узлов BullSequana XH3000 с 24 тыс. ускорителей GH200 в Quad-исполнении, объединённых 200G-интерконнектом InfiniBand NDR. Ещё приблизительно 5 Флопс в FP64 JUPITER получит от CPU-модуля cCuster из 1300 узлов с 2600 Arm-процессорам SiPearl Rhea1 с 80 ядрами и 64 Гбайт HBM2e. Узлы и интерконнект будут использоваться те же, что в Booster. Однако выпуск этих процессоров только-только начался, так что апгрейд будет завершён только в следующем году. TOP500 в целом в этот раз новизной технологий не блещет, отражая скорее типичный цикл обновления систем. 
Источник изображения: Forschungszentrum Jülich / Sascha Kreklau Всего в ноябрьском рейтинге появилось 45 новых машин. Самая крупная из них — 135,4-Пфлопс CHIE-4, построенная для SoftBank на базе NVIDIA DGX B200 с InfiniBand NDR400 — занимает аж 17 позицию. Она же единственная пополнила первую десятку рейтинга HPCG с результатом 3760,55 Тфлопс, где заняла шестую позицию. Из необычных новинок можно выделить суперкомпьютер MAXIMUS-384 на 20 месте (114,5 Пфлопс), который объединил Intel Xeon Emerald Rapids и AMD Instinct MI300X. Впрочем, вторая во всём списке и уже не такая новая система с MI300X — IronMan — объединяет их с Sapphire Rapids. 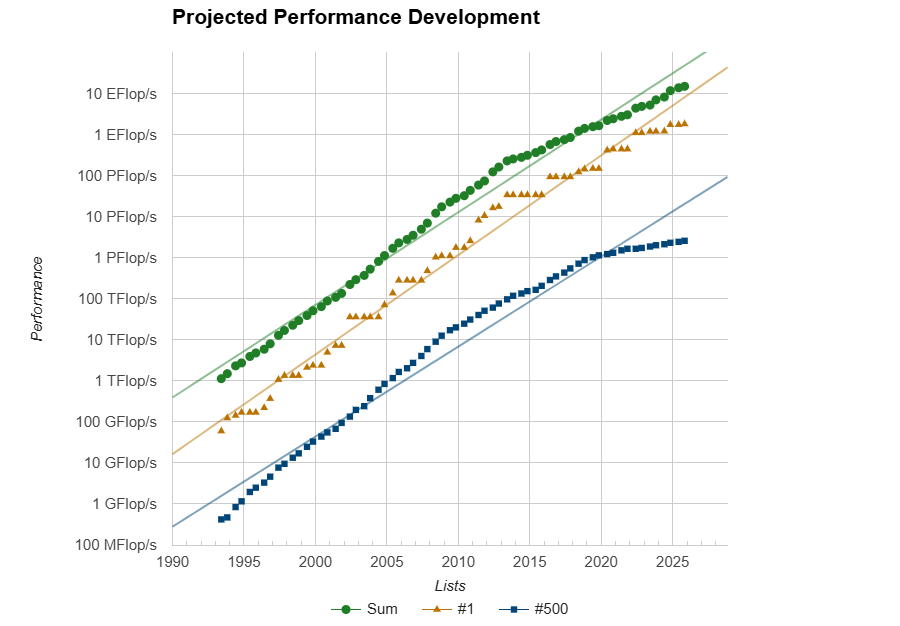
Источник изображения: TOP500 От России в TOP500 попали пять суперкомпьютеров (три от Яндекса и два от Сбера), которые если и обновляли с момента последнего официальной заявки на вхождение в рейтинг, то вряд ли бы стали громко и публично об этом рассказывать. Зато у соседнего Казахстана есть сразу две машины. На 86 позиции с производительностью 20,48 Пфлпос находится Alem.Cloud, на 103 — AI-Farabium с 17,93 Пфлопс. Обе системы используют сочетание Xeon Emerald Rapids, NVIDIA H200 (SXM) и 400G-интерконнект, но первая получила Ethernet, а вторая — InfiniBand NDR. В Green500 существенных изменений тоже не наблюдается. Ровно половину первой десятки занимают машины с NVIDIA GH200. В общей массе чипы NVIDIA тоже доминируют. При этом первая система без ускорителя занимает аж 105 строчку, и до 113 позиции это сплошь Fujitsu A64FX, лежащие в основе Fugaku. Всего TOP500 уже более половины машин оснащены ускорителями. Но от ожидаемого ранее уровня роста производительности весь рейтинг отстаёт на протяжении уже пяти лет. С другой стороны, и фокус сейчас сместился на ИИ, а новым кластерам некогда участвовать в ненужных для них рейтингах.
10.06.2025 [19:00], Игорь Осколков
Июньский TOP500 суперкомпьютеров: без сюрпризов, но не безынтересно65-я редакция TOP500 самых мощных суперкомпьютеров мира никаких особенных сюрпризов не преподнесла, но кое-какие новые и интересные машины в него попали. Лидерами списка среди стран всё ещё являются США (175 систем) и Китай (47 систем), вот только вклад их совершенно разный. Тройка лидеров по-прежнему представлена экзафлопсными суперкомпьютерами El Capitan, Frontier и Aurora Министерства энергетики США (DoE). Китайских же систем такого класса в списке нет, хотя никто не сомневается в их существовании. Хуже того, от КНР в этот раз снова не было подано ни одной заявки. Теперь к Китаю по количеству позиций в TOP500 приближается Германия — 41 машина, причём одна из них взобралась на четвёртое место июньской редакции списка. Она же является и единственным новичком в первой десятке. Это JUPITER Booster, совместный проект EuroHPC и Юлихского суперкомпьютерного центра (Jülich Supercomputing Centre). JUPITER (JU Pioneer for Innovative and Transformative Exascale Research) станет первым европейским экзафлопсным суперкомпьютером. Причём это изначально модульная система, «кусочек» которой под названием JETI (JUPITER Exascale Transition Instrument) уже попал в прошлогодний TOP500. 
