Материалы по тегу: fpga
|
31.05.2026 [11:41], Сергей Карасёв
AMD выпустила адаптивные SoC серии Versal Prime Gen 2Компания AMD анонсировала новые адаптивные SoC семейства Versal Prime Gen 2: 2VM3454, 2VM3254 и 2VM3104. Они ориентированы на профессиональное аудиовизуальное оборудование, системы вещания и устройства для промышленного интернета вещей (IIoT). В состав решений входят четыре вычислительных ядра Arm Cortex-A78AE с 64 Кбайт кеша L1 (ECC) и 512 Кбайт кеша L2, тогда как суммарный кеш L3 составляет 2 Мбайт. Кроме того, имеется процессор реального времени с шестью ядами Arm Cortex-R52. Предусмотрен одноядерный графический ускоритель Arm Mali-G78AE. Версии 2VM3254 и 2VM3454 также получили VCU-блок с поддержкой HEVC и AVC (вплоть до 4K60). Объём встроенной памяти — 1 Мбайт (ECC). 
Источник изображения: AMD Программируемая часть 2VM3104 включает 225 400 логических ячеек и 103 040 LUT, а количество движков DSP составляет 420. У версии 2VM3254 эти значения равны соответственно 302 680, 138 368 и 564, у модификации 2VM3454 — 564 760, 258 176 и 1140. Количество трансиверов GTYP — 4, 8 и 16. Может использоваться оперативная память DDR5-6400 и LPDDR5X-8533 с максимальной пропускной способностью 102 Гбайт/с. Общий размер памяти программируемой логики (PL Memory) — до 45,4 Мбит. Реализована поддержка флеш-накопителей UFS 3.1, интерфейсов DisplayPort 1.4, USB 3.2 и USB 2.0, а также 1GbE, 10GbE и 100GbE (1 × 2VM3104/2VM3254 и 2 × 2VM3454). У двух старших версий также имеется контроллер PCIe 5.0 x4. Модель 2VM3454 располагает высокопроизводительным криптомодулем. Изделия 2VM3104 и 2VM3254 имеют размеры 23 × 23 мм, вариант 2VM3454 — 29 × 29 мм. Разработчики смогут использовать пакет AMD Vivado Design Suite для проектирования аппаратного обеспечения и платформу AMD Vitis для создания софта. Поставки 2VM3454 начнутся позднее в текущем году, а чипы 2VM3254 и 2VM3104 появятся в 2027-м.
06.05.2026 [09:16], Сергей Карасёв
AMD представила адаптивную SoC Versal Prime VM2152 с поддержкой DDR5 и PCIe 5.0Компания AMD анонсировала адаптивную «систему на кристалле» (SoC) Versal Prime VM2152, предназначенную для использования в оборудовании для дата-центров, сетей связи, 5G-инфраструктур и пр. Унифицированная архитектура изделия объединяет высокоскоростные интерфейсы ввода-вывода, вычисления на базе FPGA и связь с поддержкой различных протоколов. Versal Prime VM2152 совмещает два ядра Arm Cortex-A72 с 1 Мбайт кеша L2 (ECC) и вычислительный блок реального времени с двумя ядрами Arm Cortex-R5F. Чип содержит 256 Кбайт встроенной памяти с поддержкой ECC. Реализованы интерфейсы Ethernet (×2), USB 2.0 (×1), UART (×2), SPI (×2), I2C (×2), CAN-FD (×2), PCIe 5.0 x4 (×2). Программируемая часть включает 757 тыс. логических ячеек и более 346 тыс. LUT. Упомянуты 1704 движка DSP. Пиковая производительность достигает 11,8 TOPS на операциях INT8. Предусмотрены четыре контроллера оперативной памяти с поддержкой LPDDR5-6400 и DDR5-5600. Кроме того, упомянуты по восемь трансиверов GTYP и GTM (58 Гбит/с), а также MIPI C-PHY (10 Гбит/с) и MIPI D-PHY (4,5 Гбит/с). 
Источник изображения: AMD Адаптивная SoC доступна в вариантах исполнения NFVD1024 (31 × 31 мм), NFVM1369 (35 × 35 мм), VSVD1760 (40 × 40 мм) и VSVA2197 (45 × 45 мм). Предусмотрены версии с расширенным и индустриальным диапазоном рабочих температур: в первом случае он простирается от 0 до +100 °C, во втором — от -40 до +100 °C. Разработчики могут использовать пакет AMD Vivado Design Suite для проектирования аппаратного обеспечения и платформу AMD Vitis для создания софта. На ядрах Arm Cortex-A72 можно запускать ОС Linux (PetaLinux). Блоки программируемой логики (FPGA-матрица) и DSP используются для развёртывания специализированных аппаратных ускорителей, позволяющих разгрузить CPU от ресурсоёмких вычислительных задач. Цена Versal Prime VM2152 варьируется от $6000 до $8500 в зависимости от варианта и объёма заказа.
11.04.2026 [14:18], Сергей Карасёв
Altera продлила жизненный цикл FPGA до 2045 годаКомпания Altera объявила об увеличении жизненного цикла своих FPGA-продуктов: некоторые решения серий Agilex, MAX 10 и Cyclone V будут предлагаться вплоть до 2045 года. Таким образом, клиенты, проектирующие критически важные системы на базе ПЛИС, могут быть уверены в долгосрочной доступности указанных изделий. Отмечается, что FPGA применяются в составе различных платформ в промышленном, коммуникационном, аэрокосмическом, медицинском и транспортном секторах. Такие системы зачастую рассчитаны на длительный срок службы, а поэтому для них требуется доступность основных компонентов в течение 10–20 лет и более. 
Источник изображения: Altera «Заказчикам, разрабатывающим системы с большим сроком службы, необходима предсказуемость (в отношении доступности комплектующих). Продлевая жизненный цикл FPGA до 2045 года, мы обеспечиваем стабильность и гибкость, которые требуются для обеспечения работоспособности систем на протяжении десятилетий», — говорит Майк Фиттон (Mike Fitton), вице-президент по маркетингу Altera. Компания подчёркивает, что прекращение производства компонентов может привести к дорогостоящему перепроектированию оборудования, повторной сертификации и сбоям в работе систем. Расширяя поддержку своих наиболее востребованных FPGA, Altera помогает клиентам снизить риски, упростить планирование долгосрочного технического обслуживания и поддержки, а также обеспечить непрерывность функционирования платформ. Гарантии продолжительного жизненного цикла являются одним из ключевых факторов при выборе компонентов OEM-производителями и системными интеграторами. Вместе с тем увеличение сроков доступности не распространяется на изделия Agilex 7, оснащённые чипами HBM2E. Связано это с более коротким жизненным циклом указанной памяти.
27.03.2026 [11:32], Владимир Мироненко
Altera и Arm объединят FPGA и Arm AGI для создания платформ для ИИ ЦОДAltera, специализирующаяся на разработке FPGA, объявила о расширении сотрудничества с Arm с целью объединения оптимизированных для ЦОД программируемых решений Altera с процессором Arm AGI, что позволит создавать вычислительные платформы с низкой задержкой, высокой гибкостью и масштабируемостью для ИИ ЦОД. «Следующее поколение инфраструктуры ЦОД будет формироваться под влиянием всё более интеллектуальных рабочих нагрузок ИИ и потребности в специализированных вычислительных ресурсах», — сообщил Мохамед Авад (Mohamed Awad), исполнительный вице-президент подразделения облачных вычислений ИИ компании Arm. Он добавил, что Arm AGI обеспечивает эффективную вычислительную основу, необходимую для этих систем, а сотрудничество с Altera помогает расширить эти возможности в рамках всей экосистемы. Компании отметили, что сочетание FPGA Altera и процессора Arm AGI открывает новые возможности в быстрорастущих ИИ ЦОД, где производительность в реальном времени, детерминированная обработка и адаптивность имеют решающее значение. 
Источник изображения: Arm Рагиб Хуссейн (Raghib Hussain), президент и генеральный директор Altera отметил, что у Altera и Arm имеется значительный опыт в разработке решений SoC на базе FPGA, ориентированных на рынки встраиваемых систем. Вместе с тем Altera прочно закрепилась на рынке инфраструктурных решений для ЦОД благодаря значительной базе установленных SmartNIC и DPU на основе FPGA. По его словам, расширение сотрудничества Altera с Arm позволит создать новый класс гетерогенных вычислительных систем, разработанных для удовлетворения растущих требований к производительности и гибкости ИИ ЦОД.
27.03.2026 [10:03], Руслан Авдеев
ЦЕРН: для самых больших открытий на БАК нужны самые маленькие ИИ-модели, которые «зашиты» прямо в чипыИИ-инфраструктура Большого адронного коллайдера (БАК) имеет мало общего с классическим решениями на основе TPU или GPU. Вместо этого ЦЕРН (CERN) буквально «выжигает» кастомные ИИ-модели в «кремнии» для фильтрации огромных массивов данных практически в реальном времени, сообщает The Register. Ежегодно коллайдер «генерирует» 40 тыс. Эбайт «сырых» данных от сенсоров — приблизительно четверть объёма всего интернета. Такую информацию CERN хранить не может, поэтому приходится выбирать в режиме реального времени то, что представляет какую-либо ценность. Речь идёт о потоке данных до сотен терабайт в секунду. Алгоритмы для их обработки должны быть чрезвычайно быстрыми. Именно поэтому их приходится буквально «выжигать» непосредственно в чипах. В 27-км кольце БАК субатомные частицы сталкиваются на скоростях, близких к скорости света. По кольцу постоянно перемещаются около 2,8 тыс. пучков протонов с 25-с интервалами. Хотя учёные «помогают» частицам, столкновения случаются сравнительно редко — из миллиардов протонов в каждой сессии сталкиваются лишь порядка 60 пар. При столкновении образуются новые частицы, улавливаемые детекторами CERN. 
Источник изображения: Brandon Style/unsplash.com Каждое столкновение пары частиц генерирует несколько мегабайт данных. В секунду происходит около миллиарда столкновений, что приблизительно даёт около 1 Пбайт информации. Естественно, собирать и хранить такие объёмы «сырой» информации технически невозможно, поэтому CERN создал гигантскую вычислительную систему для разделения данных на «интересные» и «неинтересные» ещё на уровне детекторов. 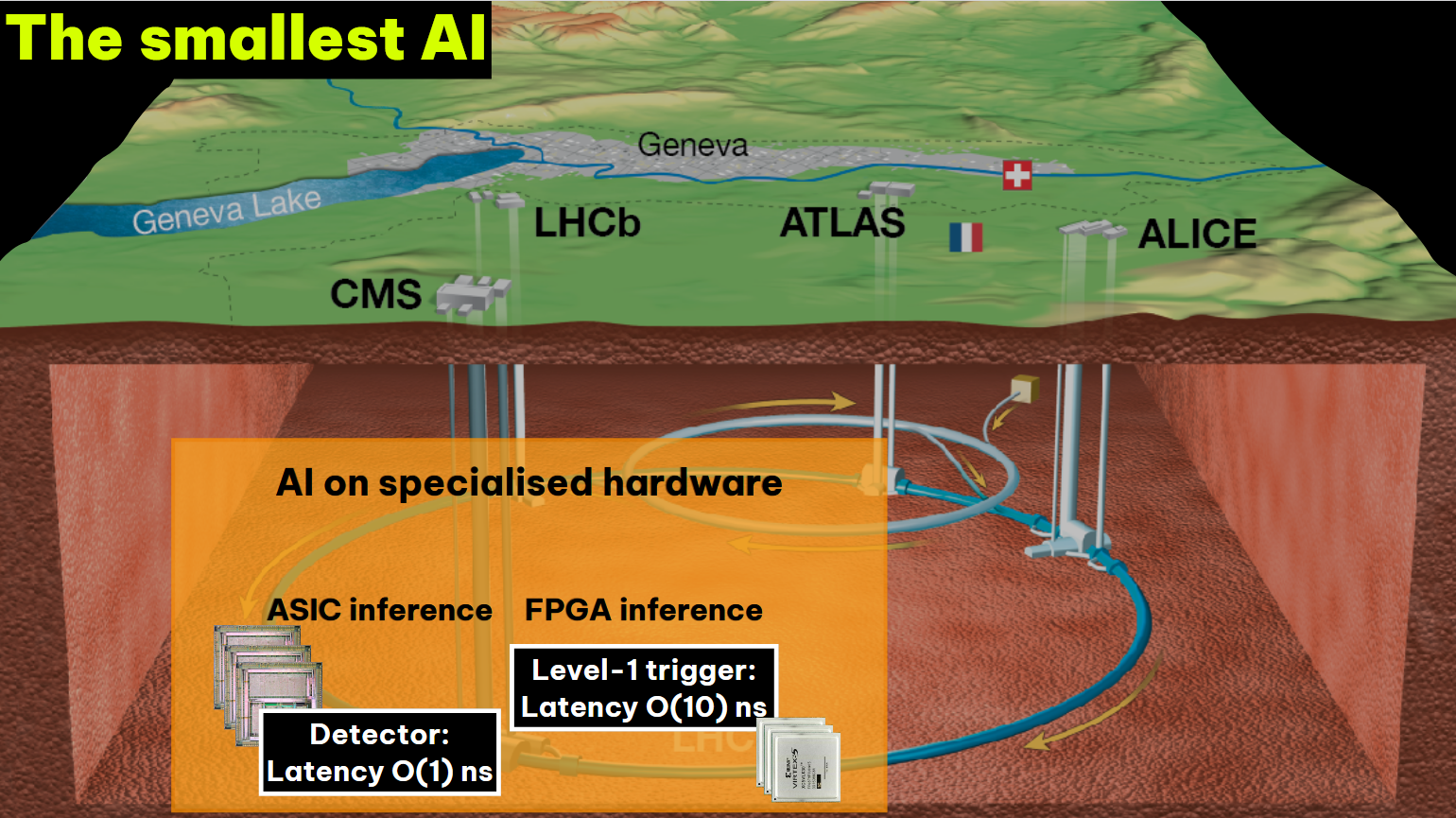
Источник изображения: Thea Klaeboe Aarrestad (ETH Zürich) Детекторы используют ASIC для буферизации данных за не более чем 4 мкс — они либо сохраняются, либо исчезают навсегда. Решение принимает фильтр Level One Trigger на базе порядка 1 тыс. FPGA, получающих данные по оптической линии на скорости около 10 Тбайт/с. Решения принимаются на лету силами самих чипов по мере поступления данных — даже самая быстрая внешняя память не справится с таким потоком информации. Специальный алгоритм AXOL1TL принимает решение не более чем за 50 нс. Фактически сохраняется лишь около 0,02 % информации о столкновениях, или приблизительно 110 тыс. событий в секунду. Отобранные сведения отправляются на поверхность, но даже после первичной фильтрации речь идёт о передаче терабайт данных ежесекундно. 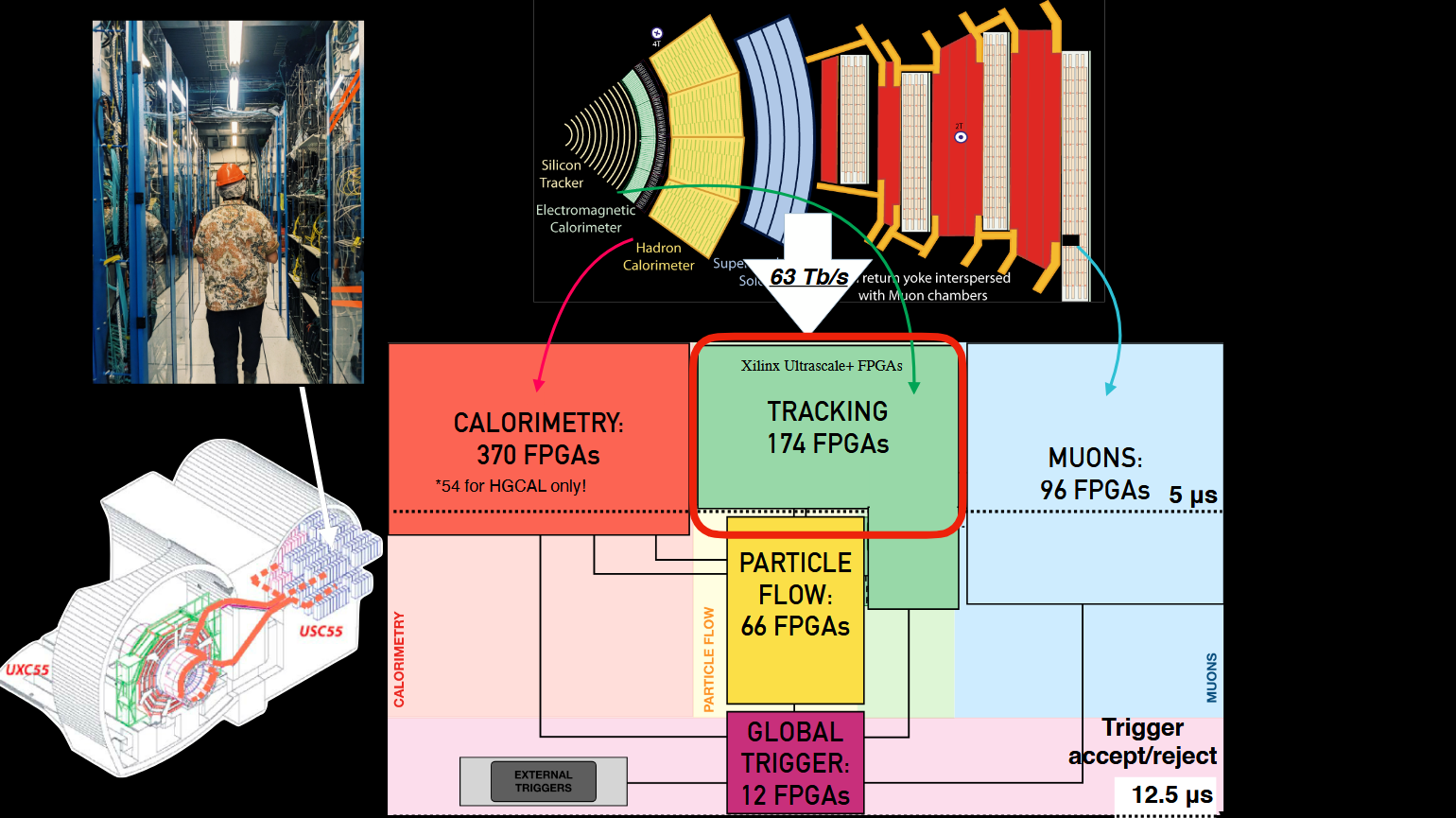
Источник изображения: Thea Klaeboe Aarrestad (ETH Zürich) На поверхности второй фильтр — High Level Trigger — оставляет для изучения уже около 1 тыс. событий в секунду. Система оснащена 25,6 тыс. CPU и 400 GPU, которые реконструируют столкновения и отбирают наиболее интересные для анализа результатов. На выходе получается около 1 Пбайт/день новых данных, которые распределяются между 170 научными центрами в 42 странах, где их могут анализировать учёные со всего света. Совокупная вычислительная мощность всех участников проекта составляет около 1,4 млн ядер. CERN стремится измерить параметры столкновений с точностью 99,999 % — это «золотой стандарт», необходимый для заявлений о научных открытиях. 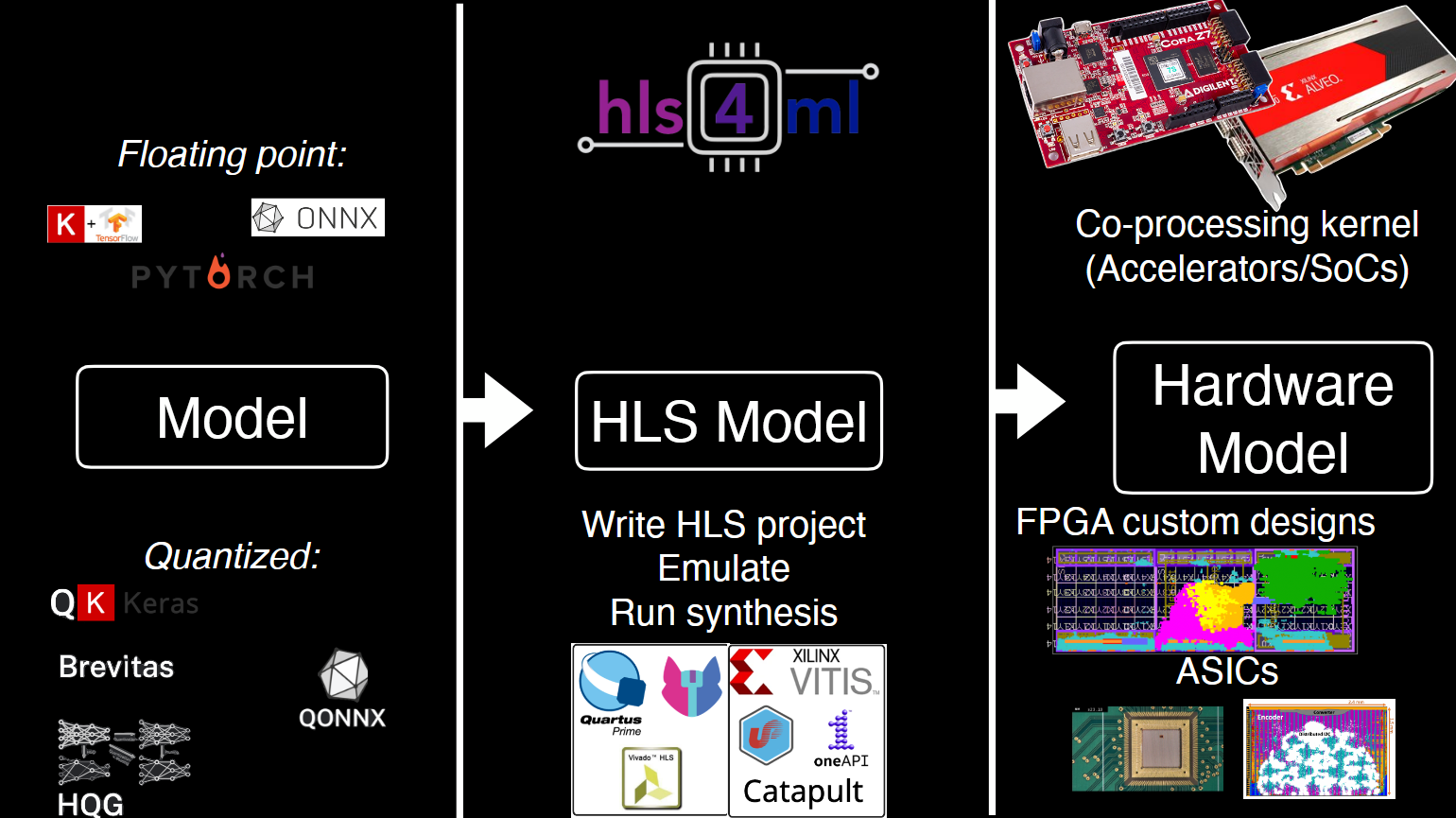
Источник изображения: Thea Klaeboe Aarrestad (ETH Zürich) Обычный ИИ-инструментарий плохо подходит для детекторов, поэтому инженерам CERN пришлось разработать собственный стек. ИИ-модели для БАК специально уменьшены, модернизированы, параллелизованы и «вымуштрованы» для выявления только действительно существенных данных. В случае с БАК они не менее производительны, но значительно «дешевле» традиционных ML-моделей. Для переноса моделей в аппаратную среду используется компилятор HLS4ML, конвертирующий модель в код C++, который можно запускать на ИИ-ускорителях, SoC, кастомных FPGA и даже «выжигать» в ASIC. При этом значительная часть ресурсов чипа отведена не под сам алгоритм, а под таблицы с предварительно рассчитанными результатами для типовых входящих значений, чтобы ещё быстрее фильтровать информацию. 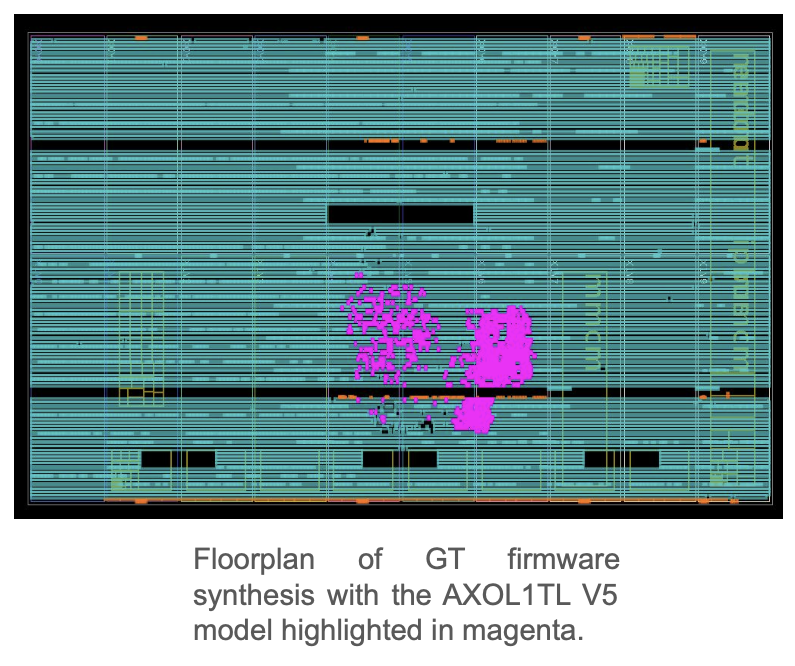
Источник изображения: CERN В конце года БАК закроют, а новый, более мощный коллайдер High Luminosity LHC должен заработать в 2031 году. Он получит более сильные магниты для фокусировки пучков частиц, сами пучки удвоятся в размерах, коллайдер будет генерировать в 10 раз больше данных, а объём информации от каждого события увеличится с 2 до 8 Мбайт. CERN уже накопил 1 Эбайт от БАК, но это лишь десятая часть от того, что предстоит хранить и обрабатывать в последующие 10 лет. И пока передовые ИИ-лаборатории создают LLM всё большего объёма, CERN движется в противоположном направлении, всеми силами упрощая и ускоряя выявление необычных событий с помощью искусственного интеллекта.
09.03.2026 [16:39], Владимир Мироненко
Ubitium стала на шаг ближе к выпуску универсального RISC-V процессора, заменяющего CPU, GPU, DSP и FPGAНемецкий стартап Ubitium объявил о завершении стадии tape-out (финальный этап проектирования) универсального RISC-V-процессора, изготовленного по 8-нм техпроцессу Samsung Foundry и предназначенного для рынка встроенных вычислительных систем автомобилей, промышленного оборудования и бытовой электроники, включая радарные и многосенсорные сигнальные цепи, аудио и голосовую связь в реальном времени, компьютерное зрение, периферийный ИИ, промышленный человеко-машинный интерфейс (HMI) и т.д. В основе процессора Ubitium лежит «универсальный процессорный массив» (Universal Processing Array) — программно-определяемая система с 256 элементами, объединяющая функции CPU, GPU, DSP и FPGA и способная мгновенно менять режимы выполнения во время работы. Такая унификация позволяет чипу переключаться между режимом работы в качестве CPU общего назначения для обслуживания ОС и режимом работы в качестве ИИ-ускорителя, избегая задержек при передаче данных между отдельными чипами. 
Источник изображения: Ubitium Завершение tape-out на 8-нм техпроцессе Samsung подтверждает работоспособность основного процессорного массива и интерфейса LPDDR5. Для Ubitium доказательство того, что один процессор может обрабатывать общие вычислительные задачи, задачи обработки в реальном времени и задачи ИИ на одном кристалле, является важным шагом на пути к коммерческой жизнеспособности, отметил EE Times. «Это решение претворяет давно существующую концепцию в жизнь», — заявил Мартин Форбах (Martin Vorbach), технический директор Ubitium. «Встроенные системы переросли архитектуры, на которые сегодня опирается отрасль. Консолидация больше не является необязательной. Она неизбежна», — добавил он. Технология, лежащая в основе этого проекта, совершенствовалась более 15 лет. Для её воплощения в жизнь Форбахом совместно с рядом специалистов была создана в 2024 году компания Ubitium. Ускорить разработку позволило привлечение $3,7 млн в рамках посевного раунда в конце прошлого года, который совместно возглавили Runa Capital, Inflection и KBC Focus Fund. Инвестиции позволили Ubitium проверить архитектуру и подготовить наборы для разработки (IDK) для первых клиентов. 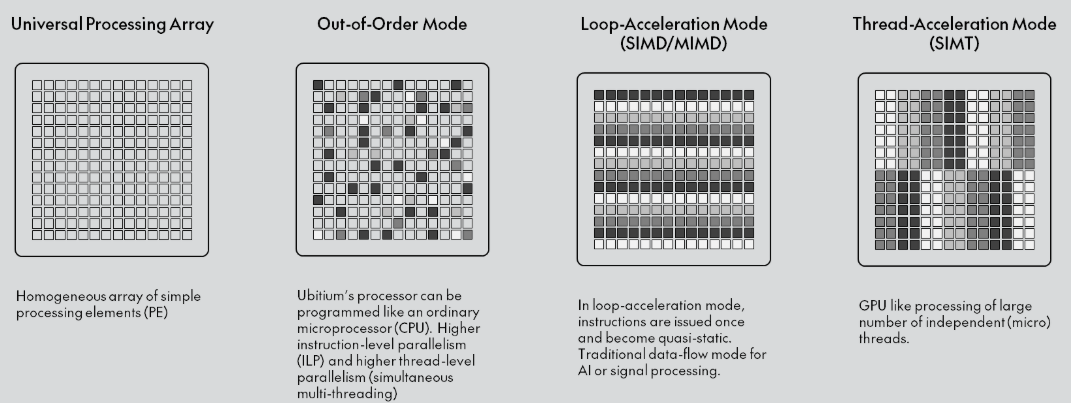
Источник изображения: Ubitium «Индустрия процессоров объёмом $500 млрд построена на жёстких границах между вычислительными задачами», — сказал Хён Шин Чо (Hyun Shin Cho), генеральный директор Ubitium и соучредитель. — Мы стираем эти границы. Наш универсальный процессор делает всё — CPU, GPU, DSP, FPGA — на одном чипе, в одной архитектуре. Это не просто постепенное улучшение. Это смена парадигмы. Это архитектура процессора, которую требует эпоха ИИ». Как отметил EE Times, завершение tape-out продукта — это не просто большая победа для Ubitium. Это также поворотный момент для экосистемы RISC-V. Открытая архитектура RISC-V используется большей частью для создания обычных ядер, которые полагаются на внешние ускорители для сложных рабочих нагрузок. Ubitium расширяет границы использования архитектуры, сохраняя полную совместимость с RISC-V. Процессор поддерживает стандартные наборы инструментов RISC-V для разработки ПО и может работать под управлением Linux и RTOS. Кроме того, унифицированный программный стек устраняет необходимость в компиляторах для конкретного поставщика или проприетарных языках, что позволяет быстро внедрять инновации и сократить время разработки. Компания сотрудничает с Samsung Foundry и ADTechnology для завершения проектирования и с Siemens Digital Industries Software — для проверки микросхемы (pre-silicon validation). Вторая стадия tape-out запланирована на конец этого года, а серийное производство начнётся в 2027 году, сообщила компания.
05.02.2026 [11:35], Сергей Карасёв
AMD представила FPGA серии Kintex UltraScale+ Gen 2 с поддержкой PCIe 4.0 и LPDDR5XКомпания AMD анонсировала FPGA серии Kintex UltraScale+ Gen 2, относящиеся к среднему классу. Эти изделия могут использоваться в разных сферах, включая здравоохранение (эндоскопия, машинное зрение, роботизированная хирургия), промышленный сектор (системы автоматизации и инспекции, периферийные платформы), вещание (видеозахват, производство материалов), среды тестирования и пр. Решения выполнены по 16-нм технологии FinFET. Реализована поддержка памяти LPDDR4X, LPDDR5 и LPDDR5X, интерфейса PCIe 4.0, а также двух блоков 100G CMAC. Упомянуты средства постквантовой криптографии в соответствии с алгоритмами, одобренными Национальным институтом стандартов и технологий США (NIST). 
Источник изображений: AMD В семейство Kintex UltraScale+ Gen 2 вошли три модели — 2KU030P, 2KU040P и 2KU050P. Первый из перечисленных чипов содержит 328 тыс. логических элементов, 150 тыс. CLB LUT (Configurable Logic Block Look-Up Table), четыре контроллера LPDDR4X/5/5X, а также в общей сложности 33,9 Мбайт памяти. Конфигурация включает два интерфейса PCIe 4.0 x8. В свою очередь, решение 2KU040P насчитывает 410 тыс. логических элементов и 187 тыс. CLB LUT, имеет шесть контроллеров LPDDR4X/5/5X, 42,4 Мбайт памяти и два интерфейса PCIe 4.0 x8. Старший вариант, 2KU050P, получил 491 тыс. логических элементов, 225 тыс. CLB LUT, шесть контроллеров LPDDR4X/5/5X, 50,9 Мбайт памяти, два интерфейса PCIe 4.0 x8 и один интерфейс PCIe 4.0 x4. 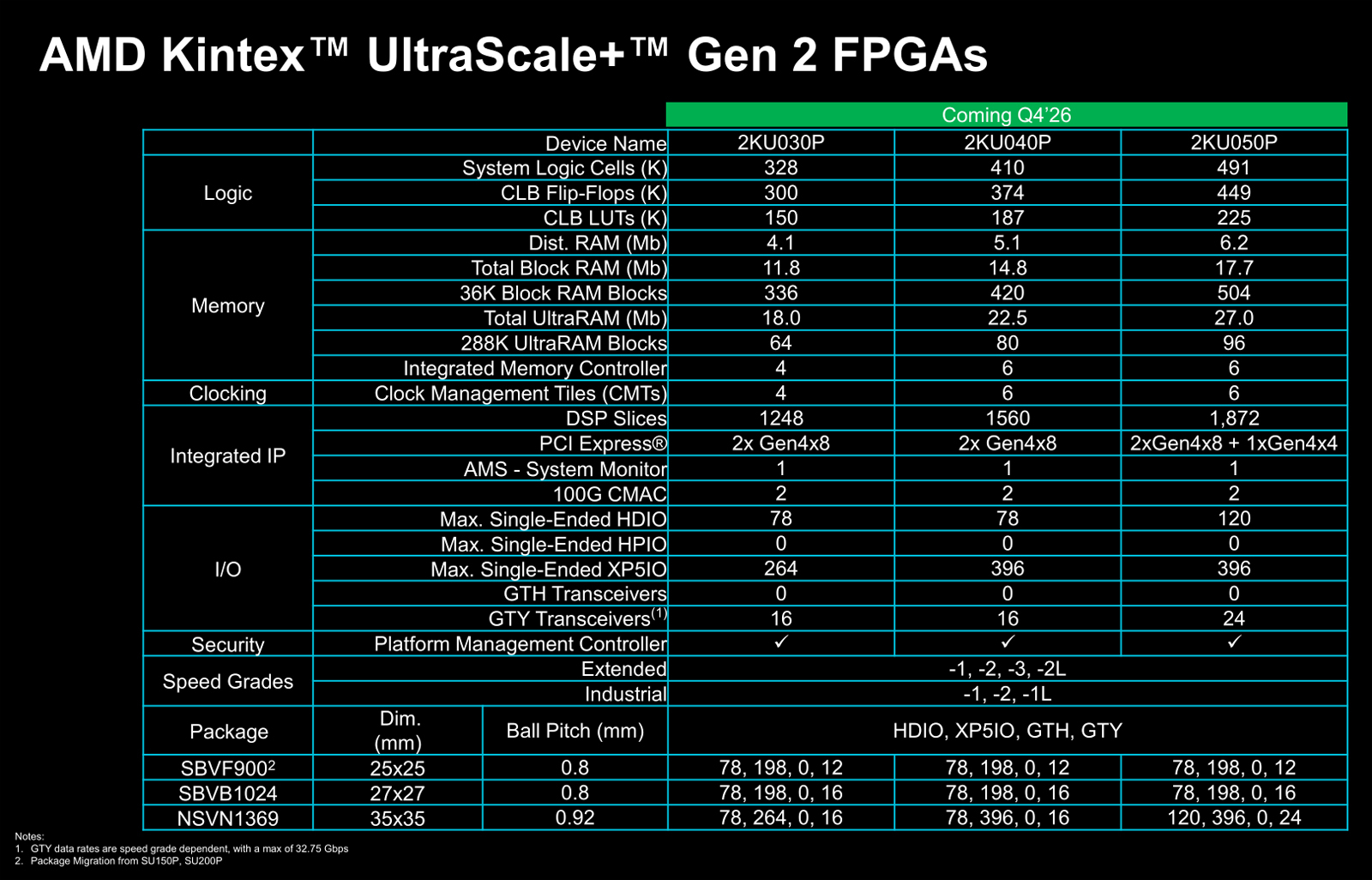 Первые инженерные образцы решений Kintex UltraScale+ Gen 2 начнут поступить заказчикам в IV квартале текущего года, тогда как серийное производство чипов должно начаться в I половине 2027-го. Компания AMD гарантирует доступность изделий как минимум до 2045 года, что должно сделать новые FPGA особенно привлекательными для отраслей с длительным жизненным циклом продукции, таких как аэрокосмическая и оборонная промышленность.
12.01.2026 [12:59], Сергей Карасёв
Sapphire представила Mini-ITX-плату EDGE+VPR-7P132 с чипом AMD Ryzen AI Embedded P132 и FPGA Versal AI Edge Gen2 VE3558Компания Sapphire Technology анонсировала плату EDGE+VPR-7P132 на платформе AMD Embedded+, предназначенную для построения различных периферийных устройств с ИИ-функциями. В новинке соседствуют процессор AMD Ryzen AI Embedded и адаптивная «система на чипе» AMD Versal AI Edge Gen 2. Решение выполнено в форм-факторе Mini-ITX с размерами 170 × 170 мм. Задействовано FPGA-решение Versal AI Edge Gen 2 VE3558 с восемью ядрами Arm Cortex-A78AE, десятью ядрами реального времени Arm Cortex-R52, графическим блоком Arm Mali-G78AE. Программируемая часть содержит 492 тыс. логических ячеек и 225 тыс. LUT. Чип обеспечивает ИИ-производительность до 123 TOPS на операциях INT8. Есть 16 Гбайт памяти LPDDR5-4266, флеш-модуль UFS 3.1 вместимостью 256 Гбайт, интерфейс Mini DisplayPort, а также модуль TPM 2.0 (Infineon OPTIGA TPM SLM 9672) и 250-контактный коннектор для плат расширения. CPU-секция получила процессор Ryzen AI Embedded P132 (V4526iX), который объединяет шесть ядер с архитектурой Zen 5 (12 потоков) с тактовой частотой до 4,5 ГГц, графический ускоритель AMD Radeon (RDNA 3.5) и нейропроцессорный блок с ИИ-производительностью до 50 TOPS в режиме INT8. Чип функционирует в тандеме с 64 Гбайт памяти LPDDR5-4266 (впаяна на плату). Предусмотрены коннектор M.2 Key M 2280 для SSD (PCIe 4.0 x4), слот M.2 Key E 2230 (PCIe 4.0 x1, I2S, USB 2.0) для адаптера Wi-Fi/Bluetooth и разъём OCulink x4. 
Источник изображения: Sapphire Плата получила два сетевых порта 10GbE, по два порта USB 3.2 Gen 2 Type-A и USB 2.0 Type-A, коннектор USB4 Type-C, четыре интерфейса Mini DisplayPort. Через внутренние разъёмы можно использовать аудиоинтерфейсы. Питание (12 В) подаётся через DC-коннектор. Диапазон рабочих температур простирается от 0 до +60 °C. Заявлена совместимость с RHEL/CentOS 7.9, RHEL 8.2-8.6 и Ubuntu 22.04. В качестве платы расширения упомянут модуль с поддержкой 12 камер для автомобильных систем и робототехники.
10.12.2025 [13:18], Сергей Карасёв
«Гравитон» представил SmartNIC SNC-QSFP2-SH01 с FPGA, 100GbE-портами и слотом SO-DIMMКомпания «Гравитон», российский производитель вычислительной техники, анонсировала сетевой адаптер SNC-QSFP2-SH01 класса SmartNIC, предназначенный для использования в дата-центрах. Устройство обеспечивает аппаратное ускорение различных сетевых функций. В основу решения положена неназванная ПЛИС, которая насчитывает свыше 1 млн логических ячеек и содержит более 50 Мбит встроенной блочной памяти. Адаптер может нести на борту до 32 Гбайт оперативной памяти DDR4. Также упоминается отечественный центральный микроконтроллер первого уровня. Карта оснащена двумя 100GbE-портами QSFP28, что, впрочем, видится избыточным, поскольку используемое подключение PCIe 3.0 x8 не способно «прокачать» столько трафика. За охлаждение отвечают радиатор и вентилятор тангенциального типа. Заявлена поддержка библиотек DPDK и совместимость с платформами Linux и Windows Благодаря возможности реконфигурирования FPGA адаптер может использоваться для решения широкого спектра задач. Среди них названы ускорение работы облачных сервисов, виртуализация, проверка сетевых пакетов по их содержимому (DPI) для регулирования и фильтрации трафика, межсетевые экраны нового поколения (NGFW). Изделие также может применяться в комплексных решениях в сфере кибербезопасности для поиска и устранения угроз в сетевом трафике. 
Источник изображения: «Гравитон» «Использование архитектуры на базе ПЛИС позволило нам создать устройство, которое не просто передаёт пакеты, а берёт на себя ресурсоёмкие вычисления: от балансировки нагрузки до глубокой инспекции пакетов. Мы предлагаем рынку мощный инструмент, который поможет оптимизировать работу облачных сервисов и систем информационной безопасности, высвобождая ресурсы CPU для прикладных задач», — говорит «Гравитон».
19.11.2025 [11:49], Сергей Карасёв
Второй европейский экзафлопсный суперкомпьютер Alice Recoque получит чипы AMD EPYC Venice и ускорители Instinct MI430XЕвропейское совместное предприятие по развитию высокопроизводительных вычислений (EuroHPC JU) и французско-нидерландский Консорциум Жюля Верна объявили о том, что в создании суперкомпьютера Alice Recoque примут участие компании Eviden (входит в состав Atos Group), AMD и SiPearl. О проекте Alice Recoque впервые стало известно в июне прошлого года. Это будет второй европейский суперкомпьютер экзафлопсного класса после системы JUPITER, смонтированной в Юлихском исследовательском центре (FZJ) в Германии. Соглашение о создании Alice Recoque подписано между EuroHPC JU и французским национальным агентством высокопроизводительных вычислений (GENCI). Комплекс будет смонтирован в дата-центре на территории Брюйер-ле-Шатель (Bruyères-le-Châtel), к юго-западу от Парижа. Как сообщается, в состав Alice Recoque войдут унифицированный вычислительный раздел и скалярный раздел. Основой первого послужит новая платформа Eviden BullSequana XH3500, содержащая серверы с 256-ядерными процессорами AMD EPYC Venice и ускорителями Instinct MI430X, оснащёнными 432 Гбайт памяти HBM4 с пропускной способностью 19,6 Тбайт/с. Кроме того, говорится о применении AMD FPGA и высокопроизводительной подсистемы хранения данных DDN. Суперкомпьютер объединит 94 стойки с суммарным энергопотреблением «менее 15 МВт». В свою очередь, скалярный раздел будет использовать 128-ядерные Arm-процессоры SiPearl Rhea2. Общее количество таких ядер превысит 100 тыс. В качестве интерконнекта в составе Alice Recoque планируется использовать технологию BullSequana eXascale Interconnect (BXI v3), обеспечивающую скорость передачи данных до 400 и 800 Гбит/с для CPU- и GPU-узлов соответственно. 
Источник изображения: AMD Машина получит систему прямого жидкостного охлаждения (DLC) пятого поколения (с тёплой водой) разработки Eviden для унифицированных стоек и технологию охлаждаемых дверей для скалярных стоек. Интеллектуальное программное обеспечение Eviden Argos обеспечит мониторинг в режиме реального времени и оптимизацию энергопотребления. Говорится о широком применении компонентов с открытым исходным кодом, таких как SLURM, Kubernetes, LUSTRE, Grafana и Prometheus. Монтаж суперкомпьютера Alice Recoque начнётся в 2026 году. Затраты на приобретение, доставку, установку и обслуживание системы составят €354,8 млн. EuroHPC JU предоставит половину этой суммы, ещё столько же обеспечат Франция, Нидерланды и Греция в рамках Консорциума Жюля Верна. Общие инвестиции в проект на протяжении пяти лет оцениваются в €554 млн. Использовать новый вычислительный комплекс планируется для решения сложных задач в сферах моделирования климата, разработки передовых материалов, энергетики и пр. Система также поможет в развитии европейских моделей ИИ следующего поколения и цифровых двойников для персонализированной медицины. |
|

