Материалы по тегу: xilinx
|
05.02.2026 [11:35], Сергей Карасёв
AMD представила FPGA серии Kintex UltraScale+ Gen 2 с поддержкой PCIe 4.0 и LPDDR5XКомпания AMD анонсировала FPGA серии Kintex UltraScale+ Gen 2, относящиеся к среднему классу. Эти изделия могут использоваться в разных сферах, включая здравоохранение (эндоскопия, машинное зрение, роботизированная хирургия), промышленный сектор (системы автоматизации и инспекции, периферийные платформы), вещание (видеозахват, производство материалов), среды тестирования и пр. Решения выполнены по 16-нм технологии FinFET. Реализована поддержка памяти LPDDR4X, LPDDR5 и LPDDR5X, интерфейса PCIe 4.0, а также двух блоков 100G CMAC. Упомянуты средства постквантовой криптографии в соответствии с алгоритмами, одобренными Национальным институтом стандартов и технологий США (NIST). 
Источник изображений: AMD В семейство Kintex UltraScale+ Gen 2 вошли три модели — 2KU030P, 2KU040P и 2KU050P. Первый из перечисленных чипов содержит 328 тыс. логических элементов, 150 тыс. CLB LUT (Configurable Logic Block Look-Up Table), четыре контроллера LPDDR4X/5/5X, а также в общей сложности 33,9 Мбайт памяти. Конфигурация включает два интерфейса PCIe 4.0 x8. В свою очередь, решение 2KU040P насчитывает 410 тыс. логических элементов и 187 тыс. CLB LUT, имеет шесть контроллеров LPDDR4X/5/5X, 42,4 Мбайт памяти и два интерфейса PCIe 4.0 x8. Старший вариант, 2KU050P, получил 491 тыс. логических элементов, 225 тыс. CLB LUT, шесть контроллеров LPDDR4X/5/5X, 50,9 Мбайт памяти, два интерфейса PCIe 4.0 x8 и один интерфейс PCIe 4.0 x4. 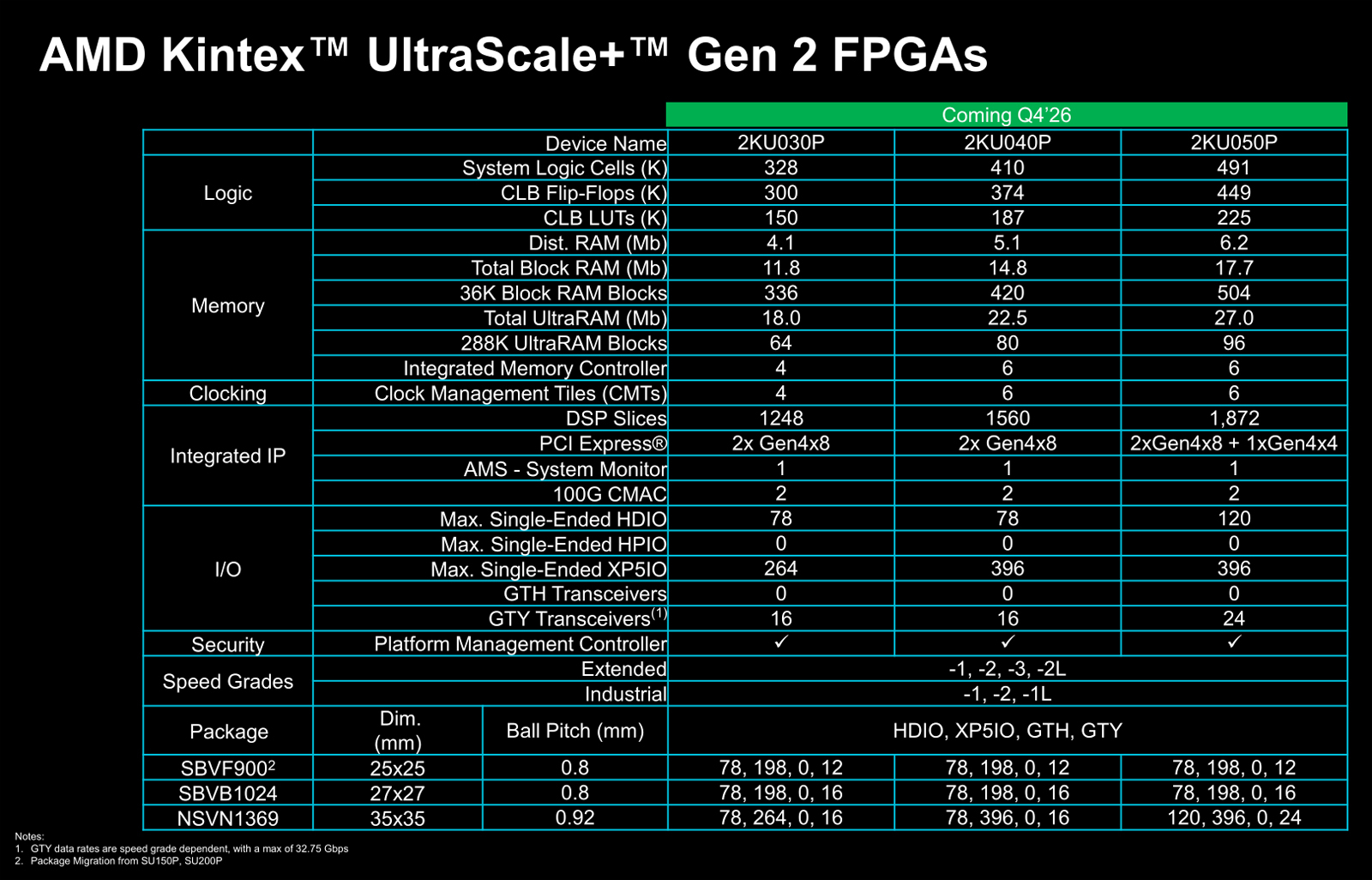 Первые инженерные образцы решений Kintex UltraScale+ Gen 2 начнут поступить заказчикам в IV квартале текущего года, тогда как серийное производство чипов должно начаться в I половине 2027-го. Компания AMD гарантирует доступность изделий как минимум до 2045 года, что должно сделать новые FPGA особенно привлекательными для отраслей с длительным жизненным циклом продукции, таких как аэрокосмическая и оборонная промышленность.
12.11.2025 [23:23], Владимир Мироненко
От ИИ ЦОД до роботов: AMD анонсировала долгосрочную стратегию роста
amd
cpu
dpu
epyc
hardware
instinct
mi400
mi500
ocp
pensando systems
ualink
ultra ethernet
venice
verano
xilinx
ии
ускоритель
финансы
AMD представила на мероприятии Financial Analyst Day 2025 план по достижению лидерства на рынке вычислительных технологий объёмом $1 трлн. Долгосрочная стратегия роста AMD построена на четырех столпах: лидерство в сфере ЦОД, повышение производительности ИИ, открытое ПО и расширение присутствия на рынках встраиваемых и полукастомных кремниевых решений. AMD ожидает, что только её бизнес в сфере ЦОД будет приносить более $100 млрд годовой выручки, с увеличением совокупного среднегодового темпа роста (CAGR) до более чем 60 %, при этом CAGR дохода от ИИ-решений увеличится до более чем 80 %. Генеральный директор AMD Лиза Су (Lisa Su) заявила, что следующий этап будет основан на унифицированной вычислительной платформе AMD, объединяющей процессоры EPYC, ускорители Instinct, сетевые решения Pensando и ПО ROCm. Новый план развития AMD призван обеспечить ей конкуренцию с NVIDIA и Intel на корпоративных рынках и в борьбе за заказы гиперскейлеров. 
Источник изображений: AMD  Ускорители серии Instinct MI350, уже развёрнутые Oracle (ещё 50 тыс. MI450 будут развёрнуты во II половине 2026 г.), являются самыми популярными ускорителями AMD на сегодняшний день. Следующей платформой станет серия MI450, которая будет запущена вместе со стоечной платформой Helios в III квартале 2026 года. Helios обеспечит пропускную способность интерконнекта 3,6 Тбайт/с на каждый ускоритель и до 72 ускорителей на стойку с совокупной пропускной способностью 260 Тбайт/с, соединённых между собой посредством UALink и Ultra Ethernet (UEC). Система поддерживает разделяемую память между ускорителями, что обеспечивает обучение крупномасштабных моделей с бесперебойным доступом к памяти и отказоустойчивой сетью с шестью плоскостями. 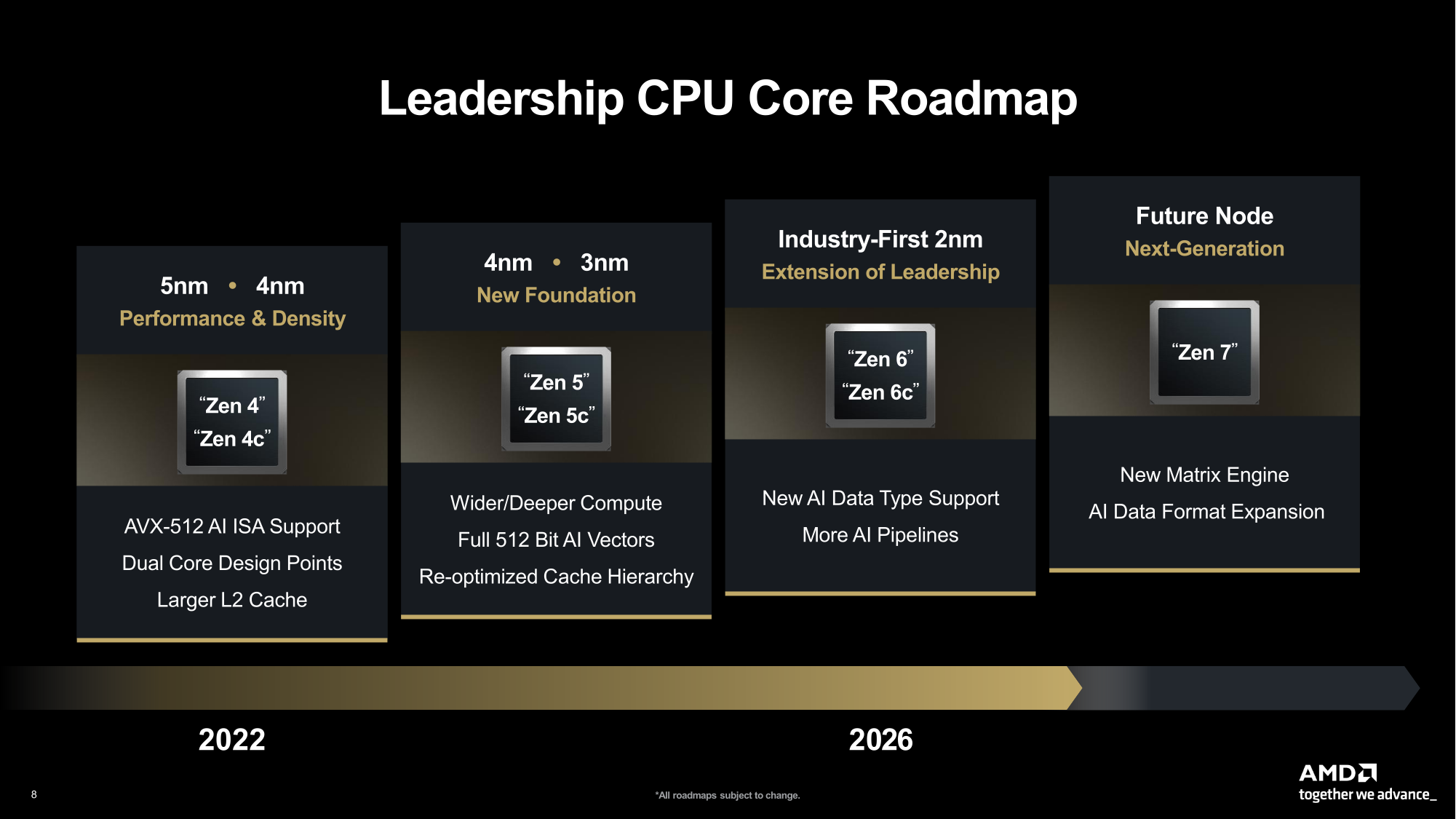 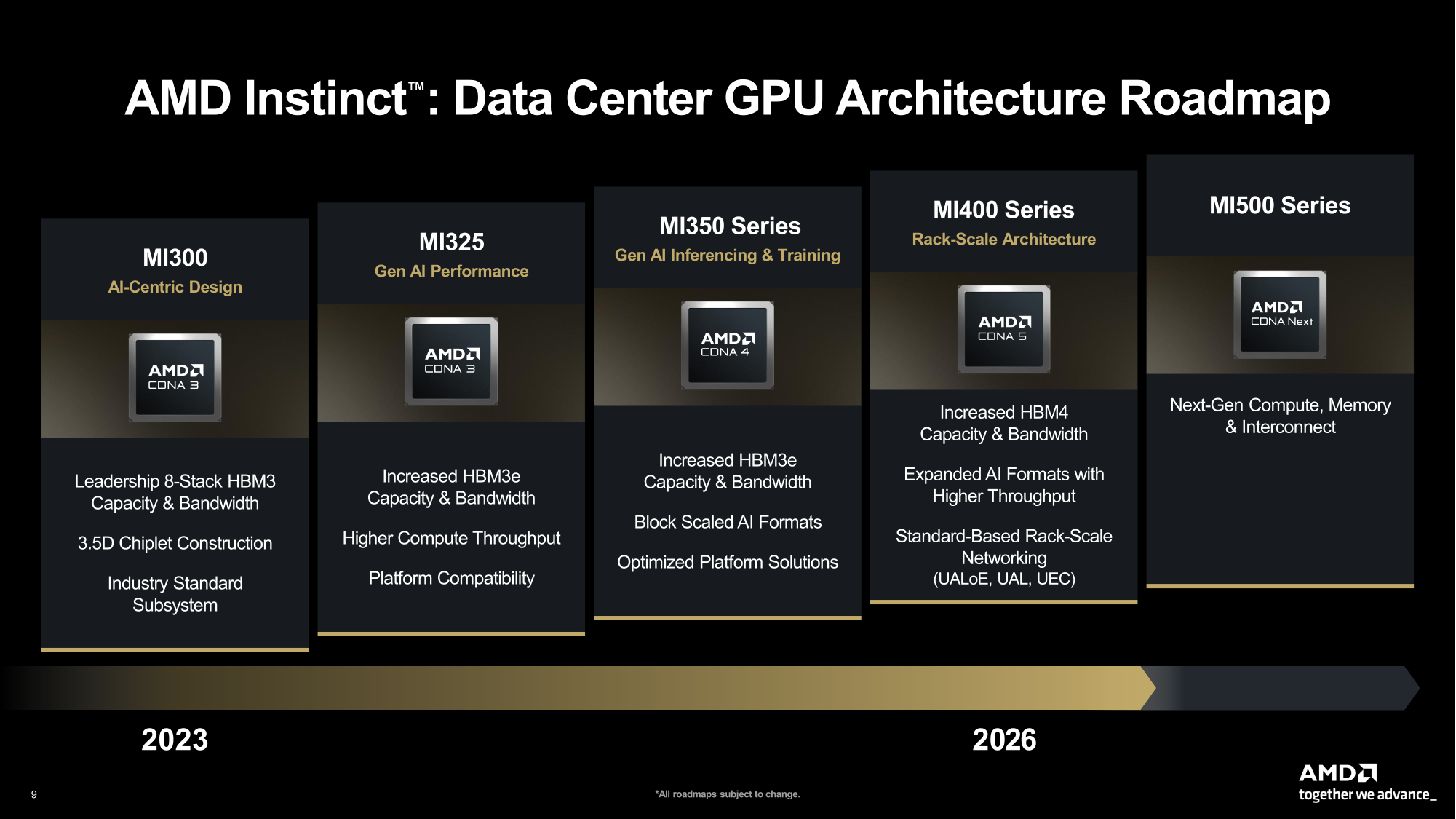 AMD характеризует Helios как свою первую ИИ-платформу стоечного масштаба — полностью интегрированную систему с открытой архитектурой, которая объединяет вычислительные мощности, ускорение, сетевые технологии и ПО в единую структуру. В отличие от традиционных серверных кластеров, Helios реализует всю стойку как единый высокопроизводительный вычислительный домен. Каждая стойка объединяет процессоры AMD EPYC Venice, CDNA5-ускорители Instinct MI450X (будет и вариант MI430X с полноценными FP64-блоками) и 400G/800G-карты Pensando Vulcano, связанные Infinity Fabric пятого поколения (PCIe 6.0, CXL 3.1, UCIe) и UALink.  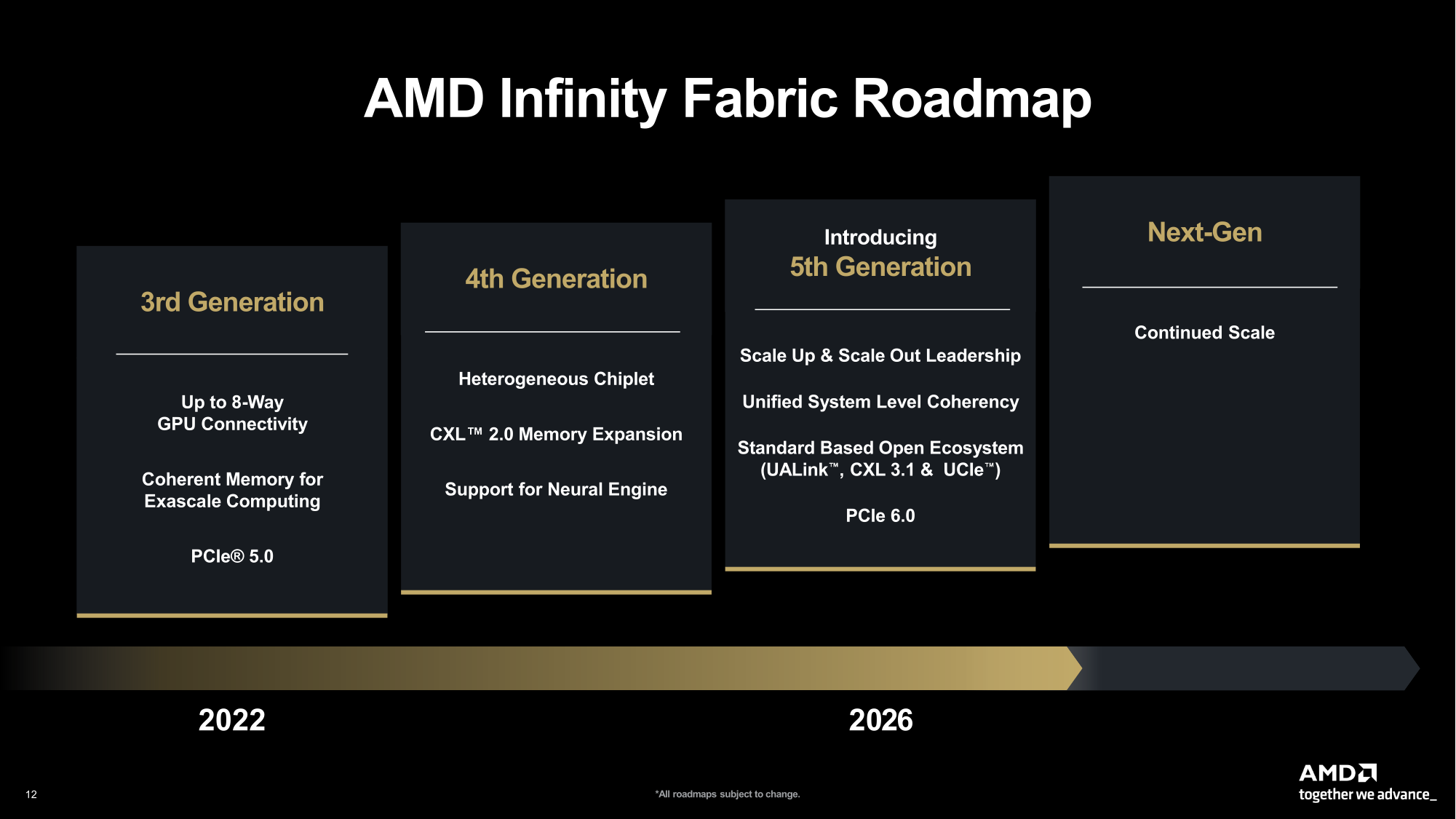 Эта архитектура минимизирует накладные расходы на перемещение данных, увеличивает пропускную способность между ускорителями и обеспечивает эффективность класса экзафлопсных вычислений в компактном корпусе. Helios фактически представляет собой проект AMD для ИИ-фабрики будущего с возможностью модульного расширения, позволяя объединять сотни стоек в одну систему в ЦОД.  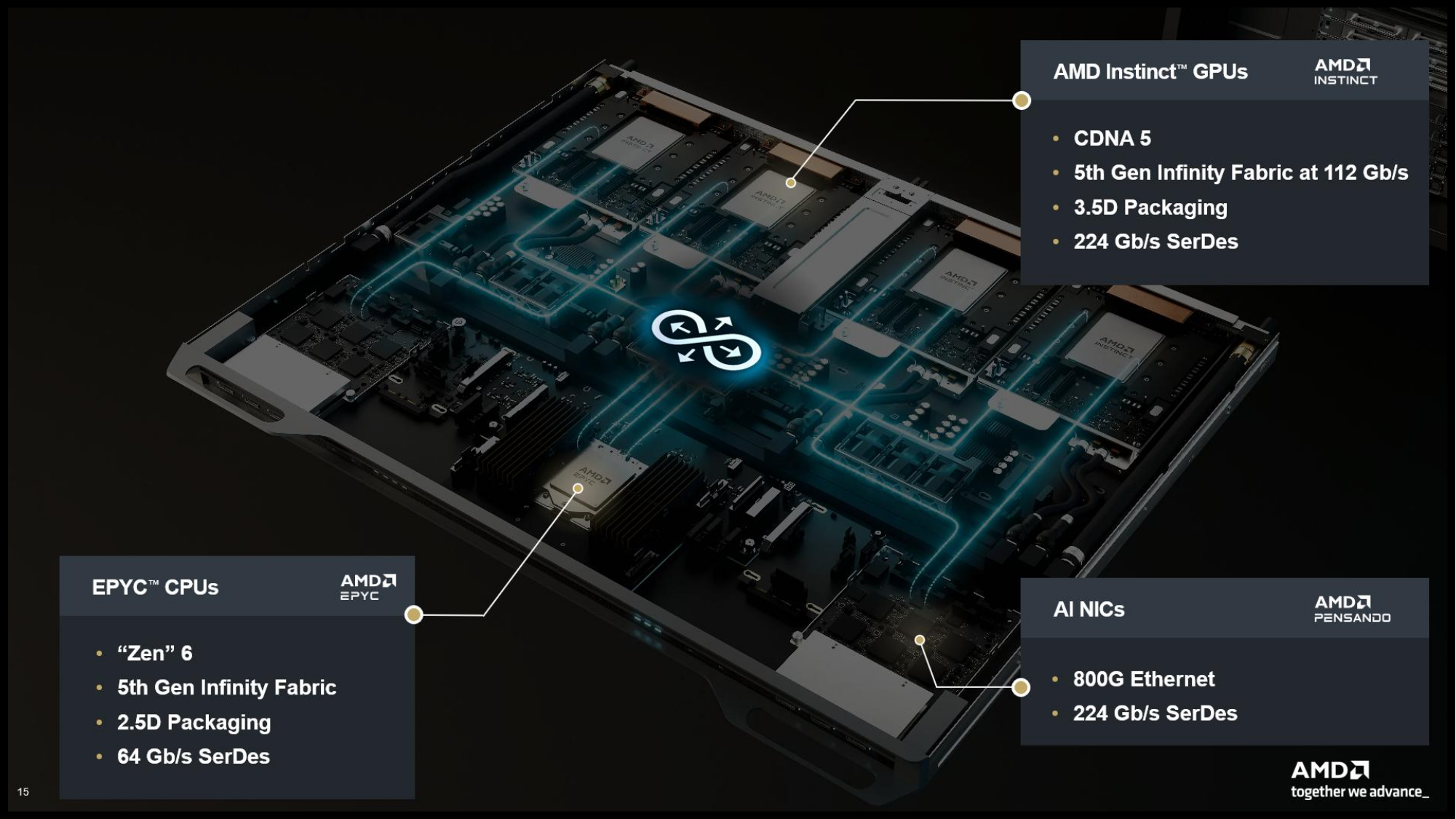 В 2027 году AMD планирует выпустить ускорители серии MI500 и процессоры EPYC Verano, продолжая тем самым ежегодный цикл совместной разработки процессоров, ускорителей и сетей. AMD заявила, что EPYC Venice, намеченные к выпуску в 2026 году, будут обладать лучшими в отрасли показателями плотности (1,3x по количеству потоков в сравнении с текущими решениями) и энергоэффективности (1,7x). Они пополнятся оптимизированными для ИИ наборами инструкций для обработки инференса и выполнения вычислений общего назначения. Указанные компоненты станут основой ИИ-фабрики, способной масштабироваться от одной стойки до глобально распределённых кластеров.  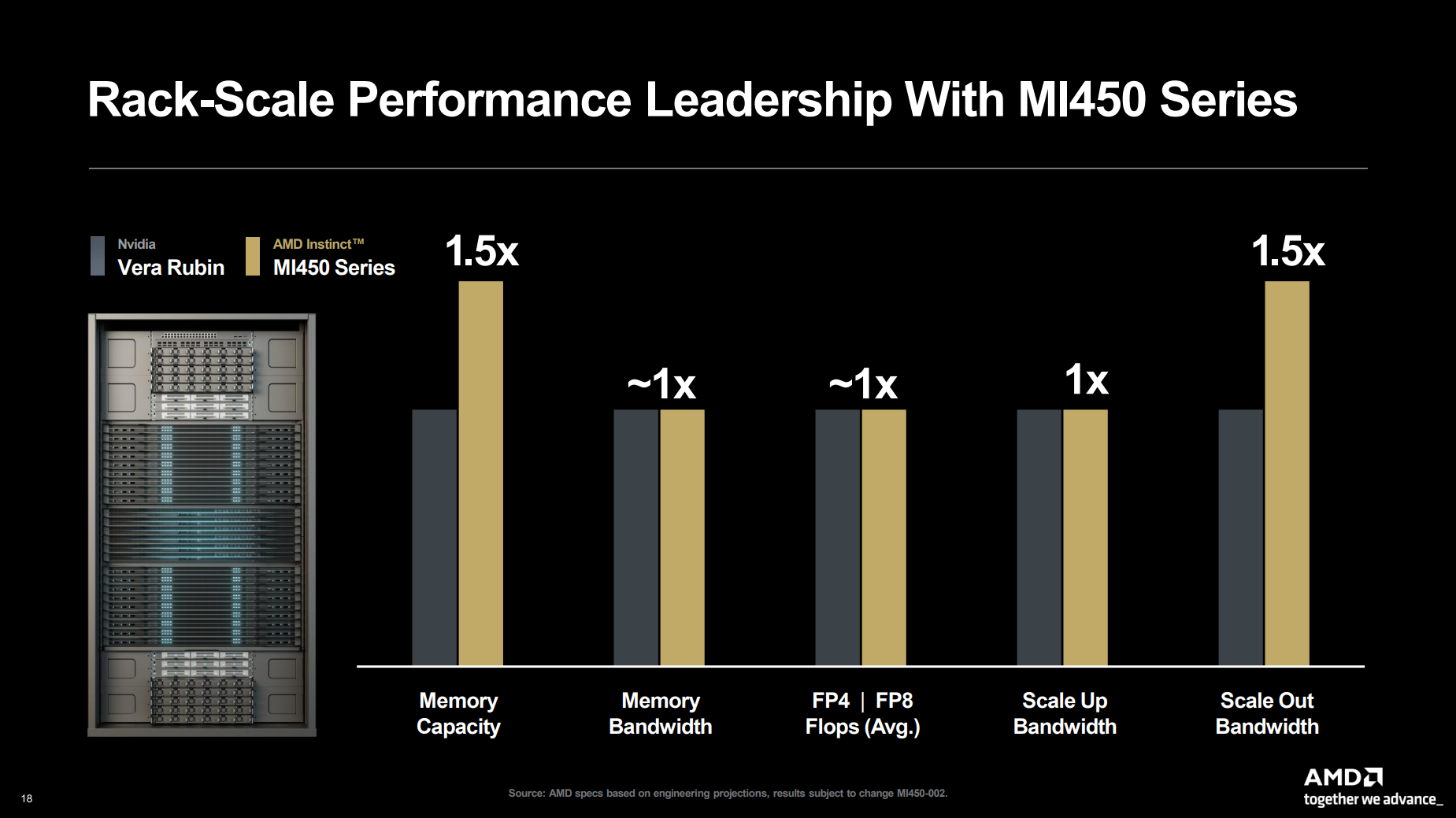 Исполнительный вице-президент AMD Форрест Норрод (Forrest Norrod) подчеркнул в своём выступлении, что производительность ИИ всё больше зависит от сети. Сетевые карты AMD Pensando Pollara и Vulcano для ИИ образуют связующую ткань архитектуры Helios. Сетевая карта Pollara 400 обеспечивает пропускную способность 400 Гбит/с, а готовящаяся к выходу сетевая карта Vulcano удвоит её до 800 Гбит/с, обеспечивая связь Ultra Ethernet между крупными кластерами ускорителей.   AMD представила четырёхуровневую архитектуру сети для масштабных ИИ-инфраструктур. Front-End часть обслуживает пользователей, хранилище и приложения. Она опирается на DPU Pensando и P4-движки, отвечающие за разгрузку сетевых функций, функции безопасности и шифрования, и работу с СХД. Вертикальное масштабирование в пределах стойки обеспечивает 3,6-Тбайт/с подключение на каждый GPU. Горизонтальное масштабирование реализуется благодаря UEC — внутренние тесты показали снижение затрат на коммутацию до 58 % по сравнению с традиционными сетями типа Fat-Tree. Наконец, Scale-Across (пространственное масштабирование) позволит объединить географически распределённые ЦОД в кластеры с интеллектуальным управлением трафиком и адаптивной балансировкой нагрузки.   AMD отметила, что открытый программный стек ROCm (Radeon open compute) по-прежнему лежит в основе её стратегии в области ИИ-платформ. По сравнению с прошлым годом число его загрузок выросло в десять раз и теперь на HuggingFace поддерживается более 2 млн моделей. ROCm интегрируется с ведущими фреймворками, включая PyTorch, TensorFlow, JAX, Triton, vLLM, ComfyUI и Ollama, и поддерживает проекты с открытым исходным кодом, такие как Unsloth. 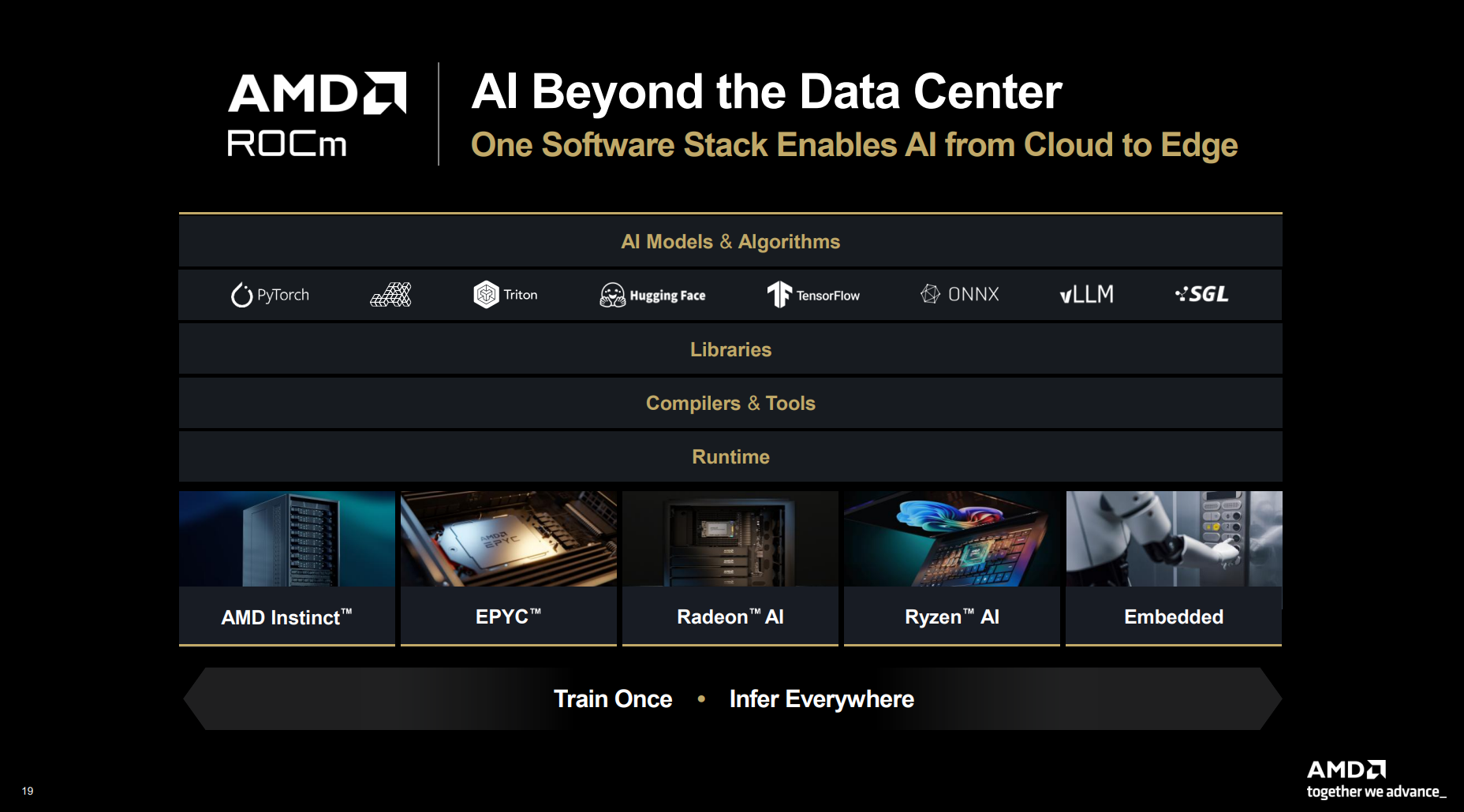  AMD также расширила своё видение «физического ИИ», когда вычисления выходят за рамки облака и охватывают роботов, транспортные средства и промышленные системы. Подразделение встраиваемых систем, усиленное приобретением Xilinx в 2022 году, превратилось из бизнеса, ориентированного на FPGA, в многоплатформенный двигатель роста, охватывающий адаптивные системы на кристалле (SoC), встраиваемые x86-процессоры и заказные кремниевые решения. По словам компании, с 2022 года решения в этой области принесли более $50 млрд. AMD рассчитывает превысить 70 % доли рынка адаптивных вычислений.   Говоря о перспективах, компания отметила, что ЦОД остаются основным драйвером роста, но наряду с этим она будет диверсифицировать свою деятельность по всем сегментам. Финансовые цели AMD включают:
27.12.2024 [12:40], Сергей Карасёв
Плата lowRISC Sonata v1.0 с системой защиты памяти CHERIoT объединяет FPGA AMD Artix-7 и микроконтроллер Raspberry Pi RP2040Участники проекта lowRISC по созданию 64-бит чипов RISC-V, как сообщает ресурс CNX Software, анонсировали аппаратную платформу Sonata v1.0 для разработчиков встраиваемых систем и всевозможных устройств Интернета вещей (IoT). Новинка поддерживает технологию CHERIoT (Capability Hardware Extension to RISC-V for IoT). Напомним, летом уходящего года lowRISC, а также Capabilities Limited, Codasip, FreeBSD Foundation, SCI Semiconducto и Кембриджский университет создали альянс CHERI для продвижения средств надёжной защиты памяти от атак. Специальные механизмы исключают ряд потенциальных уязвимостей, таких как переполнение буфера или некорректная работа с указателями. Отмечалось, что первыми новую технологию могут получить процессоры RISC-V. В основе платформы Sonata v1.0 лежит FPGA AMD Xilinx Artix-7 (XC7A35T-1CSG324C). Изделие содержит Soft-процессорное ядро AMD MicroBlaze с архитектурой RISC и 400 Кбайт распределённой памяти RAM. Ещё одной составляющей платы является микроконтроллер Raspberry Pi RP2040 (два ядра Cortex-M0+ с частотой 133 МГц), который отвечает за IO-функции. Есть 64 Мбит памяти HyperRAM (Winbond W956D8MBYA5I), 256 Мбит памяти SPI-флеш (Winbond W25Q256JVEIQ) для FPGA AMD Artix-7 или Raspberry Pi RP2040, ещё 64 Мбит SPI-флеш (Winbond W25Q64JVZEIQ) для RP2040 и 256 Мбит памяти SPI-флеш (Winbond W25Q256JVEIQ) для FPGA. 
Источник изображения: lowRISC В арсенале Sonata v1.0 — встроенный цветной ЖК-дисплей с диагональю 1,8″, сетевой порт 10/100MbE, два разъёма USB Type-C (для программирования и подачи питания) и слот microSD. Реализованы последовательные интерфейсы RS-232 и RS-485, 40-контактный разъём Raspberry Pi, две 10-контактные колодки Ibex JTAG, две 4-контактные колодки Ibex UART и пр. Размеры составляют 125 × 80 мм. Разработчики могут получить доступ к подробной документации и дополнительным ресурсам на сайтах lowRISC и GitHub, чтобы в полной мере использовать возможности платформы Sonata v1.0. Цена новинки — примерно $413.
12.12.2024 [17:36], Сергей Карасёв
FPGA + EPYC: AWS представила AMD-инстансы EC2 F2 с процессорами Milan и ПЛИС Virtex UltraScale+Облачная платформа AWS анонсировала инстансы второго поколения с FPGA на борту. Экземпляры EC2 F2 ориентированы на решение задач в области геномики, обработки мультимедийных материалов, больших данных, спутниковой связи, компьютерных сетей, моделирования кремниевых чипов и видеотрансляций в реальном времени. В новых инстансах применяются FPGA AMD Virtex UltraScale+ HBM VU47P. Эти изделия содержат 2,852 млн логических ячеек и 9024 DSP. Заявленная ИИ-производительность достигает 28 TOPS при вычислениях INT8. Кроме того, в состав EC2 F2 входят процессоры AMD EPYC поколения Milan. Новые инстансы доступны в вариантах f2.12xlarge и f2.48xlarge — с 48 и 192 vCPU и 2 и 8 FPGA соответственно. Каждая ПЛИС оперирует 16 ГиБ памяти HBM и 64 ГиБ памяти DDR4. Таким образом, в случае f2.12xlarge используется в сумме 32 ГиБ HBM и 128 ГиБ DDR4, а в случае f2.48xlarge — 128 ГиБ и 512 ГиБ соответственно. 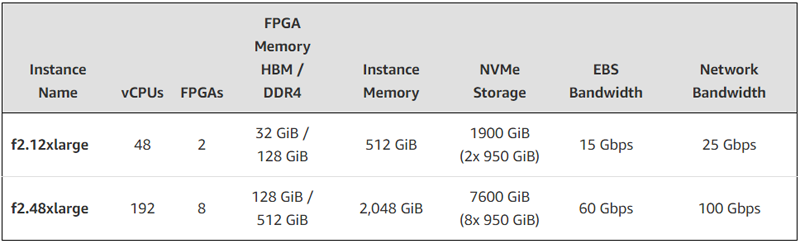
Источник изображения: AWS Конфигурация f2.12xlarge включает 512 ГиБ системной памяти и два накопителям NVMe SSD суммарной вместимостью 1900 ГиБ. Пропускная способность сетевого подключения составляет 25 Гбит/с, пропускная способность EBS-томов — 15 Гбит/с. У экземпляра f2.48xlarge объём памяти составляет 2048 ГиБ, общая вместимость NVMe SSD — 7600 ГиБ. Пропускная способность сетевого подключения и EBS-томов достигает 100 Гбит/с и 60 Гбит/с соответственно. Для этого экземпляра предусмотрена поддержка AWS Cloud Digital Interface (CDI) для надёжной передачи несжатого видео (задержка между инстансами заявлена на уровне 8 мс). |
|

