Материалы по тегу: arm
|
01.07.2026 [11:33], Сергей Карасёв
AMD представила SoС Versal Premium Gen 2 Memory on Package со встроенной памятью LPDDR5XКомпания AMD анонсировала адаптивные системы на чипе (SoC) серии Versal Premium Gen 2 Memory on Package (MoP), предназначенные для применения в таких областях, как профессиональные камеры и видеооборудование, устройства для обеспечения сетевой безопасности, тестовые платформы и пр. Особенность новинок заключается в наличии встроенной памяти LPDDR5X, объём которой может достигать 32 Гбайт (пропускная способность — до 288 Гбайт/с). Интеграция LPDDR5X непосредственно в корпус SoC обеспечивает более высокую производительность по сравнению с реализациями, в которых чипы памяти находятся отдельно. При этом достигается экономия пространства до 60 %, что позволяет проектировать более компактные устройства. Кроме того, разработчики получают дополнительную свободу при дизайне конструкции оборудования. А отказ от HBM снижает стоимость. 
Источник изображения: AMD В состав Versal Premium Gen 2 MoP входят два вычислительных ядра общего назначения Arm Cortex-A72 и два ядра реального времени Arm Cortex-R5F. В семейство вошли изделия 2VP3422, 2VP3522 и 2VP3622. Первое насчитывает 2,561 млн логических ячеек, 1,172 млн LUT и 6080 движков DSP; задействованы 56 трансиверов GTM2. Варианты 2VP3522 и 2VP3622 получили 3,273 млн логических ячеек, 1,496 млн LUT и 72 трансивера GTM2, а количество движков DSP составляет 2512 и 7616 соответственно. Упомянута поддержка CXL 3.1 и PCIe 6.0, а также 400/200/100/50/40/25/10GbE. Реализованы высокоскоростные криптографические модули 400G. AMD гарантирует доступность решений Versal Premium Gen 2 MoP в течение более чем 15 лет. Диапазон рабочих температур простирается от -40 до +110 °C. Пробные поставки новинок начнутся в конце текущего года, а массовое производство запланировано на II половину 2027-го.
26.06.2026 [12:44], Сергей Карасёв
Два кристалла, 304 ядра и 32 Гбайт HBM: подробности об Arm-чипах LX2 в китайском суперкомпьютере LineShineКитайский национальный суперкомпьютерный центр в Шэньчжэне (NSCCSZ) обнародовал дополнительную информацию о вычислительном комплексе LineShine, который возглавил свежий рейтинг самых мощных НРС-систем мира TOP500. FP64-производительность LineShine в тесте Linpack достигает 2,198 Эфлопс. В основу LineShine положены китайские 304-ядерные процессоры LX2 с архитектурой Arm. Конструкция этих изделий включает два вычислительных кристалла, каждый из которых содержит 152 ядра Armv9 с поддержкой Scalable Vector Extension (SVE) и Scalable Matrix Extension (SME). Тактовая частота составляет 1,55 ГГц. Каждый из кристаллов, в свою очередь, разделён на четыре NUMA-домена по 38 ядер. В состав каждого домена входят 4 Гбайт памяти HBM и 32 Гбайт памяти DDR5. Таким образом, в общей сложности используются 32 Гбайт HBM и 256 Гбайт DDR5. Энергопотребление LX2 находится на уровне 690 Вт. 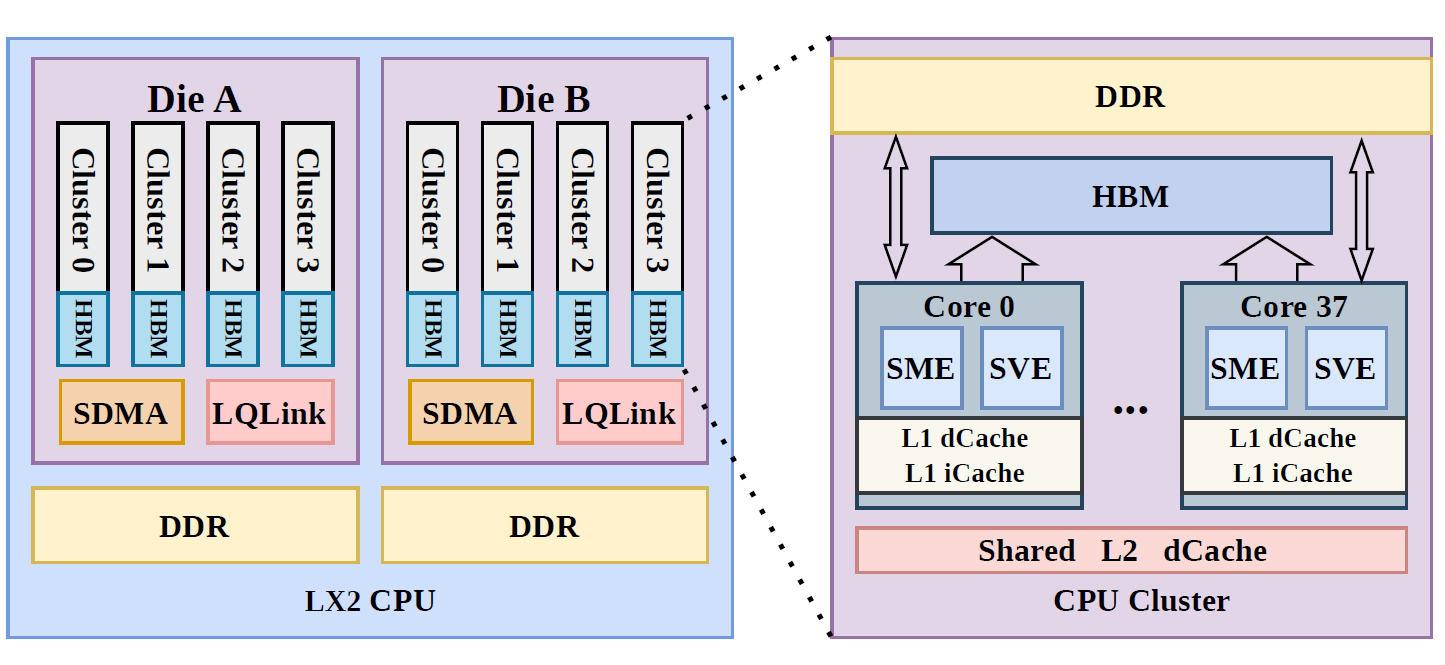
Источник изображения: NSCCSZ В составе LineShine два процессора LX2 формируют один вычислительный узел. Восемь таких узлов входят в один blade-сервер, а 16 серверов — в одно шасси. В одной стойке задействованы два шасси, что в сумме обеспечивает 512 процессоров. В целом, суперкомпьютер насчитывает около 90 стоек и примерно 14 млн вычислительных ядер. Энергопотребление LineShine достигает 42,2 МВт. Реализовано полностью жидкостное охлаждение на основе двусторонних водоблоков. Платформа использует проприетарный интерконнект LingQi, который обеспечивает пропускную способность между узлами до 1,6 Тбит/с. Технология LingQi поддерживает 2 млн портов и может масштабироваться до более чем 100 тыс. узлов. Вместимость подсистемы хранения данных LineShine составляет 200 Пбайт. Каждая стойка получает питание от шины постоянного тока LVDC на 380 В, обеспечивая вычислительную мощность до 580 кВт.
25.06.2026 [12:45], Владимир Мироненко
