Материалы по тегу: grace
|
10.03.2026 [12:52], Сергей Карасёв
QCT представила сервер QuantaEdge EGN77C-2U на базе NVIDIA Grace для инфраструктур AI-RANКомпания Quanta Cloud Technology (QCT) анонсировала сервер QuantaEdge EGN77C-2U, использующий дизайн NVIDIA Aerial RAN Computer Pro (ARC-Pro) и подход Nokia anyRAN. Новинка, как ожидается, позволит телеком-операторам ускорить переход к программно-определяемым сетям 5G и 6G с поддержкой ИИ (AI-RAN). Устройство имеет архитектуру 2U2N — два узла в корпусе 2U. Задействованы чипы NVIDIA Grace, объединяющие 72 вычислительных ядра Arm Neoverse V2 (Armv9). Объём памяти LPDDR5X составляет 512 Гбайт в расчёте на узел. В оснащение каждого узла входят GPU-ускоритель NVIDIA RTX PRO 4500 Blackwell, сетевые адаптеры NVIDIA ConnectX-8 Ethernet SuperNIC, 16 портов 25GbE и два порта 400GbE. «Отрасль вступает в новую эпоху беспроводной связи, изначально основанную на ИИ. С помощью QuantaEdge EGN77C-2U, платформы NVIDIA AI Aerial и программного обеспечения Nokia anyRAN мы формируем единую среду, которая поддерживает бесшовную интеграцию ИИ и сетей радиодоступа следующего поколения», — говорит Майк Янг (Mike Yang), президент QCT. 
Источник изображения: QCT Подчёркивается, что сети, изначально созданные на основе ИИ, предлагают качественно новые возможности в плане производительности, эффективности и функциональности. Программно-определяемая архитектура RAN на базе ИИ поможет справляться с экспоненциальным ростом объёмов передаваемых данных и появлением новых ресурсоёмких рабочих нагрузок. Алгоритмы ИИ поддерживают интеллектуальное управление, что позволяет оптимизировать работу сетей в зависимости от текущей ситуации. В результате, может быть сформирован задел для будущих систем связи 6G, которые обеспечат высочайшие скорости передачи информации при минимальных задержках.
03.03.2026 [10:50], Сергей Карасёв
Supermicro представила серверы на базе NVIDIA Grace для инфраструктур AI-RANSupermicro анонсировала серверы на платформе NVIDIA Grace, ориентированные на применение в составе систем AI-RAN. Дебютировали устройства ARS-111L-FR, ARS-221GL-NR и ARS-111GL-NHR, использующие дизайн NVIDIA Aerial RAN Computer (ARC). Модель ARS-111L-FR выполнена в форм-факторе 1U. Задействован один чип NVIDIA Grace, объединяющий 72 вычислительных ядра Arm Neoverse V2 (Armv9). Говорится об использовании 240 Гбайт памяти LPDDR5X. Возможна установка двух ускорителей NVIDIA L4. Сервер оборудован двумя коннекторами M.2 для NVMe SSD с интерфейсом PCIe 5.0 x4, двумя посадочными местами для SFF-накопителей NVMe, двумя слотами для карт PCIe 5.0 x16 FHFL, одним разъёмом PCIe 5.0 x16 HHHL, портами 1GbE (RJ45), USB 3.2 Gen1 (5 Гбит/с) и mini-DP. Могут устанавливаться два блока питания мощностью до 800 Вт с сертификатом 80 Plus Titanium. 
