Материалы по тегу: ualink
|
14.04.2026 [12:44], Владимир Мироненко
Panmnesia привлёк $10 млн на разработку интерконнекта следующего поколения для ИИ ЦОДЮжнокорейский стартап Panmnesia, специализирующийся на разработке интерконнекта для ИИ-инфраструктур, сообщил о получении финансирования в размере около $10 млн на разработку интерконнекта следующего поколения для ИИ ЦОД. Проект включает разработку контроллеров и коммутаторов на основе открытых стандартов, таких как UALink и протоколов интерконнекта на основе Ethernet. Уже имея обширный портфель продуктов CXL, Panmnesia теперь расширяет свою деятельность в области интерконнекта, ориентированного на ускорители. Компания отметила, что по мере распространения крупномасштабных ИИ-моделей в различных отраслях, ИИ ЦОД всё чаще полагаются на ИИ-ускорители разных вендоров. В этом контексте технологии интерконнекта, обеспечивающие высокоскоростную передачу данных между ускорителями, стали критически важным фактором, определяющим общую производительность ИИ-системы. 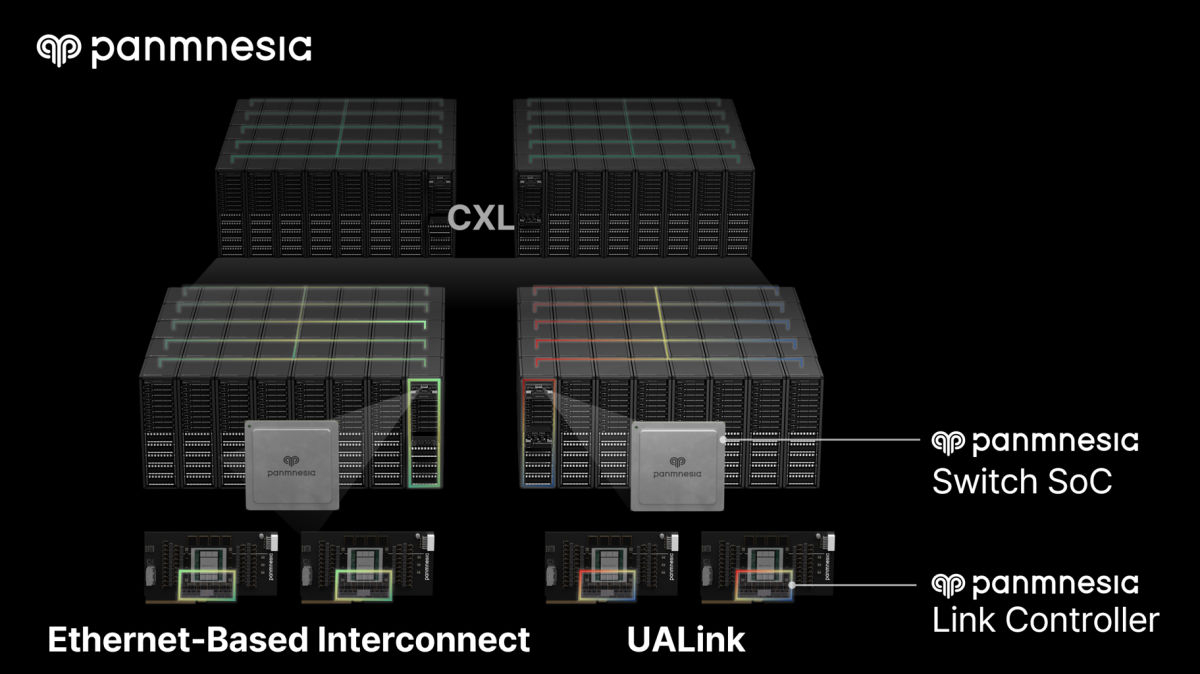
Источник изображений: Panmnesia Также Panmnesia планирует оптимизировать топологию разработанных устройств для ускорения обмена данными между ними и провести валидацию на уровне стойки. Ожидается, что чип-коммутатор с поддержкой интерконнекта, ориентированного на ускорители, такого как UALink, станет доступен во II половине 2027 года.  Портфолио продуктов CXL компании включает комплексные решения, в том числе контроллеры и IP-блоки PCIe/CXL, аппаратные SoC, такие, как коммутаторы PCIe/CXL, и специализированные кремниевые решения. В прошлом году Panmnesia представила архитектуру CXL-over-XLink, которая интегрирует специализированные каналы связи для ускорителей (известные как XLink), включая UALink, с CXL для обеспечения расширенной связи в крупных ИИ ЦОД.
08.04.2026 [17:29], Владимир Мироненко
Интерконнект UALink дорос до версии 2.0, хотя до сих пор не воплотился в «железе» — до NVLink ещё далекоКонсорциум UALink, созданный в 2024 году для разработки открытого интерконнекта для масштабируемого ИИ следующего поколения, который может стать альтернативой NVLink и NVSwitch от NVIDIA, объявил о ратификации следующей версии спецификации UALink 2.0, которая включает три основных дополнения — внутрисетевые вычисления (In-Network Compute), определение чиплетов (Chiplet Definition) и управляемость (Manageability). Как указано в пресс-релизе, «новые спецификации поддерживают развёртывание решений UALink в средах с несколькими рабочими нагрузками, одновременно способствуя повышению эффективности технологии UALink, производительности для рабочих нагрузок ИИ и упрощению внедрения». Базовая скорость обмена данными (200G на линию) не изменилась. Более того, до сих пор нет и оборудования стандарта UALink 1.0, представленного год назад. «Усовершенствования технологии UALink, представленные в этом релизе, позволят отрасли быстро и эффективно интегрировать решения UALink в свои архитектуры. Консорциум UALink по-прежнему привержен развитию инфраструктуры ИИ посредством открытых отраслевых стандартов, которые облегчают вывод на рынок приложений ИИ следующего поколения», — заявил Куртис Боуман (Kurtis Bowman), председатель совета директоров консорциума UALink. 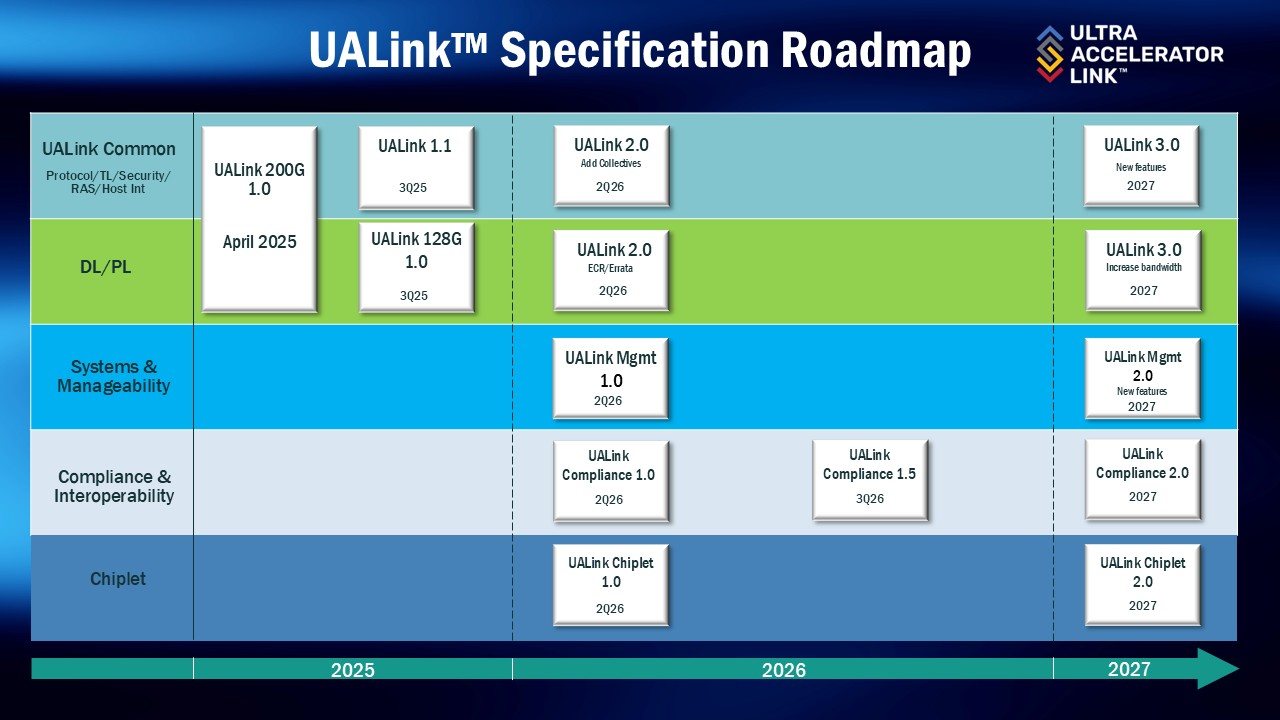
Источник изображения: UALink Консорциумом были представлены:
Боуман сообщил The Register, что чипы для спецификации 1.0 поступят в лаборатории во II половине 2026 года и появятся в продаже в 2027 году. К тому времени UALink выпустит спецификации версии 3.0 — задолго до дебюта чипов версии 2.0. Боуман признал, что версии 1.0 и 2.0 не будут полноценными конкурентами интерконнекту NVIDIA, но к версии 3.0, которая появится примерно через год, UALink достигнет паритета по производительности и темпам выпуска стандартов. Консорциум UALink стремится создать альтернативу интерконнекту NVIDIA, которая будет работать с любым ускорителем и соответствовать его уровню производительности. Консорциум считает, что развивающиеся неооблачные платформы, специализирующиеся на размещении ИИ-систем, оценят возможность создания единого интерконнекта с поддержкой любых используемых ими GPU, отметил The Register. Между тем NVIDIA не стоит на месте. В прошлом году она представила технологию NVIDIA NVLink Fusion, которая расширяет доступ к NVLink сторонним чипам. Компания уже заключила соглашения с Arm, AWS, Fujitsu, Intel, Marvell, MediaTek и SiFive. AMD же делает ставку на UALink.
