Материалы по тегу: ram
|
16.06.2026 [15:58], Руслан Авдеев
«Расширитель» памяти Mext был продан AMDAMD объявила о покупке стартапа Mext, специализирующегося на оптимизации использования имеющейся памяти в ИИ-системах с целью снижения расходов, ускорения развёртывания и масштабирования. Предполагается, что это поможет решить проблемы клиентов AMD, в настоящее время страдающих от дефицита памяти для ИИ ЦОД, сообщает Silicon Angle. Mext создала технологию многоуровневого управления памятью, интеллектуально переносящую не слишком часто используемые данные из дорогой DRAM в NAND. В основе технологии — прогнозирование обращений к памяти, благодаря которой постоянно анализируются шаблоны доступа к данным и используются ИИ-алгоритмы, чтобы попытаться «угадать», какие данные из флеш-памяти могут понадобиться в ближайшее время. Эти данные заранее извлекаются в DRAM, благодаря чему приложения получают к ним доступ без лишних задержек и снижения производительности. Сделка предполагает решение усугубляющейся проблемы операторов крупных ЦОД. По мере увеличения и усложнения ИИ-моделей, HPC, виртуализации и задач, связанных с аналитикой данных, стремительно увеличивается потребность в дефицитной памяти всех классов. Нехватка ведёт к росту цен и сложностям с покупкой. В результате дефицит серьёзно мешает оптимизировать производительность дата-центров, причём DRAM-модули нередко используются чрезвычайно неэффективно. 
Источник изображения: Sebastian Herrmann/unsplash.com В AMD рассчитывают, что проблему поможет решить технология Mext, которая сможет повысить эффективность ЦОД. Фактически решение стартапа увеличивает эффективный объём доступной памяти, благодаря чему растёт производительность уже имеющегося оборудования и снижается необходимость в закупках дополнительных DRAM-модулей. В AMD ожидают, что технология поможет снизить общую стоимость владения ИИ-инфраструктурой для облачных провайдеров и корпоративных покупателей. При этом выиграют не только ИИ ЦОД, но и обычные вычислительные площадки. AMD намерена интегрировать технологии Mext в собственное портфолио решений для ЦОД. Кроме того, компания приобрела команду талантливых разработчиков стартапа, хорошо разбирающихся в архитектурах памяти, инфраструктурном ПО и крупномасштабных вычислительных системах. По мнению экспертов, сделка вряд ли окажет заметное влияние на выручку AMD в краткосрочной перспективе, но новость в любом случае была весьма благосклонно принята на Уолл-стрит. Кратковременный всплеск стоимости акций довёл капитализацию компании до $900 млрд. Стоит отметить, что свои решения по интеллектуальному перемещению данных между DRAM и NAND также предлагают ADATA (TRUSTA AI Scaler) и Phison (aiDAPTIV+), но они совместимы только с их собственными накопителями. Broadcom встроила похожий механизм в платформу VCF. При этом сама NAND-память тоже в дефиците, так что вопрос оптимизации использования SSD стоит не менее остро.
11.05.2026 [23:59], Руслан Авдеев
Meta✴ пришлось продлить срок службы серверов из-за дефицита памятиMeta✴ вынуждена продлить срок эксплуатации некоторых из своих серверов общего назначения из-за дефицита DRAM с шести до семи лет, сообщает The Wall Street Journal со ссылкой на внутреннюю документацию техногиганта, где говорится о том, что компания не ожидала существенного дефицита поставок оборудования, в основном именно из-за нехватки оперативной памяти, а также жёстких дисков. Предполагается, что дефицит продлится минимум до 2027 года. Ежегодно компания инвестирует огромные средства в инфраструктуру ЦОД и является одним из крупнейших заказчиков серверного оборудования в мире. Однако даже увеличение капзатрат до $125–$145 млрд в этом году не позволяет обновлять серверы прежними темпами. Внутренне моделирование Meta✴ показало, что увеличение срока эксплуатации серверов компании увеличит ожидаемую годовую интенсивность отказов (AFR) с 4,8 % до 7,4 % ежегодно. Такой риск считается приемлемым, хотя до восьми лет срок службы оборудования решили не продлевать. 95 % мирового выпуска DRAM приходится на Samsung Electronics, SK hynix и Micron Technology, которые в последние полтора года делают ставку на увеличение выпуска HBM для ИИ-ускорителей, поскольку такая память значительно маржинальнее обычной серверной DRAM. По оценкам IDC, речь может идти уже не о временном, «циклическом» дефиците, а о стратегическом перераспределении производственных ресурсов. Согласно прогнозам, на HBM в 2026 году придётся порядка 25 % выпуска всех пластин DRAM, спрос на неё растёт приблизительно на 70 % ежегодно. 
