Материалы по тегу: broadcom
|
04.07.2026 [13:30], Сергей Карасёв
DriveNets представила коммутаторы 2600SL и 2601S с 64 портами на 1,6 Тбит/сКомпания DriveNets анонсировала сетевые коммуникационные платформы 2600SL и 2601S, рассчитанные на гиперскейлеров, облачных провайдеров и операторов ИИ ЦОД. В основу новинок положен чип Broadcom Tomahawk 6, обеспечивающий коммутационную способность до 102,4 Тбит/с. Модель DriveNets 2601S выполнена в форм-факторе 3U и оснащена воздушным охлаждением. В свою очередь, версия DriveNets 2600SL соответствует типоразмеру 2OU (ORv3): это устройство оснащено полностью жидкостным охлаждением, что, как утверждает разработчик, обеспечивает максимальную энергоэффективность. Обе системы оснащены 64 портами OSFP224 с пропускной способностью 1,6 Тбит/с каждый. Говорится также о поддержке конфигураций 128 × 800GbE, 256 × 400GbE и 512 × 200GbE. Кроме того, реализованы три порта управления — два 50GbE SFP56 и один 1GbE RJ45. Поддерживается до 64 Гбайт DDR4-2666 в виде двух модулей RDIMM/SODIMM (ECC). 
Источник изображения: DriveNets DriveNets отмечает, что коммутаторы оптимизированы для работы в инфраструктурах, ориентированных на наиболее ресурсоёмкие нагрузки ИИ. Это может быть обучение больших языковых моделей (LLM) с огромным количеством параметров или инференс. Поставки устройств 2600SL и 2601S планируется организовать в текущем квартале. «Чипы Broadcom Tomahawk 6 в сочетании с платформой DriveNets обеспечивают беспрецедентную производительность и надёжность в крупномасштабных кластерах», — отмечает Broadcom.
24.06.2026 [18:24], Владимир Мироненко
OpenAI и Broadcom представили кастомный ускоритель Jalapeño для ИИ-инференсаOpenAI и Broadcom представили кастомный чип Jalapeño, разработанный в тесном сотрудничестве «в соответствии с видением OpenAI будущего инференса LLM». Согласно первым тестам, ускоритель первого поколения обеспечивает производительность на ватт значительно выше, чем у современных аналогов. Как сообщает OpenAI, Jalapeño был разработан с нуля для текущих и будущих LLM. Благодаря использованию ИИ-моделей OpenAI от начала проектирования до выхода на производство чипа потребовалось всего лишь девять месяцев. OpenAI отметила, что разрабатывала Jalapeño, «руководствуясь своим планом развития моделей, ядер, систем обслуживания и потребностей продукта, совместно с партнёрами Broadcom и Celestica». Чип спроектирован не как отдельный ускоритель, а как часть масштабируемого програмнно-аппаратного комплекса. Инженерные образцы Jalapeño работают в лаборатории с задачами машинного обучения на целевой частоте и энергопотреблении, включая GPT‑5.3‑Codex‑Spark. Компания пообещала предоставить подробный технический отчёт о производительности ускорителя в ближайшие месяцы. Как сообщает Bloomberg, по словам генерального директора Broadcom Хока Тана (Hock Tan), на данный момент ускоритель демонстрирует экономию средств примерно на 50 % по сравнению с типовыми ИИ-ускорителями. 
Источник изображения: OpenAI Сообщается, что архитектура чипа снижает перемещение данных и обеспечивает баланс вычислительных и сетевых ресурсов, а также памяти для достижения фактического использования, гораздо более близкого к теоретической пиковой производительности. Реализация аппаратных и сетевых технологий Broadcom, включая Tomahawk, помогают вывести платформу на крупномасштабный производственный уровень. OpenAI отметила, что стремится создать полный стек для продукта. Она не только разрабатывает передовые модели и решения на их основе. Компания проектирует инфраструктуру под ними: архитектуру чипов, ядра, системы памяти, сети, управление, системы развёртывания и пользовательский опыт. Благодаря этому каждый слой стека может быть оптимизирован для достижения главной цели компании: сделать свои модели быстрее, надёжнее и доступнее для пользователей. Стремясь оптимизировать затраты на ИИ-инфраструктуру, Amazon (Trainium), Google (TPU), Meta✴ (MTIA) и Microsoft (Maia) тоже работают над собственными кастомными ИИ-ускорителями. Во многом это связано и с желанием снизить зависимость от чипов NVIDIA.
11.06.2026 [09:18], Сергей Карасёв
СЖО и 1,6 Тбит/с на порт: Arista представила коммутаторы 7060XE7 для ИИ ЦОДКомпания Arista Networks анонсировала коммутаторы семейства 7060XE7, ориентированные на масштабные ИИ-инфраструктуры следующего поколения с высокой интенсивностью обмена данными. Устройства обеспечивают коммутационную способность до 102,4 Тбит/с. В основу изделий положен чип Broadcom Tomahawk 6. Объём оперативной памяти составляет 32 Гбайт, вместимость встроенного SSD — 480 Гбайт. Для управления предусмотрены два разъёма RJ45, консольный порт и коннектор USB. Реализована технология LPO (Linear Pluggable Optics), которая позволяет формировать прямые соединения между оптоволоконными модулями, устраняя необходимость в традиционных компонентах вроде цифровых сигнальных процессоров (DSP). Благодаря этому повышается энергетическая эффективность. В серию вошли модели 7060XE7-64PS / 7060XE7-64PRS с 64 портами OSFP с пропускной способностью 1,6 Тбит/с, которые могут использоваться в режимах 200GbE/400GbE/800GbE. Кроме того, дебютировала версия 7060XE7-128PE со 128 портами OSFP со скоростью 800 Гбит/с (поддерживаются также режимы 100GbE/200GbE/400GbE). Все эти коммутаторы выполнены в форм-факторе 4U и оснащены воздушным охлаждением. 
Источник изображения: Arista Networks Ещё одним представителем семейства стала модель 7060XE7-64PRS-RV3-L типоразмера 2OU, наделённая системой жидкостного охлаждения. Этот коммутатор оборудован 64 портами OSFP на 1,6 Тбит/с (с поддержкой режимов 200GbE/400GbE/800GbE). Питание осуществляется от централизованного шинопровода. В качестве программной платформы на устройствах используется Arista EOS (Extensible Operating System). Говорится о поддержке функций балансировки нагрузки DLB (Dynamic Load Balancing) и CLB (Cluster Load Balancing). Поставки коммутаторов планируется начать в IV квартале текущего года.
10.06.2026 [23:34], Владимир Мироненко
Broadcom, Apollo и Blackstone запустили платформу AI XPV для развёртывания более 20 ГВт вычислительной ИИ-инфраструктурыBroadcom совместно с Apollo и Blackstone объявила о запуске платформы AI XPV с целью ускорения глобального развёртывания к 2028 году более 20 ГВт вычислительной ИИ-инфраструктуры, необходимой передовым разработчикам ИИ, включая Anthropic и OpenAI. Платформа AI XPV объединяет собственные ИИ-ускорители (XPU) и высокопроизводительные сетевые технологии Broadcom, разработанные и адаптированные для использования ведущими ИИ-лабораториями, с крупным частным институциональным капиталом. Платформа запускается с первоначальным траншем в размере $35 млрд, возглавляемым Apollo в партнёрстве с Blackstone, для содействия ранее объявленному расширению мощностей Anthropic более чем на 1 ГВт вычислительной инфраструктуры, которая, как ожидается, будет развёрнута на площадках Fluidstack, начиная с середины 2026 года. Архитектура платформы разработана для поддержки как масштабного обучения ИИ-моделей, так и ресурсоэффективных нагрузок инференса с минимальными затратами и энергопотреблением для значительного снижения стоимости генерации токенов. При этом платформа создана таким образом, чтобы привлекать новые раунды финансирования по мере роста спроса. По словам Broadcom, она создаёт повторяемую структуру для финансирования будущих ИИ-кластеров на основе специализированных архитектур XPU и высокоскоростных сетевых инфраструктур. 
Источник изображения: Broadcom Генеральный директор Broadcom Хок Тан (Hock Tan) назвал инициативу ответом на глобальный спрос на вычислительные мощности для ИИ, который в настоящее время опережает возможности традиционных рынков капитала. Платформа позволит Broadcom, ведущему поставщику специализированных решений для ИИ и масштабируемых сетевых решений для гиперскейлеров, согласовывать свои технологические планы с выделенными многомиллиардными финансовыми инструментами, чтобы устранить узкие места в развёртывании и ускорить строительство кластеров следующего поколения для обучения и инференса. «Мы находимся на историческом переломном этапе, когда спрос на вычислительные мощности для ИИ коренным образом меняет глобальный экономический ландшафт, — сказал Хок Тан, — Эта стратегическая платформа, созданная совместно с Apollo и Blackstone, объединяет самый передовой мировой капитал с технологической дорожной картой Broadcom, чтобы воспользоваться этой уникальной возможностью, позволяя нашим быстрорастущим клиентам, начиная с Anthropic, быстро и уверенно реализовать свои самые амбициозные проекты в области ИИ». Как отметил ресурс Converge! Network Digest, данный проект также отражает масштабную волну институционального частного кредитования, проникающего в технологический сектор. Управляющие альтернативными активами, такие как Apollo, Blackstone, KKR, Brookfield и BlackRock, за последний год заметно расширили своё присутствие в сегментах ЦОД, энергетики и цифровой инфраструктуры. Установив прямую структурную связь между поставками специализированных ИИ-чипов, проектированием сетей и финансированием мегамасштабных проектов, Broadcom создала конкурентное преимущество, гарантируя, что ограничения в капитале не задержат реализацию её технологической дорожной карты.
29.05.2026 [21:36], Владимир Мироненко
FuriosaAI и Broadcom создадут ИИ-ускоритель для платформы инференса для агентной эрыЮжнокорейский стартап FuriosaAI объявил о заключении соглашения о стратегическом партнёрстве с Broadcom для разработки тензорного (TCP) ИИ-ускорителя третьего поколения в качестве основы масштабируемой платформы инференса, предназначенной для обслуживания передовых агентных систем гиперскейлеров. Стартап намерен объединить передовые возможности Broadcom по упаковке, позволяющие интегрировать несколько кремниевых кристаллов в ИИ-ускоритель, и её достижения в масштабируемых сетевых решениях для ИИ со своей ИИ-архитектурой и программным стеком для создания платформы инференса в масштабе стойки По словам FuriosaAI, в результате сотрудничества с Broadcom архитектура процессора Tensor Contraction Processor (TCP) «превратится в многокристальную систему», которая лучше подходит для «высокопроизводительных требований к токенам» рабочих нагрузок инференса и агентного ИИ, пишет DataCenter Dynamics. FuriosaAI отметила, что эта архитектура сделает чипы более подходящими для «реальных рабочих ИИ-нагрузок» и что, сосредоточившись на высокоскоростной передаче данных, а не на управлении потоками вычислений, ускорители обеспечат более высокую производительность на ватт и большую «плотность» токенов, чем «передовые GPU». 
Источник изображения: FuriosaAI Сообщается, что чип третьего поколения FuriosaAI будет включать вычислительный 2-нм кристалл, выделенный IO-кристалл SUE-интерконнекта и двуслойную память HBM4/4E. Благодаря интеграции Scale-Up Ethernet (SUE) и PCIe-решений Broadcom, система будет обеспечивать низкую задержку и высокую пропускную способность интерконнекта All-to-All между сотнями чипов в масштабе стойки. Существующие системы могут объединять не более восьми ИИ-ускорителей RNGD. Как отметил президент группы полупроводниковых решений Broadcom, производительность инференса больше не определяется исключительно вычислительными ресурсами. Она всё больше зависит от повторного использования данных и эффективности обмена данными между серверами и стойками: «Сочетая архитектуру TCP FuriosaAI с ведущей на рынке технологией XPU и IP-платформой Broadcom, масштабируемым Ethernet и коммутаторами сетевых фабрик, мы создаём платформу, которая решает ключевые проблемы крупномасштабного агентного ИИ», — заявил он. «Объединение инфраструктурных возможностей Broadcom и архитектуры Tensor Contraction Processor от FuriosaAI, а также её определяющего отрасль программного стека, позволяет нам выйти за рамки уровня чипа и предложить комплексное решение для эпохи фабрик токенов», — отметил соучредитель и генеральный директор FuriosaAI. 
Источник изображения: Broadcom Хотя вычислительная мощность по-прежнему важна для рабочих ИИ-нагрузок, особенно на этапе предварительного заполнения, FuriosaAI сосредоточилась на перемещении данных между HBM и DRAM. «TCP ориентирован на высокоскоростную передачу данных и масштабные тензорные операции, а не на управление тысячами крошечных потоков. Он рассматривает доступ к памяти как первостепенную задачу, устраняя “обрыв” эффективности, с которым сталкиваются GPU, когда модели выходят за рамки жёстких иерархий кеша», — сообщается в блоге компании. Аппаратное обеспечение FuriosaAI поддерживается программным стеком, который позволяет разработчикам быстро развёртывать приложения, а также легко переключаться на новые модели и новые методы оптимизации. В то время как устаревшие платформы требуют обширной ручной настройки ядер для каждой новой модели, SDK FuriosaAI использует универсальный компилятор, который автоматически сопоставляет высокоуровневый код PyTorch с полупроводниковой архитектурой. Для разработчиков, которым требуется более детальный контроль, виртуальная архитектура набора команд FuriosaAI предлагает декларативную модель программирования, которая обеспечивает управление оборудованием без недетерминированной сложности традиционного программирования для GPU, отметила компания. Ранее сообщалось, что Broadcom продлила сотрудничество с Meta✴ для разработки нескольких поколений кастомных ИИ-чипов. Также она расширила контракт с Google по снабжению её новыми поколениями ИИ-чипов. Создаёт Broadcom специализированные чипы и для OpenAI. Всего у компании в разработке порядка десяти кастомных ASIC.
28.05.2026 [11:19], Сергей Карасёв
Broadcom представила высокоинтегрированные SoC для маршрутизаторов Wi-Fi 8Компания Broadcom выпустила чипы BCM6772, BCM6774 и BCM6776: это, как утверждается, первые в отрасли высокоинтегрированные решения для маршрутизаторов, поддерживающих стандарт Wi-Fi 8. Устройства на основе представленных изделий могут использоваться в том числе в составе mesh-сетей. Новые SoC объединяют процессор приложений, сетевой блок (берёт на себя выполнение ресурсоёмких сетевых задач), радиомодули Wi-Fi 8, а также мультигигабитный Ethernet PHY на одном кристалле. Во всех случаях задействованы четыре вычислительных ядра. Реализована поддержка памяти DDR4 и DDR5, а у BCM6776 — дополнительно LPDDR4 и LPDDR5. 
Источник изображения: Broadcom Чип BCM6772 имеет конфигурацию антенн 2 × 2 для 2,4 ГГц (полоса 40 МГц) и 2 × 2 для 5 ГГц (160 МГц). Изделие ориентировано на маршрутизаторы и повторители Wi-Fi 8 для массового рынка. Применяется упаковка FCBGA с размерами 15 × 15 мм. В свою очередь, BCM6774 получил конфигурацию антенн 2 × 2 для 2,4 ГГц и 4 × 4 для 5 ГГц в аналогичной корпусировке. Старшая из новинок, BCM6776, относится к премиальному уровню: конфигурация антенн — 2 × 2 для 2,4 ГГц и 4 × 4 для 5 ГГц. При этом предусмотрены два контроллера PCIe 3.0. Используется упаковка FCBGA с размерами 19 × 19 мм. Все модели располагают встроенными усилителями (iPA) для диапазона 2,4 ГГц. Реализована технология цифровой предварительной коррекции искажений (DPD) третьего поколения, благодаря чему достигается более низкое энергопотребление в диапазоне 5 ГГц. Пробные поставки чипов BCM677x уже начались.
27.05.2026 [15:46], Сергей Карасёв
Broadcom представила чип-шлюз 50G PON с ИИ и постквантовой криптографиейКомпания Broadcom анонсировала систему на чипе (SoC) с обозначением BCM68850 — это высокоинтегрированное изделие 50G ITU PON/XGS-PON, предназначенное для построения производительных шлюзов в широкополосных сетях. Поставки образцов новинки уже начались. В состав BCM68850 входит многоядерный процессор с архитектурой Arm v8. Реализована поддержка памяти LPDDR, интерфейсов PCIe и USB. Возможна работа в режимах 50GbE, 25GbE и 10GbE. SoC содержит встроенный нейронный модуль (NPU), который ускоряет ИИ-инференс на периферии сети. Благодаря этому уменьшаются задержки при одновременном повышении уровня защиты конфиденциальной информации. Предусмотрены расширенные средства обеспечения безопасности, включая алгоритмы постквантовой криптографии (PQC). 
Источник изображения: Broadcom Изделие BCM68850 совместимо со стандартом Wi-Fi 8. Среди прочего упомянуты функции интеллектуального самовосстановления. Операторы смогут использовать инструменты обнаружения аномалий в режиме реального времени и средства предиктивной оптимизации полосы пропускания для снижения операционных расходов и повышения средней выручки в расчёте на абонента (ARPU). Broadcom заявляет, что новый чип обеспечивает запас пропускной способности и детерминированную задержку, необходимые для следующего этапа развития широкополосной связи. Это особенно важно в свете трансформации домохозяйств в постоянно действующие точки периферийных вычислений с возрастающим трафиком данных. Изделие допускает широкий спектр сценариев развёртывания для удовлетворения потребностей как частных пользователей, так и предприятий.
19.05.2026 [17:34], Владимир Мироненко
VMware представила превью гипервизора ESXi-Arm Fling для Arm-серверовVMware официально объявила о доступности экспериментальной версии гипервизора ESXi-Arm Fling в формате превью ESX 9.1 Tech Preview, предоставляя возможности корпоративной виртуализации для 64-бит архитектур Arm. Как отметил ресурс The Register, VMware выполняет свое обещание перенести свой гипервизор и VCF на архитектуру Arm. Ранее компания в рамках Project Monterey работала над переносом части функций на Arm-процессоры в составе DPU/SmartNIC. VMware сообщила, что гипервизор поддерживает гостевые системы под управлением RHEL, Ubuntu и SLES на серверах HPE и Gigabyte с процессорами Ampere Altra (Max) или на модели Supermicro ARS-221GL с процессором NVIDIA Grace. Заявлена совместимость с NVMe/SATA-накопителями, а также с NIC Intel и Mellanox ConnectX. Компания предупредила, что релиз является неподдерживаемой сборкой Tech Preview, предназначенной для оценки и использования в лабораторных условиях, не связанных с продуктовой средой. The Register отметил, что документ содержит несколько противоречивую рекомендацию по поводу того, что «кластеры хостов Arm должны управляться отдельным автономным vCenter, работающим на x86. Мы не рекомендуем управлять установками x86 и Arm из одного и того же vCenter». Также ресурс допустил, что предварительная версия очень проста, поскольку в ней отсутствует поддержка vSAN, NSX и множества других функций, имеющихся в гипервизоре VMware для архитектуры x86 и пакете частного облака Cloud Foundation (VCF). 
Источник изображения: VMware VMware также предоставила возможность доступа к гостевым системам Arm из своих десктопных гипервизоров. Об этом было объявлено на прошлой неделе в примечаниях к выпуску новых версий продуктов Workstation и Fusion, которые добавляют «возможность подключения к удалённым ESXi на базе Arm, позволяя пользователям управлять виртуальными машинами на удалённых Arm-серверах непосредственно из VMware Workstation или Fusion на любой поддерживаемой платформе». VMware переносит свои решения на Arm-архитектуру, поскольку считает, что клиенты будут всё чаще использовать Arm-серверы на периферии сети, возможно, для ИИ-задач. В VMware также отдают отчёт в том, что Arm-процессоры более энергоэффективны, чем процессоры на x86, как и в том, что её партнёры-гиперскейлеры AWS, Google и Microsoft активно продвигают свои собственные Arm-процессоры, поскольку они обеспечивают отличную производительность на Вт. Представляя новые гипервизоры для десктопов, VMware указала ещё одну причину: «По мере диверсификации сред разработки межархитектурная совместимость становится крайне важной».
12.05.2026 [15:34], Владимир Мироненко
Broadcom обещает, что VMware Cloud Foundation 9.1 позволит значительно снизить расходы на ИИ-инфраструктуру
broadcom
kubernetes
software
vmware
виртуализация
ии
информационная безопасность
конфиденциальность
частное облако
Компания Broadcom анонсировала VMware Cloud Foundation 9.1, позиционируя платформу как основу для частного облака, оптимизированную для ИИ-нагрузок ИИ и Kubernetes, с интегрированной безопасностью и поддержкой смешанной вычислительной инфраструктуры на базе AMD, Intel и NVIDIA. Broadcom отметила, что VCF 9.1 обеспечит предприятиям при запуске производственных рабочих нагрузок, включая инференс и агентный ИИ, ряд преимуществ. В частности, VCF 9.1 обеспечит снижение затрат на серверы до 40 % благодаря интеллектуальному многоуровневому распределению памяти. Эффективность хранения данных также повышается благодаря усовершенствованным методам сжатия и дедупликации в конвейерах обработки данных ИИ, что снижает общую стоимость владения до 39 %. Использование платформы позволяет сократить эксплуатационные расходы Kubernetes до 46 % при одновременном повышении масштабируемости и скорости развёртывания. Преимущества платформы также включают четырёхкратное ускорение обновления кластеров и удвоение мощности парка серверов, что позволяет предприятиям быстрее масштабировать инфраструктуру ИИ в распределённых средах. В VCF 9.1 сделан акцент на поддержке открытой экосистемы. Обеспечены выбор нескольких GPU AMD и NVIDIA, поддержка CPU AMD и Intel, а также совместимость со стандартными сетевыми технологиями, такими как EVPN и VXLAN, и с универсальной облачной сетью Arista Universal Cloud Network. Этот подход позволяет предприятиям комбинировать оборудование в зависимости от требований к рабочей нагрузке и доступности, что в условиях дефицита является важным фактором, отметил ресурс Storagereview. 
Источник изображений: VMware Большое внимание в VCF 9.1 уделено автоматизации, благодаря которой обеспечивается удвоение возможностей управление — для 5 тыс. хостов и в четыре раза более быстрое обновление кластеров в распределённых и изолированных средах. Также была улучшена поддержка многопользовательского режима, позволяющая изолировать рабочие нагрузки ИИ между командами или клиентами на общей инфраструктуре со строгими ограничениями безопасности, максимизируя использование дорогостоящих ресурсов GPU и CPU, одновременно поддерживая суверенитет данных для конфиденциальных моделей. Это особенно актуально для поставщиков услуг и крупных предприятий, консолидирующих ИИ-инфраструктуру. Платформа устраняет необходимость во внешних устройствах для конечных точек ИИ-инференса и агентных приложений за счёт интеграции виртуализированных служб балансировки нагрузки и безопасности через VMware Avi Load Balancer и vDefend, позволяя снизить капитальные затраты, сохранив при этом отказоустойчивость приложений и автоматизацию жизненного цикла.  VCF 9.1 получила встроенную систему безопасности на уровне инфраструктуры для защиты рабочих нагрузок ИИ, проприетарных моделей и данных для обучения от гипервизора до приложения. Благодаря сегментации на основе принципа нулевого доверия (Zero Trust), суверенному восстановлению и непрерывному обновлению без дополнительных инструментов VCF обеспечивает уровень безопасности, необходимый для развёртывания ИИ в продуктовой среде. Система поддерживает восстановление после атак программ-вымогателей в локальной среде, обеспечивающее изолированные среды восстановления и интегрированные инструменты проверки, включая поддержку CrowdStrike Falcon Endpoint Security, защищающие ИИ-модели и данные от трансграничного перемещения, без высоких затрат на обеспечение пропускной способности во время восстановления в кризисных ситуациях. 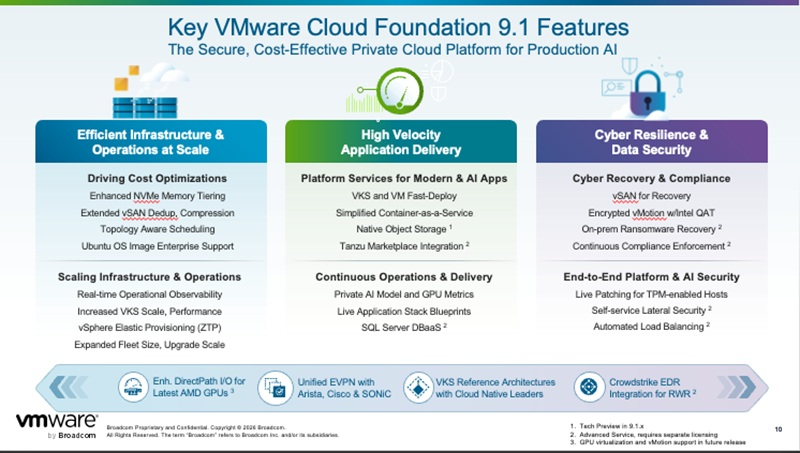 Функции непрерывного соответствия автоматизируют мониторинг и устранение неполадок в соответствии с определёнными политиками, помогая организациям поддерживать готовность к аудиту без дополнительных инструментов. Обновление в режиме реального времени дополнительно снижает операционные риски, позволяя в большинстве случаев обновлять систему без простоев, поддерживая постоянно работающие ИИ-сервисы. Система безопасности с нулевым доверием, расширяющая защиту распределённых IDS/IPS на рабочие нагрузки Kubernetes AI, обеспечивает скорость проверки угроз до 9 Тбит/с для распределённого инференса и в пять раз более высокую идентификацию приложений для частных облачных и интернет-приложений. Как отметил Storagereview, с помощью VCF 9.1 компания пытается перепозиционировать VMware как жизнеспособную платформу для корпоративного ИИ. Акцент на частном облаке, интегрированной безопасности и унифицированных операциях между виртуальными машинами, контейнерами и GPU соответствует запросам многих крупных организаций, которые приближают рабочие нагрузки инференса к своим данным. Вместе с тем современные распределённые конвейеры ИИ строятся на основе архитектур, ориентированных на Kubernetes, со всё более модульными инфраструктурными решениями, которые отдают приоритет гибкости и прямому доступу к ускоренным вычислениям. В таких средах VMware обычно не является плоскостью управления, а во многих случаях становится дополнительным уровнем, а не основой. Кроме того, хотя Broadcom позиционирует VCF 9.1 как способ сократить расходы на инфраструктуру за счёт повышения эффективности, сохраняются обоснованные опасения корпоративных клиентов по поводу условий лицензирования VMware и общей стоимости владения.
11.05.2026 [15:14], Сергей Карасёв
Broadcom представила решения 10G PON и Wi-Fi 8 для организации ШПДКомпания Broadcom анонсировала оптимизированный чип 10G PON и сопутствующие изделия Wi-Fi 8 для организации широкополосного доступа в интернет (ШПД). Решения призваны помочь операторам отказаться от устаревших медных и кабельных сетей в пользу оптоволоконных каналов и беспроводных подключений с высокой пропускной способностью. В частности, представлен продукт BCM68565 10G xPON Gateway Device. Это «система на чипе» (SoC) с поддержкой 10G ITU PON/XGS-PON/GPON/Active Ethernet. Устройство оптимизировано для предоставления широкого спектра услуг. В состав новинки входит многоядерный CPU с архитектурой Arm v8. Реализованы контроллеры PCIe, DDR (DDR4, LPDDR4, DDR5 и LPDDR5) и флеш-памяти, интерфейсы PCM и USB, а также PON MAC, 10GbE PHY, XFI/USXGMII-S и 4 × 1GbE PHY. Упомянуты функции безопасной загрузки и шифрования. 
Источник изображения: Broadcom Кроме того, дебютировали два чипа Wi-Fi 8 — изделия BCM67142 и BCM67192. В первом случае используется конфигурация антенн 3 × 3 для 2,4 ГГц и 4 × 4 для 5 ГГц, во втором — 4 × 4 для 2,4 ГГц и 4 × 4 для 5 ГГц. В обоих вариантах имеются аппаратные механизмы разгрузки, интегрированные усилители мощности и цифровая предварительная коррекция искажений третьего поколения, которая даёт возможность снизить пиковую мощность на 25 %. Технология DBE (Dynamic Bandwidth Expansion) позволяет точке доступа в реальном времени изменять ширину используемого канала связи в зависимости от загрузки сети и помех. Broadcom уже поставляет образцы чипов BCM68565, BCM67142 и BCM67192 клиентам и партнёрам. Изделия ориентированы на массовый рынок ШПД-услуг. |
|

