Материалы по тегу: 400gbe
|
21.07.2026 [12:24], Сергей Карасёв
Chelsio представила 400GbE-решения седьмого поколения для ИИ ЦОДКомпания Chelsio Communications анонсировала интерконнект седьмого поколения для дата-центров, систем хранения и инфраструктур, ориентированных на ИИ. В состав представленной платформы AI Interconnect Platform входят сетевые адаптеры SmartNIC, контроллеры хранения и процессоры обработки данных (DPU). В основу AI Interconnect Platform положена архитектура Chelsio Unified Wire: она обеспечивает поддержку стандарта 400GbE и технологии Unified RDMA, объединяющей несколько протоколов удалённого прямого доступа к памяти (iWARP и RoCEv2). Кроме того, задействованы средства ускорения работы систем хранения и оптимизации ИИ-инфраструктуры для облачных, корпоративных развёртываний и гиперскейлеров. Среди ключевых особенностей платформы названы встроенные криптографические модули для протоколов QUIC, kTLS и IPsec/TLS/kTLS, различные варианты исполнения (PCIe 5.0, OCP 3.0) и лучшие в отрасли показатели производительности в расчёте на ватт потребляемой энергии. Говорится о поддержке виртуализации SR-IOV (Single Root I/O Virtualization), виртуальной коммутации vSwitch и пр. 
Источник изображений: Chelsio Communications В число анонсированных решений входят двух- и четырёхпортовые адаптеры S7250 / S7450 / S7450-OCP SmartNIC с поддержкой 1/10/25/50GbE. Эти изделия оптимизированы для виртуализации, встраиваемых систем и периферийных развёртываний. Кроме того, дебютировали решения S72200 / S72200-OCP SmartNIC с поддержкой 40/50/100/200GbE для масштабных облачных сред, HPC и ИИ-инфраструктур. Представлен также однопортовый адаптер S71400 SmartNIC класса 400GbE с возможностью работы в режимах 4 × 100GbE и 2 × 200GbE: устройство рассчитано на сверхмасштабные сетевые инфраструктуры.  Кроме того, Chelsio выпустит контроллеры хранения T72200/T7450. Они предназначены для ускорения выполнения задач, связанных с обработкой данных. Обеспечивается аппаратная разгрузка для NVMe/TCP, NVMe-oF, iSCSI, RDMA и пр. Устройства будут предлагаться в форм-факторах PCIe и OCP. Все перечисленные изделия уже доступны для заказа. В декабре начнётся производство полностью программируемых карт T72200-DPU / T7450-DPU, которые сейчас доступны для ознакомления.
11.06.2026 [16:23], Андрей Крупин
«Мегафон» запустил магистральную линию на базе компактных 400G‑трансиверов российского производстваТелекоммуникационный оператор «Мегафон» в рамках пилотного проекта развернул магистральную линию связи между двумя московскими дата-центрами с использованием компактных высокоскоростных оптических трансиверов производства отечественной компании «Неорос». Они обеспечивают передачу данных со скоростью от 100 Гбит/c до 400 Гбит/c и выполняют функции транспондеров, но при этом устанавливаются непосредственно в маршрутизатор. Классическая схема построения магистральных каналов предполагает использование маршрутизаторов, определяющих, куда именно должны быть направлены потоки данных, и дорогостоящих DWDM‑транспондеров, которые передают информацию по оптоволоконному кабелю. С помощью сетевого оборудования «Неорос» инженеры «Мегафона» оптимизировали процесс организации магистральных каналов. Это, по заверениям компании, позволило увеличить пропускную способность каналов мобильной сети в четыре раза, и сократить затраты на строительство таких линий в шесть раз. 
Трансивер Neoros NR-QSFPDD-400G-SR8-MPO16 (источник изображения: компания «Неорос» / neoros.ru) «Мы последовательно улучшаем архитектуру магистральной сети, чтобы она соответствовала актуальным требованиям. Использование нового решения позволяет нам быстрее и эффективнее строить высокоскоростные каналы между ключевыми площадками, формируя технологическую основу для дальнейшего развития инфраструктуры. Следующим этапом станет масштабирование проекта на другие ЦОД по всей стране», — заявили в «Мегафоне». Сеть «Мегафона» насчитывает более 115 центров обработки данных. За последние два года новые ЦОД были построены в Хабаровске, Твери, Екатеринбурге и Санкт‑Петербурге.
