Материалы по тегу: grace
|
28.12.2024 [01:55], Владимир Мироненко
Дороже, но втрое эффективнее: NVIDIA готовит ускорители GB300 с 288 Гбайт HBM3E и TDP 1,4 кВтNVIDIA выпустила новые ускорители GB300 и B300 всего через шесть месяцев после выхода GB200 и B200. И это не минорное обновление, как может показаться на первый взгляд — появление (G)B300 приведёт к серьёзной трансформации отрасли, особенно с учётом значительных улучшений в инференсе «размышляющих» моделей и обучении, пишет SemiAnalysis. При этом с переходом на B300 вся цепочка поставок меняется, и от этого кто-то выиграет, а кто-то проиграет. Конструкция вычислительного кристалла B300 (ранее известного как Blackwell Ultra), изготавливаемого с использованием кастомного техпроцесса TSMC 4NP. Благодаря этому он обеспечивает на 50 % больше Флопс (FP4) по сравнению с B200 на уровне продукта в целом. Часть прироста производительности будет получена за счёт увеличения TDP, достигающим 1,4 кВт и 1,2 кВт для GB300 и B300 HGX соответственно (по сравнению с 1,2 кВт и 1 кВт для GB200 и B200). Остальное повышение производительности связано с архитектурными улучшениями и оптимизациями на уровне системы, такими как динамическое распределение мощности между CPU и GPU. Кроме того, в B300 применяется память HBM3E 12-Hi, а не 8-Hi, ёмкость которой выросла до 288 Гбайт. Однако скорость на контакт осталась прежней, так что суммарная пропускная способность памяти (ПСП) по-прежнему составляет 8 Тбайт/с. В качестве системной памяти будут применяться модули LPCAMM. Разница в производительности и экономичности из-за увеличения объёма HBM намного больше, чем кажется. Усовершенствования памяти имеют решающее значение для обучения и инференса больших языковых моделей (LLM) в стиле OpenAI O3, поскольку более длинные последовательности токенов негативно влияют на скорость обработки и задержку. 
Источник изображения: NVIDIA На примере обновления H100 до H200 хорошо видно, как память влияет на производительность ускорителя. Более высокая ПСП (H200 — 4,8 Тбайт/с, H100 — 3,35 Тбайт/с) в целом улучшила интерактивность в инференсе на 43 %. А большая ёмкость памяти снизила объём перемещаемых данных и увеличила допустимый размер KVCache, что увеличило количество генерируемых токенов в секунду втрое. Это положительно сказывается на пользовательском опыте, что особенно важно для всё более сложных и «умных» моделей, которые могут приносить больше дохода с каждого ускорителя. Валовая прибыль от использования передовых моделей превышает 70 %, тогда как для отстающих моделей в конкурентной open source среде она составляет менее 20 %. 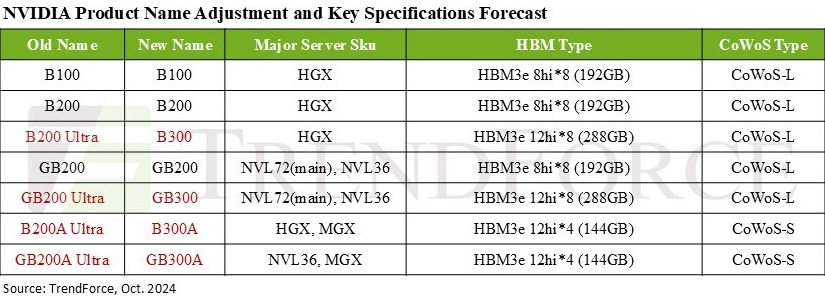
Источник изображения: TrendForce Однако одного наращивания скорости и памяти, как это делает AMD в Instinct MI300X (192 Гбайт), MI325X и MI355X (256 Гбайт и 288 Гбайт соответственно), мало. И дело не в том, что забагованное ПО компании не позволяет раскрыть потенциал ускорителей, а в особенности общения ускорителей между собой. Только NVIDIA может предложить коммутируемое соединение «все ко всем» посредством NVLink. В GB200 NVL72 все 72 ускорителя могут совместно работать над одной и той же задачей, что повышает интерактивность, снижая задержку для каждой цепочки размышлений и в то же время увеличивая их максимальную длину. На практике NVL72 — единственный способ увеличить длину инференса до более чем 100 тыс. токенов и при этом экономически эффективный, говорит SemiAnalysis. По оценкам, GB300 NVL72 обойдётся заказчиками минимум в $7,5 млн, тогда как GB200 NVL72 стоил порядка $3 млн.
05.12.2024 [16:14], Сергей Карасёв
Запущен британский Arm-суперкомпьютер Isambard 3 с суперчипами NVIDIA GraceВ Великобритании введён в эксплуатацию суперкомпьютер Isambard 3, предназначенный для ресурсоёмких приложений ИИ и задач НРС. Реализация проекта обошлась приблизительно в £10 млн, или примерно $12,7 млн. Машина пришла на смену комплексу Isambard 2, который отправился на покой в сентябре нынешнего года. Система Isambard 3 создана в рамках сотрудничества между исследовательским консорциумом GW4 Alliance, в который входят университеты Бата, Бристоля, Кардиффа и Эксетера, а также компаниями HPE, NVIDIA и Arm. Суперкомпьютер назван в честь британского инженера Изамбарда Кингдома Брюнеля, внесшего значимый вклад в Промышленную революцию. Полностью технические характеристики Isambard 3 не раскрываются. Известно, что в основу машины положены 384 суперпроцессорами NVIDIA Grace со 144 ядрами (2 × 72) Arm Neoverse V2 (Demeter), общее количество которых превышает 55 тыс. Задействована высокопроизводительная СХД HPE, которая обеспечивает расширенные IO-возможности с интеллектуальным распределением данных по нескольким уровням. Благодаря этому достигается эффективная обработка задач с интенсивным использованием информации, таких как обучение моделей ИИ. Известно также, что в составе комплекса применяется фирменный интерконнект HPE Slingshot, а в качестве внутреннего интерконнекта служит технология NVLink-C2C, которая в семь раз быстрее PCIe 5.0. Каждый узел суперкомпьютера содержит один суперчип Grace и сетевой адаптер Cassini с пропускной способностью до 200 Гбит/с. Объём системной памяти составляет 2 × 120 Гбайт (240 Гбайт). 
