Материалы по тегу: risc-v
|
01.08.2026 [15:49], Сергей Карасёв
Xcena представила вычислительную память MX1 для генеративного ИИЮжнокорейский стартап Xcena анонсировал продукты семейства MX1, призванные решить проблему дефицита памяти в масштабных платформах, ориентированных на задачи генеративного ИИ. По мере того как генеративный ИИ требует всё более крупных моделей, более длинных контекстных окон и стремительно растущих объёмов KV-кеша, память становится главным ограничивающим фактором для инфраструктуры ИИ. Изделия HBM остаются крайне дорогими при ограниченной ёмкости, тогда как расширение путём добавления серверов приводит к формированию избытка вычислительных ресурсов и росту совокупной стоимости владения, говорит Xcena. Устройства MX1 призваны переломить ситуацию. Речь идёт об использовании вычислительной памяти. Идея заключается в том, чтобы увеличить основную память системы, добавив модули DDR5 DIMM вкупе с ядрами RISC-V. Реализована поддержка PCIe 6.0 и CXL 3.2, а технология NDP (Near Data Processing) сводит к минимуму задержку при перемещении данных между интерфейсами. В результате, значительно ускоряется выполнение ресурсоёмких задач при одновременном снижении нагрузки на CPU. 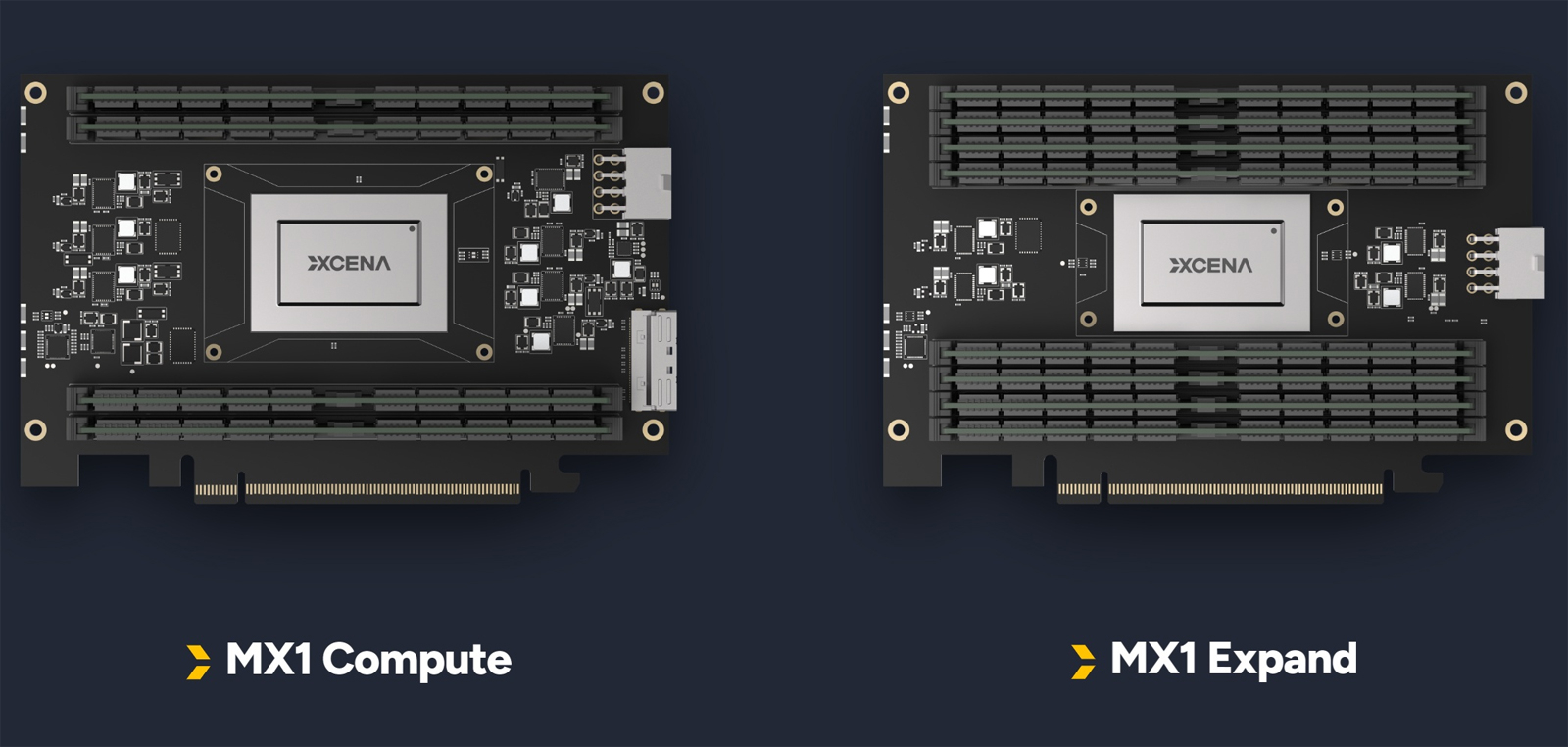
Источник изображения: Xcena В семейство входят изделия MX1 Compute и MX1 Expand. Первое представляет собой CXL-решение с 2048 ядрами RISC-V и четырьмя слотами DRAM, что позволяет выполнять вычисления рядом с памятью. Благодаря этому устраняется перемещения данных между CPU и памятью, что повышает производительность инференса и сокращает энергопотребление. В свою очередь, MX1 Expand предоставляет восемь слотов DRAM для эффективного масштабирования пула памяти.
31.07.2026 [17:42], Сергей Карасёв
Openchip представила европейский 2-нм процессор BER10 с архитектурой RISC-VКомпания Openchip анонсировала суверенный европейский процессор BER10, построенный на открытой архитектуре RISC-V. Изделие ориентировано на различные устройства, функционирующие под управлением Linux. Это могут быть серверы, периферийные платформы и пр. Чип BER10 получил четыре 64-бит вычислительных ядра с внеочередным исполнением инструкций. Тактовая частота и размер кеш-памяти пока не раскрываются. Но отмечается, что при производстве применяется передовая технология Gate-All-Around (GAA) с нормами «менее 2 нм». Таким образом, можно предположить, что решение обладает высокой энергетической эффективностью. 
Источник изображения: Openchip В процессоре реализована поддержка многоканальной оперативной памяти и высокоскоростных интерфейсов, таких как PCIe и AXI (Advanced eXtensible Interface). Кроме того, имеется аппаратный векторный блок, предназначенный для ускорения операций, связанных с ИИ, научными расчётами, обработкой изображений и другими ресурсоёмкими задачами. Openchip подчёркивает, что BER10 — это не исследовательский прототип, а чип, рассчитанный на серийное производство. Иными словами, изделие готово для работы с реальными операционными системами и прикладным софтом. Впрочем, о начале массовых поставок процессоров разработчик умалчивает. Европейская безфабричная компания Openchip была основана в Барселоне в 2021 году. В настоящее время она ведёт деятельность в Испании, Италии, Франции, Польше, Германии и Ирландии. В штат входят более 200 специалистов — в основном в области исследований и разработок. Ключевым направлением деятельности является проектирование энергоэффективных «систем на кристалле» (SoC) на основе архитектуры RISC-V.
17.07.2026 [17:12], Владимир Мироненко
Евросоюз объявил об успешном завершении второго этапа EPI для укрепления технологического суверенитетаВ Люксембурге состоялся заключительный обзор Европейской инициативы по процессорам (EPI), финансируемой EuroHPC. По итогам было объявлено об успешном завершении второго этапа проекта — EPI SGA2, целью которого было содействие укреплению технологического суверенитета Европы. В рамках обзора была проведена демонстрация уникальных технологий и микросхем, разработанных на обоих этапах проекта EPI. В частности, был продемонстрирован первый Arm-процессор SiPearl Rhea1, работающий с полным ПО для HPC. Чип запустили на тестовой плате со стандартным дистрибутивом Linux, работающим с высокоскоростной памятью HBM и соответствующими аппаратными счетчиками мониторинга производительности. Он успешно прошёл тесты HPL и STREAM, демонстрируя готовность всей аппаратной и программной экосистемы Rhea1 к высокопроизводительным вычислениям для систем экзафлопсного уровня. Также было проведено пять демонстраций, наглядно подтверждающих, что технология RISC-V, используемая EPI, перешла от отдельных блоков к полному программному стеку, реальному оборудованию и реальным приложениям и инструментам, которыми может воспользоваться обычный пользователь. Так, был развёрнут полный кластер на ускорителе VEC. Был показан новейший RTL-код (ядро RISC-V с внеочередным выполнением инструкций от Semidynamics, улучшенный векторный блок от Барселонского суперкомпьютерного центра) для запуска на FPGA в инфраструктуре MEEP. Было запущено реальное научное приложение Mini-Fall3D для оценки диффузии пыли в атмосфере, распараллеленное с помощью OpenMP и MPI, скомпилированное с использованием инструментария EPI LLVM и профилированное с помощью стандартных инструментов (PAPI, Extrae/Paraver). Запуски показали масштабируемость, продемонстрировав выполнения скалярных и векторных задач на разных узлах. Источник изображения: european-processor-initiative.eu Также был продемонстрирован готовый ИИ-чип EPAC 1.5 на базе RISC-V, подключённый к Arm-хосту через PCIe. Компилятор проекта генерирует один двоичный файл, содержащий код как Arm, так и RISC-V. Код RISC-V передаётся по PCIe через DMA, динамически загружается, выполняется, а результаты копируются обратно. Это демонстрирует оригинальную идею EPI по созданию гетерогенных систем с разными ISA и операционными средами, эффективно работающих вместе на реальном оборудовании. Kalray показала успешную доработку и оптимизацию ПО для своих KVX-процессоров на базе VLIW, которые также могут работать в режиме RISC-V. Menta продемонстрировала результаты оптимизации своей EDA Origami для больших eFPGA, которые позволили кратно ускорить разработку чипов и схем. Наконц, было продемонстрировано успешное использование технологии сжатия памяти в реальном времени ZeroPoint (DenseMem) на EPAC 1.5. Подводя итоги длившегося три года этапа SGA1 и четырёхлетнего SGA2, руководители проекта отметили, что путь к европейскому суверенитету в цифровых технологиях лежит в дальнейшем развитии этих результатов. Для этого научные партнёры проекта опубликуют результаты обширных исследований проекта, а промышленные партнёры продолжат дальнейшее развитие IP-блоков, полученных в его рамках.