07.06.2026 [10:06], Сергей Карасёв
MediaTek продемонстрировала оптический интерконнект на основе MicroLEDКомпания MediaTek показала оптический интерконнект нового поколения, построенный на основе микроскопических светодиодов (MicroLED). Решение ориентировано на дата-центры для ресурсоёмких нагрузок ИИ с высокой интенсивностью обмена информацией. MediaTek отмечает, что в современных ЦОД при построении сетей разработчики вынуждены идти на компромисс между дальностью действия, энергопотреблением и надёжностью. В частности, традиционные медные соединения обеспечивают высокую энергоэффективность, однако имеют ограниченную длину (обычно менее двух метров). В свою очередь, оптические подключения на базе лазеров предлагают значительную дальность действия, но потребляют гораздо больше энергии и подвержены сбоям. Новая конструкция активных кабелей MicroLED, как утверждается, позволяет устранить перечисленные недостатки. Вместо использования каналов с высокой пропускной способностью, как в случае стандартного оптического интерконнекта, технология предполагает разделение потока данных на сотни параллельных линий с меньшей скоростью передачи информации. В результате достигаются высокая плотность полосы пропускания, небольшие задержки и улучшенная энергоэффективность. 
Источник изображения: MediaTek В ходе мероприятия Computex 2026 компания MediaTek продемонстрировала оптические компоненты на основе MicroLED в виде СРО-изделий (Co-Packaged Optics) со скоростью передачи данных до 400 Гбит/с на одно волокно. Отмечается, что у этих решений энергопотребление на 50 % ниже, чем у обычных активных оптических кабелей на базе VCSEL (поверхностно-излучающий лазер с вертикальным резонатором). Кроме того, «стараниями» NVIDIA на рынке лазеров для оптических сетей наблюдается дефицит. MicroLED-интерконнект разрабатывается в партнёрстве с подразделением Microsoft Research в рамках проекта MOSAIC. В перспективе MediaTek намерена создать изделия с пропускной способностью 800 Гбит/с, 1,6 Тбит/с и 3,2 Тбит/с. Технология предусматривает интеграцию излучателей MicroLED непосредственно в КМОП-трансиверы. При этом заявлено сохранение совместимости с существующей инфраструктурой ЦОД.
25.03.2026 [11:46], Сергей Карасёв
Nerpa разработала новую IP-фабрику для ЦОД и облаковРоссийский IT-бренд Nerpa, созданный в 2020 году компанией OCS Distribution, анонсировал новую IP-фабрику — современную архитектуру для построения высокопроизводительных сетей в дата-центрах и облачных инфраструктурах. Она позволяет объединять различные устройства, серверы и СХД в единую производительную экосистему. В основу решения положена архитектура Clos — многоступенчатая топология сети, разработанная для обеспечения высокой пропускной способности без блокировок. Подчёркивается, что в отличие от традиционной трёхуровневой схемы «ядро — агрегация — доступ», такая модель обеспечивает равномерное распределение нагрузки и устойчивую работу сети даже при росте трафика и масштабировании инфраструктуры. В состав IP-фабрики входят коммутаторы Nerpa HC DC (98), HC DC (685) и HC DC (557). Две первые модели спроектированы для работы в дата-центрах и облачных инфраструктурах. В свою очередь, изделие HC DC (557) играет роль управляющего элемента фабрики. Устройство на базе ASIC поддерживает двухстековое управление, статическую маршрутизацию и расширенные функции безопасности. Все коммутаторы оснащены uplink-портами с пропускной способностью до 400 Гбит/с. 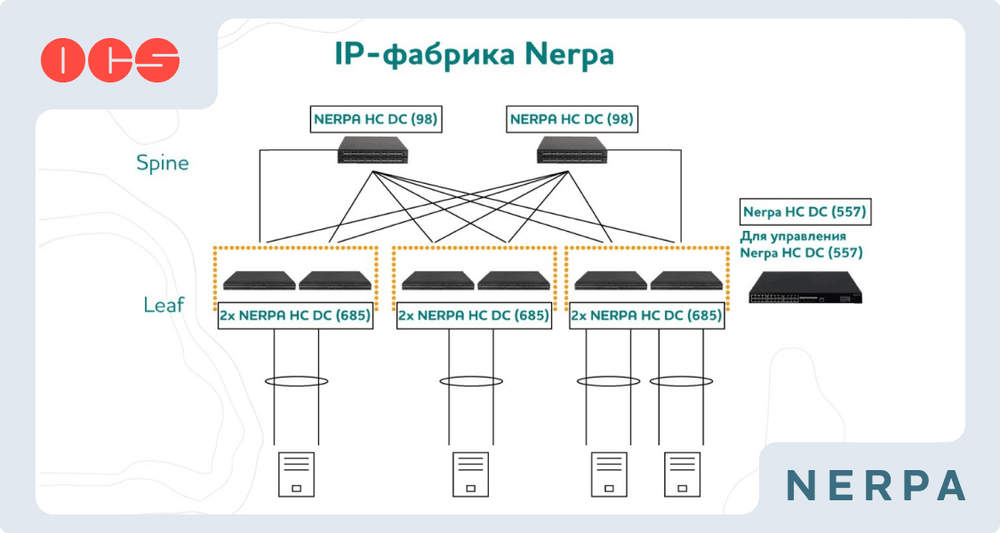
Источник изображения: Nerpa Разработчик отмечает, что IP-фабрика упрощает управление адресацией, позволяет гибко сегментировать трафик и ускоряет развёртывание виртуальных сервисов. Говорится о совместимости с серверами Nerpa, оснащёнными Ethernet-адаптерами. Упомянута поддержка протоколов VXLAN, EVPN и MLAG. На IP-фабрику Nerpa предоставляется гарантия сроком 1 год с возможностью расширения до 3 лет. Среди потенциальных заказчиков названы операторы связи, облачные провайдеры, владельцы корпоративных ЦОД и интеграторы, реализующие проекты по строительству дата-центров, говорит компания.
16.03.2026 [00:10], Владимир Мироненко
Гиперскейлеры и разработчики чипов создали консорциум OCI MSA для внедрения масштабируемого оптического интерконнекта для ИИГруппа компаний, включая AMD, Broadcom, Meta✴, Microsoft, NVIDIA и OpenAI, объявила о создании отраслевого консорциума OCI (Optical Compute Interconnect) Multi-Source Agreement (MSA) с целью формирования открытой экосистемы, управляемой гиперскейлерами, для обеспечения развития многовендорной цепочки поставок для масштабируемых оптических интерконнектов, отвечающих потребностям современной ИИ-инфраструктуры. Компании отметили, что по мере совершенствования LLM традиционные медные интерконнекты достигают физических пределов с точки зрения пропускной способности, энергоэффективности и дальности. Оптические соединения позволяют передавать данные на большие расстояния, сохраняя при этом более предсказуемое энергопотребление. Поэтому многие компании рассматривают их как решение для расширения ИИ-инфраструктуры. До сих пор в отрасли отсутствовал единый стандарт для реализации оптических каналов связи в крупномасштабных ИИ-системах. Источник изображения: OCI MSA Спецификация OCI разработана с учетом оптимизации энергопотребления, задержки и стоимости. Она основана на NRZ-модуляции с WDM-мультиплексированием. Кроме того, она отражает смещение фокуса подключения с «модульно-ориентированной» к «кремниево-ориентированной» модели. Благодаря более тесной интеграции оптики с вычислительными и сетевыми компонентами, OCI обеспечивает значительное увеличение плотности полосы пропускания и масштабируемости системы, обеспечивая энергопотребление на уровне медных линий связи. 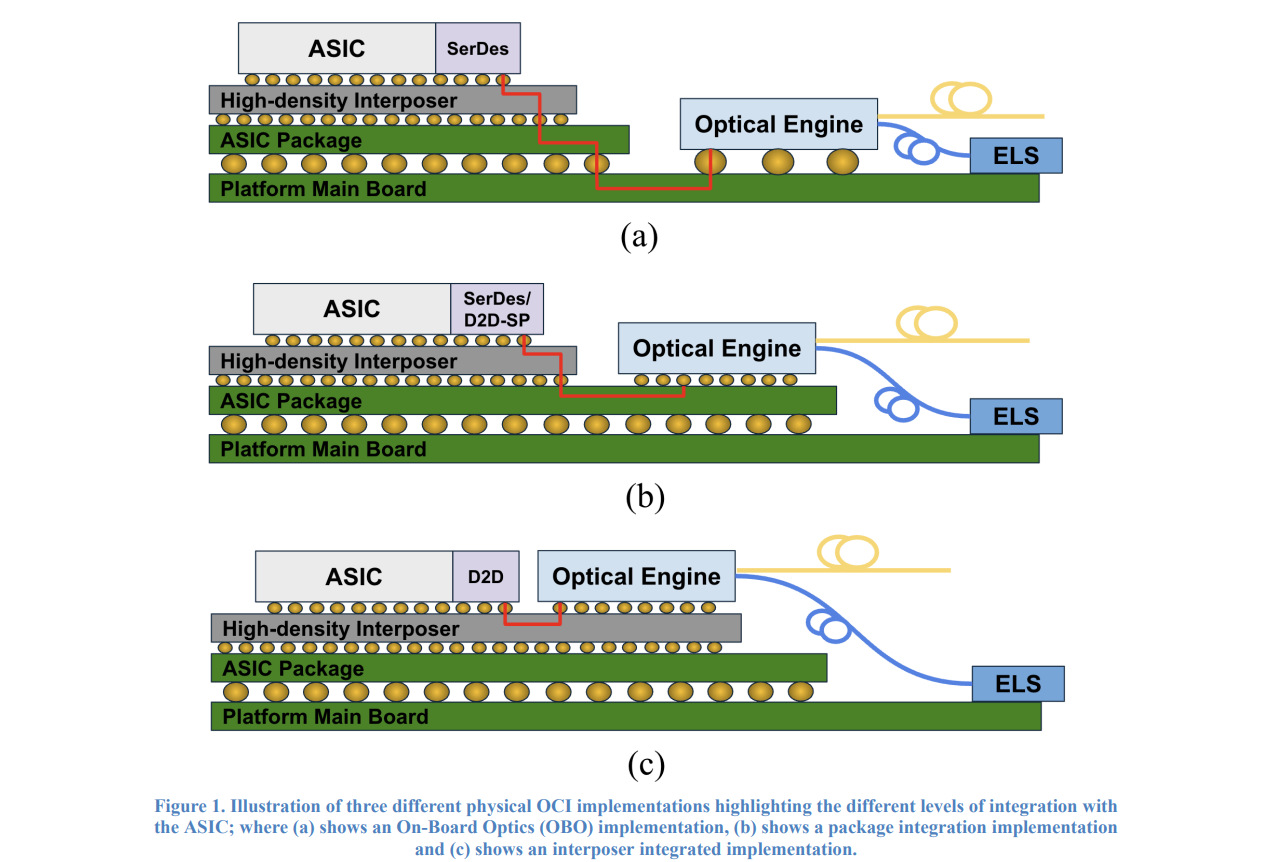
Источник изображения: OCI MSA Как сообщает консорциум, открытая и совместимая спецификация позволяет гиперскейлерам дезагрегировать любые XPU и коммутаторы на основе общего оптического физического уровня (PHY), обеспечивая соответствие лучших в своём классе вычислительных мощностей самым современным оптическим решениям. Консорциум опубликовал первоначальную спецификацию оптического интерфейса 200G, разработанного для масштабных сетей ИИ:
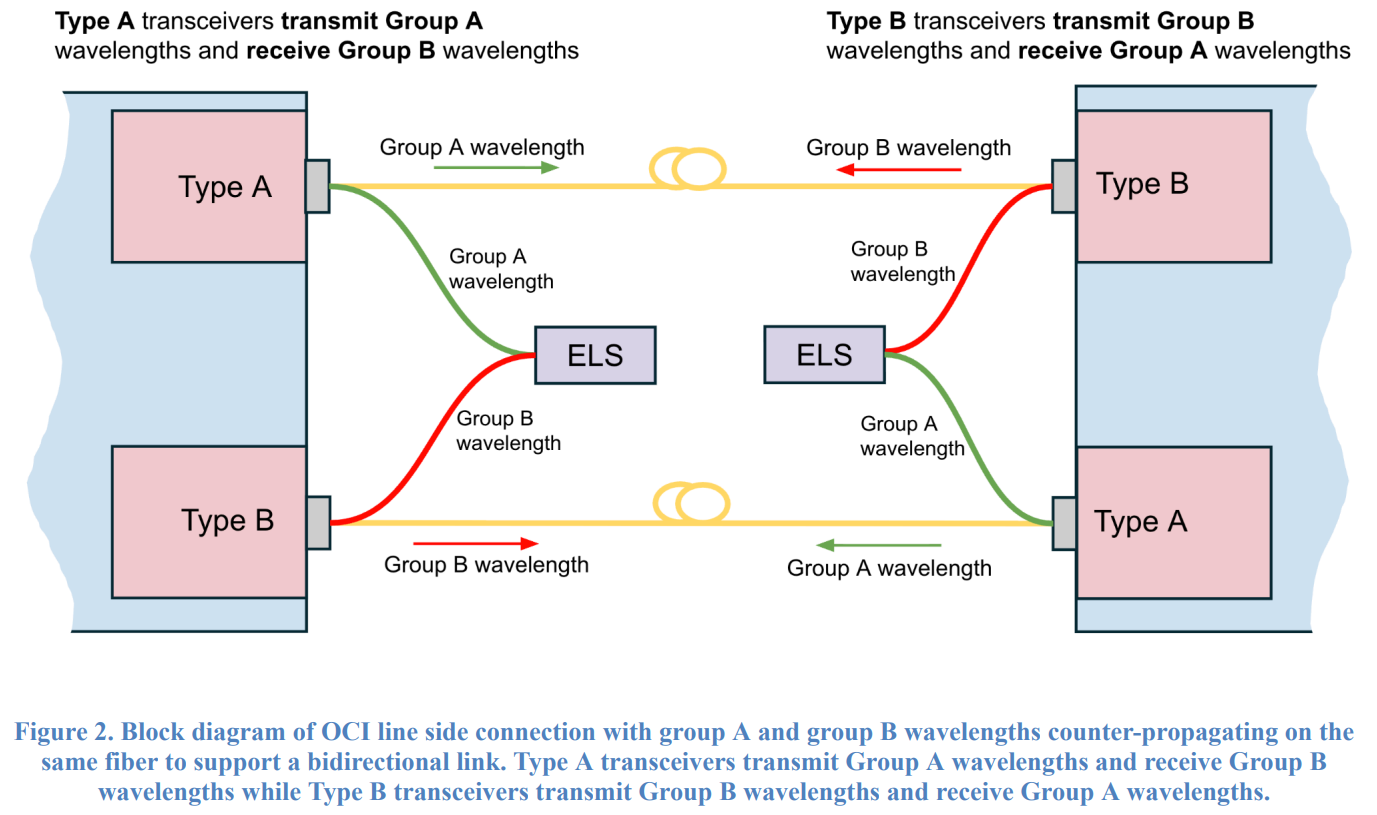
Источник изображения: OCI MSA В спецификации также подробно описаны требования к мощности сигнала, чувствительности приеъёмника, устойчивости к шуму и коррекции ошибок для поддержания стабильности сигнала на экстремальных скоростях. Стандартизированный подход и совместный план развития значительно снижают риски интеграции, сокращают циклы разработки и обеспечат всей цепочке поставок стоек для ИИ чёткий, безопасный путь для развёртывания многопоколенных оптических межсоединений от разных производителей. 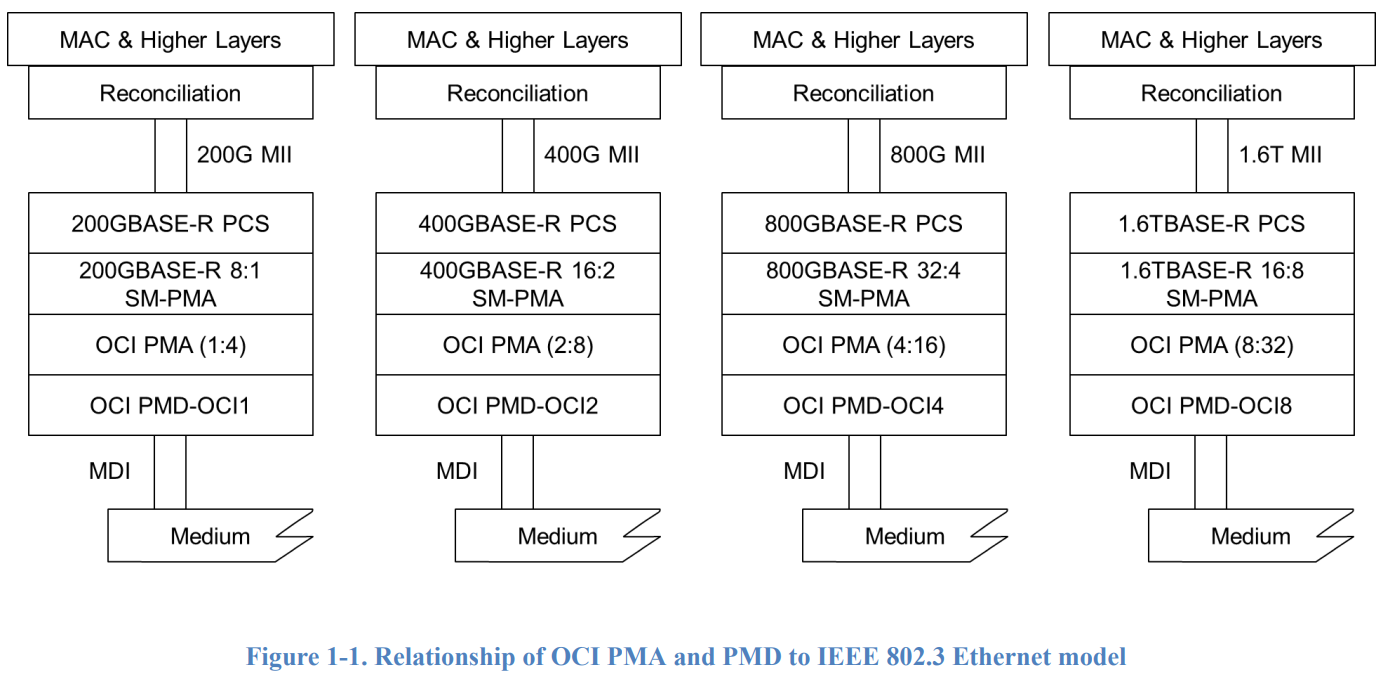
Источник изображения: OCI MSA Как отметил ресурс The Technology Express, консорциум выделяется тем, что объединяет компании, выступающие конкурентами в разработке аппаратного обеспечения для ИИ. Например, собственная разработка NVLink одной компании доминирует в высокопроизводительных кластерах GPU. В то же время другие игроки отрасли поддерживают конкурирующий открытый стандарт UALink. Однако протокол OCI MSA фокусируется на PHY, а не на протоколах. Поэтому он потенциально может поддерживать трафик NVLink и UALink по оптическому волокну вместо медных кабелей.