Источник изображений: Supermicro Устройство ARS-221GL-NR, в свою очередь, заключено в корпус 2U. Используется сборка Grace Superchip, которая состоит из двух кристаллов Grace и чипов памяти LPDDR5x общим объёмом до 960 Гбайт. Во фронтальной части располагаются отсеки для NVMe-накопителей E1.S с возможностью горячей замены. Есть два разъёма M.2 M-key 22110 для SSD с интерфейсом PCIe 5.0 x4 (NVMe), три слота для карт PCIe 5.0 x16 FHFL и два слота для карт PCIe 5.0 x16 FHFL двойной ширины. Реализованы порты 1GbE (RJ45), USB 3.0 Type-A (×2) и mini-DP. Питание обеспечивают три блока на 2000 Вт с сертификатом 80 Plus Titanium.  Сервер ARS-111GL-NHR типоразмера 1U несёт на борту NVIDIA GH200. Могут быть установлены до восьми NVMe-накопителей E1.S и два NVMe SSD формата M.2. Доступны два слота для карт PCIe 5.0 x16 FHFL, порты 1GbE (RJ45), USB 3.0 и mini-DP. За питание отвечают два блока мощностью 2000 Вт с сертификатом 80 Plus Titanium. Все новинки оснащены воздушным охлаждением. 
18.02.2026 [09:19], Сергей Карасёв
Meta✴ развернёт ИИ-инфраструктуру на «миллионах ускорителей NVIDIA Blackwell и Rubin», а также Arm-чипах GraceКомпании NVIDIA и Meta✴ объявили о многолетнем стратегическом партнёрстве, охватывающем локальную, облачную и ИИ-инфраструктуры. В частности, Meta✴ будет использовать в своих дата-центрах решения NVIDIA как для обучения больших языковых моделей (LLM), так и для инференса. Сообщается, что Meta✴ возьмёт на вооружение чипы NVIDIA Grace, которые будут использоваться в серверах, основанных исключительно на CPU-архитектуре (без ускорителей на основе GPU). Изделия Grace, напомним, объединяют 72 вычислительных ядра Armv9 Neoverse V2 (Demeter) с тактовой частотой до 3,35 ГГц и до 480 Гбайт памяти LPDDR5x. Доступна также сборка Grace Superchip, которая состоит из двух кристаллов Grace и чипов памяти LPDDR5x общим объёмом до 960 Гбайт. Meta✴ намерена применять изделия Grace для решения общих задач, а также поддержания работы ИИ-агентов, которым не требуются ИИ-ускорители. Вице-президент NVIDIA Иэн Бак (Ian Buck) отмечает, что решения Grace способны обеспечить вдвое большую производительность на 1 Вт при выполнении операций общего назначения по сравнению с альтернативными платформами. В дальнейшем Meta✴ планирует использовать Arm-процессоры NVIDIA следующего поколения — решения Vera. Крупномасштабные развёртывания систем на базе Vera намечены на 2027 год, что поможет Meta✴ в развитии энергоэффективных вычислений и формировании широкой экосистемы Arm. 
Источник изображения: Meta✴ Кроме того, в рамках партнёрства Meta✴ будет использовать «миллионы ускорителей NVIDIA Blackwell и Rubin». Так, на основе изделий NVIDIA GB300 компании создадут единую среду, охватывающую локальные дата-центры и облачные ресурсы, что позволит упростить операции при одновременном улучшении производительности и масштабируемости. Среди прочего Meta✴ будет применять сетевую платформу NVIDIA Spectrum-X Ethernet и технологию NVIDIA Confidential Computing для защиты данных. «Мы рады расширить партнёрство с NVIDIA с целью создания передовых кластеров на основе платформы Vera Rubin — это позволит предоставить персональный суперинтеллект каждому человеку в мире», — говорит Марк Цукерберг (Mark Zuckerberg), основатель и генеральный директор Meta✴. Нужно отметить, что среди гиперскейлеров только Meta✴ и Oracle используют в своих инфраструктурах сторонние чипы с архитектурой Arm. В то же время AWS, Google и Microsoft развивают собственные Arm-проекты — изделия Graviton, Axion и Cobalt соответственно.
