Материалы по тегу: ethernet
|
02.06.2026 [16:29], Сергей Карасёв
Marvell представила чип-коммутатор Teralynx T100 на 102,4 Тбит/с для ИИ ЦОДКомпания Marvell анонсировала чип-коммутатор Teralynx T100 для дата-центров и облачных платформ, ориентированных на ресурсоёмкие ИИ-нагрузки. Изделие обеспечивает пропускную способность до 102,4 Тбит/с, а его пробные поставки начнутся в текущем квартале. Marvell подчёркивает, что в отличие от традиционных коммутационных платформ, предназначенных для обычных корпоративных и облачных дата-центров, Teralynx T100 разработан с нуля для ИИ-нагрузок. Новинка будет предлагаться в различных вариантах исполнения, включая BGA, CPC и CPO. При изготовлении чипа применяется 3-нм технология. Разработчик заявляет, что из конструкции исключены устаревшие элементы, увеличивающие энергопотребление и площадь кристалла. В результате, изделие обеспечивает до 25 % меньшее энергопотребление по сравнению с конкурирующими решениями: показатель не превышает 1000 Вт. Это важно, поскольку на коммутационные и прочие сетевые компоненты может приходиться 15–25 % от общей мощности серверной стойки. Таким образом, повышение энергоэффективности коммутаторов оказывает значительное влияние на работу ЦОД в целом. 
Источник изображения: Marvell Teralynx T100 поддерживает 512-портовую архитектуру. Marvell подчёркивает, что новинка обеспечивает исключительную эффективность использования полосы пропускания, благодаря чему помогает в устранении узких мест в современных крупномасштабных кластерах ИИ. Нужно отметить, что ранее чип-коммутатор с пропускной способностью 102,4 Тбит/с представила компания Cisco: изделие получило название Silicon One G300. Кроме того, Broadcom выпустила платформу с интегрированной оптикой CPO (Co-Packaged Optics) третьего поколения Tomahawk 6 — Davisson (TH6-Davisson), которая также относится к классу 102,4 Тбит/с. Аналогичные решения есть у NVIDIA в серии Spectrum-X.
15.05.2026 [08:38], Сергей Карасёв
Сетевой протокол Multipath Reliable Connection (MRC) улучшит производительность и надёжность ИИ-кластеровOpenAI в партнёрстве с AMD, Broadcom, Intel, Microsoft и NVIDIA анонсировала технологию Multipath Reliable Connection (MRC) — сетевой протокол, призванный повысить производительность и отказоустойчивость масштабных GPU-кластеров, ориентированных на ресурсоёмкие задачи ИИ. MRC уже используется во всех крупных кластерах OpenAI c NVIDIA GB200, в том числе в первом ЦОД Stargate, а также в ЦОД Microsoft по проекту Fairwater. Отмечается, что при обучении больших языковых моделей (LLM) каждый этап предполагает огромное количество пересылок данных между узлами в кластере. При этом единственная задержка при подобных транзакциях может повлиять на весь процесс, потенциально провоцируя простои тысяч ИИ-ускорителей. Такие прерывания приводят к снижению эффективности использования имеющихся вычислительных мощностей и к увеличению временных затрат. Наиболее распространёнными причинами задержек и нестабильности при передаче данных являются перегрузка сети, сбои в работе каналов связи и коммутационных устройств. Причём по мере увеличения масштабов кластеров проблемы усугубляются: неполадки возникают всё чаще, а их устранение становится более затруднительным. Протокол MRC, как утверждается, устраняет ряд ключевых недостатков сетей Ethernet применительно к инфраструктурам ИИ. В частности, вводятся такие механизмы, как адаптивная многопутевая передача данных, многоканальные перекрёстные Ethernet-фабрики, «распыление» пакетов, быстрое восстановление после сбоев и пр. MRC коренным образом меняет способ передачи трафика по сети. 
Источник изображений: OpenAI Традиционные платформы RoCE обычно привязывают поток данных к одному сетевому пути, что может снижать эффективность при возникновении неполадок. MRC же распределяет пакеты из одной серии одновременно по сотням путей и нескольким физическим сетевым каналам. В пакетах содержатся сведения об их конечном назначении, что позволяет ускорителям размещать данные в нужной последовательности, даже если пакеты поступают не по порядку. MRC хранит информацию о состоянии множества используемых путей: если обнаруживается перегрузка какого-либо из них, выбирается альтернативный маршрут, что позволяет оперативно перераспределить нагрузку по всей сети. 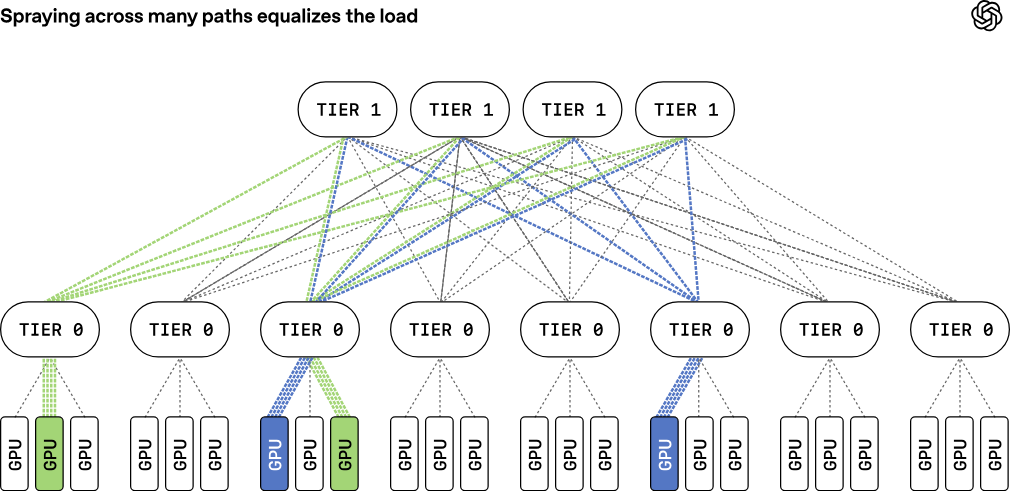 Ещё одной важной особенностью MRC является многоуровневая архитектура, которая изменяет саму физическую концепцию построения интерконнекта. Так, например, сетевой интерфейс 800GbE может быть разделён на 100GbE-каналы, связанные с восемью различными коммутаторами отдельными каналами. В результате можно построить восемь отдельных параллельных сетей. Такой подход оказывает значительное влияние на структуру кластера. В частности, коммутатор c 64 портами 800GbE можно использовать в конфигурации на 512 × 100GbE. И это позволяет построить сеть, объединяющую около 131 тыс. GPU, используя всего два уровня коммутации, против традиционных трёх- или четырёхуровневых топологий. 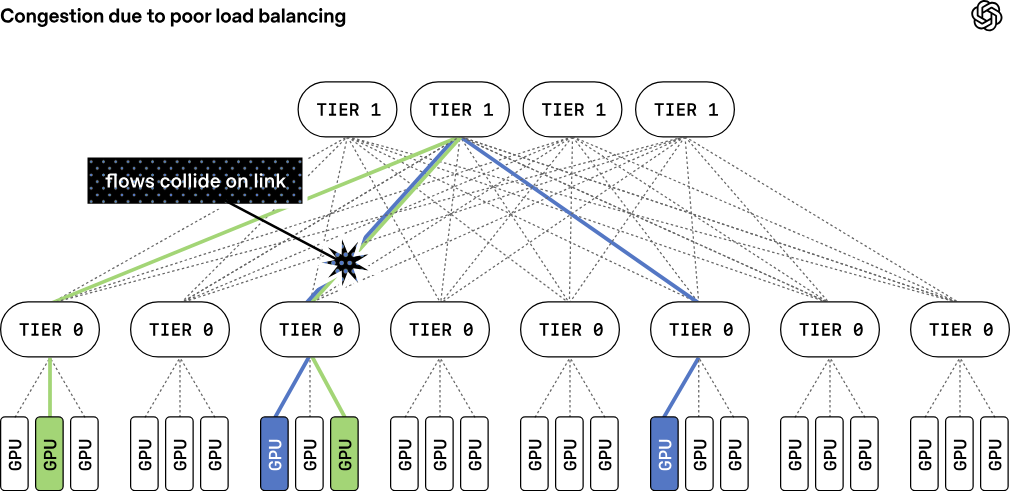 В протоколе MRC также используется новый способ обработки перегрузок и потери пакетов в сетях Ethernet. Обычно применяется технология PFC (Priority Flow Control) — управление потоками на основе приоритетов: этот механизм предполагает приостановку передачи данных для конкретных классов трафика, а не для всего порта целиком. В случае MRC задействован иной подход, основанный на выборочных подтверждениях, явных запросах на повторную передачу и обрезке пакетов. Так, когда коммутатор сталкивается с перегрузкой, он может отрезать полезную нагрузку и переслать в пункт назначения только заголовок пакета, что позволяет получателю быстро идентифицировать отсутствующие данные и запросить повторную передачу. Утверждается, что это даёт возможность восстанавливаться после сбоев и перегрузок в течение микросекунд, что на порядки быстрее по сравнению с обычными архитектурами. 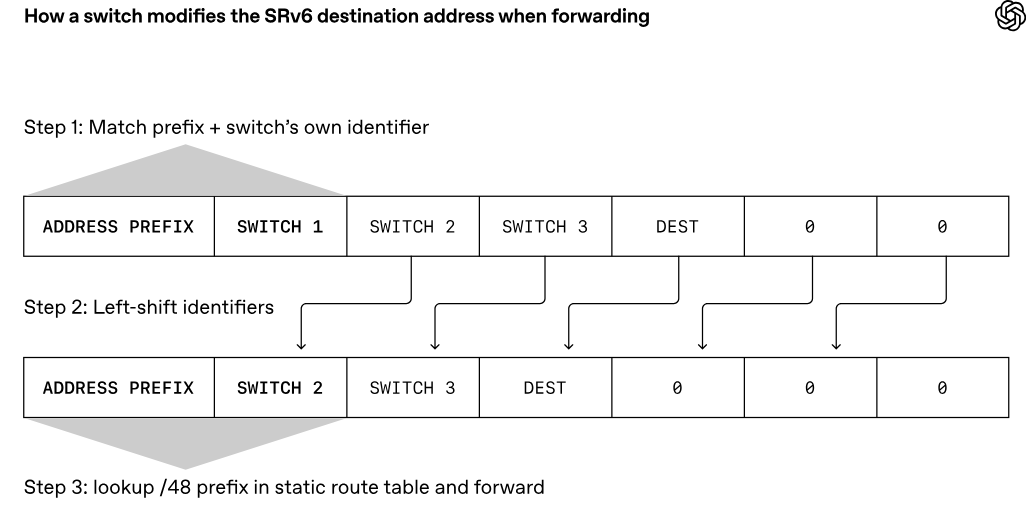 С внедрением MRC сокращается необходимость в динамической маршрутизации. Если пакеты теряются на каком-либо пути, система на основе MRC просто перестаёт использовать этот путь. Вместо динамической маршрутизации применяется так называемая сегментная маршрутизация IPv6 (IPv6 Segment Routing, SRv6), которая позволяет отправителю напрямую задать путь прохождения пакета, прописав последовательность идентификаторов коммутаторов. При пересылке данных коммутатор проверяет наличие собственного идентификатора. Если он присутствует, он удаляет из пакета свой идентификатор и ищет следующий за ним идентификатор в статической таблице маршрутизации, которая указывает, куда необходимо отправить пакет данных. 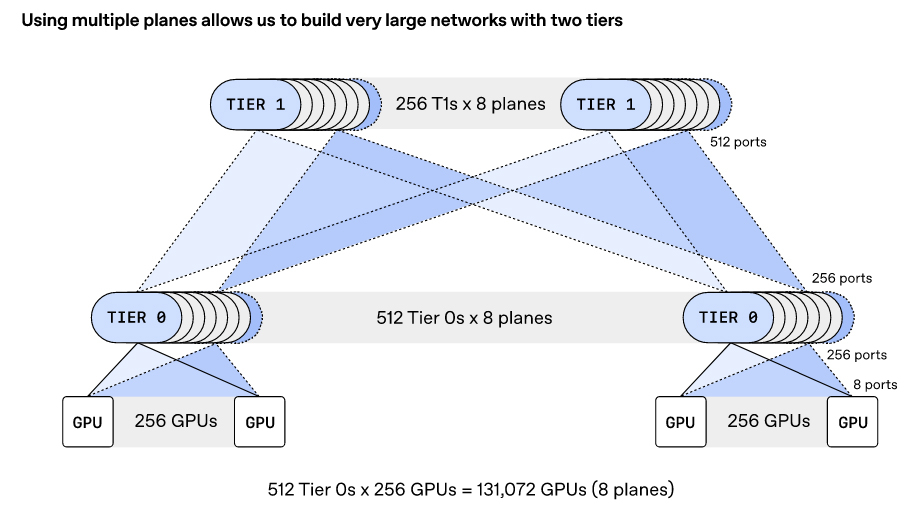 В отличие от динамической маршрутизации, такая статическая таблица формируется при первой настройке коммутатора и в дальнейшем не изменяется. MRC использует SRv6 для передачи пакетов по всем физическим каналам и уровням, а также по множеству путей в каждом из них. Если какой-либо путь становится недоступен, система игнорирует его. При этом коммутаторам не нужно пересчитывать маршруты или выполнять другие действия, кроме как строго следовать статическим маршрутам, заложенным в таблице. 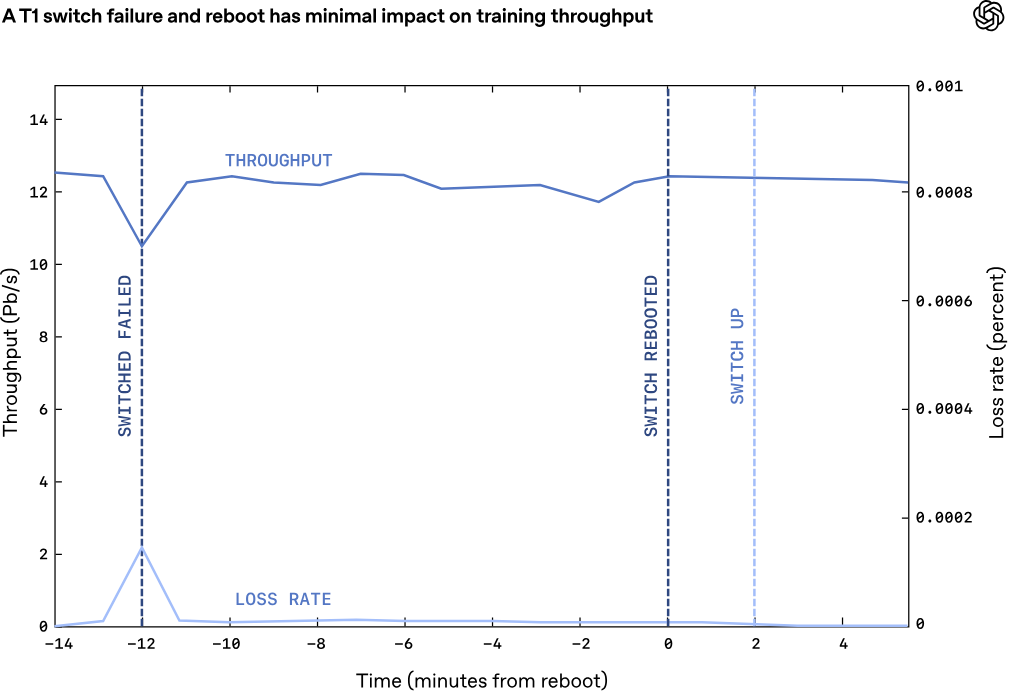 Протокол MRC выпущен в рамках проекта OCP. В целом, как отмечается, MRC обеспечивает три ключевых преимущества перед стандартными Ethernet-сетями для кластеров ИИ. Во-первых, MRC позволяет создавать многоуровневые высокоскоростные инфраструктуры для платформ с более чем 131 072 конечных точек, используя всего два уровня коммутаторов. Во-вторых, адаптивное распределение пакетов обеспечивает эффективную балансировку нагрузки, благодаря чему практически отсутствуют перегрузки в ядре сети. В-третьих, применение SRv6 обеспечивает быстрый обход сбоев и отправку пакетов только по работающим путям.  Компания Broadcom заявила, что её сетевые адаптеры Thor Ultra, а также коммутаторы Tomahawk 5 и Tomahawk 6 изначально поддерживают функциональность MRC. В частности, Thor Ultra позволяет использовать 2, 4 или 8 параллельных сетей на одном порту и распределять трафик одновременно по 128 каналам. При этом Tomahawk 5 обеспечивает коммутационную способность до 51,2 Тбит/с, а Tomahawk 6 — до 102,4 Тбит/с. В свою очередь, NVIDIA отмечает, что протокол MRC, будучи расширением RoCE, совместим с решениями Spectrum-X Ethernet. OpenAI уже использовала MRC при обучении нескольких ИИ-моделей, задействовав коммутаторы Broadcom и NVIDIA. Конкуренцию MRC составляет схожий во многих аспектах Ultra Ethernet.
14.04.2026 [12:44], Владимир Мироненко
Panmnesia привлёк $10 млн на разработку интерконнекта следующего поколения для ИИ ЦОДЮжнокорейский стартап Panmnesia, специализирующийся на разработке интерконнекта для ИИ-инфраструктур, сообщил о получении финансирования в размере около $10 млн на разработку интерконнекта следующего поколения для ИИ ЦОД. Проект включает разработку контроллеров и коммутаторов на основе открытых стандартов, таких как UALink и протоколов интерконнекта на основе Ethernet. Уже имея обширный портфель продуктов CXL, Panmnesia теперь расширяет свою деятельность в области интерконнекта, ориентированного на ускорители. Компания отметила, что по мере распространения крупномасштабных ИИ-моделей в различных отраслях, ИИ ЦОД всё чаще полагаются на ИИ-ускорители разных вендоров. В этом контексте технологии интерконнекта, обеспечивающие высокоскоростную передачу данных между ускорителями, стали критически важным фактором, определяющим общую производительность ИИ-системы. 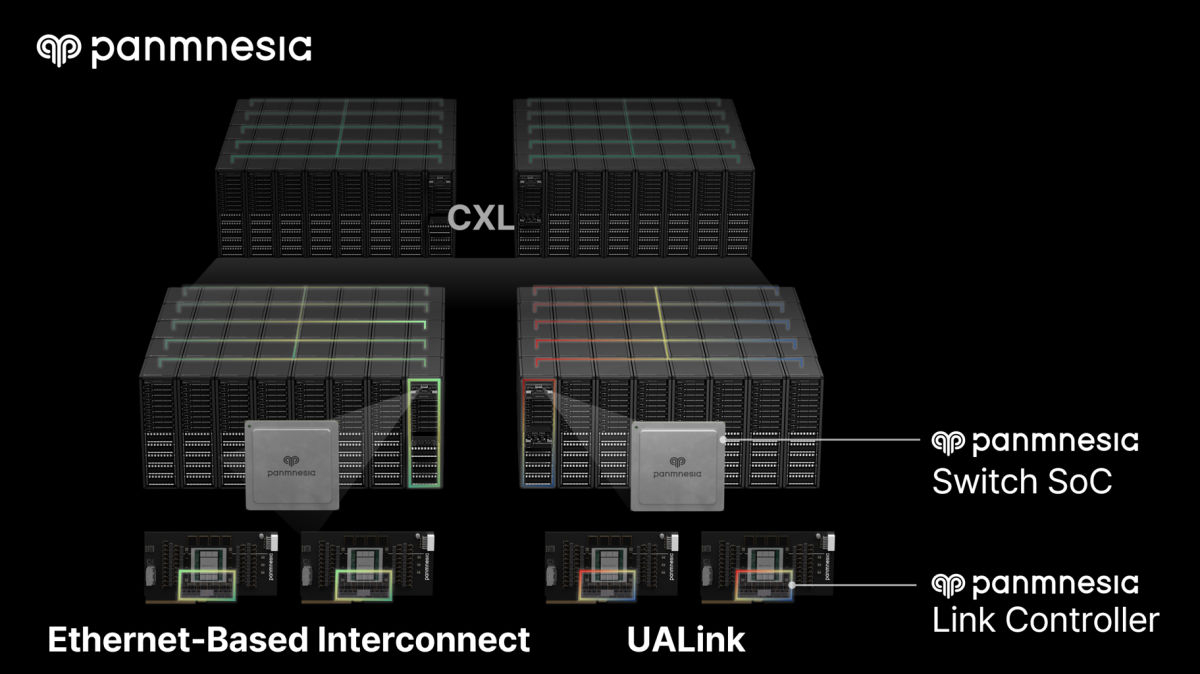
Источник изображений: Panmnesia Также Panmnesia планирует оптимизировать топологию разработанных устройств для ускорения обмена данными между ними и провести валидацию на уровне стойки. Ожидается, что чип-коммутатор с поддержкой интерконнекта, ориентированного на ускорители, такого как UALink, станет доступен во II половине 2027 года.  Портфолио продуктов CXL компании включает комплексные решения, в том числе контроллеры и IP-блоки PCIe/CXL, аппаратные SoC, такие, как коммутаторы PCIe/CXL, и специализированные кремниевые решения. В прошлом году Panmnesia представила архитектуру CXL-over-XLink, которая интегрирует специализированные каналы связи для ускорителей (известные как XLink), включая UALink, с CXL для обеспечения расширенной связи в крупных ИИ ЦОД.
13.04.2026 [13:05], Сергей Карасёв
Aria Networks представила «думающую» сетевую платформу Deep Networking для высокоэффективных ИИ-инфраструктурКомпания Aria Networks анонсировала сетевую платформу Deep Networking, призванную повысить эффективность работы ИИ-систем. Предложенное решение объединяет специализированное коммутационное оборудование, сетевую ОС SONiC, высокоточную телеметрию на коммутаторах, трансиверах и сетевых картах, а также ИИ-алгоритмы на разных уровнях вычислительной инфраструктуры. Стартап Aria Networks основан в январе 2025 года Мансуром Карамом (Mansour Karam), учредителем фирмы Apstra, которую в 2019-м приобрёл американский производитель сетевого оборудования Juniper Networks. Aria Networks занимается разработкой высокопроизводительных решений, сочетающих возможности стандартного Ethernet со специализированным ПО для управления большим количеством модульных коммутаторов как единой системой. На сегодняшний день стартап привлёк в общей сложности $125 млн инвестиций от Sutter Hill Ventures, Atreides Management, Valor Equity Partners и Eclipse Ventures. Идея Deep Networking заключается в том, чтобы рассматривать сеть в качестве активного участника кластера ИИ, а не в роли пассивного слоя. Это достигается путём сбора детальной телеметрии с коммутационных ASIC, внедрения интеллектуальных агентов на каждом уровне и постоянного распространения обновлений ПО через облако. 
Источник изображений: Aria Networks В качестве ключевых показателей быстродействия Aria Networks рассматривает MFU (уровень утилизации оборудования при обучении) и Token Efficiency (эффективность токенов). Первый параметр отражает, какой процент от теоретической максимальной производительности ИИ-ускорителя (пиковых FLOPS) реально тратится на полезные вычисления для обучения или инференса. В свою очередь, эффективность токенов показывает, уровень MFU или время на обработку одного токена. Основное техническое преимущество Deep Networking заключается в получении детализированной телеметрии. Традиционные инструменты мониторинга сети собирают данные постфактум — с относительно невысокой точностью. Решение Aria Networks обрабатывает телеметрию в реальном времени непосредственно с ASIC. Благодаря этому обеспечивается адаптивная настройка параметров DLB (динамическая балансировка нагрузки) и DCQCN (механизм управления перегрузками).  Сама платформа Deep Networking имеет многоуровневую архитектуру. На самых нижних уровнях ИИ-агенты в течение микросекунд реагируют на такие события, как сбои в работе трансиверов, перенаправляя трафик между коммутаторами. На более высоких уровнях принимаются стратегические решения о перераспределении потоков в кластере. Кроме того, внешние системы, например, планировщики заданий и маршрутизаторы, могут напрямую запрашивать сведения о состояние сети и интегрировать их в процесс принятия собственных решений. С аппаратной точки зрения инфраструктура Deep Networking базируется на коммутаторах Aria Switch 800G, Aria Switch 1.6T High Radix и Aria Switch 1.6T, оснащённых чипами Broadcom. Платформа непрерывно настраивает каждый аспект сетевой инфраструктуры для конкретного обслуживаемого ИИ-кластера без ручного вмешательства, что сводит к минимуму задержки и устраняет ошибки, обусловленные человеческим фактором. Администраторам достаточно указать свои потребности, после чего платформа соответствующим образом оптимизирует сеть. При этом система постоянно оценивает состояние сети и в режиме реального времени принимает меры для обеспечения наилучшей производительности и бесперебойной работы.  Aria Networks утверждает, что один неисправный сетевой адаптер в кластере из 10 тыс. XPU может снизить показатель MFU на 1,7 %. А сбой трансивера способен спровоцировать некорректную переадресацию трафика, что приведёт к существенным финансовым потерям. Архитектура Deep Networking позволяет эффективно решать подобные проблемы, одновременно улучшая производительность. Так, повышение MFU на 3 % в кластере из 10 тыс. XPU, по оценкам стартапа, приводит к увеличению годовой выручки на $49,8 млн.
27.03.2026 [21:04], Руслан Авдеев
«Не хотите ускорители? Возьмите хотя бы сеть!» — NVIDIA открыла свои ИИ-стойки для чужих чиповNVIDIA занялась разработкой серверных стоек, подходящих для решений на основе сторонних ИИ-ускорителей, сообщает The Information со ссылкой на знакомые с вопросом источники. Компания стремится остаться ключевым игроком на рынке ИИ-систем даже по мере того, как всё больше её клиентов разрабатывают решения, прямо конкурирующие с продуктами самой NVIDIA. На прошлой неделе компания представила новые стойки MGX ETL, специально разработанные для поддержки чипов как самой NVIDIA, так и поставщиков-конкурентов. Система основана на модульной архитектуре MGX (OCP), представленной в 2023 году и уже довольно распространённой. ETL предполагает использование сетевых решений NVIDIA Spectrum-X. Таким образом, «зелёные» чипы всё равно оказываются в инфраструктуре, даже если она базируется на сторонних решениях. Похожим образом компания развивает и фирменный интерконнект NVLink. NVLink Fusion можно интегрировать в другие чипы, что опять-таки даёт NVIDIA возможность заработать на чужих ИИ-системах. Но в случае ETL применяются широко поддерживаемые в индустрии стандарты Ethernet, что снижает для клиентов «порог вхождения» при внедрении оборудования NVIDIA. Модульный дизайн позволяет облачным гиперскейлерам одновременно использовать ускорители разных производителей, при этом оставаясь в сетевой и программной экосистемах NVIDIA. 
Источник изображения: NVIDIA NVIDIA позиционировала MGX как открытую «эталонную» архитектуру, не мешающую партнёрам использовать альтернативные компоненты. Гибкость также позволяет NVIDIA «проложить дорогу» на китайский рынок, где компании смогут применять со стойками NVIDIA чипы домашней разработки. Новый дизайн стоек также может помочь NVIDIA устранить обеспокоенность регуляторов практикой, когда компания связывала использование сетевого оборудования с определёнными ИИ-чипами. На этом фоне происходит ужесточение конкуренции на рынке технологий интерконнектов. Открытый стандарт UALink позиционируется как альтернатива NVLink и призван обеспечить высокоскоростную связь между ИИ-чипами без применения проприетарных технологий. Параллельно развивается и открытый стандарт Ultra Ethernet, который призван конкурировать и с технологией Infiniband, фактически единолично контролируемой NVIDIA. Сетевые решения являются чрезвычайно важной частью бизнеса NVIDIA. По итогам последнего квартала выручка компании в этом сегменте достигла $10,98 млрд (а за год все $31 млрд) — она выросла год к году на 268 % и составила более 15 % от всей выручки компании. При этом значительная часть сетевого оборудования продаётся не сама по себе, а в составе платформенных решений NVIDIA.
04.03.2026 [10:20], Сергей Карасёв
Intel представила сетевой адаптер E830-XXVDA4F с четырьмя портами 10/25GbEIntel продемонстрировала сетевой адаптер E830-XXVDA4F. Новинка получила однослотовое исполнение. Для установки требуется разъём PCIe 4.0 x16. Реализованы четыре порта 10/25Gb SFP28. Применено пассивное охлаждение с крупным радиатором. Заявлена совместимость с Red Hat Enterprise Linux, SUSE Linux Enterprise Server, Ubuntu, Debian 11, openEuler, а также с Windows Server. Прочие технические характеристики пока не раскрываются. В продажу сетевой адаптер E830-XXVDA4F поступит в текущем году. Он будет предлагаться в том числе в составе серверного оборудования НР. Нужно отметить, что ранее Intel анонсировала другие сетевые адаптеры семейства E830 — двухпортовые решения 25GbE PCIe и OCP 3.0. Они оптимизированы для высокоплотных виртуализированных рабочих сред. Реализованы такие функции, как PTM (Precision Time Measurement), 1588 PTP, SyncE и GNSS.  «В современном мире сетевые технологии играют важнейшую роль в развитии бизнеса и цифровой трансформации. Выпуская продукты Intel Ethernet E830, мы помогаем клиентам удовлетворять растущий спрос на высокопроизводительные и энергоэффективные решения, которые позволяют оптимизировать сетевую инфраструктуру, снизить эксплуатационные расходы и улучшить общую стоимость владения», — говорит Боб Гаффари (Bob Ghaffari), вице-президент Intel.
10.02.2026 [12:09], Сергей Карасёв
Стартап Aheesa создал первый в Индии чип RISC-V для PON-сетейИндийский безфабричный стартап Aheesa Digital Innovations, по сообщению EE Times, завершил разработку первой в стране «системы на чипе» (SoC) с архитектурой RISC-V, ориентированной на волоконно-оптические сети широкополосного доступа в интернет. Изделие получило обозначение VIHAAN-I. Новинка предназначена для инфраструктур GPON (Gigabit Passive Optical Network) и EPON (Ethernet Passive Optical Network). Решение объединяет на одном кристалле вычислительные ресурсы, средства управления и широкополосного доступа. VIHAAN-I является частью платформы Aheesa Seshnag. В состав новинки входит RISC-V-ядро C-DAC Vega. Реализована поддержка памяти DDR4 и SPI NOR, флеш-карт SD и microSD, а также интерфейса xPON. Заявлена совместимость с Ethernet-стандартами 10BASE-TE, 100BASE-TX, 100BASE-FX и 1000BASE-T. Изделие объединяет многопортовый гигабитный Ethernet и прямое оптоволоконное соединение. Среди прочего упомянуты интерфейсы USB и PCIe (четыре линии) с возможностью использование модулей M.2 и mini-PCIe. Кроме того, предусмотрена интегрированная поддержка голосовой связи. SoC будет производиться на предприятии UMC с применением 28-нм технологии. 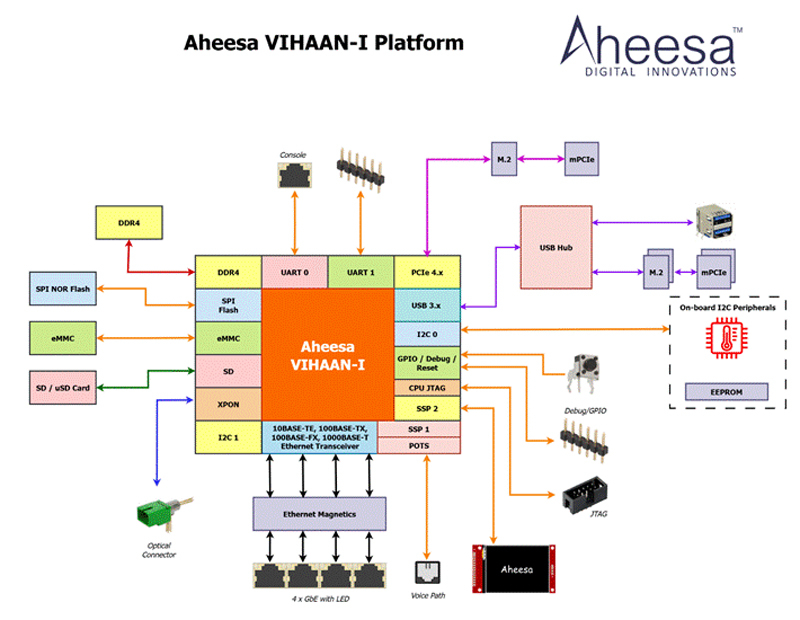
Источник изображения: Aheesa Digital Innovations / EE Times Выбор архитектуры RISC-V, как заявляет Aheesa Digital Innovations, обусловлен прежде всего соображениями безопасности. Поддерживаются стандартные сетевые функции, такие как коммутация Ethernet, маршрутизация, службы межсетевого экрана, VPN, протокол динамической конфигурации хоста и пр. Примерно на 60% решение состоит из стандартных лицензированных компонентов, таких как контроллеры памяти и интерфейсные блоки. Заявлена совместимость с последними версиями ядра Linux. Aheesa Digital Innovations основана в 2021 году Шридхараном Мани (Sridharan Mani), который занимает пост генерального директора. Компания получила поддержку в рамках индийской программы стимулирования разработок. Стартап сотрудничает с рядом государственных учреждений, включая Министерство электроники и информационных технологий (MEITy) и Центр развития передовых вычислительных технологий (C-DAC). Aheesa Digital Innovations намерена предлагать свои решения OEM- и ODM-производителям, системным интеграторам и дистрибьюторам, которые поставляют устройства телекоммуникационным операторам. В дальнейшем стартап планирует активно развивать семейство собственных SoC. В частности, готовятся решения с поддержкой 10GbE и Wi-Fi 7.
06.02.2026 [11:30], Сергей Карасёв
102,4 Тбит/с и СЖО: Aria Networks представила коммутаторы на платформе Broadcom Tomahawk 6 для ИИ-инфраструктурСтартап Aria Networks, базирующийся в Санта-Кларе (Калифорния, США), вышел из скрытого режима, анонсировав высокопроизводительные коммутаторы для крупномасштабных кластеров ИИ. В основу устройств положена аппаратная платформа Broadcom Tomahawk 6 (TH6). В новое семейство вошли три модели: Aria Tomahawk 6 (High Radix), Aria Tomahawk 6 (Liquid) и Aria Tomahawk 6 (Air). Все они обеспечивают суммарную коммутационную способность до 102,4 Тбит/с. Разработчик заявляет, что устройства могут применяться в составе ИИ-платформ с любыми типами ускорителей, будь то GPU NVIDIA и AMD, тензорные чипы или специализированные решения вроде Cerebras. 
Источник изображения: Aria Networks Модель Aria Tomahawk 6 (Air) выполнена в форм-факторе 4U и оборудована воздушным охлаждением. Задействованы 512 блоков SerDes 200G. Коммутатор располагает 64 портами с пропускной способностью 1,6 Тбит/с каждый. Модификация Aria Tomahawk 6 (Liquid) имеет аналогичные технические характеристики, но заключена в 2U-корпус с жидкостным охлаждением. Наконец, вариант Aria Tomahawk 6 (High Radix) типоразмера 4U использует 1024 блока SerDes 100G. Устройство оборудовано 128 портами 800GbE; применяется воздушное охлаждение. На базе этого коммутатора могут формироваться кластеры с простой двухуровневой топологией, насчитывающие до 32 тыс. ИИ-ускорителей. Компания Aria Networks основана Мансуром Карамом (Mansour Karam), учредителем фирмы Apstra, которую в 2019 году приобрёл американский производитель сетевого оборудования Juniper Networks. Стартап Aria Networks фокусируется на разработке высокопроизводительных решений, сочетающих возможности стандартного Ethernet со специализированным программным уровнем, позволяющим управлять большим количеством модульных коммутаторов как единой системой. Утверждается, что этот унифицированный программный слой оптимизирует производительность и гарантирует надёжность инфраструктуры. Для эффективного управления коммутаторами применяются ИИ-алгоритмы.
22.01.2026 [16:04], Владимир Мироненко
Upscale AI привлёк $200 млн для запуска ИИ-интерконнекта и коммутатора SkyHammerСтартап Upscale AI, специализирующий на разработке ИИ-интерконнекта, объявил о привлечении $200 млн в рамках раунда финансирования серии А. С учётом предыдущего раунда общая сумма инвестиций в Upscale AI достигла $300 млн, а оценка его рыночной стоимости превысила $1 млрд, что придало ему статус «единорога». Это большая сумма для любой технологической компании со 150 сотрудниками, большинство из которых инженеры. Раунд серии А возглавили Tiger Global, Premji Invest и Xora Innovation, также в нём приняли участие Maverick Silicon, StepStone Group, Mayfield, Prosperity7 Ventures, Intel Capital и Qualcomm Ventures. Upscale AI отметил, что поддержка инвесторов отражает растущее в отрасли мнение, что сети являются критически узким местом для масштабирования ИИ, а традиционные сетевые архитектуры, предназначенные для соединения вычислительных ресурсов общего назначения и хранилищ, принципиально не подходят для эпохи ИИ. Устаревшие сетевые решения для ЦОД были разработаны до появления ИИ, и слабо подходят для масштабного, синхронизированного масштабирования на уровне стоек. Когда Upscale AI был основан в начале 2024 года, консорциум UALink и стандарт ESUN, предложенный Meta✴ Platforms, ещё не были обнародованы, но идея гетерогенной инфраструктуры, безусловно, уже была, отметил ресурс The Next Platform. Созданная Upscale AI платформа объединяет GPU, ИИ-ускорители, память, хранилище и сетевые возможности в единый синхронизированный ИИ-движок. Для этого стартап разработал ASIC SkyHammer, который поддерживает ESUN, UALink, Ultra Ethernet, SONiC и Switch Abstraction Interface (SAI). Фактически Upscale AI хочет составить конкуренцию NVIDIA NVSwitch, дав возможность выбора интерконнекта при создании ИИ-инфраструктур. 
Источник изображения: Upscale AI Upscale AI сообщил, что благодаря дополнительному финансированию представит первую полнофункциональную, готовую к использованию платформу, охватывающую кремниевые компоненты, системы и ПО. Также полученные средства будут направлены на расширение инженерных, торговых и операционных команд по мере перехода к коммерческому внедрению решения. По словам Арвинда Шрикумара (Arvind Srikumar), старшего вице-президента по продуктам и маркетингу компании, поставки образцов SkyHammer клиентам начнутся в конце 2026 года, а массовые поставки — в 2027 году, когда в это же время выйдут новые поколения GPU, XPU, коммутаторов и стоек. Коммутаторы должны быть у OEM/ODM-производителей за два квартала до того, как вычислительные ядра будут готовы к поставкам, чтобы они могли собрать системы и протестировать их. «Я всегда считал, что гетерогенные вычисления — это правильный путь, и гетерогенные сети — это тоже правильный путь», — сообщил Шрикумар изданию The Next Platform. Он отметил, что Upscale AI фокусируется на демократизации интерконнекта для ИИ. Шрикумар признал, что у NVIDIA отличные технологии, и что это «потрясающая» компания, когда дело касается инноваций. Вместе с тем он считает, что в будущем, с учётом темпов развития ИИ, вряд ли одна компания сможет предоставить все необходимые технологии для ИИ. Шрикумар считает, что PCIe-коммутация хорошо работает, когда несколько СPU взаимодействуют с несколькими GPU, относительная пропускная способность памяти GPU довольно низкая, а СPU и GPU расположены довольно близко друг к другу в серверном узле. В то же время Upscale AI скептически относится к попыткам создания коммутаторов UALink, ESUN или SUE путем использования ASIC-чипов для PCIe или путём извлечения начинки ASIC-чипов Ethernet-коммутаторов. «Те, кто давно занят в сфере ASIC, знают, что можно удалить много блоков, но основные элементы остаются прежними. Базовая ДНК каждого ASIC остается неизменной», — отметил Шрикумар. Поэтому в Upscale AI решили создать ASIC с нуля, а затем обеспечить поддержку протоколов семантики памяти по мере их появления.
15.12.2025 [12:11], Сергей Карасёв
Квартальные продажи Ethernet-коммутаторов подскочили на треть благодаря спросу со стороны ЦОДКомпания International Data Corporation (IDC) подсчитала, что в III квартале уходящего года объём мирового рынка Ethernet-коммутаторов корпоративного класса достиг $14,7 млрд: это на 35,2 % больше по сравнению с аналогичным периодом 2024-го. Вместе с тем продажи маршрутизаторов для предприятий и поставщиков услуг увеличились на 15,8 % в годовом исчислении — до $3,6 млрд. Значительная положительная динамика обусловлена прежде всего развитием сегмента дата-центров. Гиперскейлеры и крупные облачные провайдеры активно закупают сетевое оборудование на фоне стремительного внедрения ИИ, которое сопровождается расширением инфраструктуры ЦОД. Поставки Ethernet-коммутаторов для дата-центров в денежном выражении выросли на 62,0 % по отношению к III четверти 2024 года. Выручка от устройств стандарта 800GbE подскочила на 91,6 % в квартальном исчислении, а их доля в общем объёме ЦОД-рынка составила 18,3 %. Продажи решений 200/400GbE взлетели на 97,8 % в годовом исчислении: на них приходится 43,9 % от общей выручки в сегменте дата-центров. В категории Ethernet-коммутаторов, не связанных с ЦОД, продажи за год поднялись на 8,2 %. Выручка от поставок решений 1GbE выросла на 1,2 %, 10GbE — на 14,3 %, 25/50GbE — на 20,9 % по сравнению с III кварталом 2024-го. 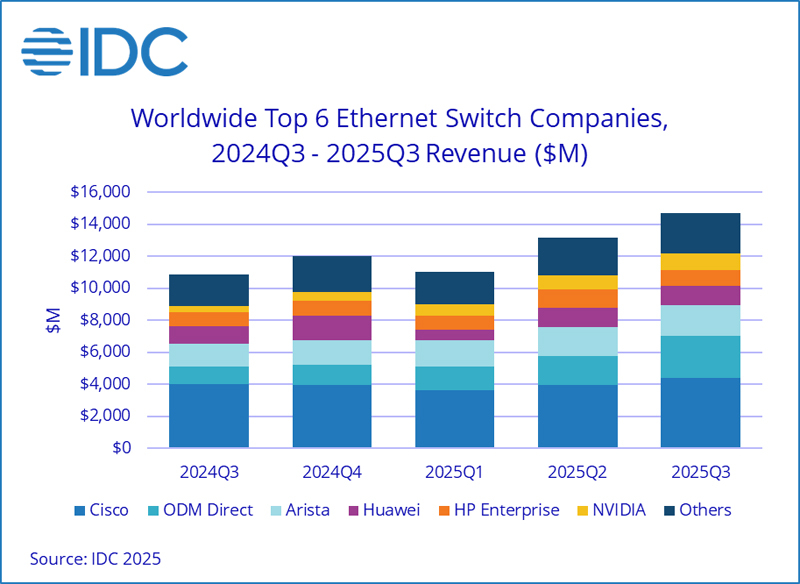
Источник изображения: IDC С географической точки зрения в Северной и Южной Америке рынок коммутаторов Ethernet в целом расширился на 41,6 %, чему способствовал активный рост в дата-центрах США. В регионе EMEA (Европа, Ближний Восток и Африка) продажи поднялись на 24,7 % в годовом исчислении, в Азиатско-Тихоокеанском регионе — на 32,7 %. В рейтинг крупнейших поставщиков коммутаторов Ethernet в глобальном масштабе входят Cisco, Arista Networks, HPE, NVIDIA и Huawei с долями соответственно 29,8 %, 12,8 %, 12,5 %, 11,6 % и 8,2 %. Отмечается, что выручка NVIDIA на рынке Ethernet-коммутаторов за год взлетела на 167,7 %. В секторе маршрутизаторов на поставщиков услуг пришлось 74,0 % от общего объёма выручки с ростом на 20,2 % в годовом исчислении. Корпоративное направление принесло 26,0 % продаж, показав прибавку на уровне 4,7 %. В региональном плане поставки маршрутизаторов в Северной и Южной Америке поднялись на 31,5 % в годовом исчислении, в Азиатско-Тихоокеанском регионе — на 7,7 %, а в регионе EMEA — на 3,5 %. |
|

