Материалы по тегу: dpu
|
02.06.2026 [10:04], Руслан Авдеев
NVIDIA усилила DPU BlueField-4 мониторингом работы ИИ-агентов в реальном времениNVIDIA Vera BlueField-4 STX (BF-4 STX) обеспечит ИИ-системам защиту ИИ-агентов, контекстной памяти и доступа к файлам непосредственно на аппаратном уровне, сообщает Blocks & Files. DPU поддерживает программную платформу DOCA (Data Center Infrastructure-on-a-Chip Architecture), обеспечивающую доступ по принципу Zero Trust, а также ведёт мониторинг и контроль деятельности ИИ-агентов для предотвращения утечки данных, несанкционированного доступа и других угроз. Решение разработано в рамках создания платформы NVIDIA Vera Rubin. Решение использует три интегрированные библиотеки безопасности и микросервисы DOCA, работающие в процессоре и памяти DPU. В частности, речь идёт о микросервисе DOCA Vault, благодаря которому доступ к нужным файлам с необходимыми правами получают только авторизованные ИИ-нагрузки. DOCA Argus обеспечивает прозрачность действий ИИ-агентов и рабочих нагрузок, а DOCA Flow помогает изолировать сетевой трафик и защитить конфиденциальные данные в экосистемах с многочисленными арендаторами ресурсов. 
Источник изображения: NVIDIA Благодаря BF-4 STX серверы и СХД могут анализировать и контролировать взаимодействие ИИ-агентов, данных и контекстной памяти в потоке данных. По информации NVIDIA, обнаружение угроз происходит до 1000 раз быстрее, чем в существующих средах без агентного мониторинга, а контроль работы осуществляется на скоростях до 800 Гбит/с. Свои решения в сфере безопасности интегрируют с Vera BlueField-4 STX компании Akamai, Armis, Check Point, Cisco, CrowdStrike, EQTY, F5, Fortinet, Palo Alto Networks, TrendAI, Xage Security и Zscaler. Платформы на базе STX предлагают провайдеры систем хранения данных: Cloudian, DDN, Dell, Everpure, Hitachi Vantara, HPE, IBM, MinIO, NetApp, Nutanix, VAST Data и WEKA. Системы на базе STX уже разрабатывают Asus, Foxconn, Gigabyte Technology, Supermicro, Wistron и Wiwynn. Заказчикам помогают внедрять соответствующие решения интеграторы Accenture, Deloitte и World Wide Technology.
10.04.2026 [23:09], Владимир Мироненко
Intel поставит Google несколько поколений Xeon и IPUIntel и Google объявили об углублении многолетнего партнёрства в области инфраструктуры ИИ и облачных вычислений, охватывающего как развёртывание процессоров, так и совместную разработку специализированных чипов инфраструктуры (IPU). За два дня до этого компания стала партнёром по производству микрочипов для мегапроекта Tesla Terafab. В итоге акции Intel за неделю выросли на треть. Intel и Google отметили, что по мере ускорения внедрения ИИ-инфраструктура становится всё более сложной и гетерогенной, что приводит к увеличению зависимости от CPU для оркестрации, обработки данных и повышения производительности на системном уровне. В рамках сотрудничества с Intel компания Google планирует использовать несколько поколений процессоров Intel Xeon для улучшения производительности, энергоэффективности и TCO в своих инстансах. Intel уже делает кастомные Xeon для AWS. Стороны подчеркнули, что одних только ускорителей недостаточно для удовлетворения потребностей современной ИИ-инфраструктуры. «ИИ меняет подход к построению и масштабированию инфраструктуры. Масштабирование ИИ требует большего, чем просто ускорители — оно требует сбалансированных систем. CPU и IPU играют центральную роль в обеспечении производительности, эффективности и гибкости, необходимых для современных рабочих нагрузок ИИ», — сообщил генеральный директор Intel Лип-Бу Тан (Lip-Bu Tan). Как отметил ресурс The Next Web, Intel потратила последние два года на переориентацию с рынка универсальных вычислений, где она когда-то доминировала, на процессоры и специализированные инфраструктурные чипы, которые играют структурную роль в развёртывании ИИ и которые постоянно недооценивали в рамках концепций, ориентированных на GPU. Одновременно компания развивает бизнес по производству кастомных чипов для ИИ-рынка. 
Источник изображения: Intel Амин Вахдат (Amin Vahdat), старший вице-президент и главный технолог Google по инфраструктуре ИИ отметил: «Процессоры и инфраструктурное ускорение остаются краеугольным камнем систем ИИ — от организации обучения до инференса и развёртывания. Intel является надёжным партнёром уже почти два десятилетия, и её план развития Xeon даёт нам уверенность в том, что мы сможем и дальше удовлетворять растущие требования к производительности и эффективности наших рабочих нагрузок». Что важно, партнёрство охватывает несколько поколений Intel Xeon, а не текущий цикл обновления оборудования Google. Партнёрство также включает расширенную совместную разработку IPU (DPU) — специализированных программируемых ускорителей на базе ASIC, предназначенных для разгрузки сетевых функций, функций хранения, функций безопасности и т.п., которые на масштабах гиперскейлера позволяют существенно сэкономить и упростить управление инфраструктурой. Ранее компании совместно разработали свой первый IPU Mount Evans. Момент для анонса партнёрства выбран подходящий. Рабочие нагрузки ИИ смещаются от обучения на ускорителях, что позволить себе могут немногие, к масштабируемому инференсу, который является распределённым, чувствительным к задержкам, непрерывным и требовательным к ресурсам CPU для оркестрации, работы с данными и управления системой в целом. По-видимому, собственные процессоры Google Axion пока не слишком годятся на эту роль. Впрочем, для внешних заказчиков компания точно так же предлагает инстансы с чипами NVIDIA, хотя её собственные TPU пользуются огромным спросом. Впрочем, расширение сотрудничество можно объяснить и более прозаично — дефицит серверных процессоров на рынке усиливается, так что заранее договориться о поставках с крупным игроком, да ещё имеющим собственное производство на территории США, всегда выгодно.
20.03.2026 [11:35], Сергей Карасёв
NVIDIA представила архитектуру хранения данных BlueField-4 STX для ИИ-системКомпания NVIDIA анонсировала модульную эталонную архитектуру BlueField-4 STX, которая поможет предприятиям, облачным провайдерам и операторам дата-центров в создании высокопроизводительных платформ хранения данных, оптимизированных для задач ИИ. Отмечается, что в традиционных ЦОД применяются хранилища общего назначения, обладающие большой вместимостью. Однако они зачастую не способны обеспечивать скорость отклика, необходимую для работы ИИ-агентов: таким системам требуются доступ к информации в реальном времени и контекстная память. Архитектура STX призвана устранить существующие узкие места. Технологической основой STX является DPU NVIDIA BlueField-4, который объединяет Arm-процессор NVIDIA Grace/Vera, 128 Гбайт LPDDR5, 512 Гбайт SSD, сетевой адаптер NVIDIA ConnectX-9 SuperNic (1,6 Тбит/с) и коммутатор PCIe 6.0 с 48 линиями. Используются микросервисы NVIDIA DOCA и программное обеспечение NVIDIA AI Enterprise. Утверждается, что архитектура STX обеспечивает в четыре раза более высокую энергоэффективность по сравнению с традиционными архитектурами хранения, построенными на основе CPU. В целом, как отмечается, STX предоставляет основу для создания универсального механизма обработки данных, ускоряющего полный жизненный цикл ИИ — от обучения и аналитики до инференса на базе агентов. 
Источник изображения: NVIDIA Первой реализацией STX в масштабе стойки является новая платформа хранения NVIDIA CMX с контекстной памятью, которая расширяет память GPU. О поддержке NVIDIA STX сообщили такие компании, как Cloudian, DDN, Dell Technologies, Everpure, Hitachi Vantara, HPE, IBM, MinIO, NetApp, Nutanix, VAST Data и WEKA. Производством систем на базе STX займутся AIC, Supermicro и Quanta Cloud Technology (QCT). Внедрить платформу в числе прочих намерены CoreWeave, Crusoe, IREN, Lambda, Mistral AI, Nebius, OCI и Vultr. Решения на базе STX станут доступны во II половине текущего года.
23.02.2026 [23:22], Владимир Мироненко
Astera Labs по-тихому купила PliopsAstera Labs приобрела Pliops, сообщил ресурс StorageNewsletter со ссылкой на заявление Мариуса Тудора (Marius Tudor), бывшего директора по развитию бизнеса Pliops, подтвердившего факт сделки на своей странице в соцсети LinkedIn. Финансовых подробностей о сделке не сообщается. Ресурс допустил, что компания приобрела Pliops для своего первого научно-исследовательского центра в Израиле. О создании своего передового R&D-центра в Израиле Astera Labs сообщила в начале февраля. Предполагается, что новый центр с офисами в Тель-Авиве и Хайфе ускорит разработку масштабируемых сетей следующего поколения для протоколов высокоскоростной связи, а также будет способствовать техническим исследованиям и разработкам, направленным на решение проблем с памятью в приложениях для обучения и инференса ИИ. Руководителем центра назначен ветеран полупроводниковой индустрии Гай Азрад (Guy Azrad), старший вице-президент по проектированию и генеральный директор Astera Labs Israel, а его помощником станет Идо Букспан (Ido Bukspan), вице-президент по проектированию ASIC, имеющий 20-летний стаж работы в Mellanox и NVIDIA, где он дошёл до должности старшего вице-президента по проектированию микросхем, разрабатывая высокопроизводительные решения InfiniBand, Ethernet и NVLink. 