22.01.2026 [16:04], Владимир Мироненко
Upscale AI привлёк $200 млн для запуска ИИ-интерконнекта и коммутатора SkyHammerСтартап Upscale AI, специализирующий на разработке ИИ-интерконнекта, объявил о привлечении $200 млн в рамках раунда финансирования серии А. С учётом предыдущего раунда общая сумма инвестиций в Upscale AI достигла $300 млн, а оценка его рыночной стоимости превысила $1 млрд, что придало ему статус «единорога». Это большая сумма для любой технологической компании со 150 сотрудниками, большинство из которых инженеры. Раунд серии А возглавили Tiger Global, Premji Invest и Xora Innovation, также в нём приняли участие Maverick Silicon, StepStone Group, Mayfield, Prosperity7 Ventures, Intel Capital и Qualcomm Ventures. Upscale AI отметил, что поддержка инвесторов отражает растущее в отрасли мнение, что сети являются критически узким местом для масштабирования ИИ, а традиционные сетевые архитектуры, предназначенные для соединения вычислительных ресурсов общего назначения и хранилищ, принципиально не подходят для эпохи ИИ. Устаревшие сетевые решения для ЦОД были разработаны до появления ИИ, и слабо подходят для масштабного, синхронизированного масштабирования на уровне стоек. Когда Upscale AI был основан в начале 2024 года, консорциум UALink и стандарт ESUN, предложенный Meta✴ Platforms, ещё не были обнародованы, но идея гетерогенной инфраструктуры, безусловно, уже была, отметил ресурс The Next Platform. Созданная Upscale AI платформа объединяет GPU, ИИ-ускорители, память, хранилище и сетевые возможности в единый синхронизированный ИИ-движок. Для этого стартап разработал ASIC SkyHammer, который поддерживает ESUN, UALink, Ultra Ethernet, SONiC и Switch Abstraction Interface (SAI). Фактически Upscale AI хочет составить конкуренцию NVIDIA NVSwitch, дав возможность выбора интерконнекта при создании ИИ-инфраструктур. 
Источник изображения: Upscale AI Upscale AI сообщил, что благодаря дополнительному финансированию представит первую полнофункциональную, готовую к использованию платформу, охватывающую кремниевые компоненты, системы и ПО. Также полученные средства будут направлены на расширение инженерных, торговых и операционных команд по мере перехода к коммерческому внедрению решения. По словам Арвинда Шрикумара (Arvind Srikumar), старшего вице-президента по продуктам и маркетингу компании, поставки образцов SkyHammer клиентам начнутся в конце 2026 года, а массовые поставки — в 2027 году, когда в это же время выйдут новые поколения GPU, XPU, коммутаторов и стоек. Коммутаторы должны быть у OEM/ODM-производителей за два квартала до того, как вычислительные ядра будут готовы к поставкам, чтобы они могли собрать системы и протестировать их. «Я всегда считал, что гетерогенные вычисления — это правильный путь, и гетерогенные сети — это тоже правильный путь», — сообщил Шрикумар изданию The Next Platform. Он отметил, что Upscale AI фокусируется на демократизации интерконнекта для ИИ. Шрикумар признал, что у NVIDIA отличные технологии, и что это «потрясающая» компания, когда дело касается инноваций. Вместе с тем он считает, что в будущем, с учётом темпов развития ИИ, вряд ли одна компания сможет предоставить все необходимые технологии для ИИ. Шрикумар считает, что PCIe-коммутация хорошо работает, когда несколько СPU взаимодействуют с несколькими GPU, относительная пропускная способность памяти GPU довольно низкая, а СPU и GPU расположены довольно близко друг к другу в серверном узле. В то же время Upscale AI скептически относится к попыткам создания коммутаторов UALink, ESUN или SUE путем использования ASIC-чипов для PCIe или путём извлечения начинки ASIC-чипов Ethernet-коммутаторов. «Те, кто давно занят в сфере ASIC, знают, что можно удалить много блоков, но основные элементы остаются прежними. Базовая ДНК каждого ASIC остается неизменной», — отметил Шрикумар. Поэтому в Upscale AI решили создать ASIC с нуля, а затем обеспечить поддержку протоколов семантики памяти по мере их появления.
07.01.2026 [16:47], Владимир Мироненко
В попытке догнать Broadcom: Marvell купила за $540 млн XConn, разработчика коммутаторов PCIe и CXLПосле объявления о заключении окончательного соглашения о приобретении XConn Technologies, поставщика передовых коммутаторов PCIe и CXL, акции Marvell Technology пошли в гору — их цена выросла на 4 %, сообщил ресурс SiliconANGLE. Сумма сделки составляет около $540 млн. Примерно 60 % будет выплачено наличными и 40 % — акциями Marvell, при этом стоимость последних будет определяться на основе средневзвешенной цены за 20 дней. По словам Marvell, приобретение позволит ей расширить портфель коммутационных решений продуктами XConn PCIe и CXL, а также укрепить команду по разработке решений UALink высококвалифицированными инженерами XConn с глубокими знаниями в области высокопроизводительной коммутации. Коммутация необходима для соединения большого количества ИИ-микросхем в гигантские кластеры для запуска мощных больших языковых моделей. Компания XConn, основанная в 2020 году и финансируемая частными инвесторами, выпустила в марте 2024 года первый в отрасли коммутатор Apollo с поддержкой CXL 2.0 и PCIe 5.0, обеспечивающий 256 линий. Его выпускает TSMC с использованием техпроцессов N16 и N5, сообщил ресурс Data Center Dynamics. Затем она выпустила в марте 2025 года гибридный коммутатор Apollo 2, объединяющий CXL 3.1 и PCIe 6.2 на одном чипе в конфигурациях от 64 до 260 линий. 
Источник изображения: Marvell Когда-то Marvell считалась одной из самых перспективных компаний после NVIDIA, и многие эксперты полагали, что она станет одним из главных бенефициаров бума ИИ. Однако она по-прежнему уступает по темпам развития NVIDIA, а заодно и своему основному конкуренту Broadcom, который разрабатывает чипы как минимум для четырёх гиперскейлеров. Покупка XConn призвана исправить ситуацию, дополняя недавнее приобретение Celestial AI. По словам Marvell, приобретение XConn добавит проверенные коммутационные продукты PCIe и CXL, IP-решения и инженерные кадры для расширения команды по масштабируемым коммутаторам UALink. «В сочетании с предстоящим приобретением Celestial AI мы будем иметь все возможности для предоставления клиентам производительности, гибкости и архитектурного выбора, необходимых им по мере роста размеров и сложности ИИ-систем», — отметил он. 
Источник изображения: XConn Сделка позволит Marvell расширить свой общий целевой рынок (Total Addressable Market, TAM) за счёт освоения растущих возможностей коммутаторов PCIe и CXL. PCIe-коммутаторы становятся критически важным строительным блоком для ИИ-инфраструктуры. В то же время CXL необходим для дезагрегации памяти в современных ЦОД. Сочетание контроллеров памяти Marvell CXL с коммутаторами XConn CXL позволит создать самый обширный в отрасли портфель коммутаторов для поддержки ресурсоёмких ИИ-задач. На данный момент у XConn насчитывается более чем 20 клиентов. Marvell ожидает, что продукты XConn CXL и PCIe начнут приносить доход во II половине 2027 финансового года. Также ожидается, что в результате сделки Marvell получит около $100 млн дополнительного дохода в 2028 финансовом году.
08.12.2025 [14:20], Владимир Мироненко
$2 млрд инвестиций NVIDIA в Synopsys несут риски для UALinkОбъявление NVIDIA о расширении сотрудничества с Synopsys, разработчиком ПО для проектирования чипов и членом совета директоров UALink, и инвестициях в размере $2 млрд в совместные инициативы, последовавшее после недавнего решения производителя ИИ-ускорителей инвестировать $5 млрд в Intel, вызвали опасения по поводу его возможного влияния на разработку UALink — альтернативы собственному интерконнекту NVLink. Как отметил Network World, Synopsys входит в совет директоров консорциума Ultra Accelerator Link (UALink) — отраслевой коалиции из более чем 80 компаний, включая AMD, Intel, Google, Microsoft и Meta✴, которая работает над созданием открытой альтернативы технологии NVIDIA NVLink для объединения ИИ-ускорителей в один домен. NVIDIA инвестировала $2 млрд в обыкновенные акции Synopsys ($414,79/ед.), получив долю в разработчике ПО и планируя в рамках партнёрства объединить преимущества своих технологий с ведущими на рынке инженерными решениями Synopsys. В сентябре NVIDIA инвестировала $5 млрд в Intel, объявив о сотрудничестве с целью разработки чипов для ЦОД и ПК с использованием NVLink Fusion. За несколько месяцев до этого Intel взяла на себя обязательство совместно разрабатывать конкурирующий стандарт UAlink. Arm тоже присоединилась к консорциуму UAlink, участвуя при этом и в экосистеме NVLink Fusion. 
Источник изображения: NVIDIA Moor Insights & Strategy считает, что с помощью инвестиций NVIDIA укрепляет свою экосистему на фоне вызовов AMD, будь то CPU, GPU или сетевые решения. Вместе с тем аналитики признают, что это «действительно усиливает давление на UALink» — финансовая «доля» NVIDIA в консорциуме UALink может повлиять на разработку открытого стандарта, специально созданного для конкуренции с технологиями самой NVIDIA и предоставления предприятиям более широкого выбора компонентов. Компании считают такие открытые стандарты критически важными для предотвращения привязки к одному поставщику и поддержания конкурентоспособных цен. В апреле консорциум ратифицировал спецификацию UALink 200G 1.0, определяющую открытый стандарт для объединения в один кластер до 1024 ИИ-ускорителей со скоростью 200 Гбит/с на линию. Это прямой конкурент NVLink, хотя и не такой производительный. При этом Synopsys играет ключевую роль в работе консорциума. Она не только вошла в совет директоров UALink, но и анонсировала первые в отрасли компоненты для проектирования UALink, позволяющие создавать ускорители, совместимые с UALink. 
Источник изображения: Synopsys Gartner признаёт наличие напряжённости: «Сделка между NVIDIA и Synopsys действительно вызывает вопросы о будущем UALink, поскольку Synopsys является ключевым партнёром консорциума и владеет критически важными IP на UALink, который конкурирует с проприетарным NVLink». По оценкам Greyhound Research, Synopsys играет ведущую роль в UALink, поэтому вхождение NVIDIA в структуру акционеров Synopsys может повлиять на заинтересованность последней в работе консорциума. UALink действует благодаря коммерческому согласованию, общим приоритетам НИОКР и близости планов развития участников. Даже потенциальная возможность влияния NVIDIA может подорвать доверие среди членов UALink. «Партнёры по консорциуму должны быть готовы к тому, что будущие версии UALink могут быть сформированы таким образом, что это либо замедлит их развитие, либо будет смещено в сторону компромиссов в дизайне для минимизации конкурентного давления на NVLink», — предупреждает Greyhound Research, призывая консорциум «срочно усилить управление, повысить прозрачность в отношении вклада Synopsys и рассмотреть механизмы защиты, если хочет сохранить доверие». 
Источник изображения: Synopsys Объявляя о партнёрстве, NVIDIA и Synopsys подчеркнули, что сотрудничество будет сосредоточено на инженерных инструментах на базе ИИ, а не на интерконнектах. В частности, библиотеки NVIDIA CUDA-X будут интегрированы в приложения Synopsys для проектирования микросхем, молекулярного моделирования и электромагнитного анализа. В пресс-релизе по поводу сотрудничества не было никакого упоминания NVLink или интерконнектов. «Поэтому это больше похоже на партнёрство в сфере ПО, чем в сфере интеллектуальной собственности», — пишет Moor Insights & Strategy. Генеральный директор Synopsys Сассин Гази (Sassine Ghazi), подчеркнул, что партнёрство никак не связано с циклическим финансированием. «Мы не намерены и не берём на себя обязательство использовать эти $2 млрд на покупку GPU NVIDIA», — сказал он, добавив, что к партнёрству могут присоединиться другие производители микросхем. Это означает, что компании могут продолжать сотрудничество в рамках более широкой экосистемы, то есть Synopsys продолжит работать с другими поставщиками, конкурирующими с NVIDIA, будь то AMD, Broadcom или один из гиперскейлеров. В ответ на просьбу Network World прокомментировать возможное влияние партнёрства на её приоритеты, Synopsys заявила, что это не меняет её стратегию. В свою очередь, NVIDIA не ответила вопрос ресурса о том, как эти инвестиции могут повлиять на деятельность Synopsys в рамках UALink или на независимость консорциума. Впрочем, аналитики сходятся во мнении, что для консорциума это партнёрство вряд ли можно считать чем-то позитивным. UALink важен для будущих ИИ-платформ AMD. HPE, которая одной из первых поддержала решение AMD Helios AI, будет использовать реализацию UALink over Ethernet (UALoE).
03.12.2025 [20:51], Владимир Мироненко
HPE одной из первых начнёт выпускать интегрированные стоечные ИИ-платформы AMD Helios AI
amd
broadcom
epyc
hardware
hpc
hpe
instinct
juniper networks
mi400
ocp
ualink
venice
германия
ии
суперкомпьютер
AMD объявила о расширении сотрудничества с HPE, в рамках которого HPE станет одним из первых поставщиков стоечных систем AMD Helios AI, которые получат коммутаторы Juniper Networking (компания с недавних пор принадлежит HPE), разработанные совместно с Broadcom, и ПО для бесперебойного высокоскоростного подключения по Ethernet. AMD Helios AI — открытая полнофункциональная ИИ-платформа на базе архитектуры OCP Open Rack Wide (ORW), разработанная для крупномасштабных рабочих нагрузок и обеспечивающая FP4-производительность до 2,9 Эфлопс на стойку благодаря ускорителям AMD Instinct MI455X, процессорам EPYC Venice шестого поколения и DPU Pensando Vulcano, работающими под управлением открытой программной экосистемы ROCm для нагрузок ИИ и HPC. Как отметил The Register, сетевая архитектура этой системы будет представлять собой масштабируемую реализацию UALink over Ethernet (UALoE) и специализированным коммутатором Juniper Networks на базе сетевого чипа Broadcom Tomahawk 6 (102,4 Тбит/с). Система разработана для упрощения развёртывания крупномасштабных ИИ-кластеров, что позволяет сократить время разработки решений и повысить гибкость инфраструктуры. В отличие от NVIDIA, AMD не выпускает коммутаторы, предлагая открытую экосистему, так что HPE и другие компании могут интегрировать собственные сетевые решения. The Register полагает, что HPE и Broadcom решили не гнаться за отдельной аппаратной реализацией UALink, если данные можно передавать поверх Ethernet. «Это первое в отрасли масштабируемое решение, использующее Ethernet, стандартный Ethernet. Это означает, что оно полностью соответствует открытому стандарту и позволяет избежать привязки к проприетарному поставщику, использует проверенную сетевую технологию HPE Juniper для обеспечения масштабируемости и оптимальной производительности для рабочих нагрузок ИИ», — заявила HPE. 
Источник изображения: HPE HPE заявила, что это позволит её стоечной системе поддерживать трафик, необходимый для обучения модели с триллионами параметров, а также обеспечить высокую пропускную способность инференса. Стоечная система HPE будет включать 72 ускорителя AMD Instinct MI455X с 31 Тбайт HBM4 с агрегиированной пропускной способностью 1,4 Пбайт/с. Агрегированная скорость интерконнекта составит 260 Тбайт/с. Новинка будет доступна в 2026 году. AMD также сообщила, что Herder, новый суперкомпьютер для Центра высокопроизводительных вычислений в Штутгарте (HLRS) (Германия), получит Instinct MI430X и EPYC Venice. Он будет построена на платформе HPE Cray Supercomputing GX5000. Поставка Herder запланирована на II половину 2027 года, а ввод в эксплуатацию — к концу 2027 года. Herder заменит используемый центром суперкомпьютер Hunter.
12.11.2025 [23:23], Владимир Мироненко
От ИИ ЦОД до роботов: AMD анонсировала долгосрочную стратегию роста
amd
cpu
dpu
epyc
hardware
instinct
mi400
mi500
ocp
pensando systems
ualink
ultra ethernet
venice
verano
xilinx
ии
ускоритель
финансы
AMD представила на мероприятии Financial Analyst Day 2025 план по достижению лидерства на рынке вычислительных технологий объёмом $1 трлн. Долгосрочная стратегия роста AMD построена на четырех столпах: лидерство в сфере ЦОД, повышение производительности ИИ, открытое ПО и расширение присутствия на рынках встраиваемых и полукастомных кремниевых решений. AMD ожидает, что только её бизнес в сфере ЦОД будет приносить более $100 млрд годовой выручки, с увеличением совокупного среднегодового темпа роста (CAGR) до более чем 60 %, при этом CAGR дохода от ИИ-решений увеличится до более чем 80 %. Генеральный директор AMD Лиза Су (Lisa Su) заявила, что следующий этап будет основан на унифицированной вычислительной платформе AMD, объединяющей процессоры EPYC, ускорители Instinct, сетевые решения Pensando и ПО ROCm. Новый план развития AMD призван обеспечить ей конкуренцию с NVIDIA и Intel на корпоративных рынках и в борьбе за заказы гиперскейлеров. 
Источник изображений: AMD  Ускорители серии Instinct MI350, уже развёрнутые Oracle (ещё 50 тыс. MI450 будут развёрнуты во II половине 2026 г.), являются самыми популярными ускорителями AMD на сегодняшний день. Следующей платформой станет серия MI450, которая будет запущена вместе со стоечной платформой Helios в III квартале 2026 года. Helios обеспечит пропускную способность интерконнекта 3,6 Тбайт/с на каждый ускоритель и до 72 ускорителей на стойку с совокупной пропускной способностью 260 Тбайт/с, соединённых между собой посредством UALink и Ultra Ethernet (UEC). Система поддерживает разделяемую память между ускорителями, что обеспечивает обучение крупномасштабных моделей с бесперебойным доступом к памяти и отказоустойчивой сетью с шестью плоскостями.  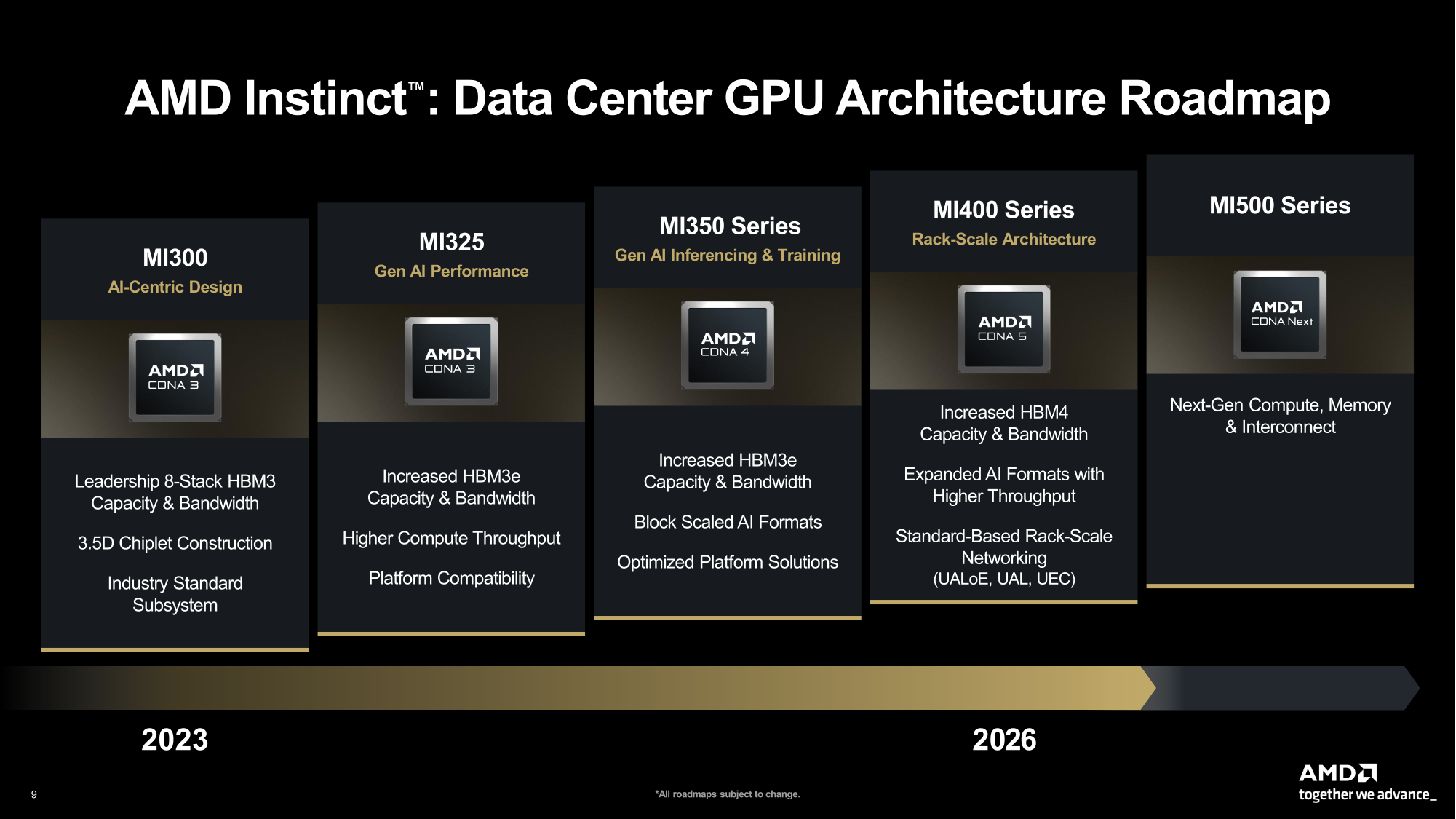 AMD характеризует Helios как свою первую ИИ-платформу стоечного масштаба — полностью интегрированную систему с открытой архитектурой, которая объединяет вычислительные мощности, ускорение, сетевые технологии и ПО в единую структуру. В отличие от традиционных серверных кластеров, Helios реализует всю стойку как единый высокопроизводительный вычислительный домен. Каждая стойка объединяет процессоры AMD EPYC Venice, CDNA5-ускорители Instinct MI450X (будет и вариант MI430X с полноценными FP64-блоками) и 400G/800G-карты Pensando Vulcano, связанные Infinity Fabric пятого поколения (PCIe 6.0, CXL 3.1, UCIe) и UALink.  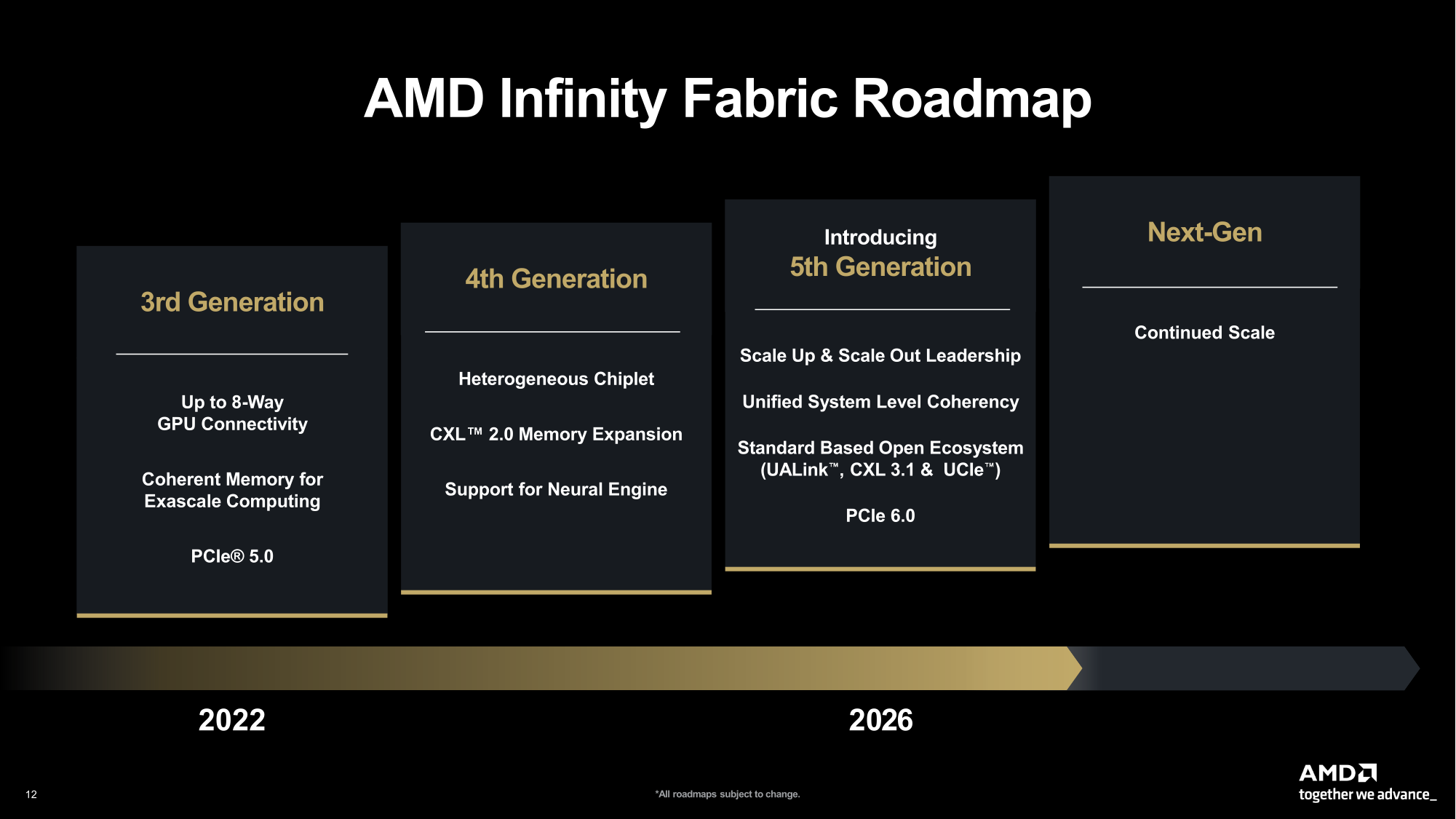 Эта архитектура минимизирует накладные расходы на перемещение данных, увеличивает пропускную способность между ускорителями и обеспечивает эффективность класса экзафлопсных вычислений в компактном корпусе. Helios фактически представляет собой проект AMD для ИИ-фабрики будущего с возможностью модульного расширения, позволяя объединять сотни стоек в одну систему в ЦОД.  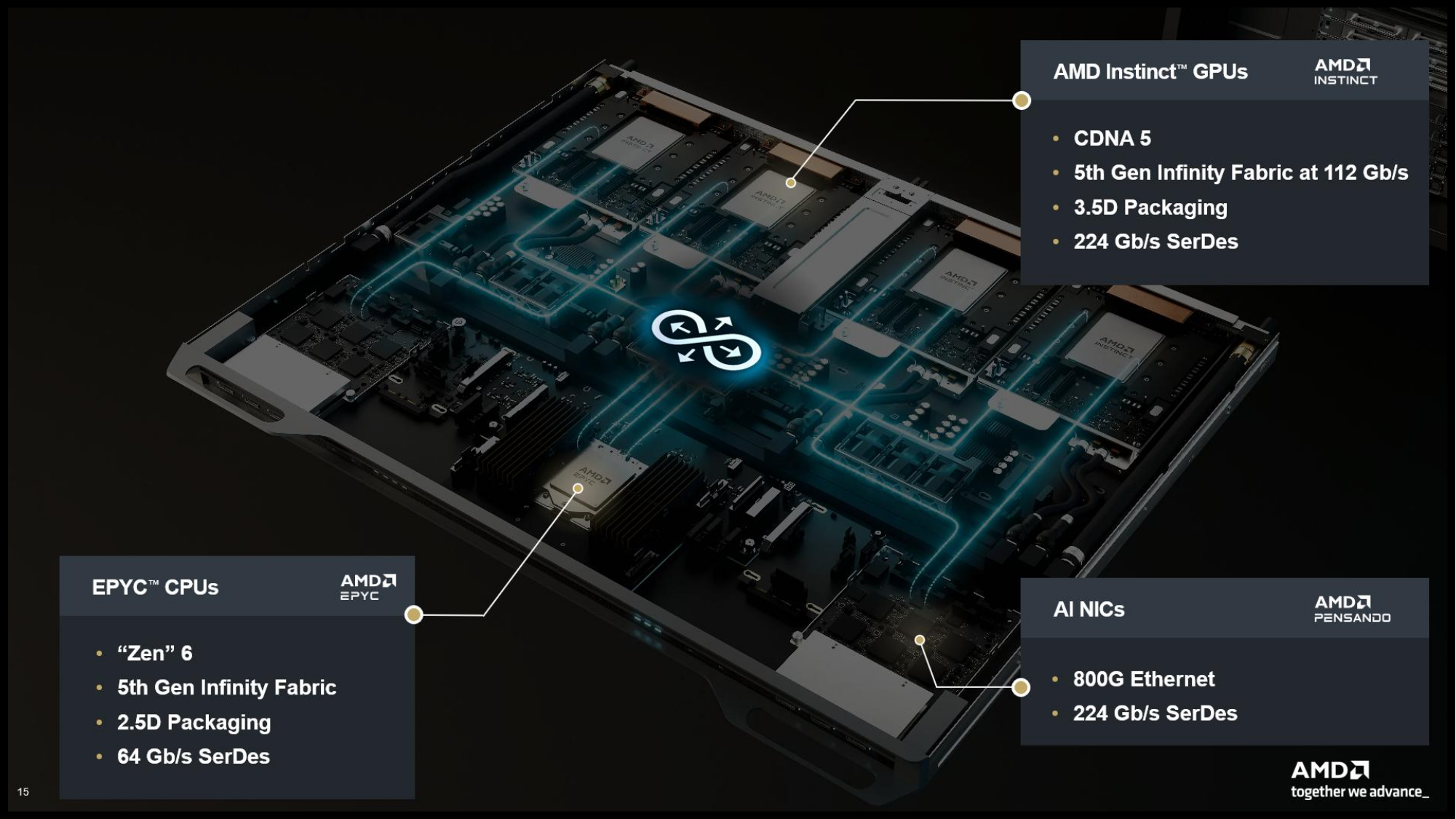 В 2027 году AMD планирует выпустить ускорители серии MI500 и процессоры EPYC Verano, продолжая тем самым ежегодный цикл совместной разработки процессоров, ускорителей и сетей. AMD заявила, что EPYC Venice, намеченные к выпуску в 2026 году, будут обладать лучшими в отрасли показателями плотности (1,3x по количеству потоков в сравнении с текущими решениями) и энергоэффективности (1,7x). Они пополнятся оптимизированными для ИИ наборами инструкций для обработки инференса и выполнения вычислений общего назначения. Указанные компоненты станут основой ИИ-фабрики, способной масштабироваться от одной стойки до глобально распределённых кластеров.  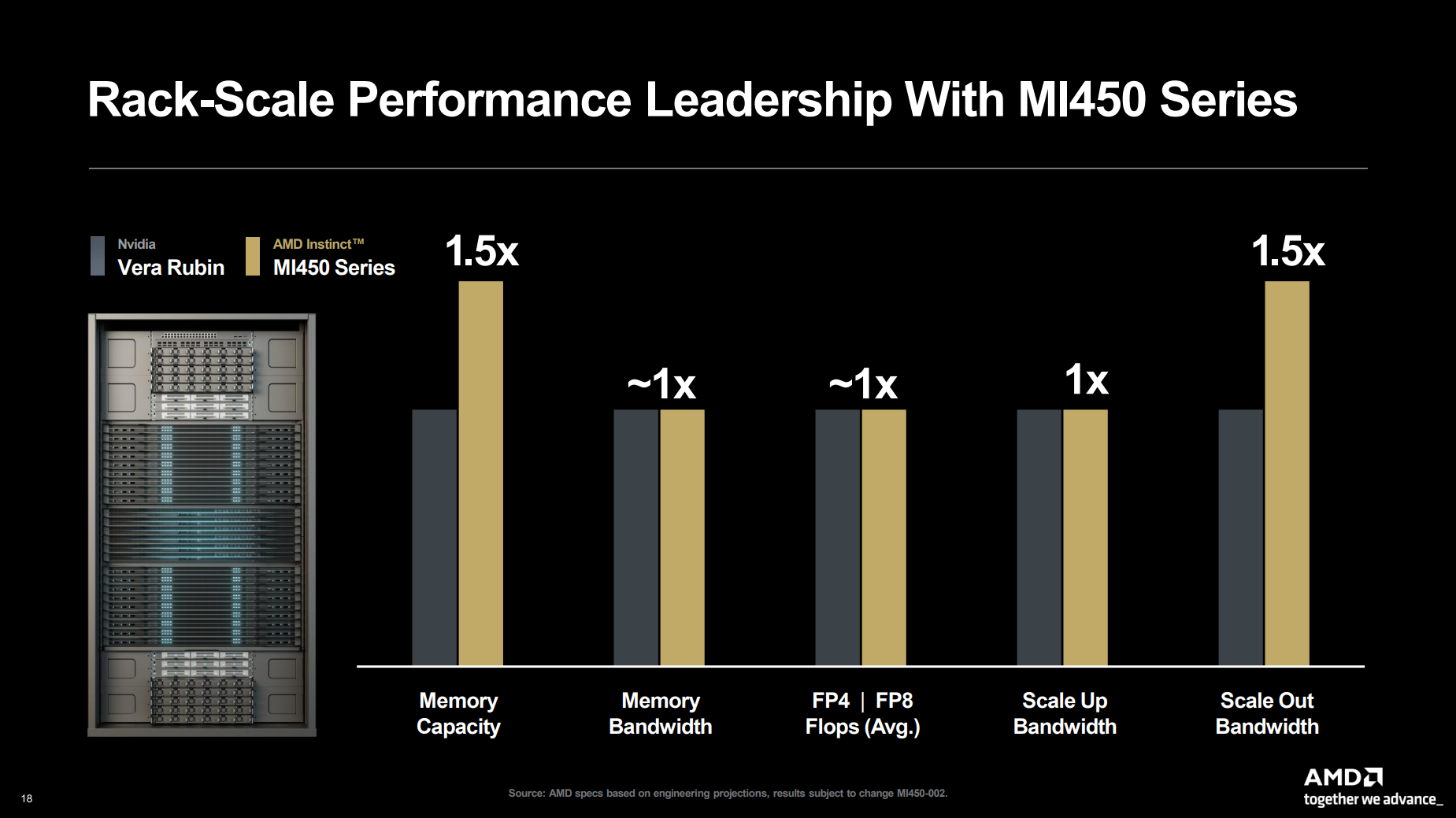 Исполнительный вице-президент AMD Форрест Норрод (Forrest Norrod) подчеркнул в своём выступлении, что производительность ИИ всё больше зависит от сети. Сетевые карты AMD Pensando Pollara и Vulcano для ИИ образуют связующую ткань архитектуры Helios. Сетевая карта Pollara 400 обеспечивает пропускную способность 400 Гбит/с, а готовящаяся к выходу сетевая карта Vulcano удвоит её до 800 Гбит/с, обеспечивая связь Ultra Ethernet между крупными кластерами ускорителей.   AMD представила четырёхуровневую архитектуру сети для масштабных ИИ-инфраструктур. Front-End часть обслуживает пользователей, хранилище и приложения. Она опирается на DPU Pensando и P4-движки, отвечающие за разгрузку сетевых функций, функции безопасности и шифрования, и работу с СХД. Вертикальное масштабирование в пределах стойки обеспечивает 3,6-Тбайт/с подключение на каждый GPU. Горизонтальное масштабирование реализуется благодаря UEC — внутренние тесты показали снижение затрат на коммутацию до 58 % по сравнению с традиционными сетями типа Fat-Tree. Наконец, Scale-Across (пространственное масштабирование) позволит объединить географически распределённые ЦОД в кластеры с интеллектуальным управлением трафиком и адаптивной балансировкой нагрузки.   AMD отметила, что открытый программный стек ROCm (Radeon open compute) по-прежнему лежит в основе её стратегии в области ИИ-платформ. По сравнению с прошлым годом число его загрузок выросло в десять раз и теперь на HuggingFace поддерживается более 2 млн моделей. ROCm интегрируется с ведущими фреймворками, включая PyTorch, TensorFlow, JAX, Triton, vLLM, ComfyUI и Ollama, и поддерживает проекты с открытым исходным кодом, такие как Unsloth. 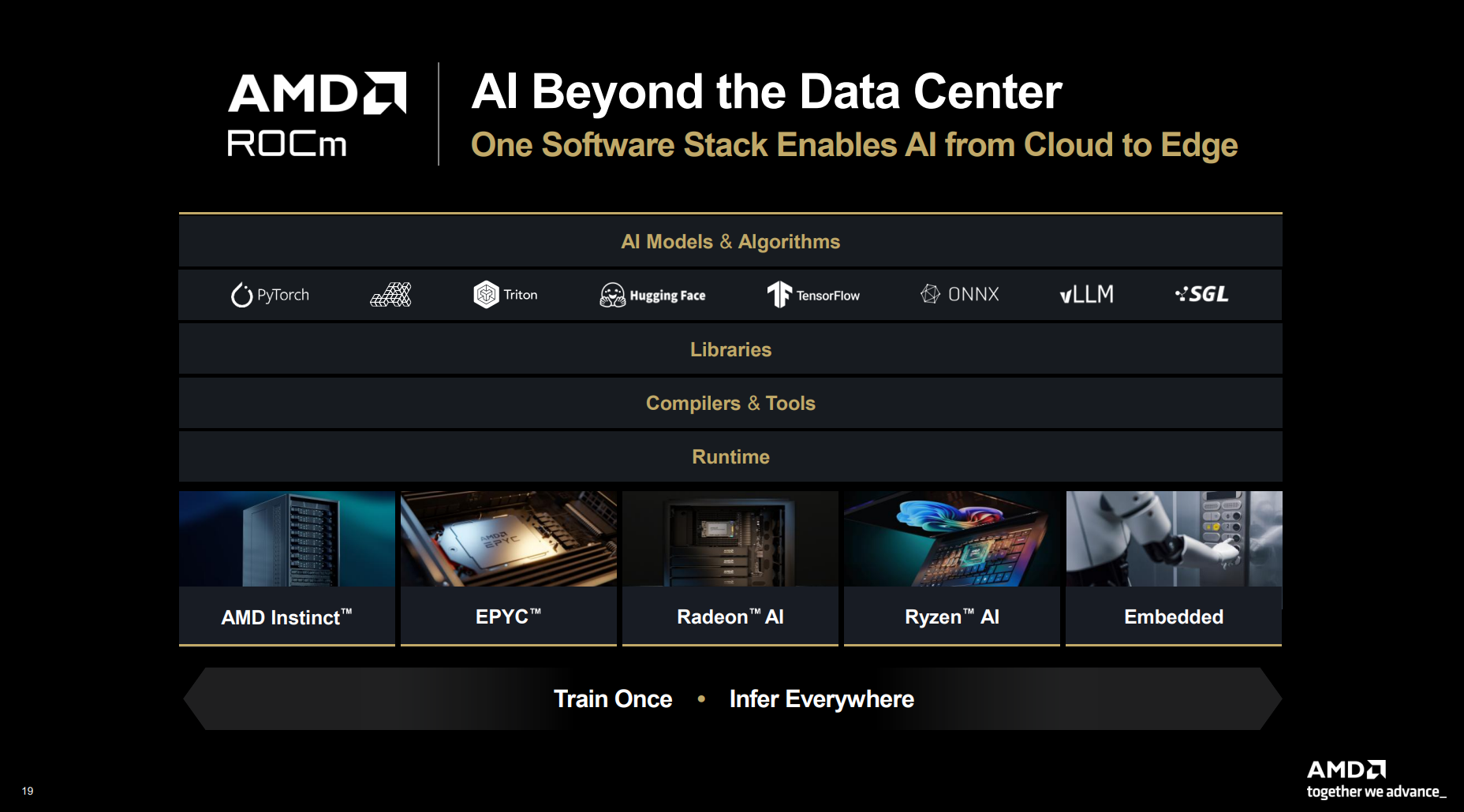  AMD также расширила своё видение «физического ИИ», когда вычисления выходят за рамки облака и охватывают роботов, транспортные средства и промышленные системы. Подразделение встраиваемых систем, усиленное приобретением Xilinx в 2022 году, превратилось из бизнеса, ориентированного на FPGA, в многоплатформенный двигатель роста, охватывающий адаптивные системы на кристалле (SoC), встраиваемые x86-процессоры и заказные кремниевые решения. По словам компании, с 2022 года решения в этой области принесли более $50 млрд. AMD рассчитывает превысить 70 % доли рынка адаптивных вычислений.   Говоря о перспективах, компания отметила, что ЦОД остаются основным драйвером роста, но наряду с этим она будет диверсифицировать свою деятельность по всем сегментам. Финансовые цели AMD включают:
05.09.2025 [11:39], Сергей Карасёв
AMD готовит суперускоритель Mega Pod с 256 ускорителями Instinct MI500Компания AMD, по сообщению ресурса Tom's Hardware, готовит платформу MI500 Scale Up MegaPod для наиболее ресурсоёмких нагрузок ИИ. Эта система, как ожидается, выйдет в 2027 году и составит конкуренцию стоечным решениям NVIDIA следующего поколения. Известно, что в основу MI500 Scale Up MegaPod лягут 64 процессора EPYC поколения Verano и 256 ускорителей серии Instinct MI500. Для сравнения: платформа AMD Helios, выход которой запланирован на 2026 год, сможет объединять до 72 ускорителей Instinct MI400, тогда как в состав системы NVIDIA NVL576 на основе стойки Kyber войдут 144 ускорителя поколения Rubin Ultra. В конструктивном плане MI500 Scale Up MegaPod, согласно имеющейся информации, будет представлять собой платформу с тремя серверными стойками. В боковых разместятся по 32 вычислительных лотка с одним процессором EPYC Verona и четырьмя ИИ-ускорителями Instinct MI500, тогда как центральная стойка получит 18 лотков, предназначенных для коммутаторов UALink. В целом, в состав системы войдут 64 узла, насчитывающих в общей сложности 256 ускорителей. 
Источник изображения: AMD По сравнению с NVIDIA NVL576 со 144 ускорителями новая платформа AMD обеспечит примерно на 78 % больше карт в расчёте на систему. Однако пока не ясно, сможет ли AMD MI500 Scale Up MegaPod превзойти решение NVIDIA по производительности: NVL576, как ожидается, получит 147 Тбайт памяти HBM4, тогда как быстродействие этой системы будет достигать 14 400 Пфлопс на операциях FP4. Отмечается также, что для AMD MI500 Scale Up MegaPod предусмотрено использование исключительно жидкостного охлаждения — как для вычислительных, так и для сетевых узлов. Предполагается, что система поступит в продажу в конце 2027 года — примерно в то же время, когда, вероятно, дебютирует NVIDIA NVL576.
13.06.2025 [02:20], Владимир Мироненко
AMD готовит ИИ-стойки Helios AI двойной ширины с Instinct MI400, AMD EPYC Venice и 800GbE DPU Pensando Vulcano
amd
dpu
epyc
hardware
instinct
mi400
pensando systems
ualink
ultra ethernet
venice
ии
стойка
ускоритель
Вместе с анонсом ускорителей MI350X и MI355X также рассказала о планах на ближайшее будущее, включая выпуск ускорителей серий MI400 (Altair) в 2026 году и MI500 (Altair+) в 2027 году, а также решений UALink, Ultra Ethernet, DPU Pensando и стоечных архитектур, которые послужат основой ИИ-кластеров. Так, AMD анонсировала новую архитектуру Helios AI с стойками двойной ширины, которая объединит процессоры AMD EPYC Venice с ядрами Zen 6, ускорители Instinct MI400 и DPU Vulcano. Благодаря приобретению ZT Systems компания смогла существенно ускорить разработку и интеграцию решений уровня стойки — Helios AI появятся уже в 2026 году. Как сообщает DataCenter Dynamics, Эндрю Дикманн (Andrew Dieckmann), корпоративный вице-президент и генеральный менеджер AMD по ЦОД рассказал перед мероприятием, что решение об увеличении ширины стойки было принято в сотрудничестве с «ключевыми партнёрами» AMD, поскольку предложение должно соответствовать «правильной точке проектирования между сложностью, надёжностью и предоставлением преимуществ производительности». По словам AMD, это позволит объединить тысячи чипов таким образом, чтобы их можно было использовать как единую систему «стоечного масштаба». «Впервые мы спроектировали каждую часть стойки как единую систему», — заявила генеральный директор AMD Лиза Су (Lisa Su) на мероприятии, пишет CNBC. 
Источник изображений: AMD Дикманн заявил, что Helios предложит на 50 % больше пропускной способности памяти и на 50 % больше горизонтальной пропускной способности (по сравнению с NVIDIA Vera Rubin), поэтому «компромисс [за счёт увеличения ширины стойки] был признан приемлемым, поскольку крупные ЦОД, как правило, ограничены не квадратными метрами, а мегаваттами». 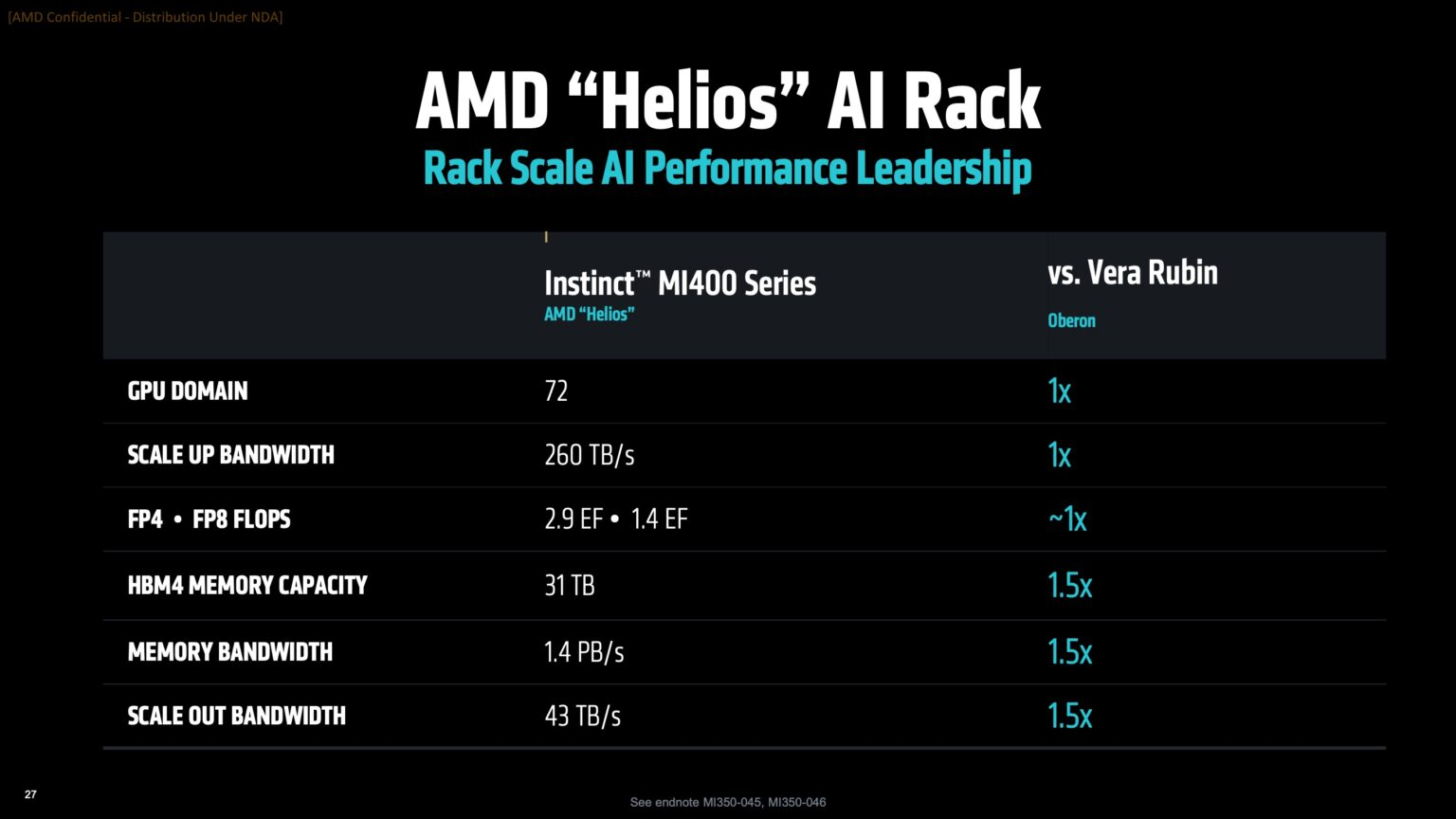 Как указано в блоге компании, «Helios создана для обеспечения вычислительной плотности, пропускной способности памяти, производительности и горизонтального масштабирования, необходимых для самых требовательных рабочих ИИ-нагрузок, в готовом к развёртыванию решении, которое ускоряет время выхода на рынок».  Helios представляет собой сочетание технологий AMD следующего поколения, включая:
 AMD отказалась сообщить стоимость анонсированных чипов, но, по словам Дикманна, ИИ-ускорители компании будут дешевле и в эксплуатации, и в приобретении в сравнении с чипами NVIDIA. «В целом, есть существенная разница в стоимости приобретения, которую мы затем накладываем на наше конкурентное преимущество в производительности, поэтому выходит значительная, исчисляемая двузначными процентами экономия», — сказал он.  AMD ожидает, что общий рынок ИИ-чипов превысит к 2028 году $500 млрд. Компания не указала, на какую долю общего пирога она будет претендовать — по оценкам аналитиков, в настоящее время у NVIDIA более 90 % рынка. Обе компании взяли на себя обязательство выпускать новые ИИ-чипы ежегодно, а не раз в два года, что говорит о том, насколько жёстче стала конкуренция и насколько важны передовые ИИ-технологии для гиперскейлеров. 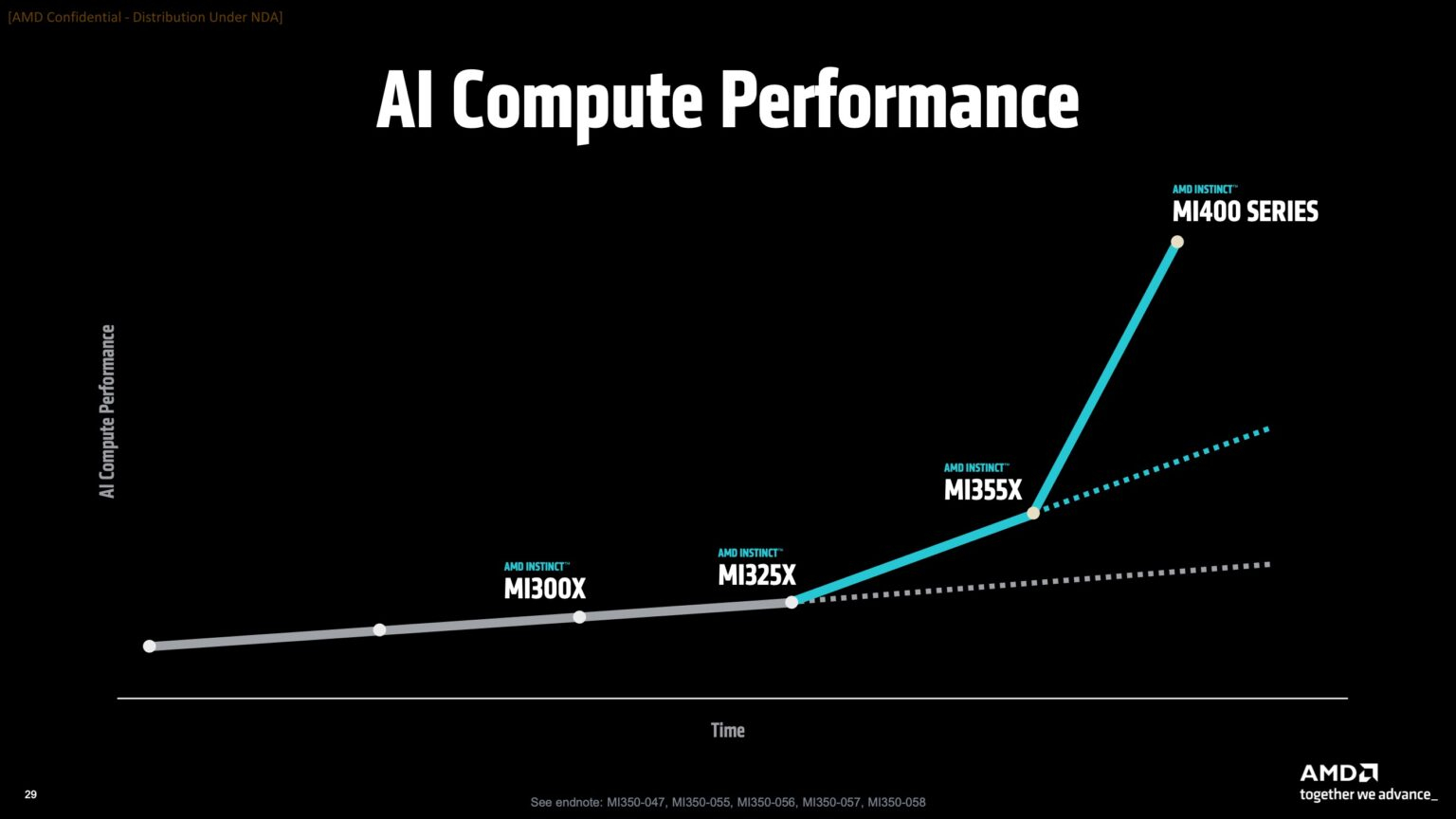 AMD сообщила, что её чипы Instinct используются семью из десяти крупнейших игроков ИИ-рынка, включая OpenAI, Tesla, xAI и Cohere. По словам AMD, Oracle планирует предложить своим клиентам кластеры с более чем 131 тыс. ускорителей MI355X. Meta✴ сообщила, что уже использует AMD-кластеры для инференса Llama и что она планирует купить серверы с чипами AMD следующего поколения. В свою очередь, представитель Microsoft сказал, что компания использует чипы AMD для обслуживания ИИ-функций чат-бота Copilot.
09.04.2025 [00:49], Алексей Степин
Все против NVIDIA: представлена открытая альтернатива NVLink — интерконнект UALink 200G 1.0Консорциум UALink, в состав которой входят AMD, AWS, Astera Labs, Cisco, Google, HPE, Intel, Meta✴ и Microsoft, опубликовала первые спецификации на разрабатываемую в рамках альянса более доступную альтернативу проприетарным решениям NVIDIA. Интерконнект UALink призван заменить в первую очередь NVLink и во многом опирается на AMD Infinity Fabric, хотя пока что по скоростям составляет конкуренцию скорее Ethernet и InfiniBand. Консорциум Ultra Accelerator Link был сформирован в конце прошлого года с целью создания высокоскоростного интерконнекта с низкими задержками, базирующегося на открытых технологиях. Речь здесь не только о приверженности открытым стандартам, но и о солидном потенциальном куске рынка — только за прошедший финансовый год сетевое подразделение NVIDIA выручило $13 млрд. 
Источник здесь и далее: UALink Появление более доступной и открытой альтернативы теоретически должно пошатнуть позиции последней в этом секторе, а также позволить разработчикам HPC-систем и ИИ-кластеров избежать жёсткой привязки к одному вендору. В том числе речь идёт о возможности организации сети UALink, включающей в себя GPU и ускорители разных поставщиков. Упор в первой версии стандарта сделан на общий доступ к памяти ускорителей с высокой скоростью, низкими задержками и простыми атомарными операциями 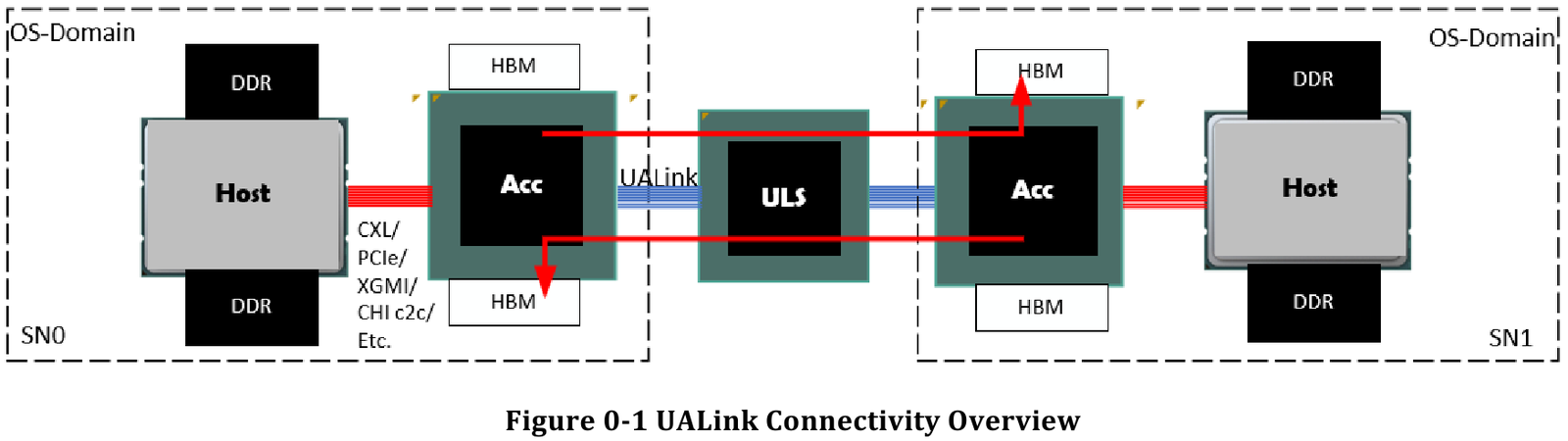 Впервые опубликованные спецификации описывают стандарт UALink 200G 1.0. В основе лежит коммутируемая сеть с пропускной способностью 200 Гбит/с на каждую линию, во многом наследующая AMD Infinity Fabric, но дополненная разработками других участников альянса. Максимальное количество линий на один ускоритель может достигать четырёх, что позволяет поднять пропускную способность до 800 Гбит/с. Поддерживается бифуркация. 