Материалы по тегу: smartnic
|
10.12.2025 [13:18], Сергей Карасёв
«Гравитон» представил SmartNIC SNC-QSFP2-SH01 с FPGA, 100GbE-портами и слотом SO-DIMMКомпания «Гравитон», российский производитель вычислительной техники, анонсировала сетевой адаптер SNC-QSFP2-SH01 класса SmartNIC, предназначенный для использования в дата-центрах. Устройство обеспечивает аппаратное ускорение различных сетевых функций. В основу решения положена неназванная ПЛИС, которая насчитывает свыше 1 млн логических ячеек и содержит более 50 Мбит встроенной блочной памяти. Адаптер может нести на борту до 32 Гбайт оперативной памяти DDR4. Также упоминается отечественный центральный микроконтроллер первого уровня. Карта оснащена двумя 100GbE-портами QSFP28, что, впрочем, видится избыточным, поскольку используемое подключение PCIe 3.0 x8 не способно «прокачать» столько трафика. За охлаждение отвечают радиатор и вентилятор тангенциального типа. Заявлена поддержка библиотек DPDK и совместимость с платформами Linux и Windows Благодаря возможности реконфигурирования FPGA адаптер может использоваться для решения широкого спектра задач. Среди них названы ускорение работы облачных сервисов, виртуализация, проверка сетевых пакетов по их содержимому (DPI) для регулирования и фильтрации трафика, межсетевые экраны нового поколения (NGFW). Изделие также может применяться в комплексных решениях в сфере кибербезопасности для поиска и устранения угроз в сетевом трафике. 
Источник изображения: «Гравитон» «Использование архитектуры на базе ПЛИС позволило нам создать устройство, которое не просто передаёт пакеты, а берёт на себя ресурсоёмкие вычисления: от балансировки нагрузки до глубокой инспекции пакетов. Мы предлагаем рынку мощный инструмент, который поможет оптимизировать работу облачных сервисов и систем информационной безопасности, высвобождая ресурсы CPU для прикладных задач», — говорит «Гравитон».
09.09.2025 [15:46], Сергей Карасёв
d-Matrix представила 400GbE-адаптер JetStream для объединения своих ИИ-ускорителейСтартап d-Matrix анонсировал специализированную IO-карту JetStream, предназначенную для распределения нагрузок ИИ-инференса между серверами в дата-центре. Устройство ориентировано на использование в связке с ускорителями d-Matrix Corsair, архитектура которых основана на модифицированных ячейках SRAM для вычислений в памяти (DIMC). JetStream использует стандарт Ethernet, благодаря чему обладает совместимостью с уже существующими коммутаторами. Новинка выполнена в виде платы расширения с интерфейсом PCIe 5.0 х16. Используются корзины QSFP-DD. Могут быть задействованы два 200GbE-порта со скоростью 200 Гбит/с или один 400GbE-порт. Архитектура серверов d-Matrix для ИИ-инференса предполагает установку ускорителей Corsair с DMX-мостом между каждыми двумя такими картами для обеспечения высокой пропускной способности без использования PCIe. Затем пары ускорителей объединяются посредством коммутатора PCIe. В эталонном дизайне один NIC JetStream обслуживает до четырёх экземпляров Corsair. d-Matrix утверждает, что сетевую задержку в такой конфигурации удалось сократить до 2 мкс. 
Источник изображений: d-Matrix По заявлениям d-Matrix, карты JetStream могут применяться в существующих ЦОД без необходимости замены дорогостоящих инфраструктурных компонентов. В связке с ИИ-ускорителями Corsair и ПО d-Matrix Aviator решения JetStream способны справляться с ИИ-моделями, насчитывающими более 100 млрд параметров. При этом, как утверждает разработчик, обеспечивается в 10 раз более высокая производительность, в три раза лучшая экономическая эффективность и втрое большая энергоэффективность по сравнению с решениями на базе GPU. 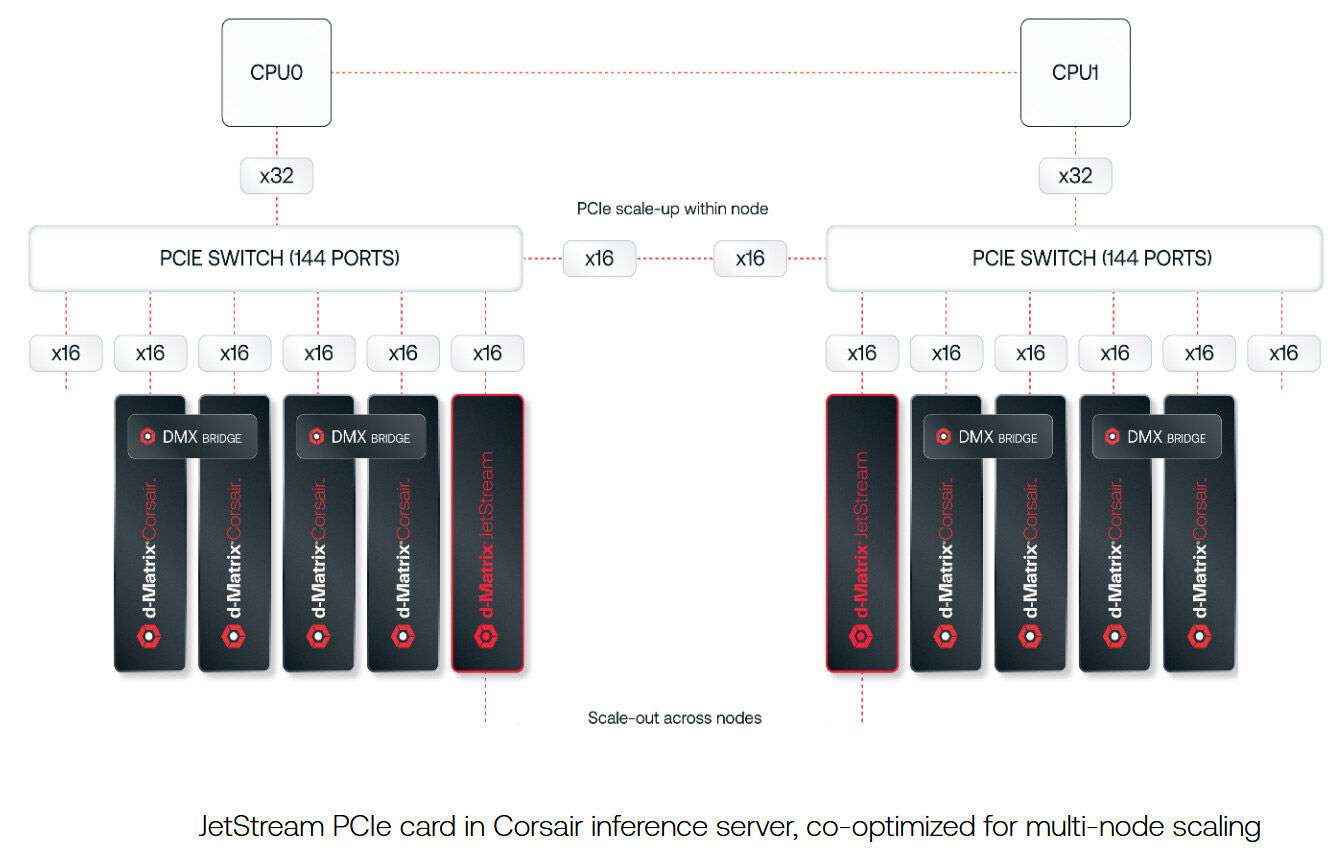 Энергопотребление JetStream составляет около 150 Вт. Адаптер оснащён системой охлаждения с радиатором и тепловыми трубками, которые охватывают зону QSFP-DD. Пробные поставки новинки уже начались, а массовое производство запланировано на конец текущего года.
