Материалы по тегу: arm
|
26.05.2026 [15:10], Владимир Мироненко
Европейский Arm-процессор SiPearl Rhea1 для суперкомпьютеров стал на шаг ближе к массовому выпускуФранцузская компания SiPearl объявила об успешном включении Arm-процессора Rhea1, разработанного для использования в суверенных суперкомпьютерах, в частности — в первом европейском суперкомпьютере экзафлопсного класса JUPITER. «Первые результаты очень позитивны, подтверждая, что европейский высокопроизводительный энергоэффективный процессор работает так, как и было задумано», — сообщается в пресс-релизе SiPearl. Компания добавила, что в рамках 12-недельного процесса функциональной проверки в лабораториях будет проведена проверка всех аппаратных и программных функций, интерфейсов и характеристик производительности Rhea1. Как ожидается, продажи Rhea1 начнутся в конце 2026 года. SiPearl отметила, что Rhea1 является самым сложным серверным процессором, когда-либо разработанным в Европе. Он включает 80 ядер Arm Neoverse V1 (Zeus), четыре стека памяти HBM2e (64 Гбайт), а также четыре канала памяти DDR5 (2DPC). Поддерживаются 104 линии PCIe 5.0 в виде шести комплексов x16 и двух x4. 
Источник изображений: SiPearl Сообщается, что Rhea1 является ключевым компонентом для всеобъемлющего вычислительного/ИИ-стека. Помимо производительности, клиенты ожидают от него безопасности без бэкдоров и аварийных выключателей, энергоэффективности, гибкости и развитой программной экосистемы.  «С помощью Rhea1 мы выполняем миссию, возложенную Европейским союзом на консорциум European Processor Initiative (EPIC), а затем и на SiPearl: вернуть в Европу высокопроизводительные процессорные технологии и связанный с ними опыт», — заявил Филипп Ноттон (Philippe Notton, на фото выше), генеральный директор и основатель SiPearl, отметив, что «не может быть цифрового суверенитета без суверенного оборудования».
19.05.2026 [17:34], Владимир Мироненко
VMware представила превью гипервизора ESXi-Arm Fling для Arm-серверовVMware официально объявила о доступности экспериментальной версии гипервизора ESXi-Arm Fling в формате превью ESX 9.1 Tech Preview, предоставляя возможности корпоративной виртуализации для 64-бит архитектур Arm. Как отметил ресурс The Register, VMware выполняет свое обещание перенести свой гипервизор и VCF на архитектуру Arm. Ранее компания в рамках Project Monterey работала над переносом части функций на Arm-процессоры в составе DPU/SmartNIC. VMware сообщила, что гипервизор поддерживает гостевые системы под управлением RHEL, Ubuntu и SLES на серверах HPE и Gigabyte с процессорами Ampere Altra (Max) или на модели Supermicro ARS-221GL с процессором NVIDIA Grace. Заявлена совместимость с NVMe/SATA-накопителями, а также с NIC Intel и Mellanox ConnectX. Компания предупредила, что релиз является неподдерживаемой сборкой Tech Preview, предназначенной для оценки и использования в лабораторных условиях, не связанных с продуктовой средой. The Register отметил, что документ содержит несколько противоречивую рекомендацию по поводу того, что «кластеры хостов Arm должны управляться отдельным автономным vCenter, работающим на x86. Мы не рекомендуем управлять установками x86 и Arm из одного и того же vCenter». Также ресурс допустил, что предварительная версия очень проста, поскольку в ней отсутствует поддержка vSAN, NSX и множества других функций, имеющихся в гипервизоре VMware для архитектуры x86 и пакете частного облака Cloud Foundation (VCF). 
Источник изображения: VMware VMware также предоставила возможность доступа к гостевым системам Arm из своих десктопных гипервизоров. Об этом было объявлено на прошлой неделе в примечаниях к выпуску новых версий продуктов Workstation и Fusion, которые добавляют «возможность подключения к удалённым ESXi на базе Arm, позволяя пользователям управлять виртуальными машинами на удалённых Arm-серверах непосредственно из VMware Workstation или Fusion на любой поддерживаемой платформе». VMware переносит свои решения на Arm-архитектуру, поскольку считает, что клиенты будут всё чаще использовать Arm-серверы на периферии сети, возможно, для ИИ-задач. В VMware также отдают отчёт в том, что Arm-процессоры более энергоэффективны, чем процессоры на x86, как и в том, что её партнёры-гиперскейлеры AWS, Google и Microsoft активно продвигают свои собственные Arm-процессоры, поскольку они обеспечивают отличную производительность на Вт. Представляя новые гипервизоры для десктопов, VMware указала ещё одну причину: «По мере диверсификации сред разработки межархитектурная совместимость становится крайне важной».