28.10.2025 [20:35], Сергей Карасёв
NVIDIA анонсировала DPU BlueField-4: 800G-порты, ConnectX-9, CPU Grace и PCIe 6.0NVIDIA анонсировала DPU BlueField 4, рассчитанный на использование в составе масштабных инфраструктур ИИ. Устройство оснащено 800G-портами. Новинка в этом отношении вдвое быстрее BlueField-3, дебютировавших ещё в 2021 году. NVIDIA отмечает, что ИИ-фабрики продолжают развиваться с беспрецедентной скоростью. При этом требуется обработка колоссальных массивов структурированных и неструктурированных данных. Для удовлетворения этих потребностей необходимо формирование инфраструктуры нового класса, на которую как раз и ориентирован DPU BlueField-4. Новинка использует программно-определяемую архитектуру для ускорения сетевых операций, функций безопасности и задач хранения данных. По заявлениям NVIDIA, BlueField-4 позволяет трансформировать дата-центры в безопасную интеллектуальную ИИ-инфраструктуру с высокой производительностью. BlueField-4 объединяет 64-ядерный Arm-процессор NVIDIA Grace (114 Мбайт L3-кеш), 128 Гбайт LPDDR5, 512 Гбайт SSD, сетевой адаптер NVIDIA ConnectX-9 SuperNic (1,6 Тбит/с), а также коммутатор PCIe 6.0 с 48 линиями. Новинка будет доступна в виде карты расширения (PCIe 6.0 x16) и в виде модуля для узлов VR NVL144. Утверждается, что по сравнению с BlueField-3 вычислительная производительность выросла в шесть раз. При этом возможно формирование ИИ-фабрик вчетверо большего масштаба. Кроме того, BlueField-4 поддерживает многопользовательскую сеть, быстрый доступ к данным и микросервисы NVIDIA DOCA. Задействована архитектура NVIDIA BlueField Advanced Secure Trusted Resource Architecture. 
Источник изображения: NVIDIA Предполагается, что BlueField-4 возьмут на вооружение такие производители серверов и платформ хранения данных, как Cisco, DDN, Dell Technologies, HPE, IBM, Lenovo, Supermicro, VAST Data и WEKA. О поддержке новинки заявили Armis, Check Point, Cisco, F5, Forescout, Palo Alto Networks и Trend Micro, а также системные интеграторы Accenture, Deloitte и World Wide Technology. Интегрировать BlueField-4 в свои платформы намерены Canonical, Mirantis, Nutanix, Rafay, Red Hat, Spectro Cloud и SUSE. На рынок BlueField-4 поступит в 2026 году как часть экосистемы Vera Rubin.
12.09.2025 [23:30], Владимир Мироненко
Благодаря NVIDIA доля Arm на рынке серверных процессоров достигла 25 %Стремительный рост вычислительных мощностей ЦОД на фоне бума ИИ-технологий способствовал росту доходов не только производителей ускорителей и серверных CPU, но и компании Arm, чью архитектуру они используют в своих чипах, передаёт The Register. В январе Arm заявила о намерении занять 50 % рынка чипов для ЦОД к концу 2025 года Согласно исследованию Dell’Oro Group, во II квартале доля Arm-чипов на рынке серверных CPU составила 25 %, тогда как годом ранее она равнялась 15 %. Движущей силой роста стало внедрение суперускорителей NVIDIA GB200 NVL72 и GB300 NVL72, которые включают 36 Arm-процессоров Grace на базе архитектуры Neoverse V2 (Demeter) с интерфейсом NVLink-C2C. Заказы на поставку чипов NVIDIA расписаны на месяцы вперёд, что обеспечивает гарантированный источник доходов Arm наряду с ростом доли на рынке. Аналитик Dell’Oro Барон Фунг (Baron Fung) сообщил The Register, что ещё год назад рост Arm на рынке серверных процессоров обеспечивался практически исключительно за счёт кастомных CPU, таких как AWS Graviton. Но теперь выручка от продаж Grace сопоставима с доходами от облачных GPU. AWS использует кастомные процессоры на архитектуре Arm с 2018 года. А Microsoft и Google лишь в последние несколько лет начали всерьёз развивать свои Arm-процессорах Cobalt и Axion соответственно, отметил The Register. 
Источник изображения: Arm Рост доли Arm на рынке зависит от того, насколько больше разработчиков чипов выведет свои чипы на рынок серверных процессоров. NVIDIA сейчас работает над новым процессором на базе Arm с использованием кастомных ядер Vera. Qualcomm и Fujitsu также работают над серверными чипами. А появление NVIDIA NVLink Fusion может привести к созданию новых гибридных чипов. По данным Dell’Oro, рост рынка ИИ-технологий также привёл к росту рынка компонентов для серверов и СХД, составившему во II квартале 44 % в годовом исчислении. Продажи SmartNIC и DPU, которые зачастую тоже используют Arm-ядра, примерно удвоились по сравнению с прошлым годом на фоне перехода на Ethernet для вычислительных ИИ-кластеров. Поставки ASIC для обработки ИИ-нагрузок сейчас сопоставимы с объёмами поставок GPU, хотя GPU по-прежнему приносят большую часть доходов.
23.06.2025 [11:58], Сергей Карасёв
Подземный суперкомпьютер Olivia стал самым мощным в НорвегииВ Норвегии введён в эксплуатацию самый мощный в стране суперкомпьютер — система Olivia, созданная корпорацией HPE. Комплекс расположен в дата-центре Лефдаль (Lefdal Mine Datacenter, LMD) на базе бывшего рудника, а для его охлаждения используется холодная вода из близлежащего фьорда. Машина построена на платформе HPE Cray Supercomputing EX (EX254n). В её состав входят 252 узла, каждый из которых содержит два 128-ядерных процессора AMD EPYC 9745 (Turin). В сумме это даёт 64 512 CPU-ядер. Кроме того, задействован GPU-кластер с 76 узлами, оснащёнными четырьмя гибридными суперчипами NVIDIA GH200: таким образом, в общей сложности применены 304 ускорителя. Используется интерконнект HPE Slingshot 11. За хранение данных отвечает система HPE Cray ClusterStor E1000 вместимостью 5,3 Пбайт. В текущей конфигурации GPU-кластер Olivia обладает производительностью 13,2 Пфлопс (FP64) и пиковым быстродействием 16,8 Пфлопс. При этом энергопотребление составляет 219 кВт. Таким образом, машина демонстрирует производительность в 60,274 Гфлопс/Вт. В июньском рейтинге мощнейших суперкомпьютеров мира TOP500 GPU-комплекс Olivia располагается на 117-й позиции, тогда как в списке самых энергоэффективных суперкомпьютеров GREEN500 он занимает 22-ю строку. CPU-блок Olivia занимает 271-е место в рейтинге с фактической и пиковой FP64-производительностью 4,25 и 4,95 Пфлопс соответственно. 
Источник изображения: Sigma2 Olivia эксплуатируется государственной компанией Sigma2. Применять суперкомпьютер планируется для проведения исследований в различных областях, включая изменения климата, здравоохранение, ИИ и пр. Суперкомпьютер обладает возможностями для дальнейшего расширения. В частности, количество ядер CPU может быть увеличено до 119 808. Кроме того, могут быть добавлены ещё 224 ускорителя.
23.06.2025 [09:05], Сергей Карасёв
Половинка суперчипа: Arm-процессор NVIDIA Grace C1 набирает популярность в телеком-оборудовании, СХД и на периферииКомпания NVIDIA отметила рост популярности своего Arm-процессора Grace C1 среди ключевых ODM-партнёров. Изделие применяется в телекоммуникационном оборудовании, СХД, периферийных и облачных решениях, а также в других системах, где первостепенное значение имеет показатель производительности в расчёте на ватт затрачиваемой энергии. Архитектура NVIDIA Grace на сегодняшний день представлена в двух основных конфигурациях: это двухпроцессорный Grace Superchip и новый однопроцессорный Grace CPU C1. Последний содержит 72 ядра Arm Neoverse V2 (Armv9) с поддержкой векторных расширений SVE2. Объём кеша L2 составляет 1 Мбайт в расчёте на ядро. Кроме того, есть 114 Мбайт кеша L3. Тактовая частота достигает 3,1 ГГц. 
