Материалы по тегу: cxl
|
27.06.2026 [23:27], Владимир Мироненко
Старая память на новый лад: ASIC Meta✴ Vistara поможет установить DDR4 из б/у серверов в современные системыMeta✴ подготовила ASIC Vistara, который позволит посредством CXL установить старую память, например, DDR4, взятую из списанных серверов, в новые серверы, что позволит хотя бы частично сгладить дефицит DRAM, из-за которого компания уже вынужденно продлила срок жизни оборудования. В числе преимуществ такого подхода авторы называют практически бесплатное добавление памяти за счёт повторного использования, повышение производительности благодаря использованию большей ёмкости памяти и снижение выбросов углекислого газа. Meta✴ отметила, что технология CXL в целом не получила широкого распространения из-за «низкой пропускной способности, высокой задержки и высоких накладных расходов». «Например, расширенная память, которую мы используем в производстве, обеспечивает примерно в 10 раз меньшую пропускную способность и примерно на 60 % большую задержку, чем локальная память», — отмечает компания. В частности, дополнительные контроллеры и мостики между различными интерфейсами добавляют порядка 150 нс задержек. Кроме того, сообщается, что «большинство решений CXL интегрируют DRAM с контроллером, что препятствует повторному использованию DIMM, и часто не поддерживают DDR4, что является обязательным условием для повторного использования старой памяти». При этом у компании были и есть в использовании около десятка различных DDR4 DIMM. По словам Meta✴, эти проблемы решают в компании с помощью совместной разработки аппаратного и программного обеспечения. 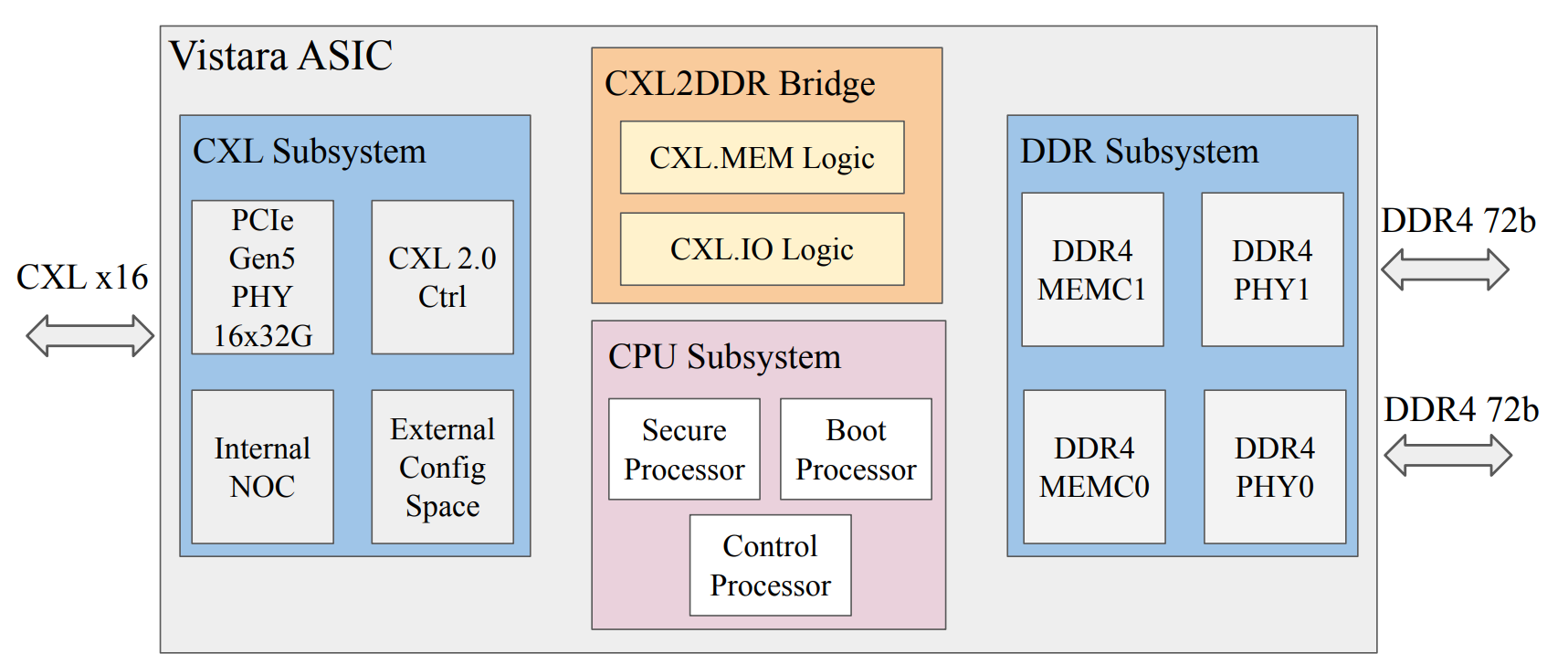