19.05.2026 [17:00], Руслан Авдеев
Arm-процессоры NVIDIA Vera поставили в ведущие ИИ-лаборатории мира — Oracle развернёт сотни тысяч таких CPUПервые CPU Vera, разработанные компанией NVIDIA, поставили в Anthropic, OpenAI, Oracle Cloud Infrastructure (OCI) и SpaceX/xAI. Процессоры специально разработаны с учётом особенностей «агентных» ИИ-систем и отличаются от обычных CPU. Это первый кастомный процессор NVIDIA, специально разработанный для агентных систем. Он обеспечивает оркестрацию, вызов инструментов, RL-нагрузки, анализ данных, «песочницы» для агентов и др. Процессор предназначен для ИИ-лабораторий, облачных провайдеров и компаний, масштабно работающих с агентными ИИ-системами. Модель получила 88 кастомных ядер Olympus, а пропускная способность памяти составляет 1,2 Тбайт/с. Глава NVIDIA Дженсен Хуанг (Jensen Huang) позиционирует Vera как новый многомиллиардный вектор развития компании. Как сообщает NVIDIA, агентный ИИ создаёт намного более высокую нагрузку на вычислительную инфраструктуру, от компиляции и тестирования программного кода до анализа данных, поиска файлов и др. При этом ИИ-агенты не просто используют ускорители, но и требуют оркестрации, управления агентными «песочницами», и т. п., это работа для CPU. Поток параллельных задач перегружает не рассчитанные на это CPU, но характеристики Vera позволяют повысить эффективность ИИ-фабрик целиком. 
Источник изображения: NVIDIA OCI намерена развернуть сотни тысяч CPU Vera для обеспечения работы нового поколения корпоративного ИИ. Это первый облачный провайдер, намеренный внедрить Vera в таких масштабах. Для корпоративных клиентов это означает, что будет создана агентная ИИ-инфраструктура уровня, недоступного другим облачным провайдерам. Ранее сообщалось, что Oracle строит «вчерашние» ЦОД, не имея на это достаточно средств и теперь, компания, похоже, готова опровергнуть этот тезис. 
Источник изображения: NVIDIA Процессор не только является самостоятельным CPU, но и лежит в основе платформы Vera Rubin NVL72, где он посредством NVLink-C2C второго поколения связан с парой GPU Rubin. Стоит отметить, что работы с Vera фактически ведутся уже давно. Например, ещё в марте HPE представила узлы на базе NVIDIA Vera для платформы Cray Supercomputing GX5000.
14.05.2026 [18:02], Владимир Мироненко
Благодаря спросу на ИИ AMD нарастила долю на рынке серверных CPU, а Intel потихоньку теснит ArmAMD добилась значительных успехов в сегменте серверных процессоров в I квартале 2026 года. По оценкам Mercury Research, на EPYC пришлось 46,2 % рынка серверных процессоров в денежном выражении, что стало новым историческим максимумом у компании в этой категории продукции. При этом в количественном выражении доля AMD EPYC в общем объёме продаж в сегменте гораздо меньше — 27,4 % (последовательный рост на 230 базисных пунктов), что указывает на их гораздо более высокую среднюю цену продажи (ASP) по сравнению с конкурентами. Общий объём поставок серверных процессоров увеличился примерно на 6 % последовательно и примерно на 19 % год к году. Больше половины рынка серверных чипов в количественном выражении (54,9 %, снижение на 370 базисных пунктов по сравнению с предыдущим кварталом) принадлежит Intel. И судя по её доле рынка в денежном выражении в размере 53,8 % и доле в количественном выражении, можно с уверенностью предположить, что средняя цена серверных процессоров Intel Xeon ниже, чем у AMD EPYC. По данным Mercury Research, на Arm-процессоры для ЦОД приходится около 17,7 % (последовательный рост на 140 базисных пунктов), что составляет почти пятую часть от общего объёма поставок в I квартале 2026 года. Вместе с тем, не уточняется, идёт ли речь о продукции Ampere и других производителей Arm-процессоров, или же о собственных разработках таких компаний, как Google, AWS или Microsoft. 
Источник изображения: AMD В 2026 году ключевым трендом на рынке ИИ стало активное внедрение ИИ-агентов и мультиагентных систем, что обусловило высокий спрос на процессоры и успех AMD. При развёртывании агентного ИИ растёт роль CPU, что привело к изменению конфигурации вычислительных систем от традиционного соотношения, когда один процессор работает в паре с четырьмя или даже восемью ускорителями, в сторону соотношения один к одному. Благодаря возросшему спросу AMD сейчас продаёт каждый произведённый процессор, а Intel реализует заинтересованным клиентам даже то, что ранее списывалось как брак. Вместе с тем в настоящее время AMD удаётся добиваться более высоких средних цен на свою продукцию.
14.05.2026 [10:00], Владимир Мироненко
«Группа Астра» запустила отечественное облако Astra Cloud на российских Arm-процессорах Baikal-S
arm
astra linux
baikal-s
iaas
software
байкал электроникс
импортозамещение
кии
облако
сделано в россии
частное облако
«Группа Астра» объявила о запуске облачного сервиса Astra Cloud, построенного на российских процессорах Baikal-S от компании «Байкал Электроникс» и ориентированного, в первую очередь, на критическую информационную инфраструктуру. Компания подчеркнула, что это первое в стране коммерческое облако, весь технологический стек которого, начиная от чипа и заканчивая конечным сервисом, разработан в России. «Группа Астра» отметила, что ключевым условием формирования суверенной и безопасной среды для субъектов КИИ является использование экосистемного и платформенного подхода, при котором контролируется каждый технологический слой, включая низкоуровневое аппаратное обеспечение. Astra Cloud на Baikal-S призвано обеспечить такую среду российским предприятиям: полная импортонезависимость с полным соответствием на уровне архитектуры регуляторным требованиям, которые вступают в силу с января 2028 года. Генеральный директор Astra Cloud заявил, что компания нацелена на создание сквозной технологию в облаке — от российского центрального процессора до конечного сервиса для использования заказчиком. «Для нас здесь нет выбора между “российским” и “эффективным”. Облако Astra Cloud на Baikal-S — это прямое и честное соответствие мировому Arm-стандарту, и мы даём бизнесу инструмент для спокойного перехода на доверенную инфраструктуру уже сегодня, а не в последнюю ночь перед дедлайном», — сообщил он. 
Источник изображений: «Группа Астра» Также это один из первых в России облачных сервисов с использованием Arm-архитектуры, отличающейся высокой энергоэффективностью, что снижает операционные расходы, обеспечивая высокую производительность обработки современных облачных нагрузок (AI/ML, СУБД или веб-сервисы) и более низкую совокупную стоимость владения (TCO) по сравнению с x86-решениями, говорит компания. Она отмечает, что Arm-архитектура получила признание среди гиперскейлеров, которые используют её в своих собственных CPU, что в целом укрепляет программную экосистему. 