Материалы по тегу: cuda
|
11.11.2025 [13:00], Сергей Карасёв
Стартап Spectral Compute по переносу CUDA-приложений на сторонние платформы получил на развитие $6 млнКомпания Spectral Compute, занимающаяся разработкой программной платформы SCALE для запуска CUDA-приложений на любых GPU-ускорителях, сообщила о проведении посевного раунда финансирования на сумму в $6 млн. Инвестиционная программа проведена при участии Costanoa, Crucible и ряда бизнес-ангелов. Стартап Spectral основан в 2018 году инженерами Майклом Сёндергаардом (Michael Søndergaard), Крисом Китчингом (Chris Kitching), Николасом Томлинсоном (Nicholas Tomlinson) и Франсуа Суше (Francois Souchay). Они обладают богатым опытом работы в сферах НРС, программирования GPU и пр. Штат компании на сегодняшний день насчитывает около 20 человек. Spectral развивает решение SCALE, которое обеспечивает компиляцию исходного кода CUDA напрямую в машинные инструкции для ускорителей на базе GPU, отличных от NVIDIA. На начальном этапе реализована возможность использования CUDA-приложений с изделиями AMD, а в дальнейшем планируется добавить поддержку ускорителей других производителей, включая Intel. Таким образом, компании смогут использовать одну и ту же кодовую базу для оборудования разных поставщиков, формируя кластеры ИИ и НРС на основе любых GPU, а не только решений NVIDIA. 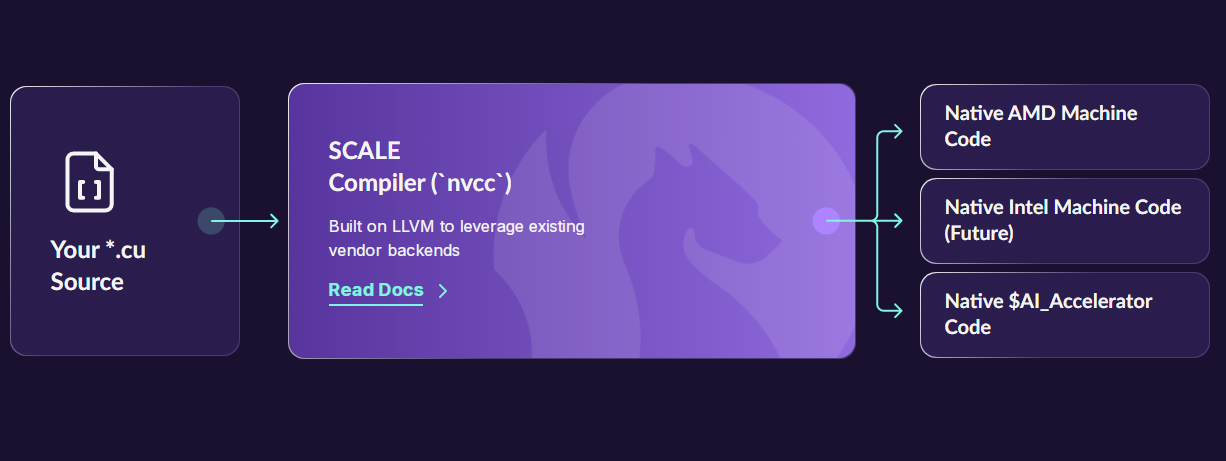
Источник изображения: Spectral Compute «Цель проекта SCALE заключается в том, чтобы предоставить организациям возможность использовать существующий код CUDA на любом графическом процессоре, будь то NVIDIA, AMD, Intel или другие изделия — без потери производительности или дорогостоящего переписывания кода», — говорит Сёндергаард. Привлечённые средства стартап намерен направить на дальнейшее развитие платформы SCALE, а также на увеличение численности персонала.