Источник изображений: Meta✴ «В аппаратной части мы разрабатываем собственную микросхему CXL ASIC, Vistara, оптимизированную для повторного использования DRAM, энергоэффективности и низкой задержки. В программной части мы создаем оптимизированное решение на основе TPP (Transparent Page Placement), определяем подходящее соотношение локальной и расширенной памяти для каждой рабочей нагрузки и автоматизируем конфигурацию для каждой задачи, в том числе отключая расширенную память для нагрузок, чувствительных к увеличению задержки», — говорит компания. 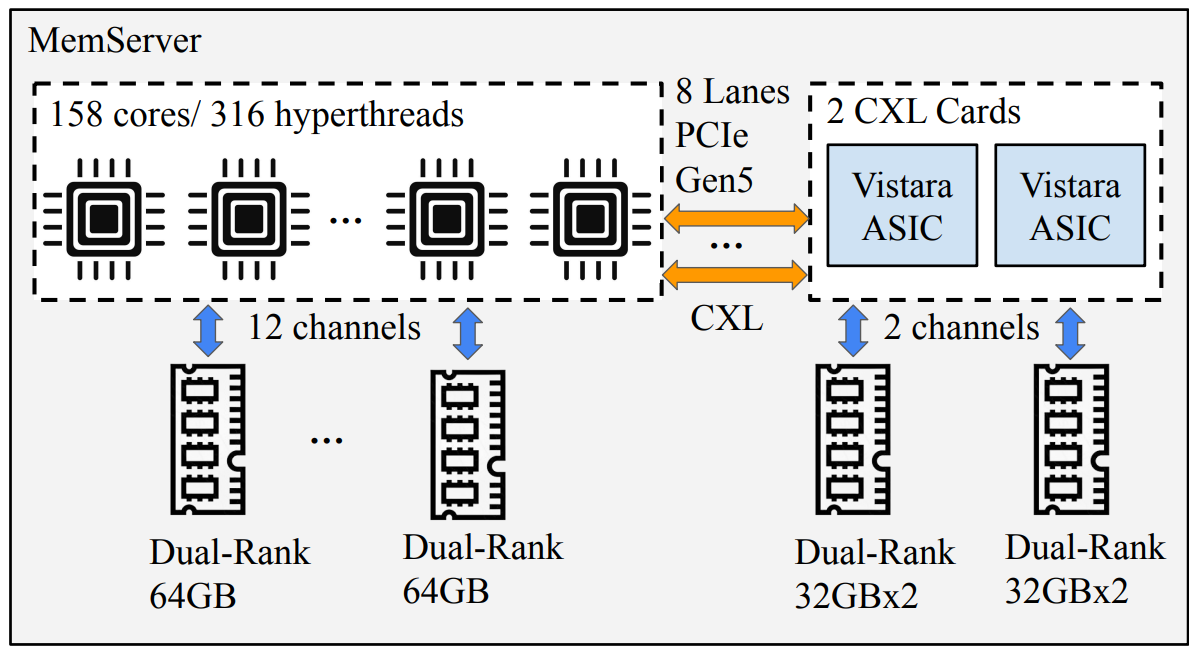 ASIC Vistara имеет два 72-бит канала DDR4-3200 (на практике частота снижена до 2400) с ECC с поддержкой 2DPC, позволяющими установить до 256 Гбайт памяти (на практике 128 Гбайт в четырёх DIMM). Для общения с хостом используется интерфейс PCIe 5.0 x16 (на практике достаточно и x8) с поддержкой CXL 1.1/2.0 Type 3. ASIC потребляет около 9 Вт, а задержка обращений к памяти составляет порядка 50 нс. В состав контроллера входят три управляющих ядра RISC-V. Модули с Vistara, по два на каждый односокетный узел, устанавливаются в отдельные слоты в задней части шасси и обдуваются отдельным потоком воздуха во избежание перегрева и для повышения стабильности работы. 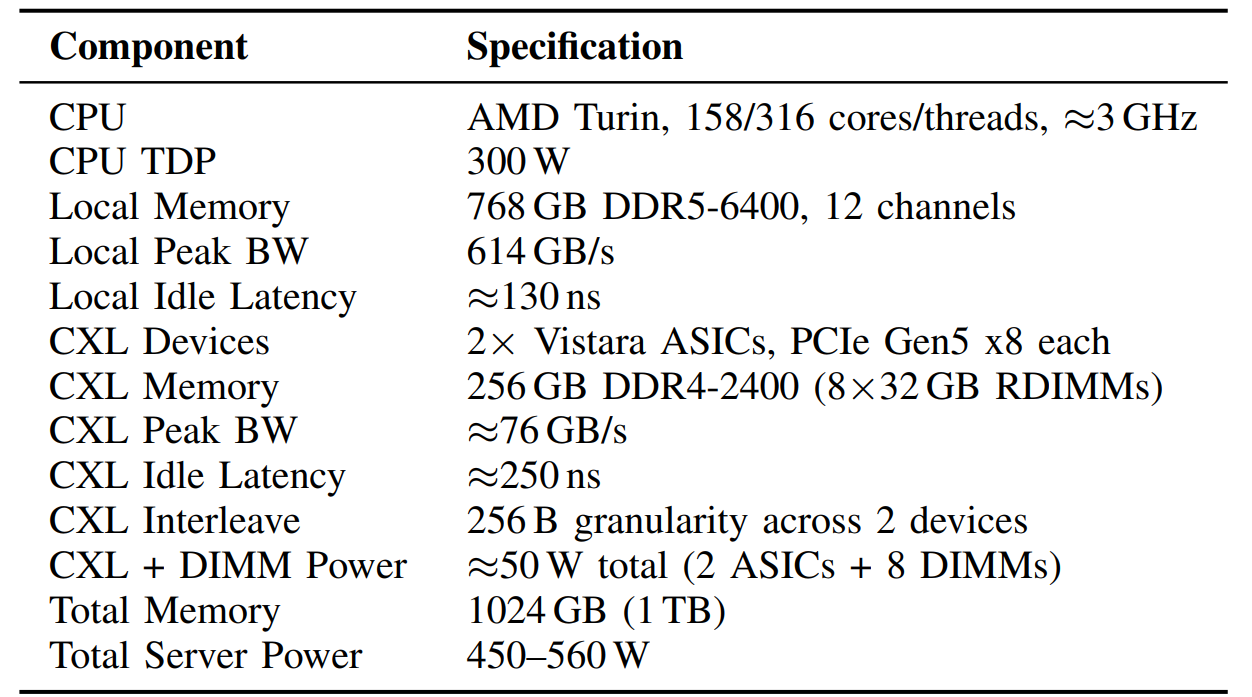 Как сообщается, это решение обеспечивает существенный прирост производительности для различных рабочих нагрузок, включая сокращение количества используемых серверов до 25 % для дезагрегированного машинного обучения и сокращение средней задержки на 29 % для распределённых кешей. Стоит отметить, что Microsoft также озаботилась возможностью использования старых модулей DDR4 и морально устаревших SSD в новых серверах в рамках проекта GreenSKU.
12.06.2026 [14:53], Сергей Карасёв
Представлен контроллер ScaleFlux MC500 CXL Type 3 для ИИ-инфраструктур и облаковКомпания ScaleFlux анонсировала контроллер MC500 CXL Type 3, разработанный в сотрудничестве с ключевыми отраслевыми партнёрами. Изделие, оптимизированное для обеспечения максимальной производительности в расчёте на 1 Вт энергоптребления, ориентировано на высоконагруженные инфраструктуры ИИ и облачные платформы. Чип поддерживает стандарты JEDEC SPDM 1.2 и Caliptra, а также передовую технологию коррекции ошибок (ECC) с применением декодирования по списку (list decoding) для обработки сложных сбоев. Применяется интерфейс PCIe 5.0 с возможностью работы в режимах x4, x8, 2x4 и 2x8. Контроллер совместим с памятью DDR5-4800 (4 канала; 2DPC) и DDR4-3200 (2 канала; 2DPC). В первом случае её объём может достигать 1 Тбайт, во втором — 512 Гбайт. На базе чипа могут проектироваться устройства типоразмера FHHL, HHHL, EDSFF E3.S 1T и E3.S 2T. Типовое заявленное энергопотребление изделия MC500 CXL Type 3 составляет около 6 Вт при использовании восьми линий PCIe или приблизительно 10 Вт в режиме 2×8 линий. Изделие выполнено в корпусе Flip Chip BGA с размерами 23 × 23 мм. 
Источник изображения: ScaleFlux Чип предназначен для объединения процессоров, памяти и ускорителей в серверах. Говорится о совместимости с компонентами ведущих отраслевых игроков, что упрощает построение систем. Контроллер поможет устранить узкие места в архитектуре дата-центров и обеспечить бесшовную совместную работу оборудования, что важно в свете стремительного увеличения объёмов обрабатываемых и передаваемых данных. Нужно отметить, что в конце прошлого года консорциум CXL Consortium представил спецификацию Compute Express Link (CXL) 4.0. В её основе лежит интерфейс PCIe 7.0, что обеспечивает поддержку линий с пропускной способности в 128 ГТ/с.
09.06.2026 [10:00], Сергей Карасёв
InnoGrit представила контроллер для SSD с интерфейсом PCIe 6.0 вместимостью до 256 ТбайтКитайская компания InnoGrit представила свой первый контроллер для SSD с интерфейсом PCIe 6.0 x4. Изделие IG5686 Crestone предназначено для построения накопителей для дата-центров и облачных платформ, ориентированных ресурсоёмкие ИИ-нагрузки. Контроллер поддерживает стандарт NVMe 2.3. Допускается использование чипов флеш-памяти SLC/MLC/TLC/QLC NAND и SCM. При этом сами SSD могут выполняться в различных форм-факторах, включая E1.S и E3.S. Решение IG5686 Crestone обеспечивает скорость чтения информации до 28 Гбайт/с и скорость записи до 22 Гбайт/с. Величина IOPS при произвольном чтении данных теоретически достигает 7 млн, при произвольной записи — 5 млн. Максимально допустимая вместимость накопителей — 256 Тбайт. Помимо этого, компания InnoGrit разработала контроллер Cascade IG5676 для устройств CXL 3.1 Type-3. Это решение поддерживает высокоскоростную память с низкой задержкой XL-Flash. Возможно создание накопителей ёмкостью до 2 Тбайт. 
Источник изображения: InnoGrit В дальнейшем InnoGrit планирует повышать производительность своих контроллеров. Так, к 2027 году компания рассчитывает довести показатель IOPS в передовых устройствах до 25–50 млн путём оптимизации и более глубокой интеграции стандартов PCIe 6.0 и CXL. В 2028 году величина IOPS, как предполагается, приблизится к 100 млн. Это позволит вывести на новый уровень быстродействие платформ хранения данных для ИИ. Нужно отметить, что контроллеры для SSD с интерфейсом PCIe 6.0 проектируют и другие участники рынка. В частности, такое решение недавно продемонстрировала компания Phison. Кроме того, соответствующими разработками занимается Silicon Motion.
15.04.2026 [11:48], Сергей Карасёв
Анонсированы китайские SSD для дата-центров PetaIO: PCIe 6.0, CXL 3.0 и 28 Гбайт/сКитайская компания PetaIO, по сообщениям сетевых источников, разработала высокопроизводительные SSD нового поколения с интерфейсом PCIe 6.0, предназначенные для использования в дата-центрах, ориентированных на ресурсоёмкие ИИ-нагрузки. Полностью характеристики устройств не раскрываются. Известно, что в их основу положен передовой контроллер Titanium Himalaya, при изготовлении которого применяется 6-нм техпроцесс. Говорится о поддержке CXL 3.0, а также о возможности формирования пулов памяти объёмом до 256 Тбайт. Заявленная скорость передачи данных при последовательном чтении превышает 28 Гбайт/с. Накопители специально оптимизированы для выполнения задач в области ИИ. Показатель IOPS при произвольном чтении информации блоками по 512 байт составляет до 50 млн. При этом обеспечивается задержка на уровне 2,7 мкс. 
Источник изображения: PetaIO Предполагается, что новые SSD помогут решить проблему «стены памяти» в масштабных инфраструктурах ИИ. О ёмкости накопителей и их форм-факторе пока ничего не сообщается. При этом подчёркивается, что устройства совместимы с современными высокопроизводительными сетевыми экосистемами. Нужно отметить, что в настоящее время на сайте PetaIO упомянуты SSD нескольких семейств. Это, в частности, решения PETA8118 формата U.2 (PCIe 4.0 x4) вместимостью до 8 Тбайт, PETA8118 типоразмера M.2 2280 (PCIe 4.0 x4) ёмкостью до 4 Тбайт, PETA8118 стандарта E1.S (PCIe 4.0 x4) на 2–8 Тбайт и изделия PETA8118 в виде карт расширения PCIe 4.0 x4 ёмкостью до 4 Тбайт.
14.04.2026 [12:44], Владимир Мироненко
Panmnesia привлёк $10 млн на разработку интерконнекта следующего поколения для ИИ ЦОДЮжнокорейский стартап Panmnesia, специализирующийся на разработке интерконнекта для ИИ-инфраструктур, сообщил о получении финансирования в размере около $10 млн на разработку интерконнекта следующего поколения для ИИ ЦОД. Проект включает разработку контроллеров и коммутаторов на основе открытых стандартов, таких как UALink и протоколов интерконнекта на основе Ethernet. Уже имея обширный портфель продуктов CXL, Panmnesia теперь расширяет свою деятельность в области интерконнекта, ориентированного на ускорители. Компания отметила, что по мере распространения крупномасштабных ИИ-моделей в различных отраслях, ИИ ЦОД всё чаще полагаются на ИИ-ускорители разных вендоров. В этом контексте технологии интерконнекта, обеспечивающие высокоскоростную передачу данных между ускорителями, стали критически важным фактором, определяющим общую производительность ИИ-системы. 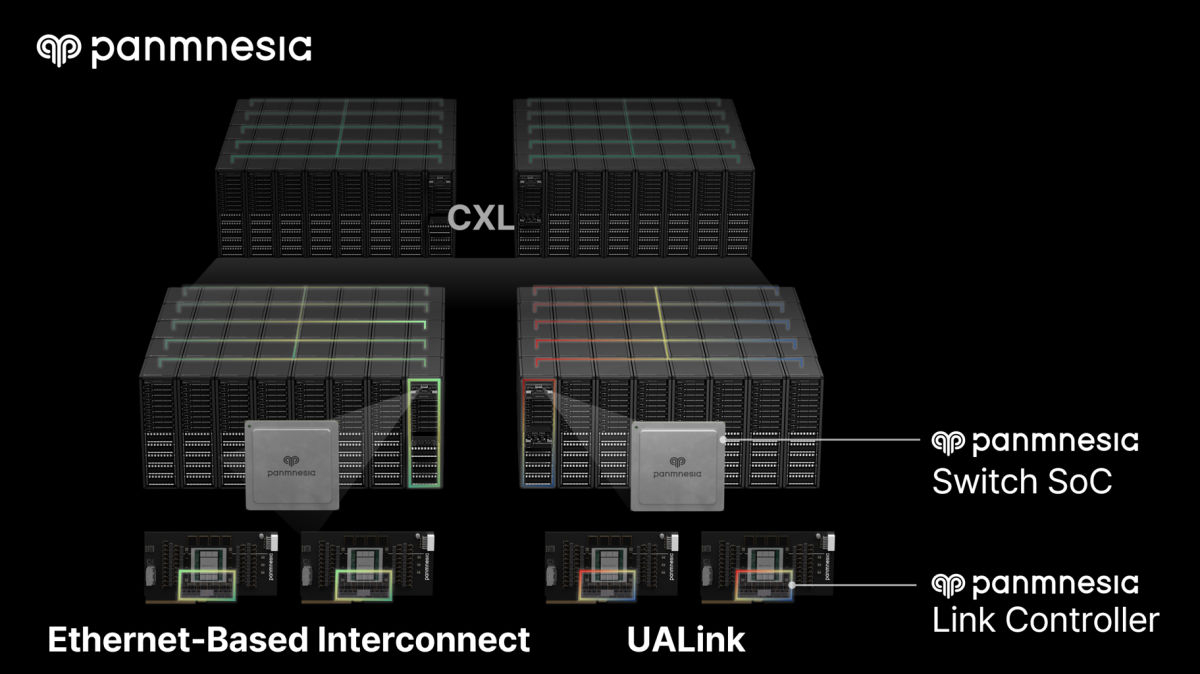
Источник изображений: Panmnesia Также Panmnesia планирует оптимизировать топологию разработанных устройств для ускорения обмена данными между ними и провести валидацию на уровне стойки. Ожидается, что чип-коммутатор с поддержкой интерконнекта, ориентированного на ускорители, такого как UALink, станет доступен во II половине 2027 года.  Портфолио продуктов CXL компании включает комплексные решения, в том числе контроллеры и IP-блоки PCIe/CXL, аппаратные SoC, такие, как коммутаторы PCIe/CXL, и специализированные кремниевые решения. В прошлом году Panmnesia представила архитектуру CXL-over-XLink, которая интегрирует специализированные каналы связи для ускорителей (известные как XLink), включая UALink, с CXL для обеспечения расширенной связи в крупных ИИ ЦОД.