Источник изображения: GW4 Отмечается, что Isambard 3 демонстрирует в шесть раз более высокую производительность и в шесть раз лучшую энергоэффективность по сравнению с Isambard 2. Пиковое быстродействие FP64 у Isambard 3 достигает 2,7 Пфлопс при энергопотреблении менее 270 кВт. Применять новый суперкомпьютер планируется для таких задач, как проектирование оптимальной конфигурации ветряных электростанций на суше и воде, моделирование термоядерных реакторов, исследования в сфере здравоохранения и пр. Суперкомпьютер расположен в автономном дата-центре с системой самоохлаждения HPE Performance Optimized Data Center (POD) в Национальном центре композитов в Научном парке Бристоля и Бата. Там же ведётся монтаж ИИ-комплекса Isambard-AI стоимостью £225 млн ($286 млн), который должен стать самым быстрым и мощным суперкомпьютером в Великобритании. Проект Isambard-AI реализуется в несколько этапов. Первая фаза предполагает монтаж 42 узлов, каждый из которых несёт на борту четыре суперчипа NVIDIA GH200 Grace Hopper и 4 × 120 Гбайт памяти для CPU (доступно 460 Гбайт — по 115 Гбайт на CPU), а также 4 × 96 Гбайт памяти для GPU (H100). В ходе второй фазы будут добавлены 1320 узлов, насчитывающих в сумме 5280 суперчипов NVIDIA GH200 Grace Hopper. Кроме того, в состав Isambard 3 входит экспериментальный x86-модуль MACS (Multi-Architecture Comparison System), включающий сразу восемь разновидностей узлов на базе процессоров AMD EPYC и Intel Xeon нескольких поколений, часть из них также имеет ускорители AMD Instinct MI100 и NVIDIA H100/A100. Все они объединены 200G-интерконнектом HPE Slingshot.
18.11.2024 [21:30], Сергей Карасёв
Счетверённые H200 NVL и 5,5-кВт GB200 NVL4: NVIDIA представила новые ИИ-ускорителиКомпания NVIDIA анонсировала ускоритель H200 NVL, выполненный в виде двухслотовой карты расширения PCIe. Изделие, как утверждается, ориентировано на гибко конфигурируемые корпоративные системы с воздушным охлаждением для задач ИИ и НРС. Как и SXM-вариант NVIDIA H200, представленный ускоритель получил 141 Гбайт памяти HBM3e с пропускной способностью 4,8 Тбайт/с. При этом максимальный показатель TDP снижен с 700 до 600 Вт. Четыре карты могут быть объединены интерконнкетом NVIDIA NVLink с пропускной способностью до 900 Гбайт/с в расчёте на GPU. При этом к хост-системе ускорители подключаются посредством PCIe 5.0 x16. В один сервер можно установить две такие связки, что в сумме даст восемь ускорителей H200 NVL и 1126 Гбайт памяти HBM3e, что весьма существенно для рабочих нагрузок инференса. Заявленная производительность FP8 у карты H200 NVL достигает 3,34 Пфлопс против примерно 4 Пфлопс у SXM-версии. Быстродействие FP32 и FP64 равно соответственно 60 и 30 Тфлопс. Производительность INT8 — до 3,34 Пфлопс. Вместе с картами в комплект входит лицензия на программную платформа NVIDIA AI Enterprise. 
Источник изображения: NVIDIA Кроме того, NVIDIA анонсировала ускорители GB200 NVL4 с жидкостным охлаждением. Они включает два суперчипа Grace-Backwell, что даёт два 72-ядерных процессора Grace и четыре ускорителя B100. Объём памяти LPDDR5X ECC составляет 960 Гбайт, памяти HBM3e — 768 Гбайт. Задействован интерконнект NVlink-C2C с пропускной способностью до 900 Гбайт/с, при этом всем шесть чипов CPU-GPU находятся в одном домене. 
Источник изображения: NVIDIA Система GB200 NVL4 наделена двумя коннекторами M.2 22110/2280 для SSD с интерфейсом PCIe 5.0, восемью слотами для NVMe-накопителей E1.S (PCIe 5.0), шестью интерфейсами для карт FHFL PCIe 5.0 x16, портом USB, сетевым разъёмом RJ45 (IPMI) и интерфейсом Mini-DisplayPort. Устройство выполнено в форм-факторе 2U с размерами 440 × 88 × 900 мм, а его масса составляет 45 кг. TDP настраиваемый — от 2,75 кВт до 5,5 кВт.
10.09.2024 [14:55], Сергей Карасёв
TACC ввёл в эксплуатацию Arm-суперкомпьютер Vista на базе NVIDIA GH200 для ИИ-задачТехасский центр передовых вычислений (TACC) при Техасском университете в Остине (США) объявил о том, что мощности нового НРС-комплекса Vista полностью доступны открытому научному сообществу. Суперкомпьютер предназначен для решения ресурсоёмких задач, связанных с ИИ. Формальный анонс машины Vista состоялся в ноябре 2023 года. Тогда говорилось, что Vista станет связующим звеном между существующим суперкомпьютером TACC Frontera и будущей системой TACC Horizon, проект которой финансируется Национальным научным фондом (NSF). Vista состоит из двух ключевых частей. Одна из них — кластер из 600 узлов на гибридных суперчипах NVIDIA GH200 Grace Hopper, которые содержат 72-ядерный Arm-процессор NVIDIA Grace и ускоритель H100/H200. Обеспечивается производительность на уровне 20,4 Пфлопс (FP64) и 40,8 Пфлопс на тензорных ядрах. Каждый узел содержит локальный накопитель вместимостью 512 Гбайт, 96 Гбайт памяти HBM3 и 120 Гбайт памяти LPDDR5. Интероконнект — Quantum 2 InfiniBand (400G). Второй раздел суперкомпьютера объединяет 256 узлов с процессорами NVIDIA Grace CPU Superchip, содержащими два кристалла Grace в одном модуле (144 ядра). Узлы укомплектованы 240 Гбайт памяти LPDDR5 и накопителем на 512 Гбайт. Интерконнект — Quantum 2 InfiniBand (200G). Узлы произведены Gigabyte, а за интеграцию всей системы отвечала Dell. 
Источник изображения: TACC Общее CPU-быстродействие Vista находится на отметке 4,1 Пфлопс. В состав комплекса входит NFS-хранилише VAST Data вместимостью 30 Пбайт. Суперкомпьютер будет использоваться для разработки и применения решений на основе генеративного ИИ в различных секторах, включая биологические науки и здравоохранение.