Источник изображения: NVIDIA Процессор Grace CPU C1 функционирует в связке со 120, 240 или 480 Гбайт памяти LPDDR5X, пропускная способность которой достигает 512 Гбайт/с (384 Гбайт/с для варианта 480 Гбайт). Реализована поддержка четырёх массивов PCIe 5.0 x16, что даёт в общей сложности 64 линии (поддерживается бифуркация). Показатель TDP составляет до 250 Вт (вместе с памятью). 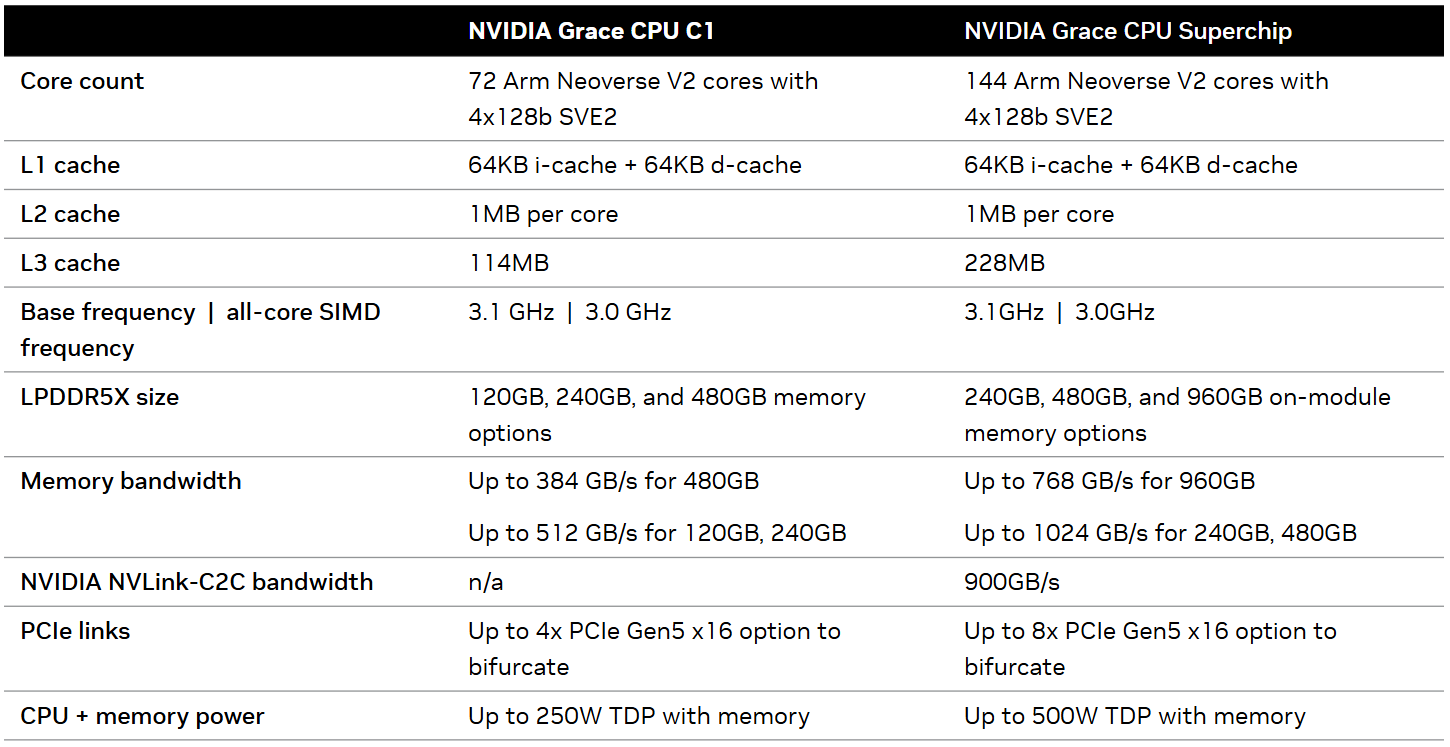
Источник изображения: NVIDIA По заявлениям NVIDIA, системы на базе Grace CPU C1 демонстрируют двукратное повышение производительности на ватт затрачиваемой энергии по сравнению с сопоставимыми по классу продуктами, построенными на чипах с архитектурой х86. Устройства на основе Grace CPU C1 проектируют такие компании, как Foxconn, Jabil, Lanner, MiTAC, Supermicro и QCT. В телекоммуникационной отрасли, как отмечается, востребован компьютер NVIDIA Compact Aerial RAN, объединяющий процессор Grace CPU C1 с ускорителем NVIDIA L4 и адаптером NVIDIA ConnectX-7 SmartNIC. Кроме того, Grace CPU C1 применяется в системах хранения WEKA и Supermicro.
01.04.2025 [14:53], Владимир Мироненко
Arm намерена занять 50 % рынка чипов для ЦОД к концу 2025 года — NVIDIA ей в этом поможетСогласно прогнозу Arm Holdings, к концу 2025 года доля процессоров с Arm-архитектурой на мировом рынке CPU для ЦОД вырастет до 50 % с 15 % в 2024 году. В интервью агентству Reuters Мохамед Авад (Mohamed Awad), руководитель подразделения инфраструктурных решений Arm, отметил, что благодаря более низкому энергопотреблению, чем у процессоров Intel и AMD, Arm-чипы становятся все более популярными среди компаний, занимающихся облачными вычислениями. Журналист ресурса The Register обратился в Arm Holdings с просьбой пояснить, благодаря чему компания рассчитывает добиться столь стремительного роста доли на рынке. Как сообщили в британской компании, принадлежащей японскому конгломерату Softbank, её прогноз в значительной степени основан на росте поставок ИИ-серверов. Мохамед Авад сообщил The Register, что в течение следующих нескольких лет, как ожидает компания, продажи ИИ-серверов вырастут на 300 %. «Для этого увеличения энергоэффективность больше не является конкурентным преимуществом — это базовое отраслевое требование. Именно здесь вычислительная платформа Arm Neoverse является явным лидером и предпочтительной платформой для ведущих партнёров отрасли, включая AWS, Google, Microsoft и NVIDIA», — заявил он. 
Источник изображения: Arm Holdings Как утверждает Arm Holdings, Arm-архитектура всё чаще используется гиперскейлерами AWS, Google, Microsoft в своих чипах. По оценкам Bernstein Research, в 2023 году почти 10 % серверов по всему миру содержат Arm-процессоры приложений в качестве «основных мозгов», и половина из них была развёрнута Amazon, сообщившей, что у нее в облаке используется более 2 млн чипов Graviton собственной разработки. В свою очередь, Google объявила в 2024 году о выпуске собственного процессора Axion на базе Neoverse V2 для своих ЦОД, а Microsoft сообщила в конце прошлого года об общедоступности в облаке Azure инстансов с использованием процессоров собственной разработки Cobalt 100. Расширение использования этими провайдерами облачных услуг Arm-процессоров может объяснить часть роста, который Авад прогнозирует на этот год, но продукты NVIDIA также, вероятно, составят значительную долю, полагает The Register. Например, система DGX GB200 NVL72 включает 36 процессора NVIDIA Grace и 72 ускорителя Blackwell B200, что составляет 2592 ядра Arm Neoverse V2, и они, вероятно, будут востребованы в этом году, отметил ресурс. Также не следует забывать о других решениях для ЦОД, которые имеют ядра на базе Arm-архитектуры, такие как SmartNIC и DPU — BlueField-3 от NVIDIA, а также карты Nitro в серверах AWS.