03.07.2026 [11:54], Сергей Карасёв
Встраиваемые системы становятся главным фронтом ИТ-суверенитета России
open source
risc-v
software
встраиваемая система
мероприятие
микроконтроллер
операционная система
разработка
россия
сделано в россии
XIII международная конференция OS DAY 2026, прошедшая в июне в РЭУ им. Плеханова, обозначила новый рубеж в битве за технологическую независимость. Если раньше дискуссии вращались вокруг импортозамещения операционных систем общего назначения, то теперь фокус сместился на «каменный фундамент» цифровой экономики — встраиваемые устройства и микроконтроллеры. От банкоматов в ритейле до датчиков на нефтяных платформах — исправное функционирование этих «невидимых» систем сегодня признано вопросом национальной безопасности. Умные пылесосы и критическая инфраструктураИндустрия 4.0 проникла в каждый уголок нашей жизни — от промышленных роботов до счётчиков электроэнергии. Однако взрывной рост количества устройств создал колоссальную поверхность для атак. «Комфортная и безопасная жизнь общества сегодня во многом зависит от корректного и безопасного функционирования огромного числа встраиваемых устройств, которые нас окружают, — отметил на открытии конференции Андрей Духвалов, вице-президент "Лаборатории Касперского". — Вся наша промышленность основана на автоматизированных системах управления, в состав которых входят контроллеры и умные датчики». 
Источник изображений: OS DAY / Вадим Мелешко Спектр применения встраиваемых систем расширяется с каждым годом. Сергей Пашала, директор департамента сопровождения продаж и консалтинга РЕД СОФТ, конкретизировал, что речь идёт о широчайшем их спектре, от промышленных контроллеров и АСУ ТП до системы мониторинга, безопасности, видеонаблюдения. «В финансовом секторе и ритейле большая доля их приходится на оборудование для самообслуживания — банкоматы, платёжные терминалы, постаматы», — добавил он. При этом сегодняшний мир настолько хаотичен, что вчерашние надёжные международные партнёры могут в одночасье отказаться от сотрудничества, а то и начать отключения от технической поддержки своей продукции или от разного рода связанных с этой продукцией услуг и сервисов. Поэтому нашей стране крайне необходим технологический суверенитет в области производства встраиваемых устройств, особенно в критических отраслях. «Вопрос заключается уже не в том, нужен ли технологический суверенитет, а в том, как именно его обеспечить, — подчеркнул, отвечая на вопросы журналистов, Арутюн Аветисян, директор Института системного программирования им. В.П. Иванникова РАН. — В системах управления критически важными объектами должны использоваться исключительно отечественные аппаратные и программные решения».  Суверенитет как цельРазумеется, не стоит на пути к технологическому суверенитету ломать все производственные цепочки с международными партнёрами, нужен взвешенный подход. Но совершенно очевидно, что необходимо иметь сильных отечественных игроков в области производства всех основных типов микроэлектронных компонентов, свои дизайн-центры, мощное контрактное производство, а также отраслевые предприятия, занимающиеся производством специализированных устройств, причём должны быть налаженные кооперационные цепочки между этими контрагентами. Ещё более важна разработка собственного ПО для встраиваемых устройств, так как, не имея доступа к «начинке» программного обеспечения, невозможно точно сказать, что на самом деле оно делает, насколько оно надёжно, как поведёт себя в том или ином случае и наконец — нет ли в нём программных закладок и скрытых функций. Собственная разработка позволяет накапливать отраслевую экспертизу и развивать функциональность встраиваемых устройств в нужном российским потребителям направлении. Также не стоит забывать об экономическом эффекте от собственной разработки, который намного больше по сравнению с приобретением подобного устройства, ввезённого из-за рубежа. Как следствие, 1 января 2025 года вступил в силу Указ Президента №166, запрещающий использование иностранного ПО на значимых объектах критической информационной инфраструктуры. Этот нормативный акт стал мощным драйвером для замены импортных решений на всех уровнях — от «железа» до операционных систем.  Ажиотаж и реальностьГлавная интрига сегодняшнего дня: сможет ли российский рынок оперативно насытить спрос? Цифры внушают оптимизм. В 2026 году российская микроэлектроника делает гигантский шаг вперед. НИИЭТ (входит в ГК «Элемент») сообщил о выпуске миллионного микроконтроллера К1921ВГ015 за год работы новой линии корпусирования, мощности которой позволяют производить до 10 млн изделий ежегодно. Параллельно «Байкал Электроникс» заключил крупнейший контракт на поставку 1,5 млн микроконтроллеров Baikal-U (BE-U1000) в течение пяти лет, планируя поставить 1 млн чипов уже в 2026 году. Эти устройства на открытой архитектуре RISC-V позиционируются как прямой аналог популярной линейки STM32 от ушедшей из РФ STMicroelectronics. Эксперты рынка подтверждают ажиотаж. По данным J’son & Partners Consulting, объём рынка лицензий российских ОС в 2024 году достиг 12,5 млрд рублей, показав рост на 37 %, а доля отечественных ОС в общем объёме выросла до 21 %. Однако достичь полного суверенитета мешают старые проблемы. «Когда ставится задача добиться технологической независимости, следует понимать, что придётся работать с каждым слоем системы: с аппаратурой и процессором, с системным и прикладным ПО, и даже со средствами разработки. Разом все поменять просто невозможно», — констатировал в ходе панельной дискуссии «Технологический суверенитет промышленного производства: встраиваемые устройства», состоявшейся в рамках OS DAY 2026, Вартан Падарян, заведующий лабораторией обратной инженерии бинарного кода ИСП РАН. Алексей Киселёв, руководитель направления НТЦ ИТ РОСА, рассказал о проблемах технического характера: «Существуют несколько не до конца проработанных вопросов, в частности, с сертификацией ФСТЭК встраиваемых устройств. Также есть проблема с большим количеством старого "железа", например, работающего на 32-бит процессорах. Создать для него специализированную ОС и поддерживать её — не самая тривиальная задача». Рынок промышленной автоматизации также сталкивается с инерцией производителей. Как отмечают эксперты, в некоторых отраслях, таких, как нефтехимия, до сих пор доминирует зарубежное оборудование, а процесс перехода на отечественные ПЛК сдерживается отсутствием гарантированного спроса и сложной интеграцией.  Дешевизна, скорость, безопасностьВыход из сложившейся ситуации эксперты видят в смещении акцента на open source и отечественные RTOS, а также в кооперации различных предприятий отрасли. «Только рыночными механизмами обеспечить долгосрочное развитие технологий на необходимом уровне качества крайне сложно, — пояснил Арутюн Аветисян. — Основная проблема здесь даже не столько в финансировании, сколько в дефиците высококвалифицированных кадров, способных годами развивать и поддерживать подобные системы. Именно поэтому необходима модель кооперации, при которой компании получают доступ к базовым технологиям, могут совместно их развивать и при этом сохраняют возможность создавать собственные конкурентоспособные продукты. Практика показывает, что десятки компаний, конкурирующих между собой на рынке, могут совместно разрабатывать единую технологическую основу, а затем создавать на её базе собственные решения для внедрения. Решить эту задачу усилиями одной компании невозможно: необходима системная совместная работа науки, индустрии и государства». Использование свободного софта в данном случае неизбежно. Как минимум, на текущем витке технологического развития. В современных разработках доля открытого кода доходит до 90 %. Именно это позволило достичь современного уровня в ИТ. Разумеется, open source в определённой мере представляет собой вызов для кибербезопасности. Хотя бы потому, что вследствие его объёмов требуемые проверки непосильны для отдельно взятой компании, даже для международной корпорации. Но, во-первых, в России сегодня развивается система национальных стандартов разработки безопасного ПО, в частности, — обновлённый ГОСТ Р 56939-2024, вступивший в силу 20 декабря 2024 года. Во-вторых, этот вызов преодолевается кооперацией, что успешно показала работа Центра исследований безопасности системного ПО. И участники конференции выразили надежду, что в составе Центра в ближайшее время оформятся и начнут развиваться технологические кластеры, посвящённые программному обеспечению с открытым исходным кодом, применяемому в АСУ ТП. Необходимость внутриотраслевой кооперации, создание мощной экосистемы так или иначе декларировали все участники OS DAY 2026. От российских производителей процессоров и аппаратных платформ ждут доступных референсных плат, от разработчиков операционных систем — развитых SDK.
16.06.2026 [09:46], Сергей Карасёв
NextSilicon готовит 128-ядерные серверные RISC-V-процессоры для ИИ и НРСКомпания NextSilicon сообщила о том, что её вычислительные ядра Arbel с архитектурой RISC-V лягут в основу процессоров корпоративного класса, ориентированных на задачи ИИ и НРС. Организовать серийное производство таких изделий планируется в I квартале 2028 года. NextSilicon проектировала Arbel с чистого листа, а первоначальной целью было создание хост-процессора для ИИ-ускорителей Maverick-3. Конструкция Arbel предусматривает наличие массивного конвейера инструкций шириной 10 команд и буфера переупорядочивания на 480 записей. Возможно выполнение 16 скалярных инструкций за цикл. Задействованы четыре интегрированных 128-бит векторных блока для обеспечения высокой производительности при параллельной обработке данных, включая нагрузки, связанные с ИИ-инференсом. 
Источник изображения: NextSilicon Сообщается, что создаваемые процессоры будут доступны в модификациях с 64 и 128 ядрами Arbel. Тактовая частота заявлена на отметке 3,4 ГГц. Тестовые изделия Arbel предполагали применение 5-нм технологии TSMC. Серийные решения будут изготавливаться по более совершенной методике для удовлетворения растущих требований к энергоэффективности и повышению плотности размещения компонентов в дата-центрах. Упомянут алгоритм прогнозирования ветвлений TAG. Говорится о полноценной поддержке профиля RVA23, который стандартизирует ISA. В RVA23 предусмотрены такие функции, как векторные операции, инструкции с плавающей запятой и атомарные инструкции, а также поддержка гипервизоров. Заявлена совместимость со стандартными дистрибутивами Linux. Ожидается, что рынок чипов с архитектурой RISC-V для дата-центров и НРС-платформ будет демонстрировать среднегодовой темп роста на уровне 33,1 % в период с 2025 по 2034 год. В результате его объём превысит $200 млрд.
25.05.2026 [10:18], Сергей Карасёв
Представлен 48-узловой ИИ-сервер Firefly CSC2-N48SPK3 с архитектурой RISC-VКомпания Firefly анонсировала многоузловой сервер CSC2-N48SPK3, предназначенный для решения ИИ-задач. Суммарная заявленная производительность этой системы, выполненной на архитектуре RISC-V, достигает 2880 TOPS на операциях INT4. Устройство получило форм-фактор 2U с 48 вычислительными узлами. Каждый из них содержит процессор SpacemiT Key Stone K3 с восемью 64-бит ядрами RISC-V X100M с тактовой частотой до 2,4 ГГц, 8/16/32 Гбайт оперативной памяти LPDDR5 и флеш-накопитель UFS 2.2 вместимостью 128 Гбайт. Говорится о полной поддержке профиля RVA23. Кроме того, в состав сервера входит один узел управления с процессором Rockchip RK3588: он содержит по четыре ядра Cortex-A76 (2,4 ГГц) и Cortex-A55 (1,8 ГГц), а также графический блок Arm Mali-G610 и нейропроцессорный узел (NPU) с производительностью до 6 TOPS. Объём ОЗУ этого узла равен 8 Гбайт. Реализован консольный порт RJ45. 
Источник изображения: Firefly Новинка располагает интерфейсом HDMI с поддержкой видео 1080p60, четырьмя сетевыми разъёмами 10GbE SFP+, двумя портами USB 3.0 и сенсорным дисплеем во фронтальной части, на котором отображаются различные параметры (температура, скорость вращения вентиляторов, сетевые данные и пр.). Опционально предлагается возможность установки до 48 накопителем формата M.2 2280 с интерфейсом PCIe (NVMe): при использовании SSD вместимостью 16 Тбайт суммарная ёмкость подсистемы хранения может достигать 768 Тбайт. Габариты составляют 724 × 430 × 88,8 мм, масса — 23,1 кг. Питание обеспечивают два блока с резервированием и возможностью горячей замены. Сервер Firefly CSC2-N48SPK3 доступен для заказа по цене $38 829 в комплектации с 48 вычислительными узлами, оборудованными 16 Гбайт оперативной памяти каждый.
14.05.2026 [10:56], Сергей Карасёв
SiFive представила RISC-V-ядра Performance P570 Gen 3 для IoT-приложенийКомпания SiFive анонсировала производительные процессорные ядра Performance P570 третьего поколения (Gen 3) с архитектурой RISC-V. Они ориентированы на требовательные периферийные ИИ-приложения, потребительские и коммерческие решения интернета вещей (IoT) и пр. Новые ядра используют 64-бит архитектуру RISC-V с поддержкой внеочередного исполнения инструкций. Допускаются конфигурации, насчитывающие до четырёх ядер в кластере. При этом возможно использование до четырёх кластеров, что в сумме даёт до 16 вычислительных ядер. Используется общий кеш L3 на уровне кластера и опциональный общий кеш L2. Для Performance P570 Gen 3 заявлена поддержка широкого спектра типов данных: INT8, INT16, INT32, INT64, FP16, FP32, FP64 и BFloat16. Заявлена полная совместимость с профилем RVA23, который стандартизирует набор инструкций ISA. Реализованы такие функции, как векторные операции, инструкции с плавающей запятой и атомарные инструкции, которые востребованы в сферах НРС и ИИ. Добавлены расширения для повышения производительности и улучшения безопасности, включая Smepmp, Zvkng, Zvksg, Zicfilp, Zicfiss, Zfbfmin, Zvfbfmin, Zvfbfwma и Zvdot4a8i. Упомянута возможность работы с современными ОС, включая Android, Ubuntu 26.04 LTS и платформы Red Hat. 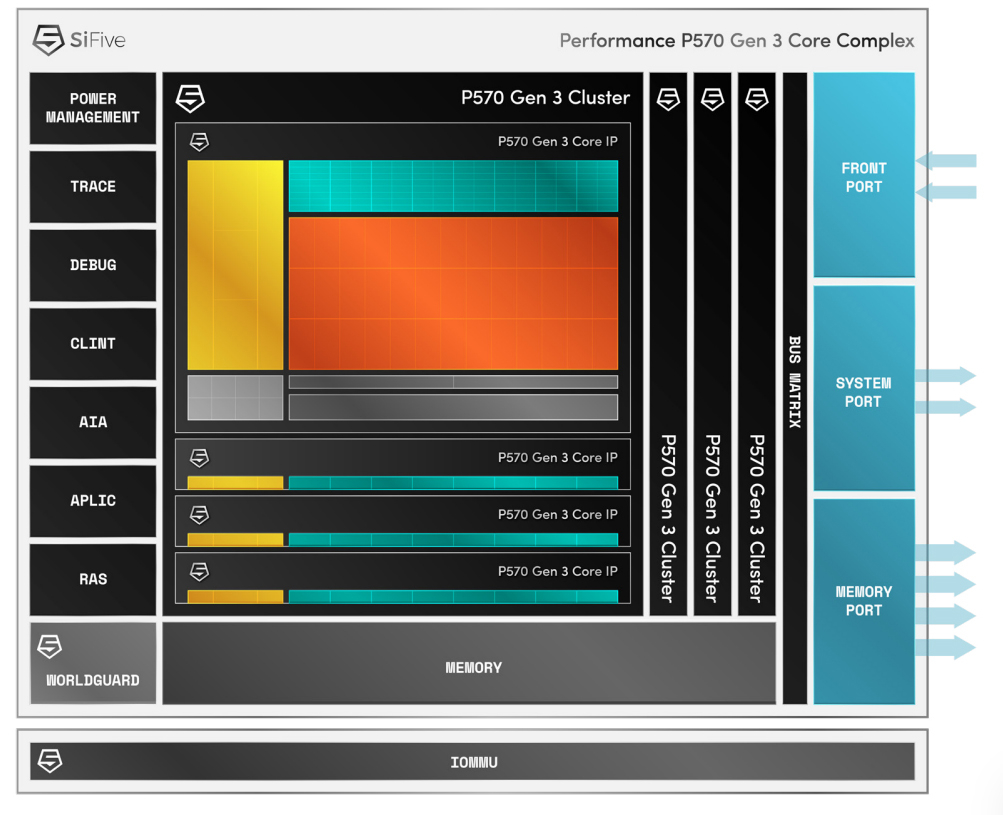
Источник изображения: SiFive В тесте Geekbench 6 ядра Performance P570 Gen 3 демонстрируют примерно вдвое более высокую производительность в расчёте на 1 ГГц по сравнению с изделиями P550. При выполнении определённых ИИ-задач, таких как распознавание объектов, достигается 21-кратный прирост быстродействия благодаря 128-битному векторному конвейеру VLEN. Если сравнивать с ядрами P470 Gen2, то у P570 выигрыш в производительности составляет 30 % и 350 %. В традиционных CPU-нагрузках, по данным SpecInt 2006/2017, ядра P570 показывают прирост быстродействия на 7–13 % по сравнению с P550 при сопоставимых значениях с P470. Кроме того, обеспечивается повышение энергетической эффективности. У ядер Performance P570 Gen 3 динамическое энергопотребление (мВт/ГГц) снижено на 13 % и 5 % по сравнению с P550 и P470 соответственно, а потери мощности (мВт) уменьшены на 51 % и 5 %.
13.05.2026 [09:32], Сергей Карасёв
Edge-компьютер Firefly AIBox-K3 оснащён чипом RISC-V с ИИ-производительностью до 60 TOPSКомпания Firefly Technology, по сообщению ресурса CNX-Software, начала продажи компьютера небольшого форм-фактора AIBox-K3, предназначенного для решения ИИ-задач на периферии: устройство, в частности, подходит для осуществления локального инференса. В основу новинки положен процессор SpacemiT K3. Чип объединяет восемь 64-бит ядер RISC-V X100 (RVA23) с тактовой частотой до 2,4 ГГц и восемь ИИ-ядер RISC-V A100 с общей производительностью до 60 TOPS на операциях INT4. В состав изделия входит GPU-блок Imagination Technologies BXM4-64-MC1 с поддержкой Vulkan 1.3, OpenCL 3.0 и OpenGL ES 1.1/2.0/3.2. Возможно декодирование материалов H.265, H.264, VP9 в формате до 4K (120 к/с) и кодирование H.265, H.264 в формате 4K (60 к/с). Объём оперативной памяти LPDDR5-6400 может составлять 8, 16 или 32 Гбайт, вместимость встроенного флеш-модуля UFS 2.2 — 128, 256 или 512 Гбайт. Есть коннектор M.2 2242/2280 для SSD с интерфейсом PCIe 3.0 x4 (NVMe). В оснащение включён двухпортовый сетевой контроллер 1GbE. 
Источник изображения: Firefly Во фронтальной части расположены порт USB 3.0 DRD Type-C (USB 2.0 OTG) и консольный разъём USB Type-C, в тыльной — два порта USB 3.0 Type-A, два гнезда RJ45 для сетевых кабелей, а также интерфейс HDMI 2.0 с возможностью вывода изображения 4K (60 Гц). Питание (9–20 В) подаётся через DC-разъём. Габариты составляют 93,4 × 93,4 × 50,0 мм, масса — около 500 г. Диапазон рабочих температур простирается от -20 до +60 °C. Устройство заключено в корпус из «алюминия промышленного класса». Утверждается, что компьютер обеспечивает быстродействие более 10 токенов в секунду при локальном запуске ИИ-моделей, насчитывающих до 30 млрд параметров. Говорится о совместимости с Bianbu OS 3.0, Ubuntu 26.04, OpenHarmony, OpenKylin, Fedora, Deepin и пр. Цена начинается с $350 за модификацию с 8 Гбайт ОЗУ и 128 Гбайт флеш-памяти.
29.04.2026 [01:23], Владимир Мироненко
Tenstorrent представила ИИ-серверы Galaxy Blackhole для быстрой генерации токенов и без дезагрегацииTenstorrent представила вычислительную систему Galaxy Blackhole на базе ускорителей Blackhole с архитектурой RISC-V, которая позиционируется как системная ИИ-платформа, способная конкурировать с другими решениями за счёт стабильной производительности инференса, высокоскоростного доступа к памяти и масштабируемой сети — трёх факторов, которые всё чаще определяют эффективность развёртывания ИИ в реальных условиях, пишет Forbes. 6U-сервер Tensorrent Galaxy Blackhole с воздушным охлаждением основан на 32 ИИ-ускорителях Blackhole суммарной производительностью 23 Пфлопс в режиме FP8. Система включает 6,2 Гбайт SRAM (суммарно 2,9 Пбайт/с) и 1 Тбайт GDDR6 (суммарно 16 Тбайт/с). Высокоскоростную связь между узлами при горизонтальном масштабировании обеспечивают 800GbE-порты — до 56 портов на систему с общей пропускной способностью 11,2 Тбайт/с (в дуплексе). Стоимость системы Tensorrent Galaxy Blackhole составляет $110 тыс. Восьмичиповые системы NVIDIA DGX будут производительнее, но и обойдутся в три-пять раз дороже, сообщил The Register. Базовый суперкластер Galaxy Supercluster стоимостью в $440 тыс. включает четыре системы Blackhole. При этом архитектура Tenstorrent поддерживает масштабирование до 32 узлов с 1024 ускорителями. Mesh-сеть Tenstorrent не ограничивается одним узлом. Подобно кластерам TPU от Google или Trainium2 от Amazon, её можно расширить для поддержки более крупных моделей, более высокой пропускной способности или большей интерактивности, добавив больше узлов и отрегулировав параллелизм тензоров и конвейеров. 
Источник изображений: Tenstorrent Как сообщает Tenstorrent, для DeepSeek V3 её четырёхузловые суперкластеры Blackhole Galaxy Supercluster могут обрабатывать запрос на 100 тыс. токенов — эквивалент 166 страниц текста — менее чем за четыре секунды. Tenstorrent заявила, что кластеры Galaxy Blackhole могут генерировать видео быстрее, чем в реальном времени, а также очень быстро генерировать токены LLM. Демонстрационные версии систем Tenstorrent настроены на обычный режим с генерацией текста с удобочитаемой скоростью, и режим Blitz, обеспечивающий максимально быструю обработку данных, подходящую для таких приложений, как генерация кода и агентный ИИ. В режиме Blitz MoE-модель DeepSeek-671B обеспечивает «до 350 т/с на пользователя со временем получения первого токена менее 4 с», сообщила компания. Ресурс EE Times протестировал этот режим за несколько дней до официального запуска, получив 255 т/с на пользователя для коротких запросов в стиле чат-бота. Этот режим поддерживает пакетную обработку от 8 до 64 и длину контекста до 128 тыс токенов. Он работает на 16 серверах Galaxy (512 чипов) с использованием конвейерного параллелизма на этапе декодирования.  Компания отметила, что её системы не нуждаются в дезагрегации. «Мы можем выполнять и [предварительное заполнение, и декодирование] на одном узле, — сообщил генеральный директор Tenstorrent Джим Келлер (Jim Keller) изданию EE Times. — Мы создаём большой кластер, на котором можно запускать предварительное заполнение и декодирование LLM, генерацию видео, агентный ИИ… мы не специализируемся на чём-то одном. У нас много чипов, большой объём SRAM, но все чипы имеют DRAM, и все они тесно связаны между собой, поэтому наша платформа гораздо более универсальна».
27.04.2026 [12:54], Сергей Карасёв
Одноплатный компьютер Banana Pi BPI-SM10 получил чип RISC-V с ИИ-производительностью 60 TOPSКоманда Banana Pi анонсировала мини-компьютер BPI-SM10, подходящий для проектирования устройств с ИИ-функциями. В основу новинки, состоящей из вычислительного модуля и сопутствующей интерфейсной платы, положен процессор с архитектурой RISC-V. CPU-модуль построен на чипе SpacemiT K3. Он содержит восемь 64-бит ядер RISC-V X100 с тактовой частотой до 2,4 ГГц и восемь ИИ-ядер RISC-V A100 с общей производительностью до 60 TOPS на операциях INT4. Есть интегрированный графический контроллер Imagination Technologies BXM4-64-MC1 с поддержкой Vulkan 1.3, OpenGL 3.0 и OpenGL ES 1.1/2.0/3.2. Возможно декодирование материалов 4K120 (H.264/H.265/VP9), а также кодирование 4K60 (H.264/H.265). Объём оперативной памяти LPDDR5-6400 может достигать 32 Гбайт. 
Источник изображения: Banana Pi Интерфейсная плата располагает коннекторами M.2 Key M (PCIe 3.0 x4) и M.2 Key M (PCIe 3.0 x1) для SSD, слотом M.2 Key E для адаптера Wi-Fi, а также сетевым портом 1GbE. Есть четыре разъёма USB 3.0 Type-A, порт USB Type-C и интерфейс DisplayPort 1.2. Среди прочего упомянуты 40-контактная колодка (UART, SPI, I2S, I2C, GPIO), два интерфейса MIPI CSI и один интерфейс MIPI DSI. Питание подаётся через DC-разъём. Размеры составляют 103 × 90,5 × 35 мм. Допускается монтаж активного кулера с радиатором и вентилятором. Утверждается, что новинка способна поддерживать работу ИИ-моделей, насчитывающих до 30 млрд параметров, обеспечивая при этом производительность на уровне 10 токенов в секунду. Banana Pi BPI-SM10 может стать основой ИИ-терминалов, систем промышленной автоматизации и машинного зрения, шлюзов AIoT, робототехнических платформ и пр. |
|