07.07.2025 [10:15], Руслан Авдеев
DPU-революция так и не состоялась, но развитие ИИ может изменить ситуациюВ 2013 году AWS представила инстансы EC2 C3, вскользь упомянув о расширенных сетевых возможностях благодаря появлению Intel Virtual Function. Позже компания пояснила, что кастомные сетевые адаптеры позволили перенести на них часть нагрузок вроде межсетевого экрана, что высвободило ресурсы серверов. Данное решение оставалось нишевым, но развитие ИИ может всё изменить, сообщает The Register. Решение нашло отклик и у других гиперскейлеров. Они начали создавать собственные SmartNIC или DPU. Mellanox в 2017 году представила DPU BlueField, изначально предназначенный для ускорения перемещения данных All-Flash хранилищ. Чуть позже VMware начала адаптацию своего гипервизора для работы со SmartNIC, предусматривающую запуск сетевых функций на DPU. Потенциал разработки оценила и NVIDIA, которая и приобрела Mellanox, а позже — ещё и Nebulon. В 2021 году Intel вместе с Google разработала Infrastructure Processing Unit (IPU), а годом позже AMD купила разработчика DPU Pensando. В 2022 году VMware представила vSphere Distributed Services Engine, предназначенный для управления SmartNIC и реализации на них распределённого файрвола. Хотя за SmartNIC стояли ключевые игроки IT-отрасли вроде VMware, Intel, AMD и NVIDIA, у каждой из которых было немало клиентов из сферы дата-центров, никакой революции с массовым применением DPU не произошло. VMware признала, что Distributed Services Engine не получил всеобщего признания, а эксперты отрасли подчеркнули, что основными потребителями DPU являются AWS и Microsoft Azure, сдающие мощности конечным заказчикам. ⅔ развёртываний DPU и SmartNIC приходится именно на этих двух гиперскейлеров, а за пределами облачного сегмента особенного прогресса нет. 
Источник изображения: Microsoft Впрочем, намечаются и новые сценарии применения DPU, например — в Ethernet-коммутаторах или даже в качестве замены CPU. Потенциально это поможет расширить клиентскую базу. Например, Cisco применяет DPU в «защитных» продуктах Hypershield и смарт-коммутаторах N9300, а первыми DPU в свои коммутаторы CX 1000 внедрила Aruba ещё в 2021 году. Но такие продукты массовыми так и не стали. Ситуацию может изменить стремительное развитие ИИ-технологий. Недавно аналитики Gartner представили «эталонную» архитектуру для работы с ИИ на периферии и в Kubernetes-средах. В обоих случаях рекомендуется использовать DPU. Аналогичный подход в архитектуре для ИИ-облаков поддерживает и NVIDIA. Red Hat тоже поддержала идею использования DPU для виртуальных коммутаторов, балансировщиков, межсетевых экранов, для оптимизации работы баз данных или аналитических нагрузок за счёт прямого взаимодействия с NVMe и даже для инференса. Так, в OpenShift скоро появится DPU Operator. Пять лет назад Fungible объявила, что DPU должны стать «третьим сокетом» наравне с CPU и GPU, а через два года она была куплена Microsoft. И ей ещё повезло, потому что, например, Kalray оказалась вынуждена продать часть своего бизнеса. Возможно, в жизни этой компании и других стартапов наступит светлая полоса — революция в сфере ИИ может привести и к революционному развитию DPU.