Qualcomm представила 250-ядерный серверный Arm-процессор Dragonfly C1000Qualcomm представила Qualcomm Dragonfly C1000 — специально разработанный для использования в ЦОД процессор, который по утверждению компании обеспечивает «лидирующие показатели производительности и эффективности использования для рабочих нагрузок агентов, общего назначения и узлов ИИ с лучшей в своем классе энергоэффективностью и совокупной стоимостью владения». В 2017 году компания уже пыталась выйти на серверный рынок, выпустив 10-нм 48-ядерные CPU Centriq 2400, но затем отменила проект в 2019 году. Qualcomm Dragonfly C1000 имеет чиплетную конструкцию с более чем 250 кастомизированными ядрами Qualcomm Oryon с частотой более 5 ГГц. По словам компании, чиплетная конструкция обеспечивает высокую производительность на ядро для агентных рабочих нагрузок, развёрнутых в масштабе. Также заявлено, что чип обеспечит лидирующую производительность в однопоточных вычислениях и в два раза лучшую производительность на Вт по сравнению с существующими эталонными показателями для конкурентных предложений серверных процессоров. 
Источник изображений: Qualcomm Qualcomm утверждает, что архитектура и конструкция Dragonfly C1000 обеспечивают оптимальную пропускную способность, масштабируемость, быстродействие и использование инфраструктуры для критически важных ЦОД, а также снижают капитальные и операционные затраты, обеспечивая лучшую в своём классе производительность на единицу совокупной стоимости владения в масштабе. Также многочиплетная архитектура обеспечивает модульную интеграцию с передовыми технологиями упаковки для масштабирования производительности и I/O, охватывая как процессоры общего назначения, так и ИИ-процессоры в ЦОД.  Процессор получит контроллер PCIe 7.0 (более 2 Тбайт/с) с CXL, поддержку ускорителей следующего поколения, таких как собственные продукты серии AI от Qualcomm, а также высокоскоростных сетей, хранилищ и дезагрегацию памяти с опциональным подключением модуля HBC (High Bandwidth Compute). Благодаря поддержке как воздушного, так и жидкостного охлаждения систему можно развёртывать в различных средах ЦОД с использованием стоек и серверов, совместимых с OCP ORv3. Что касается безопасности, Dragonfly C1000 получил расширенные функции надёжности, доступности и обслуживания (RAS), включая коррекцию ошибок памяти ECC, изоляцию неисправностей и отладку после ошибок, что обеспечивает отказоустойчивую работу в масштабе. Qualcomm сообщила, что коммерческая доступность Dragonfly C1000 ожидается в 2028 году.
23.06.2026 [12:00], Игорь Осколков
Китайский суперкомпьютер LineShine стал самым производительным в мире и возглавил TOP500Июньский рейтинг самых производительных суперкомпьютеров мира TOP500 принёс неожиданный сюрприз — впервые за несколько лет в список попала новая, крупная машина LineShine из Китая. И не только попала, но и сразу заняла в нём первое место. Более того, она же первой публично преодолела порог FP64-производительности 2 Эфлопс, опираясь только на CPU. Импортонезависимая система LineShine достигла 2,198 Эфлопс в бенчмарке HPL, что составляет порядка 80 % от пиковой теоретической производительности (2,736 Эфлопс), что для столь крупной машины хороший результат. Не менее примечательно, что и в HPCG эта система тоже занимает первое место с результатом 22 Пфлопс, обгоняя El Capitan (17,41 Пфлопс) и Fugaku (16,00). В Green500, правда, она занимает аж 50 место, поскольку потребляет 42,2 МВт, что даёт около 52,07 Гфлопс/Вт. Но, во-первых, данный суперкомпьютер лишён ускорителей, а во-вторых — улучшать энергоэффективность сложнее, чем производительность. LineShine находится в Национальном суперкомпьютерном центре Шэньчжэня (NSCCSZ) и базируется на кастомным китайских 304-ядерных Arm-процессорах LX2 (1,55 ГГц) и платформе LingKun.Всего 13,79 млн ядер, объединённых проприетарным интерконнектом LingQi работающих под управлением ОС Kylin. В ИИ-бенчмарке HPL-MxP система заняла четвёртое место с показателем 7,92 Эфлопс, т.е. разница между FP64-вычислениями в традиционном Linpack и вычислениями со смешанной точностью составляет довольно скромные 3,6x, что опять-таки указывает на архитектуру без выделенных ИИ-ускорителей. 
