Компания Broadcom анонсировала чип-коммутатор Tomahawk Ultra, специально разработанный для кластеров НРС и платформ ИИ. Новинка, как ожидается, составит конкуренцию InfiniBand в традиционных суперкомпьютерах, NVLink в стоечных решениях вроде NVIDIA GB200 NVL72, а также Ultra Accelerator Link (UALink) в масштабируемых системах ИИ в дата-центрах.
Решение Tomahawk Ultra разработано в рамках инициативы Broadcom Scaling Up Ethernet (SUE). Утверждается, что эта технология будет поддерживать масштабируемые системы с не менее чем 1024 ускорителями ИИ. Для сравнения, NVIDIA заявляет, что её коммутационная система NVLink 5/6 позволяет объединить до 576 ускорителей в одном домене.
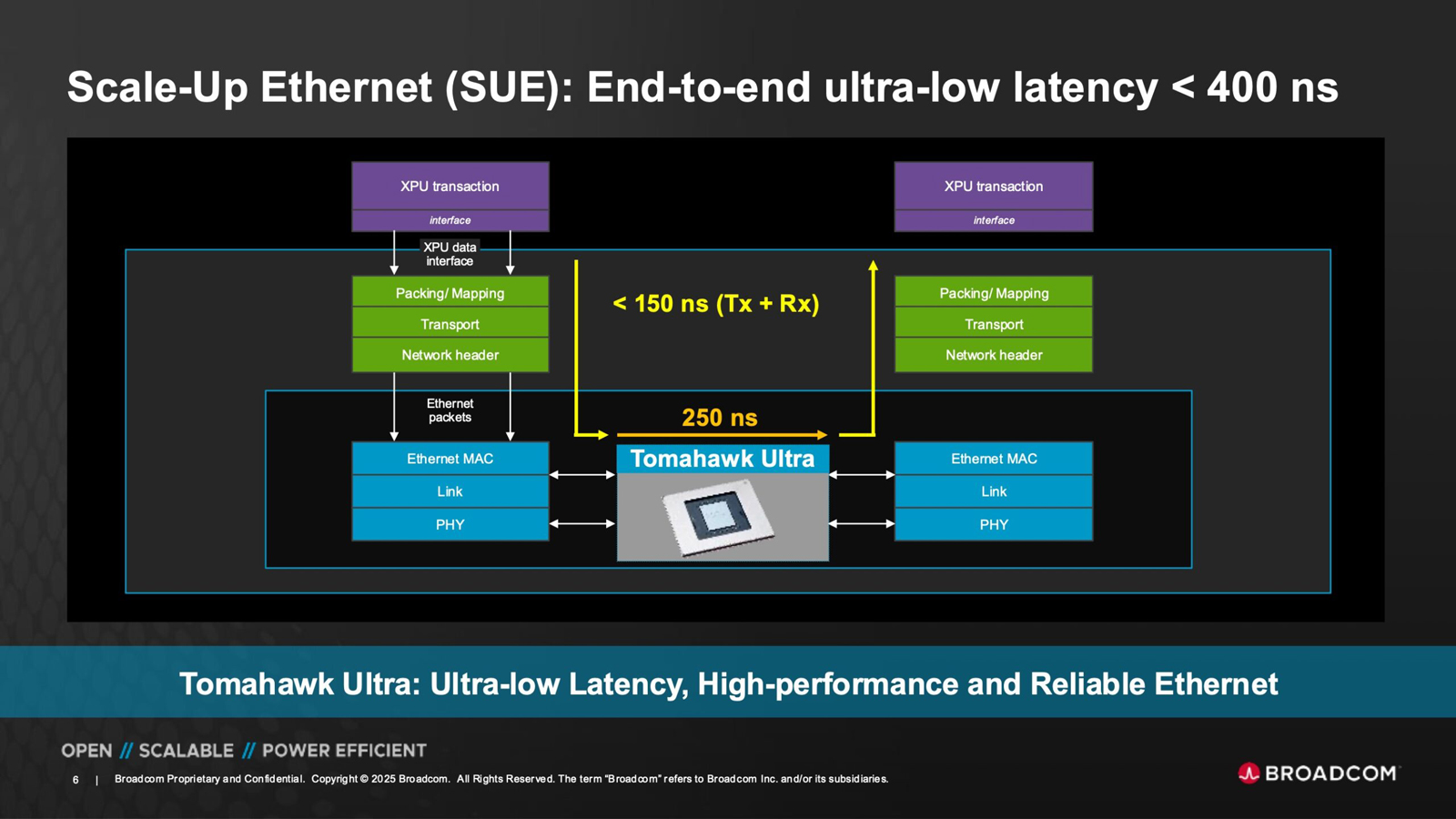
Broadcom подчёркивает, что чип Tomahawk Ultra разработан с нуля специально для удовлетворения потребностей высоконагруженных НРС-сред и ИИ-кластеров. Новинка обеспечивает коммутационную способность 51,2 Тбит/с при размере пакетов 64 байта. Задержка составляет 250 нс, что значительно меньше, чем у коммутаторов с более высокой пропускной способностью. А общая задержка при общении XPU между собой составляет не более 400 нс. Поддерживается обработка до 77 млрд пакетов в секунду.

Источник изображений: Broadcom
Основная часть трафика, передаваемого через коммутаторы Ethernet, состоит из пакетов большего размера. Поэтому при проектировании сетевого оборудования внимание уделяется прежде всего увеличению размера пакетов для оптимизации пропускной способности. Вместе с тем обмен пакетами небольшого размера широко распространен в платформах НРС/ИИ: представленная новинка Broadcom нацелена именно на такие среды.




изображения (6)
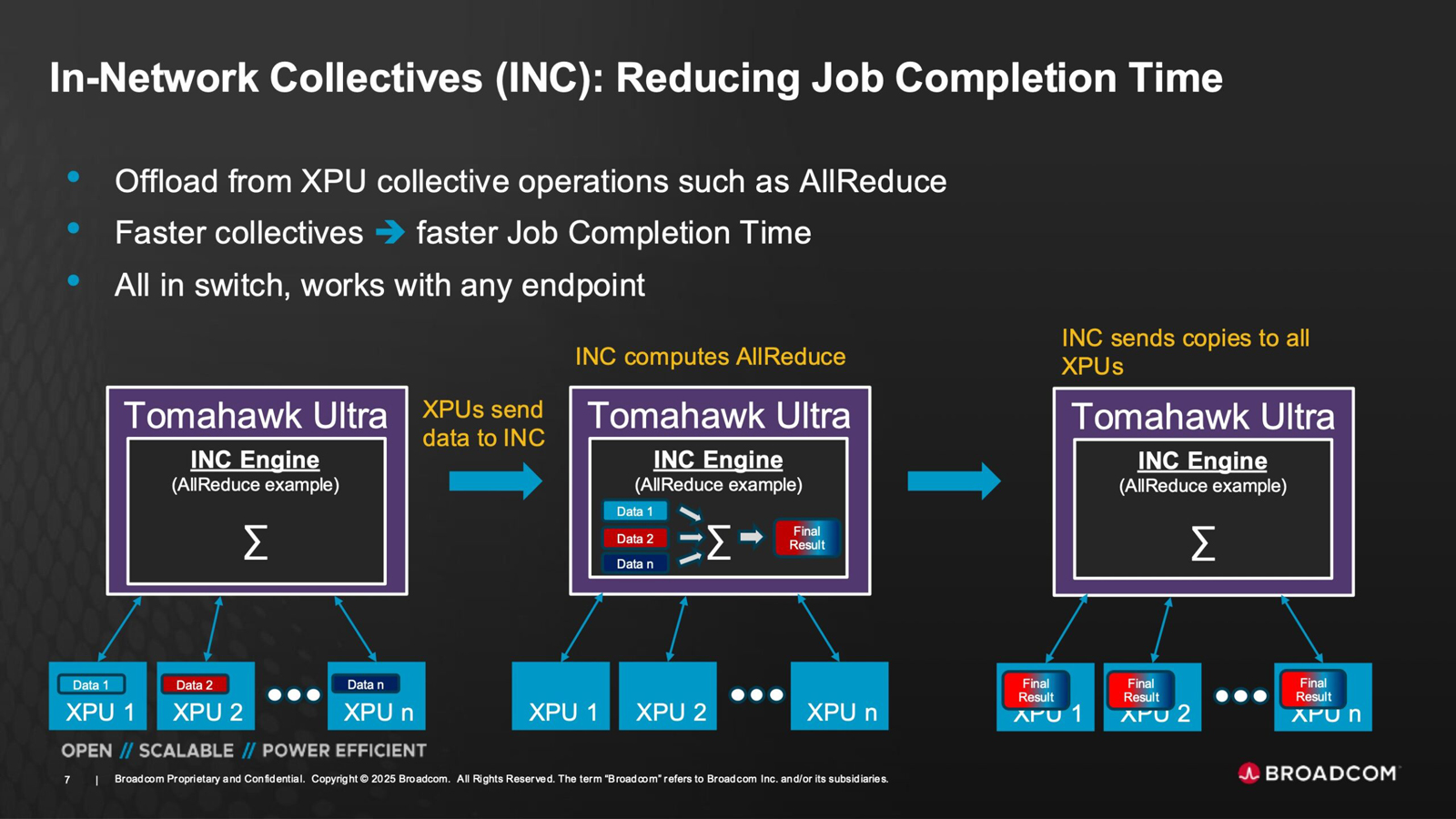
Чип-коммутатор Tomahawk Ultra (семейство BCM78920) поддерживают 64 порта 800GbE, 128 портов 400GbE или 256 портов 200GbE. Изделие использует блоки Peregrine 106.25G PAM4 SerDes. Решение совместимо по выводам с Broadcom Tomahawk 5 (TH5). Поддерживаются функции, предназначенные для масштабируемых нагрузок ИИ и HPC, включая Link Layer Retry (LLR), Credit-based Flow Control (CBFC) и AI Fabric Headers (AFH). Кроме того, непосредственно в ASIC реализована поддержка коллективных операций вроде AllReduce and AllGather.
Используются измененные заголовки Ethernet, размер которых уменьшен с 46 до 10 байт: это позволяет оптимизировать общее соотношение размера заголовка к полезной нагрузке. Упомянута совместимость с современными топологиями сетей HPC, такими как Mesh, Torus и Dragonfly. Кроме того, заявлена совместимость с Ultra Ethernet (UEC). Поставки Tomahawk Ultra уже начались.
Источник:

