Материалы по тегу: in-memory
|
25.06.2026 [16:11], Владимир Мироненко
Qualcomm анонсировала HBC — альтернативу HBM на базе LPDDRQualcomm анонсировала High Bandwidth Compute (HBC), гибридное решение для вычислений и памяти, разработанное в качестве альтернативы памяти HBM и обеспечения большей производительности, эффективности и пропускной способности. В нём используется трёхмерная архитектура Near-Memory Computing (NMC), обеспечивающая предельно близкое расположение быстрой памяти к вычислительным ядра. В HBC используется память LPDDR, размещённая вертикально в несколько слоёв, соединённых сквозными кремниевыми контактами (TSV). Такой подход обеспечивает лучшую энергоэффективность, чем традиционная HBM, в которой в вертикальных слоях размещается память DDR, поскольку микросхемы LPDDR потребляют меньше энергии, обеспечивая при этом аналогичную пропускную способность и ёмкость. При этом в основании HBC лежит вычислительный кристалл, который берёт на себя часть обработки данных основного процессора, тем самым разгружая его. Как отметил ресурс Techpowerup, эта технология аналогична используемой в памяти HBM4, где базовый кристалл представляет собой логический кристалл для лучшей интеграции вычислительных решений, таких как трассировка пакетов и подготовка данных для ввода и вывода из HBM. 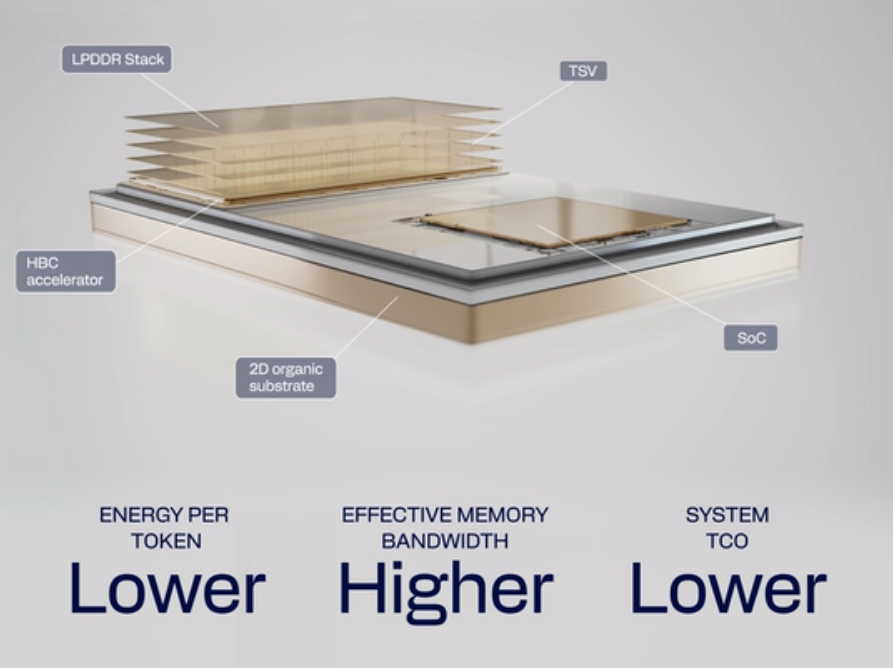
Источник изображений: Qualcomm Qualcomm сообщила, что HBC обеспечивает шестикратное увеличение пропускной способности на Вт по сравнению с HBM, согласно опубликованным характеристикам конкурирующих продуктов, нормализованным на уровне платы, а также 200-кратное увеличение ёмкости на Вт по сравнению с SRAM, согласно опубликованным характеристикам конкурирующих продуктов, нормализованным на уровне стойки.  HBC первого поколения (HBC Gen 1) достигла пропускной способности 133 Тбайт/с на ускорителе AI250, что в 18 раз больше, чем у AI200 на базе LPDDR5X. Коммерческое тестирование HBC1 с AI250 ожидается в середине 2027 года. Компания планирует выпуск решения HBC Gen 2 в 2028 году. Это решение выйдет с ИИ-ускорителем Qualcomm Dragonfly AI300 и обеспечит 54-кратное увеличение эффективной пропускной способности по сравнению с AI200 и семикратное увеличения пропускной способности на Вт по сравнению с HBM.  Dragonfly AI300 интегрирует HBC2, обеспечив высокую пропускную способность и низкую задержку для инференса больших языковых и мультимодальных моделей (LLM, LMM) и агентного ИИ. По данным Qualcomm, ожидается в 4–8 раз более высокая производительность по сравнению с существующими архитектурами на базе GPU по пропускной способности памяти на Вт на карту. Масштабирование решения будет осуществляться с помощью интерконнектов UALink и ESUN с использованием медных и оптических кабелей. Коммерческое производство образцов Dragonfly AI300 начнётся в 2028 году.
12.05.2026 [14:47], Сергей Карасёв
До 64 Тбайт RAM: HPE представила модульный суперсервер Compute Scale-up Server 3250Компания HPE анонсировала сервер Compute Scale-up Server 3250 на аппаратной платформе Intel для нагрузок, которым требуется большой объём оперативной памяти. Это могут быть резидентные базы данных, аналитические приложения, транзакционные платформы и пр. Новинка выполнена на модульной архитектуре, обеспечивающей гибкое масштабирование. Шасси стандарта 5U рассчитано на четыре процессора Intel Xeon 6700P (до 86 ядер). Доступны 64 слота для модулей оперативной памяти DDR5 ёмкостью до 256 Гбайт каждый: таким образом, суммарный объём ОЗУ может достигать 16 Тбайт. В одну систему могут быть объединены до четырёх серверов, что даст 16 CPU и 64 Тбайт RAM. Платформа управляется внешним контроллером узлов, который отвечает за интерконнект. Доступны различные конфигурации слотов PCIe 5.0 для карт расширения: 4 × FH + 2 × LP, 8 × FH + 4 × LP или 16 × LP. В оснащение входят сетевые контроллеры 1GbE и 10GbE/25GbE (SFP28), оптический привод DVD-RW (опционально) и вентиляторы охлаждения с возможностью горячей замены. Подсистема хранения данных базируется на накопителях E3.S (NVMe), количество которых может достигать 24. Есть три порта USB 3.0 Type-A (один располагается во фронтальной части, два — сзади). 
Источник изображений: HPE Габариты сервера составляют 905 × 445 × 219,2 мм, масса — от 40,82 до 56,7 кг в зависимости от комплектации. Диапазон рабочих температур простирается от +5 до +35 °C. Задействованы блоки питания мощностью 2400 Вт с сертификатом 80 Plus Titanium. Реализованы средства управления HPE Integrated Lights-Out (HPE iLO).  Отмечается, что Compute Scale-up Server 3250 — это первый масштабируемый сервер HPE на платформе Xeon 6, имеющий модульную архитектуру, оптимизированную для ресурсоёмких вычислительных задач и агентного ИИ. Кроме того, по словам компании, это первая в своём класса система, прошедшая валидацию в бенчмарках SAP BW для платформ с 48+ Тбайт RAM. Приём заказов на новинку уже начался. Производитель предоставляет на систему трёхлетнюю гарантию.
26.01.2026 [09:39], Владимир Мироненко
ИИ-расчёты — в OPU: Neurophos готовит 56-ГГц фотонный ускоритель Tulkas T100Стартап Neurophos, специализирующийся на разработках в области фотонных чипов для ИИ-нагрузок, сообщил о привлечении $110 млн в рамках переподписанного раунда финансирования серии А, в результате чего общий объём полученных им инвестиций вырос до $118 млн. Раунд возглавила Gates Frontier Билла Гейтса (Bill Gates) при участии M12 (венчурный фонд Microsoft), Carbon Direct Capital, Aramco Ventures, Bosch Ventures, Tectonic Ventures, Space Capital и др. В число инвесторов также вошли DNX Ventures, Geometry, Alumni Ventures, Wonderstone Ventures, MetaVC Partners, Morgan Creek Capital, Silicon Catalyst Ventures, Mana Ventures, Gaingels и другие. Юридическим консультантом выступает Cooley LLP. Полученные средства компания планирует использовать для ускорения разработки своей первой интегрированной фотонной вычислительной системы. Она включает в себя готовые к использованию в ЦОД модули OPU, полный программный стек и аппаратное обеспечение с ранним доступом для разработчиков. Кроме того, компания расширяет свою штаб-квартиру в Остине и открывает новый инженерный центр в Сан-Франциско для удовлетворения первоначального спроса клиентов. Стартап разработал «метаповерхностный модулятор» с оптическими свойствами, позволяющими его использовать в качестве тензорного процессора для выполнения матрично-векторного умножения. Разработанные стартапом оптические модуляторы на основе метаматериалов микронного масштаба в 10 тыс. раз меньше существующих фотонных элементов, что впервые делает фотонные вычисления реальностью. Эти модуляторы интегрируются с технологией вычислений в памяти для сокращения перемещения данных. 
Источник изображений: Neurophos «Современные задачи инференса с использованием ИИ требуют колоссальных вычислительных мощностей и ресурсов, — сообщил доктор Марк Трембле (Marc Tremblay), корпоративный вице-президент и технический эксперт по базовой ИИ-инфраструктуре ИИ. — Нам необходим прорыв в вычислительной мощности, сопоставимый с теми скачками, которые мы наблюдаем в самих ИИ-моделях, и именно этим занимается технология Neurophos и ее высококвалифицированная команда». Компания, основанная Патриком Боуэном (Patrick Bowen) и Эндрю Траверсо (Andrew Traverso), включает в себя ветеранов отрасли из NVIDIA, Apple, Samsung, Intel, AMD, Meta✴, ARM, Micron, Mellanox, Lightmatter и др. Neurophos разрабатывает оптический процессор (OPU), который объединяет более миллиона микронных оптических элементов обработки на одном чипе. Он обеспечивает до 100 раз большую производительность и энергоэффективность по сравнению с ведущими современными чипами, утверждает компания. «Закон Мура замедляется, но ИИ не может позволить себе ждать. Наш прорыв в фотонике открывает совершенно новый уровень масштабирования благодаря массивному оптическому параллелизму на одном чипе. Этот сдвиг на уровне физики означает, что как эффективность, так и скорость улучшаются по мере масштабирования, освобождаясь от энергетических барьеров, которые ограничивают традиционные GPU», — говорит Боуэн.  «Эквивалент оптического транзистора, который вы получаете сегодня на заводах, огромен. Он имеет длину около 2 мм. Вы просто не можете разместить достаточное количество таких транзисторов на чипе, чтобы получить вычислительную плотность, хотя бы отдалённо конкурирующую с современными CMOS-технологиями», — сообщил ресурсу The Register Боуэн. «В мае мы получили первый кремниевый кристалл, продемонстрировав, что можем сделать это с помощью стандартного CMOS-процесса, что означает совместимость с существующими технологиями производства. На кристалле находится одно фотонное тензорное ядро размером 1000 × 1000 [обрабатывающих элементов]», — сказал он. Это значительно больше, чем обычно встречается в большинстве GPU, которые обычно используют механизмы матричного умножения размером 256 × 256 обрабатывающих элементов. Однако для чипа Neurophos достаточно одного тензорного ядра вместо десятков или даже сотен таких, как в ускорителях NVIDIA. Боуэн говорит, что тензорное ядро в ускорителе Neurophos первого поколения будет занимать примерно 25 мм². Оснащение остальной части микросхемы размером с фотошаблон — это «главная проблема, связанная с поддержкой этого невероятно мощного тензорного ядра», сказал Боуэн. В частности, Neurophos требуется огромное количество векторных процессоров и SRAM, чтобы тензорное ядро не испытывало нехватки данных. Это связано с тем, что само тензорное ядро — которое в чипе будет всего лишь одно — работает на частоте около 56 ГГц. Но поскольку матричное умножение выполняется оптическим методом, единственная потребляемая тензорным ядром энергия уходит на преобразование электрических сигналов в оптические и обратно, сообщил Боуэн.  Как сообщает Neurophos, её первый OPU Tulkas T100 получит 768 Гбайт памяти HBM (20 Тбайт/с) и 200 Мбайт L2-кеша. Производительность системы составит 470 POPS (FP4/INT4) или 400 TOPS (FP16/INT16) при потреблении от 1 до 2 КВт под нагрузкой, демонстрируя энергоэффективность до 235 TOPS/Вт. Следует учитывать, что эти цифры пока лишь ориентиры. Чип всё ещё находится в активной разработке, и полномасштабное производство, как ожидается, начнётся не раньше середины 2028 года. Как утверждают в Neurophos, проблем с массовым производством оптических чипов не предвидится, поскольку они могут быть изготовлены с использованием стандартных материалов, инструментов и процессов полупроводниковых фабрик. Боуэн предполагает, что Tulkas T100 будет выполнять аналогичную роль, что и соускоритель NVIDIA Rubin CPX для работы с контекстом и создания KV-кеша. «Текущая концепция, которая может измениться, заключается в том, что мы разместим одну нашу стойку, состоящую из 256 наших чипов, и она будет сопряжена с чем-то вроде стойки NVL576», — сказал он. В долгосрочной перспективе возможен и переход к генерации токенов, но для этого потребуется разработка множества технологий, включая интегрированную оптику. Боуэн сообщил ресурсу TechCrunch, что Neurophos уже заключил контракты с несколькими клиентами (хотя он отказался назвать их имена), и такие компании, как Microsoft, «очень внимательно изучают» продукцию стартапа. Хотя на рынке ИИ-ускорителей и так большая конкуренция, Боуэн уверен, что повышение производительности и эффективности, обеспечиваемое оптическими вычислениями, станет достаточным конкурентным преимуществом чипов стартапа. «Все остальные, включая NVIDIA, в плане фундаментальной физики кремния, скорее эволюционны, чем революционны, и это связано с прогрессом TSMC. Если посмотреть на улучшение техпроцессов TSMC, то в среднем они повышают энергоэффективность примерно на 15 %, и на это уходит пара лет», — сказал он.
22.11.2025 [12:23], Сергей Карасёв
В Microsoft Azure появились инстансы с Intel Xeon 6 и CXL-памятьюКорпорация Microsoft в партнёрстве с SAP и Intel запустила в облаке Azure новые виртуальные машины семейства M-Series с технологией Compute Express Link (CXL). В настоящее время эти инстансы работают в режиме закрытого тестирования. Интерконнект CXL основан на интерфейсе PCIe: он обеспечивает высокоскоростную передачу данных с малой задержкой между хост-процессором и буферами памяти, акселераторами, устройствами ввода/вывода и пр. На днях была обнародована спецификация CXL 4.0, которая предусматривает поддержку линий с пропускной способности до 128 ГТ/с. Новые инстансы Azure базируются на процессорах Intel Xeon 6500P и 6700P поколения Granite Rapids-SP. В этих чипах реализована технология CXL Flat Memory Mode, которая позволяет оптимизировать соотношение вычислительных мощностей и ресурсов памяти. Это обеспечивает улучшенную масштабируемость без ущерба для производительности, что важно при работе с приложениями, требовательными к объёму памяти. 
Источник изображения: Microsoft В случае представленных виртуальных машин Azure поддержка CXL способствует более эффективной работе SAP S/4HANA. В частности, достигается большая гибкость в плане конфигурирования платформы, что помогает удовлетворять потребности конкретных бизнес-пользователей при одновременном снижении совокупной стоимости владения. «Инновационная архитектура инстансов с поддержкой CXL Flat Memory Mode ориентирована на повышение экономической эффективности и оптимизацию производительности программных решений SAP», — отмечает Intel.
18.11.2025 [16:55], Владимир Мироненко
d-Matrix привлекла ещё $275 млн и объявила о разработке первого ИИ-ускорителя с 3D-памятью Raptord-Matrix сообщила о завершении раунда финансирования серии C, в ходе которого было привлечено $275 млн инвестиций с оценкой рыночной стоимости компании в $2 млрд. Общий объём привлечённых компанией средств достиг $450 млн. Полученные средства будут направлены на расширение международного присутствия компании и помощь клиентам в развёртывании ИИ-кластеров на основе её технологий. Раунд C возглавил глобальный консорциум, включающий BullhoundCapital, Triatomic Capital и суверенный фонд благосостояния Сингапура Temasek. В раунде приняли участие Qatar Investment Authority (QIA) и EDBI, M12, венчурный фонд Microsoft, а также Nautilus Venture Partners, Industry Ventures и Mirae Asset. Сид Шет (Sid Sheth), генеральный директор и соучредитель d-Matrix, отметил, с самого начала компания была сосредоточена исключительно на инференсе. «Мы предсказывали, что когда обученным моделям потребуется непрерывная масштабная работа, инфраструктура не будет готова. Последние шесть лет мы потратили на разработку решения: принципиально новой архитектуры, которая позволяет ИИ работать везде и всегда. Это финансирование подтверждает нашу концепцию, поскольку отрасль вступает в эпоху ИИ-инференса», — добавил он. d-Matrix разработала ускоритель инференса Corsair на базе архитектуры с вычислениями в памяти DIMC (digital in-memory computing) — процессорные компоненты в нём встроены в память. Ускоритель предлагается вместе с сетевой картой JetStream. Также предлагается референсная архитектура SquadRack, которая упрощает создание ИИ-кластеров на базе Corsair. Она поддерживает до восьми серверов в стойке, каждая из которых содержит восемь ускорителей Corsair. Шасси SquadRack позволяет запускать ИИ-модели размером до 100 млрд параметров, хранящиеся полностью в SRAM. По данным d-Matrix, такая конфигурация обеспечивает на порядок большую производительность по сравнению с чипами с HBM. Вместе с оборудованием компания предлагает программный стек Aviator, который автоматизирует часть работы, связанной с развертыванием ИИ-моделей на ускорителе. Aviator также включает набор инструментов для отладки моделей и мониторинга производительности. 
Источник изображения: d-Matrix В следующем году d-Matrix планирует выпустить более производительный ускоритель инференса Raptor. Это первый в мире ускоритель на базе 3D DRAM. Решение разрабатывается в партнёрстве с Alchip, известной разработками в области ASIC. Благодаря сотрудничеству уже реализована ключевая технология d-Matrix 3DIMC, представленная в тестовом кристалле d-Matrix Pavehawk. По словам компаний, новинка обеспечит до 10 раз более быстрый инференс по сравнению с решениями на базе HBM4, что позволит повысить эффективность генеративных и агентных рабочих ИИ-нагрузок. Также в Raptor будет использоваться процессор AndesCore AX46MPV от Andes Technology. Компании заявили, что их сотрудничество представляет собой конвергенцию вычислений, ориентированных на память, и инноваций в области процессоров на основе открытых стандартов для рабочих ИИ-нагрузок в масштабах ЦОД. Andes AX46MPV будет отвечать за оркестрацию наргрузок, распределение памяти, векторные вычисления и функции активации. AX46MPV — 64-бит многоядерный RISC-V-процессор с поддержкой Linux. Он включает 2048-бит блок векторной обработки (RVV 1.0), высокоскоростную векторную память (HVM) и ряд других аппаратных блоков для работы с массивными вычислениями. В совокупности эти функции обеспечивают запас производительности и гибкость ПО, необходимые для систем инференса уровня ЦОД. Референсные ядра, являющиеся ключевыми для рабочих нагрузок ИИ-трансформеров и LLM, демонстрируют прирост производительности до 2,3 раза по сравнению с предшественником AX45MPV.
08.09.2025 [17:26], Владимир Мироненко
d-Matrix начала тестирование чипа Pavehawk с поддержкой 3DIMCСтартап d-Matrix объявил о разработке новой реализации технологии 3D-вычислений в памяти (3DIMC), которая обещает в 10 раз ускорить работу ИИ-моделей и в 10 раз повысить энергоэффективность по сравнению с текущим отраслевым стандартом HBM4, пишет ресурс SiliconANGLE. Технический директор Судип Бходжа (Sudeep Bhoja) сообщил в блоге, что первый чип компании с поддержкой 3DIMC, d-Matrix Pavehawk, разработка которого заняла более двух лет, сейчас проходит тестирование. В Pavehawk логический блок, изготовленный с использованием 5-нм техпроцесса TSMC, располагается поверх чипа памяти и интегрирован с ним посредством технологии F2F (face-to-face). По словам Бходжи, отраслевые тесты показывают, что производительность вычислений растёт примерно в 3 раза каждые два года, в то время как пропускная способность памяти — всего в 1,6 раза. Этот разрыв постоянно увеличивается, память уже стала узким местом в масштабировании ИИ. Компания утверждает, что простое увеличение количества ускорителей в ЦОД не решит проблему «стены памяти». 
