Материалы по тегу: asic
|
21.07.2026 [23:26], Владимир Мироненко
Сделано в США: сетевые ASIC Fortinet SP6 будут выпускаться на американских фабриках IntelIntel и Fortinet объявили о стратегическом сотрудничестве с целью разработки кастомного процессора безопасности Fortinet Security Processor 6 (SP6). Как указано в пресс-релизе, это сотрудничество объединяет запатентованный опыт Fortinet в разработке специализированных процессоров безопасности с передовыми возможностями Intel в области проектирования, упаковки и производства для создания «высокоинтегрированного процессора, способного поддерживать все более сложные сервисы безопасности и высокие требования к производительности современных организаций». Совместная работа также поможет повысить устойчивость и диверсификацию глобальной цепочки поставок Fortinet. Предыдущая модель SP5, вышедшая в 2023 году, поддерживает L7-фильтрацию и IPSec-подключения на скоростях, превышающих 30 Гбит/с. Пропускная способность снижается при включении расширенной защиты от угроз или SSL-инспекции, но, по данным Fortinet, при этом поддерживаются высокие скорости — 4,3 Гбит/с и 3,3 Гбит/с соответственно. Как отметил ресурс The Register, ASIC серии SP от Fortinet предназначены в первую очередь для небольших устройств, таких как шлюзы SD-WAN, а не для более крупных, ориентированных на ЦОД и построенных на базе более мощных чипов серий NP и CP. 
Источник изображения: Fortinet Хотя подробностей о новом чипе компании пока не предоставили, ресурсу The Register сообщили в Intel, что для его изготовления будет использоваться более старый техпроцесс Intel 4, а не передовая технология 18A. В Intel также предположили, что Fortinet будет использовать опыт в области проектирования и передовой упаковки полупроводников, что может означать архитектуру чиплетов. В Intel также отказались сообщить о сроках выхода чипа, лишь сообщив, что «подробности о доступности SP будут объявлены позже». Как отметил The Register, хотя SP6 не будет использовать новейшие технологии производства чипов, он будет производиться на американском заводе американской компанией, что обеспечит высокий уровень безопасности цепочки поставок. Intel делает упор на безопасность цепочки поставок, стремясь трансформироваться из интегрированного производителя устройств, обслуживающего в основном себя, а иногда и правительство США, в полноценного производителя чипов, способного конкурировать с Samsung и TSMC.
02.06.2026 [16:29], Сергей Карасёв
Marvell представила чип-коммутатор Teralynx T100 на 102,4 Тбит/с для ИИ ЦОДКомпания Marvell анонсировала чип-коммутатор Teralynx T100 для дата-центров и облачных платформ, ориентированных на ресурсоёмкие ИИ-нагрузки. Изделие обеспечивает пропускную способность до 102,4 Тбит/с, а его пробные поставки начнутся в текущем квартале. Marvell подчёркивает, что в отличие от традиционных коммутационных платформ, предназначенных для обычных корпоративных и облачных дата-центров, Teralynx T100 разработан с нуля для ИИ-нагрузок. Новинка будет предлагаться в различных вариантах исполнения, включая BGA, CPC и CPO. При изготовлении чипа применяется 3-нм технология. Разработчик заявляет, что из конструкции исключены устаревшие элементы, увеличивающие энергопотребление и площадь кристалла. В результате, изделие обеспечивает до 25 % меньшее энергопотребление по сравнению с конкурирующими решениями: показатель не превышает 1000 Вт. Это важно, поскольку на коммутационные и прочие сетевые компоненты может приходиться 15–25 % от общей мощности серверной стойки. Таким образом, повышение энергоэффективности коммутаторов оказывает значительное влияние на работу ЦОД в целом. 
Источник изображения: Marvell Teralynx T100 поддерживает 512-портовую архитектуру. Marvell подчёркивает, что новинка обеспечивает исключительную эффективность использования полосы пропускания, благодаря чему помогает в устранении узких мест в современных крупномасштабных кластерах ИИ. Нужно отметить, что ранее чип-коммутатор с пропускной способностью 102,4 Тбит/с представила компания Cisco: изделие получило название Silicon One G300. Кроме того, Broadcom выпустила платформу с интегрированной оптикой CPO (Co-Packaged Optics) третьего поколения Tomahawk 6 — Davisson (TH6-Davisson), которая также относится к классу 102,4 Тбит/с. Аналогичные решения есть у NVIDIA в серии Spectrum-X.
27.05.2026 [17:25], Руслан Авдеев
ByteDance закупит ИИ-чипы Qualcomm и увеличит капзатраты до $70 млрдКомпания Qualcomm достигла соглашения с китайской ByteDance, предусматривающего выпуск и поставки чипов для ЦОД последней. Это важное достижение для Qualcomm, пытающейся расширить бизнес за пределы производства чипсетов для смартфонов и планшетов, сообщает Bloomberg. Кроме того, Qualcomm заключила договорилась о поставках ASIC с ещё одним неназванным американским облачным провайдером, дополняет DigiTimes. ByteDance намерена приобрести миллионы ИИ ASIC Qualcomm. По данным источников, это поможет владельцу социальной сети TikTok создавать и эксплуатировать агентный ИИ. После появления новостей акции Qualcomm подорожали на 8,3 % обновив дневной исторический максимум. Ранее компания заявила, что уже начала формировать очередь клиентов, желающих приобрести такие чипы. Qualcomm давно стремилась увеличить присутствие в индустрии ИИ-чипов, но главной проблемой был поиск клиентов на её продукцию соответствующего назначения. NVIDIA продолжает доминировать на рынке ИИ-полупроводников, хотя конкуренцию ей пытаются составить AMD, Broadcom и Google. Договор ByteDance поможет Qualcomm получить крупного покупателя и, следовательно, пропуск в один из наиболее быстро растущих сегментов полупроводниковой индустрии. 
Источник изображения: Qualcomm Сегодня американская компания предлагает чипы при посредничестве TSMC, если те соответствуют американским экспортным ограничениям — нарушать санкционный режим даже ради контракта с ByteDance в Qualcomm не будут. По словам одного из источников, новая сделка поможет ByteDance превратить уже разработанный самостоятельно дизайн чипа в готовый к производству продукт. Ещё в 2024 году сообщалось, что ByteDance проектировала собственные ускорители, хотя об отказе от продукции NVIDIA речь не шла. Тем временем ByteDance наращивает расходы. Компания увеличила увеличит капитальные затраты до порядка $70 млрд, большая часть средств пойдёт на ИИ-инфраструкту, включая ЦОД и оборудование. ПО Doubao, предлагаемое компанией, аналогично ChatGPT, Claude и Gemini. Боьшую часть прошлого года, по данным Bloomberg Intelligence, это был самый загружаемый чат-бот в Китае. Вместе с тем ByteDance стремительно осваивает и китайский рынок облачных ИИ-сервисов.