Источник изображений: Meta✴ В результате цена DDR5 и других модулей резко выросла. Впрочем, с другими компонентами ситуация не лучше. Western Digital уже распродала даже не выпущенные HDD, у Seagate дела тоже идут отлично (для неё самой), а время поставок некоторых моделей серверных процессоров выросло до полугода. Таким образом, один из ключевых мировых покупателей серверного оборудования, в отличие от многих экспертов, не полагается на падение цен на память и другие компоненты к концу 2026 года, а предпочитает увеличить срок эксплуатации уже развёрнутого оборудования. Для более мелких покупателей это может служить сигналом всё более серьёзных проблем с закупками в обозримой перспективе. Если получить достаточно памяти по приемлемой цене не рассчитывает гиперскейлер, прочие могут столкнуться с более длительными сроками поставок, частичным выполнением заказов и значительным ростом цен. Вполне может оказаться, что продление сроков службы оборудования — оптимальный сценарий не только для Meta✴, что, помимо прочего, приведёт к переносу капитальных затрат и замедлению внедрения более энергоэффективных и высокопроизводительных платформ.  Более того, дефициту HDD и SSD уделяется намного меньше внимания, чем нехватке DRAM, что, по-видимому, является ошибкой при планировании закупок. Массовая скупка HDD и рост цен на NAND оставляют всё меньше места для манёвра при формировании инфраструктуры для хранения данных. По мнению экспертов, новые производственные мощности для модулей памяти заработают ещё нескоро, и дефицит может постепенно снизиться в 2027–2028 гг., когда свои плоды начнут приносить инвестиции 2024–2025 гг. В качестве временной меры возможно повышение эффективности использования имеющегося оборудования программными средствами. Например, NVIDIA анонсировала новое ПО для мониторинга и продления жизни ИИ-ускорителей в ЦОД. С другой стороны, индустрия не в первый раз прибегает к увеличению сроков службы оборудования. Так поступали Microsoft, Google, CloudFlare, Scaleway и др.
30.04.2026 [12:10], Сергей Карасёв
До 128 Тбайт памяти: Majestic Labs анонсировала ИИ-сервер нового типа PrometheusСтартап Majestic Labs анонсировал сервер нового типа Prometheus, призванный решить проблему «стены памяти» в современных ИИ-системах, оперирующих моделями с огромным количеством параметров. Утверждается, что Prometheus может обеспечить производительность, сопоставимую с несколькими стойками традиционных серверов, одновременно снижая энергопотребление и общую стоимость владения. Компания Majestic Labs вышла из скрытого режима (Stealth) в ноябре прошлого года. Стартап отмечает, что в современных ИИ-системах наблюдается разрыв между объёмом и производительностью памяти и вычислительными возможностями ускорителей. Majestic Labs предлагает решить проблему путём внедрения новой архитектуры, предполагающей разделение памяти и вычислительных ресурсов. Речь идёт об использовании специализированных ИИ-ускорителей и блоков быстрой памяти, объём которой составит до 128 Тбайт в рамках одного сервера. 
Источник изображения: Majestic Labs В составе Prometheus задействованы проприетарные чипы AI Processing Units (AIU) под названием Ignite. Они объединяют CPU-ядра на базе Arm с векторными и тензорными движками RISC-V. При этом используется единое пространство памяти. Говорится о поддержке популярных фреймворков, таких как PyTorch, vLLM и OpenAI Triton, что позволяет запускать существующие рабочие нагрузки без изменения кода. По заявлениям Majestic Labs, платформа Prometheus способна работать с ИИ-моделями с огромными контекстными окнами и триллионами параметров. При этом отсутствуют фрагментация и узкие места, присущие традиционным ИИ-серверам. Среди сфер применения названы смешанные экспертные системы, ИИ-агенты, графовые нейронные сети и пр.
11.04.2026 [19:53], Сергей Карасёв
Everspin увеличит мощности по производству MRAM-памятиКомпания Everspin Technologies, разработчик магниторезистивной энергонезависимой памяти с произвольным доступом (MRAM), объявила о заключении соглашения о стратегическом сотрудничестве с Microchip Technology. Партнёрство направлено на расширение производственных мощностей и обеспечение долгосрочных поставок MRAM-изделий. В настоящее время Everspin изготавливает MRAM-чипы и туннельные магниторезистивные (TMR) датчики на линии в Чандлере (Аризона, США), которая располагается на площадке NXP. В рамках нового соглашения Everspin создаст точную копию такого производства на объекте Microchip в американском штате Орегон. Партнёрство с Microchip, как ожидается, обеспечит ряд стратегических преимуществ. В частности, Everspin сможет нарастить объёмы выпуска продукции и обеспечить стабильность поставок. Кроме того, Everspin получит дополнительные возможности для реализации научно-исследовательских программ, направленных на улучшение характеристик MRAM и развитие соответствующей технологии. Речь идёт о новых сценариях использования такой памяти и о поддержке рабочих нагрузок следующего поколения. 