Источник изображения: Markus Winkler / Unsplash Ещё один новичок в первой десятке TOP500 — итальянский суперкомпьютер Eni HPC7 с устоявшейся производительностью 571,5 Пфлопс (в пике 861,13 Пфлопс), который занял шестое место. Он построен на ровно той же платформе, что и бывший лидер списка El Capitan: узлы HPE Cray EX255a с APU AMD Instinct MI300A. При этом у Eni теперь сразу две машины в Топ-10, поскольку система HPC6 (477,9/606,97 Пфлопс) находится на восьмом месте. Они бы, к слову, могли бы оказаться непосредственными соседями, если бы Microsoft решила обновить тесты своего облачного суперкомпьютера Eagle. Ресурсы у неё точно есть, а вот желание трать драгоценное машинное время ИИ-ускорителей на бенчмарки вряд ли есть. Система Fugaku также остаётся в первой десятке, уже шестой год подряд. Впрочем, если бы не нежелание Китая делиться информацией о своих системах, дефицита в которых явно нет, апдейты к TOP500 были бы гораздо чаще и интереснее. Авторы рейтинга отдельно отмечают разнообразие аппаратных платформ, подчёркивая, что добраться до экзафлопса можно разными путями. Речь и про процессоры, и про ускорители, и про интерконнекты. Всего в новом списке TOP500 появилось 44 новых машины, а минимальный порог вхождения повысился до округлённо 2,66 Пфлопс. Для вхождения же в первую десятку нужно как минимум 434,9 Пфлопс. Среди поставщиков в Топ-10 с точки зрения производительности лидирует HPE (El Capitan, Frontier, Aurora, HPC7, HPC6 и Alps). По процессорам в лидерах снова AMD (El Capitan, Frontier, HPC7 и HPC6). NVIDIA представлена в трёх системах (JUPITER Booster, Eagle, and Alps), а Intel — в двух (Aurora и Eagle). Atos/Eviden/Bull и Fujitsu поставили по одной системе, JUPITER Booster и Fugaku соответственно. Ну а LineShine гордо стоит в стороне от всех основных вендоров. Новых заявок от российских компаний по-прежнему нет. А из новичков среди стран можно упомянуть Индонезию с системой на объекте ASEAN-Korea HPC (436 место) и Узбекистан с государственным суперкомпьютером (321 место).
17.06.2026 [15:09], Руслан Авдеев
IDC: на x86 теперь приходится лишь чуть более половины рынка серверов, в основном из-за ИИНовейшая статистика свидетельствует, что почти половины выручки на мировом рынке серверов приходится на архитектуры, отличные от «классической» x86, сообщает The Register со ссылкой на исследование IDC. Ситуацию определяют спрос на ИИ-системы и дефицит памяти DRAM и NAND. В отчёте IDC Worldwide Quarterly Server Tracker за I квартал 2026 года говорится, что на x86-серверы с процессорами AMD и Intel приходится чуть более 50 % выручки, а на прочие архитектуры — 47,9 %. При этом последние показали рост на 107 % г/г ($58,7 млрд), тогда как x86-платформы упали, но лишь на 2,9 % г/г ($63,9 млрд). Рынок в целом вырос до $122,6 млрд, на 30,4 % г/г. Аналитики связывают такое изменение сил с ростом продаж систем NVIDIA, которые включают Arm-процессоры. Спрос на них чрезвычайно высок, а стоят они значительно выше чипов для обычных серверов ЦОД. И, если гиперскейлеры и крупные облачные провайдеры и не думают замедлять инвестиции, то рынок классических серверов, не связанных с ИИ-ускорителями, чувствует себя не особенно бодро, во многом из-за приоритетных инвестиций и поставок в ИИ. Так, производители памяти предпочитают выпускать более маржинальные продукты для ИИ-платформ, поэтому прочим сегмента рынка памяти не хватает. По данным IDC, дефицит DRAM и NAND определяет дефицит поставок обычных серверов в краткосрочной перспективе, хотя спрос на них тоже довольно высок. Но высокие цены вынуждают откладывать закупки. 
