Консорциум UALink, в состав которой входят AMD, AWS, Astera Labs, Cisco, Google, HPE, Intel, Meta✴ и Microsoft, опубликовала первые спецификации на разрабатываемую в рамках альянса более доступную альтернативу проприетарным решениям NVIDIA. Интерконнект UALink призван заменить в первую очередь NVLink и во многом опирается на AMD Infinity Fabric, хотя пока что по скоростям составляет конкуренцию скорее Ethernet и InfiniBand.
Консорциум Ultra Accelerator Link был сформирован в конце прошлого года с целью создания высокоскоростного интерконнекта с низкими задержками, базирующегося на открытых технологиях. Речь здесь не только о приверженности открытым стандартам, но и о солидном потенциальном куске рынка — только за прошедший финансовый год сетевое подразделение NVIDIA выручило $13 млрд.

Источник здесь и далее: UALink
Появление более доступной и открытой альтернативы теоретически должно пошатнуть позиции последней в этом секторе, а также позволить разработчикам HPC-систем и ИИ-кластеров избежать жёсткой привязки к одному вендору. В том числе речь идёт о возможности организации сети UALink, включающей в себя GPU и ускорители разных поставщиков. Упор в первой версии стандарта сделан на общий доступ к памяти ускорителей с высокой скоростью, низкими задержками и простыми атомарными операциями
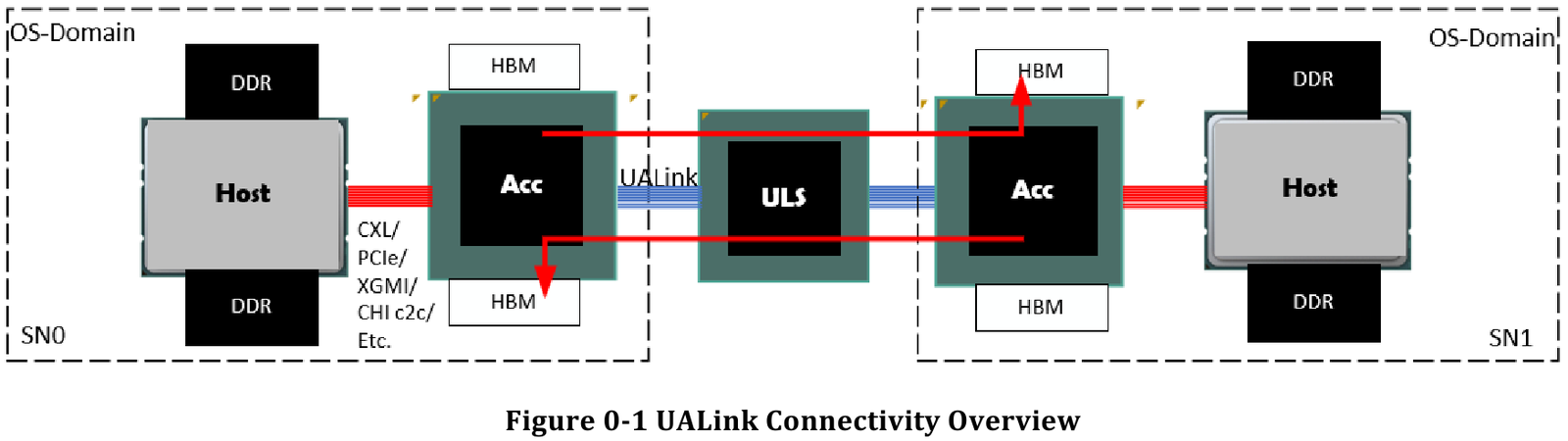
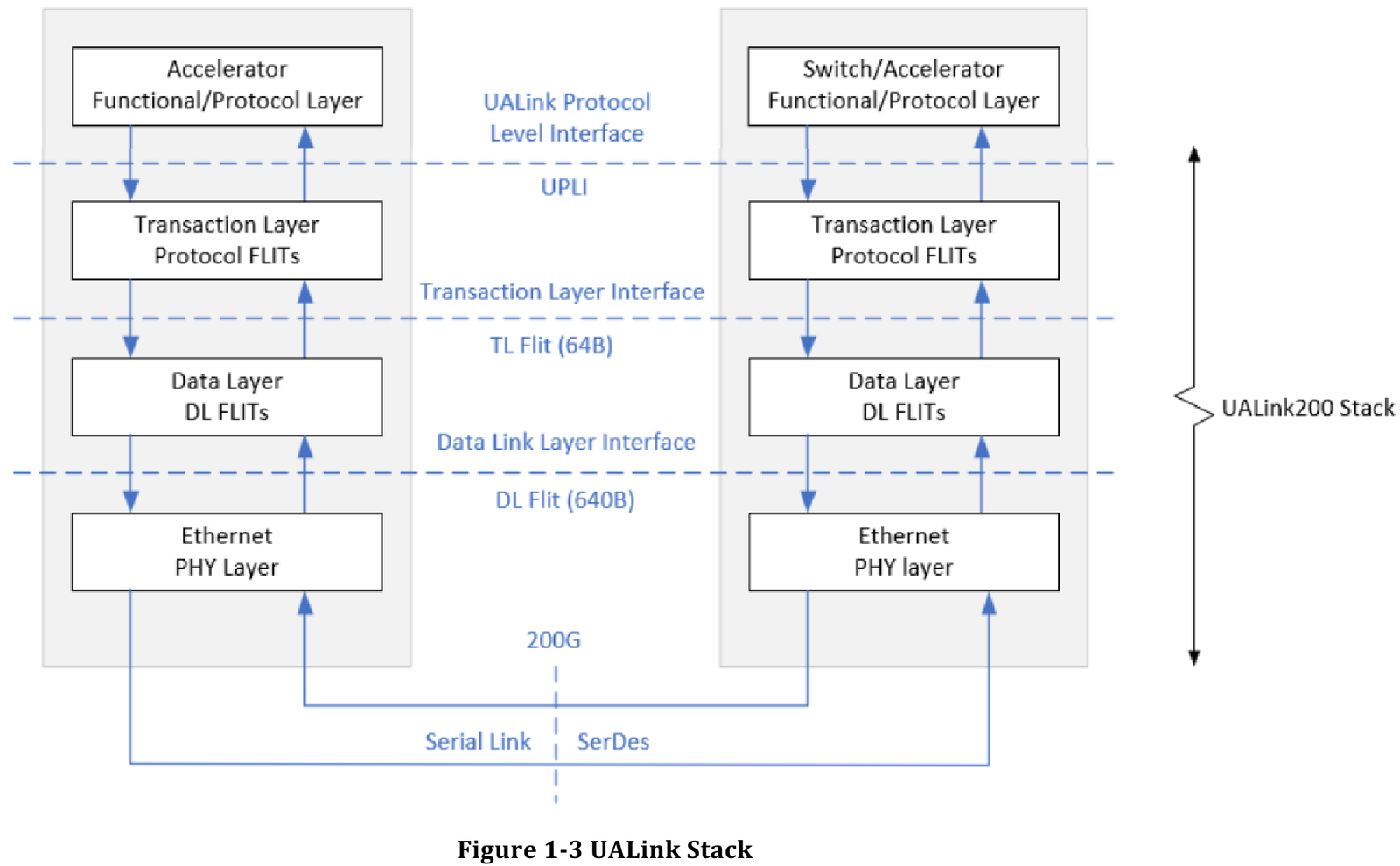
Впервые опубликованные спецификации описывают стандарт UALink 200G 1.0. В основе лежит коммутируемая сеть с пропускной способностью 200 Гбит/с на каждую линию, во многом наследующая AMD Infinity Fabric, но дополненная разработками других участников альянса. Максимальное количество линий на один ускоритель может достигать четырёх, что позволяет поднять пропускную способность до 800 Гбит/с. Поддерживается бифуркация.
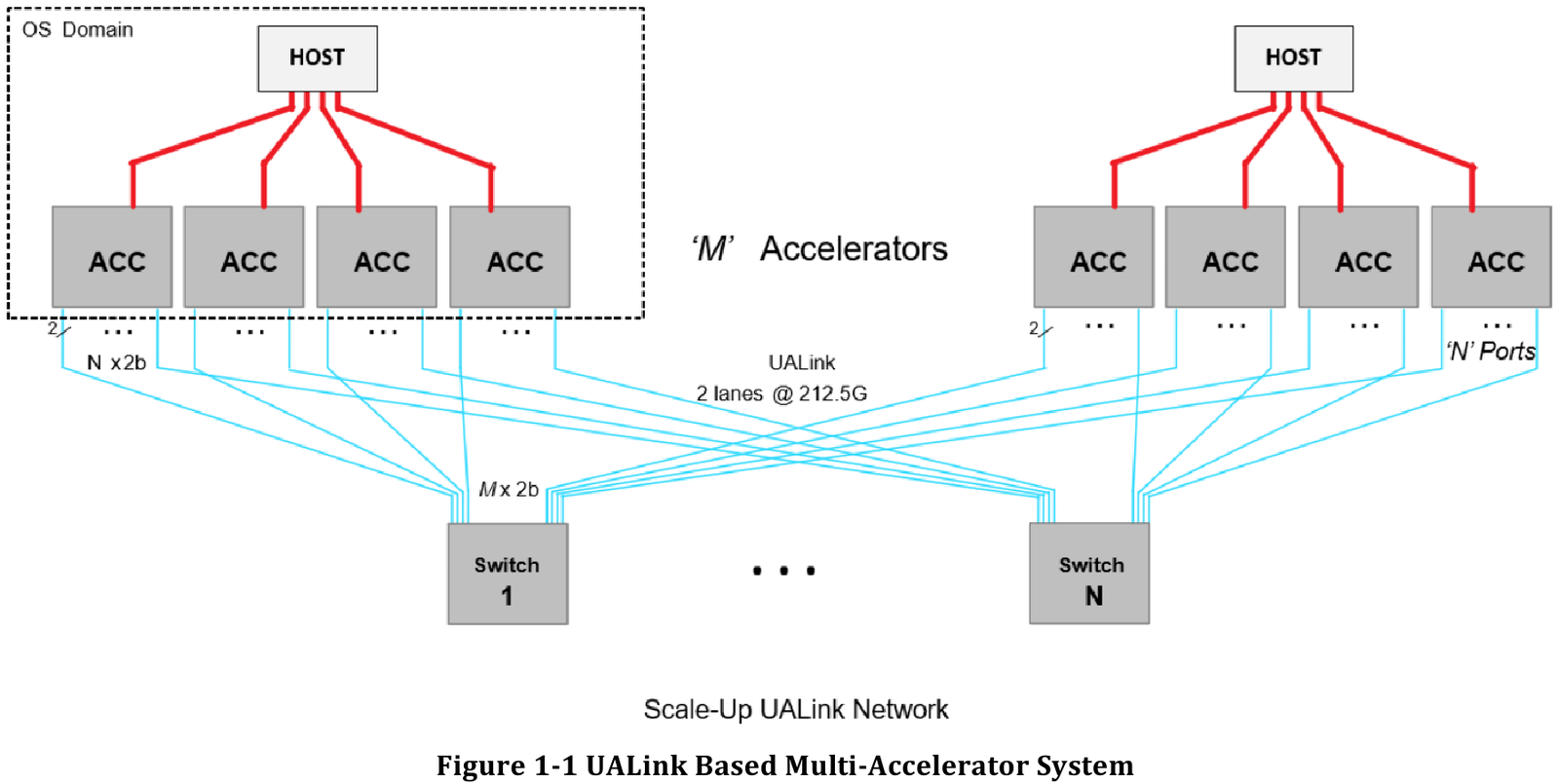
Размер кластера в данной версии стандарта UALink ограничен 1024 узлами, не считая коммутаторов. При этом гарантируются линейные скорости на уровне соответствующих версий Ethernet, но c энергопотреблением от трети до половины от аналогичного показателя последних, при времени отклика на уровне коммутируемых вариантов PCI Express. Задержка от порта к порту должна составить менее 100 нс, на уровне коммутаторов UASwitch — 100–150 нс. Для сравнения: NVLink 5/6 позволяет объединить до 576 ускорителей в одном домене со скоростью до 0,9–1,8 Тбайт/с на ускоритель.