Источник изображения: Everspin «Сотрудничество с Microchip позволит увеличить масштабы производства продукции для удовлетворения спроса, одновременно способствуя дальнейшей реализации наших планов в области MRAM», — заявил глава Everspin. Соглашение между Everspin и Microchip Technology заключено на 10 лет с возможностью последующего расширения каждые два года. Первые продукты, изготовленные на предприятии в Орегоне, поступят на рынок во II половине 2027 года. Everspin продолжит производить чипы MRAM и TMR-датчики на линии в Чандлере.
01.04.2026 [16:04], Сергей Карасёв
Дефицит памяти привёл к выпуску 3-Гбайт версии Raspberry Pi 4 и повышению цены Raspberry Pi 500+ сразу на $150Компания Raspberry Pi объявила об очередном повышении цен на свои одноплатные компьютеры и другие продукты. Удорожание связано с дефицитом чипов памяти DRAM и NAND на фоне стремительного развития инфраструктуры дата-центров для ИИ. Стоимость изделий Raspberry Pi уже была значительно увеличена два месяца назад. Новое повышение цен распространяется на Raspberry Pi 4 и Raspberry Pi 5 с объемом памяти 4 Гбайт и более, Raspberry Pi 500 и Raspberry Pi 500+, все варианты Compute Module 4, Compute Module 4S и Compute Module 5 и другие изделия. В целом, подорожали следующие продукты:

Источник изображения: Raspberry Pi Вместе с тем Raspberry Pi представила новую модификацию одноплатного компьютера Raspberry Pi 4, оснащённую 3 Гбайт ОЗУ. Такое изделие, занявшее промежуточное положение между версиями с 2 и 4 Гбайт оперативной памяти, предлагается за $83,75. Отмечается также, что пока не планируется повышать цены на классические продукты, включая Raspberry Pi Zero, Raspberry Pi Zero W и Raspberry Pi Zero 2 W, Raspberry Pi 1, Raspberry Pi 3, Raspberry Pi 3B+ и Raspberry Pi 3A+, а также Raspberry Pi Compute Module 1 и Raspberry Pi Compute Module 3+ . В этих устройствах используется более старая память LPDDR2 DRAM, которая в достаточном количестве имеется на складах Raspberry Pi.
16.03.2026 [09:32], Сергей Карасёв
Everspin представила MRAM-чипы Unisyst ёмкостью до 2 ГбитEverspin Technologies анонсировала новое семейство чипов магниторезистивной энергонезависимой памяти с произвольным доступом (MRAM) — изделия Unisyst, ориентированные на применение во встраиваемых системах. Отмечается, что решения Unisyst используют унифицированную архитектуру MRAM, объединяющую традиционную память и постоянное хранилище высокой плотности. На первом этапе чипы новой серии будут предлагаться в вариантах ёмкостью от 128 Мбит до 2 Гбит. Задействован последовательный интерфейс xSPI (8 линий, работающих на частоте 200 МГц). 
Источник изображения: Everspin Technologies Устройства на базе Unisyst будут соответствовать стандарту AEC-Q100 Grade 1. Гарантирована сохранность записанной информации в течение как минимум 10 лет. При этом чипы могут эксплуатироваться при экстремальных температурах. Заявленная скорость чтения данных достигает 400 Мбайт/с, скорость записи — приблизительно 90 Мбайт/с: это, как подчёркивает Everspin, более чем в 400 раз превосходит показатели памяти NOR. Изделия Unisyst предназначены для приложений, которым требуется энергонезависимая память, сочетающая высокую пропускную способность, износостойкость и предсказуемое поведение при изменении температуры. В качестве ключевых сфер использования названы автомобильная, аэрокосмическая и промышленная отрасли, а также периферийные системы с ИИ-функциями. Инженерные образцы MRAM-чипов Unisyst станут доступны в IV квартале 2026 года. Впоследствии Everspin намерена расширять данное семейство.