Источник изображения: Towfiqu barbhuiya/unsplash.com Серверы с GPU-ускорителями принесли $68,9 млрд, рост составил около 25 % г/г. На прочие «ускоренные» серверы с FPGA/ASIC пришлось $17,7 млрд, рост составил 122 % г/г. В IDC считают, что внедрение ИИ-инфраструктуры более не ограничено спросом гиперскейлеров. Например, суверенные ИИ-мощности пытаются создавать по всему миру на государственном уровне. IDC рассчитывает, что ситуация начнёт нормализоваться с 2027 года, когда производители чипов введут в строй новые фабрики и расширят имеющиеся производственные мощности. За последние два десятилетия на серверы, построенные не на x86-архитектуре, приходилось менее 10 % выручки, большинство из которой доставалась IBM (POWER и z-менфреймы), которая фактически была единственным крупным поставщиком проприетарных серверных решений после того, как Oracle разочаровалась в платформе Sun SPARC, а HPE решила, что поддерживать бизнес на основе «экзотических» архитектур вроде Itanium нецелесообразно. Архитектура RISC-V весьма популярна в Китае, поскольку на неё не распространяются многие ограничения политических оппонентов, однако массовыми крупные серверные CPU на её базе так и не стали, хотя цифры по отгруженным ядрам впечатляют. Так что надежды Arm занять более половины рынка чипов для ЦОД оправдались. Так, у Microsoft есть собственные Arm-процессоры Cobalt 200, у AWS — Graviton 5, у Alibaba Cloud — Yitian 710, а у Google — Axion. Среди крупных независимых остались Ampere Computing (используется Oracle), которая теперь принадлежит SoftBank, и Huawei со своими Kunpeng. Собственные Arm-процессоры также готовят сама Arm, Qualcomm, Fujitsu и NVIDIA. Причём последняя позиционирует их именно как конкурентов x86.
08.06.2026 [09:41], Сергей Карасёв
Supermicro представила Arm-серверы для агентного ИИКомпания Supermicro анонсировала серверы с Arm-процессорами, оптимизированные для агентного ИИ. Устройства обеспечивают высокую энергоэффективность и масштабируемость, позволяя формировать стойки высокой плотности. Представлены модели с воздушным и жидкостным охлаждением. В частности, дебютировал сервер ARS-222H-NR типоразмера 2U, допускающий установку двух процессоров Arm AGI с 64, 128 или 136 вычислительными ядрами. Предусмотрены 24 слота для модулей DDR5-8800 суммарным объёмом до 6 Тбайт. Во фронтальной части расположены восемь отсеков для SFF-накопителей (NVMe). Есть пять слотов PCIe 6.0 x16 для карт FHHL, по одному разъёму PCIe 6.0 x8 FHHL и PCIe 6.0 x8 AIOM (OCP 3.0), а также коннектор M.2 22110/2280 для SSD с интерфейсом PCIe 4.0 x1. Применено воздушное охлаждение. Питание обеспечивают два блока мощностью 2700 Вт с сертификатом 80 Plus Titanium. Кроме того, представлен GPU-сервер ARS-522GP-NR формата 5U с поддержкой двух чипов Arm AGI. Эта машина позволяет задействовать до восьми ИИ-ускорителей двойной ширины (восемь слотов PCIe 5.0 x16). Конфигурация включает 24 разъёма для модулей DDR5-8800 (до 6 Тбайт), четыре слота PCIe 5.0 x16 FHHL, по одному слоту PCIe 6.0 x16 FHFL и PCIe 5.0 x8 AIOM (OCP 3.0). Доступны восемь фронтальных отсеков для SFF-накопителей (NVMe) и коннектор M.2 22110/2280 (PCIe 4.0 x1). Задействованы шесть блоков питания мощностью 2700 Вт с сертификатом 80 Plus Titanium и воздушное охлаждение. 
Источник изображений: Supermicro В свою очередь, модель ARS-242TP-QNR-LCC стандарта 2OU использует четырёхузловую конфигурацию с прямым жидкостным охлаждением D2C (Direct to Chip). Каждый узел рассчитан на два чипа Arm AGI, 24 модуля DDR5-8800 (до 6 Тбайт) и два накопителя M.2 22110/2280 (PCIe 6.0 x4). Кроме того, имеются два слота PCIe 6.0 x16 AIOM (OCP 3.0) и два опциональных фронтальных отсека для накопителей E1.S (PCIe 5.0 x4). Питание осуществляется от централизованного шинопровода.  Наконец, анонсирован сервер ARS-212HE-FNR формата 2U с поддержкой одного процессора Arm AGI (до 136 ядер) и 12 модулей DDR5-8800 (до 3 Тбайт). Возможны различные варианты исполнения подсистемы хранения данных, включая четыре или шесть фронтальных отсеков E1.S и шесть тыльных посадочных мест SFF. Стандартная конфигурация предлагает три слота PCIe 6.0 x16 FHFL, по одному слоту PCIe 6.0 x8 FHFL и PCIe 6.0 x16 AIOM (OCP 3.0). Реализован один слот M.2 22110/2280 (PCIe 4.0 x1). Применено воздушное охлаждение. Мощность двух установленных блоков питания с сертификатом 80 Plus Titanium достигает 3200 Вт. У всех новинок диапазон рабочих температур простирается от +10 до +35 °C.  Помимо Arm-серверов, компания Supermicro представила 12 новых систем серии X14 на аппаратной платформе Intel Xeon 6+ Clearwater Forest, включая модели ультравысокой плотности. Устройства входят в различные семейства — Hyper, SuperBlade, FlexTwin и GrandTwin. В зависимости от варианта используется форм-фактор 1U, 2U или 6U; доступны версии с воздушным и жидкостным охлаждением.
03.06.2026 [13:49], Владимир Мироненко
Новые Arm-инстансы Azure Cobalt 200 оптимизированы для ИИ-агентов и в полтора раза быстрее ВМ Azure Cobalt 100Microsoft объявила о доступности предварительной версии Arm-инстансов Azure Cobalt 200, разработанных с нуля для масштабируемых, облачно-ориентированных и основанных на Linux ИИ-нагрузок с использованием агентов и обеспечивающих до 50 % более высокую производительность по сравнению с Cobalt 100. Компания сообщила, Cobalt 200 объединил её новейшие разработки — от «кремния» до серверов и сервисов — в области безопасности, сетей, хранения данных и разгрузки, что позволяет превосходить традиционные вычислительные решения на базе Arm. Совместная оптимизация аппаратного и программного обеспечения позволяет расширять возможности масштабирования, повышать безопасность и снижать затраты при использовании ИИ-инференса, конвейеров передачи данных, а также веб-сервисов и API, обеспечивающих работу современных сервисов. Microsoft отметила, что агенты отличаются от традиционных рабочих нагрузок тем, что они рассуждают, принимают последовательные решения и непрерывно работают в больших масштабах, что требует принципиально иного профиля вычислений. Cobalt 200 создан именно для этой среды и обеспечивает 50-% прирост производительности для таких нагрузок, делая агентов более быстрыми, функциональными и экономически эффективными в масштабах предприятия. 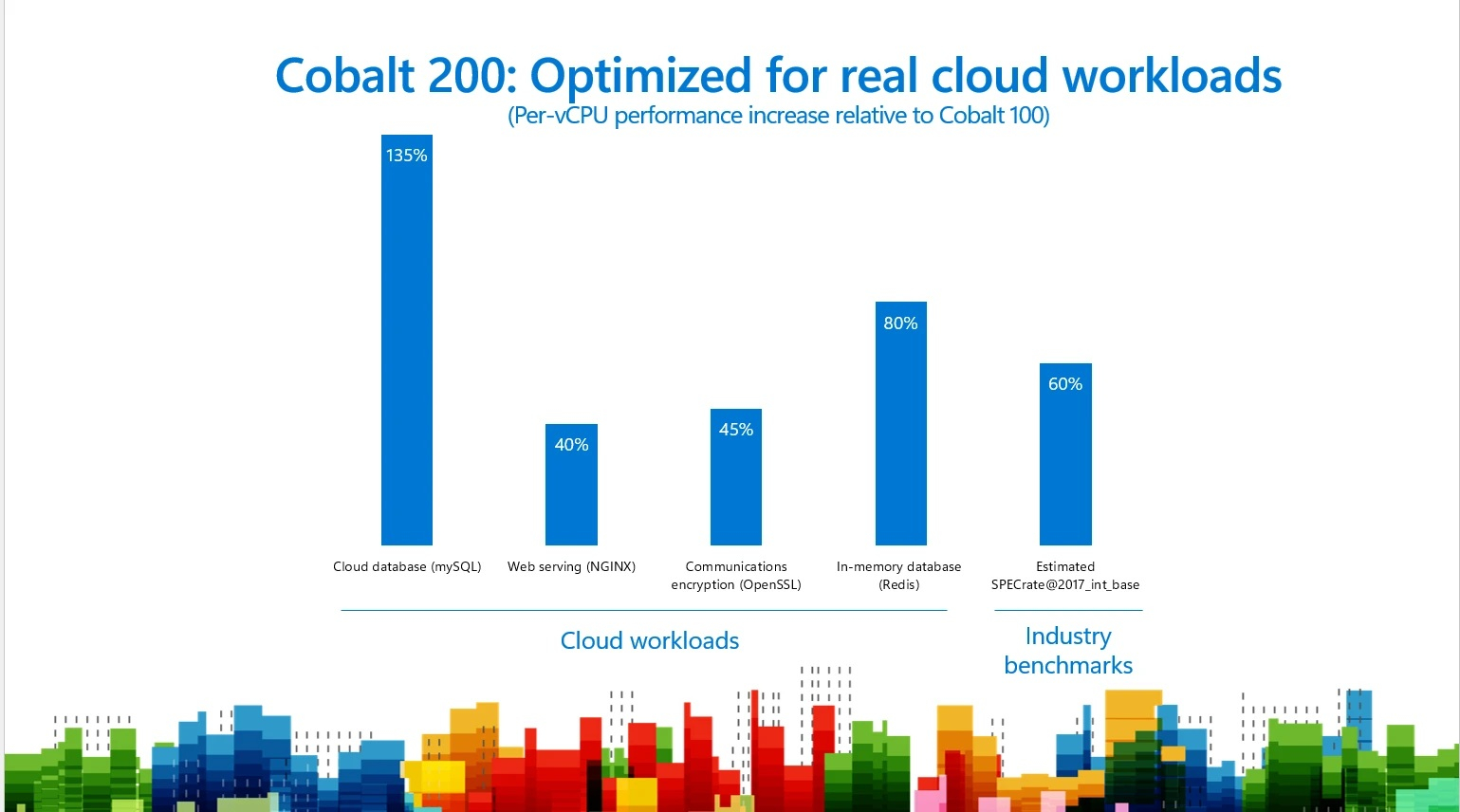
Источник изображений: Microsoft Его предшественник, Cobalt 100, доступен в 32 регионах ЦОД Azure по всему миру. Такие компании, как Databricks и Snowflake, используют Cobalt 100 для оптимизации своей облачной инфраструктуры, а такие клиенты, как Amadeus, OneTrust, Siemens, Sprinklr и Temenos, добились значительного повышения производительности и эффективности, сообщила Microsoft. На собственных облачных сервисах компании ВМ Azure Cobalt 100 обеспечивают повышение производительности до 45 % при использовании на 35 % меньшего количества вычислительных ядер по сравнению с предыдущей вычислительной платформой. Microsoft Defender for Endpoint (MDE) продемонстрировал повышение производительности на 40 % в своём инструменте управления данными. Ключевые преимущества инстансов Cobalt 200:
Компания отметила, что Cobalt 200 обеспечивает производительность на ядро и масштабируемость, необходимые для современных нагрузок агентного ИИ. Каждое ядро Cobalt 200 представляет собой полноценное физическое ядро, дополненное ёмким L2-кешем и повышенной пропускной способностью памяти на ядро. Эти конструктивные особенности обеспечивают более высокую изоляцию и стабильную производительность под нагрузкой, что позволяет агентным рабочим нагрузкам размещать больше песочниц агентов в одной виртуальной машине, одновременно удовлетворяя требованиям к задержке и пропускной способности.