Источник изображения: Forschungszentrum Jülich / Sascha Kreklau JUPITER Booster по-прежнему использует платформу Atos/Eviden BullSequana XH3000 с гибридными ускорителями NVIDIA Quad GH200 и интерконнектом InfiniBand NDR200. FP64-производительность представленного в TOP500 сегмента (это только часть всей машины) составила 793,4 Пфлопс при теоретическом пике в 930 Пфлопс. Энергопотребление составляет чуточку больше 13 МВт, но при этом в GREEN500 машина занимает только 21-е место. А на первом месте там… всё так же система JEDI на ровно той же аппаратной платформе, что неудивительно, ведь она тоже является «кусочком» JUPITER. 
Источник изображения: Forschungszentrum Jülich / Sascha Kreklau На 11-ом месте оказался ещё один «сборный» суперкомпьютер — вторая фаза британского Isambard-AI на базе опять-таки NVIDIA GH200, которая добралась до отметки 216,5 Пфлопс (пик 278,6 Пфлопс). 13-е место досталось нидерландской системе ISEG2 от Nebius (когда-то Yandex) на базе Xeon Platinum 8468 (Sapphire Rapids), NVIDIA H200 (141 Гбайт) и InfiniBand NDR400. Неожиданностью можно назвать появление двух систем на базе векторных ускорителей SX-Aurora Type 10AE, разработку которых NEC уже забросила. Две безымянные машины на 113-м и 157-м местах принадлежат немецким метеорологам Deutscher Wetterdienst. Ближе к концу списка затесались ещё две любопытные системы из Норвегии, тоже безымянные. Интересны они тем, что сделаны xFusion (бывшее серверное подразделение Huawei, выделенное в проданную впоследствии независимую компанию), оснащены процессорами Intel Xeon 6900P (Granite Rapids-AP) и AMD EPYC 9005 (Turin), и… 100G-интерконнектом Intel Omni-Path. Буквально на днях Cornelis Networks догнала остальных разработчиков интерконнекта, представив, наконец, 400G-поколение CN5000. В целом же ситуация поменялась мало. На InfiniBand полагаются 54,2 % всех систем текущего списка, на Ethernet — суммарно по всем поколениям чуть больше трети. 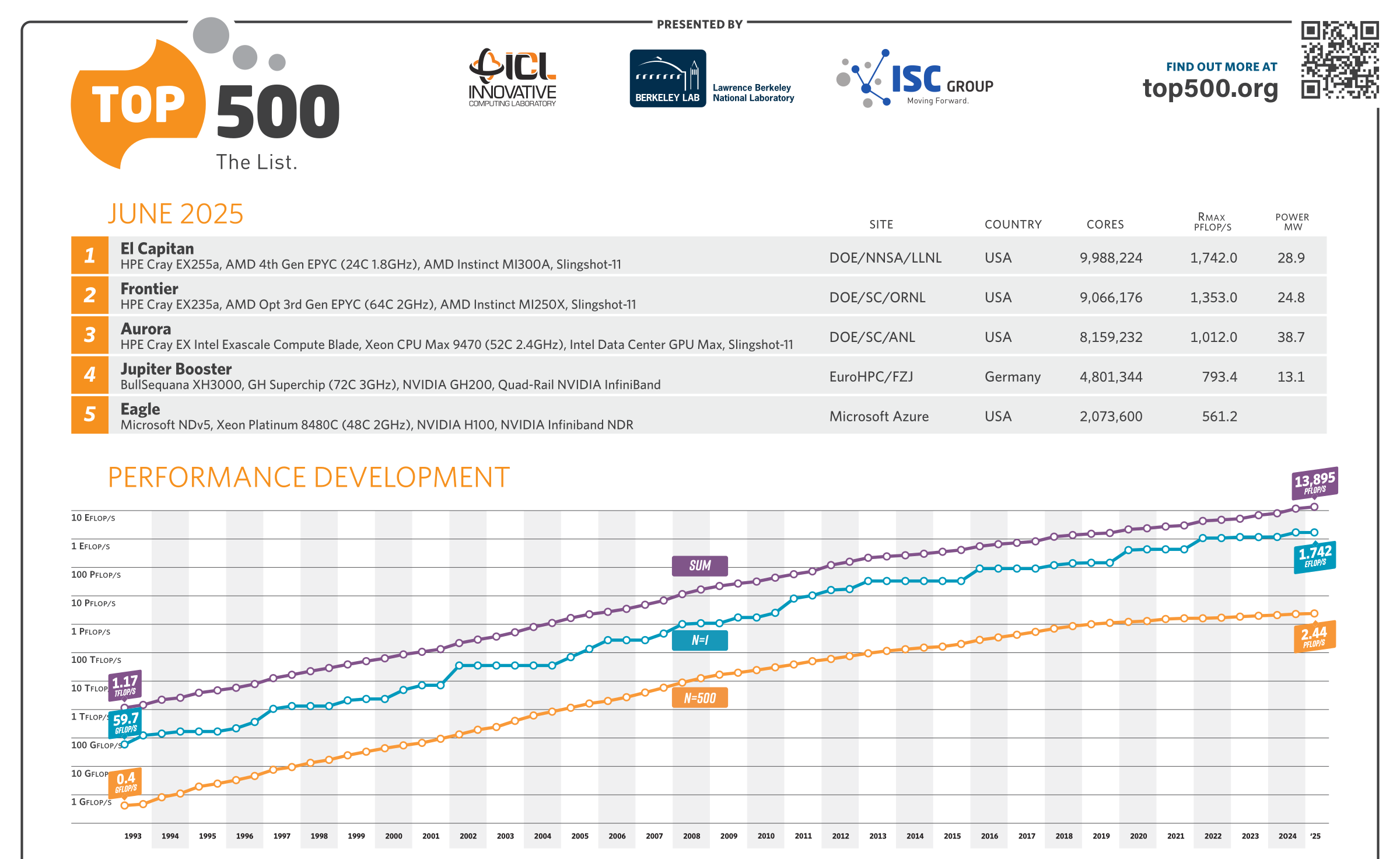
Источник: TOP500 Но если считать по Флопсам, то 48,2 % приходится на Slingshot, т.е. практически целиком на системы HPE, производительность которых суммарно составляет 47,9 % от производительности всего списка TOP500. Второе место по этому показателю у Atos/Eviden. По количеству суперкомпьютеров в списке HPE при этом занимает лишь второе место, уступая Lenovo и обгоняя Dell. Иными словам, HPE и Atos/Eviden преимущественно занимаются крупными машинами, а Lenovo, Dell и даже сама NVIDIA берут скорее числом. 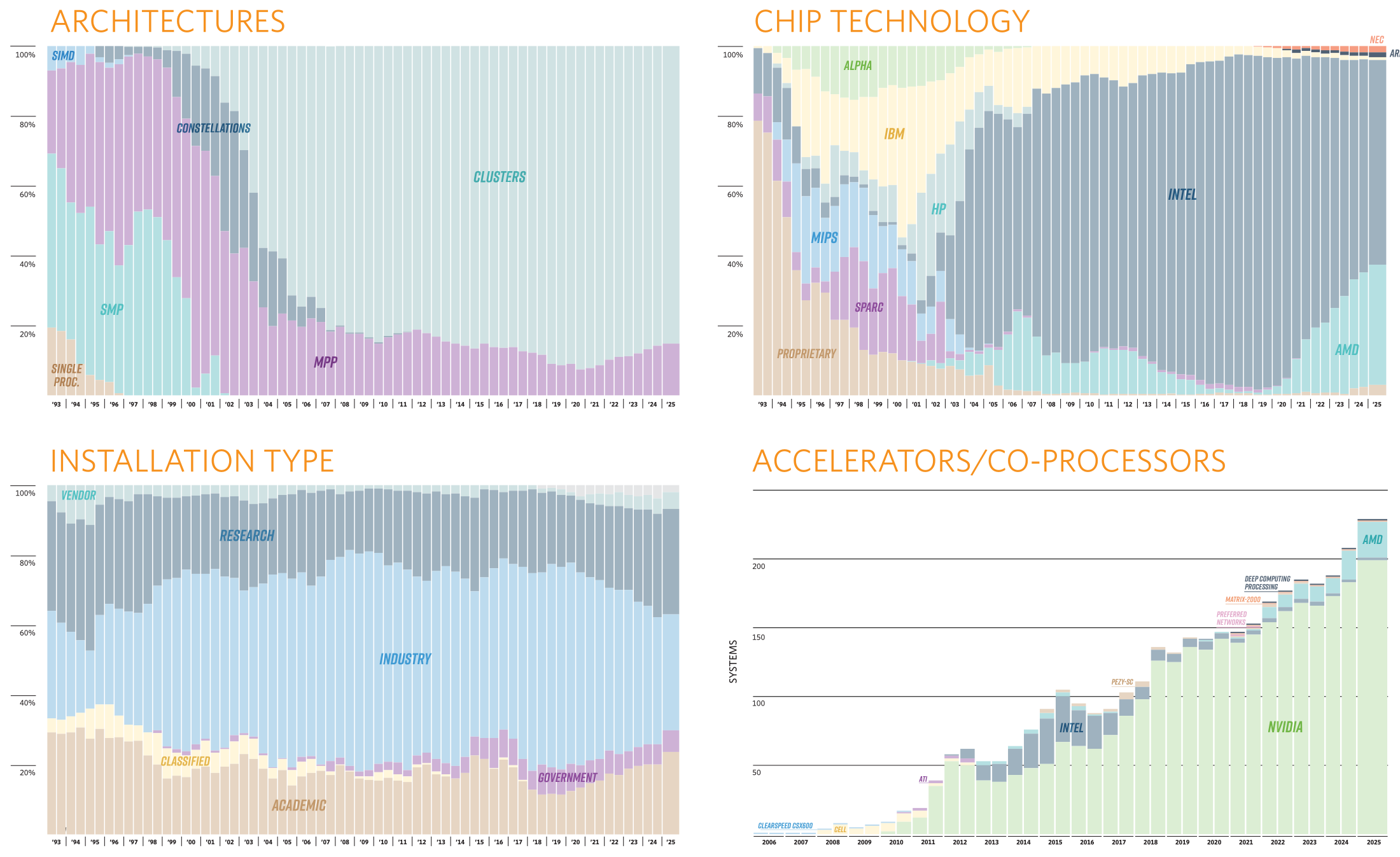
Источник: TOP500 В бенчмарке HPCG новым лидером стал El Capitan с показателем 17,407 Пфлопс, который сместил остальных участников на одну позицию вниз, отобрав первое место у Fugaku, которое она занимала несколько лет подряд. В бенчмарке HPL-MxP (HPL-AI) в расчётах смешанной точности первые места снова у El Capitan, Aurora и Frontier с показателями 16,7 Эфлопс, 11,6 Эфлопс и 11,4 Эфлопс соответственно. 
Источник изображения: NVIDIA Интересно, что в нынешнем TOP500 так и осталась только одна машина с AMD Instinct MI300X, а среди новинок всё больше MI300A да NVIDIA GH200 (а также более традиционных H100/H200). Очевидно, что новейшие NVIDIA B300 и Instinct MI325X в рейтинг могли и не попасть, но не исключено, что и в будущем вендоры будут по-прежнему ставить устаревающие ускорители как минимум NVIDIA. Всё дело в том, что в новых поколениях чипов NVIDIA сделала ставку на ИИ-нагрузки — разница между GB200 и GB300 в FP64-расчётах почти тридцатикратная. AMD якобы готовит Instinct MI430X с поддержкой FP64 и MI450X без таковой. Уже в анонсах суперкомпьютеров следующего поколения на базе Vera Rubin сама NVIDIA аккуратно обходит стороной вопрос «чистой» производительности, говоря лишь о «научных результатах» в случае системы Doudna. А в случае Blue Lion компания говорит о «слиянии симуляций, данных и ИИ». Возможно, это не совсем то, чего ждут учёные.