26.05.2026 [23:24], Руслан Авдеев
Сделка Anthropic и Microsoft расширит спрос на ИИ ASIC и повлияет на цепочки поставок для облачного рынкаКак сообщает The Information, Anthropic ведёт с Microsoft переговоры об использовании фирменных ускорителей последней для работы с ИИ-моделями Claude. Подобный шаг способен ускорить широкое внедрение Maia 200 и поддержать спрос на ASIC по всей «облачной» цепочке поставок, сообщает DigiTimes. Выиграют и поставщики компонентов для облачного рынка, от Global Unichip до Marvell с Broadcom. Как сообщают отраслевые источники, Anthropic фактически стала главным драйвером спроса на ASIC. В отличие от OpenAI, которая ранее заключала крупные долгосрочные сделки по покупке чипов, закупки Anthropic обычно соответствовали актуальному спросу на вычислительные мощности. Тем не менее, в последние месяцы она тоже повысила активность. Во-первых, компания заключила соглашение на использование ASIC с Google и (AWS), арендовала ИИ-мощности у xAI и, теперь, возможно, будет арендовать их у Microsoft. Эксперты считают, что это свидетельствует о значительном росте популярности Claude, из-за чего выросла необходимость в вычислительных ресурсах. По словам источников, Anthropic активно применяет ASIC разных поставщиков — они предпочтительнее для компании, чем более дорогие ИИ-ускорители NVIDIA, что позволяет обеспечить эффективность расходов. Подобная стратегия позволяет компании избежать зависимости от единственного поставщика, что усиливает переговорные позиции компании и снижает для неё риски, связанные с концентрацией доступных вычислительных ресурсов у одного партнёра. 
Источник изображения: Microsoft Благодаря сделке Microsoft может поддержать собственные разработки ASIC, пока уступающие по многим параметрам решениям Google и AWS. Те уже некоторое время сдают ИИ-чипы собственной разработки в аренду. Если Microsoft удастся повторить подобный успех, компания сможет сократить расходы на расширение выпуска чипов и расширить их закупки, что создаст дополнительные стимулы для фактических производителей ASIC и их партнёров. На фоне роста внимания ИИ-бизнеса к ASIC, эксперты прогнозируют увеличение соответствующего рынка. По некоторым оценкам, если их будут использовать только облачные провайдеры, закупки на рынке останутся ограниченными, но рост спроса со стороны крупных клиентов облачных платформ может существенно помочь развитию всей ниши. Текущий вектор её развития указывает на то, что спрос будет расти и дальше. В феврале сообщалось, что Anthropic планирует увеличить к 2029 году расходы на облака до $80 млрд.
04.05.2026 [10:46], Руслан Авдеев
Трудный выбор: телеком-операторы хотят и ИИ внедрить, и сэкономить, и избежать привязки к одному поставщикуТелеком-оператор Orange заявил о намерении найти оптимальный вариант для будущих сетей радиодоступа (RAN) на фоне развития ИИ-технологий. Компания предполагает, что ставка на ИИ поможет повысить эффективность мобильных сетей, сообщает блог IEEE ComSoc. Orange уже использует специально разработанные для 5G аппаратные и программные решения Nokia, до недавних пор необходимости в продуктах NVIDIA в сетях компании не было. Тем не менее, последняя сблизилась с Nokia в октябре 2025 года, приобретя 3 % долю в рамках инвестиций в объёме $1 млрд. Сейчас Nokia разрабатывает AI-RAN решения, оптимизированные для использования с ИИ-ускорителями. В немалой степени интерес Orange к ИИ-ускорителям объясняется довольно высокой стоимостью специализированных чипов (ASIC), традиционно применяемых в RAN. Их можно заменить ускорителями «общего назначения». Оправдать разработку и производство кастомных чипов довольно трудно, поскольку их цена высока, а рынок под эти продукты довольно мал и продолжает сокращаться. По данным Omdia, ежегодные расходы телеком-операторов сократились с $45 млрд в 2022 году до приблизительно $35 млрд и больше не растут, а применять такие чипы за пределами телеком-отрасли нецелесообразно. 
Источник изображения: Sophia Kunkel/unsplash.com В теории массовые продукты NVIDIA позволяют быстро и относительно экономично масштабировать RAN-сети 5G/6G и улучшить их экономику. При этом кастомные ASIC хоть и дорого, зато эффективнее и энергоэкономичнее для своих задач, а ИИ-ускорители, вероятно, чересчур производительны и энергоёмки. При этом NVIDIA остаётся финансово мощным игроком с высокой маржинальностью, что делает её привлекательным партнёром. Впрочем, Orange ожидает, что Nokia и NVIDIA разработают нечто намного более компактное, чем ускорители для дата-центров класса Blackwell, для шасси AirScale. В то же время Orange изучает возможность замены традиционных алгоритмов L1-уровня для использования ИИ-решений и повышения спектральной эффективности. 
Источник изображения: MingJun He/unspalsh.com Замена ASIC на ИИ-ускорители или CPU обсуждается не впервые. Так, Ericsson и Samsung уже давно предлагают облачные RAN-решения на процессорах Intel. Кроме того, ПО для таких процессоров при желании относительно легко переделать для использование с чипами на архитектуре x86 других производителей или даже Arm. Впрочем, пока крупнейшие поставщики оборудования, включая Ericsson и Huawei, продолжают активно вкладывать средства в собственные ASIC. Под вопросом положение и самой Intel, поскольку компания переживает не лучшие времена, а её сетевое подразделение NEX проходит через серию трансформаций. Использование ИИ-ускорителей тоже имеет значимые изъяны. В случае NVIDIA операторы будут зависеть от экосистемы CUDA, что ограничит возможность использования ПО с другим «железом». Orange признаёт опасность «привязки» к одному вендору, но считает, что преимущества масштабируемых архитектур «общего назначения» перевешивают риски, поскольку позволяют снизить совокупную стоимость владения (TCO). Впрочем, Orange не отказались бы от архитектуры, позволяющей сменить поставщика в случае необходимости. По данным IEEE ComSoc, Nokia всё-таки надеется, что значительная часть ПО, написанного для ускорителей NVIDIA, в будущем будет неким образом оптимизировано для использования с другими аппаратными платформами, в том числе и с CPU. Пока же почти монопольное положение NVIDIA оставляет участникам рынка немного альтернатив. Ericsson же пока остаётся верна кастомным ASIC. Для топ-менеджеров телеком-отрасли выбор, сделанный в следующие пару лет, может оказаться решающим для всей отрасли, поскольку на подходе уже сети 6G, внедрение которых должно начаться в 2030 году.
03.05.2026 [23:30], Владимир Мироненко
Поборы Broadcom вынудили Google обратиться к MediaTek для создания ИИ-ускорителей TPUСогласно свежему отчёту Foundry Quarterly and Monthly Intelligence от Counterpoint Research, благодаря сотрудничеству с Google доля компании MediaTek на рынке ИИ-серверов на базе кастомных ускорителей (ASIC) может вырасти к 2028 году до 26 %. В результате MediaTek может выйти на второе место, уступив лишь Broadcom. Google представила в апреле два TPU восьмого поколения: TPU 8t (Sunfish) для обучения ИИ и TPU 8i (Zebrafish) для ИИ-инференса. Как сообщается в отчёте Counterpoint Research, TPU v8t занимает ключевое место в стратегии Google в области ИИ. «Мы рассматриваем это поколение как переломный момент с точки зрения цепочки поставок, поскольку оно знаменует собой первый важный шаг в диверсификации Google от простой модели ASIC Broadcom “под ключ”», — отметили в Counterpoint Research. Что касается основной причины соглашения Google с MediaTek, в рамках которого Google разрабатывает вычислительный кристалл, а MediaTek предоставляет кристалл I/O, то Counterpoint Research объясняет это экономикой закупок HBM. В рамках модели поставок «под ключ» Broadcom сама занимается поиском поставщиков HBM, прибавляя к стоимости памяти ещё 15–20 %. С учётом того, что на HBM приходится всё более значительная доля в себестоимости ASIC, такая наценка становится всё более обременительной для Google, которая к тому же наращивает темпы развёртывания TPU в ЦОД. Взяв на себя разработку чипов и закупку HBM, начиная с TPU 8t, Google устраняет поборы посредников и снижает себестоимость своих чипов. 
Источник изображения: Google Объём производства MediaTek значительно возрастёт после того, как начнётся выпуск TPU 8t в конце 2026 года и его преемника TPU v8e (Humufish) в период до 2028 года. Исходя из последнего прогноза глобальных поставок ASIC для ИИ-вычислений, аналитики ожидают, что совокупные поставки TPU v8t и v8e приблизятся к 5 млн единиц в 2028 году, что более чем в 10 раз больше по сравнению с отгрузкой примерно 400 тыс. чипов в 2026 году. Это станет возможным благодаря ускоренному внедрению TPU Google как для внутренних рабочих нагрузок, так и для облачных клиентов. Комментируя прогноз, Counterpoint Research уточняет, что он не учитывает реализацию проекта Meta✴ MTIA. Кроме того, достижение прогнозируемого объёма зависит от наличия достаточных мощностей по упаковке TSMC CoWoS и Intel EMIB-T. Основной риск для реализации прогноза связан с TPU v8e, для которого MediaTek предлагает упаковку Intel EMIB-T: «В настоящее время компания находится на стадии проектирования и квалификации, а массовое производство запланировано не ранее конца 2027 года, и этот переход сопряжён с весьма специфическими рисками для исполнения». К числу ключевых факторов отнесены необходимое для этого увеличение производительности Intel Foundry Services (IFS) и готовность поставщиков подложек, что в конечном итоге может повлиять на объём поставок MediaTek.
02.05.2026 [23:32], Владимир Мироненко
Qualcomm готовится поставлять чипы гиперскейлеру — инвесторы довольны, поскольку на мобильном направлении не всё гладкоАкции Qualcomm выросли более чем на 15 % после сообщения компании о превышении прогнозов Уолл-стрит по прибыли и выручке во II квартале 2026 финансового года, а также заявления президента и гендиректора Кристиано Амона (Cristiano Amon) о планах начать поставки чипов для ЦОД «крупному гиперскейлеру» в течение календарного года, пишет SiliconANGLE. Выручка Qualcomm во II квартале 2026 финансового года, закончившемся 29 марта, составила $10,6 млрд, что на 3 % меньше, чем годом ранее, но чуть выше прогноза Уолл-стрит в размере $10,58 млрд. Компания сообщила о скорректированной прибыли на акцию в размере $2,65, что ниже показателя в $2,85 за тот же квартал прошлого года, но выше прогноза аналитиков в $2,55 на акцию. В полупроводниковом секторе (QCT) выручка увеличилась год к году на 4 % до $9,08 млрд. При этом выручка в автомобильном сегменте выросла на 38 % до $1,33 млрд, в сегменте IoT — на 9 % до $1,73 млрд, а в сегменте мобильных устройств упала на 13 % до $6,02 млрд. Выручка от лицензий (QTL) за квартал составила $1,38 млрд, что на 5 % больше, чем годом ранее. 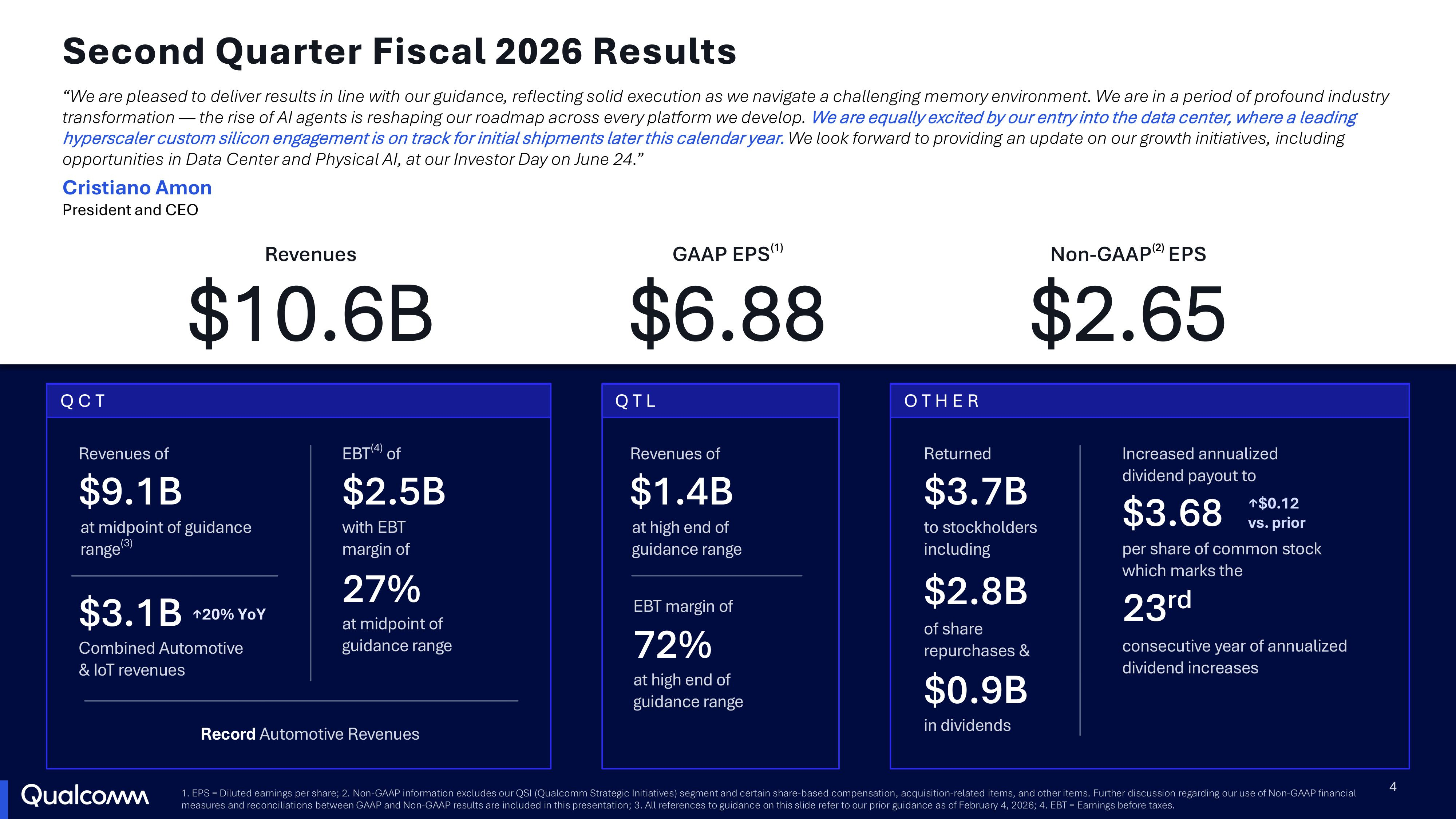
Источник изображений: Qualcomm В III финансовом квартале Qualcomm прогнозирует скорректированную прибыль на акцию в размере от $2,10 до $2,30 при прогнозе Уолл-стрит $2,43. Прогноз по выручке тоже значительно ниже консенсус-прогноза аналитиков, опрошенных LSEG (по данным Reuters) — от $9,2 до $10 млрд при прогнозе в $10,27 млрд. Свой осторожный прогноз Qualcomm объяснила ограничениями поставок памяти и связанным с этим ценовым давлением на ряд производителей мобильных устройств. Компания добавила, что выручка от продаж мобильных телефонов китайским клиентам должна достичь минимума в III квартале и вернуться к последовательному росту в следующем квартале. Qualcomm ушла с рынка продуктов для ЦОД в 2018 году, чтобы сосредоточиться на своих разработках в области смартфонов, но в августе 2025 года сообщила, что находится на «ранних этапах» возвращения на рынок и ведёт переговоры с несколькими потенциальными клиентами. Гендиректор тогда также подтвердил, что компания ведёт «продвинутые переговоры с ведущим гиперскейлером». До этого, в мае 2025 года компания подписала меморандум о взаимопонимании с Humain и объявила о работе над серверным процессором, который будет поддерживать NVIDIA NVLink.  Фактически после поглощения Nuvia компания не стала выходить на рынок ЦОД. А после долгих судебных разбирательств с Arm в связи с этой сделкой последняя фактически стала конкурентом Qualcomm и другим своим клиентам, взявшись за создание серверных CPU. С ИИ-ускорителями у компании всё тоже сложилось не очень удачно. Первое поколение широкого распространения не получило, но компания пообещала исправиться. При этом на рынке кастомных чипов для гиперскейлеров уже давно работают Broadcom и Marvell, у которых к тому же сильные компетенции в области сетевой инфраструктуры. Как пишет The Register, Кристиано Амон заявил, что компания планирует начать поставки чипов для ЦОД «ведущему гиперскейлеру» «в декабрьском квартале» и ожидает сотрудничество на несколько поколений чипов. По его словам, Qualcomm уже работает над процессором для ЦОД и высокопроизводительными ИИ-ускорителями для инференса, а также получила возможность создавать кастомные ASIC благодаря приобретению Alphawave в прошлом году за $2,4 млрд. «Мы работаем над специализированными ASIC, чего мы и хотели добиться, когда приобрели AlphaWave, — сказал Амон, — и теперь у нас есть много интеллектуальной собственности, позволяющей нам это сделать. Мы работаем над всеми тремя категориями чипов».  Амон рассказал, что Qualcomm также создала так называемый «выделенный процессор для агентских вычислений в ЦОД». По его словам, ИИ начинался с GPU для обучения, затем потребовалось специализированное оборудование для инференса, но сейчас рынок вступает в новую фазу, в которой важно «создать спрос на токены» для работы агентного ИИ. «Я думаю, что когда речь заходит об агентах, CPU становится очень важным», — сказал он, поэтому, по его словам, Qualcomm разработала именно такой чип. Кристиано Амон также прогнозирует появление «агентных смартфонов». Он привёл в качестве примера телефон ZTE, который включает в себя персонального помощника Doubao, разработанного ByteDance, и Xiaomi miclaw — ИИ-ассистента, интегрированного с ядром ОС, который анализирует запрос пользователя и определяет, какие приложения и функции смартфона нужно задействовать для его выполнения. Не исключено, что OpenAI может стать следующим крупным клиентом Qualcomm в сфере смартфонов, если генеральный директор Сэм Альтман (Sam Altman) реализует план выпустить устройство с ИИ в течение двух лет.
19.04.2026 [21:20], Владимир Мироненко
Google договаривается с Marvell о разработке двух кастомных чипов для ИИ-инференсаКомпания Google (Alphabet) ведёт переговоры с Marvell Technology о совместной разработке двух кастомных чипов, предназначенных для более эффективного ИИ-инференса, сообщил ресурс The Information со ссылкой на информированные источники. Как отметил The Information, эти переговоры свидетельствуют о стремлении Google, исторически зависящей от Broadcom в отношении базовой инфраструктуры TPU, к диверсификации поставщиков. Этот потенциальный альянс в области разработки чипов является прямым ответом на меняющуюся экономику ИИ, когда огромные вычислительные затраты на обучение масштабных моделей быстро уступают место постоянным ежедневным расходам на инференс. Один из чипов относится к подсистеме памяти TPU, второй — собственно TPU следующего поколения, созданный специально для запуска ИИ-моделей. Эти чипы предназначены для совместной работы, при этом каждый из них выполняет свою часть задачи. Как подчёркивается в публикации, «текущие обсуждения направлены на разработку полупроводников исключительно для нужд Google». 
Источник изображения: Marvell Technology Помимо технической оптимизации ИИ-инференса, привлечение Marvell — это классическая тактика диверсификации поставщиков, пишет Startup Fortune. Broadcom долгое время занимала исключительно доминирующее положение на рынке заказных чипов, тесно сотрудничая с Google в разработке TPU. Но сильная зависимость от одного партнёра по проектированию неизбежно создаёт ценовые разногласия и узкие места. Добавление ещё одного партнёра даёт Google более сильные рычаги влияния во время переговоров по контрактам, а также защищает её ЦОД от геополитических и логистических сбоев. Следует отметить, что авторитет Marvell заметно вырос за последнее время. Компания недавно заключила многомиллиардное партнёрство с NVIDIA, ориентированное на оптические сети и кастомные чипы. Её акции выросли более чем на 50 % с начала года, в основном благодаря доверию инвесторов к её опыту в области инфраструктуры данных и проектирования заказных чипов. Вместе с тем Broadcom остается ключевым партнёром в реализации планов Google. В этом месяце компании подписали соглашение о продолжении работы над новыми чипами до 2031 года, сообщается в документе, направленном Broadcom регулятору. Если переговоры пройдут успешно, Marvell укрепит свой статус ведущей альтернативы Broadcom в сегменте разработки кастомных ИИ-микросхем. Также следует ждать, что капитальные затраты гиперскейлеров будут всё больше смещаться в сторону оптимизации инференса, а не просто увеличения вычислительной мощности. Аналитики отрасли в настоящее время прогнозируют, что поставки серверных ASIC для ИИ-вычислений утроятся к 2027 году, и эта тенденция почти полностью обусловлена потребностями в развёртывании больших языковых моделей.
27.03.2026 [10:03], Руслан Авдеев
ЦЕРН: для самых больших открытий на БАК нужны самые маленькие ИИ-модели, которые «зашиты» прямо в чипыИИ-инфраструктура Большого адронного коллайдера (БАК) имеет мало общего с классическим решениями на основе TPU или GPU. Вместо этого ЦЕРН (CERN) буквально «выжигает» кастомные ИИ-модели в «кремнии» для фильтрации огромных массивов данных практически в реальном времени, сообщает The Register. Ежегодно коллайдер «генерирует» 40 тыс. Эбайт «сырых» данных от сенсоров — приблизительно четверть объёма всего интернета. Такую информацию CERN хранить не может, поэтому приходится выбирать в режиме реального времени то, что представляет какую-либо ценность. Речь идёт о потоке данных до сотен терабайт в секунду. Алгоритмы для их обработки должны быть чрезвычайно быстрыми. Именно поэтому их приходится буквально «выжигать» непосредственно в чипах. В 27-км кольце БАК субатомные частицы сталкиваются на скоростях, близких к скорости света. По кольцу постоянно перемещаются около 2,8 тыс. пучков протонов с 25-с интервалами. Хотя учёные «помогают» частицам, столкновения случаются сравнительно редко — из миллиардов протонов в каждой сессии сталкиваются лишь порядка 60 пар. При столкновении образуются новые частицы, улавливаемые детекторами CERN. 
Источник изображения: Brandon Style/unsplash.com Каждое столкновение пары частиц генерирует несколько мегабайт данных. В секунду происходит около миллиарда столкновений, что приблизительно даёт около 1 Пбайт информации. Естественно, собирать и хранить такие объёмы «сырой» информации технически невозможно, поэтому CERN создал гигантскую вычислительную систему для разделения данных на «интересные» и «неинтересные» ещё на уровне детекторов. 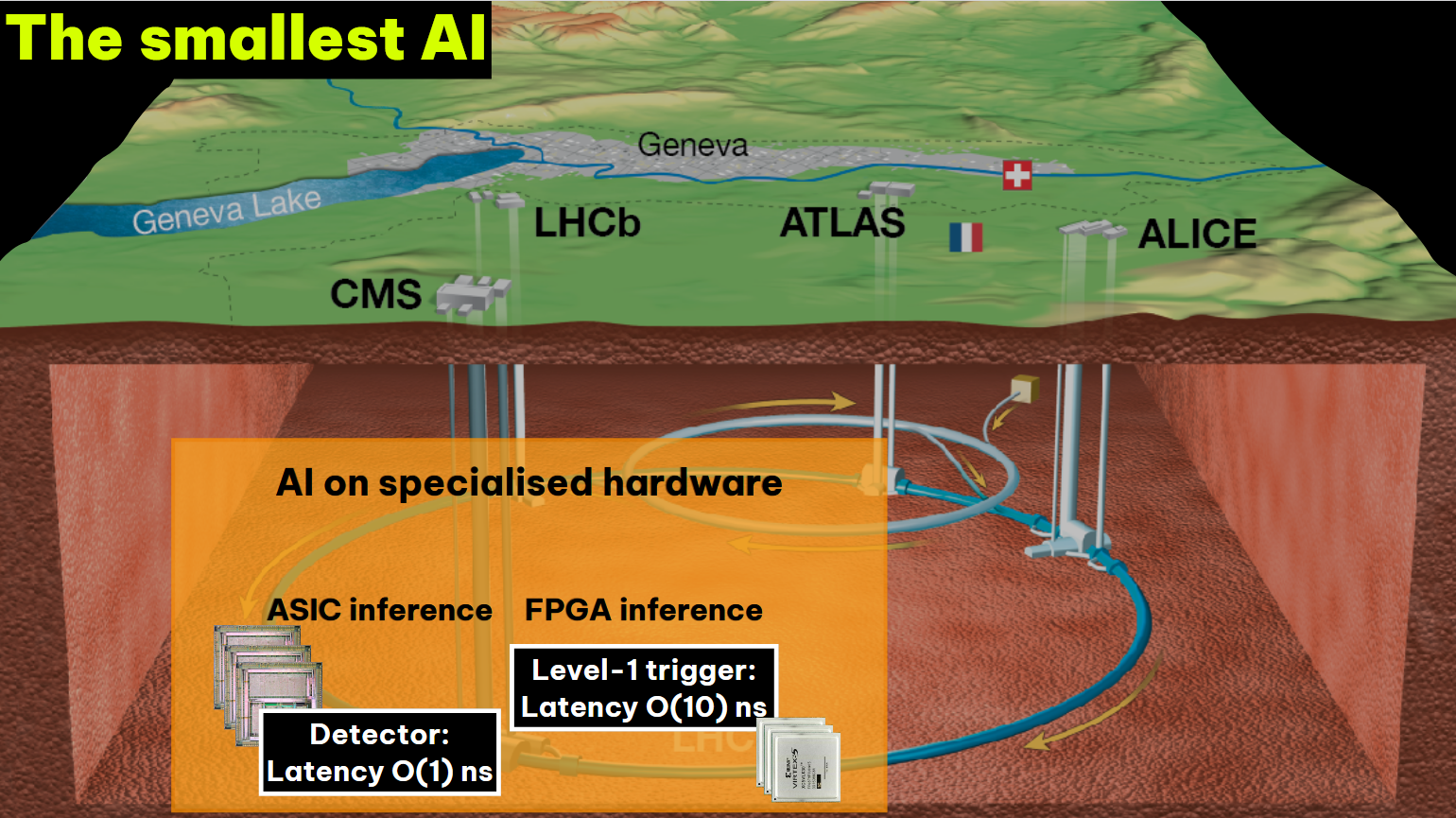
Источник изображения: Thea Klaeboe Aarrestad (ETH Zürich) Детекторы используют ASIC для буферизации данных за не более чем 4 мкс — они либо сохраняются, либо исчезают навсегда. Решение принимает фильтр Level One Trigger на базе порядка 1 тыс. FPGA, получающих данные по оптической линии на скорости около 10 Тбайт/с. Решения принимаются на лету силами самих чипов по мере поступления данных — даже самая быстрая внешняя память не справится с таким потоком информации. Специальный алгоритм AXOL1TL принимает решение не более чем за 50 нс. Фактически сохраняется лишь около 0,02 % информации о столкновениях, или приблизительно 110 тыс. событий в секунду. Отобранные сведения отправляются на поверхность, но даже после первичной фильтрации речь идёт о передаче терабайт данных ежесекундно. 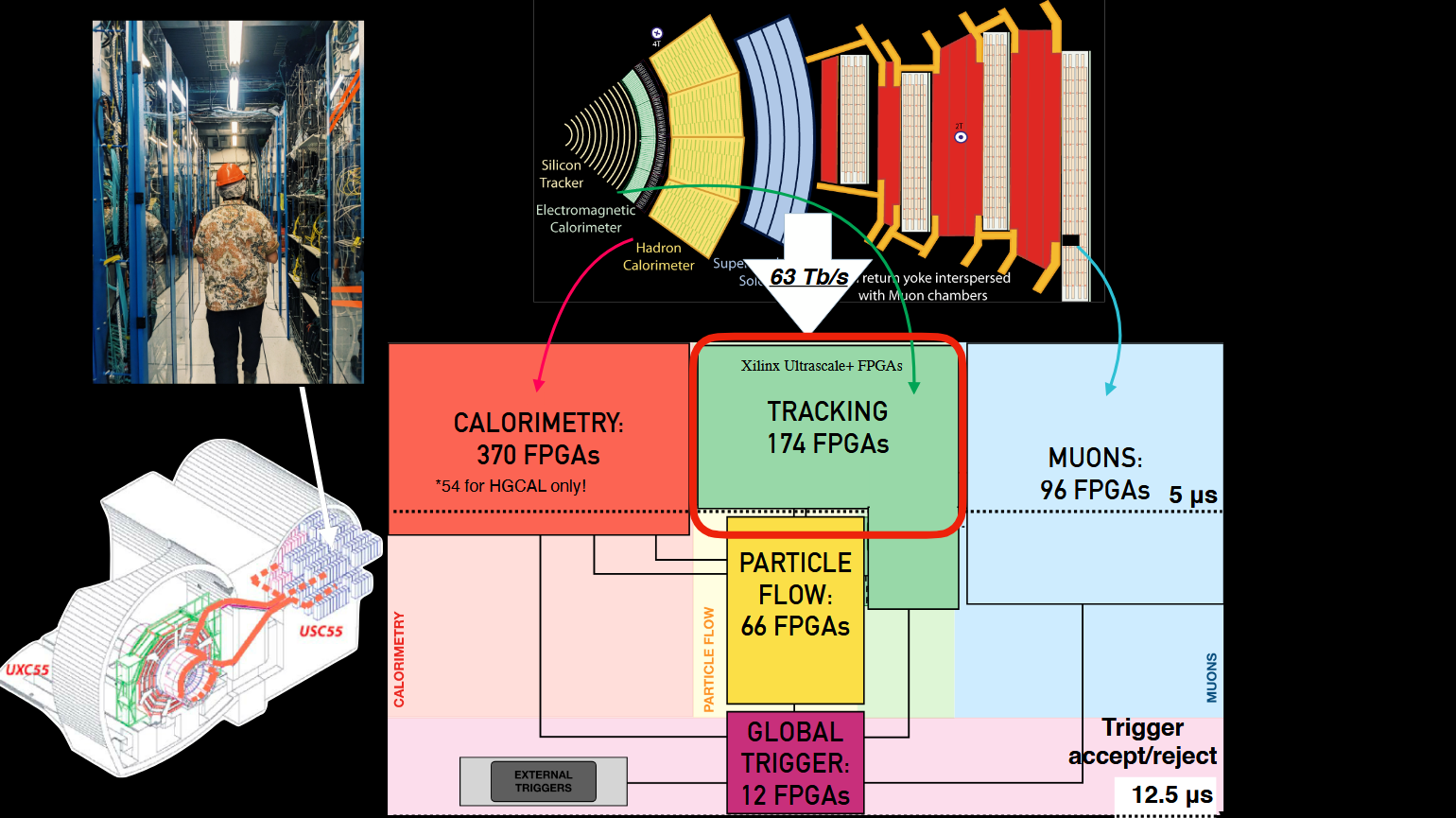
Источник изображения: Thea Klaeboe Aarrestad (ETH Zürich) На поверхности второй фильтр — High Level Trigger — оставляет для изучения уже около 1 тыс. событий в секунду. Система оснащена 25,6 тыс. CPU и 400 GPU, которые реконструируют столкновения и отбирают наиболее интересные для анализа результатов. На выходе получается около 1 Пбайт/день новых данных, которые распределяются между 170 научными центрами в 42 странах, где их могут анализировать учёные со всего света. Совокупная вычислительная мощность всех участников проекта составляет около 1,4 млн ядер. CERN стремится измерить параметры столкновений с точностью 99,999 % — это «золотой стандарт», необходимый для заявлений о научных открытиях. 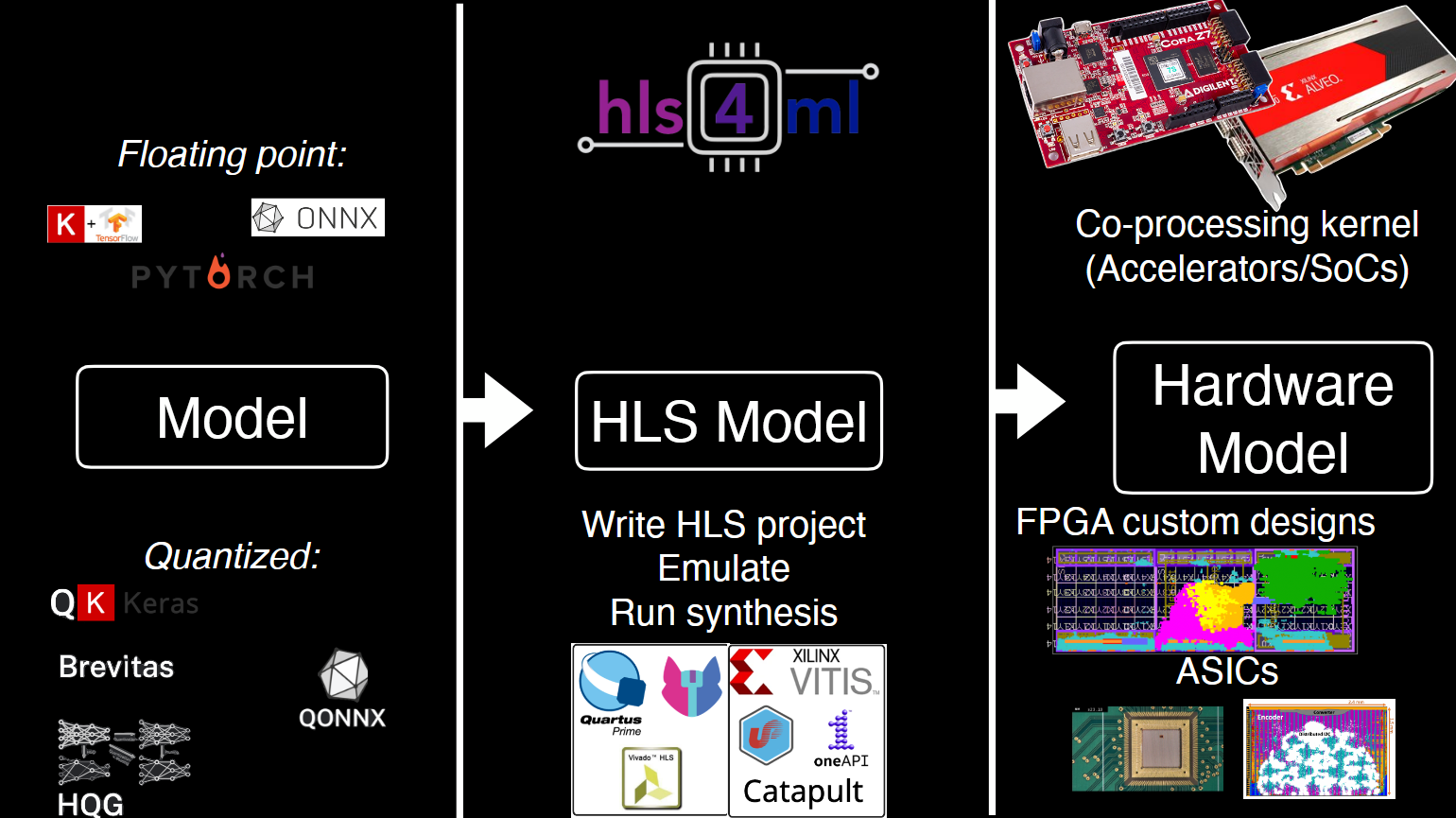
Источник изображения: Thea Klaeboe Aarrestad (ETH Zürich) Обычный ИИ-инструментарий плохо подходит для детекторов, поэтому инженерам CERN пришлось разработать собственный стек. ИИ-модели для БАК специально уменьшены, модернизированы, параллелизованы и «вымуштрованы» для выявления только действительно существенных данных. В случае с БАК они не менее производительны, но значительно «дешевле» традиционных ML-моделей. Для переноса моделей в аппаратную среду используется компилятор HLS4ML, конвертирующий модель в код C++, который можно запускать на ИИ-ускорителях, SoC, кастомных FPGA и даже «выжигать» в ASIC. При этом значительная часть ресурсов чипа отведена не под сам алгоритм, а под таблицы с предварительно рассчитанными результатами для типовых входящих значений, чтобы ещё быстрее фильтровать информацию. 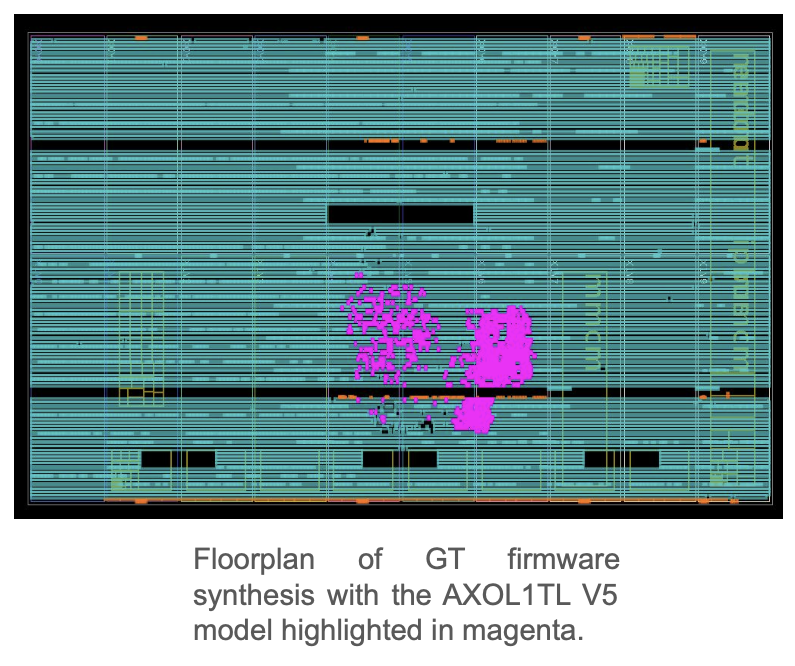
Источник изображения: CERN В конце года БАК закроют, а новый, более мощный коллайдер High Luminosity LHC должен заработать в 2031 году. Он получит более сильные магниты для фокусировки пучков частиц, сами пучки удвоятся в размерах, коллайдер будет генерировать в 10 раз больше данных, а объём информации от каждого события увеличится с 2 до 8 Мбайт. CERN уже накопил 1 Эбайт от БАК, но это лишь десятая часть от того, что предстоит хранить и обрабатывать в последующие 10 лет. И пока передовые ИИ-лаборатории создают LLM всё большего объёма, CERN движется в противоположном направлении, всеми силами упрощая и ускоряя выявление необычных событий с помощью искусственного интеллекта.
23.02.2026 [22:57], Владимир Мироненко
Чипы AMD прожорливы, NVIDIA — дороги, а Intel — ненадёжны: Ericsson остаётся верна кастомным ASICEricsson представила свой первый набор продуктов AI-RAN, подчеркнув приверженность стратегии, основанной на собственных ASIC для повышения производительности сетей радиодоступа (RAN). В то время как беспроводная индустрия всё чаще обращается к виртуализированным/облачным RAN с использованием универсальных процессоров (GPP) Intel, Ericsson защищает свои продолжающиеся инвестиции в кастомные чипы для высокопроизводительных задач, отметил ресурс IEEE ComSoc Technology Blog. Впрочем, Intel остаётся ключевым партнёром Ericsson, а вот с AMD и NVIDIA у компании не заладилось. Портфель решений Ericsson для RAN базируется на двух основных архитектурах. Большая часть основана на ASIC, разработанных как собственными силами, так и в партнёрстве с Intel. Также портфель включает Cloud RAN, которая объединяет программный стек Ericsson с процессорами Intel Xeon EE. Несмотря на надежды отрасли, что виртуализация позволит отделить аппаратное обеспечение от программного, Intel остаётся единственным партнером Ericsson по поставке микросхем для массового развёртывания, что создаёт некоторые риски. Фактически Ericsson подтвердила «коммерческую поддержку» исключительно решений Intel, в то время как в случае AMD, Arm и NVIDIA всё по-прежнему ограничивается «поддержкой прототипов». Несмотря на многолетние заявления отрасли о необходимости разнообразия микросхем в экосистеме vRAN, прогресс, похоже, застопорился. Кроме того, интеграция ИИ в ПО RAN добавляет новые уровни сложности, которые могут ещё больше укрепить зависимость компании от «железа» одного вендора. 
Источник изображений: Ericsson Отраслевые наблюдатели по-прежнему скептически относятся к стремлению Ericsson к «единому программному стеку» для гетерогенных аппаратных платформ. Хотя аппаратная и программная дезагрегация достижима на более высоких уровнях (L2/L3), PHY-уровень L1 — наиболее ресурсоёмкая часть стека — остаётся сильно оптимизированным для конкретного «кремния». Первоначально Ericsson рассчитывала на переносимость L1-кода между x86 (в т.ч. AMD) и Arm SVE2 (NVIDIA Grace) для соответствия возможностям Intel AVX-512. Однако достижение высокой производительности на этих платформах без существенного рефакторинга остается серьёзной инженерной проблемой. 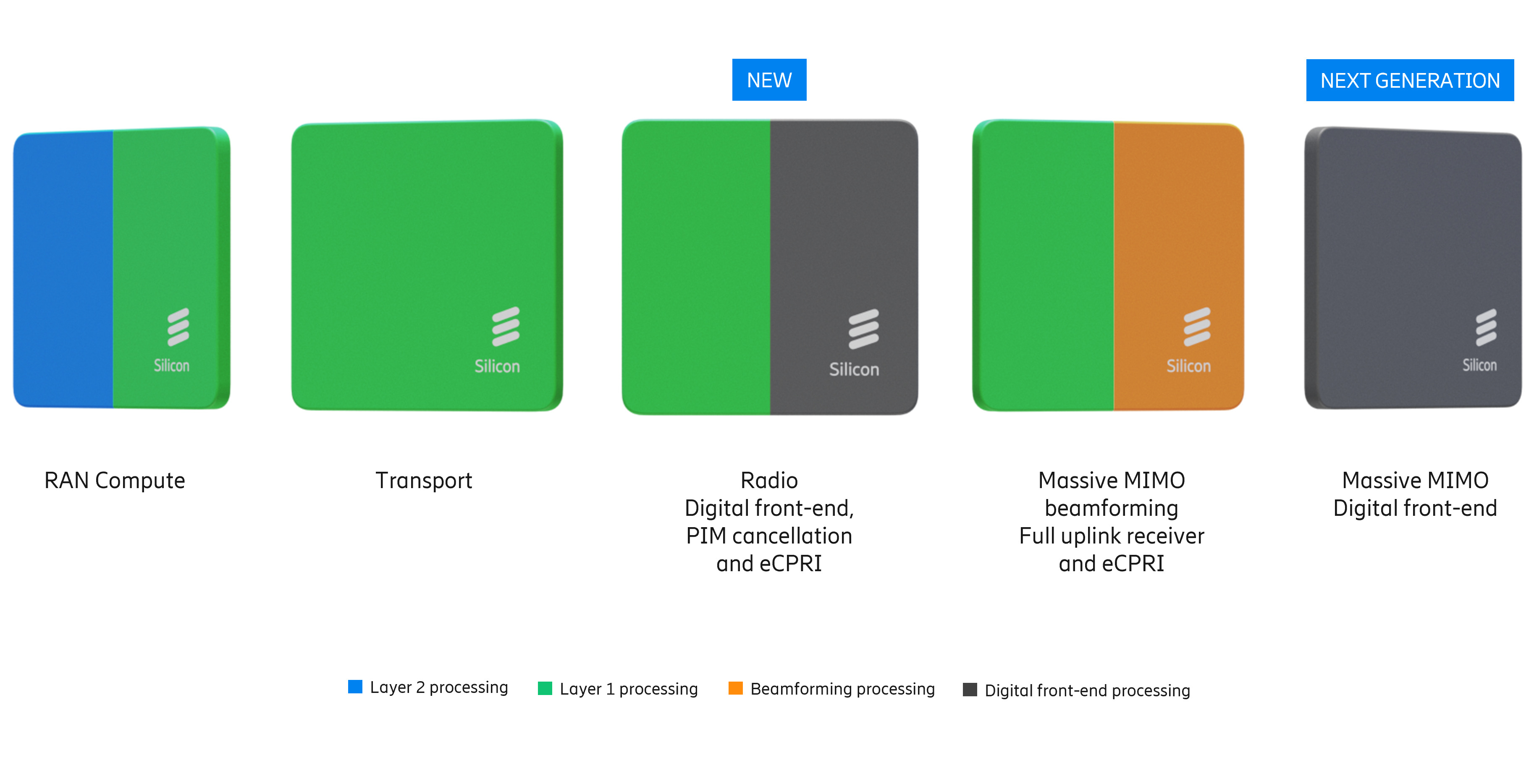 Критическим узким местом в обработке L1-трафика является коррекция ошибок (Forward Error Correction), которая традиционно требует выделенного аппаратного ускорения. Ericsson первоначально полагалась на разгрузку с переносом задач FEC на дискретные PCIe-ускорители Intel. Затем Intel внедрила ускорение FEC в Xeon EE в рамках vRAN Boost. Попытки использовать FPGA AMD показали их невысокую энергоэффективность, а GPU NVIDIA оказались слишком дороги для такой задачи.  Однако развитие AI-RAN изменило экономику, поскольку теперь ускорители можно использовать как для RAN, так и для ИИ-задач. Так, Ericsson заинтересовали тензорные процессоры Google (TPU). Тем не менее, несмотря на стремление к созданию «единого ПО», планы Ericsson подтверждают существование проблем в реализации этой идеи. В то время как уровни L2 и выше используют универсальную кодовую базу для всех аппаратных платформ, уровень L1 требует адаптации под конкретные чипы. Чтобы избежать зависимости от одного поставщика чипов, компания уделяет приоритетное внимание развитию HAL (Hardware Abstraction Layers), что позволит портировать ПО на разные аппаратные платформы с минимальными изменениями. Основные инициативы включают внедрение интерфейса BBDev (Baseband Device) для отделения ПО RAN от базового аппаратного обеспечения. Рассматривается даже возможность интеграции с NVIDIA CUDA, но здесь многое зависит от более широкой отраслевой стандартизации. Что касается радиосвязи, менее подверженной полной виртуализации, Ericsson встраивает процессоры Neural Network Accelerators (NNA) непосредственно в радиомодули. Эти программируемые матричные ядра оптимизированы для обработки данных в системах Massive MIMO, обеспечивая формирование луча и оценку канала за доли миллисекунды при соблюдении строгих ограничений по мощности. Новые AI-радиомодули оснащены ASIC Ericsson с NNA. Утверждается, что они расширяют возможности локального инференса в радиосистемах Massive MIMO, обеспечивая оптимизацию в реальном времени. |
|