Инстансы Cobalt 200 обеспечивают значительное улучшение по сравнению с Cobalt 100 в наиболее важных для продуктовой среды рабочих нагрузках, в том числе рост производительности до 135 % для облачных баз данных, до 40 % — для веб-серверов, до 45 % — для задач шифрования связи и до 80 % — для нагрузок кеширования. Инстансы Cobalt 200 полностью совместимы с инстансами Cobalt 100, что делает миграцию бесшовной. Основные платформы и языки программирования для разработчиков, включая C++, .NET, Java, Python и Rust, уже предлагают версии, разработанные специально для Arm. В числе собственных сервисов Microsoft, использующих ВМ Cobalt 200 — Dataverse и базы данных Azure. Напомним, что ранее Google объявила, что портировала около 30 тыс. внутренних нагрузок на Arm-архитектуру с использованием собственных Arm-чипов Axion и планирует перенести ещё порядка 70 тыс. В свою очередь, Oracle ещё несколько лет назад завершила миграцию всех своих облачных сервисов на Arm, как и AWS, также получившая заказы на поставку Graviton от Snowflake, Anthropic и Meta✴. Microsoft отметила, что запуск инстансов Cobalt 200 позволил ей расширить портфель Arm-инстансов для поддержки более широкого набора рабочих нагрузок. Если на базе Cobalt 100 предлагаются семейства ВМ общего назначения (Dp, Dpl) и оптимизированные по памяти (Ep), то Cobalt 200 позволил добавить ещё два семейства инстансов: Mpsv4 с увеличенным объёмом памяти и Lpsv5 с плотным локальным хранилищем. Новинки уже доступны в формате предварительных версий. Инстансы будут доступны в следующих регионах: West US3, East US2, Central US, Sweden Central, East US, West US2, Spain Central и Indonesia Central. Об их доступности в других регионах будет объявлено позже.
01.06.2026 [10:00], Руслан Авдеев
Ampere Computing: экстремальная жара в мире потребует больше энергии, повышения эффективности вычислений и сокращения количества ЦОД
ampere
arm
hardware
дефицит
ии
инференс
метео
охлаждение
прогноз
цод
экология
энергетика
энергоэффективность
Наступившее лето обещает быть чрезвычайно жарким, похожим на прошлогоднее, когда среднемировая температура достигла исторического максимума. Жара и засухи вынуждают индустрию и власти принимать трудные решения на фоне растущего расширения ЦОД, сообщил директор по продуктам Ampere Computing Джефф Виттич (Jeff Wittich). Согласно прогнозу AccuWeather на 2026 год, счета за электричество могут взлететь текущим летом из-за вероятной повсеместной жары по всей территории США. По оценкам отвечающей за надёжность электроснабжения в стране North American Electric Reliability Corporation, летний пиковый спрос на энергию вырастет на 224 ГВт за следующие 10 лет. Это более чем на 69 % выше прогноза 2024 года и на 24 % — пикового спроса 2025-го. В первую очередь ожидаемый рост спроса обусловлен потреблением электричества новыми ЦОД. В 2023 году в США дата-центры потребляли 4,4 % всей электроэнергии, а к 2028 году будут потреблять 12 %. Из-за роста спроса на электричество многим странам пришлось ужесточить правила для снижения нагрузки на энергосистемы и население. Во многом проблема в том, что энергосистемы не справляются с колебаниями энергопотребления в связи с экстремальной погодой. В июле прошлого года сообщалось, что аномальная жара привела к сбоям в лондонских дата-центрах Google и Oracle. Более того, согласно исследованию Rest of World, около 80 % всех дата-центров в мире построены в не особенно подходящих для них климатических условиях. Так, в 2025 году в США было внесено более 200 законопроектов, направленных на регулирование работы ЦОД, и по меньшей мере в 18 штатах предложены специальные тарифы для крупных потребителей электричества, а в Мэне предпринята пока не увенчавшаяся успехом попытка вовсе запретить строительство новых ЦОД. В некоторых законопроектах от желающих строить ЦОД требуют инвестиций в модернизацию инфраструктуры и обеспечение преимуществ для рядовых потребителей энергии. 
Источник изображения: Ant Rozetsky/unsplash.com В 2025 году в Амстердаме продлили мораторий на строительство новых ЦОД и расширение в столичном муниципалитете уже действующих. Приоритет отдан жилью, а новые дата-центры появятся не раньше 2030 года. Во Франкфурте на ЦОД приходится до 40 % от всего потребления городской агломерации, что создаёт непосильную нагрузку местной энергосистеме. В некоторых районах введены временные моратории на подключение новых «индустриальных» объектов, строительство новых не ожидают до II квартала 2027 года. В условиях развития ИИ-проектов дефицит ресурсов будет всё ощутимее. Поддержать этот рост без ущерба окружающей среде можно, повысив эффективность вычислений каждого отдельного ЦОД. Это позволит строить меньше дата-центров для удовлетворения спроса на вычисления или уменьшать их сами по себе, чтобы снизить энергопотребление. Кроме того, потребуется модернизация систем охлаждения. Пока же бум ИИ подталкивает отрасль к экстенсивному развитию, тогда как необходимо максимизировать реальную производительность не только на уровне чипов, но и на остальных уровнях тоже. Для этого необходимы более энергоэффективные чипы, чем сейчас. Виттич подчёркивает, что мощные ИИ-ускорители на основе GPU стоит использовать только там, где это действительно необходимо. Если для обучения и масштабного инференса без них не обойтись, то для многих других задач они избыточны. Оптимизируя вычисления для каждой задачи, следует использовать энергоёмкую инфраструктуру только там, где это действительно необходимо. 
Источник изображения: Peter Herrmann/unsplash.com Более эффективные системы охлаждения необходимо использовать независимо от снижения энергопотребления. При этом рекомендуется сочетать разные варианты охлаждения. Например, жидкостное всё чаще используется с энергоёмким ИИ-оборудованием. К сожалению для операторов ЦОД, модернизация систем охлаждения требует серьёзного изменения инфраструктуры, а на старых объектах модернизация сложна и дорога или вовсе невозможна. В существующих ЦОД нередко выгоднее использовать маломощные чипы с воздушным охлаждениями, размещая новые компоненты только там, где они действительно нужны. Фактически это означает переосмысление вычислительных архитектур для получения максимальной производительности на ватт за счёт использования современных чипов. Кроме того, придётся перераспределить рабочие нагрузки и проектировать системы, в которых производительность соответствует требованиям к допустимому тепловыделению и энергосбережению. В конечном итоге, чем больше вычислительных возможностей можно «извлечь» из каждого Вт и м2, тем меньше ЦОД нужно будет строить в будущем. Чем меньше ЦОД придётся строить, тем ниже нагрузка на водные и энергетические ресурсы в конкретных локациях. По словам представителя Ampere, для удовлетворения растущих энергетических потребностей потребуется не просто расширять инфраструктуру, но и оптимизировать её, начиная с вычислительных мощностей. И хотя Виттич прямо об этом не говорит, Ampere видит себя как раз-таки поставщиком энергоэффективных чипов, в том числе CPU для инференса. Однако на практике компания задержала выпуск AmpereOne M, была продана SoftBank и рискует лишиться одного из крупнейших заказчиков в лице Oracle, которая весьма заинтересована в NVIDIA Vera. Ей же приходится конкурировать с собственными Arm-процессорами AWS, Google, Microsoft и Alibaba, а также теперь уже и с самой Arm, Fujitsu и Qualcomm.
31.05.2026 [11:41], Сергей Карасёв
AMD выпустила адаптивные SoC серии Versal Prime Gen 2Компания AMD анонсировала новые адаптивные SoC семейства Versal Prime Gen 2: 2VM3454, 2VM3254 и 2VM3104. Они ориентированы на профессиональное аудиовизуальное оборудование, системы вещания и устройства для промышленного интернета вещей (IIoT). В состав решений входят четыре вычислительных ядра Arm Cortex-A78AE с 64 Кбайт кеша L1 (ECC) и 512 Кбайт кеша L2, тогда как суммарный кеш L3 составляет 2 Мбайт. Кроме того, имеется процессор реального времени с шестью ядами Arm Cortex-R52. Предусмотрен одноядерный графический ускоритель Arm Mali-G78AE. Версии 2VM3254 и 2VM3454 также получили VCU-блок с поддержкой HEVC и AVC (вплоть до 4K60). Объём встроенной памяти — 1 Мбайт (ECC). 
Источник изображения: AMD Программируемая часть 2VM3104 включает 225 400 логических ячеек и 103 040 LUT, а количество движков DSP составляет 420. У версии 2VM3254 эти значения равны соответственно 302 680, 138 368 и 564, у модификации 2VM3454 — 564 760, 258 176 и 1140. Количество трансиверов GTYP — 4, 8 и 16. Может использоваться оперативная память DDR5-6400 и LPDDR5X-8533 с максимальной пропускной способностью 102 Гбайт/с. Общий размер памяти программируемой логики (PL Memory) — до 45,4 Мбит. Реализована поддержка флеш-накопителей UFS 3.1, интерфейсов DisplayPort 1.4, USB 3.2 и USB 2.0, а также 1GbE, 10GbE и 100GbE (1 × 2VM3104/2VM3254 и 2 × 2VM3454). У двух старших версий также имеется контроллер PCIe 5.0 x4. Модель 2VM3454 располагает высокопроизводительным криптомодулем. Изделия 2VM3104 и 2VM3254 имеют размеры 23 × 23 мм, вариант 2VM3454 — 29 × 29 мм. Разработчики смогут использовать пакет AMD Vivado Design Suite для проектирования аппаратного обеспечения и платформу AMD Vitis для создания софта. Поставки 2VM3454 начнутся позднее в текущем году, а чипы 2VM3254 и 2VM3104 появятся в 2027-м.
