Материалы по тегу: aws
|
08.07.2026 [14:24], Руслан Авдеев
Amazon выпустила облигации на $25 млрд, чтобы покрыть затраты на ИИ-инфраструктуруКомпания Amazon вышла на рынок ценных бумаг, предложив облигации на $25 млрд. Привлечённые средства потратят на развитие ИИ-инфраструктуры и погашение долгов. Предложение разбито на восемь частей, речь идёт о старших необеспеченных облигациях со сроками погашения от 3 до 40 лет, сообщает Silicon Angle. Для большинства из них назначена фиксированная процентная ставка, хотя в некоторых случаях предусмотрена и плавающая. Спрос на ценные бумаги оказался чрезвычайно высоким. Объём заявок на покупку во вторник почти достиг $62 млрд, поэтому банки снизили предлагаемую дополнительную доходность (spread), из-за чего объём заявок упал до $41 млрд, что всё равно оказалось приблизительно в 1,6 раза больше объёма размещения. Amazon объявила, что больше занимать средства в этом году не намерена. Организаторы размещения — Barclays, Goldman Sachs Group, JPMorgan Chase и Morgan Stanley. В этом году Amazon уже продала облигации на сумму около $54 млрд в США и Европе, а также выпустила бумаги на $10 млрд в Канаде. Она продолжает привлекать новые средства, поскольку её расходы пока выше генерируемого денежного потока. 
Источник изображения: Jakub Żerdzicki/unsplash.com Инвестиционный бюджет компании постоянно растёт. В текущем году Amazon рассчитывает на $200 млрд расходов, намного больше, чем $131 млрд в 2025 году. В основном средства пошли на дата-центры, чипы и оборудование для AWS. При этом компания утверждает, что спрос на ИИ-вычисления растёт быстрее, чем она успевает вводить в строй новые мощности. Но и деньги она начинает зарабатывать на этих инвестициях быстрее, чем успевает строить ИИ-инфраструктуру. Другие техногиганты также прибегают к привлечению заёмных средств. Alphabet, Microsoft и Meta✴ активно действуют на рынках долгового и акционерного капитала для наращивания своей ИИ-инфраструктуры. Совокупно американские IT-гиганты потратят на ИИ в текущем году более $700 млрд. Сложнее всего ситуация пока у Oracle. Для Amazon важнейшим остаётся вопрос сохранения спроса на ИИ. Выручка AWS в последнем квартале выросла на 28 %. Более $10 млрд должны принести в этом году чипы Trainium и Graviton. Хотя конкуренция со стороны неооблачных компаний растёт, AWS остаётся крупнейшим облачным провайдером в мире. По статистике Synergy Research, на долю техногиганта приходится 28 % доля. Для сравнения — Microsoft занимает второе место, занимая долю в 21 %, а Google — 14 %. Только в IV квартале мощности компании выросли на 1,2 ГВт.
07.07.2026 [14:22], Руслан Авдеев
Кастомный IRHX AWS на 9 % сократит расход воды в ЦОДВ отчёте об устойчивом развитии Amazon подробно рассказала о мерах, принимаемых для сокращения потребления электричества и воды. В частности, облачное подразделение AWS модернизирует аппаратное обеспечение ЦОД, что позволило снизить расход воды, сообщает Datacenter Dynamics. Ключевую роль в сокращении водопотребления играет кастомный In-Row Heat Exchanger (IRHX), захватывающий тепло непосредственно от высокоплотного ИИ-оборудования в стойке посредством СЖО и отводящий его в теплообменник, выбрасывающий нагретый воздух в «горячий» коридор. Компания сообщает, что по мере ввода в эксплуатацию IRHX ожидается сокращение потребления воды на 9 % в сравнении с обычными ЦОД с испарительным охлаждением. AWS внедряет всё больше DLC-систем в новых и уже действующих ЦОД, хотя всё ещё полагается в некоторых задачах на воздушное охлаждение. 
Источник изображения: AWS Впервые об IRHX компания упомянула около года назад, когда сообщила о начале развёртывания кастомной СЖО для NVIDIA GB200 NVL72. Тогда новость вызвала некоторый ажиотаж на рынке, вызвав временный спад акций конкурирующих поставщиков систем охлаждения вроде Vertiv. По словам AWS, кастомный IRHX позволил компании упростить масштабирование ИИ-инфраструктуры, поскольку решение совместимо с уже построенными дата-центрами, а кроме того, компания лучше контролирует цепочку поставок. 
Источник изображения: AWS Также компания сообщила, что расширяет внедрение технологий умного учёта воды по всей сети своих ЦОД. Они в режиме реального времени могут отслеживать потребление, выявлять утечки воды и даже оперативно устранять их. В июне компания сообщала, что в 2025 году её дата-центры использовали 9,46 млн м3 воды. В целом эти и иные меры только в том году позволили сократить использование воды на 98 тыс. м3, благодаря чему индекс WUE дата-центров AWS снизился до 0,12 л/кВт∙ч, оптимизация в сравнении с 2024 годом составила 20 % и 52 % — в сравнении с уровнем 2021-го. При этом PUE дата-центров компании составил 1,14. На конец 2025 года на территории 31 ЦОД Amazon действовали собственные системы очистки воды. В 26 очищенная вода применялась для охлаждения объектов, что позволило сохранить 849 тыс. м3 пресной воды. В 14 ЦОД используются системы сбора дождевой воды. Amazon заключила соглашение с 13 коммунальными компаниями о поставке очищенной воды для систем охлаждения 130 ЦОД, что позволит ежегодно экономить около 6 млн м3 пресной воды.
03.07.2026 [15:45], Руслан Авдеев
AWS пытается удержать свою облачную корону, наращивая мощности ЦОДКомпания Amazon Web Services (AWS) в очередном годовом отчёте, посвящённом устойчивому развитию, заявила о значительном росте своего бизнеса. В прошлом году она добавила больше ЦОД, чем любая другая компания. Только в IV квартале мощности выросли на 1,2 ГВт, сообщает Datacenter Dynamics. Компания пока не раскрыла общую мощность своих дата-центров, но с октября 2024 по октябрь 2025 гг. добавилось 3,8 ГВт. Утверждается, что мощность ЦОД AWS вдвое больше, чем была в 2022 году, а к 2027 году она может снова удвоиться. Хотя точные показатели мощности ЦОД Amazon неизвестны, для контекста, согласно исследованию JLL, Великобритания в 2024 году имела всего 8 ГВт ЦОД, ещё 4 ГВт строятся. Согласно отчёту компании по форме 10-K, в 2025 году её облачный бизнес располагал 5,28 млн м2 площадей ЦОД и офисов, на 16 % больше в сравнении с 2024 годом. Около половины площадей принадлежит самой компании, остальные арендуются. В июне компания сообщала, что в 2025 году её ЦОД потребили более 9,46 млн м3 воды. 
Источник изображения: Pascal Bernardon/unsplash.com Конкуренты Amazon тоже не спешат раскрывать данные о своих мощностях. Во II квартале 2026 финансового года в эксплуатацию введены 1 ГВт ЦОД Microsoft, фактически этот финансовый квартал совпадает с IV кварталом Amazon. Всего в 2025 финансовом году Microsoft ввела в эксплуатацию ЦОД мощностью 2 ГВт. Хотя конкуренция со стороны неооблачных компаний растёт, AWS остаётся крупнейшим облачным провайдером в мире. По статистике Synergy Research, на долю техногиганта приходится 28 % доля. Для сравнения — Microsoft занимает второе место, обладая 21 %, а Google — 14 %.
03.07.2026 [15:07], Руслан Авдеев
Казахстанская «Долина ЦОД» привлекла Amazon и G42По словам президента Казахстана Касым-Жомарта Токаева, в строящейся в стране «Долины ЦОД» уже начали занимать места гиганты IT-отрасли. В том числе речь идёт о лидерах вроде Amazon и G42, сообщает «Интерфакс». По словам Токаева, «Долина ЦОД» должна стать краеугольным камнем цифровой экономики Казахстана и привлечь в страну иностранный капитал и техногигантов. Проект реализуется в Экибастузе. Речь идёт, как сообщается, о крупнейшем в Центральной Азии кампусе, для которого выделены 1,4 тыс. га, с потенциалом мощности до 1 ГВт и потенциалом заключения соглашений до $10 млрд. Проект реализуется совместно с американской Firebird, в свою очередь, очень тесно взаимодействующей с NVIDIA. Согласно плану, проект обеспечит не менее $3 млрд экспортной выручки ежегодно. 
Источник изображения: Tim Broadbent/unspalsh.com В январе этого года сообщалось, что Правительство Казахстана при содействии акимата Павлодарской области построит в Экибастузе «Долину ЦОД», энергоснабжение которых будет осуществляться за счёт местного угля. Сообщалось, что для участников проектов предполагаются налоговые льготы по принципам, характерным для специальных экономических зон (СЭЗ). В 2025 году Akashi Data Center и China Mobile заявили о постройке в Астане нового ЦОД, который тоже назван самым большим в Центральной Азии. В 2025 году в Алматы и Астане введены в эксплуатацию два новых ЦОД мощностью 7,4 МВт, в 2026 году планируется запуск ещё трех ЦОД мощностью 12,9 МВт.
27.06.2026 [22:35], Владимир Мироненко
Amazon инвестирует в ИИ-инфраструктуру Индии ещё $13 млрдAmazon объявила о новых инвестициях в расширение и поддержку инфраструктуры искусственного интеллекта и облачных вычислений Индии в размере $13 млрд в период до 2030 года в дополнение к объявленным в 2025 году $35 млрд. В общей сложности инвестиции в этот сегмент в Индии в период с 2026 по 2030 год превысят $21 млрд. Новые инвестиции будут направлены в расширение и поддержку мощностей ЦОД AWS в Мумбаи и Хайдарабаде, благодаря чему индийские компании получат доступ к ИИ-ускорителям, управляемым ИИ-сервисам, облачным технологиям и инструментам для разработчиков, что позволит быстрее внедрять инновации, быстро масштабироваться и обслуживать клиентов по всему миру. Совокупные инвестиции Amazon в Индию с 2010 по 2030 год превысят $88 млрд. С 2010 года, по данным Amazon, компания помогла оцифровать 12 млн малых предприятий, поддержала 2,8 млн рабочих мест, обеспечила экспорт в сфере электронной коммерции на сумму более $20 млрд и обучила более 10 млн человек навыкам работы с облачными технологиями. 
Источник изображения: Amazon Amazon отметила, что её бизнес-приоритеты с приоритетами Индии: демократизация доступа к ИИ, цифровизация малого бизнеса, создание рабочих мест и развитие экспорта. «В ближайшие пять лет мы инвестируем более $48 млрд, чтобы удовлетворить высокий спрос на все наши услуги в Индии и помочь стране достичь этих целей», — сообщила компания. Быстрорастущий рынок Индии привлекает внимание и других гиперскейлеров. В конце прошлого года Microsoft объявила о планах инвестировать в расширение ИИ-инфраструктуры в стране $17,5 млрд. Google планирует построить в Индии дата-центр Vizag мощностью 1 ГВт за $6 млрд.
27.06.2026 [13:17], Владимир Мироненко
Еврокомиссия взяла на карандаш AWS и Microsoft AzureЕврокомиссия сообщила, что пришла к предварительному выводу о необходимости включения ведущих облачных сервисов Amazon Web Services (AWS) и Microsoft Azure (Azure) в список поставщиков услуг, регулируемых Законом о цифровых рынках (DMA) ЕС, о чём она уведомила Amazon и Microsoft. Регулятор отметил, что AWS и Azure, «крупнейший и второй по величине поставщики облачных вычислительных услуг в ЕС соответственно», являются связующим звеном между предприятиями и их клиентами в ЕС. Оба сервиса достигли значительного оборота, а их операционные мощности и инвестиции, по-видимому, значительно превзошли показатели конкурентов. Также отмечено, что обе компании имеют «обширные и устоявшиеся пользовательские базы и, похоже, извлекают выгоду из эффекта “привязки” и высоких затрат на переход к другому поставщику, помимо обширной экосистемы». И хотя они пока не соответствуют количественным пороговым значениям DMA для включения в список поставщиков услуг, например, по охвату аудитории, их прочные и устойчивые позиции в секторе облачных вычислений ЕС привлекли внимание регулятора. Кроме того, и на острове, и на материке всё более остро стоит вопрос зависимости от американских IT-гигантов. 
Источник изображения: Guillaume Périgois/unsplash.com Оба расследования с целью оценки, следует ли отнести облачные сервисы Amazon и Microsoft к категории «привратников», Еврокомиссия начала 18 ноября 2025 года. В случае подтверждения регулятором их статуса «привратников» к компаниям будут применяться обязательства в отношении совместимости, доступа к данным и конкуренции. Чтобы привести облачные сервисы в соответствие с требованиями DMA компаниям будет отведено 6 мес. На данный момент речь идёт о предварительном мнении регулятора, которое можно оспорить. Обе компании выразили несогласие с ним. Представитель Microsoft заявил изданию The Register, что компания продолжает конструктивно взаимодействовать с Еврокомиссией, добавив следующее: «Мы по-прежнему обеспокоены тем, что игнорирование растущей мощи Google Cloud и Gemini может негативно повлиять на рынок». Представитель AWS заявил The Register, что «предварительные выводы Еврокомиссии игнорируют широкий спектр облачных услуг, доступных европейским клиентам, и рискуют отпугнуть европейские инвестиции и инновации». Он отметил, что «AWS сталкивается со здоровой конкуренцией, а клиенты по всей Европе имеют больший выбор, более низкие цены и большую гибкость, чем когда-либо прежде». 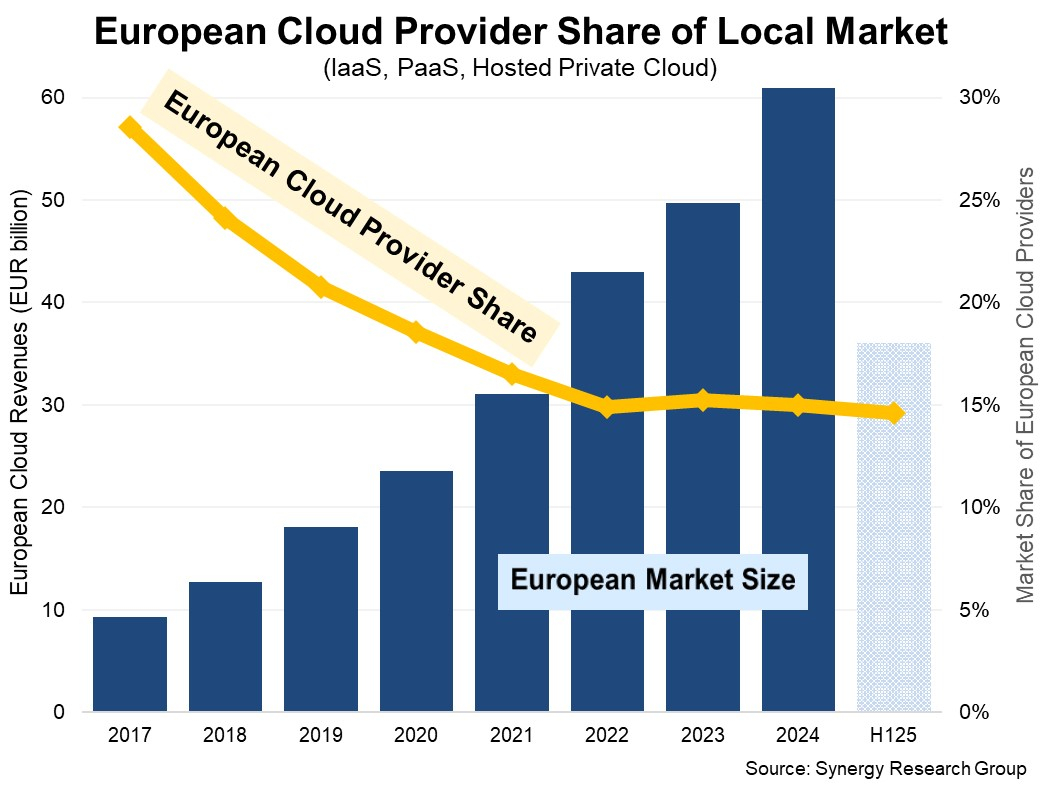
Источник изображения: Synergy Research Group Глава британского провайдера облачных услуг Civo Марк Буст (Mark Boost) назвал предварительную оценку Еврокомиссии правильной: «Это правильное решение Брюсселя, и оно давно назрело. Облако сейчас является критически важной инфраструктурой, однако горстка американских гиперскейлеров контролирует шлюзы, привязывая клиентов к себе с помощью платы за исходящий трафик, ограничительного лицензирования и слабой совместимости». Буст задался вопросом, последует ли этому примеру Великобритания. По его словам, Управление по конкуренции и рынкам Великобритании (CMA) потратило три года на расследование, придя к выводу, что конкуренция «работает плохо», и его собственная комиссия рекомендовала присвоить статус DMA компаниям AWS и Azure. Затем в марте CMA уступило и предпочло добровольные обязательства обязательным правилам. «Если Великобритания серьёзно относится к цифровому суверенитету и конкурентоспособному отечественному технологическому сектору, ей необходимо подкреплять свои выводы действиями, а не обещаниями», — заявил Буст.
20.06.2026 [16:30], Сергей Карасёв
ИИ Continuum найдёт и починит уязвимости у клиентов AWSAWS анонсировала платформу Continuum — специализированную систему на базе ИИ для автоматического выявления, подтверждения и устранения уязвимостей в программном обеспечении в среде клиента. AWS отмечает, что традиционные подходы к решению проблем в области информационной безопасности оказываются недостаточно эффективными на фоне стремительного развития угроз в эпоху ИИ. Система Continuum спроектирована для управления полным жизненным циклом уязвимостей: инструмент позволяет автоматизировать основные задачи, сведя к минимуму участие человека. В настоящее время Continuum оптимизирована для поиска уязвимостей в программном коде. Процесс работы системы включает четыре основных этапа: обнаружение, приоритезация, проверка и устранение. В ходе первой фазы платформа анализирует уже существующий список уязвимостей и проводит собственное сканирование среды, выстраивая подробную карту путей атаки. Затем система переходит к расстановке приоритетов: каждая выявленная проблема оценивается с учётом множества факторов — статуса развёртывания того или иного компонента, его доступности для атаки, потенциального риска для бизнеса и пр. В результате формируется перечень наиболее актуальных угроз. 
Источник изображения: unsplash.com / Luca Bravo На этапе проверки Continuum оценивает найденные уязвимости в изолированной среде (песочнице), генерируя рабочие эксплойты. Это позволяет подтвердить существование проблемы или отсеять её. В ходе заключительной фазы система анализирует уже действующие меры защиты и предлагает оптимальные пути устранения обнаруженной уязвимости: будь то изменения сетевой конфигурации, обновление политик безопасности или разработка патчей. При этом все изменения проходят повторную проверку, а в случаях, когда это возможно, предусматриваются варианты отката, что помогает минимизировать риски при внедрении исправлений. Работа Continuum не зависит от какой-либо одной ИИ-модели: платформа задействует несколько передовых LLM — в зависимости от того, какая из них лучше подходит для решения конкретной задачи. Система анализирует как структурированные данные, уже имеющиеся в AWS (инфраструктура, разрешения, сетевая топология и код), так и неструктурированную информацию, включая документацию клиента и бизнес-приоритеты. Уровень автоматизации повышается постепенно — по мере обучения платформы.
19.06.2026 [13:49], Владимир Мироненко
Amazon начала переговоры о продаже своих ИИ-ускорителей Trainium сторонним ЦОДAmazon ведёт переговоры о продаже своих ИИ-ускорителей Trainium другим компаниям для использования в их ЦОД. Об этом сообщил Питер ДеСантис (Peter DeSantis), старший вице-президент по ИИ, разработке чипов и квантовым вычислениям Amazon, выступая на конференции VivaTech в Париже (Paris, Франция), о чём пишет Bloomberg. Он отказался назвать потенциальных клиентов, лишь отметив растущий за пределами США спрос на вычислительные ресурсы, управляемые локально. Как сообщается, переговоры о продаже чипов находятся на ранней стадии. Начались они после ежегодного послания генерального директора Amazon Энди Джасси (Andy Jassy) акционерам в апреле, в котором он заявил, что Amazon рассматривает возможность продажи собственных ИИ-чипов сторонним компаниям, что усилит конкуренцию с NVIDIA и AMD. ДеСантис также рассказал, что решение о продаже чипов не вызывает у руководства Amazon опасений, что это ударит по доходам AWS от облачных сервисов. «В сфере ИИ наблюдается огромный дефицит ресурсов, — сказал он. — Меня это не беспокоит». 
Источник изображения: Amazon Рост спроса, особенно в Европе, привёл к призывам уменьшить зависимость от американских технологий или полностью отказаться от них. Комментируя призывы, ДеСантис заявил, что бизнес AWS никак не пострадал от этой тенденции. По его словам, ускорители Trainium3, поставки которых начались в начале этого года, «в значительной степени распроданы», и уже есть большой интерес к новому поколению Trainium4, которое, как ожидается, дебютирует в следующем году. ДеСантис также отметил высокий спрос на Arm-процессоры Graviton, которые в больших масштабах будут использовать Meta✴, Pinterest, Snowflake и Uber. За последние три года, по словам Десантиса, Amazon добавила в свои вычислительные системы больше процессоров Graviton, чем любого другого типа чипов. Что касается Trainium, то у Amazon есть очень крупные контракты с Anthropic и OpenAI. Вместе с тем в качестве альтернативы GPU NVIDIA компания будет предлагать не только свои ускорители, но и царь-чипы Cerebras. 
Источник изображения: Amazon Как сообщает TechCrunch, AWS до сих пор не спешила с продажей своих ИИ-чипов по многим причинам. Самая главная заключается в том, что прибыль, которую она получает от них, имеет каскадный характер. Хотя AWS взимает плату с клиентов за токены ИИ, обрабатываемые этими чипами в её облаке, она также может взимать плату за множество других услуг, необходимых компаниям для их ИИ-приложений, включая хранение данных, безопасность, сетевые услуги и мониторинг. Таким образом, число компаний, желающих занять долю рынка ИИ-ускорителей, на котором доминирует NVIDIA, продолжает увеличиваться. Напомним, что в апреле генеральный директор Alphabet Сундар Пичаи (Sundar Pichai) заявил, что Google начнёт поставлять TPU «избранной группе клиентов» для использования в их собственных ЦОД. Немалая часть из них достанется Anthropic. При этом важно отметить, что, как и в случае с AWS, Google является не только поставщиком, но и инвестором ИИ-стартапа.
17.06.2026 [11:53], Руслан Авдеев
Недовольные инвесторы подали иск против Microsoft, а GitHub не прочь обратиться к ресурсам AWS — всё из-за ИИMicrosoft столкнулась со связанными с ИИ проблемами на разных фронтах. Во-первых, недовольные инвесторы подали иск в суд, поскольку компания, предположительно, ввела их в заблуждение относительно показателей Copilot, во-вторых, принадлежащая ей платформа GitHub столкнулась с проблемами масштабируемости, вызванными повсеместным внедрением ИИ и, возможно, обратится за облачными ресурсами к AWS, сообщает The Register. Пенсионная система полиции и пожарной службы города Сент-Клер-Шорс (St. Clair Shores Police and Fire Retirement System) подала иск в федеральный окружной суд Сиэтла, в котором утверждает, что Microsoft, включая её главу Сатью Наделлу (Satya Nadella), сделали «в значительной степени ложные и/или вводящие в заблуждение» заявления относительно успехов внедрения технологии Copilot. В иске утверждается, что собственная флагманское ИИ-решение компании в бенчмарках по многим параметрам оказалась значительно хуже конкурентов, и у Microsoft не получилось перевести на платную версию ИИ-помощника значимую часть пользователей коммерческого варианта Microsoft 365. При этом Copilot уступил долю рынка продуктам конкурентов, и соответствующая тенденция только усиливалась. Некоторые организации всё же активно внедряют Copilot, но, как утверждается в иске, проблемы, связанные с разработкой и внедрением помощника Copilot и собственных ИИ-моделей недостаточно ясно раскрываются в документах, поданных в Комиссию по ценным бумагам и биржам США (SEC). 
Источник изображения: Sasun Bughdaryan/unsplash.com В конце января Microsoft отчиталась о результатах II квартала своего финансового года. Выяснилось, что рост Azure замедлился, а число платных пользователей Microsoft 365 составило лишь 15 млн из 450 млн пользователей всего. В иске утверждается, что после публикации этих данных акции компании упали в цене более чем на $48, приблизительно на 10 %. В самой Microsoft назвали претензии необоснованными и намерены защищать свою позицию в суде. Тем временем принадлежащей ей площадке GitHub, возможно, придётся обратиться за помощью к конкуренту — облачному гиганту AWS из-за проблем с надёжностью и масштабируемостью. Купленный в 2018 году сервис всё чаще испытывает проблемы с доступностью на фоне роста числа рабочих процессов, поддерживаемых ИИ. Уже была попытка GitHub перенести нагрузки в облако Azure, но проблемы с надёжностью сохраняются, тем более что у облака Microsoft в последнее время тоже есть проблемы с нехваткой вычислительных мощностей. По некоторым данным, GitHub могут усилить за счёт облачных ресурсов AWS, хотя непонятно, идёт ли речь о временной мере для устранения экстренных проблем или о чём-то постоянном. По словам представителя GitHub, важно понимать контекст, поскольку сообщество растёт темпами, которые никогда раньше не наблюдались. Невероятный рост разработки агентных ИИ-решений с конца прошлого года оказал значительное давление на инфраструктуру компании. Чтобы удовлетворить спрос, происходит перенос сервисов в Azure, также изучается и мультиоблачная стратегия, позволяющая обеспечить мощности, необходимые в будущем.
15.06.2026 [15:18], Руслан Авдеев
Дата-центры Amazon «выпили» почти 9,5 млн кубометров воды в 2025 годуКомпания Amazon объявила, что её дата-центрами использовано за прошлый год более 9,46 млн м3 (2,5 млрд галлонов) питьевой воды. При этом техногигант подчёркивает, что это значительно меньше, чем показатели конкурентов-гиперскейлеров. Она по-прежнему говорит о намерении стать водно-положительной к 2030 году, сообщает The Register. В своём блоге компания сообщила, что указанный расход воды касается всей её сети дата-центров в мире в 2025 году. Подчёркивается, что в США с населением около 350 млн человек приблизительно столько же ушло на полив садов и газонов. По информации Amazon, компания тратит на своих объектах 0,12 л/кВт∙ч (WUE), что значительно ниже, например, предложенных ЕС норм. При этом, по её данным, в случае с Microsoft речь в прошлом году шла о 0,27 л, а c Meta✴ — о 0,19 л, но в 2024 году. В том же году Google расходовала по 1,15 л. 
Источник изображения: Jonathan Bean/unsplash.com В Amazon уверены, что прошли уже 75 % пути к достижению «водно-положительного» баланса к 2030 году, соответствующая цель была анонсирована ещё в 2022-м. В таком случае объекты техногиганта будут возвращать больше питьевой воды в окружающую среду, чем получают, в том числе путём сбора дождевой воды и переработки сточных вод. Ранее в Сеть попала в распоряжение внутренняя документация Amazon, из которой следовало, что компания намеренно скрывает своё водопотребление и несколько манипулирует фактами, опасаясь критики за большой расход водных ресурсов. В то же время в США растёт активное сопротивление строительству дата-центров. Недавний опрос Ipsos показал, что большинство американцев не хотят ЦОД поблизости, беспокоясь из-за цен на электричество, уродливых зданий и больших расходов воды. При этом такое нежелание вынуждена была подтвердить и Microsoft. Более того, в 2022 году в ходе судебного разбирательства выяснилось, что ЦОД Google в Даллесе (Dalles, Орегон) потребляет четверть всей используемой в городке воды. 
Источник изображения: AWS Так или иначе, потребление воды ЦОД растёт. Дело как в росте числа самих объектов, так и в появлении более энергоёмких, требующих более интенсивного охлаждения в сравнении с традиционным вычислительным оборудованием. Так, в 2022 году потребление воды в кампусах Microsoft выросло на 34 % до 6,4 млн м3. В том числе причиной называется развитие ИИ-систем. Ситуация усугубляется тем, что многие новые ЦОД появятся в регионах и без того страдающих от засухи. По словам Amazon, дата-центры компании 90 % времени используют фрикулинг, хотя приходится прибегать к помощи систем испарительного охлаждения, когда погода особенно жаркая. Кроме того, говорит компания, улучшению WUE поспособствовали более эффективные системы воздушного и жидкостного охлаждения. Впрочем, как утверждают эксперты The Register, полностью отказаться от использования воды дата-центрами будет практически невозможно, что бы ни заявляли операторы ЦОД. |
|