Источник изображения: Pliops «Новый израильский дизйн-центр будет стремиться использовать лучшие в регионе инженерные таланты, чтобы сосредоточиться на полном цикле проектирования микросхем — от архитектуры до производства, включая ПО и системное проектирование для передовых ИИ-платформ и новых приложений для инференса», — заявил Азрад. Разработанная Pliops PCIe-карта расширения XDP LightningAI с программным стеком FusIOnX функционирует как ещё один уровень памяти для GPU-серверов. Она работает на базе ASIC, которая «раскладывает» KV-кеш на SSD с доступом через NVMe-oF (RDMA) и горизонтальным масштабированием. Стек Pliops FusIOnX снижает стоимость, энергопотребление и вычислительные затраты путём оптимизации рабочих процессов инференса LLM. 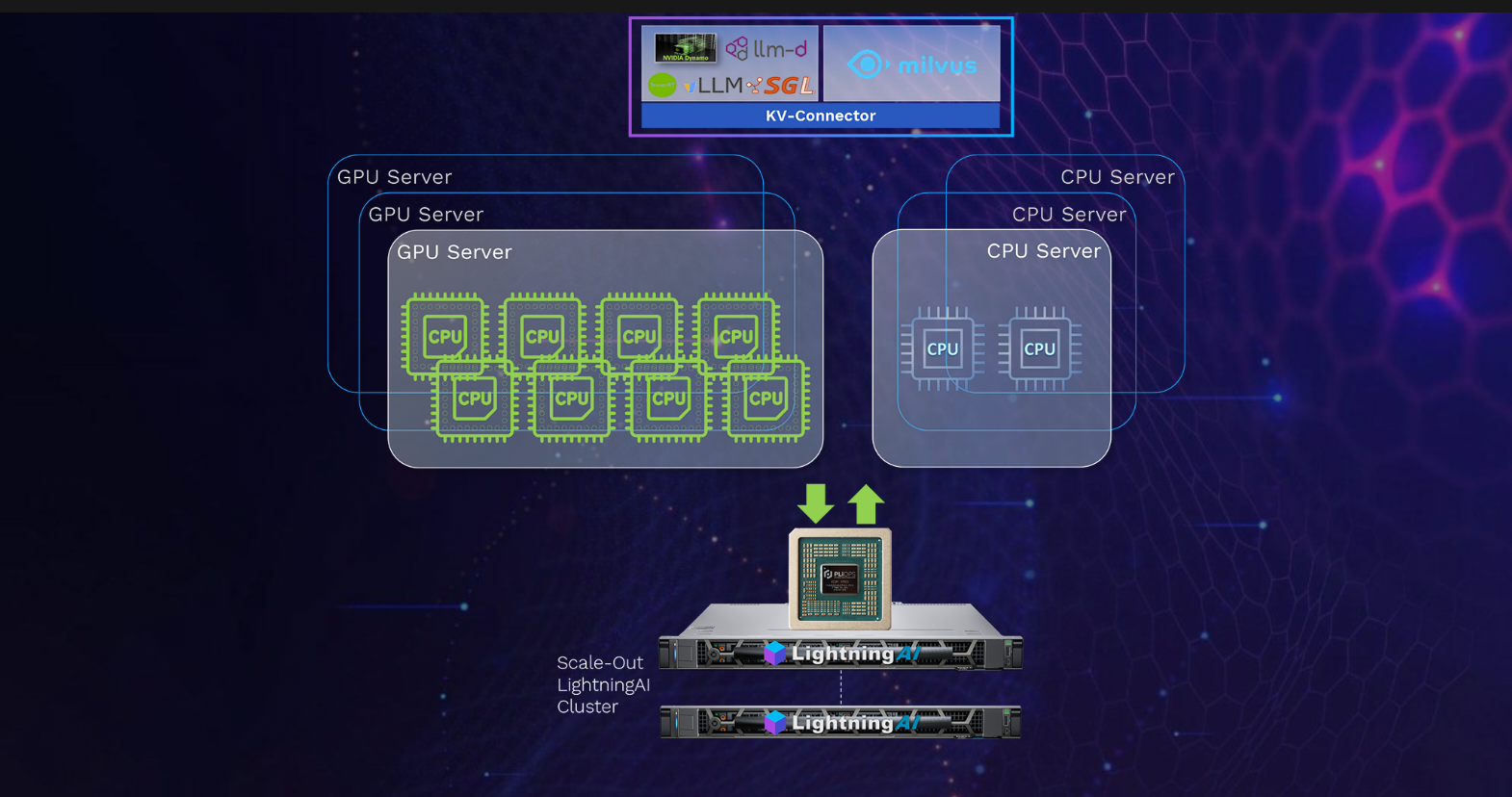
Источник изображения: Pliops «Сочетание нашего оборудования LightningAI с ПО FusIOnX устраняет узкое место, связанное с памятью GPU, обеспечивая до восьми раз более быструю обработку данных и экономию энергии на уровне стойки. И это работает от начала до конца: на любом GPU, любой LLM, любом ПО для обработки данных и любой сетевой инфраструктуре», — заявил Идо Букспан. По данным компании, Pliops XDP LightningAI вместе с ПО расширяют возможности высокоскоростной памяти (HBM) для серверов с GPU и ускоряют работу vLLM на NVIDIA в 2,5 раза.
12.01.2026 [09:54], Владимир Мироненко
От NVMe к GPU: NVIDIA представила платформу хранения контекста инференса ICMSPВместе с официальным анонсом ИИ-платформы следующего поколения Rubin компания NVIDIA также представила платформу хранения контекста инференса NVIDIA Inference Context Memory Storage Platform (ICMSP), позволяющую решить проблемы хранения KV-кеша, который становится всё крупнее по мере роста LLM и решаемых задач. При выполнении инференса контекст растёт по мере генерации новых токенов, часто превышая доступную память ускорителя. В этом случае старые записи вытесняются из памяти, сначала в системную память, а потом на диск, чтобы не пересчитывать всё заново, когда они снова понадобятся. Проблемы существенно усугубляются при работе с агентным ИИ и обработке рабочих нагрузок с большим контекстом. Агентный ИИ приводит к появлению контекстных окон в миллионы токенов, а объём моделей может составлять уже триллионы параметров. В настоящее время эти системы полагаются на долговременную память для хранения контекста, позволяя агентам опираться на предыдущие рассуждения и расширять их на протяжении многих шагов, а не начинать с нуля при каждом запросе. По мере увеличения контекстных окон растут требования к ёмкости KV-кеша, делая эффективное хранение и повторное использование данных, в том числе совместное использование различными сервисами инференса, крайне важными для повышения производительности системы. Контекст инференса является производным и пересчитываемым, что требует архитектуры хранения, которая отдаёт приоритет энергоэффективности и экономичности, а также скорости и масштабируемости, а не традиционной надёжности хранения данных. 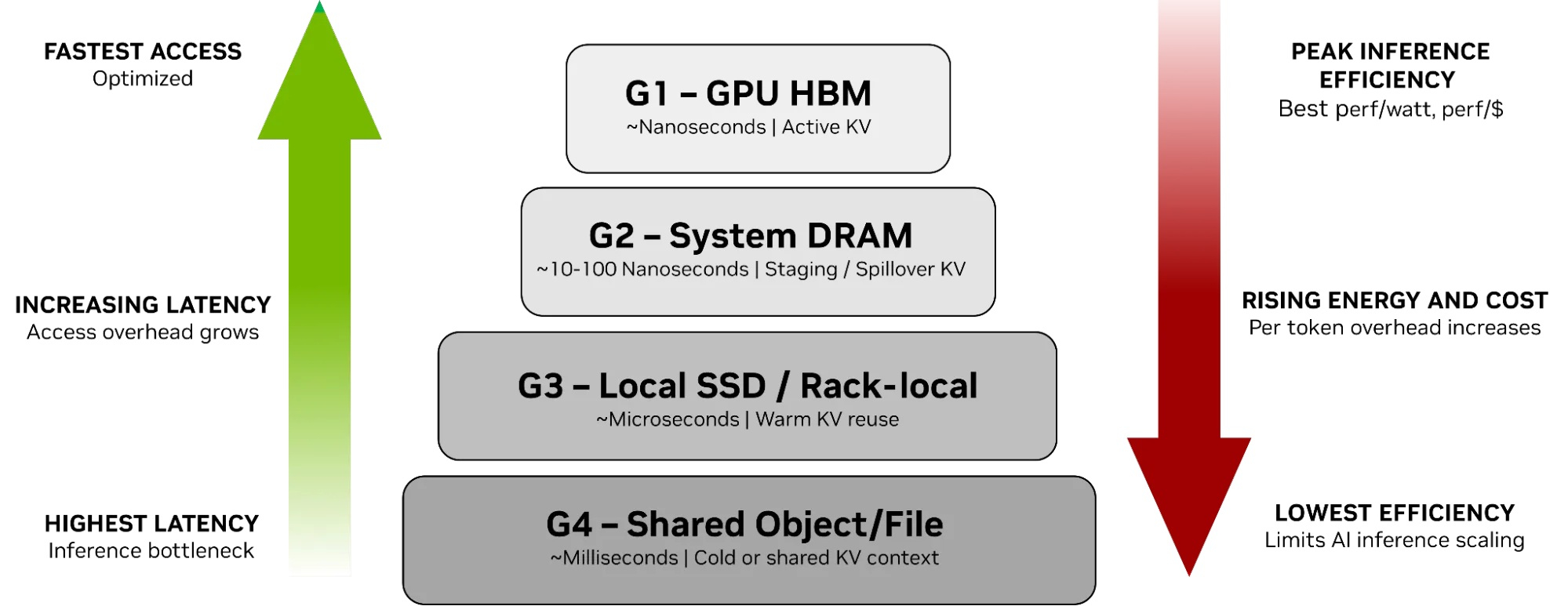
