Материалы по тегу: d-matrix
|
03.04.2026 [09:52], Сергей Карасёв
d-Matrix приобрела разработки GigaIO в области дата-центров, включая НРС-платформу SuperNODEСтартап d-Matrix, занимающийся разработкой ИИ-ускорителей и других специализированных изделий для НРС-систем, объявил о заключении соглашения по приобретению у компании GigaIO активов и разработок, связанных с дата-центрами. Стоимость сделки не раскрывается. В ассортименте d-Matrix присутствуют ускорители Corsair, базирующиеся на технологии вычислений в памяти DIMC (digital in-memory computing), а также IO-карты JetStream, предназначенные для распределения нагрузок ИИ-инференса между серверами в дата-центре. Кроме того, стартап создал стоечную систему SquadRack для пакетного инференса со сверхнизкой задержкой. В свою очередь, GigaIO предлагает так называемый суперкомпьютер в стойке SuperNODE для рабочих нагрузок генеративного ИИ и приложений НРС. Компания разработала архитектуру FabreX на базе PCI Express, которая позволяет объединять различные компоненты, включая GPU, FPGA и пулы памяти. Ещё одним продуктом GigaIO является «суперкомпьютер в чемодане» Gryf, который, как утверждается, обеспечивает ИИ-производительность класса ЦОД на периферии. 
Источник изображения: GigaIO d-Matrix и GigaIO начали сотрудничество весной 2025 года. Тогда стороны объединили усилия для создания «самого масштабируемого в мире» решения для инференса. Речь идёт об интеграции ИИ-ускорителей Corsair в состав платформы SuperNODE. В рамках нового соглашения d-Matrix приобрела у GigaIO основные технологии для дата-центров, включая SuperNODE и архитектуру FabreX. По условиям сделки, в d-Matrix перейдут ведущие специалисты GigaIO по разработке стоечных систем: предполагается, что это позволит ускорить развёртывание комплексных решений для высокопроизводительного инференса в ЦОД. Вместе с тем GigaIO сосредоточится на внедрении вычислительных мощностей уровня ЦОД непосредственно на периферии. В частности, планируется дальнейшее развитие концепции Gryf. По заявления GigaIO, рынок периферийных вычислений обладает огромным потенциалом. Благодаря решениям на основе Gryf клиенты смогут обрабатывать критически важные данные ближе к их источнику без проблем с задержками. При этом монтировать Gryf можно практически в любой локации.
16.03.2026 [10:45], Владимир Мироненко
ASIC + GPU: d-Matrix и Gimlet Labs в 10 раз ускорят инференс агентного ИИКомпании d-Matrix и Gimlet Labs сообщили о решении объединить усилия с целью повышения производительности и энергоэффективности инференса для задач агентного ИИ в режиме реального времени. В рамках партнёрства Gimlet интегрирует ускорители d-Matrix Corsair в облако Gimlet Cloud наряду с традиционными GPU. В гибридной архитектуре GPU будут отвечать за ресурсоёмкие этапы инференса, в то время как операции, чувствительные к работе с памятью и задержкам, будут обрабатывать Corsair. Компании сообщили, что совместное решение может обеспечить десятикратное улучшение задержки и пропускной способности на ватт по сравнению с использованием только GPU. Согласно пресс-релизу, решение «идеально подходит для рабочих нагрузок, чувствительных к задержке, включая спекулятивное декодирование, которое часто используется в крупномасштабных развёртываниях ИИ для снижения задержки». Corsair поставляется в виде стандартной карты PCIe с воздушным охлаждением, что позволяет быстро устанавливать решение в ЦОД внутри существующих серверов с GPU без специальных корпусов или нестандартных систем трубопроводов. Сетевые карты d-Matrix Jetstream передают данные между Corsair и GPU посредством стандартного Ethernet, упрощая интеграцию в масштабах инфраструктуры и повышая эффективность использования. 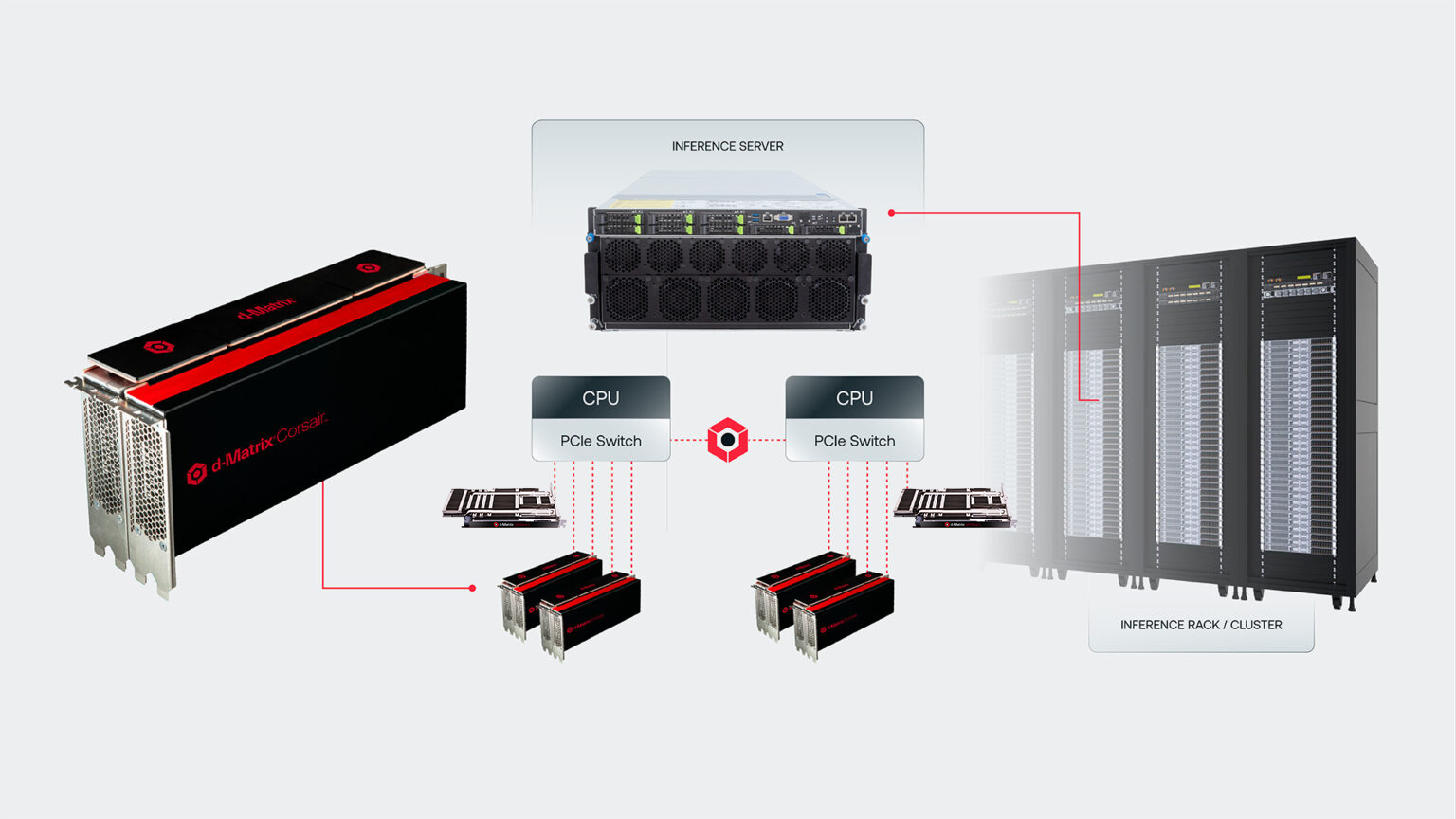
Источник изображения: d-Matrix Заин Асгар (Zain Asgar), сооснователь и генеральный директор Gimlet Labs, заявил, что «аппаратное обеспечение d-Matrix — идеальное решение для тех этапов инференса, на которых GPU тратят энергию впустую». «Используя Corsair для таких сценариев использования, как спекулятивное декодирование, мы можем обеспечить нашим клиентам значительно более высокую производительность при тех же габаритах», — добавил он. Программный стек Gimlet интеллектуально распределяет и сопоставляет рабочие нагрузки агентов между различными ускорителями разных производителей, поколений и архитектур, запуская каждый сегмент на наиболее оптимальном оборудовании. ЦОД Gimlet включают в себя различные типы оборудования и высокоскоростные интерконнекты для обслуживания передовых лабораторий и других компаний, занимающихся разработкой ИИ. Аналитик Мэтт Кимбалл (Matt Kimball) из Moor Insights & Strategy сообщил ресурсу Data Center Knowledge, что ключевым моментом является сочетание специализированного оборудования и программной оркестрации. «Архитектура d-Matrix разработана с учётом эффективности инференса, а не масштабируемости обучения, что соответствует рынку в ходе внедрения приложений ИИ в производство, — сказал Кимбалл. — Но одного оборудования недостаточно — такие платформы, как Gimlet, стремятся