Источник изображений: d-Matrix/ServeTheHome HPCwire цитирует гендиректора: d-Matrix Сида Шета (Sid Sheth): «Модели быстро развиваются, и традиционные системы памяти HBM становятся очень дорогими, энергоёмкими и ограниченными по пропускной способности». По его словам, узким местом ИИ-инференса является память, а не только количество операций с плавающей запятой, но 3DIMC меняет правила игры. «Стекируя память в трёх измерениях и обеспечивая её более тесную интеграцию с вычислениями, мы значительно сокращаем задержку, увеличиваем пропускную способность и открываем новые возможности повышения эффективности», — подчеркнул он. Компания отметила, что инференс, а не обучение, быстро становится доминирующей рабочей ИИ-нагрузкой. По словам Бходжи, CoreWeave недавно заявила, что 50 % её рабочих нагрузок теперь приходится на инференс, и аналитики прогнозируют, что в течение следующих двух-трех лет инференс будет составлять более 85 % всех корпоративных рабочих ИИ-нагрузок. Он подчеркнул, что компания не занимается перепрофилированием архитектур, созданных для обучения ИИ-моделей, — она с нуля разрабатывает решения, ориентированные на инференс. 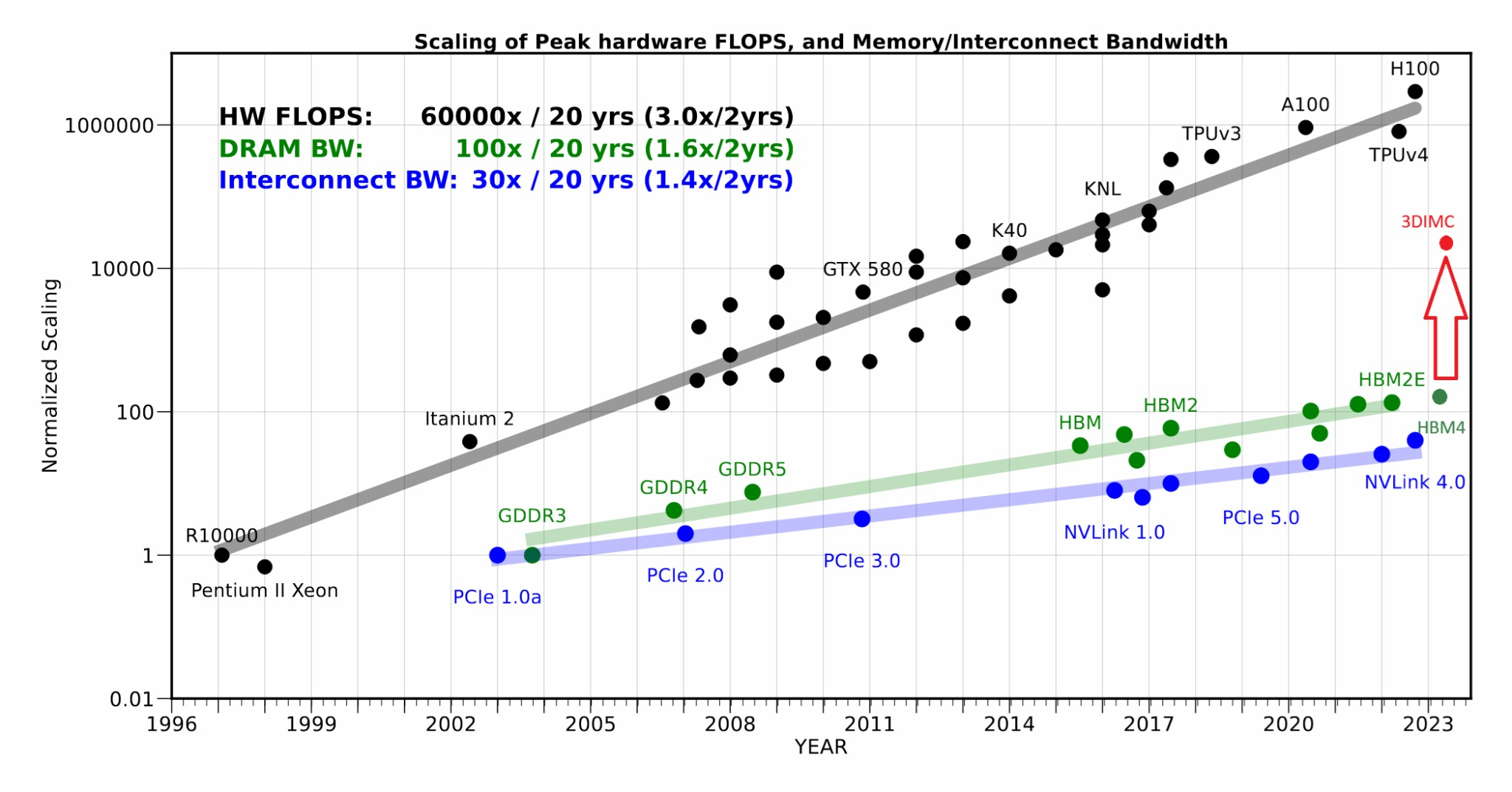 Бходжа сообщил, что первые пользователи ИИ-ускорителей Corsair, среди которых есть и гиперскейлеры, и неооблака, убедились, что архитектура с упором на память может значительно повысить пропускную способность, энергоэффективность и скорость генерации токенов по сравнению с GPU. Он также отметил, что конструкция на основе чиплетов обеспечивает не только большую пропускную способность памяти, но и «невероятную» гибкость, позволяя внедрять технологии памяти нового поколения быстрее и эффективнее, чем монолитные архитектуры. Бходжа заявил, что 3DIMC на порядок увеличит пропускную способность памяти и производительность для задач ИИ-инференса и обеспечит провайдерам сервисов и предприятиям возможность масштабировать их эффективно и экономично по мере появления новых моделей и приложений. С выводом Pavehawk на рынок компания занялось созданием следующего поколения архитектуры обработки в оперативной памяти, использующей 3DMIC, под названием Raptor. 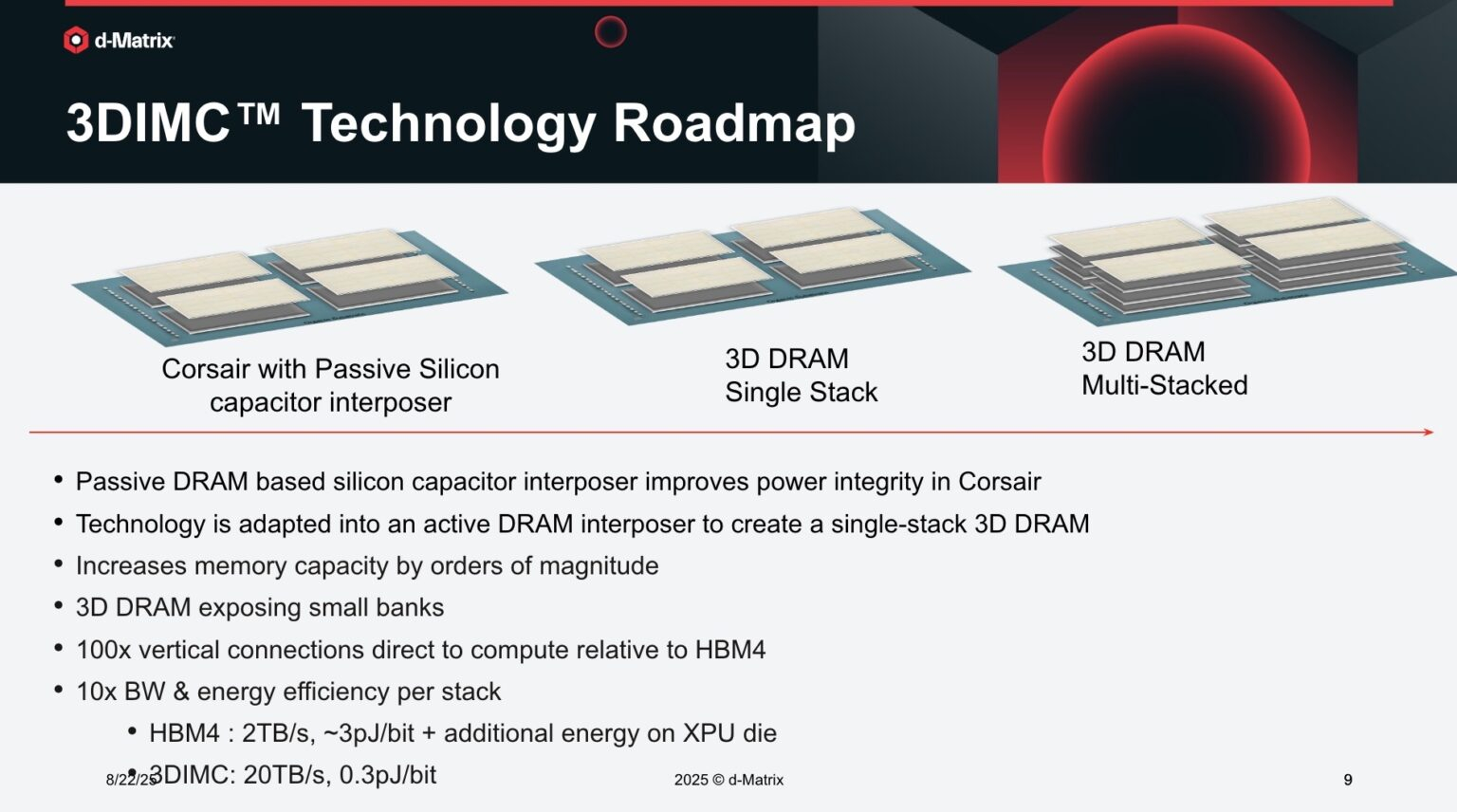 «Наша архитектура следующего поколения Raptor будет включать 3DIMC и опираться на опыт, полученный нами и нашими клиентами в ходе тестирования Pavehawk. Благодаря вертикальному размещению памяти и тесной интеграции с вычислительными чиплетами, Raptor обещает преодолеть барьер в области памяти и выйти на совершенно новый уровень производительности и совокупной стоимости владения», — утверждает Бходжа. Он добавил, что, поставив требования к памяти во главу угла при разработке своих решений — от Corsair до Raptor и далее — компания гарантирует, что инференс будет быстрее, доступнее и стабильнее при масштабировании. d-Matrix провела два раунда финансирования. В раунде A в 2022 году было привлечено $44 млн, а в раунде B в 2023 году – $110 млн, что в общей сложности составляет $154 млн. Компания сотрудничает с поставщиком решений компонуемых систем GigaIO.
08.08.2025 [10:44], Сергей Карасёв
Стартап Xcena представил вычислительную память MX1 с поддержкой PCIe 6.0 и CXL 3.2Южнокорейский стартап Xcena анонсировал свой первый продукт — вычислительную память MX1. Избранные партнёры начнут получать образцы изделий с октября, тогда как массовое производство запланировано на 2026 год. Решение MX1 обладает поддержкой PCIe 6.0 и CXL 3.2. Новинка позволяет расширить основную память системы, добавив до 1 Тбайт в виде четырёх модулей DDR5 DIMM ёмкостью 256 Гбайт каждый. Реализована технология NDP (Near Data Processing), которая сводит к минимуму задержку при перемещении данных между интерфейсами и значительно снижает совокупную стоимость владения для приложений, требующих обработки больших объемов информации. Для выполнения вычислений в оперативной памяти используются «тысячи ядер» на открытой архитектуре RISC-V. Изделия MX1 позволяют существенно ускорить выполнение таких задач, как операции с векторными и графовыми базами данных, анализ информации и пр. При этом снижается нагрузка на CPU. Прототип на базе FPGA продемонстрировал сокращение времени обработки запросов при работе с базами данных на 46 % по сравнению с серверными CPU. Теоретически выигрыш может достигать 95 % при реализации в виде ASIC. 
Источник изображения: Xcena Чип задействует 4-нм техпроцесс Samsung Foundry. Упомянута поддержка ECC. Компания Xcena предоставляет полностью интегрированный комплект для разработчиков (SDK), состоящий из низкоуровневых драйверов, библиотек среды выполнения и вспомогательных инструментов, которые помогают создавать прототипы и развертывать MX1 с минимальными усилиями по интеграции.
18.07.2025 [10:36], Сергей Карасёв
Lenovo анонсировала четырёхсокетные серверы ThinkSystem SR850 V4 и SR860 V4 на базе Intel Xeon 6Компания Lenovo анонсировала серверы ThinkSystem SR850 V4 и ThinkSystem SR860 V4 для ресурсоёмких рабочих нагрузок, которые предъявляют высокие требования к объёму оперативной памяти. Новинки получили четырёхсокетное исполнение с возможностью установки процессоров Intel Xeon 6700 с показателем TDP до 350 Вт. Обе системы поддерживают 64 модуля TruDDR5-6400 суммарной ёмкостью до 16 Тбайт. Может использоваться память CXL 2.0 в форм-факторе E3.S 2T (до 12 модулей). Есть два слота OCP 3.0 для сетевых адаптеров 1GbE, 10GbE, 25GbE, 100GbE, 200GbE и 400GbE. Модель ThinkSystem SR850 V4 имеет исполнение 2U. Могут быть реализованы до 12 разъёмов PCIe в конфигурации 11 × PCIe 5.0 и 1 × PCIe 4.0. Поддерживается установка двух GPU-ускорителей двойной ширины с TDP до 400 Вт или четырёх ускорителей одинарной ширины с TDP до 75 Вт. Подсистема хранения данных может включать 32 накопителя E3.S 1T или до 24 устройств формата SFF (NVMe). Кроме того, предусмотрены два коннектора М.2 для загрузочных SSD. Питание обеспечивают два блока с сертификатом 80 Plus Platinum или Titanium мощностью до 2600 Вт (с возможностью горячей замены). 
Источник изображений: Lenovo В свою очередь, сервер ThinkSystem SR860 V4 получил исполнение 4U. Машина располагает 18 слотами PCIe в конфигурации 16 × PCIe 5.0 и 2 × PCIe 4.0. Допускается монтаж четырёх GPU-ускорителей двойной ширины с TDP до 400 Вт или восьми карт одинарной ширины с TDP до 75 Вт. Поддерживаются до 56 накопителей в конфигурации 24 × SFF и 32 × E3.S 1T, а также два загрузочных SSD формата М.2. Могут использоваться до четырёх блоков питания 80 Plus Platinum или Titanium с горячей заменой.  Серверы оснащены двумя портами USB 3.0 и двумя разъёмами USB 3.1, интерфейсом Mini-DP, последовательным портом и выделенным сетевым портом управления 1GbE. Заявлена совместимость с Windows, Red Hat Enterprise Linux, SUSE Linux и продуктами VMware. Возможно использование системы прямого жидкостного охлаждения Neptune Core.
05.07.2025 [15:16], Алексей Разин
Повальный спрос на HBM тормозит внедрение CXL- и PIM-памятиОтраслевые аналитики уже не раз отмечали, что бурное развитие отрасли искусственного интеллекта, сопряжённое с ростом спроса на память типа HBM, ограничивает ресурсы производителей памяти на других направлениях. Помимо DDR, от этого страдают и перспективные виды памяти, которые производители хотели бы вывести на рынок. Об этом сообщило издание Business Korea, приведя в пример задержки с внедрением памяти типа CXL компанией Samsung Electronics и памяти типа PIM (Processing-in-Memory) компанией SK hynix. В последнем случае речь идёт о микросхемах памяти, способных самостоятельно выполнять специфические вычисления. Оба типа памяти могли бы в известной мере дополнить HBM в сегменте систем искусственного интеллекта. 
Источник изображения: SK hynix Samsung рассчитывала приступить к продвижению CXL-памяти ещё во II половине 2024 года, но её сертификация ключевыми клиентами до сих пор не завершена. SK hynix разрабатывает GDDR6-AiM с 2022 года, но до её фактического выпуска дело так и не дошло из-за неготовности рыночной экосистемы. Кроме того, сами производители памяти ограничены в свободных ресурсах, поскольку все силы бросили на выполнение заказов по производству HBM. Всё доступное оборудование задействовано для выпуска именно HBM, не давая производителям шанса заняться подготовкой к выпуску других перспективных типов памяти. 
Источник изображения: SK hynix На этом фоне у южнокорейских игроков рынка даже возникают опасения, что китайские конкуренты быстрее справятся с выводом на рынок модулей CXL и PIM. В этой ситуации корейские производители начали всё сильнее рассчитывать на поддержку государства, причём не столько финансовую, сколько регуляторную. С технической точки зрения к выводу на рынок CXL и PIM всё уже почти готово, но по факту на память этих типов пока нет достаточного спроса.
02.06.2025 [09:02], Сергей Карасёв
EnCharge AI представила аналоговые ИИ-ускорители EN100Компания EnCharge AI анонсировала изделия семейства EN100 — аналоговые ИИ-ускорители для in-memory вычислений. Дебютировали устройства в форм-факторе M.2 для ноутбуков и карты расширения PCIe для настольных рабочих станций. Стартап EnCharge AI, основанный в 2022 году, разрабатывает чипы, которые дают возможность перенести ИИ-нагрузки из облака на локальные платформы. Для этого применяется концепция вычислений в оперативной памяти, позволяющая увеличить эффективность и устранить узкие места, связанные с перемещением данных. NPU-ядра EnCharge AI, как утверждает сам разработчик, обеспечивают производительность на уровне 40 Топс/Вт (8-бит точность). Ускоритель EN100 для ноутбуков имеет типоразмер M.2 2280. В оснащение входят 32 Гбайт памяти с пропускной способностью до 68 Гбайт/с. Быстродействие превышает 200 Топс при общем энергопотреблении не более 8,25 Вт. Для оркестрации задействована многопоточная архитектура RISC-V. 
Источник изображений: EnCharge AI На рабочие станции ориентированы ускорители EN100 в виде карт расширения PCIe HHHL. Они несут на борту 128 Гбайт памяти с суммарной пропускной способностью 272 Гбайт/с. Производительность составляет около 1 Попс. Изделия обоих типов изготавливаются с применением 16-нм CMOS-технологии. 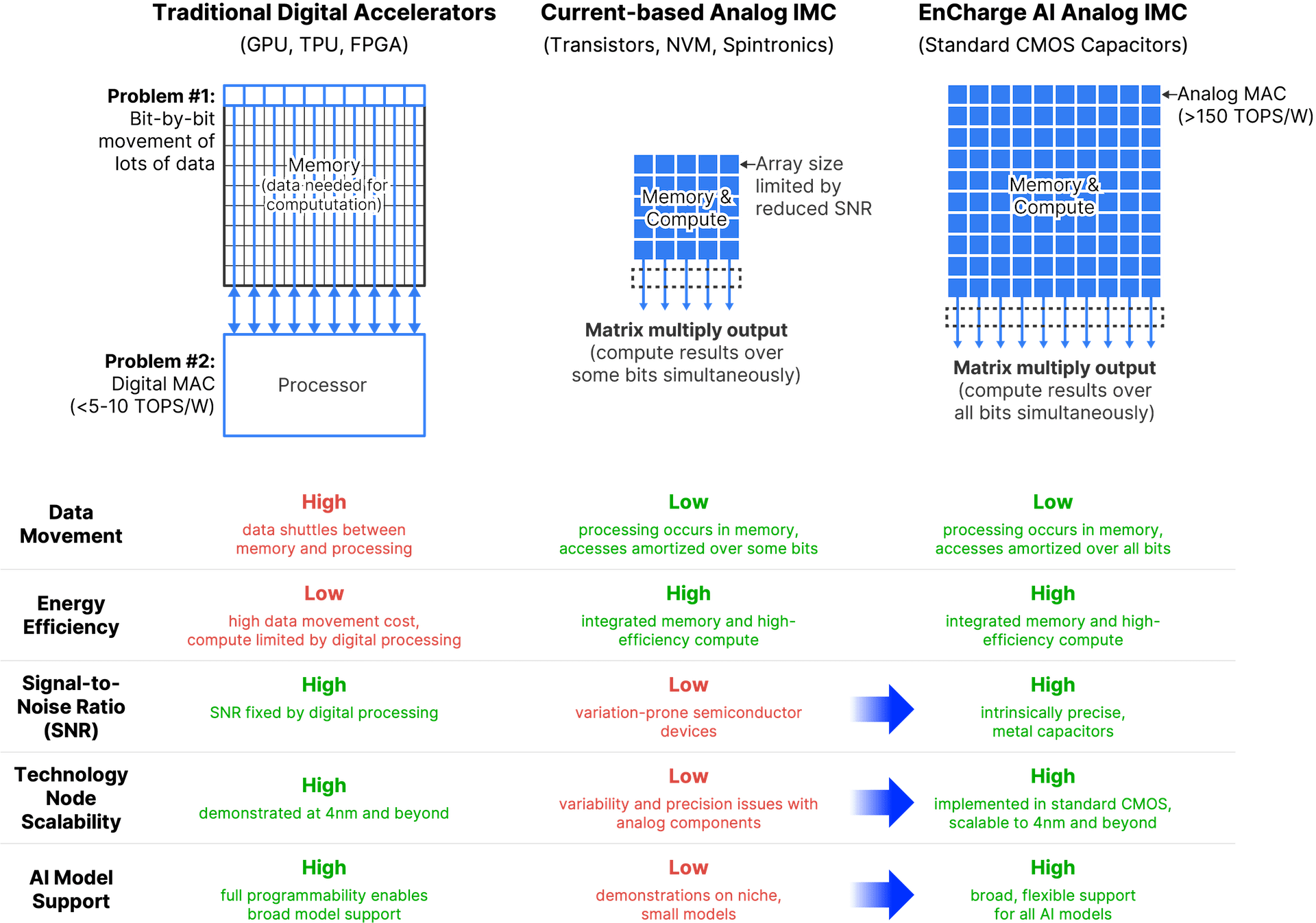 Навин Верма (Naveen Verma), генеральный директор EnCharge AI, заявляет, что решения компании позволят выполнять ресурсоёмкие задачи ИИ локально, не полагаясь на облачную инфраструктуру. Утверждается, что такие устройства по сравнению с современными ИИ-ускорителями обеспечат в 20 раз более высокую энергоэффективность (Топс/Вт) и в 9 раз более высокую плотность вычислений (Топс/мм2) при 10-кратном снижении совокупной стоимости владения (TCO). |
|