27.07.2024 [23:44], Алексей Степин
Не так просто и не так быстро: учёные исследовали особенности работы памяти и NVLink C2C в NVIDIA Grace HopperГибридный ускоритель NVIDIA Grace Hopper объединяет CPU- и GPU-модули, которые связаны интерконнектом NVLink C2C. Но, как передаёт HPCWire, в строении и работе суперчипа есть некоторые нюансы, о которых рассказали шведские исследователи. Им удалось замерить производительность подсистем памяти Grace Hopper и интерконнекта NVLink в реальных сценариях, дабы сравнить полученные результаты с характеристиками, заявленными NVIDIA. Напомним, для интерконнекта изначально заявлена скорость 900 Гбайт/с, что в семь раз превышает возможности PCIe 5.0. Память HBM3 в составе GPU-части имеет ПСП до 4 Тбайт/с, а вариант с HBM3e предлагает уже до 4,9 Тбайт/с. Процессорная часть (Grace) использует LPDDR5x с ПСП до 512 Гбайт/с. В руках исследователей оказалась базовая версия Grace Hopper с 480 Гбайт LPDDR5X и 96 Гбайт HBM3. Система работала под управлением Red Hat Enterprise Linux 9.3 и использовала CUDA 12.4. В бенчмарке STREAM исследователям удалось получить следующие показатели ПСП: 486 Гбайт/с для CPU и 3,4 Тбайт/с для GPU, что близко к заявленным характеристиками. Однако результат скорость NVLink-C2C составила всего 375 Гбайт/с в направлении host-to-device и лишь 297 Гбайт/с в обратном направлении. Совокупно выходит 672 Гбайт/с, что далеко от заявленных 900 Гбайт/с (75 % от теоретического максимума). 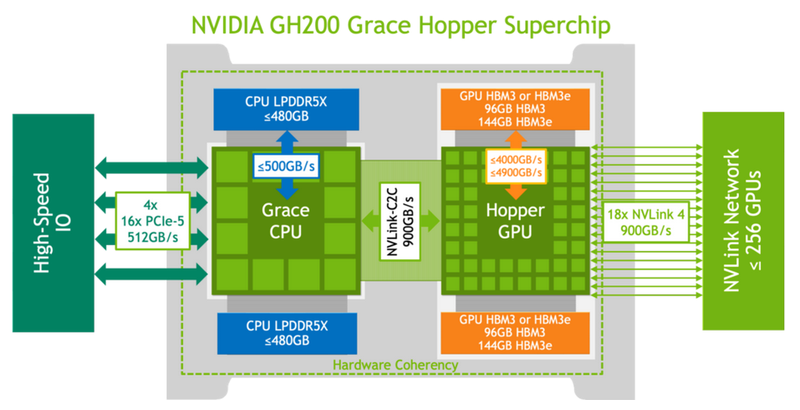
Источник: NVIDIA Grace Hopper в силу своей конструкции предлагает два вида таблицы для страниц памяти: общесистемную (по умолчанию страницы размером 4 Кбайт или 64 Кбайт), которая охватывает CPU и GPU, и эксклюзивную для GPU-части (2 Мбайт). При этом скорость инициализации зависит от того, откуда приходит запрос. Если инициализация памяти происходит на стороне CPU, то данные по умолчанию помещаются в LPDDR5x, к которой у GPU-части есть прямой доступ посредством NVLink C2C (без миграции), а таблица памяти видна и GPU, и CPU. 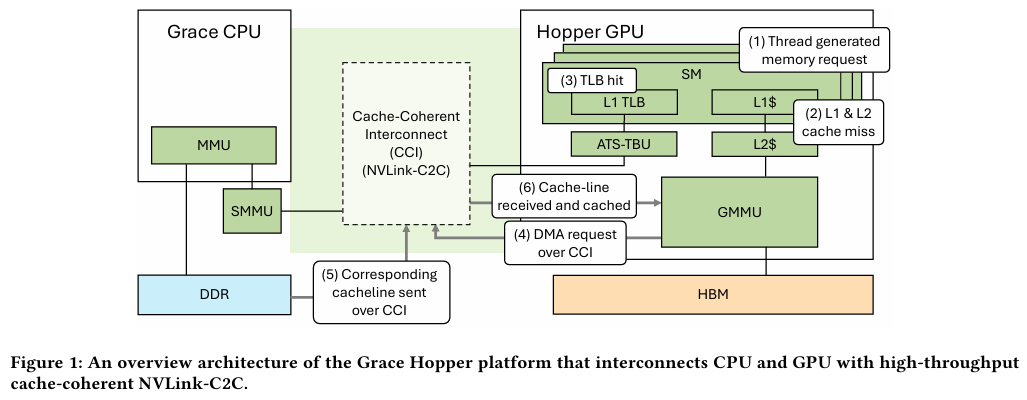
Источник: arxiv.org Если же памятью управляет не ОС, а CUDA, то инициализацию можно сразу организовать на стороне GPU, что обычно гораздо быстрее, а данные поместить в HBM. При этом предоставляется единое виртуальное адресное пространство, но таблиц памяти две, для CPU и GPU, а сам механизм обмена данными между ними подразумевает миграцию страниц. Впрочем, несмотря на наличие NVLink C2C, идеальной остаётся ситуация, когда GPU-нагрузке хватает HBM, а CPU-нагрузкам достаточно LPDDR5x. 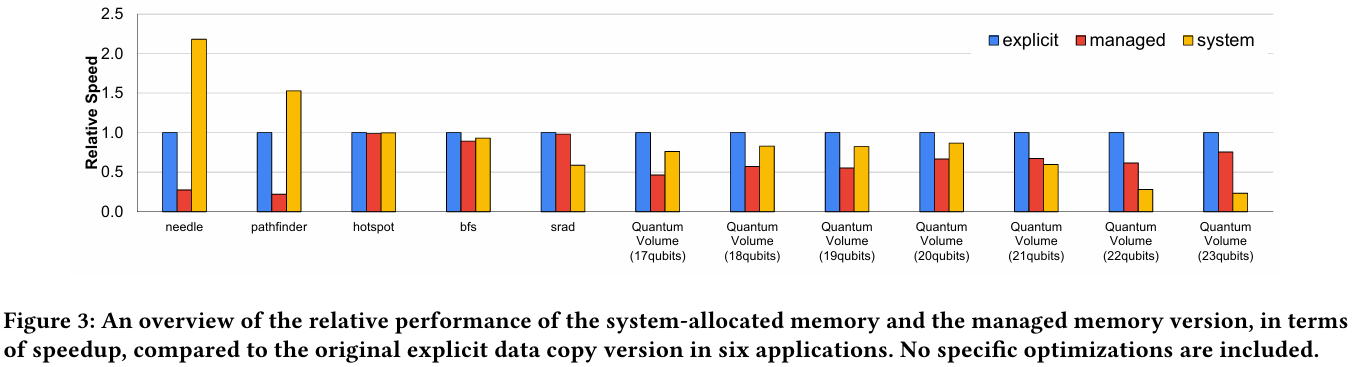
Источник: arxiv.org Также исследователи затронули вопрос производительности при использовании страниц памяти разного размера. 4-Кбайт страницы обычно используются процессорной частью с LPDDR5X, а также в тех случаях, когда GPU нужно получить данные от CPU через NVLink-C2C. Но как правило в HPC-нагрузках оптимальнее использовать 64-Кбайт страницы, на управление которыми расходуется меньше ресурсов. Когда же доступ в память хаотичен и непостоянен, страницы размером 4 Кбайт позволяют более тонко управлять ресурсами. В некоторых случаях возможно двукратное преимущество в производительности за счёт отсутствия перемещения неиспользуемых данных в страницах объёмом 64 Кбайт. В опубликованной работе отмечается, что для более глубокого понимания механизмов работы унифицированной памяти у гетерогенных решений, подобных Grace Hopper, потребуются дальнейшие исследования.
25.07.2024 [10:12], Владимир Мироненко
AMD показала превосходство чипов EPYC над Arm-процессорами NVIDIA Grace в серии бенчмарков, но не всё так простоAMD провела серию тестов, чтобы доказать преимущество своих нынешних процессоров AMD EPYC над Arm-процессорами NVIDIA Grace Superchip. Как отметила AMD, в связи с растущей востребованностью ЦОД некоторые компании начали предлагать альтернативные варианты процессоров, «часто обещающие преимущества по сравнению с обычными решениями x86». «Обычно их представляют с большой помпой и заявлениями о значительных преимуществах в производительности и энергоэффективности по сравнению с x86. Слишком часто эти утверждения довольно сложно воплотить в реальные сценарии конкурентной рабочей нагрузки — с использованием устаревших, недостаточно оптимизированных альтернатив или плохо документированных предположений», — отметила AMD. С помощью серии стандартных отраслевых тестов AMD, по её словам, продемонстрировала преимущество EPYC над решениями на базе Arm. «Благодаря проверенной архитектуре x86-64, впервые разработанной AMD, вы можете получить всё это без дорогостоящего портирования или изменений в архитектуре», — подчеркнула компания. Иными словами, тесты AMD могут быть просто попыткой развеять опасения, что архитектура x86 «выдыхается» и что Arm берёт верх. 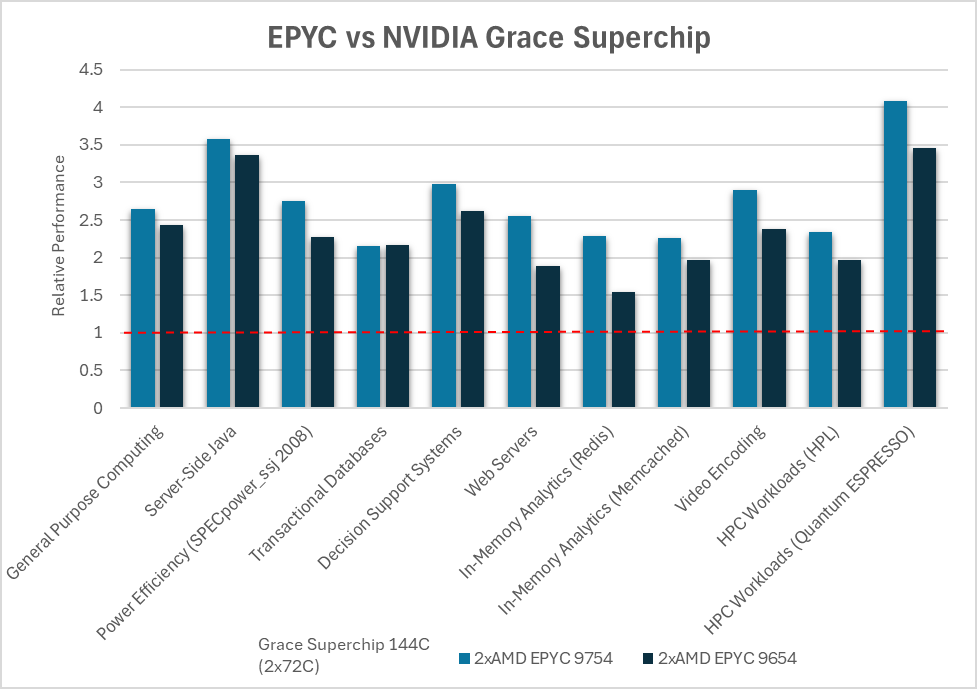
Источник изображений: AMD AMD сравнила производительность AMD EPYC и NVIDIA Grace CPU в десяти ключевых рабочих нагрузках, охватывающих вычисления общего назначения, Java, транзакционные базы данных, системы поддержки принятия решений, веб-серверы, аналитику, кодирование видео и нагрузки HPC. Согласно представленному выше графику, 128-ядерный процессор EPYC 9754 (Bergamo) и 96-ядерный EPYC 9654 (Genoa) более чем вдвое превзошли NVIDIA Grace CPU Superchip по производительности при обработке вышеуказанных нагрузок. Напомним, что Grace CPU Superchip содержит два 72-ядерных кристалла Grace, использующих ядра Arm Neoverse V2, соединённых шиной NVLink C2C с пропускной способность 900 Гбайт/с, и работает как единый 144-ядерный процессор. В свою очередь, ресурс The Register отметил, что речь идёт о версии с 480 Гбайт памяти LPDDR5x, а не с 960 Гбайт. 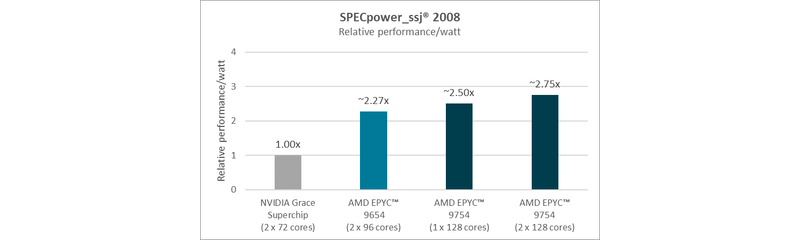 В тесте SPECpower-ssj2008, по данным AMD, одно- и двухсокетные системы на базе AMD EPYC 9754 превосходят систему NVIDIA Grace CPU Superchip по производительности на Вт примерно в 2,50 раза и 2,75 раза соответственно, а двухсокетная система AMD EPYC 9654 — примерно в 2,27 раза. Помимо производительности и эффективности, ещё одним важным фактором для операторов ЦОД является совместимость, сообщила AMD. По оценкам, во всем мире существуют триллионы строк программного кода, большая часть которого написана для архитектуры x86. EPYC основаны на архитектуре x86-64, впервые разработанной AMD, и эта архитектура является наиболее широко используемой и поддерживаемой в индустрии ЦОД, заявила компания, добавив, что изменения в архитектуре сложны, дороги и чреваты риском. AMD также отметила, что экосистема AMD EPYC включает более 250 различных конструкций серверов и поддерживает около 900 уникальных облачных инстансов. Также процессоры AMD EPYC установили более 300 мировых рекордов производительности и эффективности в широком спектре тестов. В то же время лишь немногие Arm-решения доказали свою эффективность. В свою очередь, ресурс The Register отметил, что ситуация не так проста, как AMD пытается всех убедить. В феврале сайт The Next Platform сообщил, что исследователи из университетов Стоуни-Брук и Буффало сравнили данные о производительности суперчипа NVIDIA Grace CPU Superchip и нескольких процессоров x86, предоставленные несколькими НИИ и разработчиком облачных решений. 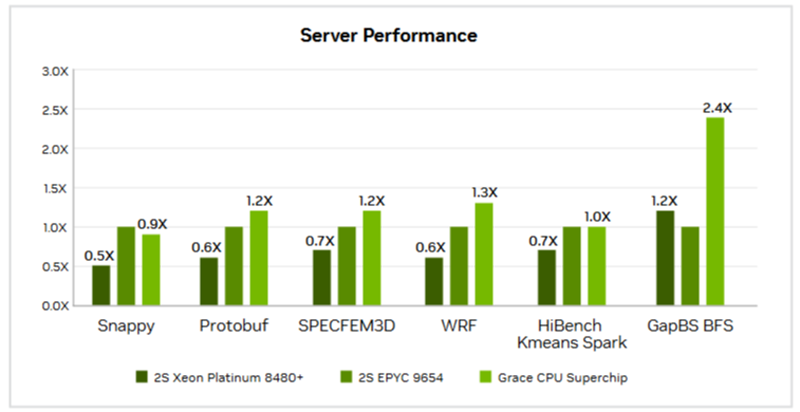
Источник изображений: NVIDIA Большинство этих тестов были ориентированы на HPC, включая Linpack, HPCG, OpenFOAM и Gromacs. И хотя производительность системы Grace сильно различалась в разных тестах, в худшем случае она находилась где-то между Intel Skylake-SP и Ice Lake-SP, превосходя AMD Milan и находясь в пределах досягаемости от показателей Xeon Max. Данные результаты отражают тот факт, что самые мощные процессоры AMD EPYC Genoa и Bergamo могут превзойти первый процессор NVIDIA для ЦОД — при правильно выбранном тесте. 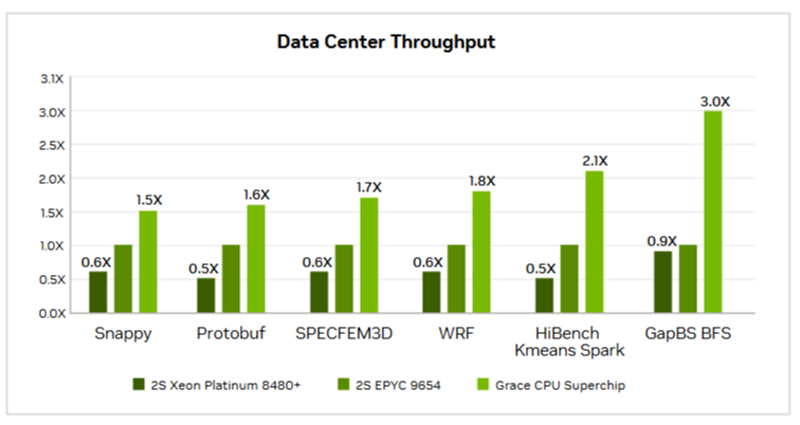 В техническом описании Grace CPU Superchip компания NVIDIA сообщает, что этот чип обеспечивает от 0,9- до 2,4-кратного увеличения производительности по сравнению с двумя 96-ядерными EPYC 9654 и предлагает до трёх раз большую пропускную способность в различных облачных и HPC-сервисах. NVIDIA отмечает, что Superchip предназначен для «обработки массивов для получения интеллектуальных данных с максимальной энергоэффективностью», говоря об ИИ, анализе данных, нагрузках облачных гиперскейлеров и приложениях HPC.
19.03.2024 [01:00], Игорь Осколков
NVIDIA B200, GB200 и GB200 NVL72 — новые ускорители на базе архитектуры BlackwellNVIDIA представила сразу несколько ускорителей на базе новой архитектуры Blackwell, названной в честь американского статистика и математика Дэвида Блэквелла. На смену H100/H200, GH200 и GH200 NVL32 на базе архитектуры Hopper придут B200, GB200 и GB200 NVL72. Все они, как говорит NVIDIA, призваны демократизировать работу с большими языковыми моделями (LLM) с триллионами параметров. В частности, решения на базе Blackwell будут до 25 раз энергоэффективнее и экономичнее в сравнении с Hopper. В разреженных FP4- и FP8-вычислениях производительность B200 достигает 20 и 10 Пфлопс соответственно. Но без толики технического маркетинга не обошлось — показанные результаты достигнуты не только благодаря аппаратным улучшениям, но и программным оптимизациям. Это ни в коей мере не умаляет их важности и полезности, но затрудняет прямое сравнение с конкурирующими решениями. В общем, появление Blackwell стоит рассматривать не как очередное поколение ускорителей, а как расширение всей экосистемы NVIDIA. В Blackwell компания использует тайловую (чиплетную) компоновку — два тайла объединены 2,5D-упаковкой CoWoS-L и на двоих имеют 208 млрд транзисторов, изготовленных по техпроцессу TSMC 4NP. В одно целое со всех точек зрения их объединяет новый интерконнект NV-HBI с пропускной способностью 10 Тбайт/с, а дополняют их восемь стеков HBM3e-памяти ёмкостью до 192 Гбайт с агрегированной пропускной способностью до 8 Тбайт/с. Такой же объём памяти предлагает и Instinct MI300X, но с меньшей ПСП (5,3 Тбайт/с), хотя это скоро изменится. FP8-производительность в разреженных вычислениях у решения AMD составляет 5,23 Пфлопс, но зато компания не забывает и про FP64 в отличие от NVIDIA. 