24.03.2026 [08:50], Сергей Карасёв
Marvell представила коммутатор Structera S 60260 с поддержкой 260 линий PCIe 6.0Компания Marvell Technology анонсировала коммутатор Structera S 60260 — это, как утверждается, первое в отрасли решение с поддержкой 260 линий PCIe 6.0. Новинка предназначена для использования в дата-центрах, ориентированных на ресурсоёмкие задачи ИИ. Одновременно компания представила и коммутатор Structera S 30260 с поддержкой 260 линий CXL 3.0. Marvell отмечает, что современные ИИ ЦОД оперируют серверами с большим количеством GPU и ускорителей других типов. На этом фоне критически важным элементом становятся коммутационные системы на основе PCIe, способные обеспечить высокую плотность вычислений и максимально эффективное использование доступных ресурсов. В традиционных инфраструктурах применяется множество коммутаторов, что приводит к увеличению энергопотребления, задержек и общей стоимости владения. Изделие Structera S 60260 позволяет решить эти проблемы. 
Источник изображения: Marvell Новинка базируется на разработках компании XConn Technologies, которую Marvell приобрела в начале текущего года за $540 млн. XConn специализируется на разработке передовых коммутаторов PCIe и CXL: в частности, с 2022 года она поставляет коммутаторы с 256 линиями PCIe 5.0. В случае решения Structera S 60260 количество линий PCIe 6.0 практически в два раза больше, чем у сопоставимых по классу продуктов конкурентов. «Коммутатор Structera S PCIe оптимизирован для обеспечения лучших в отрасли показателей производительности, гибкости, задержки и энергоэффективности при работе с ресурсоёмкими приложениями, включая ИИ, задачи машинного обучения следующего поколения и НРС», — говорит Джерри Фан (Gerry Fan), старший вице-президент Marvell. Благодаря объединению коммутаторов Structera S PCIe с ретаймерами Marvell Alaska P PCIe гиперскейлеры и операторы ИИ ЦОД получают комплексную платформу интерконнекта на основе PCIe. При использовании активных электрических кабелей (AEC) протяжённость соединений PCIe 6.0 может достигать 7 м, а при использовании активных оптических кабелей — превышать 7 м. Изделия Structera S PCIe совместимы по выводам с новыми коммутаторами Marvell Structera S CXL 3.0. Поставки тестовых образцов Structera S PCIe 6.0 уже начались. Отгрузки коммерческих коммутаторов Structera S PCIe 60260 клиентам будут организованы в III квартале 2026 года.
21.03.2026 [12:53], Сергей Карасёв
11 Тбайт памяти для ИИ: Penguin Solutions представила кеширующий сервер MemoryAI KV на основе CXL-модулейКомпания Penguin Solutions анонсировала систему MemoryAI KV Cache Server призванную решить проблему «стены памяти» в современных инфраструктурах, ориентированных на ресурсоёмкие задачи ИИ-инференса. Устройство предоставляет до 11 Тбайт CXL-памяти, что позволяет максимально эффективно использовать доступные вычислительные мощности. Сервер (модель Altus XE4318GT-KVC) выполнен в форм-факторе 4U. Он несёт на борту два процессора AMD EPYC 9005 Turin в исполнении Socket SP5 (LGA 6096) с показателем TDP до 500 Вт. В оснащение входят контроллер ASpeed AST2600 и сетевой адаптер Intel I350-AM2. Реализованы два коннектора для SSD формата M.2 2280/22110 с интерфейсом PCIe 3.0, восемь слотов для карт PCIe 5.0 x16 FHFL и два слота для карт PCIe 5.0 x16 LP, два сетевых порта 400GbE (RJ45), два порта USB 3.0 (5 Гбит/с), а также аналоговый интерфейс D-Sub. Устройство поддерживает до 3 Тбайт памяти DDR5-6400. Кроме того, установлены восемь карт CXL, каждая из которых содержит 1 Тбайт памяти. Благодаря этому расширяются возможности применяемых в инфраструктуре ИИ-ускорителей с ограниченным объёмом HBM. Говорится о совместимости с программной средой NVIDIA Dynamo, предназначенной в том числе для ускорения инференса. В целом, как отмечает Penguin Solutions, новый сервер позволяет компаниям максимально эффективно использовать GPU-ускорители благодаря добавлению больших пулов памяти. 
Источник изображения: Penguin Solutions Устройство оборудовано четырьмя блоками питания мощностью 3000 Вт с сертификатом 80 Plus Titanium. Диапазон рабочих температур — от +10 до +35 °C. Заявлена совместимость с Red Hat Enterprise Linux (RHEL) и Rocky Linux. На систему предоставляется трёхлетняя гарантия.
05.03.2026 [14:21], Владимир Мироненко
Дефицит памяти поможет Broadcom подзаработать, но не так, как вы подумалиВ связи с ростом цен на оперативную память на фоне её дефицита, который, по прогнозам экспертов, сохранится и в 2027 году, VMware (подразделение Broadcom) предложила частное облако VMware Cloud Foundation (VCF) 9.0 в качестве решения, необходимого для работы в новых условиях. VMware заявила, что «традиционный подход, заключающийся в увеличении количества оборудования для решения проблем производительности и масштабируемости, больше не является жизнеспособным». «Broadcom разработала VCF 9.0 специально для решения этой экономической задачи, предложив три различных подхода: снижение совокупной стоимости владения за счёт многоуровневого хранения памяти, отсрочка капитальных затрат за счёт передовых технологий повышения эффективности и обеспечение немедленного внедрения в существующий парк оборудования», — сообщила она. Как отметил The Register, VMware всегда продвигала многоуровневую организацию памяти VCF 9 как возможность снизить затраты на инфраструктуру за счёт уменьшения установленного объёма DRAM путём прозрачного переноса части данных на NVMe. Вместе с тем, не следует забывать, что стоимость SSD также выросла. VMware также признаёт, что её архитектура памяти подходит не для всех рабочих нагрузок и не предназначена для виртуальных машин, чувствительных к задержкам, или очень больших инстансов. 
Источник изображения: Kevin Ache/unsplash.com Но VMware всё равно утверждает, что «наиболее прямое решение проблемы стремительного роста цен на DRAM — это просто использовать её меньше», а VCF 9.0 позволяет «заменить дорогостоящую DRAM значительно более дешёвым хранилищем NVMe». Многоуровневое распределение памяти VMware в настоящее время превосходит альтернативу в виде CXL, пишет The Register. Кроме того, новые поколения серверных процессоров AMD и Intel создали возможность очередного этапа консолидации нагрузок. Dell утверждает, что её клиенты заменяют семь серверов одной новой машиной; Intel говорит о консолидации 5:1. Новые серверы позволяют запускать огромное количество ВМ, что концентрирует риски и требует огромного количества дорогостоящей памяти. Но VMware и не требует, чтобы в каждом хосте в кластере использовалось многоуровневое распределение памяти. Так что VCF 9 в текущей ситуации действительно может оказаться эффективным средством снижения затрат. В то же время The Register отметил, что многие пользователей vSphere считают VCF 9 очень дорогим продуктом, несмотря на уверения Broadcom в обратном. При этом Broadcom, похоже, в принципе не готова идти на ценовые уступки — или бери, или уходи.
07.02.2026 [13:53], Сергей Карасёв
Montage Technology представила активные кабели PCIe 6.x/CXL 3.xКомпания Montage Technology объявила о разработке активных электрических кабелей (AEC) PCIe 6.x/CXL 3.x, предназначенных для организации высокоскоростного интерконнекта с низкой задержкой в дата-центрах, ориентированных на ресурсоёмкие задачи ИИ и НРС. Отмечается, что на фоне стремительного внедрения ИИ и продолжающегося развития облачных вычислений быстро растёт нагрузка на ЦОД. При этом PCIe остаётся основным стандартом для обмена данными между CPU, GPU, сетевыми картами и высокопроизводительными хранилищами. Интерконнект на базе PCIe применяется как в рамках серверных стоек, так и в составе суперузлов, в связи с чем требуется увеличивать протяжённость соединений. В таких условиях, подчёркивает Montage Technology, медные линии на базе AEC имеют решающее значение для обеспечения целостности сигнала на больших расстояниях. 
Источник изображения: Montage Technology Кабели Montage Technology PCIe 6.x/CXL 3.x с ретаймером используют фирменные блоки SerDes и передовую архитектуру DSP. Применён высокоплотный форм-фактор OSFP-XD. Говорится о развитых функциях мониторинга и диагностики каналов связи, что упрощает обслуживание систем и повышает их эффективность. Возможно использование в инфраструктурах с различными топологиями. В разработке решения, как утверждается, принимали участие ведущие китайские производители кабелей. Проведены успешные тесты на совместимость с CPU, xPU, коммутаторами PCIe, сетевыми адаптерами и другими устройствами. В дальнейшем компания Montage Technology намерена развивать направление высокоскоростного интерконнекта, включая выпуск ретаймеров PCIe 7.0.
06.02.2026 [10:53], Владимир Мироненко
Без дефицитной HBM: Positron AI готовит ИИ-ускоритель Asimov с терабайтами LPDDR5xКомпания Positron AI сообщила о привлечении $230 млн инвестиций в рамках переподписанного раунда финансирования серии B, в результате которого оценка её рыночной стоимости превысила $1 млрд. Раунд возглавили ARENA Private Wealth, Jump Trading и Unless при участии новых инвесторов Qatar Investment Authority (QIA), Arm и Helena, а также существующих инвесторов Valor Equity Partners, Atreides Management, DFJ Growth, Resilience Reserve, Flume Ventures и 1517. Объявление было сделано на мероприятии Web Summit Qatar, что подчеркивает растущий международный авторитет компании, отметил ресурс eWeek. На то, чтобы перейти в категорию единорогов, Positron AI потребовалось 34 месяца. Positron AI отметила решение Jump Trading стать одним из лидеров раунда после того, как эта компания стала её клиентом. «Для рабочих нагрузок, которые нас интересуют, узкими местами всё чаще становятся память и энергопотребление, а не теоретические вычисления», — сказал технический директор Jump Trading. — В ходе наших тестов Positron Atlas показал примерно в три раза меньшую сквозную задержку, чем сопоставимая система на базе NVIDIA H100, при оценке рабочих нагрузок инференса, в готовом к производству корпусе с воздушным охлаждением и цепочкой поставок, которую мы можем спланировать». 
Источник изображения: Positron AI Полученные инвестиции позволят ускорить выход платформы следующего поколения Asimov, разработанной на заказ. Компания планирует завершить тестирование Asimov к концу III квартала, а пробные версии появятся в конце I квартала 2027 года. В Asimov будет использоваться память LPDDR (без HBM), но возможность приблизиться к теоретической пиковой пропускной способности памяти означает, что компании и не нужно полагаться на HBM для быстрой генерации токенов, сообщил ресурсу EE Times технический директор Positron. Вычислительные элементы Asimov — это эволюция блоков Atlas с добавлением ядер Arm и улучшенным интерконнектом. Расширить память LPDDR5x в Asimov можно с помощью CXL — с 864 Гбайт до 2,3 Тбайт на чип. Чип позволяет создать два независимых домена памяти, чтобы лучше утилизировать её. Хосит-интерфейс чипа — PCI 6.0 x32. Хотя LPDDR5x дешевле и ёмче HBM, она значительно уступает ей по пропускной способности. Если ускорители Rubin от NVIDIA оснащены 288 Гбайт памяти HBM4 с пиковой пропускной способностью 22 Тбайт/с, то для Asimov, по-видимому, потолок составляет около 3 Тбайт/с, пишет The Register (в спецификациях указано 2,76 Тбайт/с). По словам Positron, разница в том, что её чипы действительно могут использовать 90 % этой пропускной способности, в то время как GPU на базе HBM в реальных условиях едва достигают 30 % пиковой пропускной способности, хотя память Rubin даже в этом случае примерно в 2,4 раза быстрее, чем у Asimov. 
Источник изображения: Positron AI Компания сообщила, что 400-Вт чип оснащён систолической матрицей 512×512, работающей на частоте 2 ГГц и поддерживающей типы данных TF32, FP16/BF16, FP8, NVFP4 и INT4. Эта матрица управляется рядом ядер Armv9 и может быть переконфигурирована, например, в 128×512 (GEMV) или 512×128 (GEMM), в зависимости от того, какой вариант более выгоден для решения конкретной задачи. Четыре чипа Asimov образуют 4U-платформу Titan с воздушным охлаждением и пропускной способностью между чипами 16 Тбит/с. Компания отметила, что Asimov рассчитан на поддержку 2 Тбайт памяти на ускоритель и 8 Тбайт памяти на систему Titan с аналогичной пропускной способностью памяти, как у ускорителя NVIDIA Rubin. В масштабе стойки это означает объём памяти более 100 Тбайт. До 4096 систем Titan (16384 ускорителя) могут быть объединены в единый масштабируемый домен с более чем 32 Пбайт памяти. Это достигается с помощью чистого межчипового интерконнекта, а не коммутируемых масштабируемых сетей, как в стоечных архитектурах NVIDIA или AMD. Positron подчеркнула, что её архитектура, ориентированная на память, открывает доступ к высокоэффективным задачам инференса, включая большие языковые модели с длинным контекстом, агентные рабочие процессы и модели медиа и видео следующего поколения. |
|

