Материалы по тегу: 400gbe
|
02.09.2025 [10:14], Владимир Мироненко
Intel анонсировала IPU E2200 — 400GbE DPU семейства Mount MorganIntel анонсировала DPU Intel IPU E2200 под кодовым названием Mount Morgan, представляющий собой обновление 200GbE IPU E2100 (Mount Evans), разработанного при участии Google для использования в ЦОД последней, причём не слишком удачного, как отмечают некоторые аналитики. Как сообщает ресурс ServeTheHome, Intel E2200 производится по 5-нм техпроцессу TSMC. Он базируется на той же архитектуре, что и предшественник, но предлагает более высокую производительность. Вычислительный блок включает до 24 ядер Arm Neoverse N2 с 32 Мбайт кеша, четырьмя каналами LPDDR5-6400 и выделенным сопроцессором безопасности. Сетевая часть представлена 400GbE-интерфейсом с RDMA, а хост-подключение — подсистемой PCIe 5.0 x32 со встроенным коммутатором PCIe. 
Источник изображений: Intel via ServeTheHome  Для обработки пакетов используется P4-программируемый процессор FXP — модуль обработки трафика с алгоритмом синхронизации и настраиваемыми параметрами разгрузки, что позволяет распределять задачи между сетевыми ускорителями и Arm-ядрами. 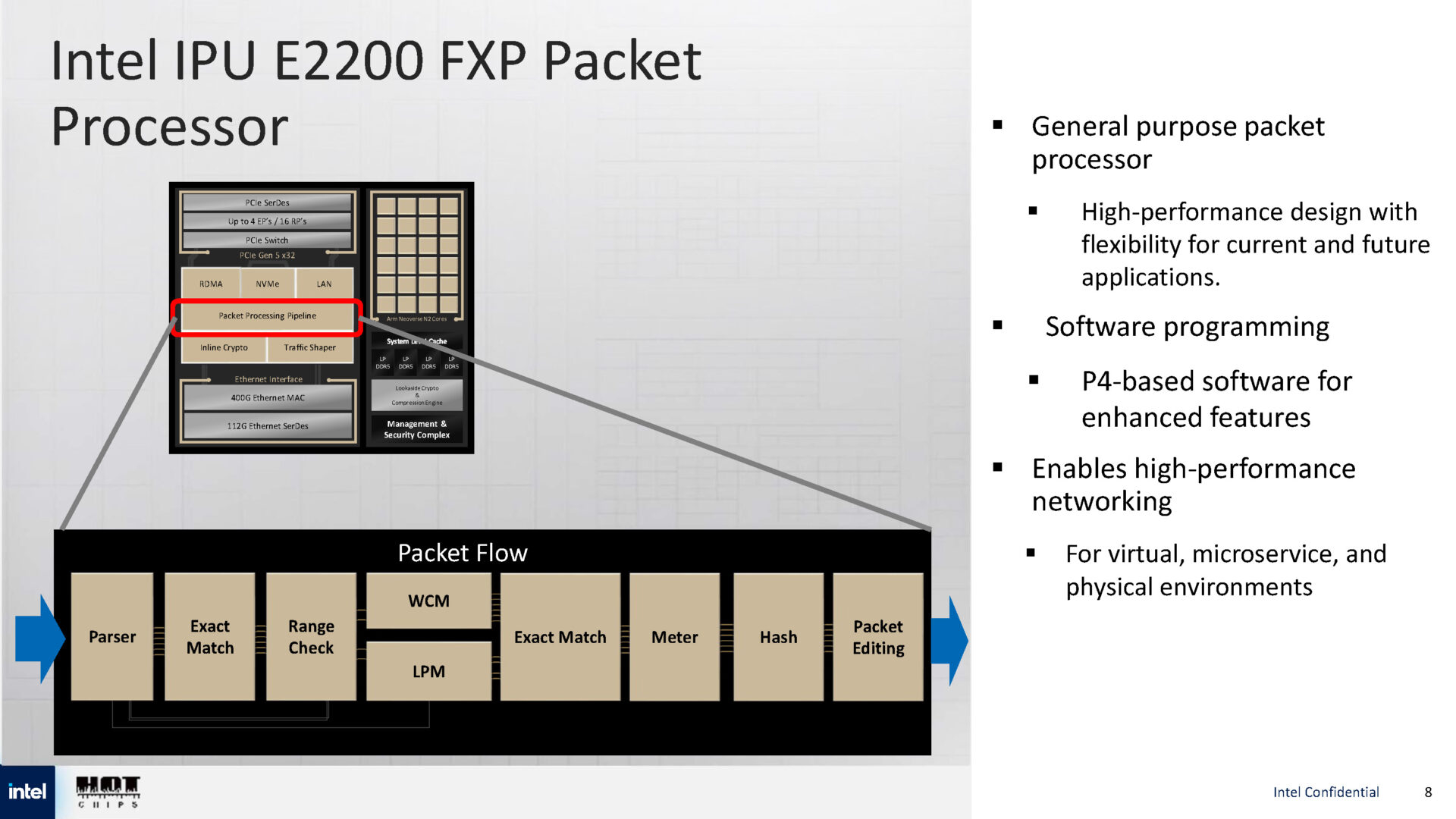 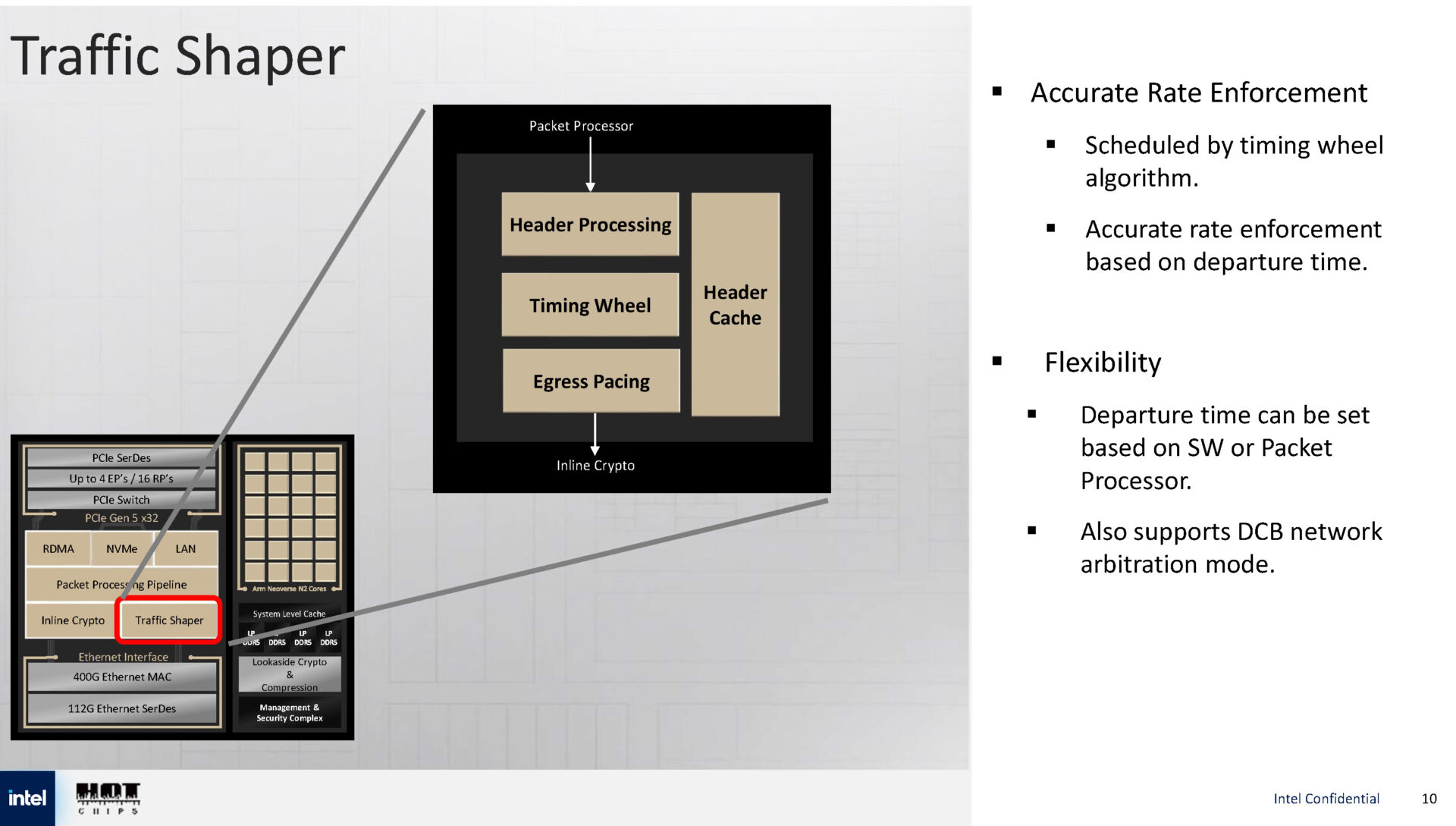 Также имеется встроенный криптографический модуль для шифрования на лету (inline) с поддержкой протоколов IPsec и PSP, настраиваемый для каждого потока. Для управления потоками данных используется модуль Traffic Shaper с поддержкой алгоритма Timing Wheel. 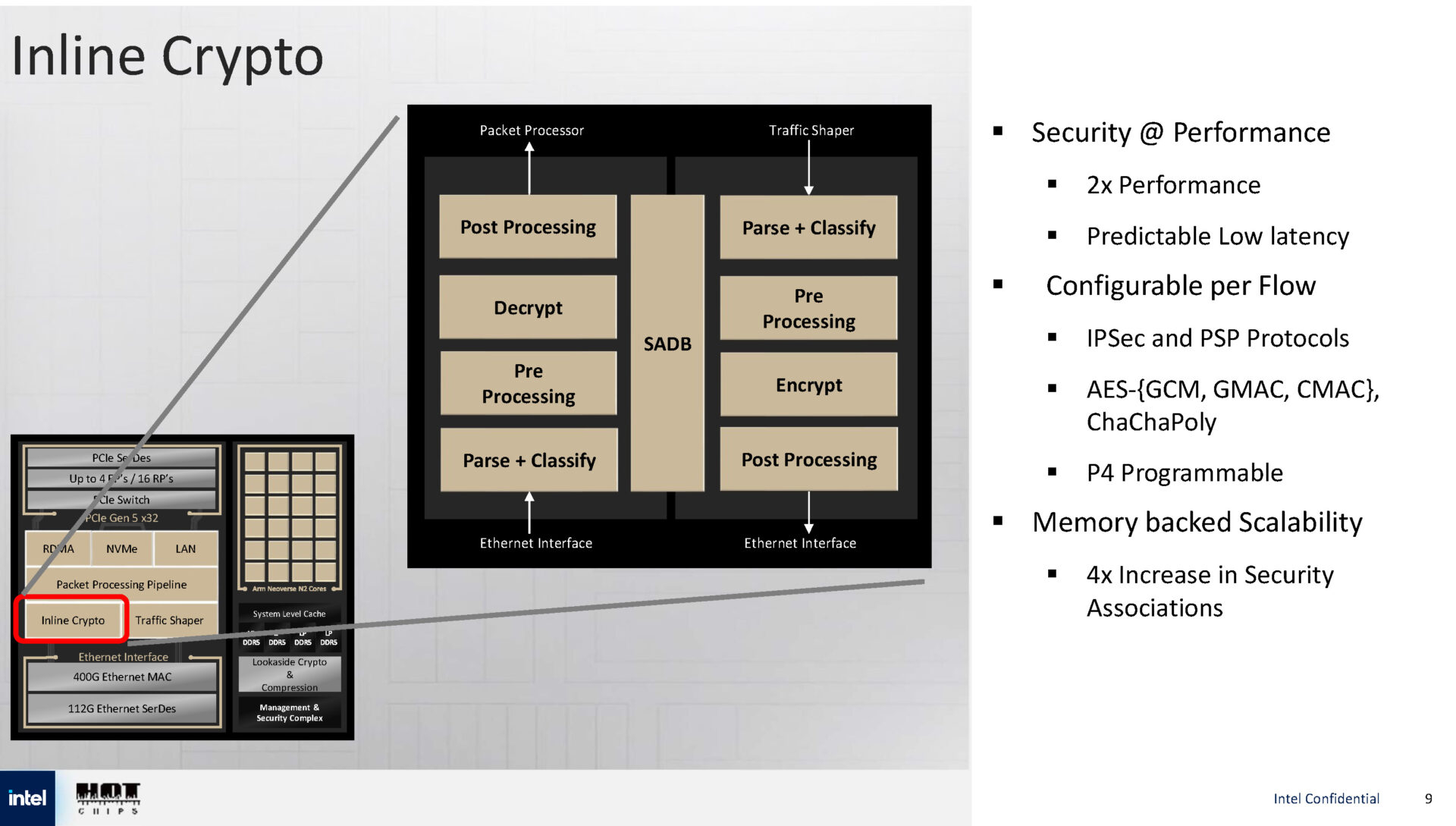  Кроме того, есть и Look-Aside-блок для компрессии и шифрования. Как и в IPU E2100, у IPU E2200 имеется выделенный модуль для независимого внешнего управления. Также поддерживаются программируемые параметры разгрузки с использованием различных ускорителей и IP-блоков.
20.08.2025 [09:34], Владимир Мироненко
Lightmatter «упаковала» 16 длин волн в одномодовое волокноLightmatter объявила о новом достижении в области оптической связи: двунаправленном оптическом канале связи Lightmatter Passage 3D CPO с 16 λ и DWDM, работающем на одном одномодовом оптоволокне. Как сообщает компания, решение, основанное на интерконнекте Lightmatter Passage и лазерной технологии Lightmatter Guide, устраняет прежние ограничения по плотности полосы пропускания волокна и использованию спектра, устанавливая новый стандарт для высокопроизводительных и отказоустойчивых интерконнектов в ЦОД. Lightmatter отметила, что с ростом числа сложности MoE-моделей с триллионами параметров масштабирование ИИ-нагрузок будет ограничено количеством портов и их пропускной способности. Lightmatter Passage 3D обеспечивает «беспрецедентную» двунаправленную пропускную способность 800 Гбит/с (по 400 Гбит/с для передачи и для приёма) для одномодового оптоволокна на расстоянии до 1 км. Это восьмикратный скачок пропускной способности на волокно по сравнению с традиционными решениями, говорится в блоге Lightmatter. При этом не требуется более дорогостоящее волокно с поддержкой поляризации (PM). 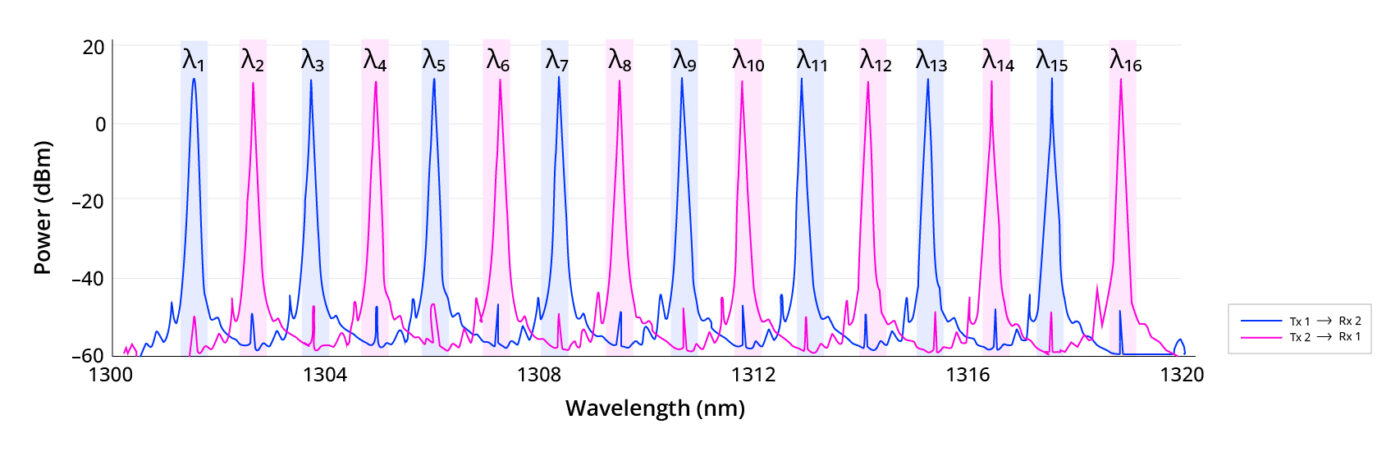
Источник изображений: Lightmatter Как и прежде, решение Lightmatter относится к системам интегрированной фотоники (CPO). Оно объединяет восемь сверхэффективных кольцевых микромодуляторов (MRM), фотодетекторы и аналоговые схемы на одном монолитном кремниевом кристалле с запатентованной системой термической стабилизации. Замкнутая система цифровой стабилизации активно компенсирует любой тепловой дрейф, обеспечивая непрерывную передачу данных с низким уровнем ошибок даже при заметных колебаниях температуры кристалла. В решении компании чередуются нечётные и чётные длины волн в диапазоне 1310 нм: восемь нечётных каналов передают в одном направлении, а восемь чётных — в противоположном. Каждый канал работает со скоростью 50 Гбит/с с интервалом 200 ГГц между соседними каналами передачи/приёма и 400 ГГц между каналами, передающими данные в одном направлении. 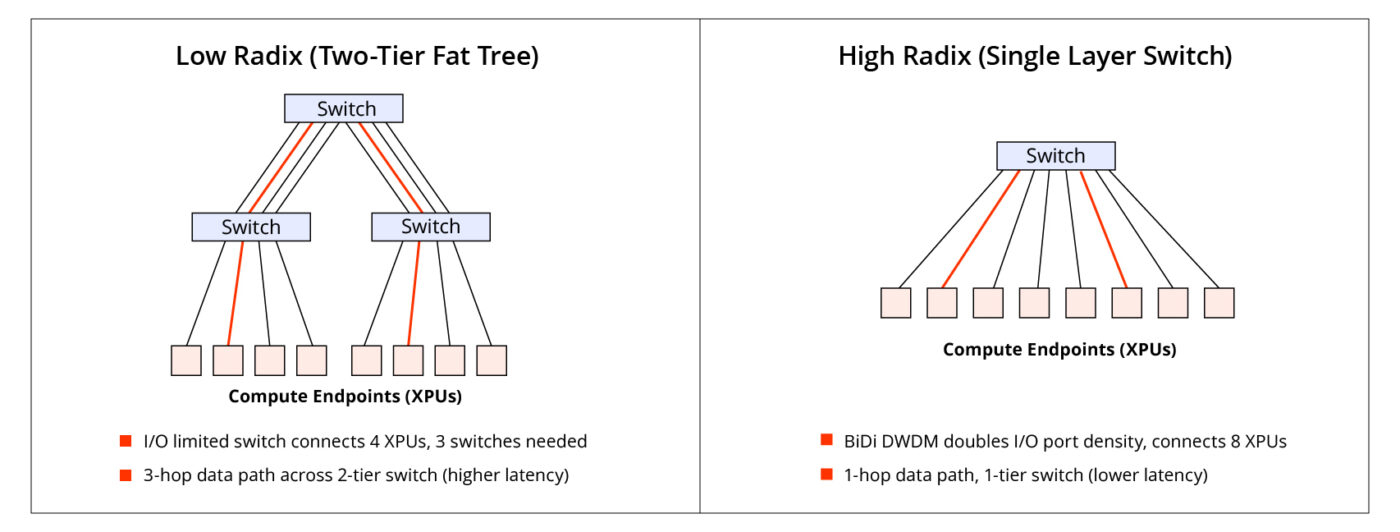 Удваивая количество I/O-портов на коммутатор или XPU, технология сокращает количество сетевых переходов, снижает задержку и энергопотребление, а также минимизирует затраты в крупных ИИ-кластерах. В крупных MoE-моделях интерконнект с большим радиксом обеспечивают взаимодействие «экспертов» с высокой пропускной способностью, что позволяет избежать узких мест при масштабировании и сократить время обучения. Lightmatter позиционирует новое решение как естественную эволюцию технологии CPO для создания ИИ-суперкомпьютеров следующего поколения. Развитием направления CPO также активно занимаются ведущие разработчики ИИ-ускорителей. AMD недавно приобрела стартап Enosemi, который специализируется на разработке фотонных чипов. NVIDIA в марте нынешнего года анонсировала 800G-коммутаторы Spectrum-X и Quantum-X, в которых применены новые ASIC, объединяющие на одной подложке чип-коммутатор и фотонные модули.
12.07.2025 [15:13], Сергей Карасёв
От 100GbE до 800GbE, недорого: стартап TORmem обещает трансформировать рынок ЦОД-коммутаторовСтартап TORmem, специализирующийся на решениях для дезагрегации памяти в дата-центрах, обнародовал планы по выпуску коммутаторов для сетей с высокой пропускной способностью. В семейство войдут модели с поддержкой стандартов от 100GbE до 800GbE. По утверждениям TORmem, она потратила четыре года на разработку «революционной технологии дезагрегации», которая позволяет реализовывать концепцию вычислений в оперативной памяти (IMC) в масштабах ЦОД. Полученный опыт стартап намерен использовать для решения другой проблемы современных дата-центров — высокой стоимости корпоративной сетевой инфраструктуры. TORmem обещает трансформировать сегмент коммутаторов корпоративного класса, выпустив высокопроизводительные устройства по цене в два раза меньше по сравнению с аналогичными решениями, уже представленными на рынке. В частности, TORmem предлагает для заказа модель стандарта 100GbE (S6500-32X) с 32 портами на основе ASIC Marvell: устройство стоит $7 тыс. против $14 тыс. или более у «стандартных продуктов», говорит компания. 
Источник изображений: TORmem В конце текущего года стартап намерен подготовиться к началу производства коммутаторов 200GbE/400GbE, которые, как ожидается, также окажутся на 50 % дешевле конкурирующих изделий: их цена составит от $12 тыс. до $20 тыс. против $25–$40 тыс., которые, как утверждается, будут просить конкуренты. Кроме того, в разработке находятся модели класса 800GbE.  На сайте Unipoe.net удалось обнаружить описание коммутатора RZ-S6500-32X. Он располагает 32 портами 40/100GbE QSFP28, а коммутируемая ёмкость достигает 6,4 Тбит/с. Устройство выполнено в форм-факторе 1U с габаритами 440 × 470 × 43 мм. Предусмотрены сетевой порт управления, консольный порт и разъём USB 2.0. В оснащение входят два блока питания и пять модульных вентиляторов с возможностью горячей замены. Максимальное энергопотребление составляет менее 650 Вт. Диапазон рабочих температур — от 0 до +40 °C. Упомянута поддержка протоколов RIP, IS-IS, RIPng, OSPFv3, BGP4+ и пр. Отраслевые аналитики прогнозируют, что объём глобального рынка высокоскоростных коммутаторов увеличится с примерно $8 млрд в 2025 году до более чем $15 млрд в 2027-м. Основным драйвером отрасли называется внедрение решений стандарта 200GbE и выше.
21.06.2025 [23:32], Сергей Карасёв
Xsight Labs выпустила DPU E1 с 64 ядрами Arm Neoverse N2 и 40 линиями PCIe 5.0Компания Xsight Labs объявила о доступности программно-определяемых «систем на чипе» (SoC) серии E1, предназначенных для создания DPU. Такие изделия могут применяться в облачных и периферийных дата-центрах, рассчитанных в том числе на ИИ-нагрузки. О подготовке решений E1 сообщалось в конце прошлого года. Для чипа предусмотрены варианты E1-32 и E1-64, конфигурация которых включает соответственно 32 и 64 ядра Arm Neoverse N2. Младшая версия имеет 16 Мбайт кеша и использует конфигурацию памяти 2 × DDR5-5200, старшая — 32 Мбайт и 4 × DDR5-5200. Доступны 40 (32+8) линий PCIe 5.0. Сетевые порты могут иметь конфигурацию 2 × 400GbE, 4 × 200GbE и 8 × 100/50/25/10GbE. 
Источник изображений: Xsight Labs На базе E1 могут создаваться карты расширения различной конфигурации. Благодаря наличию 32 программируемых линий PCIe 5.0 и восьми двухрежимных контроллеров 16 линий могут быть выделены для хост-подключения, а другие 16 линий — для подключения внешних устройств. В качестве примера приводится конфигурация с двумя портами 400GbE или возможностью подсоединения четырёх SSD с интерфейсом PCIe 5.0 х4 каждый.  Кроме того, компания Xsight Labs представила 1U-систему E1-Server в форм-факторе на основе E1. Эта платформа подходит для решения таких задач, как CDN, веб-сервер, VPN, шлюз для защиты от DDoS-атак и пр. Устройство располагает четырьмя слотами для модулей памяти DDR5-5200 суммарным объёмом до 512 Гбайт и коннекторомв для SSD формата M.2. Возможна установка двух карт расширения типоразмера FHFL/FHHL/HHHL. Диапазон рабочих температур — от 0 до +35 °C.
04.06.2025 [22:00], Владимир Мироненко
Лучше, чем InfiniBand и Ethernet: Cornelis Networks представила 400G-интерконнект Omni-Path CN5000Поставщик сетевых решений Cornelis Networks объявил о выходе 400G-интерконнекта CN5000, «самого производительного в отрасли сквозного (end-to-end) сетевого решения, специально созданного для максимизации производительности ИИ и HPC». Это первая крупная платформа Cornelis Networks после выделения из Intel в 2021 году, призванная конкурировать с Ethernet и InfiniBand. Лиза Спелман (Lisa Spelman), генеральный директор Cornelis Networks, отметила, что сети должны не только быстро перемещать данные, но и раскрывать весь потенциал каждого вычислительного цикла. «Если вы посмотрите на текущие ИИ-кластеры или кластеры HPC, вы увидите, что использование вычислений в некоторых случаях составляет менее 30 %, а… в лучших архитектурах и лучших случаях оно достигает (лишь) 50 %», — сообщила Спелман в интервью Network World. 
Источник изображений: Cornelis Networks Согласно пресс-релизу, CN5000 позволяет ИИ- и HPC-приложениям достигать более быстрого и предсказуемого времени выполнения задач и большей вычислительной эффективности за счёт минимизации перегрузок и поддержания максимальной пропускной способности под нагрузкой. В HPC-нагрузках CN5000 обеспечивает по сравнению с InfiniBand NDR до двух раз более высокую скорость отправки сообщений, на 35 % меньшую задержку и на 30 % выше производительность в таких задачах как вычислительная гидродинамика (CFD), моделирование климата и сейсмическое моделирование. CN5000 также показывает более высокую устоявшуюся пропускную способность в реальных условиях. 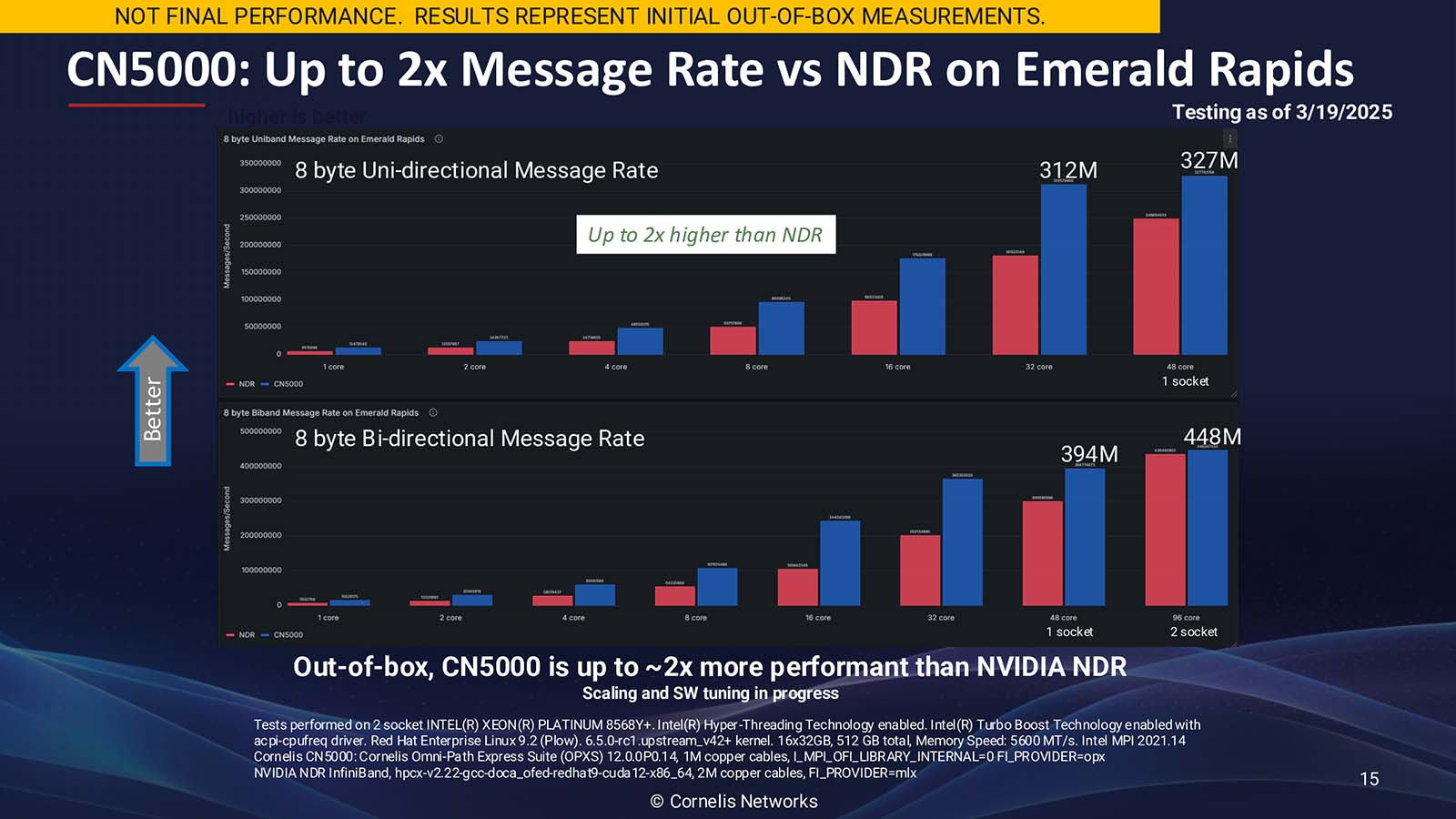 Для ИИ-приложений CN5000 предлагает в шесть раз более высокую производительность коллективных операций по сравнению RoCE. Коллективные операции, такие как all-reduce, представляют собой критические узкие места в распределённом обучении, где тысячи узлов должны эффективно синхронизировать обновления градиента. Сообщается, что CN5000 обеспечивает почти линейное масштабирование производительности обучения для больших языковых моделей (LLM) и более эффективный инференс с расширенной логикой. CN5000 является универсальным продуктом — интерконнект без проблем взаимодействует с CPU и GPU от AMD, Intel, NVIDIA и других производителей. Используется полностью открытый программный стек OpenFabrics, чтобы сделать переход от InfiniBand или Ethernet к Omni-Path «невероятно простым» для любого клиента, пояснила Спелман. Кроме того, OpenFabrics принят консорциумом Ultra Ethernet в качестве базового компонента.  Семейство CN5000 включает:
Как рассказала Спелман, CN5000 представляет собой третий архитектурный подход к высокопроизводительным сетям, отличный от реализаций Ethernet и InfiniBand. Вместо того, чтобы пытаться модернизировать существующие протоколы для рабочих ИИ- и HPC-нагрузок, Cornelis Networks расширила возможности Omni-Path от Intel с учётом конкретных вариантов использования: «Что мы сделали — это исправили архитектуру для рабочих нагрузок».  Архитектура нового решения получила несколько ключевых отличий, разработанных специально для масштабируемых параллельных вычислительных сред. В частности, управление потоком на основе кредитов обеспечивает передачу данных без потерь, в то время как тонкая адаптивная маршрутизация оптимизирует выбор пути в реальном времени. Улучшенные механизмы контроля перегрузки предназначены для поддержания стабильной производительности при высоких нагрузках, что является критически важным требованием для рабочих нагрузок ИИ-обучения, которые могут включать тысячи конечных точек. Всё это позволит улучшить использование GPU и других чипов в ИИ ЦОД, которые традиционно не используются в полной мере из-за неэффективности интерконнекта. Спелман отметила, что отличительной чертой архитектуры Cornelis Networks является то, что при той же пропускной способности можно достичь удвоения скорости передачи сообщений.  «При использовании точно таких же вычислительных ресурсов, просто заменив другую 400G-сеть на CN5000, вы увидите рост производительности приложений на 30 %, — пообещала Спелман. — Обычно для повышения производительности приложений на 30 % вам понадобится новое поколение ЦП». Более эффективное использование чипов позволяет либо работать с более крупными нагрузками на том же «железе», либо добиваться того же результата, используя меньше вычислительного оборудования.  «CN5000 — это сквозная сеть, в которой Super NIC и коммутатор или Director работают вместе», — пояснила Спелман. Платформа CN5000 поддерживает масштабирование до 500 тыс. конечных точек (250 тыс. узлов), что делает её подходящей для крупных установок, типичных для национальных лабораторий и корпоративных программ в области ИИ. Поставки CN5000 клиентам начнутся в июне, а массова она станет доступна с III квартала 2025 года у всех основных OEM-производителей. 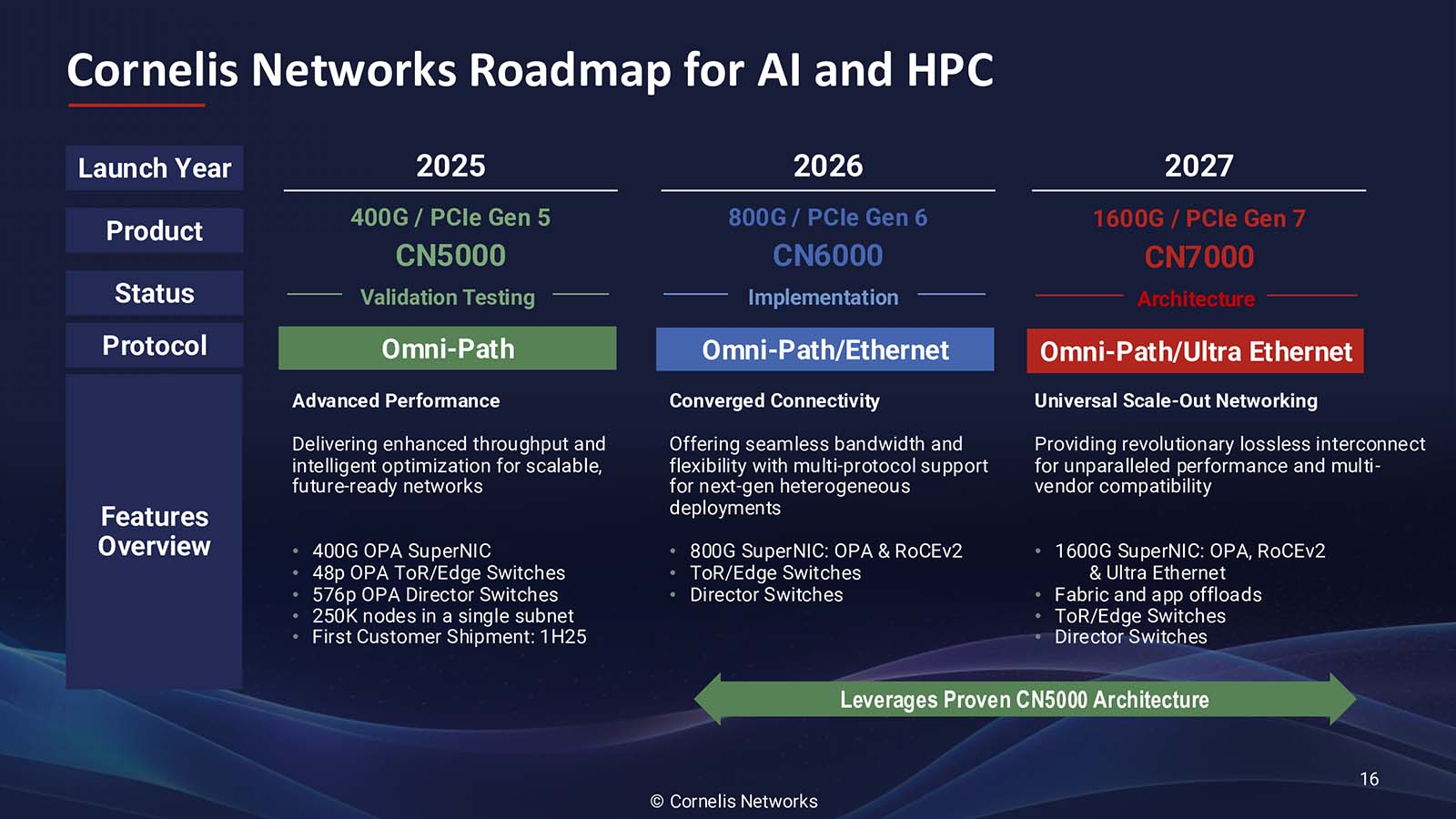 Cornelis Networks видит существенно большие рыночные возможности в следующих поколениях решения. Платформа CN6000 (800 Гбит/с) выйдет в 2026 году и будет включать возможности двухрежимного режима с поддержкой SuperNIC протоколов Ethernet для более широкой совместимости с экосистемой. В 2027 году должна выйти платформа CN7000 (1,6 Тбит/с), которая получит поддержку стандартов Ultra Ethernet на уровне коммутатора. Платформа также будет поддерживать 2 млн узлов и внутрисетевые вычисления. Анонс CN5000 состоялся ещё в конце 2023 года, т.е. у компании ушло довольно много времени на доработку продукта. Вместе с тем буквально вчера были представлены коммутаторы Broadcom Tomahawk 6, которые уже предлагают до 1,6 Тбит/с на порт, интегрированную фотонику (CPO) и поддержку Ultra Ethernet. А весной этого года NVIDIA представила 800G-платформу Ethernet/InfiniBand, причём изначально с CPO. Не осталась в стороне и Eviden (Atos), которая также анонсировала 800G-интерконнект BXI v3.
18.04.2025 [12:18], Сергей Карасёв
AMD выпустила DPU Pensando Pollara 400 для ИИ-инфраструктур с поддержкой Ultra EthernetКомпания AMD объявила о доступности DPU Pensando Pollara 400 AI NIC, первая информация о котором появилась в октябре прошлого года. Решение предназначено для построения высокопроизводительной ЦОД-инфраструктуры, ориентированной на рабочие нагрузки ИИ и машинного обучения. По заявлениям AMD, Pensando Pollara 400 — это первая в отрасли полностью программируемая сетевая карта AI NIC, разработанная с учетом стандартов консорциума Ultra Ethernet (UEC). Это обеспечивает максимальную гибкость, включая возможность добавления дополнительных функций. Новинка выполнена в виде низкопрофильной карты расширения половинной длины (HHHL) с интерфейсом PCIe 5.0 x16. Предусмотрен один порт QSFP112 400GbE с возможностью использования в режимах 25/50/100/200GbE. Заявлена поддержка RoCEv2, UEC RDMA, MCTP/SMBus, SPDM over MCTP, MCTP over PCIe VDM, а также шифрования AES-GCM 128/256. 
Источник изображения: AMD Реализованы различные функции, отвечающие за повышение быстродействия и эффективности. В частности, выборочная повторная передача помогает поднять производительность сети благодаря переотправке только потерянных или повреждённых пакетов. Контроль перегрузки с учётом пути даёт возможность оптимизировать производительность с помощью интеллектуальной балансировки нагрузки и автоматического обхода перегруженных маршрутов. Упомянуты также средства быстрого обнаружения неисправностей, инструменты обработки неупорядоченных пакетов и упорядоченной доставки сообщений. В целом, как подчёркивает AMD, благодаря совместимости с открытой экосистемой Pensando Pollara 400 помогает сократить капитальные затраты, не жертвуя при этом производительностью. Заказчики получают богатый набор функций и возможность программирования.
12.02.2025 [16:44], Сергей Карасёв
Cisco представила умные коммутаторы N9300 на базе DPU AMD Pensando и ASIC Silicon One E100Компания Cisco анонсировала интеллектуальные коммутаторы семейства N9300 Series Smart Switches, которые, как утверждаются, позволяют переосмыслить подход к обеспечению безопасности в ИИ ЦОД путём интеграции средств защиты непосредственно в сетевую структуру. В серию N9300 вошли модели Cisco 9324C-SE1U и Cisco 9348Y2C6D-SE1U типоразмера 1U. Они оснащены неназванным процессором Intel с 16 вычислительными ядрами, 96 Гбайт системной памяти и SSD вместимостью 480 Гбайт. Есть порт USB 3.0, а также порты управления RJ-45 и SFP (1 × 1GbE SFP у первой из названных версий и 2 × 10GbE SFP+ у второй). Коммутаторы несут на борту ASIC Cisco Silicon One E100, которая отвечает за сетевые функции. Кроме того, имеются сетевые сопроцессоры (DPU) AMD Pensando второго поколения: четыре чипа Elba у модели Cisco 9324C-SE1U и два чипа Giglio у модификации Cisco 9348Y2C6D-SE1U. Эти DPU отвечают за такие задачи, как распределение данных, балансировка нагрузки, обеспечение безопасности, шифрование и пр. По заявлениям Cisco, трафик интеллектуально перенаправляется между ASIC и DPU для достижения оптимальной производительности. Такой подход обеспечивает экономию средств благодаря консолидации оборудования, снижению энергопотребления и упрощению сетевой инфраструктуры. Клиенты получают возможность масштабировать сервисы и быстро адаптироваться к меняющимся бизнес-потребностям без необходимости в каких-либо дополнительных аппаратных решениях. 
Источник изображений: Cisco В составе коммутаторов DPU обеспечивают сервисную пропускную способность до 800 Гбит/с. Устройство Cisco 9324C-SE1U оснащено 24 портами 100G, а ToR-вариант Cisco 9348Y2C6D-SE1U — 48 портами 25G, двумя портами 100G и шестью портами 400G. За охлаждение отвечают шесть вентиляторов, а питание обеспечивает блок мощностью 1400 Вт. Диапазон рабочих температур — от 0 до +40 °C.  На устройствах применяется программная платформа Cisco NX-OS. Задействована фирменная система безопасности Cisco Hypershield на основе ИИ. По заявлениям разработчика, Hypershield интегрируется в коммутационный уровень, позволяя операторам дата-центров создавать защитный «микропериметр» вокруг каждой службы. Продажи младшей модели коммутатора начнутся предстоящей весной, старшей — летом.
23.12.2024 [12:20], Сергей Карасёв
Продажи Ethernet-коммутаторов и маршрутизаторов корпоративного класса падают, но 200/400GbE-решения для ЦОД только растутКомпания International Data Corporation (IDC) подвела итоги исследования мирового рынка сетевого оборудования корпоративного класса в III квартале уходящего года. Продажи Ethernet-коммутаторов и маршрутизаторов сократились в годовом исчислении. В сегменте коммутаторов выручка в период с июля по сентябрь включительно составила $10,8 млрд. Это на 7,9 % меньше по сравнению с III четвертью 2023 года. В секторе решений для дата-центров выручка поднялась на 18,0 % в годовом исчислении, в секторе решений для прочих корпоративных заказчиков, напротив, сократилась на 24,7 %. Аналитики отмечают, что спрос на ЦОД-оборудование подпитывается внедрением ИИ-приложений, которые создают высокую нагрузку на каналы передачи данных. Объём реализации коммутаторов стандартов 200/400GbE для дата-центров увеличился в денежном выражении на 126,3 % по отношению к III кварталу 2023 года. В сегменте коммутаторов, не связанных с ЦОД, продажи устройств 1GbE рухнули на 25,6 % в годовом исчислении. 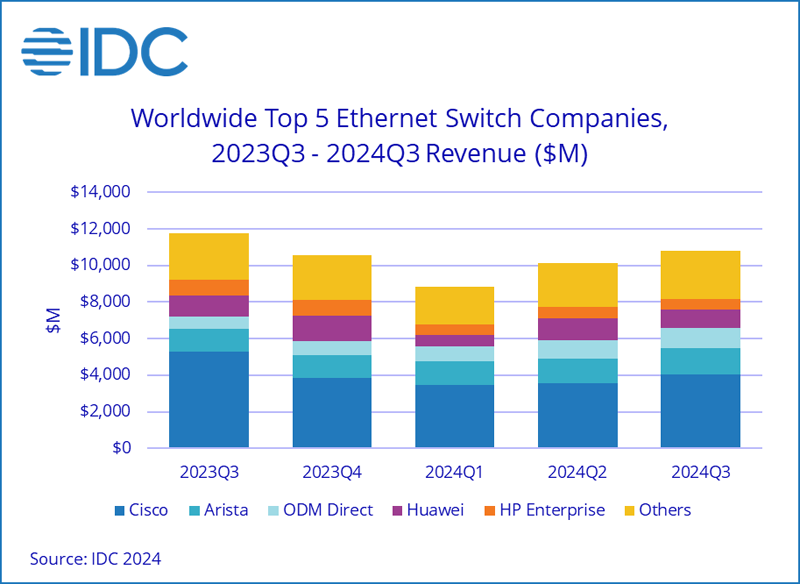
Источник изображения: IDC С географической точки зрения в США общий рынок коммутаторов Ethernet сократился на 6,5 % год к году. В Западной Европе падение составило 11,9 %, в Центральной и Восточной Европе — 17,8 %. В Азиатско-Тихоокеанском регионе, за исключением Японии и Китая, отмечено снижение на 8,7 % в годовом исчислении. В КНР продажи остались примерно на прошлогоднем уровне. В список крупнейших мировых поставщиков коммутаторов Ethernet входят Cisco, Arista Networks, Huawei, HPE и H3C с долями соответственно 37,2 %, 13,6 %, 9,7 %, 5,3 % и 4,1 %. Продажи маршрутизаторов в III квартале 2024 года сократились на 17,4 % по сравнению с 2023-м — до $3,1 млрд. На поставщиков услуг пришлось 70,8 % от общего объёма рынка, а падение год к году составило 22,3 %. Корпоративный сегмент обеспечил 29,2 % продаж с падением на 2,4 %.
16.12.2024 [11:19], Сергей Карасёв
Раскрыты характеристики сетевых устройств Eviden с технологией BXI v3В ноябре текущего года компания Eviden (дочерняя структура Atos) представила интерконнект третьего поколения BullSequana eXascale Interconnect (BXI v3) для рабочих нагрузок ИИ и HPC. Теперь, как сообщает ресурс Next Platform, раскрыты некоторые характеристики устройств с поддержкой данной технологии. BXI v3 в качестве базового протокола связи использует Ethernet. Технология BXI v3 ляжет в основу интеллектуального сетевого адаптера (Smart NIC) и соответствующего коммутатора. Говорится, что для изготовления чипов ASIC с поддержкой BXI v3 компания Eviden рассматривает возможность применения 3-нм или 4-нм методики TSMC. Коммутатор BXI v3 располагает 64 портами, работающими на скорости 800 Гбит/с. Их можно переконфигурировать в 128 портов с пропускной способностью 400 Гбит/с. В свою очередь, адаптер Smart NIC функционирует на скорости 400 Гбит/с. Он будет предлагаться в виде двухслотовой карты расширения PCIe или OCP-3 (с интерфейсом PCIe 5.0). Возможны варианты адаптеров с двумя портами 400 Гбит/с. Карта BXI v3 способна управлять пакетами объёмом до 9 Мбайт, что полезно в нагруженных инфраструктурах ИИ. 
Источник изображения: Eviden Платформа BXI v3 поддерживает топологии fat tree и dragonfly+, а также fat tree с оптимизацией маршрутов (используется при обучении больших языковых моделей). Для BXI v3 заявлена поддержка до 64 тыс. конечных точек, а задержка составляет менее 200 нс от порта к порту. Изделия с поддержкой BXI v3 поступит в продажу в 2025 году. Осенью 2027 года ожидается появление интерконнекта BXI v4, который предусматривает повышение пропускной способности портов на сетевых картах и коммутаторах до 1,6 Тбит/с. При этом сетевые адаптеры получат поддержку интерфейса PCIe 6.0. В 2029-м планируется переход на интерконнект BXI v5: он обеспечит скорость портов на коммутаторах до 3,2 Тбит/с, тогда как сетевые адаптеры продолжат работать на скоростях до 1,6 Тбит/с, но получат поддержку PCIe 7.0.
03.12.2024 [11:01], Сергей Карасёв
Delta Computers представила российские 400G-коммутатор Delta Dragonfly и PCIe-коммутатор Delta FirebirdРоссийский производитель IT-оборудования Delta Computers анонсировал Ethernet-коммутатор Delta Dragonfly типа Bare Metal, предназначенный для развёртывания высокоскоростных инфраструктур уровня ядра сети, а также уровней агрегации и доступа в средних и крупных компаниях. Решение выполнено в форм-факторе 1U с габаритами 630 × 439 × 43 мм. Задействованы ASIC Broadcom Tomahawk 3 (коммутационная ёмкость — 12,8 Тбит/с), а также процессор Intel Xeon Emerald Rapids. Предусмотрены четыре слота для модулей оперативной памяти DDR5-5600. Для Delta Dragonfly доступны модификации DN5032, DN4032, DN3032, DN4424, а также DN3424 с поддержкой соответственно 32 портов QSFP-DD 400 Гбит/с, 32 портов QSFP-56 200 Гбит/с, 32 портов QSFP-28 100 Гбит/с, 24 портов QSFP-56 200 Гбит/с и четырёх портов QSFP-DD 400 Гбит/с, а также 24 портов QSFP-28 100 Гбит/с и четырёх портов QSFP-DD 400 Гбит/с. Все варианты располагают двумя разъёмами SFP+ 10 Гбит/с. 
Источник изображений: Delta Computers Коммутаторы могут получать питание от двух блоков CRPS, общей DC-шины OCP (12 В) или от сети 48–60 В телеком-стандарта (Telco Rack). В системе охлаждения задействованы пять вентиляторов. Применяется созданные в России прошивки Delta BIOS и Delta BMC. Утверждается, что Delta Dragonfly является оптимальным выбором для ЦОД, корпоративных сред и HPC-платформ.  Кроме того, компания Delta Computers представила высокоскоростной PCIe-коммутатор Delta Firebird, обеспечивающий возможность объединения до шести устройств по интерфейсу PCIe 5.0 x16 в кластер. Горизонтальная масштабируемость на базе PCIe 5.0 позволяет создавать разнообразные конфигурации кластеров высоконагруженных систем. Изделие выполнено в формате 1U с размерами 481 × 629 × 43 мм. Возможно питание от двух блоков CRPS или от централизованного шинопровода OCP на 12 В. Применено встроенное ПО Delta BMC. Оба коммутатора могут быть использованы в стандартных 19″ серверных стойках и в OCP-шасси формата 21″. |
|