18.01.2026 [13:05], Сергей Карасёв
Компактный коммутатор MikroTik CRS804 DDQ для ИИ-платформ получил четыре порта 400GbEКомпания MikroTik расширила ассортимент коммутаторов, анонсировав компактную модель CRS804 DDQ, ориентированную на сравнительно небольшие по масштабу инфраструктуры ИИ. Новинка выполнена в форм-факторе 1U половинной ширины, благодаря чему в серверной стойке бок о бок могут размещаться два устройства. L3-коммутатор CRS804 DDQ построен на чипе Marvell 98DX7335, который функционирует в тандеме с четырёхъядерным Arm-процессором Annapurna Labs AL52400 с тактовой частотой до 2 ГГц. Объём оперативной памяти составляет 4 Гбайт. Предусмотрено 512 Мбайт флеш-памяти NAND. В качестве программной платформы применяется RouterOS v7. 
Источник изображения: MikroTik Во фронтальной части расположены четыре порта QSFP56-DD с пропускной способностью 400 Гбит/с каждый. Кроме того, есть два порта 10GbE (RJ45) и консольный порт RJ45. Установлены два вентилятора и два блока питания (100–240 В) с возможностью горячей замены. Максимальное заявленное энергопотребление — 123 Вт. Диапазон рабочих температур простирается от -10 до +60 °C. Величина MTBF (средняя наработка на отказ) достигает примерно 200 тыс. часов при температуре +25 °C. Коммутатор, как утверждается, обеспечивает стабильную работу в условиях интенсивных сетевых нагрузок. Реализованы инструменты мониторинга напряжения, а также температуры процессора и основной платы. Решение имеет класс защиты IP20. В комплект поставки входит монтажный набор RMK-2x10/19, позволяющий установить два коммутатора в один слот 1U стандартной 19″ серверной стойки. Коммутатор MikroTik CRS804 DDQ предлагается по ориентировочной цене $1300.
12.12.2025 [12:44], Сергей Карасёв
Чипы-коммутаторы Xsight Labs X2 пропишутся в спутниках SpaceX Starlink V3Компания Xsight Labs объявила о том, что её программируемые чипы-коммутаторы X2 будут использоваться в составе космических аппаратов SpaceX Starlink V3, предназначенных для организации высокоскоростного спутникового интернет-доступа в глобальном масштабе. Изделия Xsight X2 изготавливаются по техпроцессу TSMC N5. Они обеспечивают пропускную способность до 12,8 Тбит/с. Возможно использование до 128 портов; поддерживаются режимы 100GbE, 200GbE и 400GbE. Заявленное энергопотребление составляет менее 200 Вт. Задержка при работе на скорости 100GbE — менее 700 нс. Чипы выполнены в корпусе с размерами 55 × 55 мм. Каждый спутник Starlink V3 обеспечивает пропускную способность канала связи свыше 1 Тбит/с, что более чем в 10 раз превышает показатель Starlink V2. При этом скорость передачи данных по восходящему каналу составляет около 160 Гбит/с. Решения Xsight X2 помогут в обеспечении надёжной связи при больших нагрузках. Отмечается, что работа глобальной инфраструктуры Starlink зависит от передачи больших объёмов данных в реальном времени, включая трафик, передаваемый по оптическим каналам между спутниками. При этом задействованы технологии адаптивного управления лучом. 
Источник изображений: Xsight Labs via ServeTheHome В такой ситуации полностью программируемая архитектура чипа Xsight X2 позволяет динамически адаптироваться к меняющимся требованиям орбитальных линий связи, обеспечивая оптимальную производительность в различных условиях. В результате, для конечных потребителей услуг обеспечивается скорость интернет-доступа, сопоставимая с оптическими каналами.  Утверждается, что изделия Xsight X2 прошли комплексные испытания на соответствие требованиям, предъявляемым к компонентам для работы в экстремальных условиях космического пространства. Речь идет об устойчивости к вибрации, радиации, низким температурам и пр.
05.12.2025 [12:15], Сергей Карасёв
HPE представила 102,4-Тбит/с коммутатор Juniper Networking QFX5250 с СЖОКомпания HPE анонсировала производительный коммутатор Juniper Networking QFX5250, ориентированный на ИИ-инфраструктуры следующего поколения. В устройстве применяется технология прямого жидкостного охлаждения Direct-To-Chip (DTC), благодаря чему достигается высокая энергоэффективность. В основу решения положен чип Broadcom Tomahawk 6, который поддерживает коммутационную способность до 102,4 Тбит/с. Возможны следующие конфигурации портов: 64 × 1,6 Тбитс, 128 × 800 Гбит/с, 256 × 400 Гбит/с, 512 × 200 Гбит/с, 512 × 100 Гбит/с и 512 × 50 Гбит/с. Новинка выполнена в форм-факторе 2U с габаритами 92,7 × 537 × 805 мм, а масса составляет 48 кг. Коммутатор может монтироваться в 21″ серверную стойку стандарта ORv3. Применена программная платформа Junos OS, оптимизированная для задач ИИ. Эта ОС, как утверждается, обеспечивает максимальную производительность с улучшенными функциями контроля, управления и предотвращения перегрузок. Кроме того, доступен набор API для автоматизации с помощью Terraform и Ansible. Кроме того, HPE объявила о выходе маршрутизатора Juniper Networking MX301 для ИИ-систем. Это устройство, рассчитанное на использование на периферии, обеспечивает пропускную способность до 1,6 Тбит/с. Решение предлагает 16 портов 1/10/25/50GbE, 10 портов 100GbE и 4 порта 400 GbE. Форм-фактор — 1U с размерами 440 × 450 × 44,5 мм. Применено воздушное охлаждение. 
Источник изображения: HPE Маршрутизатор Juniper Networking MX301 уже доступен для заказа. Коммутатор Juniper Networking QFX5250 поступит в продажу в I квартале наступающего года.
14.11.2025 [09:36], Сергей Карасёв
HPE представила CPU- и GPU-узлы суперкомпьютерной платформы Cray Supercomputing GX5000Компания HPE анонсировала новые решения для НРС-задач, являющиеся частью суперкомпьютерной платформы Cray Supercomputing GX5000. В частности, дебютировали узлы GX250 Compute Blade, GX350a Accelerated Blade и GX440n Accelerated Blade, а также высокопроизводительная СХД Storage Systems K3000. Устройство HPE Cray Supercomputing GX250 Compute Blade представляет собой CPU-сервер, оснащённый восемью процессорами AMD EPYC Venice (появятся во II половине 2026 года). В одной стойке могут быть размещены до 40 таких серверов, что обеспечивает самую высокую в отрасли плотность компоновки x86-ядер следующего поколения, говорит компания. В паре с CPU-узлами могут функционировать новые GPU-модули. Так, изделие HPE Cray Supercomputing GX350a Accelerated Blade несёт на борту один чип AMD EPYC Venice и четыре ускорителя AMD Instinct MI430X. В стойку могут устанавливаться до 28 таких серверов, что даёт в сумме 112 ускорителей MI430X. В свою очередь, HPE Cray Supercomputing GX440n Accelerated Blade содержит четыре NVIDIA Vera CPU и восемь NVIDIA Rubin GPU. Допускается монтаж до 24 подобных серверов на стойку, что обеспечивает 192 ускорителя Rubin. Все новинки оборудованы жидкостным охлаждением. СХД HPE Cray Supercomputing Storage Systems K3000 выполнена на сервере HPE ProLiant Compute DL360 Gen12. Могут устанавливаться 8, 12, 16 или 20 накопителей NVMe вместимостью 3,84, 7,68 или 15,36 Тбайт каждый. Объём памяти DRAM — 512 Гбайт, 1 или 2 Тбайт. Применяется платформа DAOS, разработанная для требовательных рабочих нагрузок, таких как анализ данных и машинное обучение. Поддерживаются технологии HPE Slingshot 200, HPE Slingshot 400, InfiniBand NDR и 400GbE. 
Источник изображения: HPE via The Next Platform Кроме того, HPE сообщила о том, что для платформы HPE Cray Supercomputing GX5000 доступен интерконнект HPE Slingshot 400. Соответствующие коммутаторы с прямым жидкостным охлаждением наделены 64 портами на 400 Гбит/с. Возможны конфигурации с 8, 16 и 32 коммутаторами, что в сумме позволяет использовать до 512, 1024 и 2048 портов соответственно. 
Источник изображения: HPE О выборе платформы HPE Cray Supercomputing GX5000 для НРС-комплексов нового поколения уже объявили Центр высокопроизводительных вычислений Штутгартского университета (HLRS) и Центр суперкомпьютеров имени Лейбница (LRZ) Баварской академии естественных и гуманитарных наук (BADW). Кроме того, новая платформа является основой суперкомпьютера Discovery Министерства энергетики США (DOE).
30.09.2025 [10:26], Сергей Карасёв
MikroTik выпустила коммутатор CRS812 DDQ с поддержкой 400GbEКомпания MikroTik начала продажи коммутатора CRS812 DDQ (модель CRS812-8DS-2DQ-2DDQ-RM), поддерживающего стандарт 400GbE. Новинка, выполненная в форм-факторе 1U, доступна для заказа по ориентировочной цене $1300. В устройстве задействованы коммутационный чип Marvell 98DX7335 и процессор Annapurna Labs AL52400, который содержит четыре вычислительных Arm-ядра с тактовой частотой до 2 ГГц. Объём оперативной памяти DDR4 составляет 4 Гбайт, вместимость встроенного флеш-модуля — 512 Мбайт. Коммутатор оборудован двумя портами 400G QSFP56-DD и двумя разъёмами 200G QSFP56, восемью портами 50G SFP56, а также двумя портами 1/2.5/5/10GbE RJ45. Кроме того, имеется консольный порт RJ45. Все гнёзда для подключения сетевых кабелей сосредоточены на фронтальной панели. 
Источник изображений: MikroTik Габариты новинки составляют 443 × 268 × 44 мм. Установлены два блока питания и четыре вентиляторных модуля с возможностью горячей замены. Максимальное заявленное энергопотребление — 134 Вт. Диапазон рабочих температур простирается от -10 до +50 °C. Показатель MTBF (средняя наработка на отказ) достигает 200 тыс. часов при температуре 25 °C.  На коммутаторе применяется программная платформа RouterOS v7. В комплект поставки входят кабели питания и крепёж для монтажа в серверную стойку. Дополнительно можно приобрести оптический трансивер DDQ+85MP01D стандарта 400G стоимостью около $160, также кабели DDQ+DA0001 и DDQ+DA0003 длиной 1 и 3 м соответственно по цене примерно $80 и $110. |
|