19.05.2025 [08:49], Владимир Мироненко
На одном ИИ не выедешь: США рискуют потерять лидерство в HPC
hardware
hpc
top500
государство
дефицит
ии
кадры
квантовые вычисления
обучение
прогноз
разработка
суперкомпьютер
сша
ускоритель
финансы
энергоэффективность
Проблемы, связанные с высокопроизводительными вычислениями (HPC), угрожают инновациям в США, утверждает Джек Донгарра (Jack Dongarra), лауреат премии А. М. Тьюринга и один создателей рейтинга самых мощных суперкомпьютеров в мире TOP500, чьи разработки и реализации многих библиотек, включая EISPACK, LINPACK, BLAS, LAPACK и ScaLAPACK, сыграли важную роль в продвижении HPC. В статье, опубликованной The Conversation, Донгарра рассказал о прогрессе HPC и проблемах с инновациями в США. Учёный отметил, что HPC являются одной из самых важных технологий в современном мире, позволяющей решать различные задачи — от прогнозирования погоды до поиска новых лекарств и обучения ИИ-моделей, которые слишком сложны или слишком велики для обычных компьютеров. Сейчас HPC находятся на переломном этапе, и выбор, который правительство США, исследователи и технологическая отрасль делают сегодня, может повлиять на будущее инноваций, национальной безопасности и мирового лидерства, предупреждает Донгарра. Используя тысячи и даже миллионы чипов с передовыми системами памяти и хранения для быстрого перемещения и сохранения огромных объёмов данных, HPC-платформы позволять выполнять чрезвычайно подробные симуляции и вычисления, говорит Донгарра. Важность HPC ещё больше возросла с развитием ИИ-технологий, требующих огромных вычислительных мощностей для обучения. «В результате ИИ и HPC теперь тесно сотрудничают, подталкивая друг друга вперёд», — отметил учёный. По словам Донгарра, сегмент HPC находится под большим давлением, чем когда-либо, с более высокими требованиями к системам по скорости, данным и энергопотреблению. Также он отметил, что HPC сталкиваются с некоторыми серьёзными техническими проблемами. Донгарра назвал одной из ключевых проблем разрыв между производительностью чипов и подсистем памяти. «Представьте себе, что у вас есть сверхбыстрый автомобиль, но вы застряли в пробке — мощность бесполезна, если дорога не может с ней справиться», — говорит учёный. Точно так же подсистемы памяти не способны «прокормить» вычислительные блоки, которые простаивают, что отражается на эффективности всей вычислительной системы. 
Источник изображения: OLCF Ещё одна проблема HPC — энергопотребление. Закон масштабирования Деннарда, согласно которому с уменьшением размеров транзистора уменьшается и энергопотребление при росте производительности, прекратил своё действие в 2006 году. Теперь, чем мощнее компьютеры, тем больше они потребляют энергии. Чтобы исправить это, исследователи ищут новые способы проектирования как аппаратного, так и программного обеспечения HPC. Также существует проблема с типами производимых чипов, отметил учёный. Сейчас индустрия чипов в основном сосредоточена на ИИ, который отлично работает с вычислениями с низкой точностью. Однако для многих научных приложений по-прежнему требуется FP64-вычисления. В частности, NVIDIA сделала ставку исключительно на ИИ, поэтому FP64-производительность новейших GB300 почти в 30 раз меньше, чему GB200. У AMD, по слухам, в следующем поколении Instinct будет сразу два варианта ускорителей MI430X с поддержкой FP64 и MI450X, полностью лишённый тензорных ядер с FP64. Но и она может сделать ставку только на ИИ. Если производители прекратят выпускать чипы, которые требуются учёным, это негативно отразится на выполнении важных исследований. Таким образом тенденции в производстве полупроводников и коммерческие приоритеты могут разниться с потребностями научного сообщества, а отсутствие специализированного оборудования может помешать прогрессу в исследованиях. Можно попытаться создавать специализированные чипы для HPC, но это дорого и сложно. Исследователи, тем не менее, изучают возможность применения новых конструкций для изготовления чипов, включая чиплеты, чтобы сделать их более доступными. В прошлом у США было преимущество в области HPC благодаря государственному финансированию, поддержке и открытости разработок, но теперь многие страны вкладывают значительные средства в HPC в стремлении снизить зависимость от иностранных технологий и выйти на лидирующие позиции в таких областях, как моделирование климата и персонализированная медицина. В Европе развивают программу EuroHPC, у Японии есть собственный суперкомпьютер Fugaku (а скоро будет ещё один), а у Китая — целая серия «автохтонных» машин. 
Источник изображения: WIkipedia / DoE Правительства стран понимают, что HPC являются ключом к их национальной безопасности, экономической мощи и научному лидерству, отметил Донгарра, подчеркнув, что у США всё ещё нет чёткого долгосрочного плана на будущее. Другие страны развивают это направление быстро, а без национальной стратегии США рискуют отстать, предупредил он: «Национальная стратегия США должна включать финансирование создания новых машин и обучение людей их использованию. Она также должна включать партнёрство с университетами, национальными лабораториями и частными компаниями. Самое главное, что план должен быть сосредоточен не только на оборудовании, но и на ПО и алгоритмах, которые делают HPC полезными», — заявил учёный. Он отметил, что некоторые шаги в этом направлении уже предприняты, включая принятие в 2022 году «Закона о чипах и науке» (CHIPS and Science Act) и создание управления, которое поможет превратить научные исследования в реальные продукты. В 2025 году также была сформирована целевая группа Vision for American Science and Technology, призванная объединить некоммерческие организации, академические круги и промышленность для помощи правительству в принятии решений. Кроме того, получили развитие квантовые вычисления. Но они пока находятся на ранних стадиях и, скорее всего, будут дополнять, а не заменять традиционные HPC. Поэтому важно продолжать инвестировать в оба вида вычислений. Донгарра назвал это правильными шагами, но они не решат проблему поддержки HPC в долгосрочной перспективе. Помимо краткосрочного финансирования и инвестиций в инфраструктуру, учёный предложил:
Донгарра отметил, что HPC — это больше, чем просто быстрые суперкомпьютеры. Это основа научных открытий, экономического роста и национальной безопасности. Если США примут предложенные меры, то можно гарантировать, что HPC продолжат поддерживать инновации в течение десятилетий.
28.12.2024 [12:42], Сергей Карасёв
Итальянская нефтегазовая компания Eni запустила суперкомпьютер HPC6 с производительностью 478 ПфлопсИтальянский нефтегазовый гигант Eni запустил вычислительный комплекс HPC6. На сегодняшний день это самый мощный суперкомпьютер в Европе и один из самых производительных в мире: в свежем рейтинге TOP500 он занимает пятую позицию. О подготовке HPC6 сообщалось в начале 2024 года. В основу системы положены процессоры AMD EPYC Milan и ускорители AMD Instinct MI250X. Комплекс выполнен на платформе HPE Cray EX4000 с хранилищем HPE Cray ClusterStor E1000 и интерконнектом HPE Slingshot 11. В общей сложности в состав HPC6 входят 3472 узла, каждый из которых несёт на борту 64-ядерный CPU и четыре ускорителя. Таким образом, суммарное количество ускорителей Instinct MI250X составляет 13 888. Суперкомпьютер обладает FP64-быстродействием 477,9 Пфлопс в тесте Linpack (HPL), тогда как пиковый теоретический показатель достигает 606,97 Пфлопс. Максимальная потребляемая мощность системы составляет 10,17 МВА. Комплекс HPC6 смонтирован на площадке Eni Green Data Center в Феррера-Эрбоньоне: это, как утверждается, один из самых энергоэффективных и экологически чистых дата-центров в Европе. Новый суперкомпьютер оснащён системой прямого жидкостного охлаждения, которая способна рассеивать 96 % вырабатываемого тепла. ЦОД, где располагается HPC6, оборудован массивом солнечных батарей мощностью 1 МВт. 
Источник изображения: Eni Как отмечает ресурс Siliconangle, на создание суперкомпьютера потрачено более €100 млн. Применять комплекс планируется, в частности, для оптимизации работы промышленных предприятий, повышения точности геологических и гидродинамических исследований, разработки источников питания нового поколения, оптимизации цепочки поставок биотоплива, создания инновационных материалов и моделирования поведения плазмы при термоядерном синтезе с магнитным удержанием.
28.12.2024 [11:35], Сергей Карасёв
Обнародован рейтинг Тор-100 суперкомпьютеров Китая: систем экзафлопсного класса в нём нетОбщество компьютерных наук Китая обнародовало свежий рейтинг 100 самых производительных суперкомпьютеров страны. Как отмечает ресурс Tom's Hardware, власти КНР, похоже, скрывают свой истинный вычислительный потенциал. Дело в том, что в опубликованном списке Тор-100 не только нет систем экзафлопсного класса, но и не представлено ни одной новой машины за год. В тройку лидеров в 2024 году вошли те же самые гетерогенные системы (CPU + GPU), которые возглавляли рейтинг в 2023-м. На первом месте располагается комплекс, обладающий FP64-быстродействием 487,94 Пфлопс в тесте Linpack (HPL) и пиковой производительностью на уровне 620 Пфлопс. Эта система, введённая в эксплуатацию в 2023 году, насчитывает в общей сложности 15 974 400 ядер CPU. 
Источник изображения: Xinhua На второй позиции списка находится машина, запущенная в 2022 году: она использует 460 000 ядер CPU. Заявленное быстродействие составляет 208,26 Пфлопс, пиковое значение — 390 Пфлопс. Замыкает тройку система с 285 000 тыс. CPU-ядер, введённая в эксплуатацию в 2021-м: у неё показатели производительности достигают 125,04 и 240 Пфлопс. Фактически, как отмечается, единственное различие между списками Тор-100 суперкомпьютеров Китая от 2023 и 2024 годов заключается в их совокупной мощности, но даже этот показатель вырос незначительно — с 1,398 Эфлопс до 1,406 Эфлопс. Для сравнения: самый производительный в мире суперкомпьютер — американская система El Capitan — обладает быстродействием 1,742 Эфлопс. 
Источник: Hyperion Research По косвенным признакам понятно, что у Китая есть несколько машин экзафлопсного класса. По оценкам Hyperion Research, в КНР развёрнуто уже пять подобных систем. Эти сведения официально не подтверждены, но участники рынка говорят, что китайские организации намеренно скрывают информацию о своих самых мощных НРС-системах, чтобы не спровоцировать дополнительные ограничения со стороны США. С 2021 года китайские компании не подают заявки на участие в рейтинге TOP500.
02.12.2024 [11:39], Сергей Карасёв
Один из модулей будущего европейского экзафлопсного суперкомпьютера JUPITER вошёл в двадцатку самых мощных систем мираЮлихский исследовательский центр (FZJ) в Германии объявил о достижении важного рубежа в рамках проекта JUPITER (Joint Undertaking Pioneer for Innovative and Transformative Exascale Research) по созданию европейского экзафлопсного суперкомпьютера. Введён в эксплуатацию JETI — второй модуль этого НРС-комплекса. Напомним, контракт на создание JUPITER заключён между Европейским совместным предприятием по развитию высокопроизводительных вычислений (EuroHPC JU) и консорциумом, в который входят Eviden (подразделение Atos) и ParTec. Суперкомпьютер JUPITER создаётся на базе модульного дата-центра, за строительство которого отвечает Eviden. Система JUPITER получит, в частности, энергоэффективные высокопроизводительные Arm-процессоры SiPearl Rhea1 с HBM. Кроме того, в состав машины входят узлы с NVIDIA Quad GH200, а общее количество суперчипов GH200 Grace Hopper составит почти 24 тыс. Узлы объединены интерконнектом NVIDIA Mellanox InfiniBand. Запущенный модуль JETI (JUPITER Exascale Transition Instrument) обладает FP64-производительностью 83,14 Пфлопс, тогда как пиковый теоретический показатель достигает 95 Пфлопс. С такими результатами эта машина попала на 18-ю строку нынешнего рейтинга мощнейших суперкомпьютеров мира TOP500. В составе JETI задействованы в общей сложности 391 680 ядер. Энергопотребление модуля равно 1,31 МВт. Отмечается, что JETI обеспечивает примерно одну двенадцатую от общей расчётной производительности машины JUPITER. Попутно JETI занял шестое место в рейтинге энергоэффективных систем Green500. 
Источник изображения: Eviden Ожидается, что после завершения строительства суммарное быстродействие JUPITER на операциях обучения ИИ составит до 93 Эфлопс, а FP64-производительность превысит 1 Эфлопс. Затраты на создание комплекса оцениваются в €273 млн, включая доставку, установку и обслуживание НРС-системы.
27.11.2024 [11:48], Сергей Карасёв
El Dorado, младший брат самого мощного в мире суперкомпьютера El Capitan, вошёл в двадцатку TOP500Сандийские национальные лаборатории (SNL) Министерства энергетики США (DOE) объявили о том, что новый НРС-комплекс El Dorado занял 20-е место в свежем рейтинге самых мощных суперкомпьютеров мира TOP500, обнародованном на конференции SC24. На вершине ноябрьского списка TOP500 находится машина El Capitan, построенная специалистами HPE Cray. Эта система демонстрирует FP64-быстродействие на уровне 1,742 Эфлопс в тесте Linpack (HPL), а пиковый теоретический показатель достигает 2,746 Эфлопс. Основой El Capitan служит платформа HPE Cray Shasta на базе AMD Instinct MI300A. Отмечается, что комплекс El Dorado, по сути, приходится младшим братом El Capitan. Машина El Dorado меньше по масштабу, но архитектурно идентична лидеру рейтинга TOP500. Система построена компанией HPE на платформе Cray EX4000: в общей сложности задействованы 384 узла на основе Instinct MI300A. Суммарное количество ядер составляет 383 040. Используется интерконнект HPE Slingshot-11. Вычислительные узлы используют прямое жидкостное охлаждение. 
Источник изображения: SNL Производительность El Dorado достигает 68,02 Пфлопс, а теоретическое пиковое быстродействие находится на отметке 95,29 Пфлопс. Суперкомпьютер фактически представляет собой мощную тестовую площадку для создания, тестирования и подготовки программного кода перед запуском на машине экзафлопсного класса El Capitan. Кроме того, El Dorado позволит осуществлять определённые научно-исследовательские и опытно-конструкторские работы.
19.11.2024 [17:30], Сергей Карасёв
1,742 Эфлопс: El Capitan стал самым мощным в мире суперкомпьютером рейтинга TOP500Ливерморская национальная лаборатория им. Э. Лоуренса (LLNL) Министерства энергетики США (DOE), Администрация по национальной ядерной безопасности США (NNSA), компании AMD и HPE официально представили El Capitan — самый производительный в мире суперкомпьютер. Эта машина возглавила ноябрьский рейтинг мощнейших вычислительных систем TOP500. Комплекс El Capitan создан специалистами HPE Cray. Суперкомпьютер обладает FP64-быстродействием 1,742 Эфлопс в тесте Linpack (HPL), тогда как пиковый теоретический показатель достигает 2,746 Эфлопс. Прежний лидер TOP500 — система Frontier — с производительностью 1,353 Эфлопс теперь находится на втором месте рейтинга. Машина Aurora, так и не прибавившая в производительности, хотя и заявленная когда-то как 2-Эфлопс система, занимает теперь третье место. В основу El Capitan легла платформа HPE Cray Shasta. Используется гибридная архитектура AMD с APU Instinct MI300A: изделие содержит 24 ядра Zen 4 общего назначения, блоки CDNA 3 и 128 Гбайт памяти HBM3. В общей сложности в составе суперкомпьютера объединены 11 136 узлов, каждый из которых несёт на борту четыре экземпляра Instinct MI300A. Применён интерконнект HPE Slingshot-11 с пропускной способностью 200 Гбит/с. Система включает узлы Rabbit, которые формируют дезагрегированное NVMe-хранилище с прямым PCIe-подключением к вычислительным узлам. 
Источник изображений: LLNL Суммарное количество ядер CPU и GPU в составе El Capitan достигает 11 039 616, объём памяти — 5,4375 Пбайт. За отвод тепла отвечает система прямого жидкостного охлаждения HPE. Заявленная энергетическая эффективность составляет 58,89 Гфлопс/Вт: с таким показателем машина оказалась на 18-м месте в списке «зелёных» суперкомпьютеров GREEN500, но с учётом масштаба и общего энергопотребления 29,58 МВт — это хороший показатель. Система охлаждения HPC-объекта использует 28 тыс. т воды. Отмечается, что El Capitan станет главным вычислительным ресурсом для Tri-lab — группы, в которую вместе с LLNL входят Сандийские национальные лаборатории (SNL) и Лос-Аламосская национальная лаборатория (LANL). Использовать мощности нового суперкомпьютера планируется для обеспечения национальной безопасности и решения сложных задач, связанных с ядерным оружием. В частности, El Capitan обеспечит беспрецедентные возможности моделирования и имитации, необходимые для Программы управления ядерными запасами NNSA. Кроме того, НРС-комплекс поможет в модернизации и создании нового оружия, такого как боеголовки W87-1 и W93, которые в настоящее время находятся на стадии разработки.  Отмечается также, что на 10-й позиции в рейтинге TOP500 оказался суперкомпьютер Tuolumne, также построенный в рамках проекта LLNL и NNSA. Фактически Tuolumne — это младший брат El Capitan: машина использует ту же архитектуру на базе Instinct MI300A, но обладает примерно на порядок меньшей FP64-производительностью 208,10 Пфлопс с пиковым значением 288,88 Пфлопс. Применять мощности Tuolumne планируется для «несекретных» задач, таких как исследования в области энергетической безопасности, изменений климата, вычислительной биологии, разработки лекарственных препаратов следующего поколения и пр. Стоит отметить, что Frontier — не единственная система, которая уступила пальму первенства более новым НРС-комплексам в ноябрьском рейтинге TOP500. Та же участь постигла самый мощный суперкомпьютер Европы LUMI, который опустился с пятого на восьмое место. На пятой позиции оказалась совершенно новая система HPC6, расположенная в центре нефтегазовой компании Eni в Феррера-Эрбоньоне (Италия). Её производительность достигает 477,9 Пфлопс при пиковом показателе 606,97 Пфлопс.
30.05.2022 [10:00], Игорь Осколков
Июньский TOP500: есть экзафлопс!59-я редакция TOP500, публичного рейтинга самых производительных суперкомпьютеров мира, стала наиболее знаменательной за последние 14 лет, поскольку официально был преодолён экзафлопсный барьер. Путь от петафлопса оказался долгим — первой петафлопсной системой стал суперкомпьютер IBM Roadrunner, и произошло это аж в 2008 году. Но минимальным порогом для попадания в TOP500 эта отметка стала только в 2019 году. Как и было обещано, официально и публично отметку в 1 Эфлопс в бенчмарке HPL на FP64-вычислениях первым преодолел суперкомпьютер Frontier — его устоявшаяся производительность составила 1,102 Эфлопс при теоретическом пике в 1,686 Эфлопс. Система на платформе HPE Cray EX235a использует оптимизированные 64-ядерные процессоры AMD EPYC Milan (2 ГГц), ускорители AMD Instinct MI250X и фирменный интерконнект Slingshot 11-го поколения. Система имеет суммарно 8 730 112 ядер, потребляет 21,1 МВт и выдаёт 52,23 Гфлопс/Вт, что делает её второй по энергоэффективности в мире. 
Суперкомпьютер Frontier (Фото: AMD) Впрочем, первое место в Green500 по данному показателю всё равно занимает тестовый кластер в составе всё того же Frontier: 120 832 ядра, 19,2 Пфлопс, 309 кВт, 62,68 Гфлопс/Вт. Третье и четвёртое места достались европейским машинам LUMI и Adastra, новичкам TOP500, которые по «железу» идентичны Frontier, но значительно меньше. Да и разница в Гфлопс/Вт между ними минимальна. Скопом они сместили предыдущего лидера — экзотичную японскую систему MN-3 от Preferred Networks. Японская система Fugaku, лидер по производительности в течение двух последних лет, сместилась на второе место TOP500. Третье место у финской системы LUMI с показателем производительности 151,9 Пфлопс — обратите внимание, насколько велик разрыв в первой тройке машин. Наконец, в Топ-10 последнее место занял новичок Adastra (46,1 Пфлопс), который расположен во Франции. 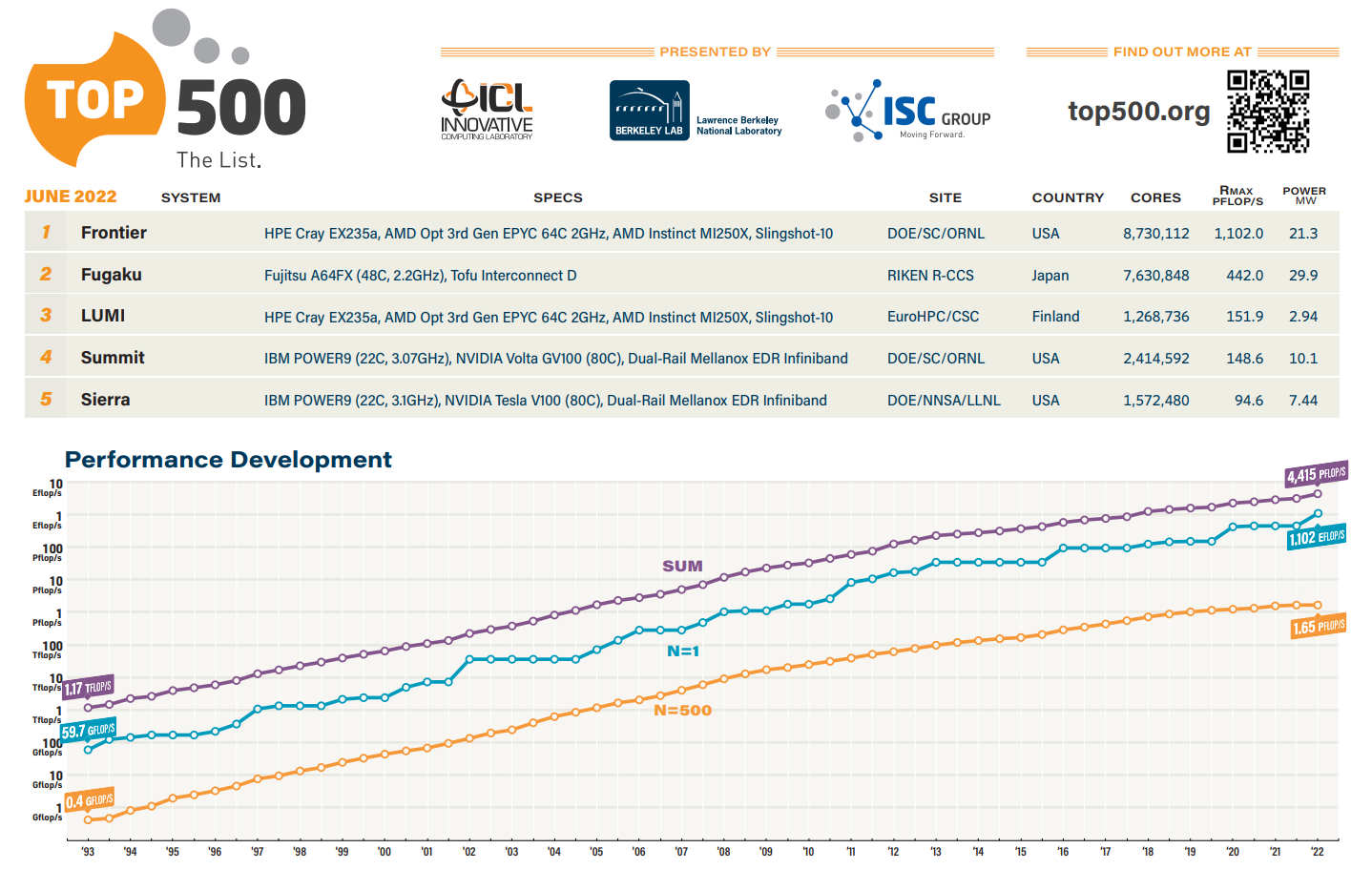