упростить развёртывание и легко интегрироваться в существующие рабочие процессы. Именно это делает данное решение привлекательным». Аналитик добавил, что реальная ценность решения заключается в уровне абстракции, который предоставляет Gimlet, позволяя запускать рабочие нагрузки на гетерогенных чипах без переписывания кода. «Рабочие нагрузки в области ИИ становятся всё более гетерогенными, но большая часть инфраструктуры по-прежнему оптимизирована под один тип ускорителя», — отметил он. По его словам, если Gimlet сможет упростить разработчикам развёртывание на нескольких чипах, это обеспечит реальное повышение эффективности системы. «Успешные платформы — это те, которые разработчики могут использовать, не задумываясь об оборудовании», — считает Кимбалл. Компании планируют предоставить своё объединённое решение отдельным клиентам в рамках Gimlet Cloud во II половине 2026 года. Data Center Knowledge отметил, что это также подчёркивает более широкую тенденцию в инфраструктуре ИИ: гетерогенные системы, вероятно, будут доминировать на следующем этапе развёртывания ИИ, и успех будет зависеть как от оркестрации ПО, так и от производительности оборудования. NVIDIA тоже добавил к своим GPU Rubin новые ASIC Groq.
18.11.2025 [16:55], Владимир Мироненко
d-Matrix привлекла ещё $275 млн и объявила о разработке первого ИИ-ускорителя с 3D-памятью Raptord-Matrix сообщила о завершении раунда финансирования серии C, в ходе которого было привлечено $275 млн инвестиций с оценкой рыночной стоимости компании в $2 млрд. Общий объём привлечённых компанией средств достиг $450 млн. Полученные средства будут направлены на расширение международного присутствия компании и помощь клиентам в развёртывании ИИ-кластеров на основе её технологий. Раунд C возглавил глобальный консорциум, включающий BullhoundCapital, Triatomic Capital и суверенный фонд благосостояния Сингапура Temasek. В раунде приняли участие Qatar Investment Authority (QIA) и EDBI, M12, венчурный фонд Microsoft, а также Nautilus Venture Partners, Industry Ventures и Mirae Asset. Сид Шет (Sid Sheth), генеральный директор и соучредитель d-Matrix, отметил, с самого начала компания была сосредоточена исключительно на инференсе. «Мы предсказывали, что когда обученным моделям потребуется непрерывная масштабная работа, инфраструктура не будет готова. Последние шесть лет мы потратили на разработку решения: принципиально новой архитектуры, которая позволяет ИИ работать везде и всегда. Это финансирование подтверждает нашу концепцию, поскольку отрасль вступает в эпоху ИИ-инференса», — добавил он. d-Matrix разработала ускоритель инференса Corsair на базе архитектуры с вычислениями в памяти DIMC (digital in-memory computing) — процессорные компоненты в нём встроены в память. Ускоритель предлагается вместе с сетевой картой JetStream. Также предлагается референсная архитектура SquadRack, которая упрощает создание ИИ-кластеров на базе Corsair. Она поддерживает до восьми серверов в стойке, каждая из которых содержит восемь ускорителей Corsair. Шасси SquadRack позволяет запускать ИИ-модели размером до 100 млрд параметров, хранящиеся полностью в SRAM. По данным d-Matrix, такая конфигурация обеспечивает на порядок большую производительность по сравнению с чипами с HBM. Вместе с оборудованием компания предлагает программный стек Aviator, который автоматизирует часть работы, связанной с развертыванием ИИ-моделей на ускорителе. Aviator также включает набор инструментов для отладки моделей и мониторинга производительности. 
Источник изображения: d-Matrix В следующем году d-Matrix планирует выпустить более производительный ускоритель инференса Raptor. Это первый в мире ускоритель на базе 3D DRAM. Решение разрабатывается в партнёрстве с Alchip, известной разработками в области ASIC. Благодаря сотрудничеству уже реализована ключевая технология d-Matrix 3DIMC, представленная в тестовом кристалле d-Matrix Pavehawk. По словам компаний, новинка обеспечит до 10 раз более быстрый инференс по сравнению с решениями на базе HBM4, что позволит повысить эффективность генеративных и агентных рабочих ИИ-нагрузок. Также в Raptor будет использоваться процессор AndesCore AX46MPV от Andes Technology. Компании заявили, что их сотрудничество представляет собой конвергенцию вычислений, ориентированных на память, и инноваций в области процессоров на основе открытых стандартов для рабочих ИИ-нагрузок в масштабах ЦОД. Andes AX46MPV будет отвечать за оркестрацию наргрузок, распределение памяти, векторные вычисления и функции активации. AX46MPV — 64-бит многоядерный RISC-V-процессор с поддержкой Linux. Он включает 2048-бит блок векторной обработки (RVV 1.0), высокоскоростную векторную память (HVM) и ряд других аппаратных блоков для работы с массивными вычислениями. В совокупности эти функции обеспечивают запас производительности и гибкость ПО, необходимые для систем инференса уровня ЦОД. Референсные ядра, являющиеся ключевыми для рабочих нагрузок ИИ-трансформеров и LLM, демонстрируют прирост производительности до 2,3 раза по сравнению с предшественником AX45MPV.
26.10.2025 [14:20], Сергей Карасёв
d-Matrix представила систему SquadRack для ИИ-инференса со сверхнизкой задержкойКомпания d-Matrix анонсировала систему SquadRack — стоечное решение для пакетного инференса со сверхнизкой задержкой. Это, как утверждается, первый в отрасли продукт данного класса. В его разработке приняли участие специалисты Arista, Broadcom и Supermicro. В основу SquadRack положена серверная платформа Supermicro X14 AI. Судя по изображениям, используется модель SYS-522GA-NRT, которая допускает установку двух процессоров Intel Xeon 6900 (Granite Rapids) и 24 модулей оперативной памяти DDR5-8800. Доступны 24 фронтальных отсека для SFF-накопителей U.2/U.3 (NVMe). Устройство выполнено в форм-факторе 5U. Система SquadRack предусматривает использование ускорителей d-Matrix Corsair. Их архитектура основана на модифицированных ячейках SRAM для вычислений в памяти (DIMC), работающих на скорости около 150 Тбайт/с. По заявлениям d-Matrix, решение обеспечивает непревзойдённую производительность ИИ-инференса: быстродействие достигает 2,4 Пфлопс (8-бит вычисления). Кроме того, задействованы IO-карты d-Matrix JetStream, предназначенные для распределения нагрузок инференса. Одна такая карта может обслуживать до четырёх экземпляров Corsair, обеспечивая сетевую задержку на уровне 2 мкс. 
Источник изображения: d-Matrix Решение SquadRack также оборудовано PCIe-коммутаторами Broadcom для масштабирования в пределах одного узла. В свою очередь, связь между узлами обеспечивают коммутаторы Arista Leaf Ethernet, подключённые к картам JetStream. Применяется программный стек d-Matrix Aviator. В одну стойку могут быть установлены до восьми экземпляров SquadRack, что позволяет с высокой скоростью обрабатывать модели ИИ, насчитывающие до 100 млрд параметров. В целом, возможно масштабирование до сотен узлов в нескольких серверных стойках.
09.09.2025 [15:46], Сергей Карасёв
d-Matrix представила 400GbE-адаптер JetStream для объединения своих ИИ-ускорителейСтартап d-Matrix анонсировал специализированную IO-карту JetStream, предназначенную для распределения нагрузок ИИ-инференса между серверами в дата-центре. Устройство ориентировано на использование в связке с ускорителями d-Matrix Corsair, архитектура которых основана на модифицированных ячейках SRAM для вычислений в памяти (DIMC). JetStream использует стандарт Ethernet, благодаря чему обладает совместимостью с уже существующими коммутаторами. Новинка выполнена в виде платы расширения с интерфейсом PCIe 5.0 х16. Используются корзины QSFP-DD. Могут быть задействованы два 200GbE-порта со скоростью 200 Гбит/с или один 400GbE-порт. Архитектура серверов d-Matrix для ИИ-инференса предполагает установку ускорителей Corsair с DMX-мостом между каждыми двумя такими картами для обеспечения высокой пропускной способности без использования PCIe. Затем пары ускорителей объединяются посредством коммутатора PCIe. В эталонном дизайне один NIC JetStream обслуживает до четырёх экземпляров Corsair. d-Matrix утверждает, что сетевую задержку в такой конфигурации удалось сократить до 2 мкс. 
Источник изображений: d-Matrix По заявлениям d-Matrix, карты JetStream могут применяться в существующих ЦОД без необходимости замены дорогостоящих инфраструктурных компонентов. В связке с ИИ-ускорителями Corsair и ПО d-Matrix Aviator решения JetStream способны справляться с ИИ-моделями, насчитывающими более 100 млрд параметров. При этом, как утверждает разработчик, обеспечивается в 10 раз более высокая производительность, в три раза лучшая экономическая эффективность и втрое большая энергоэффективность по сравнению с решениями на базе GPU. 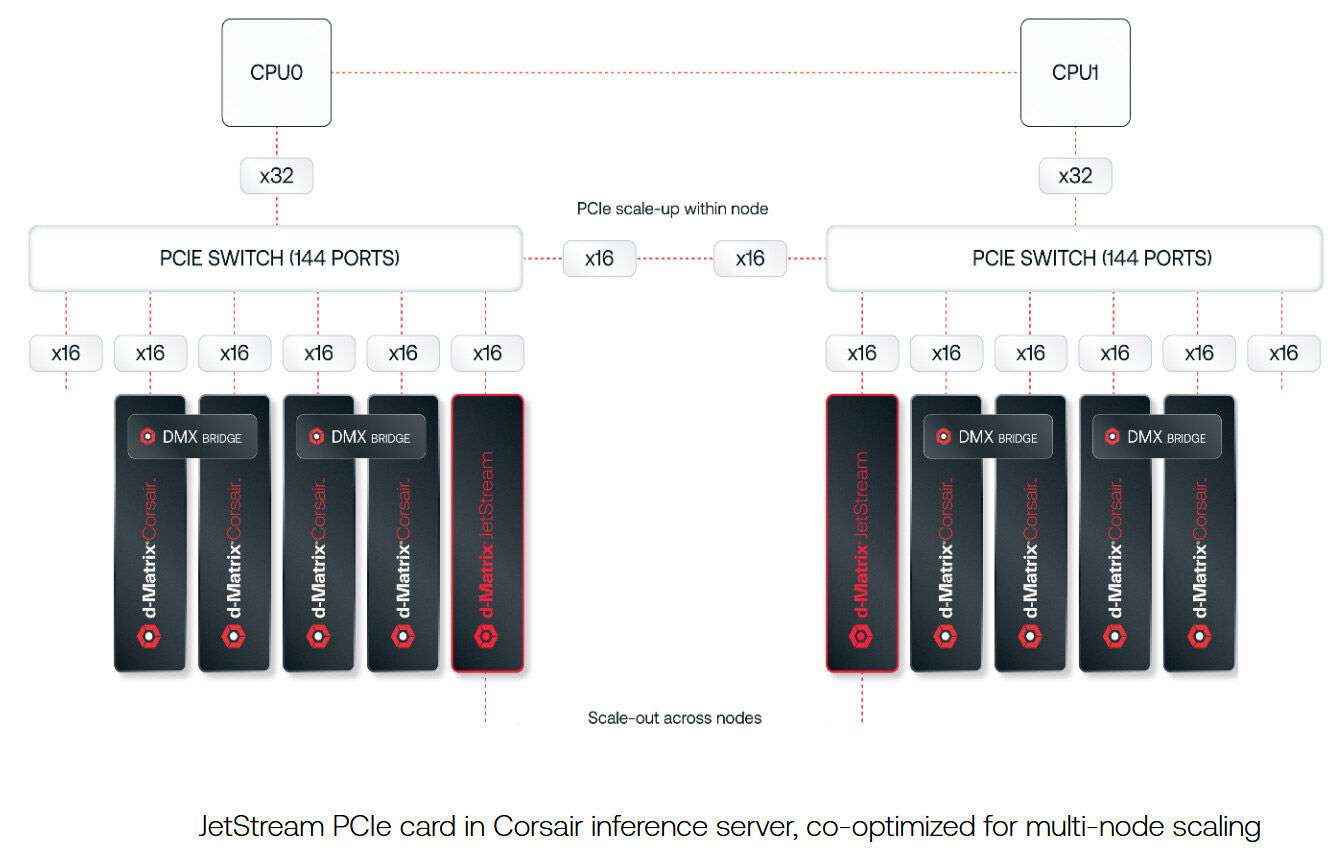 Энергопотребление JetStream составляет около 150 Вт. Адаптер оснащён системой охлаждения с радиатором и тепловыми трубками, которые охватывают зону QSFP-DD. Пробные поставки новинки уже начались, а массовое производство запланировано на конец текущего года.
08.09.2025 [17:26], Владимир Мироненко
d-Matrix начала тестирование чипа Pavehawk с поддержкой 3DIMCСтартап d-Matrix объявил о разработке новой реализации технологии 3D-вычислений в памяти (3DIMC), которая обещает в 10 раз ускорить работу ИИ-моделей и в 10 раз повысить энергоэффективность по сравнению с текущим отраслевым стандартом HBM4, пишет ресурс SiliconANGLE. Технический директор Судип Бходжа (Sudeep Bhoja) сообщил в блоге, что первый чип компании с поддержкой 3DIMC, d-Matrix Pavehawk, разработка которого заняла более двух лет, сейчас проходит тестирование. В Pavehawk логический блок, изготовленный с использованием 5-нм техпроцесса TSMC, располагается поверх чипа памяти и интегрирован с ним посредством технологии F2F (face-to-face). По словам Бходжи, отраслевые тесты показывают, что производительность вычислений растёт примерно в 3 раза каждые два года, в то время как пропускная способность памяти — всего в 1,6 раза. Этот разрыв постоянно увеличивается, память уже стала узким местом в масштабировании ИИ. Компания утверждает, что простое увеличение количества ускорителей в ЦОД не решит проблему «стены памяти». 
Источник изображений: d-Matrix/ServeTheHome HPCwire цитирует гендиректора: d-Matrix Сида Шета (Sid Sheth): «Модели быстро развиваются, и традиционные системы памяти HBM становятся очень дорогими, энергоёмкими и ограниченными по пропускной способности». По его словам, узким местом ИИ-инференса является память, а не только количество операций с плавающей запятой, но 3DIMC меняет правила игры. «Стекируя память в трёх измерениях и обеспечивая её более тесную интеграцию с вычислениями, мы значительно сокращаем задержку, увеличиваем пропускную способность и открываем новые возможности повышения эффективности», — подчеркнул он. Компания отметила, что инференс, а не обучение, быстро становится доминирующей рабочей ИИ-нагрузкой. По словам Бходжи, CoreWeave недавно заявила, что 50 % её рабочих нагрузок теперь приходится на инференс, и аналитики прогнозируют, что в течение следующих двух-трех лет инференс будет составлять более 85 % всех корпоративных рабочих ИИ-нагрузок. Он подчеркнул, что компания не занимается перепрофилированием архитектур, созданных для обучения ИИ-моделей, — она с нуля разрабатывает решения, ориентированные на инференс. 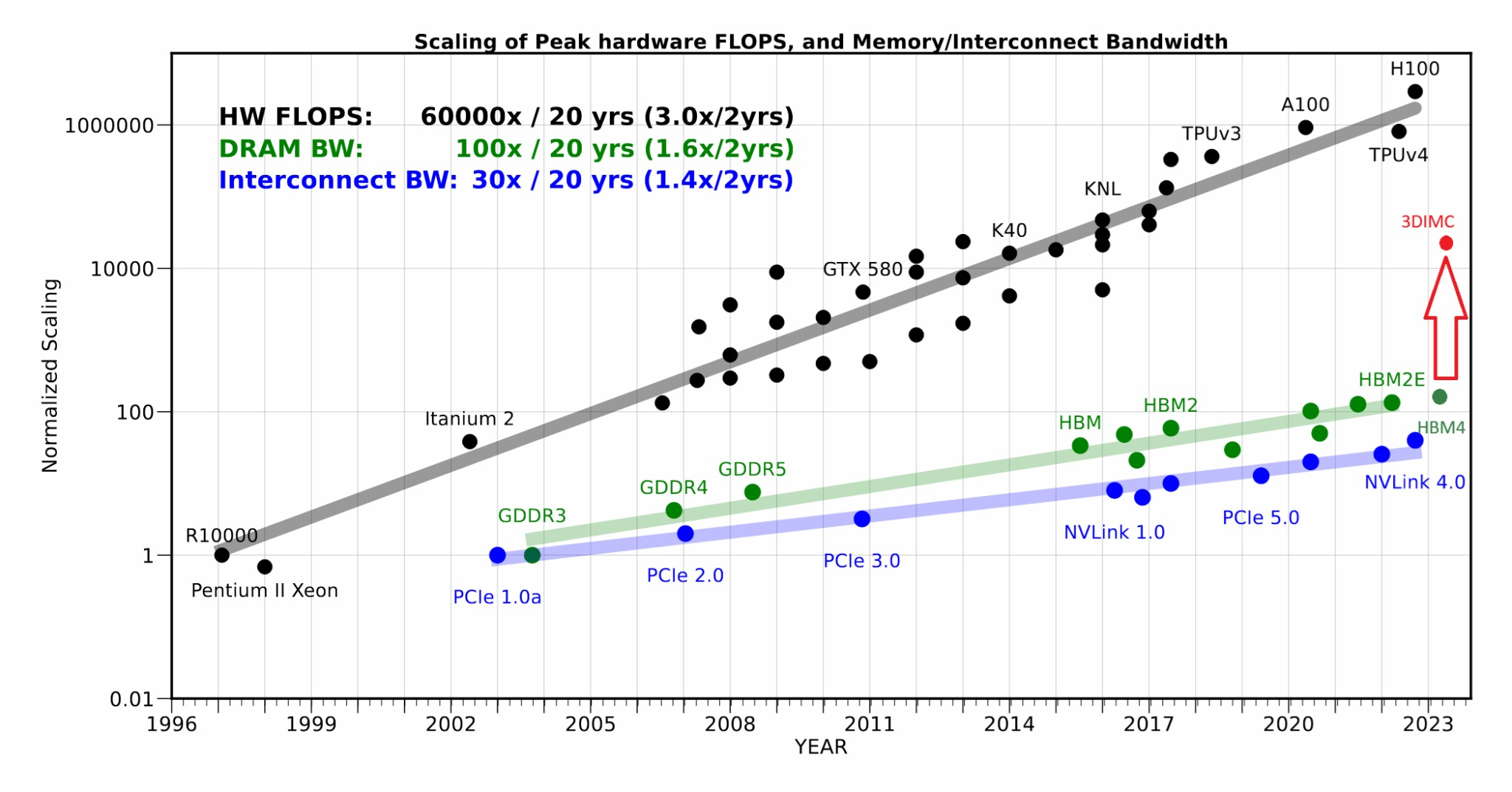 Бходжа сообщил, что первые пользователи ИИ-ускорителей Corsair, среди которых есть и гиперскейлеры, и неооблака, убедились, что архитектура с упором на память может значительно повысить пропускную способность, энергоэффективность и скорость генерации токенов по сравнению с GPU. Он также отметил, что конструкция на основе чиплетов обеспечивает не только большую пропускную способность памяти, но и «невероятную» гибкость, позволяя внедрять технологии памяти нового поколения быстрее и эффективнее, чем монолитные архитектуры. Бходжа заявил, что 3DIMC на порядок увеличит пропускную способность памяти и производительность для задач ИИ-инференса и обеспечит провайдерам сервисов и предприятиям возможность масштабировать их эффективно и экономично по мере появления новых моделей и приложений. С выводом Pavehawk на рынок компания занялось созданием следующего поколения архитектуры обработки в оперативной памяти, использующей 3DMIC, под названием Raptor. 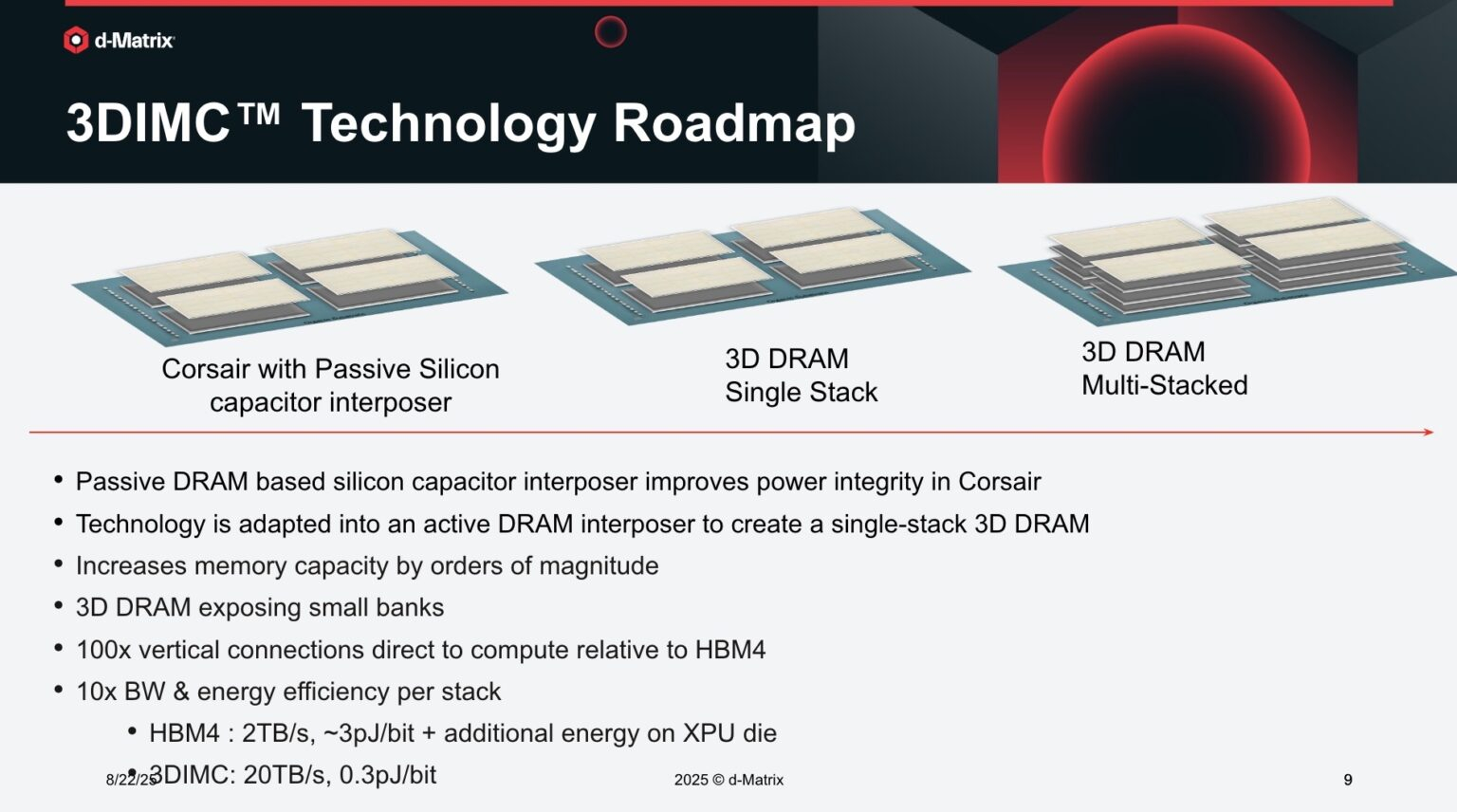 «Наша архитектура следующего поколения Raptor будет включать 3DIMC и опираться на опыт, полученный нами и нашими клиентами в ходе тестирования Pavehawk. Благодаря вертикальному размещению памяти и тесной интеграции с вычислительными чиплетами, Raptor обещает преодолеть барьер в области памяти и выйти на совершенно новый уровень производительности и совокупной стоимости владения», — утверждает Бходжа. Он добавил, что, поставив требования к памяти во главу угла при разработке своих решений — от Corsair до Raptor и далее — компания гарантирует, что инференс будет быстрее, доступнее и стабильнее при масштабировании. d-Matrix провела два раунда финансирования. В раунде A в 2022 году было привлечено $44 млн, а в раунде B в 2023 году – $110 млн, что в общей сложности составляет $154 млн. Компания сотрудничает с поставщиком решений компонуемых систем GigaIO.
05.05.2025 [13:28], Сергей Карасёв
GigaIO и d-Matrix предоставят инференс-платформу для масштабных ИИ-развёртыванийКомпании GigaIO и d-Matrix объявили о стратегическом партнёрстве с целью создания «самого масштабируемого в мире» решения для инференса, ориентированного на крупные предприятия, которые разворачивают ИИ в большом масштабе. Ожидается, что новая платформа поможет устранить узкие места в плане производительности и упростить внедрение крупных ИИ-систем. В рамках сотрудничества осуществлена интеграция ИИ-ускорителей d-Matrix Corsair в состав НРС-платформы GigaIO SuperNODE. Архитектура Corsair основана на модифицированных ячейках SRAM для вычислений в памяти (DIMC), работающих на скорости около 150 Тбайт/с. По заявлениям d-Matrix, ускоритель обеспечивает непревзойдённую производительность и эффективность инференса для генеративного ИИ. Устройство выполнено в виде карты расширения с интерфейсом PCIe 5.0 х16. Быстродействие достигает 2,4 Пфлопс с (8-бит вычисления). Изделие имеет двухслотовое исполнение, а показатель TDP равен 600 Вт. В свою очередь, SuperNODE использует фирменную архитектуру FabreX на базе PCIe, которая позволяет объединять различные компоненты, включая GPU, FPGA и пулы памяти. По сравнению с обычными серверными кластерами SuperNODE обеспечивает более эффективное использование ресурсов. 
Источник изображения: d-Matrix Новая модификация SuperNODE поддерживает десятки ускорителей Corsair в одном узле. Производительность составляет до 30 тыс. токенов в секунду при времени обработки 2 мс на токен для таких моделей, как Llama3 70B. По сравнению с решениями на базе GPU обещаны трёхкратное повышение энергоэффективности и в три раза более высокое быстродействие при сопоставимой стоимости владения. «Наша система избавляет от необходимости создания сложных многоузловых конфигураций и упрощает развёртывание, позволяя предприятиям быстро адаптироваться к меняющимся рабочим нагрузкам ИИ, при этом значительно улучшая совокупную стоимость владения и операционную эффективность», — говорит Alan Benjamin (Алан Бенджамин), генеральный директор GigaIO.
20.01.2025 [07:53], Владимир Мироненко
SRAM, да и только: d-Matrix готовит ИИ-ускоритель CorsairСтартап d-Matrix создал ИИ-ускоритель Corsair, оптимизированный для быстрого пакетного инференса больших языковых моделей (LLM). Архитектура ускорителя основана на модифицированных ячейках SRAM для вычислений в памяти (DIMC), работающих на скорости порядка 150 Тбайт/с. Новинка, по словам компании, отличается производительностью и энергоэффективностью, пишет EE Times. Массовое производство Corsair начнётся во II квартале. Среди инвесторов d-Matrix — Microsoft, Nautilus Venture Partners, Entrada Ventures и SK hynix. d-Matrix фокусируется на пакетном инференсе с низкой задержкой. В случае Llama3-8B сервер d-Matrix (16 четырёхчиплетных ускорителей в составе восьми карт) может производить 60 тыс. токенов/с с задержкой 1 мс/токен. Для Llama3-70B стойка d-Matrix (128 чипов) может производить 30 тыс. токенов в секунду с задержкой 2 мс/токен. Клиенты d-Matrix могут рассчитывать на достижение этих показателей для размеров пакетов порядка 48–64 (в зависимости от длины контекста), сообщила EE Times руководитель отдела продуктов d-Matrix Шри Ганесан (Sree Ganesan). 
Источник изображений: d-Matrix Производительность оптимизирована для исполнения моделей в расчёте до 100 млрд параметров на одну стойку. По словам Ганесан, это реалистичный сценарий использования LLM. В таких сценариях решение d-Matrix обеспечивает 10-кратное преимущество в интерактивности (время до получения токена) по сравнению с решениями на базе традиционных ускорителей, таких как NVIDIA H100. Corsair ориентирован на модели размером менее 70 млрд параметров, подходящих для генерации кода, интерактивной генерации видео или агентского ИИ, которые требуют высокой интерактивности в сочетании с пропускной способностью, энергоэффективностью и низкой стоимостью.  Ранние версии архитектуры d-Matrix использовали MAC-блоки на базе SRAM-ячеек, дополненных большим количеством транзисторов для операций умножения. Сложение же выполнялось в аналоговом виде с использованием разрядных линий, измерения тока и аналого-цифрового преобразования. В 2020 году компания выпустила чиплетную платформу Nighthawk на основе этой архитектуры. «[Nighthawk] продемонстрировал, что мы можем значительно повысить точность по сравнению с традиционными аналоговыми решениями, но мы всё ещё отстаем на пару процентных пунктов от традиционных решений типа GPU», — сказал EE Times генеральный директор d-Matrix Сид Шет (Sid Sheth). 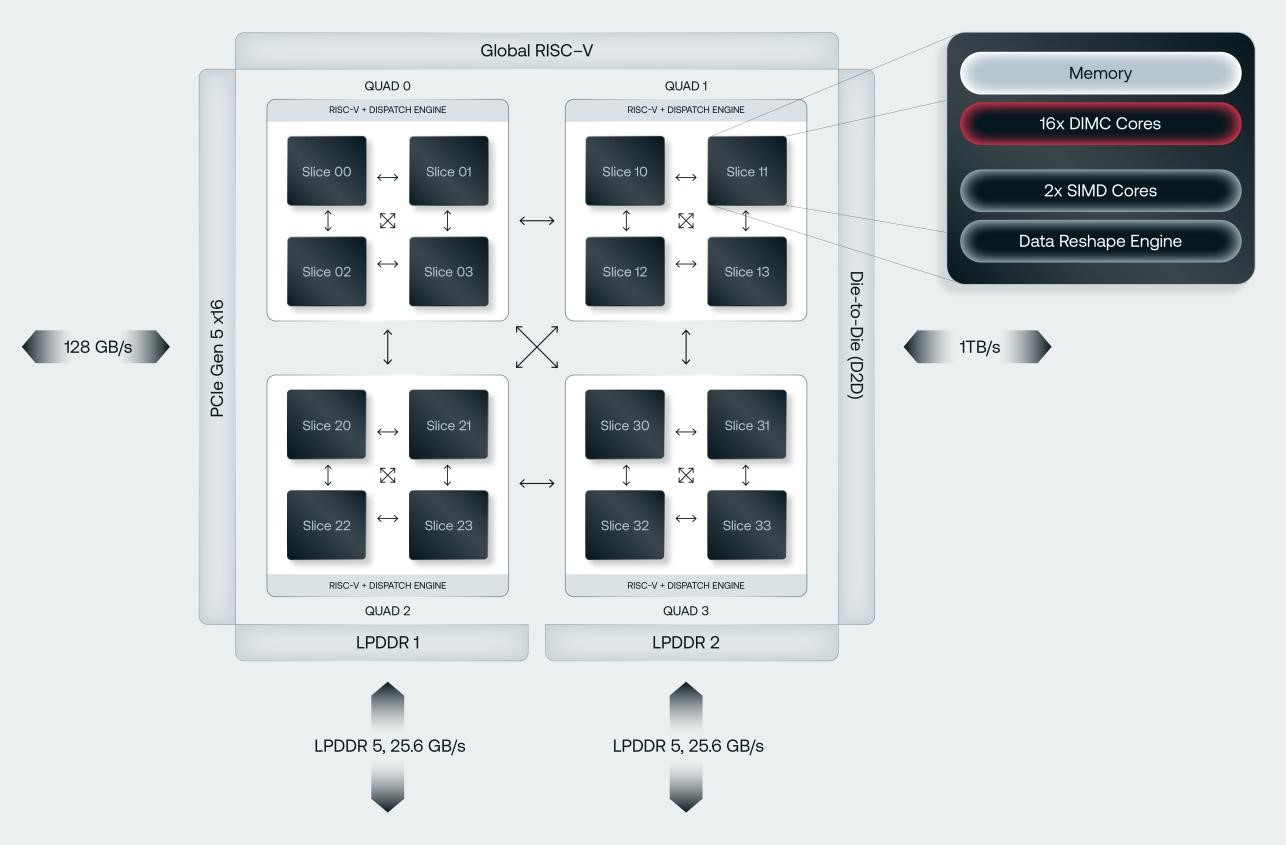 Однако потенциальным клиентам не понравилось, что при таком подходе возможно снижение точности, так что в Corsair компания вынужденно сделала выбор в пользу полностью цифрового сумматора. ASIC d-Matrix включает четыре чиплета, каждый из которых содержит по четыре вычислительных блока, объединённых посредством DMX Link по схеме каждый-с-каждым, и по одному планировщику и RISC-V ядру. Внутри каждого вычислительного блока есть 16 DIMC-ядер, состоящих из наборов SRAM-ячеек (64×64), а также два SIMD-ядра и движок преобразования данных. Суммарно доступен 1 Гбайт SRAM с пропускной способностью 150 Тбайт/с. 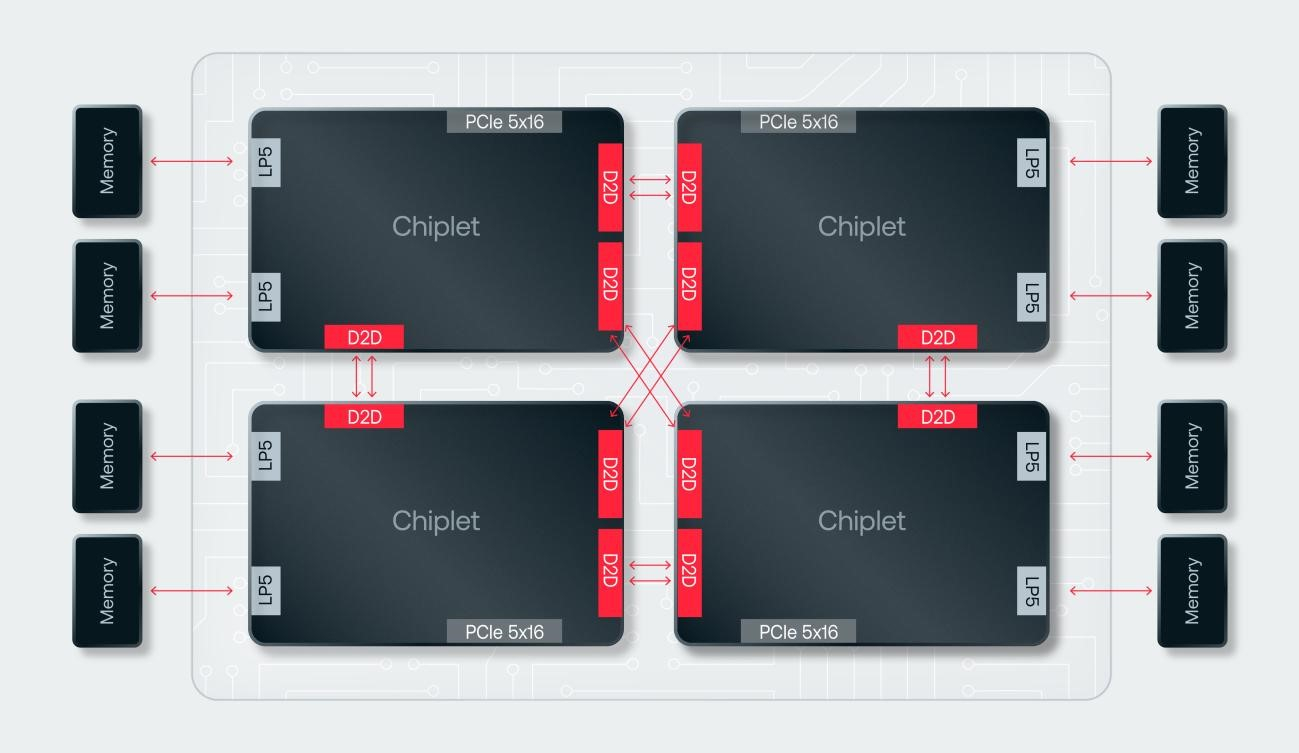 ASIC объединён со 128 Гбайт LPDDR5 (до 400 Гбайт/с) посредством органической подложки (без дорогостоящего кремниевого интерпозера). Хотя текущее поколение ASIC включает только четыре чиплета именно из-за ограничений подложки, в будущем их количество увеличится. Внешние интерфейсы ASIC представлены стандартным PCIe 5.0 x16 (128 Гбайт/с) и фирменным интерконнектом DMX Link (1 Тбайт/с) для объединения чиплетов. 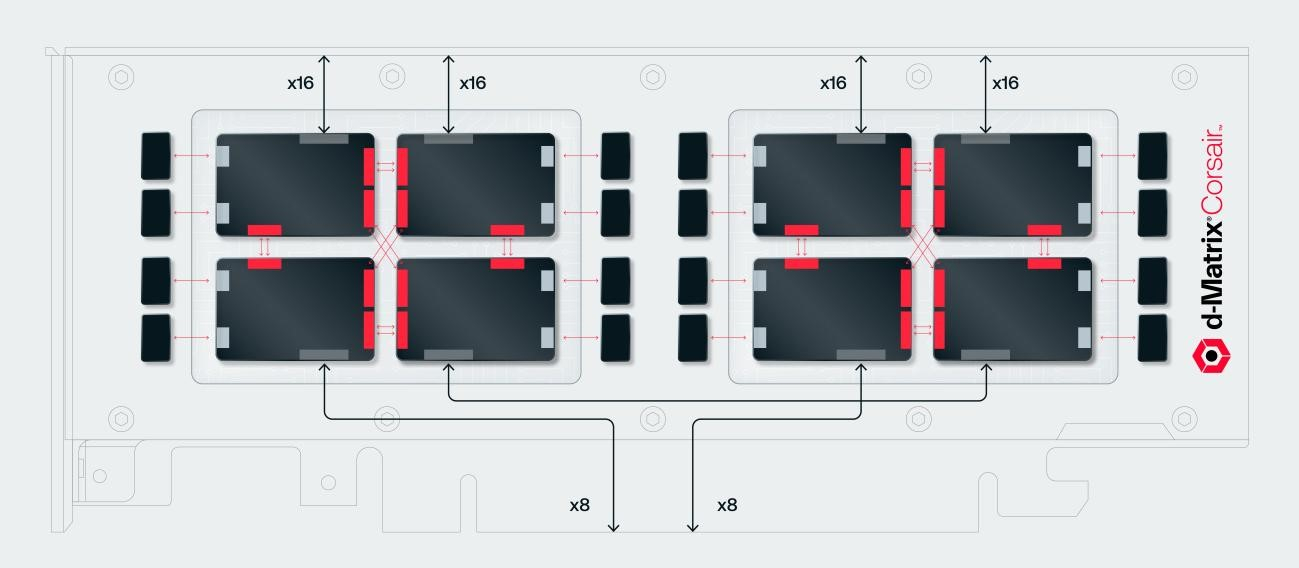 FHFL-карта Corsair включает два ASIC d-Matrix (т.е. всего восемь чиплетов) и имеет TDP на уровне 600 Вт. Ускоритель работает с форматами данных OCP MX (Microscaling Formats) и обеспечивает до 2400 Тфлопс в MXINT8-вычислениях или 9600 Тфолпс в случае MXINT4. Две карты Corsair можно объединить посредством 512-Гбайт/с мостика DMX Bridge. Их, по словам компании, достаточно для задействования тензорного параллелизма. Дальнейшее масштабирование возможно посредством PCIe-коммутации. Именно поэтому d-Matrix работает с GigaIO и Liqid. В одно шасси можно поместить восемь карт Corsair, а в стойку, которая будет потреблять порядка 6–7 кВт — 64 карты. 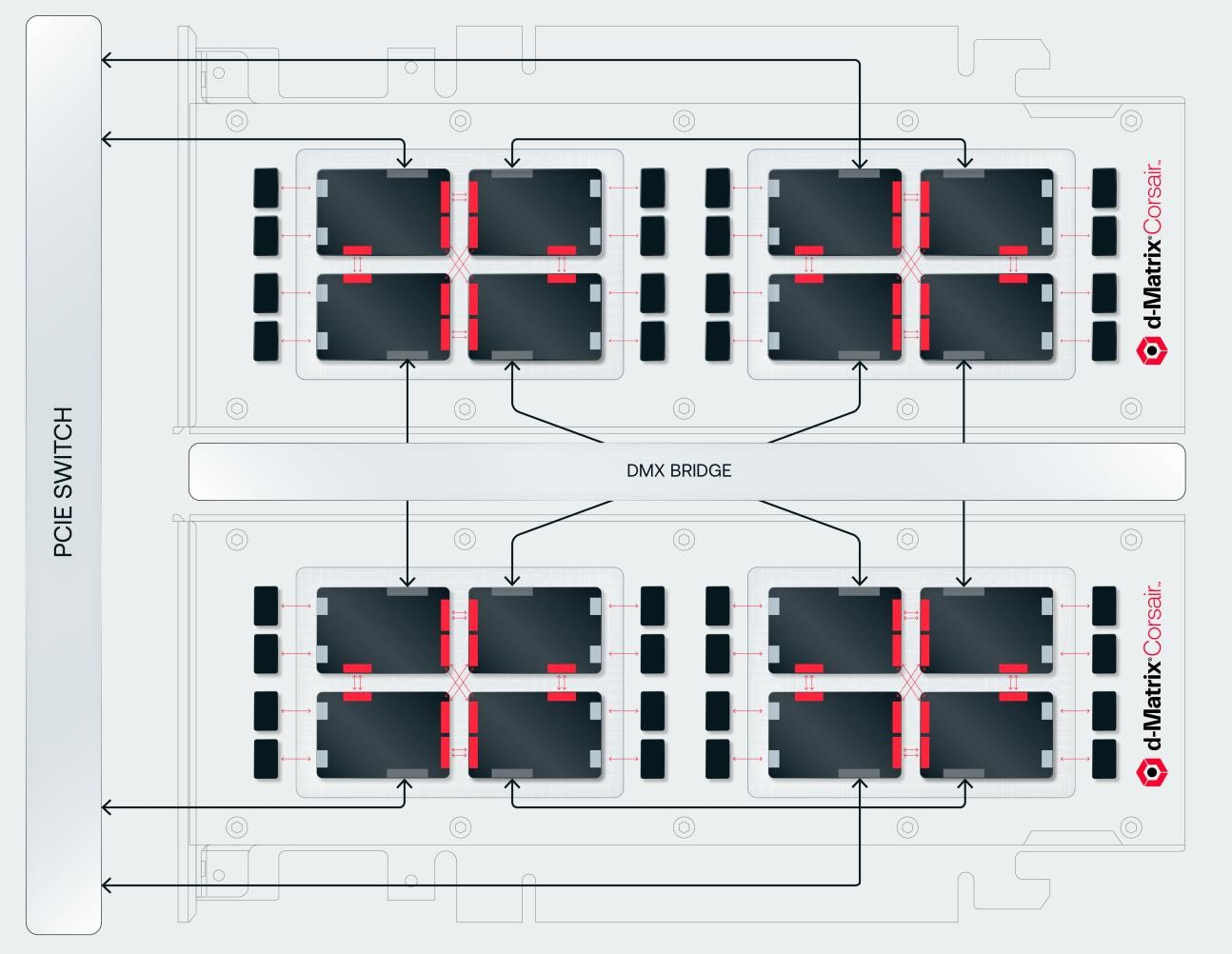 d-Matrix уже разрабатывает ASIC следующего поколения Raptor, который должен выйти в 2026 году. Raptor будет ориентирован на «думающие» модели и получит ещё больше памяти за счёт размещения DRAM непосредственно поверх вычислительных чиплетов. SRAM-чиплеты Raptor также перейдут с 6-нм техпроцесса TSMC, который используется при изготовлении Corsair, к 4 нм без существенных изменений микроархитектуры. По словам компании, она потратила два года на работу с TSMC, чтобы создать 3D-упаковку для нового поколения ASIC. 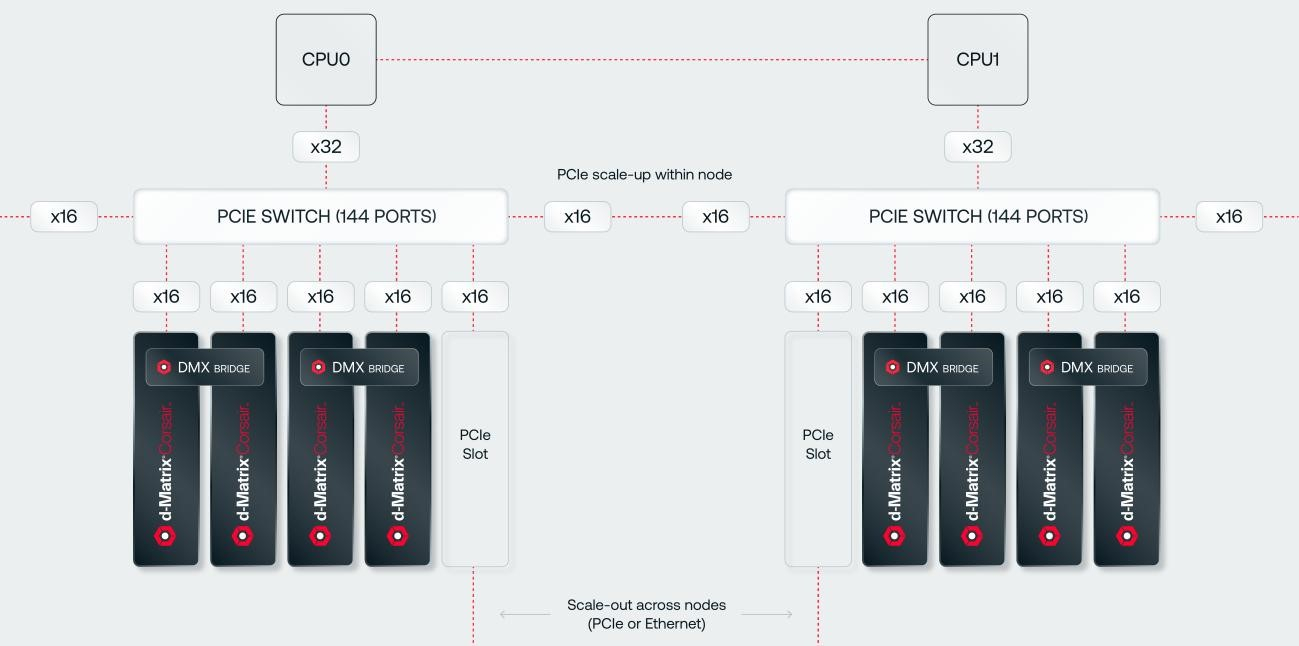 Как отмечает EETimes, команда разработчиков ПО d-Matrix в два раза больше команды разработчиков оборудования (120 против 60). Стратегия компании в области ПО заключается в максимальном использовании open source экосистемы, включая PyTorch, OpenAI Triton, MLIR, OpenBMC и т.д. Вместе они образуют программный стек Aviator, который отвечает за конвертацию моделей в числовые форматы d-Matrix, применяет к ним фирменные методы разрежения, компилирует их, распределяет нагрузку по картам и серверам, а также управляет исполнением моделей, включая обслуживание большого количества запросов. |
|

