Материалы по тегу: ocp
|
21.07.2026 [12:24], Сергей Карасёв
Chelsio представила 400GbE-решения седьмого поколения для ИИ ЦОДКомпания Chelsio Communications анонсировала интерконнект седьмого поколения для дата-центров, систем хранения и инфраструктур, ориентированных на ИИ. В состав представленной платформы AI Interconnect Platform входят сетевые адаптеры SmartNIC, контроллеры хранения и процессоры обработки данных (DPU). В основу AI Interconnect Platform положена архитектура Chelsio Unified Wire: она обеспечивает поддержку стандарта 400GbE и технологии Unified RDMA, объединяющей несколько протоколов удалённого прямого доступа к памяти (iWARP и RoCEv2). Кроме того, задействованы средства ускорения работы систем хранения и оптимизации ИИ-инфраструктуры для облачных, корпоративных развёртываний и гиперскейлеров. Среди ключевых особенностей платформы названы встроенные криптографические модули для протоколов QUIC, kTLS и IPsec/TLS/kTLS, различные варианты исполнения (PCIe 5.0, OCP 3.0) и лучшие в отрасли показатели производительности в расчёте на ватт потребляемой энергии. Говорится о поддержке виртуализации SR-IOV (Single Root I/O Virtualization), виртуальной коммутации vSwitch и пр. 
Источник изображений: Chelsio Communications В число анонсированных решений входят двух- и четырёхпортовые адаптеры S7250 / S7450 / S7450-OCP SmartNIC с поддержкой 1/10/25/50GbE. Эти изделия оптимизированы для виртуализации, встраиваемых систем и периферийных развёртываний. Кроме того, дебютировали решения S72200 / S72200-OCP SmartNIC с поддержкой 40/50/100/200GbE для масштабных облачных сред, HPC и ИИ-инфраструктур. Представлен также однопортовый адаптер S71400 SmartNIC класса 400GbE с возможностью работы в режимах 4 × 100GbE и 2 × 200GbE: устройство рассчитано на сверхмасштабные сетевые инфраструктуры.  Кроме того, Chelsio выпустит контроллеры хранения T72200/T7450. Они предназначены для ускорения выполнения задач, связанных с обработкой данных. Обеспечивается аппаратная разгрузка для NVMe/TCP, NVMe-oF, iSCSI, RDMA и пр. Устройства будут предлагаться в форм-факторах PCIe и OCP. Все перечисленные изделия уже доступны для заказа. В декабре начнётся производство полностью программируемых карт T72200-DPU / T7450-DPU, которые сейчас доступны для ознакомления.
24.06.2026 [12:00], Сергей Карасёв
Dell представила сервер PowerEdge XE8812 на базе NVIDIA Vera Rubin NVL4Компания Dell Technologies анонсировала сервер PowerEdge XE8812 для ресурсоёмких нагрузок ИИ и HPC. Устройство, относящееся к семейству Dell AI Factory with NVIDIA, ориентировано на использование в составе стоечной платформы Dell PowerRack 9100, основанной на стандартах OCP. Модель PowerEdge XE8812 выполнена на архитектуре NVIDIA Vera Rubin NVL4, которая включает четыре ускорителя Rubin. Таким образом, в составе стойки могут быть задействованы в общей сложности до 144 GPU, что обеспечивает высочайшую плотность вычислений. Сама стойка Dell PowerRack 9100 соответствует стандарту ORv3. Она поддерживает работу с оборудованием суммарной мощностью более 300 кВт. Реализовано прямое жидкостное охлаждение, которое охватывает как CPU, так и GPU. Интегрированный контроллер удалённого доступа Dell (iDRAC) позволяет настраивать, обновлять и контролировать серверы PowerEdge дистанционно из любой точки с подключением к сети. 
Источник изображения: Dell В целом, как отмечает Dell, переход на платформу Vera Rubin обеспечивает 50-% прирост объёма памяти в расчёте на сокет и GPU по сравнению с решениями NVIDIA предыдущего поколения. В сочетании с библиотеками NVIDIA CUDA-X это даёт предприятиям возможность запускать крупные ИИ-модели и симуляции полностью в оперативной памяти. Сервер предназначен для решения сложных задач, таких как, например, молекулярное моделирование. Поставки PowerEdge XE8812 планируется организовать в начале следующего года.
18.06.2026 [10:15], Руслан Авдеев
Google представила Brazos — СЖО для ИИ-стоек в ЦОД с воздушным охлаждениемПоскольку современные ИИ-чипы нередко имеют TDP более 1000 Вт, классическое воздушное охлаждение не готово эффективно справляться с подобными тепловыми нагрузками. Однако установка контуров жидкостного охлаждения требует времени и больших затрат, поэтому Google предложила гибридную замкнутую стоечную систему Bezos, которая позволяет развернуть в ЦОД с воздушным охлаждением высокоплотные стойки с СЖО. Brazos фактически представляет собой автономную СЖО, захватывающую тепло с помощью циркулирующей жидкости непосредственно от компонентов оборудования. После этого тепло отводится в «горячий коридор» через теплообменники. Подобные решения можно быстро развернуть практически в любом действующем ЦОД, стойка за стойкой проводя модернизацию инфраструктуры и сохраняя при этом простоту эксплуатации, характерную для обычных воздушных систем — лишь бы хватало холода и питания в зале. 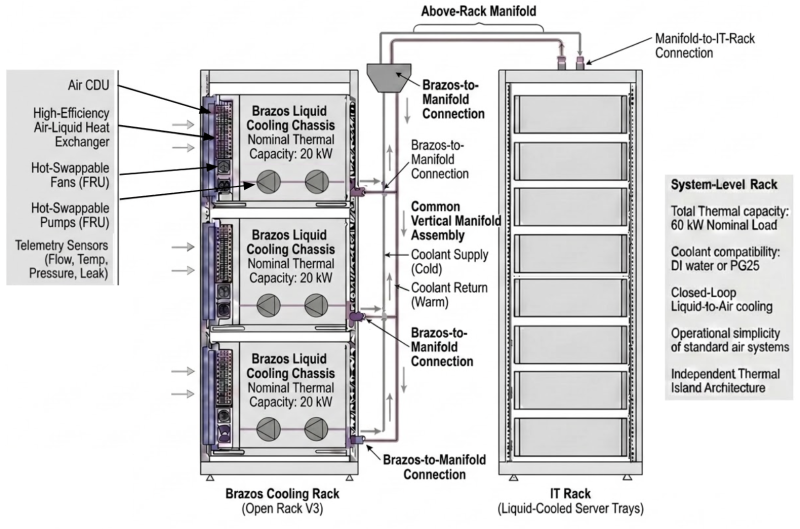
Источник изображения: Google Brazos представляет собой модульную систему, включающую три охлаждающих блока высотой 11OU и встроенные коллекторы для стоек. Модули совместимы со стандартными стойками OCP ORv3. По словам Google, Brazos отличают:

Источник изображения: Google Систему конструировали с учётом удобства обслуживания непосредственно на площадке. Шасси имеет направляющие с низким трением, что позволяет легко выдвигать блоки. Ключевые элементы вроде насосов и вентиляторов выполнены в виде модулей с возможностью «горячей» замены (FRU), что даёт возможность свести к минимуму среднее время ремонта (MTTR). Похожие решения используют Meta✴ и Microsoft. В ближайшие месяцы Google намерена выложить в open source технические спецификации, принципы разработки и «визуальные активы» Brazos. Наработки рассчитаны на архитекторов вычислительных систем, производителей оборудования, а также специалистов по теплотехнике. Партнёры Google уже готовы к производству решений на основе Brazos. Ранее компания поделилась с OCP проектом CDU Deschutes.
15.06.2026 [09:32], Сергей Карасёв
96 NVMe SSD с СЖО и четыре RTX Pro 6000: Wiwynn показала сверхбыстрое хранилище на базе NVIDIA SCADAКомпания Wiwynn (дочерняя структура Wistron), по сообщению ресурса Tom's Hardware, продемонстрировала один из первых в отрасли серверов хранения NVIDIA SCADA (SCaled Accelerated Data Access). Устройство ориентировано на высокопроизводительную обработку больших объёмов данных в рамках задач обучения ИИ-моделей и инференса. 
Источник изображений: Wiwynn Новинка выполнена в MGX-шасси высотой 6U и рассчитана на монтаж в 19″ серверную стойку. Задействован процессор NVIDIA Vera, который содержит 88 ядер Olympus, или Intel Xeon (в составе HPM-). Доступны восемь слотов для модулей DDR5. Система несёт на борту четыре ускорителя NVIDIA RTX Pro 6000 Blackwell Server Edition, четыре коммутатора PCIe 6.x и четыре 800G-карты ConnectX-9 SuperNIC/DPU BlueField-4 (опционально GPU можно поменять на DPU). Реализовано полностью жидкостное охлаждение.  Сервер рассчитан на 96 накопителей EDSFF E3.S SSD с вертикальной загрузкой. При использовании изделий Micron 9650 Pro вместимостью 30,72 Тбайт с интерфейсом PCIe 6.0 суммарная ёмкость достигает 2,949 Пбайт. При этом обеспечивается показатель IOPS на операциях случайного чтения до 528 млн. Максимальное энергопотребление новинки — 9 кВт (питание DC 50 В). Кабели питания и гибкие шланги СЖО расположенные в нишах по бокам, что позволяет выдвигать лоток с накопителями и производить «горячую» замену SSD. 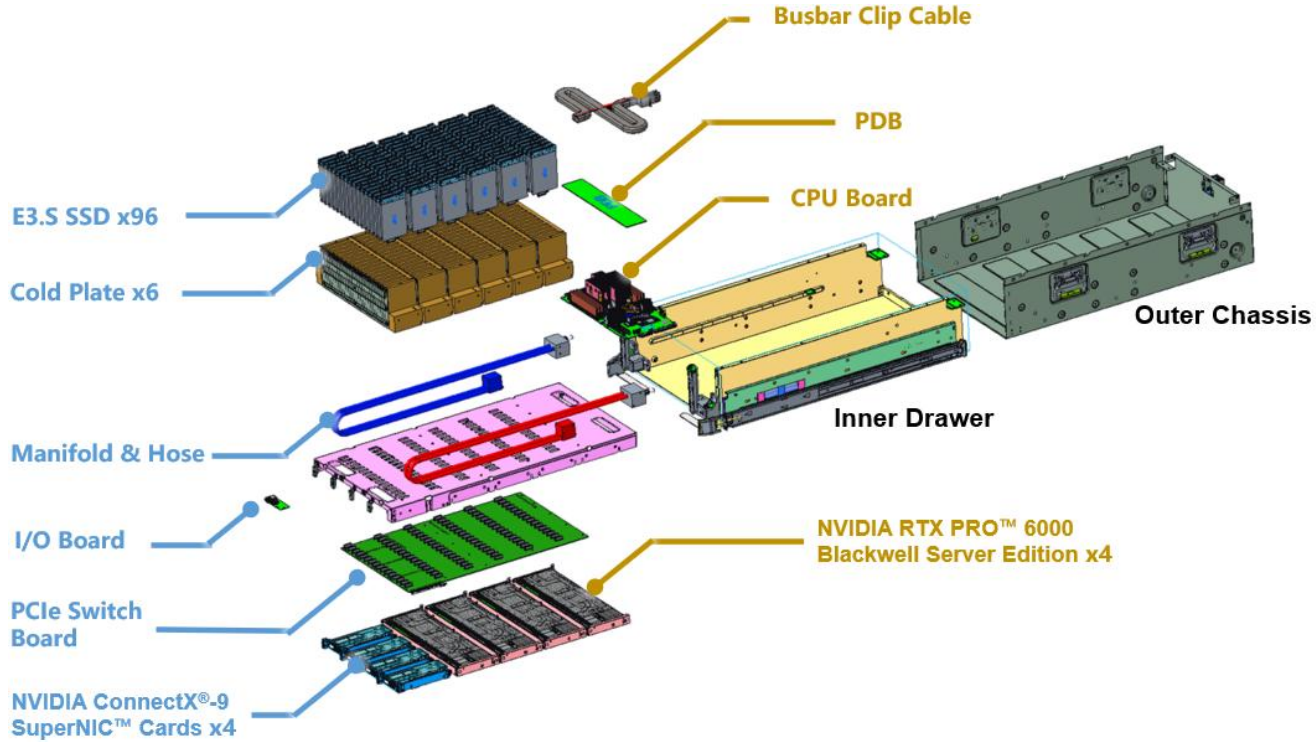 Отмечается, что традиционные серверы на основе CPU плохо справляются с такими задачами, как векторный поиск, генерация с дополненной выборкой (RAG), анализ графов и извлечение данных из KV-кеша. При таких нагрузках процессору необходимо выдавать команды, обрабатывать запросы и контролировать передачу данных, из-за чего создаются узкие места. 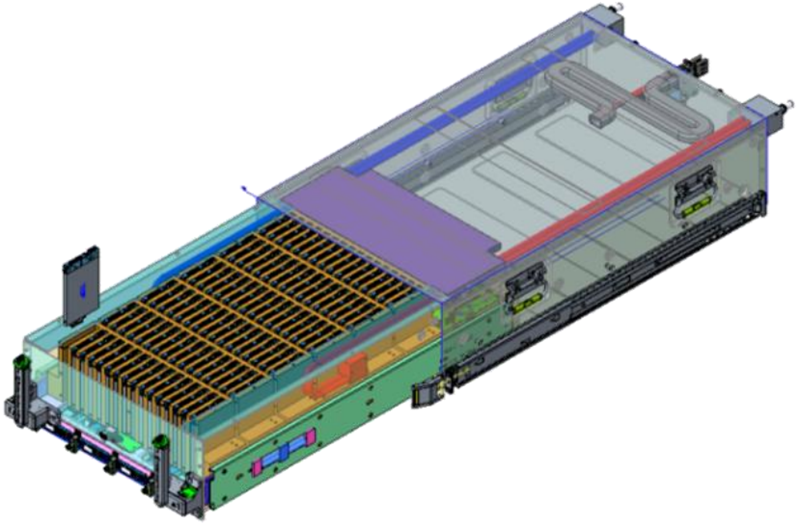 Платформа SCADA позволяет решить проблему благодаря тому, что операции ввода-вывода и обработка данных возлагаются на GPU — без участия CPU. По сути, ускорители RTX Pro 6000 Blackwell Server Edition в составе машины выполняют функции процессоров хранения, которые инициируют и обрабатывают транзакции и миллионы запросов со стороны ИИ-приложений, а также передают данные на вычислительные узлы посредством карт ConnectX-9.
11.06.2026 [09:18], Сергей Карасёв
СЖО и 1,6 Тбит/с на порт: Arista представила коммутаторы 7060XE7 для ИИ ЦОДКомпания Arista Networks анонсировала коммутаторы семейства 7060XE7, ориентированные на масштабные ИИ-инфраструктуры следующего поколения с высокой интенсивностью обмена данными. Устройства обеспечивают коммутационную способность до 102,4 Тбит/с. В основу изделий положен чип Broadcom Tomahawk 6. Объём оперативной памяти составляет 32 Гбайт, вместимость встроенного SSD — 480 Гбайт. Для управления предусмотрены два разъёма RJ45, консольный порт и коннектор USB. Реализована технология LPO (Linear Pluggable Optics), которая позволяет формировать прямые соединения между оптоволоконными модулями, устраняя необходимость в традиционных компонентах вроде цифровых сигнальных процессоров (DSP). Благодаря этому повышается энергетическая эффективность. В серию вошли модели 7060XE7-64PS / 7060XE7-64PRS с 64 портами OSFP с пропускной способностью 1,6 Тбит/с, которые могут использоваться в режимах 200GbE/400GbE/800GbE. Кроме того, дебютировала версия 7060XE7-128PE со 128 портами OSFP со скоростью 800 Гбит/с (поддерживаются также режимы 100GbE/200GbE/400GbE). Все эти коммутаторы выполнены в форм-факторе 4U и оснащены воздушным охлаждением. 
Источник изображения: Arista Networks Ещё одним представителем семейства стала модель 7060XE7-64PRS-RV3-L типоразмера 2OU, наделённая системой жидкостного охлаждения. Этот коммутатор оборудован 64 портами OSFP на 1,6 Тбит/с (с поддержкой режимов 200GbE/400GbE/800GbE). Питание осуществляется от централизованного шинопровода. В качестве программной платформы на устройствах используется Arista EOS (Extensible Operating System). Говорится о поддержке функций балансировки нагрузки DLB (Dynamic Load Balancing) и CLB (Cluster Load Balancing). Поставки коммутаторов планируется начать в IV квартале текущего года.
08.06.2026 [09:41], Сергей Карасёв
Supermicro представила Arm-серверы для агентного ИИКомпания Supermicro анонсировала серверы с Arm-процессорами, оптимизированные для агентного ИИ. Устройства обеспечивают высокую энергоэффективность и масштабируемость, позволяя формировать стойки высокой плотности. Представлены модели с воздушным и жидкостным охлаждением. В частности, дебютировал сервер ARS-222H-NR типоразмера 2U, допускающий установку двух процессоров Arm AGI с 64, 128 или 136 вычислительными ядрами. Предусмотрены 24 слота для модулей DDR5-8800 суммарным объёмом до 6 Тбайт. Во фронтальной части расположены восемь отсеков для SFF-накопителей (NVMe). Есть пять слотов PCIe 6.0 x16 для карт FHHL, по одному разъёму PCIe 6.0 x8 FHHL и PCIe 6.0 x8 AIOM (OCP 3.0), а также коннектор M.2 22110/2280 для SSD с интерфейсом PCIe 4.0 x1. Применено воздушное охлаждение. Питание обеспечивают два блока мощностью 2700 Вт с сертификатом 80 Plus Titanium. Кроме того, представлен GPU-сервер ARS-522GP-NR формата 5U с поддержкой двух чипов Arm AGI. Эта машина позволяет задействовать до восьми ИИ-ускорителей двойной ширины (восемь слотов PCIe 5.0 x16). Конфигурация включает 24 разъёма для модулей DDR5-8800 (до 6 Тбайт), четыре слота PCIe 5.0 x16 FHHL, по одному слоту PCIe 6.0 x16 FHFL и PCIe 5.0 x8 AIOM (OCP 3.0). Доступны восемь фронтальных отсеков для SFF-накопителей (NVMe) и коннектор M.2 22110/2280 (PCIe 4.0 x1). Задействованы шесть блоков питания мощностью 2700 Вт с сертификатом 80 Plus Titanium и воздушное охлаждение. 
Источник изображений: Supermicro В свою очередь, модель ARS-242TP-QNR-LCC стандарта 2OU использует четырёхузловую конфигурацию с прямым жидкостным охлаждением D2C (Direct to Chip). Каждый узел рассчитан на два чипа Arm AGI, 24 модуля DDR5-8800 (до 6 Тбайт) и два накопителя M.2 22110/2280 (PCIe 6.0 x4). Кроме того, имеются два слота PCIe 6.0 x16 AIOM (OCP 3.0) и два опциональных фронтальных отсека для накопителей E1.S (PCIe 5.0 x4). Питание осуществляется от централизованного шинопровода.  Наконец, анонсирован сервер ARS-212HE-FNR формата 2U с поддержкой одного процессора Arm AGI (до 136 ядер) и 12 модулей DDR5-8800 (до 3 Тбайт). Возможны различные варианты исполнения подсистемы хранения данных, включая четыре или шесть фронтальных отсеков E1.S и шесть тыльных посадочных мест SFF. Стандартная конфигурация предлагает три слота PCIe 6.0 x16 FHFL, по одному слоту PCIe 6.0 x8 FHFL и PCIe 6.0 x16 AIOM (OCP 3.0). Реализован один слот M.2 22110/2280 (PCIe 4.0 x1). Применено воздушное охлаждение. Мощность двух установленных блоков питания с сертификатом 80 Plus Titanium достигает 3200 Вт. У всех новинок диапазон рабочих температур простирается от +10 до +35 °C.  Помимо Arm-серверов, компания Supermicro представила 12 новых систем серии X14 на аппаратной платформе Intel Xeon 6+ Clearwater Forest, включая модели ультравысокой плотности. Устройства входят в различные семейства — Hyper, SuperBlade, FlexTwin и GrandTwin. В зависимости от варианта используется форм-фактор 1U, 2U или 6U; доступны версии с воздушным и жидкостным охлаждением.
07.06.2026 [10:09], Владимир Мироненко
15 тыс. ампер на стойку: Molex представила шину питания с многоканальным жидкостным охлаждением для ИИ ЦОДКомпания Molex представила шину питания с многоканальным жидкостным охлаждением, предназначенную для использования в ИИ ЦОД. Как сообщает компания, предложенная технология объединяет распределение электроэнергии и жидкостное охлаждение в единый инфраструктурный компонент, предназначенный для поддержки ИИ-систем следующего поколения. Molex отметила, что с ростом интенсивности ИИ-нагрузок требования к мощности стоек приближаются к порогу в 1 МВт, в связи с чем традиционная инфраструктура с воздушным охлаждением достигла физического предела. Компания попыталась решить эту проблему, распространив жидкостное охлаждение на уровень распределения питания, обеспечив поддержку силы тока до 15 тыс. А и планируя в будущем достичь 25 тыс. А. Вместо одного канала, используемого в традиционной конструкции с жидкостным охлаждением, Molex предложила архитектуру с семью отдельными каналами СЖО. Многоканальная структура призвана уменьшить количество зон перегрева, а также обеспечить более равномерное и эффективное отведение тепла и более стабильную работу электрооборудования при высоких токах. 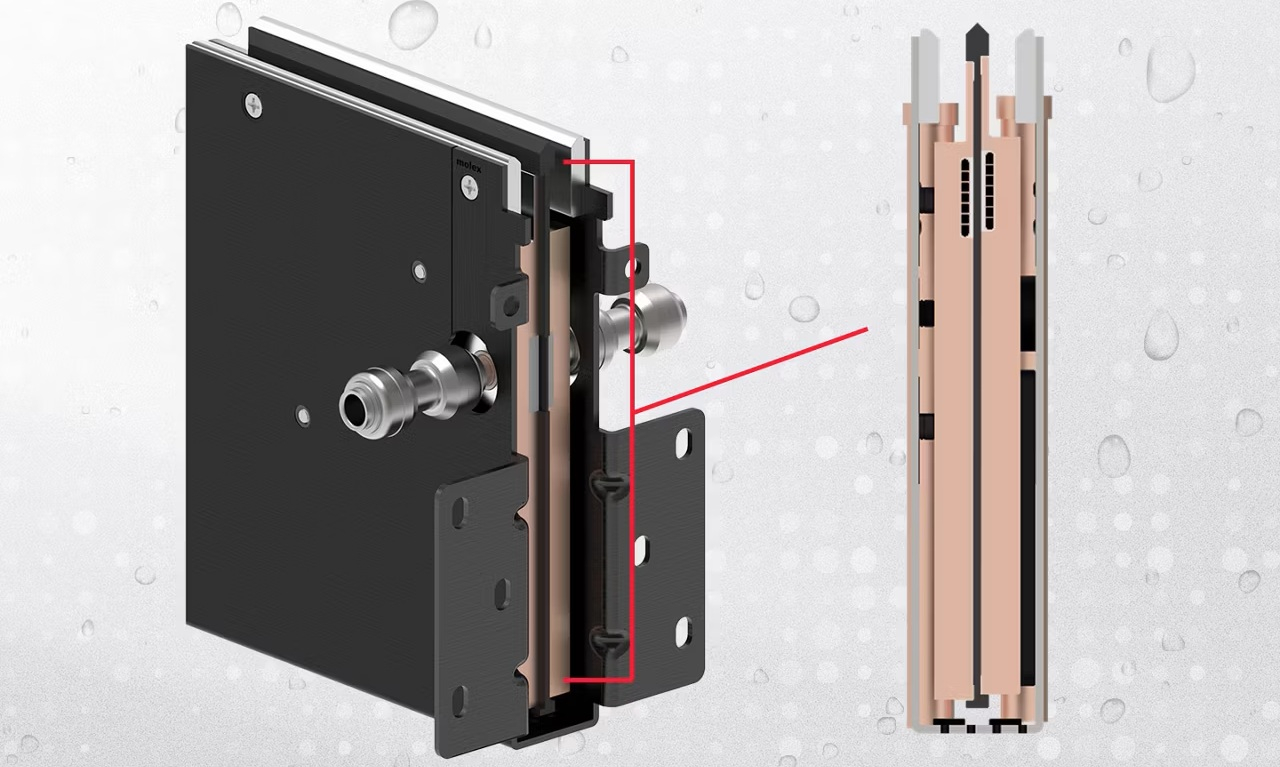
Источник изображений: Molex По данным моделирования Molex, эффективность охлаждения повышается до 20 % по сравнению с одноканальной конструкцией. При этом растёт показатель тепловой эффективности — до 15 °C T-Rise при токе 15 тыс. А. Возможность максимизировать отведение тепла при тех же габаритах позволяет архитекторам ЦОД масштабировать мощность без ущерба для ценного пространства в стойке, отметила компания. Шины могут быть сконфигурированы по длине, глубине, а также по положению входного и выходного отверстий для жидкости. Эта гибкость в сочетании со стандартным интерфейсом plug-and-play обеспечивает плавный переход к жидкостному охлаждению без необходимости перепроектирования инфраструктуры стойки. 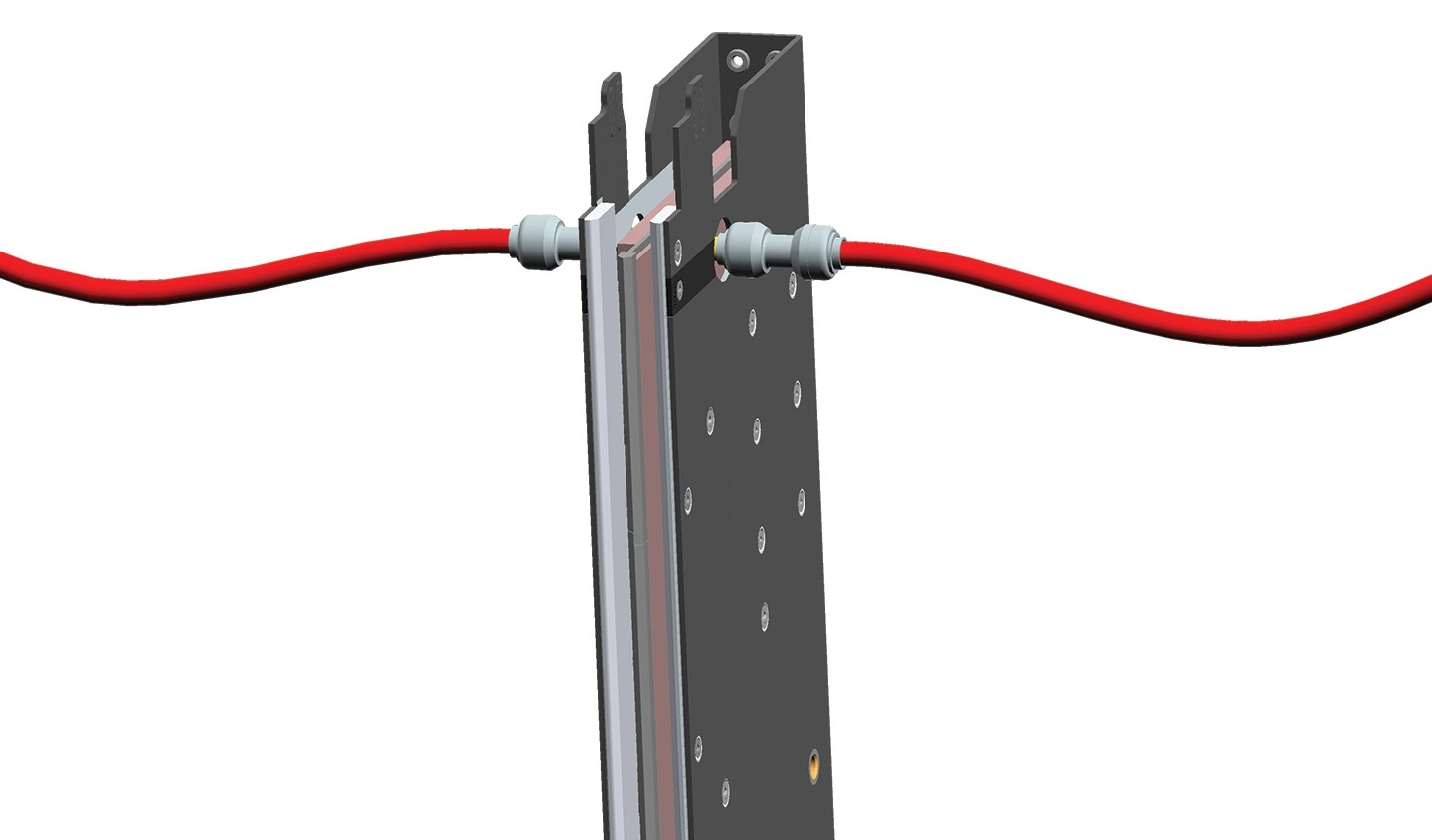 Благодаря совместимости габаритов с механическими стандартами ORV3 и HPR упрощается интеграция в стоечные архитектуры, которые уже разрабатываются с учётом всё более высоких токовых нагрузок и более высокой тепловой плотности. Совместимость с диэлектрическими и недиэлектрическими жидкостями гарантирует беспрепятственную интеграцию технологии в различные существующие контуры охлаждения объектов. Развёртывание ИИ-инфраструктуры изменило роль оборудования распределения питания. Ускорители и высокоскоростная память повышают плотность размещения оборудования в стойках, в то время как прямое охлаждение чипов уже вошло в состав основных высокопроизводительных систем. Проводники, разъёмы и шины, передающие питание по стойке, теперь подвергаются тому же тепловому и механическому воздействию, что и вычислительный слой, который они питают, отметил ресурс IN Electronics.  Распределение более высокого напряжения предлагает один из способов снижения нагрузки на медь и ограничения потерь при преобразовании. Работа Infineon с экосистемой стоек NVIDIA на 800 В DC показывает, как архитектуры на уровне стойки отходят от постепенных изменений в системе питания в сторону более масштабной электрической модернизации. Разработка Molex решает ту же проблему масштаба стойки со стороны проводников и охлаждения. Жидкостно-охлаждаемые шины питания не устранят необходимость в эффективных преобразовательных каскадах или надёжной защите, но они решают проблему обеспечения температурного режима для стоек с высокими токами. По мере повышения силы тока, силовая магистраль становится одновременно и электрическим каналом, и тепловой структурой, а её конструкция все больше влияет на плотность размещения оборудования в стойках, надёжность, удобство обслуживания и циклы модернизации.
01.06.2026 [12:35], Сергей Карасёв
Двухтонный ИИ: Dell начала поставки первых стоек NVIDIA Vera Rubin NVL72Компания Dell Technologies поставила свою первую стойку NVIDIA Vera Rubin NVL72. Получателем системы стала компания CoreWeave — неоооблачный провайдер, который активно расширяет инфраструктуру для ресурсоёмких нагрузок ИИ. 
Источник изображений: Dell Стойка содержит 72 ускорителя Rubin и 36 процессоров Vera на архитектуре Arm. Суммарный объём памяти HBM4 составляет 20,7 Тбайт, системной памяти LPDDR5X — 54 Тбайт. Реализовано жидкостное охлаждение горячей водой (+45 °C). Сама стойка в собранном виде весит около 1,8 т и потребляет до 230 кВт. Заявленная ИИ-производительность достигает 3,6 Эфлопс в режиме NVFP4 при инференсе, что примерно в пять раз превышает показатель Blackwell. На задачах обучения быстродействие NVFP4 составляет 2,5 Эфлопс.  Отмечается, что Dell успешно провела все необходимые диагностические тесты Vera Rubin NVL72, по результатам которых система готова к дальнейшему развёртыванию на площадке заказчика. CoreWeave намерена использовать новый кластер для расширения своей инфраструктуры НРС. Масштабный вывод платформы на рынок намечен на II половину текущего года.  Между тем сама NVIDIA объявила о начале массового производства решений поколения Vera Rubin. В числе партнёров, объявивших о поддержке этих систем, названы Dell Technologies, HPE, Lenovo и Supermicro, а также AIC, Aivres, ASRock Rack, ASUS, Cloudian, Compal, DDN, Everpure, Foxconn, GIGABYTE, Hitachi Vantara, Hyve Solutions, IBM, Inventec, MinIO, MiTAC Computing, MSI, NetApp, Nutanix, Pegatron, Quanta Cloud Technology (QCT), VAST Data, WEKA, Wistron и Wiwynn. Вместе с тем CoreWeave, а также Lambda и Oracle Cloud Infrastructure одними из первых начнут развёртывание стоек Vera Rubin в своих ИИ-инфраструктурах.
30.05.2026 [14:18], Сергей Карасёв
Microchip представила RoT-контроллеры для постквантовой криптографииКомпания Microchip Technology анонсировала новые решения Trust Shield для устройств с поддержкой постквантовой криптографии. В частности, дебютировали контроллеры TS1800, TS500 и TS501, которые доступны в составе предварительно сконфигурированной платформы TrustFLEX, что помогает ускорить вывод конечных продуктов на рынок. Изделие TS1800 — это внешний контроллер Root of Trust (RoT), отвечающий за безопасную загрузку устройства, безопасные обновления прошивки, аттестацию и обработку сертификатов с использованием аппаратного ускорения алгоритмов постквантовой криптографии. Говорится о поддержке таких решений Национального института стандартов и технологий США (NIST), как ML-DSA (Module Lattice‑Based Digital Signature Algorithm), LMS (Leighton–Micali Signature) и ML-KEM (Module Lattice-Based Key Encapsulation Mechanism). В основу контроллера TS1800 положено ядро Arm Cortex-M4F, функционирующее на тактовой частоте до 192 МГц. Достигается двукратный прирост производительности по сравнению с RoT-контроллерами Microchip предыдущего поколения. Кроме того, улучшена энергетическая эффективность. Реализована поддержка интерфейса USB 2.0 и расширенных функций безопасности, предусмотренных стандартами OCP. 
Источник изображения: Microchip Technology В свою очередь, изделия TS50x предназначены для обеспечения безопасной загрузки. Они ориентированы на оборудование, которому не требуется полный набор функций RoT, доступный в микросхеме TS1800. При этом в дополнение к алгоритмам постквантовой криптографии поддерживаются традиционные инструменты, в частности, Elliptic Curve Cryptography (ECC) P-384. Поставки контроллеров TS1800 и TS50x уже начались.
26.05.2026 [09:40], Руслан Авдеев
Но есть и плюсы: OCP напомнила местным властям о возможности использования избыточнго тепла ЦОДОрганизация OCP предложила представителям муниципальных властей направить избыточное тепло дата-центров на пользу локальным сообществам, сообщает The Register, чтобы хоть как-то смягчить негативное отношение жителей к самой идее постройки ЦОД в округе, которые ссылаются на большое потребление воды и энергии, потенциальный рост цен на ресурсы, высокий уровень шума и др. По некоторым данным, ЦОД даже создают «острова тепла» вокруг себя, так что порой действительно луше было бы обогревать дома, а не отапливать атмосферу. Протесты против строительства ЦОД не только иногда приводят к смещению местных властей, но и заканчиваются насильственными акциями. Иногда представители властей идут навстречу гражданам — как в штате Мэн, хотя речь идёт скорее о показательной политической акции, не влияющей на окончательный результат. На этом фоне эксперты OCP, участвовавшие в группе, занимавшейся повторным использованием тепла, недавно опубликовали пост, в котором восхваляли достоинства ЦОД — там, где местные власти достаточно умны, чтобы пользоваться избыточным теплом от их работы. Сообщается, что использование тепла дата-центров открывает большие возможности для безуглеродного отопления в разных секторах, неся экологические, экономические и общественные выгоды. Действительно, о проектах использования «мусорного» тепла для выращивания растений, обогрева бассейнов и в других целях информация появляется регулярно. В публикации OCP выражено сожаление тем, что местные органы власти недостаточно осведомлены о возможностях использования тепла дата-центров. 
Источник изображения: he gong/unsplash.com Эксперты указывают на отсутствие коммуникаций между ЦОД и близко расположенными потребителями тепла, а также политики, стимулирующей соответствующие проекты на местном, национальном и наднациональном уровнях. Предполагается, что компетентные власти должны сделать согласие на использование избыточного тепла обязательным условием для выдачи разрешений на строительство ЦОД. Впрочем, признаётся, что обосновать затраты на проекты использования такого тепла может быть довольно непросто. На вики-странице группы, занимающейся вопросами применения тепла ЦОД в OCP, размещаются образцы типовых писем и другие материалы, которые можно направлять регуляторам, чтобы стимулировать использование ими систем рекуперации тепловых ресурсов. Фактически это распространённая тактика лоббирования. Сам факт того, что OCP, преимущественно работающая в интересах Meta✴, Microsoft и Google, обращает внимание на подобные возможности ЦОД на фоне оппозиции их строительству, примечательнее, чем сами советы. |
|