21.04.2025 [11:45], Сергей Карасёв
Atto представила сетевые адаптеры Celerity FC-644E с четырьмя портами FC64G и FastFrame N424 с четырьмя портами 25GbEКомпания Atto Technology анонсировала сетевые адаптеры Celerity FC-644E и FastFrame N424, рассчитанные на дата-центры. Изделия, выполненные в виде низкопрофильных карт расширения с интерфейсом PCIe 4.0 х16, ориентированы на поддержание ресурсоёмких нагрузок, таких как приложения ИИ и НРС. Celerity FC-644E относится к решениям Fibre Channel HBA седьмого поколения. Предусмотрены четыре порта 64Gb FC, что обеспечивает суммарную пропускную способность до 256 Гбит/с. Говорится о совместимости со спецификациями FC-PI-7, SFF-8431, PCI Express CEM Spec 3.0 и PCI Hot Plug spec 1.1. Изделие оборудовано системой пассивного охлаждения с радиатором. Диапазон рабочих температур — от 0 до +55 °C. Заявлена поддержка Windows, Windows Server, Linux, illumos, VMware, FreeBSD и macOS. В свою очередь, FastFrame N424 представляет собой карту SmartNIC четвёртого поколения. Она располагает четырьмя портами 25GbE SFP28. Реализована поддержка RoCE. Заявленная задержка находится на уровне 1 мкс. 
Источник изображения: Atto Фирменное программное обеспечение Atto 360 предоставляет инструменты для настройки, мониторинга и аналитики. Упомянута совместимость с Windows, Windows Server, macOS и Linux. Средства Atto Ethernet Suite для Windows и Linux упрощают установку. Сетевой адаптер может эксплуатироваться при температурах от 0 до +55 °C. На новинки предоставляется трёхлетняя гарантия. В комплект поставки входят монтажные планки стандартной и уменьшенной высоты.
19.08.2021 [18:04], Алексей Степин
Intel представила IPU Mount Evans и Oak Springs Canyon, а также ODM-платформу N6000 Arrow CreekВесной Intel анонсировала свои первые DPU (Data Processing Unit), которые она предпочитает называть IPU (Infrastructure Processing Unit), утверждая, что такое именования является более корректным. Впрочем, цели у этого класса устройств, как их не называй, одинаковые — перенос части функций CPU по обслуживанию ряда подсистем на выделенные аппаратные блоки и ускорители. Классическая архитектура серверных систем такова, что при работе с сетью, хранилищем, безопасностью значительная часть нагрузки ложится на плечи центральных процессоров. Это далеко не всегда приемлемо — такая нагрузка может отъедать существенную часть ресурсов CPU, которые могли бы быть использованы более рационально, особенно в современных средах с активным использованием виртуализации, контейнеризации и микросервисов. 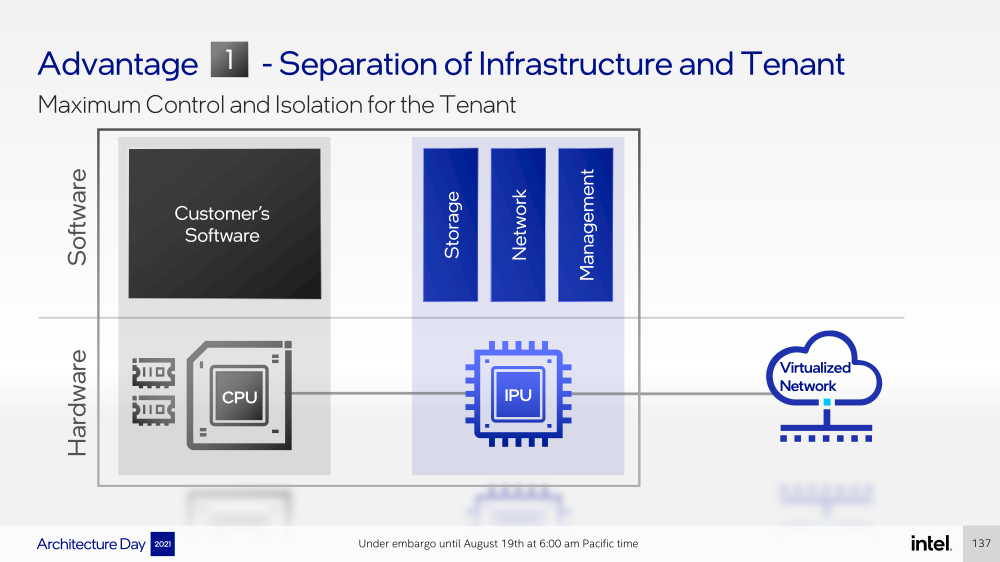 Для решения этой проблемы и были созданы DPU, которые эволюционировали из SmartNIC, бравших на себя «тяжёлые» задачи по обработке трафика и данных. DPU имеют на борту солидный пул вычислительных возможностей, что позволяет на некоторых из них запускать даже гипервизор. Однако Intel IPU имеют свои особенности, отличающие их и от SmartNIC, и от виденных ранее DPU. 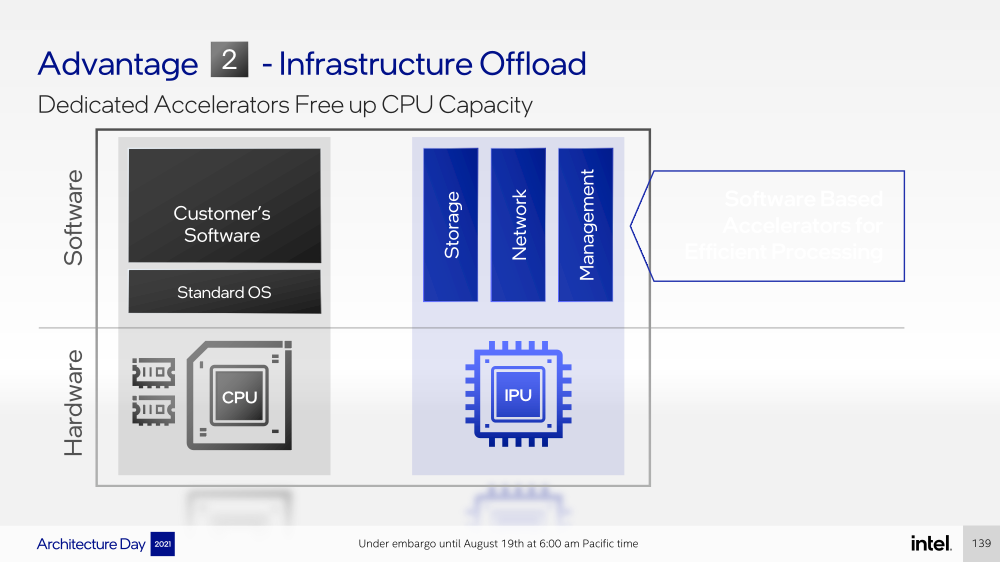 Новый класс сопроцессоров Intel должен взять на себя все заботы по обслуживанию инфраструктуры во всех её проявлениях, будь то работа с сетью, с подсистемами хранения данных или удалённое управление. При этом и DPU, и IPU в отличие от SmartNIC полностью независим от хост-системы. Полное разделение инфраструктуры и гостевых задач обеспечивает дополнительную прослойку безопасности, поскольку аппаратный Root of Trust включён в IPU. 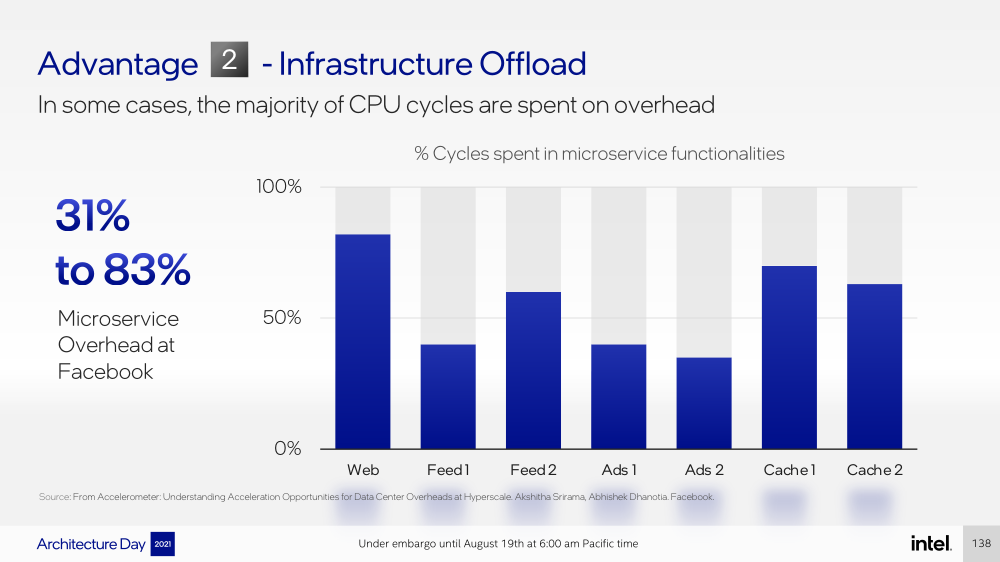 Это не единственное преимущество нового подхода. Компания приводит статистику Facebook✴, из которой видно, что иногда более 50% процессорных тактов серверы тратят на «обслуживание самих себя». Все эти такты могут быть пущены в дело, если за это обслуживание возьмётся IPU. Кроме того, новый класс сетевых ускорителей открывает дорогу к бездисковой серверной инфраструктуре: виртуальные диски создаются и обслуживаются также чипом IPU. 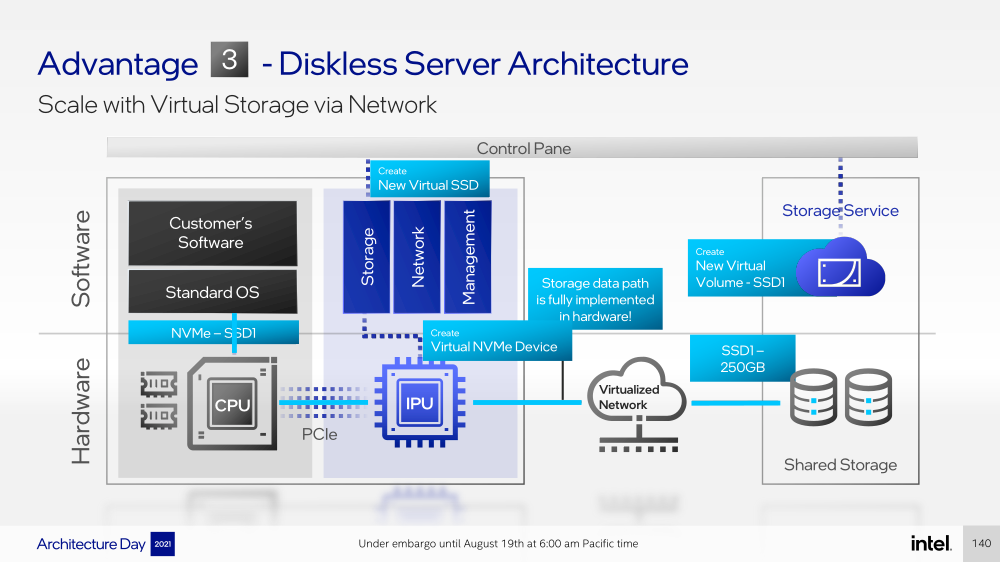 Первый чип в новом семействе IPU, получивший имя Mount Evans, создавался в сотрудничестве с крупными облачными провайдерами. Поэтому в нём широко используется кремний специального назначения (ASIC), обеспечивающий, однако, и нужную степень гибкости, За основу взяты ядра общего назначения Arm Neoverse N1 (до 16 шт.), дополненные тремя банками памяти LPDRR4 и различными ускорителями. 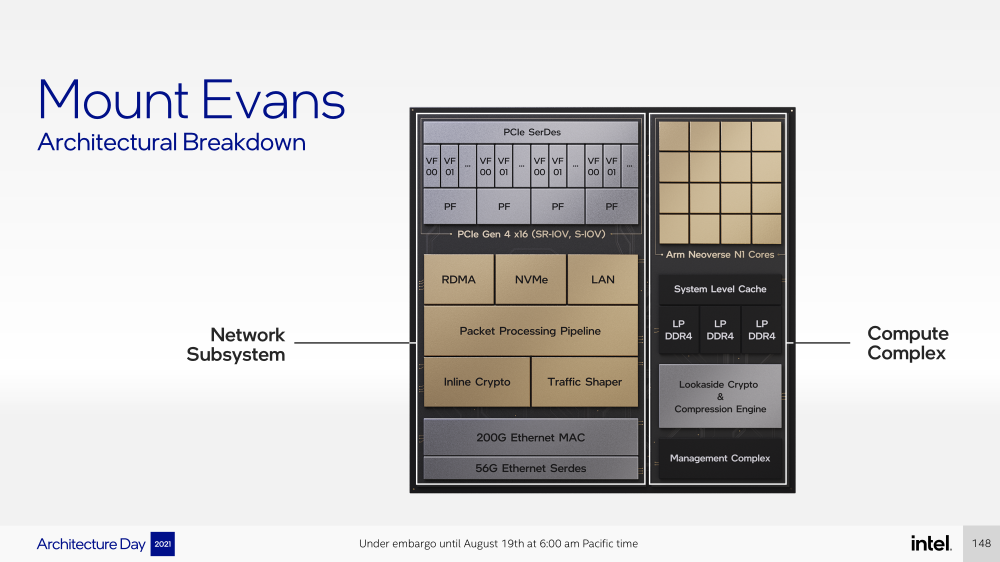 Сетевая часть представлена 200GbE-интерфейсом с выделенным P4-программируемым движком для обработки сетевых пакетов и управления QoS. Дополняет его выделенный IPSec-движок, способный на лету шифровать весь трафик без потери скорости. Естественно, есть поддержка RDMA (RoCEv2) и разгрузки NVMe-oF, причём отличительной чертой является возможность создавать для хоста виртуальные NVMe-накопители — всё благодаря контроллеру, который был позаимствован у Optane SSD.  Дополняют этот комплекс ускорители (де-)компресии и шифрования данных на лету. Они базируются на технологиях Intel QAT и, в частности, предложат поддержку современного алгоритма сжатия Zstandard. Наконец, у IPU будет выделенный блок для независимого внешнего управления. Работать с устройством можно будет посредством привычных SPDK и DPDK. Один IPU Mount Evans может обслуживать до четырёх процессоров. В целом, новинку можно назвать интересной и более доступной альтернативной AWS Nitro.  Также Intel представила платформу Oak Springs Canyon с двумя 100GbE-интерфейсами, которая сочетает процессоры Xeon-D и FPGA семейства Agilex. Каждому чипу которых полагается по 16 Гбайт собственной памяти DDR4. Платформа может использоваться для ускорения Open vSwitch и NVMe-oF с поддержкой RDMA/RocE, имеет аппаратные криптодвижки т.д. Наличие FPGA позволяет выполнять специфичные для конкретного заказчика задачи, но вместе с тем совместимость с x86 существенно упрощает разработку ПО для этой платформы. В дополнение к SPDK и DPDK доступны и инструменты OFS.  Наконец, компания показала и референсную плаформу для разработчиков Intel N6000 Acceleration Development Platform (Arrow Creek). Она несколько отличается от других IPU и относится скорее к SmartNIC, посколько сочетает FPGA Agilex, CPLD Max10 и сетевые контроллеры Intel Ethernet 800 (2 × 100GbE). Дополняет их аппаратный Root of Trust, а также PTP-блок.  Работать с устройством можно также с помощью DPDK и OFS, да и функциональность во многом совпадает с Oak Springs Canyon. Но это всё же платформа для разработки конечных решений ODM-партнёрами Intel, которые могут с её помощью имплементировать какие-то специфические протоколы или функции с ускорением на FPGA, например, SRv6 или Juniper Contrail. IPU могут стать частью высокоинтегрированной ЦОД-платформы Intel, и на этом поле она будет соревноваться в первую очередь с NVIDIA, которая активно продвигает DPU BluefIeld, а вскоре обзаведётся ещё и собственным процессором. Из ближайших интересных анонсов, вероятно, стоит ждать поддержку Project Monterey, о которой уже заявили NVIDIA и Pensando.
16.10.2020 [23:17], Юрий Поздеев
DPU в стиле Intel: сетевые адаптеры с Xeon D, FPGA, HBM и SSDМир сетевых карт становится умнее. Это следующий шаг в дезагрегации ресурсов центров обработки данных. Наличие расширенных возможностей сетевых карт позволяет разгрузить центральный процессор, при этом специализированные сетевые адаптеры обеспечивают более совершенные функции и безопасность. В этой новости мы познакомим вас сразу с двумя адаптерами: Silicom SmartNIC N5010 и Inventec SmartNIC C5020X. Silicom FPGA SmartNIC N5010 предназначена для систем крупных коммуникационных провайдеров. Операторы все чаще стремятся заменить проприетарные форм-факторы от поставщиков телекоммуникационного оборудования на более стандартные варианты. В рамках этого мы видим, что производители ПЛИС не прочи освоить и эту нишу.  В Silicom FPGA SmartNIC N5010 используется Intel Stratix 10 DX с 8 Гбайт памяти HBM. Поскольку пропускная способность памяти становится все большим аспектом производительности системы, HBM будет продолжать распространяться за пределы графических процессоров и FPGA. В SmartNIC и DPU память HBM может использоваться для размещения индексных таблиц поиска и других функций для интенсивных сетевых нагрузок. Помимо HBM SmartNIC N5010 имеет еще 32 Гбайт памяти DDR4 ECC. SmartNIC N5010 потребляет до 225 Вт, что предполагает несколько вариантов исполнения карты, в том числе и с активным охлаждением.  Самая интересная особенность новой карты — 4 сетевых порта по 100 Гбит/с. На плате SmartNIC N5010 установлены две базовые сетевые карты Intel E810 (Columbiaville). На приведенной схеме можно заметить, что используется интерфейс PCIe Gen4 x16, причем их тут сразу два. Для работы четырех 100GbE-портов уже недостаточно одного интерфейса PCIe 4.0 x16. Второй порт PCIe 4.0 x16 может быть подключен через дополнительный кабель к линиям второго процессора, чтобы избежать межпроцессорного взаимодействия для передачи данных.  Вторая новинка, Inventec FPGA SmartNIC C5020X, совмещает на одной плате процессор Intel Xeon D и FPGA Intel Stratix 10. Этот адаптер предназначен для разгрузки центрального процессора в серверах крупных облачных провайдеров. На плате установлен процессор Intel Xeon D-1612 с 32-Гбайт SSD и 16 Гбайт DDR4, подключение к ПЛИС Intel Stratix 10 DX 1100 осуществляется через PCIe 3.0 x8. Нужно отметить, что FPGA Stratix имеет свои собственные 16 Гбайт памяти DDR4, а также обеспечивает сетевые подключения 25/50 Гбит/с и оснащен интерфейсом PCIe 4.0 x8, через который адаптер подключается к хосту. 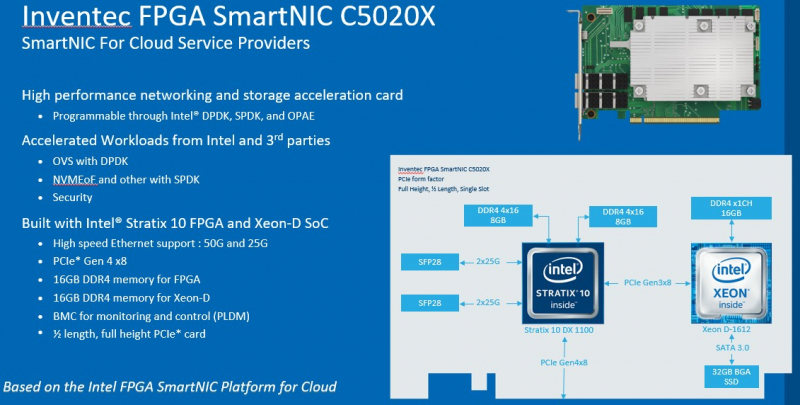 У Inventec уже есть решение на базе Arm (Inventec X250), которое использует ПЛИС Arria 10 GX660 вместе с сетевым адаптером Broadcom Stingray BCM8804, которое имеет аналогичный форм-фактор и TPD не более 75 Вт. Однако для некоторых организаций наличие единой x86 платформы, включая SmartNIC, упрощает развертывание, поэтому вариант C5020X для таких компаний более предпочтителен. Решение получилось очень интересным, однако вряд ли его можно назвать адаптером для массового рынка, как Intel Columbiaville. На примере этого адаптера Intel показала, что может объединить элементы своего портфеля для создания комплексных решений. Inventec FPGA SmartNIC C5020X является хорошей альтернативой предложению на базе Broadcom, что позволит крупным облачным провайдерам диверсифицировать свои платформы.  Несмотря на то, что обе новинки классифицируются как «умные» сетевые адаптеры SmartNIC, вторая, пожалуй, уже ближе к DPU, если сравнивать её с адаптерами NVIDIA DPU, в которых сетевая часть дополнена Arm-процессором и GPU-ускорителем. В данном случае есть и x86-ядра общего назначения, и ускоритель, хотя и на базе ПЛИС. Впрочем, устоявшегося определения DPU и списка критериев соответствия этому классу процессоров пока нет.
29.09.2020 [19:57], Алексей Степин
VMware возложит часть нагрузки vSphere на DPU и SmartNICКогда-то архитектура x86 была очень простой, хотя её CISC-основа и была сложнее пути, по которому пошли процессоры RISC. Но за всё время своей эволюции она постоянно усложнялась и на процессоры возлагались всё новые и новые задачи, требующие дополнительных расширений, а то и перекладывались задачи с плеч специализированных чипов. Эта тенденция сохраняется и поныне, однако один из лидеров в мире виртуализации, компания VMware, имеет иное видение. Перекладывание на x86 несвойственных этой архитектуре задач началось с внедрения расширений MMX. Сегодня современные серверные процессоры умеют практически всё и продолжают усложняться — достаточно вспомнить Intel VNNI, подмножество AVX-512, ускоряющее работу с всё более популярными задачами машинного обучения. Однако VMware считает, что x86 не успевает за усложнением программного обеспечения и полагает, что будущее ЦОД лежит в дезагрегации вычислительных ресурсов. 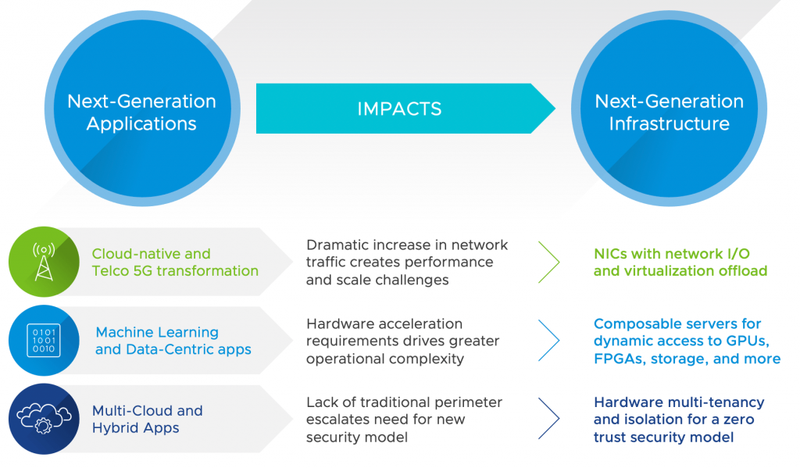
Сложность приложений и сценариев растёт, x86 может не успевать за возрастающей нагрузкой С учётом того, что задачи перед серверами и ЦОД встают всё более и более сложные, неудивительно, что наблюдается расцвет всевозможных ускорителей и сопроцессоров, от умных сетевых адаптеров и уже ставших привычными ГП-ускорителей до относительно экзотических идей, вроде «процессора обработки данных» (DPU). Последнюю концепцию на конференции VMworld 2020 поддержал такой гигант в сфере виртуализации, как VMware. Переработкой своей основной платформы виртуализации vSphere компания занимается уже давно, и в проекте прошлого года под кодовым названием Pacific переработано было многое. В частности, в основу системы управления была окончательно положена контейнерная модель на базе коммерческой системы для Kubernetes под названием Tanzu. Проект этого года, получивший имя Monterey, ознаменовал дальнейшее движение в этом направлении. 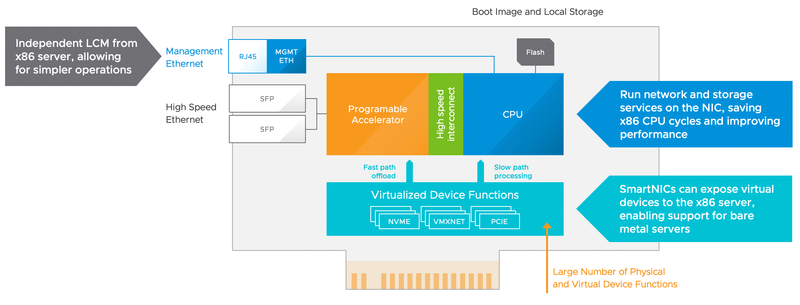
Но ряд задач можно переложить на плечи ускорителей типа SmartNIC или DPU Теперь Kubernetes стал не дополнением, пусть и включенным изначально, но единственным движком для управления как виртуальными машинами первого поколения, так и более современными контейнерами. Но из этого следует дальнейшее повышение вычислительной нагрузки на серверы. В частности, как отмечает VMware, обработка данных ввода-вывода становится всё сложнее. Как мы уже знаем, это привело к зарождению таких устройств, как «умные сетевые адаптеры» (SmartNIC) и даже специализированных чипов DPU. Как первые, так и вторые, как правило, содержат ядра на базе архитектуры ARM, и именно их-то и предлагает использовать для разгрузки основных процессоров VMware. Информация о том, что компания работает над переносом гипервизора ESXi на архитектуру ARM официально подтвердилась. 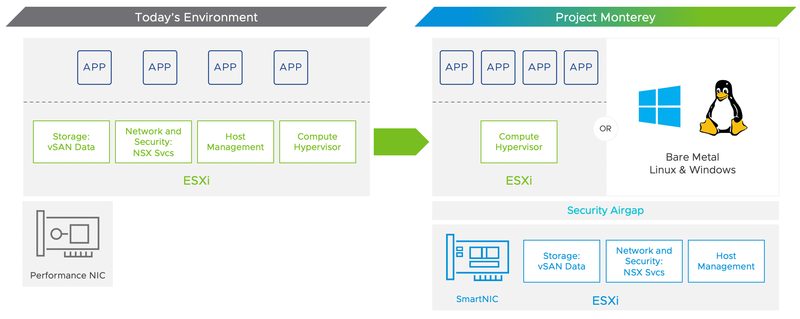
Новая версия платформы vSphere проще, но она эффективнее использует имеющиеся вычислительные ресурсы Важной частью ESXi, как известно, является виртуализация сетевой части — «коммутаторов» и «микро-файрволлов», и в Project Monterey появилась возможность запускать сетевую часть ESXi полностью на ресурсах DPU или SmartNIC, благо современные ускорители этих классов имеют весьма солидную производительность, а иногда и превосходят в этом плане классические центральные процессоры. Сама идея ускорения сетевой части, в частности, задач обеспечения сетевой безопасности в серверах за счёт SmartNIC не нова. Новизна подхода VMware заключается в другом: теперь реализация ESXi-on-ARM позволит не просто снять нагрузку в этих сценариях с плеч основных процессоров, но и представить за счёт виртуализации все сетевые ресурсы безопасно, в виде единого унифицированного пула и вне зависимости от типа процессоров, занятых в этих задачах. Среди уже существующих на рынке устройств, совместимых с новой концепцией VMware числятся, к примеру, и NVIDIA BlueField-2 — «умный сетевой адаптер», разработанный Mellanox — и решения Intel. 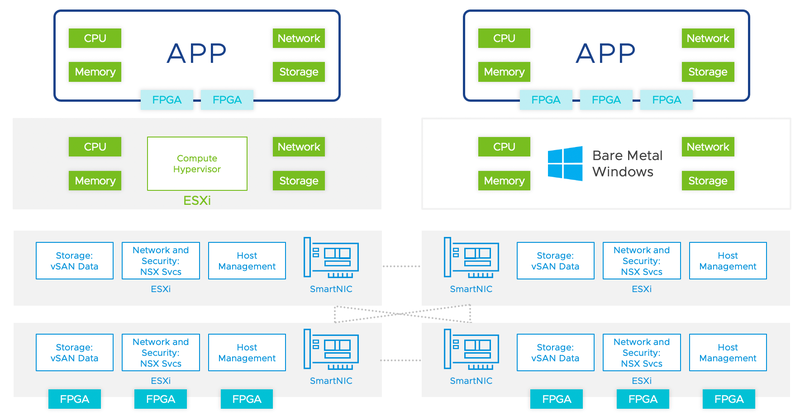
Новое видение кластера по версии VMware: каждый процессор и сопроцессор занят своим делом Как считает VMware, такой подход кардинально изменит архитектуру и экономику ЦОД нового поколения. На это есть основания, ведь если объединить пару 64-ядерных процессоров AMD EPYC второго поколения с сетевым ускорителем или DPU, работающим под управлением ESXi в составе единой платформы vSphere, то эту систему можно будет с полным правом назвать «ЦОД в коробке». Такое сочетание позволит запускать множество виртуальных машин с достаточным уровнем производительности, ведь основным x86-процессорам не придётся вывозить на себе виртуализацию сети, функционирование файрволлов и задачи класса data storage. Пока Project Monterey имеет статус «технологического демо», но сама идея дизагрегации серверов, над которой продолжает работу VMware, выглядит логичной и законченной. Каждый процессор будет выполнять ту задачу, к которой он лучше всего приспособлен, но за счёт единой системы виртуализации платформа не будет выглядеть сегментировано, и разработка ПО не усложнится. Кроме того, VMware уже подтвердила возможность запуска на SmartNIC и DPU приложений сторонних разработчиков, так что лёд явно тронулся. |
|