02.10.2025 [13:10], Руслан Авдеев
Meta✴ приобрела Rivos, разработчика RISC-V-ускорителей, совместимых с CUDAMeta✴ Platforms приобрела занимающийся разработкой ИИ-чипов на базе RISC-V стартап Rivos. Это должно ускорить разработку собственных полупроводников и снизить зависимость от сторонних поставщиков, сообщает Silicon Angle. Условия покупки пока неизвестны, но ключевой инвестор стартапа, Walden Catalyst, с гордостью сообщил о сделке, а нынешний генеральный директор Intel Лип-Бу Тан (Lip-Bu Tan), имевший прямое отношение к созданию и развитию стартапа, поздравил команду. Стартап был основан в 2021 году, а в 2023-м к нему присоединились около полусотни бывших инженеров Apple. Meta✴ будет использовать опыт Rivos для расширения работ над семейством собственных ИИ-ускорителей Meta✴ Training and Inference Accelerator (MTIA). Впрочем, Rivos использовала комплексный подход, разрабатывая CPU и GPUGPU-чипы с кеш-когерентностью и унифицированным доступом к памяти (DDR и HBM), дополненные интегрированным 800G-интерконнектом на базе Ultra Ethernet. Это похоже на подход NVIDIA при создании суперускорителей. В 2025 году Rivos выпустила на TSMC тестовый чип, работающий на частоте 3,1 ГГц и программный стек, совместимый с NVIDIA CUDA. Изначальная стратегия предполагала создание энергоэффективного ИИ-ускорителя с частотой до 3,5 ГГц, совместимого с существующей экосистемой, который планировалось продавать гиперскейлерам (хотя бы одному). Первую коммерческую платформу компания собиралась выпустить в следующем году, она позволила бы перекомпилировать, а не переписывать с нуля приложения, созданные для платформ NVIDIA. Компания также принимала участие в создании RISC-V RVA23 Profile. 
Источник изображения: Rivos Хотя Meta✴ не раскрыла стоимость сделки, вероятно, речь идёт о миллиардных тратах. В августе сообщалось, что стартап вёл переговоры с инвесторами о возможном раунде финансирования в объёме $300–$400 млн, а то и $500 млн, что повысило бы оценку стоимости компании до более чем $2 млрд. ИИ-проекты Meta✴ полагаются преимущественно на сторонние аппаратные решения. Компания потратила миллиарды долларов на покупку ускорителей, в основном NVIDIA, и потратит ещё миллиарды на аренду ИИ-инфраструктуры у сторонних игроков. В частности, буквально на днях она подписала новую сделку с CoreWeave на $14,2 млрд. В этом году капзатраты могут достигнуть $72 млрд, а выпуск собственных чипов позволил бы компании сэкономить миллиарды долларов, снизив зависимость от NVIDIA и облачных операторов. 
Источник изображения: Rivos По словам Constellation Research, Meta✴ является единственным крупным ИИ-предприятием, почти полностью зависящим от инфраструктурных решений NVIDIA. Имеются данные, что компания уже взаимодействовала с Rivos некоторое время, поэтому и решила приобрести стартап целиком. Если инициатива увенчается успехом, это поможет Meta✴ снизить расходы как на обучение, так и на инференс. Также сообщается, что Meta✴ работает с TSMC над выпуском своего нового чипа, и уже отправила на производство необходимую документацию для выпуска пробных образцов для оценки их эффективности.
28.08.2025 [13:03], Руслан Авдеев
Китайский бизнес переходит на подержанные ускорители NVIDIA A100 и H100 из-за проблем с поставками H20Китайская ИИ-индустрия постепенно переходит на восстановленные или подержанные ИИ-ускорители NVIDIA A100 и H100 после того, как очередные экспортные ограничения на NVIDIA H20 заставили компании искать альтернативы этому продукту. Искусственно ослабленный ускоритель H20 должен был сохранить присутствие NVIDIA на китайском рынке, но чип фактически «оказался на обочине» даже после того, как на его продажи вновь дали зелёный свет после временного запрета — китайские регуляторы поставили под сомнение его безопасность, сообщает Tom’s Hardware со ссылкой на Digitimes. Всё это привело к стремительному росту спроса на старые модели A100 и H100, китайские компании проводят некую «реконфигурацию» таких ускорителей для использования в недорогих, но высокопроизводительных системах инференса. Последний требует значительно меньше ресурсов, чем обучение ИИ-моделей, рабочие нагрузки могут эффективно выполняться на относительно слабом оборудовании. Именно поэтому даже A100 с 80 Гбайт HBM2e (2 Тбайт/с), представленный ещё в 2020 году, в некоторых случаях остаётся вполне востребованным. Хотя архитектура Ampere уступает Hopper по пиковой производительности, она всё ещё эффективна для инференса благодаря относительно большому объёму памяти и развитой экосистеме ПО CUDA. Для чат-ботов и рекомендательных систем экономически эффективно использовать системы без самых современных чипов. Представленные в 2022 году H100 значительно производительнее A100 в задачах, связанных с обучением. В то же время H20 изначально был оптимизирован для менее ресурсоёмкого инференса, но его возможности урезали так сильно, что производительность в сравнении с H100 у этой модели ниже в 3–7 раз, а в задачах, связанных с вычислениями FP64, он медленнее более чем в 30 раз. Другими словами, даже A100 всё ещё могут быть привлекательнее для китайских покупателей, чем новые H20. 
Источник изображения: NVIDIA Поскольку пока никому не удалось создать что-то сопоставимое с программной экосистемой NVIDIA CUDA, старые GPU вполне востребованы. Тем более что оборудование для инференса менее требовательно во всех отношениях, а китайские ЦОД, по-видимому, не испытывают проблем с энергий и готовы платит за восстановленную устаревшую электронику, даже с пониженной надёжностью. В результате NVIDIA оказалась в странном положении. Компания в своё время списала $5,5 млрд из-за нераспроданных запасов H20 — когда в США решили полностью запретить их поставки в Китай. После снятия запрета компания резко нарастила выпуск H20, но теперь столкнулась уже с нежеланием властей КНР видеть эти чипы в стране. Тем не менее, её ускорители по-прежнему являются одним из главных катализаторов бума ИИ в Китае. Другими словами, чипы компании по-прежнему доминируют на рынке Поднебесной, но активность на теневых рынках может снизить выгоду от бизнеса с Китаем. Впрочем, уже появилась информация о разработке нового ускорителя на основе современной архитектуры Blackwell — хотя и тоже ослабленного.
25.08.2025 [18:15], Руслан Авдеев
China Mobile заказала CUDA-совместимые ИИ-ускорители Kunlunxin на сумму более ¥1 млрдKunlunxin, «дочка» китайского IT-гиганта Baidu, получила от China Mobile заказ на ИИ-ускорители, совместимые с программной экосистемой NVIDIA CUDA, на сумму более ¥1 млрд ($140 млн), сообщает передаёт Reuters. Чипы достанутся поставщикам China Mobile, включая H3C и ZTE. Кроме того, компания закупит ускорители у Huawei. Заключение контракта — часть более широкой стратегии Китая по обретению технологического суверенитета в ИИ-секторе. В апреле Baidu успешно развернула кластер и 30 тыс. чипов собственной разработки — ИИ-ускорителей третьего поколения P800 Kunlun, способных обучать модели уровня DeepSeek. Технологический прогресс подчеркивает потенциал китайских разработок и позиционирует Baidu и Kunlunxin как ключевых игроков на рынке ИИ-ускорителей. Успех Kunlunxin и других китайских бизнесов может иметь важные последствия для мировой индустрии ИИ-ускорителей, в которой пока доминирует NVIDIA. По мере прогресса китайских технологий, позиции NVIDIA могут оказаться под вопросом, особенно в Поднебесной и на других рынках. 
Источник изображения: Kunlunxin Развитие технологий происходит на фоне технологического соперничества между США и Китаем. Практически сразу после послаблений США на поставки H20 Китай развернул активную кампанию против этих чипов, поэтому NVIDIA затормозила выпуск H20 и готовит для местного рынка другой, более мощный ускоритель. Глава NVIDIA Дженсен Хуанг (Jensen Huang) критиковал запреты на экспорт ИИ-полупроводников в Китай, подчёркивая, что из-за этого прогресс собственных технологий в КНР только ускорится.
21.07.2025 [14:05], Сергей Карасёв
NVIDIA CUDA обзавелась поддержкой RISC-VКомпания NVIDIA в ходе саммита RISC-V 2025 в Китае объявила о том, что ее платформа параллельных вычислений CUDA обзавелась поддержкой открытой архитектуры RISC-V. Это событие отражает растущий интерес к чипам RISC-V в сегменте дата-центров. Представленное решение предполагает использование типичной конфигурации: графический ускоритель обрабатывает параллельные рабочие нагрузки, тогда как CPU на основе RISC-V отвечает за функционирование системных драйверов, логики приложений и операционной системы. Такая модель позволяет CPU полностью координировать GPU-вычисления в среде CUDA. 
Источник изображения: RISC-V International (X/@risc_v) Кроме того, в дополнение к CPU с архитектурой RISC-V и ускорителю NVIDIA может быть задействован специализированный сопроцессор для обработки данных (DPU). Таким образом, могут формироваться гетерогенные вычислительные среды, в которых процессор RISC-V играет ключевую роль в управлении рабочими нагрузками. Предполагается, что чипы RISC-V будут использоваться на периферийных устройствах с поддержкой CUDA, включая решения с модулями NVIDIA Jetson. Поддержка RISC-V расширяет возможности CUDA в системах, где предпочтение отдаётся открытым наборам команд или где требуются специально оптимизированные чипы. По сути, NVIDIA создаёт мост между проприетарным стеком CUDA и открытой архитектурой RISC-V, которая активно развивается по всему миру, в том числе в Китае. 
Источник изображения: NVIDIA Ранее ряд китайских компаний, включая T-Head (принадлежит гиганту Alibaba Group Holding), Shanghai Shiqing Technology, Juquan Optoelectronics, Xinsiyuan Microelectronics и StarFive, сформировали патентный альянс в сфере RISC-V. Разработкой RISC-V-процессоров занимается научно-исследовательский институт Damo Academy (подразделение Alibaba Group Holding), Китайская академия наук, а также ряд других участников местного рынка. Не имея возможности поставлять флагманские ИИ-ускорители в Китай из-за американских санкций, NVIDIA вынуждена искать другие способы развития экосистемы CUDA в КНР.
09.06.2025 [14:02], Руслан Авдеев
Перегрев, плохое ПО и сила привычки: китайские компании не горят желанием закупать ИИ-ускорители HuaweiНесмотря на дефицит передовых ИИ-ускорителей на китайском рынке, китайская компания Huawei, выпустившая модель Ascend 910C, может столкнуться с проблемами при её продвижении. Она рассчитывала помочь китайскому бизнесу в преодолении санкций на передовые полупроводники, но перспективы нового ускорителя остаются под вопросом, сообщает The Information. Китайские гиганты вроде ByteDance, Alibaba и Tencent всё ещё не разместили крупных заказов на новые ускорители. Основная причина в том, что экосистема NVIDIA доминирует во всём мире (в частности, речь идёт о программной платформе CUDA), а решения Huawei недостаточно развиты. В результате компания продвигает продажи государственным структурам (при поддержке самих властей КНР) — это косвенно свидетельствует о сложности выхода на массовый рынок. Китайский бизнес годами инвестировал в NVIDIA CUDA для ИИ- и HPC-задач. Соответствующий инструментарий, библиотеки и сообщество разработчиков — настолько развитая экосистема, что альтернатива в лице Huawei CANN (Compute Architecture for Neural Networks) на её фоне выглядит весьма слабо. У многих компаний всё ещё хранятся огромные запасы ускорителей NVIDIA, накопленные в преддверии очередного раунда антикитайских санкций, поэтому у их владельцев нет стимула переходить на новые и незнакомые решения. Они скорее предпочтут оптимизировать программный стек, как это сделала DeepSeek, чтобы повысить утилизацию имеющегося «железа». Если бы, например, та же DeepSeek перешла на ускорители Huawei, это подтолкнуло бы к переходу и других разработчиков, но пока этого не происходит. Кроме того, некоторые компании вроде Tencent и Alibaba не желают поддерживать продукты конкурентов, что усложняет Huawei продвижение её ускорителей. 
Источник изображения: Huawei Есть и технические проблемы. Самый передовой ускоритель Huawei Ascend 910C периодически перегревается, поэтому возникла проблема доверия к продукции. Поскольку сбои во время длительного обучения модели обходятся весьма дорого. Кроме того, он не поддерживает ключевой для эффективного обучения ИИ формат FP8. Ascend 910С представляет собой сборку из двух чипов 910B. Он обеспечивает производительность на уровне 800 Тфлопс (FP16) и пропускную способность памяти 3,2 Тбайт/с, что сопоставимо с параметрами NVIDIA H100. Также Huawei представила кластер CloudMatrix 384. Наконец, проблема в собственно американских санкциях. В мае 2025 года Министерство торговли США предупредило, что использование чипов Huawei без специального разрешения может расцениваться, как нарушение экспортных ограничений — якобы в продуктах Huawei незаконно используются американские технологии. Такие ограничения особенно важны для компаний, ведущих международный бизнес — даже если они китайского происхождения. Хотя NVIDIA ограничили продажи в Китае, она по-прежнему демонстрирует рекордные показатели. По данным экспертов UBS, у компании есть перспективные проекты суммарной мощностью «десятки гигаватт» — при этом, каждый гигаватт ИИ-инфраструктуры, по заявлениям NVIDIA, приносит ей $40–50 млрд. Если взять вероятную очередь проектов на 20 ГВт с периодом реализации два-три года, то только сегмент ЦОД может обеспечить NVIDIA около $400 млрд годовой выручки. Это подчеркивает доминирующее положение компании на рынке аппаратного обеспечения для ИИ.
22.01.2025 [08:08], Руслан Авдеев
Ускорители Ascend не готовы состязаться с чипами NVIDIA в деле обучения ИИ, но за эффективность инференса Huawei будет бороться всеми силамиХотя на китайском рынке ИИ-ускорителей по-прежнему доминирует NVIDIA, Huawei намерена отнять у неё значительную его долю. Для этого китайский разработчик намерен помочь китайским ИИ-компаниям внедрять чипы собственного производства для инференса, сообщает The Financial Times. Для обучения ИИ-моделей китайские производители в массе своей применяют чипы NVIDIA. Huawei пока не готова заменить продукты NVIDIA в этом деле из-за ряда технических проблем, в том числе из-за проблем с интерконнектом ускорителей при работе с крупными моделями. Предполагается, что в будущем именно инференс станет пользоваться большим спросом, если темпы обучения ИИ-моделей замедлятся, а приложения вроде чат-ботов будут распространены повсеместно. Если инференс нужен постоянно, то к обучению ИИ-моделей прибегают лишь время от времени. По словам сотрудников и клиентов Ascend, компания сосредоточена на менее сложном, но, возможно, более прибыльном пути. Но поскольку ускорители NVIDIA и Huawei используют разные программные экосистемы, последняя предлагает бизнесам ПО для обеспечения совместимости. Продукция Huawei продвигается при поддержке китайского правительства, внутри страны именно эта компания считается наиболее серьёзным конкурентом NVIDIA. И хотя китайские компании всё более ограничены в доступе к аппаратным решениям NVIDIA из-за санкций, они охотно покупают даже урезанные чипы H20, которые всё равно считают более предпочтительным вариантом, чем китайские альтернативы. 
Источник изображения: Huawei Задача Huawei — убедить разработчиков отказаться от платформы CUDA, во многом благодаря которой NVIDIA и смогла добиться успеха на рынке. От проблем с ПО страдает и AMD — по словам экспертов, именно оно не позволяет раскрыть потенциал ускорителей Instinct MI300X. Впрочем, готовящаяся к релизу версия Huawei Ascend 910C должна решить эти проблемы, поскольку новое поколение ускорителей получит ПО, упрощающее работу разработчиков. Тем временем китайские Baidu и Cambricon добились определённых успехов в разработке собственных ИИ-ускорителей, а ByteDance обратилась за помощью к Broadcom. По оценкам SemiAnalysis, в прошлом году NVIDIA заработала $12 млрд на продажах своей продукции в Китае, поставив 1 млн ускорителей H20, т.е. вдвое больше, чем Ascend 910B. Впрочем, отрыв, по словам экспертов, быстро сокращается, поскольку Huawei наращивает производство. Отмечается, что рост доли Huawei на рынке ИИ-ускорителей отчасти сдерживается лишь недостаточным предложением её продукции. По мнению экспертов, наращивать производство будет трудно, поскольку Китайское вынужден использовать устаревшее оборудование из-за санкций США. Специализация на инференсе может свидетельствовать и об особом векторе развития китайских ИИ-систем, отличающемся от американского. Китайские компании не участвуют в гонке Meta✴, xAI и OpenAI по созданию мегакластеров на базе решений NVIDIA. Зато большей эффективности в задачах инференса можно добиться даже с более слабыми чипами. Снизив стоимость работы ИИ-моделей, можно будет сохранять конкурентоспособность даже в таких условиях. В прошлом месяце китайский стартап DeepSeek представил ИИ-модель V3, обеспечивающую низкие затраты на обучение и инференс в сравнении с сопоставимыми по возможностям моделями из США. DeepSeek утверждает, что Huawei успешно адаптировала V3 к Ascend. Ранее сообщалось, что Huawei охотно направляет к клиентам специалистов для помощи с переходом с NVIDIA на Ascend.
12.08.2024 [17:26], Руслан Авдеев
AMD сначала разрешила, а потом запретила доступ к коду проекта ZLUDA по запуску CUDA-приложений на своих ускорителяхПохоже, команда юристов AMD намерена получить полный контроль над значительной частью базы ПО, созданной в рамках открытого проекта ZLUDA. По данным The Register, ранее в этом году компания прекратила финансовую поддержку инициативы, позволяющей использовать CUDA-код на сторонних ускорителях. Теперь, похоже, AMD ужесточает политику. Изначально проект ZLUDA создавался для запуска CUDA-приложений без каких-либо модификаций на GPU Intel при поддержке со стороны самой Intel. Позже автор проекта Анджей Яник (Andrzej Janik) подписал с AMD контракт, в рамках которого предполагалось создание аналогичного инструмента для ускорителей AMD. В начале 2022 года проект стал закрытым, но уже в начале 2024 года Яник снова сделал проект открытым по соглашению сторон, поскольку AMD решила прекратить финансирование и дальнейшее развитие ZLUDA. 
Источник изображения: Mapbox/unsplash.com Однако позже AMD изменила своё решение. Именно по её запросу соответствующее ПО стало недоступным. По словам Яника, юристы AMD заявили, что предыдущее письмо с разрешением на публикацию кода не является юридически значимым документом. Яник после консультации с юристом пришёл к выводу, что законность писем не имеет значения, поскольку потенциальная судебная тяжба с AMD отняла бы у него слишком много ресурсов, а её результат трудно предсказать. Проще и быстрее переписать проект на базе старых наработок, хотя часть функций, вероятно, воссоздать не выйдет. Почему в AMD решили попытаться «похоронить» ZLUDA, достоверно неизвестно. Первой и самой очевидной причиной может быть желание AMD дистанцироваться от проекта, возможно, нарушающего права NVIDIA на интеллектуальную собственность. NVIDIA уже запретила использовать CUDA-код на других аппаратных платформах, создавая «слои трансляции CUDA», и прибегать к декомпиляции всего, что создано с помощью CUDA SDK, для адаптации ПО для запуска на других GPU. Кроме того, в AMD могли посчитать, что само существование ZLUDA могло бы помешать внедрению собственного ПО. Собственный инструментарий AMD предполагает именно портирование и рекомпиляцию исходного кода CUDA вместо запуска уже готовых программ. Кроме того, мог возникнуть конфликт относительного того, какой код, созданный в рамках ZLUDA, можно выпускать, а какой нет.
27.07.2024 [23:44], Алексей Степин
Не так просто и не так быстро: учёные исследовали особенности работы памяти и NVLink C2C в NVIDIA Grace HopperГибридный ускоритель NVIDIA Grace Hopper объединяет CPU- и GPU-модули, которые связаны интерконнектом NVLink C2C. Но, как передаёт HPCWire, в строении и работе суперчипа есть некоторые нюансы, о которых рассказали шведские исследователи. Им удалось замерить производительность подсистем памяти Grace Hopper и интерконнекта NVLink в реальных сценариях, дабы сравнить полученные результаты с характеристиками, заявленными NVIDIA. Напомним, для интерконнекта изначально заявлена скорость 900 Гбайт/с, что в семь раз превышает возможности PCIe 5.0. Память HBM3 в составе GPU-части имеет ПСП до 4 Тбайт/с, а вариант с HBM3e предлагает уже до 4,9 Тбайт/с. Процессорная часть (Grace) использует LPDDR5x с ПСП до 512 Гбайт/с. В руках исследователей оказалась базовая версия Grace Hopper с 480 Гбайт LPDDR5X и 96 Гбайт HBM3. Система работала под управлением Red Hat Enterprise Linux 9.3 и использовала CUDA 12.4. В бенчмарке STREAM исследователям удалось получить следующие показатели ПСП: 486 Гбайт/с для CPU и 3,4 Тбайт/с для GPU, что близко к заявленным характеристиками. Однако результат скорость NVLink-C2C составила всего 375 Гбайт/с в направлении host-to-device и лишь 297 Гбайт/с в обратном направлении. Совокупно выходит 672 Гбайт/с, что далеко от заявленных 900 Гбайт/с (75 % от теоретического максимума). 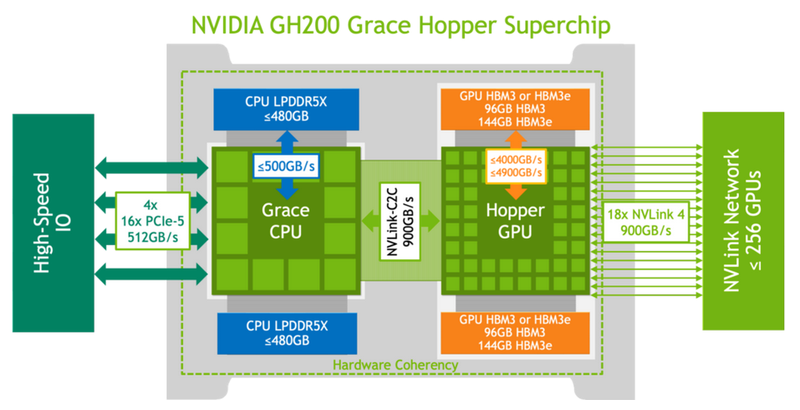
Источник: NVIDIA Grace Hopper в силу своей конструкции предлагает два вида таблицы для страниц памяти: общесистемную (по умолчанию страницы размером 4 Кбайт или 64 Кбайт), которая охватывает CPU и GPU, и эксклюзивную для GPU-части (2 Мбайт). При этом скорость инициализации зависит от того, откуда приходит запрос. Если инициализация памяти происходит на стороне CPU, то данные по умолчанию помещаются в LPDDR5x, к которой у GPU-части есть прямой доступ посредством NVLink C2C (без миграции), а таблица памяти видна и GPU, и CPU. 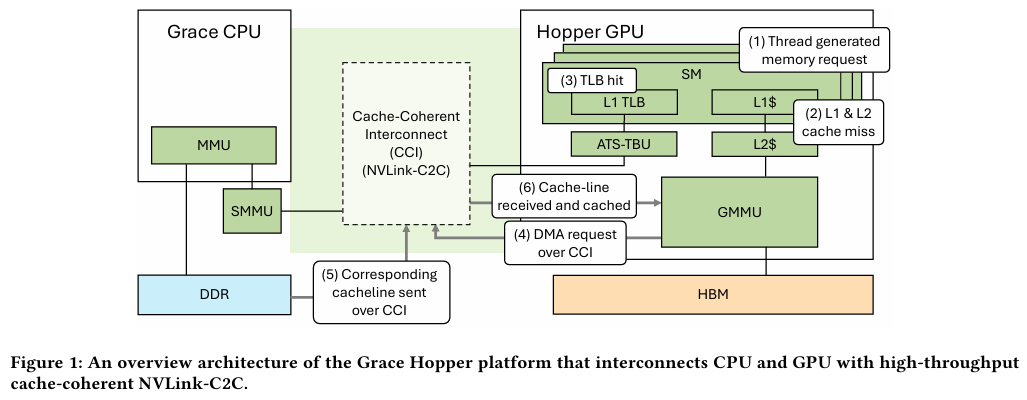
Источник: arxiv.org Если же памятью управляет не ОС, а CUDA, то инициализацию можно сразу организовать на стороне GPU, что обычно гораздо быстрее, а данные поместить в HBM. При этом предоставляется единое виртуальное адресное пространство, но таблиц памяти две, для CPU и GPU, а сам механизм обмена данными между ними подразумевает миграцию страниц. Впрочем, несмотря на наличие NVLink C2C, идеальной остаётся ситуация, когда GPU-нагрузке хватает HBM, а CPU-нагрузкам достаточно LPDDR5x. 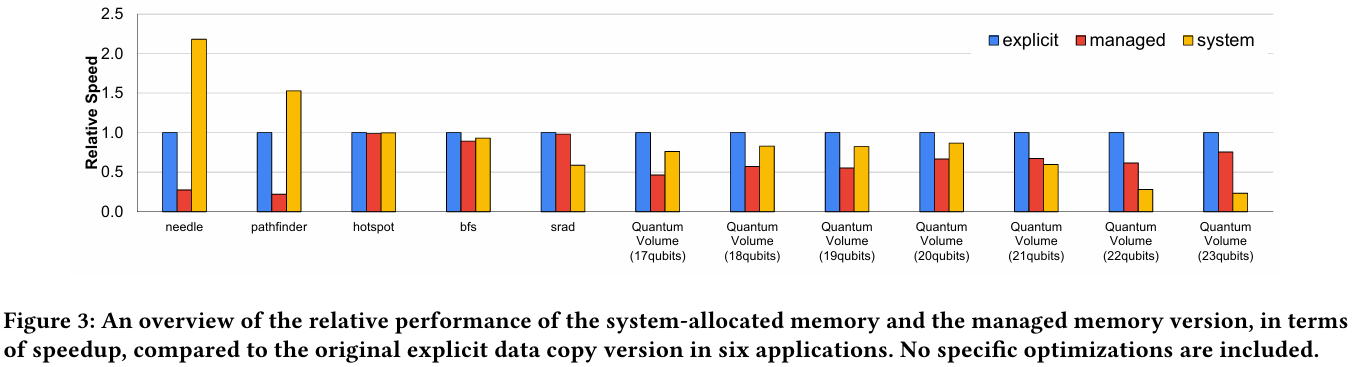
Источник: arxiv.org Также исследователи затронули вопрос производительности при использовании страниц памяти разного размера. 4-Кбайт страницы обычно используются процессорной частью с LPDDR5X, а также в тех случаях, когда GPU нужно получить данные от CPU через NVLink-C2C. Но как правило в HPC-нагрузках оптимальнее использовать 64-Кбайт страницы, на управление которыми расходуется меньше ресурсов. Когда же доступ в память хаотичен и непостоянен, страницы размером 4 Кбайт позволяют более тонко управлять ресурсами. В некоторых случаях возможно двукратное преимущество в производительности за счёт отсутствия перемещения неиспользуемых данных в страницах объёмом 64 Кбайт. В опубликованной работе отмечается, что для более глубокого понимания механизмов работы унифицированной памяти у гетерогенных решений, подобных Grace Hopper, потребуются дальнейшие исследования.
11.06.2023 [15:27], Владимир Мироненко
Barracuda порекомендовала клиентам выкинуть заражённые почтовые шлюзы ESG — патчи уже не смогут им помочьПоставщик ИБ-решений Barracuda Networks заявил, что клиентам необходимо немедленно заменить затронутые эксплойтом шлюзы Email Security Gateway (ESG), даже если те установили все доступные патчи. При этом компания пообещала оказывать клиентам, в числе которых Samsung, Delta Airlines, Mitsubishi и Kraft Heinz, необходимую помощь в замене ESG. Шлюзы ESG предназначены для защиты входящего и исходящего трафика электронной почты. Они доступны как в виде физических серверов, так и в виде программных комплексов, в том числе в AWS и Microsoft Azure. Уязвимость в ESG была обнаружена в мае этого года. 18 мая компания заявила о том, что обратилась за помощью к Mandiant, специализирующейся на сложных кибератаках, после того как был обнаружен аномальный трафик, направлявшийся с устройств ESG. 
Изображение: Barracuda Networks 19 мая в устройствах была выявлена критическая уязвимость нулевого дня CVE-2023-2868, позволявшая хакерам удалённо выполнять произвольный код на шлюзах ESG. Уязвимость затрагивает версии ПО ESG с 5.1.3.001 по 9.2.0.006, позволяя злоумышленнику добиться удалённого выполнения кода (RCE) с повышенными привилегиями. Расследование Mandiant и Barracuda показало, что уязвимость активно используется хакерами с октября 2022 года. Было установлено, что уязвимость использовалась для получения несанкционированного доступа к множеству шлюзов ESG, на которых сначала размещались бэкдоры Saltwater и Seaspy, а затем модуль Seaside, отслеживающий входящий трафик и устанавливающий оболочку для выполнения команд на удалённом сервере. Всё вместе это даёт возможность хакеру сохранять доступ к серверу или шлюзу даже после устранения уязвимости основного ПО с помощью патча. 20–21 мая компания выпустила патчи против уязвимости, однако это не дало результата, поскольку злоумышленники оставили вредоносное ПО на затронутых системах, которое продолжало действовать. «Если вы не заменили своё устройство после получения уведомления в пользовательском интерфейсе, обратитесь в службу поддержки сейчас, — сообщила компания клиентам. — Рекомендация Barracuda по исправлению в настоящее время заключается в полной замене затронутых ESG». 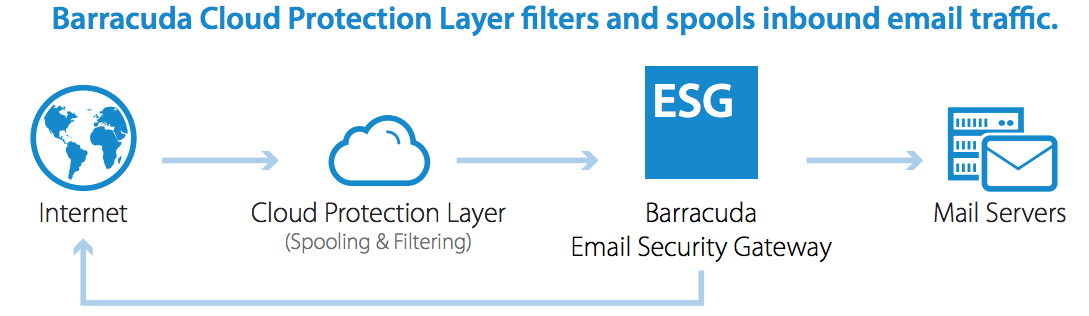
Изображение: Barracuda Networks По словам Rapid7, решение о полной замене «подразумевает, что вредоносное ПО, установленное злоумышленниками, каким-то образом достигает устойчивости на достаточно низком уровне, так что даже очистка устройства не уничтожит доступ к нему злоумышленника». К Сети может быть подключено до 11 тыс. устройств ESG — Rapid7 выявила значительные объёмы вредоносной активности в те же сроки, о которых сообщила Barracuda. В дополнение к прекращению использования и замене уязвимых устройств ESG компания Barracuda рекомендовала клиентам немедленно обновить учётные данные любых устройств или служб, подключавшихся к ESG. Также было предложено провести проверку сетевых журналов, которая может помочь выявить любое потенциальное вторжение. |
|