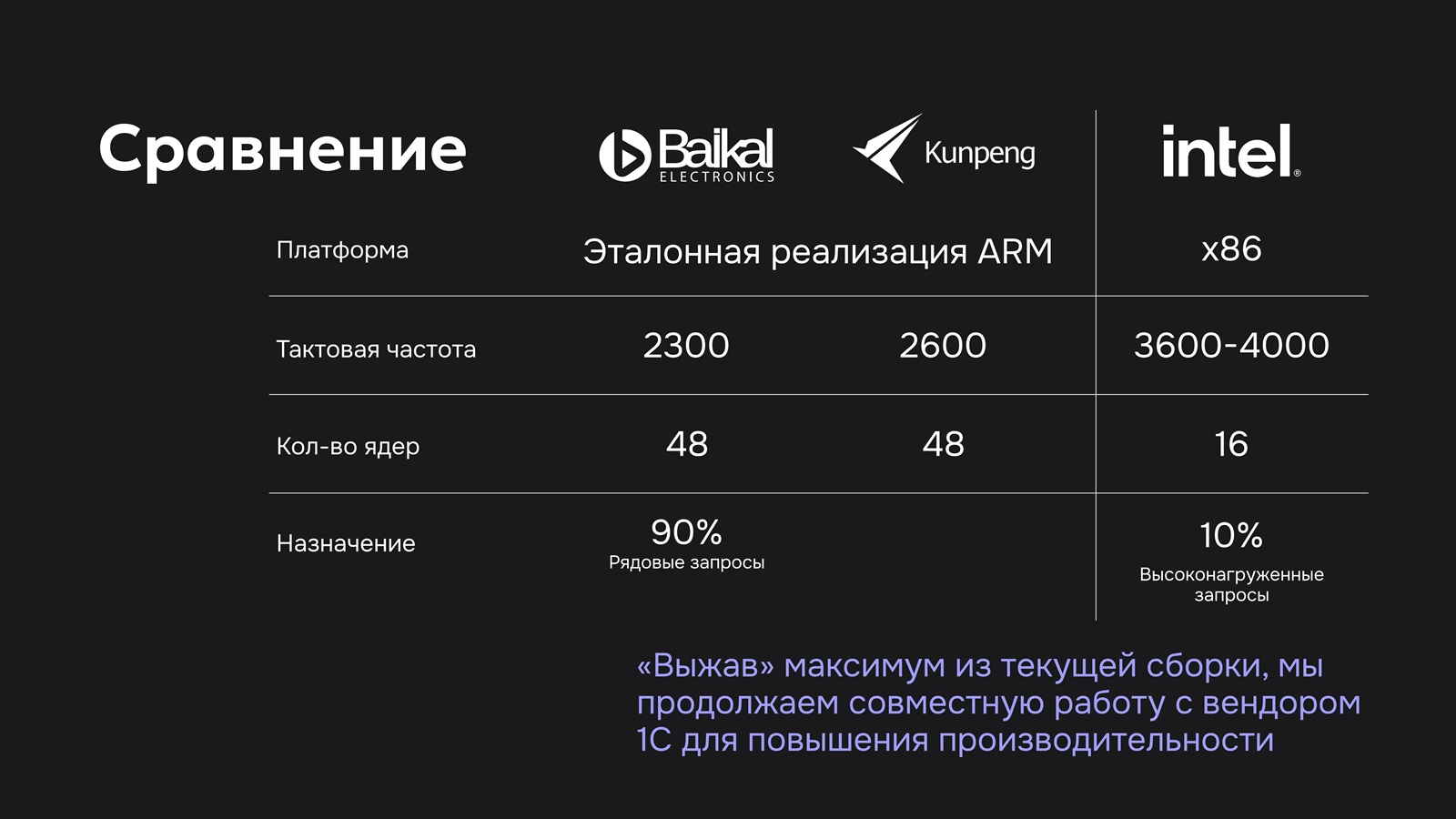 У Microsoft есть Arm-процессоры Cobalt 200, у AWS — Graviton 5, у Alibaba Cloud — Yitian 710, а у Google — Axion. Среди крупных независимых поставщиков серверных процессоров можно выделить Ampere Computing (активно используется Oracle), которая теперь принадлежит SoftBank, и Huawei, активно использующую процессоры Kunpeng в своей продукции, в том числе в облаке. Собственные процессоры также готовят сама Arm, Qualcomm и Fujitsu. Последние, как и чипы NVIDIA Vera, ориентированы в первую очередь на ИИ.  Компания «Байкал электроникс» поставила в Россию не менее 85 тыс. процессоров собственной разработки, включая модели Baikal-T, Baikal-M и Baikal-S, но из-за санкций производство чипов пришлось прекратить, а также отменить выпуск Baikal-S. Также пришлось отменить планы по старту серийного производства в 2025–2026 гг. 128-ядерных серверных Arm-процессоров второго поколения Baikal-S2. Однако вскоре будут доступны и они.  «Группа Астра» также готовит для партнёров и интеграторов совместные пакеты поставки, чтобы обеспечить их не только технологией, но и отлаженными коммерческими сценариями её внедрения. Например, в публичном облаке Astra Cloud с Baikal-S заказчик получит защищённую аттестованную инфраструктуру и приложения в ЦОД Astra Cloud, предоставляемые как сервис, для использования под конкретные бизнес-задачи (от пилота до промышленной нагрузки) без надобности в создании собственной аппаратной площадки.  В свою очередь, частное облако на Baikal-S — это выделенная инфраструктура в контуре заказчика для тех, кому важен контроль с максимальной изоляцией данных. Также предлагается ПАК XCloud на Baikal-S — готовая облачная платформа «под ключ», которая разворачивается либо в контуре заказчика по лицензии, либо в ЦОД Astra Cloud по подписке. Пока что предоставляется IaaS (узлы 2 × 48 ядер, 128–768 Гбайт RAM, 1 Тбайт системный диск + HDD/SSD), а в будущем появятся VDI, Kubernets, почтовая служба и т.д. — всё, что запланировано к реализации в платформе Astra Cloud, будет доступно и на Baikal S. 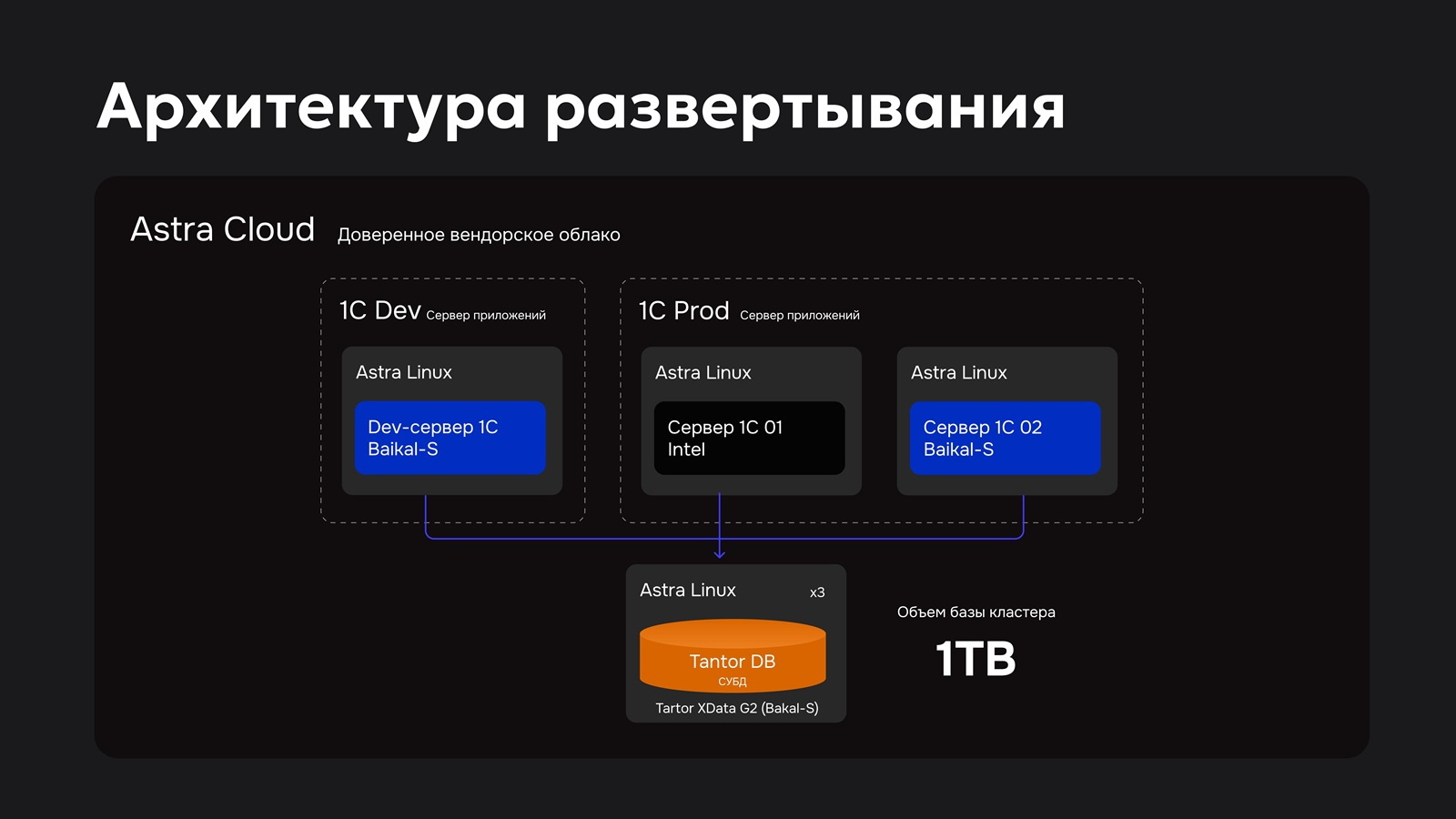 В настоящее время облако Astra Cloud на Baikal-S проходит финальную доработку на реальных нагрузках в «Группе Астра». Речь, в частности, о полноценном развёртывании платформы 1С. Ожидается, что до конца июля для избранных клиентов будет открыт пилотный доступ в неаттестованном сегменте с возможностью бесплатного тестирования до конца года. Также в этом году будет запущен аттестованный сегмент с дальнейшим расширением сервисов для разработчиков и коммерческой подписки.  Одновременно с облачной инфраструктурой Astra Cloud предоставит готовую платформу разработки, включающую репозитории кода, CI/CD-конвейеры и инструменты безопасной разработки, что позволит заказчикам существенно ускорить адаптацию приложений под архитектуру Baikal-S без необходимости в самостоятельном построении DevOps-цепочек. Также компания планирует в течение этого года дополнить облако Astra Cloud на Baikal-S GPU-серверами для ИИ- и HPC-задач, чтобы позволит запускать ИИ-нагрузки на полностью отечественном стеке без необходимости параллельного использования зарубежных ИИ-облаков для машинного обучения. Для участия в пилоте Astra Cloud на Baikal-S компаниям необходимо заполнить заявку на предтестирование и предзаказ IaaS на Baikal-S, указав планируемые сценарии использования — например, перенос продуктивных нагрузок, разработка и CI/CD, запуск ИИ-задач или отработка сценариев отказоустойчивости. Это позволит компании заранее подобрать конфигурацию ресурсов под реальный профиль заказчика и сопроводить пилот методически. «Группа Астра» выразила уверенность в том, что облако на Baikal-S в ближайшем будущем станет «стандартом для российских значимых объектов, а в горизонте двух-пяти лет — основой для экспорта доверенной инфраструктуры». Компания приглашает к сотрудничеству разработчиков, вендоров в сфере информационной безопасности и облачных интеграторов, которые «видят в технологическом суверенитете пространство для качественного рывка».
07.05.2026 [14:02], Руслан Авдеев
Arm рассчитывает заработать миллиарды долларов на серверных процессорах Arm AGIКомпания Arm отчиталась о рекордной квартальной выручке и в докладе особо подчеркнула своё стремление усилить позиции на рынке ИИ-инфраструктур, CPU для дата-центров и ИИ-задачи в целом. По итогам IV квартала 2026 финансового года выручка компании составила $1,49 млрд, рост составил 20 % г/г, сообщает Converge! Digest. Важная роль в стратегии развития компании отводится новым CPU Arm AGI. Отмечается, что роялти принесли компании $671 млн (+11 % г/г), а выручка от лицензирования увеличилась на 29 % до $819 млн. По данным Arm, рост связан с расширенным внедрением архитектуры Armv9, платформы Compute Subsystems (CSS) и возрастающей востребованностью Arm-процессоров в облачных ИИ ЦОД. Особое внимание уделено частичному отходу от обычного лицензирования интеллектуальной собственности в пользу выпуска собственных полупроводников для гиперскейлеров. Не так давно компания совместно с Meta✴ разработала и представила процессор Arm AGI CPU. По оценкам компании, в ближайшие два года спрос на такие чипы превысит $2 млрд. Arm позиционирует AGI CPU как специализированный процессор для координации работы крупных ИИ-кластеров. В компании уверены, что развитие агентных ИИ-систем существенно увеличит нагрузку на процессоры, поскольку ИИ-ускорители отвечают преимущественно за генерацию токенов. В то же время, CPU займутся планированием, управлением памятью, сетевым взаимодействием и координацией вычислений. 
Источник изображения: Arm Компания располагает долгосрочным прогнозом развития ИИ-инфраструктуры. По её расчётам, совокупный рынок облачной ИИ-инфраструктуры вырастет с $245 млрд в 2026 финансовом году до более $1 трлн — к 2031. Это произойдёт благодаря развитию систем инференса и агентного ИИ. В компании рассчитывают, что бизнес AGI CPU к 2031 году позволит генерировать порядка $15 млрд/год при одновременном росте сегментов бизнеса, связанных с традиционным лицензированием и получением роялти. Руководство Arm уверено, что процессоры компании со временем превратятся в специальный «слой оркестрации» для ИИ-кластеров гиперскейлеров, в т.ч. AWS, Google Cloud, Microsoft Azure, Meta✴, Oracle Cloud Infrastructure и даже NVIDIA. Arm подчёркивает, что выручка третий год подряд растёт более чем на 20 % благодаря высокому спросы на вычислительную платформу компании, а поскольку ИИ становится всё более «агентным», спрос на Arm AGI превысил ожидания, и это укрепляет позиции компании в качестве вычислительной платформы для эпохи ИИ. По словам отраслевых экспертов, в отчёте Arm отражается более масштабный сдвиг ИИ-инфрастурктуры в направлении «гетерогенных» вычислительных архитектур, в которых CPU вновь приобрели важнейшее значение, поскольку обеспечивают координацию крупных ИИ-кластеров. Хотя при обучении и инференсе доминирующую роль играют ИИ-ускорители на базе GPU и ASIC, гиперскейлеры всё чаще делают ставку на использование CPU для координации ключевых задач, от оркестрации нагрузок до управления энергопотреблением. В то же время Arm фактически начинает конкурировать с продуктами собственных клиентов. При этом компания продолжает получать финансовые поступления как от NVIDIA Grace, так и от гиперскейлеров, которые используют Arm-архитектуры в своих собственных CPU. Так, у У Microsoft имеются Arm-процессоры Cobalt 200, у AWS — Graviton 5, у Alibaba Cloud — Yitian 710, а у Google — Axion. Oracle долгое время полагалась чипы Ampere Computing, которая теперь принадлежит SoftBank.
06.05.2026 [09:16], Сергей Карасёв
AMD представила адаптивную SoC Versal Prime VM2152 с поддержкой DDR5 и PCIe 5.0Компания AMD анонсировала адаптивную «систему на кристалле» (SoC) Versal Prime VM2152, предназначенную для использования в оборудовании для дата-центров, сетей связи, 5G-инфраструктур и пр. Унифицированная архитектура изделия объединяет высокоскоростные интерфейсы ввода-вывода, вычисления на базе FPGA и связь с поддержкой различных протоколов. Versal Prime VM2152 совмещает два ядра Arm Cortex-A72 с 1 Мбайт кеша L2 (ECC) и вычислительный блок реального времени с двумя ядрами Arm Cortex-R5F. Чип содержит 256 Кбайт встроенной памяти с поддержкой ECC. Реализованы интерфейсы Ethernet (×2), USB 2.0 (×1), UART (×2), SPI (×2), I2C (×2), CAN-FD (×2), PCIe 5.0 x4 (×2). Программируемая часть включает 757 тыс. логических ячеек и более 346 тыс. LUT. Упомянуты 1704 движка DSP. Пиковая производительность достигает 11,8 TOPS на операциях INT8. Предусмотрены четыре контроллера оперативной памяти с поддержкой LPDDR5-6400 и DDR5-5600. Кроме того, упомянуты по восемь трансиверов GTYP и GTM (58 Гбит/с), а также MIPI C-PHY (10 Гбит/с) и MIPI D-PHY (4,5 Гбит/с). 
Источник изображения: AMD Адаптивная SoC доступна в вариантах исполнения NFVD1024 (31 × 31 мм), NFVM1369 (35 × 35 мм), VSVD1760 (40 × 40 мм) и VSVA2197 (45 × 45 мм). Предусмотрены версии с расширенным и индустриальным диапазоном рабочих температур: в первом случае он простирается от 0 до +100 °C, во втором — от -40 до +100 °C. Разработчики могут использовать пакет AMD Vivado Design Suite для проектирования аппаратного обеспечения и платформу AMD Vitis для создания софта. На ядрах Arm Cortex-A72 можно запускать ОС Linux (PetaLinux). Блоки программируемой логики (FPGA-матрица) и DSP используются для развёртывания специализированных аппаратных ускорителей, позволяющих разгрузить CPU от ресурсоёмких вычислительных задач. Цена Versal Prime VM2152 варьируется от $6000 до $8500 в зависимости от варианта и объёма заказа.
30.04.2026 [12:24], Руслан Авдеев
ИИ-облако Verda развернёт процессоры Arm AGI в своих ЦОДФинская компания Verda намерена предложить клиентам новые решения в сфере ИИ и доступ к новейшему процессору AGI, разработанный компанией Arm. По словам Arm, Verda является самым быстрорастущим поставщиком неооблачных решений в Европе. В настоящее время компания работает над развёртыванием Arm AGI в комбинации с решениями NVIDIA GB300 и, в перспективе — с NVIDIA Vera Rubin. Предполагается, что взаимодействие с NVIDIA обеспечит совместную работу стоек разных типов и поколений в одном дата-центре. Сотрудничество с техногигантом позволяет добиться большей согласованности ПО и серверов и дать ИИ-агентам возможность автономно распределять рабочие нагрузки. Подробности о масштабах развёртывания и сроках доступности процессоров будут объявлены позже. 
Источник изображения: Verda Verda сообщает, что управляет ИИ-облаком, работающим на возобновляемой энергии и созданном для команд, занимающимся машинным обучением (ML). Сочетание Arm AGI с NVIDIA GB300 и готовящимися к выпуску VR200 обеспечит клиентам эффективноcть, необходимую для агентного ИИ. Фактически Arm AGI создан специально для современных систем агентного ИИ и будет выполнять роль «координатора», работая вместе с ускорителями и управляя потоками данных и взаимодействием компонентов в больших ИИ-системах. Чип создан в по 3-нм техпроцессу TSMC и включает 136 ядер. Verda, ранее известная как DataCrunch, основана в 2020 году и сегодня имеет дата-центры в Финляндии, работающие на 100 % возобновляемой энергии. Также она управляет ЦОД в Исландии и намерена построить ЦОД в Латвии.
29.04.2026 [15:34], Сергей Карасёв
Китай анонсировал 2,5-Эфлопс Arm-суперкомпьютер LineShine на домашних процессорахКитайский национальный суперкомпьютерный центр в Шэньчжэне (NSCCSZ) анонсировал проект вычислительного комплекса LineShine (LingSheng), производительность которого после полноценного ввода в эксплуатацию окажется на уровне 2 Эфлопс. Особенностью системы является то, что её конфигурация предполагает применение исключительно CPU-серверов — без ускорителей на базе GPU. Как отмечает ресурс HPC Wire, LineShine будет создаваться в несколько этапов. Одна из секций нового суперкомпьютера получит серверы Huawei Kunpeng с десятками тысяч вычислительных ядер. Предусмотрено использование 428 узлов хранения с суммарной вместимостью 650 Пбайт. Заявленная пропускная способность — 10 Тбайт/с. Вторая секция LineShine предполагает применение 20480 вычислительных узлов, каждый из которых будет оснащён двумя процессорами LX2 на архитектуре Armv9. Конструкция чипов LX2 включает два вычислительных кристалла со 152 ядрами (в сумме 304 ядра) и восемь стеков памяти HBM (32 Гбайт, 4 Тбайт/с). Каждый кристалл использует 128 Гбайт внешней памяти DDR. За обмен данными между блоками DDR и HBM отвечает специальный механизм SDMA. Каждый кристалл поделён на четыре NUMA-домена (38 ядер и 4 Гбайт HBM). Узлы соединены между собой высокоскоростным интерконнектом LingQi, обеспечивающим пропускную способность до 1,6 Тбит/с на узел. Говорится о поддержке режимов FP64/FP32/FP16/INT8. Заявленная производительность LX2 достигает 60,3 Тфлопс на операциях FP64 и 120,6 Тфлопс на операциях FP32. Таким образом, пиковая теоретическая FP64-производительность составляет 2,47 Эфлопс. 
Источник изображения: South China Morning Post Для сравнения, самый быстрый на сегодняшний день суперкомпьютер в мире по версии TOP500 — американский комплекс El Capitan — обладает быстродействием 1,809 Эфлопс с пиковым значением 2,821 Эфлопс, но в нём применяются как CPU, так и ускорители (AMD Instinct MI300A). Таким образом, LineShine станет самым мощным НРС-комплексом, построенным исключительно на базе CPU. Другой особенностью машины станет то, что в её составе будут применяться только китайские компоненты, включая процессоры, накопители и сетевое оборудование. При этом официально КНР не участвует в TOP500 уже пять лет, да и в целом не любит рассказывать о своих самых мощных суперкомпьютерах. Нужно отметить, что в Китае действует другой суперкомпьютер экзафлопсного класса — система China New-generation Intelligent Supercomputer (CNIS). Этот комплекс имеет гетерогенную конфигурацию с 5632 вычислительными узлами. Каждый из них наделён двумя 64-бит серверными процессорами на базе CISC с 64 ядрами (2,4 ГГц) и восемью ускорителями GPGPU с архитектурой SIMT с 64 Гбайт HBM (1,8 Тбайт/с). Задействованы 8-канальная подсистема памяти DDR5-6400. Каждый GPGPU обеспечивает пиковую производительность 32,7 Тфлопс в режиме FP64, 65,5 Тфлопс на операциях FP32 и 470 Тфлопс в режиме FP16, что в сумме даёт пиковую теоретическую FP64-произвоидительность на уровне 1,47 Эфлопс.
09.04.2026 [11:24], Сергей Карасёв
Uber перенесёт рабочие нагрузки на чипы AWS Graviton и Trainium нового поколенияКомпания Uber сообщила о расширении использования облачной платформы Amazon Web Services (AWS). Оператор сервисов для вызова такси и частных водителей, а также доставки еды и грузов перенесёт определённые нагрузки на чипы AWS Graviton и Trainium нового поколения. Компания уже использует Arm-процессоры Ampere в облаке Oracle. В частности, Uber будет использовать изделия Graviton4, насчитывающие до 96 ядер, для поддержания работы своих зон обслуживания поездок (Trip Serving Zones). Соответствующая инфраструктура функционирует в режиме реального времени: каждый раз, когда пользователь заказывает поездку или доставку, система рассчитывает оптимальный маршрут, выбирает подходящего водителя и определяет время. В часы пик и при проведении крупных мероприятий создаётся огромная вычислительная нагрузка: требуются анализ миллионов возможных сценариев поездок и обработка данных о местоположении пользователей и водителей. Ожидается, что применение Graviton4 позволит сократить задержки и оптимизировать затраты, а также обеспечит необходимую масштабируемость в периоды всплеска запросов без ущерба для надёжности, доступности или безопасности. 
Источник изображения: AWS Кроме того, Uber начнёт применять ускорители Trainium3 для обучения некоторых своих ИИ-моделей, которые лежат в основе приложений вызова такси и доставки. Эти изделия оснащены 144 Гбайт памяти HBM3E, а производительность на операциях FP8 достигает 2,52 Пфлопс. ИИ-модели Uber, как отмечается, анализируют данные миллиардов поездок для выбора водителя или курьера, оценки времени прибытия и генерации рекомендаций для пользователей. Обучение ИИ в таком масштабе требует колоссальных вычислительных возможностей: решения Trainium3, как подчёркивается, способны предоставить необходимые ресурсы. «Uber — одно из самых требовательных приложений в мире, работающих в режиме реального времени. Мы помогаем Uber обеспечивать надёжность, на которую рассчитывают сотни миллионов людей, а также внедрять ИИ-функции, определяющие будущее сервисов совместных поездок и доставки по запросу», — говорит Рич Гераффо (Rich Geraffo), вице-президент и управляющий директор AWS в Северной Америке. |
|