27.05.2026 [00:56], Владимир Мироненко
Серверные Arm-процессоры NVIDIA Vera обогнали современные Intel Xeon и AMD EPYC в некоторых тестахПортал Phoronix провёл тестирование серверного Arm-процессора NVIDIA Vera, разработанного специально для обеспечения функционирования агентного ИИ, взяв для сравнения одно- и двухсокетные конфигурации на базе Intel Xeon 6980P (Granite Rapids-AP), а также AMD EPYC Turin: 9755, 9575F и 9475F. Также в сравнительное тестирование включили процессоры NVIDIA первого поколения Grace на базе ядер Arm Neoverse V2 (Demeter). Сообщается, что NVIDIA дала добро на проведение на этом предрелизном чипе тестов только для определённых рабочих нагрузок, соответствующих предполагаемым задачам/областям применения Vera в ЦОД, включая стандартные рабочие нагрузки, такие как компиляция, STREAM, кодирование видео, Python/Java и производительность СУБД. Исходя из среднего геометрического значения результатов тестов NVIDIA Vera занял первое место, превысив почти на 11 % лучшие результаты самых передовых разработок AMD, и примерно на 55,3 % показатели лучшей односокетной конфигурации Intel Xeon. Он также превзошёл в тестах двухсокетные конфигурации, что говорит о проблемах масштабирования некоторых рабочих нагрузок на нескольких сокетах. Эти ограниченные тесты отражают превосходство NVIDIA Vera по сравнению с любой архитектурой на базе Arm, с TDP 450 Вт для процессора и 50 Вт для пула памяти объемом 768 Гбайт. 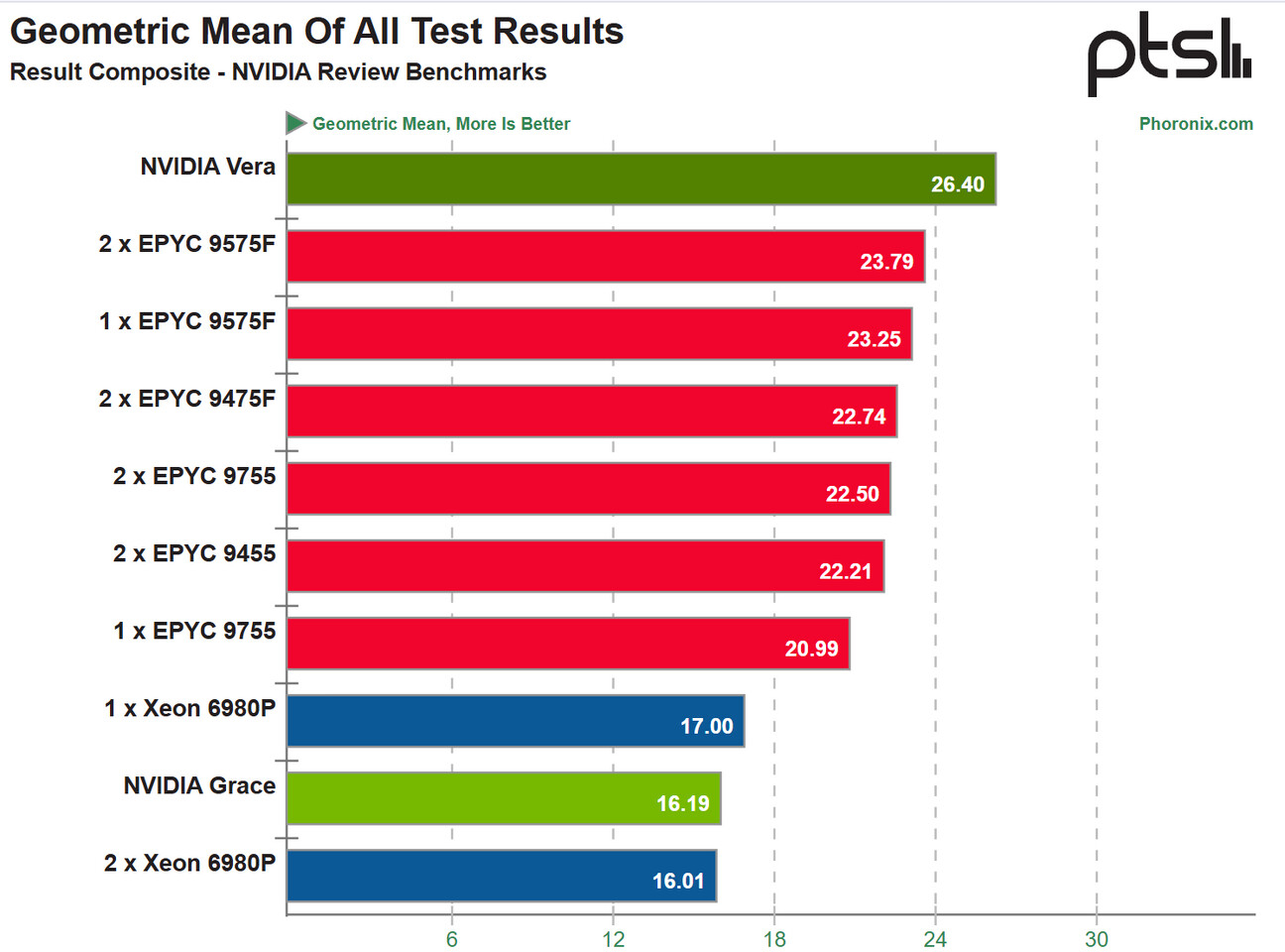
Источник изображения: Phoronix Предполагается, что NVIDIA продаст процессоров Vera и Grace на сумму около $20 млрд, охватив общий потенциальный рынок (TAM) в $200 млрд. NVIDIA сотрудничает со всеми крупными гиперскейлерами для поставки стоек с процессорами Vera (чаще всего в составе Vera Rubin), также наблюдается множество развёртываний у поставщиков инфраструктуры для их собственных задач и предложений для сторонних клиентов. Такой подход позволит NVIDIA выйти на огромный рынок процессоров, став одним из лидеров уже в этом году. |
|