Источник изображений: NVIDIA Одними из ключевых нововведений, отвечающих за повышение производительности, стали новые Tensor-ядра и второе поколение механизма Transformer Engine, который научился заглядывать внутрь тензоров, ещё более тонко подбирая необходимую точность вычислений, что влияет и на скорость обучения с инференсом, и на максимальный объём модели, умещающейся в памяти ускорителя. 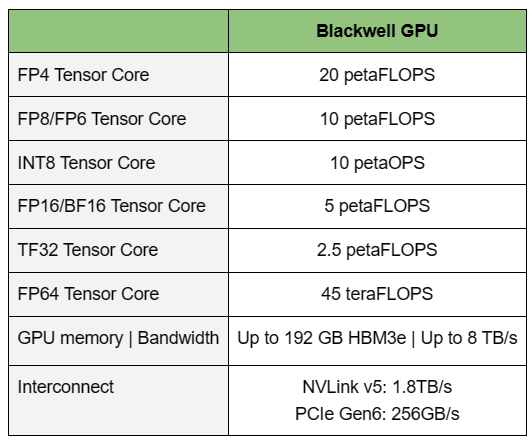 Теперь NVIDIA намекает на то, что обучение можно делать в FP8-формате, а для инференса хватит и FP4. Всё это без потери качества. Но вообще Blackwell поддерживает FP4/FP6/FP8, INT8, BF16/FP16, TF32 и FP64. И только для последнего нет поддержки разреженных вычислений. 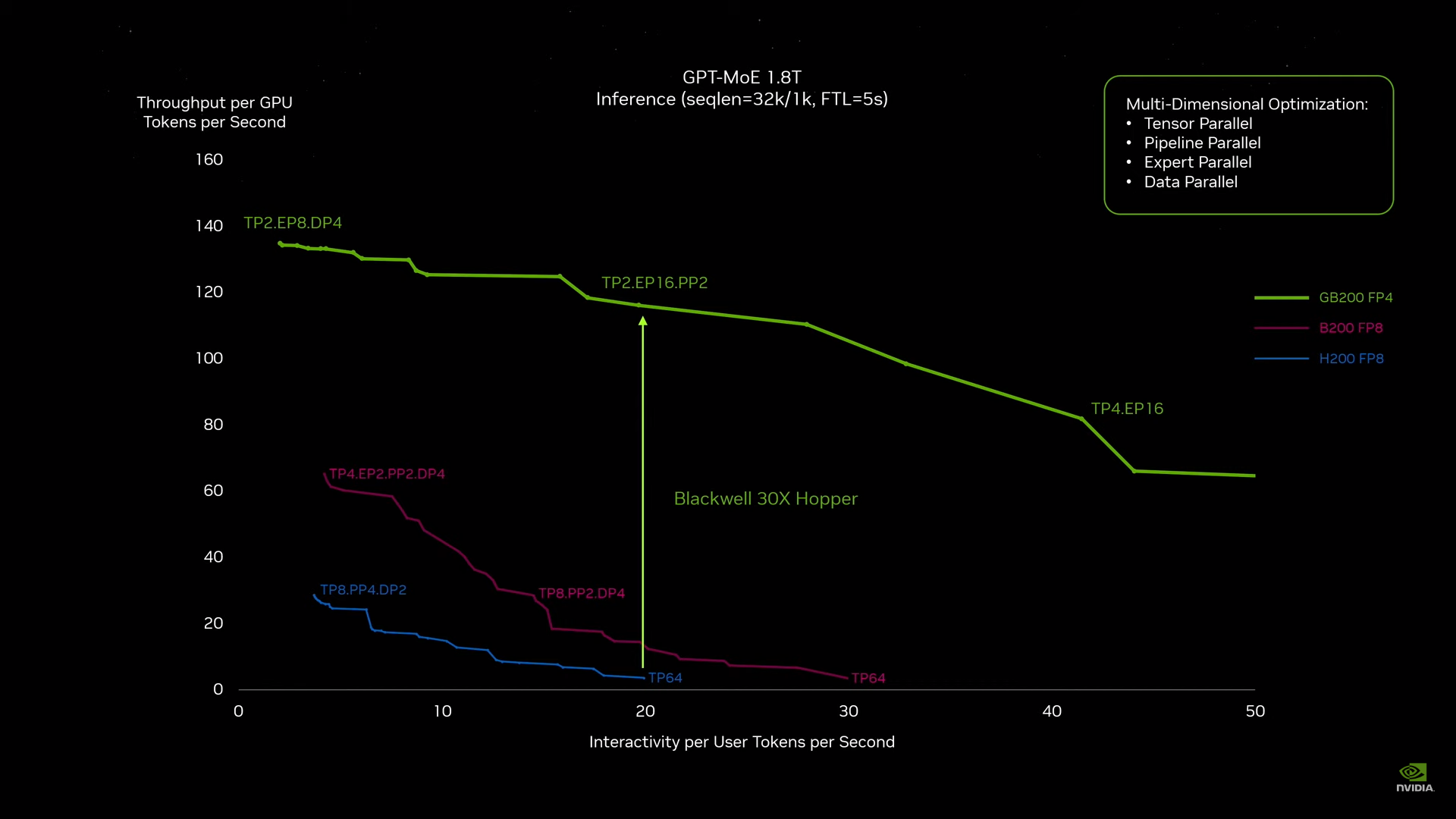 Дополнительно Blackwell обзавёлся движком для декомпрессии (в первую очередь LZ4, Deflate, Snappy) входящих данных со скоростью до 800 Гбайт/с, что тоже должно повысить производительность, т.к. теперь распаковкой будет заниматься не CPU и, соответственно, ускоритель не будет «голодать». Эта функция рассчитана в основном на Apache Spark и другие системы для аналитики больших данных. Также есть по семь движков NVDEC и NVJPEG.  Наконец, NVIDIA упоминает ещё две новых возможности Blackwell: шифрование данных в памяти и RAS-функции. В первом случае речь идёт о защите конфиденциальности обрабатываемых данных, что важно в целом ряде областей. Причём формирование TEE-анклава возможно в рамках группы из 128 ускорителей. MIG-доменов по-прежнему семь. В случае RAS говорится о телеметрии и предиктивной аналитике (естественно, на базе ИИ), которые помогут заранее выявить возможные сбои и снизить время простоя. Это важно, поскольку многие модели могут обучаться неделями и месяцами, так что потеря даже относительно небольшого куска данных крайне неприятна и финансово затратна.  Однако всё эти инновации не имеют смысла без возможности масштабирования, поэтому NVIDIA оснастила Blackwell не только интерфейсом PCIe 6.0 (32 линии), который играет всё меньшую роль, но и пятым поколением интерконнекта NVLink. NVLink 5 по сравнению с NVLink 4 удвоил пропускную способность до 1,8 Тбайт/с (по 900 Гбайт/с в каждую сторону), а соответствующий коммутатор NVSwitch 7.2T позволяет объединить до 576 ускорителей в одном домене. SHARP-движки с поддержкой FP8 дополнительно помогут ускорить обработку моделей, избавив ускорители от части работ по предобработке и трансформации данных. Чип коммутатора тоже изготавливается по техпроцессу TSMC N4P и содержит 50 млрд транзисторов.  Для дальнейшего масштабирования и формирования кластеров из 10 тыс. ускорителей и более, вплоть до 100 тыс. ускорителей на уровне ЦОД, NVIDIA предлагает 800G-коммутаторы Quantum-X800 InfiniBand XDR и Spectrum-X800 Ethernet, имеющие соответственно 144 и 64 порта. Узлам же полагаются DPU ConnectX-8 SuperNIC и BlueField-3. Правда, последний предлагает только 400G-порты в отличие от первого. От InfiniBand компания отказываться не собирается.  С базовыми кирпичиками разобрались, пора переходить к конструированию продуктов. Первым идёт HGX B100, в основе которой всё та же базовая плата с восемью ускорителями Blackwell, точно так же провязанных между собой NVLink 5 с агрегированной скоростью 14,4 Тбайт/с. Для связи с внешним миром предлагается пара интерфейсов PCIe 6.0 x16. HGX B100 предназначена для простой замены HGX H100, поэтому ускорители имеют TDP не более 700 Вт, что ограничивает пиковую производительность в разреженных FP4- и FP8/FP6/INT8-вычислениях до 14 и 7 Пфлопс соответственно, а для всей системы — 112 и 56 Пфлопс соответственно. 