20.03.2025 [15:58], Сергей Карасёв
Supermicro анонсировала петабайтное 1U-хранилище All-Flash на базе Arm-суперчипа NVIDIA GraceКомпания Supermicro представила сервер ARS-121L-NE316R в форм-факторе 1U, на базе которого могут формироваться системы хранения данных петабайтной вместимости. В основу новинки положен суперчип NVIDIA Grace со 144 ядрами Arm Neoverse V2 и 960 Гбайт памяти LPDDR5x. Устройство оборудовано 16 фронтальными отсеками для NVMe-накопителей E3.S 1T. При использовании SSD ёмкостью 61,44 Тбайт суммарная вместимость может достигать 983 Тбайт. При этом до 40 серверов могут быть установлены в одну стойку, что обеспечит 39,3 Пбайт «сырой» ёмкости. Новинка располагает двумя внутренними посадочными местами для M.2 NVMe SSD и двумя слотами PCIe 5.0 x16 для карт типоразмера FHHL. Присутствуют сетевой порт управления 1GbE (RJ45), порт USB 3.0 Type-A и разъём mini-DP. Габариты сервера составляют 772,15 × 438,4 × 43,6 мм, масса — 19,8 кг без установленных накопителей. 
Источник изображения: Supermicro Питание обеспечивают два блока мощностью 1600 Вт с сертификатом 80 Plus Titanium. Применена система воздушного охлаждения с восемью съёмными вентиляторами диаметром 40 мм. Диапазон рабочих температур — от +10 до +35 °C. При необходимости сервер может быть оснащён двумя DPU NVIDIA BlueField-3 или двумя адаптерами ConnectX-8. Система подходит для поддержания рабочих нагрузок с интенсивным обменом данными, таких как ИИ-инференс, аналитика и пр. Отмечается, что при создании новинки Supermicro тесно сотрудничала с NVIDIA и WEKA (разработчик платформ хранения данных).
07.01.2025 [16:10], Владимир Мироненко
NVIDIA представила «персональный ИИ-суперкомпьютер» Project DIGITS на базе гибридного ускорителя GB10Компания NVIDIA представила «персональный ИИ-суперкомпьютер» Project DIGITS — это самая компактная аппаратная платформа на базе суперчипов Grace Blackwell. Разработанная для исследователей ИИ, специалистов по данным и студентов система поставляется с полным набором ПО для создания, тюнинга и инференса ИИ-моделей. Это позволяет локально создавать и дорабатывать модели, а затем разворачивать их в облаке или ЦОД. Project DIGITS будет доступен в мае по цене от $3000. Project DIGITS оснащён чипом GB10 с FP4-производительностью до 1 Пфлопс, разработанным в партнёрстве с MediaTek. GB10 включает ускоритель Blackwell, подключённый посредством NVLink-C2C к 20-ядерному Arm-процессору Grace, 128 Гбайт унифицированной когерентной памяти LPDDR5x и 4-Тбайт NVMe SSD. В оснащение также входит адаптеры Wi-Fi, Bluetooth и Ethernet (RJ45). На задней стенке есть видеовыход HDMI и четыре разъёма USB-C. По словам компании, Project DIGITS позволит запускать модели размером до 200 млрд параметров, а при объединении двух таких систем посредством NIC ConnectX (два порта SFP28) возможен запуск моделей с 405 млрд параметров. 
Источник изображений: NVIDIA Работает новинка под управлением NVIDIA DGX OS — специализированной сборки Ubuntu Linux, оптимизированной для работы с ИИ-нагрузками. Пользователи Project DIGITS получат доступ к обширной библиотеке ПО NVIDIA AI, включая комплекты для разработки ПО, инструменты оркестрации, фреймворки и модели, доступные в каталоге NVIDIA NGC и на портале NVIDIA Developer. Разработчики смогут настраивать модели с помощью фреймворка NVIDIA NeMo, использовать в работе с данными библиотеки NVIDIA RAPIDS и задействовать популярные программные платформы, включая PyTorch, Python и Jupyter notebooks. 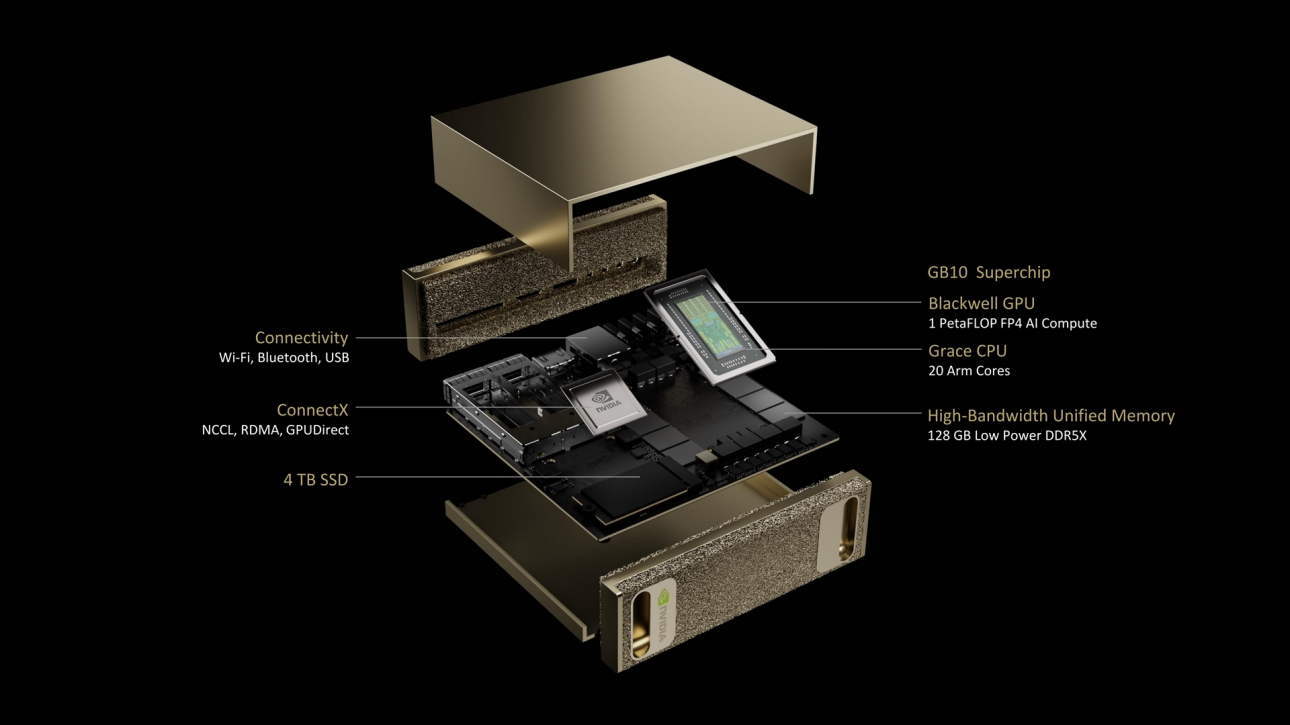 Для создания агентских приложений AI можно будет использовать NVIDIA Blueprints и микросервисы NVIDIA NIM, доступные для исследований, разработки и тестирования в рамках программы NVIDIA Developer Program. Благодаря единой архитектуре Grace Blackwell предприятия и индивидуальные исследователи смогут прототипировать, настраивать и тестировать ИИ-модели на локальных системах Project DIGITS с последующим развёртыванием в NVIDIA DGX Cloud, облачных инстансах или собственной инфраструктуре ЦОД. |
|

