Материалы по тегу: npu
|
05.06.2026 [15:58], Сергей Карасёв
Phison представила SSD-контроллер с поддержкой PCIe 6.0Компания Phison продемонстрировала SSD-контроллер следующего поколения PS5303-X3-66. Изделие предназначено для построения высокопроизводительных накопителей корпоративного класса с интерфейсом PCIe 6.0 х4. Контроллер соответствует спецификациям NVMe 2.3 и OCP v2.6. Говорится о поддержке средств безопасности TCG Opal 2.3, DOE, IDE, Caliptra и CNSA 2.0. Решение теоретически позволяет создавать SSD вместимостью до 2 Пбайт. 
Источник изображений: Phison Чип PS5303-X3-66 обеспечивает производительность до 28 000 Мбайт/с в режимах последовательного чтения и записи. Величина IOPS (операций ввода/вывода в секунду) при произвольных чтении и записи достигает 6,8 млн. Энергетическая эффективность находится на уровне 4000 Мбайт/с/Вт. По всем этим показателям новый контроллер в два раза превосходит решения предыдущего поколения с поддержкой PCIe 5.0.  Кроме того, Phison показала новые накопители на основе PS5303-X3-66 — устройства Pascari. Они будут предлагаться в различных вариантах исполнения, включая E3.S и E1.S. В конструкцию этих SSD входят модули DRAM-памяти производства SK Hynix (Hynix H25T3TG88G). В дополнение к новому контроллеру Phison готовит другие решения с поддержкой PCIe 6.0, включая ретаймеры и редрайверы.  Кроме того, компания разработала собственный нейропроцессор (AI NPU) с кодовым именем Topaz, который содержит четыре специализированных ядра. Заявленная ИИ-производительность достигает 40 TOPS. Реализована поддержка памяти LPDDR5/5X-8533. При изготовлении применяется 6-нм технология TSMC. Восемь таких NPU положены в основу карты расширения с интерфейсом PCIe 6.0 x4, которая обеспечивает суммарное быстродействие на уровне 320 TOPS.
05.04.2026 [13:21], Сергей Карасёв
Fujitsu планирует выпуск 1,4-нм NPU для ИИ-системЯпонская корпорация Fujitsu, по сообщению агентства Nikkei, намерена заняться разработкой передовых нейронных процессоров (NPU) для ИИ-систем. Предполагается, что чипы будут изготавливаться по 1,4-нм технологии на мощностях Rapidus — это консорциум, в который входят японские компании NTT, SoftBank, Denso, MUFG Bank, NEC, Sony, Toyota и Kioxia. Подробностей о проекте пока не слишком много. Ранее 1,4-нм NPU корпорация Fujitsu упоминала в контексте процессоров MONAKA-X для суперкомпьютера FugakuNEXT, которые станут преемниками изделий MONAKA. Конструкция последних предполагает использование четырёх 36-ядерных вычислительных чиплетов, изготовленных по 2-нм технологии TSMC. Общее число ядер достигает 144. Сами чиплеты монтируются поверх «плиток» SRAM с использованием гибридного медного соединения (HCB). Упомянуты 12 каналов оперативной памяти DDR5, а также интерфейс PCIe 6.0 с CXL 3.0. 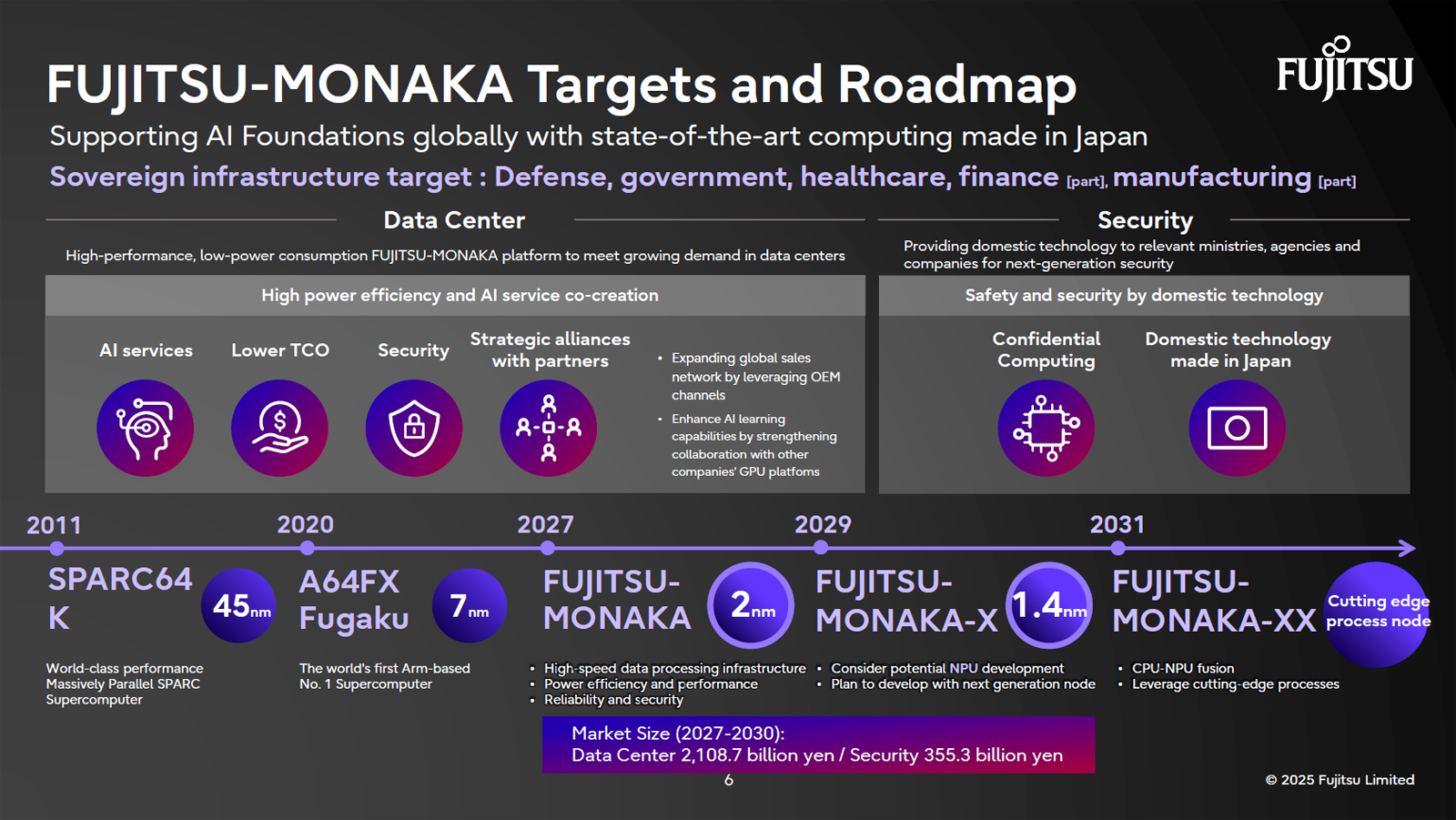
Источник изображения: Fujitsu Выпуск MONAKA запанирован на 2027 год, тогда как изделия MONAKA-X должны появиться в период с 2029-го по 2031-й. Консорциум Rapidus намерен начать опытное производство изделий по 1,4-нм технологии в 2029 году. Детали о техпроцессе пока держатся в секрете, за исключением того, что Rapidus при его разработке и внедрении сотрудничает с IBM, Canon и другими японскими компаниями. Сроки масштабирования производства будут определены после запуска соответствующего завода. По имеющейся информации, часть затрат на создание 1,4-нм NPU покроет Министерство экономики, торговли и промышленности Японии (METI). По оценкам, на первом этапе разработка нейропроцессора Fujitsu обойдётся примерно в $360 млн. Если проект будет одобрен властями Японии, две трети от этой суммы поступят из государственного бюджета. Чипы будут полностью производиться собственными силами на территории страны.
30.12.2025 [22:09], Сергей Карасёв
Rockchip представила комплекты для разработчиков с ИИ-модулями RK1820/RK1828 в формате SO-DIMMКомпания Rockchip, по сообщению ресурса CNX Software, анонсировала комплекты серии RK182X 3D RAM Stacking Development Kit, ориентированные на разработчиков систем с ИИ-функциями. В основу изделий положена интерфейсная плата AIO-GS1N2, на которую устанавливаются различные вычислительные и вспомогательные модули. Доступны варианты с основными модулями Core-3588JD4, Core-3588SJD4 AI и Core-3576JD4. Первый содержит процессор Rockchip RK3588 с восемью ядрами (квартеты Cortex-A76 и Cortex-A55), графическим блоком Arm Mali-G610 и нейроузлом (NPU) с ИИ-производительностью до 6 TOPS. Объём оперативной памяти LPDDR4/LPDDR4x варьируется от 4 до 32 Гбайт, вместимость флеш-модуля eMMC — от 32 до 256 Гбайт. Решение Core-3588SJD4 AI использует процессор Rockchip RK3588S со схожими характеристиками, но при этом работает только с памятью LPDDR5 (4–32 Гбайт), а ёмкость чипа eMMC составляет от 32 до 128 Гбайт. Наконец, версия Core-3576JD4 получила процессор Rockchip RK3576 с восемью ядрами (по четыре Cortex-A72 и Cortex-A53), графическим блоком Arm Mali-G52 и NPU с ИИ-производительностью до 6 TOPS. Поддерживается 2–16 Гбайт памяти LPDDR4/LPDDR4x и 16–256 Гбайт eMMC. 
Источник изображения: CNX Software В качестве вспомогательных модулей выступают ИИ-ускорители Rockchip RK1820 и RK1828 в форм-факторе SO-DIMM: первый содержит 2,5 Гбайт памяти DRAM, второй — 5 Гбайт. Возможна работа с LLM, насчитывающими соответственно до 3 и 7 млрд параметров. ИИ-производительность в обоих случаях достигает 20 TOPS (INT8). В оснащение входят слот microSD, порты SATA-3 для подключения накопителей, разъём M.2 2280 Key-M для SSD (NVMe), интерфейсы HDMI 2.0 и D-Sub, два порта USB 3.0, аудиогнёзда, девять портов 1GbE (RJ45) и выделенный порт управления 1GbE. Опционально может быть добавлен адаптер Wi-Fi (2,4/5 ГГц) в виде изделия M.2 E-Key. Имеются две 10-контактные колодки с поддержкой RS485, UART, GPIO. Питание может подаваться через DC-коннектор (24 В / 5 A), 6- или 4-контактный разъём ATX. Габариты составляют 231,27 × 164,13 × 33,57 мм, масса — 350 г. Диапазон рабочих температур простирается от -20 до +60 °C.
27.10.2025 [11:16], Сергей Карасёв
Axelera AI представила ИИ-чип Europa с производительностью 629 TOPSНидерландский стартап Axelera AI анонсировал ИИ-ускоритель (AIPU) под названием Europa, предназначенный для таких задач, как генеративные сервисы и приложения компьютерного зрения. По заявлениям разработчиков, чип может использоваться в оборудовании разного класса — от периферийных устройств до корпоративных серверов. В состав Europa AIPU входят восемь «ядер ИИ второго поколения», которые используют векторные движки и технологию цифровых вычислений в оперативной памяти (D-IMC), разработанные специалистами Axelera. Заявленная ИИ-производительность достигает 629 TOPS на операциях INT8. Кроме того, чип содержит 16 специализированных векторных ядер с архитектурой RISC-V, сгруппированных в два кластера: они предназначены для операций пред- и постобработки, не связанных с ИИ. Пиковая производительность блока RISC-V достигает 4915 GOPS (млрд операций в секунду). Интегрированный декодер H.264/H.265 ускоряет выполнение медиазадач. 
Источник изображения: Axelera AI Процессор располагает 256-бит интерфейсом памяти LPDDR5 с пропускной способностью 200 Гбайт/с и 128 Мбайт памяти L2 SRAM. Новинка будет предлагаться в различных форм-факторах, включая компактное исполнение с размерами 35 × 35 мм и карты расширения PCIe 4.0 х4 в различных конфигурациях, в частности, с одним чипом и 16 Гбайт памяти, а также с четырьмя чипами и 256 Гбайт памяти. Разработчикам предоставляет комплект Voyager SDK, который позволяет полностью раскрыть потенциал процессора. В целом, как утверждается, новинка обеспечивает в 3–5 раз более высокую производительность в расчёте на 1 Вт и $1 по сравнению с ведущими отраслевыми решениями в той же категории. Поставки Europa AIPU и PCIe-карт начнутся в I половине 2026 года.
09.09.2025 [17:00], Владимир Мироненко
Быстрее и «умнее»: SiFive представила второе поколени RISC-V-ядер IntelligentSiFive представила семейство ядер Intelligent второго поколения с архитектурой RISC-V, включающее новые ядра X160 Gen 2 и X180 Gen 2, а также обновлённые решения X280 Gen 2, X390 Gen 2 и XM Gen 2. Новые решения разработаны для расширения возможностей скалярной, векторной и, в случае серии XM, матричной обработки данных, адаптированных для современных задач в сфере ИИ. Как отметил ресурс EE Times, анонсируя новую линейку продуктов, SiFive стремится воспользоваться быстрорастущим спросом на решения для обработки ИИ-нагрузок, который, по прогнозам Deloitte, вырастет как минимум на 20 % во всех технологических средах, включая впечатляющий скачок на 78 % в сфере периферийных вычислений с использованием ИИ. Ядра SiFive второго поколения позволяют решать критически важные задачи в области внедрения ИИ, в частности, в области управления памятью и ускорения нелинейных функций. Ключевым нововведением в процессорах серии X является их способность функционировать в качестве блока управления ускорителем (ACU). Это позволяет ядрам SiFive обеспечивать основные функции управления и поддержки для ускорителя заказчика через интерфейсы SiFive Scalar Coprocessor Interface (SSCI) и Vector Coprocessor Interface eXtension (VCIX). Данная архитектура позволяет заказчикам сосредоточиться на инновациях в обработке данных на уровне платформы, оптимизируя программный стек. 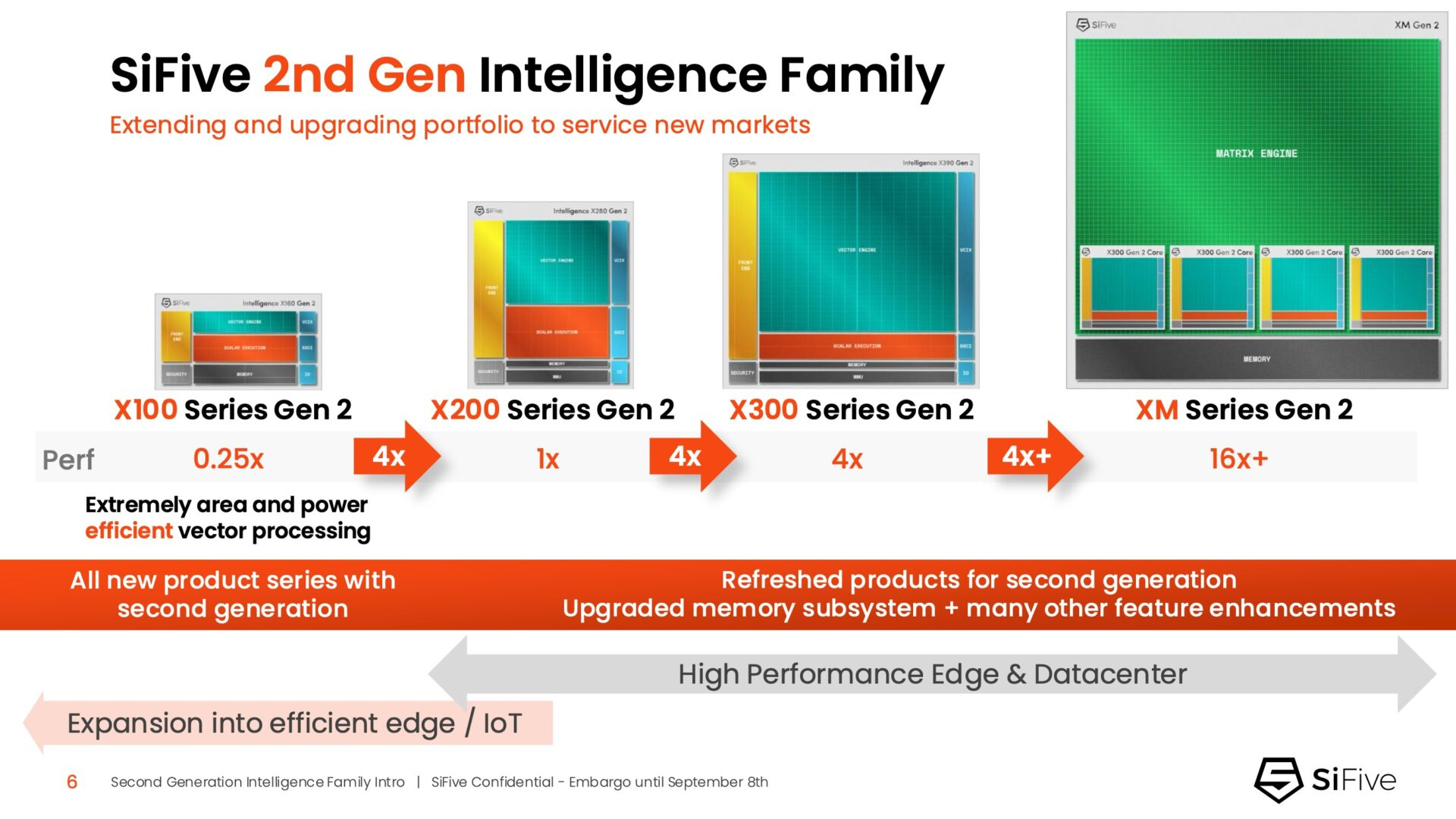
Источник изображений: SiFive/ServeTheHome Джон Симпсон (John Simpson), главный архитектор SiFive, сообщил ресурсу EE Times, что интеллектуальные ядра SiFive обеспечивают гибкость, сокращают трафик системной шины за счёт локальной обработки на чипе ускорителя и обеспечивают более тесную связь для задач пред- и постобработки. Он рассказал, что SiFive представила два важных усовершенствования в архитектуре, которые напрямую устраняют узкие места производительности: устойчивость к задержкам памяти и более эффективную подсистему памяти. 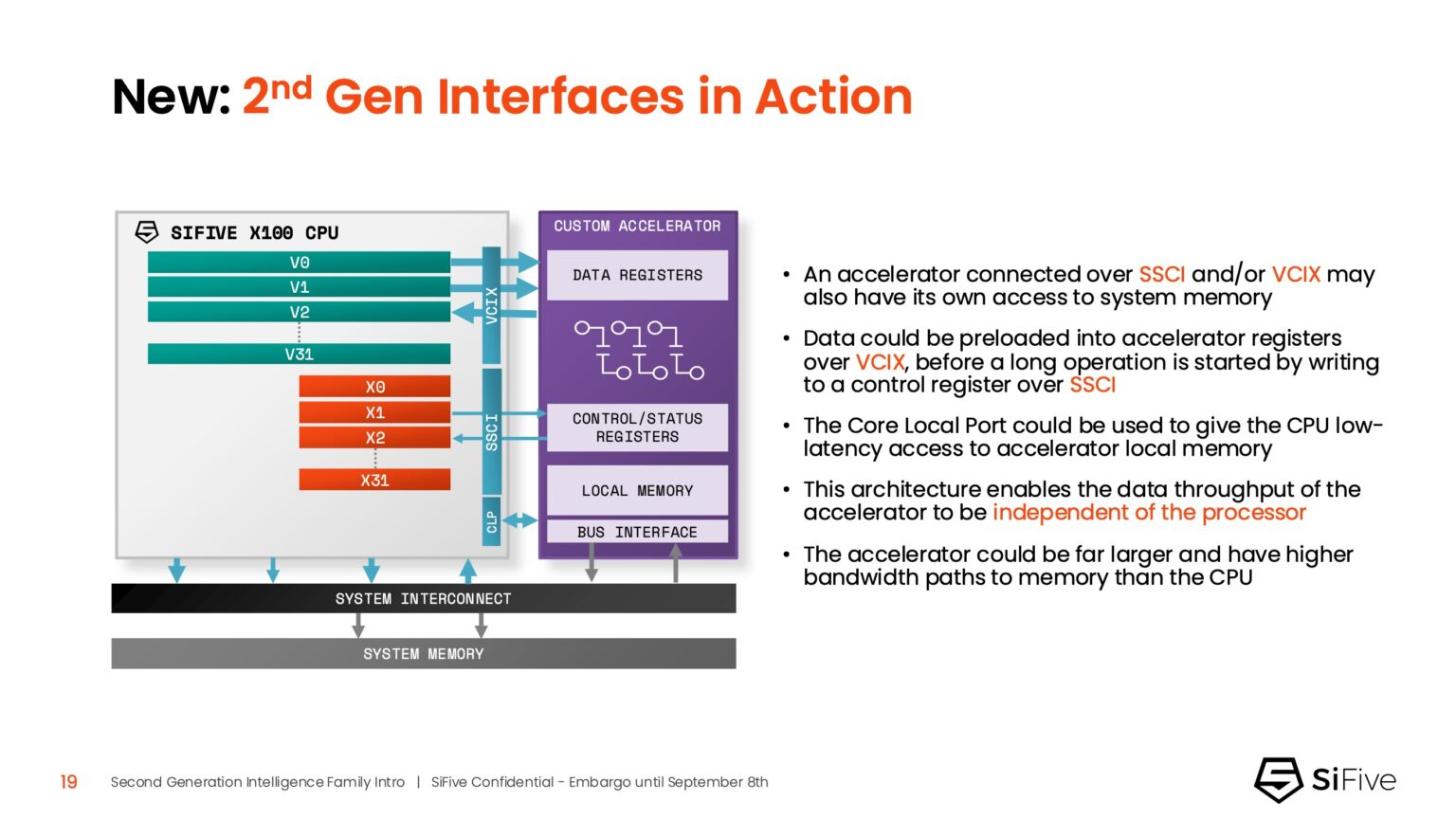 Функцию Memory Latency Tolerance позволяет снизить задержку загрузки. Симпсон рассказал, что блок скалярных вычислений, обрабатывающий все инструкции, отправляет векторные инструкции в очередь векторных команд (VCQ). При обнаружении такого инструкции одновременно отправляется запрос в подсистему памяти (кеш L2 или выше). Ранняя отправка запросов, отделённая от исполнения, позволяет быстрее получить ответ от памяти и поместить его в переупорядочиваемую настраиваемую очередь загрузки векторных данных (VLDQ). Это гарантирует готовность данных к моменту, когда инструкция в конечном итоге покинет VCQ, что приводит к «загрузке вектора в течение одного цикла». 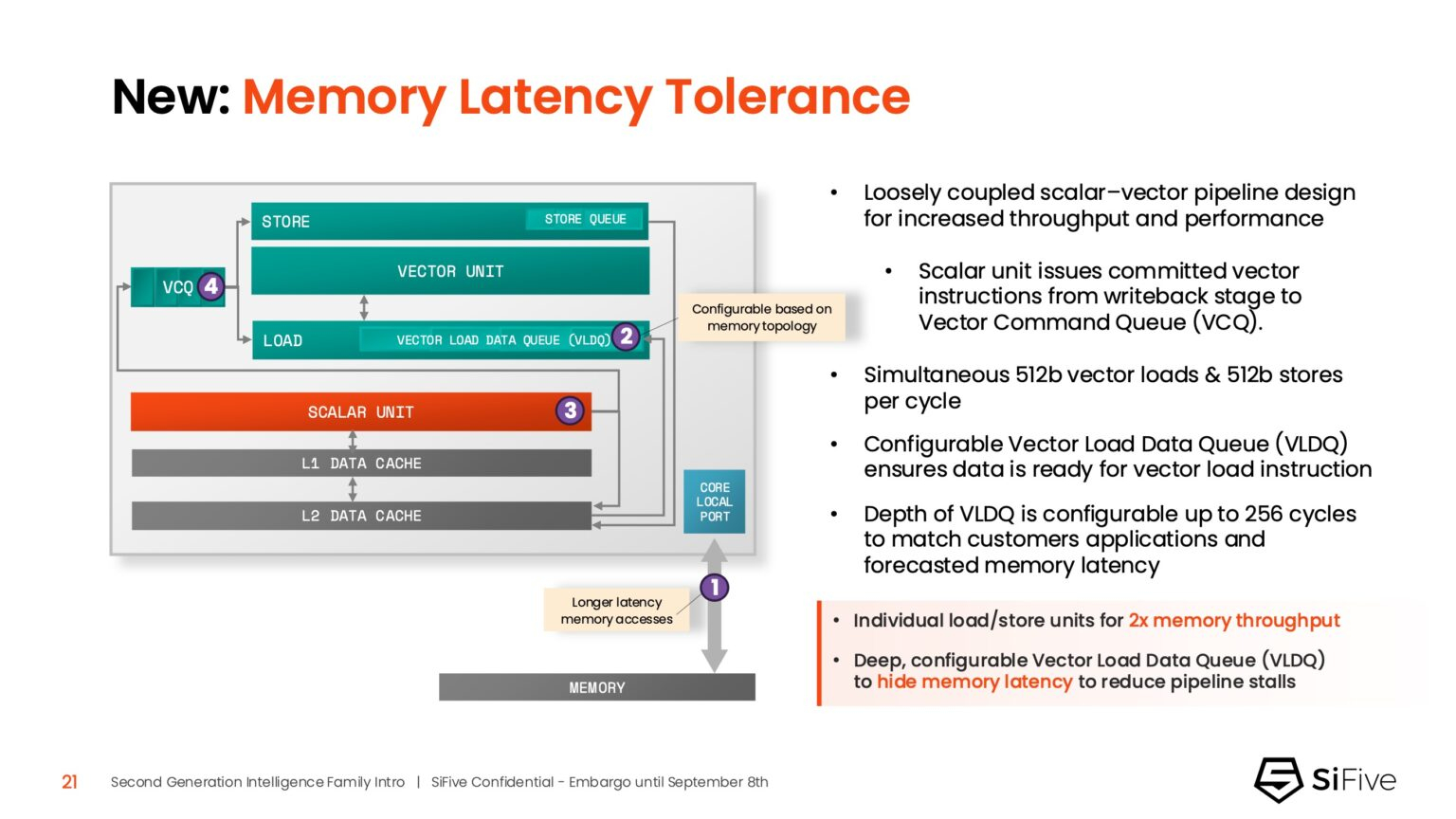 Симпсон подчеркнул конкурентное преимущество решения, отметив: «Xeon, представленный на Hot Chips, может обслуживать 128 невыполненных запросов, и это топовый показатель для Xeon, а в нашем четырёхъядерном процессоре этот показатель составляет 1024». Эта «прекрасная технология» обеспечивает непрерывную обработку данных, эффективно предотвращая простои конвейера.  Более эффективная подсистема памяти, которая представляет собой ещё одно существенное обновление, основана на переходе от инклюзивной к неинклюзивной иерархии кешей. В инклюзивной системе кеширования предыдущего поколения данные из общего кеша L3 реплицировались в частные кеши L1/L2, что компания посчитала неэффективным расходом «кремния». Конструкция ядер второго поколения исключает копирование, что, по словам Симпсона, даёт «в 1,5 раза большую производительность по сравнению с первым поколением» при меньшей занимаемой площади на кристалле. 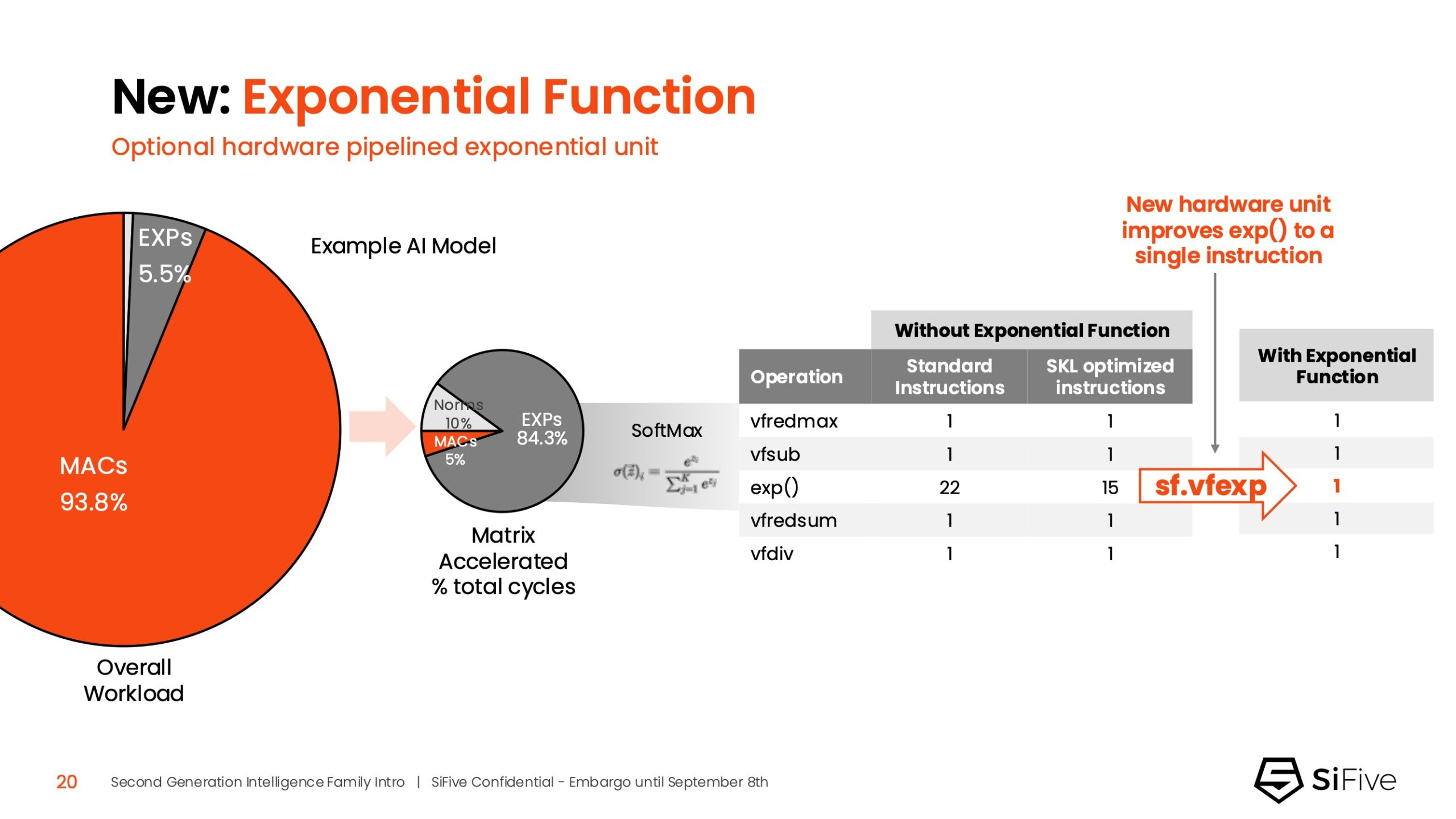 SiFive также интегрировала новый аппаратный конвейерный экспоненциальный блок. В то время как MAC-операции доминируют в рабочих ИИ-нагрузках, возведение в степень становится следующим серьёзным узким местом. Например, в BERT LLM, ускоренных матричным движком, операции softmax, включающие возведение в степень, занимают более 50 % оставшихся циклов. Программными оптимизациями SiFive сократила выполнение функции возведения в степень с 22 до 15 циклов, а новый аппаратный блок сокращает её до одной инструкции, уменьшая общее время выполнения функции до пяти циклов. Программный стек для семейства Intelligence второго поколения поддерживает масштабируемость. В серии XM среда выполнения машинного обучения уже распределяет рабочие нагрузки между несколькими кластерами XM на одном кристалле. Впрочем, пока масштабирование за пределы одного кристалла требует дальнейшей разработки библиотеки межпроцессорного взаимодействия (IPC).  Флагманские решения X160 Gen 2 и X180 Gen 2 могут быть настроены для работы под управлением операционной системы реального времени, пишет SiliconANGLE. 32-бит IP-ядро Intelligence X160 разработано для оптимизации энергоэффективности и приложений с жесткими ограничениями по площади кристалла, в то время как 64-бит IP-ядро Intelligence X180 обеспечивает более высокую производительность и лучшую интеграцию с более крупными подсистемами памяти, сообщил ресурс CNX-Software.  X160 поставляется с кеш-памятью объёмом до 200 КиБ и памятью объёмом 2 МиБ. Помимо промышленного оборудования, ядро может найти применение в потребительских устройствах, таких как фитнес-трекеры. Кроме того, X160 можно установить в системах с несколькими ИИ-ускорителями для управления чипами и предотвращения изменения прошивки. Благодаря двум встроенным кешам общей ёмкостью более 4 МиБ ядро позволяет работать с большим объёмом данных. По данным SiFive, X160 подходит для обучения ИИ-моделей и использования в оборудовании ЦОД.  В свою очередь, ядро X280 ориентировано на потребительские устройства, такие как гарнитуры дополненной реальности, а X390 также может использоваться в автомобилях и инфраструктурных системах. Последнее ядро выполняет векторную обработку в четыре раза быстрее, чем X280.  Все пять продуктов Intelligence Gen 2 уже доступны для лицензирования, а появление первых чипов на их основе ожидается во II квартале 2026 года. SiFive сообщила, что два ведущих американских производителя полупроводников лицензировали новую серию X100 ещё до её публичного анонса. Они используют IP-ядро X100 в двух различных сценариях: одна компания задействует сочетание скалярного векторного ядра SiFive с матричным движком, выступающим в качестве блока управления ускорителем, а вторая использует векторный движок в качестве автономного ИИ-ускорителя.
24.07.2025 [11:37], Сергей Карасёв
QNAP выпустила ИИ-ускорители для NAS: QAI-M100 и QAI-U100Компания QNAP Systems анонсировала ИИ-ускорители QAI-M100 и QAI-U100, предназначенные для решения различных задач на периферии: это может быть распознавание лиц и объектов, анализ данных в режиме реального времени и пр. Новинки могут использоваться с сетевыми хранилищами QNAP. Изделие QAI-M100 выполнено в форм-факторе M.2 2280 (M+B key) с интерфейсом PCIe 2.0 x1. Задействован процессор Rockchip RK1808 с двумя вычислительными ядрами Arm Cortex-A35, работающими на частоте до 1,6 ГГц. Интегрированный нейропроцессорный блок с поддержкой TensorFlow, Caffe и ONNX обеспечивает производительность до 3 TOPS на операциях INT8. Модуль VPU способен декодировать видеоматериалы H.264 в формате 1080p60 и кодировать 1080p30. Говорится о поддержки памяти LPDDR2/LPDDR3/DDR3/DDR3L/DDR4-800 (в оснащение ускорителя входит 1 Гбайт). В комплект поставки включён тонкий радиатор для рассеяния тепла. В свою очередь, вариант QAI-U100 представляет собой внешний ускоритель в виде USB-брелока с интерфейсом USB 3.2 Gen1. Размеры составляют 92,5 × 29 × 11 мм. Прочие технические характеристики аналогичны устройству типоразмера М.2. 
Источник изображений: QNAP Для работы с новинками требуется NAS под управлением QTS 5.2.1.2930 build 20241025 (или более поздней версией) или QuTS hero h5.2.1.2929 build 20241025 (или выше). Обеспечивается совместимость с софтом QNAP AI Core v3.5.0 (и выше), Multimedia Console v2.7.0 (или более поздними версиями) и QuMagie v1.5.1 (и выше).  Модель QAI-M100 может устанавливать в такие сетевые хранилища QNAP, как TS-435XeU, TS-473A, TS-673A, TS-h765eU и TS-873A. Модификация QAI-U100 может подключаться к различным NAS с количеством отсеков от трёх до 16, включая ТС-332Х, TS-432PXU, TS-432PXU-RP, TS-432X, TS-432XU, TS-432XU-RP, TS-435XeU, TS-473A, TS-632X, TS-673A, TS-h765eU, TS-832PX, TS-832PXU, TS-832PXU-RP, TS-832X, TS-832XU, TS-932PX, TS-932X, TS-h973AX, TS-1232PXU-RP, TS-1232XU, TS-1673AU-RP и др.
19.07.2025 [13:46], Сергей Карасёв
Rockchip анонсировала ИИ-ускоритель RK182X с архитектурой RISC-VКомпания Rockchip, по сообщению ресурса CNX Software, представила в Китае ИИ-ускоритель RK182X, предназначенный для работы с большими языковыми моделями (LLM) и визуально-языковыми моделями (VLM) на периферии. Новинка ориентирована на совместное использование с другими SoC Rockchip. Изделие получило многоядерную архитектуру RISC-V (точное количество ядер пока не раскрывается). В зависимости от модификации задействованы 2,5 или 5 Гбайт памяти DRAM со «сверхвысокой пропускной способностью» (ПСП тоже не раскрывается). Реализована поддержка интерфейсов PCIe 2.0, USB 3.0 и Ethernet. По заявлениям Rockchip, ИИ-ускоритель RK182X способен обрабатывать LLM/VLM, насчитывающие до 7 млрд параметров. В частности, таким моделям требуется примерно 3,5 Гбайт памяти при использовании режимов INT4/FP4. Говорится о совместимости с фреймворками PyTorch, ONNX и TensorFlow, а также форматом HuggingFace GGUF (GPT-Generated Unified Format). 
Источник изображений: CNX Software ИИ-ускоритель спроектирован для применения в связке с такими процессорами Rockchip, как RK3576/RK3588 и другими, вероятно, включая решения RK3668 и RK3688, которые были также представлены вчера. Эти чипы содержат собственный интегрированный NPU-модуль с производительностью 6 TOPS или более для обработки ИИ-нагрузок. 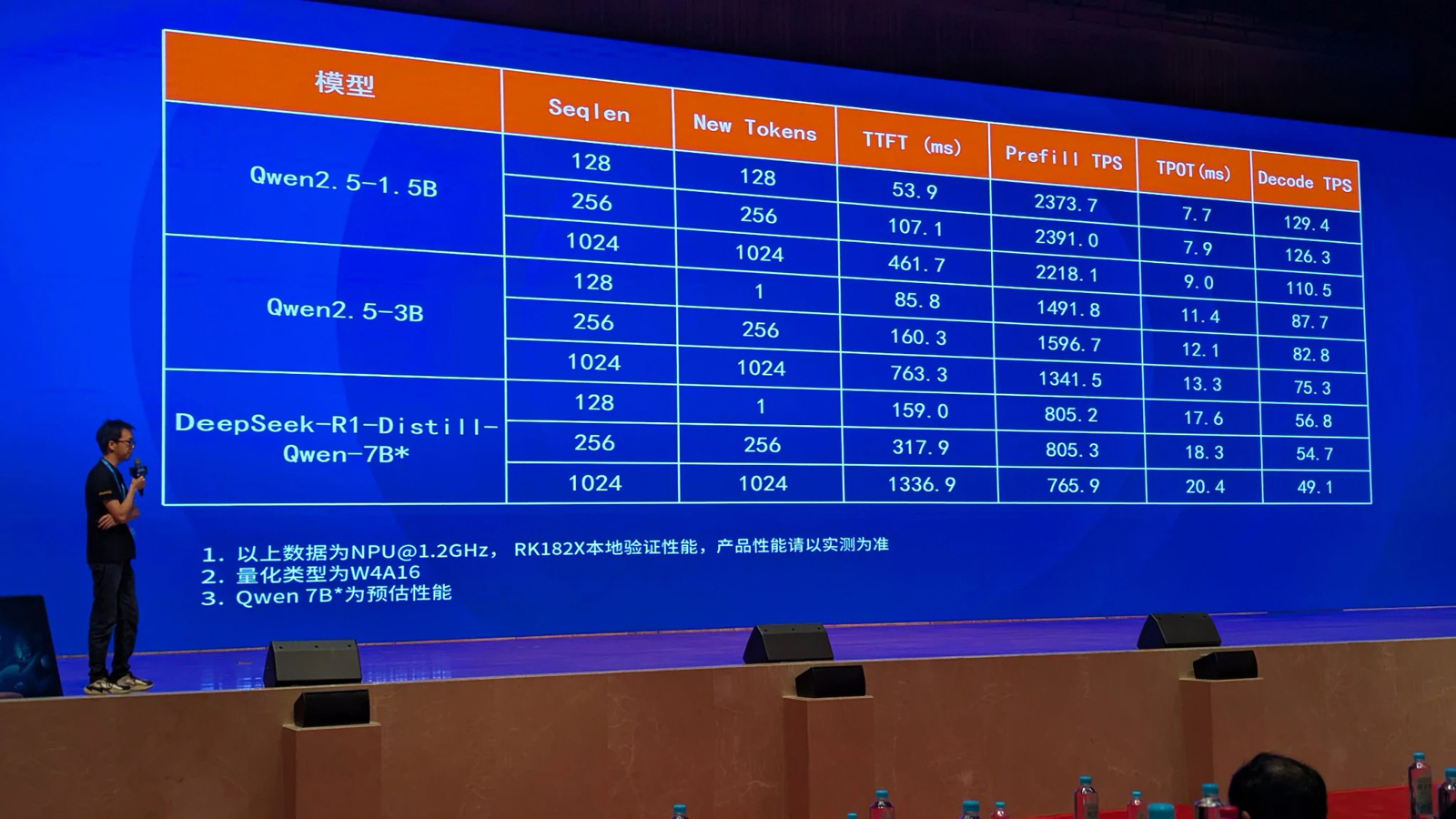 Однако благодаря применению отдельного ускорителя ИИ-быстродействие на определённых задачах может быть повышено в 8–10 раз. Rockchip, в частности, обнародовала скоростные показатели RK182X для таких популярных моделей, как DeepSeek-R1-Distill-Qwen-7B, Qwen2.5-1.5B и Qwen2.5-3B.
12.02.2025 [08:29], Владимир Мироненко
NXP Semiconductors купила Kinara, разработчика NPU для периферийных вычисленийНидерландский производитель микросхем NXP Semiconductors N.V. сообщил о приобретении за $307 млн калифорнийского стартапа Kinara, специализирующегося на разработке программируемых дискретных нейропроцессорных модулей (NPU) для обработки ИИ-нагрузок на периферии. Как ожидается, сделка будет закрыта во II половине 2025 года после получения одобрения регуляторами. NXP и Kinara являются давними партнёрами, так что интеграция решений не займёт много времени. В пресс-релизе указано, что инновационные NPU и комплексное ПО Kinara обеспечивают высокую производительность в сочетании энергоэффективностью при обработке различных нейронных сетей, включая генеративный ИИ, для удовлетворения быстрорастущих потребностей в интеллектуальных функциях на промышленных и автомобильных рынках. Приобретение Kinara позволит расширить возможности NXP по предложению масштабируемых ИИ-платформ, от облегчённых и оптимизированных вариантов (TinyML) до полноценного генеративного ИИ. 
Источник изображения: NXP Сообщается, что дискретные NPU Kinara, включая Ara-1 и Ara-2, предназначенные для периферийных вычислений, входят в число лидеров отрасли по производительности и энергоэффективности, что делает их предпочтительным решением для новых приложений ИИ в области визуализации, обработки голоса, жестов и множества других многомодальных вариантов генеративного ИИ. Оба чипа имеют инновационную архитектуру, которая отличается не только энергоэффективностью в задачах инференса, но и программируемостью, что позволяет со временем задействовать всё новые модели и сценарии, включая, например, агентный ИИ в будущем. 
Источник изображения: Kinara NPU второго поколения Ara-2 обеспечивает производительность до 40 TOPS, оптимизирован для достижения высокой производительности на системном уровне для генеративного ИИ. NPU Ara-1 и Ara-2 можно легко интегрировать со встраиваемыми системами для расширения их возможностей, включая модернизацию уже развёрнутых систем. Также Kiara предоставляет полный комплект инструментов для разработки ПО, позволяющий клиентам оптимизировать производительность моделей и упростить их развёртывание. Инструмены и библиотеки ИИ Kinara будут интегрированы в среду разработки NXP eIQ AI/ML, чтобы клиенты могли быстро и легко создавать сквозные готовые ИИ-решения.
10.10.2024 [21:18], Алексей Степин
«Элитный» Wi-Fi 7 с ИИ-поддержкой: Qualcomm представила сетевую платформу Pro A7 EliteКомпания Qualcomm объявила о выпуске новой беспроводной сетевой платформы Pro A7 Elite класса «всё-в-одном» с поддержкой беспроводного стандарта Wi-Fi 7 (802.11be) и XGS-PON. Платформа предназначена для размещения на периферии и оснащена широким спектром самых современных сетевых возможностей, дополненных ИИ-функциями. 
Источник изображений: Qualcomm Сердцем новинки является четырёхъядерный процессор, тип и модель которого Qualcomm не разглашает, известно лишь, что в основе лежит 14-нм техпроцесс, а ядра работают на частоте 1,8 ГГц. Процессор работает в паре с памятью DDR3L/DDR4, в качестве накопителя возможно использование флеш-памяти NOR, NAND или eMMC. Зато часть, ответственная за ИИ, хорошо известна — это один из вариантов Qualcomm Hexagon NPU с заявленной производительностью 40 Топс (INT8). Его целью является улучшение работы Wi-Fi, в том числе реализация функций умного классификатора трафика, интеллектуальное управление усилением беспроводного сигнала, детектирование ошибок и др. 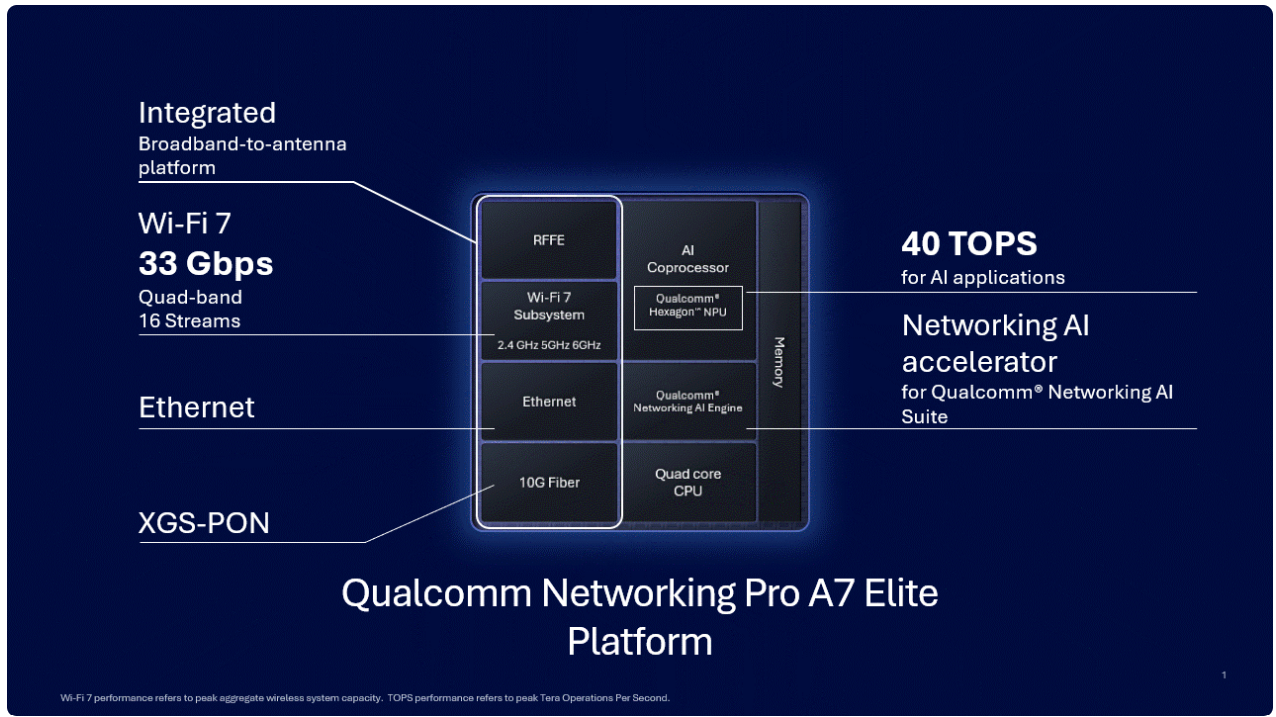 Платформа может похвастаться развитой сетевой подсистемой: во-первых, в ней реализована поддержка подключений XGS-PON, допускающая работу в качестве шлюза/терминала HGS/ONT или SFU/SFU+ ONU. При этом поддерживается скорость 10 Гбит/с как в восходящем, так и в нисходящем потоках. Проводная Ethernet-часть представлена двумя портами 2.5GbE и одним 10GbE (USXGMII/SGMII+). 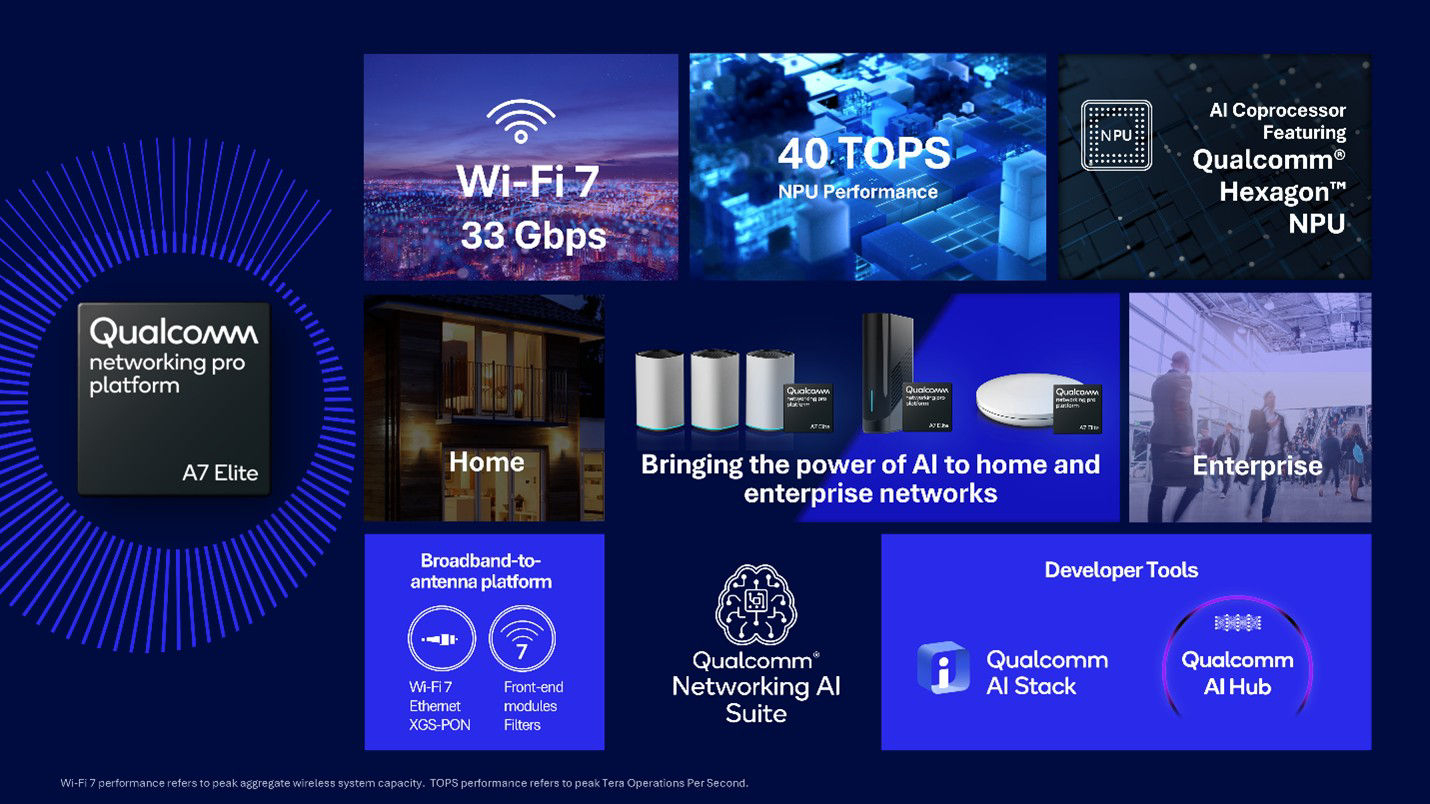 Wi-Fi-часть Pro A7 Elite предлагает пиковую агрегированную канальную скорость до 33 Гбит/с. Есть поддержка Wi-Fi 7 (802.11be) и Wi-Fi 6/6E (802.11ax), а также совместимость с Wi-Fi 5/4. Радиочасть может обслуживать четыре диапазона одновременно (6/5/2,4 ГГц) и 16 пространственных потоков. Максимальная ширина канала составляет 320 МГц. Для улучшения качества и скорости подключений реализованы технологии Qualcomm Automatic Frequency Coordination (AFC) Service, Simultaneous & Alternating Multi Link и Adaptive Interference Puncturing. Поддерживается WPA3 Personal/Enterprise/Easy Connect. Опционально доступна поддержка 4G/5G FWA, 802.15.4 (Zigbee/Thread) и Bluetooth, реализуемая посредством отдельных модулей. Дополнительно предусмотрено четыре порта PCIe 3.0, порты USB 2.0/3.0, а также интерфейсы I²C, I²S, PTA Coex, SPI и UART. SoC совместима с популярным открытым ПО: OpenWRT, RDK, TiP OpenWiFi, prplOS и OpenSync. Qualcomm уже поставляет образцы Pro A7 Elite.
20.09.2024 [21:27], Алексей Степин
От IoT до ЦОД: SiFive представила экономичные ИИ-ядра Intelligence XMРазработчик SiFive, известный своими процессорными ядрами с архитектурой RISC-V, решил подключиться к буму систем ИИ, анонсировав кластеры Intelligence XM — первые в индустрии RISC-V решения, оснащённые масштабируемым движком матричных вычислений для обработки ИИ-нагрузок. Как отмечает SiFive, новый дизайн должен помочь разработчикам чипов на базе RISC-V в создании кастомных ИИ-систем, в том числе для автономного транспорта, робототехники, БПЛА, IoT, периферийных вычислений и т.п., где роль таких нагрузок в последнее время серьёзно выросла, а требование к энергоэффективности никуда не делись. Но при желании можно создать и серверные ускорители, говорит компания. Каждый матричный блок в составе одного XM-кластера дополнен четырьмя ядрами X Core, каждое из которых имеет в своём составе два блока векторных вычислений и один блок скалярных вычислений. Все вместе они делят общий L2-кеш. XM-кластер располагает шиной с пропускной способностью 1 Тбайт/с и поддерживает подключение к памяти двух типов — когерентное через общую шину CHI, к которой подключается и внешняя память DDR/HBM, или высокоскоростной порт для SRAM. Производительность одного XM-кластера 8 Тфлопс в режиме BF16 и 16 Топс в режиме INT8 на каждый ГГц частоты. 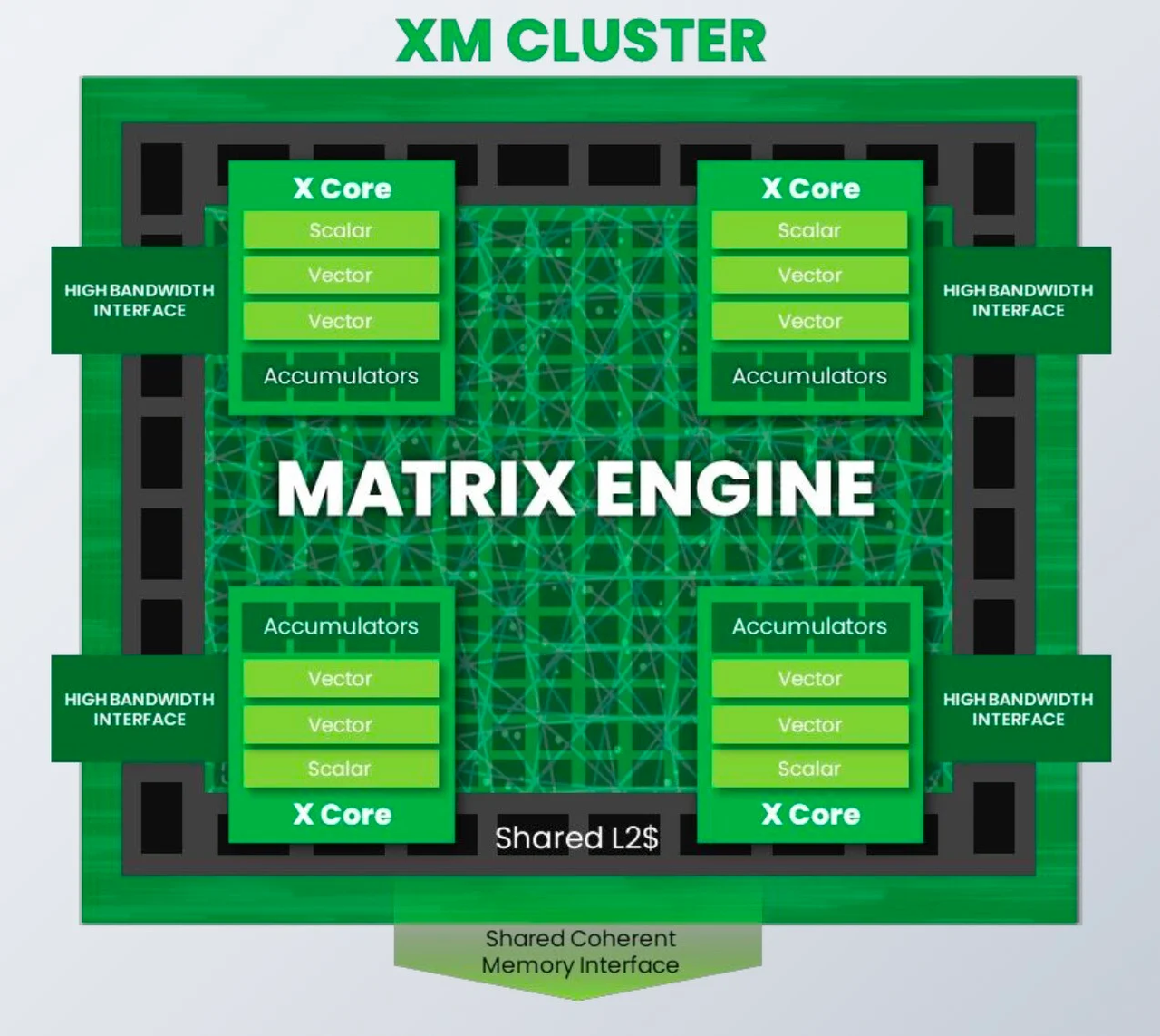
Источник здесь и далее: SiFive Тип хост-ядра не важен, это может быть RISC-V, Arm или даже x86. Впрочем, хост-ядра могут отсутствовать вовсе. Ожидается, что чипы на базе XM в среднем будут иметь от четырёх до восьми кластеров, что даст им до 8 Тбайт/с пропускной способности памяти и до 64 Тфлопс производительности в режиме BF16, и это лишь на частоте 1 ГГц при малом уровне энергопотребления. Но возможно и масштабирование до 512 XM-блоков, что даст уже 4 Пфлопс BF16. У NVIDIA Blackwell, например, в том же режиме производительность составляет 5 Пфлопс. 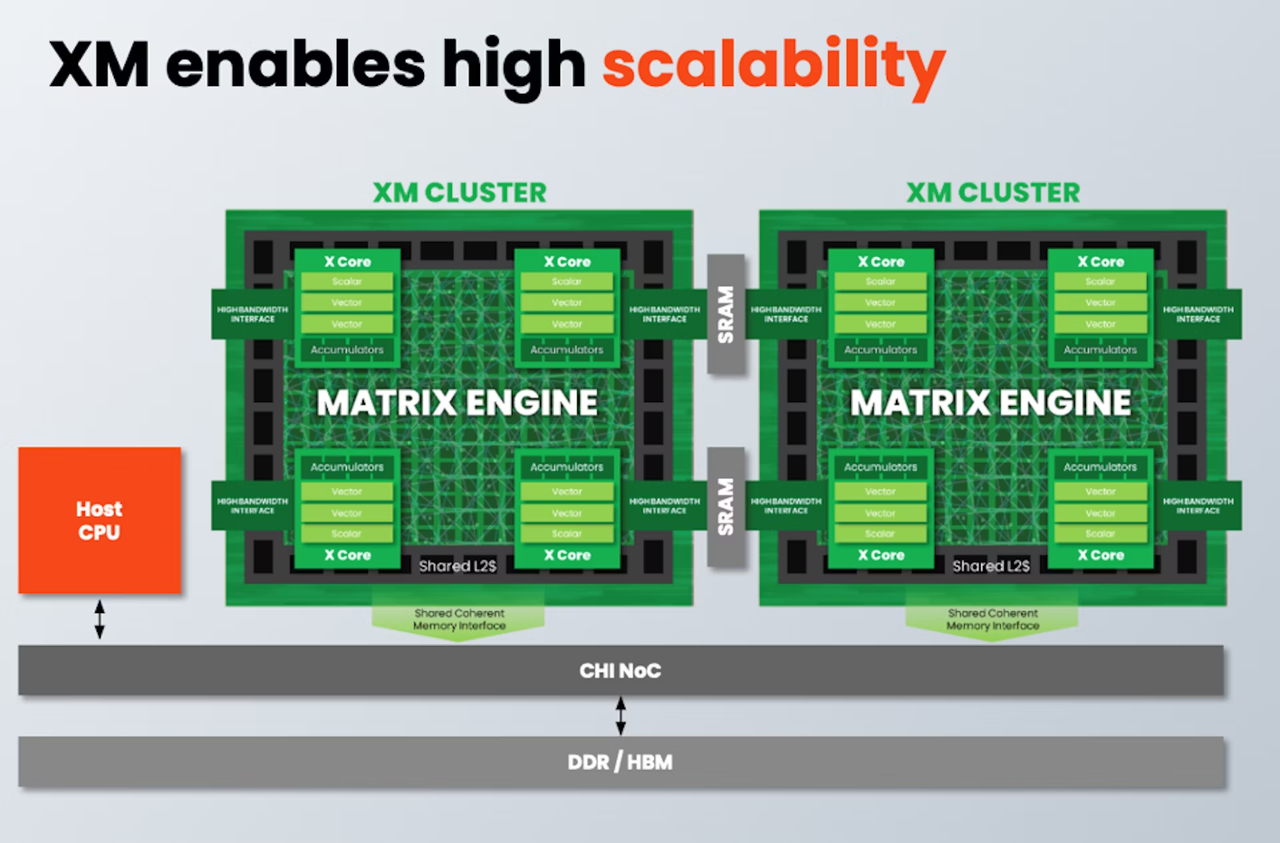 В целях дальнейшей популяризации архитектуры RISC-V компания также планирует сделать открытой (open source) референсную имплементацию SiFive Kernel Library (SKL). SKL включает оптимизированную для RISC-V ядер SiFive реализацю различных востребованных алгоритмов, в том числе для работы с нейронными сетями, обработки сигналов, линейной алгебры и т.д. 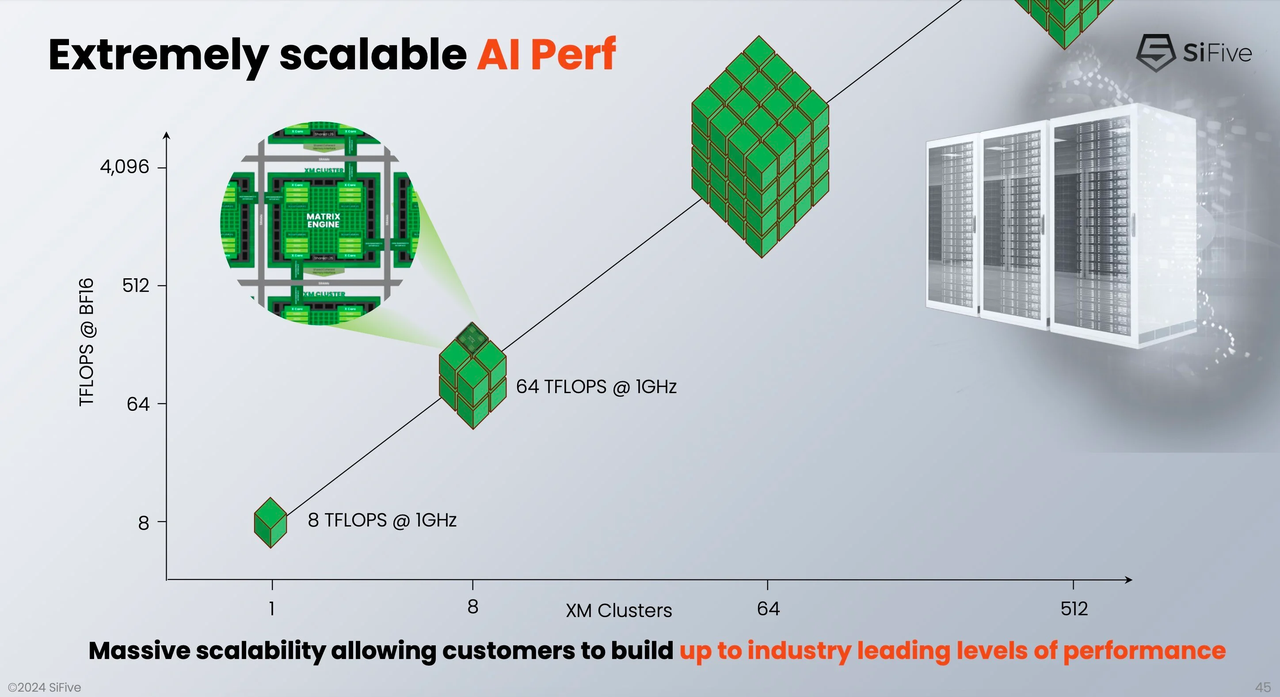 Дела у SiFive идут, судя по всему, неплохо, и, как отметил глава компании Патрик Литтл (Patrick Little), новые дизайны ядер помогут ей сохранить темпы роста и не отстать от эволюции ИИ, оставаясь в то же время поставщиком уникальных процессорных решений с открытой архитектурой. На данный момент решения SiFive уже поставляет свои решения таким гигантам, как Alphabet, Amazon, Apple, Meta✴, Microsoft, NVIDIA и Tesla. |
|

