Материалы по тегу: qualcomm
|
25.06.2026 [16:11], Владимир Мироненко
Qualcomm анонсировала HBC — альтернативу HBM на базе LPDDRQualcomm анонсировала High Bandwidth Compute (HBC), гибридное решение для вычислений и памяти, разработанное в качестве альтернативы памяти HBM и обеспечения большей производительности, эффективности и пропускной способности. В нём используется трёхмерная архитектура Near-Memory Computing (NMC), обеспечивающая предельно близкое расположение быстрой памяти к вычислительным ядра. В HBC используется память LPDDR, размещённая вертикально в несколько слоёв, соединённых сквозными кремниевыми контактами (TSV). Такой подход обеспечивает лучшую энергоэффективность, чем традиционная HBM, в которой в вертикальных слоях размещается память DDR, поскольку микросхемы LPDDR потребляют меньше энергии, обеспечивая при этом аналогичную пропускную способность и ёмкость. При этом в основании HBC лежит вычислительный кристалл, который берёт на себя часть обработки данных основного процессора, тем самым разгружая его. Как отметил ресурс Techpowerup, эта технология аналогична используемой в памяти HBM4, где базовый кристалл представляет собой логический кристалл для лучшей интеграции вычислительных решений, таких как трассировка пакетов и подготовка данных для ввода и вывода из HBM. 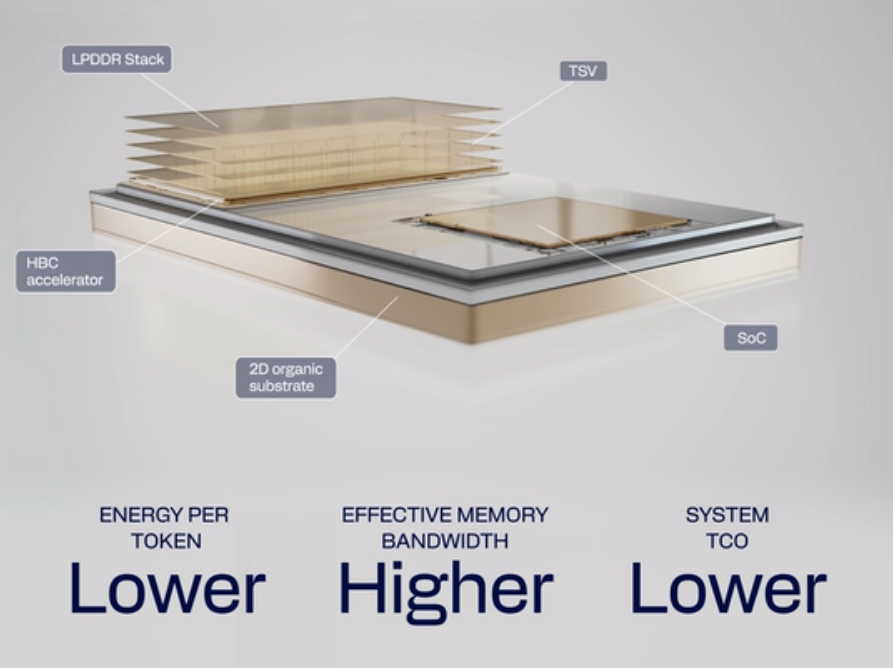
Источник изображений: Qualcomm Qualcomm сообщила, что HBC обеспечивает шестикратное увеличение пропускной способности на Вт по сравнению с HBM, согласно опубликованным характеристикам конкурирующих продуктов, нормализованным на уровне платы, а также 200-кратное увеличение ёмкости на Вт по сравнению с SRAM, согласно опубликованным характеристикам конкурирующих продуктов, нормализованным на уровне стойки.  HBC первого поколения (HBC Gen 1) достигла пропускной способности 133 Тбайт/с на ускорителе AI250, что в 18 раз больше, чем у AI200 на базе LPDDR5X. Коммерческое тестирование HBC1 с AI250 ожидается в середине 2027 года. Компания планирует выпуск решения HBC Gen 2 в 2028 году. Это решение выйдет с ИИ-ускорителем Qualcomm Dragonfly AI300 и обеспечит 54-кратное увеличение эффективной пропускной способности по сравнению с AI200 и семикратное увеличения пропускной способности на Вт по сравнению с HBM.  Dragonfly AI300 интегрирует HBC2, обеспечив высокую пропускную способность и низкую задержку для инференса больших языковых и мультимодальных моделей (LLM, LMM) и агентного ИИ. По данным Qualcomm, ожидается в 4–8 раз более высокая производительность по сравнению с существующими архитектурами на базе GPU по пропускной способности памяти на Вт на карту. Масштабирование решения будет осуществляться с помощью интерконнектов UALink и ESUN с использованием медных и оптических кабелей. Коммерческое производство образцов Dragonfly AI300 начнётся в 2028 году.
25.06.2026 [12:45], Руслан Авдеев
Qualcomm прогнозирует продажи чипов для ЦОД на $15 млрд к 2029 году, Meta✴ и Microsoft — в числе ключевых покупателейКомпания Qualcomm заявила о намерении продать полупроводники в рамках связанного с ЦОД бизнеса на сумму $15 млрд к 2029 году. Она отходит от выпуска преимущественно чипсетов для смартфонов и прочей потребительской электроники — новость вызвала рост акций компании после закрытия торгов в среду на 12 %, сообщает Reuters. По словам представителя компании, связанный с ЦОД бизнес принесёт в 2027 финансовом году $5 млрд, из них $1 млрд поступит от покупателей новых кастомных чипов. Также компания объявила, что рассчитывает получить к 2029 году $40 млрд выручки за пределами связанного со смартфонами бизнеса (ранее говорилось о $22 млрд), к тому времени выручка от решений для смартфонов будет не превышать трети от общей. Ранее аналитики Bank of America заявляли, что ежегодная выручка Qualcomm от связанного с ЦОД бизнеса к 2027–2028 гг. будет значительно скромнее, приблизительно $2–$5 млрд ежегодно. 
Источник изображений: Qualcomm После озвученного прогноза на 5 % выросли в цене и акции Arm Holdings, на основе технологий которой Qualcomm разрабатывает многие из своих чипов. Также объявлено, что новые чипы компании будут покупать Meta✴ и Microsoft. Qualcomm рассчитывает выпускать и кастомные чипы для двух других неназванных гиперскейлеров. Рост интереса Qualcomm к ИИ-чипам отражает рост давления на рынке смартфонов, который страдает от дефицита чипов памяти, вызванного стремительным ростом спроса на ИИ-инфраструктуру. Кроме того, крупные производители смартфонов вроде Apple и Samsung разрабатывают чипы самостоятельно. В среду Qualcomm объявила, что Microsoft будет использовать новую категорию решений компании, использующих дешёвые чипы памяти, применяемые в смартфонах и ноутбуках, вместо дорогой HBM-памяти, применяемой NVIDIA или SRAM-модулей, используемых Cerebras Systems. Qualcomm назвала категорию High Bandwidth Compute (HBC). Утверждается, что индустрия получит невероятно ценное предложение в плане соотношения цены и производительности.  По данным Qualcomm, компания Meta✴ будет использовать её новый CPU, получивший название Dragonfly C1000, специально разработанный для ИИ ЦОД — на этом рынке уже есть решения NVIDIA и самой Arm. О двух других гиперскейлерах сообщается, что для них будут выпускаться кастомные чипы, а выручка начнёт поступать ещё до конца текущего календарного года. По данным Qualcomm, запрос на такие решения исходил от самих гиперскейлеров. Qualcomm, неоднократно пытавшаяся развивать свой бизнес, связанный с ЦОД, снова делает попытку выйти на рынок ИИ и серверов, полный сильных игроков вроде NVIDIA и прочих разработчиков, включая Amazon (Graviton), Google (Axion), Microsoft (Cobalt). Весной заявлялось, что компания планирует начать поставки чипов для ЦОД «ведущему гиперскейлеру» «в декабрьском квартале» и ожидает сотрудничество на несколько поколений чипов. Также по её данным ведётся работа над тремя вариантами чипов: CPU, ускорителями ИИ-инференса и кастомными ASIC-модулями — в последнем сегменте активно действуют Broadcom и Marvell. Ключевым «полем битвы» называется ниша чипов для ИИ-инференса.
25.06.2026 [12:45], Владимир Мироненко
Qualcomm представила 250-ядерный серверный Arm-процессор Dragonfly C1000Qualcomm представила Qualcomm Dragonfly C1000 — специально разработанный для использования в ЦОД процессор, который по утверждению компании обеспечивает «лидирующие показатели производительности и эффективности использования для рабочих нагрузок агентов, общего назначения и узлов ИИ с лучшей в своем классе энергоэффективностью и совокупной стоимостью владения». В 2017 году компания уже пыталась выйти на серверный рынок, выпустив 10-нм 48-ядерные CPU Centriq 2400, но затем отменила проект в 2019 году. Qualcomm Dragonfly C1000 имеет чиплетную конструкцию с более чем 250 кастомизированными ядрами Qualcomm Oryon с частотой более 5 ГГц. По словам компании, чиплетная конструкция обеспечивает высокую производительность на ядро для агентных рабочих нагрузок, развёрнутых в масштабе. Также заявлено, что чип обеспечит лидирующую производительность в однопоточных вычислениях и в два раза лучшую производительность на Вт по сравнению с существующими эталонными показателями для конкурентных предложений серверных процессоров. 
Источник изображений: Qualcomm Qualcomm утверждает, что архитектура и конструкция Dragonfly C1000 обеспечивают оптимальную пропускную способность, масштабируемость, быстродействие и использование инфраструктуры для критически важных ЦОД, а также снижают капитальные и операционные затраты, обеспечивая лучшую в своём классе производительность на единицу совокупной стоимости владения в масштабе. Также многочиплетная архитектура обеспечивает модульную интеграцию с передовыми технологиями упаковки для масштабирования производительности и I/O, охватывая как процессоры общего назначения, так и ИИ-процессоры в ЦОД.  Процессор получит контроллер PCIe 7.0 (более 2 Тбайт/с) с CXL, поддержку ускорителей следующего поколения, таких как собственные продукты серии AI от Qualcomm, а также высокоскоростных сетей, хранилищ и дезагрегацию памяти с опциональным подключением модуля HBC (High Bandwidth Compute). Благодаря поддержке как воздушного, так и жидкостного охлаждения систему можно развёртывать в различных средах ЦОД с использованием стоек и серверов, совместимых с OCP ORv3. Что касается безопасности, Dragonfly C1000 получил расширенные функции надёжности, доступности и обслуживания (RAS), включая коррекцию ошибок памяти ECC, изоляцию неисправностей и отладку после ошибок, что обеспечивает отказоустойчивую работу в масштабе. Qualcomm сообщила, что коммерческая доступность Dragonfly C1000 ожидается в 2028 году.
08.06.2026 [09:33], Сергей Карасёв
Чип Qualcomm и два порта 2.5GbE: вышел крошечный одноплатный компьютер Radxa Dragon Q5EКомпания Radxa пополнила ассортимент одноплатных компьютеров моделью Dragon Q5E, выполненной на аппаратной платформе Qualcomm. Новинка может использоваться для построения компактных устройств с ИИ-возможностями, функционирующих под управлением Radxa OS (на основе Debian) или Ubuntu. Изделие имеет размеры всего 65 × 56 мм. Применён процессор Qualcomm Dragonwing QCS6690 с восемью ядрами в конфигурации 1 × Kryo Prime с частотой 2,0 ГГц, 3 × Kryo Gold с частотой 2,0 ГГц и 4 × Kryo Silver с частотой 1,8 ГГц. В состав чипа входят графический ускоритель Qualcomm Adreno GPU 7-Series (1,15 ГГц) и нейропроцессорный узел с ИИ-производительностью до 6 TOPS. Интегрированный VPU-блок обеспечивает возможность кодирования видео 4Kр60 в форматах H.264/H.265 и декодирования материалов 4Kр120 в форматах H.264/HEVC. Реализована поддержка Wi-Fi 7 и Bluetooth 6, а также PCIe 3.0. 
Источник изображения: Radxa Одноплатный компьютер может нести на борту до 16 Гбайт LPDDR5. Есть слот для карты microSD и коннектор для подключения флеш-накопителя UFS. Новинка располагает двумя сетевыми портами 2.5GbE RJ45 с опциональной поддержкой PoE, интерфейсом HDMI (1080p90), коннекторами MIPI DSI (4 линии) и MIPI CSI (4 линии, возможно подключение камер с разрешением до 32 Мп), портом USB 3.0 Type-A, а также 40-контактной колодкой GPIO с поддержкой UART, SPI, I2C, I3C и пр. Устройство получает питание через разъём USB Type-C (5 В). Имеется коннектор для подключения вентилятора охлаждения с ШИМ-управлением. Для новинки будет доступен корпус с ребристой верхней поверхностью, выполняющей функции радиатора для отвода тепла.
07.06.2026 [10:23], Сергей Карасёв
Одноплатный компьютер Radxa Dragon Q8B получил чип Snapdragon 8cx Gen3 и два порта 2.5GbEКомпания Radxa представила одноплатный компьютер Dragon Q8B, предназначенный для построения периферийных устройств с поддержкой ИИ. Это могут быть маломощные edge-серверы, робототехнические платформы, IoT-оборудование, дроны, системы видеонаблюдения и пр. В основу новинки положен процессор Qualcomm Snapdragon 8cx Gen3 с восемью ядрами в конфигурации 4 × Kryo Prime с частотой до 3 ГГц и 4 × Kryo Gold с частотой до 2,4 ГГц. В состав изделия входят графический ускоритель Adreno 690 с поддержкой DirectX 12 и нейропроцессорный блок Qualcomm AI Engine с ИИ-производительностью более 29 TOPS. Объём оперативной памяти LPDDR4Х-4266 может достигать 32 Гбайт. Поддерживается декодирование видеоматериалов в формате до 4K@120 и кодирование 4K@60. 
Источник изображения: Radxa Одноплатный компьютер располагает слотами M.2 Key-M 2280 (PCIe 3.0 x4) и M.2 Key-M 2280 (PCIe 3.0 x2) для SSD, коннектором M.2 Key-E 2230 для комбинированного адаптера Wi-Fi/Bluetooth, слотом для карты microSD и разъёмом для подключения флеш-модуля UFS 3.1. Есть два сетевых порта 2.5GbE с гнёздами RJ45, по два порта USB 3.1 Type-C (DisplayPort 1.4b Alt Mode), USB 3.1 Type-A и USB 2.0 Type-A, интерфейс HDMI 2.1, 3,5-мм аудиогнездо, порт USB Type-C для подачи питания. Предусмотрены также 40-контактная колодка GPIO (с поддержкой UART, I2C, SPI и пр.), 16-контактный FPC-коннектор PCIe 3.0 и разъем для подключения вентилятора охлаждения. Изделие имеет размеры 100 × 75 мм. Заявлена совместимость с программными платформами Radxa OS, Windows, Ubuntu, Armbian, Arch Linux и Nix OS.
27.05.2026 [17:25], Руслан Авдеев
ByteDance закупит ИИ-чипы Qualcomm и увеличит капзатраты до $70 млрдКомпания Qualcomm достигла соглашения с китайской ByteDance, предусматривающего выпуск и поставки чипов для ЦОД последней. Это важное достижение для Qualcomm, пытающейся расширить бизнес за пределы производства чипсетов для смартфонов и планшетов, сообщает Bloomberg. Кроме того, Qualcomm заключила договорилась о поставках ASIC с ещё одним неназванным американским облачным провайдером, дополняет DigiTimes. ByteDance намерена приобрести миллионы ИИ ASIC Qualcomm. По данным источников, это поможет владельцу социальной сети TikTok создавать и эксплуатировать агентный ИИ. После появления новостей акции Qualcomm подорожали на 8,3 % обновив дневной исторический максимум. Ранее компания заявила, что уже начала формировать очередь клиентов, желающих приобрести такие чипы. Qualcomm давно стремилась увеличить присутствие в индустрии ИИ-чипов, но главной проблемой был поиск клиентов на её продукцию соответствующего назначения. NVIDIA продолжает доминировать на рынке ИИ-полупроводников, хотя конкуренцию ей пытаются составить AMD, Broadcom и Google. Договор ByteDance поможет Qualcomm получить крупного покупателя и, следовательно, пропуск в один из наиболее быстро растущих сегментов полупроводниковой индустрии. 
Источник изображения: Qualcomm Сегодня американская компания предлагает чипы при посредничестве TSMC, если те соответствуют американским экспортным ограничениям — нарушать санкционный режим даже ради контракта с ByteDance в Qualcomm не будут. По словам одного из источников, новая сделка поможет ByteDance превратить уже разработанный самостоятельно дизайн чипа в готовый к производству продукт. Ещё в 2024 году сообщалось, что ByteDance проектировала собственные ускорители, хотя об отказе от продукции NVIDIA речь не шла. Тем временем ByteDance наращивает расходы. Компания увеличила увеличит капитальные затраты до порядка $70 млрд, большая часть средств пойдёт на ИИ-инфраструкту, включая ЦОД и оборудование. ПО Doubao, предлагаемое компанией, аналогично ChatGPT, Claude и Gemini. Боьшую часть прошлого года, по данным Bloomberg Intelligence, это был самый загружаемый чат-бот в Китае. Вместе с тем ByteDance стремительно осваивает и китайский рынок облачных ИИ-сервисов.
02.05.2026 [23:32], Владимир Мироненко
Qualcomm готовится поставлять чипы гиперскейлеру — инвесторы довольны, поскольку на мобильном направлении не всё гладкоАкции Qualcomm выросли более чем на 15 % после сообщения компании о превышении прогнозов Уолл-стрит по прибыли и выручке во II квартале 2026 финансового года, а также заявления президента и гендиректора Кристиано Амона (Cristiano Amon) о планах начать поставки чипов для ЦОД «крупному гиперскейлеру» в течение календарного года, пишет SiliconANGLE. Выручка Qualcomm во II квартале 2026 финансового года, закончившемся 29 марта, составила $10,6 млрд, что на 3 % меньше, чем годом ранее, но чуть выше прогноза Уолл-стрит в размере $10,58 млрд. Компания сообщила о скорректированной прибыли на акцию в размере $2,65, что ниже показателя в $2,85 за тот же квартал прошлого года, но выше прогноза аналитиков в $2,55 на акцию. В полупроводниковом секторе (QCT) выручка увеличилась год к году на 4 % до $9,08 млрд. При этом выручка в автомобильном сегменте выросла на 38 % до $1,33 млрд, в сегменте IoT — на 9 % до $1,73 млрд, а в сегменте мобильных устройств упала на 13 % до $6,02 млрд. Выручка от лицензий (QTL) за квартал составила $1,38 млрд, что на 5 % больше, чем годом ранее. 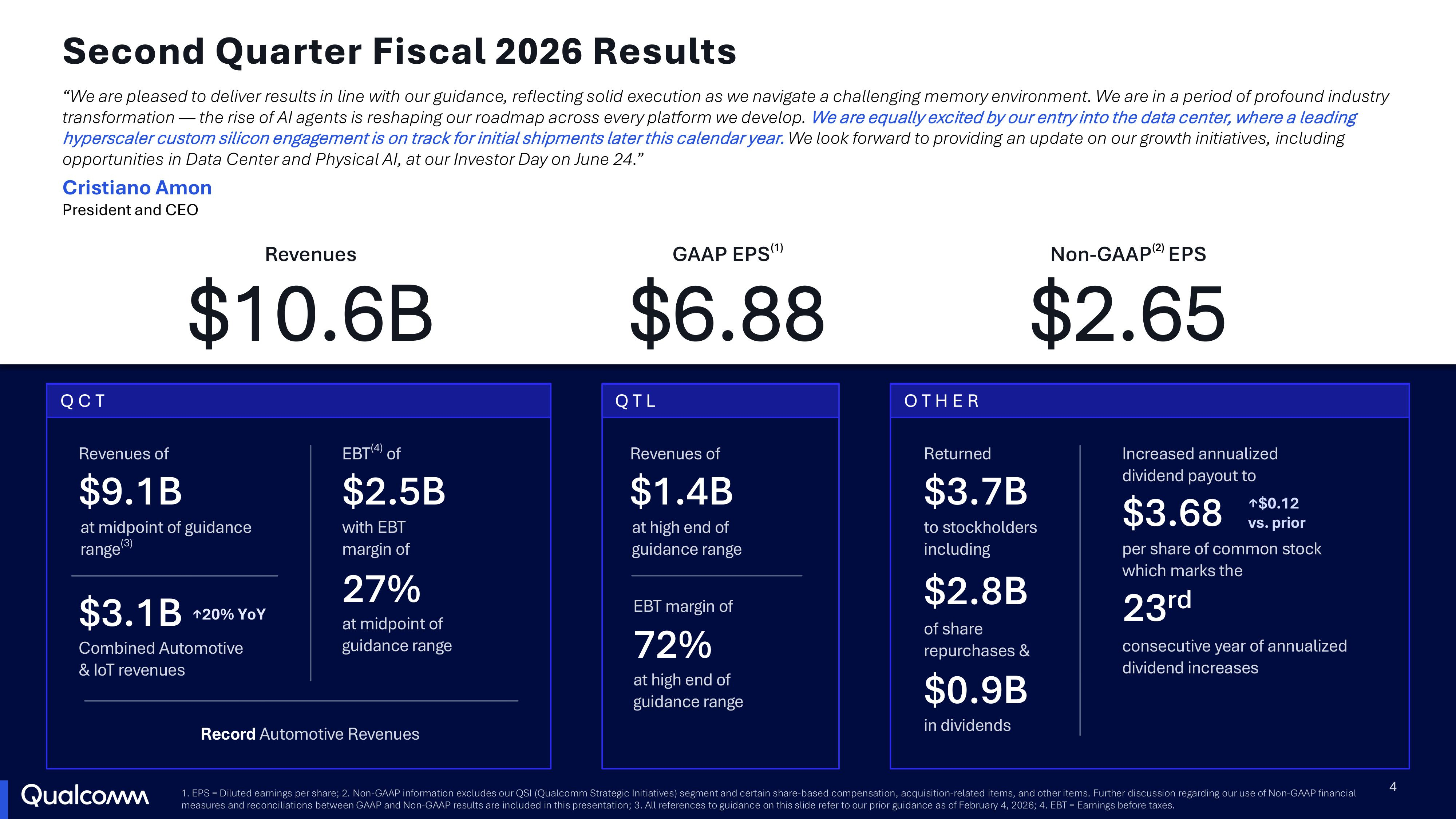
Источник изображений: Qualcomm В III финансовом квартале Qualcomm прогнозирует скорректированную прибыль на акцию в размере от $2,10 до $2,30 при прогнозе Уолл-стрит $2,43. Прогноз по выручке тоже значительно ниже консенсус-прогноза аналитиков, опрошенных LSEG (по данным Reuters) — от $9,2 до $10 млрд при прогнозе в $10,27 млрд. Свой осторожный прогноз Qualcomm объяснила ограничениями поставок памяти и связанным с этим ценовым давлением на ряд производителей мобильных устройств. Компания добавила, что выручка от продаж мобильных телефонов китайским клиентам должна достичь минимума в III квартале и вернуться к последовательному росту в следующем квартале. Qualcomm ушла с рынка продуктов для ЦОД в 2018 году, чтобы сосредоточиться на своих разработках в области смартфонов, но в августе 2025 года сообщила, что находится на «ранних этапах» возвращения на рынок и ведёт переговоры с несколькими потенциальными клиентами. Гендиректор тогда также подтвердил, что компания ведёт «продвинутые переговоры с ведущим гиперскейлером». До этого, в мае 2025 года компания подписала меморандум о взаимопонимании с Humain и объявила о работе над серверным процессором, который будет поддерживать NVIDIA NVLink.  Фактически после поглощения Nuvia компания не стала выходить на рынок ЦОД. А после долгих судебных разбирательств с Arm в связи с этой сделкой последняя фактически стала конкурентом Qualcomm и другим своим клиентам, взявшись за создание серверных CPU. С ИИ-ускорителями у компании всё тоже сложилось не очень удачно. Первое поколение широкого распространения не получило, но компания пообещала исправиться. При этом на рынке кастомных чипов для гиперскейлеров уже давно работают Broadcom и Marvell, у которых к тому же сильные компетенции в области сетевой инфраструктуры. Как пишет The Register, Кристиано Амон заявил, что компания планирует начать поставки чипов для ЦОД «ведущему гиперскейлеру» «в декабрьском квартале» и ожидает сотрудничество на несколько поколений чипов. По его словам, Qualcomm уже работает над процессором для ЦОД и высокопроизводительными ИИ-ускорителями для инференса, а также получила возможность создавать кастомные ASIC благодаря приобретению Alphawave в прошлом году за $2,4 млрд. «Мы работаем над специализированными ASIC, чего мы и хотели добиться, когда приобрели AlphaWave, — сказал Амон, — и теперь у нас есть много интеллектуальной собственности, позволяющей нам это сделать. Мы работаем над всеми тремя категориями чипов».  Амон рассказал, что Qualcomm также создала так называемый «выделенный процессор для агентских вычислений в ЦОД». По его словам, ИИ начинался с GPU для обучения, затем потребовалось специализированное оборудование для инференса, но сейчас рынок вступает в новую фазу, в которой важно «создать спрос на токены» для работы агентного ИИ. «Я думаю, что когда речь заходит об агентах, CPU становится очень важным», — сказал он, поэтому, по его словам, Qualcomm разработала именно такой чип. Кристиано Амон также прогнозирует появление «агентных смартфонов». Он привёл в качестве примера телефон ZTE, который включает в себя персонального помощника Doubao, разработанного ByteDance, и Xiaomi miclaw — ИИ-ассистента, интегрированного с ядром ОС, который анализирует запрос пользователя и определяет, какие приложения и функции смартфона нужно задействовать для его выполнения. Не исключено, что OpenAI может стать следующим крупным клиентом Qualcomm в сфере смартфонов, если генеральный директор Сэм Альтман (Sam Altman) реализует план выпустить устройство с ИИ в течение двух лет.
09.03.2026 [13:15], Сергей Карасёв
Arduino представила одноплатный компьютер Ventuno Q для ИИ-роботовУчастники проекта Arduino расширили ассортимент одноплатных компьютеров, анонсировав решение Ventuno Q: это старший собрат модели Uno Q, дебютировавшей в октябре прошлого года. Новинка предназначена для построения различных устройств с ИИ-функциями, таких как роботизированные платформы, системы машинного зрения, решения с распознаванием жестов и речи и пр. В основу Ventuno Q положен процессор Qualcomm Dragonwing IQ-8275. Чип содержит восемь вычислительных ядер Kryo с тактовой частотой до 2,35 ГГц, графический ускоритель Adreno 623 с поддержкой OpenGL ES 3.2, блок обработки изображений Spectra 690 и цифровой сигнальный процессор Hexagon. Заявленная ИИ-производительность достигает 40 TOPS. Говорится о возможности использования до 12 камер, двух дисплеев, памяти LPDDR5x-3200, интерфейсов USB 3.1, Ethernet и PCIe. 
Источник изображения: Arduino В дополнение к процессору Dragonwing IQ-8275 задействован микроконтроллер реального времени STMicroelectronics STM32H5 на основе ядра Arm Cortex-M33 с частотой до 250 МГц, отвечающий за работу сенсоров, силовых приводов и пр. Основной процессор работает под управлением Ubuntu/Debian, тогда как микроконтроллер STM32H5 использует Arduino Core на базе Zephyr OS. Одноплатный компьютер несёт на борту 16 Гбайт LPDDR5, флеш-накопитель eMMC вместимостью 64 Гбайт, контроллеры Wi-Fi и Bluetooth, а также сетевой адаптер 2.5GbE. Кроме того, предусмотрен коннектор М.2 для дополнительного SSD. 
Источник изображения: Arduino via ComputerBase Реализованы интерфейсы MIPI-CSI (4 линии), MIPI-DSI, порты USB Type-C, USB Type-А и HDMI, а также 40-контактная колодка, совместимая с Raspberry Pi. Среди прочего упомянуты матрица светодиодов 13 × 8, коннекторы JMISC, JMEDIA и JOMEGA. Могут применяться модули Arduino Modulino, сенсоры Qwiic и платы Raspberry Pi Hat. В продажу Arduino Ventuno Q поступит во II квартале 2026 года. Приобрести одноплатный компьютер можно будет через магазин Arduino Store, а также через площадки реселлеров, включая DigiKey, Farnell, Macfos, Mouser и RS.
02.03.2026 [11:39], Сергей Карасёв
5G-платформа Qualcomm Dragonwing FWA Gen 5 Elite получила поддержку Wi-Fi 8 и встроенный ИИ-движокКомпания Qualcomm представила платформу Dragonwing FWA Gen 5 Elite, предназначенную для построения устройств, обеспечивающих фиксированный беспроводной доступ (FWA) в интернет через сотовую инфраструктуру. Решение рассчитано на работу в сетях 5G в диапазоне ниже 6 ГГц. В состав изделия входит модем Qualcomm X85 5G Modem-RF с поддержкой режима DSDA (Dual SIM Dual Active) — две активные SIM-карты. Пиковая скорость загрузки данных достигает 12,5 Гбит/с, скорость передачи информации в сторону базовой станции — 3,7 Гбит/с. Радиус доступности покрытия составляет до 14 км. Реализована поддержка TDD-TDD, FDD-FDD, FDDTDD, Dynamic Spectrum Sharing (DSS), LTE, LAA, GSM/EDGE, CBRS, 5G FDD, 5G TDD, 5G SA и 5G NSA, F + F ULCA, FDD UL MIMO. Платформа Dragonwing FWA Gen 5 Elite включает контроллер Wi-Fi 8 с частотными диапазонами 2,4, 5 и 6 ГГц. Кроме того, заявлена совместимость с Wi-Fi 7/6E/6/5/4 (стандарты 802.11bn/be/ax/ac/n/g/b/a). Упомянуты средства безопасности WPA3 Personal, WPA3 Enterprise, WPA3 Enhanced Open, WPA3 Easy Connect, WPA2, WPS, 802.11i security, PRNG, TKIP, WAPI2, WAPI1, WEP, шифрование AES-CCMP и AES-GCMP. Могут использоваться два сетевых порта 10GbE. 
Источник изображения: Qualcomm Новинка получила движок Agentic AI Engine на основе нейропроцессорного модуля Qualcomm Hexagon NPU для выполнения ИИ-операций на периферии. Среди таких задач названы обеспечение безопасности, аналитика, автоматизация на основе данных об окружении, регистрация движений и пр. Заявлена совместимость с OpenWRT, RDK-B, prplOS.
02.03.2026 [11:36], Сергей Карасёв
Qualcomm представила Wi-Fi 8 платформу Dragonwing NPro A8 Elite с ИИ-движком и детектором передвижения людейКомпания Qualcomm анонсировала платформу Dragonwing NPro A8 Elite, предназначенную для построения беспроводных решений стандарта Wi-Fi 8 — высокопроизводительных точек доступа корпоративного класса и премиальных маршрутизаторов для домашнего использования. Изделие оснащено пятью вычислительными ядрами с тактовой частотой до 2 ГГц. Задействован движок Packet Processing Engine (PPE), спроектированный для сетей с ультравысокой пропускной способностью — в десятки Гбит/с. Кроме того, в оснащение входит нейропроцессорный модуль Qualcomm Hexagon NPU, обеспечивающий локальное выполнение ИИ-задач, таких как поддержание безопасности, аналитика, обнаружение движения и контекстно-ориентированная автоматизация. Заявлена поддержка Wi-Fi 4/5/6/6E/7/8 (стандарты IEEE 802.11a/b/g/n/ac/ax/be/bn/i/w/d/h/u/r/k/v/mc). Говорится о возможности использования частотных диапазонов 2,4, 5 и 6 ГГц. Кроме того, допускается работа в полосе 4,9 ГГц, которая предназначена для общественных служб безопасности (public safety) и критически важной инфраструктуры. Могут использоваться каналы на 320 МГц и до 20 антенн. Пиковое быстродействие достигает 33 Гбит/с; возможно обслуживание до 1500 клиентов одновременно. 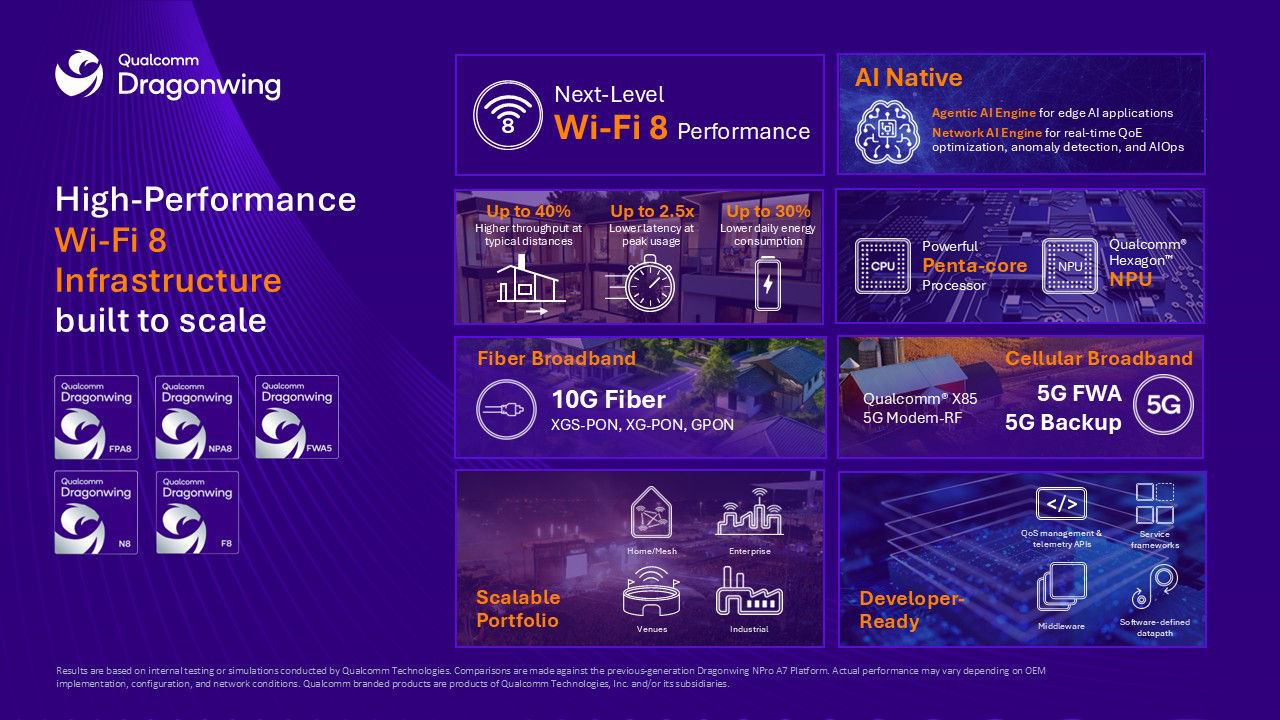
Источник изображения: Qualcomm Реализованы функции шифрования AES-CCMP и AES-GCMP, а также средства безопасности WPA3 Enhanced Open, WPS, WPA2, WEP, TKIP, PRNG, WAPI2, WAPI1, 802.11i security, WPA3 Personal, WPA3 Enterprise и WPA3 Easy Connect. Упомянута технология 802.11az для отслеживания местоположения в сетях Wi-Fi. Вместе с тем инструмент Wi-Fi Sensing на базе стандарта 802.11bf позволяет Wi-Fi-устройствам функционировать в качестве датчиков для определения присутствия и количества людей, их перемещений и даже жестов. Платформа Dragonwing NPro A8 Elite даёт возможность использовать до шести Ethernet-портов в конфигурации 2 × 25GbE и 4 × 2.5GbE. Поддерживаются оперативная память DDR4/DDR5, флеш-память eMMC/NAND/NOR, интерфейсы USB 3.0, USB 2.0, UART, SPI, I2C, SDIO, GPIO. Возможности расширения включают 4G/5G FWA, 802.15.4 (Zigbee/Thread), Bluetooth. Версия платформы FiberPro A8 Elite также поддерживает XG(S)-PON/GPON, |
|