Источник изображений: NVIDIA NVIDIA отметила, что ИИ-фабрикам необходим дополнительный, специально разработанный уровень контекста, который рассматривает KV-кеш как собственный класс данных, предназначенный для ИИ, а не принудительно помещает его в дефицитную память HBM или в хранилище общего назначения. Платформа ICMSP использует DPU BlueField-4 для создания специализированного уровня памяти, чтобы преодолеть разрыв между высокоскоростной памятью GPU и масштабируемым общим хранилищем. Хранилище KV-кеша на основе NVMe должно эффективно обслуживать ускорители, узлы, стойки и кластеры целиком, говорит компания. Платформа ICMSP создаёт новый уровень (G3.5 на схеме выше) — флеш-память, подключённая через Ethernet и оптимизированная специально для KV-кеша. Этот уровень выступает в качестве долговременной агентной памяти на уровне ИИ-инфраструктуры, достаточно большой для одновременного хранения общего, развивающегося контекста многих агентов, но при этом достаточно близко расположенной для частой работы с памятью ускорителей и хостов. BlueField-4 отвечает за аппаратное ускорение размещения кеша и устранение накладных расходов на подготовку и перемещение данных и обеспечение безопасного, изолированного доступа к ним узлов с GPU, снижая зависимость от CPU хоста и минимизируя сериализацию и работу с системной памятью хоста. Программные продукты, такие как фреймворк DOCA, механизм разгрузки KV-кеша Dynamo и входящее в комплект ПО NIXL (Nvidia Inference Transfer Library), обеспечивают интеллектуальное, ускоренное совместное использование данных KV-кеша между ИИ-узлами. А Spectrum-X Ethernet обеспечивает оптимизированный RDMA-интерконнект, который связывает ICMS и узлы GPU. 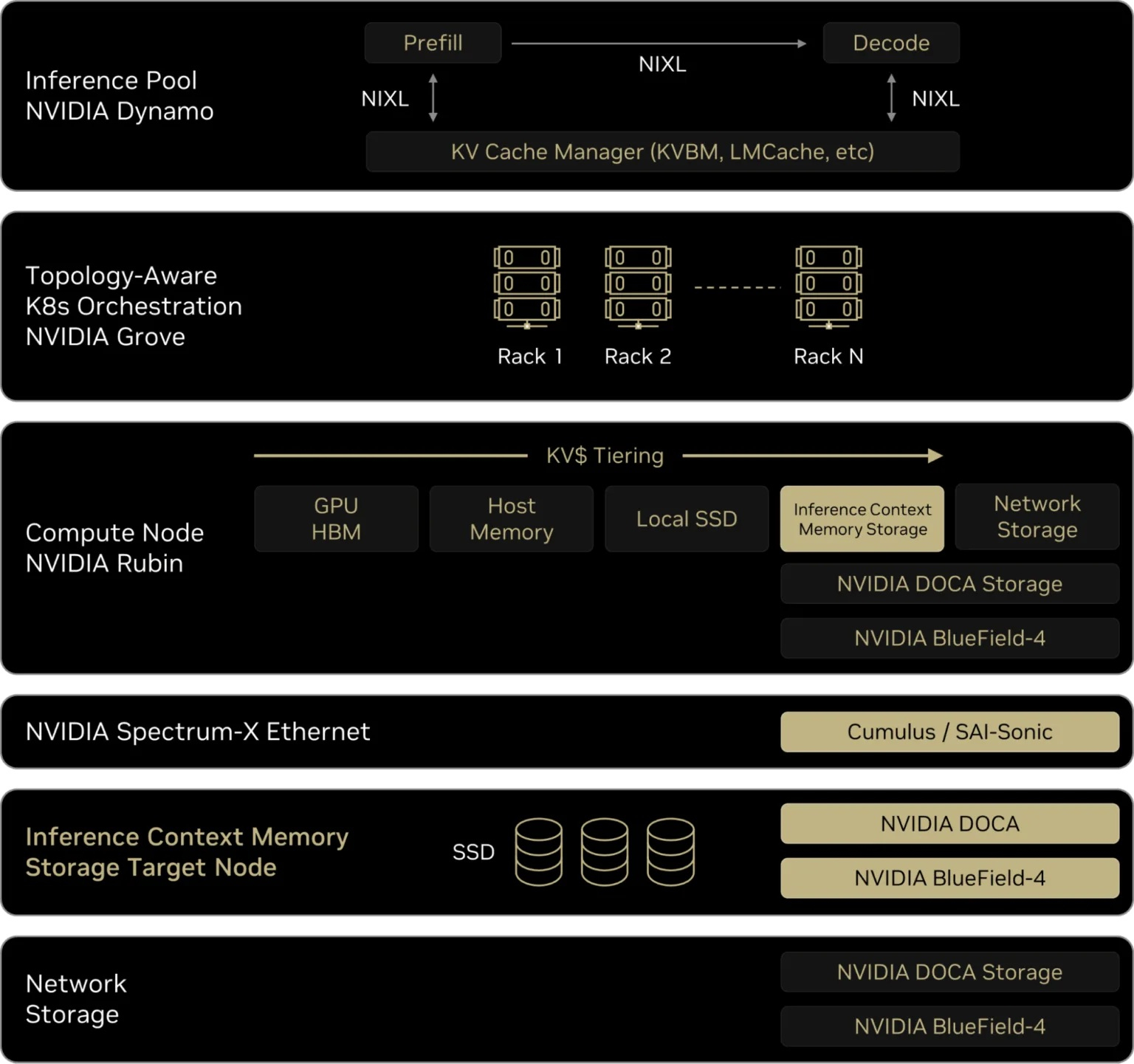 KV-кеш принципиально отличается от корпоративных данных: он является временным, производным и может быть пересчитан в случае потери. В качестве контекста инференса он не требует надёжности, избыточности или обширных механизмов защиты данных, разработанных для долговременных записей. Выделяя KV-кеш как отдельный, изначально предназначенный для ИИ класс данных, ICMS устраняет избыточные накладные расходы, обеспечивая повышение энергоэффективности до пяти раз по сравнению с универсальными подходами к хранению данных, сообщила NVIDIA. А своевременная подготовка и отдача данных более полно нагружает ускорители, что позволяет увеличить темп генерации токенов до пяти раз. Как сообщила NVIDIA, первоначальный список её партнёров, готовых обеспечить поддержку ICMSP с BlueField-4, который будет доступен во II половине 2026 года, включает AIC, Cloudian, DDN, Dell, HPE, Hitachi Vantara, IBM, Nutanix, Pure Storage, Supermicro, VAST Data и WEKA.
12.11.2025 [23:23], Владимир Мироненко
От ИИ ЦОД до роботов: AMD анонсировала долгосрочную стратегию роста
amd
cpu
dpu
epyc
hardware
instinct
mi400
mi500
ocp
pensando systems
ualink
ultra ethernet
venice
verano
xilinx
ии
ускоритель
финансы
AMD представила на мероприятии Financial Analyst Day 2025 план по достижению лидерства на рынке вычислительных технологий объёмом $1 трлн. Долгосрочная стратегия роста AMD построена на четырех столпах: лидерство в сфере ЦОД, повышение производительности ИИ, открытое ПО и расширение присутствия на рынках встраиваемых и полукастомных кремниевых решений. AMD ожидает, что только её бизнес в сфере ЦОД будет приносить более $100 млрд годовой выручки, с увеличением совокупного среднегодового темпа роста (CAGR) до более чем 60 %, при этом CAGR дохода от ИИ-решений увеличится до более чем 80 %. Генеральный директор AMD Лиза Су (Lisa Su) заявила, что следующий этап будет основан на унифицированной вычислительной платформе AMD, объединяющей процессоры EPYC, ускорители Instinct, сетевые решения Pensando и ПО ROCm. Новый план развития AMD призван обеспечить ей конкуренцию с NVIDIA и Intel на корпоративных рынках и в борьбе за заказы гиперскейлеров. 
Источник изображений: AMD  Ускорители серии Instinct MI350, уже развёрнутые Oracle (ещё 50 тыс. MI450 будут развёрнуты во II половине 2026 г.), являются самыми популярными ускорителями AMD на сегодняшний день. Следующей платформой станет серия MI450, которая будет запущена вместе со стоечной платформой Helios в III квартале 2026 года. Helios обеспечит пропускную способность интерконнекта 3,6 Тбайт/с на каждый ускоритель и до 72 ускорителей на стойку с совокупной пропускной способностью 260 Тбайт/с, соединённых между собой посредством UALink и Ultra Ethernet (UEC). Система поддерживает разделяемую память между ускорителями, что обеспечивает обучение крупномасштабных моделей с бесперебойным доступом к памяти и отказоустойчивой сетью с шестью плоскостями. 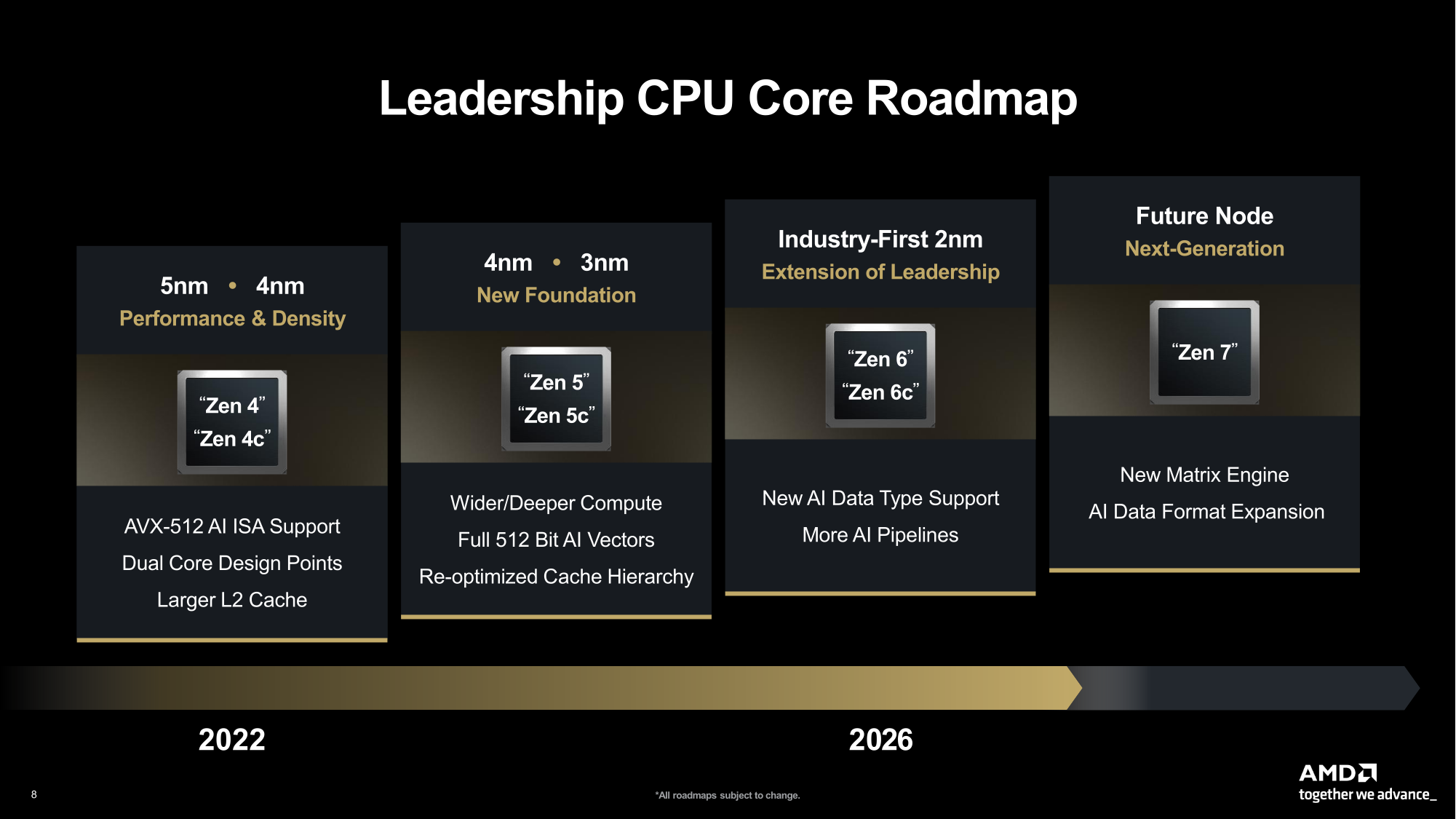 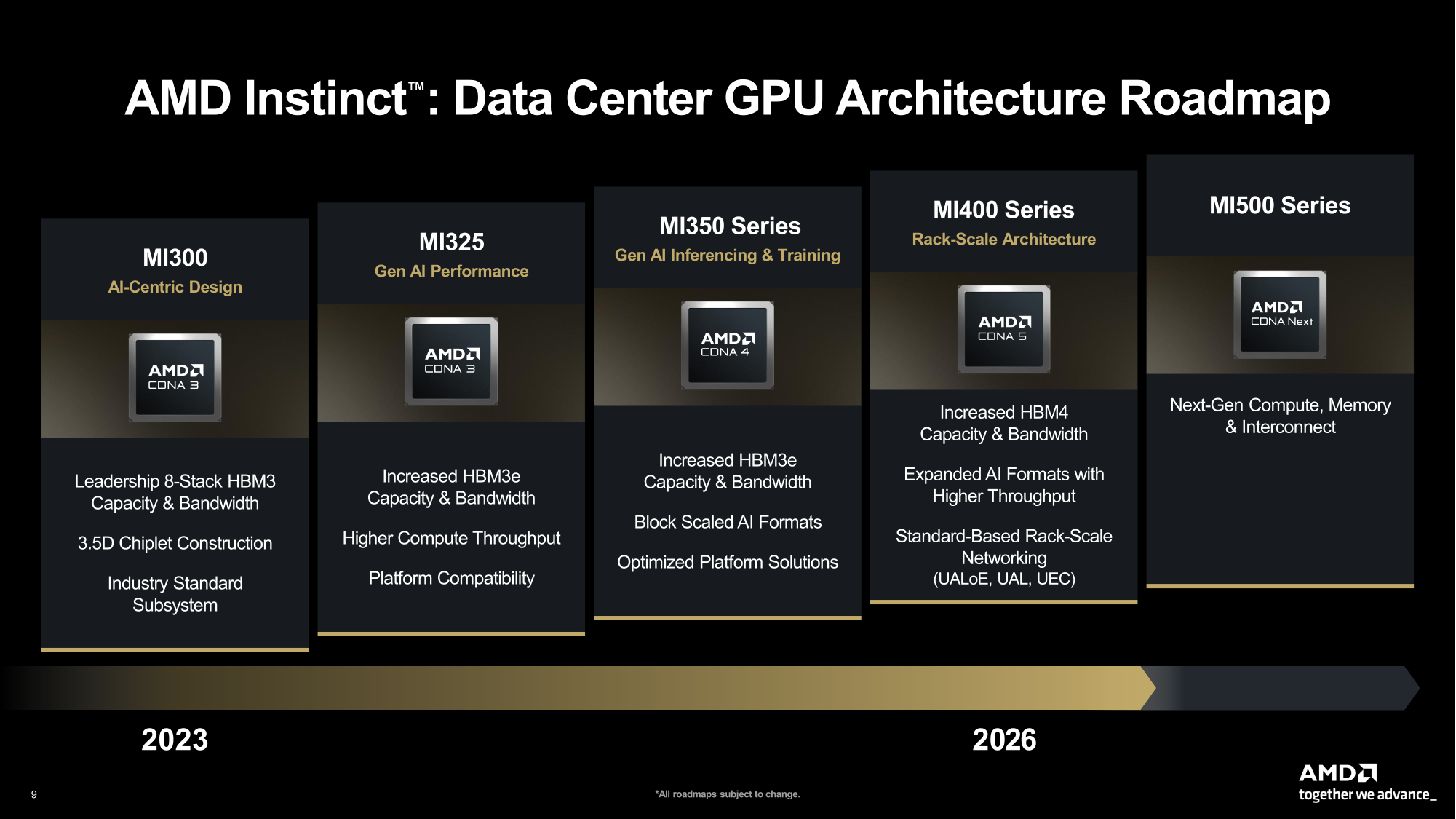 AMD характеризует Helios как свою первую ИИ-платформу стоечного масштаба — полностью интегрированную систему с открытой архитектурой, которая объединяет вычислительные мощности, ускорение, сетевые технологии и ПО в единую структуру. В отличие от традиционных серверных кластеров, Helios реализует всю стойку как единый высокопроизводительный вычислительный домен. Каждая стойка объединяет процессоры AMD EPYC Venice, CDNA5-ускорители Instinct MI450X (будет и вариант MI430X с полноценными FP64-блоками) и 400G/800G-карты Pensando Vulcano, связанные Infinity Fabric пятого поколения (PCIe 6.0, CXL 3.1, UCIe) и UALink.  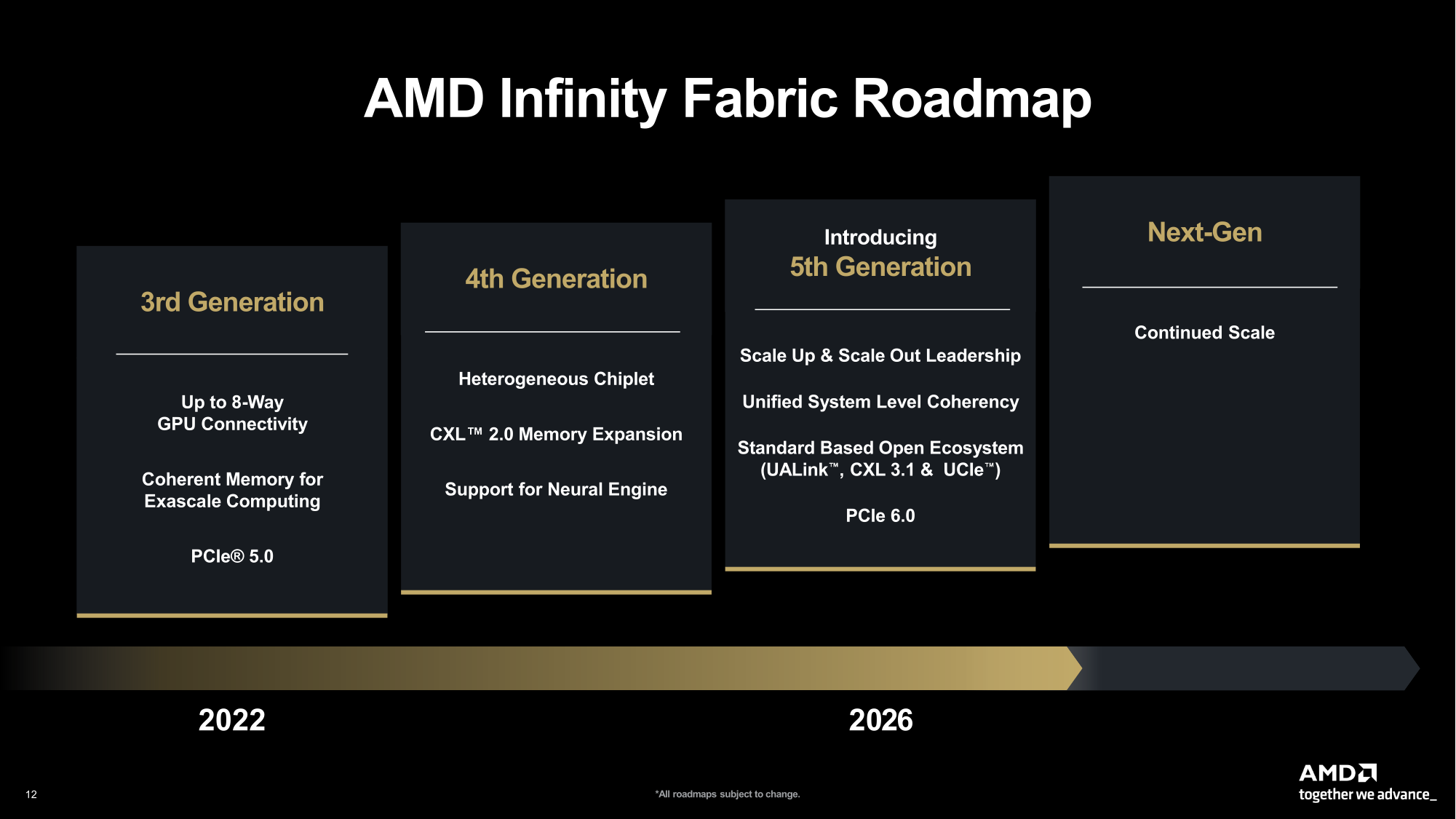 Эта архитектура минимизирует накладные расходы на перемещение данных, увеличивает пропускную способность между ускорителями и обеспечивает эффективность класса экзафлопсных вычислений в компактном корпусе. Helios фактически представляет собой проект AMD для ИИ-фабрики будущего с возможностью модульного расширения, позволяя объединять сотни стоек в одну систему в ЦОД.  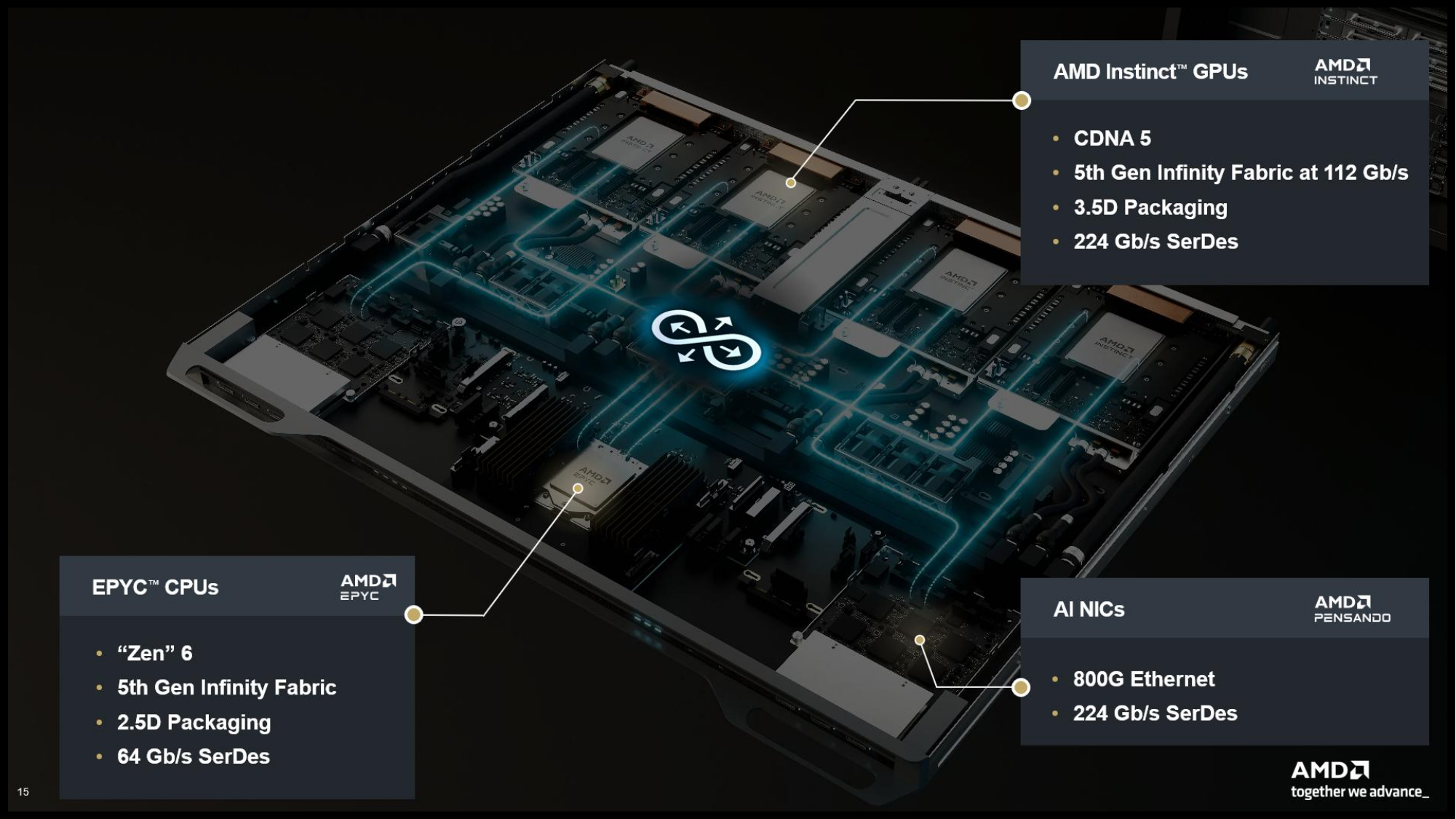 В 2027 году AMD планирует выпустить ускорители серии MI500 и процессоры EPYC Verano, продолжая тем самым ежегодный цикл совместной разработки процессоров, ускорителей и сетей. AMD заявила, что EPYC Venice, намеченные к выпуску в 2026 году, будут обладать лучшими в отрасли показателями плотности (1,3x по количеству потоков в сравнении с текущими решениями) и энергоэффективности (1,7x). Они пополнятся оптимизированными для ИИ наборами инструкций для обработки инференса и выполнения вычислений общего назначения. Указанные компоненты станут основой ИИ-фабрики, способной масштабироваться от одной стойки до глобально распределённых кластеров.  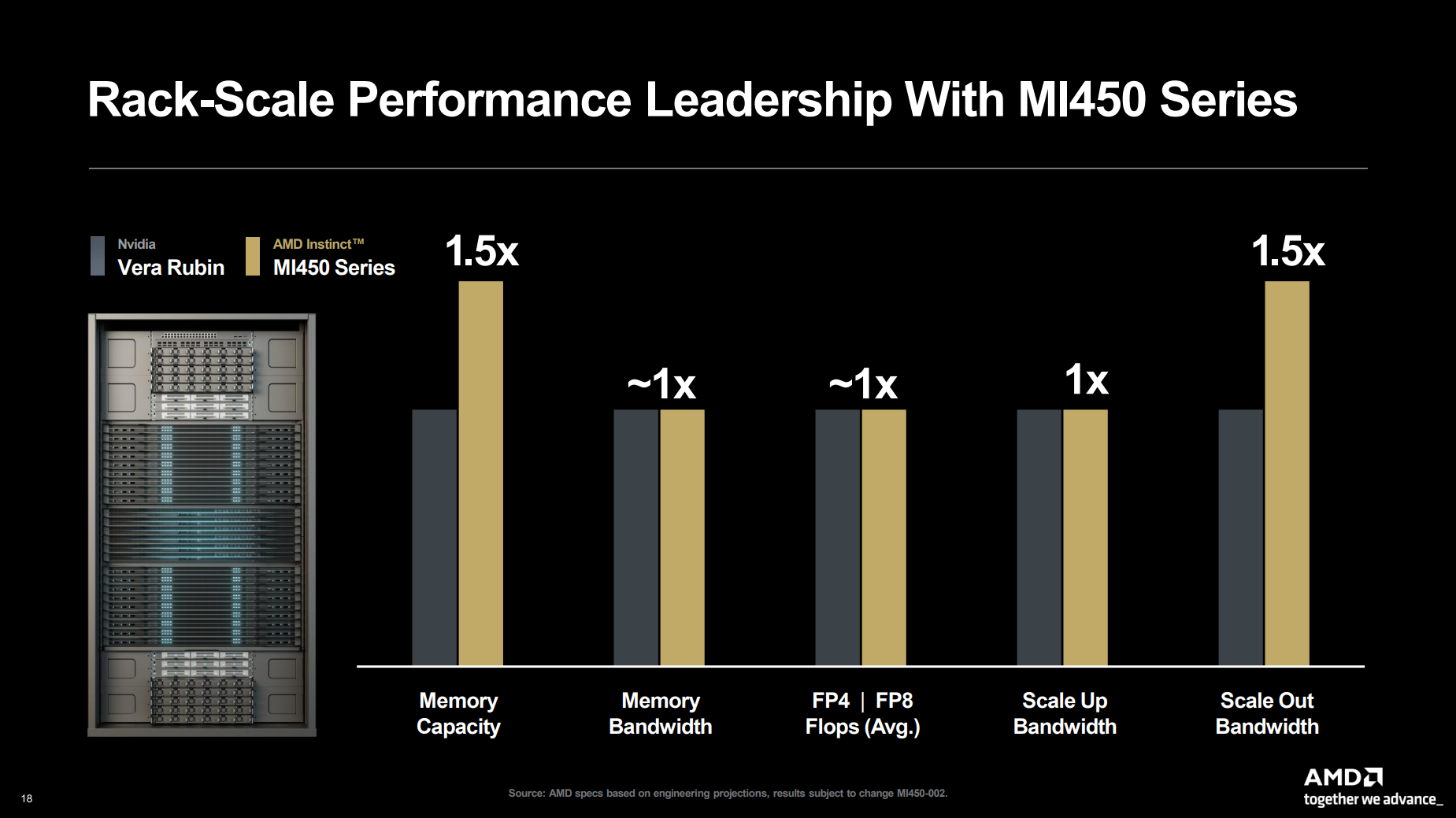 Исполнительный вице-президент AMD Форрест Норрод (Forrest Norrod) подчеркнул в своём выступлении, что производительность ИИ всё больше зависит от сети. Сетевые карты AMD Pensando Pollara и Vulcano для ИИ образуют связующую ткань архитектуры Helios. Сетевая карта Pollara 400 обеспечивает пропускную способность 400 Гбит/с, а готовящаяся к выходу сетевая карта Vulcano удвоит её до 800 Гбит/с, обеспечивая связь Ultra Ethernet между крупными кластерами ускорителей.   AMD представила четырёхуровневую архитектуру сети для масштабных ИИ-инфраструктур. Front-End часть обслуживает пользователей, хранилище и приложения. Она опирается на DPU Pensando и P4-движки, отвечающие за разгрузку сетевых функций, функции безопасности и шифрования, и работу с СХД. Вертикальное масштабирование в пределах стойки обеспечивает 3,6-Тбайт/с подключение на каждый GPU. Горизонтальное масштабирование реализуется благодаря UEC — внутренние тесты показали снижение затрат на коммутацию до 58 % по сравнению с традиционными сетями типа Fat-Tree. Наконец, Scale-Across (пространственное масштабирование) позволит объединить географически распределённые ЦОД в кластеры с интеллектуальным управлением трафиком и адаптивной балансировкой нагрузки.   AMD отметила, что открытый программный стек ROCm (Radeon open compute) по-прежнему лежит в основе её стратегии в области ИИ-платформ. По сравнению с прошлым годом число его загрузок выросло в десять раз и теперь на HuggingFace поддерживается более 2 млн моделей. ROCm интегрируется с ведущими фреймворками, включая PyTorch, TensorFlow, JAX, Triton, vLLM, ComfyUI и Ollama, и поддерживает проекты с открытым исходным кодом, такие как Unsloth. 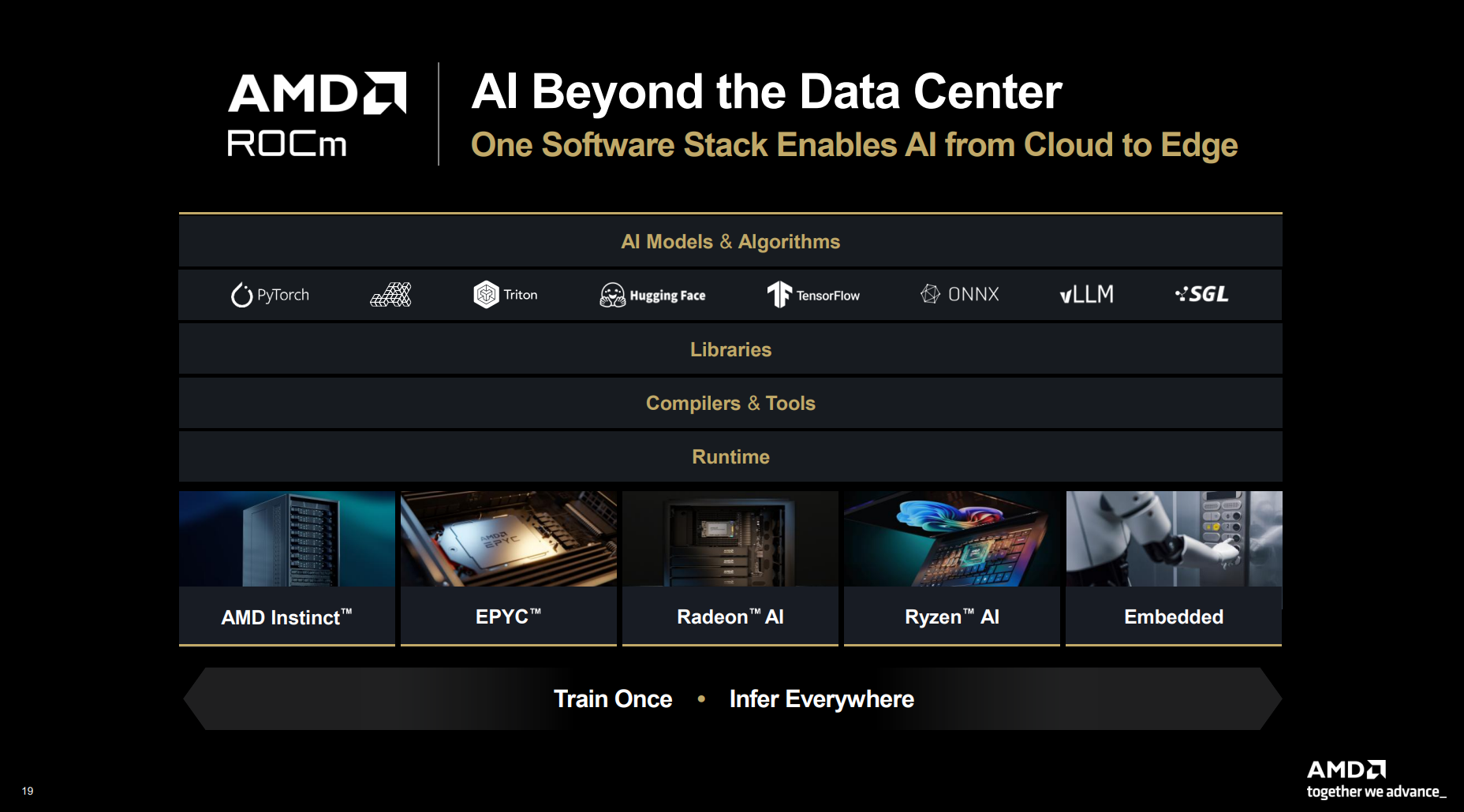  AMD также расширила своё видение «физического ИИ», когда вычисления выходят за рамки облака и охватывают роботов, транспортные средства и промышленные системы. Подразделение встраиваемых систем, усиленное приобретением Xilinx в 2022 году, превратилось из бизнеса, ориентированного на FPGA, в многоплатформенный двигатель роста, охватывающий адаптивные системы на кристалле (SoC), встраиваемые x86-процессоры и заказные кремниевые решения. По словам компании, с 2022 года решения в этой области принесли более $50 млрд. AMD рассчитывает превысить 70 % доли рынка адаптивных вычислений.   Говоря о перспективах, компания отметила, что ЦОД остаются основным драйвером роста, но наряду с этим она будет диверсифицировать свою деятельность по всем сегментам. Финансовые цели AMD включают:
28.10.2025 [20:35], Сергей Карасёв
NVIDIA анонсировала DPU BlueField-4: 800G-порты, ConnectX-9, CPU Grace и PCIe 6.0NVIDIA анонсировала DPU BlueField 4, рассчитанный на использование в составе масштабных инфраструктур ИИ. Устройство оснащено 800G-портами. Новинка в этом отношении вдвое быстрее BlueField-3, дебютировавших ещё в 2021 году. NVIDIA отмечает, что ИИ-фабрики продолжают развиваться с беспрецедентной скоростью. При этом требуется обработка колоссальных массивов структурированных и неструктурированных данных. Для удовлетворения этих потребностей необходимо формирование инфраструктуры нового класса, на которую как раз и ориентирован DPU BlueField-4. Новинка использует программно-определяемую архитектуру для ускорения сетевых операций, функций безопасности и задач хранения данных. По заявлениям NVIDIA, BlueField-4 позволяет трансформировать дата-центры в безопасную интеллектуальную ИИ-инфраструктуру с высокой производительностью. BlueField-4 объединяет 64-ядерный Arm-процессор NVIDIA Grace (114 Мбайт L3-кеш), 128 Гбайт LPDDR5, 512 Гбайт SSD, сетевой адаптер NVIDIA ConnectX-9 SuperNic (1,6 Тбит/с), а также коммутатор PCIe 6.0 с 48 линиями. Новинка будет доступна в виде карты расширения (PCIe 6.0 x16) и в виде модуля для узлов VR NVL144. Утверждается, что по сравнению с BlueField-3 вычислительная производительность выросла в шесть раз. При этом возможно формирование ИИ-фабрик вчетверо большего масштаба. Кроме того, BlueField-4 поддерживает многопользовательскую сеть, быстрый доступ к данным и микросервисы NVIDIA DOCA. Задействована архитектура NVIDIA BlueField Advanced Secure Trusted Resource Architecture. 
Источник изображения: NVIDIA Предполагается, что BlueField-4 возьмут на вооружение такие производители серверов и платформ хранения данных, как Cisco, DDN, Dell Technologies, HPE, IBM, Lenovo, Supermicro, VAST Data и WEKA. О поддержке новинки заявили Armis, Check Point, Cisco, F5, Forescout, Palo Alto Networks и Trend Micro, а также системные интеграторы Accenture, Deloitte и World Wide Technology. Интегрировать BlueField-4 в свои платформы намерены Canonical, Mirantis, Nutanix, Rafay, Red Hat, Spectro Cloud и SUSE. На рынок BlueField-4 поступит в 2026 году как часть экосистемы Vera Rubin.
22.10.2025 [17:09], Владимир Мироненко
AWS пожертвовала компактностью GB300 NVL72, лишь бы снизить зависимость от NVIDIAAmazon Web Services (AWS) нашла выход, как использовать собственные Nitro DPU K2v5/6 (EFA) в новейших стоечных системах NVIDIA GB300 NVL72, которые, как считает гиперскейлер, превосходит адаптеры NVIDIA ConnectX-7/8 по производительности. В связи с тем, что в стойках NVIDIA Oberon используются укороченные лотки высотой 1U, AWS размещает NIC в отдельной стойке JBOK, предназначенной только для сетевых карт, пишет SemiAnalysis. Причина кроется в невозможности установить в 1U сразу девять фирменных адаптеров (8 × EFA + 1 × ENA/EBS). Для серверных систем GB200 NVL предыдущего поколения AWS выбрала вариант NVL36×2, поскольку только в этом случае использовались 2U-узлы, где достаточно места для всех NIC. Однако сдвоенная конфигурация менее эффективна, чем нативная конструкция NVL72. NVIDIA сама была не очень довольна вариантами NVL36. Meta✴, например, и вовсе «растянула» NVL36×2 на шесть стоек, чтобы обойтись воздушным охлаждением. 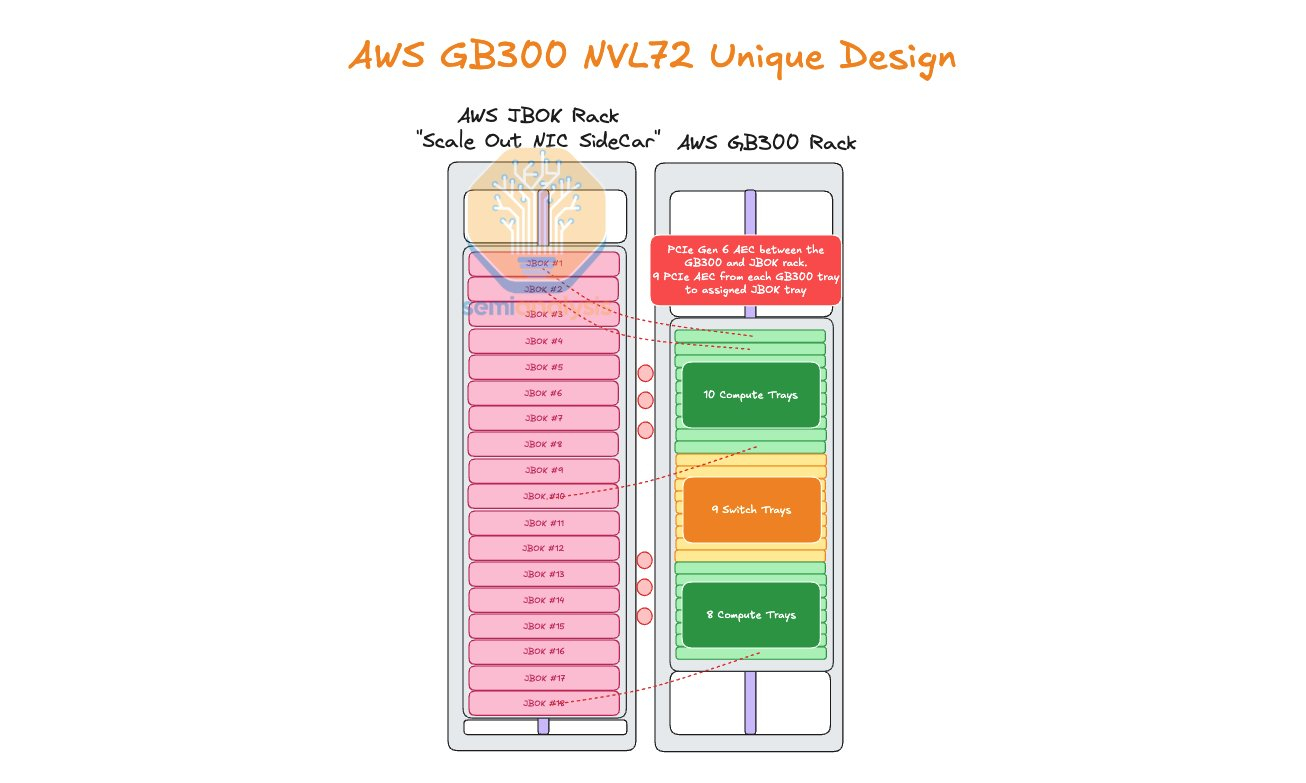
Источник изображения: SemiAnalysis AWS в случае Blackwell Ultra предпочла остановиться на NVL72-варианте, а DPU вынести в отдельную стойку — всего 18 узлов высотой 2U, по 9 NIC в каждом. С узлами NVIDIA они соединены активными электрическими кабелями (AEC) и портами OSFP-XD для передачи сигналов PCIe 6.0. По словам AWS, её адаптеры лучше справляются с нагрузками, чем ConnectX-8 (RoCEv2), что отчасти спорно. В любом случае таким образом компания снижается зависимость от NVIDIA. 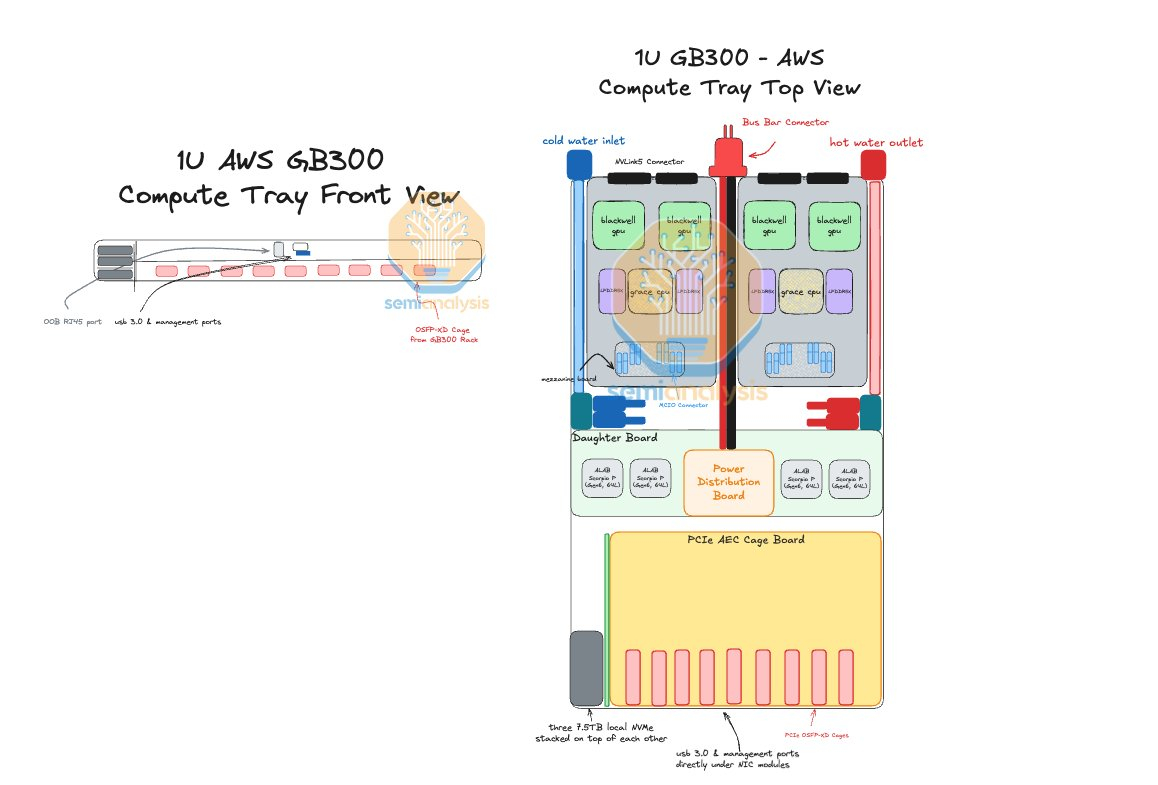
Источник изображения: SemiAnalysis С точки зрения SemiAnalysis, доработка GB300 в AWS помогает устранить единую точку отказа в референсной архитектуре NVIDIA, где каждый ускоритель взаимодействует только с одним сетевым адаптером ConnectX-8, тогда как в конфигурации AWS каждый ускоритель общается с двумя NIC. У AWS накоплен богатый опыт разработки собственного оборудования для ЦОД. Ранее компания в партнёрстве с Broadcom разрабатывала специализированные сетевые коммутаторы. Также недавно представленные ею EC2-инстансы P6-B200 и P6e-GB200 оснащены собственным сетевым стеком Elastic Fabric Adapter (EFAv4) на базе собственных контроллеров Nitro, который оптимизирует обработку сетевых пакетов и снижает задержки для высокопроизводительных приложений.
02.09.2025 [10:14], Владимир Мироненко
Intel анонсировала IPU E2200 — 400GbE DPU семейства Mount MorganIntel анонсировала DPU Intel IPU E2200 под кодовым названием Mount Morgan, представляющий собой обновление 200GbE IPU E2100 (Mount Evans), разработанного при участии Google для использования в ЦОД последней, причём не слишком удачного, как отмечают некоторые аналитики. Как сообщает ресурс ServeTheHome, Intel E2200 производится по 5-нм техпроцессу TSMC. Он базируется на той же архитектуре, что и предшественник, но предлагает более высокую производительность. Вычислительный блок включает до 24 ядер Arm Neoverse N2 с 32 Мбайт кеша, четырьмя каналами LPDDR5-6400 и выделенным сопроцессором безопасности. Сетевая часть представлена 400GbE-интерфейсом с RDMA, а хост-подключение — подсистемой PCIe 5.0 x32 со встроенным коммутатором PCIe. 