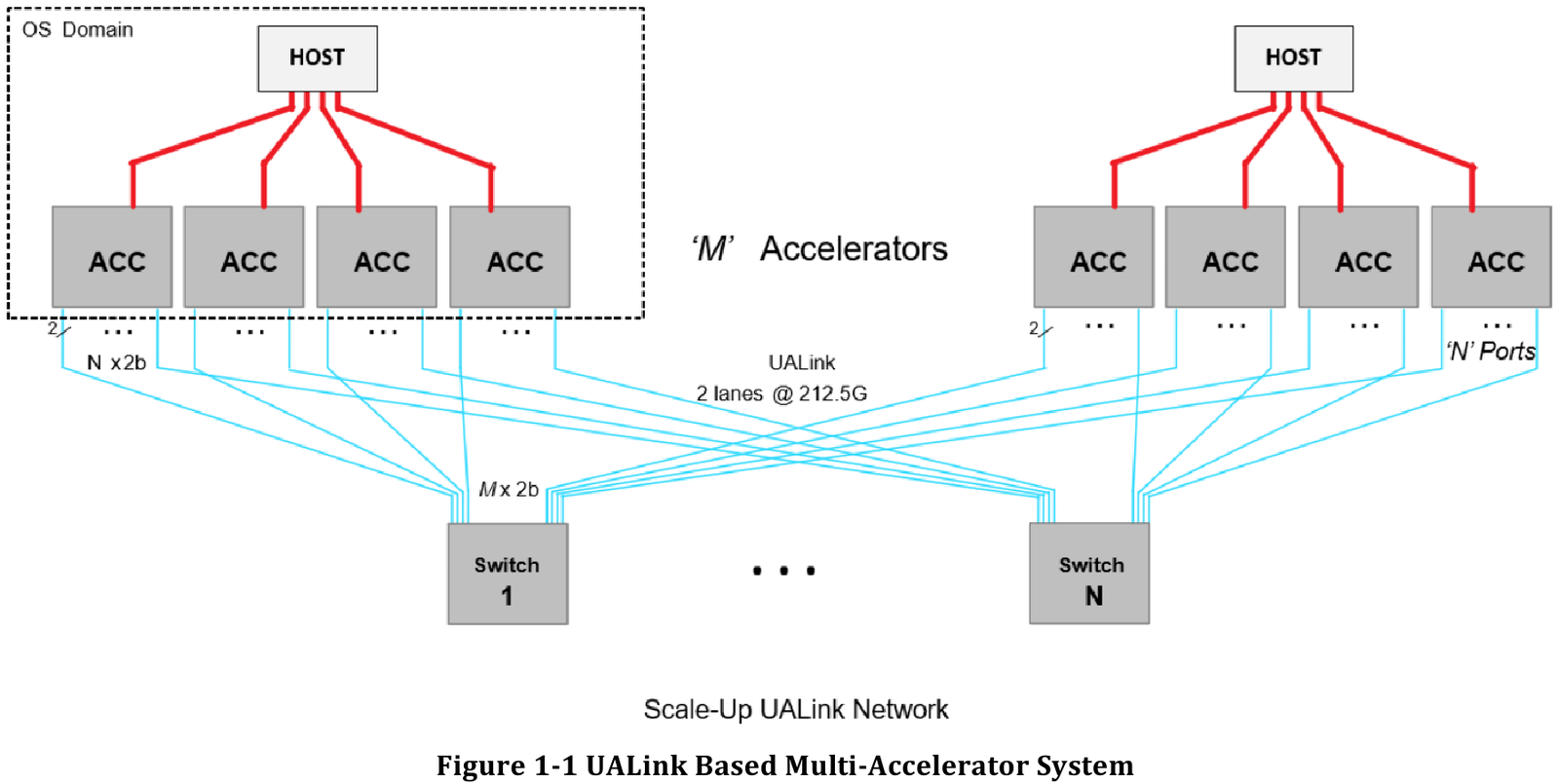 Размер кластера в данной версии стандарта UALink ограничен 1024 узлами, не считая коммутаторов. При этом гарантируются линейные скорости на уровне соответствующих версий Ethernet, но c энергопотреблением от трети до половины от аналогичного показателя последних, при времени отклика на уровне коммутируемых вариантов PCI Express. Задержка от порта к порту должна составить менее 100 нс, на уровне коммутаторов UASwitch — 100–150 нс. Для сравнения: NVLink 5/6 позволяет объединить до 576 ускорителей в одном домене со скоростью до 0,9–1,8 Тбайт/с на ускоритель. 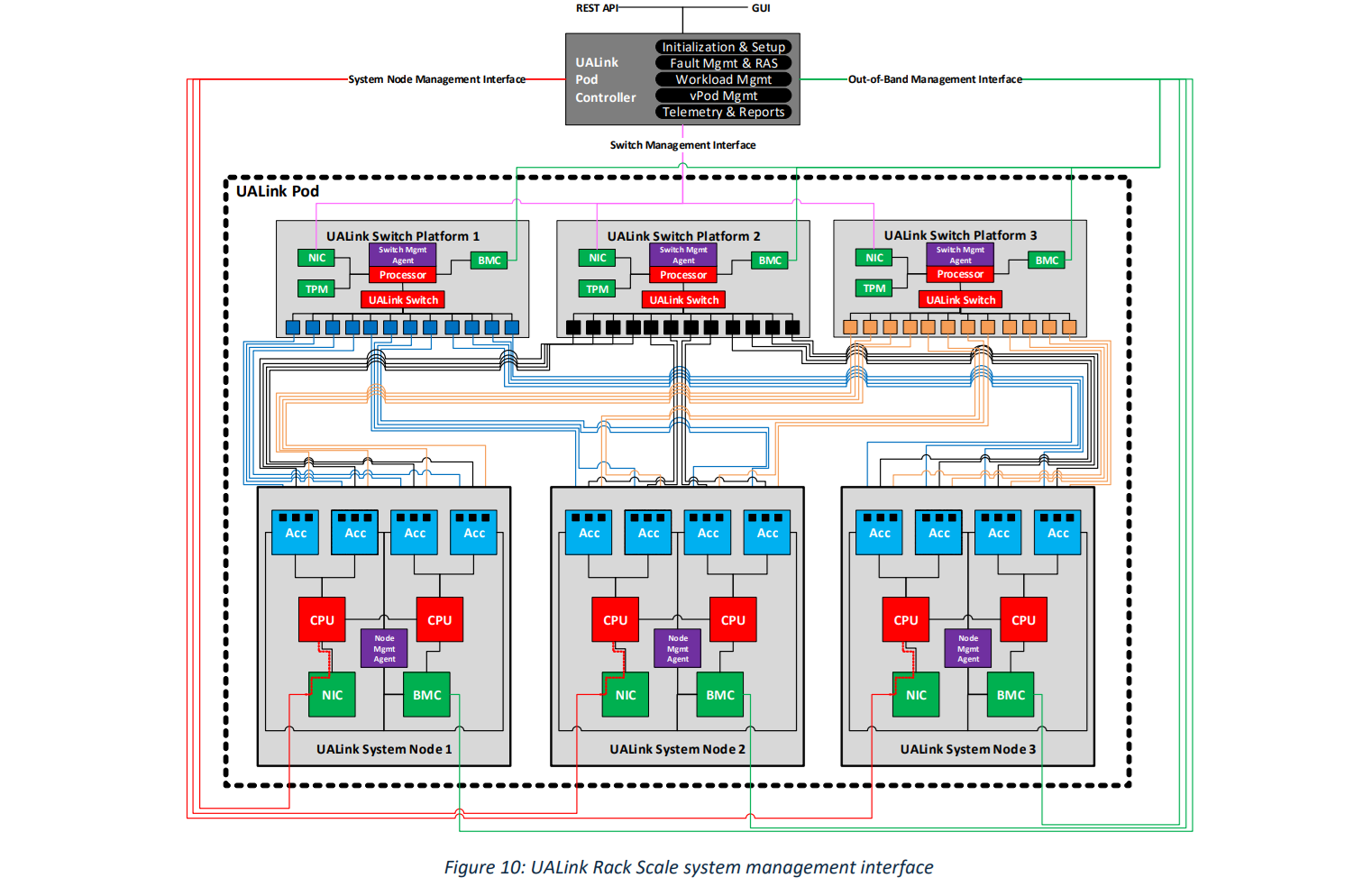 Также предусмотрена совместная работа с Ethernet в составе GPU-кластера, где хост-процессоры общаются между собой посредством традиционной сети (в том числе Ultra Ethernet), а ускорители могут использовать либо прямое, либо коммутируемое подключение UALink. 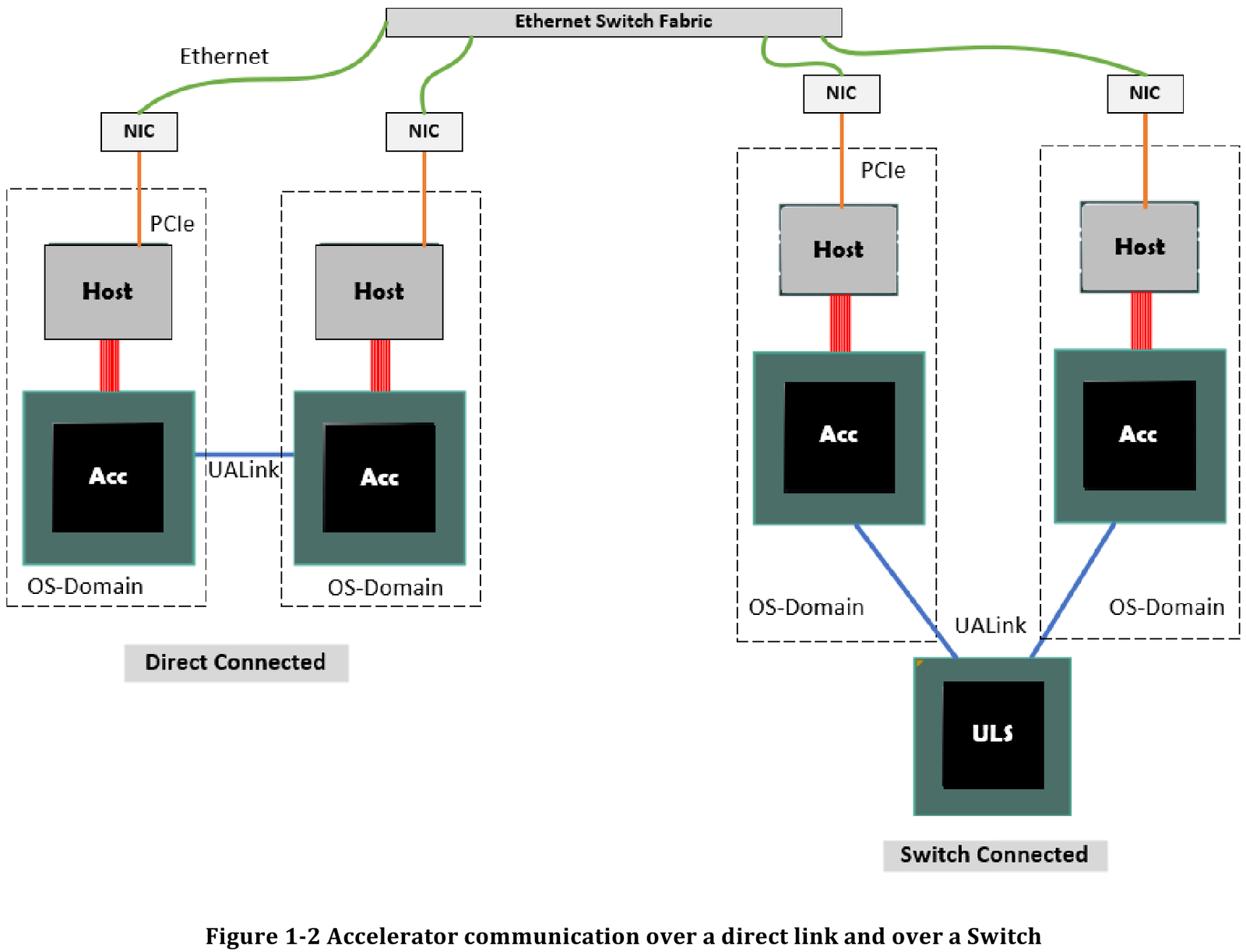 Передача данных осуществляется словами длиной 680 байт: 640-байт флит-пакеты + 40 байт накладных расходов на упреждающую коррекцию ошибок (FEC) и кодирование 256B/257B. Реализованы механизмы доступа к удалённой памяти, но когерентность на аппаратном уровне не поддерживается, также имеются различия на подуровне PCS (Physical coding sublayer). На физическом уровне используется стандарт IEEE 802.3dj: 200GBASE-KR1/CR1, 400GBASE-KR2/CR2 и 800GBASE-KR4/CR4. Имеющиеся ретаймеры для Ethernet также совместимы с UALink. 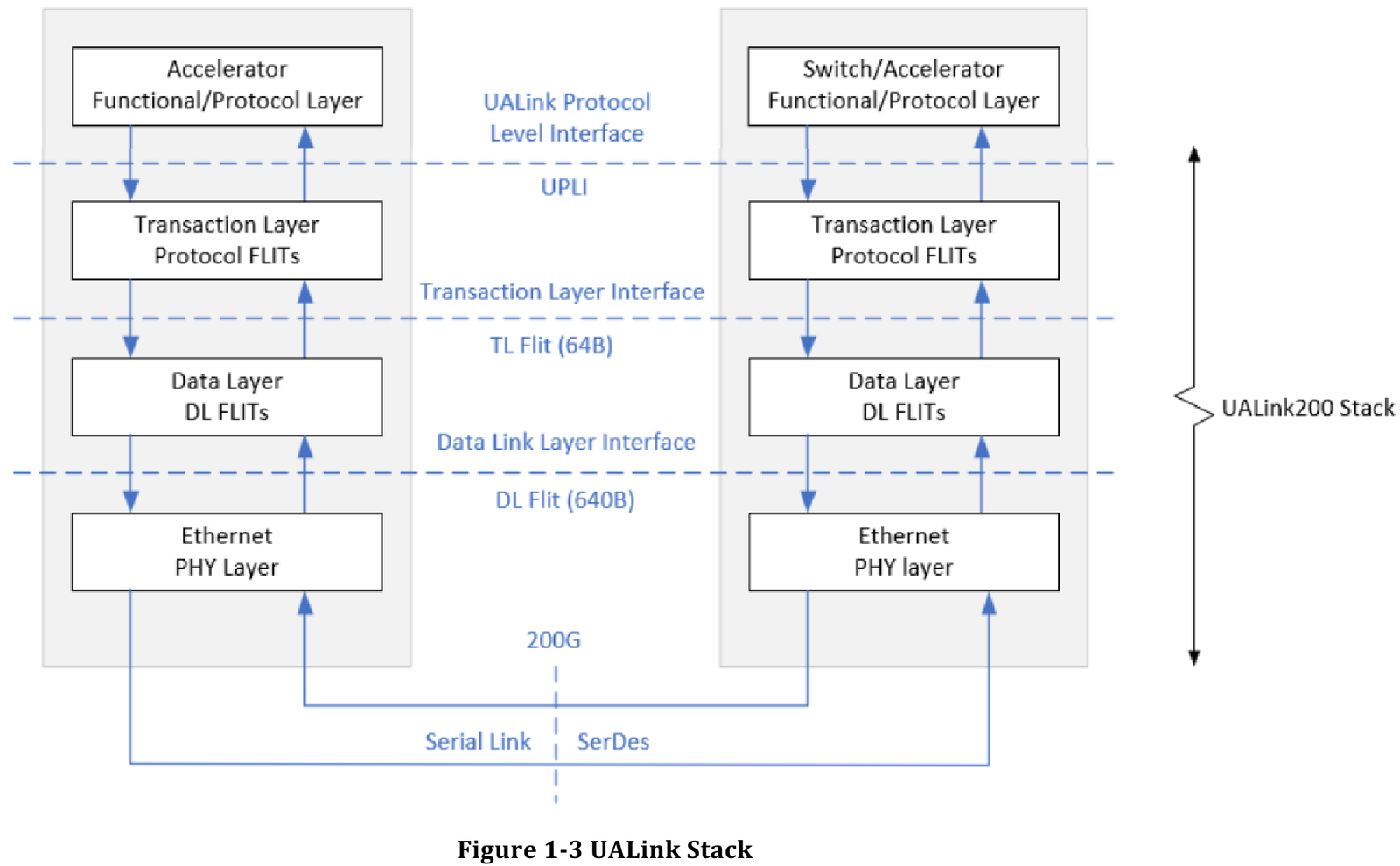 Спецификации UALink 200G 1.0 доступны на сайте проекта. Глава консорциума UALink, Кёртис Боумен (Kurtis Bowman) настроен оптимистично и говорит примерно о 18 месяцах до появления первых аппаратных решений, что на полгода быстрее типичных сценариев воплощения спецификаций «в железо». Тем временем, альянс уже начал работу над второй версией UALink, использующей стек технологий 400G. |
|