Источник: TOP500 В бенчмарке HPCG всё ещё лидирует Fugaku (16 Пфлопс), но, судя по всему, только потому, что для Frontier данных пока нет. Ну и потому, что результат суперкомпьютера LUMI, который почти на порядок медленнее Frontier, в HPCG составляет 1,94 Пфлопс. Наконец, в HPL-AI Frontier также отобрал первенство у Fugaku — 6,86 Эфлопс в вычислениях смешанной точности против 2 Эфлопс. В общем, у Frontier полная победа по всем фронтам, и эту машину можно назвать не только самой быстрой в мире, но первой по-настоящему экзафлопсной системой. Если, конечно, не учитывать неофициальные результаты OceanLight и Tianhe-3 из Поднебесной, которые в TOP500 никто не заявил. Число китайских систем в нынешнем рейтинге осталось прежним (173 шт.), тогда как США «ужались» со 150 до 127 шт. Российских систем в списке всё так же семь. Лидерами по числу поставленных систем остаются Lenovo, HPE и Inspur, а по их суммарной производительности — HPE, Fujitsu и Lenovo. С другой стороны, массовых изменений и не было — в нынешнем списке всего около сорока новых систем. 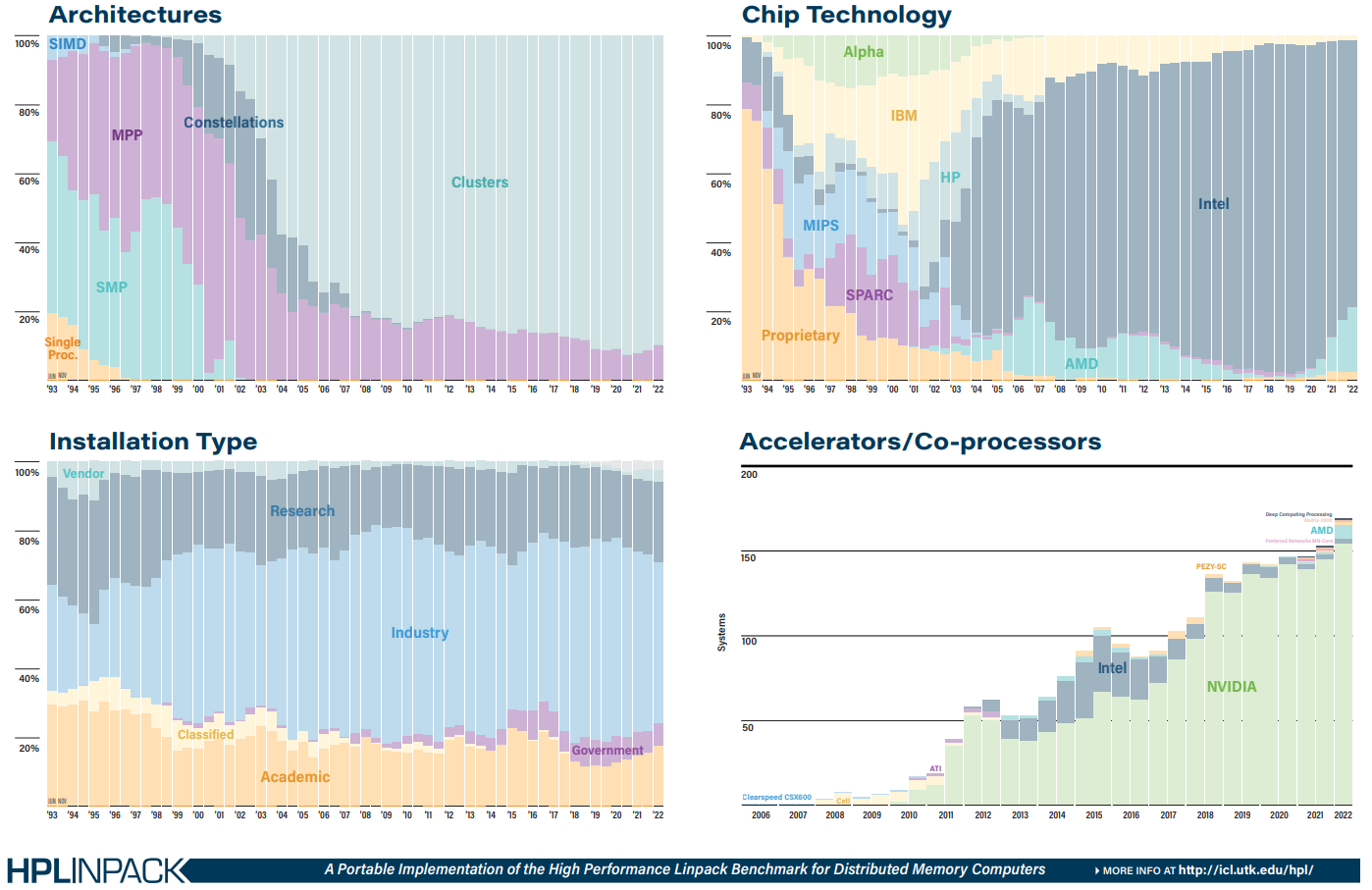
Источник: TOP500 Однако нельзя не отметить явный прогресс AMD — да, чуть больше трёх четвертей машин из списка используют процессоры Intel, но AMD удалось за полгода отъесть около 4 %. При этом AMD EPYC Milan присутствует в более чем трёх десятках систем, а доля Intel Xeon Ice Lake-SP вдвое меньше, хотя эти процессоры появились практически одновременно. Ускорители ожидаемо стали использовать больше — они применяются в 170 системах (было 150). Подавляющее большинство приходится на решения NVIDIA разных поколений, но и для новых Instinct MI250X нашлось место в восьми машинах. Ну а в области интерконнекта Infiniband потихоньку догоняет Ethernet: 226 машин против 196 + ещё 40 с Omni-Path + редкие проприетарные решения. |
|