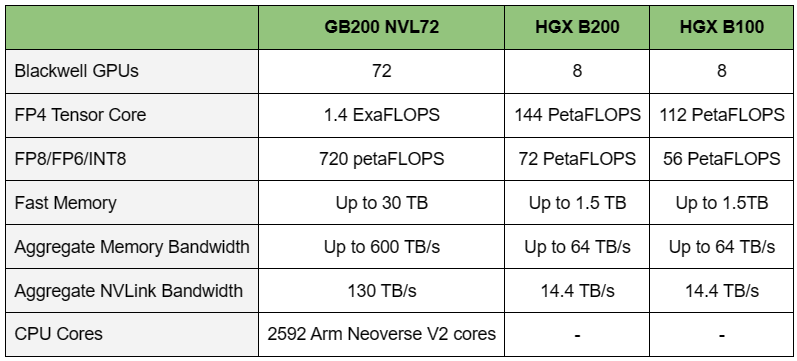 У HGX B200 показатель TDP ограничен уже 1 кВт, причём возможность воздушного охлаждения по-прежнему сохраняется. Производительность одного B200 в разреженных FP4- и FP8/FP6/INT8-вычислениях достигает уже 18 и 9 Пфлопс, а для всей системы — 144 и 72 Пфлопс соответственно. DGX B200 повторяет HGX B200 в плане производительности и является готовой системой от NVIDIA, тоже с воздушным охлаждением. В системе используются два чипа Intel Xeon Emerald Rapids. По словам NVIDIA, DGX B200 до 15 раз быстрее в задачах инференса «триллионных» моделей по сравнению с DGX-узлами прошлого поколения. 800G-интерконнект Ethernet/InfiniBand этим трём платформам не достался, только 400G.  Основным же строительным блоком сама компания явно считает гибридный суперчип GB200, объединяющий уже имеющийся у неё Arm-процессор Grace сразу с двумя ускорителями Blackwell B200. CPU-часть включает 72 ядра Neoverse V2 (по 64 Кбайт L1-кеша для данных и инструкций, L2-кеш 1 Мбайт), 144 Мбайт L3-кеша и до 480 Гбайт LPDDR5x-памяти с ПСП до 512 Гбайт/с. С двумя B200 процессор связан 900-Гбайт/с шиной NVLink-C2C — по 450 Гбайт/с на каждый ускоритель. Между собой B200 напрямую подключены уже по полноценной 1,8-Тбайт/с шине NVLink 5.  Вся эта немаленькая конструкция шириной в половину стойки имеет TDP до 2,7 кВт. 1U-узел с парой чипов GB200, каждый из которых может отъедать до 1,2 кВт, уже требует жидкостное охлаждение. FP4- и FP8/FP6/INT8-производительность (речь всё ещё о разреженных вычислениях) GB200 достигает 40 и 20 Пфлопс. И именно эти цифры NVIDIA нередко использует для сравнения новинок со старыми решениями.  18 узлов с парой GB200 (суммарно 72 шт.) и 9 узлов с парой коммутаторов NVSwitch 7.2T, которые провязывают все ускорители по схеме каждый-с-каждым (агрегированно 130 Тбайт/с, более 3 км соединений), формируют 120-кВт суперускоритель GB200 NVL72 размером со стойку (Oberon), оснащённый СЖО и единой DC-шиной питания. Всё это даёт до 1,44 Эфлопс в FP4-вычислениях и до 720 Пфлопс в FP8, а также до 13,5 Тбайт HBM3e с агрегированной ПСП до 576 Тбайт/с. Ну а общий объём памяти составляет порядка 30 Тбайт. GB200 NVL72 одновременно является и узлом DGX GB200. Восемь DGX GB200 формируют DGX SuperPOD. Впрочем, будет доступен и SuperPOD попроще, на базе DGX B200.  Ускорители B200 появятся в этом году и будут стоить в диапазоне $30–$40 тыс., что ненамного больше начальной цены Hopper в диапазоне $25–$40 тыс. Глава NVIDIA уже предупредил, что Blackwell сразу будут в дефиците. Вероятно, получить доступ к ним проще всего будет в облаках Amazon, Google, Microsoft и Oracle.
13.11.2023 [17:00], Игорь Осколков
NVIDIA анонсировала ускорители H200 и «фантастическую четвёрку» Quad GH200NVIDIA анонсировала ускорители H200 на базе всё той же архитектуры Hopper, что и их предшественники H100, представленные более полутора лет назад. Новый H200, по словам компании, первый в мире ускоритель, использующий память HBM3e. Вытеснит ли он H100 или останется промежуточным звеном эволюции решений NVIDIA, покажет время — H200 станет доступен во II квартале следующего года, но также в 2024-м должно появиться новое поколение ускорителей B100, которые будут производительнее H100 и H200. 
HGX H200 (Источник здесь и далее: NVIDIA) H200 получил 141 Гбайт памяти HBM3e с суммарной пропускной способностью 4,8 Тбайт/с. У H100 было 80 Гбайт HBM3, а ПСП составляла 3,35 Тбайт/с. Гибридные ускорители GH200, в состав которых входит H200, получат до 480 Гбайт LPDDR5x (512 Гбайт/с) и 144 Гбайт HBM3e (4,9 Тбайт/с). Впрочем, с GH200 есть некоторая неразбериха, поскольку в одном месте NVIDIA говорит о 141 Гбайт, а в другом — о 144 Гбайт HBM3e. Обновлённая версия GH200 станет массово доступна после выхода H200, а пока что NVIDIA будет поставлять оригинальный 96-Гбайт вариант с HBM3. Напомним, что грядущие конкурирующие AMD Instinct MI300X получат 192 Гбайт памяти HBM3 с ПСП 5,2 Тбайт/с.  На момент написания материала NVIDIA не раскрыла полные характеристики H200, но судя по всему, вычислительная часть H200 осталась такой же или почти такой же, как у H100. NVIDIA приводит FP8-производительность HGX-платформы с восемью ускорителями (есть и вариант с четырьмя), которая составляет 32 Пфлопс. То есть на каждый H200 приходится 4 Пфлопс, ровно столько же выдавал и H100. Тем не менее, польза от более быстрой и ёмкой памяти есть — в задачах инференса можно получить прирост в 1,6–1,9 раза.  При этом платы HGX H200 полностью совместимы с уже имеющимися на рынке платформами HGX H100 как механически, так и с точки зрения питания и теплоотвода. Это позволит очень быстро обновить предложения партнёрам компании: ASRock Rack, ASUS, Dell, Eviden, GIGABYTE, HPE, Lenovo, QCT, Supermicro, Wistron и Wiwynn. H200 также станут доступны в облаках. Первыми их получат AWS, Google Cloud Platform, Oracle Cloud, CoreWeave, Lambda и Vultr. Примечательно, что в списке нет Microsoft Azure, которая, похоже, уже страдает от недостатка H100.  GH200 уже доступны избранным в облаках Lamba Labs и Vultr, а в начале 2024 года они появятся у CoreWeave. До конца этого года поставки серверов с GH200 начнут ASRock Rack, ASUS, GIGABYTE и Ingrasys. В скором времени эти чипы также появятся в сервисе NVIDIA Launchpad, а вот про доступность там H200 компания пока ничего не говорит.  Одновременно NVIDIA представила и базовый «строительный блок» для суперкомпьютеров ближайшего будущего — плату Quad GH200 с четырьмя чипами GH200, где все ускорители связаны друг с другом посредством NVLink по схеме каждый-с-каждым. Суммарно плата несёт более 2 Тбайт памяти, 288 Arm-ядер и имеет FP8-производительность 16 Пфлопс. На базе Quad GH200 созданы узлы HPE Cray EX254n и Eviden Bull Sequana XH3000. До конца 2024 года суммарная ИИ-производительность систем с GH200, по оценкам NVIDIA, достигнет 200 Эфлопс.
31.05.2023 [14:23], Сергей Карасёв
Supermicro представила MGX-сервер ARS-221GL-NR с суперчипами NVIDIA GraceКомпания Supermicro официально анонсировала сервер ARS-221GL-NR, построенный на новейшей модульной архитектуре NVIDIA MGX. Решение ориентировано на корпоративных заказчиков, реализующих проекты в области НРС, ИИ, метавселенных и пр. Сервер выполнен в форм-факторе 2U с габаритами 438,4 × 900 × 88 мм. Применена материнская плата Super G1SMH для процессоров NVIDIA Grace CPU Superchip, насчитывающих 144 ядра Arm. Возможна установка до четырёх ускорителей NVIDIA H100. 
Источник изображения: Supermicro Система несёт на борту до 480 Гбайт памяти LPDDR5X-4800. В комплектацию может быть включён адаптер 10GbE NVIDIA ConnectX-7 или Bluefield-3 DPU. Предусмотрены 16 отсеков для накопителей E1.S NVMe с возможностью горячей замены.  В общей сложности есть семь слотов расширения PCIe 5.0 x16 FHFL. Упомянут аналоговый интерфейс D-Sub. Питание обеспечивают блоки мощностью 3000 Вт с сертификатом 80 PLUS Titanium. Диапазон рабочих температур — от +10 до +35 °C. Сервер оборудован системой воздушного охлаждения с шестью вентиляторами, рассчитанными на продолжительную работу под высокими нагрузками.  Компания Supermicro также сообщила о намерении применять в своих продуктах Ethernet-платформу NVIDIA Spectrum-X. Она обеспечивает возможность обслуживания до 256 портов 200GbE (или 64 × 800GbE, или 128 × 400GbE) одним коммутатором.
29.05.2023 [07:30], Сергей Карасёв
NVIDIA представила 1-Эфлопс ИИ-суперкомпьютер DGX GH200: 256 суперчипов Grace Hopper и 144 Тбайт памятиКомпания NVIDIA анонсировала вычислительную платформу нового типа DGX GH200 AI Supercomputer для генеративного ИИ, обработки огромных массивов данных и рекомендательных систем. HPC-платформа станет доступна корпоративным заказчикам и организациям в конце 2023 года. Платформа представляет собой готовый ПАК и включает, в частности, наборы ПО NVIDIA AI Enterprise и Base Command. Для платформы предусмотрено использование 256 суперчипов NVIDIA GH200 Grace Hopper, объединённых при помощи NVLink Switch System. Каждый суперчип содержит в одном модуле Arm-процессор NVIDIA Grace и ускоритель NVIDIA H100. Задействован интерконнект NVLink-C2C (Chip-to-Chip), который, как заявляет NVIDIA, значительно быстрее и энергоэффективнее, нежели PCIe 5.0. В результате, скорость обмена данными между CPU и GPU возрастает семикратно, а затраты энергии сокращаются примерно в пять раз. Пропускная способность достигает 900 Гбайт/с. 
Источник изображений: NVIDIA Технология NVLink Switch позволяет всем ускорителям в составе системы функционировать в качестве единого целого. Таким образом обеспечивается производительность на уровне 1 Эфлопс (~ 9 Пфлопс FP64), а суммарный объём памяти достигает 144 Тбайт — это почти в 500 раз больше, чем в одной системе NVIDIA DGX A100. Архитектура DGX GH200 AI Supercomputer позволяет добиться 10-кратного увеличения общей пропускной способности по сравнению с HPC-платформой предыдущего поколения.  Ожидается, что Google Cloud, Meta✴ и Microsoft одними из первых получат доступ к суперкомпьютеру DGX GH200, чтобы оценить его возможности для генеративных рабочих нагрузок ИИ. В перспективе собственные проекты на базе DGX GH200 смогут реализовывать крупнейшие провайдеры облачных услуг и гиперскейлеры. Для собственных нужд NVIDIA до конца 2023 года построит суперкомпьютер Helios, который посредством Quantum-2 InfiniBand объединит сразу четыре DGX GH200. |
|