Источник изображений: Intel via ServeTheHome  Для обработки пакетов используется P4-программируемый процессор FXP — модуль обработки трафика с алгоритмом синхронизации и настраиваемыми параметрами разгрузки, что позволяет распределять задачи между сетевыми ускорителями и Arm-ядрами. 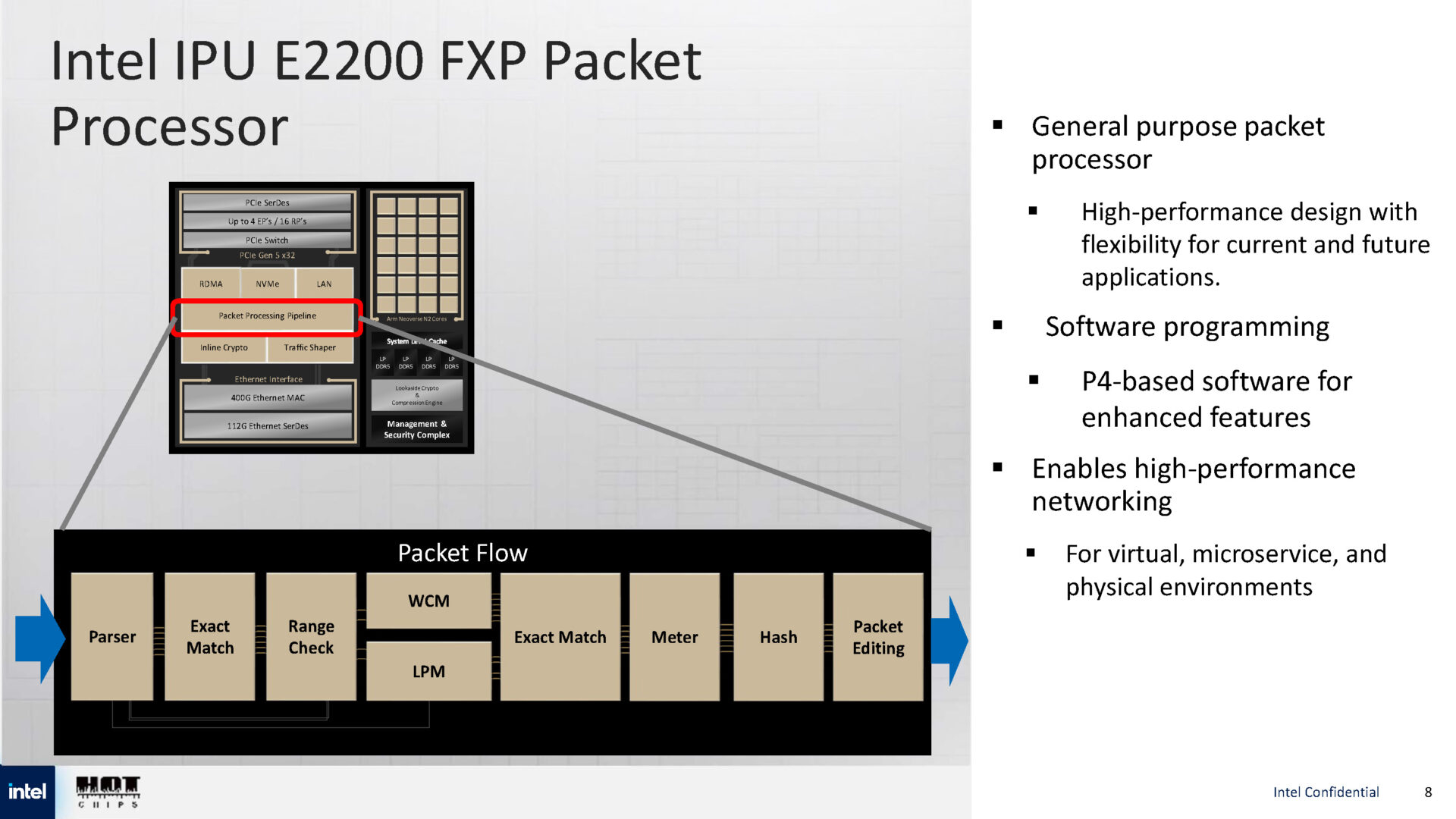 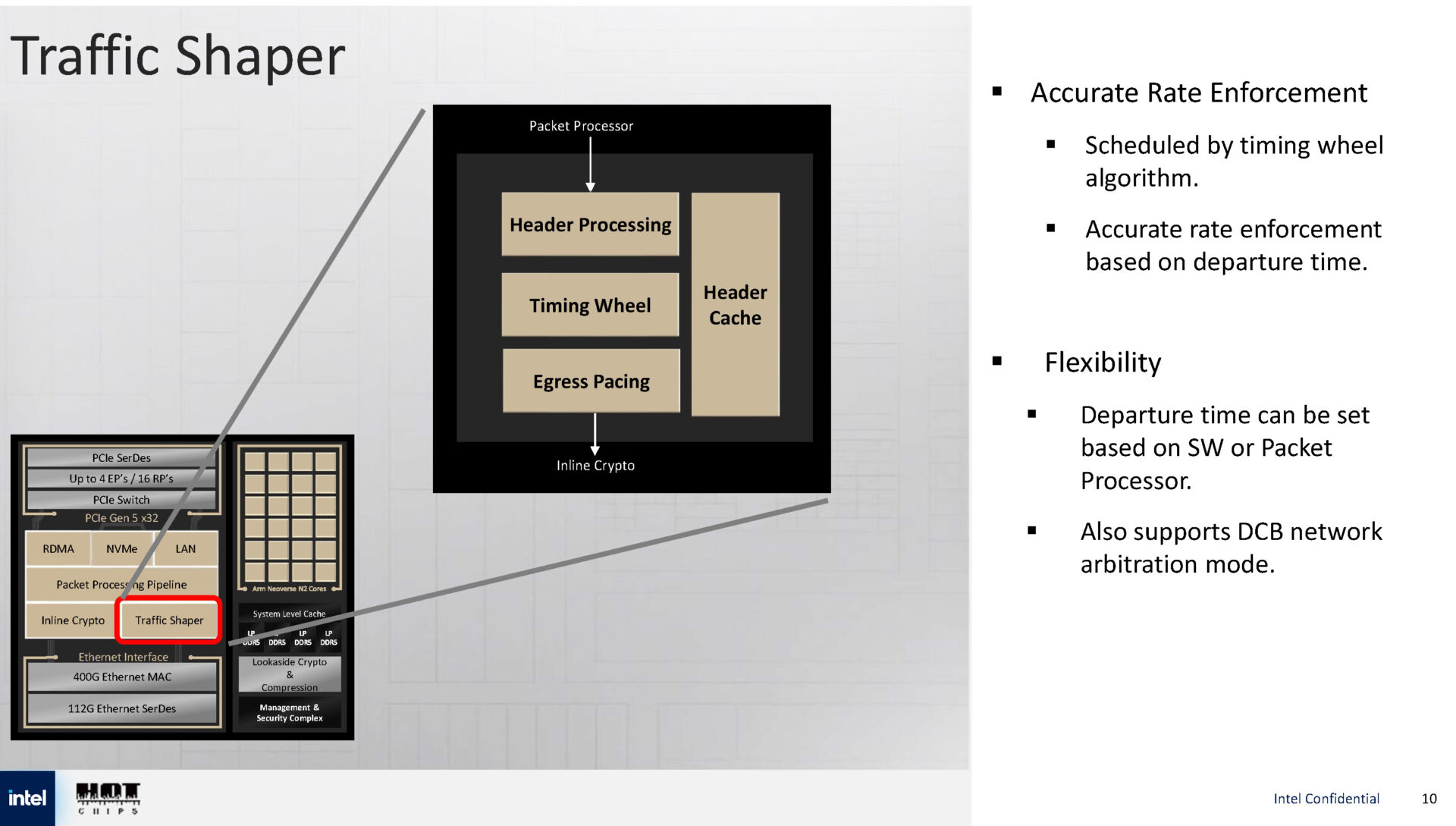 Также имеется встроенный криптографический модуль для шифрования на лету (inline) с поддержкой протоколов IPsec и PSP, настраиваемый для каждого потока. Для управления потоками данных используется модуль Traffic Shaper с поддержкой алгоритма Timing Wheel. 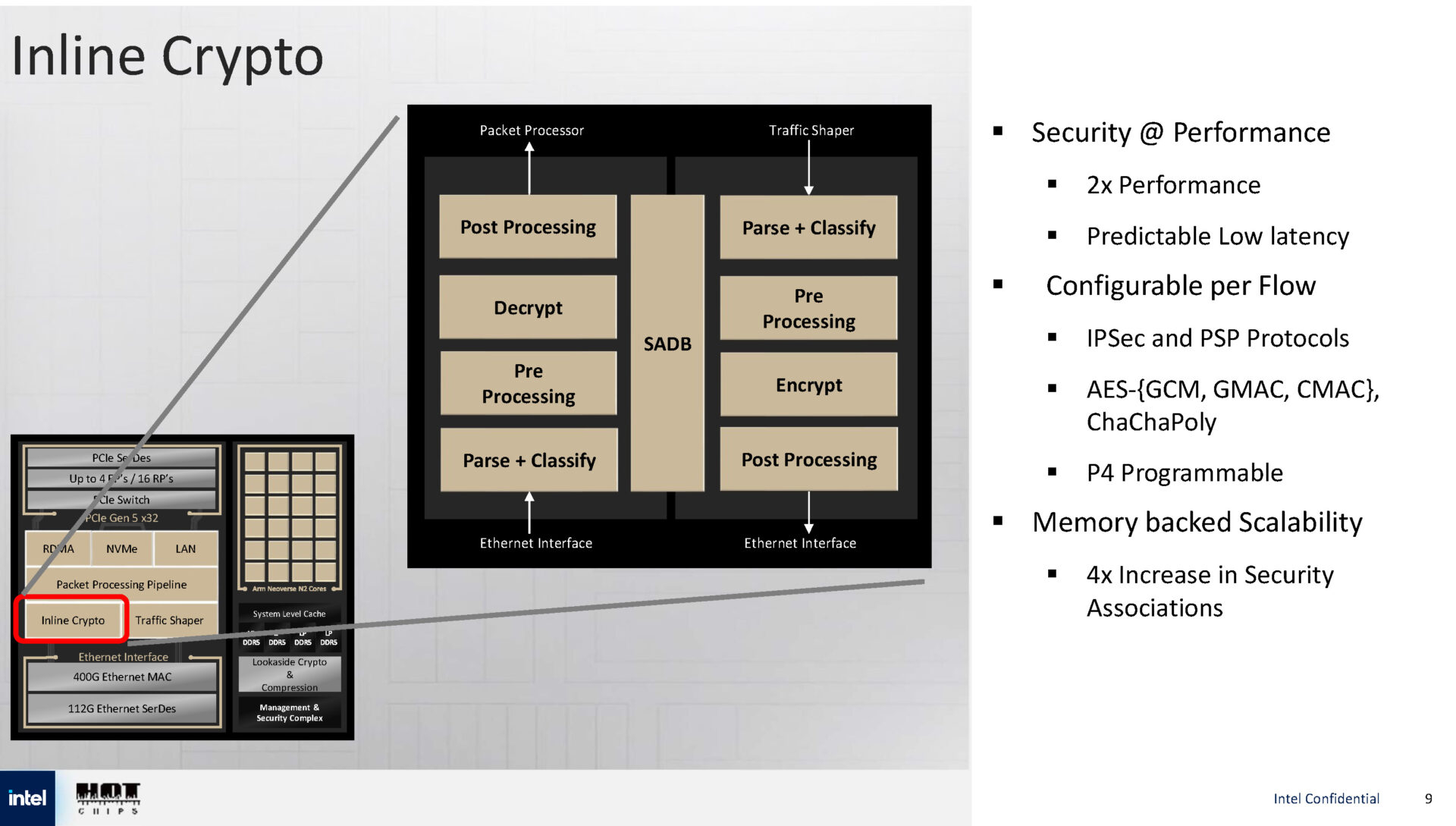  Кроме того, есть и Look-Aside-блок для компрессии и шифрования. Как и в IPU E2100, у IPU E2200 имеется выделенный модуль для независимого внешнего управления. Также поддерживаются программируемые параметры разгрузки с использованием различных ускорителей и IP-блоков.
24.08.2025 [23:18], Сергей Карасёв
NeuReality готовит чип NR2 для оркестрации инференсаКомпания NeuReality раскрыла предварительную информацию об изделии NR2 — чипе второго поколения, предназначенном специально для оркестрации инференса. Изделие представляет собой более эффективную альтернативу связке CPU и NIC в высокопроизводительных системах ИИ. Чип первого поколения NR1 дебютировал в июне нынешнего года. Изделие может применяться в связке с любым GPU или ИИ-ускорителем. При этом, как утверждается, NR1 позволяет повысить эффективность использования GPU почти до 100 % по сравнению со средним показателем в 30–50 % при традиционном сочетании CPU и NIC в современных серверах. В состав NR1 входят четыре декодера видео/изображений, 16 DSP для аудио/речи, 16 векторных DSP общего назначения, два порта 10/25/50/100GbE и пр. Характеристики NR2 на данный момент полностью не раскрываются. Известно, что в основу решения положена платформа Arm Neoverse Compute Subsystems (CSS) V3. Чип может объединять до 128 ядер, оптимизированных для масштабных рабочих нагрузок обучения моделей ИИ и инференса. По сравнению с оригинальной версией в NR2 реализована более глубокая интеграция между CPU-блоком и NIC для координации ИИ-моделей в реальном времени, дезагрегации на основе микросервисов, потоковой передачи токенов, оптимизации KV-кеша и оркестровки. 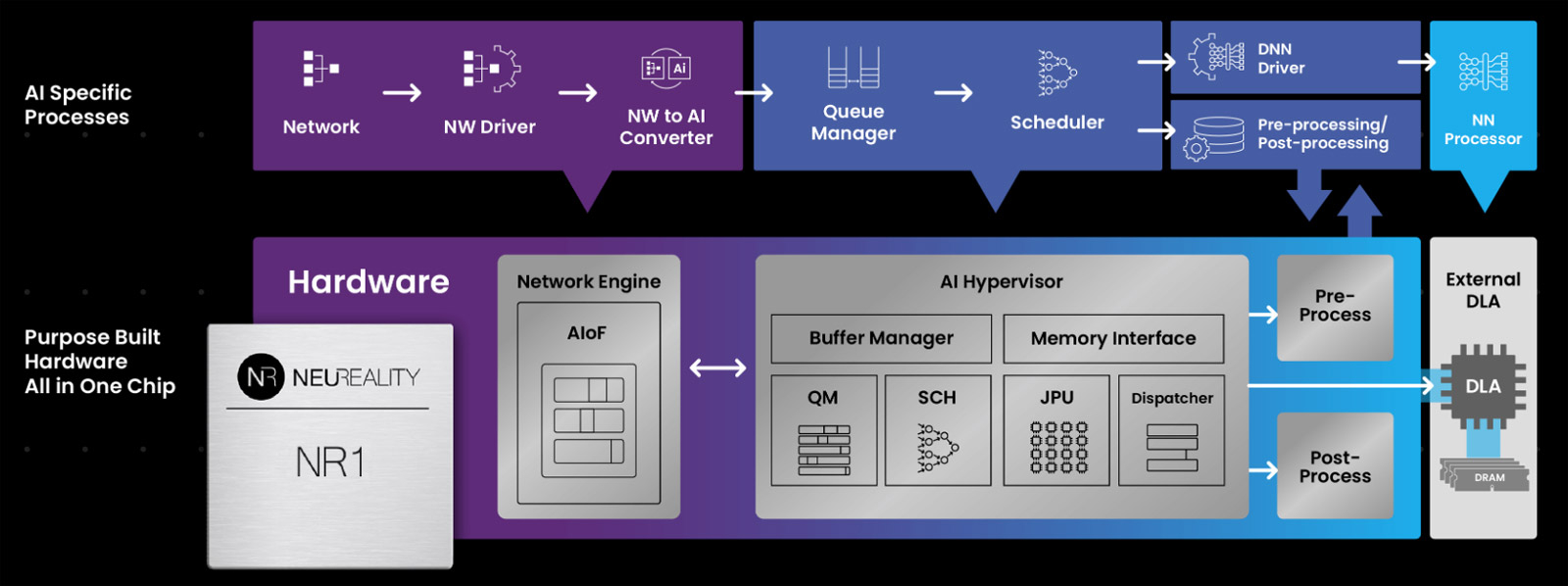
Источник изображения: NeuReality В целом, как отмечает NeuReality, чипы серии NR представляют собой качественно новый класс изделий, способных управлять рабочими нагрузками инференса с непревзойдённой эффективностью. Гипервизор ИИ в сочетании с ядрами Arm Neoverse обеспечивает оптимальную оркестровку и максимальную загрузку доступных ресурсов. |
|