05.03.2026 [14:21], Владимир Мироненко
Дефицит памяти поможет Broadcom подзаработать, но не так, как вы подумалиВ связи с ростом цен на оперативную память на фоне её дефицита, который, по прогнозам экспертов, сохранится и в 2027 году, VMware (подразделение Broadcom) предложила частное облако VMware Cloud Foundation (VCF) 9.0 в качестве решения, необходимого для работы в новых условиях. VMware заявила, что «традиционный подход, заключающийся в увеличении количества оборудования для решения проблем производительности и масштабируемости, больше не является жизнеспособным». «Broadcom разработала VCF 9.0 специально для решения этой экономической задачи, предложив три различных подхода: снижение совокупной стоимости владения за счёт многоуровневого хранения памяти, отсрочка капитальных затрат за счёт передовых технологий повышения эффективности и обеспечение немедленного внедрения в существующий парк оборудования», — сообщила она. Как отметил The Register, VMware всегда продвигала многоуровневую организацию памяти VCF 9 как возможность снизить затраты на инфраструктуру за счёт уменьшения установленного объёма DRAM путём прозрачного переноса части данных на NVMe. Вместе с тем, не следует забывать, что стоимость SSD также выросла. VMware также признаёт, что её архитектура памяти подходит не для всех рабочих нагрузок и не предназначена для виртуальных машин, чувствительных к задержкам, или очень больших инстансов. 
Источник изображения: Kevin Ache/unsplash.com Но VMware всё равно утверждает, что «наиболее прямое решение проблемы стремительного роста цен на DRAM — это просто использовать её меньше», а VCF 9.0 позволяет «заменить дорогостоящую DRAM значительно более дешёвым хранилищем NVMe». Многоуровневое распределение памяти VMware в настоящее время превосходит альтернативу в виде CXL, пишет The Register. Кроме того, новые поколения серверных процессоров AMD и Intel создали возможность очередного этапа консолидации нагрузок. Dell утверждает, что её клиенты заменяют семь серверов одной новой машиной; Intel говорит о консолидации 5:1. Новые серверы позволяют запускать огромное количество ВМ, что концентрирует риски и требует огромного количества дорогостоящей памяти. Но VMware и не требует, чтобы в каждом хосте в кластере использовалось многоуровневое распределение памяти. Так что VCF 9 в текущей ситуации действительно может оказаться эффективным средством снижения затрат. В то же время The Register отметил, что многие пользователей vSphere считают VCF 9 очень дорогим продуктом, несмотря на уверения Broadcom в обратном. При этом Broadcom, похоже, в принципе не готова идти на ценовые уступки — или бери, или уходи.
02.03.2026 [12:35], Сергей Карасёв
Team Group анонсировала новые индустриальные NVMe SSD и модули памятиTeam Group готовит новые SSD в различных форм-факторах, а также модули оперативной памяти для индустриальных и встраиваемых систем. В частности, готовятся накопители Team Group Industrial R252 стандарта U.2 (NVMe), предназначенные для серверов. Эти устройства оснащены интерфейсом PCIe 5.0 x4. Они обеспечивают скорость последовательного чтения информации до 14 000 Мбайт/с, скорость последовательной записи — до 10 000 Мбайт/с. Кроме того, выйдут SSD серии Team Group Industrial R253, ориентированные на решение разнообразных задач в современных дата-центрах и на периферии. Такие устройства, получившие формат EDSFF E3.S, позиционируются в качестве накопителей большой ёмкости с улучшенной защитой данных. Они подходят для обработки ИИ-нагрузок, аналитики в реальном времени и пр. Дебютируют также SSD семейства Team Group Industrial R251 стандарта EDSFF E1.S, оптимизированные для серверов форм-фактора 1U. Эти накопители имеют сертификацию по стандартам виброустойчивости MIL-STD, что означает надёжность при эксплуатации в системах с высокой плотностью размещения оборудования. 
Источник изображений: Team Group В сегменте оперативной памяти Team Group представит новые модули Industrial DDR4 U-DIMM и SO-DIMM, специально разработанные для промышленного применения и IoT-устройств. Помимо этого, готовятся изделия Industrial DDR5 CU-DIMM и CSO-DIMM с частотой до 7200 МГц, рассчитанные на ИИ-платформы. На системы со значительной интенсивностью вычислений ориентированы решения Team Group Industrial LPDDR5X CAMM2: они обеспечивают высокую пропускную способность и низкую задержку. 
05.02.2026 [17:58], Сергей Карасёв
Из-за дефицита памяти у Raspberry Pi 4 появился версия со «сдвоенной» RAM, а 16-Гбайт версия Raspberry Pi 5 существенно подорожалаКомпания Raspberry Pi, по сообщению ресурса CNX Software, из-за дефицита чипов памяти, сформировавшегося на фоне бума ИИ, продолжает поднимать цены на свои одноплатные компьютеры. А в конструкцию отдельных моделей даже внесены изменения с целью обеспечения гибкости в цепочке поставок DRAM. Напомним, в конце прошлого года повысились цены на изделия Raspberry Pi 4 и Raspberry Pi 5: прирост составил от $5 до $25 в зависимости от модификации. Очередное изменение стоимости затронуло названные одноплатные компьютеры, а также вычислительные модули Raspberry Pi Compute Module 4 и Raspberry Pi Compute Module 5, несущие на борту 2 Гбайт оперативной памяти и более (модификации с 1 Гбайт ОЗУ предлагаются по прежней цене). Прибавка выглядит следующим образом:

Источник изображений: CNX Software Вместе с тем выпущен новый вариант Raspberry Pi 4 — изделие Raspberry Pi 4 v1.5 Dual RAM (маркировка «Raspberry Pi 4 Model B © Raspberry Pi 2025»). У такого одноплатного компьютера вместо одного чипа LPDDR4 используются два, которые расположены на лицевой и обратной сторонах. CNX Software отмечает, что на фоне нехватки компонентов DRAM может сложиться ситуация, когда два чипа памяти на 4 Гбайт будут стоить дешевле одного на 8 Гбайт. Кроме того, такая компоновка позволит решить проблему недоступности модулей LPDDR4 большой ёмкости: производитель сможет заменять их парой чипов вдвое меньшего объема. 
04.02.2026 [10:12], Сергей Карасёв
Intel и SoftBank займутся разработкой памяти Z-Angle Memory (ZAM) — альтернативы HBM для ИИ-системКорпорации Intel и SoftBank объявили о сотрудничестве в рамках проекта по разработке высокопроизводительной памяти нового типа Z-Angle Memory (ZAM), ориентированной на ИИ-системы. Предполагается, что в перспективе такие решения составят конкуренцию HBM. В инициативе принимает участие Saimemory — дочернее предприятие SoftBank, сформированное в декабре 2024 года. Речь идёт о разработке многослойной архитектуры DRAM с вертикальной компоновкой. Цель заключается в увеличении ёмкости чипов памяти и их пропускной способности по сравнению с HBM при одновременном снижении энергопотребления. Проект ZAM основан на результатах исследований, полученных по программе передовых технологий памяти AMT (Advanced Memory Technology), которая управляется Министерством энергетики США (DOE) и Администрацией по национальной ядерной безопасности США (NNSA). В данной программе участвуют Сандийские национальные лаборатории (SNL), Ливерморская национальная лаборатория имени Лоуренса (LLNL) и Лос-Аламосская национальная лаборатория (LANL) в составе DOE. Планируется использование технологии сборки Intel Next Generation DRAM Bonding (NGDB), которая, как утверждается, значительно повышает производительность DRAM, снижает энергопотребление и оптимизирует затраты на память. 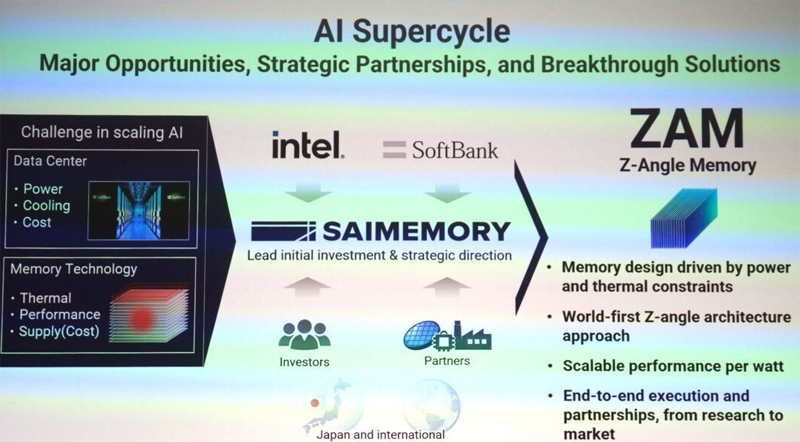
Источник изображения: TechPowerUp В целом, в рамках нового проекта Intel и Saimemory планируют увеличить ёмкость модулей памяти в два–три раза по сравнению с современными HBM, снизить энергопотребление на 40–50 % и при этом сохранить конкурентоспособную стоимость. Предполагается, что появление ZAM позволит устранить ключевые узкие места при масштабировании высокопроизводительных систем ИИ. Работы над памятью нового типа начнутся в текущем квартале. Демонстрация прототипов запланирована на 2027 год, а коммерциализация технологии — на 2030-й. |
|