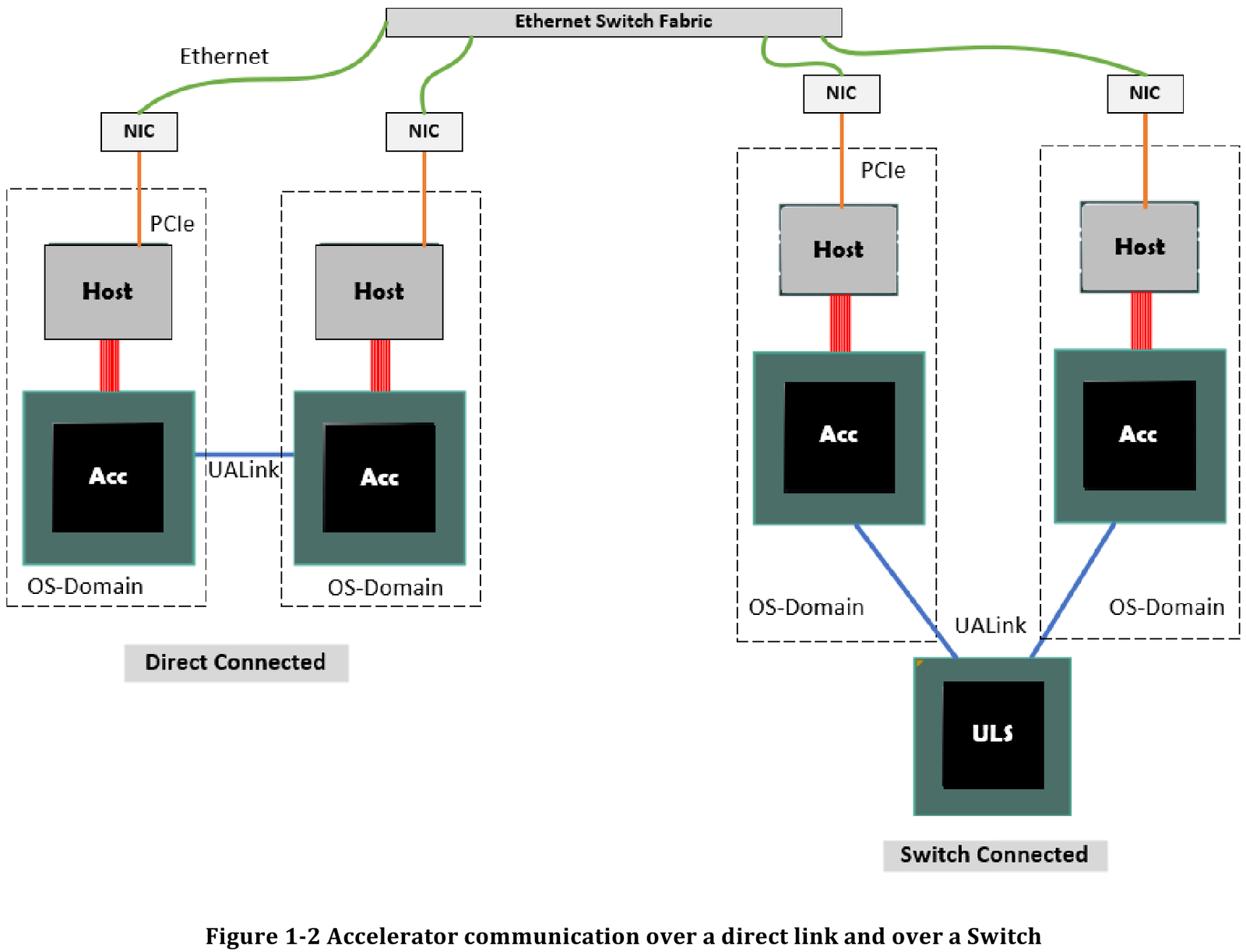
Также предусмотрена совместная работа с Ethernet в составе GPU-кластера, где хост-процессоры общаются между собой посредством традиционной сети (в том числе Ultra Ethernet), а ускорители могут использовать либо прямое, либо коммутируемое подключение UALink.
Передача данных осуществляется словами длиной 680 байт: 640-байт флит-пакеты + 40 байт накладных расходов на упреждающую коррекцию ошибок (FEC) и кодирование 256B/257B. Реализованы механизмы доступа к удалённой памяти, но когерентность на аппаратном уровне не поддерживается, также имеются различия на подуровне PCS (Physical coding sublayer). На физическом уровне используется стандарт IEEE 802.3dj: 200GBASE-KR1/CR1, 400GBASE-KR2/CR2 и 800GBASE-KR4/CR4. Имеющиеся ретаймеры для Ethernet также совместимы с UALink.
Спецификации UALink 200G 1.0 доступны на сайте проекта. Глава консорциума UALink, Кёртис Боумен (Kurtis Bowman) настроен оптимистично и говорит примерно о 18 месяцах до появления первых аппаратных решений, что на полгода быстрее типичных сценариев воплощения спецификаций «в железо». Тем временем, альянс уже начал работу над второй версией UALink, использующей стек технологий 400G.
Источники:

